Operacje grupowego przesyłania komunikatów
|
|
|
- Sylwester Małek
- 5 lat temu
- Przeglądów:
Transkrypt
1 Operacje grupowego przesyłania komunikatów 1
2 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami nazywane są operacjami komunikacji grupowej (collective communication) lub operacjami globalnymi Przykładami takich operacji są m.in. rozgłaszanie (broadcast), rozpraszanie (scatter), zbieranie (gather), redukcja (reduction) czy wymiana (exchange) Wydajność realizacji takich operacji może być bardzo różna, zależnie od przyjętej strategii Optymalna strategia realizacji wymaga często uwzględnienia architektury systemu komputerowego i sposobu przesyłania komunikatów w sieci połączeń 2
3 Operacje grupowego przesyłania komunikatów Schematy grupowego przesyłania komunikatów: rozgłaszanie (broadcast) jeden do wszystkich rozpraszanie (scatter) jeden do wszystkich zbieranie (gather) wszyscy do jednego redukcja (gromadzenie, reduction) wszyscy do jednego rozgłaszanie wszyscy do wszystkich (równoważne zbieraniu wszyscy do wszystkich) gromadzenie (redukcja) wszyscy do wszystkich wymiana wszyscy do wszystkich (równoważna rozpraszaniu wszyscy do wszystkich) Nieoptymalna i optymalna realizacja rozgłaszania dla p procesorów i różnych technologii i topologii sieciowych 3
4 Sieci połączeń w systemach równoległych Rodzaje sieci połączeń: podział ze względu na łączone elementy: połączenia procesory pamięć (moduły pamięci) połączenia międzyprocesorowe (międzywęzłowe) podział ze względu na charakterystyki łączenia: sieci statyczne zbiór połączeń dwupunktowych sieci dynamiczne przełączniki o wielu dostępach 4
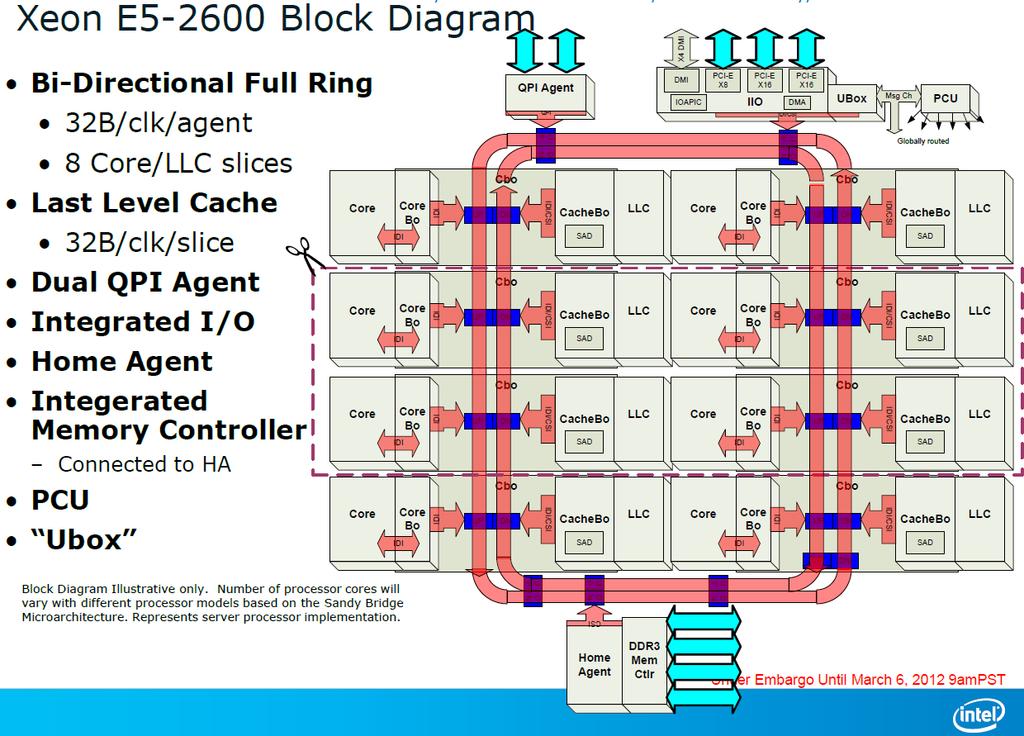
5 5

6 Intel Knights Landing 6

7 Sieci połączeń Sieci (połączenia) dynamiczne magistrala (bus) krata przełączników (crossbar switch przełącznica krzyżowa) sieć wielostopniowa (multistage network) Sieć wielostopniowa p wejść i p wyjść, stopnie pośrednie (ile?) każdy stopień pośredni złożony z p/2 przełączników 2x2 poszczególne stopnie połączone w sposób realizujący idealne przetasowanie (perfect shuffle) (j=2i lub j=2i+1 p) przy dwójkowym zapisie pozycji wejść i wyjść idealne przetasowanie odpowiada rotacji bitów, przełączniki umożliwiają zmianę wartości ostatniego bitu 7
8 Sieci połączeń Porównanie sieci dynamicznych: wydajność szerokość pasma transferu (przepustowość) możliwość blokowania połączeń koszt liczba przełączników skalowalność zależność wydajności i kosztu od liczby procesorów 8
9 Sieci połączeń Sieci statyczne Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D Kraty z zawinięciem, torusy Drzewa: zwykłe lub tłuste Hiperkostki: 1D, 2D, 3D itd.. Wymiar d, liczba procesorów 2^d Bitowy zapis położenia węzła Najkrótsza droga między 2 procesorami = ilość bitów, którymi różnią się kody położenia procesorów 9

10 Topologia torusa 10

11 Topologie hiperkostki i drzewa 11


12 Sieci połączeń 12
13 Procedury komunikacji grupowej MPI Realizacja procedur komunikacja grupowej w MPI polega na wywołaniu odpowiedniej procedury przez wszystkie procesy w grupie Argumentami procedur komunikacji grupowej są i bufory z danymi wysyłanymi i (jeśli trzeba) bufory na dane odbierane Wszystkie procedury komunikacji grupowej są blokujące (ale zakończenie operacji przez proces nie oznacza koniecznie, że inne procesy także ją zakończyły) 13
14 Procedury komunikacji grupowej MPI bariera int MPI_Barrier( MPI_Comm comm ) rozgłaszanie jeden do wszystkich int MPI_Bcast( void *buff, int count, MPI_Datatype datatype, int root, MPI_Comm comm ) zbieranie wszyscy do jednego int MPI_Gather(void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, int root, MPI_Comm comm) zbieranie wszyscy do wszystkich równoważne rozgłaszaniu wszyscy do wszystkich (brak wyróżnionego procesu root) int MPI_Allgather( void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, MPI_Comm comm ) 14
15 Procedury komunikacji grupowej MPI rozpraszanie jeden do wszystkich int MPI_Scatter(void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, int root, MPI_Comm comm) rozpraszanie wszyscy do wszystkich równoważne wymianie wszyscy do wszystkich (brak wyróżnionego procesu root) int MPI_Alltoall( void *sbuf, int scount, MPI_Datatype sdtype, void *rbuf, int rcount, MPI_Datatype rdtype, MPI_Comm comm ) redukcja wszyscy do jednego int MPI_Reduce(void *sbuf, void *rbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm) redukcja połączona z rozgłaszaniem MPI_Allreduce 15
16 Procedury komunikacji grupowej MPI Operacje stosowane przy realizacji redukcji: predefiniowane operacje uchwyty do obiektów typu MPI_Op (każda z operacji ma swoje dozwolone typy argumentów): MPI_MAX maksimum MPI_MIN minimum MPI_SUM suma MPI_PROD iloczyn operacje maksimum i minimum ze zwróceniem indeksów operacje logiczne i bitowe operacje definiowane przez użytkownika za pomocą procedury: int MPI_Op_create(MPI_User_function *func, int commute, MPI_Op *pop); 16
17 Procedury komunikacji grupowej MPI przykład 1 Całkowanie w przedziale warianty dekompozycji: dekompozycja w dziedzinie w problemu podział przedziału na podprzedziały zrównoleglenie pętli algorytm sekwencyjny narzędzia zrównoleglenia pętli:» automatyczne (OpenMP)» ręczne (Pthreads,MPI) wyniki w obu przypadkach mogą być różne różne liczby podprzedziałów i ich długości 17
18 Procedury komunikacji grupowej MPI przykład 1 MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); if( rank == 0 ) scanf("%lf %lf %d", &a, &b, &N); root=0; MPI_Bcast( &N, 1, MPI_INT, root, MPI_COMM_WORLD ); MPI_Bcast( &a, 1, MPI_DOUBLE, root, MPI_COMM_WORLD ); MPI_Bcast( &b, 1, MPI_DOUBLE, root, MPI_COMM_WORLD ); n_loc = ceil(n/size); dx = (b a)/n; x1 = a + rank*n_loc*dx; if(rank==size 1) n_loc = N n_loc*(size 1); c=0; for(i=0;i<n_loc;i++) { x2 = x1+dx; c += 0.5*(f(x1)+f(x2))*dx; x1=x2; } MPI_Reduce( &c, &calka, 1, MPI_DOUBLE, MPI_SUM, root, MCW); 18
19 Procedury komunikacji grupowej MPI przykład 2 Mnożenie macierz wektor algorytm sekwencyjny, naiwny dekompozycja danych warianty: wierszowy kolumnowy blokowy algorytmy dla rozmaitych wariantów dekompozycji implementacja procedury MPI wykorzystywane w implementacji 19
20 Procedury komunikacji grupowej MPI przykład 2 double x[wymiar], y[wymiar], a[wymiar*wymiar]; // inicjowanie a, x, y MPI_Init( &argc, &argv ); MPI_Comm_rank( MPI_COMM_WORLD, &rank ); MPI_Comm_size( MPI_COMM_WORLD, &size ); n_wier = ceil(wymiar / size); // dodatkowy kod dla WYMIAR niepodzielnego przez size MPI_Allgather(&x[rank*n_wier], n_wier, MPI_DOUBLE, x, n_wier, MPI_DOUBLE, MPI_COMM_WORLD ); for(i=0;i<n_wier;i++){ int ni = n*i; for(j=0;j<n;j++){ y[i] += a[ni+j] * x[j]; } } 20
Operacje grupowego przesyłania komunikatów. Krzysztof Banaś Obliczenia równoległe 1
 Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Operacje grupowego przesyłania komunikatów Krzysztof Banaś Obliczenia równoległe 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany
Message Passing Interface
 Message Passing Interface Interfejs programowania definiujący powiązania z językami C, C++, Fortran Standaryzacja (de facto) i rozszerzenie wcześniejszych rozwiązań dla programowania z przesyłaniem komunikatów
Message Passing Interface Interfejs programowania definiujący powiązania z językami C, C++, Fortran Standaryzacja (de facto) i rozszerzenie wcześniejszych rozwiązań dla programowania z przesyłaniem komunikatów
Architektury systemów równoległych
 Architektury systemów równoległych 1 Architektury systemów z pamięcią wspólną Architektury procesorów Procesory wielordzeniowe Procesory graficzne Akceleratory Procesory hybrydowe Architektury systemów
Architektury systemów równoległych 1 Architektury systemów z pamięcią wspólną Architektury procesorów Procesory wielordzeniowe Procesory graficzne Akceleratory Procesory hybrydowe Architektury systemów
Programowanie Równoległe Wykład 5. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 5 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW www.ift.uni.wroc.pl/~koma/pr/index.html MPI, wykład 2. Plan: - komunikacja
Programowanie Równoległe Wykład 5 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW www.ift.uni.wroc.pl/~koma/pr/index.html MPI, wykład 2. Plan: - komunikacja
Programowanie w modelu przesyłania komunikatów specyfikacja MPI. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Operacje kolektywne MPI
 Operacje kolektywne MPI 1 Operacje kolektywne Do tej pory w operacje przesyłania komunikatu miały charakter punkt-punkt (najczęściej pomiędzy nadawcą i odbiorcą). W operacjach grupowych udział biorą wszystkie
Operacje kolektywne MPI 1 Operacje kolektywne Do tej pory w operacje przesyłania komunikatu miały charakter punkt-punkt (najczęściej pomiędzy nadawcą i odbiorcą). W operacjach grupowych udział biorą wszystkie
Wydajność komunikacji grupowej w obliczeniach równoległych. Krzysztof Banaś Obliczenia wysokiej wydajności 1
 Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 2 Jan Kazimirski 1 MPI 1/2 2 Dlaczego klastry komputerowe? Wzrost mocy obliczeniowej jednego jest coraz trudniejszy do uzyskania. Koszt dodatkowej mocy obliczeniowej
Programowanie współbieżne i rozproszone WYKŁAD 2 Jan Kazimirski 1 MPI 1/2 2 Dlaczego klastry komputerowe? Wzrost mocy obliczeniowej jednego jest coraz trudniejszy do uzyskania. Koszt dodatkowej mocy obliczeniowej
Programowanie Równoległe Wykład 4. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Przetwarzanie równoległesprzęt. Rafał Walkowiak Wybór
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Przetwarzanie równoległesprzęt
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 4.0.204 7.0.2 Sieci połączeń komputerów równoległych () Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi Parametry: liczba wejść, wyjść,
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 4.0.204 7.0.2 Sieci połączeń komputerów równoległych () Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi Parametry: liczba wejść, wyjść,
Modele programowania równoległego. Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak
 Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak MPP - Cechy charakterystyczne 1 Prywatna - wyłączna przestrzeń adresowa. Równoległość
Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak MPP - Cechy charakterystyczne 1 Prywatna - wyłączna przestrzeń adresowa. Równoległość
Modele programowania równoległego. Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP
 Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP MPP - Cechy charakterystyczne 1 Prywatna, wyłączna przestrzeń adresowa.
Modele programowania równoległego Programowanie z przekazywaniem komunikatów Message-Passing Programming Rafał Walkowiak dla PR PP MPP - Cechy charakterystyczne 1 Prywatna, wyłączna przestrzeń adresowa.
Programowanie Równoległe Wykład 5. MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej
 Maciej Matyka Instytut Fizyki Teoretycznej") Programowanie Równoległe Wykład 5 MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej MPI, wykład 3. Plan: - wirtualne topologie - badanie skalowanie czasu rozwiązania
Programowanie Równoległe Wykład 5 MPI - Message Passing Interface (część 3) Maciej Matyka Instytut Fizyki Teoretycznej MPI, wykład 3. Plan: - wirtualne topologie - badanie skalowanie czasu rozwiązania
Tryby komunikacji między procesami w standardzie Message Passing Interface. Piotr Stasiak Krzysztof Materla
 Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Miary Wydajności. Efektywność programu równoległego (E) jest definiowana jako stosunek przyśpieszenia do liczby procesorów
 jest definiowana jako stosunek przyśpieszenia do liczby procesorów") Miary Wydajności Czas wykonania równoległego (Tpar) jest czasem pomiędzy momentem rozpoczęcia obliczeń do momentu gdy ostatni procesor zakończy obliczenia Przyspieszenie (S) jest definiowane jako stosunek
Miary Wydajności Czas wykonania równoległego (Tpar) jest czasem pomiędzy momentem rozpoczęcia obliczeń do momentu gdy ostatni procesor zakończy obliczenia Przyspieszenie (S) jest definiowane jako stosunek
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne
 Wykład 4 Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne Spis treści: 1. Statyczne sieci połączeń w systemach równoległych 2. Dynamiczne sieci połączeń
Wykład 4 Architektura sieci połączeń między procesorami, sterowanie komunikacjami, biblioteki komunikacyjne Spis treści: 1. Statyczne sieci połączeń w systemach równoległych 2. Dynamiczne sieci połączeń
Programowanie współbieżne... (4) Andrzej Baran 2010/11
 Andrzej Baran 2010/11") Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Rozszerzenia MPI-2 1
 Rozszerzenia MPI-2 1 2 Dynamiczne tworzenie procesów Aplikacja MPI 1 jest statyczna z natury Liczba procesów określana jest przy starcie aplikacji i się nie zmienia. Gwarantuje to szybką komunikację procesów.
Rozszerzenia MPI-2 1 2 Dynamiczne tworzenie procesów Aplikacja MPI 1 jest statyczna z natury Liczba procesów określana jest przy starcie aplikacji i się nie zmienia. Gwarantuje to szybką komunikację procesów.
Sprzęt czyli architektury systemów równoległych
 Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Systemy rozproszone. Państwowa Wyższa Szkoła Zawodowa w Chełmie. ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej w Lublinie
 Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
http://www.mcs.anl.gov/research/projects/mpi/standard.html
 z przedmiotu, prowadzonych na Wydziale BMiI, Akademii Techniczno-Humanistycznej w Bielsku-Białej. MPI czyli Message Passing Interface stanowi specyfikację pewnego standardu wysokopoziomowego protokołu
z przedmiotu, prowadzonych na Wydziale BMiI, Akademii Techniczno-Humanistycznej w Bielsku-Białej. MPI czyli Message Passing Interface stanowi specyfikację pewnego standardu wysokopoziomowego protokołu
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
5. Model komunikujących się procesów, komunikaty
 Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Jędrzej Ułasiewicz str. 1 5. Model komunikujących się procesów, komunikaty Obecnie stosuje się następujące modele przetwarzania: Model procesów i komunikatów Model procesów komunikujących się poprzez pamięć
Numeryczna algebra liniowa. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Programowanie w standardzie MPI
 Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Wprowadzenie do MPI. Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.
 Wprowadzenie do MPI Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl
Wprowadzenie do MPI Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Jak wygląda praca na klastrze
 Jak wygląda praca na klastrze Upraszczając nieco sprawę można powiedzieć, że klaster to dużo niezależnych komputerów (jednostek) połączonych mniej lub bardziej sprawną siecią. Często poszczególne jednostki
Jak wygląda praca na klastrze Upraszczając nieco sprawę można powiedzieć, że klaster to dużo niezależnych komputerów (jednostek) połączonych mniej lub bardziej sprawną siecią. Często poszczególne jednostki
Łagodne wprowadzenie do Message Passing Interface (MPI)
") Łagodne wprowadzenie do Message Passing Interface (MPI) Szymon Łukasik Zakład Automatyki PK szymonl@pk.edu.pl Szymon Łukasik, 8 listopada 2006 Łagodne wprowadzenie do MPI - p. 1/48 Czym jest MPI? Własności
Łagodne wprowadzenie do Message Passing Interface (MPI) Szymon Łukasik Zakład Automatyki PK szymonl@pk.edu.pl Szymon Łukasik, 8 listopada 2006 Łagodne wprowadzenie do MPI - p. 1/48 Czym jest MPI? Własności
Równoległe algorytmy sortowania. Krzysztof Banaś Obliczenia równoległe 1
 Równoległe algorytmy sortowania Krzysztof Banaś Obliczenia równoległe 1 Algorytmy sortowania Algorytmy sortowania dzielą się na wewnętrzne (bez użycia pamięci dyskowej) zewnętrzne (dla danych nie mieszczących
Równoległe algorytmy sortowania Krzysztof Banaś Obliczenia równoległe 1 Algorytmy sortowania Algorytmy sortowania dzielą się na wewnętrzne (bez użycia pamięci dyskowej) zewnętrzne (dla danych nie mieszczących
Macierzowe algorytmy równoległe
 Macierzowe algorytmy równoległe Zanim przedstawimy te algorytmy zapoznajmy się z metodami dekompozycji macierzy, możemy wyróżnić dwa sposoby dekompozycji macierzy: Dekompozycja paskowa - kolumnowa, wierszowa
Macierzowe algorytmy równoległe Zanim przedstawimy te algorytmy zapoznajmy się z metodami dekompozycji macierzy, możemy wyróżnić dwa sposoby dekompozycji macierzy: Dekompozycja paskowa - kolumnowa, wierszowa
PARADYGMATY I JĘZYKI PROGRAMOWANIA. Programowanie współbieżne... (w13)
") PARADYGMATY I JĘZYKI PROGRAMOWANIA Programowanie współbieżne... (w13) Treść 2 Wstęp Procesy i wątki Szybkość obliczeń prawo Amdahla Wyścig do zasobów Synchronizacja i mechanizmy synchronizacji semafory
PARADYGMATY I JĘZYKI PROGRAMOWANIA Programowanie współbieżne... (w13) Treść 2 Wstęp Procesy i wątki Szybkość obliczeń prawo Amdahla Wyścig do zasobów Synchronizacja i mechanizmy synchronizacji semafory
Programowanie aplikacji równoległych i rozproszonych. Wykład 8
 Wykład 8 p. 1/?? Programowanie aplikacji równoległych i rozproszonych Wykład 8 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Plan wykładu
Wykład 8 p. 1/?? Programowanie aplikacji równoległych i rozproszonych Wykład 8 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Plan wykładu
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Języki i paradygmaty programowania 1 studia stacjonarne 2018/19. Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach.
 Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach. 1. Dynamiczna alokacja pamięci dla tablic wielowymiarowych - Przykładowa
Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach. 1. Dynamiczna alokacja pamięci dla tablic wielowymiarowych - Przykładowa
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Algorytmy numeryczne 1
 Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Kolejne funkcje MPI 1
 Kolejne funkcje MPI 1 Przypomnienie: sieci typu mesh (Grama i wsp.) 2 Topologie MPI Standard MPI abstrahuje od topologii systemu wieloprocesorowego. Sposób uruchamiania aplikacji (mpirun) nie jest częścią
Kolejne funkcje MPI 1 Przypomnienie: sieci typu mesh (Grama i wsp.) 2 Topologie MPI Standard MPI abstrahuje od topologii systemu wieloprocesorowego. Sposób uruchamiania aplikacji (mpirun) nie jest częścią
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych
 Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Programowanie Współbieżne
 Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Programowanie współbieżne Wykład 12 MPI c.d. Rafał Skinderowicz
 Programowanie współbieżne MPI c.d. Rafał Skinderowicz Komunikacja grupowa Poprzednio rozważaliśmy komunikację między parami procesów synchroniczna (blokująca) np. MPI Recv, MPI Send asynchroniczna (nieblokująca)
Programowanie współbieżne MPI c.d. Rafał Skinderowicz Komunikacja grupowa Poprzednio rozważaliśmy komunikację między parami procesów synchroniczna (blokująca) np. MPI Recv, MPI Send asynchroniczna (nieblokująca)
Programowanie współbieżne WYKŁADY - CZ. 5EX. PRZYKŁAD. LICZBY PIERWSZE. Andrzej Baran
 Programowanie współbieżne WYKŁADY - CZ. 5EX. PRZYKŁAD. LICZBY PIERWSZE. Andrzej Baran baran@kft.umcs.lublin.pl Liczby pierwsze I Program: pierwsze.f90 - znajdowanie liczb pierwszych w przedziale 2..n Metoda:
Programowanie współbieżne WYKŁADY - CZ. 5EX. PRZYKŁAD. LICZBY PIERWSZE. Andrzej Baran baran@kft.umcs.lublin.pl Liczby pierwsze I Program: pierwsze.f90 - znajdowanie liczb pierwszych w przedziale 2..n Metoda:
Programowanie Równoległe Wykład 6. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 6 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW Za tydzień 1. wykład z CUDY (Z. Koza) www.ift.uni.wroc.pl/~koma/pr/index.html
Programowanie Równoległe Wykład 6 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Dorobiliśmy się strony WWW Za tydzień 1. wykład z CUDY (Z. Koza) www.ift.uni.wroc.pl/~koma/pr/index.html
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Działanie komputera i sieci komputerowej.
 Działanie komputera i sieci komputerowej. Gdy włączymy komputer wykonuje on kilka czynności, niezbędnych do rozpoczęcia właściwej pracy. Gdy włączamy komputer 1. Włączenie zasilania 2. Uruchamia
Działanie komputera i sieci komputerowej. Gdy włączymy komputer wykonuje on kilka czynności, niezbędnych do rozpoczęcia właściwej pracy. Gdy włączamy komputer 1. Włączenie zasilania 2. Uruchamia
Obliczenia równoległe
 Instytut Informatyki Politechnika Śląska Obliczenia równoległe Opracował: Zbigniew J. Czech materiały dydaktyczne Gliwice, luty 1 Spis treści 1 Procesy współbieżne Podstawowe modele obliczeń równoległych
Instytut Informatyki Politechnika Śląska Obliczenia równoległe Opracował: Zbigniew J. Czech materiały dydaktyczne Gliwice, luty 1 Spis treści 1 Procesy współbieżne Podstawowe modele obliczeń równoległych
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Optymalizacja komunikacji w systemach rozproszonych i równoległych
 Optymalizacja komunikacji w systemach rozproszonych i równoległych Szkolenie PCSS, 16.12.2001 literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster,
Optymalizacja komunikacji w systemach rozproszonych i równoległych Szkolenie PCSS, 16.12.2001 literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster,
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Podstawy programowania w języku C
 Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Podstawy programowania w języku C WYKŁAD 1 Proces tworzenia i uruchamiania programów Algorytm, program Algorytm przepis postępowania prowadzący do rozwiązania określonego zadania. Program zapis algorytmu
Podstawy programowania. Wykład Funkcje. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Programowanie w modelu przesyłania komunikatów specyfikacja MPI. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Środowisko przesyłania komunikatów MPI Rodzaje procedur: blokujące nieblokujące Tryby przesyłania
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Obliczenia rozproszone z wykorzystaniem MPI
 Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Wykład 1 Wprowadzenie do algorytmów. Zawartość wykładu 1. Wstęp do algorytmów i struktur danych 2. Algorytmy z rozgałęzieniami.
 Wykład 1 Wprowadzenie do algorytmów Zawartość wykładu 1. Wstęp do algorytmów i struktur danych 2. Algorytmy z rozgałęzieniami Wykaz literatury 1. N. Wirth - Algorytmy+Struktury Danych = Programy, WNT Warszawa
Wykład 1 Wprowadzenie do algorytmów Zawartość wykładu 1. Wstęp do algorytmów i struktur danych 2. Algorytmy z rozgałęzieniami Wykaz literatury 1. N. Wirth - Algorytmy+Struktury Danych = Programy, WNT Warszawa
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Mosty przełączniki. zasady pracy pętle mostowe STP. Domeny kolizyjne, a rozgłoszeniowe
 Mosty przełączniki zasady pracy pętle mostowe STP Domeny kolizyjne, a rozgłoszeniowe 1 Uczenie się mostu most uczy się na podstawie adresu SRC gdzie są stacje buduje na tej podstawie tablicę adresów MAC
Mosty przełączniki zasady pracy pętle mostowe STP Domeny kolizyjne, a rozgłoszeniowe 1 Uczenie się mostu most uczy się na podstawie adresu SRC gdzie są stacje buduje na tej podstawie tablicę adresów MAC
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Programowanie współbieżne... (5)
") Programowanie współbieżne... (5) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html 6 FUNKCJI Proste programy MPI można pisać używając tylko 6 funkcji Programowanie współbieżne...
Programowanie współbieżne... (5) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html 6 FUNKCJI Proste programy MPI można pisać używając tylko 6 funkcji Programowanie współbieżne...
Mikroprocesor Operacje wejścia / wyjścia
 Definicja Mikroprocesor Operacje wejścia / wyjścia Opracował: Andrzej Nowak Bibliografia: Urządzenia techniki komputerowej, K. Wojtuszkiewicz Operacjami wejścia/wyjścia nazywamy całokształt działań potrzebnych
Definicja Mikroprocesor Operacje wejścia / wyjścia Opracował: Andrzej Nowak Bibliografia: Urządzenia techniki komputerowej, K. Wojtuszkiewicz Operacjami wejścia/wyjścia nazywamy całokształt działań potrzebnych
POZNA SUPERCOMPUTING AND NETWORKING. Wprowadzenie do MPI
 Wprowadzenie do MPI literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster, Designing and Building Parallel Programs, Addison-Wesley 1995, http://www-unix.mcs.anl.gov/dbpp/
Wprowadzenie do MPI literatura W. Gropp, E. Lusk, An Introduction to MPI, ANL P.S. Pacheco, A User s Guide to MPI, 1998 Ian Foster, Designing and Building Parallel Programs, Addison-Wesley 1995, http://www-unix.mcs.anl.gov/dbpp/
Interfejs MPI. Maciej Kasperski, Rafał Kozik. 16 kwietnia 2008
 16 kwietnia 2008 Wprowadzenie Co to jest MPI? Plan prezentacji: co to jest MPI? komunikatory i grupy procesów; przesyłanie komunikatów; komunikacja kolektywna; wirtualne topologie;. Co to jest MPI? Wstęp
16 kwietnia 2008 Wprowadzenie Co to jest MPI? Plan prezentacji: co to jest MPI? komunikatory i grupy procesów; przesyłanie komunikatów; komunikacja kolektywna; wirtualne topologie;. Co to jest MPI? Wstęp
Przykładowe pytania DSP 1
 Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
Przykładowe pytania SP Przykładowe pytania Systemy liczbowe. Przedstawić liczby; -, - w kodzie binarnym i hexadecymalnym uzupełnionym do dwóch (liczba 6 bitowa).. odać dwie liczby binarne w kodzie U +..
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych dr Artur Bartoszewski Układy we/wy jak je widzi procesor? Układy wejścia/wyjścia Układy we/wy (I/O) są kładami pośredniczącymi w wymianie informacji pomiędzy procesorem
Architektura systemów komputerowych dr Artur Bartoszewski Układy we/wy jak je widzi procesor? Układy wejścia/wyjścia Układy we/wy (I/O) są kładami pośredniczącymi w wymianie informacji pomiędzy procesorem
Podstawy Projektowania Przyrządów Wirtualnych. Wykład 9. Wprowadzenie do standardu magistrali VMEbus. mgr inż. Paweł Kogut
 Podstawy Projektowania Przyrządów Wirtualnych Wykład 9 Wprowadzenie do standardu magistrali VMEbus mgr inż. Paweł Kogut VMEbus VMEbus (Versa Module Eurocard bus) jest to standard magistrali komputerowej
Podstawy Projektowania Przyrządów Wirtualnych Wykład 9 Wprowadzenie do standardu magistrali VMEbus mgr inż. Paweł Kogut VMEbus VMEbus (Versa Module Eurocard bus) jest to standard magistrali komputerowej
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Spis treści. Dzień 1. I Rozpoczęcie pracy ze sterownikiem (wersja 1707) II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400
 II Bloki danych (wersja 1707) ZAAWANSOWANY TIA DLA S7-300/400") ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
ZAAWANSOWANY TIA DLA S7-300/400 Spis treści Dzień 1 I Rozpoczęcie pracy ze sterownikiem (wersja 1707) I-3 Zadanie Konfiguracja i uruchomienie sterownika I-4 Etapy realizacji układu sterowania I-5 Tworzenie
Weryfikacja oprogramowania, korzystajacego z MPI
 Weryfikacja oprogramowania, korzystajacego z MPI Krzysztof Nozderko kn201076@students.mimuw.edu.pl 23 maja 2005 Wprowadzenie Równoległe obliczenia olbiczenia naukowców sa często bardzo kosztowne obliczeniowo
Weryfikacja oprogramowania, korzystajacego z MPI Krzysztof Nozderko kn201076@students.mimuw.edu.pl 23 maja 2005 Wprowadzenie Równoległe obliczenia olbiczenia naukowców sa często bardzo kosztowne obliczeniowo
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Programowanie współbieżne... (12) Andrzej Baran 2010/11
 Andrzej Baran 2010/11") Programowanie współbieżne... (12) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Dekompozycja danych. Wejście. rank 0 rank 1 rank 2 A B C A B C A B C indata indata indata wejście
Programowanie współbieżne... (12) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Dekompozycja danych. Wejście. rank 0 rank 1 rank 2 A B C A B C A B C indata indata indata wejście
Bramki logiczne Podstawowe składniki wszystkich układów logicznych
 Układy logiczne Bramki logiczne A B A B AND NAND A B A B OR NOR A NOT A B A B XOR NXOR A NOT A B AND NAND A B OR NOR A B XOR NXOR Podstawowe składniki wszystkich układów logicznych 2 Podstawowe tożsamości
Układy logiczne Bramki logiczne A B A B AND NAND A B A B OR NOR A NOT A B A B XOR NXOR A NOT A B AND NAND A B OR NOR A B XOR NXOR Podstawowe składniki wszystkich układów logicznych 2 Podstawowe tożsamości
Podstawy Informatyki Elementarne podzespoły komputera
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Reprezentacja informacji Podstawowe bramki logiczne 2 Przerzutniki Przerzutnik SR Rejestry Liczniki 3 Magistrala Sygnały
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Reprezentacja informacji Podstawowe bramki logiczne 2 Przerzutniki Przerzutnik SR Rejestry Liczniki 3 Magistrala Sygnały
51. Metody komunikacji nieblokującej.
 51. Metody komunikacji nieblokującej. Funkcje nieblokujace różnia sie od wersji blokujacych przedrostkiem I (immediate) w nazwie oraz jednym dodatkowym argumentem: request, który jest używany do sprawdzenia,
51. Metody komunikacji nieblokującej. Funkcje nieblokujace różnia sie od wersji blokujacych przedrostkiem I (immediate) w nazwie oraz jednym dodatkowym argumentem: request, który jest używany do sprawdzenia,
Zaawansowane operacje grupowe
 Zaawansowane operacje grupowe Zakres ćwiczenia Celem ćwiczenia jest zapoznanie się z zaawansowanymi funkcjami biblioteki PVM wspierającymi tworzenie aplikacji rozproszonych. Przedstawienie problemu W tworzeniu
Zaawansowane operacje grupowe Zakres ćwiczenia Celem ćwiczenia jest zapoznanie się z zaawansowanymi funkcjami biblioteki PVM wspierającymi tworzenie aplikacji rozproszonych. Przedstawienie problemu W tworzeniu
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 3 Jan Kazimirski 1 Literatura 2 MPI 2/2 3 Komunikacja blokująca Funkcja MPI_Recv działa w trybie blokującym Powrót z MPI_Recv nastąpi dopiero po odebraniu
Programowanie współbieżne i rozproszone WYKŁAD 3 Jan Kazimirski 1 Literatura 2 MPI 2/2 3 Komunikacja blokująca Funkcja MPI_Recv działa w trybie blokującym Powrót z MPI_Recv nastąpi dopiero po odebraniu
Komunikacja kolektywna w środowisku MPI
 Komunikacja kolektywna w środowisku MPI Zakres ćwiczenia W tym ćwiczeniu dowiesz się, co to jest komunikacja kolektywna i w jaki sposób napisać swój pierwszy program wykorzystujący komunikację kolektywną
Komunikacja kolektywna w środowisku MPI Zakres ćwiczenia W tym ćwiczeniu dowiesz się, co to jest komunikacja kolektywna i w jaki sposób napisać swój pierwszy program wykorzystujący komunikację kolektywną
Task Parallel Library
 Task Parallel Library Daan Leijen, Wolfram Schulte, and Sebastian Burckhardt prezentacja Michał Albrycht Agenda O potrzebie zrównoleglania Przykłady użycia TPL Tasks and Replicable Tasks Rozdzielanie zadań
Task Parallel Library Daan Leijen, Wolfram Schulte, and Sebastian Burckhardt prezentacja Michał Albrycht Agenda O potrzebie zrównoleglania Przykłady użycia TPL Tasks and Replicable Tasks Rozdzielanie zadań
Wstęp do programowania obiektowego. Wykład 1 Algorytmy i paradygmaty Podstawowe pojęcia PO
 Wstęp do programowania obiektowego Wykład 1 Algorytmy i paradygmaty Podstawowe pojęcia PO 1 Cele przedmiotu Zapoznanie z podstawowymi pojęciami oraz technikami programowania obiektowego na przykładzie
Wstęp do programowania obiektowego Wykład 1 Algorytmy i paradygmaty Podstawowe pojęcia PO 1 Cele przedmiotu Zapoznanie z podstawowymi pojęciami oraz technikami programowania obiektowego na przykładzie
Magistrala. Magistrala (ang. Bus) służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.
 służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.") Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki
 Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych
 Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych Autor: Piotr Majkowski Pod opieką: prof. Zbigniew Kotulski Politechnika
Automatyzacja procesu tworzenia sprzętowego narzędzia służącego do rozwiązywania zagadnienia logarytmu dyskretnego na krzywych eliptycznych Autor: Piotr Majkowski Pod opieką: prof. Zbigniew Kotulski Politechnika
Wprowadzenie do MPI. Interdyscyplinarne Centrum Modelowania. Matematycznego i Komputerowego Uniwersytet Warszawski
 Wprowadzenie do MPI Matematycznego i Komputerowego Uniwersytet Warszawski http:// Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl 31.03.2010 Wprowadzenie do MPI 1 Podziękowania
Wprowadzenie do MPI Matematycznego i Komputerowego Uniwersytet Warszawski http:// Maciej Cytowski m.cytowski@icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl 31.03.2010 Wprowadzenie do MPI 1 Podziękowania
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Architektura komputerów
 Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły
Architektura komputerów Tydzień 5 Jednostka Centralna Zadania realizowane przez procesor Pobieranie rozkazów Interpretowanie rozkazów Pobieranie danych Przetwarzanie danych Zapisanie danych Główne zespoły