CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
|
|
|
- Ludwika Klimek
- 9 lat temu
- Przeglądów:
Transkrypt
1 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka

2 Bariery sprzętowe (procesory) ok na la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK)

3 Rozwój i dalej? O roku ów (ZK)

4 Specjalizowane układy graficzne GPU?? (ZK)
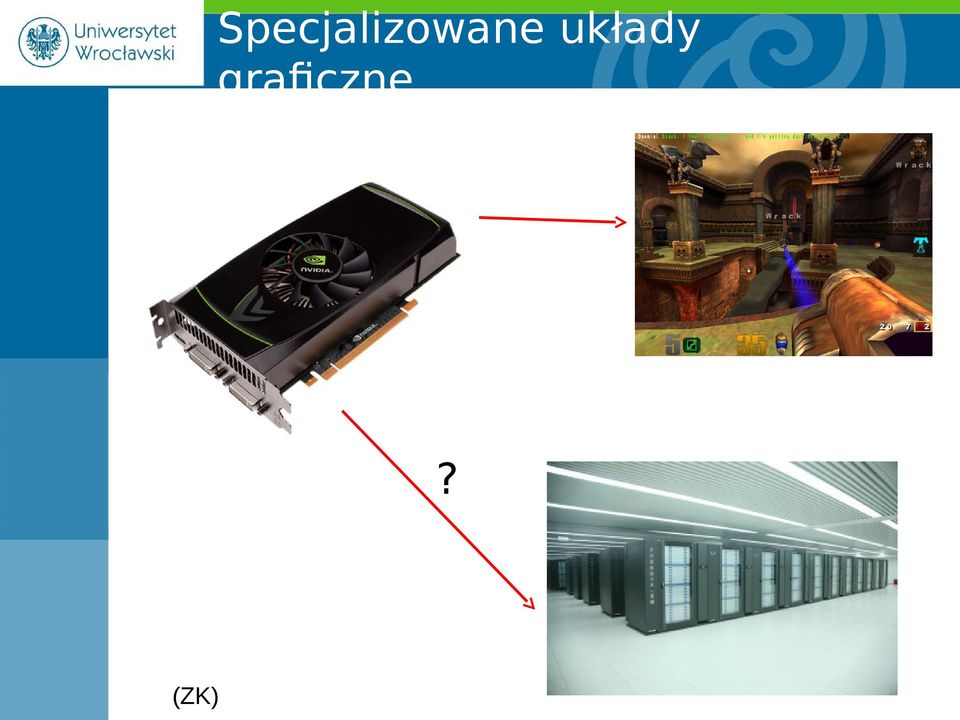
5 Obliczenia wysokiej wydajności Superkomputer: Altix 3700, 128 procesorów (Intel Itanium 2) Używana np. w Cyfronet AGH TFLOPS mocy obliczeniowej Cena: 1/2 miliona zł!

6 Superkomputer na biurku? Karta graficzna: GeForce 285 (używana w pokoju 521 w IFT ) 240 procesory CUDA 1.06 TFLOPS mocy obliczeniowej (teoretycznie) Cena: 670zł

7 Rachunek wydaje się prosty x więcej mocy za 0.134% ceny (+ energia + pomieszczenia + chłodzenie etc.) Zasada zachowania trudności, czyli coś za coś Kartę trzeba jeszcze oprogramować!

8 GPGPU GPGPU General-purpose computing on graphics processing units

9 Gdzie umiejscowić GPGPU? SISD Single Instruction Single Data SIMD Single Instruction Multiple Data (MSIMD?) SPMD Single Process Multiple Data MISD Multiple Instruction Single Data MIMD - Multiple Instruction Multiple Data ( )
 SPMD Single Process Multiple Data MISD Multiple Instruction Single Data")
10 Na jakiej platformie programować GPU? Niskopoziomowe API Vertex i Pixel Shaders (OpenGL) Direct Compute (DirectX) CUDA driver API C runtime for CUDA OpenCL Kompilatory PGI OpenACC API wysokiego poziomu

11 C runtime for CUDA Co to jest CUDA? Compute Unified Device Architecture Platforma programowania GPU (dla kart nvidii) Rozszerzenie języka C (działa również z C++) kompilator (nvcc) zbiór dyrektyw kompilatora i dodatkowych funkcji Np. słowa kluczowe: device, host wyróżniające rodzaj sprzętu na którym implementowana jest funkcja lub dana Np. funkcja: cudamemcpy( ) (kopiowanie pamięci CPU <-> GPU)

12 CUDA pod Windows Microsoft Visual C++ (2008, 2010) można użyć darmowej wersji Express Sterownik (ze strony Parallel NSIGHT): CUDA Toolkit CUDA SDK nvidia Parallel NSIGHT HOST/MONITOR

13 CUDA pod LINUX-em Inaczej niż pod Windows nie używamy Parallel Nsight Sterowniki nvidia-current (repozytoria) Cuda Toolkit (biblioteki, pliki nagłówkowe,.so) Po zainstalowaniu kompilacja (plik program.cu): > nvcc program.cu >./a.out
 Po zainstalowaniu kompilacja (plik program.")
14 Hello World Pierwszy prosty program w CUDA 1. CPU wywołuje funkcję na GPU Funkcja wstawia do pamięci GPU ciąg Hello world! 2. Kopiujemy dane z GPU do pamięci CPU 3. Dane wypisujemy przy pomocy funkcji i/o (cout etc.)

15 Hello World Pierwszy prosty program w CUDA 1. CPU wywołuje funkcję na GPU Funkcja wstawia do pamięci GPU ciąg Hello world! 2. Kopiujemy dane z GPU do pamięci CPU 3. Dane wypisujemy przy pomocy funkcji i/o (cout etc.)

16 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
!['e'; napis_device[11] = '!](/docs-images/44/13911617/images/page_16.jpg "'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char")
17 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
!['e'; napis_device[11] = '!](/docs-images/44/13911617/images/page_17.jpg "'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char")
18 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
!['e'; napis_device[11] = '!](/docs-images/44/13911617/images/page_18.jpg "'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char")
19 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
!['e'; napis_device[11] = '!](/docs-images/44/13911617/images/page_19.jpg "'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char")
20 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
!['e'; napis_device[11] = '!](/docs-images/44/13911617/images/page_20.jpg "'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char")
21 Hello World #include <stdio.h> #include <cuda.h> device char napis_device[14]; global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } int main(void) { helloworldondevice <<< 1, 1 >>> (); char napis_host[14]; const char *symbol="napis_device"; cudamemcpyfromsymbol (napis_host, symbol, sizeof(char)*13, 0, cudamemcpydevicetohost); printf("%s",napis_host); }
22 Deklaracja funkcji na GPU Funkcja uruchamiana na GPU to kernel (jądro) Zmienne na GPU przedrostek device Preambuła jądra - przedrostek global char napis_device[14]; device char napis_device[14]; void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } global void helloworldondevice(void) { napis_device[0] = 'H'; napis_device[1] = 'e'; napis_device[11] = '!'; napis_device[12] = '\n'; napis_device[13] = 0; } CPU GPU
23 Wywołanie funkcji na GPU Wywołanie funkcji GPU: funkcja <<< numblocks, threadsperblock >>> ( parametry ); numblocks liczba bloków w macierzy wątków threadsperblock liczba wątków na blok W naszym przykładzie <<<1,1>>> oznaczało uruchomienie jądra na jednym wątku który zawierał się w jednym jedynym bloku macierzy wątków.
24 numblocks, threadsperblock <<< 1, 1 >>> <<<4,1>>> <<< 1, 4 >>> <<< dim3(3,2,1), 4 >>>

25 A tak to widzi nvidia CUDA Programming Guide 3.2 <<< dim3(3,2,1), dim3(4,3,1) >>>
26 Hello World wielowątkowo 1. CPU wywołuje funkcję na GPU Funkcja wstawia do pamięci GPU ciąg Hello world! jedna litera na jeden wątek! (pomoc: P. Czubiński)
27 Hello World wielowątkowo jedna litera na jeden wątek stwórzmy 14 bloków po 1 wątku Każdy wątek widzi swój numer i numer bloku Numer bloku -> miejsce w tablicy do skopiowania
28 Hello World wielowątkowo Jądro dla hello world w wersji wielowątkowej: constant device char hw[] = "Hello World!\n"; device char napis_device[14]; global void helloworldondevice(void) { int idx = blockidx.x; napis_device[idx] = hw[idx]; } idxhelloworldondevice <<< 14, 1 >>> (); zawiera numer bloku w którym znajduje się wątek mapowanie blok/wątek -> fragment problemu wątek z idx-ego bloku kopiuje idx-ą literę napisu Kopiowanie GPU-GPU (bez sensu, ale chodzi nam o najprostszy problem)
29 Hello World wielowątkowo Jądro dla hello world w wersji wielowątkowej: constant device char hw[] = "Hello World!\n"; device char napis_device[14]; global void helloworldondevice(void) { int idx = blockidx.x; napis_device[idx] = hw[idx]; } idxhelloworldondevice <<< 14, 1 >>> (); zawiera numer bloku w którym znajduje się wątek mapowanie blok/wątek -> fragment problemu wątek z idx-ego bloku kopiuje idx-ą literę napisu Kopiowanie GPU-GPU (bez sensu, ale chodzi nam o najprostszy problem)
30 Hello World wielowątkowo Jądro dla hello world w wersji wielowątkowej: constant device char hw[] = "Hello World!\n"; device char napis_device[14]; global void helloworldondevice(void) { int idx = blockidx.x; napis_device[idx] = hw[idx]; } idxhelloworldondevice <<< 14, 1 >>> (); zawiera numer bloku w którym znajduje się wątek mapowanie blok/wątek -> fragment problemu wątek z idx-ego bloku kopiuje idx-ą literę napisu Kopiowanie GPU-GPU (bez sensu, ale chodzi nam o najprostszy problem)
31 Hello World wielowątkowo Jądro dla hello world w wersji wielowątkowej: constant device char hw[] = "Hello World!\n"; device char napis_device[14]; global void helloworldondevice(void) { int idx = blockidx.x; napis_device[idx] = hw[idx]; } idxhelloworldondevice <<< 14, 1 >>> (); zawiera numer bloku w którym znajduje się wątek mapowanie blok/wątek -> fragment problemu wątek z idx-ego bloku kopiuje idx-ą literę napisu Kopiowanie GPU-GPU (bez sensu, ale chodzi nam o najprostszy problem)
32 W praktyce

33 Modele ośrodków porowatych P=0.4 P=0.7 Ogromne układy (miliony komórek obliczeniowych).
34 Przykład rozwiązania P=0.4, T=1.7 P=0.7, T=1.28

35 Model gazu sieciowego LGA Uproszczenie: model gazu sieciowego opisany przez U. Frisha, B. Hasslachera i Y. Pomeau gaz FHP 1) Transport 2) Kolizje Rys. Kolizje w modelu FHP5 U. Frish, B. Hasslacher, Y. Pomeau 1986 Lattice-Gas Automata for the Navier-Stokes Equation, Phys. Rev. Lett. 56, Matyka, M. and Koza, Z., Spreading of a density front in the Kuentz-Lavallee model of porous media J. Phys. D: Appl. Phys. 40, (2007)
36 Metoda gazu sieciowego Boltzmanna Historycznie wprowadzona jako rozwinięcie LGA Zmienne ni (0,1) zastąpione funkcją rozkładu
37 Podstawowy Algorytm LBM Podstawowy algorytm LBM to dwa kroki: kolizji: transportu: Lokalność!

")
38 Przykład działania LBM na CUDA 512 x 512 CPU stoi. GPU w tym czasie.. (przykład cpu, gpu)
39 Hydrodynamika cząstek rozmytych 1. Lagrangian Fluid Dynamics, Using Smoothed Particle Hydrodynamics, Micky Kelager, Podejście Lagrange a (ruchome punkty) Każda cząstka reprezentuje pewną objętość cieczy Wielkości fizyczne interpolowane po sąsiadach Gdzie Wij jest tytułowym rozmyciem np.
.")
40 Rys. Algorytm SPH na CUDA (GTX285). (w działaniu)
41 Rys. Skalowanie algorytmów LBM i SPH na karcie GTX 285 względem jednego rdzenia CPU.
42 Łyżka dziegciu
43 Analiza wydajności CPU / GPU Przypadek testowy: driven cavity 3d Porównanie czasów określonej liczby iteracji Kody: Palabos (MPI) i Sailfish (CUDA) Rys: Wizualizacja przepływu przez trójwymiarową komorę wyznaczonego kodem Sailfish dla liczby Reynoldsa Re=100. Matyka, M., Miroslaw, Ł., Koza,Z., Wydajność otwartych implementacji metody sieciowej Boltzmanna na CPU i GPU, (KOWBAN) XVIII (2011)
44 Wydajność Sailfish / Palabos Czas wykonania kroków na 4xCPU i GPU (Gtx460 i Tesla). Matyka, M., Miroslaw, Ł., Koza,Z., Wydajność otwartych implementacji metody sieciowej Boltzmanna na CPU i GPU, (KOWBAN) XVIII (2011)
45 Przyszłość? Niskopoziomowe API Vertex i Pixel Shaders (OpenGL) Direct Compute (DirectX) CUDA driver API C runtime for CUDA OpenCL Kompilatory PGI OpenACC API wysokiego poziomu
46 Czym się zajmujemy? Grant MNiSW Grant N N Przepływ płynu (LBM) w ośrodkach porowatych na GPU Projekt Zielony Transfer (Vratis Sp. z o.o.) akceleracja CFD metod FVM na GPU 2011 Akceleracja obliczeń macierzowych (z Z. Kozą, J. Połą) na GPU Wizualizacja przepływów 3D w ośrodkach porowatych z użyciem OpenCL (multi GPU) beccaclunn/home.html
47 Dziękuję za uwagę
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Modelowanie komputerowe dynamiki płynów Maciej Matyka Instytut Fizyki Teoretycznej
 Modelowanie komputerowe dynamiki płynów 2011-12-05 Maciej Matyka Instytut Fizyki Teoretycznej Hydrodynamika http://www.realflow.com/ Konkursy na wydziale fizyki Lata 1999-2011 Oprogramowanie popularyzujące
Modelowanie komputerowe dynamiki płynów 2011-12-05 Maciej Matyka Instytut Fizyki Teoretycznej Hydrodynamika http://www.realflow.com/ Konkursy na wydziale fizyki Lata 1999-2011 Oprogramowanie popularyzujące
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Programowanie Równoległe wykład 13. Symulacje komputerowe cieczy LBM w CUDA. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 13 Symulacje komputerowe cieczy LBM w CUDA Maciej Matyka Instytut Fizyki Teoretycznej Transport cieczy i gazów W wielu dziedzinach trzeba rozwiązać zagadnienie transportu
Programowanie Równoległe wykład 13 Symulacje komputerowe cieczy LBM w CUDA Maciej Matyka Instytut Fizyki Teoretycznej Transport cieczy i gazów W wielu dziedzinach trzeba rozwiązać zagadnienie transportu
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
CUDA ćwiczenia praktyczne
 CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
CUDA ćwiczenia praktyczne 7 kwietnia 2011, Poznań Marek Błażewicz, marqs@man.poznan.pl Michał Kierzynka, michal.kierzynka@man.poznan.pl Agenda Wprowadzenie do narzędzi umożliwiających tworzenie programów
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii.
 Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii. Opiekun naukowy: dr hab. prof. UŚ Marcin Kostur Celem tych badań jest zastosowanie symulacji układu krwionośnego do diagnostyki
Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii. Opiekun naukowy: dr hab. prof. UŚ Marcin Kostur Celem tych badań jest zastosowanie symulacji układu krwionośnego do diagnostyki
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych.
 Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych. Jedną z metod symulacji dynamiki cieczy jest zastosowanie metody siatkowej Boltzmanna.
Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych. Jedną z metod symulacji dynamiki cieczy jest zastosowanie metody siatkowej Boltzmanna.
OpenGL - Open Graphics Library. Programowanie grafiki komputerowej. OpenGL 3.0. OpenGL - Architektura (1)
") OpenGL - Open Graphics Library Programowanie grafiki komputerowej Rados$aw Mantiuk Wydzia$ Informatyki Zachodniopomorski Uniwersytet Technologiczny! OpenGL: architektura systemu do programowania grafiki
OpenGL - Open Graphics Library Programowanie grafiki komputerowej Rados$aw Mantiuk Wydzia$ Informatyki Zachodniopomorski Uniwersytet Technologiczny! OpenGL: architektura systemu do programowania grafiki
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
CUDA. obliczenia na kartach graficznych. Łukasz Ligowski. 11 luty Łukasz Ligowski () CUDA 11 luty / 36
 CUDA 11 luty / 36") CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
CUDA obliczenia na kartach graficznych Łukasz Ligowski 11 luty 2008 Łukasz Ligowski () CUDA 11 luty 2008 1 / 36 Plan 1 Ogólne wrażenia 2 Obliczenia na kartach - wstęp 3 Wprowadzenie 4 CUDA Łukasz Ligowski
Modelowanie przepływu krwi przez aortę brzuszną człowieka
 Modelowanie przepływu krwi przez aortę brzuszną człowieka Maciej Matyka1, Zbigniew Koza1 Łukasz Mirosław2 1 Uniwersytet Wrocławski Instytut Fizyki Teoretycznej we współpracy z 2 Fizyka komputerowa we Wrocławiu
Modelowanie przepływu krwi przez aortę brzuszną człowieka Maciej Matyka1, Zbigniew Koza1 Łukasz Mirosław2 1 Uniwersytet Wrocławski Instytut Fizyki Teoretycznej we współpracy z 2 Fizyka komputerowa we Wrocławiu
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
GRAFIKA KOMPUTEROWA. Rozwiązania sprzętowe i programowe. Przyspieszanie sprzętowe. Synteza dźwięku i obrazu
 Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
GRAFIKA KOMPUTEROWA. Rozwiązania sprzętowe i programowe. Przyspieszanie sprzętowe. Synteza i obróbka obrazu
 Synteza i obróbka obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Synteza i obróbka obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złożonych obliczeń, szczególnie jeżeli chodzi o generowanie płynnej
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU
 Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Budowa i użytkowanie klastrów w opaciu o układy Cell BE oraz GPU Daniel Kubiak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V sor@czlug.icis.pcz.pl Streszczenie Celem pracy jest
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Obliczenia na GPU w technologii CUDA
 Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
Obliczenia na GPU w technologii CUDA 1 Różnica szybkości obliczeń (GFLOP/s) pomiędzy CPU a GPU źródło NVIDIA 2 Różnica w przepustowości pamięci pomiędzy CPU a GPU źródło NVIDIA 3 Różnice architektoniczne
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Wstęp do programowania
 Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
Wstęp do programowania Przemysław Gawroński D-10, p. 234 Wykład 1 8 października 2018 (Wykład 1) Wstęp do programowania 8 października 2018 1 / 12 Outline 1 Literatura 2 Programowanie? 3 Hello World (Wykład
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE. Wykład 02
 METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
METODY I JĘZYKI PROGRAMOWANIA PROGRAMOWANIE STRUKTURALNE Wykład 02 NAJPROSTSZY PROGRAM /* (Prawie) najprostszy przykład programu w C */ /*==================*/ /* Między tymi znaczkami można pisać, co się
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
4 NVIDIA CUDA jako znakomita platforma do zrównoleglenia obliczeń
 Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Spis treści Spis treści i 1 Wstęp 1 1.1 Wprowadzenie.......................... 1 1.2 Dostępne technologie, pozwalające zrównoleglić obliczenia na kartach graficznych....................... 1 1.2.1 Open
Programowanie Obiektowo Zorientowane w języku c++ Przestrzenie nazw
 Programowanie Obiektowo Zorientowane w języku c++ Przestrzenie nazw Mirosław Głowacki 1 1 Akademia Górniczo-Hutnicza im. Stanisława Staszica w Ktrakowie Wydział Inżynierii Metali i Informatyki Stosowanej
Programowanie Obiektowo Zorientowane w języku c++ Przestrzenie nazw Mirosław Głowacki 1 1 Akademia Górniczo-Hutnicza im. Stanisława Staszica w Ktrakowie Wydział Inżynierii Metali i Informatyki Stosowanej
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Programowanie Równoległe wykład 12. Thrust C Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 Thrust C++ 30.01.2013 Maciej Matyka Instytut Fizyki Teoretycznej Co to jest Thrust C++? Thrust C++ biblioteka szablonów Interfejs w pewnym sensie spójny z STL Biblioteka
Programowanie Równoległe wykład 12 Thrust C++ 30.01.2013 Maciej Matyka Instytut Fizyki Teoretycznej Co to jest Thrust C++? Thrust C++ biblioteka szablonów Interfejs w pewnym sensie spójny z STL Biblioteka
Grzegorz Cygan. Wstęp do programowania mikrosterowników w języku C
 Grzegorz Cygan Wstęp do programowania mikrosterowników w języku C Mikrosterownik Inne nazwy: Microcontroler (z języka angielskiego) Ta nazwa jest powszechnie używana w Polsce. Mikrokomputer jednoukładowy
Grzegorz Cygan Wstęp do programowania mikrosterowników w języku C Mikrosterownik Inne nazwy: Microcontroler (z języka angielskiego) Ta nazwa jest powszechnie używana w Polsce. Mikrokomputer jednoukładowy
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Potok graficzny i shadery. Hubert Rutkowski
 Potok graficzny i shadery Hubert Rutkowski 1. Coś o mnie Zakład Technologii Gier Uniwerytetu Jagiellońskiego 2. Potok graficzny jak w OpenGL Cry Engine 3 (zródło: CryTek) Vertex specification
Potok graficzny i shadery Hubert Rutkowski 1. Coś o mnie Zakład Technologii Gier Uniwerytetu Jagiellońskiego 2. Potok graficzny jak w OpenGL Cry Engine 3 (zródło: CryTek) Vertex specification
Przykładowe sprawozdanie. Jan Pustelnik
 Przykładowe sprawozdanie Jan Pustelnik 30 marca 2007 Rozdział 1 Sformułowanie problemu Tematem pracy jest porównanie wydajności trzech tradycyjnych metod sortowania: InsertionSort, SelectionSort i BubbleSort.
Przykładowe sprawozdanie Jan Pustelnik 30 marca 2007 Rozdział 1 Sformułowanie problemu Tematem pracy jest porównanie wydajności trzech tradycyjnych metod sortowania: InsertionSort, SelectionSort i BubbleSort.
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Introduction to Computer Science
 Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł.
 Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Akceleracja obliczeń algebry liniowej z wykorzystaniem masywnie równoległych, wielordzeniowych procesorów GPU Świerczewski Ł. Wprowadzenie do koncepcji budowy akceleratorów graficznych Pierwsze procesory
Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU
 Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU 1 GPGPU motywacja 2 GPGPU motywacja 3 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane
Programowanie procesorów graficznych do obliczeń ogólnego przeznaczenia GPGPU 1 GPGPU motywacja 2 GPGPU motywacja 3 Tendencje Mało dużych rdzeni rozbudowane potoki wykonanie poza kolejnością wyrafinowane
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Dodatek A. CUDA. 1 Stosowany jest w tym kontekście skrót GPCPU (od ang. general-purpose computing on graphics processing units).
.") Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
Dodatek A. CUDA Trzy ostatnie rozdziały książki poświęcone są zagadnieniom związanym z programowaniem równoległym. Skłoniła nas do tego wszechobecność maszyn wieloprocesorowych. Nawet niektóre notebooki
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wykład VII. Programowanie. dr inż. Janusz Słupik. Gliwice, 2014. Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2014 Janusz Słupik
 Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Programowanie równoległe Wprowadzenie do OpenCL. Rafał Skinderowicz
 Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
Programowanie równoległe Wprowadzenie do OpenCL Rafał Skinderowicz OpenCL architektura OpenCL Open Computing Language otwarty standard do programowania heterogenicznych platform złożonych ze zbioru CPU,
WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM OPENCL
 POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 85 Electrical Engineering 06 Wojciech PIETROWSKI* Grzegorz D. WIŚNIEWSKI Konrad GÓRNY WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM
POZNAN UNIVE RSITY OF TE CHNOLOGY ACADE MIC JOURNALS No 85 Electrical Engineering 06 Wojciech PIETROWSKI* Grzegorz D. WIŚNIEWSKI Konrad GÓRNY WIDMOWA I FALKOWA ANALIZA PRĄDU SILNIKA LSPMSM Z WYKORZYSTANIEM
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
CUDA PROGRAMOWANIE PIERWSZE PROSTE PRZYKŁADY RÓWNOLEGŁE. Michał Bieńkowski Katarzyna Lewenda
 PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
Laboratorium 1 Temat: Przygotowanie środowiska programistycznego. Poznanie edytora. Kompilacja i uruchomienie prostych programów przykładowych.
 Laboratorium 1 Temat: Przygotowanie środowiska programistycznego. Poznanie edytora. Kompilacja i uruchomienie prostych programów przykładowych. 1. Przygotowanie środowiska programistycznego. Zajęcia będą
Laboratorium 1 Temat: Przygotowanie środowiska programistycznego. Poznanie edytora. Kompilacja i uruchomienie prostych programów przykładowych. 1. Przygotowanie środowiska programistycznego. Zajęcia będą
Podsystem graficzny. W skład podsystemu graficznego wchodzą: karta graficzna monitor
 Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA
 Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Zeszyty Naukowe WSEI seria: TRANSPORT I INFORMATYKA, 6(1/2016), s. 77 85 Michał MAJ Wyższa Szkoła Ekonomii i Innowacji w Lublinie ZARZĄDZANIE PAMIĘCIĄ W TECHNOLOGII CUDA MANAGEMENT COMPUTER MEMORY IN CUDA
Grafika komputerowa. Grafika komputerowa. Grafika komputerowa
 OpenGL - Koncepcja i architektura Aplikacja odwo!uje si" poprzez funkcje API OpenGL bezpo#rednio do karty graficznej (z pomini"ciem systemu operacyjnego). Programowanie grafiki komputerowej Rados!aw Mantiuk
OpenGL - Koncepcja i architektura Aplikacja odwo!uje si" poprzez funkcje API OpenGL bezpo#rednio do karty graficznej (z pomini"ciem systemu operacyjnego). Programowanie grafiki komputerowej Rados!aw Mantiuk
Przyspieszanie sprzętowe
 Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złoŝonych obliczeń, szczególnie jeŝeli chodzi o generowanie płynnej
Synteza dźwięku i obrazu GRAFIKA KOMPUTEROWA Rozwiązania sprzętowe i programowe Przyspieszanie sprzętowe Generowanie obrazu 3D wymaga złoŝonych obliczeń, szczególnie jeŝeli chodzi o generowanie płynnej
Politechnika Rzeszowska
 Politechnika Rzeszowska i m. I g n a c e g o Ł u k a s i e w i c z a Wydział Elektrotechniki i Informatyki Katedra Informatyki i Automatyki Bogusław Rymut ŚLEDZENIE OBIEKTÓW PRZY WYKORZYSTANIU GPU Praca
Politechnika Rzeszowska i m. I g n a c e g o Ł u k a s i e w i c z a Wydział Elektrotechniki i Informatyki Katedra Informatyki i Automatyki Bogusław Rymut ŚLEDZENIE OBIEKTÓW PRZY WYKORZYSTANIU GPU Praca
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Implementacja modelu FHP w technologii NVIDIA CUDA
 Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 1 Model 1.1
Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 1 Model 1.1
Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny**
 AUTOMATYKA 2011 Tom 15 Zeszyt 3 Magdalena Szymczyk*, Piotr Szymczyk* Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny** 1. Wprowadzenie Aplikacje stosowane do przetwarzania obrazu
AUTOMATYKA 2011 Tom 15 Zeszyt 3 Magdalena Szymczyk*, Piotr Szymczyk* Mo liwoœæ zastosowania GPU do przetwarzania obrazów dla celów analizy sceny** 1. Wprowadzenie Aplikacje stosowane do przetwarzania obrazu
Microsoft IT Academy kurs programowania
 Microsoft IT Academy kurs programowania Podstawy języka C# Maciej Hawryluk Język C# Język zarządzany (managed language) Kompilacja do języka pośredniego (Intermediate Language) Kompilacja do kodu maszynowego
Microsoft IT Academy kurs programowania Podstawy języka C# Maciej Hawryluk Język C# Język zarządzany (managed language) Kompilacja do języka pośredniego (Intermediate Language) Kompilacja do kodu maszynowego
Jacek Matulewski - Fizyk zajmujący się na co dzień optyką kwantową i układami nieuporządkowanymi na Wydziale Fizyki, Astronomii i Informatyki
 Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Michał Matuszak, Jacek Matulewski CUDA i czyny Technologia NVIDIA CUDA W zeszłomiesięcznym numerze SDJ w artykule pt. Czyń cuda opisaliśmy
Programowanie niskopoziomowe. dr inż. Paweł Pełczyński ppelczynski@swspiz.pl
 Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Wykład I. Programowanie II - semestr II Kierunek Informatyka. dr inż. Janusz Słupik. Wydział Matematyki Stosowanej Politechniki Śląskiej
 Wykład I - semestr II Kierunek Informatyka Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2015 c Copyright 2015 Janusz Słupik Zaliczenie przedmiotu Do zaliczenia przedmiotu niezbędne jest
Wykład I - semestr II Kierunek Informatyka Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2015 c Copyright 2015 Janusz Słupik Zaliczenie przedmiotu Do zaliczenia przedmiotu niezbędne jest
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Programowanie proceduralne w języku C++ Podstawy
 Programowanie proceduralne w języku C++ Podstawy Mirosław Głowacki 1 1 Akademia Górniczo-Hutnicza im. Stanisława Staszica w Ktrakowie Wydział Inżynierii Metali i Informatyki Stosowanej Katedra Informatyki
Programowanie proceduralne w języku C++ Podstawy Mirosław Głowacki 1 1 Akademia Górniczo-Hutnicza im. Stanisława Staszica w Ktrakowie Wydział Inżynierii Metali i Informatyki Stosowanej Katedra Informatyki
Wprowadzenie do OpenMP
 Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Implementacje algorytmów oddziałujących cząstek na architekturach masywnie równoległych
 Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki Katedra Informatyki Autoreferat rozprawy doktorskiej Implementacje algorytmów
Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie Wydział Elektrotechniki, Automatyki, Informatyki i Elektroniki Katedra Informatyki Autoreferat rozprawy doktorskiej Implementacje algorytmów
Procesory kart graficznych i CUDA wer 1.2 6.05.2015
 wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
wer 1.2 6.05.2015 Litreratura: CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. CUDA w przykładach. Wprowadzenie do ogólnego programowania procesorów GP, J.Sanders, E.Kandrot, Helion
Technologia GPGPU na przykładzie środowiska CUDA
 Technologia GPGPU na przykładzie środowiska CUDA Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Plan prezentacji CPU Architektura CPU GPU Architektura GPU Architektura CUDA Istniejące środowiska programowania
Technologia GPGPU na przykładzie środowiska CUDA Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Plan prezentacji CPU Architektura CPU GPU Architektura GPU Architektura CUDA Istniejące środowiska programowania