CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (
|
|
|
- Beata Lis
- 9 lat temu
- Przeglądów:
Transkrypt
1 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA ( 1

2 Architektura karty graficznej W porównaniu z tradycyjnym procesorem karta graficzna ma stosunkowo prosty moduł kontrolny, który jest silnie zrównoleglony. Dodatkową cechą charakterystyczną jest duża liczba jednostek obliczeniowych i relatywnie mniej pamięci cache.

3 Potencjał obliczeniowy Uwaga: rysunek przedstawia TEORETYCZNE możliwości sprzętu.
4 Przepustowość pamięci Uwaga: rysunek przedstawia TEORETYCZNE możliwości sprzętu.

5 Wady i zalety Zalety Bardzo dobry stosunek ceny do (potencjalnej) szybkości. Szybki rozwój sprzętu. Rozwojowa technologia. Wady Konieczność przepisania kodu problem przenośności. Uzyskanie rzeczywistej wydajności zbliżonej do teoretycznych możliwości sprzętu wymaga dużo pracy.
 OpenCL (Open Computing Language) szkielet do aplikacji na heterogenicznych platformach z CPU, GPU, DSP. (Język oparty o C99 i API).")
6 Technologie CUDA (od Compute Unified Device Architecture) platforma programistyczna i model programowania stworzony przez firmę NVIDIA. (C/C++, Fortran,...) OpenCL (Open Computing Language) szkielet do aplikacji na heterogenicznych platformach z CPU, GPU, DSP. (Język oparty o C99 i API). DirectCompute API dla Windows (Vista, 7, 8) wspierane przez Microsoft, część DirectX.
7 Dojrzałość CUDA wydaje się być rozwiązaniem najbardziej dojrzałym: powstała w 2006 roku ( upubliczniona dla MS Windows i Linuksa); obecna wersja to 5.0 (październik 2012); wsparcie dla wielu języków; zaimplementowane liczne biblioteki.
8 CUDA Specyfikacja architektury urządzenia pozwala wprowadzić drobnoziarnistą równoległość danych (Pcam) wątki, pozwala zoptymalizować współpracę wątków (pcam) grupy wątków, pozwala transparentnie mapować strukturę programu na architekturę urządzenia (pcam). Model programistyczny zbiór rozszerzeń/restrykcji/konwencji dla języków programowania, biblioteki.
 wykonywanych na raz przez SM (w 4 cyklach zegara), do 24 aktywnych warpów w jednym SM, wątki współdzielą część pamięci, każdy wątek ma własną pamięć")
9 Streaming Multiprocesor SM podstawowa jednostka architektury karty 8 skalarnych procesorów, wszystkie mogą działać (lub spać) równocześnie, przydział instrukcji za darmo, do 32 wątków (warp) wykonywanych na raz przez SM (w 4 cyklach zegara), do 24 aktywnych warpów w jednym SM, wątki współdzielą część pamięci, każdy wątek ma własną pamięć rejestrową.

10 Architektura GPU dla programu CPU

11 Skalowalność Użytkownik (programista) projektuje sieć wątków dopasowaną do danych. Sprzęt (karta) dopasowuje bloki do aktualnej architektury.
12 Przykład (1) oer:~/downloads/nvidia_cuda 5.0_Samples/bin/linux/release>./deviceQuery [...] Device 0: "GeForce 9800 GT" CUDA Driver Version / Runtime Version 5.0 / 5.0 CUDA Capability Major/Minor version number: 1.1 Total amount of global memory: 1023 MBytes ( bytes) (14) Multiprocessors x ( 8) CUDA Cores/MP: 112 CUDA Cores GPU Clock rate: 1500 MHz (1.50 GHz) Memory Clock rate: 900 Mhz Memory Bus Width: 256 bit Max Texture Dimension Size (x,y,z) 1D=(8192), 2D=(65536,32768), 3D=(2048,2048,2048) Max Layered Texture Size (dim) x layers 1D=(8192) x 512, 2D=(8192,8192) x 512 Total amount of constant memory: bytes Total amount of shared memory per block: bytes Total number of registers available per block: 8192 Warp size: 32 Maximum number of threads per multiprocessor: 768 Maximum number of threads per block: 512 Maximum sizes of each dimension of a block: 512 x 512 x 64 Maximum sizes of each dimension of a grid: x x 1 Maximum memory pitch: bytes Texture alignment: 256 bytes Concurrent copy and kernel execution: Yes with 1 copy engine(s) Run time limit on kernels: Yes Integrated GPU sharing Host Memory: No Support host page locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Disabled Device supports Unified Addressing (UVA): No Device PCI Bus ID / PCI location ID: 1 / 0 [...] 1: Tesla
13 Przykład (2) ~/cuda/bin/linux/release]./devicequery [...] Detected 4 CUDA Capable device(s) Device 0: "Tesla C2070" CUDA Driver Version / Runtime Version 5.0 / 5.0 CUDA Capability Major/Minor version number: 2.0 Total amount of global memory: 5375 MBytes ( bytes) (14) Multiprocessors x ( 32) CUDA Cores/MP: 448 CUDA Cores GPU Clock rate: 1147 MHz (1.15 GHz) Memory Clock rate: 1494 Mhz Memory Bus Width: 384 bit L2 Cache Size: bytes Max Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536,65535), 3D=(2048,2048,2048) Max Layered Texture Size (dim) x layers 1D=(16384) x 2048, 2D=(16384,16384) x 2048 Total amount of constant memory: bytes Total amount of shared memory per block: bytes Total number of registers available per block: Warp size: 32 Maximum number of threads per multiprocessor: 1536 Maximum number of threads per block: 1024 Maximum sizes of each dimension of a block: 1024 x 1024 x 64 Maximum sizes of each dimension of a grid: x x Maximum memory pitch: bytes Texture alignment: 512 bytes Concurrent copy and kernel execution: Yes with 2 copy engine(s) Run time limit on kernels: No Integrated GPU sharing Host Memory: No Support host page locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Enabled Device supports Unified Addressing (UVA): Yes Device PCI Bus ID / PCI location ID: 2 / 0 [...] 2: Fermi
14 CUDA Kernel Kernel (jądro) to specjalna funkcja, która może być uruchomiona przez wiele wątków na raz. Strukturę sieci wątków używanej do uruchomienia kernela określa się w momencie jego wywołania.

15 Przykład kernela W powyższym przykładzie kernel VecAdd jest uruchamiany na liniowej strukturze N wątków. Numer wątku jest dostępny wewnątrz kernela przy pomocy struktury (dim3) threadidx
16 Struktura wątków Zmienna threadidx ma trzy wymiary (x,y,z) do pozwala naturalnie rozpraszać obliczenia dla danych 1D, 2D i 3D Zmienna threadidx indeksuje wątki w ramach bloku, którego maksymalna wielkość nie może obecnie przekraczać 1024 (starsze karty mogą pozwalać na mniej). W ramach bloku wątki są numerowane zgodnie z zasadą x+y Dx + z Dx Dy

17 Przykład 2D

18 Sieć bloków wątków Bloki wątków można organizować w sieci. Kernel może zostać uruchomiony na dowolnej sieci bloków o identycznym kształcie. Podobnie jak blok, także i sieć może być 1-, 2- lub 3wymiarowa. Numer bloku jest dostępny wewnątrz kernela przez zmieną (strukturę dim3) blockidx.

19 Przykład sieci bloków (1) 256 (16x16) wątków w bloku, N/16 x N/16 = N2/256 bloków = 1 wątek na element tablicy.
 Bloki są wykonywane niezależnie, w dowolnym porządku, równolegle lub sekwencyjnie.")
20 threadidx.x blockdim.x blockdim.y Przykład sieci bloków (2) Bloki są wykonywane niezależnie, w dowolnym porządku, równolegle lub sekwencyjnie. Wątki w bloku współdzielą część pamięci (szybkiej). Wątki w bloku można synchronizować (lekka bariera).

21 Pamięć Wątki mogą korzystać z kilku obszarów pamięci: Każdy wątek ma przydzieloną prywatną pamięć lokalną Każdy blok wątków ma przydzielony wspólny obszar pamięci Wszystkie sieci wątków mogą korzystać z obszaru pamięci globalnej Wszystkie sieci wątków mogą też czytać pamięć stałą i pamięć tekstur.

22 Model programu Model programu CUDA przypomina trochę model OpenMP: części równoległe wykonywane na urządzeniu CUDA przeplatają się z kodem sekwencyjnym wykonywanym przez procesor. Urządzenie CUDA można traktować jako ko-procesor posiadający własną pamięć. Kopiowanie danych pomiędzy pamięcią procesora i pamięcią karty może być wąskim gardłem programu.
.")
23 Program Pamięć karty może być dostępna na dwa sposoby. Przy pierwszym (dostęp liniowy) jest alokowana przez cudamalloc i zwalniana za pomocą cudafree. Adres jest 32b dla urządzeń 1.x i 40b dla urządzeń 2.x i nowszych (można używać wskaźników pomiędzy adresami). Kopiowanie danych na/z urządzenia za pomocą cudamemcpy.
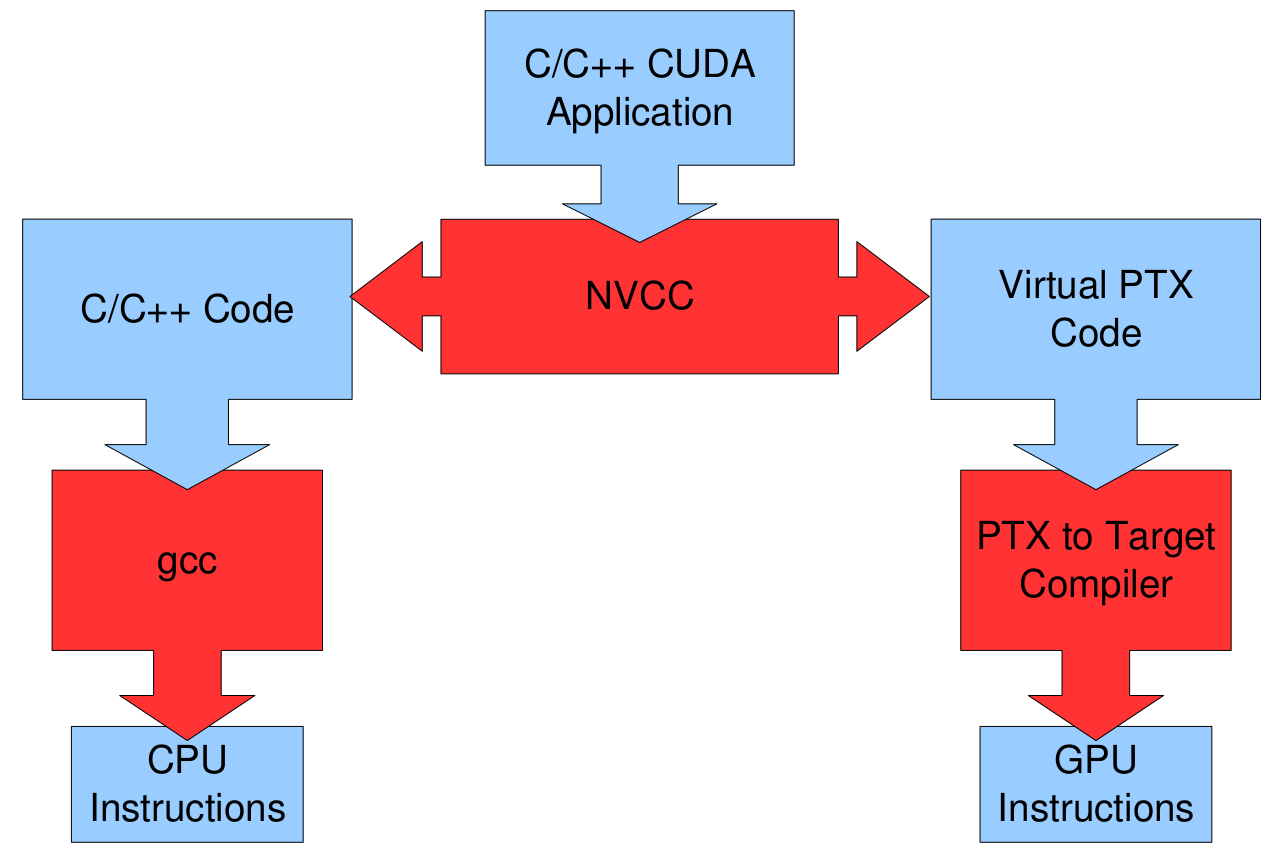
24 Kompilacja (JIT)
25 Efektywność (szybkość) Maksymalizacja zrównoleglenia Aplikacja (w miarę możliwości asynchronicznie) Urządzenie CUDA (liczba bloków == liczba MP, użycie strumieni) Multiprocesor (aktywne warpy) Optymalizacja dostępu do pamięci Jak najmniej transferów host urządzenie Użycie szybkiej pamięci (shared, cache) Dopasowanie danych do struktury pamięci Optymalizacja użycia instrukcji Użycie lekkich instrukcji/funkcji Minimalizacja zróżnicowania wątków Minimalizacja zróżnicowania używanych instrukcji
26 Zrównoleglenie aplikacja Równoległe działanie hosta i urządzenia Nakładanie transferu danych i kerneli Równoległy transfer danych Strumienie Zdarzenia
27 Równoległe działanie hosta i urządzenia Następujące funkcje są wykonywane asynchronicznie Uruchamianie kerneli Kopiowanie danych w ramach jednego urządzenia Kopiowanie host urządzenie porcji danych <64kB Asynchroniczne funkcje kopiujące (xxxasync) Ustawianie wartości w pamięci Kernele uruchamiane są synchronicznie pod debuggerem, profilerem, przy kontroli pamięci i na urządzeniach 1.x. Można zablokować asynchroniczne uruchamianie kerneli przez ustawienie zmiennej środowiskowej CUDA_LAUNCH_BLOCKING=1
28 Równoległe działanie urządzenia w skali makro (1) Od urządzeń 1.1 kopiowanie danych z/na host może być wykonywane równolegle z wykonywaniem kerneli. Można sprawdzić, czy urządzenie umożliwia to przez wartość właściwości asyncenginecount (0 nie, dodatnie tak). W urządzeniach 1.x dotyczy to tylko liniowych danych. Od urządzeń 2.x wiele urządzeń potrafi kopiować z i na urządzenie równolegle. Można sprawdzić, czy urządzenie umożliwia to przez wartość właściwości asyncenginecount (2 i więcej tak).
29 Równoległe działanie urządzenia w skali makro (2) Od urządzeń 2.x wiele kerneli może być uruchamianych równolegle na tym samym urządzeniu. Można sprawdzić, czy urządzenie umożliwia to przez wartość właściwości concurrentkernels (1 tak). Liczba równoległych kerneli jest ograniczona do 16 (32 dla urządzeń 3.5 i nowszych). Ograniczeniem może też być pamięć używana przez kernel. Wszystkie rónoległe kernele muszą należeć do tego samego kontekstu (CUDA context ~ proces dla CPU).
30 Strumienie Strumień (stream) to sekwencja poleceń. Domyślnie istnieje jeden strumień o numerze 0. Można tworzyć dodatkowe strumienie i używać ich numerów, tworząc w ten sposób równoległe sekwencje poleceń.

31 Strumienie przykład (1) Dwa strumienie, każdy z nich kopiuje z hosta na urządzenie size danych, uruchamia MyKernel dla swoich danych, kopiuje dane na host. Ten kod będzie działał na kartach, które obsługują równoległy transfer danych.
32 Synchronizacja strumieni Jawna zestaw funkcji cudadevicesynchronize() cudastreamsynchronize() cudastream WaitEvent() cudastreamquery() Niejawna Alokacja pamięci na hoscie (cudamalloc) Alokacja/zapis/kopiowanie na urządzeniu Polecenie CUDA dla strumienia 0 Zmiana konfiguracji pamięci w urządzeniach 2.x

33 Wywołania wsteczne Funkcja MyCallback zostanie uruchomiona po zakończeniu wszystkich operacji na strumieniu uruchomionych przed rejestracją wywołania wstecznego.

34 Zdarzenia Zdarzenia są rejestrowane asynchronicznie w strumieniach Zdarzenia są kończone w momencie, gdy skończą się wszystkie zadania i komendy strumienia poprzedzające rejestrację zdarzenia. Zdarzenia w strumieniu 0 są kończone, gdy skończą się wszystkie zadania i komendy we wszystkich strumieniach.

35 Strumienie przykład (2) Dwa strumienie, każdy z nich kopiuje z hosta na urządzenie size danych, uruchamia MyKernel dla swoich danych, kopiuje dane na host. Ten kod będzie działał na kartach, które obsługują równoległy transfer danych i działanie kerneli.
36 Optymalizacja dostępu do pamięci urządzenia Pamięć współdzielona przez blok jest znacznie szybsza, niż pamięć globalna. Odpowiednia organizacja wątków i wykorzystanie pamięci współdzielonej może bardzo znacznie przyspieszyć kod.

37 Mnożenie macierzy (1)

38 Mnożenie macierzy (2.1)

39 Mnożenie macierzy (2.2)

40 Naiwnie Pamięć współdzielona
41 Transpozycja macierzy (1) #define NN (4096) int main(int args, char** vargs) { const int HEIGHT = NN; const int WIDTH = NN; const int SIZE = WIDTH * HEIGHT * sizeof(float); cudaevent_t start, stop; cudaeventcreate(&start); cudaeventcreate(&stop); dim3 blockdim(block_dim,block_dim); dim3 griddim(width / blockdim.x, HEIGHT / blockdim.y); float* m = (float*)malloc(size); float* md = NULL; cudaeventrecord(start, 0); cudamalloc((void**)&md, SIZE); cudamemcpy(md, m, SIZE, cudamemcpyhosttodevice ); float* td = NULL; cudamalloc((void**)&td, SIZE); global void transpose_naive(float *odata, float* idata, int w, int h) { unsigned int x = blockdim.x * blockidx.x + threadidx.x; unsigned int y = blockdim.y * blockidx.y + threadidx.y; if (x < w && y < h ) { transpose_naive<<<griddim, blockdim>>>(td, md, WIDTH, HEIGHT); unsigned int idx_in = x + w * y ; unsigned int idx_out = y + h * x; odata[idx_out] = idata[idx_in]; cudamemcpy(m, td, SIZE, cudamemcpydevicetohost); } } cudaeventrecord(stop, 0); cudaeventsynchronize(stop); float elapsedtime; cudaeventelapsedtime(&elapsedtime, start, stop); cudaeventdestroy(start); cudaeventdestroy(stop); ms printf( "Time=%g\n", elapsedtime ); return 0; }
42 Transpozycja macierzy (2) global void transpose(float *odata, float *idata, int w, int h) { shared float block[block_dim][block_dim+1]; // read the matrix tile into shared memory unsigned int x = blockidx.x * BLOCK_DIM + threadidx.x; unsigned int y = blockidx.y * BLOCK_DIM + threadidx.y; if((x < w ) && (y < h )) { unsigned int index_in = y * w + x ; block[threadidx.y][threadidx.x] = idata[index_in]; } syncthreads(); // write the transposed matrix tile to global memory x = blockidx.y * BLOCK_DIM + threadidx.x; y = blockidx.x * BLOCK_DIM + threadidx.y; if((x < h ) && (y < w )) { unsigned int index_out = y * h + x ; odata[index_out] = block[threadidx.x][threadidx.y]; } }
43 Transpozycja macierzy (3) global void transpose(float *odata, float *idata, int w, int h) { shared float block[block_dim][block_dim+1]; // read the matrix tile into shared memory unsigned int x = blockidx.x * BLOCK_DIM + threadidx.x; unsigned int y = blockidx.y * BLOCK_DIM + threadidx.y; if((x < w ) && (y < h )) { unsigned int index_in = y * w + x ; block[threadidx.y][threadidx.x] = idata[index_in]; } syncthreads(); // write the transposed matrix tile to global memory x = blockidx.y * BLOCK_DIM + threadidx.x; y = blockidx.x * BLOCK_DIM + threadidx.y; if((x < h ) && (y < w )) { unsigned int index_out = y * h + x ; odata[index_out] = block[threadidx.x][threadidx.y]; } } ms
44 Transpozycja na różnych zdolności obliczeniowych oer:~/pliki/dydaktyka/prir/prir/programy/cuda>./a.out Time of copy kernel= Time of transpose_naive kernel= Time of transpose kernel= oer:~/pliki/dydaktyka/prir/prir/programy/cuda> [jstar@n1 ~/mycuda]./a.out Time of copy kernel= Time of transpose_naive kernel= Time of transpose kernel= [jstar@n1 ~/mycuda] Tesla (1.1) Fermi (2.0)
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Procesory kart graficznych i CUDA wer 1.2 6.05.2015
 wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie CUDA informacje praktycznie i przykłady. Wersja
 Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych. Architektura i API część 1
 Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie PKG - informacje praktycznie i przykłady. Wersja z Opracował: Rafał Walkowiak
 Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Procesory kart graficznych i CUDA wer PR
 wer 1.3 14.12.2016 PR Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
wer 1.3 14.12.2016 PR Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Procesory kart graficznych i CUDA
 4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
Jacek Matulewski - Fizyk zajmujący się na co dzień optyką kwantową i układami nieuporządkowanymi na Wydziale Fizyki, Astronomii i Informatyki
 Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Procesory kart graficznych i CUDA wer
 wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe Wprowadzenie do OpenCL. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
GTX260 i CUDA wer
 GTX260 i CUDA wer 1.1 25.11.2014 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders,
GTX260 i CUDA wer 1.1 25.11.2014 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders,
4 NVIDIA CUDA jako znakomita platforma do zrównoleglenia obliczeń
 Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA
 Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Dodatek A. CUDA. 1 Stosowany jest w tym kontekście skrót GPCPU (od ang. general-purpose computing on graphics processing units).
.") Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
Co to jest sterta? Sterta (ang. heap) to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).
 to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).") Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł.
 Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
CUDA PROGRAMOWANIE PIERWSZE PROSTE PRZYKŁADY RÓWNOLEGŁE. Michał Bieńkowski Katarzyna Lewenda
 PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
Podstawy programowania komputerów
 Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych.
 Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Programowanie kart graficznych. Kompilator NVCC Podstawy programowania na poziomie API sterownika
 Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
PROE wykład 9 C++11, rzutowanie, optymalizacja. dr inż. Jacek Naruniec
 PROE wykład 9 C++11, rzutowanie, optymalizacja dr inż. Jacek Naruniec Rzutowanie Różne typy rzutowania są szczególnie istotne przy dziedziczeniu. Załóżmy sobie prostą hierarchię klas: A B C Rzutowanie
PROE wykład 9 C++11, rzutowanie, optymalizacja dr inż. Jacek Naruniec Rzutowanie Różne typy rzutowania są szczególnie istotne przy dziedziczeniu. Załóżmy sobie prostą hierarchię klas: A B C Rzutowanie
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Programowanie GPU jako procesora ogólnego przeznaczenia.
 Programowanie GPU jako procesora ogólnego przeznaczenia Wykład III Architektura CUDA Witold Rudnicki Łukasz Ligowski Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski
Programowanie GPU jako procesora ogólnego przeznaczenia Wykład III Architektura CUDA Witold Rudnicki Łukasz Ligowski Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH
 ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
ROZPROSZONY SYSTEM DO KRYPTOANALIZY SZYFRÓW OPARTYCH NA KRZYWYCH ELIPTYCZNYCH Krzysztof Skowron, Mariusz Rawski, Paweł Tomaszewicz 1/23 CEL wykorzystanie środowiska Altera OpenCL do celów akceleracji obliczeń
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++
 Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Hybrydowy system obliczeniowy z akceleratorami GPU
 Przemysław Stpiczyński Hybrydowy system obliczeniowy z akceleratorami GPU [A hybrid computing system with GPU accelerators] Wstęp Konstrukcja komputerów oraz klastrów komputerowych o dużej mocy obliczeniowej
Przemysław Stpiczyński Hybrydowy system obliczeniowy z akceleratorami GPU [A hybrid computing system with GPU accelerators] Wstęp Konstrukcja komputerów oraz klastrów komputerowych o dużej mocy obliczeniowej
Tablice i struktury. czyli złożone typy danych. Programowanie Proceduralne 1
 Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Język ludzki kod maszynowy
 Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
Wątek - definicja. Wykorzystanie kilku rdzeni procesora jednocześnie Zrównoleglenie obliczeń Jednoczesna obsługa ekranu i procesu obliczeniowego
 Wątki Wątek - definicja Ciąg instrukcji (podprogram) który może być wykonywane współbieżnie (równolegle) z innymi programami, Wątki działają w ramach tego samego procesu Współdzielą dane (mogą operować
Wątki Wątek - definicja Ciąg instrukcji (podprogram) który może być wykonywane współbieżnie (równolegle) z innymi programami, Wątki działają w ramach tego samego procesu Współdzielą dane (mogą operować
Wskaźniki. Przemysław Gawroński D-10, p marca Wykład 2. (Wykład 2) Wskaźniki 8 marca / 17
 Wskaźniki 8 marca / 17") Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Implementacja modelu FHP w technologii NVIDIA CUDA
 Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Linux Kernel III. Character devices
 Linux Kernel III Character devices Urządzenia systemu Linux (I) Character device Block device Network device Do urządzenia piszemy jak do pliku, Dozwolone działania: open, close, read, write, Np. /dev/tty1.
Linux Kernel III Character devices Urządzenia systemu Linux (I) Character device Block device Network device Do urządzenia piszemy jak do pliku, Dozwolone działania: open, close, read, write, Np. /dev/tty1.
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Szablony funkcji i szablony klas
 Bogdan Kreczmer bogdan.kreczmer@pwr.wroc.pl Zakład Podstaw Cybernetyki i Robotyki Instytut Informatyki, Automatyki i Robotyki Politechnika Wrocławska Kurs: Copyright c 2011 Bogdan Kreczmer Niniejszy dokument
Bogdan Kreczmer bogdan.kreczmer@pwr.wroc.pl Zakład Podstaw Cybernetyki i Robotyki Instytut Informatyki, Automatyki i Robotyki Politechnika Wrocławska Kurs: Copyright c 2011 Bogdan Kreczmer Niniejszy dokument
Wykład Ćwiczenia Laboratorium Projekt Seminarium
 WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Programowanie współbieżne Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Wstęp do obliczeń równoległych na GPU
 Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Wykład 14. Zagadnienia związane z systemem IO
 Wykład 14 Zagadnienia związane z systemem IO Wprowadzenie Urządzenia I/O zróżnicowane ze względu na Zachowanie: wejście, wyjście, magazynowanie Partnera: człowiek lub maszyna Szybkość transferu: bajty
Wykład 14 Zagadnienia związane z systemem IO Wprowadzenie Urządzenia I/O zróżnicowane ze względu na Zachowanie: wejście, wyjście, magazynowanie Partnera: człowiek lub maszyna Szybkość transferu: bajty