Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
|
|
|
- Wiktoria Skrzypczak
- 6 lat temu
- Przeglądów:
Transkrypt
1 Procesory wielordzeniowe (multiprocessor on a chip) 1
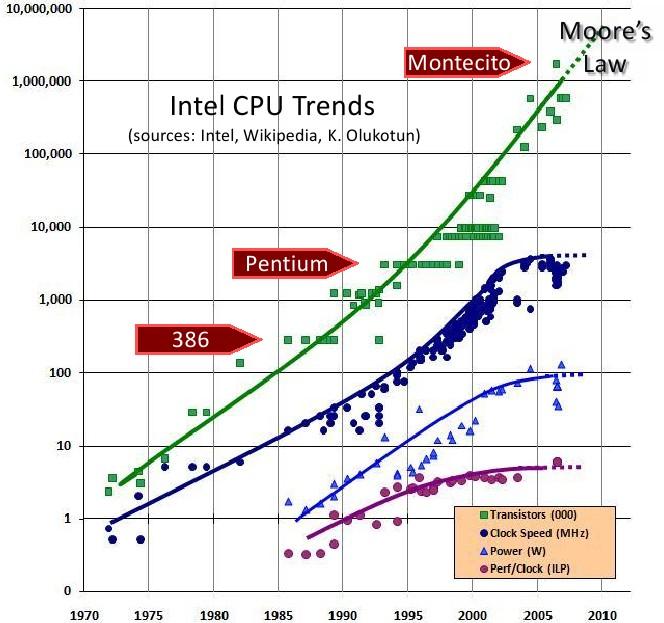
2 Procesory wielordzeniowe 2
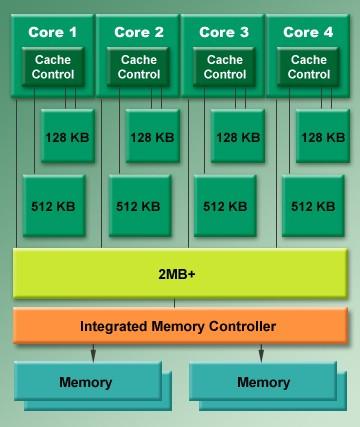

3 Procesory wielordzeniowe 3

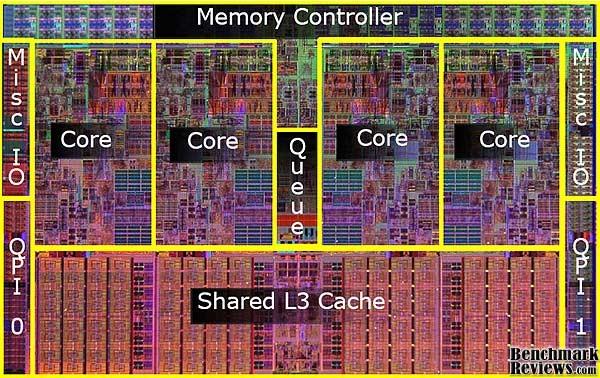
4 Intel Nehalem 4
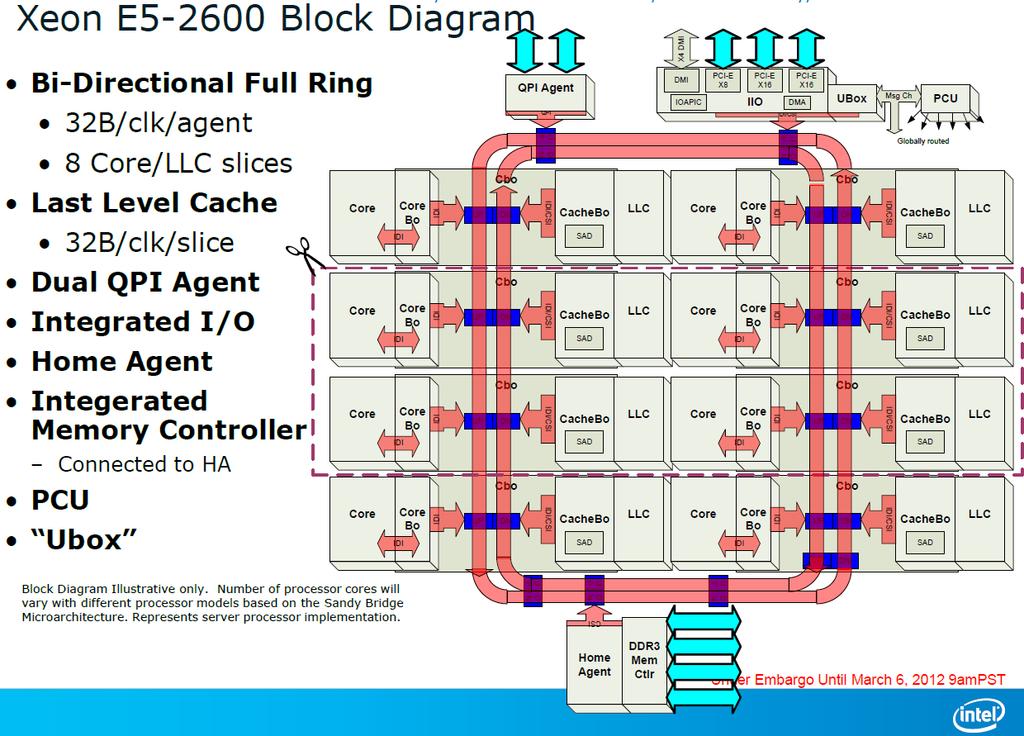
5 5

6 NVIDIA Tesla 6
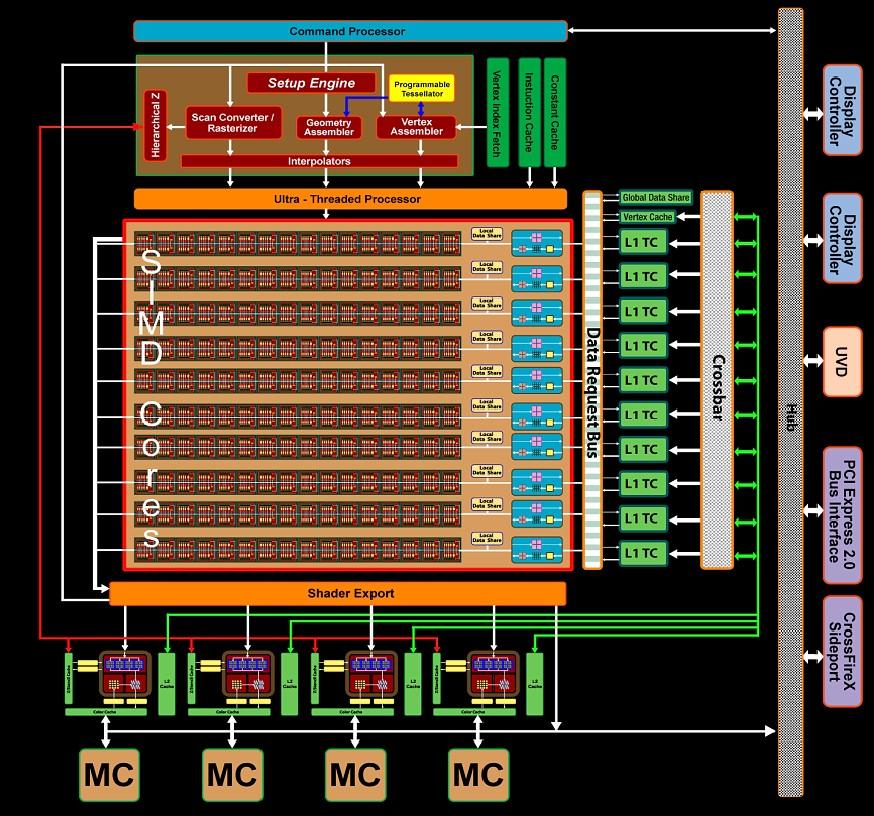
7 ATI FireStream 7


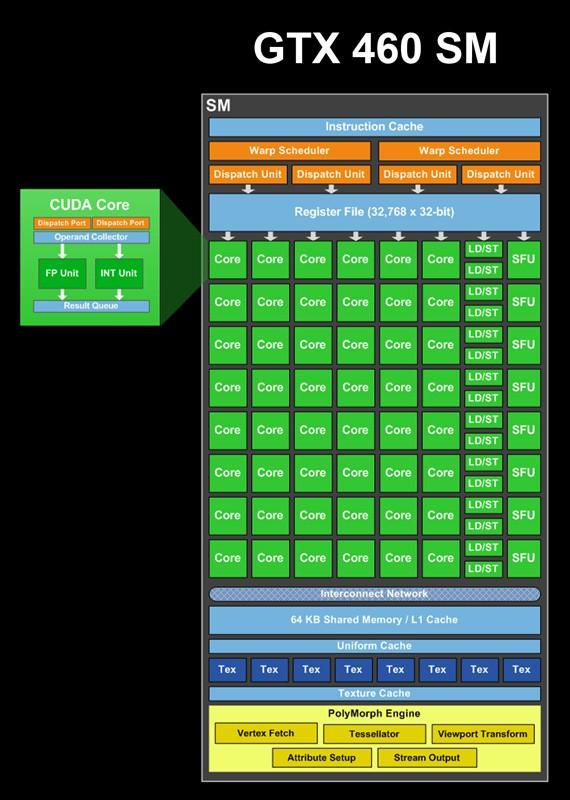
8 NVIDIA Fermi 8
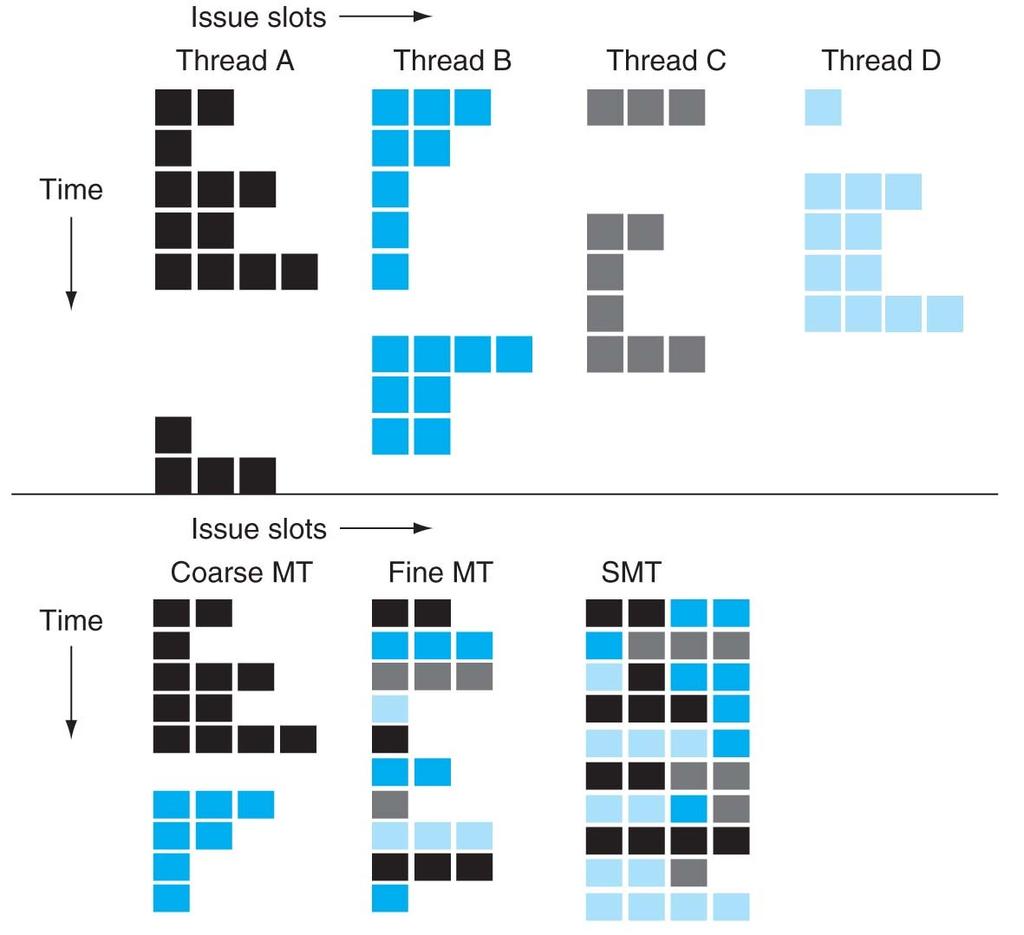
9 Sprzętowa wielowątkowość 9
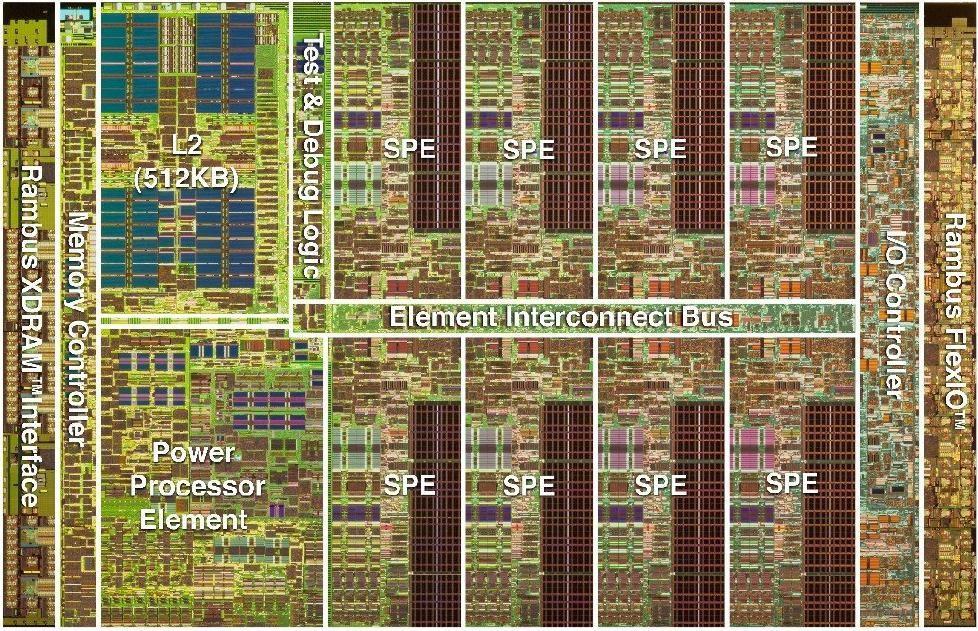

10 Architektury hybrydowe 1

11 Zasoby węzła z pamiecią wspólną 11
.22.13.14.11.13.14.12.")
12 Wydajność pamięci STREAM (GB/s) mat_vec (sek.)
13 Przypisanie wątków, rdzeni i pamięci $likwid-topology CPU: Intel(R) Core(TM) i GHz Intel Core Haswell processor ******************************************************************************** Hardware Thread Topology: Sockets: 1 Cores per socket: 4 Threads per core: HWThread Thread Core Socket Socket : ( ) ******************************************************************************** Cache Topology: Level: 1 Size: 32 kb Cache groups: (4)(15)(26)(37) Level: 2 Size: 256 kb Cache groups: (4)(15)(26)(37) Level: 3 Size: 8 MB Cache groups: ( ) ******************************************************************************** NUMA Topology: Domain: Processors: ( ) 13
 wątków do rdzeni 14")
14 Test STREAM dla Intel Sandy Bridge Wpływ przypięcia (pinning) wątków do rdzeni 14



")
15 Roofline performance model Attainable GPLOPs/sec = Max ( Peak Memory BW Arithmetic Intensity, Peak FP Performance ) Przykłady obliczeń (BLAS 2, BLAS 3) 15

16 Roofline performance model 16
17 Systemy wieloprocesorowe Problem podstawowy: wielowątkowy dostęp do hierarchii pamięci (mikroprocesory wielordzeniowe) L1 prywatna dla procesora (rdzenia) L2 prywatna lub w pewien sposób współdzielona L3 wspólna dla mikroprocesora (jeśli jest) Problemy konkretne: spójność pamięci podręcznej wydajność dostępu minimalizacja liczby chybień false sharing i wspólna sterta dla wątków 17
18 Systemy wieloprocesorowe Problemy szeregowania zadań dla systemów wieloprocesorowych afiniczność i lokalność odniesień do pamięci sterowanie za pomocą np. numactl, sched_setaffinity, sched_getaffinity, zmiennych środowiskowych KMP_AFFINITY, GOMP_AFFINITY, opcji mpirun, mpiexec GOMP_AFFINITY=<proc_list>, np. [,1,2,3,4,...] KMP_AFFINITY="granularity=fine,proclist=[<proc_list>],explicit" podział zadań i iteracji pętli uwzględniający afiniczność Systemy NUMA zaleta: skalowalność przepustowości pamięci problemy: lokalne chybienia pamięci podręcznej odległe (zdalne, remote) chybienia pamięci podręcznej koszt false sharing 18

19 NUMA Architektura AMD Opteron 19
20 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane przewidywanie rozgałęzień wiele jednostek funkcjonalnych Dużo małych rdzeni prostsza budowa, krótsze potoki wykonanie w kolejności proste przewidywanie rozgałęzień mniej jednostek funkcjonalnych 2
21 Programowanie procesorów wielordzeniowych Standardy programowania: wątki: systemowe, POSIX, w ramach języków programowania: Java, C++ dyrektywy programowania wielowątkowego: OpenMP, OpenACC specjalne środowiska: zarządzanie wątkami GPU realizującymi programy w specjalnych językach: CUDA, OpenCL specjalne języki programowania równoległego: Cilk, UPC, Ada, Erlang, C++AMP, Linda i wiele, wiele innych 21
22 Wydajność systemów z pamięcią wspólną Czas dostępu do danych prywatnych zależy od sprzętu Dostęp do danych wspólnych wymaga synchronizacji klasyczna synchronizacja zamki (muteksy), zmienne warunku operacje atomowe Operacje atomowe wspierane sprzętowo są najefektywniejszym sposobem synchronizacji implementacja zamków, zmiennych warunku korzysta z operacji atomowych operacje atomowe można bezpośrednio wykorzystywać w implementacji współbieżnych struktur danych Rozwijaną w ostatnich latach alternatywą jest korzystanie z pamięci transakcyjnej (na razie mało wydajne) 22
23 Wydajność systemów wielordzeniowych Narzut wykonania: procedury systemowe: tworzenie i zarządzanie wątkami synchronizacja współdzielenie zasobów procesora: pamięci podręczne (L2?, L3, TLB?) dostęp do pamięci głównej Wydajność wykonania równoległego może znacząco różnić się pomiędzy różnymi uruchomieniami tego samego kodu! 23
24 Modelowanie wydajności Określenie czasu wykonania T konkretnego programu, na konkretnym sprzęcie,dla konkretnego egzemplarza danych Czas wykonania można wyrazić wzorem: T = Tcomp + Tmem + Tnarzut Toverlap exec przybliżone oszacowania aproksymują pewne z powyższych wartości i pomijają pozostałe dwa typowe podejścia: T = Tcomp ; pozostałe pominięte (dla programów o exec wydajności ograniczanej przez procesor) Texec = Tmem ; pozostałe pominięte (dla programów o wydajności ograniczanej przez pamięć) 24
25 Modelowanie wydajności Jak uzyskać Tcomp i Tmem? wzór ogólny: T = 1 / wydajność wydajność może pochodzić z: analizy sprzętu (zazwyczaj zawyżona, pytanie o ile) (mikro)benchmarków muszą być reprezentatywne i dla sprzętu, i dla programu, i dla danych mnożenie macierz-macierz jest często wykorzystywanym benchmarkiem dla programów o wydajności ograniczanej przez procesor, a test STREAM dla programów o wydajności ograniczanej przez pamięć 25
26 Optymalizacja wydajności Wydajność w (mikro)benchmarkach zazwyczaj zakłada optymalną realizację operacji Jeśli czas wykonania znacząco odbiega od czasu przewidywanego przez model (wydajność znacząco odbiega od wydajności z testów) należy przeprowadzić optymalizację Optymalizacja polega na minimalizacji narzutu i maksymalizacji nakładania się poszczególnych operacji (operacje na liczbach całkowitych, zmiennoprzecinkowych, dostępy do pamięci) 26
27 Optymalizacja wydajności Optymalizacja poprzez usuwanie kolejnych przeszkód na drodze do wydajności wskazywanej przez testy i możliwości sprzętu nazywana jest optymalizacją wąskiego gardła (bottleneck optimization) sposób postępowania polega na wyodrębnieniu w kodzie fragmentów odpowiedzialnych za wydłużanie czasu wykonania (na podstawie profilu wykonania), a następnie na optymalizacji poprzez usuwanie narzutów i ewentualne zwiększanie współczynnika intensywności obliczeń (arithmetic intensity) 27
28 Pamięć w systemach wieloprocesorowych AK Działanie pamięci podręcznej: strategie utrzymywania zgodności pamięci podręcznej (cache coherence protocols) write through każdy zapis do pamięci podręcznej jest przenoszony do pamięci głównej copy back zapis do pamięci podręcznej jest przenoszony do pamięci głównej przy podmianie linii (linia musi wiedzieć czy była zmieniona) inne, bardziej złożone np. MESI 28
29 Protokoły zgodności pamięci podręcznej AK protokoły katalogowe (directory protocols) istnieje katalog z informacją o zawartości pamięci podręcznej i centralny sterownik katalogu pośredniczący w wymianie danych protokoły podglądania (snoopy protocols) procesory podglądają stan pamięci podręcznych i rozgłaszają zmiany zapis z aktualizacją (procesor dokonujący zmianę rozgłasza ją i wszystkie procesory aktualizują swoje pamięci podręczne) zapis z unieważnieniem (procesor dokonujący zmiany unieważnia zawartość pamięci podręcznych innych procesorów); przykład MESI 29
30 Protokół MESI AK Blok w pamięci podręcznej może być w jednym z czterech stanów: M (modified): zmodyfikowany w pamięci podręcznej, różny od odpowiedniego bloku w pamięci głównej E (exclusive): wyłącznie w jednej pamięci podręcznej, zawartość identyczna jak w pamięci głównej S (shared): w kilku pamięciach podręcznych, zawartość identyczna jak w pamięci głównej I (invalid): unieważniony przez zmiany dokonane w innej pamięci podręcznej 3
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Ograniczenia efektywności systemu pamięci
 Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Ograniczenia efektywności systemu pamięci Parametry pamięci : opóźnienie (ang. latency) - czas odpowiedzi pamięci na żądanie danych przez procesor przepustowość systemu pamięci (ang. bandwidth) - ilość
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Organizacja pamięci współczesnych systemów komputerowych : pojedynczy procesor wielopoziomowa pamięć podręczna pamięć wirtualna
 Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Pamięć Wydajność obliczeń Dla wielu programów wydajność obliczeń może być określana poprzez pobranie danych z pamięci oraz wykonanie operacji przez procesor Często istnieją algorytmy, których wydajność
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Wydajność programów sekwencyjnych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Wydajność programów sekwencyjnych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci i przetwarzania
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
METODY ELIMINACJI STUDENTÓW INFORMATYKI. Czyli co student INF-EKA powinien wiedzieć o MESI...
 METODY ELIMINACJI STUDENTÓW INFORMATYKI Czyli co student INF-EKA powinien wiedzieć o MESI... copyright Mahryanuss 2004 Data Cache Consistency Protocol Czyli po naszemu protokół zachowujący spójność danych
METODY ELIMINACJI STUDENTÓW INFORMATYKI Czyli co student INF-EKA powinien wiedzieć o MESI... copyright Mahryanuss 2004 Data Cache Consistency Protocol Czyli po naszemu protokół zachowujący spójność danych
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Przetwarzanie wielowątkowe przetwarzanie współbieżne. Krzysztof Banaś Obliczenia równoległe 1
 Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Maciej Sypniewski. lato 2014, Politechnika Warszawska, Wydział Elektroniki i Technik Informacyjnych
 lato 2014,, Wydział Elektroniki i Technik Informacyjnych SSE, SSE2, SSE3, SSE4, AVX, C++11 threads OpenMP, OpenACC CUDA, OpenCL, C++ AMP 2 Prawo Amdahla Prawo Gustafsona Czy warto zajmować się obliczeniami
lato 2014,, Wydział Elektroniki i Technik Informacyjnych SSE, SSE2, SSE3, SSE4, AVX, C++11 threads OpenMP, OpenACC CUDA, OpenCL, C++ AMP 2 Prawo Amdahla Prawo Gustafsona Czy warto zajmować się obliczeniami
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP
 Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP Wykład przetwarzanie równoległe cz.3 NUMA versus SMP systemy wieloprocesorowe NUMA- każdy procesor jest bliżej
Przykłady praktycznych rozwiązań architektur systemów obliczeniowych AMD, Intel, NUMA, SMP Wykład przetwarzanie równoległe cz.3 NUMA versus SMP systemy wieloprocesorowe NUMA- każdy procesor jest bliżej
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Systemy wieloprocesorowe. Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010
 Systemy wieloprocesorowe Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010 Pożądane cechy aplikacji wielowątkowych Skalowalna wielowątkowość
Systemy wieloprocesorowe Sprzęt i oprogramowanie wspomagające perspektywa - Windows i Linux Wykład Przetwarzanie równoległe Listopad 2010 Pożądane cechy aplikacji wielowątkowych Skalowalna wielowątkowość
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykład 13. Systemy wieloprocesorowe. Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB
 Wykład 13 Systemy wieloprocesorowe Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Ograniczenia w zwiększaniu szybkości procesorów Ograniczenie związane z prędkością światła:
Wykład 13 Systemy wieloprocesorowe Wojciech Kwedlo Wykład z Systemów Operacyjnych -1- Wydział Informatyki PB Ograniczenia w zwiększaniu szybkości procesorów Ograniczenie związane z prędkością światła:
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Struktura systemu operacyjnego. Opracował: mgr Marek Kwiatkowski
 Struktura systemu operacyjnego Schemat budowy systemu operacyjnego model warstwowy Schemat budowy systemu operacyjnego części składowe Większość systemów operacyjnych opiera się o koncepcję jądra, która
Struktura systemu operacyjnego Schemat budowy systemu operacyjnego model warstwowy Schemat budowy systemu operacyjnego części składowe Większość systemów operacyjnych opiera się o koncepcję jądra, która
Programowanie współbieżne. Iwona Kochańska
 1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie współbieżne Wykład 7. Iwona Kochaoska
 Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
Programowanie współbieżne Wykład 7 Iwona Kochaoska Poprawnośd programów współbieżnych Właściwości związane z poprawnością programu współbieżnego: Właściwośd żywotności - program współbieżny jest żywotny,
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
IMPLEMENTACJA I PORÓWNANIE WYDAJNOŚCI WYBRANYCH ALGORYTMÓW GRAFOWYCH W WARUNKACH OBLICZEŃ RÓWNOLEGŁYCH
 IMPLEMENTACJA I PORÓWNANIE WYDAJNOŚCI WYBRANYCH ALGORYTMÓW GRAFOWYCH W WARUNKACH OBLICZEŃ RÓWNOLEGŁYCH Michał Podstawski Praca dyplomowa napisana pod kierunkiem Prof. WSTI dr hab. inż. Jarosława Śmiei
IMPLEMENTACJA I PORÓWNANIE WYDAJNOŚCI WYBRANYCH ALGORYTMÓW GRAFOWYCH W WARUNKACH OBLICZEŃ RÓWNOLEGŁYCH Michał Podstawski Praca dyplomowa napisana pod kierunkiem Prof. WSTI dr hab. inż. Jarosława Śmiei
Architektura Systemów Komputerowych
 Architektura Systemów Komputerowych Wykład 9: Pamięć podręczna procesora jako warstwa hierarchii pamięci Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Zasada
Architektura Systemów Komputerowych Wykład 9: Pamięć podręczna procesora jako warstwa hierarchii pamięci Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Zasada
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Przykładem jest komputer z procesorem 4 rdzeniowym dostępny w laboratorium W skład projektu wchodzi:
 Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Architektura von Neumanna. Jak zbudowany jest współczesny komputer? Schemat architektury typowego PC-ta. Architektura PC wersja techniczna
 Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
Architektura von Neumanna CPU pamięć wejście wyjście Jak zbudowany jest współczesny komputer? magistrala systemowa CPU jednostka centralna (procesor) pamięć obszar przechowywania programu i danych wejście
Rys. 1. Podłączenie cache do procesora.
 Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Cel stosowania pamięci cache w procesorach Aby określić cel stosowania pamięci podręcznej cache, należy w skrócie omówić zasadę działania mikroprocesora. Jest on układem cyfrowym taktowanym przez sygnał
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Sprzęt czyli architektury systemów równoległych
 Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8
 Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8 Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8...które mają 16GB RAM Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8...które
Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8 Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8...które mają 16GB RAM Kto mówi? Inżynier systemów wbudowanych Linux, ARMv7, ARMv8...które
Od uczestników szkolenia wymagana jest umiejętność programowania w języku C oraz podstawowa znajomość obsługi systemu Linux.
 Kod szkolenia: Tytuł szkolenia: PS/LINUX Programowanie systemowe w Linux Dni: 5 Opis: Adresaci szkolenia Szkolenie adresowane jest do programistów tworzących aplikacje w systemie Linux, którzy chcą poznać
Kod szkolenia: Tytuł szkolenia: PS/LINUX Programowanie systemowe w Linux Dni: 5 Opis: Adresaci szkolenia Szkolenie adresowane jest do programistów tworzących aplikacje w systemie Linux, którzy chcą poznać
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia
 Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
1. Zasady projektowania aplikacji wielowątkowych. 2. Funkcje wspomagające równoległość przetwarzania. Wykład PR 2012
 1. Zasady projektowania aplikacji wielowątkowych. 2. Funkcje wspomagające równoległość przetwarzania. Wykład PR 2012 Zasady projektowania aplikacji wielowątkowychprzegląd A. Określenie zadań niezależnych
1. Zasady projektowania aplikacji wielowątkowych. 2. Funkcje wspomagające równoległość przetwarzania. Wykład PR 2012 Zasady projektowania aplikacji wielowątkowychprzegląd A. Określenie zadań niezależnych
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
REFERAT PRACY DYPLOMOWEJ
 REFERAT PRACY DYPLOMOWEJ Temat pracy: Implementacja i porównanie wydajności wybranych algorytmów grafowych w warunkach obliczeń równoległych Autor pracy: Michał Podstawski Promotor: Prof. WSTI, dr hab.
REFERAT PRACY DYPLOMOWEJ Temat pracy: Implementacja i porównanie wydajności wybranych algorytmów grafowych w warunkach obliczeń równoległych Autor pracy: Michał Podstawski Promotor: Prof. WSTI, dr hab.
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
Architektura komputerów egzamin końcowy
 Architektura komputerów egzamin końcowy Warszawa, dn. 25.02.11 r. I. Zaznacz prawidłową odpowiedź (tylko jedna jest prawidłowa): 1. Czteroetapowe przetwarzanie potoku architektury superskalarnej drugiego
Architektura komputerów egzamin końcowy Warszawa, dn. 25.02.11 r. I. Zaznacz prawidłową odpowiedź (tylko jedna jest prawidłowa): 1. Czteroetapowe przetwarzanie potoku architektury superskalarnej drugiego
System pamięci. Pamięć wirtualna
 System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
System pamięci Pamięć wirtualna Pamięć wirtualna Model pamięci cache+ram nie jest jeszcze realistyczny W rzeczywistych systemach działa wiele programów jednocześnie Każdy może używać tej samej przestrzeni
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
Instruction Set Instruction Set Extensions Embedded Options Available. Recommended Customer Price TRAY: $999.00
 Processor Number i7-3960x # of Cores 6 # of Threads 12 Clock Speed 3.3 GHz Max Turbo Frequency 3.9 GHz Intel Smart Cache 15 MB Bus/Core Ratio 33 DMI 5 GT/s Instruction Set 64-bit Instruction Set Extensions
Processor Number i7-3960x # of Cores 6 # of Threads 12 Clock Speed 3.3 GHz Max Turbo Frequency 3.9 GHz Intel Smart Cache 15 MB Bus/Core Ratio 33 DMI 5 GT/s Instruction Set 64-bit Instruction Set Extensions
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Programowanie współbieżne OpenMP wybrane wydajność. Rafał Skinderowicz
 Programowanie współbieżne OpenMP wybrane wydajność Rafał Skinderowicz OpenMP niskopoziomowa synchronizacja OpenMP udostępnia mechanizm zamków (lock) znany z typowych bibliotek programowania współbieżnego
Programowanie współbieżne OpenMP wybrane wydajność Rafał Skinderowicz OpenMP niskopoziomowa synchronizacja OpenMP udostępnia mechanizm zamków (lock) znany z typowych bibliotek programowania współbieżnego
Model pamięci. Rafał Skinderowicz
 Model pamięci Rafał Skinderowicz Czym jest model pamięci Model pamięci dotyczy programów współbieżnych W programie współbieżnym może się zdarzyć, że dany wątek nie będzie widział od razu wartości zmiennej
Model pamięci Rafał Skinderowicz Czym jest model pamięci Model pamięci dotyczy programów współbieżnych W programie współbieżnym może się zdarzyć, że dany wątek nie będzie widział od razu wartości zmiennej
Podstawy architektury systemów z równoległością na poziomie wątków
 Wykład 7 Podstawy architektury systemów z równoległością na poziomie wątków Spis treści: 1. Wątki i wielowątkowość 2. Wielowątkowość z przeplotem pojedyńczych instrukcji 3. Wielowątkowość z przeplotem
Wykład 7 Podstawy architektury systemów z równoległością na poziomie wątków Spis treści: 1. Wątki i wielowątkowość 2. Wielowątkowość z przeplotem pojedyńczych instrukcji 3. Wielowątkowość z przeplotem
MESco. Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075. Stanisław Wowra
 MESco Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075 Stanisław Wowra swowra@mesco.com.pl Lider w dziedzinie symulacji na rynku od 1994 roku. MESco
MESco Testy skalowalności obliczeń mechanicznych w oparciu o licencje HPC oraz kartę GPU nvidia Tesla c2075 Stanisław Wowra swowra@mesco.com.pl Lider w dziedzinie symulacji na rynku od 1994 roku. MESco
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Wykład 13. Linux 2.0.x na maszynach SMP. Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB
 Wykład 13 Linux 2.0.x na maszynach SMP Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB Architektura SMP Skrót od słów Symmetric Multiprocessing (Symetryczne Przetwarzenie Wieloprocesorowe)
Wykład 13 Linux 2.0.x na maszynach SMP Wojciech Kwedlo, Systemy Operacyjne II -1- Wydział Informatyki PB Architektura SMP Skrót od słów Symmetric Multiprocessing (Symetryczne Przetwarzenie Wieloprocesorowe)
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016
 Rafał Walkowiak Wersja: wiosna 2016") OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
OWS1 (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: wiosna 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora