Programowanie Równoległe wykład 13. Symulacje komputerowe cieczy LBM w CUDA. Maciej Matyka Instytut Fizyki Teoretycznej
|
|
|
- Damian Mazurek
- 9 lat temu
- Przeglądów:
Transkrypt
1 Programowanie Równoległe wykład 13 Symulacje komputerowe cieczy LBM w CUDA Maciej Matyka Instytut Fizyki Teoretycznej

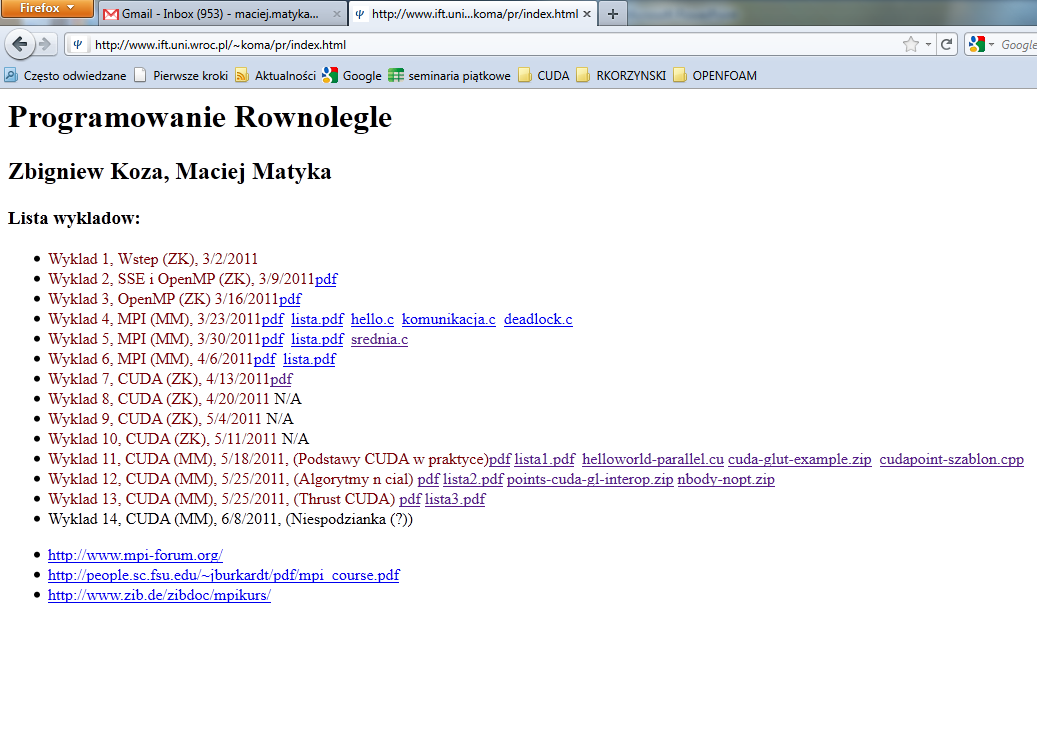
2
3 Transport cieczy i gazów W wielu dziedzinach trzeba rozwiązać zagadnienie transportu cieczy lub gazów aerodynamika opływ (np. samochodów sport biologia i medycyna przepływy w naczyniach krwionośnych próby przewidzenia miejsc narażonych na deformacje technika transport w ośrodkach porowatych problemy optymalizacji przewidywanie pogody etc.

4 Metody rozwiązania Skala makro (continuum) Navier Stokes Equations (NSE) Smoothed Particle Hydrodynamics (SPH) Dissipative Particle Dynamics (DPD) The Lattice Boltzmann Method (LBM) Lattice Gas Automata (LGA) Molecular Dynamics (MD) Skala mikro (poziom atomowy)
 Molecular Dynamics (MD) Skala mikro")
5 Metody rozwiązania Skala makro (continuum) Navier Stokes Equations (NSE) Lattice Gas Automata (LGA) Molecular Dynamics (MD) Skala mikro (poziom atomowy)
 Skala mikro")
6 Równania Naviera--Stokesa Równania Naviera-Stokesa dla cieczy nieściśliwej: Nieliniowe równanie różniczkowe drugiego rzędu + równanie ciągłości (gęstość stała) equations
 http://en.wikipedia.")
7 Rozwiązywanie równań NS Linearyzacja do postaci Ax=B Metody: FDM, FVM, FEM rozwiązanie układu równań liniowych (np. metody iteracyjne) Problemy: Problem nieliniowy zamieniamy na problem liniowy Stabilność / dokładność / istnienie rozwiązania Czas obliczeń Skala w zasadzie tylko continuum Złożoność algorytmów i podatność na błędy (zadanie w zasadzie na lata)

8 Dynamika molekularna Ogromna ilość atomów Potencjał L-J równania ruchu oddziaływanie atomu z atomem Skala mikroskopowa Allen, M.P et al., Computer Simulation of Liquids, Oxford Univ. Press.


9 Model gazu sieciowego LGA Najbardziej znanym modelem gazu sieciowego jest opisany przez U. Frisha, B. Hasslachera iy. Pomeau gaz FHP Rys. Kolizje w modelu FHP5 Transport Kolizje U. Frish, B. Hasslacher, Y. Pomeau 1986 Lattice-Gas Automata for the Navier-Stokes Equation, Phys. Rev. Lett. 56,


10 LGA w praktyce Praca magisterska: Sebastian Szkoda, Implementacja modelu FHP w technologii NVIDIA CUDA astianszkoda_msc.pdf Implementacja przez podział przestrzenny z komunikacją Przyspieszenie względem CPU Porównanie FHP3 do doświadczenia MPI Bremen)

11 Problemy Model gazu sieciowego LGA szum statystyczny wymaga uśredniania w czasie wymaga uśredniania w przestrzeni wymaga dużych siatek (pamięć)

12 Metoda gazu sieciowego Boltzmanna Historycznie wprowadzona jako rozwinięcie LGA Zmienne ni (0,1) zamienione na funkcje rozkładu
 zamienione")
13 Popularność LBM Artykuły w PRE / PRL wspominające o metodzie Boltzmanna czasopisma najbardziej znane dla nas fizyków Wybór sposobu szukania tendencyjny, ale rezultat o czymś mówi

14 Funkcja rozkładu Funkcja rozkładu jest zdefiniowana jako liczba cząsteczek w skończonym elemencie przestrzeni pędów i położeń: Zadaniem teorii kinetycznej jest znalezienie funkcji dystrybucji dla zadanych oddziaływań międzycząsteczkowych.

15 Równanie Boltzmanna Ewolucja czasowa funkcji rozkładu jest opisana przez równanie Boltzmanna: Założenia : molekularny chaos (brak korelacji między prędkością, a położeniem cząsteczek) uwzględnienie tylko kolizji dwuciałowych
 uwzględnienie tylko kolizji")
16 Przybliżenie BGK Człon kolizji, przybliżenie BGK (Bhatnagar, Gross, Krook (1954)): Liniowa relaksacja do stanu równowagi feq feq wyznaczana np. z rozkładu Macwella- Boltzmanna Uwaga: istnieją bardziej zaawansowane modele kolizji o lepszych właściwościach np. MRT


17 Model d2q9 Dyskretyzacja i model LBM Wprowadźmy dyskretne wektory prędkości i funkcję rozkładu: f > fi v > ci Thorne, D., Sukop, M., Lattice Boltzmann Method for the Elder Problem, FIU, CMWR(2004)

18 Wielkości makroskopowe Prędkości i gęstość wyznaczmy przez sumowanie funkcji rozkładu: Gęstość: Prędkość:

19 Równanie transportu (dyskretnie) Równanie transportu w modelu sieciowym LBM: gdzie zakres i zależy od użytej sieci.

20 t=0 Krok transportu

21 t=1/4 Krok transportu
22 t=1/2 Krok transportu
23 t=3/4 Krok transportu
24 t=1 Krok transportu
25 Krok Transportu - Implementacja Implementacja kroku transportu: void propagatelbm(int _nx, int _ny, int curr) { int prev = 1 - curr; for(i=0; i < _nx ; i++) for(j=0; j < _ny ; j++) if(f[ j * _nx + i ] & C_FLD) { for(k=0; k< 9; k++) { ip = i+ex[k]; jp = j+ey[k]; } } if( F[ jp * _nx + ip ] & C_BND ) { df [curr][ jp * _nx + ip ][inv[k]] = df [prev][ j * _nx + i ][k]; } else { df [curr][ jp * _nx + ip ][k] = df[prev][ j * _nx + i ][k]; }
26 Funkcja rozkładu w równowadze Lokalną funkcję rozkładu w równowadze zwykle wyznacza się z rozwinięcia funkcji rozkładu Maxwella-Boltzmanna [1]: gęstość płynu prędkość dźwięku dla sieci współczynniki wagowe sieci macierz jednostkowa [1] S. Succi, O. Filippova, G. Smith, E. Kaxiras Applying the Lattice Boltzmann Equation to Multiscale Fluid Problems, Comp. Sci. Eng., Nov-Dec 2001, 26 36
27 Kolizje - Implementacja Wyznaczanie członu kolizji: (...) for(k=0; k< 9; k++) { f0 = w[k] * rho * (1.0 - (3.0/2.0) * (ux*ux + uy*uy) * (ex[k] * ux + ey[k]*uy) + (9.0/2.0) * (ex[k] * ux + ey[k]*uy) * (ex[k] * ux + ey[k]*uy)); } df [curr][ j * _nx + i ][k] = (1-omega) * df[curr][ j * _nx + i ][k] + omega*f0; (omega = 1/tau)
28 Warunki brzegowe Bounce-back na sztywnej ściance Można uzyskać dokładność 2 rzędu stosując wersję mid-grid, szczegóły [2] [2] Succi, Sauro (2001). The Lattice Boltzmann Equation for Fluid Dynamics and Beyond. Oxford University Press
29 Warunki brzegowe Bounce-back na sztywnej ściance Można uzyskać dokładność 2 rzędu stosując wersję mid-grid, szczegóły [2] [2] Succi, Sauro (2001). The Lattice Boltzmann Equation for Fluid Dynamics and Beyond. Oxford University Press
30 Warunki brzegowe Bounce-back na sztywnej ściance Można uzyskać dokładność 2 rzędu stosując wersję mid-grid, szczegóły [2] [2] Succi, Sauro (2001). The Lattice Boltzmann Equation for Fluid Dynamics and Beyond. Oxford University Press
31 Kolizje + transport w jednym kroku Kolizje i transport mogą być umieszczone w pojedynczym wyrażeniu Można powiedzieć, że poniższy kod to pełny algorytm LBM (bez kilku detali )! for(int k=0; k< 9; k++) { int ip = ( i+ex[k] + L ) % (L); int jp = ( j+ey[k] + L ) % (L); // collision + streaming } if( FLAG[ip+jp*L] == 1 ) df [1-c][ i+j*l ][inv[k]] = (1-omega) * df[c][ i+j*l ][k] + omega* w[k] * rho * (1.0f - (3.0f/2.0f) * (ux*ux + uy*uy) + 3.0f * (ex[k] * ux + ey[k]*uy) + (9.0f/2.0f) * (ex[k] * ux + ey[k]*uy) * (ex[k] * ux + ey[k]*uy)); else df [1-c][ip+jp*L][k] = (1-omega) * df[c][ i+j*l ][k] + omega* w[k] * rho * (1.0f - (3.0f/2.0f) * (ux*ux + uy*uy)+ 3.0f * (ex[k] * ux + ey[k]*uy) + (9.0f/2.0f) * (ex[k] * ux + ey[k]*uy) * (ex[k] * ux + ey[k]*uy));
32 Podsumowanie algorytm LBM Najbardziej podstawowy model LBM składa się z dwóch kroków: Krok kolizji: Krok transportu:
33 LBM na CUDA LBM nadaje się bardzo dobrze do urównoleglenia Operacje w algorytmie LBM: Wyznaczenie wielkości makroskopowych (lokalna) Wyznaczenie funkcji rozkładu (lokalna) Krok propagacji (nielokalna!): 1) podział sieci na podsieci (jak w pracy S. Szkody) Problem: wymaga komunikacji 2) użycie drugiej siatki (propagacja ping-pong) Problem: wymaga więcej pamięci
34 Jak przepisać LBM na CUDA? Start: gpu2d.zip (strona wykładu) alokuje pamięć na host (malloc) alokuje pamięć na gpu (cudamalloc) wywołuje kernel CUDA przekazując wskaźnik na pamięć urządzenia jako argument kopiuje dane z pamięci gpu->cpu zapisuje skopiowane dane jako rysunek.ppm (dołączony) global void Trace(float3 *IMG) { int x = blockidx.x * blockdim.x + threadidx.x; int y = blockidx.y * blockdim.y + threadidx.y; if(x*h + y>=w*h) return; IMG[x*H + y].x = float(x)/float(w); IMG[x*H + y].y = float(y)/float(h); IMG[x*H + y].z = float(x+y)/float(w+h); }
 Zwięzła implementacja LBM na CPU Adwekcja")
35 Jak przepisać LBM na CUDA? lbm-cpu.zip (strona wykładu) Zwięzła implementacja LBM na CPU Adwekcja cząstek przez pole prędkości
36 Kroki do wykonania Aby zaimplementować tę wersję LBM na CUDA należy (wersja z dodatkową pamięcią): 1. zmienić strukturę funkcji rozkładu (np. tablice 1d) // df on the device float * c0f0; float * c0f1; float * c0f2; float * c0f3; float * c0f4; float * c0f5; float * c0f6; float * c0f7; float * c0f8; float * c1f0; float * c1f1; float * c1f2; float * c1f3; float * c1f4; float * c1f5; float * c1f6; float * c1f7; float * c1f8; ( ) cudamalloc(&c0f0, _nx*sizeof(float) * _ny * nz); cudamalloc(&c0f1, _nx*sizeof(float) * _ny * nz); cudamalloc(&c0f2, _nx*sizeof(float) * _ny * nz); cudamalloc(&c0f3, _nx*sizeof(float) * _ny * nz); cudamalloc(&c0f4, _nx*sizeof(float) * _ny * nz); ( )
37 Kroki do wykonania 2. Zamiplementować kernel kolizji: global void devicecollision(float *f0, float *f1,float *f2, float *f3, float *f4, float *f5, float *f6, float *f7, float *f8, int width, int height, int depth, float *U, float *V, int *F) { int i = blockidx.x * blockdim.x + threadidx.x; int j = blockidx.y * blockdim.y + threadidx.y; } ( ) // kod jak w wersji CPU z małymi modyfikacjami // wynikającymi głównie z nowego formatu funkcji rozkładu
38 Kroki do wykonania 3. Zamiplementować kernel transportu: global void devicepropagate( float *fromf0, float *fromf1,float *fromf2, float *fromf3, float *fromf4, float *fromf5, float *fromf6,float *fromf7, float *fromf8, float *tof0, float *tof1,float *tof2, float *tof3, float *tof4, float *tof5, float *tof6,float *tof7, float *tof8, int width, int height, int depth, float *U, float *V, int *F) { int i = blockidx.x * blockdim.x + threadidx.x; int j = blockidx.y * blockdim.y + threadidx.y; } ( ) // kod jak na CPU z jawnie // wypisanym transportem wg formatu funkcji gęstości // jak w preabule kernela
39 Schemat działania 1. Inicjalizuj dane (CPU) 2. Inicjalizuj dane (CPU -----> GPU) 3. W pętli: a) Wywołuj kernel kolizji (CUDA) b) Wywołuj kernel transportu (CUDA) c) Przesuń cząstki po polu prędkości w nowe położenia - To też można urównoleglić -> pierwszy wykład z CUDA! d) Narysuj cząstki na ekranie


40 512 x 512 Przykład działania LBM na CUDA CPU stoi. gdy w tym czasie GPU.
41 CPU_time / GPU_time Skalowanie LBM dało się szybko (dzień pracy) przyspieszyć około 100 razy Można przyspieszyć jeszcze bardziej (wiele prac) Klastrów obliczeniowych nie da się jeszcze przebić (pamięć, skala obliczeń) multi GPU? Mniejsze zastosowania osobiste tu jak najbardziej CUDA ma sens L
42 fin
, 2332 2335.")
43 Literatura S. Succi, The Lattice Boltzmann Equation for Fluid Dynamics and Beyond., Oxford University Press (2001) U. Frish, B. Hasslacher, Y. Pomeau 1986 Lattice-Gas Automata for the Navier-Stokes Equation, Phys. Rev. Lett. 56, G.R. McNamara, G. Zanetti Use of the Boltzmann Equation to Simulate Lattice-Gas Automata, Phys. Rev. Lett. 61(20), S. Succi, O. Filippova, G. Smith, E. Kaxiras Applying the Lattice Boltzmann Equation to Multiscale Fluid Problems, Comp. Sci. Eng., Nov-Dec 2001,
Modelowanie komputerowe dynamiki płynów Maciej Matyka Instytut Fizyki Teoretycznej
 Modelowanie komputerowe dynamiki płynów 2011-12-05 Maciej Matyka Instytut Fizyki Teoretycznej Hydrodynamika http://www.realflow.com/ Konkursy na wydziale fizyki Lata 1999-2011 Oprogramowanie popularyzujące
Modelowanie komputerowe dynamiki płynów 2011-12-05 Maciej Matyka Instytut Fizyki Teoretycznej Hydrodynamika http://www.realflow.com/ Konkursy na wydziale fizyki Lata 1999-2011 Oprogramowanie popularyzujące
Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych.
 Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych. Jedną z metod symulacji dynamiki cieczy jest zastosowanie metody siatkowej Boltzmanna.
Katarzyna Jesionek Zastosowanie symulacji dynamiki cieczy oraz ośrodków sprężystych w symulatorach operacji chirurgicznych. Jedną z metod symulacji dynamiki cieczy jest zastosowanie metody siatkowej Boltzmanna.
CUDA część 1. platforma GPGPU w obliczeniach naukowych. Maciej Matyka
 CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
CUDA część 1 platforma GPGPU w obliczeniach naukowych Maciej Matyka Bariery sprzętowe (procesory) ok na. 1 10 00 la raz t y Gdzie jesteśmy? a ok. 2 razy n 10 lat (ZK) Rozwój 1985-2004 i dalej? O roku ów
Modelowanie przepływu krwi przez aortę brzuszną człowieka
 Modelowanie przepływu krwi przez aortę brzuszną człowieka Maciej Matyka1, Zbigniew Koza1 Łukasz Mirosław2 1 Uniwersytet Wrocławski Instytut Fizyki Teoretycznej we współpracy z 2 Fizyka komputerowa we Wrocławiu
Modelowanie przepływu krwi przez aortę brzuszną człowieka Maciej Matyka1, Zbigniew Koza1 Łukasz Mirosław2 1 Uniwersytet Wrocławski Instytut Fizyki Teoretycznej we współpracy z 2 Fizyka komputerowa we Wrocławiu
Implementacja modelu FHP w technologii NVIDIA CUDA
 Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 1 Model 1.1
Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 1 Model 1.1
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
CUDA jako platforma GPGPU w obliczeniach naukowych
 CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA jako platforma GPGPU w obliczeniach naukowych Seminarium Grupy Neutrinowej, 12.12.2011 Maciej Matyka, Zbigniew Koza Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Bariery sprzętowe (procesory)
CUDA. cudniejsze przyk ady
 CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
CUDA cudniejsze przyk ady Agenda: CPU vs. GPU Mnożenie macierzy CPU Mnożenie macierzy - GPU Sploty Macierze CPU vs. GPU CPU: GPU: Mnożenie wykonywane w kolejnych iteracjach pętli. Przechodzimy przez pierwszy
Programowanie kart graficznych
 CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
CUDA Compute Unified Device Architecture Programowanie kart graficznych mgr inż. Kamil Szostek AGH, WGGIOŚ, KGIS Wykorzystano materiały z kursu Programowanie kart graficznych prostsze niż myślisz M. Makowski
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Modelowanie i Animacja
 Maciej Matyka Uniwersytet Wrocławski Maciej Matyka Plan wykładu Dlaczego animujemy używając komputera? Dlaczego animujemy używając komputera? Wyciąg z minimum programowego fizyki w liceum... Kinematyka
Maciej Matyka Uniwersytet Wrocławski Maciej Matyka Plan wykładu Dlaczego animujemy używając komputera? Dlaczego animujemy używając komputera? Wyciąg z minimum programowego fizyki w liceum... Kinematyka
OPIS PRZEDMIOTU/MODUŁU KSZTAŁCENIA (SYLABUS)
") Załącznik nr 2 do zarządzenia Nr 33/2012 z dnia 25 kwietnia 2012 r. OPIS PRZEDMIOTU/MODUŁU KSZTAŁCENIA (SYLABUS) 1. Nazwa przedmiotu/modułu w języku polskim Symulacje komputerowe dynamiki płynów 2. Nazwa
Załącznik nr 2 do zarządzenia Nr 33/2012 z dnia 25 kwietnia 2012 r. OPIS PRZEDMIOTU/MODUŁU KSZTAŁCENIA (SYLABUS) 1. Nazwa przedmiotu/modułu w języku polskim Symulacje komputerowe dynamiki płynów 2. Nazwa
Programowanie Równoległe Wykład, CUDA praktycznie 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Programowanie Równoległe Wykład, 07.01.2014 CUDA praktycznie 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce Wykład 2: Cuda +
Projekt 6: Równanie Poissona - rozwiązanie metodą algebraiczną.
 Projekt 6: Równanie Poissona - rozwiązanie metodą algebraiczną. Tomasz Chwiej 9 sierpnia 18 1 Wstęp 1.1 Dyskretyzacja n y V V 1 V 3 1 j= i= 1 V 4 n x Rysunek 1: Geometria układu i schemat siatki obliczeniowej
Projekt 6: Równanie Poissona - rozwiązanie metodą algebraiczną. Tomasz Chwiej 9 sierpnia 18 1 Wstęp 1.1 Dyskretyzacja n y V V 1 V 3 1 j= i= 1 V 4 n x Rysunek 1: Geometria układu i schemat siatki obliczeniowej
Wielkoskalowe obliczenia komputerowej dynamiki płynów na procesorach graficznych -- pakiet Sailfish
 Michał Januszewski Materialy do broszury końcowej TWING. Wielkoskalowe obliczenia komputerowej dynamiki płynów na procesorach graficznych -- pakiet Sailfish Od około 5 lat procesory graficzne (GPU) znajdują
Michał Januszewski Materialy do broszury końcowej TWING. Wielkoskalowe obliczenia komputerowej dynamiki płynów na procesorach graficznych -- pakiet Sailfish Od około 5 lat procesory graficzne (GPU) znajdują
Programowanie Współbieżne
 Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Programowanie Współbieżne Agnieszka Łupińska 5 października 2016 Hello World! helloworld.cu: #include global void helloworld(){ int thid = (blockidx.x * blockdim.x) + threadidx.x; printf("hello
Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii.
 Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii. Opiekun naukowy: dr hab. prof. UŚ Marcin Kostur Celem tych badań jest zastosowanie symulacji układu krwionośnego do diagnostyki
Od wielkoskalowych obliczeń równoległych do innowacyjnej diagnostyki w kardiologii. Opiekun naukowy: dr hab. prof. UŚ Marcin Kostur Celem tych badań jest zastosowanie symulacji układu krwionośnego do diagnostyki
17.1 Podstawy metod symulacji komputerowych dla klasycznych układów wielu cząstek
 Janusz Adamowski METODY OBLICZENIOWE FIZYKI 1 Rozdział 17 KLASYCZNA DYNAMIKA MOLEKULARNA 17.1 Podstawy metod symulacji komputerowych dla klasycznych układów wielu cząstek Rozważamy układ N punktowych cząstek
Janusz Adamowski METODY OBLICZENIOWE FIZYKI 1 Rozdział 17 KLASYCZNA DYNAMIKA MOLEKULARNA 17.1 Podstawy metod symulacji komputerowych dla klasycznych układów wielu cząstek Rozważamy układ N punktowych cząstek
Fizyka komputerowa(ii)
") Instytut Fizyki Fizyka komputerowa(ii) Studia magisterskie Prowadzący kurs: Dr hab. inż. Włodzimierz Salejda, prof. PWr Godziny konsultacji: Poniedziałki i wtorki w godzinach 13.00 15.00 pokój 223 lub
Instytut Fizyki Fizyka komputerowa(ii) Studia magisterskie Prowadzący kurs: Dr hab. inż. Włodzimierz Salejda, prof. PWr Godziny konsultacji: Poniedziałki i wtorki w godzinach 13.00 15.00 pokój 223 lub
Wprowadzenie do programowania w środowisku CUDA. Środowisko CUDA
 Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
Wprowadzenie do programowania w środowisku CUDA Środowisko CUDA 1 Budowa procesora CPU i GPU Architektura GPU wymaga większej ilości tranzystorów na przetwarzanie danych Control ALU ALU ALU ALU Cache DRAM
METODA ELEMENTÓW SKOŃOCZNYCH Projekt
 METODA ELEMENTÓW SKOŃOCZNYCH Projekt Wykonali: Maciej Sobkowiak Tomasz Pilarski Profil: Technologia przetwarzania materiałów Semestr 7, rok IV Prowadzący: Dr hab. Tomasz STRĘK 1. Analiza przepływu ciepła.
METODA ELEMENTÓW SKOŃOCZNYCH Projekt Wykonali: Maciej Sobkowiak Tomasz Pilarski Profil: Technologia przetwarzania materiałów Semestr 7, rok IV Prowadzący: Dr hab. Tomasz STRĘK 1. Analiza przepływu ciepła.
Programowanie Równoległe wykład 12. OpenGL + algorytm n ciał. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie Równoległe wykład 12 OpenGL + algorytm n ciał Maciej Matyka Instytut Fizyki Teoretycznej CUDA z OpenGL 1. Dane dla kerneli znajdują się na karcie GFX. 2. Chcemy liczyć i rysować używając
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 Projektowanie kerneli Zasady optymalizacji: należy maksymalizować liczbę wątków (w rozsądnych granicach, granice zależą
Symulacje komputerowe dynamiki płynów LBM i Karman vortex street
 Symulacje komputerowe dynamiki płynów LBM i Karman vortex street Beata Kowal 1 Wstęp 1.1 LMP LBM (Lattice Boltzmann methods) to metody komputerowej symulacji płynów. Zamiast rozwiazywac równanie Naviera-Stokesa
Symulacje komputerowe dynamiki płynów LBM i Karman vortex street Beata Kowal 1 Wstęp 1.1 LMP LBM (Lattice Boltzmann methods) to metody komputerowej symulacji płynów. Zamiast rozwiazywac równanie Naviera-Stokesa
Rozkłady statyczne Maxwella Boltzmana. Konrad Jachyra I IM gr V lab
 Rozkłady statyczne Maxwella Boltzmana Konrad Jachyra I IM gr V lab MODEL STATYCZNY Model statystyczny hipoteza lub układ hipotez, sformułowanych w sposób matematyczny (odpowiednio w postaci równania lub
Rozkłady statyczne Maxwella Boltzmana Konrad Jachyra I IM gr V lab MODEL STATYCZNY Model statystyczny hipoteza lub układ hipotez, sformułowanych w sposób matematyczny (odpowiednio w postaci równania lub
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Moc płynąca z kart graficznych
 Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Moc płynąca z kart graficznych Cuda za darmo! Czyli programowanie generalnego przeznaczenia na kartach graficznych (GPGPU) 22 października 2013 Paweł Napieracz /20 Poruszane aspekty Przetwarzanie równoległe
Przegląd 4 Aerodynamika, algorytmy genetyczne, duże kroki i dynamika pozycji. Modelowanie fizyczne w animacji komputerowej Maciej Matyka
 Przegląd 4 Aerodynamika, algorytmy genetyczne, duże kroki i dynamika pozycji Modelowanie fizyczne w animacji komputerowej Maciej Matyka Wykład z Modelowania przegląd 4 1. Animation Aerodynamics 2. Algorytmy
Przegląd 4 Aerodynamika, algorytmy genetyczne, duże kroki i dynamika pozycji Modelowanie fizyczne w animacji komputerowej Maciej Matyka Wykład z Modelowania przegląd 4 1. Animation Aerodynamics 2. Algorytmy
Szybka wielobiegunowa metoda elementów brzegowych w analizie układów liniowosprężystych
 Katedra Wytrzymałości Materiałów i Metod Komputerowych Mechaniki Politechnika Śląska, Gliwice Szybka wielobiegunowa metoda elementów brzegowych w analizie układów liniowosprężystych Algorytm SWMEB. Część
Katedra Wytrzymałości Materiałów i Metod Komputerowych Mechaniki Politechnika Śląska, Gliwice Szybka wielobiegunowa metoda elementów brzegowych w analizie układów liniowosprężystych Algorytm SWMEB. Część
Drgania poprzeczne belki numeryczna analiza modalna za pomocą Metody Elementów Skończonych dr inż. Piotr Lichota mgr inż.
 Drgania poprzeczne belki numeryczna analiza modalna za pomocą Metody Elementów Skończonych dr inż. Piotr Lichota mgr inż. Joanna Szulczyk Politechnika Warszawska Instytut Techniki Lotniczej i Mechaniki
Drgania poprzeczne belki numeryczna analiza modalna za pomocą Metody Elementów Skończonych dr inż. Piotr Lichota mgr inż. Joanna Szulczyk Politechnika Warszawska Instytut Techniki Lotniczej i Mechaniki
Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr zimowy 2017/2018
 Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr zimowy 2017/2018 Tomasz Chwiej 22 stycznia 2019 1 Równania różniczkowe zwyczajne Zastosowanie szeregu Taylora do konstrukcji ilorazów
Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr zimowy 2017/2018 Tomasz Chwiej 22 stycznia 2019 1 Równania różniczkowe zwyczajne Zastosowanie szeregu Taylora do konstrukcji ilorazów
Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr 1
 Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr 1 Tomasz Chwiej 6 czerwca 2016 1 Równania różniczkowe zwyczajne Zastosowanie szeregu Taylora do konstrukcji ilorazów różnicowych: iloraz
Zagdanienia do egzaminu z Inżynierskich Metod Numerycznych - semestr 1 Tomasz Chwiej 6 czerwca 2016 1 Równania różniczkowe zwyczajne Zastosowanie szeregu Taylora do konstrukcji ilorazów różnicowych: iloraz
Implementacja modelu FHP w technologii NVIDIA CUDA
 Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Uniwersytet Wrocławski Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Sebastian Szkoda Implementacja modelu FHP w technologii NVIDIA CUDA Opiekun: dr hab. Zbigniew Koza, prof. UWr. 2 Streszczenie
Metody rozwiązania równania Schrödingera
 Metody rozwiązania równania Schrödingera Równanie Schrödingera jako algebraiczne zagadnienie własne Rozwiązanie analityczne dla skończonej i nieskończonej studni potencjału Problem rozwiązania równania
Metody rozwiązania równania Schrödingera Równanie Schrödingera jako algebraiczne zagadnienie własne Rozwiązanie analityczne dla skończonej i nieskończonej studni potencjału Problem rozwiązania równania
Rola superkomputerów i modelowania numerycznego we współczesnej fzyce. Gabriel Wlazłowski
 Rola superkomputerów i modelowania numerycznego we współczesnej fzyce Gabriel Wlazłowski Podział fizyki historyczny Fizyka teoretyczna Fizyka eksperymentalna Podział fizyki historyczny Ogólne równania
Rola superkomputerów i modelowania numerycznego we współczesnej fzyce Gabriel Wlazłowski Podział fizyki historyczny Fizyka teoretyczna Fizyka eksperymentalna Podział fizyki historyczny Ogólne równania
Programowanie CUDA informacje praktycznie i. Wersja
 Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Programowanie CUDA informacje praktycznie i przykłady Wersja 16.12.2013 Podstawowe operacje na GPU cudasetdevice() Określenie GPU i ustanowienie kontekstu (analog w GPU tego czym jest proces dla CPU) dla
Symulacje komputerowe dynamiki płynów Model FHP i przepływ Poiseuille a
 Symulacje komputerowe dynamiki płynów Model FHP i przepływ Poiseuille a Beata Kowal 1 Wstęp 1.1 Model FHP Model gazu sieciowego służy do symulowania przepływu płynów. Model gazu FHP oparty jest na sieci
Symulacje komputerowe dynamiki płynów Model FHP i przepływ Poiseuille a Beata Kowal 1 Wstęp 1.1 Model FHP Model gazu sieciowego służy do symulowania przepływu płynów. Model gazu FHP oparty jest na sieci
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Nowoczesne narzędzia obliczeniowe do projektowania i optymalizacji kotłów
 Nowoczesne narzędzia obliczeniowe do projektowania i optymalizacji kotłów Mateusz Szubel, Mariusz Filipowicz Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and
Nowoczesne narzędzia obliczeniowe do projektowania i optymalizacji kotłów Mateusz Szubel, Mariusz Filipowicz Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and
Numeryczna symulacja rozpływu płynu w węźle
 231 Prace Instytutu Mechaniki Górotworu PAN Tom 7, nr 3-4, (2005), s. 231-236 Instytut Mechaniki Górotworu PAN Numeryczna symulacja rozpływu płynu w węźle JERZY CYGAN Instytut Mechaniki Górotworu PAN,
231 Prace Instytutu Mechaniki Górotworu PAN Tom 7, nr 3-4, (2005), s. 231-236 Instytut Mechaniki Górotworu PAN Numeryczna symulacja rozpływu płynu w węźle JERZY CYGAN Instytut Mechaniki Górotworu PAN,
Zaawansowane algorytmy i struktury danych
 Zaawansowane algorytmy i struktury danych u dr Barbary Marszał-Paszek Opracowanie pytań praktycznych z egzaminów. Strona 1 z 12 Pytania praktyczne z kolokwium zaliczeniowego z 19 czerwca 2014 (studia dzienne)
Zaawansowane algorytmy i struktury danych u dr Barbary Marszał-Paszek Opracowanie pytań praktycznych z egzaminów. Strona 1 z 12 Pytania praktyczne z kolokwium zaliczeniowego z 19 czerwca 2014 (studia dzienne)
Algorytm. a programowanie -
 Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
Algorytm a programowanie - Program komputerowy: Program komputerowy można rozumieć jako: kod źródłowy - program komputerowy zapisany w pewnym języku programowania, zestaw poszczególnych instrukcji, plik
Politechnika Wrocławska, Wydział Informatyki i Zarządzania. Modelowanie
 Politechnika Wrocławska, Wydział Informatyki i Zarządzania Modelowanie Zad Wyznacz transformaty Laplace a poniższych funkcji, korzystając z tabeli transformat: a) 8 3e 3t b) 4 sin 5t 2e 5t + 5 c) e5t e
Politechnika Wrocławska, Wydział Informatyki i Zarządzania Modelowanie Zad Wyznacz transformaty Laplace a poniższych funkcji, korzystając z tabeli transformat: a) 8 3e 3t b) 4 sin 5t 2e 5t + 5 c) e5t e
Wykład 2. Przykład zastosowania teorii prawdopodobieństwa: procesy stochastyczne (Markova)
") Wykład 2 Przykład zastosowania teorii prawdopodobieństwa: procesy stochastyczne (Markova) 1. Procesy Markova: definicja 2. Równanie Chapmana-Kołmogorowa-Smoluchowskiego 3. Przykład dyfuzji w kapilarze
Wykład 2 Przykład zastosowania teorii prawdopodobieństwa: procesy stochastyczne (Markova) 1. Procesy Markova: definicja 2. Równanie Chapmana-Kołmogorowa-Smoluchowskiego 3. Przykład dyfuzji w kapilarze
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie. W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.
 CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
CUDA obliczenia ogólnego przeznaczenia na mocno zrównoleglonym sprzęcie W prezentacji wykorzystano materiały firmy NVIDIA (http://www.nvidia.com) 1 Architektura karty graficznej W porównaniu z tradycyjnym
Programowanie Równoległe wykład, 21.01.2013. CUDA, przykłady praktyczne 1. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Programowanie Równoległe wykład, 21.01.2013 CUDA, przykłady praktyczne 1 Maciej Matyka Instytut Fizyki Teoretycznej Motywacja l CPU vs GPU (anims) Plan CUDA w praktyce Wykład 1: CUDA w praktyce l aplikacja
Maciej Matyka. Modelowanie numeryczne transportu. płynów przez ośrodki porowate. Rozprawa doktorska. Promotor: dr hab.
 Rozprawa doktorska Modelowanie numeryczne transportu płynów przez ośrodki porowate Maciej Matyka Promotor: dr hab. Zbigniew Koza Uniwersytet Wrocławski Wydział Fizyki i Astronomii Wrocław, 2008 Spis treści
Rozprawa doktorska Modelowanie numeryczne transportu płynów przez ośrodki porowate Maciej Matyka Promotor: dr hab. Zbigniew Koza Uniwersytet Wrocławski Wydział Fizyki i Astronomii Wrocław, 2008 Spis treści
Sieci obliczeniowe poprawny dobór i modelowanie
 Sieci obliczeniowe poprawny dobór i modelowanie 1. Wstęp. Jednym z pierwszych, a zarazem najważniejszym krokiem podczas tworzenia symulacji CFD jest poprawne określenie rozdzielczości, wymiarów oraz ilości
Sieci obliczeniowe poprawny dobór i modelowanie 1. Wstęp. Jednym z pierwszych, a zarazem najważniejszym krokiem podczas tworzenia symulacji CFD jest poprawne określenie rozdzielczości, wymiarów oraz ilości
CUDA PROGRAMOWANIE PIERWSZE PROSTE PRZYKŁADY RÓWNOLEGŁE. Michał Bieńkowski Katarzyna Lewenda
 PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
PROGRAMOWANIE RÓWNOLEGŁE PIERWSZE PROSTE PRZYKŁADY Michał Bieńkowski Katarzyna Lewenda Programowanie równoległe Dodawanie wektorów SPIS TREŚCI Fraktale Podsumowanie Ćwiczenia praktyczne Czym jest? PROGRAMOWANIE
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki
 Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki dr inż. Marek Wojtyra Instytut Techniki Lotniczej
Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki dr inż. Marek Wojtyra Instytut Techniki Lotniczej
Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy. Wykład 6. Karol Tarnowski A-1 p.
 Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy Wykład 6 Karol Tarnowski karol.tarnowski@pwr.edu.pl A-1 p. 411B Plan prezentacji Funkcje w języku C Zasięg zmiennych Przekazywanie
Wstęp do programowania INP001213Wcl rok akademicki 2017/18 semestr zimowy Wykład 6 Karol Tarnowski karol.tarnowski@pwr.edu.pl A-1 p. 411B Plan prezentacji Funkcje w języku C Zasięg zmiennych Przekazywanie
Wykład 5. Metoda eliminacji Gaussa
 1 Wykład 5 Metoda eliminacji Gaussa Rozwiązywanie układów równań liniowych Układ równań liniowych może mieć dokładnie jedno rozwiązanie, nieskończenie wiele rozwiązań lub nie mieć rozwiązania. Metody dokładne
1 Wykład 5 Metoda eliminacji Gaussa Rozwiązywanie układów równań liniowych Układ równań liniowych może mieć dokładnie jedno rozwiązanie, nieskończenie wiele rozwiązań lub nie mieć rozwiązania. Metody dokładne
Plan Zajęć. Ćwiczenia rachunkowe
 Plan Zajęć 1. Termodynamika, 2. Grawitacja, Kolokwium I 3. Elektrostatyka + prąd 4. Pole Elektro-Magnetyczne Kolokwium II 5. Zjawiska falowe 6. Fizyka Jądrowa + niepewność pomiaru Kolokwium III Egzamin
Plan Zajęć 1. Termodynamika, 2. Grawitacja, Kolokwium I 3. Elektrostatyka + prąd 4. Pole Elektro-Magnetyczne Kolokwium II 5. Zjawiska falowe 6. Fizyka Jądrowa + niepewność pomiaru Kolokwium III Egzamin
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Inżynierskie metody numeryczne II. Konsultacje: wtorek 8-9:30. Wykład
 Inżynierskie metody numeryczne II Konsultacje: wtorek 8-9:30 Wykład Metody numeryczne dla równań hiperbolicznych Równanie przewodnictwa cieplnego. Prawo Fouriera i Newtona. Rozwiązania problemów 1D metodą
Inżynierskie metody numeryczne II Konsultacje: wtorek 8-9:30 Wykład Metody numeryczne dla równań hiperbolicznych Równanie przewodnictwa cieplnego. Prawo Fouriera i Newtona. Rozwiązania problemów 1D metodą
Układy równań liniowych. Krzysztof Patan
 Układy równań liniowych Krzysztof Patan Motywacje Zagadnienie kluczowe dla przetwarzania numerycznego Wiele innych zadań redukuje się do problemu rozwiązania układu równań liniowych, często o bardzo dużych
Układy równań liniowych Krzysztof Patan Motywacje Zagadnienie kluczowe dla przetwarzania numerycznego Wiele innych zadań redukuje się do problemu rozwiązania układu równań liniowych, często o bardzo dużych
Modelowanie rynków finansowych z wykorzystaniem pakietu R
 Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
Programowanie kart graficznych. Architektura i API część 2
 Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Programowanie kart graficznych Architektura i API część 2 CUDA hierarchia pamięci c.d. Globalna pamięć urządzenia: funkcje CUDA API takie jak cudamalloc() i cudafree() z założenia służą do manipulowania
Zaawansowane metody numeryczne Komputerowa analiza zagadnień różniczkowych 4. Równania różniczkowe zwyczajne podstawy teoretyczne
 Zaawansowane metody numeryczne Komputerowa analiza zagadnień różniczkowych 4. Równania różniczkowe zwyczajne podstawy teoretyczne P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ semestr letni 2005/06 Wstęp
Zaawansowane metody numeryczne Komputerowa analiza zagadnień różniczkowych 4. Równania różniczkowe zwyczajne podstawy teoretyczne P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ semestr letni 2005/06 Wstęp
Modelowanie absorbcji cząsteczek LDL w ściankach naczyń krwionośnych
 Modelowanie absorbcji cząsteczek LDL w ściankach naczyń krwionośnych Plan prezentacji Co to jest LDL? 1 Budowa naczynia krwionośnego 2 Przykładowe wyniki 3 Mechanizmy wnikania blaszki miażdżycowej w ścianki
Modelowanie absorbcji cząsteczek LDL w ściankach naczyń krwionośnych Plan prezentacji Co to jest LDL? 1 Budowa naczynia krwionośnego 2 Przykładowe wyniki 3 Mechanizmy wnikania blaszki miażdżycowej w ścianki
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Technologia informacyjna Algorytm Janusz Uriasz
 Technologia informacyjna Algorytm Janusz Uriasz Algorytm Algorytm - (łac. algorithmus); ścisły przepis realizacji działań w określonym porządku, system operacji, reguła komponowania operacji, sposób postępowania.
Technologia informacyjna Algorytm Janusz Uriasz Algorytm Algorytm - (łac. algorithmus); ścisły przepis realizacji działań w określonym porządku, system operacji, reguła komponowania operacji, sposób postępowania.
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: MODELOWANIE PROCESÓW ENERGETYCZNYCH Kierunek: ENERGETYKA Rodzaj przedmiotu: specjalności obieralny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE
Nazwa przedmiotu: MODELOWANIE PROCESÓW ENERGETYCZNYCH Kierunek: ENERGETYKA Rodzaj przedmiotu: specjalności obieralny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE
Implementacja sieci neuronowych na karcie graficznej. Waldemar Pawlaszek
 Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Implementacja sieci neuronowych na karcie graficznej Waldemar Pawlaszek Motywacja Czyli po co to wszystko? Motywacja Procesor graficzny GPU (Graphics Processing Unit) Wydajność Elastyczność i precyzja
Metody Obliczeniowe w Nauce i Technice
 9 - Rozwiązywanie układów równań nieliniowych Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl Contributors Anna Marciniec
9 - Rozwiązywanie układów równań nieliniowych Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl Contributors Anna Marciniec
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Wprowadzenie do numerycznej mechaniki płynów Kierunek: Mechanika i Budowa Maszyn Rodzaj przedmiotu: obowiązkowy na specjalności: Inżynieria cieplna i samochodowa Rodzaj zajęć: wykład,
Nazwa przedmiotu: Wprowadzenie do numerycznej mechaniki płynów Kierunek: Mechanika i Budowa Maszyn Rodzaj przedmiotu: obowiązkowy na specjalności: Inżynieria cieplna i samochodowa Rodzaj zajęć: wykład,
Rzadkie gazy bozonów
 Rzadkie gazy bozonów Tomasz Sowiński Proseminarium Fizyki Teoretycznej 15 listopada 2004 Rzadkie gazy bozonów p.1/25 Bardzo medialne zdjęcie Rok 1995. Pierwsza kondensacja. Zaobserwowana w przestrzeni
Rzadkie gazy bozonów Tomasz Sowiński Proseminarium Fizyki Teoretycznej 15 listopada 2004 Rzadkie gazy bozonów p.1/25 Bardzo medialne zdjęcie Rok 1995. Pierwsza kondensacja. Zaobserwowana w przestrzeni
Ramowy Program Specjalizacji MODELOWANIE MATEMATYCZNE i KOMPUTEROWE PROCESÓW FIZYCZNYCH Studia Specjalistyczne (III etap)
") Ramowy Program Specjalizacji MODELOWANIE MATEMATYCZNE i KOMPUTEROWE PROCESÓW FIZYCZNYCH Studia Specjalistyczne (III etap) Z uwagi na ogólno wydziałowy charakter specjalizacji i możliwość wykonywania prac
Ramowy Program Specjalizacji MODELOWANIE MATEMATYCZNE i KOMPUTEROWE PROCESÓW FIZYCZNYCH Studia Specjalistyczne (III etap) Z uwagi na ogólno wydziałowy charakter specjalizacji i możliwość wykonywania prac
Metody numeryczne Wykład 4
 Metody numeryczne Wykład 4 Dr inż. Michał Łanczont Instytut Elektrotechniki i Elektrotechnologii E419, tel. 4293, m.lanczont@pollub.pl, http://m.lanczont.pollub.pl Zakres wykładu Metody skończone rozwiązywania
Metody numeryczne Wykład 4 Dr inż. Michał Łanczont Instytut Elektrotechniki i Elektrotechnologii E419, tel. 4293, m.lanczont@pollub.pl, http://m.lanczont.pollub.pl Zakres wykładu Metody skończone rozwiązywania
Wykład 3 Zjawiska transportu Dyfuzja w gazie, przewodnictwo cieplne, lepkość gazu, przewodnictwo elektryczne
 Wykład 3 Zjawiska transportu Dyfuzja w gazie, przewodnictwo cieplne, lepkość gazu, przewodnictwo elektryczne W3. Zjawiska transportu Zjawiska transportu zachodzą gdy układ dąży do stanu równowagi. W zjawiskach
Wykład 3 Zjawiska transportu Dyfuzja w gazie, przewodnictwo cieplne, lepkość gazu, przewodnictwo elektryczne W3. Zjawiska transportu Zjawiska transportu zachodzą gdy układ dąży do stanu równowagi. W zjawiskach
Komputerowe modelowanie zjawisk fizycznych
 Komputerowe modelowanie zjawisk fizycznych Ryszard Kutner Zakład Dydaktyki Fizyki Instytut Fizyki Doświadczalnej, Wydział Fizyki Uniwersytet Warszawski IX FESTIWAL NAUKI WARSZAWA 2005 BRAK INWESTYCJI W
Komputerowe modelowanie zjawisk fizycznych Ryszard Kutner Zakład Dydaktyki Fizyki Instytut Fizyki Doświadczalnej, Wydział Fizyki Uniwersytet Warszawski IX FESTIWAL NAUKI WARSZAWA 2005 BRAK INWESTYCJI W
Ćwiczenie 2 Numeryczna symulacja swobodnego spadku ciała w ośrodku lepkim (Instrukcja obsługi interfejsu użytkownika)
") Ćwiczenie 2 Numeryczna symulacja swobodnego spadku ciała w ośrodku lepkim (Instrukcja obsługi interfejsu użytkownika) 1 1 Cel ćwiczenia Celem ćwiczenia jest rozwiązanie równań ruchu ciała (kuli) w ośrodku
Ćwiczenie 2 Numeryczna symulacja swobodnego spadku ciała w ośrodku lepkim (Instrukcja obsługi interfejsu użytkownika) 1 1 Cel ćwiczenia Celem ćwiczenia jest rozwiązanie równań ruchu ciała (kuli) w ośrodku
Teoria kinetyczno cząsteczkowa
 Teoria kinetyczno cząsteczkowa Założenie Gaz składa się z wielkiej liczby cząstek znajdujących się w ciągłym, chaotycznym ruchu i doznających zderzeń (dwucząstkowych) Cel: Wyprowadzić obserwowane (makroskopowe)
Teoria kinetyczno cząsteczkowa Założenie Gaz składa się z wielkiej liczby cząstek znajdujących się w ciągłym, chaotycznym ruchu i doznających zderzeń (dwucząstkowych) Cel: Wyprowadzić obserwowane (makroskopowe)
Wskaźniki. Programowanie Proceduralne 1
 Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
Wskaźniki Programowanie Proceduralne 1 Adresy zmiennych Sterta 1 #include 2 3 int a = 2 ; 4 5 int main ( ) 6 { 7 int b = 3 ; 8 9 printf ( " adres zmiennej a %p\n", &a ) ; 10 printf ( " adres
FIZYKA STATYSTYCZNA. Liczne eksperymenty dowodzą, że ciała składają się z wielkiej liczby podstawowych
 FIZYKA STATYSTYCZA Liczne eksperymenty dowodzą, że ciała składają się z wielkiej liczby podstawowych elementów takich jak atomy czy cząsteczki. Badanie ruchów pojedynczych cząstek byłoby bardzo trudnym
FIZYKA STATYSTYCZA Liczne eksperymenty dowodzą, że ciała składają się z wielkiej liczby podstawowych elementów takich jak atomy czy cząsteczki. Badanie ruchów pojedynczych cząstek byłoby bardzo trudnym
FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego)
") 2019-09-01 FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego) Treści z podstawy programowej przedmiotu POZIOM ROZSZERZONY (PR) SZKOŁY BENEDYKTA Podstawa programowa FIZYKA KLASA 1 LO (4-letnie po szkole
2019-09-01 FIZYKA klasa 1 Liceum Ogólnokształcącego (4 letniego) Treści z podstawy programowej przedmiotu POZIOM ROZSZERZONY (PR) SZKOŁY BENEDYKTA Podstawa programowa FIZYKA KLASA 1 LO (4-letnie po szkole
Informatyka I. Klasy i obiekty. Podstawy programowania obiektowego. dr inż. Andrzej Czerepicki. Politechnika Warszawska Wydział Transportu 2018
 Informatyka I Klasy i obiekty. Podstawy programowania obiektowego dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2018 Plan wykładu Pojęcie klasy Deklaracja klasy Pola i metody klasy
Informatyka I Klasy i obiekty. Podstawy programowania obiektowego dr inż. Andrzej Czerepicki Politechnika Warszawska Wydział Transportu 2018 Plan wykładu Pojęcie klasy Deklaracja klasy Pola i metody klasy
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tablice i struktury. czyli złożone typy danych. Programowanie Proceduralne 1
 Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Tablice i struktury czyli złożone typy danych. Programowanie Proceduralne 1 Tablica przechowuje elementy tego samego typu struktura jednorodna, homogeniczna Elementy identyfikowane liczbami (indeksem).
Wstęp do fizyki statystycznej: krytyczność i przejścia fazowe. Katarzyna Sznajd-Weron
 Wstęp do fizyki statystycznej: krytyczność i przejścia fazowe Katarzyna Sznajd-Weron Co to jest fizyka statystyczna? Termodynamika poziom makroskopowy Fizyka statystyczna poziom mikroskopowy Marcin Weron
Wstęp do fizyki statystycznej: krytyczność i przejścia fazowe Katarzyna Sznajd-Weron Co to jest fizyka statystyczna? Termodynamika poziom makroskopowy Fizyka statystyczna poziom mikroskopowy Marcin Weron
Rok akademicki: 2013/2014 Kod: WGG s Punkty ECTS: 5. Poziom studiów: Studia I stopnia Forma i tryb studiów: -
 Nazwa modułu: Matematyka stosowana Rok akademicki: 2013/2014 Kod: WGG-1-304-s Punkty ECTS: 5 Wydział: Wiertnictwa, Nafty i Gazu Kierunek: Górnictwo i Geologia Specjalność: - Poziom studiów: Studia I stopnia
Nazwa modułu: Matematyka stosowana Rok akademicki: 2013/2014 Kod: WGG-1-304-s Punkty ECTS: 5 Wydział: Wiertnictwa, Nafty i Gazu Kierunek: Górnictwo i Geologia Specjalność: - Poziom studiów: Studia I stopnia
Symulacje komputerowe
 Fizyka w modelowaniu i symulacjach komputerowych Jacek Matulewski (e-mail: jacek@fizyka.umk.pl) http://www.fizyka.umk.pl/~jacek/dydaktyka/modsym/ Symulacje komputerowe Dynamika bryły sztywnej Wersja: 8
Fizyka w modelowaniu i symulacjach komputerowych Jacek Matulewski (e-mail: jacek@fizyka.umk.pl) http://www.fizyka.umk.pl/~jacek/dydaktyka/modsym/ Symulacje komputerowe Dynamika bryły sztywnej Wersja: 8
Ćwiczenie 3. Iteracja, proste metody obliczeniowe
 Ćwiczenie 3. Iteracja, proste metody obliczeniowe Instrukcja iteracyjna ( pętla liczona ) Pętla pozwala na wielokrotne powtarzanie bloku instrukcji. Liczba powtórzeń wynika z definicji modyfikowanej wartości
Ćwiczenie 3. Iteracja, proste metody obliczeniowe Instrukcja iteracyjna ( pętla liczona ) Pętla pozwala na wielokrotne powtarzanie bloku instrukcji. Liczba powtórzeń wynika z definicji modyfikowanej wartości
Wydajność otwartych implementacji metody sieciowej Boltzmanna na CPU i GPU
 Maciej Matyka Zbigniew Koza Wydział Fizyki i Astronomii Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Uniwersytet Wrocławski oraz Vratis Sp.
Maciej Matyka Zbigniew Koza Wydział Fizyki i Astronomii Wydział Fizyki i Astronomii Instytut Fizyki Teoretycznej Instytut Fizyki Teoretycznej Uniwersytet Wrocławski Uniwersytet Wrocławski oraz Vratis Sp.
Informatyka i komputerowe wspomaganie prac inżynierskich
 Informatyka i komputerowe wspomaganie prac inżynierskich Dr Zbigniew Kozioł - wykład Dr Grzegorz Górski - laboratorium Wykład III Numeryczne rozwiązywanie równań różniczkowych. MES, Metoda Elementów Skończonych
Informatyka i komputerowe wspomaganie prac inżynierskich Dr Zbigniew Kozioł - wykład Dr Grzegorz Górski - laboratorium Wykład III Numeryczne rozwiązywanie równań różniczkowych. MES, Metoda Elementów Skończonych
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
Programowanie procesorów graficznych GPGPU 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń (processing element): jeden wątek wykonywany
RÓWNANIA NIELINIOWE Maciej Patan
 RÓWNANIA NIELINIOWE Maciej Patan Uniwersytet Zielonogórski Przykład 1 Prędkość v spadającego spadochroniarza wyraża się zależnością v = mg ( 1 e c t) m c gdzie g = 9.81 m/s 2. Dla współczynnika oporu c
RÓWNANIA NIELINIOWE Maciej Patan Uniwersytet Zielonogórski Przykład 1 Prędkość v spadającego spadochroniarza wyraża się zależnością v = mg ( 1 e c t) m c gdzie g = 9.81 m/s 2. Dla współczynnika oporu c
Wykład 1 i 2. Termodynamika klasyczna, gaz doskonały
 Wykład 1 i 2 Termodynamika klasyczna, gaz doskonały dr hab. Agata Fronczak, prof. PW Wydział Fizyki, Politechnika Warszawska 1 stycznia 2017 dr hab. A. Fronczak (Wydział Fizyki PW) Wykład: Elementy fizyki
Wykład 1 i 2 Termodynamika klasyczna, gaz doskonały dr hab. Agata Fronczak, prof. PW Wydział Fizyki, Politechnika Warszawska 1 stycznia 2017 dr hab. A. Fronczak (Wydział Fizyki PW) Wykład: Elementy fizyki
Podstawy Programowania Algorytmy i programowanie
 Podstawy Programowania Algorytmy i programowanie Katedra Analizy Nieliniowej, WMiI UŁ Łódź, 3 października 2013 r. Algorytm Algorytm w matematyce, informatyce, fizyce, itp. lub innej dziedzinie życia,
Podstawy Programowania Algorytmy i programowanie Katedra Analizy Nieliniowej, WMiI UŁ Łódź, 3 października 2013 r. Algorytm Algorytm w matematyce, informatyce, fizyce, itp. lub innej dziedzinie życia,
Wykład 6. Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym
 1 Wykład 6 Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym ELIMINACJA GAUSSA Z WYBOREM CZĘŚCIOWYM ELEMENTÓW PODSTAWOWYCH 2 Przy pomocy klasycznego algorytmu eliminacji
1 Wykład 6 Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym ELIMINACJA GAUSSA Z WYBOREM CZĘŚCIOWYM ELEMENTÓW PODSTAWOWYCH 2 Przy pomocy klasycznego algorytmu eliminacji
IX. MECHANIKA (FIZYKA) KWANTOWA
 KWANTOWA") IX. MECHANIKA (FIZYKA) KWANTOWA IX.1. OPERACJE OBSERWACJI. a) klasycznie nie ważna kolejność, w jakiej wykonujemy pomiary. AB = BA A pomiar wielkości A B pomiar wielkości B b) kwantowo wartość obserwacji
IX. MECHANIKA (FIZYKA) KWANTOWA IX.1. OPERACJE OBSERWACJI. a) klasycznie nie ważna kolejność, w jakiej wykonujemy pomiary. AB = BA A pomiar wielkości A B pomiar wielkości B b) kwantowo wartość obserwacji
Rozważmy nieustalony, adiabatyczny, jednowymiarowy ruch gazu nielepkiego i nieprzewodzącego ciepła. Mamy następujące równania rządzące tym ruchem:
 WYKŁAD 13 DYNAMIKA MAŁYCH (AKUSTYCZNYCH) ZABURZEŃ W GAZIE Rozważmy nieustalony, adiabatyczny, jednowymiarowy ruch gazu nielepkiego i nieprzewodzącego ciepła. Mamy następujące równania rządzące tym ruchem:
WYKŁAD 13 DYNAMIKA MAŁYCH (AKUSTYCZNYCH) ZABURZEŃ W GAZIE Rozważmy nieustalony, adiabatyczny, jednowymiarowy ruch gazu nielepkiego i nieprzewodzącego ciepła. Mamy następujące równania rządzące tym ruchem:
Ściśliwa magnetyczna warstwa graniczna jako prosty model Tachokliny we wnętrzu Słońca. Krzysztof Mizerski,
 Ściśliwa magnetyczna warstwa graniczna jako prosty model Tachokliny we wnętrzu Słońca Krzysztof Mizerski, Univ. Leeds, School of Maths, Woodhouse Lane, Leeds, UK przy współpracy z: Davidem Hughes 23 Czerwca
Ściśliwa magnetyczna warstwa graniczna jako prosty model Tachokliny we wnętrzu Słońca Krzysztof Mizerski, Univ. Leeds, School of Maths, Woodhouse Lane, Leeds, UK przy współpracy z: Davidem Hughes 23 Czerwca
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Dotyczy to zarówno istniejących już związków, jak i związków, których jeszcze dotąd nie otrzymano.
 Chemia teoretyczna to dział chemii zaliczany do chemii fizycznej, zajmujący się zagadnieniami związanymi z wiedzą chemiczną od strony teoretycznej, tj. bez wykonywania eksperymentów na stole laboratoryjnym.
Chemia teoretyczna to dział chemii zaliczany do chemii fizycznej, zajmujący się zagadnieniami związanymi z wiedzą chemiczną od strony teoretycznej, tj. bez wykonywania eksperymentów na stole laboratoryjnym.
Podstawy programowania. Wykład 6 Wskaźniki. Krzysztof Banaś Podstawy programowania 1
 Podstawy programowania. Wykład 6 Wskaźniki Krzysztof Banaś Podstawy programowania 1 Adresy zmiennych Język C pozwala na operowanie adresami w pamięci stąd, między innymi, kwalifikowanie C jako języka relatywnie
Podstawy programowania. Wykład 6 Wskaźniki Krzysztof Banaś Podstawy programowania 1 Adresy zmiennych Język C pozwala na operowanie adresami w pamięci stąd, między innymi, kwalifikowanie C jako języka relatywnie
Przedmowa Przewodność cieplna Pole temperaturowe Gradient temperatury Prawo Fourier a...15
 Spis treści 3 Przedmowa. 9 1. Przewodność cieplna 13 1.1. Pole temperaturowe.... 13 1.2. Gradient temperatury..14 1.3. Prawo Fourier a...15 1.4. Ustalone przewodzenie ciepła przez jednowarstwową ścianę
Spis treści 3 Przedmowa. 9 1. Przewodność cieplna 13 1.1. Pole temperaturowe.... 13 1.2. Gradient temperatury..14 1.3. Prawo Fourier a...15 1.4. Ustalone przewodzenie ciepła przez jednowarstwową ścianę
Laboratorium komputerowe z wybranych zagadnień mechaniki płynów
 ANALIZA PRZEKAZYWANIA CIEPŁA I FORMOWANIA SIĘ PROFILU TEMPERATURY DLA NIEŚCIŚLIWEGO, LEPKIEGO PRZEPŁYWU LAMINARNEGO W PRZEWODZIE ZAMKNIĘTYM Cel ćwiczenia Celem ćwiczenia będzie obserwacja procesu formowania
ANALIZA PRZEKAZYWANIA CIEPŁA I FORMOWANIA SIĘ PROFILU TEMPERATURY DLA NIEŚCIŚLIWEGO, LEPKIEGO PRZEPŁYWU LAMINARNEGO W PRZEWODZIE ZAMKNIĘTYM Cel ćwiczenia Celem ćwiczenia będzie obserwacja procesu formowania