Programowanie PKG - informacje praktycznie i przykłady. Wersja z Opracował: Rafał Walkowiak
|
|
|
- Kamila Lisowska
- 6 lat temu
- Przeglądów:
Transkrypt
1 Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z Opracował: Rafał Walkowiak
2 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu dla GPU wykorzystywanego przez wątek CPU. (Analog w GPU obiektu takiego jak proces dla CPU.) Alokacje pamięci DEVICE I i uruchomienia kernela będą realizowane na wybranym urządzeniu, z nim związane są strumienie i zdarzenia. Domyślnie wybrane jest urządzenie o devid =0. cudagetdevice(&devid) służy do sprawdzenia efektu wykonania cudasetdevice(), zwraca ewentualnie błąd. cudadevicereset() usuwa kontekst GPU używany przez wątek, wywołanie niezbędne do zakończenie profilowania. 2
3 Pomiar czasu obliczeń kernela cudaevent_t start; error = cudaeventcreate(&start); if (error!= cudasuccess) { fprintf(stderr, Nie udało się utworzyć zdarzenia start (kod bledu %s)!\n, cudageterrorstring(error)); exit(exit_failure); } cudaevent_t stop; error = cudaeventcreate(&stop); if (error!= cudasuccess)... error = cudaeventrecord(start, 0); strumieniu zerowym // uruchomienie kernela error = cudaeventrecord(stop, 0); strumieniu zerowym error = cudaeventsynchronize(stop); if (error!= cudasuccess)... //zapisywanie zdarzenia startowego w if (error!= cudasuccess)... //zapisywanie zdarzenia końcowego w if (error!= cudasuccess)...//oczekiwanie na zakończenie float msectotal = 0.0f; error = cudaeventelapsedtime(&msectotal, start, stop); if (error!= cudasuccess)... //porządki cudaeventdestroy(start); cudaeventdestroy(stop); Zwracane wartości są mierzone w oparciu o zegar GPU i dlatego rozdzielczość pomiaru jest niezależna od sprzętu i systemu operacyjnego komputera host. 3
4 Informacja o błędach przetwarzania CUDA Wszystkie wywołania funkcji CUDA (oprócz uruchomienia kernela) zwracają kod błędu typu cudaerror_t cudaerror_t cudagetlasterror(void) Zwraca kod ostatniego błędu (braku błędu) do wykorzystania dla wywołań asynchronicznych CUDA i wywołań kernela char* cudageterrorstring(cudaerror_t code) Zwraca zakończony zerem ciąg znaków opisujący błąd. Użycie: printf( %s\n, cudageterrorstring( cudagetlasterror() ) ); Funkcje informacyjne cudagetdevicecount(),cudagetdeviceproperties() 4
5 Błędy uruchomienia kernela Uruchomienie kernela nie zwraca kodu błędu. Pobieranie błędu konfiguracji kernela - Wywołania cudapeekatlasterror() lub cudagetlasterror() powinny być zrealizowane dla uzyskania informacji o błędach przeduruchomieniowych ( parametrów, konfiguracji uruchomienia). Dla zapewnienia, że błąd zwracany przez cudapeekatlasterror() cudagetlasterror() nie pochodzi z wcześniejszych wywołań ważne jest wyzerowanie zmiennej błędu (ustawienie jej na cudasuccess) lub wywołanie cudagetlasterror() (funkcja zeruje błąd) przed wywołaniem kernela. Pobieranie błędu obliczeń kernela - po synchronizacji / zakończeniu kernela - Wywołanie kernela jest asynchroniczne względem przetwarzania CPU i dlatego w celu odczytu aktualnych danych o błędzie należy wywołanie zsynchronizować (np. cudadevicesynchronize()) z przetwarzaniem CPU przed wywołaniami pobrania błędu - cudapeekatlasterror(), cudagetlasterror(), aby mieć pewność, że wywołanie kernela się zakończyło i pobierane informacje (błąd lub brak) dotyczą wywołania kernela. 5
6 Tworzenie wiązek (warp) z wątków bloku - przykład Warp osnowa - system logicznych synchronicznych procesorów. Wiązka do 32 wątków używa osnowy do obliczeń. Stąd wiązka (max 32 wątki) nazywana jest również WARP. Załóżmy blok wątków o wymiarach 7 na 7 Dla CC 1.3: liczba wątków bloku wynosi 49 MAX liczba bloków na SM (cc 1.3) = 8 MAX liczba wątków na SM (cc 1.3) = 1024 = 32x32 49 wątków to 2 wiązki max 32 wątkowe (zajmują 2 osnowy) max zajętość SM blokami to 8 bloków (obowiązuje gdy nie brakuje innych zasobów) 8 bloków po 2 wiązki to 16 wiązek zajętość SM (teoretyczna maksymalna) przez wiązki wynosi 16/32 = 50%, zajętość SM (teoretyczna maksymalna) wątkami 392/1024 = 38 % Efektywność: może zabraknąć wątków do zapewnienia ciągłości obliczeń (ze względu na długo trwające dostępy do pamięci globalnej i niskie CGMA) 6
7 Tworzenie wiązek (warp) z wątków bloku - przykład Blok wątków 7x7 (dwuwymiarowy) dość egzotyczny Przydział bloku wątków do wiązek wątków 4wątki 3 wątki wątki Niewykorzystane pozycje wiązki 32 wątki 17 wątków 1. Wymiar bloku wpływa na zajętość SM. 2. Wymiar bloku wpływa na zajętość wiązki. 3. Żądania dostępów do pamięci globalnej generowane przez sąsiednie wątki w 4. wiązce mogą być zaspokajane w ramach jednoczesnych transferów wielo bajtowych. 5. Położenie wątku w bloku wątków wpływa na realizowany dostęp, zatem jakość dostępu jest również zależna od wymiarów bloku. 7
8 Mnozenie macierzy Warianty procedur: 1. Jeden blok wątków (wiele wyników na wątek) 2. Wiele bloków wątków (1w/1w) 3. Wykorzystanie pamięci współdzielonej (1w/1w) 4. Zwiększenie ilości przetwarzania między synchronizacjami (1w/1w) 5. Wzrost ilości pracy dla wątku (skalowanie w dół przetwarzania) (1w/Nw) 6. Zrównoleglenie transferów danych host-gpu, GPU-host z przetwarzaniem GPU 8
9 Dostęp do elementów tablic Tablica dwu wymiarowa: Ze względu na lokację tablic wierszami, pozycję: j-tego elementu w i-tym wierszu tablicy określamy wzorem: i*width+j width Kolejne elementy tablicy w przestrzeni adresowej pamięci karty 9
10 Wyznaczanie elementu macierzy A * B = C For (k=0, k<width,k++) C[i*width+j]+=A[i*width+k]*B[k*width+j]; //czyli C[i][j]=A[i][k]*B[k,j]; //kod obliczania dla jedengo wątku gdy liczy on jeden wynik 10
11 Mnożenie macierzy PKG wer.1 global void MatrixMulKernel_1(float* Ad, float* Bd, float* Cd, int WIDTH) { // indeksy obliczanego elementu jeden wątek - jeden element ograniczenie wielości instancji do max wielości bloku int tx = threadidx.x; int ty = threadidx.y; float C_local = 0; //zmienna w rejestrze - obliczany wynik for (int k = 0; k < WIDTH; ++k) { float A_d_element = Ad[ty * WIDTH+ k]; // Ad[ty,k] pobranie z pamięci globalnej oceniane jako transfer nieefektywny (potencjalnie) ta sama wartość potrzebna jednocześnie wątkom ½ wiązki float B_d_element = Bd[k * WIDTH + tx]; // Bd[k,tx] pobranie z pamięci globalnej oceniane jako transfer efektywny łączone dostępy (potencjalnie) sąsiednie lokacje pamieci dla ½ wiązki C_local += A_d_element * B_d_element; } Cd[ty * WIDTH + tx] = C_local; //zapis do pamieci globalnej wyniku - jednokrotnie // UWAGA: w przypadku potrzeby obliczeń wielu wyników (instancja większa od wielkości zastosowanego lub możliwego bloku wątków) konieczne jest poszerzenie kodu o kolejne pętle umożliwiające wykonanie obliczeń przez jeden wątek dla wielu wyników. Warto aby sąsiednie wątki liczyły wartości macierzy oddalone o wielość bloku wątków. } Obliczenia za pomocą jednego bloku wątków (kluczowe są zmienne threadidx.x, threadidx.y) Lokacja zmiennych Każdy wątek oblicza jeden element wyniku tutaj liczba wątków równa liczbie elementów macierzy (zadanie z laboratorium nie). Rozmiar bloku wątków równy rozmiarowi macierzy lub więcej pracy (dodatkowa pętla po obliczanych elementach) dla każdego wątku (ilość pracy zależna od stosunku wielkości tablicy i wielkości bloku) 11
12 Uruchomienie przetwarzania - MM jeden blok wątków // parametry konfiguracji uruchomienia kernela dim3 wymiarybloku(width, WIDTH); dim3 wymiarygridu(1, 1); // jeden blok // uruchomienie obliczeń MatrixMulKernel_1<<< wymiarygridu, wymiarybloku >>> (Ad, Bd, Cd,WIDTH); 12
13 Analiza efektywność - MM ver.1 Jeden blok - obliczenia wykonywane na jednym SM. W każdej chwili obliczany jest maksymalnie tylko jedna wiązka 32 wątki (GTX260). Dla pozostałych wątków (z innych 32 el. wiązek) możliwe jest pobieranie operandów z pamięci globalnej GPU. Maksymalna liczba wątków na SM i wielkość bloku wątków ograniczona przez parametry CC (zdolności obliczeniowej) i zasoby GPU wynosi 512. Max wydajność rozwiązania - obliczenia używamy tylko 1 SM: 1,4 *10 9 (częstotliwość) 8 X 3 = 30 Gflop 8 oznacza liczbę rdzeni w SM (używane dla kodu) 3 oznacza liczbę instrukcji na cykl w przeliczeniu na liczbę rdzeni ((8+16)/8) Max przepustowość pamięci dla karty: 112 GB/s (GTX260) Brak ograniczenia prędkości obliczeń przepustowością dostępu do pamięci. Ograniczenie prędkości obliczeń karty poprzez wykorzystanie tylko jednego SM. 13
14 Analiza ograniczenia prędkości obliczeń MM ver.1 Współczynnik CGMA (compute to global memory access ratio) stosunek liczby operacji do liczby dostępów do pamięci. Dla mnożenia macierzy 2 operacje (+,*) przypadają na 2 dostępy do pamięci globalnej (pobranie operandów) CGMA =1 CGMA wyrażone w bajtach - 2/8 opearacji / bajt Liczba transferów zależna od struktury i dostępów wiązki wątków. Model przetwarzania: Po zakończeniu kroku obliczeń dla jednej wiązki (2 operacje dla 32 watków ok. 4 cykli) przechodzi ona do pobierania danych z pamięci globalnej. Kolejna praca tej wiązki możliwa po odebraniu danych - czas rzędu 100 cykli (czas dostępu do pamięci globalnej). Zakładając równoległość 2 dostępów do pamięci globalnej realizowanej przez wiązkę potrzeba 100/4 cykle pracy (obliczenia i pobrania) różnych wiązek realizujących obliczenia dla zapewnienia ciągłości (max efektywności obliczeń). (jest to niemożliwe w tej wersji kodu - mamy maksymalnie 16 wiązek - 1 blok watków) (CGMA=1). 14
15 Mnożenie macierzy (wiele bloków) Określenie elementu dużej macierzy obliczanego przez wątek bloku wątków Zakładamy, że wymiar macierzy WIDTH jest podzielny przez wymiar podmacierzy SUB_WIDTH Kwadratowy blok wątków oblicza kwadratowy blok elementów macierzy wynikowej, każdy wątek oblicza jeden element podmacierzy, SUB_WIDTH= blockdim.x= blockdim.y Dla określenia lewego górnego elementu podtablicy obliczanej przez blok potrzebne są zmienne automatyczne środowiska - indeksy bloków blockid.x, blockid.y blockid.x* blockdim.x, blockid.y* blockdim.y Dla wyznaczenia elementu w ramach bloku potrzebne są indeksy wątków w bloku: threadid.x, threadid.y Indeksy elementów tablicy zatem dla wątku to: blockid.x* blockdim.x + threadid.x, blockidd.y* blockdim.y + threadid.y Zrzutowanie odwołania na elementy w macierzy jednowymiarowej: (blockid.y* blockdim.y + threadid.y )* WIDTH + (blockid.x* blockdim.x + threadid.x ) 1,1 0,0 0,1 0,2 1,0 1,1 1,2 2,0 2,1 2,2 blockid.x* SUB_WIDTH, blockid.y* SUB_WIDTH threadid.x threadid.y 15
16 Mnożenie macierzy wer2 Obliczenia za pomocą wielu bloków wątków o wielkości blockdim.x * blockdim.y Każdy wątek oblicza jeden element wyniku liczba wątków równa liczbie elementów macierzy. Liczba bloków równa (rozmiar_macierzy/ blockdim.x) 2 - zależna od wielkości macierzy i wielkości bloku Obliczenia mogą być wykonywane na wielu SM, gdyż różne bloki nie muszą być uruchomione w tym samym SM. Liczba jednocześnie przetwarzanych wiązek zależy od: liczby SM ograniczenia sprzętu (GTX 260) jeden warp w jednym SM równoczesnie, Liczby bloków - kolejny SM wymaga kolejnego bloku Liczby aktywnych wiązek im więcej wiązek można przydzielić do SM jednocześnie (ograniczenia zasobowe) tym większa możliwość ukrycia kosztu dostępu do pamięci zachowania ciągłości obliczeń. 16
17 global void MatrixMulKernel_2(float* Ad, float* Bd, float* Cd, int WIDTH) { // wyznaczenie indeksu wiersza/kolumny obliczanego elementu tablicy Cd int Row = blockid.y * blockdim.y + threadid.y; int Col = blockid.x * blockdim.x + threadid.x; float C_local= 0; // każdy wątek z bloku oblicza jeden element macierzy for (int k = 0; k < WIDTH; ++k) C_local += A_d[Row][k] * B_d[k][Col]; Cd[Row][Col] = C_local; } Analiza efektywności dostępów do pamięci globalnej taka sama jak dla wer.1 A_d[Row][k] dostęp nieefektywny - nie wykorzystuje przepustowości łącza jednocześnie potrzebna ta sama wartość B_d[k][Col] dostęp efektywny sąsiednie wątki warpu czytają sąsiednie słowa z pamięci globalnej. Efektywny zapis do pamięci sąsiednich wartości. MM wer. 2 17
18 Uruchomienie przetwarzania Mnożenie macierzy wer2 // parametry konfiguracji uruchomienia kernela dim3 wymiarybloku(sub_width, SUB_WIDTH); dim3 wymiarygridu(width / SUB_WIDTH, WIDTH / SUB_WIDTH); (uwaga na liczbę wątków aby ich starczyło (SUFIT) i wszystkie realizowały właściwą pracę należy sprawdzić czy wątek ze swoimi współrzędnymi jest w zakresie pracy do wykonania? ) // uruchomienie obliczeń MatrixMulKernel_2<<< wym_gridu, wym_bloku >>>(Ad, Bd, Cd,WIDTH); 18
19 Ograniczenia na poziom równoległości przetwarzania Ograniczenia wydajnościowe: 1. Dla wielu SM - poziom równoległości zależy od liczby bloków wątków przetwarzających grid. 2. Dla jednego SM poziom równoległości i efektywność obliczeń w ramach jednego SM zależy od liczby wiązek, które można równocześnie przydzielić do jednego SM. Jest ona ograniczona: liczbą bloków w SM 8 problemem są małe bloki liczba warps w SM 32 - czyli max 1024 wątki (CC 1.3) wymaganiami na liczbę rejestrów bloku wątków (wielkość bloku * liczba rejestrów potrzebnych wątkowi) 3. Im więcej bloków tym możliwe większe zrównoważenie pracy SMów. 4. Im więcej wątków w SM (bloków jednocześnie w SM) tym większe szanse zapewnienia ciągłości pracy jednostek wykonawczych. 19
20 Wydajność rozwiązania - mnożenie macierzy wer2 Różnice względem wersji 1: Można wykorzystać potencjalnie wszystkie SM wzrost maksymalnej prędkości obliczeń 27 x (GTX 260) Można uzyskać większą maksymalną zajętość SM dla uruchomienia np. 4 bloki 256 wątków dają maksimum 1024 watki na SM maksymalna, bo zależna od wielkości instancji. Co najmniej dwukrotny (1024 zamiast 512) wzrost liczby wątków nie zapewni ciągłości obliczeń dla CGMA=1 nadal dłużej trwa dostęp do danych (pobieranie) niż ich obliczenia. Nasz cel - zwiększyć CGMA liczba operacji arytmetycznych stała (złożoność), trzeba zmniejszyć liczbę dostępów do pamięci globalnej, celem jest zapewnienie pracy rdzeni bez przestojów w oczekiwaniu na dane z pamięci globalnej. 20
21 Strona z innego wykładu: Mnożenie macierzy pamięć podręczna [zapewnienie etapów lokalności czasowej dostępu do danych w pamięci podręcznejcpu/ pamieci współdzielonej GPU ] r x r C A B for (int kk = k ; kk < k+r ; kk++) C[ii][jj] + = A[ii][kk] * B[kk][jj]; for (int jj = j ; jj < j+r ; jj++) for (int kk = k ; kk < k+r ; kk++) C[ii][jj] + = A[ii][kk] * B[kk][jj]; for ( int ii = i ; ii < i+r; ii++) for (int jj = j ; jj < j+r ; jj++) for (int kk = k ; kk < k+r ; kk++) C[ii][jj] + = A[ii][kk] * B[kk][jj]; for (int k = 0 ; k < n ; k+=r) for ( int ii = i ; ii < i+r; ii++) for (int jj = j ; jj < j+r ; jj++) for (int kk = k ; kk < k+r ; kk++) C[ii][jj] + = A[ii][kk] * B[kk][jj]; 21
22 MM wer.3 - przebieg Zastosujemy podejście użyte w mnożeniu macierzy algorytmem zagnieżdżonych 6 pętli i optymalizację wykorzystania pamięci podręcznej. Zamiast lokalności czasowej dostępu do pamięci podręcznej wykorzystujemy czasowo lokalnie dane w pamięć współdzielonej. Pobrania danych do pamięci współdzielonej realizują wątki kolektywnie przed obliczeniami. Konieczna synchronizacja zakończenia pobrania i zakończenia obliczeń, gdyż wątki nie mają gwarancji (bloki > 32 watków) na wykonywane równocześnie. ETAPY pracy: Pobranie danych do pamięci współdzielonej bloku wątków możliwość łączenia dostępów (przepisywanie bloków danych realizować można w sposób efektywny) Każdy wątek wylicza wynik częściowy na podstawie danych w dostępnej mu pamięci współdzielonej. Synchronizacja każdego bloku wątków przed wymianą danych w pamięci współdzielonej. Kolejne kroki kolektywnego pobrania danych przez blok wątków do pamięci współdzielonej, a następnie uzupełnianie sum częściowych o wyniki mnożeń elementów z kolejno pobranych bloków. Zapis wyników (każdy wątek jeden wynik) do pamięci. 22
23 MM wer.3 - efektywność Zyski: mniej pobrań z pamięci globalnej, wielokrotne (przez inne wątki) wykorzystanie danych dostępnych w pamięci podręcznej (krotność wykorzystania danych zależna od wielkości bloku wątków) - Możliwe efektywne dostępy podczas odczytu danych z pamięci globalnej (transfery łączone). Straty: - Brak jednoczesności obliczeń i odczytu danych z pamięci globalnej w ramach bloku. - Konieczność synchronizacji wątków w bloku po i przed etapem pobierania danych (spadek równoległości). Im większy blok tym większa krotność wykorzystania raz pobranych do pamięci współdzielonej danych - wzrost CGMA. Im większy blok tym niższy stopień zrównoleglenia pobrań danych i obliczeń w ramach jednego SM. LECZ: Różne bloki mogą realizować różne etapy obliczeń. 23
24 Mnożenie macierzy wersja 3 cz.1 global void MatrixMulKernel_3(float* Ad, float* Bd, float* Cd, int Width) { shared float Ads[SUB_WIDTH][SUB_WIDTH]; shared float Bds[SUB_WIDTH][SUB _WIDTH]; // tutaj określenie obliczanego przez wątek elementu macierzy (jak w poprzednim kodzie) for (int m = 0; m < WIDTH/ SUB_WIDTH; ++m) { Ads[tx][ty] = Ad [Row][m*SUB_WIDTH + tx]; //kolejny element dla sąsiedniego wątku Bds[tx][ty] = Bd[m*SUB_WIDTH + ty][col]; // używana kolumna jakość pobrań? } syncthreads(); for (int k = 0; k < SUB_WIDTH; ++k) C_local += Ads[tx][k] * Bds[k][ty]; syncthreads(); Cd[Row][Col] = C_local; } Mnożenie macierzy przez bloki wątków w przy użyciu pamięci współdzielonej. 24
25 Mnożenie macierzy wersja 3 wyjaśnienia // wątki wspólnie bloku ładują podmacierze do pamięci współdzielonej // WĄTKI O SĄSIEDNICH ID ładują sąsiednie elementy z pamięci //oczekiwanie na dane podmacierzy w pamięci współdzielonej - synchronizacja //oczekiwanie na koniec obliczeń przed pobraniem nowych danych - synchronizacja 25
26 Efektywność MM wersji 3 Im większy blok ładowany do pamięć współdzielonej (SHM) tym mniej razy dane pobierane i mniejsze wymagania na przepustowość pamięci globalnej. Dla tego kodu rozmiar bloku danych każdej macierzy wejściowej jest równy rozmiarowi bloku wątków. Rozmiar bloku wątków wpływa na wielkość potrzebnej pamięci SHM i możliwości uruchamiania bloków w SM. W wewnętrznej pętli każdy wątek bloku o rozmiarach BLOCK_SIZE x BLOCK_SIZE wykonuje BLOCK_SIZE operacji MUL_ADD i dwa pobrania danych macierzy wejściowej, CGMA = BLOCK_SIZE Ograniczeniem na prędkość tych obliczeń są: synchronizacja pracy wątków w bloku wątków faza pobrań danych i faza obliczeń dla bloku wątków nie są równoległe, czas dostępu do pamięci globalnej. 26
27 Wersja 3 Pętla po blokach macierzy { Mnożenie macierzy wersja 4 Ładowanie kolejnego bloku danych do pamięci współdzielonej A; Synchronizacja; Obliczenia na pw A; Synchronizacja; } Wersja 4 Pobranie pierwszego bloku danych z pamięci globalnej do A (do rejestru lub pamięci współdzielonej) Pętla po blokach { Przepisanie danych z A do pamięci współdzielonej B; -- zwolnienie A Synchronizacja; Pobranie kolejnego bloku danych z pamięci globalnej do A; Obliczenia na pamięci pw B; Synchronizacja; -- zwolnienie B } Wzrost ilości operacji w kodzie i większe wymagania zasobowe, lecz inna synchronizacja umożliwiająca nakładanie obliczeń i pobrania danych dla wątków jednego bloku. 27
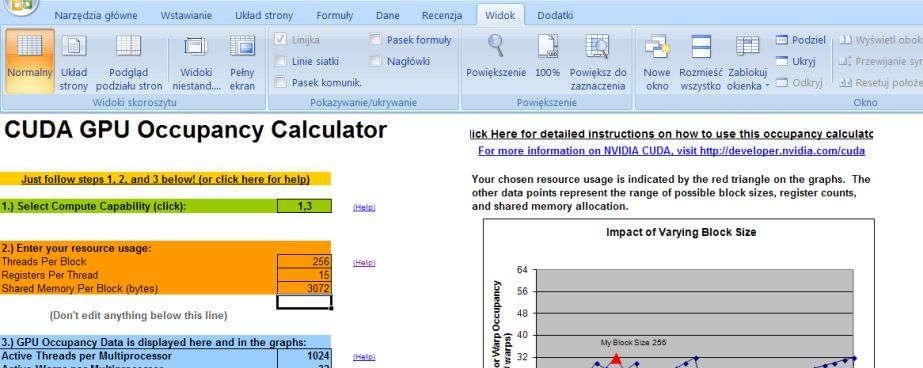
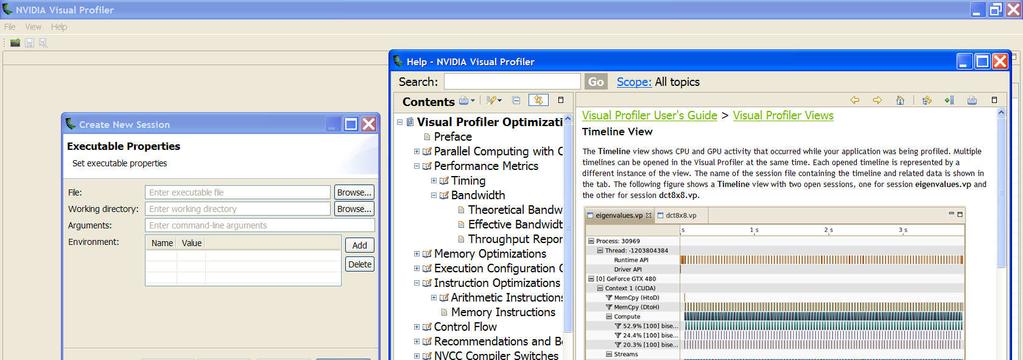
28 Dalsze optymalizacje #pragma unroll - rozwinięcie pętli zmniejsza liczbę operacji (obsługujące pętle). Wzrost ilości pracy realizowanej przez wątek obliczanie większej liczby wyników (w oparciu o częściowo te same dane). Obliczenia dla wielu tablic przesłanie danych do obliczeń na kartę równoczesne z obliczeniami dla poprzednio odebranych danych. Ocena efektywności wprowadzonych rozwiązań: CUDA_Occupancy_Calculator.xls Nvidia Visual profiler 28
29 Sterowanie realizacją instrukcji przez wątki warpu w SM Problemem efektywnościowym związanym z rozgałęzieniami w kodzie jest rozbieżność przetwarzania. Załóżmy, że różne grupy wątków jednego warpu mają realizować inne ciągi instrukcji. Realizacja: różne ścieżki przetwarzania są pokonywane dla każdej grupy wątków sekwencyjnie spadek poziomu równoległości przetwarzania spadek efektywności. Rozbieżność przetwarzania może się pojawić jako efekt wystąpienia w kodzie warunku uzależnionego od identyfikatora wątku np. : if (threadidx.x >16) może tworzyć dwie ścieżki realizacji kodu dla wątków jednego warpu. if (threadidx.x / rozmiar_warpu >1) może powodować rozbieżność przetwarzania w ramach bloku lecz nie powoduje rozbieżności przetwarzania w ramach warpu (inne przetwarzanie (0-31), inne 31-N (rozbieżność ta nie będzie problemem) 29
30 Równoległa redukcja - problem Problem polega na scaleniu elementów wektora do jednej wartości. Przykładem redukcji równoległej może być wyznaczenie sumy elementów wektora danych dostępnego w pamięci współdzielonej systemu równoległego. Przetwarzanie odbywa się przy użyciu procesorów kart graficznych. Dane początkowo przechowywane są w pamięci globalnej. Wyniki pośrednie przechowywane są w pamięci współdzielonej bloku wątków lub w pamięci globalnej. Wynik obliczeń jest przekazywany do pamięci komputera host na potrzeby testów poprawności obliczeń. 30
31 Równoległa redukcja etapy przetwarzania 1. Uruchomienie pierwszego etapu obliczeń w oparciu o niezbędną liczbę wątków wynikającą: z liczby sumowanych elementów i liczby sumowań przypadających na wątek. 2. Każdy blok wątków generuje jeden wynik sumę częściową ze swoich elementów. 3. Konieczna synchronizacja (zależność kolejnościowa) przed każdym etapem przetwarzania realizowana przez sekwencyjne przetwarzania kernela w jednym strumieniu. 4. Uruchomienie obliczeń w oparciu o niezbędną liczbę wątków wynikającą z liczby bloków w poprzednio uruchomionym gridzie i liczby sumowań przypadających na wątek. 5. Powtarzanie procedury od kroku 2 do uzyskania jednego wyniku globalnego. 6. UWAGA: Dodatkowo ze względu na współdzielenie danych między wątkami w bloku (w kolejnych etapach sumowania) konieczna synchronizacja pracy wątków bloku po każdym etapie sumowania. 31
32 Równoległa redukcja - Struktura przetwarzania 1 Pamięć globalna ,2,4,8,16,..ok 100 W jakiej odległości sa liczące wątki ½,1/4, 1/8, 1/16 bloku, załóżmy blok 512 wątków, ile warpów pracuje? 0 Zapis do pamięci globalnej Rysunek: Jeden etap przetwarzania dla bloku 16 wątków, okręgi oznaczają wątki, strzałki oznaczają pobrania danych z pamięci. Każdy wątek zapisuje w pamięci współdzielonej wartość, a następnie, jeśli jest odpowiedzialny za wygenerowanie wyniku - dodaje Problem: Kolejne wątki z wiązki nie uczestniczą w kolejnych etapach obliczeń wiązka zostaje uszeregowana do procesora, lecz coraz mniej wątków wykonuje II obliczenia utrata efektywności przetwarzania. Wynik - pracy bloku (suma lokalna bloku) zapisany zostaje w pamięci globalnej dla wykorzystania w kolejnym etapie sumowania przez nowy grid. Rozbieżności można częściowo uniknąć dla bloków większych niż WARP. Dlaczego źle? 32
33 Konsekwencja rozbieżności przetwarzania wersja 1 kodu Etap Ile wątków? Który wątek aktywny? Ile wiązek aktywnych? Min liczba wiązek Każdy Co Co Co Co Co Co Co Co Liczba zajętych osnów Konieczność synchronizacji między sumowaniami 33
34 Równoległa redukcja - Struktura przetwarzania Pamięć globalna 6 7 W jakiej odległości są liczące wątki 1,1,1,1.. załóżmy blok 512 wątków, ile warpów pracuje? Rysunek: Jeden etap przetwarzania dla bloku 16 wątków. 0 1 Każdy wątek zapisuje w pamięci współdzielonej wartość, a następnie, jeśli jest odpowiedzialny za wygenerowanie wyniku 0 realizuje operację sumowania. Kolejne wątki wiązki uczestniczą w obliczeniach, wiązki kończące przetwarzanie przestają ubiegać się o procesor. Wynik pracy bloku (suma lokalna bloku) zapisany zostaje w pamięci Zapis do globalnej dla wykorzystania w kolejnym etapie sumowania przez pamięci nowy grid. globalnej Dlaczego źle: równoczesne (wątki wiązki) dostępy do oddalonych lokacji pamięci współdzielonej możliwy konflikt dostępu do tych samych banków pamięci współdzielonej. (Pamięć globalna? dostępy oddalone) 34
35 Równoległa redukcja - Struktura przetwarzania 3 Pamięć globalna czas Zapis do pamięci globalnej 35 Rysunek: Jeden etap przetwarzania dla bloku 16 wątków. Każdy wątek zapisuje w pamięci współdzielonej wartość, a następnie, jeśli jest odpowiedzialny za wygenerowanie wyniku - realizuje operację sumowania. Wątek zerowy realizuje 4 sumowania. Sąsiednie wątki odwołują się do sąsiednich danych w pamięci brak konfliktu banków pw, łączenie dostępów pg Grupa sumujących - sąsiednich wątków zmniejsza się dwukrotnie w każdym kroku.
36 Równoległa redukcja - struktura przetwarzania 3 Pamięć globalna czas Zapis do pamięci globalnej 36 Efektywność: Powyższa organizacja przetwarzania zapewnia: Przetwarzanie realizowane przez ciągły zakres wątków bloku ograniczenie rozbieżności przetwarzania wątków warpu (dla bloków > 32 wątki). Dostęp w jednym kroku pracy wątków do kolejnych słów z pamięci: globalnej odczyt współdzielonej odczyty i zapisy Pozwala na efektywny dostęp poprzez różne banki pamięci współdzielonej.
37 Warianty struktury przetwarzania Korzystanie z pamięci globalnej lub pamięci współdzielonej wątków do zapisu wyników pośrednich. Realizacja sumowań pierwszego etapu przez wszystkie wątki bloku. Realizacja wielu sumowań przez wątki bloku łączone pobieranie z pamięci globalnej i sumowanie z wartością w pamięci współdzielonej. 37
38 Przykładowy kod kernela wg pierwszej struktury przetwarzania //sumowanie (w pamięci globalnej) przez blok wątków 2* blockdim.x elementów global void block_sum(float *dane, float *wyniki, const size_t rozmiar_danych) { unsigned int i = 2*(blockIdx.x * blockdim.x + threadidx.x); //identyfikator elementu zależny od identyfikatora wątku i bloku (suma 2 elementów) for(unsigned int odstep =1; odstep< 2*blockDim.x; odstep *=2) //odstęp dla sumowanych elementów { if (threadidx.x %odstep ==0) //wykluczenie wątków w kolejnych etapach co 2,4,8, if (i+odstep< rozmiar_danych) //test rozmiaru danych dane[i] += dane[i+odstep]; syncthreads(); //synchronizacja gotowości danych } if (threadidx.x == 0) // wątek 0 zapisuje wynik { wyniki[blockidx.x] = dane[2*blockidx.x * blockdim.x]; } } 38
39 Efektywność przetwarzania GTX MB 4B *4M elementy Instancja: 16MB 4B *4M elementów konieczne 3 uruchomienia kernela (512 wątków) I uruchomienie kernela: Grid: 4K bloków, Blok: 512 wątków (2M) II uruchomienie kernela: Grid: 4 blok, Blok: 512 wątków (2K) III uruchomienie kernela: 2 wątki (4) Metoda 3S pozwala na 3,4 krotne przyspieszenie obliczeń Wersja Użyta Czas Przepustowość Wzrost Struktury pamięć obliczeń Obliczeń efektywności ms GB/s względem 1G o 1 G 13,6 1,17 1 S 12,6 1,27 9% 2 G 9,2 1,74 49% 2 S 8,6 1,86 59% 3 G?? 3 S 3,1 5,16 340% 39

40 40

41 41
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady. Wersja
 Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla roku.ak. 2015/2016 Rafał Walkowiak, 30.01.2016 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Przykładem jest komputer z procesorem 4 rdzeniowym dostępny w laboratorium W skład projektu wchodzi:
 Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Materiały pomocnicze do laboratorium. 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych
 Materiały pomocnicze do laboratorium 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych 4. Optymalizacja dostępu do pamięci Miary efektywności systemów współbieżnych System
Materiały pomocnicze do laboratorium 1. Miary oceny efektywności 2. Mnożenie macierzy 3. Znajdowanie liczb pierwszych 4. Optymalizacja dostępu do pamięci Miary efektywności systemów współbieżnych System
MATERIAŁY POMOCNICZE DO LABORATORIUM Z PRZETWARZANIA RÓWNOLEGŁEGO KWIECIEŃ 2018
 Analiza efektywności mnożenia macierzy w systemach z pamięcią współdzieloną MATERIAŁY POMOCNICZE DO LABORATORIUM Z PRZETWARZANIA RÓWNOLEGŁEGO KWIECIEŃ 2018 1 Mnożenie macierzy dostęp do pamięci podręcznej
Analiza efektywności mnożenia macierzy w systemach z pamięcią współdzieloną MATERIAŁY POMOCNICZE DO LABORATORIUM Z PRZETWARZANIA RÓWNOLEGŁEGO KWIECIEŃ 2018 1 Mnożenie macierzy dostęp do pamięci podręcznej
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych
 Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Algorytmy równoległe. Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2010
 Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Podstawy Programowania C++
 Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Wykład 3 - podstawowe konstrukcje Instytut Automatyki i Robotyki Warszawa, 2014 Wstęp Plan wykładu Struktura programu, instrukcja przypisania, podstawowe typy danych, zapis i odczyt danych, wyrażenia:
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Wskaźniki i dynamiczna alokacja pamięci. Spotkanie 4. Wskaźniki. Dynamiczna alokacja pamięci. Przykłady
 Wskaźniki i dynamiczna alokacja pamięci. Spotkanie 4 Dr inż. Dariusz JĘDRZEJCZYK Wskaźniki Dynamiczna alokacja pamięci Przykłady 11/3/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Wskaźnik to
Wskaźniki i dynamiczna alokacja pamięci. Spotkanie 4 Dr inż. Dariusz JĘDRZEJCZYK Wskaźniki Dynamiczna alokacja pamięci Przykłady 11/3/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Wskaźnik to
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Tablice mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Katowice, 2011
 Tablice mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Katowice, 2011 Załóżmy, że uprawiamy jogging i chcemy monitorować swoje postępy. W tym celu napiszemy program, który zlicza, ile czasu
Tablice mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Katowice, 2011 Załóżmy, że uprawiamy jogging i chcemy monitorować swoje postępy. W tym celu napiszemy program, który zlicza, ile czasu
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
ZASADY PROGRAMOWANIA KOMPUTERÓW
 POLITECHNIKA WARSZAWSKA Instytut Automatyki i i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW Język Język programowania: C/C++ Środowisko programistyczne: C++Builder 6 Wykład 9.. Wskaźniki i i zmienne dynamiczne.
POLITECHNIKA WARSZAWSKA Instytut Automatyki i i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW Język Język programowania: C/C++ Środowisko programistyczne: C++Builder 6 Wykład 9.. Wskaźniki i i zmienne dynamiczne.
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Lab 8. Tablice liczbowe cd,. Operacje macierzowo-wektorowe, memcpy, memmove, memset. Wyrażenie warunkowe.
 Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 8. Tablice liczbowe cd,. Operacje macierzowo-wektorowe, memcpy, memmove, memset. Wyrażenie warunkowe. 1. Wektory i macierze: a. Przykład
Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 8. Tablice liczbowe cd,. Operacje macierzowo-wektorowe, memcpy, memmove, memset. Wyrażenie warunkowe. 1. Wektory i macierze: a. Przykład
Wstęp do informatyki. Maszyna RAM. Schemat logiczny komputera. Maszyna RAM. RAM: szczegóły. Realizacja algorytmu przez komputer
 Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
Stałe, tablice dynamiczne i wielowymiarowe
 Stałe, tablice dynamiczne i wielowymiarowe tylko do odczytu STAŁE - CONST tablice: const int dni_miesiaca[12]=31,28,31,30,31,30,31,31,30,31,30,31; const słowo kluczowe const sprawia, że wartość zmiennej
Stałe, tablice dynamiczne i wielowymiarowe tylko do odczytu STAŁE - CONST tablice: const int dni_miesiaca[12]=31,28,31,30,31,30,31,31,30,31,30,31; const słowo kluczowe const sprawia, że wartość zmiennej
Za pierwszy niebanalny algorytm uważa się algorytm Euklidesa wyszukiwanie NWD dwóch liczb (400 a 300 rok przed narodzeniem Chrystusa).
.") Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla r.ak. 2014/2015 Rafał Walkowiak,
 Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla r.ak. 2014/2015 Rafał Walkowiak, 17.01.2015 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego wykonują
Zadania na zaliczenie przedmiotu Przetwarzanie równoległe Zebrał dla r.ak. 2014/2015 Rafał Walkowiak, 17.01.2015 Zagadnienia sprzętowe w przetwarzaniu równoległym 1.1 Procesory systemu równoległego wykonują
Wiadomości wstępne Środowisko programistyczne Najważniejsze różnice C/C++ vs Java
 Wiadomości wstępne Środowisko programistyczne Najważniejsze różnice C/C++ vs Java Cechy C++ Język ogólnego przeznaczenia Można programować obiektowo i strukturalnie Bardzo wysoka wydajność kodu wynikowego
Wiadomości wstępne Środowisko programistyczne Najważniejsze różnice C/C++ vs Java Cechy C++ Język ogólnego przeznaczenia Można programować obiektowo i strukturalnie Bardzo wysoka wydajność kodu wynikowego
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI. Wprowadzenie do środowiska Matlab
 LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
LABORATORIUM 3 ALGORYTMY OBLICZENIOWE W ELEKTRONICE I TELEKOMUNIKACJI Wprowadzenie do środowiska Matlab 1. Podstawowe informacje Przedstawione poniżej informacje maja wprowadzić i zapoznać ze środowiskiem
Procesory kart graficznych i CUDA wer
 wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
Algorytm poprawny jednoznaczny szczegółowy uniwersalny skończoność efektywność (sprawność) zmiennych liniowy warunkowy iteracyjny
 zmiennych liniowy warunkowy iteracyjny") Algorytm to przepis; zestawienie kolejnych kroków prowadzących do wykonania określonego zadania; to uporządkowany sposób postępowania przy rozwiązywaniu zadania, problemu, z uwzględnieniem opisu danych
Algorytm to przepis; zestawienie kolejnych kroków prowadzących do wykonania określonego zadania; to uporządkowany sposób postępowania przy rozwiązywaniu zadania, problemu, z uwzględnieniem opisu danych
Co to jest sterta? Sterta (ang. heap) to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).
 to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).") Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Informacje wstępne #include <nazwa> - derektywa procesora umożliwiająca włączenie do programu pliku o podanej nazwie. Typy danych: char, signed char
 Programowanie C++ Informacje wstępne #include - derektywa procesora umożliwiająca włączenie do programu pliku o podanej nazwie. Typy danych: char, signed char = -128 do 127, unsigned char = od
Programowanie C++ Informacje wstępne #include - derektywa procesora umożliwiająca włączenie do programu pliku o podanej nazwie. Typy danych: char, signed char = -128 do 127, unsigned char = od
Języki i paradygmaty programowania 1 studia stacjonarne 2018/19. Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach.
 Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach. 1. Dynamiczna alokacja pamięci dla tablic wielowymiarowych - Przykładowa
Języki i paradygmaty programowania 1 studia stacjonarne 2018/19 Lab 9. Tablice liczbowe cd,. Operacje na tablicach o dwóch indeksach. 1. Dynamiczna alokacja pamięci dla tablic wielowymiarowych - Przykładowa
Ćwiczenie 1. Wprowadzenie do programu Octave
 Politechnika Wrocławska Wydział Elektroniki Mikrosystemów i Fotoniki Przetwarzanie sygnałów laboratorium ETD5067L Ćwiczenie 1. Wprowadzenie do programu Octave Mimo że program Octave został stworzony do
Politechnika Wrocławska Wydział Elektroniki Mikrosystemów i Fotoniki Przetwarzanie sygnałów laboratorium ETD5067L Ćwiczenie 1. Wprowadzenie do programu Octave Mimo że program Octave został stworzony do
Pętle i tablice. Spotkanie 3. Pętle: for, while, do while. Tablice. Przykłady
 Pętle i tablice. Spotkanie 3 Dr inż. Dariusz JĘDRZEJCZYK Pętle: for, while, do while Tablice Przykłady 11/26/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Pętla w największym uproszczeniu służy
Pętle i tablice. Spotkanie 3 Dr inż. Dariusz JĘDRZEJCZYK Pętle: for, while, do while Tablice Przykłady 11/26/2016 AGH, Katedra Informatyki Stosowanej i Modelowania 2 Pętla w największym uproszczeniu służy
MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW
 MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW Projektowanie urządzeń cyfrowych przy użyciu układów TTL polegało na opracowaniu algorytmu i odpowiednim doborze i zestawieniu układów realizujących różnorodne funkcje
MOŻLIWOŚCI PROGRAMOWE MIKROPROCESORÓW Projektowanie urządzeń cyfrowych przy użyciu układów TTL polegało na opracowaniu algorytmu i odpowiednim doborze i zestawieniu układów realizujących różnorodne funkcje
wagi cyfry 7 5 8 2 pozycje 3 2 1 0
 Wartość liczby pozycyjnej System dziesiętny W rozdziale opiszemy pozycyjne systemy liczbowe. Wiedza ta znakomicie ułatwi nam zrozumienie sposobu przechowywania liczb w pamięci komputerów. Na pierwszy ogień
Wartość liczby pozycyjnej System dziesiętny W rozdziale opiszemy pozycyjne systemy liczbowe. Wiedza ta znakomicie ułatwi nam zrozumienie sposobu przechowywania liczb w pamięci komputerów. Na pierwszy ogień
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE. K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3
, D. Kosiorowski (89762) Informatyka, grupa dziekańska I3") PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3 17 lutego 2011 Spis treści 1 Opis problemu 2 2 Implementacja problemu 3 2.1 Kod współdzielony........................
PROJEKT 3 PROGRAMOWANIE RÓWNOLEGŁE K. Górzyński (89744), D. Kosiorowski (89762) Informatyka, grupa dziekańska I3 17 lutego 2011 Spis treści 1 Opis problemu 2 2 Implementacja problemu 3 2.1 Kod współdzielony........................
tablica: dane_liczbowe
 TABLICE W JĘZYKU C/C++ tablica: dane_liczbowe float dane_liczbowe[5]; dane_liczbowe[0]=12.5; dane_liczbowe[1]=-0.2; dane_liczbowe[2]= 8.0;... 12.5-0.2 8.0...... 0 1 2 3 4 indeksy/numery elementów Tablica
TABLICE W JĘZYKU C/C++ tablica: dane_liczbowe float dane_liczbowe[5]; dane_liczbowe[0]=12.5; dane_liczbowe[1]=-0.2; dane_liczbowe[2]= 8.0;... 12.5-0.2 8.0...... 0 1 2 3 4 indeksy/numery elementów Tablica
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Wykład 1_2 Algorytmy sortowania tablic Sortowanie bąbelkowe
 I. Struktury sterujące.bezpośrednie następstwo (A,B-czynności) Wykład _2 Algorytmy sortowania tablic Sortowanie bąbelkowe Elementy języka stosowanego do opisu algorytmu Elementy Poziom koncepcji Poziom
I. Struktury sterujące.bezpośrednie następstwo (A,B-czynności) Wykład _2 Algorytmy sortowania tablic Sortowanie bąbelkowe Elementy języka stosowanego do opisu algorytmu Elementy Poziom koncepcji Poziom
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Tablice i struktury. czyli złożone typy danych. Programowanie Proceduralne 1
 Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
INFORMATYKA Z MERMIDONEM. Programowanie. Moduł 5 / Notatki
 INFORMATYKA Z MERMIDONEM Programowanie Moduł 5 / Notatki Projekt współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego. Realizator projektu: Opracowano w ramach projektu
INFORMATYKA Z MERMIDONEM Programowanie Moduł 5 / Notatki Projekt współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego. Realizator projektu: Opracowano w ramach projektu
Zadania jednorodne 5.A.Modele przetwarzania równoległego. Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011
 Zadania jednorodne 5.A.Modele przetwarzania równoległego Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011 Zadanie podzielne Zadanie podzielne (ang. divisible task) może zostać
Zadania jednorodne 5.A.Modele przetwarzania równoległego Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011 Zadanie podzielne Zadanie podzielne (ang. divisible task) może zostać
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych.
 Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Wymiar musi być wyrażeniem stałym typu całkowitego, tzn. takim, które może obliczyć kompilator. Przykłady:
 5 Tablice Tablica jest zestawem obiektów (zmiennych) tego samego typu, do których można się odwołać za pomocą wspólnej nazwy. Obiekty składowe tablicy noszą nazwę elementów tablicy. Dostęp do nich jest
5 Tablice Tablica jest zestawem obiektów (zmiennych) tego samego typu, do których można się odwołać za pomocą wspólnej nazwy. Obiekty składowe tablicy noszą nazwę elementów tablicy. Dostęp do nich jest
Zmienne i struktury dynamiczne
 Zmienne i struktury dynamiczne Zmienne dynamiczne są to zmienne, które tworzymy w trakcie działania programu za pomocą operatora new. Usuwa się je operatorem delete. Czas ich występowania w programie jest
Zmienne i struktury dynamiczne Zmienne dynamiczne są to zmienne, które tworzymy w trakcie działania programu za pomocą operatora new. Usuwa się je operatorem delete. Czas ich występowania w programie jest
Lab 9 Podstawy Programowania
 Lab 9 Podstawy Programowania (Kaja.Gutowska@cs.put.poznan.pl) Wszystkie kody/fragmenty kodów dostępne w osobnym pliku.txt. Materiały pomocnicze: Wskaźnik to specjalny rodzaj zmiennej, w której zapisany
Lab 9 Podstawy Programowania (Kaja.Gutowska@cs.put.poznan.pl) Wszystkie kody/fragmenty kodów dostępne w osobnym pliku.txt. Materiały pomocnicze: Wskaźnik to specjalny rodzaj zmiennej, w której zapisany
Dr inż. Grażyna KRUPIŃSKA. D-10 pokój 227 WYKŁAD 7 WSTĘP DO INFORMATYKI
 Dr inż. Grażyna KRUPIŃSKA Grazyna.Krupinska@fis.agh.edu.pl D-10 pokój 227 WYKŁAD 7 WSTĘP DO INFORMATYKI Wyrażenia 2 Wyrażenia w języku C są bardziej elastyczne niż wyrażenia w jakimkolwiek innym języku
Dr inż. Grażyna KRUPIŃSKA Grazyna.Krupinska@fis.agh.edu.pl D-10 pokój 227 WYKŁAD 7 WSTĘP DO INFORMATYKI Wyrażenia 2 Wyrażenia w języku C są bardziej elastyczne niż wyrażenia w jakimkolwiek innym języku
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
DYNAMICZNE PRZYDZIELANIE PAMIECI
 DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Wskaźniki. Przemysław Gawroński D-10, p marca Wykład 2. (Wykład 2) Wskaźniki 8 marca / 17
 Wskaźniki 8 marca / 17") Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Procesory kart graficznych i CUDA
 4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
Programowanie kart graficznych. Architektura i API część 1
 Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Lekcja : Tablice + pętle
 Lekcja : Tablice + pętle Wprowadzenie Oczywiście wiesz już jak dużo można osiągnąć za pomocą tablic oraz jak dużo można osiągnąć za pomocą pętli, jednak tak naprawdę prawdziwe możliwości daje połączenie
Lekcja : Tablice + pętle Wprowadzenie Oczywiście wiesz już jak dużo można osiągnąć za pomocą tablic oraz jak dużo można osiągnąć za pomocą pętli, jednak tak naprawdę prawdziwe możliwości daje połączenie
- - Ocena wykonaniu zad3. Brak zad3
 Indeks Zad1 Zad2 Zad3 Zad4 Zad Ocena 20986 218129 ocena 4 Zadanie składa się z Cw3_2_a oraz Cw3_2_b Brak opcjonalnego wywołania operacji na tablicy. Brak pętli Ocena 2 Brak zad3 Ocena wykonaniu zad3 po
Indeks Zad1 Zad2 Zad3 Zad4 Zad Ocena 20986 218129 ocena 4 Zadanie składa się z Cw3_2_a oraz Cw3_2_b Brak opcjonalnego wywołania operacji na tablicy. Brak pętli Ocena 2 Brak zad3 Ocena wykonaniu zad3 po
Wskaźniki. Programowanie Proceduralne 1
 Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Podstawy programowania w języku Visual Basic dla Aplikacji (VBA)
") Podstawy programowania w języku Visual Basic dla Aplikacji (VBA) Instrukcje Język Basic został stworzony w 1964 roku przez J.G. Kemeny ego i T.F. Kurtza z Uniwersytetu w Darthmouth (USA). Nazwa Basic jest
Podstawy programowania w języku Visual Basic dla Aplikacji (VBA) Instrukcje Język Basic został stworzony w 1964 roku przez J.G. Kemeny ego i T.F. Kurtza z Uniwersytetu w Darthmouth (USA). Nazwa Basic jest
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Programowanie w języku C++
 Programowanie w języku C++ Część siódma Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie zawiera skrót treści wykładu, lektura tych materiałów nie zastąpi
Programowanie w języku C++ Część siódma Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie zawiera skrót treści wykładu, lektura tych materiałów nie zastąpi
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
// Liczy srednie w wierszach i kolumnach tablicy "dwuwymiarowej" // Elementy tablicy są generowane losowo #include <stdio.h> #include <stdlib.
 Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Architektura komputera. Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt
 Architektura komputera Architektura von Neumanna: Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt Zawartośd tej pamięci jest adresowana przez wskazanie miejsca, bez względu
Architektura komputera Architektura von Neumanna: Dane i rozkazy przechowywane są w tej samej pamięci umożliwiającej zapis i odczyt Zawartośd tej pamięci jest adresowana przez wskazanie miejsca, bez względu
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wykład z Technologii Informacyjnych. Piotr Mika
 Wykład z Technologii Informacyjnych Piotr Mika Uniwersalna forma graficznego zapisu algorytmów Schemat blokowy zbiór bloków, powiązanych ze sobą liniami zorientowanymi. Jest to rodzaj grafu, którego węzły
Wykład z Technologii Informacyjnych Piotr Mika Uniwersalna forma graficznego zapisu algorytmów Schemat blokowy zbiór bloków, powiązanych ze sobą liniami zorientowanymi. Jest to rodzaj grafu, którego węzły