Tesla. Architektura Fermi
|
|
|
- Magdalena Skowrońska
- 8 lat temu
- Przeglądów:
Transkrypt
1 Tesla Architektura Fermi
2 Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki komputerowej: Polecam drugie wideo
3 Tesla cechy: Procesory równoległe Skalowalne Oparte o architekturę CUDA Pamięć ECC Do 6 GB pamięci GDDR5 na każdy układ GPU Wydajność obliczeń zmiennoprzecinkowych podwójnej precyzji: 515 Gflops
4 Tesla cechy c.d. Maksymalny pobór mocy: 225 W zestawy narzędzi dla CUDA: C/C++/Fortran OpenCL i DirectCompute NVIDIA Parallel Nsight dla Visual Studio
5 Tesla dostępna jako: Pojedyncze urządzenia: karta wpinana w port PCI-Express Wolnostojące zestawy kilku kart; wersja Desktop Zestawy kilku urządzeń w formie modułów 1U do montowania w szafach montażowych. Wersja Server
6 Architektura Fermi Architektura Tesla o nazwie kodowej Fermi jest nową generacją rewolucyjnej architektury zaprezentowanej w Karcie graficznej GeForce 8800, która stworzyła podstawy dla CUDA.
7 Architektura CUDA wsparcie GPU dla języka programowania C/C++, dzięki czemu programiści nie muszą uczyć się nowych języków uniwersalne potoki przetwarzające wierzchołki, geometrię, piksele oraz programy obliczeniowe - wcześniej istniały tylko potoki dedykowane do przetwarzania wierzchołków lub pikseli
8 Architektura CUDA Tryb wykonawczy SIMT: Single-Instruction Multiple-Thread; wiele niezależnych wątków wykonuje się równocześnie wykorzystując jedną instrukcję Wprowadzenie współdzielonej pamięci i synchronizacji barierowej dla komunikacji między-wątkowej
9 Fermi W czerwcu roku pojawiła się druga generacja tej zunifikowanej architektury. Wraz z nią zaprezentowano układ Tesla. W tej generacji zwiększono ilość procesorów z 128 do 240, podwojono rozmiary rejestrów procesorów. Dodano wsparcie dla liczb zmiennoprzecinkowych podwójnej precyzji.
10 Fermi NVidia - producent Tesla nazywa technologię Fermi największym skokiem od czasów wprowadzenia technologii CUDA
11 Termin - Kernel Kernele mogą być pojmowane jako ciało pętli. Na przykład wykonując sekwencyjne obliczenia na CPU, kod może wyglądać następująco: void transform_10k_by_10k_grid(float in[10000][10000], float out[10000][10000]) { for(int x = 0; x < 10000; x++) { for(int y = 0; y < 10000; y++) { // The next line is executed 100 million times out[x][y] = do_some_hard_work( in[x][y] ); } } } Dla GPU kernelem będzie ciało pętli oraz zestaw danych
12 Architektura Fermi 3 miliardy tranzystorów 512 procesorów CUDA Rdzeń CUDA wykonuje jedną operację na liczbach całkowitych lub zmiennoprzecinkowych w cyklu zegara 512 procesorów CUDA zorganizowane w 16 Streaming Multiprocessor - 32 rdzenie CUDA na SM
13 Architektura Fermi GPU posiada 6 x 64 bitowe partycje pamięci obsługuje do 6GB GDDR5 interfejs PCI-Express GigaThread globalny zarządca procesów (scheduler) dystrybuuje bloki wątków do zarządcy procesów Streaming Multiprocessor
14 Architektura Fermi
15 Termin: Thread block (Blok wątków) Zbiór równocześnie wykonujących się wątków, które mogą ze sobą kooperować dzięki barierze synchronizacyjnej i pamięci współdzielonej. Blok wątków posiada ID bloku wewnątrz sieci.
16 Termin: Grid (sieć) Sieć jest tablicą bloków wątków, które korzystają z tego samego kernela, czytają dane z pamięci globalnej, zapisują wyniki do pamięci globalnej i synchronizują się z zależnymi kernela
17 Pamięć prywatna W technologii CUDA każdy wątek ma prywatną przestrzeń pamięciową przeznaczoną na rejestry, wywołania funkcji, oraz automatyczne zmienne tablicowe języka C.
18 Pamięć współdzielona Każdy blok wątków ma swoją pamięć współdzieloną, służącą do komunikacji między wątkami, wymianę danych oraz wymianę wyników w algorytmach równoległych
19 Pamięć globalna Sieci bloków współdzielą wyniki w pamięci globalnej po globalnej synchronizacji.
20 Hierarchia
21 Wykonanie sprzętowe Hierarchia wątków jest dopasowywana do hierarchii procesorów na GPU. GPU wykonuje jedną lub więcej sieć kerneli. Streaming Multiprocessor (SM) wykonuje jeden blok wątków lub więcej. Procesory CUDA oraz inne jednostki obliczeniowe wykonują wątki. SM wykonują wątki w grupach liczących 32 wątki, które nazwane zostały "warp"
22 Procesor CUDA posiada Arithmetic Logic Unit (ALU) oraz Floating Point Unit (FPU) FPU obsługuje Fused Multiply Add (FMA): algorytm wykonujący z większą precyzją mnożenie i dodawanie macierzy, niż standardowe sekwencyjne mnożenie i dodawanie tych argumentów
23 Streaming Multiprocessor 32 procesory CUDA 16 jednostek zapis/odczyt 4 specjalne jednostki funkcyjne: Special Function Units (SFU) wykonują takie funkcje jak sinus, cosinus, obliczanie liczby odwrotnej, pierwiastek kwadratowy jedna operacja na wątek na cykl zegara
24 Streaming Multiprocessor
25 Dual Warp Scheduler Warp - grupa 32 równoległych wątków Na każdy Streaming Multiprocessor przypada 2 warp schedulers oraz 2 dispatch units (planista niskopoziomowy, przydziela czas procesora), dzięki czemu dwa warpy mogą być wykonywane równocześnie
26 Zunifikowana przestrzeń adresowa w architekturze Fermi występują trzy rodzaje pamięci: lokalna pamięć wątku, pamięć współdzielona dla sieci wątków, pamięć globalna przestrzenie te zostały zunifikowane, jest to jedna ciągła przestrzeń adresowa
27 Zunifikowana przestrzeń adresowa implementacja zunifikowanej przestrzeni adresowej umożliwiło zastosowanie języków C/C++ możliwe jest przekazywanie obiektów z każdej przestrzeni adresowej, ponieważ sprzętowa jednostka dokona mapowania adresu na odpowiednią przestrzeń pamięci
28 Zunifikowana przestrzeń adresowa
29 Improved Conditional Performance through Predication Mechanizm wykonujący krótkie segmenty kodu instrukcji warunkowych bez znanego wyniku instrukcji warunkowej
30 NVIDIA Parallel DataCache 64kB pamięć L1 na Streaming Multiprocessor Jedna pamięć L2-768kB - służąca do wszystkich operacji (load, store, texture) Architektura Fermi umożliwia konfigurowanie pamięci L1 jako cache lub pamięć współdzielona
31 NVIDIA Parallel DataCache Np. 48kb na cache L1 i pozostałe 16 na pamięć współdzieloną Można dostosować rozmiary pamięci do wykonywanych zadań, dzięki czemu uzyskiwane jest znaczne przyspieszenie obliczeń. Na przykład symulacja zjawisk elektrodynamicznych często korzysta z pamięci wpsółdzielonej
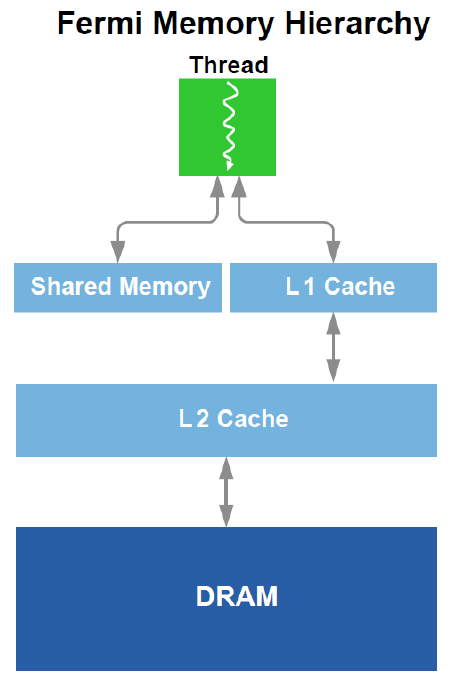
32 Hierarchia pamięci
33 Concurrent Kernel Execution możliwe jest wykonywanie różnych kerneli jednej aplikacji w jednym czasie mechanizm ten umożliwia efektywniejsze wykorzystanie czasu procesorów dla aplikacji wykonujących wiele małych kerneli Przykład: symulacja fizyczna obliczająca symulację płynów oraz ciała stałego

34 Concurrent Kernel Execution
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski
 JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
JCuda Czy Java i CUDA mogą się polubić? Konrad Szałkowski Agenda GPU Dlaczego warto używać GPU Budowa GPU CUDA JCuda Przykładowa implementacja Co to jest? GPU GPU Graphical GPU Graphical Processing GPU
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
LEKCJA TEMAT: Współczesne procesory.
 LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo.
 Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Konrad Szałkowski Libra.cs.put.poznan.pl/mailman/listinfo/skisrkolo Skisr-kolo@libra.cs.put.poznan.pl Po co? Krótka prezentacja Skąd? Dlaczego? Gdzie? Gdzie nie? Jak? CPU Pamięć DDR3-19200 19,2 GB/s Wydajność
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Programowanie współbieżne Wprowadzenie do programowania GPU. Rafał Skinderowicz
 Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Programowanie współbieżne Wprowadzenie do programowania GPU Rafał Skinderowicz Literatura Sanders J., Kandrot E., CUDA w przykładach, Helion. Czech Z., Wprowadzenie do obliczeń równoległych, PWN Ben-Ari
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Budowa i zasada działania komputera. dr Artur Bartoszewski
 Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Programowanie kart graficznych. Sprzęt i obliczenia
 Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych Sprzęt i obliczenia CUDA Szczegóły implementacji sprzętowej Architektura SIMT: podstawą konstrukcji urządzeń CUDA jest skalowalna macierz wielowątkowych multiprocesorów strumieniowych
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Architektura komputerów
 Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Architektura komputerów Wykład 3 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) 2 Plan wykładu Podstawowe komponenty komputera Procesor CPU Cykl rozkazowy Typy instrukcji Stos Tryby adresowania
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych
 Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Wysokowydajna implementacja kodów nadmiarowych typu "erasure codes" z wykorzystaniem architektur wielordzeniowych Ł. Kuczyński, M. Woźniak, R. Wyrzykowski Instytut Informatyki Teoretycznej i Stosowanej
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Programowanie aplikacji równoległych i rozproszonych
 Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Programowanie aplikacji równoległych i rozproszonych Dr inż. Krzysztof Rojek krojek@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Strumienie operacji na GPU Domyślne
Przegląd architektury PlayStation 3
 Przegląd architektury PlayStation 3 1 Your Name Your Title Your Organization (Line #1) Your Organization (Line #2) Sony PlayStation 3 Konsola siódmej generacji Premiera: listopad 2006 33,5 mln sprzedanych
Przegląd architektury PlayStation 3 1 Your Name Your Title Your Organization (Line #1) Your Organization (Line #2) Sony PlayStation 3 Konsola siódmej generacji Premiera: listopad 2006 33,5 mln sprzedanych
Architektura potokowa RISC
 Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura mikroprocesorów z rdzeniem ColdFire
 Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Larrabee GPGPU. Zastosowanie, wydajność i porównanie z innymi układami
 Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Larrabee GPGPU Zastosowanie, wydajność i porównanie z innymi układami Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee a inne GPU Różnią się w trzech podstawowych aspektach: Larrabee
Wstęp do programowania 2
 Wstęp do programowania 2 wykład 10 Zadania Agata Półrola Wydział Matematyki UŁ 2005/2006 http://www.math.uni.lodz.pl/~polrola Współbieżność dotychczasowe programy wykonywały akcje sekwencyjnie Ada umożliwia
Wstęp do programowania 2 wykład 10 Zadania Agata Półrola Wydział Matematyki UŁ 2005/2006 http://www.math.uni.lodz.pl/~polrola Współbieżność dotychczasowe programy wykonywały akcje sekwencyjnie Ada umożliwia
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera
 Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Zastosowanie technologii nvidia CUDA do zrównoleglenia algorytmu genetycznego dla problemu komiwojażera Adam Hrazdil Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V hrazdil@op.pl
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Organizacja pamięci w procesorach graficznych
 Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Organizacja pamięci w procesorach graficznych Pamięć w GPU przechowuje dane dla procesora graficznego, służące do wyświetlaniu obrazu na ekran. Pamięć przechowuje m.in. dane wektorów, pikseli, tekstury
Wstęp do obliczeń równoległych na GPU
 Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
Spis treści 1 Wstęp do obliczeń równoległych na GPU 1.1 Zadanie 1.2 Profilowanie 1.2.1 Zadanie Wstęp do obliczeń równoległych na GPU W tej części ćwiczeń stworzymy pierwszy program wykorzystujący bibliotekę
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Logiczny model komputera i działanie procesora. Część 1.
 Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Procesy i wątki. Krzysztof Banaś Obliczenia równoległe 1
 Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Procesy i wątki Krzysztof Banaś Obliczenia równoległe 1 Procesy i wątki Proces: ciąg rozkazów (wątek główny) i ewentualnie inne wątki stos (wątku głównego) przestrzeń adresowa dodatkowe elementy tworzące
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
Wykład 6. Mikrokontrolery z rdzeniem ARM
 Wykład 6 Mikrokontrolery z rdzeniem ARM Plan wykładu Cortex-A9 c.d. Mikrokontrolery firmy ST Mikrokontrolery firmy NXP Mikrokontrolery firmy AnalogDevices Mikrokontrolery firmy Freescale Mikrokontrolery
Wykład 6 Mikrokontrolery z rdzeniem ARM Plan wykładu Cortex-A9 c.d. Mikrokontrolery firmy ST Mikrokontrolery firmy NXP Mikrokontrolery firmy AnalogDevices Mikrokontrolery firmy Freescale Mikrokontrolery
Układ sterowania, magistrale i organizacja pamięci. Dariusz Chaberski
 Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Kurs Zaawansowany S7. Spis treści. Dzień 1
 Spis treści Dzień 1 I Konfiguracja sprzętowa i parametryzacja stacji SIMATIC S7 (wersja 1211) I-3 Dlaczego powinna zostać stworzona konfiguracja sprzętowa? I-4 Zadanie Konfiguracja sprzętowa I-5 Konfiguracja
Spis treści Dzień 1 I Konfiguracja sprzętowa i parametryzacja stacji SIMATIC S7 (wersja 1211) I-3 Dlaczego powinna zostać stworzona konfiguracja sprzętowa? I-4 Zadanie Konfiguracja sprzętowa I-5 Konfiguracja
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Architektura systemów komputerowych
 Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]
![Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]](/thumbs/57/40653782.jpg "Procesor ma architekturę rejestrową L/S. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset nand Rx, Ry, A add Rx, #1, Rz store Rx, [Rz]") Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Procesor ma architekturę akumulatorową. Wskaż rozkazy spoza listy tego procesora. bgt Rx, Ry, offset or Rx, Ry, A add Rx load A, [Rz] push Rx sub Rx, #3, A load Rx, [A] Procesor ma architekturę rejestrową
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany. sprzęt L P. Parametry techniczne
 L P Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany Parametry techniczne Ilość sprzęt Gwaran Cena Cena Wartość Wartość (model cja jednostk % jednostkow ogółem ogółem i parametry
L P Załącznik nr 6 do SIWZ nr postępowania II.2420.1.2014.005.13.MJ Zaoferowany Parametry techniczne Ilość sprzęt Gwaran Cena Cena Wartość Wartość (model cja jednostk % jednostkow ogółem ogółem i parametry
Akceleracja sprzętowa symulacji elektromagnetycznych. graficznych (GPU)
") Posiedzenie Polskiego Chapteru IEEE EMC-s Wrocław, 13 czerwca 2013 Akceleracja sprzętowa symulacji elektromagnetycznych za pomocą kart graficznych (GPU) Politechnika Śląska Posiedzenie Polskiego Chapteru
Posiedzenie Polskiego Chapteru IEEE EMC-s Wrocław, 13 czerwca 2013 Akceleracja sprzętowa symulacji elektromagnetycznych za pomocą kart graficznych (GPU) Politechnika Śląska Posiedzenie Polskiego Chapteru
Projektowanie oprogramowania systemów PROCESY I ZARZĄDZANIE PROCESAMI
 Projektowanie oprogramowania systemów PROCESY I ZARZĄDZANIE PROCESAMI plan Cechy, właściwości procesów Multitasking Scheduling Fork czym jest proces? Działającą instancją programu Program jest kolekcją
Projektowanie oprogramowania systemów PROCESY I ZARZĄDZANIE PROCESAMI plan Cechy, właściwości procesów Multitasking Scheduling Fork czym jest proces? Działającą instancją programu Program jest kolekcją
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Karty graficzne możemy podzielić na:
 KARTY GRAFICZNE Karta graficzna karta rozszerzeo odpowiedzialna generowanie sygnału graficznego dla ekranu monitora. Podstawowym zadaniem karty graficznej jest odbiór i przetwarzanie otrzymywanych od komputera
KARTY GRAFICZNE Karta graficzna karta rozszerzeo odpowiedzialna generowanie sygnału graficznego dla ekranu monitora. Podstawowym zadaniem karty graficznej jest odbiór i przetwarzanie otrzymywanych od komputera
Bibliografia: pl.wikipedia.org www.intel.com. Historia i rodzaje procesorów w firmy Intel
 Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
4. Procesy pojęcia podstawowe
 4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
4. Procesy pojęcia podstawowe 4.1 Czym jest proces? Proces jest czymś innym niż program. Program jest zapisem algorytmu wraz ze strukturami danych na których algorytm ten operuje. Algorytm zapisany bywa
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Programowanie Niskopoziomowe
 Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Programowanie Niskopoziomowe Wykład 3: Architektura procesorów x86 Dr inż. Marek Mika Państwowa Wyższa Szkoła Zawodowa im. Jana Amosa Komeńskiego W Lesznie Plan Pojęcia ogólne Budowa mikrokomputera Cykl
Wstęp do informatyki. Architektura co to jest? Architektura Model komputera. Od układów logicznych do CPU. Automat skończony. Maszyny Turinga (1936)
") Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Widoczność zmiennych Czy wartości każdej zmiennej można zmieniać w dowolnym miejscu kodu? Czy można zadeklarować dwie zmienne o takich samych nazwach?
 Część XVIII C++ Funkcje Widoczność zmiennych Czy wartości każdej zmiennej można zmieniać w dowolnym miejscu kodu? Czy można zadeklarować dwie zmienne o takich samych nazwach? Umiemy już podzielić nasz
Część XVIII C++ Funkcje Widoczność zmiennych Czy wartości każdej zmiennej można zmieniać w dowolnym miejscu kodu? Czy można zadeklarować dwie zmienne o takich samych nazwach? Umiemy już podzielić nasz
Interfejsy w Java. Przetwarzanie równoległe. Wątki.
 Informatyka I Interfejsy w Java. Przetwarzanie równoległe. Wątki. dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Interfejsy w Java Pojęcie interfejsu w programowaniu Deklaracja
Informatyka I Interfejsy w Java. Przetwarzanie równoległe. Wątki. dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2017 Interfejsy w Java Pojęcie interfejsu w programowaniu Deklaracja
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Struktura i działanie jednostki centralnej
 Struktura i działanie jednostki centralnej ALU Jednostka sterująca Rejestry Zadania procesora: Pobieranie rozkazów; Interpretowanie rozkazów; Pobieranie danych Przetwarzanie danych Zapisywanie danych magistrala
Struktura i działanie jednostki centralnej ALU Jednostka sterująca Rejestry Zadania procesora: Pobieranie rozkazów; Interpretowanie rozkazów; Pobieranie danych Przetwarzanie danych Zapisywanie danych magistrala
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Task Parallel Library
 Task Parallel Library Daan Leijen, Wolfram Schulte, and Sebastian Burckhardt prezentacja Michał Albrycht Agenda O potrzebie zrównoleglania Przykłady użycia TPL Tasks and Replicable Tasks Rozdzielanie zadań
Task Parallel Library Daan Leijen, Wolfram Schulte, and Sebastian Burckhardt prezentacja Michał Albrycht Agenda O potrzebie zrównoleglania Przykłady użycia TPL Tasks and Replicable Tasks Rozdzielanie zadań
Organizacja typowego mikroprocesora
 Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Zarządzanie pamięcią operacyjną
 SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
SOE Systemy Operacyjne Wykład 7 Zarządzanie pamięcią operacyjną dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW Hierarchia pamięci czas dostępu Rejestry Pamięć podręczna koszt
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
PAKIET nr 12 Instytut Fizyki Teoretycznej
 L.P. NAZWA ASORTYMENTU Opis urządzeń technicznych minimalne wymagania ILOŚĆ PAKIET nr 2 Instytut Fizyki Teoretycznej Zaoferowana gwarancja ZAOFEROWANY SPRZĘT (model i/lub parametry) CENA JEDNOSTKOWA NETTO
L.P. NAZWA ASORTYMENTU Opis urządzeń technicznych minimalne wymagania ILOŚĆ PAKIET nr 2 Instytut Fizyki Teoretycznej Zaoferowana gwarancja ZAOFEROWANY SPRZĘT (model i/lub parametry) CENA JEDNOSTKOWA NETTO
System operacyjny MACH
 Emulacja w systemie MCH System operacyjny MCH 4. SD Systemu V HP/UX MS-DOS VMS inne Mikrojądro Zbigniew Suski Zbigniew Suski Podstawowe cele projektu MCH! Dostarczenie podstawy do budowy innych systemów
Emulacja w systemie MCH System operacyjny MCH 4. SD Systemu V HP/UX MS-DOS VMS inne Mikrojądro Zbigniew Suski Zbigniew Suski Podstawowe cele projektu MCH! Dostarczenie podstawy do budowy innych systemów