Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
|
|
|
- Paweł Romanowski
- 9 lat temu
- Przeglądów:
Transkrypt
1 Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1

2 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej i wyświetlania jej na ekranie monitora Motorem rozwoju GPU jest rynek gier komputerowych Fotorealizm w czasie rzeczywistym Cechy GPU Przetwarzanie równoległe Ilość rdzeni > 100 (1 CPU = 8 rdzeni) Przyspieszone operacje na macierzach. Wydajność rzędu Tfps Przetwarzanie wierzchołków i pixeli Przetwarzania światła Obsługa efektów fizycznych Obsługa biblioteki OpenGL i DirectX

3 Naukowe obliczenia numeryczne 3 najszybsze komputery świata korzystają z kart graficznych do zwiększenia swojej mocy obliczeniowej. TESLA (Fermi core) 448 CUDA Cores Tianhe 1a - Chiny 515 Gigaflops (podwójna precyzja) 14,336 procesorów Xeon X Teraflop (pojedyncza precyzja) 7,168 GPU Nvidia Tesla M2050 Maksymalna wydajność petaflops operacji zmiennoprzecinkowych na sekundę
 7,168 GPU Nvidia Tesla M2050 Maksymalna")
4 Obliczenia na GPU Model Cg ( C for graphics) Obliczenia wykonywane były w ramach jednostek obliczeniowych pixel shader i vertex shader. Wynik obliczeń nie dało się odczytać bezpośrednio w postaci numerycznej tylko jako zestaw pixeli na ekranie monitora. Model CUDA (Compute Unified Device Architecture) Obliczenia wykonywane są na wszystkich dostępnych rdzeniach. Wynik obliczeń można odebrać w postaci numerycznej (terminal) Cechy CUDA Wielowątkowość Wielozadaniowość Programowanie w językach wysokiego poziomu
 Cechy CUDA Wielowątkowość Wielozadaniowość Programowanie w")
 Pamięć globalna dostępna dla wszystkich wątków (raczej wolna).")
5 Architektura CUDA Model pamięci Pamięć lokalna dostępna tylko dla wątku (bardzo szybka) Pamięć dzielona dostępna tylko dla wszystkich wątków w bloku (bardzo szybka) Pamięć globalna dostępna dla wszystkich wątków (raczej wolna).

6 Architektura CUDA RAM CPU >= GPU Większa ilość pamięci na karcie i w komputerze zwiększa prędkość obliczeń Wspierane języki programowania. Dodatkowo istniej możliwość programowania CUDA w językach JAVA i Python

7 Programowanie CUDA C Kompilator: nvcc Dostęþny jest w pakiecie CUDA toolkit dla różnych systemów operacyjnych takich jak Windows, Linux, Mac. Pełne wsparcie dla standardu ANSI C z elementami C++ CUDA w wersji 1.0 dostępne jest już dla kart NVIDA GeForce 8600 Kod programu Kod CPU Kod GPU

8 Programowanie CUDA C Zadania Kod CPU Informacja o sprzęcie Inicjalizacja pamięci Operacje I/O CPU->GPU, GPU->CPU Zwalnianie pamięci Zadania Kod GPU Sterowanie programem Pamięci lokalne i dzielone Obliczenia numeryczne Synchronizacja wątków Program oddaje sterowanie do GPU i czeka na wynik obliczeń. Wykonane może to być w sposób synchroniczny lub asynchroniczny. GPU rozwiązuje zadanie na wszystkich dostępnych rdzeniach równolegle. Kod programu musi być specjalnie urównoleglony.

9 Programowanie CUDA C Wymagania systemowe Windows XP/VISTA/7 CUDA developer driver, CUDA toolkit, MS Visual Studio C++ Linux: nowsze dystrybucje. CUDA developer driver, CUDA toolkit, gcc4.4 Dodatkowo dla wszystkich systemów GPUComputingSDK, w którym są przykłady programów CUDA. Działanie tych programów jest gwarancją prawidłowej instalacji sterowników CUDA w systemie. Uwaga!!! WINDOWS VISTA/7 resetuje karte po braku odpowiedzi w przeciągu 90 s. Warto ten czas przedłużyć gdy nie będziemy korzystać z grafiki.

10 Kod CPU (informacja o zainstalowanej karcie) #include <stdio.h> #include <cutil.h> W pliku nagłówkowym cutil.h zawarte są informacje o wszystkich nagłówkach CUDA. Aby zastosować tą funkcje w systemi musi być dostępna biblioteka libcutil_x86_64.a (Linux64), która znajduje się w GPUComputingSDK. void PrintDevicesInformation() { int devicecount,nrdev,nmulproc; cudagetdevicecount(&devicecount); printf("number of CUDA devices: %d\n",devicecount); for(nrdev = 0; nrdev < devicecount; nrdev++) { cudadeviceprop deviceprop; cudagetdeviceproperties(&deviceprop, nrdev); printf("device %d: %s\n", nrdev, deviceprop.name); printf("maxthreadsperblock: %d\n", deviceprop.maxthreadsperblock); nmulproc=deviceprop.multiprocessorcount; printf("multiprocessorcount: %d\n", nmulproc); printf("computemode: %d\n", deviceprop.computemode); printf("sharedmemperblock: %ld\n", deviceprop.sharedmemperblock);
; printf(\"device %d: %s\n\", nrdev, deviceprop.name); printf(\"maxthreadsperblock: %d\n\", deviceprop.")
11 Kod CPU (informacja o zainstalowanej karcie) int main(int argc, char* argv[]) { PrintDevicesInformation(); return 0; Kompilacja gcc4.4 UBUNTU > nvcc program.cu lcudart pathtolib/libcutil_x86_64.a o program Wynik działania Number of CUDA devices: 1 Device 0: Quadro FX 5800 maxthreadsperblock: 512 multiprocessorcount: 30 computemode: 0 sharedmemperblock: Często stosowane rozszerzenie.cu zarówno w Linux jak i w Windows

12 Kod CPU (CPU->GPU) #define real float real* R; size_t size; void CPUMemAlloc() { size = 16*sizeof(real); // 16 liczb typu real R = (real*)malloc(size); memset(r,0,size); Funkcja CPUMemAlloc alokuje pamięć dla 16 liczb typu real czyli float real* d_r; void GPUMemAlloc() { cudamalloc((void**)&d_r, size); Funkcja GPUMemAlloc alokuje pamięć na karcie graficznej dla 16 liczb typu real
&d_r, size); Funkcja GPUMemAlloc alokuje pamięć na karcie graficznej dla 16")
13 Kod CPU (CPU->GPU) void CopyCPUToGPU() { cudamemcpy(d_r, R, size, cudamemcpyhosttodevice); Funkcja kopiuje size bloków pamięci z komputera na kartę graficzną Host komputer z CPU Device karta graficzna void CopyGPUToCPU() { cudamemcpy(r, d_r, size, cudamemcpydevicetohost); Odwrotna operacja W operacjach tych brakuje obsługi wyjątków, które mogą wystąpić z różnych przyczyn. Funkcja cudagetlasterror()podaje numer ostatniego błędu.

14 Kod CPU (CPU->GPU) int main(int argc, char* argv[]) { CPUMemAlloc(); GPUMemAlloc(); R[0]=5; CopyCPUToGPU(); CopyGPUToCPU(); printf("r[0]=%f\n",r[0]); return 0; Brakuje operacji wykonywanych na karcie graficznej Musimy stworzyć tzw. Kernel, który będzie wykonywany na GPU.
![CopyGPUToCPU(); printf("r[0]=%f\n",r[0]); return 0; Brakuje](/docs-images/40/1784358/images/page_14.jpg "operacji wykonywanych na karcie graficznej Musimy stworzyć tzw.")
15 Kod CPU (Inicjalizacja Kernela GPU) int threadsperblock, blockspergrid, sharedsize; void InitKernel() { threadsperblock = 16; //Tyle samo wątków w bloku ile liczb mamy do //przeliczenia blockspergrid = 1; sharedsize = size; //Szybka pami ęć dzielona na 16 liczb real Każda karta graficzna ma inną maksymalną ilość wątków w jednym bloku. Wartość ta waha się między 128 a Tutaj blok został ustalony na 16 wątków. Ilość bloków w macierzy obliczeniowej też zależy od karty, tutaj ustalamy 1 blok. Teraz możemy już pisać program dla GPU

16 Kod GPU (Przemnożenie macierzy przez dwa) global void MultByTwo(real* R){ extern shared real rs[]; unsigned int id = threadidx.x; R[id]=R[id]*2; Główna procedura w GPU tworzona jest przez dyrektywę global. shared oznacza pamięć dostępną dla całego bloku. int main(int argc, char* argv[]) { CPUMemAlloc(); GPUMemAlloc(); R[0]=5; CopyCPUToGPU(); InitKernel(); MultByTwo<<<blocksPerGrid, threadsperblock, sharedsize>>>(d_r); CopyGPUToCPU(); printf( R[0]=%f\n,R[0]); return 0;
 { CPUMemAlloc(); GPUMemAlloc(); R[0]=5; CopyCPUToGPU(); InitKernel();")
 Kod sekwencyjny Kod równoległy")
17 Przetwarzanie Kod sekwencyjny Wielokrotne wywoływanie kodu równoległego dla tego samego zestawu danych Kod równoległy kernel0<<<>>>() Kod sekwencyjny Kod równoległy kernel1<<<>>>()
 Kod sekwencyjny Kod")
18 Kod GPU (Sumowanie elementów macierzy) global void SumM(real* R){ extern shared real rs[]; unsigned int id = threadidx.x; rs[id]=r[id]; syncthreads(); if(id==0){ real SUM=0; for(int i=0;i<16;i++){ SUM+=rS[i]; R[0]=SUM; int main(int argc, char* argv[]) { CPUMemAlloc(); GPUMemAlloc(); R[0]=5;R[1]=2;R[2]=4; CopyCPUToGPU(); InitKernel(); SumM<<<blocksPerGrid, threadsperblock, sharedsize>>>(d_r); CopyGPUToCPU(); printf( R[0]=%f\n,R[0]); return 0;
![x; rs[id]=r[id]; syncthreads(); if(id==0){ real SUM=0; for(int i=0;i<16;i++){ SUM+=rS[i]; R[0]=SUM; int](/docs-images/40/1784358/images/page_18.jpg "main(int argc, char* argv[]) { CPUMemAlloc(); GPUMemAlloc(); R[0]=5;R[1]=2;R[2]=4; CopyCPUToGPU();")
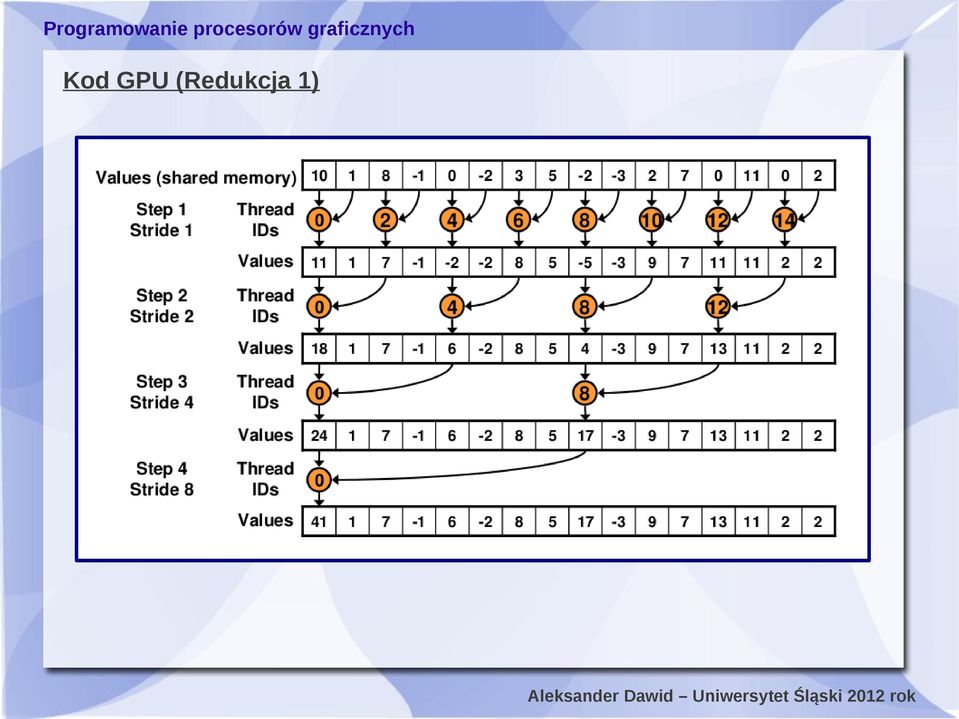
19 Kod GPU (Redukcja 1) W poprzednim programie do sumowania liczb z każdego wątku użyte został tylko jeden wątek o identyfikatorze 0 global void SumReducto(real* R){ extern shared real rs[]; unsigned int id = threadidx.x; rs[id]=r[id]; syncthreads(); for(unsigned int s=1; s < blockdim.x; s *= 2) { if (id % (2*s) == 0) { rs[id] += rs[id + s]; syncthreads(); if(id == 0) R[0] = rs[0];
![unsigned int id = threadidx.x; rs[id]=r[id]; syncthreads(); for(unsigned int s=1; s < blockdim.](/docs-images/40/1784358/images/page_19.jpg "x; s *= 2) { if (id % (2*s) == 0) { rs[id] += rs[id + s]; syncthreads(); if(id == 0) R[0] =")
20 Kod GPU (Redukcja 1)
21 Kod GPU (Redukcja 2) Operacja modulo (%) jest bardzo wolna i wymaga zmiany. global void SumReducto2(real* R){ extern shared real rs[]; unsigned int id = threadidx.x; rs[id]=r[id]; syncthreads(); for(unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * id; if (index < blockdim.x) { rs[index] += rs[index + s]; syncthreads(); if(id == 0) R[0] = rs[0];
22 Kod GPU (Obliczanie numeryczne całki metoda trapezów) Polega na sumowaniu pól trapezów pod krzywą
23 Kod GPU (Obliczanie numeryczne całki metoda trapezów) global void Trapez(real* Y, real* R){ extern shared real rs[]; unsigned int id = threadidx.x; rs[id]=y[id]; syncthreads(); if(id<blockdim.x 1){ real field; field=(rs[id] + 0.5* abs(rs[id] rs[id+1]))*dxgpu; syncthreads(); rs[id]=field; for(unsigned int s=1; s < blockdim.x; s *= 2) { int index = 2 * s * id; if (index < blockdim.x) { rs[index] += rs[index + s]; syncthreads(); if(id == 0) R[0] = rs[0];
24 Kod CPU (Obliczanie numeryczne całki metoda trapezów) constant real dxgpu=0; int main(int argc, char* argv[]) { CPUMemAlloc(); GPUMemAlloc(); InitKernel(); // threadsperblock=128 dx= ; //1/128 cudamemcpytosymbol(dxgpu, &dx, sizeof(real)); for(int i=0;i<threadsperblock;i++){ Y[i]=sqrt(1 (i*dx)*(i*dx)); CopyCPUToGPU(); Trapez<<<blocksPerGrid, threadsperblock, sharedsize>>>(d_y, d_r); CopyGPUToCPU(); printf( R[0]=%f\n,R[0]); return 0;
25 KONIEC WYKŁADU
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Wstęp do Programowania, laboratorium 02
 Wstęp do Programowania, laboratorium 02 Zadanie 1. Napisać program pobierający dwie liczby całkowite i wypisujący na ekran największą z nich. Zadanie 2. Napisać program pobierający trzy liczby całkowite
Wstęp do Programowania, laboratorium 02 Zadanie 1. Napisać program pobierający dwie liczby całkowite i wypisujący na ekran największą z nich. Zadanie 2. Napisać program pobierający trzy liczby całkowite
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE. Wykład 02
 METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie kart graficznych. Architektura i API część 1
 Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Programowanie CUDA informacje praktycznie i przykłady. Wersja
 Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Wstęp do programowania
 Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Wykład VII. Programowanie. dr inż. Janusz Słupik. Gliwice, 2014. Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2014 Janusz Słupik
 Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
CUDA PROGRAMOWANIE PIERWSZE PROSTE PRZYKŁADY RÓWNOLEGŁE. Michał Bieńkowski Katarzyna Lewenda
 PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie kart graficznych. Kompilator NVCC Podstawy programowania na poziomie API sterownika
 Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Języki i metodyka programowania. Wprowadzenie do języka C
 Literatura: Brian W. Kernighan, Dennis M. Ritchie Język Ansi C, Wydawnictwa Naukowo - Techniczne, 2007 http://cm.bell-labs.com/cm/cs/cbook/index.html Scott E. Gimpel, Clovis L. Tondo Język Ansi C. Ćwiczenia
Literatura: Brian W. Kernighan, Dennis M. Ritchie Język Ansi C, Wydawnictwa Naukowo - Techniczne, 2007 http://cm.bell-labs.com/cm/cs/cbook/index.html Scott E. Gimpel, Clovis L. Tondo Język Ansi C. Ćwiczenia
Programowanie PKG - informacje praktycznie i przykłady. Wersja z Opracował: Rafał Walkowiak
 Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Zmienne, stałe i operatory
 Zmienne, stałe i operatory Przemysław Gawroński D-10, p. 234 Wykład 2 4 marca 2019 (Wykład 2) Zmienne, stałe i operatory 4 marca 2019 1 / 21 Outline 1 Zmienne 2 Stałe 3 Operatory (Wykład 2) Zmienne, stałe
Zmienne, stałe i operatory Przemysław Gawroński D-10, p. 234 Wykład 2 4 marca 2019 (Wykład 2) Zmienne, stałe i operatory 4 marca 2019 1 / 21 Outline 1 Zmienne 2 Stałe 3 Operatory (Wykład 2) Zmienne, stałe
2 Przygotował: mgr inż. Maciej Lasota
 Laboratorium nr 2 1/7 Język C Instrukcja laboratoryjna Temat: Wprowadzenie do języka C 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do języka C. Język C jest językiem programowania ogólnego zastosowania
Laboratorium nr 2 1/7 Język C Instrukcja laboratoryjna Temat: Wprowadzenie do języka C 2 Przygotował: mgr inż. Maciej Lasota 1) Wprowadzenie do języka C. Język C jest językiem programowania ogólnego zastosowania
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Programowanie I C / C++ laboratorium 01 Organizacja zajęć
 Programowanie I C / C++ laboratorium 01 Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-12 Program zajęć Zasady zaliczenia Program operacje wejścia i wyjścia instrukcje
Programowanie I C / C++ laboratorium 01 Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-12 Program zajęć Zasady zaliczenia Program operacje wejścia i wyjścia instrukcje
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Grzegorz Cygan. Wstęp do programowania mikrosterowników w języku C
 Grzegorz Cygan Wstęp do programowania mikrosterowników w języku C Mikrosterownik Inne nazwy: Microcontroler (z języka angielskiego) Ta nazwa jest powszechnie używana w Polsce. Mikrokomputer jednoukładowy
Grzegorz Cygan Wstęp do programowania mikrosterowników w języku C Mikrosterownik Inne nazwy: Microcontroler (z języka angielskiego) Ta nazwa jest powszechnie używana w Polsce. Mikrokomputer jednoukładowy
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Temat 1: Podstawowe pojęcia: program, kompilacja, kod
 Temat 1: Podstawowe pojęcia: program, kompilacja, kod wynikowy. Przykłady najprostszych programów. Definiowanie zmiennych. Typy proste. Operatory: arytmetyczne, przypisania, inkrementacji, dekrementacji,
Temat 1: Podstawowe pojęcia: program, kompilacja, kod wynikowy. Przykłady najprostszych programów. Definiowanie zmiennych. Typy proste. Operatory: arytmetyczne, przypisania, inkrementacji, dekrementacji,
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych.
 Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Katedra Elektrotechniki Teoretycznej i Informatyki. wykład 12 - sem.iii. M. Czyżak
 Katedra Elektrotechniki Teoretycznej i Informatyki wykład 12 - sem.iii M. Czyżak Język C - preprocesor Preprocesor C i C++ (cpp) jest programem, który przetwarza tekst programu przed przekazaniem go kompilatorowi.
Katedra Elektrotechniki Teoretycznej i Informatyki wykład 12 - sem.iii M. Czyżak Język C - preprocesor Preprocesor C i C++ (cpp) jest programem, który przetwarza tekst programu przed przekazaniem go kompilatorowi.
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Programowanie w języku C++
 Programowanie w języku C++ Część siódma Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie zawiera skrót treści wykładu, lektura tych materiałów nie zastąpi
Programowanie w języku C++ Część siódma Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie zawiera skrót treści wykładu, lektura tych materiałów nie zastąpi
Argumenty wywołania programu, operacje na plikach
 Temat zajęć: Argumenty wywołania programu, operacje na plikach Autor: mgr inż. Sławomir Samolej Zagadnienie 1. (Zmienne statyczne) W języku C można decydować o sposobie przechowywania zmiennych. Decydują
Temat zajęć: Argumenty wywołania programu, operacje na plikach Autor: mgr inż. Sławomir Samolej Zagadnienie 1. (Zmienne statyczne) W języku C można decydować o sposobie przechowywania zmiennych. Decydują
Tablice, funkcje - wprowadzenie
 Tablice, funkcje - wprowadzenie Przemysław Gawroński D-10, p. 234 Wykład 5 25 marca 2019 (Wykład 5) Tablice, funkcje - wprowadzenie 25 marca 2019 1 / 12 Outline 1 Tablice jednowymiarowe 2 Funkcje (Wykład
Tablice, funkcje - wprowadzenie Przemysław Gawroński D-10, p. 234 Wykład 5 25 marca 2019 (Wykład 5) Tablice, funkcje - wprowadzenie 25 marca 2019 1 / 12 Outline 1 Tablice jednowymiarowe 2 Funkcje (Wykład
Karty graficzne możemy podzielić na:
 KARTY GRAFICZNE Karta graficzna karta rozszerzeo odpowiedzialna generowanie sygnału graficznego dla ekranu monitora. Podstawowym zadaniem karty graficznej jest odbiór i przetwarzanie otrzymywanych od komputera
KARTY GRAFICZNE Karta graficzna karta rozszerzeo odpowiedzialna generowanie sygnału graficznego dla ekranu monitora. Podstawowym zadaniem karty graficznej jest odbiór i przetwarzanie otrzymywanych od komputera
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory
 Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-19 Pętla while Pętla while Pętla
Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-19 Pętla while Pętla while Pętla
// Liczy srednie w wierszach i kolumnach tablicy "dwuwymiarowej" // Elementy tablicy są generowane losowo #include <stdio.h> #include <stdlib.
 Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1 Pętle Pętla jest konstrukcją sterującą stosowaną w celu wielokrotnego wykonania tego samego zestawu instrukcji jednokrotne
Podstawy programowania. Wykład Pętle. Tablice. Krzysztof Banaś Podstawy programowania 1 Pętle Pętla jest konstrukcją sterującą stosowaną w celu wielokrotnego wykonania tego samego zestawu instrukcji jednokrotne
Wykład 1
 Wstęp do programowania 1 Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 1 Wprowadzenie Cel wykładów z programowania proceduralnego Wykład jest poświęcony językowi C i jego
Wstęp do programowania 1 Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 1 Wprowadzenie Cel wykładów z programowania proceduralnego Wykład jest poświęcony językowi C i jego
Podstawy Programowania.
 Podstawy Programowania http://www.saltbox.com/img/under_the_hood.png O mnie... dr inż. Łukasz Graczykowski Zakład Fizyki Jądrowej Wydział Fizyki Politechniki Warszawskiej lgraczyk@if.pw.edu.pl www.if.pw.edu.pl/~lgraczyk/wiki
Podstawy Programowania http://www.saltbox.com/img/under_the_hood.png O mnie... dr inż. Łukasz Graczykowski Zakład Fizyki Jądrowej Wydział Fizyki Politechniki Warszawskiej lgraczyk@if.pw.edu.pl www.if.pw.edu.pl/~lgraczyk/wiki
wykład II uzupełnienie notatek: dr Jerzy Białkowski Programowanie C/C++ Język C - funkcje, tablice i wskaźniki wykład II dr Jarosław Mederski Spis
 i cz. 2 Programowanie uzupełnienie notatek: dr Jerzy Białkowski 1 i cz. 2 2 i cz. 2 3 Funkcje i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje instrukcje } i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje
i cz. 2 Programowanie uzupełnienie notatek: dr Jerzy Białkowski 1 i cz. 2 2 i cz. 2 3 Funkcje i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje instrukcje } i cz. 2 typ nazwa ( lista-parametrów ) { deklaracje
ISO/ANSI C - funkcje. Funkcje. ISO/ANSI C - funkcje. ISO/ANSI C - funkcje. ISO/ANSI C - funkcje. ISO/ANSI C - funkcje
 Funkcje (podprogramy) Mianem funkcji określa się fragment kodu, który może być wykonywany wielokrotnie z różnych miejsc programu. Ogólny zapis: typ nazwa(argumenty) ciało funkcji typ określa typ danych
Funkcje (podprogramy) Mianem funkcji określa się fragment kodu, który może być wykonywany wielokrotnie z różnych miejsc programu. Ogólny zapis: typ nazwa(argumenty) ciało funkcji typ określa typ danych
Część 4 życie programu
 1. Struktura programu c++ Ogólna struktura programu w C++ składa się z kilku części: część 1 część 2 część 3 część 4 #include int main(int argc, char *argv[]) /* instrukcje funkcji main */ Część
1. Struktura programu c++ Ogólna struktura programu w C++ składa się z kilku części: część 1 część 2 część 3 część 4 #include int main(int argc, char *argv[]) /* instrukcje funkcji main */ Część
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Co to jest sterta? Sterta (ang. heap) to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).
 to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).") Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Jacek Matulewski - Fizyk zajmujący się na co dzień optyką kwantową i układami nieuporządkowanymi na Wydziale Fizyki, Astronomii i Informatyki
 Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Podstawy programowania C. dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/
 Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Typy złożone. Struktury, pola bitowe i unie. Programowanie Proceduralne 1
 Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
Struktura programu. Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem.
 Struktura programu Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem. W ostatnich latach najbardziej używanym stylem oprogramowania
Struktura programu Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem. W ostatnich latach najbardziej używanym stylem oprogramowania
Wykład 3. Procesy i wątki. Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB
 Wykład 3 Procesy i wątki Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Pojęcie procesu Program = plik wykonywalny na dysku Proces = uruchomiony i wykonywany program w pamięci
Wykład 3 Procesy i wątki Wojciech Kwedlo, Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Pojęcie procesu Program = plik wykonywalny na dysku Proces = uruchomiony i wykonywany program w pamięci
Strona główna. Strona tytułowa. Programowanie. Spis treści. Sobera Jolanta 16.09.2006. Strona 1 z 26. Powrót. Full Screen. Zamknij.
 Programowanie Sobera Jolanta 16.09.2006 Strona 1 z 26 1 Wprowadzenie do programowania 4 2 Pierwsza aplikacja 5 3 Typy danych 6 4 Operatory 9 Strona 2 z 26 5 Instrukcje sterujące 12 6 Podprogramy 15 7 Tablice
Programowanie Sobera Jolanta 16.09.2006 Strona 1 z 26 1 Wprowadzenie do programowania 4 2 Pierwsza aplikacja 5 3 Typy danych 6 4 Operatory 9 Strona 2 z 26 5 Instrukcje sterujące 12 6 Podprogramy 15 7 Tablice
Pliki w C/C++ Przykłady na podstawie materiałów dr T. Jeleniewskiego
 Pliki w C/C++ Przykłady na podstawie materiałów dr T. Jeleniewskiego 1 /24 Pisanie pojedynczych znaków z klawiatury do pliku #include void main(void) { FILE *fptr; // wkaznik do pliku, tzw. uchwyt
Pliki w C/C++ Przykłady na podstawie materiałów dr T. Jeleniewskiego 1 /24 Pisanie pojedynczych znaków z klawiatury do pliku #include void main(void) { FILE *fptr; // wkaznik do pliku, tzw. uchwyt
System komputerowy. System komputerowy
 System komputerowy System komputerowy System komputerowy układ współdziałających ze sobą (według pewnych zasad) dwóch składowych: sprzętu komputerowego (hardware) oraz oprogramowania (software) po to,
System komputerowy System komputerowy System komputerowy układ współdziałających ze sobą (według pewnych zasad) dwóch składowych: sprzętu komputerowego (hardware) oraz oprogramowania (software) po to,
Spis treści WSTĘP CZĘŚĆ I. PASCAL WPROWADZENIE DO PROGRAMOWANIA STRUKTURALNEGO. Rozdział 1. Wybór i instalacja kompilatora języka Pascal
 Spis treści WSTĘP CZĘŚĆ I. PASCAL WPROWADZENIE DO PROGRAMOWANIA STRUKTURALNEGO Rozdział 1. Wybór i instalacja kompilatora języka Pascal 1.1. Współczesne wersje kompilatorów Pascala 1.2. Jak zainstalować
Spis treści WSTĘP CZĘŚĆ I. PASCAL WPROWADZENIE DO PROGRAMOWANIA STRUKTURALNEGO Rozdział 1. Wybór i instalacja kompilatora języka Pascal 1.1. Współczesne wersje kompilatorów Pascala 1.2. Jak zainstalować
Podstawy programowania komputerów
 Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Wprowadzenie do OpenMP
 Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
I - Microsoft Visual Studio C++
 I - Microsoft Visual Studio C++ 1. Nowy projekt z Menu wybieramy File -> New -> Projekt -> Win32 Console Application w okienku Name: podajemy nazwę projektu w polu Location: wybieramy miejsce zapisu i
I - Microsoft Visual Studio C++ 1. Nowy projekt z Menu wybieramy File -> New -> Projekt -> Win32 Console Application w okienku Name: podajemy nazwę projektu w polu Location: wybieramy miejsce zapisu i
Podział programu na moduły
 Materiały Podział programu na moduły Informatyka Szczegółowe informacje dotyczące wymagań odnośnie podziału na moduły: http://www.cs.put.poznan.pl/wcomplak/bfiles/c_w_5.pdf Podział programu na moduły pozwala
Materiały Podział programu na moduły Informatyka Szczegółowe informacje dotyczące wymagań odnośnie podziału na moduły: http://www.cs.put.poznan.pl/wcomplak/bfiles/c_w_5.pdf Podział programu na moduły pozwala
Programowanie Procesorów Graficznych
 Programowanie Procesorów Graficznych Wykład 1 9.10.2012 Prehistoria Zadaniem karty graficznej było sterowanie sygnałem do monitora tak aby wyświetlić obraz zgodnie z zawartościa pamięci. Programiści pracowali
Programowanie Procesorów Graficznych Wykład 1 9.10.2012 Prehistoria Zadaniem karty graficznej było sterowanie sygnałem do monitora tak aby wyświetlić obraz zgodnie z zawartościa pamięci. Programiści pracowali
Fizyka laboratorium 1
 Rozdzia l Fizyka laboratorium.. Elementy analizy matematycznej Funkcje Zmienna y nazywa sie zmienna zależna albo funkcja zmiennej x, jeżeli przyjmuje ona określone wartości dla każdej wartości zmiennej
Rozdzia l Fizyka laboratorium.. Elementy analizy matematycznej Funkcje Zmienna y nazywa sie zmienna zależna albo funkcja zmiennej x, jeżeli przyjmuje ona określone wartości dla każdej wartości zmiennej
GLKit. Wykład 10. Programowanie aplikacji mobilnych na urządzenia Apple (IOS i ObjectiveC) #import "Fraction.h" #import <stdio.h>
 #import Fraction.h #import <stdio.h>") #import "Fraction.h" #import @implementation Fraction -(Fraction*) initwithnumerator: (int) n denominator: (int) d { self = [super init]; } if ( self ) { [self setnumerator: n anddenominator:
#import "Fraction.h" #import @implementation Fraction -(Fraction*) initwithnumerator: (int) n denominator: (int) d { self = [super init]; } if ( self ) { [self setnumerator: n anddenominator:
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński
 Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Wykład I. Programowanie. dr inż. Janusz Słupik. Gliwice, 2014. Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2014 Janusz Słupik
 Wykład I I Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Zaliczenie przedmiotu Na laboratorium można zdobyć 100 punktów. Do zaliczenia niezbędne jest
Wykład I I Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Zaliczenie przedmiotu Na laboratorium można zdobyć 100 punktów. Do zaliczenia niezbędne jest
DYNAMICZNE PRZYDZIELANIE PAMIECI
 DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne