HPC na biurku. Wojciech De bski
|
|
|
- Zofia Olejniczak
- 9 lat temu
- Przeglądów:
Transkrypt

1 na biurku Wojciech De bski

2 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one could get out of a typical desktop computer or workstation in order to solve large problems in science engineering or business. pp.1


3 Historia (Supercomputing) pp.2

4 Obliczenia szeregowe i ro wnoległe podział według M. Flyna Klasyczny komputer for(i=0;i<n;i++) c[i] = a[i] + b[i]; c[0] = a[0] + b[0]; c[1] = a[1] + b[1];... c[n] = a[n] + b[n]; pp.3

![Obliczenia szeregowe i ro wnoległe Image processing (GPU) a a[0] a[1]](/docs-images/23/1992269/images/5-0.jpg "a[2] a[3] a[4] = ==> a * 0.5 a[0]*0.5 a[1]*0.5 a[2]*0.5 a[3]*0.5 a[4]*0.")
5 Obliczenia szeregowe i ro wnoległe Image processing (GPU) a a[0] a[1] a[2] a[3] a[4] = ==> a * 0.5 a[0]*0.5 a[1]*0.5 a[2]*0.5 a[3]*0.5 a[4]*0.5 pp.4
![a[2] a[3] a[4] = ==> a * 0.5 a[0]*0.](/docs-images/46/1992269/images/page_5.jpg "5 a[1]*0.5 a[2]*0.5 a[3]*0.5 a[4]*0.")
 a[0]=sin(x) b[0]=cos(x) a[1]=sin(x) b[1]=cos(x) a[2]=sin(x) b[2]=cos(x)... pp.")
6 Obliczenia szeregowe i ro wnoległe Analiza sygnalow (procesory DSP) a b = = sin(x) cos(x) a[0]=sin(x) b[0]=cos(x) a[1]=sin(x) b[1]=cos(x) a[2]=sin(x) b[2]=cos(x)... pp.5
![cos(x) a[0]=sin(x) b[0]=cos(x) a[1]=sin(x)](/docs-images/46/1992269/images/page_6.jpg "b[1]=cos(x) a[2]=sin(x) b[2]=cos(x)... pp.")

7 Obliczenia szeregowe i ro wnoległe Symulacja pola falowego pp.6

8 Dwie podstawowe konfiguracje superkomputero w F systemy rozproszone - wiele niezalez nych jednostek obliczeniowych komunikujacych sie ze soba poprzez zewnetrzn a siec F systemy upakowane gdzie wszystkie jednostki obliczeniowe dziela wspo lna pamiec przez kto ra wymieniaja informacje pp.7

9 Architektury komputero w - wspo lna pamiec pp.8


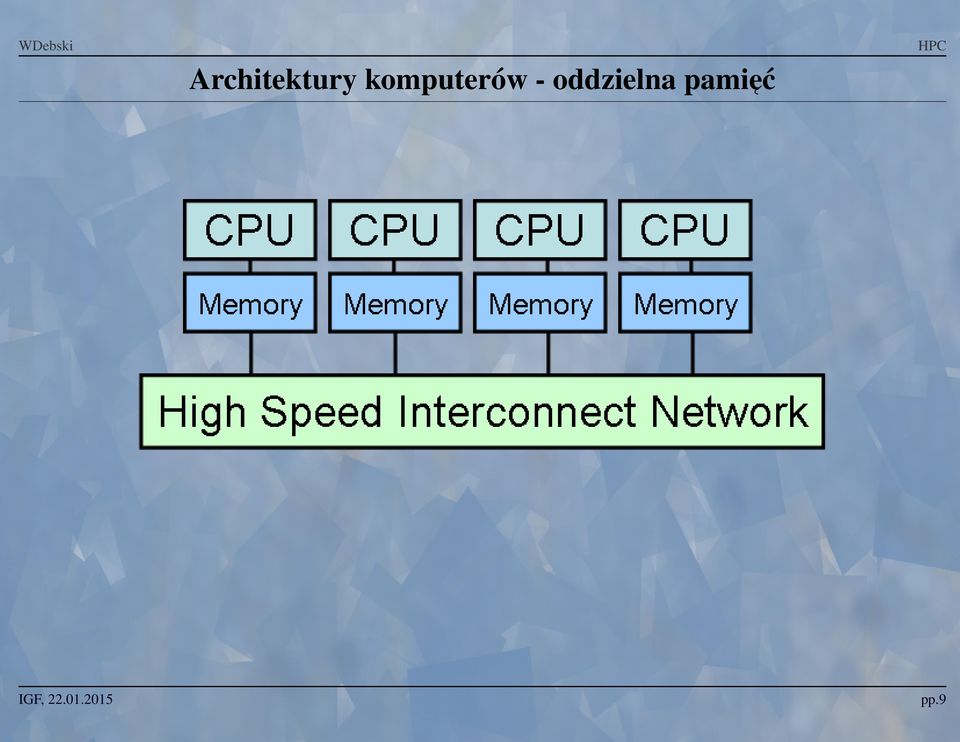
10 Architektury komputero w - oddzielna pamiec pp.9
11 Klastry obliczeniowe - klasyczne rozwiazanie z dzielona pamieci a pp.10

12 Architektury komputero w - hybrydy pp.11

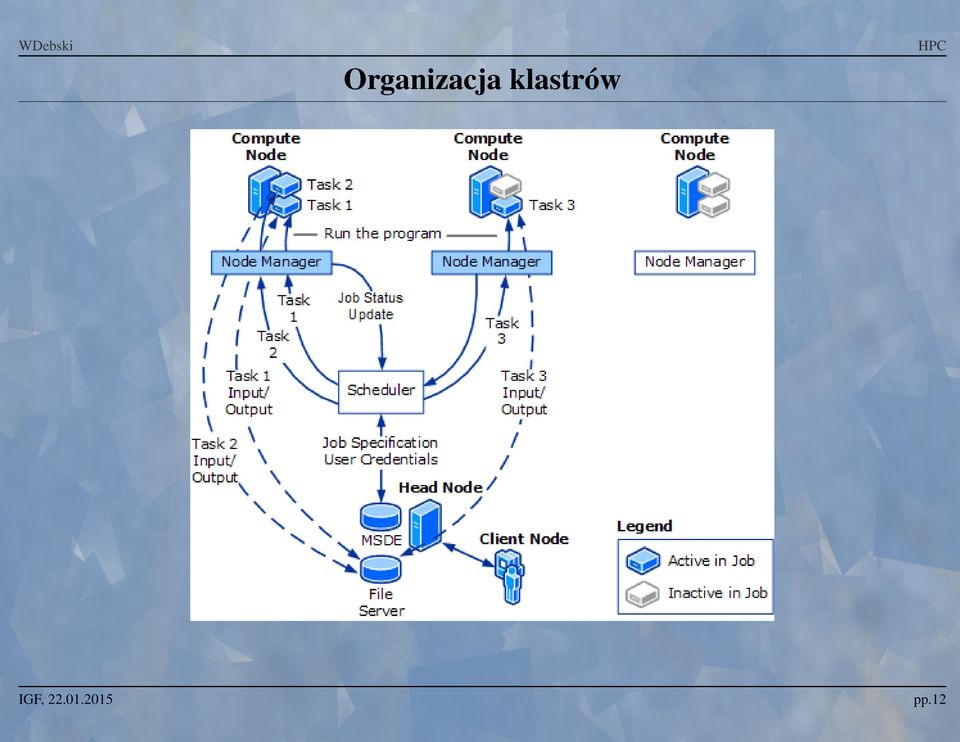
13 Organizacja klastro w pp.12

14 MPI - Message Passing Interface pp.13

15 MPI - Message Passing Interface ro wnoległe dodanie wektoro w ~c = ~a + ~b for(i=0;i<n;i++) c[i]= a[i] + b[i] for (i=0;i<=nx;i++) MPI_Send(&c33[i][0] nz+1 MPI_FLOAT dest21 MPI_COMM_WORLD); for (i=0;i<=nx;i++) MPI_Send(&c44[i][0] nz+1 MPI_FLOAT dest21 MPI_COMM_WORLD);.. for (i=0;i<=nxs;i++) sxm[i][0]=xs+(float)i*dxs;.. for (dest=1;dest<=all_proc-1;dest++) { MPI_Recv(&pom 1 MPI_INT dest101 MPI_COMM_WORLD &status); printf ("Proc:%d Transfer succeed!\n"pom);} pp.14
![nz+1 MPI_FLOAT dest21 MPI_COMM_WORLD);.. for (i=0;i<=nxs;i++) sxm[i][0]=xs+(float)i*dxs;.](/docs-images/46/1992269/images/page_15.jpg ". for (dest=1;dest<=all_proc-1;dest++) { MPI_Recv(&pom 1 MPI_INT dest101 MPI_COMM_WORLD &status); printf (\"Proc:%d")

16 Shared memory model pp.15


17 Shared memory + heterogeneous environment pp.16


18 GPGPU - general purpose graphic processing units pp.17

19 GPGPU - Tesla K80 F 4992 procesory potokowe F pamiec 24Gb F zegar 1 GHz F wydajnos c 6 Tflops pp.18

20 Cel seminarium - pytania 1. Jak wykorzystac wielo-rdzeniowos c naszych PC to w? 2. Jak wykorzystac posiadane karty graficzne jako akceleratory obliczeniowe (GPGPU)? bez koniecznos ci stawania sie zawodowym programista uczenia nowego jezyka programowa nia budowy kart graficznych itp. pp.19
?")
21 Odpowiedz Wykorzystac modele programowania ro wnoległego dla architektury wspo łdzielonej pamieci: F OpenMP3 F OpenMP4 pp.20
22 Wsparcie dla OpenMP F kompilator gcc ver. 3.* ver 4.* (OpenMP3) F kompilator gcc ver 5.* (styczen 2015) (OpenMP4) pp.21
23 Co to jest OpenMP? OpenMP (ang. Open Multi-Processing) jest interfejs programowania aplikacji (API) umoz liwiaja cy tworzenie programo w komputerowych dla systemw wieloprocesorowych z pamieci Składa sie ze a dzielona. zbioru dyrektyw kompilatora bibliotek oraz zmiennych s rodowiskowych majacych wpływ na sposb wykonywa nia programu. pp.22

24 Informacje o OpenMP: pp.23
25 Model programowania ro wnoległego OpenMP F Zadanie dzielone jest pomiedzy watki F Watki do obliczen uz ywaja prywatnych kopii zmiennych kto re sa niedostepne dla innych watko w F Watki komunikuja sie przez zmienne wspo łdzielone (zmienne shared) lub dodatkowe mechanizmy synchronizacji watko w (np. tzw barrier) F niebezpieczen stwo tzw. data race pp.24
26 Podstawowa struktura: watki f or(i = 0; i < N ; i + +)c[i] = a[i] + b[i] f or(i = 0; i < 10; i + +) f or(i = 11; i < 20; i + +) f or(i = 21; i < 30; i + +) c[i] = a[i] + b[i] c[i] = a[i] + b[i] c[i] = a[i] + b[i] pp.25

27 Uz ywanie pamieci pp.26
28 Co musi zrobic programista F podac kto ra czes c ma byc zro wnoleglona F okres lic kto re zmienne sa prywatne dla kaz dego z watko w F okres lic warunki synchronizacji Reszte pracy wykona za nas kompilator! pp.27
29 Przykład petla for #include<stdio.h> #include<math.h> #define NS int main() { double sum=0x; long unsigned int i; #pragma omp parallel for private (i) reduction(+:sum) for (i=0; i<ns; i++) sum+=exp(-i*i); printf("sum=%g\n"sum); return; } pp.28
30 Kompilacja: gcc e1.c -fopenmp -lm -o e1 pp.29
31 Przykład 2 Uwaga na hazard czasowy: nigdy nie wiadomo kto ry watek skon czy prace pierwszy pp.30
32 KONIEC Prepared: 21 stycznia 2015 W prezentacji wykorzystano materiały z Wikipedii oraz Nvidi pp.31
Wprowadzenie do OpenMP
 Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Wprowadzenie do OpenMP OZUKO Kamil Dworak OZUKO Wprowadzenie do OpenMP Kamil Dworak 1 / 25 OpenMP (ang. Open Multi-Processing) opracowany w 1997 przez radę Architecture Review Board, obliczenia rówoległe
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm
 Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Spis treści. 1 Wprowadzenie. 1.1 Podstawowe pojęcia. 1 Wprowadzenie Podstawowe pojęcia Sieci komunikacyjne... 3
 Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Współbieżne
 Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Programowanie Współbieżne MPI ( główne źródło http://pl.wikipedia.org/wiki/mpi) 1 Historia Początkowo (lata 80) różne środowiska przesyłania komunikatów dla potrzeb programowania równoległego. Niektóre
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++
 Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
Zaawansowane programowanie w języku C++ Zarządzanie pamięcią w C++ Prezentacja jest współfinansowana przez Unię Europejską w ramach Europejskiego Funduszu Społecznego w projekcie pt. Innowacyjna dydaktyka
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią
 Pro Dialog 15 (2003), 107 121 Wydawnictwo NAKOM Poznań OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią Monika DEMICHOWICZ, Paweł MAZUR Politechnika Wrocławska, Wydział Informatyki
Pro Dialog 15 (2003), 107 121 Wydawnictwo NAKOM Poznań OpenMP środowisko programowania komputerów równoległych ze wspólną pamięcią Monika DEMICHOWICZ, Paweł MAZUR Politechnika Wrocławska, Wydział Informatyki
Pojęcia podstawowe. Oprogramowanie systemów równoległych i rozproszonych. Wykład 1. Klasyfikacja komputerów równoległych I
 Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
Systemy operacyjne III
 Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Ćwiczenie nr: 9 Obliczenia rozproszone MPI
 Ćwiczenie nr: 9 Temat: Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach
Ćwiczenie nr: 9 Temat: Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach
Programowanie współbieżne Wstęp do OpenMP. Rafał Skinderowicz
 Programowanie współbieżne Wstęp do OpenMP Rafał Skinderowicz Czym jest OpenMP? OpenMP = Open Multi-Processing interfejs programowania aplikacji (API) dla pisania aplikacji równoległych na komputery wieloprocesorowe
Programowanie współbieżne Wstęp do OpenMP Rafał Skinderowicz Czym jest OpenMP? OpenMP = Open Multi-Processing interfejs programowania aplikacji (API) dla pisania aplikacji równoległych na komputery wieloprocesorowe
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Programowanie współbieżne... (2)
") Programowanie współbieżne... (2) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Prawo Amdahla - powtórka Wydajność E = S/n (na procesor). Stąd S = En E 1 f + 1 f n 1 fn+1 f
Programowanie współbieżne... (2) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Prawo Amdahla - powtórka Wydajność E = S/n (na procesor). Stąd S = En E 1 f + 1 f n 1 fn+1 f
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
2. Charakterystyka obliczeń współbieżnych i rozproszonych.
 Od autora(ooo to o mnie mowa :)): Starałem się wygrzebać w necie trochę więcej niż u Gronka na samych slajdach, dlatego odpowiedzi na niektóre pytania są długie (w sensie dłuższe niż normalnie :)), wydaje
Od autora(ooo to o mnie mowa :)): Starałem się wygrzebać w necie trochę więcej niż u Gronka na samych slajdach, dlatego odpowiedzi na niektóre pytania są długie (w sensie dłuższe niż normalnie :)), wydaje
Obliczenia rozproszone z wykorzystaniem MPI
 Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Obliczenia rozproszone z wykorzystaniem Zarys wst u do podstaw :) Zak lad Metod Obliczeniowych Chemii UJ 8 sierpnia 2005 1 e konkretniej Jak szybko, i czemu tak wolno? 2 e szczegó lów 3 Dyspozytor Macierz
Obliczenia rozproszone MPI
 Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach rozproszonych. Aktualna
Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach rozproszonych. Aktualna
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Obliczenia rozproszone MPI
 Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach rozproszonych. Aktualna
Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach rozproszonych. Aktualna
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Programowanie współbieżne. Iwona Kochańska
 1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
Programowanie w modelu przesyłania komunikatów specyfikacja MPI. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Programowanie w modelu przesyłania komunikatów specyfikacja MPI Krzysztof Banaś Obliczenia równoległe 1 Model przesyłania komunikatów Paradygmat send receive wysyłanie komunikatu: send( cel, identyfikator_komunikatu,
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Enterprise, czyli instytutowy klaster obliczeniowy
 Enterprise, czyli instytutowy klaster obliczeniowy Janusz Szwabiński szwabin@ift.uni.wroc.pl Enterprise, czyli instytutowy klaster obliczeniowy p.1/28 Plan wykładu Klastry komputerowe Enterprise od podszewki
Enterprise, czyli instytutowy klaster obliczeniowy Janusz Szwabiński szwabin@ift.uni.wroc.pl Enterprise, czyli instytutowy klaster obliczeniowy p.1/28 Plan wykładu Klastry komputerowe Enterprise od podszewki
 Ą ź ń Ś Ź ń Ę Ś ź Ę ń ć ć ż ż ż ż ć ń Ę Ż ń ż ć ć Ł Ż Ż ćń Ą ć ć Ą Ż Ź Ą ż Ż ż Ą Ą Ę ń ć ć ń ń Ę ń ź ń Ż ż ć ń Ż ż ć Ż ń ż Ą ć ć Ą Ż Ą Ż Ł ź Ą ń Ź ń Ę ż Ń Ę Ń ż ć ż Ń ń ń Ę Ę ż Ź Ż ć Ą Ż ń ń Ż ć ż Ż ń
Ą ź ń Ś Ź ń Ę Ś ź Ę ń ć ć ż ż ż ż ć ń Ę Ż ń ż ć ć Ł Ż Ż ćń Ą ć ć Ą Ż Ź Ą ż Ż ż Ą Ą Ę ń ć ć ń ń Ę ń ź ń Ż ż ć ń Ż ż ć Ż ń ż Ą ć ć Ą Ż Ą Ż Ł ź Ą ń Ź ń Ę ż Ń Ę Ń ż ć ż Ń ń ń Ę Ę ż Ź Ż ć Ą Ż ń ń Ż ć ż Ż ń
Systemy operacyjne. Systemy operacyjne. Systemy operacyjne. Zadania systemu operacyjnego. Abstrakcyjne składniki systemu. System komputerowy
 Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Ćwiczenie nr: 9 Obliczenia rozproszone MPI
 Ćwiczenie nr: 9 Temat: Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach
Ćwiczenie nr: 9 Temat: Obliczenia rozproszone MPI 1. Informacje ogólne MPI (Message Passing Interface) nazwa standardu biblioteki przesyłania komunikatów dla potrzeb programowania równoległego w sieciach
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Programowanie systemów z pamięcią wspólną specyfikacja OpenMP Krzysztof Banaś Obliczenia równoległe 1 OpenMP Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
GRIDY OBLICZENIOWE. Piotr Majkowski
 GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie procesorów graficznych GPGPU. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
Programowanie procesorów graficznych GPGPU Krzysztof Banaś Obliczenia równoległe 1 OpenCL projektowanie kerneli Przypomnienie: kernel program realizowany przez urządzenie OpenCL wątek (work item) rdzeń
OpenMP. Programowanie aplikacji równoległych i rozproszonych. Wykład 2. Model programowania. Standard OpenMP. Dr inż. Tomasz Olas
 OpenMP Programowanie aplikacji równoległych i rozproszonych Wykład 2 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP (Open Multi-Processing)
OpenMP Programowanie aplikacji równoległych i rozproszonych Wykład 2 Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP (Open Multi-Processing)
Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP
 OpenMP p. 1/4 Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP OpenMP
OpenMP p. 1/4 Wprowadzenie do zrównoleglania aplikacji z wykorzystaniem standardu OpenMP Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska OpenMP OpenMP
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Podsystem graficzny. W skład podsystemu graficznego wchodzą: karta graficzna monitor
 Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Podstawy programowania C. dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/
 Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Podstawy programowania C dr. Krystyna Łapin http://www.mif.vu.lt/~moroz/c/ Tematy Struktura programu w C Typy danych Operacje Instrukcja grupująca Instrukcja przypisania Instrukcja warunkowa Struktura
Programowanie współbieżne... (4) Andrzej Baran 2010/11
 Andrzej Baran 2010/11") Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
Programowanie współbieżne... (4) Andrzej Baran 2010/11 LINK: http://kft.umcs.lublin.pl/baran/prir/index.html Przykład Zaczniemy od znanego już przykładu: Iloczyn skalarny różne modele Programowanie współbieżne...
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI
 Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI Patryk Mach Uniwersytet Jagielloński, Instytut Fizyki im. Mariana Smoluchowskiego OpenMP (Open Multi Processing) zbiór dyrektyw kompilatora, funkcji
Komputerowe Obliczenia Równoległe: Wstęp do OpenMP i MPI Patryk Mach Uniwersytet Jagielloński, Instytut Fizyki im. Mariana Smoluchowskiego OpenMP (Open Multi Processing) zbiór dyrektyw kompilatora, funkcji
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie kart graficznych
 Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Programowanie kart graficznych Sławomir Wernikowski swernikowski@wi.zut.edu.pl Wykład #1: Łagodne wprowadzenie do programowania w technologii NVIDIA CUDA Terminologia: Co to jest GPGPU? General-Purpose
Zadania badawcze prowadzone przez Zakład Technik Programowania:
 Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
Zadania badawcze prowadzone przez Zakład Technik Programowania: - Opracowanie metod zrównoleglania programów sekwencyjnych o rozszerzonym zakresie stosowalności. - Opracowanie algorytmów obliczenia tranzytywnego
OpenMP część praktyczna
 .... OpenMP część praktyczna Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 17 marca 2011 Zbigniew Koza (WFiA UWr) OpenMP część praktyczna 1 / 34 Spis treści Spis treści...1
.... OpenMP część praktyczna Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 17 marca 2011 Zbigniew Koza (WFiA UWr) OpenMP część praktyczna 1 / 34 Spis treści Spis treści...1
Biblioteka PCJ do naukowych obliczeń równoległych
 Biblioteka PCJ do naukowych obliczeń równoległych Zakład Obliczeń Równoległych i Rozproszonych Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika Chopina 12/18, 87-100 Toruń faramir@mat.umk.pl
Biblioteka PCJ do naukowych obliczeń równoległych Zakład Obliczeń Równoległych i Rozproszonych Wydział Matematyki i Informatyki Uniwersytet Mikołaja Kopernika Chopina 12/18, 87-100 Toruń faramir@mat.umk.pl
Programowanie procesorów graficznych w CUDA.
 Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Programowanie procesorów graficznych w CUDA. Kompilujemy program Alokacja zasobów gpgpu oraz załadowanie modułu CUDA odbywa się za pomocą komend: qsub -q gpgpu -I -l walltime=2:00:00,nodes=1:ppn=1:gpus=1
Informatyka. informatyka i nauki komputerowe (computer science)
") Informatyka informacja i jej reprezentacje informatyka i nauki komputerowe (computer science) algorytmika efektywność algorytmów poprawność algorytmów złożoność obliczeniowa, problemy NP-trudne (NP-zupełne)
Informatyka informacja i jej reprezentacje informatyka i nauki komputerowe (computer science) algorytmika efektywność algorytmów poprawność algorytmów złożoność obliczeniowa, problemy NP-trudne (NP-zupełne)
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Programowanie w modelu równoległości danych oraz dzielonej globalnej pamięci wspólnej Krzysztof Banaś Obliczenia równoległe 1 Model równoległości danych Model SPMD (pierwotnie dla maszyn SIMD) Zrównoleglenie
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki
 Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Robotyki i Mechatroniki, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Infrastruktura PLGrid Nowa jakość usług informatycznych w służbie nauki Maciej Czuchry, Mariola Czuchry ACK Cyfronet AGH Katedra Robotyki i Mechatroniki, Kraków 2015 Agenda ACK Cyfronet AGH główne kompetencje
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE APLIKACJI RÓWNOLEGŁYCH I ROZPROSZONYCH Programming parallel and distributed applications Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach specjalności: Inżynieria
Nazwa przedmiotu: PROGRAMOWANIE APLIKACJI RÓWNOLEGŁYCH I ROZPROSZONYCH Programming parallel and distributed applications Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach specjalności: Inżynieria
DYNAMICZNE PRZYDZIELANIE PAMIECI
 DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
DYNAMICZNE PRZYDZIELANIE PAMIECI Pamięć komputera, dostępna dla programu, dzieli się na cztery obszary: kod programu, dane statyczne ( np. stałe i zmienne globalne programu), dane automatyczne zmienne
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład VII. Programowanie. dr inż. Janusz Słupik. Gliwice, 2014. Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2014 Janusz Słupik
 Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Wykład VII Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2014 c Copyright 2014 Janusz Słupik Kompilacja Kompilator C program do tłumaczenia kodu źródłowego na język maszynowy. Preprocesor
Programowanie Równoległe Wykład 4. MPI - Message Passing Interface. Maciej Matyka Instytut Fizyki Teoretycznej
 Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Programowanie Równoległe Wykład 4 MPI - Message Passing Interface Maciej Matyka Instytut Fizyki Teoretycznej Jak używać w MPI? Donald Knuth: We should forget about small efficiencies, say about 97% of
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński
 Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
Programowanie aplikacji na iphone. Wstęp do platformy ios. Łukasz Zieliński Plan Prezentacji. Programowanie ios. Jak zacząć? Co warto wiedzieć o programowaniu na platformę ios? Kilka słów na temat Obiective-C.
Typy złożone. Struktury, pola bitowe i unie. Programowanie Proceduralne 1
 Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
Typy złożone Struktury, pola bitowe i unie. Programowanie Proceduralne 1 Typy podstawowe Typy całkowite: char short int long Typy zmiennopozycyjne float double Modyfikatory : unsigned, signed Typ wskaźnikowy
MMX i SSE. Zbigniew Koza. Wydział Fizyki i Astronomii Uniwersytet Wrocławski. Wrocław, 10 marca 2011. Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16
 MMX i SSE 1 / 16") MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
MMX i SSE Zbigniew Koza Wydział Fizyki i Astronomii Uniwersytet Wrocławski Wrocław, 10 marca 2011 Zbigniew Koza (WFiA UWr) MMX i SSE 1 / 16 Spis treści Spis treści 1 Wstęp Zbigniew Koza (WFiA UWr) MMX
Klaster obliczeniowy
 Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Warsztaty promocyjne Usług kampusowych PLATON U3 Klaster obliczeniowy czerwiec 2012 Przemysław Trzeciak Centrum Komputerowe Politechniki Łódzkiej Agenda (czas: 20min) 1) Infrastruktura sprzętowa wykorzystana
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Programowanie w standardzie MPI
 Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Programowanie w standardzie MPI 1 2 Podstawy programowania z przesyłaniem komunikatów Model systemu równoległego w postaci p procesów, każdy z nich z własną przestrzenią adresową, nie współdzieloną z innymi
Informatyka Studia II stopnia
 Wydział Elektrotechniki, Elektroniki, Informatyki i Automatyki Politechnika Łódzka Informatyka Studia II stopnia Katedra Informatyki Stosowanej Program kierunku Informatyka Specjalności Administrowanie
Wydział Elektrotechniki, Elektroniki, Informatyki i Automatyki Politechnika Łódzka Informatyka Studia II stopnia Katedra Informatyki Stosowanej Program kierunku Informatyka Specjalności Administrowanie
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego
 Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Zasoby i usługi Wrocławskiego Centrum Sieciowo-Superkomputerowego Mateusz Tykierko WCSS 20 stycznia 2012 Mateusz Tykierko (WCSS) 20 stycznia 2012 1 / 16 Supernova moc obliczeniowa: 67,54 TFLOPS liczba
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Open MP wer Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna
 Open MP wer. 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna 2019.0 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny i przenośny model równoległości (typu rozgałęzienie
Open MP wer. 2.5 Rafał Walkowiak Instytut Informatyki Politechniki Poznańskiej Wiosna 2019.0 OpenMP standard specyfikacji przetwarzania współbieżnego uniwersalny i przenośny model równoległości (typu rozgałęzienie
Systemy rozproszone. Państwowa Wyższa Szkoła Zawodowa w Chełmie. ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej w Lublinie
 Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory
 Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-19 Pętla while Pętla while Pętla
Programowanie I C / C++ laboratorium 02 Składnia pętli, typy zmiennych, operatory Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2013-02-19 Pętla while Pętla while Pętla
Elementy składowe: Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
 dla różnych języków programowania") OpenMP Elementy składowe: o o o dyrektywy dla kompilatorów funkcje biblioteczne zmienne środowiskowe Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
OpenMP Elementy składowe: o o o dyrektywy dla kompilatorów funkcje biblioteczne zmienne środowiskowe Przenośność oprogramowania Model SPMD Szczegółowe wersje (bindings) dla różnych języków programowania
Obliczenia równoległe. Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205
 Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl http://aragorn.pb.bialystok.pl/~wkwedlo pokój 205 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem
Sosnowiec, dn... Imię i nazwisko...
 Sosnowiec, dn.... Imię i nazwisko... Test znajomości zaawansowanch technik programowania składa się z 10 ptań. Dla każdego ptania zaproponowano czter odpowiedzi, z którch tlko jedna jest prawidłowa. Na
Sosnowiec, dn.... Imię i nazwisko... Test znajomości zaawansowanch technik programowania składa się z 10 ptań. Dla każdego ptania zaproponowano czter odpowiedzi, z którch tlko jedna jest prawidłowa. Na
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1
 Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
Programowanie w modelu przesyłania komunikatów specyfikacja MPI, cd. Krzysztof Banaś Obliczenia równoległe 1 MPI dynamiczne zarządzanie procesami MPI 2 umożliwia dynamiczne zarządzanie procesami, choć
PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP.
 P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
Testowanie przypuszczenia Beal'a z wykorzystaniem klasycznych procesorów
 Testowanie przypuszczenia Beal'a z wykorzystaniem klasycznych procesorów Testing Beal conjecture using classical processors Monika Kwiatkowska 1 i Łukasz Świerczewski 2 Treść: Praca obejmuje testowanie
Testowanie przypuszczenia Beal'a z wykorzystaniem klasycznych procesorów Testing Beal conjecture using classical processors Monika Kwiatkowska 1 i Łukasz Świerczewski 2 Treść: Praca obejmuje testowanie
Budowa karty sieciowej; Sterowniki kart sieciowych; Specyfikacja interfejsu sterownika sieciowego; Open data link interface (ODI); Packet driver
; Packet driver") BUDOWA KART SIECIOWYCH I ZASADA DZIAŁANIA Karty sieciowe i sterowniki kart sieciowych Budowa karty sieciowej; Sterowniki kart sieciowych; Specyfikacja interfejsu sterownika sieciowego; Open data link interface
BUDOWA KART SIECIOWYCH I ZASADA DZIAŁANIA Karty sieciowe i sterowniki kart sieciowych Budowa karty sieciowej; Sterowniki kart sieciowych; Specyfikacja interfejsu sterownika sieciowego; Open data link interface
Język ludzki kod maszynowy
 Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
Język ludzki kod maszynowy poziom wysoki Język ludzki (mowa) Język programowania wysokiego poziomu Jeśli liczba punktów jest większa niż 50, test zostaje zaliczony; w przeciwnym razie testu nie zalicza
UNIWERSYTET MARII CURIE-SKŁODOWSKIEJ W LUBLINIE Wydział Matematyki, Fizyki i Informatyki
 UNIWERSYTET MARII CURIE-SKŁODOWSKIEJ W LUBLINIE Wydział Matematyki, Fizyki i Informatyki Kierunek: Informatyka Specjalność: Informatyka medyczna i telemedycyna Łukasz Świerczewski nr albumu: 260172 Testowanie
UNIWERSYTET MARII CURIE-SKŁODOWSKIEJ W LUBLINIE Wydział Matematyki, Fizyki i Informatyki Kierunek: Informatyka Specjalność: Informatyka medyczna i telemedycyna Łukasz Świerczewski nr albumu: 260172 Testowanie
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń