Obliczenia Wysokiej Wydajności
|
|
|
- Aleksander Matusiak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Obliczenia wysokiej wydajności 1

2 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk każdego oprogramowania Niniejsze wykłady przedstawiają sposoby analizy i osiągania wysokiej wydajności w programach Tradycyjnie zagadnieniom wysokiej wydajności najwięcej uwagi poświęca się w ramach specjalnej dziedziny informatyki: Obliczeń Wysokiej Wydajności (High Performance Computing) Wyniki osiągnięte w ramach HPC mają swoje zastosowanie we wszystkich dziedzinach informatyki 2
 Wyniki osiągnięte w ramach HPC mają swoje zastosowanie we wszystkich dziedzinach")
3 Wykład OWW Osiąganie wysokiej wydajności Wydajność aplikacji: Języki i środowiska wysokiego poziomu abstrakcji i złożoności: SQL i systemy baz danych OpenGL, DirectX i systemy graficzne HTML, PHP i aplikacje internetowe Java, C# i ich środowiska wykonania Języki relatywnie niskiego poziomu blisko sprzętu C Asemblery Ze względu na rozmaitość języków i środowisk wysokiego poziomu oraz asemblerów daleko wykraczającą poza ograniczenia czasowe jednego przedmiotu wykład koncentruje się na programowaniu w języku C 3

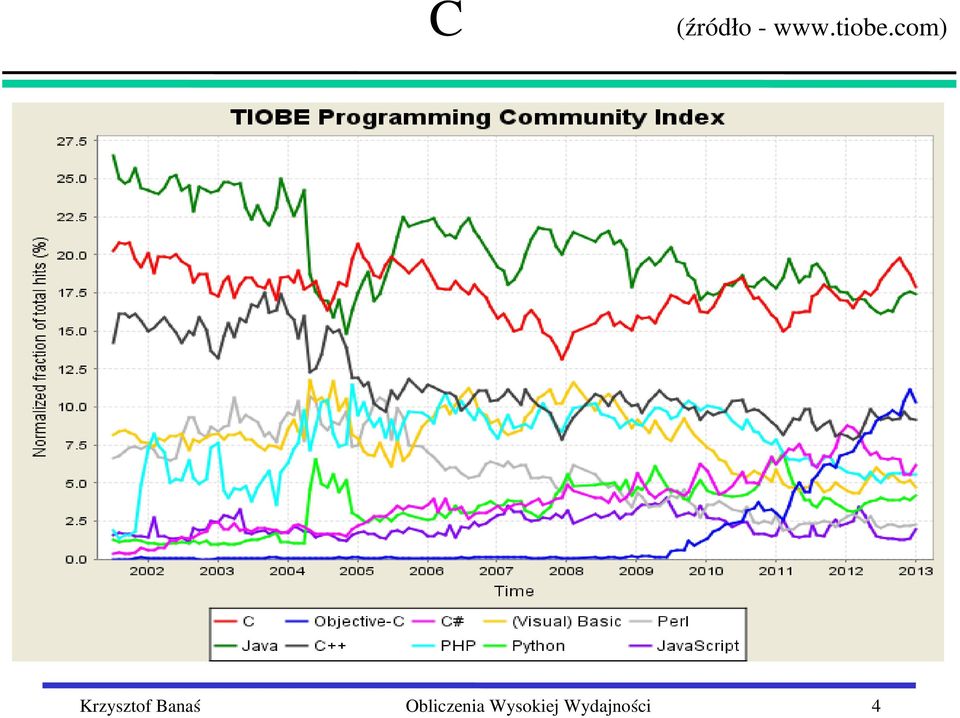
4 C (źródło 4
5 Wykład OWW Osiąganie wysokiej wydajności programy w C Analiza wydajności dla architektur sprzętowych obejmujących procesory (CPU, GPU), układ pamięci, układ komunikacji międzyprocesorowej Optymalizacja wykonywania instrukcji: kod źródłowy kod assemblera wykonanie przez procesor Optymalizacja dostępu do pamięci: komunikacja w systemach z pamięcią rozproszoną dostęp do pamięci wspólnej w systemach wieloprocesorowych i wielordzeniowych funkcjonowanie hierarchii pamięci w CPU i GPU (pamięć podręczna, ewentualne inne formy pamięci lokalnej, pamięć globalna) sprzętowa organizacja pamięci i jej funkcjonowanie 5
 sprzętowa organizacja pamięci i jej")
6 Obliczenia wysokiej wydajności Obliczenia wysokiej wydajności to obliczenia, w których stara się uzyskać maksymalną szybkość przetwarzania Maksymalizacja szybkości przetwarzania ma doprowadzić do minimalizacji czasu rozwiązania danego problemu (time to solution) Zależnie od rodzaju wykonywanych obliczeń, stosuje się różne miary szybkości przetwarzania Najpopularniejszą miarą (zwłaszcza w dziedzinie obliczeń naukowo technicznych) jest liczba wykonywanych operacji zmiennoprzecinkowych na sekundę (FLOPS) Inne możliwe miary to np. liczba wykonywanych w sekundzie instrukcji, liczba przetwarzanych transakcji na sekundę, liczba wyświetlanych pikseli na sekundę itp. 6
 Inne możliwe miary to np.")
7 Numbers everyone should know Google forum L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns Mutex lock/unlock 100 ns Main memory reference 100 ns Compress 1K bytes with Zippy 10,000 ns Send 2K bytes over 1 Gbps network 20,000 ns Read 1 MB sequentially from memory 250,000 ns Round trip within same datacenter 500,000 ns Disk seek 10,000,000 ns Read 1 MB sequentially from network 10,000,000 ns Read 1 MB sequentially from disk 30,000,000 ns Send packet CA >Netherlands >CA 150,000,000 ns 7

8 Historia obliczeń wysokiej wydajności komputery macierzowe komputery wektorowe komputery masowo równoległe klastry 8

9 Komputery macierzowe (SIMD) Odrębny procesor przetwarzający rozkazy Macierz procesorów przetwarzających dane Illiac IV, ~100 MFLOPS, ~ USD 9

10 Komputery macierzowe Dzisiejsze zastosowania: rozkazy SIMD w procesorach ogólnego przeznaczenia przetwarzanie sygnałów procesory graficzne, GPU superkomputery specjalnego przeznaczenia (np. apenext SPMD komputer do symulacji w dziedzinie LQCD, 4096 procesorów, 7 TFLOPS) 10

11 11

12 Komputery wektorowe Podstawowy element procesor wektorowy: rejestry wektorowe przetwarzanie potokowe operacji zmiennoprzecinkowych kilka potoków i jednostek funkcjonalnych Współczesne zastosowania: przetwarzanie superskalarne i potokowe w procesorach ogólnego przeznaczenia superkomputery Cray-1, 1975 ~100 MFLOPS, ~ USD Cray 2, ~2 GFLOPS 12

13 Komputery wektorowe w procesorze jednostki skalarne i wektorowe (czasem adresowe) operacje wektorowe (w tym operacje redukcji) op V > V (np. a[i]:= b[i]) op V > S redukcja (np. r:=max(b[i])) V op V > V (np. a[i]:=b[i]+c[i]) V op S > V (np. a[i]:= s*b[i]) dostęp do pamięci: wielobankowość, przeplot, potoki rejestry wektorowe (długość 64 do 128) w tym maska potokowe jednostki funkcjonalne łączenie operacji w łańcuchy (chaining) (a[i] := b[i] + s*c[i] ) 13
![a[i]:=b[i]+c[i]) V op S > V (np.](/docs-images/44/14924633/images/page_13.jpg "a[i]:= s*b[i]) dostęp do pamięci: wielobankowość, przeplot, potoki rejestry wektorowe (długość 64 do 128) w tym")
14 14

15 Earth Simulator 5120 procesorów ~ 35 TFLOPS 15

16 Earth Simulator 16

17 Earth Simulator 17

18 Komputery masowo równoległe Komputery posiadające setki, tysiące i więcej procesorów (komputery wektorowe kilkadziesiąt) Komputery złożone z niezależnych procesorów, najczęściej wyposażonych w indywidualną pamięć CM-2, procesorów CM-5, 1991, 512 węzłów ~65.5 GFLOPS,~ USD 18

19 IBM Blue Gene/L Architektura Blue Gene węzłów obliczeniowych 280 TFLOPS 64 szafy 1.2 MW

20 20

21 Klastry Niezależne komputery połączone siecią Silna integracja poprzez specjalne oprogramowanie Do kilku tysięcy komputerów Relatywnie tanie (kilka tysięcy USD / komputer) 21
22 And the winner is... TOP500 najpopularniejsza klasyfikacja najpotężniejszych systemów komputerowych świata Dokonywana dwa razy w roku (w czerwcu i listopadzie) od 1993 Klasyfikacja oparta na szybkości rozwiązywania układu równań liniowych metodą Gaussa Tylko systemy ogólnego przeznaczenia 22
23 Lista Top500 23
24 Czy to już wszystko? Systemy umieszczone na liście TOP 500 nie są jedynymi potężnymi systemami obliczeniowymi świata Równie potężne bywają organizowane ad hoc zespoły rozproszonych po całym świecie i połączonych siecią różnorodnych komputerów Projekt SETI@home (obecnie jako BOINC, projekt Folding@home ( kilkaset tysięcy komputerów na całym świecie kilka PFLOPS łącznej mocy obliczeniowej 24
25 Systemy równoległe wysokiej wydajności 25
26 Gdzie potrzebne są wysokie moce obliczeniowe? Internet & Ecommerce Aerodynamika Nauki biologiczne CAD/CAM Wojskowość Medycyna 26
27 Gdzie potrzebne są wysokie moce obliczeniowe? 27

28 Znaczenie algebry liniowej 28
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Organizacja pamięci współczesnych systemów komputerowych : pojedynczy procesor wielopoziomowa pamięć podręczna pamięć wirtualna
 Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Klasyfikacja sprzętu i oprogramowania nowoczesnego banku. Informatyka bankowa, AE w Poznaniu, dr Grzegorz Kotliński
 1 Klasyfikacja sprzętu i oprogramowania nowoczesnego banku Informatyka bankowa, AE w Poznaniu, dr Grzegorz Kotliński 2 Podstawowe typy komputerów Mikrokomputery Minikomputery Mainframe Superkomputery Rodzaj
1 Klasyfikacja sprzętu i oprogramowania nowoczesnego banku Informatyka bankowa, AE w Poznaniu, dr Grzegorz Kotliński 2 Podstawowe typy komputerów Mikrokomputery Minikomputery Mainframe Superkomputery Rodzaj
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura systemów komputerowych. Przetwarzanie potokowe I
 Architektura systemów komputerowych Plan wykładu. Praca potokowa. 2. Projekt P koncepcja potoku: 2.. model ścieżki danych 2.2. rejestry w potoku, 2.3. wykonanie instrukcji, 2.3. program w potoku. Cele
Architektura systemów komputerowych Plan wykładu. Praca potokowa. 2. Projekt P koncepcja potoku: 2.. model ścieżki danych 2.2. rejestry w potoku, 2.3. wykonanie instrukcji, 2.3. program w potoku. Cele
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Informatyka I stopień (I stopień / II stopień) Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)
 Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)") KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Wykład I. Podstawowe pojęcia. Studia Podyplomowe INFORMATYKA Architektura komputerów
 Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
GRIDY OBLICZENIOWE. Piotr Majkowski
 GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM. Juliusz Pukacki,PCSS
 DLA FIRM. Juliusz Pukacki,PCSS") USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Zagadnienia egzaminacyjne INFORMATYKA. Stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Programowanie Rozproszone i Równoległe. Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl
 Programowanie Rozproszone i Równoległe Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl Motywacja wyboru Programowanie rozproszone równoległość (wymuszona) Oprogramowanie równoległe/rozproszone:
Programowanie Rozproszone i Równoległe Edward Görlich http://th.if.uj.edu.pl/~gorlich goerlich@th.if.uj.edu.pl Motywacja wyboru Programowanie rozproszone równoległość (wymuszona) Oprogramowanie równoległe/rozproszone:
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Programowanie niskopoziomowe. dr inż. Paweł Pełczyński ppelczynski@swspiz.pl
 Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Zagadnienia egzaminacyjne INFORMATYKA. stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne. Wykład Ćwiczenia
 Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 2016/2017 Język wykładowy: Polski Semestr 1 IIN-1-103-s
Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 2016/2017 Język wykładowy: Polski Semestr 1 IIN-1-103-s
Technologie Informacyjne
 POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 3: Wprowadzenie do algorytmów i ich
POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 3: Wprowadzenie do algorytmów i ich
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Optymalizacja skalarna. Piotr Bała. bala@mat.uni.torun.pl. Wykład wygłoszony w ICM w czercu 2000
 Optymalizacja skalarna - czerwiec 2000 1 Optymalizacja skalarna Piotr Bała bala@mat.uni.torun.pl Wykład wygłoszony w ICM w czercu 2000 Optymalizacja skalarna - czerwiec 2000 2 Optymalizacja skalarna Czas
Optymalizacja skalarna - czerwiec 2000 1 Optymalizacja skalarna Piotr Bała bala@mat.uni.torun.pl Wykład wygłoszony w ICM w czercu 2000 Optymalizacja skalarna - czerwiec 2000 2 Optymalizacja skalarna Czas
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU
 Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Kierunek:Informatyka- - inż., rok I specjalność: Grafika komputerowa
 :Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
:Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Architektura mikroprocesorów z rdzeniem ColdFire
 Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
I. KARTA PRZEDMIOTU CEL PRZEDMIOTU
 I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
I. KARTA PRZEDMIOTU 1. Nazwa przedmiotu: TECHNOLOGIA INFORMACYJNA 2. Kod przedmiotu: Ot 3. Jednostka prowadząca: Wydział Mechaniczno-Elektryczny 4. Kierunek: Automatyka i Robotyka 5. Specjalność: Informatyka
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Kierunek:Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia
 :Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia Podstawy prawne. 1 15 1 Podstawy ekonomii. 1 15 15 2 Metody uczenia się i studiowania. 1 15 1 Środowisko programisty. 1 30 3 Komputerowy
:Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia Podstawy prawne. 1 15 1 Podstawy ekonomii. 1 15 15 2 Metody uczenia się i studiowania. 1 15 1 Środowisko programisty. 1 30 3 Komputerowy
Oprogramowanie komputerów
 Oprogramowanie komputerów wer. 10 z drobnymi modyfikacjami! Wojciech Myszka 2018-11-04 20:13:59 +0100 Od czego zależy szybkość komputerów? Od czego zależy szybkość komputerów? 1. Częstość zegara. Od czego
Oprogramowanie komputerów wer. 10 z drobnymi modyfikacjami! Wojciech Myszka 2018-11-04 20:13:59 +0100 Od czego zależy szybkość komputerów? Od czego zależy szybkość komputerów? 1. Częstość zegara. Od czego
Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne. Wykład Ćwiczenia
 Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 2016/2017 Język wykładowy: Polski Semestr 1 IIN-1-103-s
Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 2016/2017 Język wykładowy: Polski Semestr 1 IIN-1-103-s
Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f)
 i częstotliwości (f)") Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW)
") Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Magistrala. Magistrala (ang. Bus) służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.
 służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.") Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Klaster obliczeniowy
 Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
SUPERKOMPUTER OKEANOS BADAWCZE GRANTY OBLICZENIOWEWE
 SUPERKOMPUTER OKEANOS BADAWCZE GRANTY OBLICZENIOWEWE SUPERKOMPUTER OKEANOS Z początkiem lipca 2016 roku ICM UW udostępni naukowcom superkomputer Okeanos system wielkoskalowego przetwarzania Cray XC40.
SUPERKOMPUTER OKEANOS BADAWCZE GRANTY OBLICZENIOWEWE SUPERKOMPUTER OKEANOS Z początkiem lipca 2016 roku ICM UW udostępni naukowcom superkomputer Okeanos system wielkoskalowego przetwarzania Cray XC40.
Systemy operacyjne. Wprowadzenie. Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Architektura komputerów II - opis przedmiotu
 Architektura komputerów II - opis przedmiotu Informacje ogólne Nazwa przedmiotu Architektura komputerów II Kod przedmiotu 11.3-WI-INFP-AK-II Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki
Architektura komputerów II - opis przedmiotu Informacje ogólne Nazwa przedmiotu Architektura komputerów II Kod przedmiotu 11.3-WI-INFP-AK-II Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Podstawy programowania obliczeń równoległych
 Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Historia modeli programowania
 Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu
Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu