Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
|
|
|
- Roman Sobczyk
- 7 lat temu
- Przeglądów:
Transkrypt
1 Procesory wielordzeniowe (multiprocessor on a chip) 1
2 Procesory wielordzeniowe 2
3 Procesory wielordzeniowe 3

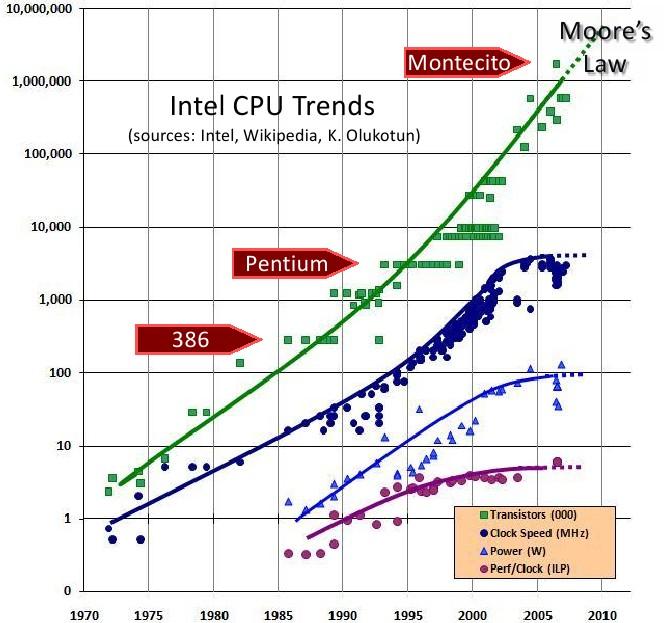
4 Konsekwencje prawa Moore'a 4

5 Procesory wielordzeniowe 5

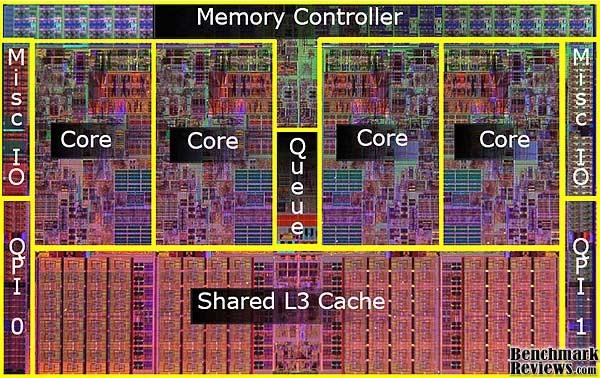
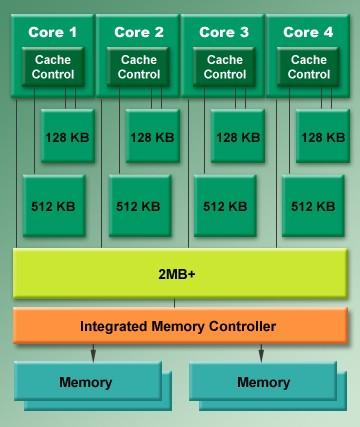
6 Intel Nehalem 6

7 Architektura Intel Nehalem 7
8 Procesory wielordzeniowe Problem podstawowy: wielowątkowy dostęp do hierarchii pamięci L1 prywatna dla rdzenia L2 prywatna lub w pewien sposób współdzielona L3 wspólna (jeśli jest) Problemy konkretne: spójność pamięci podręcznej wydajność dostępu minimalizacja liczby chybień cache oblivious algorithms false sharing i wspólna sterta dla wątków 8
9 Procesory wielordzeniowe Problemy szeregowania zadań dla procesorów wielordzeniowych afiniczność i lokalność odniesień do pamięci podział zadań i iteracji pętli uwzględniający afiniczność Systemy NUMA lokalne chybienia pamięci podręcznej odległe (zdalne, remote) chybienia pamięci podręcznej koszt false sharing 9

10 NUMA Architektura AMD Opteron 10
11 Pamięć podręczna Działanie pamięci podręcznej: strategie utrzymywania zgodności pamięci podręcznej (cache coherence protocols) write through każdy zapis do pamięci podręcznej jest przenoszony do pamięci głównej copy back zapis do pamięci podręcznej jest przenoszony do pamięci głównej przy podmianie linii (linia musi wiedzieć czy była zmieniona) inne, bardziej złożone np. MESI 11
12 Protokoły zgodności pamięci podręcznej protokoły katalogowe (directory protocols) istnieje katalog z informacją o zawartości pamięci podręcznej i centralny sterownik katalogu pośredniczący w wymianie danych protokoły podglądania (snoopy protocols) procesory podglądają stan pamięci podręcznych i rozgłaszają zmiany zapis z aktualizacją (procesor dokonujący zmianę rozgłasza ją i wszystkie procesory aktualizują swoje pamięci podręczne) zapis z unieważnieniem (procesor dokonujący zmiany unieważnia zawartość pamięci podręcznych innych procesorów); przykład MESI 12
13 Protokół MESI Blok w pamięci podręcznej może być w jednym z czterech stanów: M (modified): zmodyfikowany w pamięci podręcznej, różny od odpowiedniego bloku w pamięci głównej E (exclusive): wyłącznie w jednej pamięci podręcznej, zawartość identyczna jak w pamięci głównej S (shared): w kilku pamięciach podręcznych, zawartość identyczna jak w pamięci głównej I (invalid): unieważniony przez zmiany dokonane w innej pamięci podręcznej 13
14 Pamięć odległa (zdalna) Jednym z najpoważniejszych ograniczeń systemów jedno i wieloprocesorowych (wielordzeniowych) o jednorodnym dostępie do pamięci jest zbyt mała przepustowość połączenia pamięć procesory Ograniczenie to można usunąć wyposażając procesory (lub grupy procesorów rdzeni) w lokalne pamięci Łączna przepustowość pamięć procesor takich systemów staje się wtedy skalowalna rośnie wraz z rosnącą liczbą procesorów 14
15 Pamięć odległa (zdalna) Systemy z pamięciami lokalnymi procesorów są systemami o niejednorodnym dostępie do pamięci W programach równoległych pojawia się kolejny szczebel hierarchii pamięci oprócz lokalnej pamięci głównej, pamięć główna odległa (remote memory) Dostęp do pamięci odległej można uzyskać, albo bezpośrednio jeśli system operacyjny i środowisko programowania i realizacji udostępnia taką możliwość, albo poprzez wymianę informacji z innym procesorem, dla którego pamięć jest pamięcią lokalną 15
16 Pamięć odległa (zdalna) W przypadku bezpośredniego dostępu do pamięci odległej (np. w rozszerzeniach standardu OpenMP dla klastrów) system może umożliwiać istnienie danych globalnych i ich (niejawnych) lokalnych kopii Dla zwiększenia wydajności procesory mogą wykonywać operacje (w tym zapis) na swoich lokalnych kopiach danych Pojawia się wtedy, podobnie jak w przypadku pamięci podręcznej, problem utrzymania zgodności pomiędzy lokalnymi kopiami i danymi globalnymi 16
17 Pamięć odległa (zdalna) Czas dostępu do pamięci odległej jest zawsze znacznie dłuższy od czasu dostępu do pamięci lokalnej (rzędu mikrosekund, a nie nanosekund) Należy projektować algorytmy i ich odwzorowanie na procesory w taki sposób, aby minimalizować liczbę odniesień do pamięci odległej Czas realizacji dostępu do pamięci odległej uwzględnia się przy analizie wydajności obliczeń równoległych jako czas komunikacji 17
18 Pamięć odległa (zdalna) W przypadku programowania w modelu przesyłania komunikatów każde odniesienie do pamięci jest odniesieniem lokalnym, każde odniesienie do pamięci odległej odbywa się w sposób jawny poprzez wymianę komunikatów ułatwia to szacowanie wydajności programów w fazach projektowania, analizy i optymalizacji 18
 0.22 0.13 0.14 0.11 0.13 0.14 0.12 0.")
19 Wydajność pamięci STREAM (GB/s) mat_vec (sek.)
20 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane przewidywanie rozgałęzień wiele jednostek funkcjonalnych Dużo małych rdzeni prostsza budowa, krótsze potoki wykonanie w kolejności proste przewidywanie rozgałęzień mniej jednostek funkcjonalnych 20
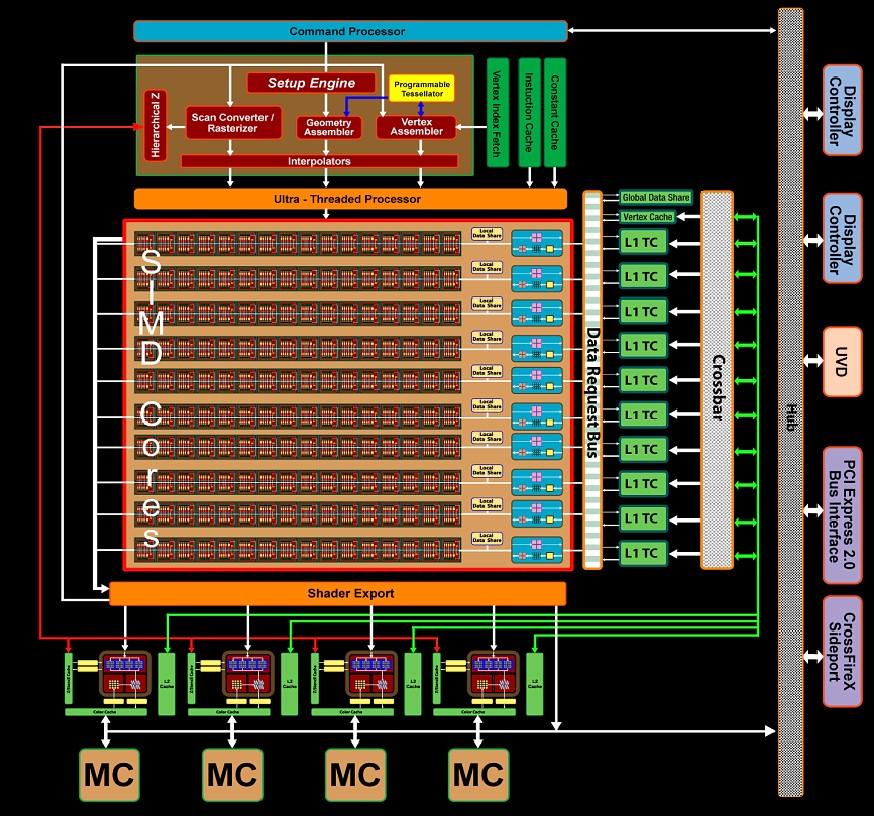
21 ATI FireStream 21

22 NVIDIA Tesla 22



23 NVIDIA Fermi 23


24 Architektury hybrydowe 24
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
METODY ELIMINACJI STUDENTÓW INFORMATYKI. Czyli co student INF-EKA powinien wiedzieć o MESI...
 METODY ELIMINACJI STUDENTÓW INFORMATYKI Czyli co student INF-EKA powinien wiedzieć o MESI... copyright Mahryanuss 2004 Data Cache Consistency Protocol Czyli po naszemu protokół zachowujący spójność danych
METODY ELIMINACJI STUDENTÓW INFORMATYKI Czyli co student INF-EKA powinien wiedzieć o MESI... copyright Mahryanuss 2004 Data Cache Consistency Protocol Czyli po naszemu protokół zachowujący spójność danych
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Architektura Systemów Komputerowych
 Architektura Systemów Komputerowych Wykład 9: Pamięć podręczna procesora jako warstwa hierarchii pamięci Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Zasada
Architektura Systemów Komputerowych Wykład 9: Pamięć podręczna procesora jako warstwa hierarchii pamięci Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Zasada
Organizacja pamięci współczesnych systemów komputerowych : pojedynczy procesor wielopoziomowa pamięć podręczna pamięć wirtualna
 Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Rys. 1. Podłączenie cache do procesora.
 Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Pamięć wirtualna. Przygotował: Ryszard Kijaka. Wykład 4
 Pamięć wirtualna Przygotował: Ryszard Kijaka Wykład 4 Wstęp główny podział to: PM- do pamięci masowych należą wszelkiego rodzaju pamięci na nośnikach magnetycznych, takie jak dyski twarde i elastyczne,
Pamięć wirtualna Przygotował: Ryszard Kijaka Wykład 4 Wstęp główny podział to: PM- do pamięci masowych należą wszelkiego rodzaju pamięci na nośnikach magnetycznych, takie jak dyski twarde i elastyczne,
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
System pamięci. Pamięć podręczna
 System pamięci Pamięć podręczna Technologia Static RAM (SRAM) Ułamki nanosekund, $500-$1000 za GB (2012r) Dynamic RAM (DRAM) 50ns 70ns, $10 $20 za GB Pamięci Flash 5000-50000 ns, $0.75 - $1 Dyski magnetyczne
System pamięci Pamięć podręczna Technologia Static RAM (SRAM) Ułamki nanosekund, $500-$1000 za GB (2012r) Dynamic RAM (DRAM) 50ns 70ns, $10 $20 za GB Pamięci Flash 5000-50000 ns, $0.75 - $1 Dyski magnetyczne
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Rozproszona pamiêæ dzielona - 1
 Rozproszona pamiêæ dzielona - 1 Wieloprocesor - wiele ma dostêp do wspólnej pamiêci g³ównej Wielokomputer - ka dy ma w³asn¹ pamiêæ g³ówn¹; nie ma wspó³dzielenia pamiêci Aspekt sprzêtowy: Skonstruowanie
Rozproszona pamiêæ dzielona - 1 Wieloprocesor - wiele ma dostêp do wspólnej pamiêci g³ównej Wielokomputer - ka dy ma w³asn¹ pamiêæ g³ówn¹; nie ma wspó³dzielenia pamiêci Aspekt sprzêtowy: Skonstruowanie
Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP
 Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP Wykład przetwarzanie równoległe cz.3 NUMA versus SMP systemy wieloprocesorowe NUMA- każdy procesor jest bliżej
Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP Wykład przetwarzanie równoległe cz.3 NUMA versus SMP systemy wieloprocesorowe NUMA- każdy procesor jest bliżej
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Systemy wieloprocesorowe. Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010
 Systemy wieloprocesorowe Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010 Pożądane cechy aplikacji wielowątkowych Skalowalna wielowątkowość
Systemy wieloprocesorowe Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010 Pożądane cechy aplikacji wielowątkowych Skalowalna wielowątkowość
Wykład 13. Systemy wieloprocesorowe. Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB
 Wykład 13 Systemy wieloprocesorowe Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Ograniczenia w zwiększaniu szybkości procesorów Ograniczenie związane z prędkością światła:
Wykład 13 Systemy wieloprocesorowe Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Ograniczenia w zwiększaniu szybkości procesorów Ograniczenie związane z prędkością światła:
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]
![Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]](/thumbs/57/40653782.jpg "Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]") Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Weryfikacja protokołu zgodności cachu COMA
 Weryfikacja protokołu zgodności cachu COMA Krzysztof Nozderko kn201076@students.mimuw.edu.pl 8 maj 2006 Architektura systemu Communication Bus Wiele procesorów Każdy procesor ma swoja lokalna pamięć (cache)
Weryfikacja protokołu zgodności cachu COMA Krzysztof Nozderko kn201076@students.mimuw.edu.pl 8 maj 2006 Architektura systemu Communication Bus Wiele procesorów Każdy procesor ma swoja lokalna pamięć (cache)
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016
 Rafał Walkowiak Wersja: wiosna 2016") OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016
 Rafał Walkowiak Wersja: jesień 2016") PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
Wydajność komunikacji grupowej w obliczeniach równoległych. Krzysztof Banaś Obliczenia wysokiej wydajności 1
 Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
ARCHITEKTURA KOMPUTERÓW Bufory pamięci bufor zawiera kopie aktualnie przetwarzanych danych
 Bufory pamięci bufor zawiera kopie aktualnie przetwarzanych danych M(AT) M(AH+2) M(AH+1) M(AH) M(A+N+1) M(A+N) M(A+2) M(A+1) M(A+0) M(A 1) AT AH A 2 A N A 0 A 1 M(A 2) M(A N) M(A 0) M(A 1) M(A N) M(A 1)
Bufory pamięci bufor zawiera kopie aktualnie przetwarzanych danych M(AT) M(AH+2) M(AH+1) M(AH) M(A+N+1) M(A+N) M(A+2) M(A+1) M(A+0) M(A 1) AT AH A 2 A N A 0 A 1 M(A 2) M(A N) M(A 0) M(A 1) M(A N) M(A 1)
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Wykład 13. Linux 2.0.x na maszynach SMP. Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB
 Wykład 13 Linux 2.0.x na maszynach SMP Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB Architektura SMP Skrót od słów Symmetric Multiprocessing (Symetryczne Przetwarzenie Wieloprocesorowe)
Wykład 13 Linux 2.0.x na maszynach SMP Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB Architektura SMP Skrót od słów Symmetric Multiprocessing (Symetryczne Przetwarzenie Wieloprocesorowe)
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Spis treúci. Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1. Przedmowa... 9. Wstęp... 11
 Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
Przetwarzanie równoległesprzęt
 Przetwarzanie równoległesprzęt 1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: przed wykładem 2013/2014 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący
Przetwarzanie równoległesprzęt 1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: przed wykładem 2013/2014 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Wydajność obliczeń a architektura procesorów
 Wydajność obliczeń a architektura procesorów 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych zadań, np.: liczba rozkazów na sekundę
Wydajność obliczeń a architektura procesorów 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych zadań, np.: liczba rozkazów na sekundę
Programowanie współbieżne Wykład 7. Iwona Kochaoska
 Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Programowanie mikroprocesorów jednoukładowych
 Programowanie mikroprocesorów jednoukładowych Pamięć cache Mariusz Naumowicz Programowanie mikroprocesorów jednoukładowych 11 września 2017 1 / 22 Plan I Cache Mariusz Naumowicz Programowanie mikroprocesorów
Programowanie mikroprocesorów jednoukładowych Pamięć cache Mariusz Naumowicz Programowanie mikroprocesorów jednoukładowych 11 września 2017 1 / 22 Plan I Cache Mariusz Naumowicz Programowanie mikroprocesorów
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Programowanie współbieżne Rozwiązywanie problemu wzajemnego wykluczania. Rafał Skinderowicz
 Programowanie współbieżne Rozwiązywanie problemu wzajemnego wykluczania Rafał Skinderowicz Wady protokołów WW z zastosowaniem atomowych rejestrów RW Rozwiązywanie problemu wzajemnego wykluczania za pomocą
Programowanie współbieżne Rozwiązywanie problemu wzajemnego wykluczania Rafał Skinderowicz Wady protokołów WW z zastosowaniem atomowych rejestrów RW Rozwiązywanie problemu wzajemnego wykluczania za pomocą
Schematy zarzadzania pamięcia
 Schematy zarzadzania pamięcia Segmentacja podział obszaru pamięci procesu na logiczne jednostki segmenty o dowolnej długości. Postać adresu logicznego: [nr segmentu, przesunięcie]. Zwykle przechowywana
Schematy zarzadzania pamięcia Segmentacja podział obszaru pamięci procesu na logiczne jednostki segmenty o dowolnej długości. Postać adresu logicznego: [nr segmentu, przesunięcie]. Zwykle przechowywana
Wstęp do informatyki. System komputerowy. Magistrala systemowa. Architektura komputera. Cezary Bolek
 Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Wstęp do informatyki Architektura komputera Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki System komputerowy systemowa (System Bus) Pamięć operacyjna ROM,
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
System pamięci. Pamięć podręczna
 System pamięci Pamięć podręczna Technologia Static RAM (SRAM) Ułamki nanosekund, $500-$1000 za GB (2012r) Dynamic RAM (DRAM) 50ns 70ns, $10 $20 za GB Pamięci Flash 5000-50000 ns, $0.75 - $1 Dyski magnetyczne
System pamięci Pamięć podręczna Technologia Static RAM (SRAM) Ułamki nanosekund, $500-$1000 za GB (2012r) Dynamic RAM (DRAM) 50ns 70ns, $10 $20 za GB Pamięci Flash 5000-50000 ns, $0.75 - $1 Dyski magnetyczne
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Architektura komputerów
 Architektura komputerów Tydzień 9 Pamięć operacyjna Właściwości pamięci Położenie Pojemność Jednostka transferu Sposób dostępu Wydajność Rodzaj fizyczny Własności fizyczne Organizacja Położenie pamięci
Architektura komputerów Tydzień 9 Pamięć operacyjna Właściwości pamięci Położenie Pojemność Jednostka transferu Sposób dostępu Wydajność Rodzaj fizyczny Własności fizyczne Organizacja Położenie pamięci
Magistrala systemowa (System Bus)
") Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
Cezary Bolek cbolek@ki.uni.lodz.pl Uniwersytet Łódzki Wydział Zarządzania Katedra Informatyki systemowa (System Bus) Pamięć operacyjna ROM, RAM Jednostka centralna Układy we/wy In/Out Wstęp do Informatyki
architektura komputerów w. 7 Cache
 architektura komputerów w. 7 Cache Pamięci cache - zasada lokalności Program używa danych i rozkazów, które były niedawno używane - temporal locality kody rozkazów pętle programowe struktury danych zmienne
architektura komputerów w. 7 Cache Pamięci cache - zasada lokalności Program używa danych i rozkazów, które były niedawno używane - temporal locality kody rozkazów pętle programowe struktury danych zmienne
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017
 Rafał Walkowiak Wersja: wiosna 2017") OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2017 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego