Analiza wariancji, część 2
|
|
|
- Natalia Marczak
- 7 lat temu
- Przeglądów:
Transkrypt
1 Analiza wariancji, część 2 1 / 74
2 Analiza kontrastów a priori Testy post hoc porównują wszystkie możliwe pary średnich i wykonuje się je dopiero po stwierdzeniu za pomocą testu F istotności danego czynnika. Kontrasty (porównania) a priori (planowane), to te które planuje się przed przeprowadzeniem eksperymentu. Wynikają one z teorii (merytorycznego uzasadnienia), na której opiera się eksperyment. Na przykład, jeśli badamy wpływ czynnika kontrolowanego na trzech poziomach i chcemy sprawdzić, czy pierwsza z tych grup różni się od pozostałych, to hipoteza zerowa ma postać H 0 : µ 1 = µ 2+µ 3 2, co możemy zapisać w postaci: H 0 : µ µ µ 3 = 0 lub H 0 : 2µ 1 µ 2 µ 3 = 0. 2 / 74
3 Analiza kontrastów a priori Testy post hoc porównują wszystkie możliwe pary średnich i wykonuje się je dopiero po stwierdzeniu za pomocą testu F istotności danego czynnika. Kontrasty (porównania) a priori (planowane), to te które planuje się przed przeprowadzeniem eksperymentu. Wynikają one z teorii (merytorycznego uzasadnienia), na której opiera się eksperyment. Na przykład, jeśli badamy wpływ czynnika kontrolowanego na trzech poziomach i chcemy sprawdzić, czy pierwsza z tych grup różni się od pozostałych, to hipoteza zerowa ma postać H 0 : µ 1 = µ 2+µ 3 2, co możemy zapisać w postaci: H 0 : µ µ µ 3 = 0 lub H 0 : 2µ 1 µ 2 µ 3 = 0. 2 / 74
4 Analiza kontrastów a priori Testy post hoc porównują wszystkie możliwe pary średnich i wykonuje się je dopiero po stwierdzeniu za pomocą testu F istotności danego czynnika. Kontrasty (porównania) a priori (planowane), to te które planuje się przed przeprowadzeniem eksperymentu. Wynikają one z teorii (merytorycznego uzasadnienia), na której opiera się eksperyment. Na przykład, jeśli badamy wpływ czynnika kontrolowanego na trzech poziomach i chcemy sprawdzić, czy pierwsza z tych grup różni się od pozostałych, to hipoteza zerowa ma postać H 0 : µ 1 = µ 2+µ 3 2, co możemy zapisać w postaci: H 0 : µ µ µ 3 = 0 lub H 0 : 2µ 1 µ 2 µ 3 = 0. 2 / 74
5 Aby przetestować tą hipotezę należy przypisać wagi c 1 = 2, c 2 = 1, c 3 = 1 odpowiednim średnim. Kontrastem liniowym dla k średnich w populacji µ 1, µ 2,... µ k nazywamy każdą liniową funkcję K = k c i µ i, gdzie k c i = 0. i=1 i=1 Kontrast jest więc ważoną sumą średnich. K = k c i x i jest oceną z próby tego kontrastu. i=1 3 / 74
6 Aby przetestować tą hipotezę należy przypisać wagi c 1 = 2, c 2 = 1, c 3 = 1 odpowiednim średnim. Kontrastem liniowym dla k średnich w populacji µ 1, µ 2,... µ k nazywamy każdą liniową funkcję K = k c i µ i, gdzie k c i = 0. i=1 i=1 Kontrast jest więc ważoną sumą średnich. K = k c i x i jest oceną z próby tego kontrastu. i=1 3 / 74
7 Aby przetestować tą hipotezę należy przypisać wagi c 1 = 2, c 2 = 1, c 3 = 1 odpowiednim średnim. Kontrastem liniowym dla k średnich w populacji µ 1, µ 2,... µ k nazywamy każdą liniową funkcję K = k c i µ i, gdzie k c i = 0. i=1 i=1 Kontrast jest więc ważoną sumą średnich. K = k c i x i jest oceną z próby tego kontrastu. i=1 3 / 74
8 Suma kwadratów, za które odpowiedzialny jest kontrast dana jest wzorem SS K = K 2, gdzie r jest liczbą powtórzeń. 1 r k c 2 i i=1 Ponieważ kontrast jest różnicą między dwoma zbiorami średnich (jedna z wagami dodatnimi, a druga ujemnymi), to liczba stopni swobody związana z kontrastem wynosi 1. Test F do weryfikacji istotności kontrastu przyjmuje postać: F = MS K MS błąd = SS K SS błąd = SS K(n k) SS błąd. n k 4 / 74
9 Suma kwadratów, za które odpowiedzialny jest kontrast dana jest wzorem SS K = K 2, gdzie r jest liczbą powtórzeń. 1 r k c 2 i i=1 Ponieważ kontrast jest różnicą między dwoma zbiorami średnich (jedna z wagami dodatnimi, a druga ujemnymi), to liczba stopni swobody związana z kontrastem wynosi 1. Test F do weryfikacji istotności kontrastu przyjmuje postać: F = MS K MS błąd = SS K SS błąd = SS K(n k) SS błąd. n k 4 / 74
10 Suma kwadratów, za które odpowiedzialny jest kontrast dana jest wzorem SS K = K 2, gdzie r jest liczbą powtórzeń. 1 r k c 2 i i=1 Ponieważ kontrast jest różnicą między dwoma zbiorami średnich (jedna z wagami dodatnimi, a druga ujemnymi), to liczba stopni swobody związana z kontrastem wynosi 1. Test F do weryfikacji istotności kontrastu przyjmuje postać: F = MS K MS błąd = SS K SS błąd = SS K(n k) SS błąd. n k 4 / 74
11 Istotność pojedynczego kontrastu można weryfikować też za pomocą statystyki t = K MS błąd 1 r k c 2 i i=1, która przy założeniu zerowego kontrastu ma rozkład t Studenta z n k stopniami swobody. Statystyka ta służy też do wyznaczania przedziałów ufności dla kontrastów: K ± t(1 α 2 ; n k) MS błąd 1 r k c 2 i. i=1 5 / 74
12 Istotność pojedynczego kontrastu można weryfikować też za pomocą statystyki t = K MS błąd 1 r k c 2 i i=1, która przy założeniu zerowego kontrastu ma rozkład t Studenta z n k stopniami swobody. Statystyka ta służy też do wyznaczania przedziałów ufności dla kontrastów: K ± t(1 α 2 ; n k) MS błąd 1 r k c 2 i. i=1 5 / 74
13 Definiowanie kontrastów 1 Kontrast zawiera zawsze tyle współczynników, ile jest poziomów czynnika (średnich). 2 Średnim, które mają być pominięte w kontraście przypisujemy wartość 0. 3 Średnim, które mają być porównywane nawzajem przypisujemy wartości o przeciwnych znakach. 4 Średnim, które mają być łączone przypisujemy jednakowe wartości. 5 Suma współczynników musi być równa 0. 6 / 74
14 Definiowanie kontrastów 1 Kontrast zawiera zawsze tyle współczynników, ile jest poziomów czynnika (średnich). 2 Średnim, które mają być pominięte w kontraście przypisujemy wartość 0. 3 Średnim, które mają być porównywane nawzajem przypisujemy wartości o przeciwnych znakach. 4 Średnim, które mają być łączone przypisujemy jednakowe wartości. 5 Suma współczynników musi być równa 0. 6 / 74
15 Definiowanie kontrastów 1 Kontrast zawiera zawsze tyle współczynników, ile jest poziomów czynnika (średnich). 2 Średnim, które mają być pominięte w kontraście przypisujemy wartość 0. 3 Średnim, które mają być porównywane nawzajem przypisujemy wartości o przeciwnych znakach. 4 Średnim, które mają być łączone przypisujemy jednakowe wartości. 5 Suma współczynników musi być równa 0. 6 / 74
16 Definiowanie kontrastów 1 Kontrast zawiera zawsze tyle współczynników, ile jest poziomów czynnika (średnich). 2 Średnim, które mają być pominięte w kontraście przypisujemy wartość 0. 3 Średnim, które mają być porównywane nawzajem przypisujemy wartości o przeciwnych znakach. 4 Średnim, które mają być łączone przypisujemy jednakowe wartości. 5 Suma współczynników musi być równa 0. 6 / 74
17 Definiowanie kontrastów 1 Kontrast zawiera zawsze tyle współczynników, ile jest poziomów czynnika (średnich). 2 Średnim, które mają być pominięte w kontraście przypisujemy wartość 0. 3 Średnim, które mają być porównywane nawzajem przypisujemy wartości o przeciwnych znakach. 4 Średnim, które mają być łączone przypisujemy jednakowe wartości. 5 Suma współczynników musi być równa 0. 6 / 74
18 Predefiniowane kontrasty W programie Statistica możemy korzystać z pewnych zdefiniowanych kontrastów: Odchylenie - kontrast służący do porównania odchyleń każdej średniej grupowej od średniej ogólnej zmiennej zależnej. Na przykład dla czynnika o trzech poziomach, jeśli chcemy porównać µ 1 z µ 1+µ 2 +µ 3 3, mamy µ 1 µ 1+µ 2 +µ 3 3 = 2µ 1 µ 2 µ 3 = 0, czyli dostajemy kontrast (2, 1, 1). Podobnie, porównując µ 2 ze średnią µ 1+µ 2 +µ 3 3, dostajemy kontrast ( 1, 2, 1). Mamy więc macierz kontrastów (2, 1, 1) ( 1, 2, 1) ( 1, 1, 2) 7 / 74
19 Predefiniowane kontrasty W programie Statistica możemy korzystać z pewnych zdefiniowanych kontrastów: Odchylenie - kontrast służący do porównania odchyleń każdej średniej grupowej od średniej ogólnej zmiennej zależnej. Na przykład dla czynnika o trzech poziomach, jeśli chcemy porównać µ 1 z µ 1+µ 2 +µ 3 3, mamy µ 1 µ 1+µ 2 +µ 3 3 = 2µ 1 µ 2 µ 3 = 0, czyli dostajemy kontrast (2, 1, 1). Podobnie, porównując µ 2 ze średnią µ 1+µ 2 +µ 3 3, dostajemy kontrast ( 1, 2, 1). Mamy więc macierz kontrastów (2, 1, 1) ( 1, 2, 1) ( 1, 1, 2) 7 / 74
20 Różnica - kontrast służący do porównywania średniej ze średnią wszystkich poprzednich poziomów. Dla czynnika o trzech poziomach mamy porównania: µ 1 z µ 2 oraz µ 3 z µ 1+µ 2 2, czyli mamy macierz kontrastów ( 1, 1, 0) ( 1, 1, 2) 8 / 74
21 Helmerta - kontrast porównuje średnią danego poziomu ze średnią wszystkich następnych poziomów badanego czynnika. W przypadku istotności sprawdzamy wkład każdego z kontrastów wyliczając proporcję zmienności, którą możemy przypisać danemu kontrastowi. Dla trzech poziomów macierz kontrastów ma postać: (2, 1, 1) (0, 1, 1) 9 / 74
22 Prosty - ten kontrast służy do porównywania średniej dla każdego poziomu ze średnią ostatniego poziomu. Dla trzech poziomów otrzymujemy macierz kontrastów (1, 0, 1) (0, 1, 1) Powtarzany - ten kontrast służy do porównywania średnich sąsiednich poziomów czynnika. Dla trzech poziomów mamy macierz kontrastów (1, 1, 0) (0, 1, 1) 10 / 74
23 Prosty - ten kontrast służy do porównywania średniej dla każdego poziomu ze średnią ostatniego poziomu. Dla trzech poziomów otrzymujemy macierz kontrastów (1, 0, 1) (0, 1, 1) Powtarzany - ten kontrast służy do porównywania średnich sąsiednich poziomów czynnika. Dla trzech poziomów mamy macierz kontrastów (1, 1, 0) (0, 1, 1) 10 / 74
24 Wykrywanie trendu Za pomocą odpowiednich kontrastów możemy wykryć kształt badanej zależności, czyli trend: liniowy, kwadratowy, sześcienny, itd. Oczywiście, aby mówić o trendzie liniowym, powinniśmy mieć co najmniej trzy średnie (dwa punkty zawsze można połączyć prostą). Aby mówić o trendzie kwadratowym, potrzebujemy mieć co najmniej trzy średnie, a o trendzie sześciennym cztery średnie, itd. 11 / 74
25 Wykrywanie trendu Za pomocą odpowiednich kontrastów możemy wykryć kształt badanej zależności, czyli trend: liniowy, kwadratowy, sześcienny, itd. Oczywiście, aby mówić o trendzie liniowym, powinniśmy mieć co najmniej trzy średnie (dwa punkty zawsze można połączyć prostą). Aby mówić o trendzie kwadratowym, potrzebujemy mieć co najmniej trzy średnie, a o trendzie sześciennym cztery średnie, itd. 11 / 74
26 Wykrywanie trendu Liczba średnich Kontrast Wagi kontrastu 2 liniowy (-1,1) 3 liniowy (-1,0,1) kwadratowy (1,-2,1) 4 liniowy (-3,-1,1,3) kwadratowy (1,-1,-1,1) sześcienny (-1,3,-3,1) 5 liniowy (-2,-1,0,1,2) kwadratowy (2,-1,-2,-1,2) sześcienny (-1,2,0,-2,1) 6 liniowy (-5,-3,-1,1,3,5) kwadratowy (5,-1,-4,-4,-1,5) sześcienny (-5,7,4,-4,-7,5) 12 / 74
27 Analizę kontrastów można przeprowadzać w analogiczny sposób dla doświadczeń wieloczynnikowych (także w planach z powtarzanymi pomiarami). 13 / 74
28 Kontrasty ortogonalne Kontrasty ortogonalne Dwa kontrasty K 1 = k c 1i µ i i K 2 = k c 2i µ i są względem siebie i=1 ortogonalne, gdy suma iloczynów odpowiadających sobie wag jest równa zero (niezależność wektorów), czyli i=1 k c 1i c 2i = 0. i=1 Zbiór m kontrastów tworzy zbiór kontrastów względem siebie ortogonalny, gdy wszystkie pary kontrastów w tym zbiorze są ortogonalne. 14 / 74
29 Kontrasty ortogonalne Kontrasty ortogonalne Dwa kontrasty K 1 = k c 1i µ i i K 2 = k c 2i µ i są względem siebie i=1 ortogonalne, gdy suma iloczynów odpowiadających sobie wag jest równa zero (niezależność wektorów), czyli i=1 k c 1i c 2i = 0. i=1 Zbiór m kontrastów tworzy zbiór kontrastów względem siebie ortogonalny, gdy wszystkie pary kontrastów w tym zbiorze są ortogonalne. 14 / 74
30 1 Dla zbioru k średnich możemy utworzyć maksymalnie k 1 kontrastów ortogonalnych. 2 Suma sum kwadratów k 1 ortogonalnych kontrastów daje sumę kwadratów dla efektu badanego czynnika. 3 Rozkład sumy kwadratów na kontrasty ortogonalne nie jest jednoznaczny (możemy budować różne zbiory kontrastów ortogonalnych). 4 Nie musimy badać wszystkich kontrastów ortogonalnych. Najczęściej mamy konkretne interesujące nas kontrasty badawcze. Pozostałe kontrasty można powiązać w efekt łączny, tworząc kontrast pomiędzy średnimi wykorzystanymi i niewykorzystanymi w dotychczasowych kontrastach. 15 / 74
31 1 Dla zbioru k średnich możemy utworzyć maksymalnie k 1 kontrastów ortogonalnych. 2 Suma sum kwadratów k 1 ortogonalnych kontrastów daje sumę kwadratów dla efektu badanego czynnika. 3 Rozkład sumy kwadratów na kontrasty ortogonalne nie jest jednoznaczny (możemy budować różne zbiory kontrastów ortogonalnych). 4 Nie musimy badać wszystkich kontrastów ortogonalnych. Najczęściej mamy konkretne interesujące nas kontrasty badawcze. Pozostałe kontrasty można powiązać w efekt łączny, tworząc kontrast pomiędzy średnimi wykorzystanymi i niewykorzystanymi w dotychczasowych kontrastach. 15 / 74
32 1 Dla zbioru k średnich możemy utworzyć maksymalnie k 1 kontrastów ortogonalnych. 2 Suma sum kwadratów k 1 ortogonalnych kontrastów daje sumę kwadratów dla efektu badanego czynnika. 3 Rozkład sumy kwadratów na kontrasty ortogonalne nie jest jednoznaczny (możemy budować różne zbiory kontrastów ortogonalnych). 4 Nie musimy badać wszystkich kontrastów ortogonalnych. Najczęściej mamy konkretne interesujące nas kontrasty badawcze. Pozostałe kontrasty można powiązać w efekt łączny, tworząc kontrast pomiędzy średnimi wykorzystanymi i niewykorzystanymi w dotychczasowych kontrastach. 15 / 74
33 1 Dla zbioru k średnich możemy utworzyć maksymalnie k 1 kontrastów ortogonalnych. 2 Suma sum kwadratów k 1 ortogonalnych kontrastów daje sumę kwadratów dla efektu badanego czynnika. 3 Rozkład sumy kwadratów na kontrasty ortogonalne nie jest jednoznaczny (możemy budować różne zbiory kontrastów ortogonalnych). 4 Nie musimy badać wszystkich kontrastów ortogonalnych. Najczęściej mamy konkretne interesujące nas kontrasty badawcze. Pozostałe kontrasty można powiązać w efekt łączny, tworząc kontrast pomiędzy średnimi wykorzystanymi i niewykorzystanymi w dotychczasowych kontrastach. 15 / 74
34 Miara r 2 = SS K SS efekt, wyrażana w procentach, informuje w jakim procencie dany kontrast wyjaśnia zmienność wśród zmiennych grupowych. 16 / 74

.")
35 Przykład 1 Badano wpływ czterech dawek pewnego leku na poprawę zdrowia pacjentów z depresją. Ocenę stanu zdrowia przeprowadzono według pewnej umownej skali, przy czym wyższym wartościom tej skali odpowiada większe nasilenie choroby. W badaniu uwzględniono również płeć pacjentów. Eksperyment przeprowadzono dla 32 losowo wybranych pacjentów (4 poziomy dawki x 2 rodzaje płci x 4 powtórzenia). Eksperymentatorów interesowała zależność funkcyjna między wielkością dawki a stanem zdrowia pacjenta. 17 / 74
36 Obserwacje z eksperymentu zawiera plik depresja.sta. Wykresy normalności nie wykazują istotnych odchyleń rozkładu oceny zdrowia dla poszczególnych poziomów badanych czynników od rozkładu normalnego. Test Levene a nie wykrywa istotnych różnic pomiędzy wariancjami grupowymi. 18 / 74
37 Obserwacje z eksperymentu zawiera plik depresja.sta. Wykresy normalności nie wykazują istotnych odchyleń rozkładu oceny zdrowia dla poszczególnych poziomów badanych czynników od rozkładu normalnego. Test Levene a nie wykrywa istotnych różnic pomiędzy wariancjami grupowymi. 18 / 74
38 Obserwacje z eksperymentu zawiera plik depresja.sta. Wykresy normalności nie wykazują istotnych odchyleń rozkładu oceny zdrowia dla poszczególnych poziomów badanych czynników od rozkładu normalnego. Test Levene a nie wykrywa istotnych różnic pomiędzy wariancjami grupowymi. 18 / 74

39 Wykres interakcji ma następującą postać. Wykres ten wskazuje na istnienie trendu liniowego dla kobiet i trendu kwadratowego dla mężczyzn. 19 / 74
40 Aby zbadać kontrast liniowy dla kobiet określamy kontrast dla zmiennej PŁEĆ (1,0) i wybieramy ze zdefiniowanych kontrastów kontrast liniowy dla czynnika DAWKA (-3,-1,1,3). Trend liniowy jest wysoce istotny. Zwiększenie dawki powoduje liniowy wzrost średniego stopnia poprawy zdrowia. 20 / 74
41 Badanie trendu kwadratowego, wykazuje jego nieistotność. 21 / 74

42 U mężczyzn trend liniowy jest nieistotny (p = 0, 0845), natomiast występuje wysoce istotny trend kwadratowy (p = 0, ). Początkowe zwiększanie dawki leku u mężczyzn powoduje szybką poprawę stanu zdrowia. Dalsze zwiększanie dawki powoduje jednak pogorszenia stanu zdrowia pacjentów. 22 / 74
43 Porównania zaplanowane traktujemy jako alternatywę wobec ogólnego testu F. Oznacza, to, że po wykonaniu analizy kontrastów nie powinniśmy przeprowadzać już tradycyjnej analizy wariancji i testów post-hoc. Dzięki sprawdzaniu istotności konkretnych porównań, mamy większą moc testu niż w testach post-hoc. Jeśli chcemy zweryfikować kilka kontrastów zwykle stosujemy kontrasty ortogonalne. 23 / 74
44 Porównania zaplanowane traktujemy jako alternatywę wobec ogólnego testu F. Oznacza, to, że po wykonaniu analizy kontrastów nie powinniśmy przeprowadzać już tradycyjnej analizy wariancji i testów post-hoc. Dzięki sprawdzaniu istotności konkretnych porównań, mamy większą moc testu niż w testach post-hoc. Jeśli chcemy zweryfikować kilka kontrastów zwykle stosujemy kontrasty ortogonalne. 23 / 74
45 Porównania zaplanowane traktujemy jako alternatywę wobec ogólnego testu F. Oznacza, to, że po wykonaniu analizy kontrastów nie powinniśmy przeprowadzać już tradycyjnej analizy wariancji i testów post-hoc. Dzięki sprawdzaniu istotności konkretnych porównań, mamy większą moc testu niż w testach post-hoc. Jeśli chcemy zweryfikować kilka kontrastów zwykle stosujemy kontrasty ortogonalne. 23 / 74
46 Porównania zaplanowane traktujemy jako alternatywę wobec ogólnego testu F. Oznacza, to, że po wykonaniu analizy kontrastów nie powinniśmy przeprowadzać już tradycyjnej analizy wariancji i testów post-hoc. Dzięki sprawdzaniu istotności konkretnych porównań, mamy większą moc testu niż w testach post-hoc. Jeśli chcemy zweryfikować kilka kontrastów zwykle stosujemy kontrasty ortogonalne. 23 / 74
47 Hierarchiczna analiza wariancji (układ zagnieżdżony) Układy hierarchiczne umożliwiają analizę planów doświadczalnych, gdy dla różnych poziomów pewnych czynników występują inne poziomy czynników w nich zagnieżdżonych. Układy zagnieżdżone są układami niekompletnymi, w odróżnieniu od układów czynnikowych kompletnych, w których obserwowane były wszystkie kombinacje poziomów badanych czynników. Na przykład rozważmy eksperyment badający trzy leki L 1, L 2 i L 3 stosowane w sześciu klinikach: K 1,..., K 6. Przy czym lek L 1 był stosowany w klinikach K 1 i K 2, lek L 2 w klinikach K 3 i K 4, zaś lek L 3 w klinikach K 5 i K / 74
48 Hierarchiczna analiza wariancji (układ zagnieżdżony) Układy hierarchiczne umożliwiają analizę planów doświadczalnych, gdy dla różnych poziomów pewnych czynników występują inne poziomy czynników w nich zagnieżdżonych. Układy zagnieżdżone są układami niekompletnymi, w odróżnieniu od układów czynnikowych kompletnych, w których obserwowane były wszystkie kombinacje poziomów badanych czynników. Na przykład rozważmy eksperyment badający trzy leki L 1, L 2 i L 3 stosowane w sześciu klinikach: K 1,..., K 6. Przy czym lek L 1 był stosowany w klinikach K 1 i K 2, lek L 2 w klinikach K 3 i K 4, zaś lek L 3 w klinikach K 5 i K / 74
49 Hierarchiczna analiza wariancji (układ zagnieżdżony) Układy hierarchiczne umożliwiają analizę planów doświadczalnych, gdy dla różnych poziomów pewnych czynników występują inne poziomy czynników w nich zagnieżdżonych. Układy zagnieżdżone są układami niekompletnymi, w odróżnieniu od układów czynnikowych kompletnych, w których obserwowane były wszystkie kombinacje poziomów badanych czynników. Na przykład rozważmy eksperyment badający trzy leki L 1, L 2 i L 3 stosowane w sześciu klinikach: K 1,..., K 6. Przy czym lek L 1 był stosowany w klinikach K 1 i K 2, lek L 2 w klinikach K 3 i K 4, zaś lek L 3 w klinikach K 5 i K / 74
50 Plan eksperymentu wyglądałby więc następująco: Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K 6 n osób n osób n osób n osób n osób n osób W tym eksperymencie kliniki są zagnieżdżone w lekach. Kliniki są czynnikiem zagnieżdżonym. W eksperymentach takich nie możemy badać interakcji, gdyż kliniki nie są skrzyżowane z lekami tylko zagnieżdżone i czynnik stopnia niższego działa tylko w obrębie jednego poziomu stopnia wyższego. Nie ma więc możliwości zbadania współdziałania tych czynników. Jeśli czynnik B jest zagnieżdżony w czynniku A, to zapisujemy to symbolicznie B(A). 25 / 74
51 Plan eksperymentu wyglądałby więc następująco: Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K 6 n osób n osób n osób n osób n osób n osób W tym eksperymencie kliniki są zagnieżdżone w lekach. Kliniki są czynnikiem zagnieżdżonym. W eksperymentach takich nie możemy badać interakcji, gdyż kliniki nie są skrzyżowane z lekami tylko zagnieżdżone i czynnik stopnia niższego działa tylko w obrębie jednego poziomu stopnia wyższego. Nie ma więc możliwości zbadania współdziałania tych czynników. Jeśli czynnik B jest zagnieżdżony w czynniku A, to zapisujemy to symbolicznie B(A). 25 / 74
52 Plan eksperymentu wyglądałby więc następująco: Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K 6 n osób n osób n osób n osób n osób n osób W tym eksperymencie kliniki są zagnieżdżone w lekach. Kliniki są czynnikiem zagnieżdżonym. W eksperymentach takich nie możemy badać interakcji, gdyż kliniki nie są skrzyżowane z lekami tylko zagnieżdżone i czynnik stopnia niższego działa tylko w obrębie jednego poziomu stopnia wyższego. Nie ma więc możliwości zbadania współdziałania tych czynników. Jeśli czynnik B jest zagnieżdżony w czynniku A, to zapisujemy to symbolicznie B(A). 25 / 74
53 Plan eksperymentu wyglądałby więc następująco: Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K 6 n osób n osób n osób n osób n osób n osób W tym eksperymencie kliniki są zagnieżdżone w lekach. Kliniki są czynnikiem zagnieżdżonym. W eksperymentach takich nie możemy badać interakcji, gdyż kliniki nie są skrzyżowane z lekami tylko zagnieżdżone i czynnik stopnia niższego działa tylko w obrębie jednego poziomu stopnia wyższego. Nie ma więc możliwości zbadania współdziałania tych czynników. Jeśli czynnik B jest zagnieżdżony w czynniku A, to zapisujemy to symbolicznie B(A). 25 / 74
54 Model analizy hierarchicznej dwustopniowej Załóżmy, że czynniki A i B są stałe i mają odpowiednio a i b poziomów oraz, że czynnik B jest zagnieżdżony w A. Ponadto, każdy poziom czynnika B ma jednakową liczbę n replikacji. Mamy więc a b n wszystkich obserwacji. X ijk = µ + α i + β j(i) + ε k(ij), gdzie X ijk - k-ta obserwacja w j-tej podgrupie czynnika B i-tego poziomu czynnika A, µ - średnia ogólna, α i - efekt główny i-tego poziomu czynnika A, β j(i) - efekt główny j-tej podgrupy czynnika B w i-tym poziomie czynnika A, ε k(ij) - losowy błąd o rozkładzie normalnym N(0, σ). 26 / 74
55 Model analizy hierarchicznej dwustopniowej Załóżmy, że czynniki A i B są stałe i mają odpowiednio a i b poziomów oraz, że czynnik B jest zagnieżdżony w A. Ponadto, każdy poziom czynnika B ma jednakową liczbę n replikacji. Mamy więc a b n wszystkich obserwacji. X ijk = µ + α i + β j(i) + ε k(ij), gdzie X ijk - k-ta obserwacja w j-tej podgrupie czynnika B i-tego poziomu czynnika A, µ - średnia ogólna, α i - efekt główny i-tego poziomu czynnika A, β j(i) - efekt główny j-tej podgrupy czynnika B w i-tym poziomie czynnika A, ε k(ij) - losowy błąd o rozkładzie normalnym N(0, σ). 26 / 74
56 Ponadto zakładamy, że suma wszystkich efektów czynnika A jest równa zero oraz suma wszystkich efektów czynnika B w obrębie każdego poziomu czynnika A jest równa zero, czyli a α i = 0, i=1 b β j(i) = 0. j=1 Za pomocą hierarchicznej analizy wariancji będziemy weryfikować hipotezy: H0 A : α 1 = α 2 =... = α a = 0 (brak istotnego działania czynnika A) wobec hipotezy alternatywnej, że α i 0 dla pewnego i, H0 B : β 1(i) = β 2(i) =... = β b(i) = 0 dla każdego i (brak istotnego działania czynnika B na wszystkich poziomach czynnika A) wobec hipotezy β j(i) 0 dla pewnego j(i). 27 / 74
57 Ponadto zakładamy, że suma wszystkich efektów czynnika A jest równa zero oraz suma wszystkich efektów czynnika B w obrębie każdego poziomu czynnika A jest równa zero, czyli a α i = 0, i=1 b β j(i) = 0. j=1 Za pomocą hierarchicznej analizy wariancji będziemy weryfikować hipotezy: H0 A : α 1 = α 2 =... = α a = 0 (brak istotnego działania czynnika A) wobec hipotezy alternatywnej, że α i 0 dla pewnego i, H0 B : β 1(i) = β 2(i) =... = β b(i) = 0 dla każdego i (brak istotnego działania czynnika B na wszystkich poziomach czynnika A) wobec hipotezy β j(i) 0 dla pewnego j(i). 27 / 74
58 Ponadto zakładamy, że suma wszystkich efektów czynnika A jest równa zero oraz suma wszystkich efektów czynnika B w obrębie każdego poziomu czynnika A jest równa zero, czyli a α i = 0, i=1 b β j(i) = 0. j=1 Za pomocą hierarchicznej analizy wariancji będziemy weryfikować hipotezy: H0 A : α 1 = α 2 =... = α a = 0 (brak istotnego działania czynnika A) wobec hipotezy alternatywnej, że α i 0 dla pewnego i, H0 B : β 1(i) = β 2(i) =... = β b(i) = 0 dla każdego i (brak istotnego działania czynnika B na wszystkich poziomach czynnika A) wobec hipotezy β j(i) 0 dla pewnego j(i). 27 / 74
59 Całkowitą sumę kwadratów rozbijamy na trzy składniki: a b i=1 j=1 k=1 n (x ijk x) 2 = } {{ } SS n a i=1 j=1 b ( x ij x i ) 2 a b i=1 j=1 k=1 n (x ijk x ij ) 2 + bn }{{} SS błąd a ( x i x) 2 + i=1 }{{} SS efekta }{{} SS efektb(a) i analogicznie rozbijamy liczbę stopni swobody na trzy składniki nab 1 }{{} df = a 1 }{{} + a(b 1) + ab(n 1) }{{}}{{} df efekt A df efekt B(A) df błąd. 28 / 74
60 Całkowitą sumę kwadratów rozbijamy na trzy składniki: a b i=1 j=1 k=1 n (x ijk x) 2 = } {{ } SS n a i=1 j=1 b ( x ij x i ) 2 a b i=1 j=1 k=1 n (x ijk x ij ) 2 + bn }{{} SS błąd a ( x i x) 2 + i=1 }{{} SS efekta }{{} SS efektb(a) i analogicznie rozbijamy liczbę stopni swobody na trzy składniki nab 1 }{{} df = a 1 }{{} + a(b 1) + ab(n 1) }{{}}{{} df efekt A df efekt B(A) df błąd. 28 / 74
61 Dzieląc sumy kwadratów (SS) przez liczbę stopni swobody (df) otrzymujemy średnie kwadraty odchyleń (M S). Tabela z analizą wariancji dla eksperymentu dwuczynnikowego z jednym czynnikiem zagnieżdżonym ma postać: zmienność SS df MS Statystyka F czynnik A SS efekt A a 1 MS A F A = MS A MS błąd czynnik B(A) SS efekt B(A) a(b 1) MS B(A) F B(A) = MS B(A) MS błąd błąd SS błąd ab(n 1) MS błąd - ogólna SS abn / 74
62 Dzieląc sumy kwadratów (SS) przez liczbę stopni swobody (df) otrzymujemy średnie kwadraty odchyleń (M S). Tabela z analizą wariancji dla eksperymentu dwuczynnikowego z jednym czynnikiem zagnieżdżonym ma postać: zmienność SS df MS Statystyka F czynnik A SS efekt A a 1 MS A F A = MS A MS błąd czynnik B(A) SS efekt B(A) a(b 1) MS B(A) F B(A) = MS B(A) MS błąd błąd SS błąd ab(n 1) MS błąd - ogólna SS abn / 74
63 Współczynnik ω 2 do oceny wpływu czynnika A na wyniki eksperymentu w układzie zagnieżdżonym wyraża się wzorem ω 2 A B(A) = a 1 abn (MS A MS B(A) ) a 1. abn (MS A MS B(A) )+MS błąd Współczynnik ten wyrażany w procentach jest stosunkiem wariancji wyjaśnionej przez dany czynnik do wariancji całkowitej. 30 / 74
64 Układy hierarchiczne mogą być bardziej złożone. Na przykład w czynniku KLINIKI może być zagnieżdżony kolejny czynnik LEKARZE. Ponadto, jeden czynnik może być zagnieżdżony, a pozostałe skrzyżowane. Na przykład, możemy pacjentów rozdzielić na dwie grupy w zależności od płci i wówczas czynniki LEK i PŁEĆ są skrzyżowane, a czynnik KLINIKA jest zagnieżdżony. Mamy wtedy do czynienia z układem hierarchiczno-czynnikowym (hierarchiczno-krzyżowym). 31 / 74
65 Układy hierarchiczne mogą być bardziej złożone. Na przykład w czynniku KLINIKI może być zagnieżdżony kolejny czynnik LEKARZE. Ponadto, jeden czynnik może być zagnieżdżony, a pozostałe skrzyżowane. Na przykład, możemy pacjentów rozdzielić na dwie grupy w zależności od płci i wówczas czynniki LEK i PŁEĆ są skrzyżowane, a czynnik KLINIKA jest zagnieżdżony. Mamy wtedy do czynienia z układem hierarchiczno-czynnikowym (hierarchiczno-krzyżowym). 31 / 74
66 Przykład 2 Doświadczenie z trzema środkami farmakologicznymi (L 1, L 2,L 3 ) stosowanymi w leczeniu depresji przeprowadzono w sześciu klinikach (każdy lek testowały dwie różne kliniki). Oceniano poprawę stanu zdrowia po kuracji tymi środkami (kliniki.sta). Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K / 74
67 Przykład 2 Doświadczenie z trzema środkami farmakologicznymi (L 1, L 2,L 3 ) stosowanymi w leczeniu depresji przeprowadzono w sześciu klinikach (każdy lek testowały dwie różne kliniki). Oceniano poprawę stanu zdrowia po kuracji tymi środkami (kliniki.sta). Lek L 1 Lek L 2 Lek L 3 K 1 K 2 K 3 K 4 K 5 K / 74
68 Sprawdźmy założenia analizy wariancji: Wykresy normalności nie wykazują istotnych odchyleń obserwacji w grupach od rozkładu normalnego, dlatego nie przeprowadzamy już testu Shapiro-Wilka. Testem Levene a sprawdzamy założenie o jednorodności wariancji. 33 / 74
69 Sprawdźmy założenia analizy wariancji: Wykresy normalności nie wykazują istotnych odchyleń obserwacji w grupach od rozkładu normalnego, dlatego nie przeprowadzamy już testu Shapiro-Wilka. Testem Levene a sprawdzamy założenie o jednorodności wariancji. 33 / 74
70 Sprawdźmy założenia analizy wariancji: Wykresy normalności nie wykazują istotnych odchyleń obserwacji w grupach od rozkładu normalnego, dlatego nie przeprowadzamy już testu Shapiro-Wilka. Testem Levene a sprawdzamy założenie o jednorodności wariancji. 33 / 74
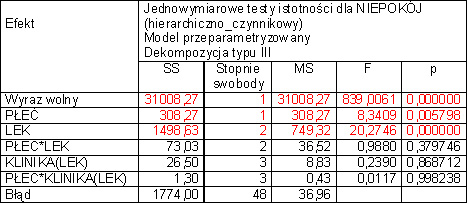
71 Wynik hierarchicznej analizy wariancji zawiera tabela. Wyniki leczenia w istotny sposób zależą od zastosowanego leku (p = 0, ). Natomiast, poprawa stanu zdrowia nie zależy w istotny sposób od kliniki, w której zastosowano leczenie. 34 / 74
.")
72 Wynik hierarchicznej analizy wariancji zawiera tabela. Wyniki leczenia w istotny sposób zależą od zastosowanego leku (p = 0, ). Natomiast, poprawa stanu zdrowia nie zależy w istotny sposób od kliniki, w której zastosowano leczenie. 34 / 74

73 Wykres średnich wygląda następująco: 35 / 74
74 Zastosujmy test post-hoc Scheffe dla zbadania różnic pomiędzy parami średnich. Lek L 3 jest istotnie lepszy od od dwóch pozostałych. 36 / 74
75 Zastosujmy test post-hoc Scheffe dla zbadania różnic pomiędzy parami średnich. Lek L 3 jest istotnie lepszy od od dwóch pozostałych. 36 / 74
76 Zastosujmy test post-hoc Scheffe dla zbadania różnic pomiędzy parami średnich. Lek L 3 jest istotnie lepszy od od dwóch pozostałych. 36 / 74
77 Obliczmy współczynnik ω 2 = (5546,33 212,56) (5546,33 212,56)+272,02 = 52, 14%. Zatem, 52% całkowitej zmienności poprawy zdrowia można wyjaśnić rodzajem zastosowanego leku. 37 / 74
78 Przykład 3 (eksperyment hierarchiczno-czynnikowy) Losowo wybranym pacjentom z depresją podawano dwa leki zmniejszające stres (Lek 1, Lek 2) oraz placebo. Leczenie przeprowadzono w sześciu klinikach. W dwóch pierwszych podawano lek pierwszy, w dwóch kolejnych drugi i placebo w dwóch ostatnich. Ponadto, w celu sprawdzenia, czy jakiś lek jest lepszy dla kobiet dodano czynnik PŁEĆ. Eksperyment zawiera więc trzy czynniki: LEK (3 poziomy), KLINIKA (czynnik zagnieżdżony, 2 poziomy), PŁEĆ (2 poziomy). Zmienną zależną jest poziom stresu (niepokoju) w 45-stopniowej skali (wyższe wartości oznaczają wyższy poziom stresu). Dla każdego obiektu mamy 5 replikacji, czyli próba obejmuje = 60 pacjentów (hierarchiczno-czynnikowy.sta). 38 / 74
79 PŁEĆ Lek 1 Lek 2 Placebo K1 K2 K3 K4 K5 K6 K M / 74
80 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
81 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
82 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
83 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
84 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
85 W ten sposób zaplanowany eksperyment pozwoli odpowiedzieć na następujące pytania: 1 Czy istnieje efekt główny czynnika LEK? 2 Czy istnieje efekt główny czynnika zagnieżdżonego KLINIKA? 3 Czy istnieje efekt główny czynnika PŁEĆ? 4 Czy ma miejsce interakcja pomiędzy czynnikami LEK i PŁEĆ? 5 Czy jest interakcja pomiędzy czynnikami KLINIKA i PŁEĆ? 40 / 74
86 41 / 74
87 42 / 74
88 Wynik terapii zależy w sposób istotny od zastosowanego leku (p < 0, ). Poziom niepokoju jest uzależniony w sposób istotny od płci pacjenta (p = 0, ). Badanie nie potwierdziło przypuszczenia o interakcji pomiędzy lekiem i płcią pacjenta. Nie ma potwierdzenia, że jakiś lek jest lepszy dla kobiet, a jakiś dla mężczyzn. Badanie nie wykazało istotnych różnic dla wyników terapii w różnych klinikach, a także interakcji pomiędzy kliniką i płcią. 43 / 74
89 Wynik terapii zależy w sposób istotny od zastosowanego leku (p < 0, ). Poziom niepokoju jest uzależniony w sposób istotny od płci pacjenta (p = 0, ). Badanie nie potwierdziło przypuszczenia o interakcji pomiędzy lekiem i płcią pacjenta. Nie ma potwierdzenia, że jakiś lek jest lepszy dla kobiet, a jakiś dla mężczyzn. Badanie nie wykazało istotnych różnic dla wyników terapii w różnych klinikach, a także interakcji pomiędzy kliniką i płcią. 43 / 74
90 Wynik terapii zależy w sposób istotny od zastosowanego leku (p < 0, ). Poziom niepokoju jest uzależniony w sposób istotny od płci pacjenta (p = 0, ). Badanie nie potwierdziło przypuszczenia o interakcji pomiędzy lekiem i płcią pacjenta. Nie ma potwierdzenia, że jakiś lek jest lepszy dla kobiet, a jakiś dla mężczyzn. Badanie nie wykazało istotnych różnic dla wyników terapii w różnych klinikach, a także interakcji pomiędzy kliniką i płcią. 43 / 74
91 Wynik terapii zależy w sposób istotny od zastosowanego leku (p < 0, ). Poziom niepokoju jest uzależniony w sposób istotny od płci pacjenta (p = 0, ). Badanie nie potwierdziło przypuszczenia o interakcji pomiędzy lekiem i płcią pacjenta. Nie ma potwierdzenia, że jakiś lek jest lepszy dla kobiet, a jakiś dla mężczyzn. Badanie nie wykazało istotnych różnic dla wyników terapii w różnych klinikach, a także interakcji pomiędzy kliniką i płcią. 43 / 74
92 Wykres średnich dla czynnika LEK wskazuje, że prawdopodobnie oba leki są skuteczne (istotnie lepiej działają niż placebo) i nie ma istotnych różnic pomiędzy ich działaniem. 44 / 74
 i nie ma istotnych różnic pomiędzy ich działaniem.")
93 Wykres średnich dla czynnika LEK wskazuje, że prawdopodobnie oba leki są skuteczne (istotnie lepiej działają niż placebo) i nie ma istotnych różnic pomiędzy ich działaniem. 44 / 74

94 Aby zweryfikować tę obserwację przeprowadźmy test post-hoc. Istotnie, oba leki są skuteczniejsze w porównaniu z placebo. Nie ma natomiast istotnej statystycznie różnicy w działaniu obu leków. Zaobserwowana różnica wynika z przypadkowych odchyleń. 45 / 74

95 Istotnie niższy poziom niepokoju występuje w grupie mężczyzn w porównaniu z grupą kobiet. 46 / 74
96 ANOVA z powtarzanymi pomiarami Wiele eksperymentów wymaga wielokrotnego dokonywania pomiarów na tych samych jednostkach statystycznych w różnych warunkach. Pomiary powtarzane mogą być stosowane w eksperymentach jedno i wieloczynnikowych. Pomiary powtarzane są ze sobą silnie skorelowane, ponieważ są przeprowadzane na tych samych badanych jednostkach. Korelacje te zmniejszają składnik błędu. Zaletą eksperymentów z powtarzanymi pomiarami jest mała liczba jednostek statystycznych użyta do badania. 47 / 74
97 ANOVA z powtarzanymi pomiarami Wiele eksperymentów wymaga wielokrotnego dokonywania pomiarów na tych samych jednostkach statystycznych w różnych warunkach. Pomiary powtarzane mogą być stosowane w eksperymentach jedno i wieloczynnikowych. Pomiary powtarzane są ze sobą silnie skorelowane, ponieważ są przeprowadzane na tych samych badanych jednostkach. Korelacje te zmniejszają składnik błędu. Zaletą eksperymentów z powtarzanymi pomiarami jest mała liczba jednostek statystycznych użyta do badania. 47 / 74
98 ANOVA z powtarzanymi pomiarami Wiele eksperymentów wymaga wielokrotnego dokonywania pomiarów na tych samych jednostkach statystycznych w różnych warunkach. Pomiary powtarzane mogą być stosowane w eksperymentach jedno i wieloczynnikowych. Pomiary powtarzane są ze sobą silnie skorelowane, ponieważ są przeprowadzane na tych samych badanych jednostkach. Korelacje te zmniejszają składnik błędu. Zaletą eksperymentów z powtarzanymi pomiarami jest mała liczba jednostek statystycznych użyta do badania. 47 / 74
99 ANOVA z powtarzanymi pomiarami Wiele eksperymentów wymaga wielokrotnego dokonywania pomiarów na tych samych jednostkach statystycznych w różnych warunkach. Pomiary powtarzane mogą być stosowane w eksperymentach jedno i wieloczynnikowych. Pomiary powtarzane są ze sobą silnie skorelowane, ponieważ są przeprowadzane na tych samych badanych jednostkach. Korelacje te zmniejszają składnik błędu. Zaletą eksperymentów z powtarzanymi pomiarami jest mała liczba jednostek statystycznych użyta do badania. 47 / 74
100 Pewne zagadnienia eksperymentalne wymagają bezwzględnie zastosowania planu z powtarzanymi pomiarami. Wadą eksperymentów z powtarzanymi pomiarami jest tzw. efekt przeniesienia, polegający na tym, że przeprowadzenie eksperymentu w jednych warunkach może wpływać na wynik eksperymentu w innych warunkach. Może występować efekt wyćwiczenia, zmęczenia, działania jeszcze wcześniej zastosowanego leku. 48 / 74
101 Pewne zagadnienia eksperymentalne wymagają bezwzględnie zastosowania planu z powtarzanymi pomiarami. Wadą eksperymentów z powtarzanymi pomiarami jest tzw. efekt przeniesienia, polegający na tym, że przeprowadzenie eksperymentu w jednych warunkach może wpływać na wynik eksperymentu w innych warunkach. Może występować efekt wyćwiczenia, zmęczenia, działania jeszcze wcześniej zastosowanego leku. 48 / 74
102 Model analizy wariancji jednoczynnikowej z powtarzanymi pomiarami X ij = µ + τ i + π j + ε ij, i = 1, 2,..., k, j = 1, 2,..., n, gdzie: X ij - i-ty pomiar dla j-tej jednostki, µ - średnia ogólna w populacji, τ i - efekt i-tego pomiaru (czynnik powtarzanych pomiarów - czynnik stały, zakładamy dodatkowo,że k τ i = 0, ) i=1 49 / 74
103 Model analizy wariancji jednoczynnikowej z powtarzanymi pomiarami X ij = µ + τ i + π j + ε ij, i = 1, 2,..., k, j = 1, 2,..., n, gdzie: X ij - i-ty pomiar dla j-tej jednostki, µ - średnia ogólna w populacji, τ i - efekt i-tego pomiaru (czynnik powtarzanych pomiarów - czynnik stały, zakładamy dodatkowo,że k τ i = 0, ) i=1 49 / 74
104 Model analizy wariancji jednoczynnikowej z powtarzanymi pomiarami X ij = µ + τ i + π j + ε ij, i = 1, 2,..., k, j = 1, 2,..., n, gdzie: X ij - i-ty pomiar dla j-tej jednostki, µ - średnia ogólna w populacji, τ i - efekt i-tego pomiaru (czynnik powtarzanych pomiarów - czynnik stały, zakładamy dodatkowo,że k τ i = 0, ) i=1 49 / 74
105 Model analizy wariancji jednoczynnikowej z powtarzanymi pomiarami X ij = µ + τ i + π j + ε ij, i = 1, 2,..., k, j = 1, 2,..., n, gdzie: X ij - i-ty pomiar dla j-tej jednostki, µ - średnia ogólna w populacji, τ i - efekt i-tego pomiaru (czynnik powtarzanych pomiarów - czynnik stały, zakładamy dodatkowo,że k τ i = 0, ) i=1 49 / 74
106 π j - efekt j-tej jednostki (czynnik losowy o rozkładzie normalnym i średniej 0), ε ij - zmienna losowa o rozkładzie normalnym N(0, σ), wyrażająca wpływy losowe. Weryfikujemy hipotezę: H A 0 : τ 1 = τ 2 =... = τ k = 0 o braku efektów powtarzanych pomiarów. 50 / 74
107 π j - efekt j-tej jednostki (czynnik losowy o rozkładzie normalnym i średniej 0), ε ij - zmienna losowa o rozkładzie normalnym N(0, σ), wyrażająca wpływy losowe. Weryfikujemy hipotezę: H A 0 : τ 1 = τ 2 =... = τ k = 0 o braku efektów powtarzanych pomiarów. 50 / 74
108 π j - efekt j-tej jednostki (czynnik losowy o rozkładzie normalnym i średniej 0), ε ij - zmienna losowa o rozkładzie normalnym N(0, σ), wyrażająca wpływy losowe. Weryfikujemy hipotezę: H A 0 : τ 1 = τ 2 =... = τ k = 0 o braku efektów powtarzanych pomiarów. 50 / 74
109 Analizę wariancji jednoczynnikową z powtarzanymi pomiarami możemy schematycznie przedstawić w tabeli: zmienność SS df MS Statystyka F pomiary SS efekt A k 1 MS A F A = MS A MS błąd jednostki SS jedn. n 1 MS jedn. - błąd SS błąd (k 1)(n 1) MS błąd - ogólna SS kn Rozkład sumy kwadratów i stopni swobody jest taki sam jak w analizie dwuczynnikowej efektów głównych. 51 / 74
110 Oprócz założenia normalności i jednorodności wariacji we wszystkich grupach eksperyment z powtarzanymi pomiarami wymaga ponadto założenia jednorodności kowariancji wśród pomiarów tej samej jednostki. Zatem wszystkie warunki pomiarów powinny być w takim samym stopniu skorelowane (zależne). Założenie to nazywa się założeniem symetrii połączonej. Nieco słabszym założeniem, ale w zupełności wystarczającym dla jednowymiarowego testu F jest założenie o sferyczności. Zakłada ono równość wariancji różnic wszystkich par eksperymentalnych. 52 / 74
111 Oprócz założenia normalności i jednorodności wariacji we wszystkich grupach eksperyment z powtarzanymi pomiarami wymaga ponadto założenia jednorodności kowariancji wśród pomiarów tej samej jednostki. Zatem wszystkie warunki pomiarów powinny być w takim samym stopniu skorelowane (zależne). Założenie to nazywa się założeniem symetrii połączonej. Nieco słabszym założeniem, ale w zupełności wystarczającym dla jednowymiarowego testu F jest założenie o sferyczności. Zakłada ono równość wariancji różnic wszystkich par eksperymentalnych. 52 / 74
112 Oprócz założenia normalności i jednorodności wariacji we wszystkich grupach eksperyment z powtarzanymi pomiarami wymaga ponadto założenia jednorodności kowariancji wśród pomiarów tej samej jednostki. Zatem wszystkie warunki pomiarów powinny być w takim samym stopniu skorelowane (zależne). Założenie to nazywa się założeniem symetrii połączonej. Nieco słabszym założeniem, ale w zupełności wystarczającym dla jednowymiarowego testu F jest założenie o sferyczności. Zakłada ono równość wariancji różnic wszystkich par eksperymentalnych. 52 / 74
113 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
114 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
115 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
116 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
117 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
118 STATISTICA oferuje test Mauchley a, weryfikujący założenie o sferyczności. Statystyka testowa W przyjmuje wartości z przedziału [0, 1] i im mniejsza wartość tej statystyki, tym większe odchylenia od sferyczności. Test ten jest bardzo wrażliwy na odchylenia od wielowymiarowej normalności. W przypadku niespełnienia założenia o sferyczności możemy zastosować czynniki korygujące dla stopni swobody testu F: poprawka Greenhouse a-geissera, poprawka Huynha-Felda, poprawka ograniczenia dolnego. W przypadku niespełnienia założenia o sferyczności bardziej (w stosunku do poprawek) zalecane jest zastosowanie metod wielowymiarowej analizy wariancji (MANOVA), które nie wymagają założenia sferyczności. 53 / 74
119 Przykład 4 Z populacji pacjentów z rozpoznaniem depresji o przebiegu psychozy maniakalno-depresyjnej pobrano próbę 20 osób, którym zaordynowano w sposób losowy jeden z dwóch leków antydepresyjnych: amitryptylinę i imipraminę. Leki te podawano pacjentom w równych odstępach. Efekty leczenia oceniano w skali jedenastostopniowej, klinicznej funkcjonowania pacjentów depresyjnych. Ocenę leczenia przeprowadzono pięciokrotnie co pięć dni (plik dwa leki.sta.) 54 / 74
120 Sprawdzamy założenia analizy wariancji z powtarzanymi pomiarami: Wykresy normalności nie wykrywają istotnych odchyleń od normalności w badanych grupach. Test Levene a jednorodności wariancji wykazuje pewne różnice wariancji rozkładów dla Okresu 2, ale pozostałe testy jednorodności wariancji nie wykrywają tych różnic. Sprawdzamy założenie sferyczności testem Mauchleya. Założenie jest poważnie naruszone (p = 0, ) i wartość statystyki jest niewielka W = 0, / 74
121 Sprawdzamy założenia analizy wariancji z powtarzanymi pomiarami: Wykresy normalności nie wykrywają istotnych odchyleń od normalności w badanych grupach. Test Levene a jednorodności wariancji wykazuje pewne różnice wariancji rozkładów dla Okresu 2, ale pozostałe testy jednorodności wariancji nie wykrywają tych różnic. Sprawdzamy założenie sferyczności testem Mauchleya. Założenie jest poważnie naruszone (p = 0, ) i wartość statystyki jest niewielka W = 0, / 74
122 Sprawdzamy założenia analizy wariancji z powtarzanymi pomiarami: Wykresy normalności nie wykrywają istotnych odchyleń od normalności w badanych grupach. Test Levene a jednorodności wariancji wykazuje pewne różnice wariancji rozkładów dla Okresu 2, ale pozostałe testy jednorodności wariancji nie wykrywają tych różnic. Sprawdzamy założenie sferyczności testem Mauchleya. Założenie jest poważnie naruszone (p = 0, ) i wartość statystyki jest niewielka W = 0, / 74
123 Sprawdzamy założenia analizy wariancji z powtarzanymi pomiarami: Wykresy normalności nie wykrywają istotnych odchyleń od normalności w badanych grupach. Test Levene a jednorodności wariancji wykazuje pewne różnice wariancji rozkładów dla Okresu 2, ale pozostałe testy jednorodności wariancji nie wykrywają tych różnic. Sprawdzamy założenie sferyczności testem Mauchleya. Założenie jest poważnie naruszone (p = 0, ) i wartość statystyki jest niewielka W = 0, / 74
124 Musimy skorzystać ze skorygowanych testów jednowymiarowych (poprawki na df), a najlepiej z ANOVA wielowymiarowa. Widzimy, że poprawka Greenhouse a-geissera, poprawka Huynha-Feldta, jak i poprawka ograniczenia dolnego potwierdzają wynik jednowymiarowy o istotnym wpływie CZASU i interakcji pomiędzy LEKIEM i CZASEM. 56 / 74
125 Musimy skorzystać ze skorygowanych testów jednowymiarowych (poprawki na df), a najlepiej z ANOVA wielowymiarowa. Widzimy, że poprawka Greenhouse a-geissera, poprawka Huynha-Feldta, jak i poprawka ograniczenia dolnego potwierdzają wynik jednowymiarowy o istotnym wpływie CZASU i interakcji pomiędzy LEKIEM i CZASEM. 56 / 74

126 Musimy skorzystać ze skorygowanych testów jednowymiarowych (poprawki na df), a najlepiej z ANOVA wielowymiarowa. Widzimy, że poprawka Greenhouse a-geissera, poprawka Huynha-Feldta, jak i poprawka ograniczenia dolnego potwierdzają wynik jednowymiarowy o istotnym wpływie CZASU i interakcji pomiędzy LEKIEM i CZASEM. 56 / 74
127 Sprawdźmy jeszcze wynik testów wielowymiarowych, nie wymagających spełnienia założenia sferyczności. Testy wielowymiarowe zdecydowanie potwierdzają wynik testu jednowymiarowego. 57 / 74
128 Sprawdźmy jeszcze wynik testów wielowymiarowych, nie wymagających spełnienia założenia sferyczności. Testy wielowymiarowe zdecydowanie potwierdzają wynik testu jednowymiarowego. 57 / 74

129 Sprawdźmy jeszcze wynik testów wielowymiarowych, nie wymagających spełnienia założenia sferyczności. Testy wielowymiarowe zdecydowanie potwierdzają wynik testu jednowymiarowego. 57 / 74
130 Pacjenci depresyjni zażywający lek imipramina funkcjonują istotnie lepiej od pacjentów zażywających lek amitryptylina. 58 / 74

131 Pacjenci depresyjni zażywający lek imipramina funkcjonują istotnie lepiej od pacjentów zażywających lek amitryptylina. 58 / 74
132 Stwierdzamy wysoką istotność poprawy funkcjonowania pacjentów w czasie. 59 / 74

133 Stwierdzamy wysoką istotność poprawy funkcjonowania pacjentów w czasie. 59 / 74
134 60 / 74
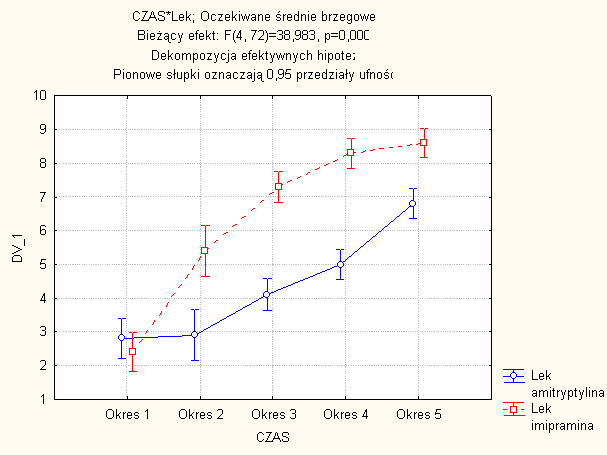
135 Wykres pokazuje, że interakcja czynnika LEK i CZAS polega na szybszej poprawie funkcjonowania pacjentów szczególnie w początkowym okresie przy zastosowaniu leku imipramina, podczas, gdy poprawa zdrowia przy zastosowaniu amitryptyliny następuje później i trochę słabiej. 61 / 74
136 Test Friedmana - ANOVA nieparametryczna dla pomiarów powtarzanych Jeśli nie spełnione jest założenie o normalności rozkładów, czy jednorodności wariancji w eksperymencie z powtarzanymi pomiarami przeprowadzamy nieparametryczny test Friedmana. Test ten zakłada, że zmienne są mierzone przynajmniej w skali porządkowej. Dane wprowadzamy kolumnami, tak, że wartości kolejnych pomiarów zapisywane są w kolejnych kolumnach (zmiennych). Najczęściej są to wyniki dla tych samych osób uzyskane w k różnych badaniach. 62 / 74
137 Test Friedmana - ANOVA nieparametryczna dla pomiarów powtarzanych Jeśli nie spełnione jest założenie o normalności rozkładów, czy jednorodności wariancji w eksperymencie z powtarzanymi pomiarami przeprowadzamy nieparametryczny test Friedmana. Test ten zakłada, że zmienne są mierzone przynajmniej w skali porządkowej. Dane wprowadzamy kolumnami, tak, że wartości kolejnych pomiarów zapisywane są w kolejnych kolumnach (zmiennych). Najczęściej są to wyniki dla tych samych osób uzyskane w k różnych badaniach. 62 / 74
138 Test Friedmana - ANOVA nieparametryczna dla pomiarów powtarzanych Jeśli nie spełnione jest założenie o normalności rozkładów, czy jednorodności wariancji w eksperymencie z powtarzanymi pomiarami przeprowadzamy nieparametryczny test Friedmana. Test ten zakłada, że zmienne są mierzone przynajmniej w skali porządkowej. Dane wprowadzamy kolumnami, tak, że wartości kolejnych pomiarów zapisywane są w kolejnych kolumnach (zmiennych). Najczęściej są to wyniki dla tych samych osób uzyskane w k różnych badaniach. 62 / 74
139 Test Friedmana - ANOVA nieparametryczna dla pomiarów powtarzanych Jeśli nie spełnione jest założenie o normalności rozkładów, czy jednorodności wariancji w eksperymencie z powtarzanymi pomiarami przeprowadzamy nieparametryczny test Friedmana. Test ten zakłada, że zmienne są mierzone przynajmniej w skali porządkowej. Dane wprowadzamy kolumnami, tak, że wartości kolejnych pomiarów zapisywane są w kolejnych kolumnach (zmiennych). Najczęściej są to wyniki dla tych samych osób uzyskane w k różnych badaniach. 62 / 74
140 Weryfikujemy hipotezę zerową, że kolumny danych zawierają próby pobrane z tej samej populacji (populacje, z których pochodzą próby mają takie same rozkłady). Hipoteza alternatywna jest zaprzeczeniem hipotezy zerowej. Rangujemy wartości w wierszach (rangujemy pomiary dla każdej jednostki) i sumujemy rangi w kolumnach (grupach, które porównujemy). 63 / 74
141 Weryfikujemy hipotezę zerową, że kolumny danych zawierają próby pobrane z tej samej populacji (populacje, z których pochodzą próby mają takie same rozkłady). Hipoteza alternatywna jest zaprzeczeniem hipotezy zerowej. Rangujemy wartości w wierszach (rangujemy pomiary dla każdej jednostki) i sumujemy rangi w kolumnach (grupach, które porównujemy). 63 / 74
142 Statystyka testowa oparta jest na sumie kwadratów różnic rang obserwowanych z sumą rang oczekiwanych χ 2 = 12 nk(k + 1) 12 nk(k + 1) k i=1 ( R i ) n(k + 1) 2 = 2 k Ri 2 3n(k + 1), i=1 gdzie R i - suma rang i-tego pomiaru, k - liczba pomiarów (grup), n - liczba jednostek statystycznych (liczba obserwacji w grupie). 64 / 74
143 Statystyka ta przy założeniu prawdziwości hipotezy zerowej ma asymptotyczny rozkład χ 2 z k 1 stopniami swobody. Obszar krytyczny jest prawostronny, gdyż duże różnice sum rang obserwowanych i oczekiwanych, wskazują na fałszywość testowanej hipotezy zerowej. Przybliżenie rozkładem χ 2 jest prawdziwe dla dużych n lub k (n > 15 lub k > 4). Dla mniejszych prób należy korzystać z dokładnego rozkładu statystyki. 65 / 74
144 Statystyka ta przy założeniu prawdziwości hipotezy zerowej ma asymptotyczny rozkład χ 2 z k 1 stopniami swobody. Obszar krytyczny jest prawostronny, gdyż duże różnice sum rang obserwowanych i oczekiwanych, wskazują na fałszywość testowanej hipotezy zerowej. Przybliżenie rozkładem χ 2 jest prawdziwe dla dużych n lub k (n > 15 lub k > 4). Dla mniejszych prób należy korzystać z dokładnego rozkładu statystyki. 65 / 74
145 Statystyka ta przy założeniu prawdziwości hipotezy zerowej ma asymptotyczny rozkład χ 2 z k 1 stopniami swobody. Obszar krytyczny jest prawostronny, gdyż duże różnice sum rang obserwowanych i oczekiwanych, wskazują na fałszywość testowanej hipotezy zerowej. Przybliżenie rozkładem χ 2 jest prawdziwe dla dużych n lub k (n > 15 lub k > 4). Dla mniejszych prób należy korzystać z dokładnego rozkładu statystyki. 65 / 74
146 Wartość statystyki z poprawką na rangi wiązane wyliczamy ze wzoru χ 2 p = χ 2 s n j (t 3 jk t jk ) j=1 k=1 1 n(k 3 k) gdzie s j - liczba rang wiązanych dla j-tej jednostki (w wierszu), t jk - liczba obserwacji w k-tej randze wiązanej w j-tym wierszu., 66 / 74
147 Wartość statystyki z poprawką na rangi wiązane wyliczamy ze wzoru χ 2 p = χ 2 s n j (t 3 jk t jk ) j=1 k=1 1 n(k 3 k) gdzie s j - liczba rang wiązanych dla j-tej jednostki (w wierszu), t jk - liczba obserwacji w k-tej randze wiązanej w j-tym wierszu., 66 / 74
148 Współczynnik zgodności W Kendalla Współczynnik zgodności W Kendalla jest unormowaną wersją statystyki Friedmana. Jest on używany do badania zgodności pomiędzy rankingami pochodzącymi z wielu źródeł, na przykład ocenami wielu ekspertów. Przyjmuje on wartości z przedziału [0, 1], gdzie 0 oznacza całkowity brak zgodności, a 1 pełną zgodność. Współczynnik ten jest stosowany często w psychometrii do badania zgodności sędziów kompetentnych. 67 / 74
149 Współczynnik zgodności W Kendalla Współczynnik zgodności W Kendalla jest unormowaną wersją statystyki Friedmana. Jest on używany do badania zgodności pomiędzy rankingami pochodzącymi z wielu źródeł, na przykład ocenami wielu ekspertów. Przyjmuje on wartości z przedziału [0, 1], gdzie 0 oznacza całkowity brak zgodności, a 1 pełną zgodność. Współczynnik ten jest stosowany często w psychometrii do badania zgodności sędziów kompetentnych. 67 / 74
150 Współczynnik zgodności W Kendalla Współczynnik zgodności W Kendalla jest unormowaną wersją statystyki Friedmana. Jest on używany do badania zgodności pomiędzy rankingami pochodzącymi z wielu źródeł, na przykład ocenami wielu ekspertów. Przyjmuje on wartości z przedziału [0, 1], gdzie 0 oznacza całkowity brak zgodności, a 1 pełną zgodność. Współczynnik ten jest stosowany często w psychometrii do badania zgodności sędziów kompetentnych. 67 / 74
151 Współczynnik zgodności W Kendalla Współczynnik zgodności W Kendalla jest unormowaną wersją statystyki Friedmana. Jest on używany do badania zgodności pomiędzy rankingami pochodzącymi z wielu źródeł, na przykład ocenami wielu ekspertów. Przyjmuje on wartości z przedziału [0, 1], gdzie 0 oznacza całkowity brak zgodności, a 1 pełną zgodność. Współczynnik ten jest stosowany często w psychometrii do badania zgodności sędziów kompetentnych. 67 / 74
152 Współczynnik W Kendalla obliczamy ze wzoru W = χ 2 n(k 1). Aby ocenić jaki procent ogólnej wariancji ocen stanowi wspólna wariancja ocen, wyliczamy kwadrat ( r r ) 2 średniej korelacji rangowej ocen r r = nw 1 n / 74
153 Współczynnik W Kendalla obliczamy ze wzoru W = χ 2 n(k 1). Aby ocenić jaki procent ogólnej wariancji ocen stanowi wspólna wariancja ocen, wyliczamy kwadrat ( r r ) 2 średniej korelacji rangowej ocen r r = nw 1 n / 74
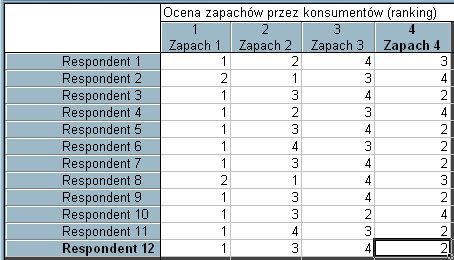
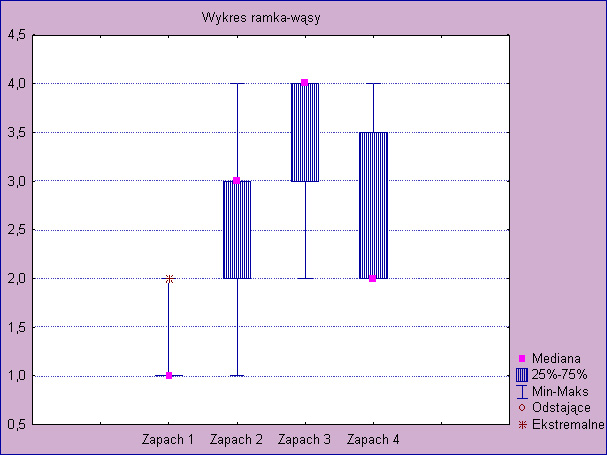
154 Przykład 5 Losowa próbę 12 konsumentów poproszono o określenie rankingu preferencji co do czterech nowych zapachów, które producent perfum chce wprowadzić na rynek jesienią. Zapach, który najbardziej się podobał miał rangę 1, a ten który najmniej się podobał miał rangę / 74
155 70 / 74

156 Wartość statystyki Friedmana wynosi χ 2 = 20, 4, p = 0, 00014, a więc na podstawie testu nieparametrycznego ANOVA możemy na podstawie ocen badanych respondentów stwierdzić istotne różnice w preferencji badanych zapachów przez konsumentów. 71 / 74
157 Współczynnik zgodności Kendalla wynosi 0, 57, a średnia korelacja rangowa 0, 53. Zgodność pomiędzy ocenami konsumentów jest znaczna, korelacja pomiędzy ocenami jest silna. 72 / 74
158 73 / 74

159 Statystyka jest bardziej sposobem myślenia lub wnioskowania niż pęczkiem recept na młócenie danych w celu odsłonięcia odpowiedzi. C. R. Rao
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Elementy statystyki STA - Wykład 5
 STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA
 ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że kilka średnich dla analizowanej zmiennej grupującej mają jednakowe wartości średnie.
ANALIZA WARIANCJI - KLASYFIKACJA WIELOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że kilka średnich dla analizowanej zmiennej grupującej mają jednakowe wartości średnie.
ANOVA-ćwiczenia 2 - rozwiązania
 1 ANALIZA KONTRASTÓW 1.1 Przeprowadź porównanie nowych metod leczenia nadciśnienia z metodą tradycyjną wykorzystując analizę kontrastów i plik nadciśnienie_zmienna_grupująca.sta. (Eksperyment ten był rozważany
1 ANALIZA KONTRASTÓW 1.1 Przeprowadź porównanie nowych metod leczenia nadciśnienia z metodą tradycyjną wykorzystując analizę kontrastów i plik nadciśnienie_zmienna_grupująca.sta. (Eksperyment ten był rozważany
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Analiza wariancji. dr Janusz Górczyński
 Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Analiza wariancji dr Janusz Górczyński Wprowadzenie Powiedzmy, że badamy pewną populację π, w której cecha Y ma rozkład N o średniej m i odchyleniu standardowym σ. Powiedzmy dalej, że istnieje pewien czynnik
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Bioinformatyka Wykład 4 Wrocław, 17 października 2011 Temat. Weryfikacja hipotez statystycznych dotyczących wartości oczekiwanej w dwóch populacjach o rozkładach normalnych. Model 3. Porównanie średnich
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA
 ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
Jednoczynnikowa analiza wariancji
 Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Szkice rozwiązań z R:
 Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
Szkice rozwiązań z R: Zadanie 1. Założono doświadczenie farmakologiczne. Obserwowano przyrost wagi ciała (przyrost [gram]) przy zadanych dawkach trzech preparatów (dawka.a, dawka.b, dawka.c). Obiektami
Efekt główny Efekt interakcyjny efekt jednego czynnika zależy od poziomu drugiego czynnika Efekt prosty
 ANOVA DWUCZYNNIKOWA testuje różnice między średnimi w grupach wyznaczonych przez dwa czynniki i ich kombinacje. Analiza pozwala ustalić wpływ dwóch czynników na wartości zmiennej zależnej (ilościowej!)
ANOVA DWUCZYNNIKOWA testuje różnice między średnimi w grupach wyznaczonych przez dwa czynniki i ich kombinacje. Analiza pozwala ustalić wpływ dwóch czynników na wartości zmiennej zależnej (ilościowej!)
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Statystyczna analiza danych w programie STATISTICA (wykład 2) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Analiza wariancji i kowariancji
 Analiza wariancji i kowariancji Historia Analiza wariancji jest metodą zaproponowaną przez Ronalda A. Fishera. Po zakończeniu pierwszej wojny światowej był on pracownikiem laboratorium statystycznego w
Analiza wariancji i kowariancji Historia Analiza wariancji jest metodą zaproponowaną przez Ronalda A. Fishera. Po zakończeniu pierwszej wojny światowej był on pracownikiem laboratorium statystycznego w
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
JEDNOCZYNNIKOWA ANOVA
 Analizę ANOVA wykorzystujemy do wykrycia różnic pomiędzy średnimi w więcej niż dwóch grupach/więcej niż w dwóch pomiarach JEDNOCZYNNIKOWA ANOVA porównania jednej zmiennej pomiędzy więcej niż dwoma grupami
Analizę ANOVA wykorzystujemy do wykrycia różnic pomiędzy średnimi w więcej niż dwóch grupach/więcej niż w dwóch pomiarach JEDNOCZYNNIKOWA ANOVA porównania jednej zmiennej pomiędzy więcej niż dwoma grupami
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Metody Statystyczne. Metody Statystyczne. #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji
 gkrol@mail.wz.uw.edu.pl #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji 1 Ryzyko błędu - powtórzenie Statystyka niczego nie dowodzi, czyni tylko wszystko mniej lub bardziej prawdopodobnym
gkrol@mail.wz.uw.edu.pl #8 Błąd I i II rodzaju powtórzenie. Dwuczynnikowa analiza wariancji 1 Ryzyko błędu - powtórzenie Statystyka niczego nie dowodzi, czyni tylko wszystko mniej lub bardziej prawdopodobnym
Jak sprawdzić normalność rozkładu w teście dla prób zależnych?
 Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
STATYSTYKA I DOŚWIADCZALNICTWO. Wykład 2
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analizę wariancji, często określaną skrótem ANOVA (Analysis of Variance), zawdzięczamy angielskiemu biologowi Ronaldowi A. Fisherowi, który opracował ją w 1925 roku dla rozwiązywania
Analiza wariancji - ANOVA Analizę wariancji, często określaną skrótem ANOVA (Analysis of Variance), zawdzięczamy angielskiemu biologowi Ronaldowi A. Fisherowi, który opracował ją w 1925 roku dla rozwiązywania
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice
 Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
Matematyka i statystyka matematyczna dla rolników w SGGW
 Było: Testowanie hipotez (ogólnie): stawiamy hipotezę, wybieramy funkcję testową f (test statystyczny), przyjmujemy poziom istotności α; tym samym wyznaczamy obszar krytyczny testu (wartość krytyczną funkcji
Było: Testowanie hipotez (ogólnie): stawiamy hipotezę, wybieramy funkcję testową f (test statystyczny), przyjmujemy poziom istotności α; tym samym wyznaczamy obszar krytyczny testu (wartość krytyczną funkcji
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Jednoczynnikowa analiza wariancji i porównania wielokrotne (układ losowanych bloków randomized block design RBD) Układ losowanych bloków Stosujemy, gdy podejrzewamy,
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Jednoczynnikowa analiza wariancji i porównania wielokrotne (układ losowanych bloków randomized block design RBD) Układ losowanych bloków Stosujemy, gdy podejrzewamy,
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008
 Redaktor: Alicja Zagrodzka Korekta: Krystyna Chludzińska Projekt okładki: Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008 ISBN 978-83-7383-296-1 Wydawnictwo Naukowe Scholar
Redaktor: Alicja Zagrodzka Korekta: Krystyna Chludzińska Projekt okładki: Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2000, 2008 ISBN 978-83-7383-296-1 Wydawnictwo Naukowe Scholar
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Testy post-hoc. Wrocław, 6 czerwca 2016
 Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
Przykład 1. (A. Łomnicki)
") Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
Zadania ze statystyki cz.8. Zadanie 1.
 Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
b) Niech: - wśród trzech wylosowanych opakowań jest co najwyżej jedno o dawce 15 mg. Wówczas:
 Niech: - wśród trzech wylosowanych opakowań jest co najwyżej jedno o dawce 15 mg. Wówczas:") ROZWIĄZANIA I ODPOWIEDZI Zadanie A1. Można założyć, że przy losowaniu trzech kul jednocześnie kolejność ich wylosowania nie jest istotna. A więc: Ω = 20 3. a) Niech: - wśród trzech wylosowanych opakowań
ROZWIĄZANIA I ODPOWIEDZI Zadanie A1. Można założyć, że przy losowaniu trzech kul jednocześnie kolejność ich wylosowania nie jest istotna. A więc: Ω = 20 3. a) Niech: - wśród trzech wylosowanych opakowań
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
Stosowana Analiza Regresji
 Model jako : Stosowana Analiza Regresji Wykład XI 21 Grudnia 2011 1 / 11 Analiza kowariancji Model jako : Oprócz czynnika o wartościach nominalnych chcemy uwzględnić wpływ predyktora o wartościach ilościowych
Model jako : Stosowana Analiza Regresji Wykład XI 21 Grudnia 2011 1 / 11 Analiza kowariancji Model jako : Oprócz czynnika o wartościach nominalnych chcemy uwzględnić wpływ predyktora o wartościach ilościowych
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
, a ilość poziomów czynnika A., b ilość poziomów czynnika B. gdzie
 Test Scheffego, gdzie (1) n to ilość powtórzeń (pomiarów) w jednej grupie (zabiegu) Test NIR Istnieje wiele testów dla porównań wielokrotnych opartych o najmniejszą istotna różnicę między średnimi (NIR).
Test Scheffego, gdzie (1) n to ilość powtórzeń (pomiarów) w jednej grupie (zabiegu) Test NIR Istnieje wiele testów dla porównań wielokrotnych opartych o najmniejszą istotna różnicę między średnimi (NIR).
Weryfikacja hipotez statystycznych testy dla dwóch zbiorowości
 Weryfikacja hipotez statystycznych testy dla dwóch zbiorowości Informatyka 007 009 aktualizacja dla 00 JERZY STEFANOWSKI Instytut Informatyki Politechnika Poznańska Plan wykładu. Przypomnienie testu dla
Weryfikacja hipotez statystycznych testy dla dwóch zbiorowości Informatyka 007 009 aktualizacja dla 00 JERZY STEFANOWSKI Instytut Informatyki Politechnika Poznańska Plan wykładu. Przypomnienie testu dla
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA
 analiza wariancji ANOVA") Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
Statystyka. #6 Analiza wariancji. Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik. rok akademicki 2015/ / 14
 Statystyka #6 Analiza wariancji Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2015/2016 1 / 14 Analiza wariancji 2 / 14 Analiza wariancji Analiza wariancji jest techniką badania wyników,
Statystyka #6 Analiza wariancji Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2015/2016 1 / 14 Analiza wariancji 2 / 14 Analiza wariancji Analiza wariancji jest techniką badania wyników,
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH
 RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych.
 Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
... i statystyka testowa przyjmuje wartość..., zatem ODRZUCAMY /NIE MA POD- STAW DO ODRZUCENIA HIPOTEZY H 0 (właściwe podkreślić).
.") Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja) założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)
 założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)") PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe
 Zjazd 7. SGGW, dn. 28.11.10 r. Matematyka i statystyka matematyczna Tematy 1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe nna Rajfura 1 Zagadnienia Przykład porównania wielu obiektów w
Zjazd 7. SGGW, dn. 28.11.10 r. Matematyka i statystyka matematyczna Tematy 1. Jednoczynnikowa analiza wariancji 2. Porównania szczegółowe nna Rajfura 1 Zagadnienia Przykład porównania wielu obiektów w
Wykład 5 Teoria eksperymentu
 Wykład 5 Teoria eksperymentu Wrocław, 22.03.2017r Co to jest teoria eksperymentu? eksperyment - badanie jakiegoś zjawiska polegające na celowym wywołaniu tego zjawiska lub jego zmian oraz obserwacji i
Wykład 5 Teoria eksperymentu Wrocław, 22.03.2017r Co to jest teoria eksperymentu? eksperyment - badanie jakiegoś zjawiska polegające na celowym wywołaniu tego zjawiska lub jego zmian oraz obserwacji i
Elementarne metody statystyczne 9
 Elementarne metody statystyczne 9 Wybrane testy nieparametryczne - ciąg dalszy Test McNemary W teście takim dysponujemy próbami losowymi z dwóch populacji zależnych pewnej cechy X. Wyniki poszczególnych
Elementarne metody statystyczne 9 Wybrane testy nieparametryczne - ciąg dalszy Test McNemary W teście takim dysponujemy próbami losowymi z dwóch populacji zależnych pewnej cechy X. Wyniki poszczególnych
Założenia do analizy wariancji. dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW
 Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
1 Estymacja przedziałowa
 1 Estymacja przedziałowa 1. PRZEDZIAŁY UFNOŚCI DLA ŚREDNIEJ (a) MODEL I Badana cecha ma rozkład normalny N(µ, σ) o nieznanym parametrze µ i znanym σ. Przedział ufności: [ ( µ x u 1 α ) ( σn ; x + u 1 α
1 Estymacja przedziałowa 1. PRZEDZIAŁY UFNOŚCI DLA ŚREDNIEJ (a) MODEL I Badana cecha ma rozkład normalny N(µ, σ) o nieznanym parametrze µ i znanym σ. Przedział ufności: [ ( µ x u 1 α ) ( σn ; x + u 1 α
), którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0
, którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0") Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
TABELKA ANOVA (jednoczynnikowa)
") TABELKA ANOVA (jednoczynnikowa) Jednoczynnikowa ANOVA nazwa zmiennej zależnej Między grupami Suma kwadratów df Średni kwadrat F Istotność k 1 SSMG / dfmg MSMG / MSWG brane z tablic Wewnątrz grup 2 z 3
TABELKA ANOVA (jednoczynnikowa) Jednoczynnikowa ANOVA nazwa zmiennej zależnej Między grupami Suma kwadratów df Średni kwadrat F Istotność k 1 SSMG / dfmg MSMG / MSWG brane z tablic Wewnątrz grup 2 z 3
Przedmowa Wykaz symboli Litery alfabetu greckiego wykorzystywane w podręczniku Symbole wykorzystywane w zagadnieniach teorii
 SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
Weryfikacja hipotez statystycznych za pomocą testów statystycznych
 Weryfikacja hipotez statystycznych za pomocą testów statystycznych Weryfikacja hipotez statystycznych za pomocą testów stat. Hipoteza statystyczna Dowolne przypuszczenie co do rozkładu populacji generalnej
Weryfikacja hipotez statystycznych za pomocą testów statystycznych Weryfikacja hipotez statystycznych za pomocą testów stat. Hipoteza statystyczna Dowolne przypuszczenie co do rozkładu populacji generalnej
Statystyka. #5 Testowanie hipotez statystycznych. Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik. rok akademicki 2016/ / 28
 Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Analiza autokorelacji
 Analiza autokorelacji Oblicza się wartości współczynników korelacji między y t oraz y t-i (dla i=1,2,...,k), czyli współczynniki autokorelacji różnych rzędów. Bada się statystyczną istotność tych współczynników.
Analiza autokorelacji Oblicza się wartości współczynników korelacji między y t oraz y t-i (dla i=1,2,...,k), czyli współczynniki autokorelacji różnych rzędów. Bada się statystyczną istotność tych współczynników.
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
BADANIE POWTARZALNOŚCI PRZYRZĄDU POMIAROWEGO
 Zakład Metrologii i Systemów Pomiarowych P o l i t e c h n i k a P o z n ańska ul. Jana Pawła II 24 60-965 POZNAŃ (budynek Centrum Mechatroniki, Biomechaniki i Nanoinżynierii) www.zmisp.mt.put.poznan.pl
Zakład Metrologii i Systemów Pomiarowych P o l i t e c h n i k a P o z n ańska ul. Jana Pawła II 24 60-965 POZNAŃ (budynek Centrum Mechatroniki, Biomechaniki i Nanoinżynierii) www.zmisp.mt.put.poznan.pl
TEST STATYSTYCZNY. Jeżeli hipotezę zerową odrzucimy na danym poziomie istotności, to odrzucimy ją na każdym większym poziomie istotności.
 TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
Testowanie hipotez statystycznych cd.
 Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
Temat Testowanie hipotez statystycznych cd. Kody znaków: żółte wyróżnienie nowe pojęcie pomarańczowy uwaga kursywa komentarz 1 Zagadnienia omawiane na zajęciach 1. Przykłady testowania hipotez dotyczących:
Hipotezy statystyczne
 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej
Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej