Programowanie procesorów graficznych GPGPU
|
|
|
- Miłosz Grzelak
- 6 lat temu
- Przeglądów:
Transkrypt
1 Programowanie procesorów graficznych GPGPU 1
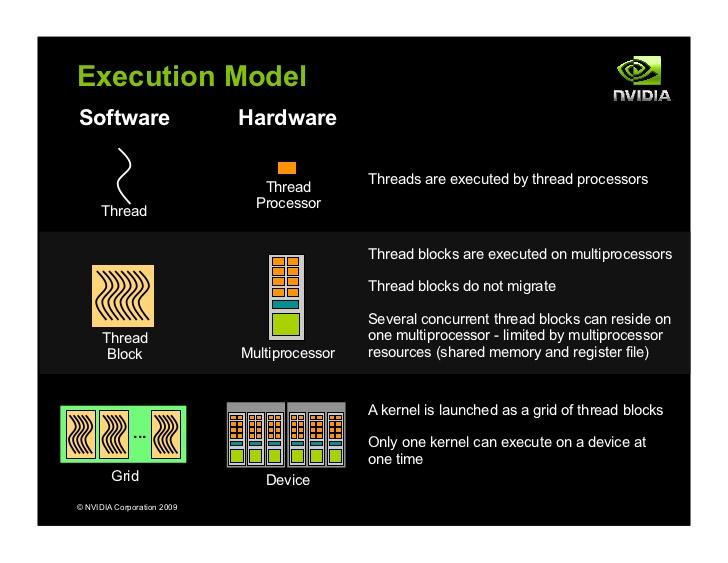
2 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany jest przez jeden rdzeń grupa wątków (work group) jednostka obliczeniowa (compute unit): grupa wątków wykonuje obliczenia na jednej jednostce obliczeniowej grupa wątków powinna mieć więcej wątków niż rdzeni w jednostce obliczeniowej grupa dzielona jest na podgrupy, wavefronts/warps, wątków wykonywanych jednocześnie w modelu SIMD przestrzeń wątków urządzenie: wszystkie watki z przestrzeni realizują zlecony kernel na urządzeniu 2
3 3

4 OpenCL organizacja wątków 4
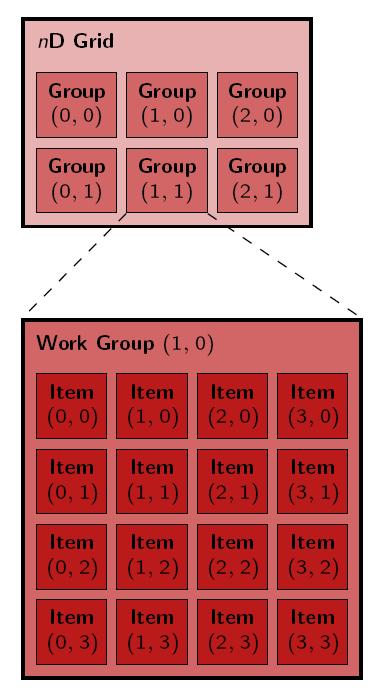
5 Przestrzeń wątków 5
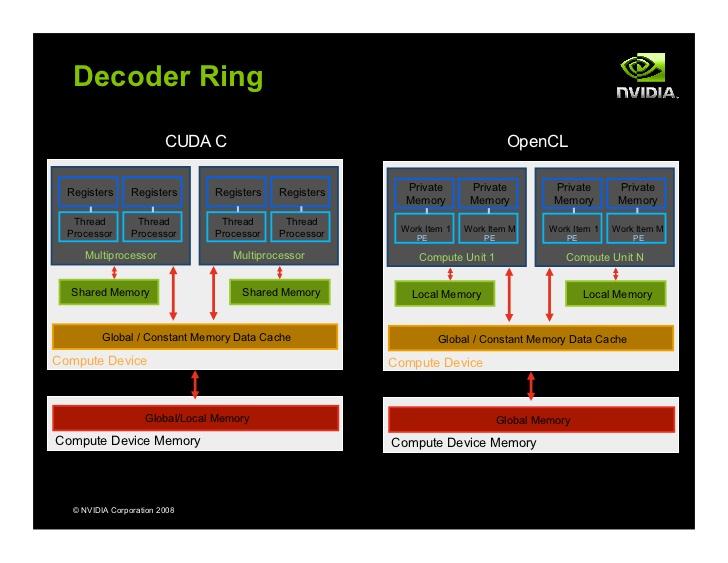
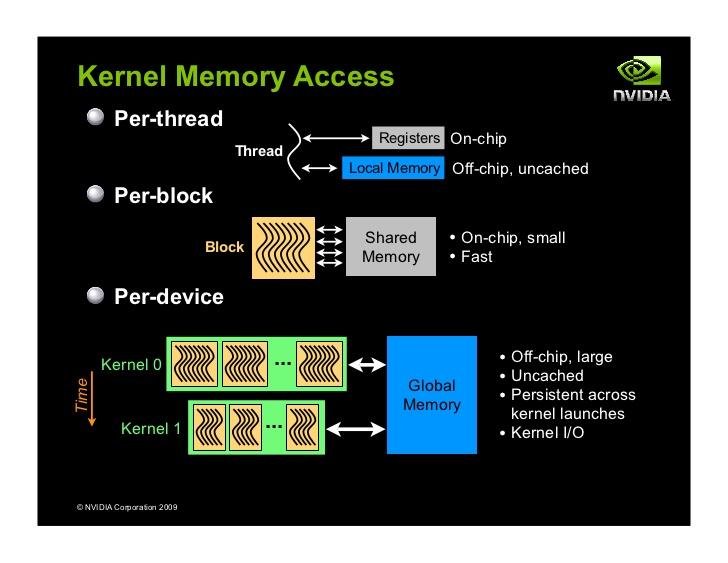
6 OpenCL projektowanie kerneli Przypomnienie: wielopoziomowa hierarchia pamięci: rejestry najszybsze zmienne lokalne (jeśli nie jest ich za dużo, register spilling) prywatne dla każdego wątku pamięć wspólna szybka zmienne (tablice) z atrybutem local wspólne dla wątków z jednej grupy roboczej pamięć globalna powolna zmienne lokalne nie mieszczące się w rejestrach zmienne (tablice) z atrybutem local» wspólne dla wszystkich wątków dodatkowe rodzaje pamięci: constant, texture 6

7 OpenCL model pamięci 7
8 8
9 9
10 OpenCL ukrywanie opóźnienia Ukrywanie opóźnienia (latency hiding) w dostępie do pamięci dla CPU i GPU Konieczne jest współbieżne wykonywanie co najmniej kilku (najlepiej kilkunastu) grup wątków (AMD wavefronts, NVIDIA warps) Podział na grupy wątków dokonujących jednoczesnego dostępu do pamięci jest ukryty przed programistą 10

11 OpenCL zależności danych 11
12 Projektowanie kerneli Model równoległości danych (data parallel programming) model zrównoleglenia: dekompozycja danych (data decomposition) każdy wątek realizuje ten sam kod (SPMD) synchronizacja sprzętowa (SIMD, SIMT) OpenCL pozwala uzyskać informacje o liczbie wymiarów przestrzeni wątków, liczbie wątków (globalnej oraz w pojedynczej grupie), liczbie grup oraz o identyfikatorze wątku: lokalnym (w grupie), globalnym, a także o identyfikatorze grupy: get_work_dim() get_global_id(dim_id), get_local_id(dim_id) get_global_size(dim_id), get_local_size(dim_id) get_num_groups(dim_id), get_group_id(dim_id) 12
13 Projektowanie kerneli Model SPMD wprowadzany klasycznie poprzez identyfikatory wątków wątek na podstawie swojego identyfikatora może: zlokalizować dane, na których dokonuje przetwarzania dane[ f(my_id) ] wybrać ścieżkę wykonania programu if(my_id ==...){...} określić iteracje pętli, które ma wykonać for( i=f1(my_id); i< f2(my_id); i += f3(my_id) ){... } w tym aspekcie programowanie GPU jest zbliżone do modeli Pthreads i MPI Środowiska programowania GPU pozwalają na wykorzystanie liczb wątków rzędu milionów 13
14 OpenCL model pamięci Spójność pamięci: dla wątków tej samej grupy spójny obraz pamięci jest uzyskiwany w punktach synchronizacji np. wywołanie barrier (CLK_GLOBAL_MEM_FENCE); barrier (CLK_LOCAL_MEM_FENCE); dla wszystkich wątków wykonujących kernel spójny obraz pamięci jest uzyskiwany po wykonaniu kernela Szybkość pamięci: global local: ponad 100GB/s zależna od wzorca dostępu (coalesced memory access) host global: 6GB/s (PCIe 2.0) 14
15 Przykład Przykład dodawania wektorów (OpenCL) dekompozycja zadania analiza wydajności wydajność przetwarzania wydajność dostępu do pamięci czynniki wpływające na wydajność:» liczba wątków» liczba współbieżnych żądań dostępu do pamięci dla pojedynczego wątku» rozmiar danych w pojedynczym żądaniu 15
16 Projektowanie kerneli przykład Przykład programu dodawania wektorów dekompozycja danych wariant 1 jeden wątek na jeden element wektora wykorzystanie możliwości tworzenia milionów wątków zawstydzająco równoległy algorytm brak komunikacji, synchronizacji kernel void vecadd_1_kernel( global const float *a, global const float *b, global float *result) { int gid = get_global_id(0); result[gid] = a[gid] + b[gid]; } 16
17 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 2 wykorzystanie wariantów podziału danych blokowanie jeden wątek operuje na bloku danych kernel void vecadd_2_blocks_kernel(..., const int size, const int size_per_thread) { int gid = get_global_id(0); int index_start = gid * size_per_thread; int index_end = (gid+1) * size_per_thread; for (int i=index_start; i < index_end && i < size; i++) { result[i] = a[i]+b[i]; }} 17
18 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 3 wykorzystanie wariantów podziału danych podział cykliczny kolejne wątki z grupy operują na kolejnych elementach wektorów strategia niewłaściwa dla CPU, najlepsza dla GPU kernel void vecadd_3_cyclic_kernel(..., const int size) { int index_start = get_global_id(0); int index_end = size; int stride = get_local_size(0) * get_num_groups(0); for (int i=index_start; i < index_end; i+=stride) { result[i] = a[i]+b[i]; }} 18
19 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 3 wykorzystanie wariantów podziału danych podział cykliczny wykorzystanie typów wektorowych żądanie dostępu do pamięci dla pojedynczego wątku dotyczy 128 bitów, zamiast 32 kernel void vecadd_4_cyclic_vect_kernel( global const float4 *a, global const float4 *b, global float4 *result, const int size) { int index_start = 4 * get_global_id(0); int index_end = size/4; int stride = 4 * get_local_size(0) * get_num_groups(0); for (int i=index_start; i < index_end; i+=stride) { result[i] = a[i]+b[i]; }} 19
20 Analiza wydajności Analiza wydajności może być przeprowadzana na dwa standardowe sposoby: wydajność względna klasycznie oznacza to przyspieszenie i efektywność jako funkcje liczby procesorów/rdzeni dla pojedynczego GPU trudno przeprowadzać takie analizy analizy porównujące wydajność CPU i GPU stwarzają wiele problemów metodologicznych i powinny być używane tylko jako pewne wskazówki wydajność bezwzględna procent teoretycznej maksymalnej wydajności uzyskany dla danego wykonania programu wydajność może być ograniczana przez wydajność przetwarzania lub wydajność transferu danych z/do pamięci (dla obliczeń na GPU powinno się uwzględnić szybkości transferu dla wszystkich poziomów pamięci) 20
21 Analiza wydajności W przypadku prostego kernela dodawania wektorów wydajność jest w całości ograniczana przez szybkość dostępu do pamięci W celu maksymalizacji szybkości zapisu/odczytu należy wygenerować maksymalna liczbę żądań dostępu do pamięci: należy zwiększać liczbę aktywnych wątków ale istnieją ograniczenia na liczbę aktywnych wątków i grup wątków można zwiększać liczbę niezależnych dostępów do danych przez pojedynczy wątek np. poprzez wykorzystanie pobierania float4 (128 bitów) zamiast zamiast zwykłego float (32 bity) lub przez modyfikację kodu źródłowego, np. rozwijanie pętli (należy upewnić się, że dostępy są traktowane jako niezależne) 21
22 Przykład paramerów GPU Przykład karty graficznej (laptop Dell Vostro 3450): AMD Radeon HD 6630M 6 CU 480 PE rejestrów wektorowych (128 bitowych) / CU 32 kb pamięci wspólnej (32 banki) / CU 8 kb L1 / CU, 256 kb L2 / GPU 480 Gflops 25,6 GB/s DDR3, 51,2 GDDR5 ok. 250 GB/s pamięć wspólna maksymalny rozmiar grupy 256 (cztery wavefronts ) maksymalna liczba wavefronts 248 / GPU 22
23 Przykład paramerów GPU NVIDIA Tesla M2075 (architektura Fermi) 14 CU 448 PE ( 32PE / CU ) rejestrów 32 bitowych / CU 48 kb pamięci wspólnej / CU 73.6 GB/s / CU 16 kb L1 / CU, 224 kb L2 / GPU 515 DP GFLOPS 150 GB/s GDDR5 maksymalny rozmiar grupy 1024 (32 warps ) maksymalna liczba aktywnych grup / CU 8 maksymalna liczba aktywnych warps / CU 48 maksymalna liczba rejestrów na wątek 63 maksymalna liczba aktywnych wątków
24 Przykład paramerów GPU NVIDIA Tesla K20 (architektura Kepler) 13 CU 2496 PE ( 192PE / CU ) rejestrów 32 bitowych / CU 48 kb pamięci wspólnej / CU 16 kb L1 / CU, 208 kb L2 / GPU 1170 DP GFLOPS 5GB GDDR5 RAM przepustowość 208 GB/s maksymalny rozmiar grupy 1024 (32 warps ) maksymalna liczba aktywnych grup / CU 16 maksymalna liczba aktywnych warps / CU 64 maksymalna liczba rejestrów na wątek 255 maksymalna liczba aktywnych wątków
25 Przykład paramerów GPU AMD (ATI) Radeon HD CU 320x5 PE ( 16x5PE / CU ) każdy rdzeń posiada 5 ALU 544 DP GFLOPS rejestrów 4x32 bitowych / CU GB/s 32 kb pamięci wspólnej / CU 100 GB/s / CU, 2176 GB/s 8 kb L1 / CU przepustowość 1088 GB/s 512 kb L2 / GPU przepustowość L1 L2: 435 GB/s 1 GB GDDR5 RAM przepustowość 154 GB/s maksymalny rozmiar grupy 1024 (32 warps ) maksymalna liczba aktywnych grup / CU 8 maksymalna liczba aktywnych wavefronts / CU 24.8 maksymalna liczba rejestrów na wątek 63 maksymalna liczba aktywnych wątków
26 Wyniki AMD Radeon HD 5870 PARAMETERS: nr_cu 20, nr_cores 6400, nr_cores_per_cu 320 workgroup size 256, nr_workgroups 240,nr_workgroups_per_CU 12 nr_threads 61440, nr_threads_per_cu 3072, nr_threads_per_core 3840 array size , nr_entries_per_thread 512, nr_entries_per_core executing kernel 1, on platform 0 and device 0 EXECUTION TIME: executing kernel: (profiler: ) Number of operations , performance GFlops GBytes transferred to processor , speed GB/s 4. executing kernel 2, on platform 0 and device 0 EXECUTION TIME: executing kernel: (profiler: ) Number of operations , performance GFlops GBytes transferred to processor , speed GB/s 4. executing kernel 3, on platform 0 and device 0 (GPU) EXECUTION TIME: executing kernel: (profiler: ) Number of operations , performance GFlops GBytes transferred to processor , speed GB/s 26
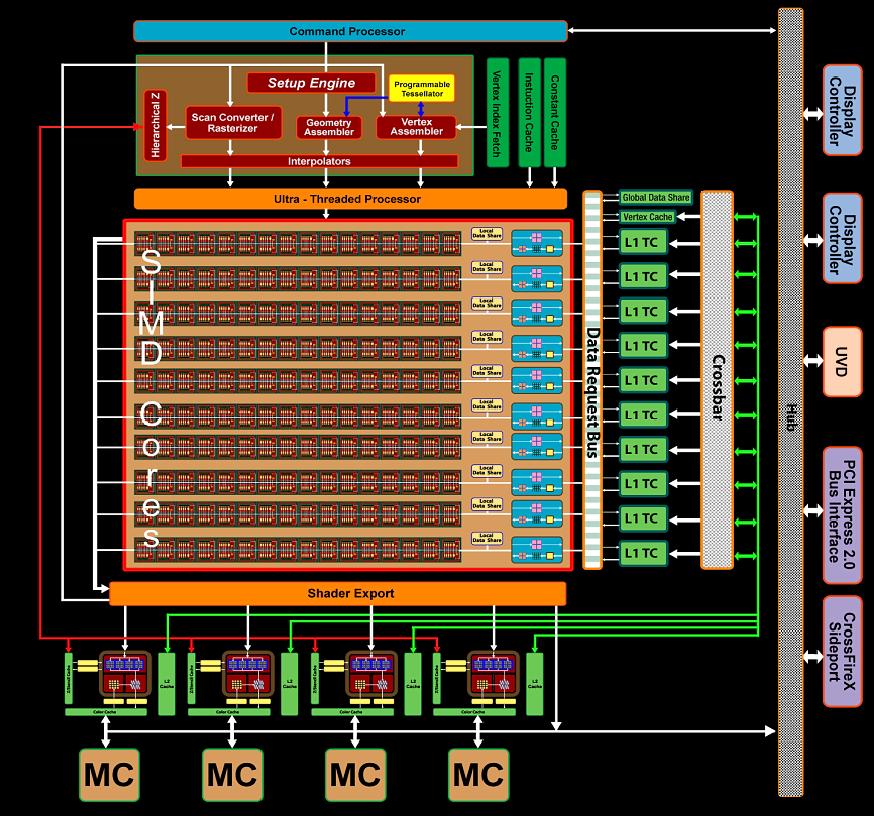
27 GPGPU 27

28 Przykład transpozycja macierzy 28

29 Przykład transpozycja macierzy 29
30 Przykład transpozycja macierzy Wykorzystanie: pamięci wspólnej: jako szybkiej pamięci podręcznej umożliwiającej komunikację pomiędzy watkami jawnej synchronizacji pracy wątków 30
31 CUDA kernel global void transpose( float *out, float *in, int w, int h ) { shared float block[block_dim*block_dim]; unsigned int xblock = blockdim.x * blockidx.x; unsigned int yblock = blockdim.y * blockidx.y; unsigned int xindex = xblock + threadidx.x; unsigned int yindex = yblock + threadidx.y; unsigned int index_out, index_transpose; if ( xindex < width && yindex < height ) { unsigned int index_in = width * yindex + xindex; unsigned int index_block = threadidx.y * BLOCK_DIM + threadidx.x; block[index_block] = in[index_in]; index_transpose = threadidx.x * BLOCK_DIM + threadidx.y; index_out = height * (xblock + threadidx.y) + yblock + threadidx.x; } synchthreads(); if(xindex<width&&yindex<height) out[index_out]=block[index_transpose]; } 31
32 Przykład mnożenie macierzy Przypomnienie: mnożenie macierzy jest algorytmem, dla którego przy nieskończonej liczbie rejestrów występuje bardzo korzystny stosunek liczby operacji do liczby dostępów do pamięci 3 2 s = (2n )/(3n ) ~ 2n/3 pm (n rozmiar macierzy) przy małej liczbie rejestrów i małym rozmiarze pamięci podręcznej naiwna implementacja prowadzi do znacznego spadku stosunku spm: 3 3 spm = (2n )/(n +...) ~ 2 implementacja naiwna schemat przechowywania wierszami: c(row, col) = c[row*n + col] for(i=0;i<n;i++){ for(j=0;j<n;j++){ c[i*n+j]=0.0; for(k=0;k<n;k++){ c[i*n+j] += a[i*n+k]*b[k*n+j]; } } } 32
33 Przykład mnożenie macierzy Naiwna implementacja GPU jeden wątek na jeden element macierzy wynikowej C Operacje wyłącznie na pamięci globalnej Nieoptymalny dostęp do tablicy A kernel void mat_mul_1_kernel( global float* A, global float* B, global float* C, int N ) { int i; int row = get_global_id(1); int col = get_global_id(0); float temp = 0.0; for (i = 0; i < N; i++) { temp += A[row * N + i] * B[i * N + col]; } C[row * N + col] = temp; } 33

34 Przykład mnożenie macierzy Klasyczna technika optymalizacji blokowanie Wyróżnienie bloków w tablicach A, B i C przechowywanych w szybkiej pamięci Wykonanie jak największej liczby operacji na blokach w szybkiej pamięci 34
35 Przykład mnożenie macierzy Implementacja blokowania: wariant 1 duże bloki: rozmiar bloku dobrany tak, żeby blok mieścił się w szybkiej pamięci (cache blocking) pojedynczy wątek wykonuje obliczenia dla wielu wyrazów bloku wariant 2 małe bloki: rozmiar bloku dobrany tak, żeby wartości mogły być przechowywane w rejestrach dla CPU i jednego wątku wiele zmiennych dla GPU np. jedna zmienna, ale wiele wątków 35
36 Przykład mnożenie macierzy int row = get_global_id(1); int local_row = get_local_id(1); float temp = 0.0; int col = get_global_id(0); int local_col = get_local_id(0); int nr_blocks = N/BLOCK_SIZE; for(iblock = 0; iblock < nr_blocks; iblock++){ A_local[local_row * BLOCK_SIZE + local_col] = A[row * N + iblock*block_size + local_col]; B_local[local_row * BLOCK_SIZE + local_col] = B[(local_row+iblock*BLOCK_SIZE) * N + col]; barrier(clk_local_mem_fence); for(i=0; i< BLOCK_SIZE; i++){ temp += A_local[local_row*BLOCK_SIZE+i] * B_local[i*BLOCK_SIZE+local_col]; } barrier(clk_local_mem_fence); } } C[row * N + col] = temp; 36
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 GPGPU Modele programowania GPGPU CUDA pierwszy naprawdę popularny model programowania GPGPU OpenCL wzorowany na CUDA,
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 GPGPU Modele programowania GPGPU CUDA pierwszy naprawdę popularny model programowania GPGPU OpenCL wzorowany na CUDA,
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie CUDA informacje praktycznie i przykłady. Wersja
 Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Programowanie PKG - informacje praktycznie i przykłady. Wersja z Opracował: Rafał Walkowiak
 Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł.
 Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Programowanie równoległe Wprowadzenie do OpenCL. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Wstęp do obliczeń równoległych na GPU
 Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Julia 4D - raytracing
 i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
PROBLEMATYKA OBLICZEŃ MASOWYCH W NAUKACH O ZIEMI. Satelitarny monitoring środowiska
 Satelitarny monitoring środowiska Dane satelitarne to obecnie bardzo ważne źródło informacji o powierzchni Ziemi i procesach na niej zachodzących. Obliczono, że na początku roku 2014 na orbitach okołoziemskich
Satelitarny monitoring środowiska Dane satelitarne to obecnie bardzo ważne źródło informacji o powierzchni Ziemi i procesach na niej zachodzących. Obliczono, że na początku roku 2014 na orbitach okołoziemskich
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1
 Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Operacje grupowego przesyłania komunikatów
 Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
XIII International PhD Workshop OWD 2011, October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH
 XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Programowanie równoległe Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do programowania GPU Rafał Skinderowicz CPU Fetch/ Decode ALU (Execute) Data cache (a big one) Execution Context Out-of-order control logic Fancy branch predictor
Programowanie równoległe Wprowadzenie do programowania GPU Rafał Skinderowicz CPU Fetch/ Decode ALU (Execute) Data cache (a big one) Execution Context Out-of-order control logic Fancy branch predictor
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU
 Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Operacje grupowego przesyłania komunikatów. Krzysztof Banaś Obliczenia równoległe 1
 Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH
 ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
Optymalizacja skalarna. Piotr Bała. bala@mat.uni.torun.pl. Wykład wygłoszony w ICM w czercu 2000
 Optymalizacja skalarna - czerwiec 2000 1 Optymalizacja skalarna Piotr Bała bala@mat.uni.torun.pl Wykład wygłoszony w ICM w czercu 2000 Optymalizacja skalarna - czerwiec 2000 2 Optymalizacja skalarna Czas
Optymalizacja skalarna - czerwiec 2000 1 Optymalizacja skalarna Piotr Bała bala@mat.uni.torun.pl Wykład wygłoszony w ICM w czercu 2000 Optymalizacja skalarna - czerwiec 2000 2 Optymalizacja skalarna Czas
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Programowanie współbieżne Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Wprowadzenie do GPGPU
 (py)opencl na kartach graficznych: Wprowadzenie do GPGPU kolodziejj.info wyszukiwanie obiektów na zdjęciu CPU-bound 32 MPix implementacje: Matlab: 6 godzin Python + OpenCL: 1 minuta Tak, słownie: jedna
(py)opencl na kartach graficznych: Wprowadzenie do GPGPU kolodziejj.info wyszukiwanie obiektów na zdjęciu CPU-bound 32 MPix implementacje: Matlab: 6 godzin Python + OpenCL: 1 minuta Tak, słownie: jedna
Numeryczna algebra liniowa. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak