Programowanie procesorów graficznych GPGPU
|
|
|
- Stanisława Popławska
- 10 lat temu
- Przeglądów:
Transkrypt
1 Programowanie procesorów graficznych GPGPU 1

2 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja potoku przetwarzania grafiki 3D (OpenGL, DirectX) vertex shaders pixel shaders procesory graficzne 3D XXI wiek programowalne układy graficzne (programmable shaders) język Cg początek GPGPU 2
 język Cg")
3 GPGPU historia 3
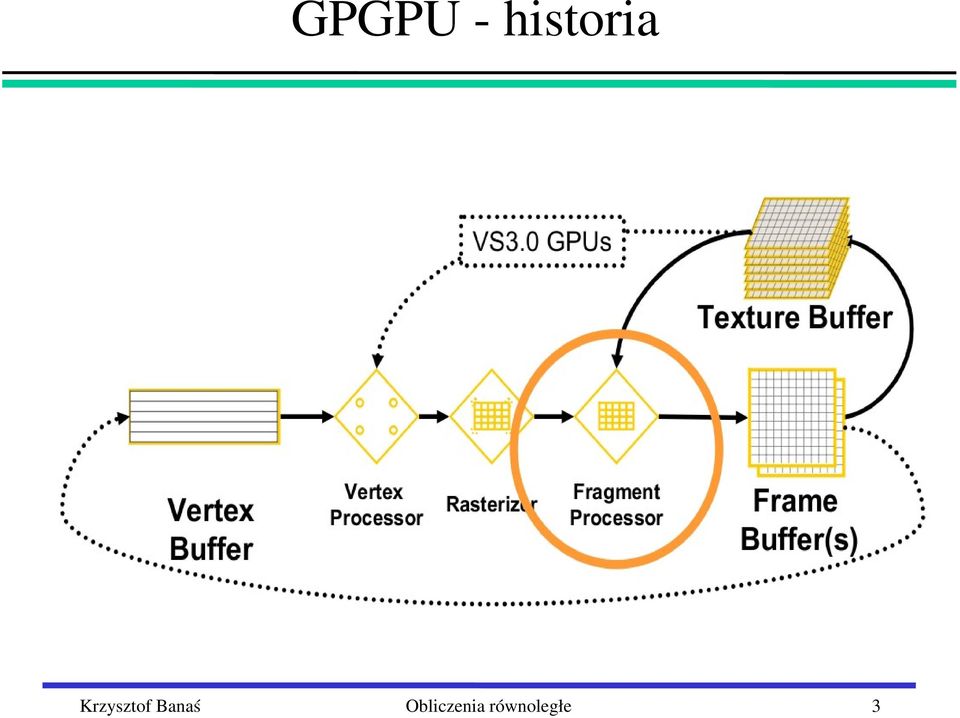

4 GPGPU historia 4
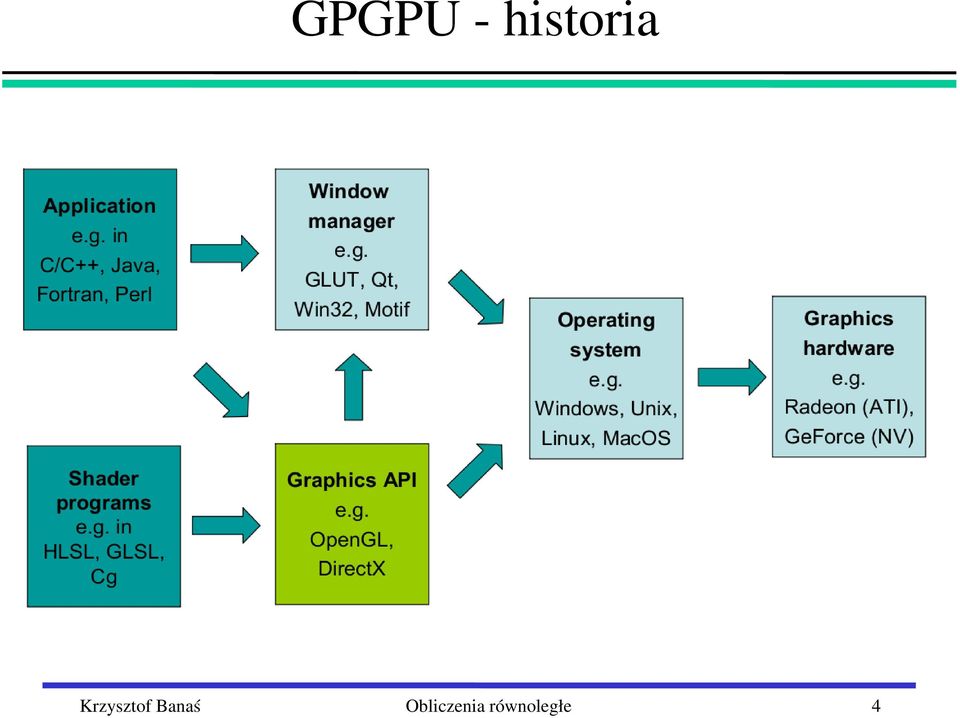

5 GPGPU historia 5
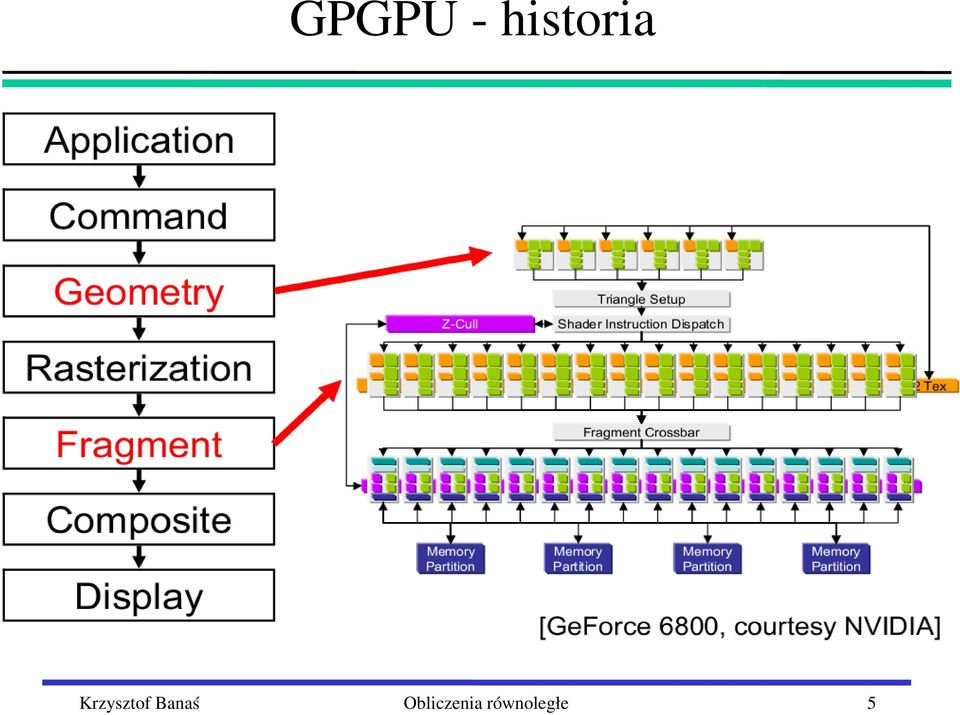
6 GPGPU Listopad 2006: architektura Tesla ujednolicona architektura, zamiast pixel shaders i vertex shaders standardowe skalarne procesory (nazywane obecnie rdzeniami CUDA CUDA cores ) procesor G80 karta graficzna NVIDIA GeForce 8800 model programowania CUDA (Compute Unified Device Architecture) środowisko programowania C for CUDA 6
 środowisko programowania")
7 TESLA architecture CUDA G

8 CUDA 8

9 GPGPU historia 9
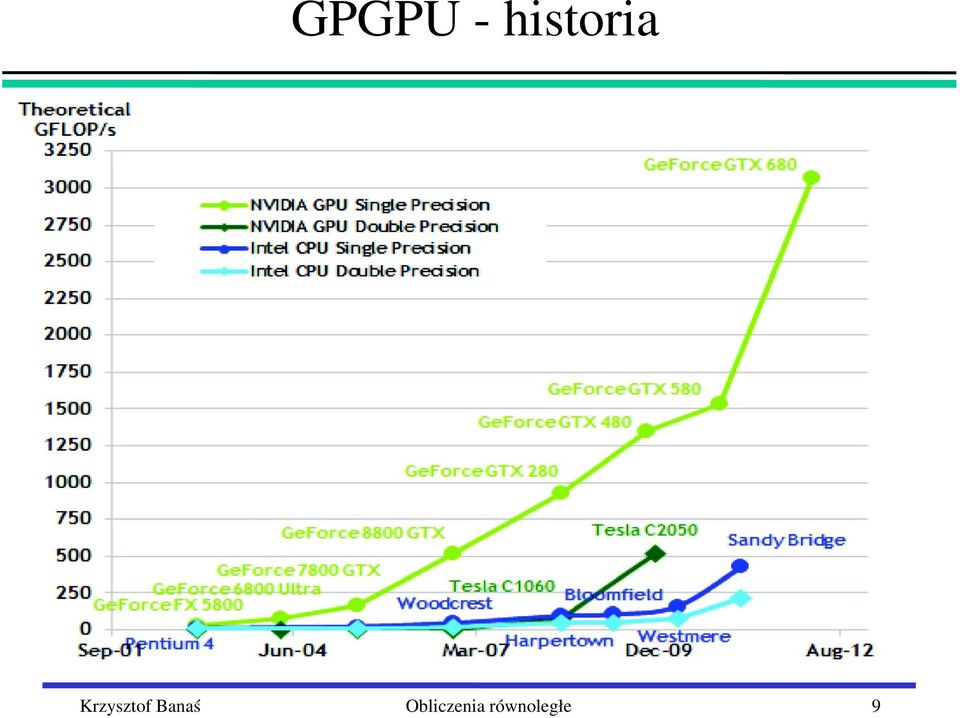
10 GPGPU historia 10
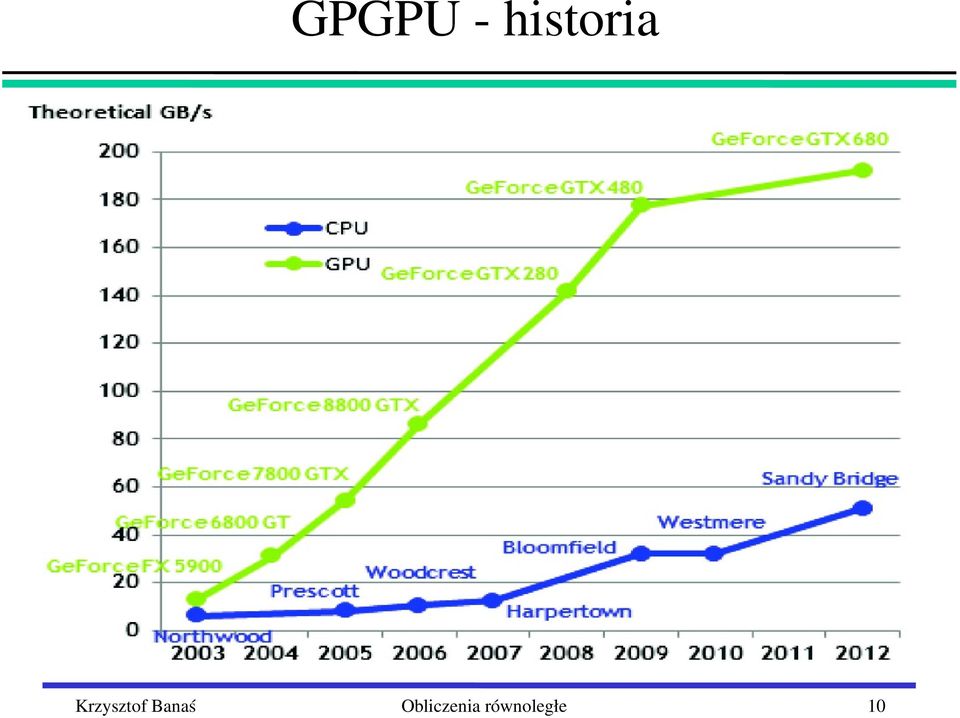
11 GPGPU Programowanie ogólnego przeznaczenia na procesorach graficznych (GPGPU) nowe narzędzia zbliżone do narzędzi programowania równoległego na CPU rozszerzenia C + biblioteki CUDA, OpenCL dyrektywy OpenACC, OpenMP for accelerators model przetwarzania wyrażany w kategoriach zbliżonych do tradycyjnych rdzenie jako elementy przetwarzania hierarchia pamięci rejestry pamięć lokalna (nowość zarządzana z poziomu programu!) pamięć globalna (brak dostępu do pamięci dyskowej) 11

12 GPGPU Tworzenie programów GPGPU wykrycie współbieżności uwaga: masowa wielowątkowość opłacalność wykonywania na GPU tylko w przypadku wysokiego stopnia współbieżności (setki, tysiące wątków) odwzorowanie na architekturę uwaga: konieczność synchronizacji przy dostępie do pamięci GPU dobrze nadają się do obliczeń w stylu równoległości danych (te same obliczenia dla wielu egzemplarzy danych) duże możliwości konfiguracji obliczeń, a co za tym, idzie optymalizacji optymalizacja jawna (w ramach pojęć modelu programowania) optymalizacja niejawna (taka organizacja obliczeń, aby optymalnie wykorzystać elementy sprzętowe niewidoczne z poziomu modelu (języka, środowiska) programowania 12
 optymalizacja niejawna (taka organizacja obliczeń, aby optymalnie wykorzystać elementy sprzętowe niewidoczne z poziomu modelu (języka, środowiska)")
13 GPGPU Modele programowania GPGPU Obydwa modele wykorzystują język C i biblioteki CUDA pierwszy naprawdę popularny model programowania GPGPU OpenCL wzorowany na CUDA, dla szerszej grupy urządzeń (GPU, CPU, procesory heterogeniczne, akceleratory) kod dla GPU w języku będącym rozszerzeniem standardu C99 założenie istnienia kompilatora, przetwarzającego kod dla GPU konieczne wsparcie ze strony systemu operacyjnego, który pośredniczy w wykonaniu programu (m.in. poprzez sterownik karty graficznej) Wykonanie programu realizowane jest w modelu SPMD/SIMD(SIMT) ten sam program wykonywany jest przez wiele wątków synchronizowanych sprzętowo 13
 Wykonanie programu realizowane jest w modelu SPMD/SIMD(SIMT) ten sam program wykonywany jest przez wiele wątków")
14 GPGPU Kod programu dla GPU tradycyjnie nazywa się kernelem Model SPMD jest wprowadzany klasycznie poprzez identyfikatory wątków wątek na podstawie swojego identyfikatora może: zlokalizować dane, na których dokonuje przetwarzania dane[ f(my_id) ] wybrać ścieżkę wykonania programu if(my_id ==...){...} określić iteracje pętli, które ma wykonać for( i=f1(my_id); i< f2(my_id); i += f3(my_id) ){... } w tym aspekcie programowanie GPU jest zbliżone do modeli Pthreads i MPI Środowiska programowania GPU pozwalają na wykorzystanie liczb wątków rzędu milionów 14

15 GPGPU Specyfika programowania GPU: dwa poziomy organizacji obliczeń wątki realizują obliczenia grupy wątków umożliwiają synchronizacją pracy wątków poziom grup wątków można pominąć (np. dla programów zawstydzająco równoległych (embarrassingly parallel) ) dwupoziomowa hierarchia pamięci dostępna programiście: zmienne lokalne dla grupy wątków o szybkim dostępie zmienne globalne o powolnym dostępie istnieje jeszcze poziom rejestrów jak zwykle ukryty przed programistą 15

16 16
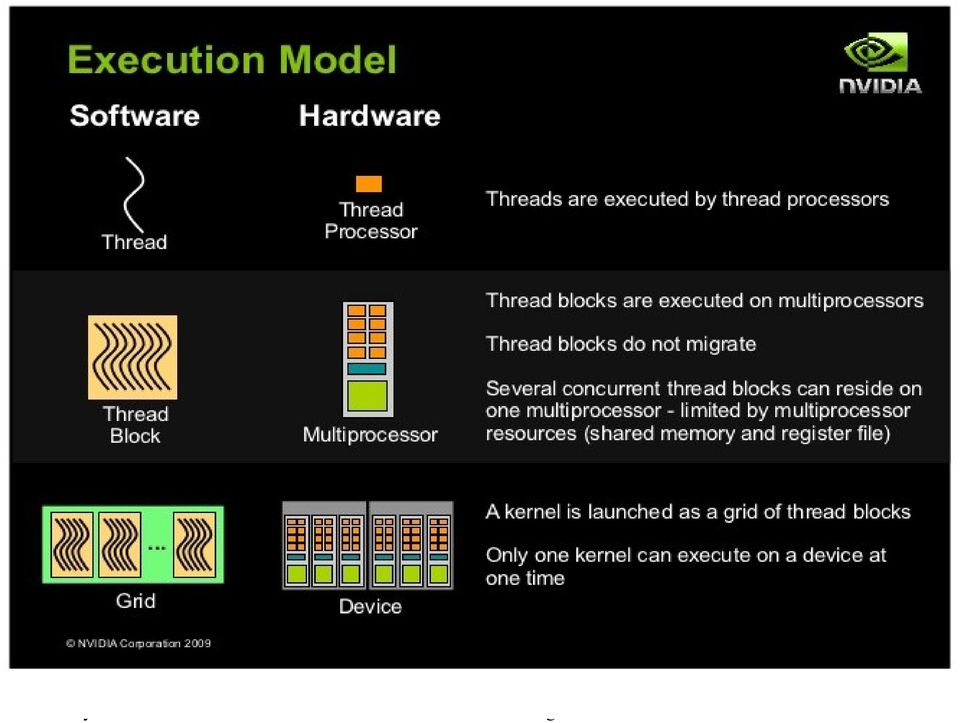
17 17

18 18

19 Przebieg obliczeń Model wykonania: Komunikacja: synchroniczny data parallel SPMD (wykorzystanie identyfikatora wątku do podziału zadań) asynchroniczny task parallel poprzez argumenty procedur poprzez pamięć wspólną Synchronizacja bariery 19

20 Przebieg obliczeń Alokacja i inicjowanie pamięci na urządzeniu Przesłanie kernela do urządzenia w OpenCL można dokonywać w locie kompilacji kodu z dostarczanych źródeł Zlecenie wykonania obliczeń Kopiowanie danych z pamięci urządzenia Dodatkowo OpenCL umożliwia realizacje fazy wstępnej, w której pobiera się dane o środowisku wykonania i dostosowuje wykonywany program do konkretnego środowiska (urządzenia) 20

21 Przykład kod CPU iloczyn macierz wektor kod GPU (CUDA) iloczyn macierz wektor 21
22 Przykład Przykład dodawania wektorów (OpenCL) dekompozycja zadania analiza wydajności wydajność przetwarzania wydajność dostępu do pamięci informacje o liczbie wymiarów przestrzeni wątków, liczbie wątków (globalnej oraz w pojedynczej grupie), liczbie grup oraz o identyfikatorze wątku: lokalnym (w grupie), globalnym, a także o identyfikatorze grupy: get_work_dim() get_global_id(dim_id), get_local_id(dim_id) get_global_size(dim_id), get_local_size(dim_id) get_num_groups(dim_id), get_group_id(dim_id) 22
23 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 1 jeden wątek na jeden element wektora wykorzystanie możliwości tworzenia milionów wątków zawstydzająco równoległy algorytm brak komunikacji, synchronizacji kernel void vecadd_1_kernel( global const float *a, global const float *b, global float *result) { int gid = get_global_id(0); result[gid] = a[gid] + b[gid]; } 23
24 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 2 wykorzystanie wariantów podziału danych blokowanie jeden wątek operuje na bloku danych kernel void vecadd_2_blocks_kernel(..., const int size, const int size_per_thread) { int gid = get_global_id(0); int index_start = gid * size_per_thread; int index_end = (gid+1) * size_per_thread; for (int i=index_start; i < index_end && i < size; i++) { result[i] = a[i]+b[i]; } } 24
25 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 3 wykorzystanie wariantów podziału danych podział cykliczny kolejne wątki z grupy operują na kolejnych elementach wektorów strategia niewłaściwa dla CPU, najlepsza dla GPU kernel void vecadd_3_cyclic_kernel(..., const int size) { int index_start = get_global_id(0); int index_end = size; int stride = get_local_size(0) * get_num_groups(0); for (int i=index_start; i < index_end; i+=stride) { result[i] = a[i]+b[i]; } } 25
26 Projektowanie kerneli przykład Prosty przykład programu dodawania wektorów dekompozycja danych wariant 3 wykorzystanie wariantów podziału danych podział cykliczny wykorzystanie typów wektorowych nie zawsze optymalne (zależy od GPU NVIDIA rdzenie skalarne, AMD wektorowe) kernel void vecadd_4_cyclic_vect_kernel( global const float4 *a, global const float4 *b, global float4 *result, const int size) { int index_start = 4 * get_global_id(0); int index_end = size/4; int stride = 4 * get_local_size(0) * get_num_groups(0); for (int i=index_start; i < index_end; i+=stride) { result[i] = a[i]+b[i]; } } 26
27 Analiza wydajności Analiza wydajności może być przeprowadzana ma dwa standardowe sposoby: wydajność względna klasycznie oznacza to przyspieszenie i efektywność jako funkcje liczby procesorów/rdzeni dla pojedynczego GPU trudno przeprowadzać takie analizy analizy porównujące wydajność CPU i GPU stwarzają wiele problemów metodologicznych i powinny być używane tylko jako pewne wskazówki wydajność bezwzględna procent teoretycznej maksymalnej wydajności uzyskany dla danego wykonania programu wydajność może być ograniczana przez wydajność przetwarzania lub wydajność transferu danych z/do pamięci (dla obliczeń na GPU powinno się uwzględnić szybkości transferu dla wszystkich poziomów pamięci) 27
28 Przykład paramerów GPU Przykład karty graficznej (laptop Dell Vostro 3450): AMD Radeon HD 6630M 6 CU 480 PE rejestrów wektorowych (128 bitowych) / CU 32 kb pamięci wspólnej (32 banki) / CU 8 kb L1 / CU, 256 kb L2 / GPU 480 Gflops 25,6 GB/s DDR3, 51,2 GDDR5 ok. 250 GB/s pamięć wspólna maksymalny rozmiar grupy 256 (cztery wavefronts ) maksymalna liczba wavefronts 248 / GPU 28
29 GPGPU 29
30 Dalszy rozwój Platformy GPGPU innych producentów Rozwój architektur NVIDIA Fermi, Kepler AMD Radeon 79xx Środowiska programowania AMD (ATI Radeon) CtM, Stream, Brook IBM (PowerXCell) Cell SDK OpenCL OpenACC, C++AMP, Renderscript Wzrost wydajności 30
31 Problemy GPGPU GPU wymagają specyficznych algorytmów masowa wielowątkowość zgodny dostęp do obszarów pamięci wspólnej mało komunikacji, synchronizacji Aplikacje dostosowane do GPU zyskują wiele Jest wiele aplikacji, które zyskują mało lub nic 31
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 GPGPU Modele programowania GPGPU CUDA pierwszy naprawdę popularny model programowania GPGPU OpenCL wzorowany na CUDA,
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 GPGPU Modele programowania GPGPU CUDA pierwszy naprawdę popularny model programowania GPGPU OpenCL wzorowany na CUDA,
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU
 Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU 1 GPGPU motywacja 2 GPGPU motywacja 3 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane
Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU 1 GPGPU motywacja 2 GPGPU motywacja 3 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
GRAFIKA KOMPUTEROWA. Rozwiązania sprzętowe i programowe. Przyspieszanie sprzętowe. Synteza i obróbka obrazu
 Synteza i obróbka obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Synteza i obróbka obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
GRAFIKA KOMPUTEROWA. Rozwiązania sprzętowe i programowe. Przyspieszanie sprzętowe. Synteza dźwięku i obrazu
 Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Programowanie równoległe Wprowadzenie do OpenCL. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH
 ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU
 Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Programowanie niskopoziomowe. dr inż. Paweł Pełczyński ppelczynski@swspiz.pl
 Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1
 Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Wstęp. Przetwarzanie równoległe. Krzysztof Banaś Obliczenia równoległe 1 Historia i pojęcia wstępne Obliczenia równoległe: dwa lub więcej procesów (wątków) jednocześnie współpracuje (komunikując się wzajemnie)
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Spis treści. I. Skuteczne. Od autora... Obliczenia inżynierskie i naukowe... Ostrzeżenia...XVII
 Spis treści Od autora..................................................... Obliczenia inżynierskie i naukowe.................................. X XII Ostrzeżenia...................................................XVII
Spis treści Od autora..................................................... Obliczenia inżynierskie i naukowe.................................. X XII Ostrzeżenia...................................................XVII
OpenGL - Open Graphics Library. Programowanie grafiki komputerowej. OpenGL 3.0. OpenGL - Architektura (1)
") OpenGL - Open Graphics Library Programowanie grafiki komputerowej Rados$aw Mantiuk Wydzia$ Informatyki Zachodniopomorski Uniwersytet Technologiczny! OpenGL: architektura systemu do programowania grafiki
OpenGL - Open Graphics Library Programowanie grafiki komputerowej Rados$aw Mantiuk Wydzia$ Informatyki Zachodniopomorski Uniwersytet Technologiczny! OpenGL: architektura systemu do programowania grafiki
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
XIII International PhD Workshop OWD 2011, October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH
 XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
XIII International PhD Workshop OWD 2011, 22 25 October 2011 REALIZACJA OBLICZEŃ W ARCHITEKTURZE MASOWO RÓWNOLEGŁEJ W HETEROGENICZNYCH SYSTEMACH CALCULATIONS IN THE MASSIVELY PARALLEL ARCHITECTURE IN HETEROGENEOUS
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Operacje grupowego przesyłania komunikatów. Krzysztof Banaś Obliczenia równoległe 1
 Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
5. Model komunikujących się procesów, komunikaty
 Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Przegląd architektury PlayStation 3
 Przegląd architektury PlayStation 3 1 Your Name Your Title Your Organization (Line #1) Your Organization (Line #2) Sony PlayStation 3 Konsola siódmej generacji Premiera: listopad 2006 33,5 mln sprzedanych
Przegląd architektury PlayStation 3 1 Your Name Your Title Your Organization (Line #1) Your Organization (Line #2) Sony PlayStation 3 Konsola siódmej generacji Premiera: listopad 2006 33,5 mln sprzedanych
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Zaawansowane programowanie w języku C++
 Kod szkolenia: Tytuł szkolenia: C/ADV Zaawansowane programowanie w języku C++ Dni: 3 Opis: Uczestnicy szkolenia zapoznają się z metodami wytwarzania oprogramowania z użyciem zaawansowanych mechanizmów
Kod szkolenia: Tytuł szkolenia: C/ADV Zaawansowane programowanie w języku C++ Dni: 3 Opis: Uczestnicy szkolenia zapoznają się z metodami wytwarzania oprogramowania z użyciem zaawansowanych mechanizmów
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Przyspieszanie sprzętowe
 Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złoŝonych obliczeń, szczególnie jeŝeli chodzi o generowanie płynnej
Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złoŝonych obliczeń, szczególnie jeŝeli chodzi o generowanie płynnej
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Wstęp do obliczeń równoległych na GPU
 Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Julia 4D - raytracing
 i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
i przykładowa implementacja w asemblerze Politechnika Śląska Instytut Informatyki 27 sierpnia 2009 A teraz... 1 Fraktale Julia Przykłady Wstęp teoretyczny Rendering za pomocą śledzenia promieni 2 Implementacja
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM OPENCL
 POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 85 Electrical Engineering 06 Wojciech PIETROWSKI* Grzegorz D. WIŚNIEWSKI Konrad GÓRNY WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM
POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 85 Electrical Engineering 06 Wojciech PIETROWSKI* Grzegorz D. WIŚNIEWSKI Konrad GÓRNY WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się