Nowoczesne technologie przetwarzania informacji
|
|
|
- Roman Leśniak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Projekt Nowe metody nauczania w matematyce Nr POKL /11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego w ramach Europejskiego Funduszu Społecznego

2 Programowanie równoległe Początki programowania równoległego to lata Obecnie programowanie równoległe oparte jest na: znanych od dekad modeli programowania równoległego (MPI, OpenMP), nowych paradygmatów programowania równoległego (CUDA, OpenCL), językach przyszłości tworzonych dla przyszłych architektur komputerowych (X10, Chapel, Fortress). Znajomość technik programowania równoległego to obowiązek każdego programisty w ramach Europejskiego Funduszu Społecznego 2
.")
3 Czym są obliczenia równoległe? Obliczenia równoległe to takie, w których wiele operacji obliczeniowych wykonuje się jednocześnie w ramach dostępnych jednostek obliczeniowych (procesorów, rdzeni, węzłów obliczeniowych). Bardzo często duże problemy obliczeniowe mogą być podzielone na mniejsze podproblemy, które mogą wykonywać się jednocześnie. Przez wiele lat obliczenia równoległe wykonywane były jedynie w branży HPC (High Performance Computing). Dzisiaj wiedza o programowaniu równoległym i umiejętności przeprowadzania równoległych obliczeń potrzebne są wszystkim w ramach Europejskiego Funduszu Społecznego 3

4 Ograniczenia programowania równoległego Jaką maksymalną wydajność może uzyskać nasz program, jeśli: użyjemy szybszego procesora, użyjemy kilku lub wielu procesorów. Odpowiedzi na takie pytania szukano w latach 60tych XX wieku. w ramach Europejskiego Funduszu Społecznego 4

5 Gene Amdahl Urodzony 16 listopada 1922 w USA w rodzinie skandynawskich imigrantów Architekt komputerowy w firmie IBM, pracujący nad systemami typu mainframe. Założyciel Amdahl Corporation. Bardzo znana publikacja: Validity of the single processor approach to achieving large scale computing capabilities, IBM Sunnyvale, California, AFIPS Spring Joint Computer Conference, 1967 Na podstawie pracy G.Amdahla sformułowane zostało jedno z najbardziej znanych praw w dziedzinie obliczeń równoległych Prawo to do dziś nazywane Prawem Amdahl'a wyraża ograniczenia w prowadzeniu obliczeń równoległych w ramach Europejskiego Funduszu Społecznego 5

6 Prawo Amdahl a Potencjalne możliwe przyśpieszenie S algorytmu o jest równe: n liczba procesów T1 S( n) T n F 1 1 F n T_ - czas wykonania algorytmu F udział części nierównoległej w ramach Europejskiego Funduszu Społecznego 6

7 w ramach Europejskiego Funduszu Społecznego 7
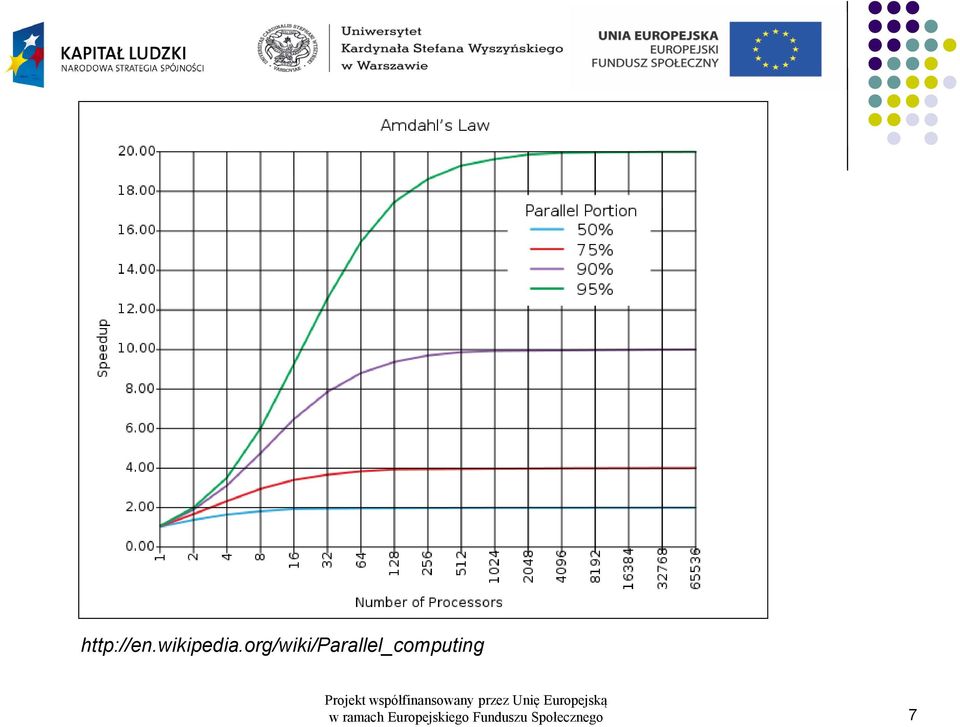
8 Krytyka prawa Amdahl a Prawo i teoria Amdahl a znalazła wielu krytyków Główny zarzut: prawo Amdahl a ma zastosowanie tylko dla aplikacji z niezmiennym rozmiarem zadania Maksymalne przyśpieszenie: 2x w ramach Europejskiego Funduszu Społecznego 8


9 Prawo Gustafsona (1988) S( P) P ( P 1) Każdy wystarczająco duży problem może być efektywnie zrównoleglony P ilość procesorów, S przyśpieszenie, alfa część programu, której nie da się zrównoleglić w ramach Europejskiego Funduszu Społecznego 9

10 Skalowalność Speed-up przyśpieszenie - stosunek czasu wykonania algorytmu i liczby użytych procesów skalowalność zmiana czasu wykonania programu mierzona dla zmiennej liczby procesorów lub zmiennego rozmiaru zadania program równoległy jest uznawany za optymalny gdy jego skalowalność jest bliska liniowej w zastosowaniach znane jest mało programów optymalnych dla liczby procesorów większej od kilkunastu Rodzaje skalowalności: Strong scalability stały rozmiar problemu, zmienna liczba procesów Weak scalability stała liczba procesów, zmienny rozmiar zadania w ramach Europejskiego Funduszu Społecznego 10

11 Model idealnego komputera równoległego PRAM = Parallel Random Access Machine n jednostek obliczeniowych oraz globalna jednorodna pamięć jednostki są sterowane wspólnym zegarem, ale mogą wykonywać różne instrukcje w każdym cyklu Model PRAM ignoruje wpływ i koszty komunikacji między komponentami komputera równoległego. Modele PRAM służą do projektowania i analizy algorytmów. Realizacja komputera typu PRAM dla dużej liczby n, jest technicznie bardzo złożona i kosztowna. w ramach Europejskiego Funduszu Społecznego 11

12 Taksonomia Flynna SISD = Single Instruction Single Data Klasyczny komputer skalarny wykonujący kolejne instrukcje, jedna po drugiej na pojedynczych danych SIMD = Single Instruction Multiple Data Procesor / komputer potrafi wykonać pojedynczą instrukcję dla całego potoku (wektora) danych (procesor wektorowy) Zakłada równoległość danych MISD = Multiple Instruction Single Data Komputer potrafi wykonać jednocześnie zbiór instrukcji na jednej danej MIMD = Multiple Instruction Multiple Data Zbiór procesorów może wykonywać równolegle i niezależnie instrukcje na wielu danych Najczęściej spotykana forma równoległości sprzętowej w ramach Europejskiego Funduszu Społecznego 12

13 Rozszerzenia modelu MIMD SPMD = Single Program Multiple Data pojedynczy program jest uruchamiany w wielu kopiach na różnych zestawach danych najbardziej rozpowszechniony sposób tworzenia programów równoległych MPMD = Multiple Program Multiple Data wiele niezależnych procesorów wykonuje równolegle różne programy w ramach Europejskiego Funduszu Społecznego 13

14 Współczesne typy architektur równoległych Modele, języki oraz mechanizmy programowania równoległego są ściśle związane z typem architektury równoległej. Przedstawione zostaną podstawowe typy architektur. w ramach Europejskiego Funduszu Społecznego 14

15 Model pamięci współdzielonej Procesory współdzielą globalną przestrzeń adresową Technologia: ograniczona liczba procesorów Szybka komunikacja i synchronizacja Równoległe typy danych: shared, private Ochrona dostępu do danych współdzielonych Komunikacja poprzez zmienne współdzielone Równoległe wątki Modele programowania: OpenMP, Pthreads, OpenCL w ramach Europejskiego Funduszu Społecznego 15

16 Model pamięci współdzielonej Procesory operują na prywatnej, lokalnej pamięci Technologia: duża liczba procesorów Mechanizmy komunikacji i synchronizacji Operowanie na danych lokalnych Komunikacja poprzez połączenie sieciowe Koszt komunikacji rośnie z liczbą procesorów Równoległe procesy Modele programowania: MPI Obecnie wiele architektur to architektury o równoległości hierarchicznej. Węzły obliczeniowe są wielordzeniowe. Popularny model programowania to MPI + OpenMP. w ramach Europejskiego Funduszu Społecznego 16

17 Model obliczeń akcelerowanych (hybrydowych) Węzły obliczeniowe wyposażone są w dodatkowe akceleratory (np. karty graficzne) Technologia: duża liczba węzłów wyposażonych w 1-4 kart GPU Mechanizmy odciążania czasochłonnych obliczeń na akceleratorach Skomplikowane modele programowania Ograniczenia komunikacji CPU - GPU Modele programowania: CUDA, OpenCL, HMPP w ramach Europejskiego Funduszu Społecznego 17

18 Mechanizmy programowania równoległego Zaprojektowanie wydajnego algorytmu równoległego wymaga znajomości podstawowych mechanizmów dostępnych w modelach równoległych. Przedstawione zostaną podstawowe mechanizmy programowania równoległego. w ramach Europejskiego Funduszu Społecznego 18

19 Mechanizmy podział zadania Dekompozycja problemu - podział na podproblemy metoda i sposób podziału determinuje typ równoległości Stopień i schemat zależności podproblemów prowadzi do projektu algorytmu Gdy znamy zależności pomiędzy podproblemami: wybieramy model algorytmu odpowiednią architekturę komputera równoległego Interesuje nas poprawne i szybkie rozwiązanie problemu w ramach Europejskiego Funduszu Społecznego 19

20 Mechanizmy - komunikacja Obliczenia realizowane równolegle na kilku komputerach w ramach jednego algorytmu często wymagają wymiany informacji Komunikacja realizowana jest poprzez wywołanie funkcji, która definiuje nadawcę, odbiorcę oraz typ i rodzaj wiadomości Istnieje wiele rodzajów komunikacji: Komunikacja punkt-punkt (synchroniczna i asynchroniczna) Komunikacja wspólna (np. redukcja, wszyscy-do-wszystkich) Pokazana w kolejnej lekcji na przykładzie biblioteki MPI (Message Passing Interface). w ramach Europejskiego Funduszu Społecznego 20
 Pokazana w kolejnej lekcji na przykładzie biblioteki MPI (Message Passing Interface).")
21 Mechanizmy - synchronizacja Obliczenia realizowane równolegle na kilku komputerach w ramach jednego algorytmu często wymagają zapewnienia, że wszystkie procesy realizują ten sam fragment algorytmu Synchronizacja realizowana jest poprzez wywołanie funkcji, która: blokuje wykonanie procesów równoległych, zwalnia blokadę w momencie gdy wszystkie procesy wywołały tą funkcję. Pokazana w kolejnej lekcji na przykładzie biblioteki MPI (Message Passing Interface). w ramach Europejskiego Funduszu Społecznego 21
22 Mechanizmy ochrona dostępu Obliczenia realizowane na architekturach o pamięci współdzielonej często operują na tzw. zmiennych współdzielonych Należy unikać sytuacji, w których jeden wątek odczytuje wartość zmiennej podczas gdy drugi realizuje zmianę wartości tej zmiennej Do ochrony dostępu służą różnego rodzaju mechanizmy: zamki, określanie zmiennych atomowych oraz regionów krytycznych. Pokazana w kolejnej lekcji na przykładzie OpenMP. w ramach Europejskiego Funduszu Społecznego 22
23 Mechanizmy - akceleracja Obliczenia na architekturach wyposażonych dodatkowo w akceleratory (np. karty graficzne) Wybieranie najbardziej obciążających obliczeniowo fragmentów programu i programowanie ich wykonania na dostępnym akceleratorze. Programowanie takich architektur jest trudne i czasochłonne. w ramach Europejskiego Funduszu Społecznego 23
24 Mechanizmy - równoważenie obciążenia (ang. load balancing) Load balancing = podział obliczeń pomiędzy dostępne procesory Aby zminimalizować czas wykonania programu równoległego należy zapewnić równomierne rozłożenie obliczeń. Nierówny podział obliczeń pomiędzy procesami prowadzi do niskiej skalowalności programu. w ramach Europejskiego Funduszu Społecznego 24
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Programowanie współbieżne Wstęp do obliczeń równoległych. Rafał Skinderowicz
 Programowanie współbieżne Wstęp do obliczeń równoległych Rafał Skinderowicz Plan wykładu Modele obliczeń równoległych Miary oceny wydajności algorytmów równoległych Prawo Amdahla Prawo Gustavsona Modele
Programowanie współbieżne Wstęp do obliczeń równoległych Rafał Skinderowicz Plan wykładu Modele obliczeń równoległych Miary oceny wydajności algorytmów równoległych Prawo Amdahla Prawo Gustavsona Modele
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Spis treści. 1 Wprowadzenie. 1.1 Podstawowe pojęcia. 1 Wprowadzenie Podstawowe pojęcia Sieci komunikacyjne... 3
 Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia
 Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Wprowadzenie do architektury komputerów. Taksonomie architektur Podstawowe typy architektur komputerowych
 Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f)
 i częstotliwości (f)") Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Zadania badawcze prowadzone przez Zakład Technik Programowania:
 Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Systemy operacyjne III
 Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM
 Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Tryby komunikacji między procesami w standardzie Message Passing Interface. Piotr Stasiak Krzysztof Materla
 Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Tryby komunikacji między procesami w standardzie Message Passing Interface Piotr Stasiak 171011 Krzysztof Materla 171065 Wstęp MPI to standard przesyłania wiadomości (komunikatów) pomiędzy procesami programów
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
procesów Współbieżność i synchronizacja procesów Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Abstrakcja programowania współbieżnego Instrukcje atomowe i ich przeplot Istota synchronizacji Kryteria poprawności programów współbieżnych
Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Abstrakcja programowania współbieżnego Instrukcje atomowe i ich przeplot Istota synchronizacji Kryteria poprawności programów współbieżnych
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Wprowadzenie do systemów wieloprocesorowych
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Wprowadzenie do systemów wieloprocesorowych Wstęp Do tej pory mówiliśmy głównie o systemach z jednym procesorem Coraz trudniej wycisnąć
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Wprowadzenie do systemów wieloprocesorowych Wstęp Do tej pory mówiliśmy głównie o systemach z jednym procesorem Coraz trudniej wycisnąć
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM. Juliusz Pukacki,PCSS
 DLA FIRM. Juliusz Pukacki,PCSS") USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Programowanie współbieżne... (1) Andrzej Baran 2010/11
 Andrzej Baran 2010/11") Programowanie współbieżne... (1) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Uwagi wstępne OR = obliczenia równoległe OW = obliczenia współbieżne W czasie wykładu zajmiemy
Programowanie współbieżne... (1) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Uwagi wstępne OR = obliczenia równoległe OW = obliczenia współbieżne W czasie wykładu zajmiemy
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Co to jest lista top500. Omów mikrotechnologię Core
 Co to jest lista top500 Lista top500 to lista 500 najbardziej wydajnych systemów komputerowych na świecie. Lista uaktualniana jest 2 razy do roku. Głównym celem listy top500 jest możliwość śledzenia postępu
Co to jest lista top500 Lista top500 to lista 500 najbardziej wydajnych systemów komputerowych na świecie. Lista uaktualniana jest 2 razy do roku. Głównym celem listy top500 jest możliwość śledzenia postępu
Jacek Naruniec. lato 2014, Politechnika Warszawska, Wydział Elektroniki i Technik Informacyjnych
 lato 2014,, Wydział Elektroniki i Technik Informacyjnych Wykład (poniedziałek 10:15) dr inż. Jacek Naruniec, dr inż. Maciej Sypniewski Laboratoria (3-godzinne) w 08 Środy 12:15 Projekt Punktacja: Laboratorium
lato 2014,, Wydział Elektroniki i Technik Informacyjnych Wykład (poniedziałek 10:15) dr inż. Jacek Naruniec, dr inż. Maciej Sypniewski Laboratoria (3-godzinne) w 08 Środy 12:15 Projekt Punktacja: Laboratorium
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Obliczenia równoległe. Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205
 Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Wydajność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Programowanie niskopoziomowe. dr inż. Paweł Pełczyński ppelczynski@swspiz.pl
 Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Programowanie niskopoziomowe dr inż. Paweł Pełczyński ppelczynski@swspiz.pl 1 Literatura Randall Hyde: Asembler. Sztuka programowania, Helion, 2004. Eugeniusz Wróbel: Praktyczny kurs asemblera, Helion,
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Introduction to Computer Science
 Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Wstęp do programowania równoległego
 Wstęp do programowania równoległego Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl Maciej Cytowski
Wstęp do programowania równoległego Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl Maciej Cytowski
Alternatywne modele programowania równoległego
 Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Alternatywne modele programowania równoległego 1 PRAM Teoretyczne modele obliczeń (do analizy algorytmów) maszyna o dostępie swobodnym (RAM) procesor, rejestry, magistrala, pamięć równoległa maszyna o
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Podstawy programowania obliczeń równoległych
 Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
SYSTEMY OPERACYJNE: STRUKTURY I FUNKCJE (opracowano na podstawie skryptu PP: Królikowski Z., Sajkowski M. 1992: Użytkowanie systemu operacyjnego UNIX)
") (opracowano na podstawie skryptu PP: Królikowski Z., Sajkowski M. 1992: Użytkowanie systemu operacyjnego UNIX) W informatyce występują ściśle obok siebie dwa pojęcia: sprzęt (ang. hardware) i oprogramowanie
(opracowano na podstawie skryptu PP: Królikowski Z., Sajkowski M. 1992: Użytkowanie systemu operacyjnego UNIX) W informatyce występują ściśle obok siebie dwa pojęcia: sprzęt (ang. hardware) i oprogramowanie
WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH
 ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Pojęcia podstawowe. Oprogramowanie systemów równoległych i rozproszonych. Wykład 1. Klasyfikacja komputerów równoległych I
 Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa