Programowanie kart graficznych
|
|
|
- Wiktoria Czerwińska
- 6 lat temu
- Przeglądów:
Transkrypt
1 Programowanie kart graficznych Sławomir Wernikowski
2 Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA
3 Terminologia: Co to jest GPGPU? General-Purpose computing on a Graphics Processing Unit wykorzystanie sprzętu graficznego (specjalizowanego) do niegraficznych obliczeń (ogólnego przeznaczenia)
4 Terminologia: Co to jest CUDA? Compute Unified Device Architecture architektura sprzętowo-programowa ukierunkowana na przetwarzanie typu data parallel
5 Krótki rys historyczny: 2006: Pierwsze implementacje pod postacią kart graficznych PCI-E z zabudowanymi dedykowanymi układami VLSI GeForce 8
6 Krótki rys historyczny: 2006: Kolejne implementacje pod postacią kart pozbawionych części generującej sygnał wizyjny NVIDIA Tesla Personal Supercomputer (Dell, Lenovo)
7 Krótki rys historyczny: CC = Compute Capability: 1.0 wczesne konstrukcje architektury CUDA, implementowane przez układy GPU serii 8800; dla przykładu, maksymalna liczba równolegle pracujących wątków jest tu równa 768, a każdy z multiprocesorów dysponuje 8192 rejestrami o szerokości 32 bitów
8 Krótki rys historyczny: CC: 1.1 implementowane w układach GPU serii 1x0; od 1.0 odróżnia się możliwością kodowania funkcji stałoprzecinkowych operujących na danych o szerokości 32 bitów, przechowywanych w pamięci urządzenia
9 Krótki rys historyczny: CC: 1.2 powiązane z układami GPU serii GT 2x0; maksymalna liczba jednocześnie uruchomionych wątków jest tu równa 1024, a liczba rejestrów dostępnych dla multiprocesorów wynosi 16384
10 Krótki rys historyczny: CC: 1.3 wersja rozwojowa w stosunku do CC 1.2; jako pierwsza wprowadziła do architektury CUDA arytmometr zmiennoprzecinkowy dla danych podwójnej precyzji; implementowana w układach serii GTX 2x0
11 Krótki rys historyczny: CC: 2.0 implementowana w układach serii 4x0; maksymalna liczba wątków to 1536 przy liczbie dostępnych rejestrów równej 32768
12 Krótki rys historyczny: CC: 3.0 maksymalna liczba wątków: 2048
13 Krótka charakterystyka
14 Rdzeń jednostka przetwarzająca zawiera pewną liczbę procesorów, określanych w tej technologii mianem rdzeni (ang. cores) liczba rdzeni zmienia się w różnych wykonaniach kart CUDA w zależności od pożądanych cech urządzenia i docelowej grupy przyszłych użytkowników oraz aktualnego zaawansowania technologii wczesne karty serii 8800GS zawierały 64 rdzenie, urządzenia serii 8800 GTS 128 rdzeni, a 8800 Ultra 1512 rdzeni; dla porównania karta serii NVIDIA Tesla S2050 zawiera 1792 rdzenie;
15 Pamięć wszystkie rdzenie korzystają ze swobodnego dostępu do pamięci (w oryginale: device memory), która funkcjonuje niezależnie od pamięci operacyjnej komputera macierzystego (w oryginale: host memory) pamięć karty CUDA posługuje się własną przestrzenią adresową; wielkość dostępnej pamięci zmienia się w zależności od wykonania i w kartach 8800 GTS sięgała 1940 MB, 8800 GTX 1800 MB, 8800 Ultra 2160 MB i MB na karcie NVIDIA Tesla S2050;
16 Komunikacja interfejs programowy architektury CUDA dostarcza wydajnych usług transferu bloków danych do i z pamięci operacyjnej hosta np. poprzez funkcje: cudamemcpy() cudamemcpy2d() cudamemcpy3d() istnieje inny sposób komunikacji z pamięcią hosta, w szczególności kod wykonywany na rdzeniu GPU może mieć możliwości sięgania do danych znajdujących się poza własną przestrzenią adresową karty (o tym przy okazji)
17 Pamięć dzielona wszystkie rdzenie mają dostęp do szybkiej pamięci lokalnej (niezależnej funkcjonalnie od reszty pamięci operacyjnej karty), która może być wykorzystywana jako pamięć podręczna dla danych wykorzystywanych szczególnie intensywnie przez kod wykonywany przez rdzenie; typowy rozmiar tej pamięci to 16KB

18 Jak to wygląda?
19 API środowisko programisty definiowane przez CUDA SDK dostarcza zestawu środków służących do zarządzania pamięcią urządzenia, a w szczególności do: przydzielania bloku pamięci (cudamalloc(), cudamallocpitch(), cudamalloc3d()) zwalniania bloku pamięci (cudafree()); słowo kluczowe shared, stanowiące część rozszerzonego dialektu języka C używanego w implementacji CUDA SKD, służy do deklarowania danych przeznaczonych do przechowywania w szybkiej pamięci dzielonej
20 Kod źródłowy kod wynikowy, przeznaczony do wykonania na rdzeniach architektury CUDA w chwili obecnej uzyskuje się na dwa sposoby: poprzez wykorzystanie języka niskiego poziomu (asemblera), odwzorowującego listę rozkazów architektury (język PTX ang. Parallel Thread Execution) poprzez wykorzystanie języków wysokiego poziomu, rozbudowanych - bądź to na poziomie składni, bądź poprzez wykorzystanie zewnętrznych bibliotek - o konstrukcje umożliwiające jawne kontrolowanie zachowania rdzeni
21 Kod źródłowy w typowym przypadku z jednego, wspólnego kodu źródłowego uzyskuje się dwuczęściowy kod wykonywalny: jedna z części przeznaczona jest do uruchomieniu w środowisku hosta (tu znajduje się prolog i epilog programu, zawierający m.in. inicjację sprzętu karty) druga część zawiera kod przeznaczony do wykonania na rdzeniach urządzenia CUDA; chwili obecnej NVIDIA dostarcza środowiska typu SDK dla języków C/C++ i Fortran oraz platform MS Windows i Linux
22 Skalowalność interfejs programowany, udostępniany przez architekturę CUDA, gwarantuje, że przy umiejętnym wykorzystaniu jego udogodnień kod wynikowy jest w pełni skalowalny oznacza to między innymi, że może być bez konieczności powtórnej kompilacji wykonywany na silniejszych (w tym również jeszcze nie istniejących) modelach kart CUDA z pełnym wykorzystaniem przyrostu liczby dostępnych rdzeni;
23 Dialekt CUDA C/C++ dialekt języka C, wykorzystywany do kodowania programów dla rdzeni CUDA, jest podzbiorem języka wzorcowego, a najważniejsze nałożone ograniczenia to: niemożność wykorzystywania rekurencji wykluczenie możliwości posługiwania się wskaźnikami do funkcji oraz funkcjami ze zmienną liczbą parametrów implementacja arytmetyki zmiennopozycyjnej w architekturze CUDA odbiega od definicji zawartej w normie IEEE 754
24 Rozszerzenia dialekt języka CUDA C zawiera także kilka rozszerzeń, w szczególności dodatkowych deklaratorów i specyfikatorów, pozwalających wprowadzać do kodu źródłowego byty swoiste dla środowiska CUDA; ocenę elegancji tych rozszerzeń pozostawimy programistom...
25 Host vs device kod wynikowy CUDA jest wykonywany dopiero na żądanie emitowane z kodu hosta; kod CUDA wykonywany jest na wszystkich rdzeniach jednocześnie
26 Wątki kod wykonywany indywidualnie na pojedynczym rdzeniu nosi nazwę wątku (ang. thread); środki dostępne w środowisku CUDA pozwalają wątkowi na dokładne zidentyfikowanie rdzenia, na którym jest wykonywany, co z kolei umożliwia różnicowanie zachowania algorytmu w zależności od np. rozmiaru danych lub liczby dostępnych rdzeni; taka filozofia przetwarzania pozwala zakwalifikować architekturę CUDA do paradygmatu przetwarzania strumieniowego;
27 Synchronizacja środowisko CUDA nie zapewnia żadnych mechanizmów synchronizacji poza elementarnym mechanizmem bariery, zatrzymującej wykonanie wątku do momentu osiągnięcia tej bariery przez wątki na wszystkich rdzeniach; operację ten wykonuje się wywołując bezparametrową funkcję usługę środowiska CUDA o nazwie syncthreads(); jakiekolwiek inne mechanizmy synchronizacji wątków muszą zostać zaimplementowanie przez programistę z wykorzystaniem np. dostępu do pamięci dzielonej wątków.
28 Kod wątków tekst źródłowy kodu przeznaczony do uruchomienia w ramach wątku musi zostać jawnie spreparowany przez programistę; na poziomie języka C/C++ dokonuje się tego poprzez wydzielenie w kodzie kompletnej funkcji opatrzonej specyfikatorem global (jest to słowo kluczowe dialektu CUDA) wymaga się, aby funkcja taka była zadeklarowana jako nie zwracająca wyniku (void); funkcje tego rodzaju w terminologii dokumentów NVIDIA SDK nazywa się mianem kernel.
29 Kod wątków każdy kernel, zadeklarowany w kodzie źródłowym, stanie się treścią (tekstem) wszystkich wątków uruchomionych równolegle na każdym z procesorów architektury CUDA uruchomienie wątków następuje w wyniku wywołania funkcji deklarowanej dla każdego kernela,
30 Odpalenie wątku wywołanie funkcji wątku przybiera w dialekcie CUDA C postać poniższą* kernname<<<blocksnum,threadsperblocks>>>(par1,par2); *) podano jeden z prostszych wariantów
31 Odpalenie wątku kernname<<<blocksnum,threadsperblocks>>>(par1,par2); gdzie: kernelname jest nazwą funkcji kernela zadeklarowanej z zasięgu osiągalnym z miejsca wywołania
32 Odpalenie wątku kernname<<<blocksnum,threadsperblocks>>>(par1,par2); gdzie: blocksnum jest wyrażeniem typu int, określającym liczbę tzw. bloków wątków, które będą uruchamiane kolejno w celu odpalenia (ang. launch) żądanej liczby wątków
33 Odpalenie wątku kernname<<<blocksnum,threadsperblocks>>>(par1,par2); gdzie: threadsperblocks jest wyrażeniem typu int, określającym liczbę wątków, które zostaną odpalone wewnątrz każdego z bloków; wymaga się, aby liczba ta nie przewyższała liczby procesorów dostępnych w konkretnym środowisku
34 Odpalenie wątku kernname<<<blocksnum,threadsperblocks>>>(par1,par2); gdzie: par i są parametrami aktualnymi o liczbie i typach określonych w deklaracjach parametrów formalnych zdefiniowanych w nagłówku wywoływanego kernela.
35 Odpalenie wątku Formalizm ten daje prosty i efektywny sposób samoskalowania się kodu w zależności od architektury docelowej i liczby dostępnych procesorów. Jeśli rozwiązanie pewnego problemu wymaga równoległego wykonania N wątków, a architektura docelowa udostępnia M procesorów, można założyć, że: threadsperblock=m blocksnum=(n+threadsperblock 1)/threadsPerBlock
36 Odpalenie wątku UWAGA: wszystkie wątki w bloku wykonują się równolegle wszystkie bloki wątków wykonują się sekwencyjnie
37 Co ma wątek? Odpalony wątek ma możliwość ustalenia: w ramach którego z bloków pracuje na którym procesorze w bloku został odpalony to daje możliwość zbudowania takiego kodu kernela, który będzie modyfikował swoje działanie np. w zależności od momentu jego uruchomienia
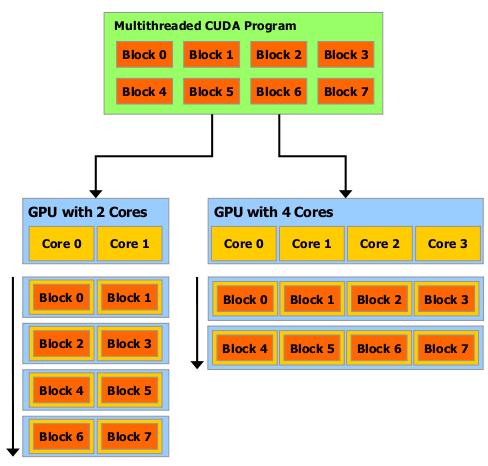
38 Skalowalność
39 Trywialny przypadek wymagana liczba wątków nie dzieli się bez reszty przez wyznaczoną liczbę bloków część wątków w ostatnim bloku powinna pozostać bezczynna, tzn. zakończyć pracę natychmiast po odpaleniu.
40 Rozwiązanie predefiniowane zmienne (struktury): blockidx i threadidx ilustracja sposobu, w jaki wątek zabezpiecza się przed odpaleniem swojego kodu na rzecz nieistniejącego elementu tablicy T[N]: if(blockidx.x * threadsperblock + threadidx.x < N) { // kod przetwarzający element tablicy }
41 W praktyce krok #1 I stała się jasność... array Host s Memory GPU Card s Memory
42 W praktyce krok #2 rezerwujemy obszar w pamięci urządzenia array Host s Memory array_d GPU Card s Memory
43 W praktyce krok #3 Transferujemy dane... array Host s Memory array_d GPU Card s Memory
44 W praktyce krok #4 Odpalamy obliczenia... GPU MPs array Host s Memory array_d GPU Card s Memory
45 W praktyce krok #5 Transferujemy wyniki array Host s Memory array_d GPU Card s Memory
46 W praktyce krok #5 Zwalniamy pamięć... array Host s Memory GPU Card s Memory
47 Przykład #1 // dodawanie wektorów global void VecAdd(float* A, float* B, float* C) { int i = threadidx.x; C[i] = A[i] + B[i]; } : : int main() { : : VecAdd<<<1, N>>>(A, B, C); }
48 Przykład #2 // dodawanie macierzy _global void MatAdd (float A[N][N], float B[N][N],float C[N][N]) { int i = threadidx.x; int j = threadidx.y; C[i][j] = A[i][j] + B[i][j]; } int main() { : : //1 blok złożony z N * N * 1 wątków int numblocks = 1; dim3 threadsperblock(n, N); MatAdd<<<numBlocks, threadsperblock>>>(a, B, C); }
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie kart graficznych. Architektura i API część 1
 Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie kart graficznych Architektura i API część 1 Literatura NVIDIA CUDA Programming Guide version 4.2 http//developer.download.nvidia.com/compute/devzone/ docs/html/c/doc/cuda_c_programming_guide.pdf
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Podstawy programowania. Wykład Funkcje. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Podstawy programowania. Wykład Funkcje Krzysztof Banaś Podstawy programowania 1 Programowanie proceduralne Pojęcie procedury (funkcji) programowanie proceduralne realizacja określonego zadania specyfikacja
Programowanie w języku C++ Grażyna Koba
 Programowanie w języku C++ Grażyna Koba Kilka definicji: Program komputerowy to ciąg instrukcji języka programowania, realizujący dany algorytm. Język programowania to zbiór określonych instrukcji i zasad
Programowanie w języku C++ Grażyna Koba Kilka definicji: Program komputerowy to ciąg instrukcji języka programowania, realizujący dany algorytm. Język programowania to zbiór określonych instrukcji i zasad
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++
 Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Opracował Jan T. Biernat
 Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
Programowanie Strukturalne i Obiektowe Słownik podstawowych pojęć 1 z 5 Program, to lista poleceń zapisana w jednym języku programowania zgodnie z obowiązującymi w nim zasadami. Celem programu jest przetwarzanie
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Podstawy programowania. Wykład: 7. Funkcje Przekazywanie argumentów do funkcji. dr Artur Bartoszewski -Podstawy programowania, sem 1 - WYKŁAD
 programowania Wykład: 7 Funkcje Przekazywanie argumentów do funkcji 1 dr Artur Bartoszewski - programowania, sem 1 - WYKŁAD programowania w C++ Funkcje 2 dr Artur Bartoszewski - programowania sem. 1 -
programowania Wykład: 7 Funkcje Przekazywanie argumentów do funkcji 1 dr Artur Bartoszewski - programowania, sem 1 - WYKŁAD programowania w C++ Funkcje 2 dr Artur Bartoszewski - programowania sem. 1 -
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Podstawy programowania. Wykład 6 Wskaźniki. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład 6 Wskaźniki Krzysztof Banaś Podstawy programowania 1 Adresy zmiennych Język C pozwala na operowanie adresami w pamięci stąd, między innymi, kwalifikowanie C jako języka relatywnie
Podstawy programowania. Wykład 6 Wskaźniki Krzysztof Banaś Podstawy programowania 1 Adresy zmiennych Język C pozwala na operowanie adresami w pamięci stąd, między innymi, kwalifikowanie C jako języka relatywnie
Budowa i zasada działania komputera. dr Artur Bartoszewski
 Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Programowanie strukturalne i obiektowe. Funkcje
 Funkcje Często w programach spotykamy się z sytuacją, kiedy chcemy wykonać określoną czynność kilka razy np. dodać dwie liczby w trzech miejscach w programie. Oczywiście moglibyśmy to zrobić pisząc trzy
Funkcje Często w programach spotykamy się z sytuacją, kiedy chcemy wykonać określoną czynność kilka razy np. dodać dwie liczby w trzech miejscach w programie. Oczywiście moglibyśmy to zrobić pisząc trzy
ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA
 Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Algorytm. a programowanie -
 Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Programowanie sterowników przemysłowych / Jerzy Kasprzyk. wyd. 2 1 dodr. (PWN). Warszawa, Spis treści
. Warszawa, Spis treści") Programowanie sterowników przemysłowych / Jerzy Kasprzyk. wyd. 2 1 dodr. (PWN). Warszawa, 2017 Spis treści Przedmowa 11 ROZDZIAŁ 1 Wstęp 13 1.1. Rys historyczny 14 1.2. Norma IEC 61131 19 1.2.1. Cele i
Programowanie sterowników przemysłowych / Jerzy Kasprzyk. wyd. 2 1 dodr. (PWN). Warszawa, 2017 Spis treści Przedmowa 11 ROZDZIAŁ 1 Wstęp 13 1.1. Rys historyczny 14 1.2. Norma IEC 61131 19 1.2.1. Cele i
UKŁADY MIKROPROGRAMOWALNE
 UKŁAD MIKROPROGRAMOWALNE Układy sterujące mogą pracować samodzielnie, jednakże w przypadku bardziej złożonych układów (zwanych zespołami funkcjonalnymi) układ sterujący jest tylko jednym z układów drugim
UKŁAD MIKROPROGRAMOWALNE Układy sterujące mogą pracować samodzielnie, jednakże w przypadku bardziej złożonych układów (zwanych zespołami funkcjonalnymi) układ sterujący jest tylko jednym z układów drugim
Zarządzanie pamięcią operacyjną
 Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP z technologią NVIDIA CUDA
 Dariusz Sychel Wydział Informatyki, Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 71-210 Szczecin, Żołnierska 49 Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP
Dariusz Sychel Wydział Informatyki, Zachodniopomorski Uniwersytet Technologiczny w Szczecinie 71-210 Szczecin, Żołnierska 49 Redukcja czasu wykonania algorytmu Cannego dzięki zastosowaniu połączenia OpenMP
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
JAVA. Java jest wszechstronnym językiem programowania, zorientowanym. apletów oraz samodzielnych aplikacji.
 JAVA Java jest wszechstronnym językiem programowania, zorientowanym obiektowo, dostarczającym możliwość uruchamiania apletów oraz samodzielnych aplikacji. Java nie jest typowym kompilatorem. Źródłowy kod
JAVA Java jest wszechstronnym językiem programowania, zorientowanym obiektowo, dostarczającym możliwość uruchamiania apletów oraz samodzielnych aplikacji. Java nie jest typowym kompilatorem. Źródłowy kod
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Wstęp do obliczeń równoległych na GPU
 Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Język programowania PASCAL
 Język programowania PASCAL (wersja podstawowa - standard) Literatura: dowolny podręcznik do języka PASCAL (na laboratoriach Borland) Iglewski, Madey, Matwin PASCAL STANDARD, PASCAL 360 Marciniak TURBO
Język programowania PASCAL (wersja podstawowa - standard) Literatura: dowolny podręcznik do języka PASCAL (na laboratoriach Borland) Iglewski, Madey, Matwin PASCAL STANDARD, PASCAL 360 Marciniak TURBO
INFORMATYKA, TECHNOLOGIA INFORMACYJNA ORAZ INFORMATYKA W LOGISTYCE
 Studia podyplomowe dla nauczycieli INFORMATYKA, TECHNOLOGIA INFORMACYJNA ORAZ INFORMATYKA W LOGISTYCE Przedmiot JĘZYKI PROGRAMOWANIA DEFINICJE I PODSTAWOWE POJĘCIA Autor mgr Sławomir Ciernicki 1/7 Aby
Studia podyplomowe dla nauczycieli INFORMATYKA, TECHNOLOGIA INFORMACYJNA ORAZ INFORMATYKA W LOGISTYCE Przedmiot JĘZYKI PROGRAMOWANIA DEFINICJE I PODSTAWOWE POJĘCIA Autor mgr Sławomir Ciernicki 1/7 Aby
Wstęp do programowania 2
 Wstęp do programowania 2 wykład 10 Zadania Agata Półrola Wydział Matematyki UŁ 2005/2006 http://www.math.uni.lodz.pl/~polrola Współbieżność dotychczasowe programy wykonywały akcje sekwencyjnie Ada umożliwia
Wstęp do programowania 2 wykład 10 Zadania Agata Półrola Wydział Matematyki UŁ 2005/2006 http://www.math.uni.lodz.pl/~polrola Współbieżność dotychczasowe programy wykonywały akcje sekwencyjnie Ada umożliwia
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
4 NVIDIA CUDA jako znakomita platforma do zrównoleglenia obliczeń
 Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
ZASADY PROGRAMOWANIA KOMPUTERÓW
 POLITECHNIKA WARSZAWSKA Instytut Automatyki i i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW Język Język programowania: C/C++ Środowisko programistyczne: C++Builder 6 Wykład 9.. Wskaźniki i i zmienne dynamiczne.
POLITECHNIKA WARSZAWSKA Instytut Automatyki i i Robotyki ZASADY PROGRAMOWANIA KOMPUTERÓW Język Język programowania: C/C++ Środowisko programistyczne: C++Builder 6 Wykład 9.. Wskaźniki i i zmienne dynamiczne.
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł.
 Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
4 Literatura. c Dr inż. Ignacy Pardyka (Inf.UJK) ASK MP.01 Rok akad. 2011/2012 2 / 24
 ASK MP.01 Rok akad. 2011/2012 2 / 24") Wymagania proceduralnych języków wysokiego poziomu ARCHITEKTURA SYSTEMÓW KOMPUTEROWYCH modele programowe procesorów ASK MP.01 c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad.
Wymagania proceduralnych języków wysokiego poziomu ARCHITEKTURA SYSTEMÓW KOMPUTEROWYCH modele programowe procesorów ASK MP.01 c Dr inż. Ignacy Pardyka UNIWERSYTET JANA KOCHANOWSKIEGO w Kielcach Rok akad.
Programowanie w języku Python. Grażyna Koba
 Programowanie w języku Python Grażyna Koba Kilka definicji Program komputerowy to ciąg instrukcji języka programowania, realizujący dany algorytm. Język programowania to zbiór określonych instrukcji i
Programowanie w języku Python Grażyna Koba Kilka definicji Program komputerowy to ciąg instrukcji języka programowania, realizujący dany algorytm. Język programowania to zbiór określonych instrukcji i
Zarządzanie pamięcią operacyjną
 SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1
 dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
dr inż. Konrad Sobolewski Politechnika Warszawska Informatyka 1 Cel wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działanie systemu operacyjnego
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Podsystem graficzny. W skład podsystemu graficznego wchodzą: karta graficzna monitor
 Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Księgarnia PWN: Włodzimierz Stanisławski, Damian Raczyński - Programowanie systemowe mikroprocesorów rodziny x86
 Księgarnia PWN: Włodzimierz Stanisławski, Damian Raczyński - Programowanie systemowe mikroprocesorów rodziny x86 Spis treści Wprowadzenie... 11 1. Architektura procesorów rodziny x86... 17 1.1. Model procesorów
Księgarnia PWN: Włodzimierz Stanisławski, Damian Raczyński - Programowanie systemowe mikroprocesorów rodziny x86 Spis treści Wprowadzenie... 11 1. Architektura procesorów rodziny x86... 17 1.1. Model procesorów
Dariusz Brzeziński. Politechnika Poznańska, Instytut Informatyki
 Dariusz Brzeziński Politechnika Poznańska, Instytut Informatyki Język programowania prosty bezpieczny zorientowany obiektowo wielowątkowy rozproszony przenaszalny interpretowany dynamiczny wydajny Platforma
Dariusz Brzeziński Politechnika Poznańska, Instytut Informatyki Język programowania prosty bezpieczny zorientowany obiektowo wielowątkowy rozproszony przenaszalny interpretowany dynamiczny wydajny Platforma
1 Podstawy c++ w pigułce.
 1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
1 Podstawy c++ w pigułce. 1.1 Struktura dokumentu. Kod programu c++ jest zwykłym tekstem napisanym w dowolnym edytorze. Plikowi takiemu nadaje się zwykle rozszerzenie.cpp i kompiluje za pomocą kompilatora,
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
Laboratorium nr 12. Temat: Struktury, klasy. Zakres laboratorium:
 Zakres laboratorium: definiowanie struktur terminologia obiektowa definiowanie klas funkcje składowe klas programy złożone z wielu plików zadania laboratoryjne Laboratorium nr 12 Temat: Struktury, klasy.
Zakres laboratorium: definiowanie struktur terminologia obiektowa definiowanie klas funkcje składowe klas programy złożone z wielu plików zadania laboratoryjne Laboratorium nr 12 Temat: Struktury, klasy.
Rekurencja (rekursja)
") Rekurencja (rekursja) Rekurencja wywołanie funkcji przez nią samą wewnątrz ciała funkcji. Rekurencja może być pośrednia funkcja jest wywoływana przez inną funkcję, wywołaną (pośrednio lub bezpośrednio)
Rekurencja (rekursja) Rekurencja wywołanie funkcji przez nią samą wewnątrz ciała funkcji. Rekurencja może być pośrednia funkcja jest wywoływana przez inną funkcję, wywołaną (pośrednio lub bezpośrednio)
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Informatyka I. Klasy i obiekty. Podstawy programowania obiektowego. dr inż. Andrzej Czerepicki. Politechnika Warszawska Wydział Transportu 2018
 Informatyka I Klasy i obiekty. Podstawy programowania obiektowego dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2018 Plan wykładu Pojęcie klasy Deklaracja klasy Pola i metody klasy
Informatyka I Klasy i obiekty. Podstawy programowania obiektowego dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2018 Plan wykładu Pojęcie klasy Deklaracja klasy Pola i metody klasy
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
1 Wątki 1. 2 Tworzenie wątków 1. 3 Synchronizacja 3. 4 Dodatki 3. 5 Algorytmy sortowania 4
 Spis treści 1 Wątki 1 2 Tworzenie wątków 1 3 Synchronizacja 3 4 Dodatki 3 5 Algorytmy sortowania 4 6 Klasa Runnable 4 Temat: Wątki Czym są wątki. Grafika. Proste animacje. Małe podsumowanie materiału.
Spis treści 1 Wątki 1 2 Tworzenie wątków 1 3 Synchronizacja 3 4 Dodatki 3 5 Algorytmy sortowania 4 6 Klasa Runnable 4 Temat: Wątki Czym są wątki. Grafika. Proste animacje. Małe podsumowanie materiału.
Technika mikroprocesorowa. Struktura programu użytkownika w systemie mikroprocesorowym
 Struktura programu użytkownika w systemie mikroprocesorowym start inicjalizacja niekończaca się pętla zadania niekrytyczne czasowo przerwania zadania krytyczne czasowo 1 Znaczenie problematyki programowania
Struktura programu użytkownika w systemie mikroprocesorowym start inicjalizacja niekończaca się pętla zadania niekrytyczne czasowo przerwania zadania krytyczne czasowo 1 Znaczenie problematyki programowania
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Podstawy programowania komputerów
 Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana
Podstawy programowania komputerów Wykład 10: Sterowanie pamięcią w C Pamięć na stosie!każdy program napisany w języku C ma dostęp do dwóch obszarów pamięci - stosu i sterty, w których może być przechowywana