ANOVA podstawy analizy wariancji
|
|
|
- Amalia Lis
- 8 lat temu
- Przeglądów:
Transkrypt
1 ANOVA podstawy analizy wariancji Marcin Kolankowski 11 marca 2009

2 Do czego służy analiza wariancji Analiza wariancji (ang. ANalysis Of VAriance - ANOVA) służy do wykrywania różnic pomiędzy średnimi w wielu populacjach. Zmienna lub zmienne objaśniające występują na różnych poziomach, przez co możemy wyodrębnić grupy w całej populacji. Analiza wariancji sprawdza, czy znajdowanie się w danej grupie ma wpływ na wartość zmiennej objaśnianej - wynik eksperymentu.

3 Przykłady Możemy badać: wagę osób poddanych kilku rodzajom diety i badać, czy średnia waga w danej grupie różni się istotnie w zależności od przynależności do grupy. trwałość stopu metalu w zależności od proporcji składników użytych przy wytopie plon zboża w zależności od poziomu nawożenia

4 Co i jak testujemy Zakładamy, że mamy k grup z których każda liczy N k obserwacji. Wynik naszych obserwacji możemy przedstawić jako: Y 1,1 Y 1,2... Y 1,k Y 2,1 Y 2,2... Y 2,k Y N1,1 Y N2,2... Y Nk,k gdzie Y i,j to i-ta obserwacja z grupy j-tej. Obserwacje pochodzą odpowiedno z rozkładów N (µ 1, σ 2 ), N (µ 2, σ 2 ),..., N (µ k, σ 2 )
, N (µ 2, σ 2 ),.")
5 Hipotezy do testowania Testujemy hipotezę zerową, która mówi o tym, że średnie we wszystkich grupach są takie same przeciw alternatywie, że przynajmniej jedna z grup posiada inną średnią. H 0 : µ 1 = µ 2 = = µ k H 1 : i, j : µ i µ j

6 Procedura testowania Model analizy wariancji oparty jest o następujące spostrzeżenie: suma kwadratów odchyleń wszystkich pomiarów od średniej ogólnej ze wszyskich obserwacji jest równa sumie kwadratów odchyleń wszystkich pomiarów od odpowiednich średnich z grup i sumie odpowiednio ważonych odchyleń średnich z grup od średniej ogólnej N k j (Y i,j Y ) 2 = j=1 i=1 N k j (Y i,j Y j ) 2 + j=1 i=1 k N j (Y j Y ) 2 j=1 gdzie Y j oznacza średnią w grupie j, a Y - średnią ze wszystkich obserwacjach.
 2 + j=1 i=1 k N j (Y j Y ) 2 j=1 gdzie Y j oznacza średnią w grupie j, a Y - średnią ze")
7 Procedura testowania cd Wprowadźmy dalej oznaczeniach: s 2 w = s 2 b = k j=1 Nj i=1 (Y i,j Y j ) 2 N k k j=1 N j(y j Y ) 2 k 1 Okazuje się, że s 2 w jest nieobciążonym estymatorem parametru σ 2. Gdy założymy prawdziwość hipotezy zerowej o równości średnich, również s 2 b jest nieobciążonym estymatorem parametru σ 2. Gdy jednak średnie różnią się od siebie, wartość oczekiwana s 2 b nie zbiega do σ2. Ponadto s 2 b /s2 w ma rozkład F-Snedecora odpowiednio z N k i k 1 stopniami swobody. Dlatego konstrukcja testu opiera się na porównywaniu wartości otrzymanych przy policzeniu ilorazu s 2 b /s2 w z odpowiednią wartością krytyczną dla rozkładu F.

8 Opis modelu - jednoczynnikowa analiza wariancji Rozpatrujemy k grup dzielących całą populacje. Każda z tych grup składa się z N k obserwacji. Zakładamy ponadto, że obserwacje pochodzą z modelu: Y i,j = µ + α i + ε i,j i = 1,..., k j = 1,..., N k gdzie: Y i,j - j-ta wartość zmiennej objaśnianej w i-tej grupie; µ - stała wartość ta sama dla każdej z grup; α i - wpływ i-tego czynnika na wartość zmiennej objaśnianej; ε i,j - czynnik losowy, z założenia o rozkładzie N (0, σ 2 );

9 Założenia dotyczące modelu Model analizy wariancji zakłada, że: czynniki losowe ε i,j są niezależne; czynniki losowe mają rozkład N (0, σ 2 ); ostatnie założenie jest równoważne z tym, że wariancje w grupach są takie same;

10 Dane i ich wstępna analizak W dalszej części będziemy analizować przykładowe dane o nazwie coagulation,związne z krzepnięciem krwi u zwierząt poddanych różnym rodzajom diety. Pierwsze, co możemy zrobić to przyjrzeć się danym używając wykresów pudełkowych - boxplot. Dzieki temu możemy wychwycić: obserwacje odstające - outliers to obserwacje widoczne w postaci pojedyńczych punktów skośność rozkładu - asymetria wykresów pudełkowych wielkość wariancji - związana z rozmiarem wykresu pudełkowego Należy pamiętać, że duży wpływ na wielkość wykresów pudełkowych ma liczba obserwacji, więc nierówność związana z rozmiarem nie koniecznie musi oznaczać różne wariancje w grupach

11 Boxplot dla danych coagulation plot(coag diet, data=coagulation, lwd=2, cex.axis=1.5, cex.lab=1.5)

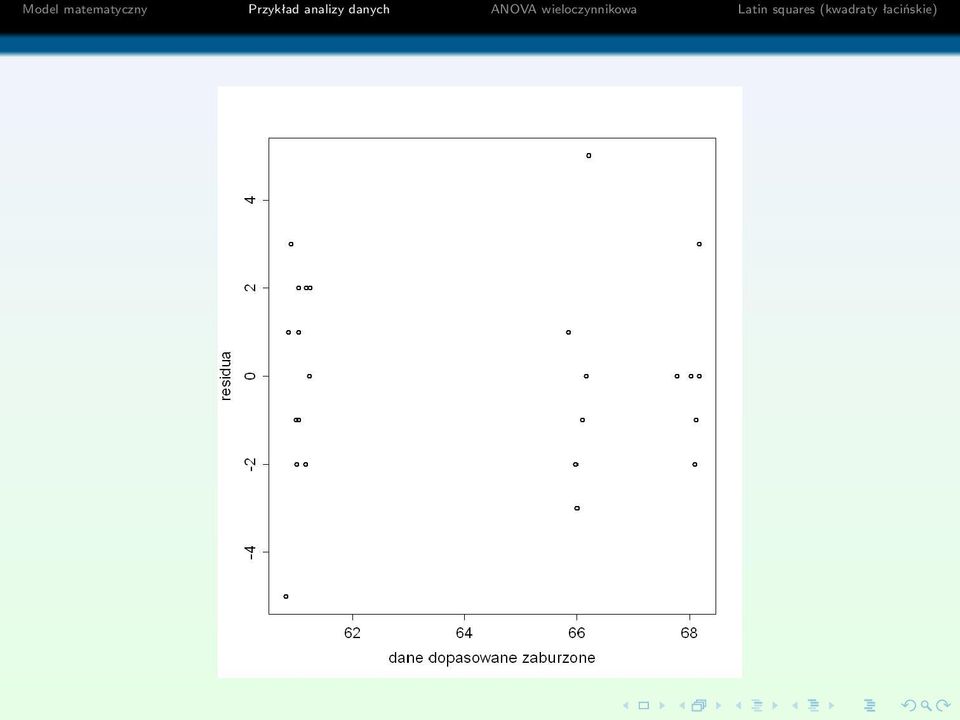
12 Dalsza diagnostyka danych Możemy dopasować model liniowy do naszych danych. Dzięki temu możemy wykonać dalszą diagnostykę danych - porównać dopasowany model z danymi przez wykresy residuów oraz przez QQ-plot. model=lm(coag diet, data=coagulation) qqnorm(model$res, lwd=2, cex.main=1.5, cex.lab=1.5, cex.axis=1.5) plot((model$fit+(rnorm(24, 0, 1))/7), model$res, xlab= dane dopasowane zaburzone, ylab= residua, cex.main=1.5, cex.axis=1.5, lwd=2, cex.lab=1.5)
 plot((model$fit+(rnorm(24, 0, 1))/7), model$res, xlab= dane dopasowane zaburzone, ylab= residua, cex.main=1.")
13

14
15 Testowanie założeń o homogeniczności warianjci Do testowania założeń o jednorodności wariancji używam testu Levene a. Większość testów przy analizie wariancji nie jest bardzo czuła na niejednorodność wariancji, więc problem nie spełnienia założeń zaczynamy dostrzegać przy p-value mniejszym niż Test ten stosujemy biorąc do modelu liniowego wartości bezwzględne residuów i patrzymy na wartość statystyki F. summary(lm(abs(model$res) coagulation$diet)) Coefficients: Estimate Std.Error t value Pr(> t ) (Intercept) coag$dietb coag$dietc coag$dietd F-statistic: on 3 and 20 DF, p-value: 0.56
 coagulation$diet)) Coefficients: Estimate Std.Error t value Pr(> t ) (Intercept) 1.500 0.716 2.10 0.049 coag$dietb 0.500 0.924 0.54 0.")
16 Wykrywanie różnic pomiędzy grupami W celu wykrycia różnic pomiędzy grupami stosujemy opisaną wcześniej procedurę związaną z rozkładem F. Test ten przeprowadzany jest automatycznie przy dopasowaniu modelu. Aby sprawdzić p-value wybieramy albo podsumowanie dla modelu liniowego albo funkcją anova. summary(model) Call: lm(formula = coag diet, data = coagulation)... Coefficients: Estimate Std.Error t value Pr(> t ) (Intercept) 6.100e e <2e-16 *** dietb 5.000e e ** dietc 7.000e e *** dietd e e e F-statistic: on 3 and 20 DF, p-value: 4.658e-05

17 Porównywanie poszczególnych grup ze sobą Porównywanie poszczególnych grup ze sobą przeprowadzimy po dopasowaniu modelu. Gdy testujemy tylko jedną hipotezę: α i = α j możemy użyć testu t-studenta, dokładniej: ˆα i ˆα j ± t α/2 N kˆσ 1 N i + 1 N j Przyjmujemy hipotezę α i = α j, gdy w przedziale (( ˆα i ˆα j ) t α/2 N kˆσ 1 N i + 1 N j, ( ˆα i ˆα j ) + t α/2 N kˆσ 1 N i + 1 N j ) znajduje się zero.
 t α/2 N")
18 Parametry do testowania różnic w R Parametry do obliczenia przedziału uzyskujemy dzięki: t α/2 N k =qt(1-α/2, N-k) ˆσ=summary(model)$ sig k=levels(coagulation$ diet) N =length(coagulation$ diet) N i =length(coagulation$diet[coagulation$diet==levels(coagulation$diet)[i]])]) ˆα i ˆα j - odczytujemy z tabeli summary(model)
[i]])]) ˆα i")
19 Przykład testowania różnic pomiędzy grupami Dla testowania różnic pomiędzy dietą A i B uzyskujemy: qt(1-0.05/2, 20)*2.366*sqrt(1/4+1/6) [1] c( , ) [1] więc diety A i B różnią się (gdyż otrzymany przedział nie zawiera 0) Dla testowania różnic pomiędzy dietą B i C uzyskujemy: qt(1-0.05/2, 20)*2.366*sqrt(1/6+1/6) [1] c( , ) [1] więc diety B i C nie różnią się
*2.366*sqrt(1/6+1/6) [1] 2.849448 c(2-2.849, 2+2.849) [1] -0.849 4.")
20 Wielokrotne porównywanie grup - HSD Opisana wyżej procedura sprawdza się przy pojedyńczych porównaniach grup. Gdy testujemy więcej hipotez błąd I rodzaju wzrasta znacząco przy zwiększaniu liczby porównań. Pewnym rozwiązaniem jest stosowanie procedur Bonferroni ego. Jednak dla dużej liczby porównań stosujemy w analizie wariancji procedure zwaną Tukey s Honest Significant Difference (HSD). Opiera się ona na porównaniu różnic pomiędzy α i i α j z tzw studentized range distribution. Taki rozkład ma zmienna określona w następujący sposób: ( max X i min X i)/ˆσ i=1,...,n i=1,...,n gdzie X 1,..., X n - niezależne, jednakowo rozłożone zmienne losowe o rozkładzie N (µ, σ 2 ).

21 HSD w praktyce Aby porównywać wielokrotnie różnice pomiędzy poszczegółnymi grupami stosujemy funkcje TukeyHSD. Przykład jej wywołania poniżej TukeyHSD(aov(coag diet, coagulation)) diet diff lwr upr p adj B-A C-A D-A C-B D-B D-C
22 Model matematyczny analizy dwuczynnikowej W rzeczywistości często wynik eksperymentu lub badania zależy nie od jednego czynnika na wielu poziomach, tylko od kilku czynników. Dlatego też stosuje się analizę wielu czynników jednocześnie. Najprostrzy model zakłada wpływ dwóch różnych czynników na wynik eksperymentu: Y i,j,k = µ + α i + β j + Ψα i β j + ε i,j,k gdzie: Y i,j,k - k-ta wartość zmiennej objaśnianej w grupe α i, β j ; µ - stała wartość ta sama dla każdej z grup; α i - wpływ i-tego czynnika α na wartość zmiennej objaśnianej; β j - wpływ j-tego czynnika β na wartość zmiennej objaśnianej; α i β j - interakcja czynnika α i β ε i,j,k - czynnik losowy, z założenia o rozkładzie N (0, σ 2 );
23 Założenia do modelu niezależne czynniki losowe o rozkładzie normalnym ze taką samą wariancją w poszczególnych grupach równoliczność obserwacji w każdej z grup
24 Interakcje czynników Rzeczą różniącą jednoczynnikową analizę wariancji od wieloczynnikowej jest fakt występowania interakcji pomiędzy czynnikami. W najprostrzym przypadku z dwoma czynnikami występuje interakcja w postaci czynnika α i β j, ale w większych modelach takich interakcji jest odpowiedno więcej. Interakcje to po prostu oddziaływanie na siebie dwóch czynników i związany z tym ich wpływ na zmienną objaśnianą.
25 Wykrywanie iterakcji za pomocą wykresów Do wykrywania interakcji pomiędzy czynnikami możemu użyć polecenia interaction.plot. Interakcje zachodzą, gdy krzywe otrzymane przez powyższe polecenie przecinają się. Czasami ciężko za pomocą wykresu odczytać prawidłowo, czy interakcje zachodzą, ze względu na zaburzenia związane z losowością. Przykład wywołania dla danych dotyczących czasu do wyleczenia przy podaniu 3 rodzajów leku z podziałem na płeć. Jak widać na dalszym rysunku dla leku 1 i 2 nie ma interakcji, natomiast lek 2 i 3 wchodzą ze sobą w interkacje. interaction.plot(dane$lek,dane$plec,dane$czas, xlab= rodzaj leku, ylab= czas, col=c( red, blue ))
26
27 Interakcje a model liniowy Aby zbadać, czy występujące interakcje są istotne, możemy umieścić je w formule przy konstrukcji modelu liniowego. W tabeli podsumowującej model możemy odczytać p-value dla zmiennej odpowiadającej za interakcje. Duże wartości p-value świadczą o nieistotności interakcji. model1=lm(czas lek*plec, data=dane) anova(model1) Analysis of Variance Table Responce:czas Df Sum Sq Mean Sq F value Pr(>F) lek plec lek:plec e-05 Residuals
28 Jak postępować z interakcjami W przypadku, gdy interakcje nie są istotne, możemy skonstruować model pomijający ich wpływ. Dokładniej możemy zbadać tylko wpływ czynników głównych ich wzajemną relacje na zmienną objaśnianą. W przypadku, gdy interakcje są istotne jedynym rozwiązaniem jest konstrukcja modelu w postaci: Y i,j,k = µ i,j,k + ε i,j,k Czyli traktować model jako model jednoczynnikowej analizy wariancji z parametrem znajdującym się na większej ilości poziomów.
29 Definicja Kwadraty łacińskie stosujemy, gdy chcemy porównać wpływ danego czynnika, który znajduje się na kilku poziomach, mając dodatkowo dwa inne czynniki znajdujące sie na tylu samych poziomach. Przykładem mogą być badania w rolnictwie dotyczące plonów. Załużmy, że dysponujemy 4 gatunkami nasion: A, B, C, D, które rozsiewane są przez 4 różne maszyny prowadzone przez 4 osoby. Wpływ na plon może mieć zarówno gatunek rośliny jak i użyta maszyna przy sadzeniu oraz sposób siewu za który odpowiada operator. Najłatwiej takie dane przedstawić w formie tabeli, która ma postać kwadratu łacińskiego: I A B C D II B D A C III C A D B IV D C B A
30 Model matematyczny Zakładamy, że obserwacje pochodzą z modelu opisanego równaniem: Y i,j,k = µ + τ i + β j + γ k + ε i,j,k dla i, j, k = 1,..., n Do testowania istotności różnic pomiędzy grupami stosujemy przedziały, niech q n,(n 1)(n 2) oznacza wartość krytyczna dla zmiennej losowej o rozkładzie jak przy HSD z odpowiednimi parametrami. Przedziały konstruujemy jak wcześniej. 1 τ i τ j ± q n,(n 1)(n 2)ˆσ n
31 Przykład analizy danych Jako przykład możemy użyć danych breaking. Dane te dotyczą stopu metalu tworzonego przez materiał pochodzący od 4 dostawców - A, B, C, D. Dodatkowo każdy stop jest tworzony przez 4 różnych operatorów i w 4 różne dni. Dane możemy przedstawić w postaci tabeli:
32 data(breaking) matrix(breaking$supplier,4, 4) [, 1] [, 2] [, 3] [, 4] [1, ] B C D A [2, ] C D A B [3, ] A B C D [4, ] D A B C matrix(breaking$y, 4, 4) [, 1] [, 2] [, 3] [, 4] [1, ] [2, ] [3, ] [4, ]
33 Dopasowanie modelu Dopasowanie modelu do danych i odczytanie efektu poszczególnych zmiennych robimy standardowo. W tym miejscu oczywiście należy sprawdzić założenia dotyczące modelu, poprzez np wykresy boxplot i rozkład residuów, co pomijamy. model3=lm(y day+operator+supplier, data=breaking) anova(model3) Analysis of Variance Table Responce:czas Df Sum Sq Mean Sq F value Pr(>F) day operator supplier Residuals Z p-value widać, że istnieje wpływ czynnika dostawca, natomiast pozostałe czynniki nie są istotne.
34 Aby porównać dostawców możemy użyć boxplot lub porównać parametry wyestymowane z danych: summary(model3) Call: lm(formula = y day+operator+supplier, data = breaking)... Coefficients: Estimate Std.Error t value Pr(> t ) (Intercept) <3.9e-05 *** dayday dayday dayday operatorop operatorop operatorop supplierb * supplierc *** supplierd ** F-statistic: on 9 and 6 DF, p-value:
35 plot(y supplier, data=breaking)
36 Z wykresów i estymowanych parametrów modelu wynika, że najlepszym dostawcą jest C, zaraz za nim D. Aby sprawdzić, czy różnica jest istotna statystycznie wyznaczamy przedziały i sprawdzamy, czy znajduje się w nich 0: qtukey(0.95, 4, 6)*55.7/sqrt(4) Konstrukcje przedziałów możemy pominąć, wystarczy znać różnice pomiędzy poszczególnymi wpływami dostawców. Możemy to zrobić konstruując tabelę: x=c(0, model3$coef[8:10]) outer(x, x, - ) supplierb supplierc supplierd supplierb supplierc supplierd Z danych wynika, że dostawcy (B, D) i (C, D) nie różnią się między sobą, pozostali natomiast tak.
37 Bibliografia Przy opracowaniu prezentacji korzystałem głównie z: Julian J. Faraway, Practical Regression and Anova using R, dostępnej pod adresem:
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA
 analiza wariancji ANOVA") Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
Statystyczna analiza danych w programie STATISTICA (wykład 2) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Jednoczynnikowa analiza wariancji i porównania wielokrotne (układ losowanych bloków randomized block design RBD) Układ losowanych bloków Stosujemy, gdy podejrzewamy,
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Jednoczynnikowa analiza wariancji i porównania wielokrotne (układ losowanych bloków randomized block design RBD) Układ losowanych bloków Stosujemy, gdy podejrzewamy,
1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe
 Zjazd 7. SGGW, dn. 28.11.10 r. Matematyka i statystyka matematyczna Tematy 1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe nna Rajfura 1 Zagadnienia Przykład porównania wielu obiektów w
Zjazd 7. SGGW, dn. 28.11.10 r. Matematyka i statystyka matematyczna Tematy 1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe nna Rajfura 1 Zagadnienia Przykład porównania wielu obiektów w
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
Elementy statystyki STA - Wykład 5
 STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
JEDNOCZYNNIKOWA ANOVA
 Analizę ANOVA wykorzystujemy do wykrycia różnic pomiędzy średnimi w więcej niż dwóch grupach/więcej niż w dwóch pomiarach JEDNOCZYNNIKOWA ANOVA porównania jednej zmiennej pomiędzy więcej niż dwoma grupami
Analizę ANOVA wykorzystujemy do wykrycia różnic pomiędzy średnimi w więcej niż dwóch grupach/więcej niż w dwóch pomiarach JEDNOCZYNNIKOWA ANOVA porównania jednej zmiennej pomiędzy więcej niż dwoma grupami
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analizę wariancji, często określaną skrótem ANOVA (Analysis of Variance), zawdzięczamy angielskiemu biologowi Ronaldowi A. Fisherowi, który opracował ją w 1925 roku dla rozwiązywania
Analiza wariancji - ANOVA Analizę wariancji, często określaną skrótem ANOVA (Analysis of Variance), zawdzięczamy angielskiemu biologowi Ronaldowi A. Fisherowi, który opracował ją w 1925 roku dla rozwiązywania
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Statystyka w analizie i planowaniu eksperymentu
 28 marca 2012 Analiza wariancji klasyfikacja jednokierunkowa - wst ep Przypuśćmy, że chcemy porównać wieksz a (niż dwie) liczbe grup. Aby porównać średnie w kilku grupach, można przeprowadzić analize wariancji.
28 marca 2012 Analiza wariancji klasyfikacja jednokierunkowa - wst ep Przypuśćmy, że chcemy porównać wieksz a (niż dwie) liczbe grup. Aby porównać średnie w kilku grupach, można przeprowadzić analize wariancji.
Analiza wariancji. dr Janusz Górczyński
 Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
STATYSTYKA I DOŚWIADCZALNICTWO. Wykład 2
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA
 ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
TEST STATYSTYCZNY. Jeżeli hipotezę zerową odrzucimy na danym poziomie istotności, to odrzucimy ją na każdym większym poziomie istotności.
 TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Jednoczynnikowa analiza wariancji
 Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Regresja liniowa wprowadzenie
 Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Matematyka i statystyka matematyczna dla rolników w SGGW
 Było: Testowanie hipotez (ogólnie): stawiamy hipotezę, wybieramy funkcję testową f (test statystyczny), przyjmujemy poziom istotności α; tym samym wyznaczamy obszar krytyczny testu (wartość krytyczną funkcji
Było: Testowanie hipotez (ogólnie): stawiamy hipotezę, wybieramy funkcję testową f (test statystyczny), przyjmujemy poziom istotności α; tym samym wyznaczamy obszar krytyczny testu (wartość krytyczną funkcji
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
Zestaw 6 (jednoczynnikowa i wieloczynnikowa analiza wariancji (ANOVA))
)") Zestaw 6 (jednoczynnikowa i wieloczynnikowa analiza wariancji (ANOVA)) ANOVA Hipoteza: H: µ 1(mi) = µ 2 = µ 3 = = µ r (Czynnik nie wpływa na zmienną objaśnianą) (Czynnik wpływa) Założenia ANOVY: 0) Próby
Zestaw 6 (jednoczynnikowa i wieloczynnikowa analiza wariancji (ANOVA)) ANOVA Hipoteza: H: µ 1(mi) = µ 2 = µ 3 = = µ r (Czynnik nie wpływa na zmienną objaśnianą) (Czynnik wpływa) Założenia ANOVY: 0) Próby
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Matematyka i statystyka matematyczna dla rolników w SGGW WYKŁAD 11 DOŚWIADCZENIE JEDNOCZYNNIKOWE W UKŁADZIE CAŁKOWICIE LOSOWYM PORÓWNANIA SZCZEGÓŁOWE
 WYKŁAD 11 DOŚWIADCZENIE JEDNOCZYNNIKOWE W UKŁADZIE CAŁKOWICIE LOSOWYM PORÓWNANIA SZCZEGÓŁOWE Było: Przykład. W doświadczeniu polowym załoŝonym w układzie całkowicie losowym w czterech powtórzeniach porównano
WYKŁAD 11 DOŚWIADCZENIE JEDNOCZYNNIKOWE W UKŁADZIE CAŁKOWICIE LOSOWYM PORÓWNANIA SZCZEGÓŁOWE Było: Przykład. W doświadczeniu polowym załoŝonym w układzie całkowicie losowym w czterech powtórzeniach porównano
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Regresja liniowa w R Piotr J. Sobczyk
 Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA
 ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że kilka średnich dla analizowanej zmiennej grupującej mają jednakowe wartości średnie.
ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że kilka średnich dla analizowanej zmiennej grupującej mają jednakowe wartości średnie.
Wykład 5 Teoria eksperymentu
 Wykład 5 Teoria eksperymentu Wrocław, 22.03.2017r Co to jest teoria eksperymentu? eksperyment - badanie jakiegoś zjawiska polegające na celowym wywołaniu tego zjawiska lub jego zmian oraz obserwacji i
Wykład 5 Teoria eksperymentu Wrocław, 22.03.2017r Co to jest teoria eksperymentu? eksperyment - badanie jakiegoś zjawiska polegające na celowym wywołaniu tego zjawiska lub jego zmian oraz obserwacji i
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH
 RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
Statystyczna analiza danych w programie STATISTICA 7.1 PL (wykład 3) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA 7.1 PL (wykład 3) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Dwuczynnikowa analiza wariancji (2-way
Statystyczna analiza danych w programie STATISTICA 7.1 PL (wykład 3) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Dwuczynnikowa analiza wariancji (2-way
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Testy post-hoc. Wrocław, 6 czerwca 2016
 Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
Analiza wariancji, część 2
 Analiza wariancji, część 2 1 / 74 Analiza kontrastów a priori Testy post hoc porównują wszystkie możliwe pary średnich i wykonuje się je dopiero po stwierdzeniu za pomocą testu F istotności danego czynnika.
Analiza wariancji, część 2 1 / 74 Analiza kontrastów a priori Testy post hoc porównują wszystkie możliwe pary średnich i wykonuje się je dopiero po stwierdzeniu za pomocą testu F istotności danego czynnika.
Analiza wariancji i kowariancji
 Analiza wariancji i kowariancji Historia Analiza wariancji jest metodą zaproponowaną przez Ronalda A. Fishera. Po zakończeniu pierwszej wojny światowej był on pracownikiem laboratorium statystycznego w
Analiza wariancji i kowariancji Historia Analiza wariancji jest metodą zaproponowaną przez Ronalda A. Fishera. Po zakończeniu pierwszej wojny światowej był on pracownikiem laboratorium statystycznego w
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Szkice rozwiązań z R:
 Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
Efekt główny Efekt interakcyjny efekt jednego czynnika zależy od poziomu drugiego czynnika Efekt prosty
 ANOVA DWUCZYNNIKOWA testuje różnice między średnimi w grupach wyznaczonych przez dwa czynniki i ich kombinacje. Analiza pozwala ustalić wpływ dwóch czynników na wartości zmiennej zależnej (ilościowej!)
ANOVA DWUCZYNNIKOWA testuje różnice między średnimi w grupach wyznaczonych przez dwa czynniki i ich kombinacje. Analiza pozwala ustalić wpływ dwóch czynników na wartości zmiennej zależnej (ilościowej!)
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego
 Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
Przykład 2. Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku
 Przykład 2 Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku Sondaż sieciowy analiza wyników badania sondażowego dotyczącego motywacji w drodze do sukcesu Cel badania: uzyskanie
Przykład 2 Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku Sondaż sieciowy analiza wyników badania sondażowego dotyczącego motywacji w drodze do sukcesu Cel badania: uzyskanie
Typy zmiennych. Zmienne i rekordy. Rodzaje zmiennych. Graficzne reprezentacje danych Statystyki opisowe
 Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI. Test zgodności i analiza wariancji Analiza wariancji
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y. 2. Współczynnik korelacji Pearsona
 KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Przykład 1. (A. Łomnicki)
") Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Wprowadzenie do statystyki dla. chemików testowanie hipotez
 chemików testowanie hipotez Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl http://www.sites.google.com/site/chemomlab/
chemików testowanie hipotez Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl http://www.sites.google.com/site/chemomlab/
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Założenia do analizy wariancji. dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW
 Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Wykład 3 Testowanie hipotez statystycznych o wartości średniej. średniej i wariancji z populacji o rozkładzie normalnym
 Wykład 3 Testowanie hipotez statystycznych o wartości średniej i wariancji z populacji o rozkładzie normalnym Wrocław, 08.03.2017r Model 1 Testowanie hipotez dla średniej w rozkładzie normalnym ze znaną
Wykład 3 Testowanie hipotez statystycznych o wartości średniej i wariancji z populacji o rozkładzie normalnym Wrocław, 08.03.2017r Model 1 Testowanie hipotez dla średniej w rozkładzie normalnym ze znaną
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI TESTOWANIE HIPOTEZ PARAMETRYCZNYCH
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI TESTOWANIE HIPOTEZ PARAMETRYCZNYCH Co to są hipotezy statystyczne? Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej. Dzielimy je
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI TESTOWANIE HIPOTEZ PARAMETRYCZNYCH Co to są hipotezy statystyczne? Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej. Dzielimy je
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Jak sprawdzić normalność rozkładu w teście dla prób zależnych?
 Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008
 Redaktor: Alicja Zagrodzka Korekta: Krystyna Chludzińska Projekt okładki: Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008 ISBN 978-83-7383-296-1 Wydawnictwo Naukowe Scholar
Redaktor: Alicja Zagrodzka Korekta: Krystyna Chludzińska Projekt okładki: Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008 ISBN 978-83-7383-296-1 Wydawnictwo Naukowe Scholar
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Weryfikacja hipotez statystycznych za pomocą testów statystycznych
 Weryfikacja hipotez statystycznych za pomocą testów statystycznych Weryfikacja hipotez statystycznych za pomocą testów stat. Hipoteza statystyczna Dowolne przypuszczenie co do rozkładu populacji generalnej
Weryfikacja hipotez statystycznych za pomocą testów statystycznych Weryfikacja hipotez statystycznych za pomocą testów stat. Hipoteza statystyczna Dowolne przypuszczenie co do rozkładu populacji generalnej
OBLICZENIE PRZEPŁYWÓW MAKSYMALNYCH ROCZNYCH O OKREŚLONYM PRAWDOPODOBIEŃSTWIE PRZEWYŻSZENIA. z wykorzystaniem programu obliczeniowego Q maxp
 tel.: +48 662 635 712 Liczba stron: 15 Data: 20.07.2010r OBLICZENIE PRZEPŁYWÓW MAKSYMALNYCH ROCZNYCH O OKREŚLONYM PRAWDOPODOBIEŃSTWIE PRZEWYŻSZENIA z wykorzystaniem programu obliczeniowego Q maxp DŁUGIE
tel.: +48 662 635 712 Liczba stron: 15 Data: 20.07.2010r OBLICZENIE PRZEPŁYWÓW MAKSYMALNYCH ROCZNYCH O OKREŚLONYM PRAWDOPODOBIEŃSTWIE PRZEWYŻSZENIA z wykorzystaniem programu obliczeniowego Q maxp DŁUGIE
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
WNIOSKOWANIE STATYSTYCZNE
 STATYSTYKA WNIOSKOWANIE STATYSTYCZNE ESTYMACJA oszacowanie z pewną dokładnością wartości opisującej rozkład badanej cechy statystycznej. WERYFIKACJA HIPOTEZ sprawdzanie słuszności przypuszczeń dotyczących
STATYSTYKA WNIOSKOWANIE STATYSTYCZNE ESTYMACJA oszacowanie z pewną dokładnością wartości opisującej rozkład badanej cechy statystycznej. WERYFIKACJA HIPOTEZ sprawdzanie słuszności przypuszczeń dotyczących
JEDNOCZYNNIKOWA ANALIZA WARIANCJI, ANOVA
 JEDNOCZYNNIKOWA ANALIZA WARIANCJI, ANOVA 1 Obserwowana (badana) cecha Y Czynnik wpływający na Y (badany) A A i i ty poziom czynnika A a liczba poziomów (j=1..a), n i liczba powtórzeń w i tej populacji
JEDNOCZYNNIKOWA ANALIZA WARIANCJI, ANOVA 1 Obserwowana (badana) cecha Y Czynnik wpływający na Y (badany) A A i i ty poziom czynnika A a liczba poziomów (j=1..a), n i liczba powtórzeń w i tej populacji
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Wykład 4. Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym. 2. Rozkłady próbkowe. 3. Centralne twierdzenie graniczne
 Wykład 4 Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym 2. Rozkłady próbkowe 3. Centralne twierdzenie graniczne Przybliżenie rozkładu dwumianowego rozkładem normalnym Niech Y ma rozkład
Wykład 4 Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym 2. Rozkłady próbkowe 3. Centralne twierdzenie graniczne Przybliżenie rozkładu dwumianowego rozkładem normalnym Niech Y ma rozkład
ANALIZA WARIANCJI - PRZYPOMNIENIE
 ANALIZA WARIANCJI - PRZYPOMNIENIE Dr Wioleta Drobik ANALIZA WARIACJI Podział zaobserwowanej zmienności (wariancji) na zmienność między grupami i w obrębie grup Pozwala na ocenę istotności różnic wielu
ANALIZA WARIANCJI - PRZYPOMNIENIE Dr Wioleta Drobik ANALIZA WARIACJI Podział zaobserwowanej zmienności (wariancji) na zmienność między grupami i w obrębie grup Pozwala na ocenę istotności różnic wielu
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Wnioskowanie statystyczne i weryfikacja hipotez statystycznych
 Wnioskowanie statystyczne i weryfikacja hipotez statystycznych Wnioskowanie statystyczne Wnioskowanie statystyczne obejmuje następujące czynności: Sformułowanie hipotezy zerowej i hipotezy alternatywnej.
Wnioskowanie statystyczne i weryfikacja hipotez statystycznych Wnioskowanie statystyczne Wnioskowanie statystyczne obejmuje następujące czynności: Sformułowanie hipotezy zerowej i hipotezy alternatywnej.
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Model regresji wielokrotnej Wykład 14 ( ) Przykład ceny domów w Chicago
 Przykład ceny domów w Chicago") Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.
 znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.") Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Testowanie hipotez statystycznych cd.
 Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
HISTOGRAM. Dr Adam Michczyński - METODY ANALIZY DANYCH POMIAROWYCH Liczba pomiarów - n. Liczba pomiarów - n k 0.5 N = N =
 HISTOGRAM W pewnych przypadkach interesuje nas nie tylko określenie prawdziwej wartości mierzonej wielkości, ale także zbadanie całego rozkład prawdopodobieństwa wyników pomiarów. W takim przypadku wyniki
HISTOGRAM W pewnych przypadkach interesuje nas nie tylko określenie prawdziwej wartości mierzonej wielkości, ale także zbadanie całego rozkład prawdopodobieństwa wyników pomiarów. W takim przypadku wyniki
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych