Programowanie kart graficznych
|
|
|
- Sebastian Lewicki
- 6 lat temu
- Przeglądów:
Transkrypt

1 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski i inni
2 Literatura NVIDIA CUDA Programming Guide NVIDIA CUDA Reference Manual NVIDIA CUDA Best Practices Guide CUDA w przykładach - J. Sanders, E. Kandrot 2
3 Po co? 3

4 Schemat architektur CPU vs GPU 4

5 Warstwy Aplikacji GPU 5
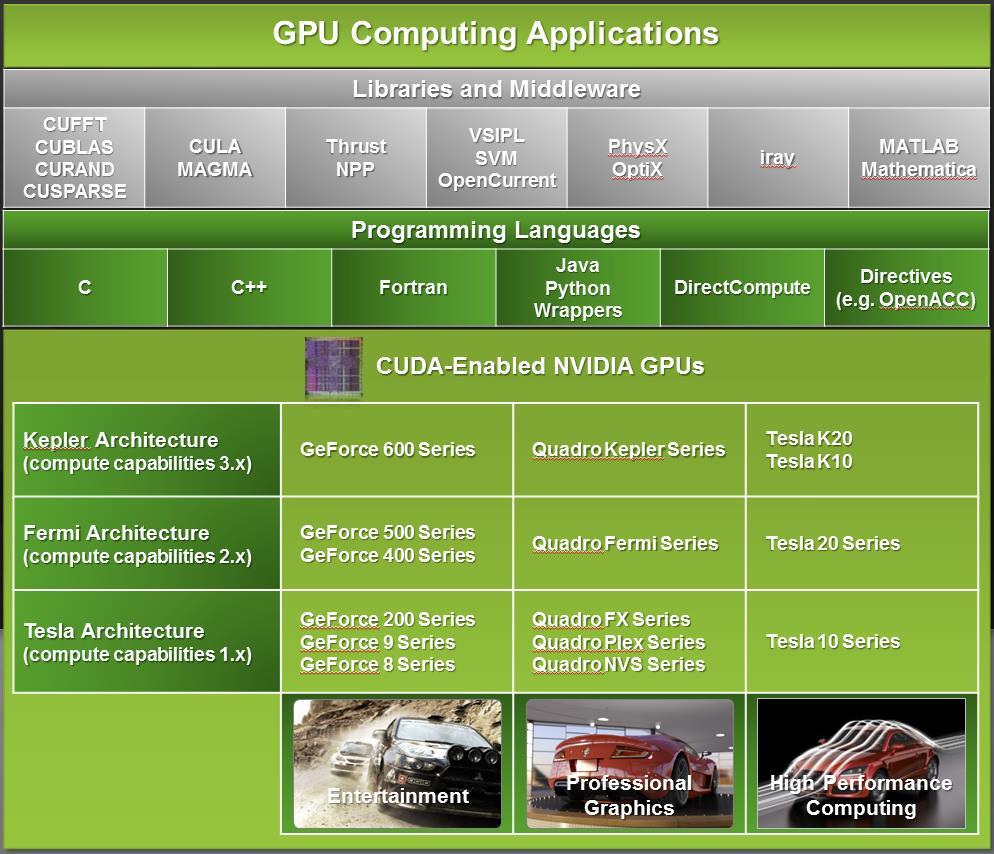
6 6
7 Architektury Compute Capability (Potencjał obliczeniowy) 1.0 Architektura Tesla GPUs 1.1 G92, G94, G96, G98, G84, G GT218, GT216, GT215 G GT200, GT200b Fermi Kepler GF100, GF110 GF104, GF106 GF108, GF114, GF116, GF117, GF119 GK104, GK106, GK Tegra K1 3.5 GK110, GK GK Maxwell GM107, GM GM200, GM204, GM Tegra X1 7
8 CUDA C + CUDA Łatwy start dla programistów C/C++ Podstawy Kluczowe abstrakcje hierarchia wątków hierarcha pamięci model pamięci dzielonej na potrzeby współpracy wątków model synchronizacji 8
 program, ale mogą wchodzić w różne gałęzie każdy blok i każdy wątek posiadają unikalny identyfikator bloki mogą być jedno-, dwu- lub")
9 Hierarchia wątków wątki uruchamiane i wykonywane równolegle przy pomocy kernela - kodu uruchamianego na GPU (device) wszystkie wątki wykonują ten sam (szeregowy) program, ale mogą wchodzić w różne gałęzie każdy blok i każdy wątek posiadają unikalny identyfikator bloki mogą być jedno-, dwu- lub trojwymiarowe 9

10 Multiprocesor tworzy, zarządza, kolejkuje i uruchamia wątki w 32 elementowych grupach wątków równoległych zwanych warp. 10
11 Hierarchia pamięci rejestry (registers) p. lokalna (local) p. dzielona (shared) p. globalna (global) p. stałych (constant) 11
12 Kwalifikatory zmiennych Przykład deklaracji Typ pamięci Widoczność double v; rejestr (chyba, że przekroczono jego wielkość) wątek double array[10]; lokalna wątek shared double v; dzielona blok device double v; globalna aplikacja constant double v; globalna aplikacja 12
13 Wydajność pamięci przepustowość opóźnienia Typ pamięci Koszt (obrazowo) rejestry 1 dzielona 1 globalna lokalna pamięć stałych 1 13
14 Kwalifikatory funkcji global konieczny dla kernela musi mieć typ void uruchamiany z hosta (chyba, że CC >= 3.5) device wywoływane na GPU z innych funkcji host wywoływane przez hosta (domyślnie) można połączyć z device 14
15 Zmienne wewnątrz kernela Specjalne zmienne do identyfikacji wątków dim3 threadidx;// id wątku dim3 blockidx; // id bloku dim3 blockdim; // rozmiar bloku dim3 griddim; // rozmiar siatki = ilość bloków Synchronizacja wewnątrz bloku syncthreads(); 15

16 Podstawowy wzorzec uruchamiania obliczeń 16

17 Klasyczne podejście 17
 cudagetdeviceproperties( cudadeviceprop* prop, int device ) cudachoosedevice( int *device,")
18 Zarządzanie urządzeniami cudagetdevicecount( int* count ) cudasetdevice( int device ) cudagetdevice( int *current_device ) cudagetdeviceproperties( cudadeviceprop* prop, int device ) cudachoosedevice( int *device, cudadeviceprop* prop ) 18
 cudamemcpy(void *dst, void* src, size_t nbytes, dir); cudamemset(void *pointer, int value, size_t count) cudafree(void")
19 Zarządzanie pamięcią Możliwe jest zarządzanie pamięcią GPU zarówno z poziomu hosta jak i urządzenia Alokowanie i zwalnianie pamięci Kopiowanie danych do i z globalnej pamięci urządzenia: cudamalloc(void **pointer, size_t nbytes) cudamemcpy(void *dst, void* src, size_t nbytes, dir); cudamemset(void *pointer, int value, size_t count) cudafree(void *pointer) 19
20 Przykład alokacji pamięci bez transferu danych int nbytes = 1024*sizeof(int); int *d_a = 0; cudamalloc( (void**)&d_a, nbytes ); cudamemset( d_a, 0, nbytes); //opcjonalnie... cudafree(d_a); 20
21 Przykład alokacji pamięci z transferem danych 1. // alokacja pamięci Hosta 2. int numbytes = N * sizeof(float) 3. float* h_a = (float*) malloc(numbytes); 4. //... Wypełnianie h_a // alokacja pamięci na urządzeniu 6. float* d_a = 0; 7. cudamalloc((void**)&d_a, numbytes); 8. // kopiowanie danych z pamięci hosta do urządzenia 9. cudamemcpy(d_a, h_a, numbytes, cudamemcpyhosttodevice); 10. // uruchomienie kernela gpu_func <<<exec-dims>>> (params) 12. // kopiowanie danych z pamięci urządzenia do hosta 13. cudamemcpy(h_a, d_a, numbytes, cudamemcpydevicetohost); 14. //zwalnianie pamięci urządzenia 15. cudafree(d_a); 16. //... Dalsze operacja na danych 21
22 Uruchamianie kernela nazwakernela <<<dim3 grid, dim3 block>>>( ) Przykłady: nazwakernela <<<500, 128>>>(...); // uruchamia 500 bloków, w każdym 128 wątków dim3 rozmiar_grida(128,32); dim3 rozmiar_blokow(16,16,2); nazwakernela <<< rozmiar_grida, rozmiar_grida >>>(...); // uruchamia 128*32=4096 bloków, w każdym 16*16*2=512 wątków 22
23 #include "stdio.h" Printf wewnątrz kernela dla CC >=2.0 global void hellocuda(float f) { printf("hello thread %d, f=%f\n", threadidx.x, f); } int main() { hellocuda<<<1, 5>>>(1.2345f); cudadevicesynchronize(); return 0; } // na wyjściu: Hello thread 2, f= Hello thread 1, f= Hello thread 4, f= Hello thread 0, f= Hello thread 3, f=

24 BRAK SYNCHRONIZACJI BLOKÓW! 24
 R / - pamięć tekstur")
25 Pamięć Każdy wątek może: R / W rejestr wątku R / W pamięć lokalna wątku R / W pamięć dzielona bloku R / W pamięć globalna R / - pamięć stała (constant) R / - pamięć tekstur 25
26 26
27 27
28 // alokacja pamięci Hosta int numbytes = N * sizeof(float) float* h_a = (float*) malloc(numbytes); //... Wypełnianie h_a... // alokacja pamięci na urządzeniu float* d_a = 0; cudamalloc((void**)&d_a, numbytes); // kopiowanie danych z pamięci hosta do urządzenia cudamemcpy(d_a, h_a, numbytes, cudamemcpyhosttodevice); // uruchomienie kernela increment_gpu<<< N/blockSize, blocksize>>>(d_a, b); decrement_gpu<<< N/blockSize, blocksize>>>(d_a, b); // kopiowanie danych z pamięci urządzenia do hosta // SYNCHRONIZACJA! cudamemcpy(h_a, d_a, numbytes, cudamemcpydevicetohost); //zwalnianie pamięci urządzenia cudafree(d_a); //... Dalsze operacja na danych 28
29 Porównanie kodów CPU i GPU CPU GPU void increment_cpu(float *a, float b, int N) { for (int idx = 0; idx<n; idx++) a[idx] = a[idx] + b; } global void increment_gpu(float *a, float b, int N) { } int idx = blockidx.x * blockdim.x + threadidx.x; if (idx < N) a[idx] = a[idx] + b; void main() {... increment_cpu(a, b, N); } void main() {... dim3 dimblock (blocksize); dim3 dimgrid( ceil( N / (float)blocksize) ); increment_gpu<<<dimgrid, dimblock>>>(a, b, N);... } 29
30 Przykład optymalizacji odczytów pamięci global void increment_gpu(float *a, { } float *b, float *c, float *a_out, float *b_out, int N) int idx = blockidx.x * blockdim.x + threadidx.x; if (idx < N) { } a_out[idx] = a[idx] + b[idx] + c[idx]; b_out[idx] = a[idx] * b[idx] * c[idx]; global void increment_gpu(float *a, { } float *b, float *c, float *a_out, float *b_out, int N) int idx = blockidx.x * blockdim.x + threadidx.x; float a = a[idx]; float b = b[idx]; float c = c[idx]; if (idx < N) { } a_out[idx] = a + b + c; b_out[idx] = a * b * c; 30
31 Pamięć dzielona shared short cache[size]; extern shared int cache[]; Kernell<<<gridS, blocks, sharedsize>>>( ) syncthreads(); 31
32 Redukcja 32
33 Redukcja 33
34 34
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Procesory kart graficznych i CUDA wer
 wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
wer 1.4 18.04.2016 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
Programowanie kart graficznych. Architektura i API część 1
 Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Procesory kart graficznych i CUDA wer PR
 wer 1.3 14.12.2016 PR Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
wer 1.3 14.12.2016 PR Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot,
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
GTX260 i CUDA wer
 GTX260 i CUDA wer 1.1 25.11.2014 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders,
GTX260 i CUDA wer 1.1 25.11.2014 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders,
Procesory kart graficznych i CUDA
 4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
4.05.2019 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion Getting
Procesory kart graficznych i CUDA wer 1.2 6.05.2015
 wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie CUDA informacje praktycznie i przykłady. Wersja
 Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
Programowanie CUDA informacje praktycznie i przykłady problemów obliczeniowych Wersja 25.11.2014 cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie kontekstu (analog w
ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA
 Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
CUDA PROGRAMOWANIE PIERWSZE PROSTE PRZYKŁADY RÓWNOLEGŁE. Michał Bieńkowski Katarzyna Lewenda
 PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
Programowanie PKG - informacje praktycznie i przykłady. Wersja z Opracował: Rafał Walkowiak
 Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie PKG - informacje praktycznie i przykłady problemów obliczeniowych Wersja z 7.05.2018 Opracował: Rafał Walkowiak cudasetdevice() Podstawowe operacje na urządzeniu GPU Określenie GPU i ustanowienie
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 4 Jan Kazimirski 1 Programowanie GPU 1/2 2 Literatura CUDA w przykładach, J. Sanders, E. Kandrot, 2012 Computing Gems. Emerald Edition, Wen-mei W. Hwu ed.,
Programowanie współbieżne i rozproszone WYKŁAD 4 Jan Kazimirski 1 Programowanie GPU 1/2 2 Literatura CUDA w przykładach, J. Sanders, E. Kandrot, 2012 Computing Gems. Emerald Edition, Wen-mei W. Hwu ed.,
4 NVIDIA CUDA jako znakomita platforma do zrównoleglenia obliczeń
 Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Jacek Matulewski - Fizyk zajmujący się na co dzień optyką kwantową i układami nieuporządkowanymi na Wydziale Fizyki, Astronomii i Informatyki
 Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Dodatek A. CUDA. 1 Stosowany jest w tym kontekście skrót GPCPU (od ang. general-purpose computing on graphics processing units).
.") Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych.
 Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Temat: Dynamiczne przydzielanie i zwalnianie pamięci. Struktura listy operacje wstawiania, wyszukiwania oraz usuwania danych. 1. Rodzaje pamięci używanej w programach Pamięć komputera, dostępna dla programu,
Podstawy programowania komputerów
 Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Programowanie kart graficznych. Kompilator NVCC Podstawy programowania na poziomie API sterownika
 Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
Programowanie kart graficznych Kompilator NVCC Podstawy programowania na poziomie API sterownika Kompilator NVCC Literatura: The CUDA Compiler Driver NVCC v4.0, NVIDIA Corp, 2012 NVCC: według firmowego
DYNAMICZNE PRZYDZIELANIE PAMIECI
 DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
Stałe, tablice dynamiczne i wielowymiarowe
 Stałe, tablice dynamiczne i wielowymiarowe tylko do odczytu STAŁE - CONST tablice: const int dni_miesiaca[12]=31,28,31,30,31,30,31,31,30,31,30,31; const słowo kluczowe const sprawia, że wartość zmiennej
Stałe, tablice dynamiczne i wielowymiarowe tylko do odczytu STAŁE - CONST tablice: const int dni_miesiaca[12]=31,28,31,30,31,30,31,31,30,31,30,31; const słowo kluczowe const sprawia, że wartość zmiennej
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Struktura programu. Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem.
 Struktura programu Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem. W ostatnich latach najbardziej używanym stylem oprogramowania
Struktura programu Projekty złożone składają się zwykłe z różnych plików. Zawartość każdego pliku programista wyznacza zgodnie z jego przeznaczeniem. W ostatnich latach najbardziej używanym stylem oprogramowania
Programowanie równoległe Wprowadzenie do OpenCL. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Co to jest sterta? Sterta (ang. heap) to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).
 to obszar pamięci udostępniany przez system operacyjny wszystkim działającym programom (procesom).") Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Zarządzanie pamięcią Pamięć: stos i sterta Statyczny i dynamiczny przydział pamięci Funkcje ANSI C do zarządzania pamięcią Przykłady: Dynamiczna tablica jednowymiarowa Dynamiczna tablica dwuwymiarowa 154
Globalne / Lokalne. Wykład 15. Podstawy programowania (język C) Zmienne globalne / lokalne (1) Zmienne globalne / lokalne (2)
 Zmienne globalne / lokalne (1) Zmienne globalne / lokalne (2)") Podstawy programowania (język C) Globalne / Lokalne Wykład 15. Tomasz Marks - Wydział MiNI PW -1- Tomasz Marks - Wydział MiNI PW -2- Zmienne globalne / lokalne (1) int A, *Q; // definicja zmiennych globalnych
Podstawy programowania (język C) Globalne / Lokalne Wykład 15. Tomasz Marks - Wydział MiNI PW -1- Tomasz Marks - Wydział MiNI PW -2- Zmienne globalne / lokalne (1) int A, *Q; // definicja zmiennych globalnych
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Hybrydowy system obliczeniowy z akceleratorami GPU
 Przemysław Stpiczyński Hybrydowy system obliczeniowy z akceleratorami GPU [A hybrid computing system with GPU accelerators] Wstęp Konstrukcja komputerów oraz klastrów komputerowych o dużej mocy obliczeniowej
Przemysław Stpiczyński Hybrydowy system obliczeniowy z akceleratorami GPU [A hybrid computing system with GPU accelerators] Wstęp Konstrukcja komputerów oraz klastrów komputerowych o dużej mocy obliczeniowej
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE. Wykład 02
 METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
Wątek - definicja. Wykorzystanie kilku rdzeni procesora jednocześnie Zrównoleglenie obliczeń Jednoczesna obsługa ekranu i procesu obliczeniowego
 Wątki Wątek - definicja Ciąg instrukcji (podprogram) który może być wykonywane współbieżnie (równolegle) z innymi programami, Wątki działają w ramach tego samego procesu Współdzielą dane (mogą operować
Wątki Wątek - definicja Ciąg instrukcji (podprogram) który może być wykonywane współbieżnie (równolegle) z innymi programami, Wątki działają w ramach tego samego procesu Współdzielą dane (mogą operować
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Języki i metodyka programowania. Wskaźniki i tablice.
 Wskaźniki i tablice. Zmienna1 Zmienna2 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Zmienna to fragment pamięci o określonym rozmiarze identyfikowany za pomocą nazwy, w którym może być przechowywana
Wskaźniki i tablice. Zmienna1 Zmienna2 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Zmienna to fragment pamięci o określonym rozmiarze identyfikowany za pomocą nazwy, w którym może być przechowywana
Wstęp do Programowania, laboratorium 02
 Wstęp do Programowania, laboratorium 02 Zadanie 1. Napisać program pobierający dwie liczby całkowite i wypisujący na ekran największą z nich. Zadanie 2. Napisać program pobierający trzy liczby całkowite
Wstęp do Programowania, laboratorium 02 Zadanie 1. Napisać program pobierający dwie liczby całkowite i wypisujący na ekran największą z nich. Zadanie 2. Napisać program pobierający trzy liczby całkowite
Wskaźniki. Programowanie Proceduralne 1
 Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Implementacja modelu FHP w technologii NVIDIA CUDA
 Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Wstęp do programowania
 Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy. Wykład 6. Karol Tarnowski A-1 p.
 Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy Wykład 6 Karol Tarnowski karol.tarnowski@pwr.edu.pl A-1 p. 411B Plan prezentacji Funkcje w języku C Zasięg zmiennych Przekazywanie
Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy Wykład 6 Karol Tarnowski karol.tarnowski@pwr.edu.pl A-1 p. 411B Plan prezentacji Funkcje w języku C Zasięg zmiennych Przekazywanie
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł.
 Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Język C zajęcia nr 11. Funkcje
 Język C zajęcia nr 11 Funkcje W języku C idea podprogramów realizowana jest wyłącznie poprzez definiowanie i wywołanie funkcji. Każda funkcja musi być przed wywołaniem zadeklarowana. Deklaracja funkcji
Język C zajęcia nr 11 Funkcje W języku C idea podprogramów realizowana jest wyłącznie poprzez definiowanie i wywołanie funkcji. Każda funkcja musi być przed wywołaniem zadeklarowana. Deklaracja funkcji
Czyń CUDA (część 1) Powinieneś wiedzieć: Od czytelnika wymagana jest znajomość C++ oraz podstawowych zasad programowania równoległego.
 Powinieneś wiedzieć: Od czytelnika wymagana jest znajomość C++ oraz podstawowych zasad programowania równoległego.") Warsztaty Czyń CUDA (część 1) Architektura GPGPU to skrót, który na ustach informatyków pojawia się coraz częściej. Oznacza general-purpose computing on graphics processing units, czyli możliwość przeprowadzania
Warsztaty Czyń CUDA (część 1) Architektura GPGPU to skrót, który na ustach informatyków pojawia się coraz częściej. Oznacza general-purpose computing on graphics processing units, czyli możliwość przeprowadzania
Programowanie współbieżne Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Wskaźniki w C. Anna Gogolińska
 Wskaźniki w C Anna Gogolińska Zmienne Zmienną w C można traktować jako obszar w pamięci etykietowany nazwą zmiennej i zawierający jej wartość. Przykład: kod graficznie int a; a a = 3; a 3 Wskaźniki Wskaźnik
Wskaźniki w C Anna Gogolińska Zmienne Zmienną w C można traktować jako obszar w pamięci etykietowany nazwą zmiennej i zawierający jej wartość. Przykład: kod graficznie int a; a a = 3; a 3 Wskaźniki Wskaźnik
Zmienne, stałe i operatory
 Zmienne, stałe i operatory Przemysław Gawroński D-10, p. 234 Wykład 2 4 marca 2019 (Wykład 2) Zmienne, stałe i operatory 4 marca 2019 1 / 21 Outline 1 Zmienne 2 Stałe 3 Operatory (Wykład 2) Zmienne, stałe
Zmienne, stałe i operatory Przemysław Gawroński D-10, p. 234 Wykład 2 4 marca 2019 (Wykład 2) Zmienne, stałe i operatory 4 marca 2019 1 / 21 Outline 1 Zmienne 2 Stałe 3 Operatory (Wykład 2) Zmienne, stałe
main( ) main( void ) main( int argc, char argv[ ] ) int MAX ( int liczba_1, liczba_2, liczba_3 ) źle!
![main( ) main( void ) main( int argc, char argv[ ] ) int MAX ( int liczba_1, liczba_2, liczba_3 ) źle!](/thumbs/65/52328524.jpg "main( ) main( void ) main( int argc, char argv[ ] ) int MAX ( int liczba_1, liczba_2, liczba_3 ) źle!") Funkcja wysoce niezależny blok definicji i instrukcji programu (podprogram) Każdy program napisany w języku C/C++ zawiera przynajmniej jedną funkcję o predefiniowanej nazwie: main( ). Najczęściej wykorzystuje
Funkcja wysoce niezależny blok definicji i instrukcji programu (podprogram) Każdy program napisany w języku C/C++ zawiera przynajmniej jedną funkcję o predefiniowanej nazwie: main( ). Najczęściej wykorzystuje
Język ludzki kod maszynowy
 Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
Wykład 4: Klasy i Metody
 Wykład 4: Klasy i Metody Klasa Podstawa języka. Każde pojęcie które chcemy opisać w języku musi być zawarte w definicji klasy. Klasa definiuje nowy typ danych, których wartościami są obiekty: klasa to
Wykład 4: Klasy i Metody Klasa Podstawa języka. Każde pojęcie które chcemy opisać w języku musi być zawarte w definicji klasy. Klasa definiuje nowy typ danych, których wartościami są obiekty: klasa to
Tablice i struktury. czyli złożone typy danych. Programowanie Proceduralne 1
 Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Wskaźniki. Informatyka
 Materiały Wskaźniki Informatyka Wskaźnik z punktu widzenia programisty jest grupą komórek pamięci (rozmiar wskaźnika zależy od architektury procesora, najczęściej są to dwa lub cztery bajty ), które mogą
Materiały Wskaźniki Informatyka Wskaźnik z punktu widzenia programisty jest grupą komórek pamięci (rozmiar wskaźnika zależy od architektury procesora, najczęściej są to dwa lub cztery bajty ), które mogą
Wskaźniki. Przemysław Gawroński D-10, p marca Wykład 2. (Wykład 2) Wskaźniki 8 marca / 17
 Wskaźniki 8 marca / 17") Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
Wskaźniki Przemysław Gawroński D-10, p. 234 Wykład 2 8 marca 2019 (Wykład 2) Wskaźniki 8 marca 2019 1 / 17 Outline 1 Wskaźniki 2 Tablice a wskaźniki 3 Dynamiczna alokacja pamięci (Wykład 2) Wskaźniki 8
wykład III uzupełnienie notatek: dr Jerzy Białkowski Programowanie C/C++ Język C - zarządzanie pamięcią, struktury,
 , Programowanie, uzupełnienie notatek: dr Jerzy Białkowski , 1 2 3 4 , Wczytywanie liczb , Wczytywanie liczb 1 #include 2 #include < s t d l i b. h> 3 4 int main ( ) { 5 int rozmiar, numer
, Programowanie, uzupełnienie notatek: dr Jerzy Białkowski , 1 2 3 4 , Wczytywanie liczb , Wczytywanie liczb 1 #include 2 #include < s t d l i b. h> 3 4 int main ( ) { 5 int rozmiar, numer
Typy złożone. Struktury, pola bitowe i unie. Programowanie Proceduralne 1
 Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
Temat zajęć: Tworzenie i obsługa wątków.
 Temat zajęć: Tworzenie i obsługa wątków. Czas realizacji zajęć: 180 min. Zakres materiału, jaki zostanie zrealizowany podczas zajęć: Tworzenie wątków, przekazywanie parametrów do funkcji wątków i pobieranie
Temat zajęć: Tworzenie i obsługa wątków. Czas realizacji zajęć: 180 min. Zakres materiału, jaki zostanie zrealizowany podczas zajęć: Tworzenie wątków, przekazywanie parametrów do funkcji wątków i pobieranie
// Liczy srednie w wierszach i kolumnach tablicy "dwuwymiarowej" // Elementy tablicy są generowane losowo #include <stdio.h> #include <stdlib.
 Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Wykład 10 Przykłady różnych funkcji (cd) - przetwarzanie tablicy tablic (tablicy "dwuwymiarowej") - sortowanie przez "selekcję" Dynamiczna alokacja pamięci 1 // Liczy srednie w wierszach i kolumnach tablicy
Lab 9 Podstawy Programowania
 Lab 9 Podstawy Programowania (Kaja.Gutowska@cs.put.poznan.pl) Wszystkie kody/fragmenty kodów dostępne w osobnym pliku.txt. Materiały pomocnicze: Wskaźnik to specjalny rodzaj zmiennej, w której zapisany
Lab 9 Podstawy Programowania (Kaja.Gutowska@cs.put.poznan.pl) Wszystkie kody/fragmenty kodów dostępne w osobnym pliku.txt. Materiały pomocnicze: Wskaźnik to specjalny rodzaj zmiennej, w której zapisany
Politechnika Rzeszowska
 Politechnika Rzeszowska i m. I g n a c e g o Ł u k a s i e w i c z a Wydział Elektrotechniki i Informatyki Katedra Informatyki i Automatyki Bogusław Rymut ŚLEDZENIE OBIEKTÓW PRZY WYKORZYSTANIU GPU Praca
Politechnika Rzeszowska i m. I g n a c e g o Ł u k a s i e w i c z a Wydział Elektrotechniki i Informatyki Katedra Informatyki i Automatyki Bogusław Rymut ŚLEDZENIE OBIEKTÓW PRZY WYKORZYSTANIU GPU Praca
Wstęp do programowania
 wykład 8 Agata Półrola Wydział Matematyki i Informatyki UŁ semestr zimowy 2018/2019 Podprogramy Czasami wygodnie jest wyodrębnić jakiś fragment programu jako pewną odrębną całość umożliwiają to podprogramy.
wykład 8 Agata Półrola Wydział Matematyki i Informatyki UŁ semestr zimowy 2018/2019 Podprogramy Czasami wygodnie jest wyodrębnić jakiś fragment programu jako pewną odrębną całość umożliwiają to podprogramy.
Podstawy programowania w języku C++
 Podstawy programowania w języku C++ Część jedenasta Przetwarzanie plików amorficznych Konwencja języka C Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie
Podstawy programowania w języku C++ Część jedenasta Przetwarzanie plików amorficznych Konwencja języka C Autor Roman Simiński Kontakt roman.siminski@us.edu.pl www.us.edu.pl/~siminski Niniejsze opracowanie
Podstawy programowania C. dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/
 Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Funkcje. czyli jak programować proceduralne. Programowanie Proceduralne 1
 Funkcje czyli jak programować proceduralne. Programowanie Proceduralne 1 Struktura programu w C # include / Dyrektywy p r e p r o c e s o r a / #define PI 3.1415 float g =. 5 ; / Zmienne
Funkcje czyli jak programować proceduralne. Programowanie Proceduralne 1 Struktura programu w C # include / Dyrektywy p r e p r o c e s o r a / #define PI 3.1415 float g =. 5 ; / Zmienne
Plan. krótkie opisy modułów. 1 Uwagi na temat wydajności CPython a. 2 Podstawowe techniki poprawiające wydajność obliczeniową
 Plan 1 Uwagi na temat wydajności CPython a 2 Podstawowe techniki poprawiające wydajność obliczeniową 3 Podstawowe techniki poprawiające zużycie pamięci krótkie opisy modułów 1 array - jak oszczędzić na
Plan 1 Uwagi na temat wydajności CPython a 2 Podstawowe techniki poprawiające wydajność obliczeniową 3 Podstawowe techniki poprawiające zużycie pamięci krótkie opisy modułów 1 array - jak oszczędzić na
Podstawy programowania. Wykład Funkcje. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Uzupełnienie dot. przekazywania argumentów
 Uzupełnienie dot. przekazywania argumentów #include #include struct nowa { int f; char line[20000]; int k; } reprezentant; int main() { void funkcja7( struct nowa x); reprezentant.k=17;
Uzupełnienie dot. przekazywania argumentów #include #include struct nowa { int f; char line[20000]; int k; } reprezentant; int main() { void funkcja7( struct nowa x); reprezentant.k=17;
PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO
 PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO LABORATORIUM Temat: QNX Neutrino Interrupts Mariusz Rudnicki 2016 Wstęp W QNX Neutrino wszystkie przerwania sprzętowe przechwytywane są przez jądro systemu. Obsługę
PROGRAMOWANIE SYSTEMÓW CZASU RZECZYWISTEGO LABORATORIUM Temat: QNX Neutrino Interrupts Mariusz Rudnicki 2016 Wstęp W QNX Neutrino wszystkie przerwania sprzętowe przechwytywane są przez jądro systemu. Obsługę
Stałe i zmienne znakowe. Stała znakowa: znak
 Stałe i zmienne znakowe. Stała znakowa: znak Na przykład: a, 1, 0 c Każdy znak jest reprezentowany w pamięci przez swój kod. Kody alfanumerycznych znaków ASCII to liczby z przedziału [32, 127]. Liczby
Stałe i zmienne znakowe. Stała znakowa: znak Na przykład: a, 1, 0 c Każdy znak jest reprezentowany w pamięci przez swój kod. Kody alfanumerycznych znaków ASCII to liczby z przedziału [32, 127]. Liczby
Metody Metody, parametry, zwracanie wartości
 Materiał pomocniczy do kursu Podstawy programowania Autor: Grzegorz Góralski ggoralski.com Metody Metody, parametry, zwracanie wartości Metody - co to jest i po co? Metoda to wydzielona część klasy, mająca
Materiał pomocniczy do kursu Podstawy programowania Autor: Grzegorz Góralski ggoralski.com Metody Metody, parametry, zwracanie wartości Metody - co to jest i po co? Metoda to wydzielona część klasy, mająca
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem