Modelowanie Ekonometryczne i Prognozowanie
|
|
|
- Irena Stefaniak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Modelowanie Ekonometryczne i Prognozowanie David Ramsey david.ramsey@pwr.edu.pl strona domowa: 27 lutego / 77

2 Opis Kursu 1. Podstawy oraz Cele Modelowania Ekonometrycznego i Prognozowania. 2. Regresja. 3. Szeregi Czasowe. 2 / 77

3 1. Podstawy i Cele Ogólnie mówiąc, chcemy modelować jak pewna zmienna Y (zwana zależna) zależy od grupy zmiennych wyjaśniających X 1, X 2,..., X k. Tutaj używam słowa zależność w sensie matematycznym (czyli jeżeli Y zależy od X i, to nie znaczy koniecznie że istnieje związek przyczniowo-skutkowy między nimi). np. Liczba zachorowań na grypę zależy od sprzedaży lodów (im więcej lodów sprzedano, czyli gdy ogólnie jest ciepło, tym mniej zachorowań). np. Liczba urodzeń na 1000 osób w gminie zależy od liczby bocianów na kilometr kwadratowy (jest więcej urodzeń w gminach wiejskich). 3 / 77
. np.")
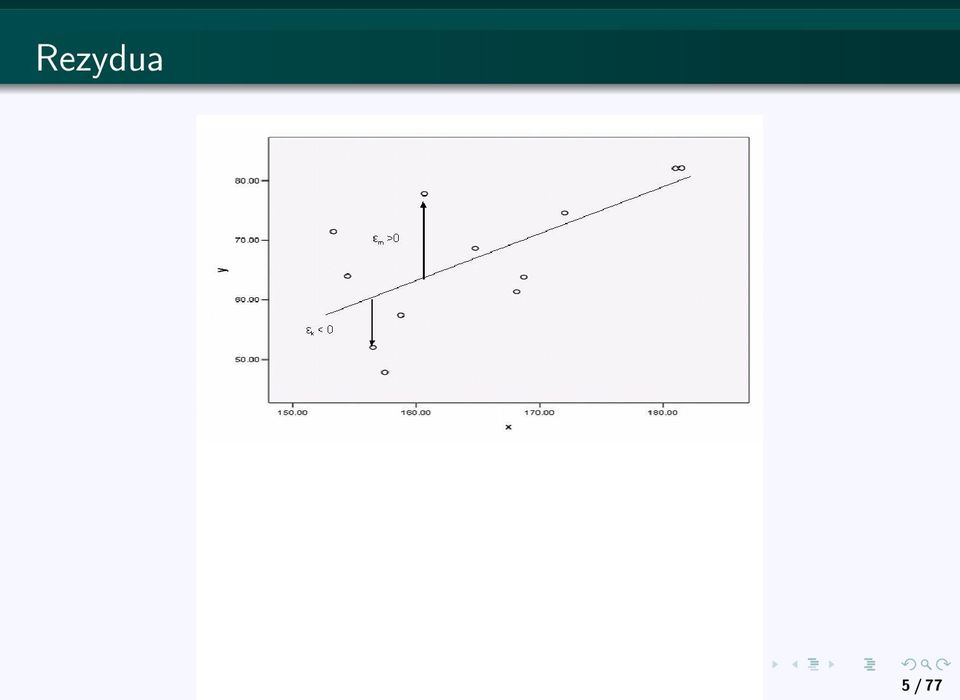
4 Podstawy i Cele W tym celu, zbieramy obserwacje zmiennej Y, oznaczono Y 1, Y 2,..., Y n oraz odpowiadające im obserwacje zmiennych wyjaśniających. Obserwacje zmiennej X i oznaczono X i,1, X i,2,..., X i,n. Chcemy zbudować model (ekonometryczny), np. Y = f (X 1, X 2,..., X k ) + ɛ, który opisuje jak wartość Y zależy od wartości zmiennych wyjaśniających. Tutaj ɛ jest tak zwanym rezyduum (błędem losowym). Gdy ɛ > 0, Y jest więsze niż przewidujemy z modelu, a gdy ɛ < 0, Y jest mniejsze niż przewidujemy. 4 / 77
 + ɛ, który opisuje jak wartość Y zależy od wartości zmiennych wyjaśniających.")
5 Rezydua 5 / 77
6 Regresja i Szeregi Czasowe Ogólnie, można podzielić modele na dwa rodzaje. 1. Modele regresyjne. 2. Szeregi czasowe. Mamy obserwacje X 1, X 2, X 3,..., X T, gdzie X t jest obserwacją zmiennej X w czasie t. 6 / 77

7 2. Regresja Wstęp Używamy modeli regresyjnych gdy obserwacje zmiennej Y nie są uporządkowane w czasie (lub możemy założyć że obserwacja zmiennej Y w danym momencie nie zależy od poprzednich obserwacji tej zmiennej). Na przykład, jeżeli popularny, niesezonowy produkt pierwszej potrzeby (np. szampon, makaron) jest na rynku od pewnego czasu, możemy założyć że sprzedaż nie zależy od czasu. 7 / 77
. Na przykład, jeżeli popularny, niesezonowy produkt pierwszej potrzeby (np.")
8 Regresja Chcemy zobaczyć jak sprzedaż tego produktu zależy od wydatków na reklamy a) telewizyjne, b) radiowe, c) na billboardach w danym miesiącu. Możemy zbudować prosty model liniowy Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 3 + ɛ, gdzie Y jest sprzedażą, X 1, X 2 i X 3 wydatkami na reklamy telewizyjne, radiowe i billboardowe, odpowiednio. W ten sposób zbudowaliśmy model sprzedaży zaobserwowanej w przeszłości (jest to pierwszy z celów modelowania). 8 / 77

9 Regresja i Prognozowanie Drugim celem jest prognozowanie sprzedaży w przyszłości przy danej strategii. W tym przypadku, firma ma kontrolę nad wyborem wartości zmiennych wyjaśniających. Według tego modelu, każda złotówka wydana na np. reklamy telewizyjne powiększy sprzedaż o β 1 złotówkach. Korzystając z takiego podejścia, firma powinna zainwestować w medium odpowiadające największemu współczynnikowi β i. 9 / 77

10 Reszty i Diagnostyka George Box ( ), który był bardzo ważną postacią w rozwoju modeli ekonometrycznych, powiedział: Każdy model jest błędny, niektóre są przydatne Na przykład, nasz model Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 3 + ɛ jest na pewno błędny, bo zakłada że każda dodatkowa złotówka wydana na pewne medium przynosi ten sam wzrost przychodu. 10 / 77

11 Reszty i Diagnostyka Ale z powodu nasycenia, po jakimś czasie każda dodatkowa złotówka przynosi coraz mniejsze wzrosty przychodu (z powodu zmeczenia reklamami, przychód może nawet maleć). Z tego powodu, gdy bardzo dużo wydajemy na reklamy telewizyjne, sprzedaż będzie mniejsza niż przewidujemy. To znaczy że duże wydatki na reklamy telewizyjne są związane z ujemnymi rezyduami. 11 / 77

12 Reszty i Diagnostyka Regresja zakłada że rezydua nie są skorelowane z wartościami zmiennych wyjaśniającymi. Jeżeli rezydua się zmieniają dosyć systematcznie wzgłędem jednej zmiennej wyjaśniającej, jest to znak że model nie jest przydatny. 12 / 77

13 Wybór Zmiennych Wyjaśniających Mamy n obserwacji zmiennej zależnej Y oraz k zmiennych wyjaśniających. Chcemy żeby n było dużo większe niż k. Uwaga: Możemy DOKŁADNIE opisać n obserwacji zmiennej Y za pomocą obserwacji n 1 DOWOLNYCH zmiennych wyjaśniających, ale jak chcemy przewidzieć przyszłe obserwacje zmiennej Y, model taki jest KOMPLETNIE NIEPRZYDATNY. 13 / 77

14 Wybór Zmiennych Wyjaśniających Wybieramy zmienne wyjaśniające żeby 1. Zmienne X 1, X 2,..., X k były skorelowane z Y (najlepiej żeby istniał bezpośredni związek między X i a Y ). 2. Zmienne X 1, X 2,..., X k nie powinny być mocno skorelowane z sobą. Uwaga: Jeżeli chcemy modelować sprzedaż lodów, lepiej wziąć temperaturę jako zmienną wyjaśniająca (związek bezpośredni) niż liczbę zachorowań na grypę (związek pośredni poprzez temperaturę). 14 / 77

15 Problem Mocnych Korelacji między Zmiennymi Wyjaśniającymi Zakładamy że Y = X 1 + ɛ oraz X 1 = 2X 2, czyli istnieje doskonała korelacja między zmiennymi wyjaśniającymi X 1 a X 2. Wtedy, następujące modele regresyjne są RÓWNOWAŻNE. Y =X 1 + ɛ Y =2X 2 + ɛ Y =100X 1 198X 2 + ɛ Y =202X 2 100X 1 + ɛ 15 / 77

16 Problem Mocnych Korelacji między Zmiennymi Wyjaśniającymi Z pierwszych dwóch modeli, widać że Y jest dodatnio skorelowane z obiema zmiennymi wyjaśniającymi. Natomiast, z trzeciego modelu, wygląda na to, że X 2 jest ujemnie skorelowane z Y. Z ostatniego modelu, wygląda na to, że X 1 jest ujemnie skorelowane z Y. Chociaż wszystkie prognozy z tych modeli byłyby identyczne, ich interpretacje są skrajnie różne. 16 / 77

17 Problem Mocnych Korelacji między Zmiennymi Wyjaśniającymi Jeden sposób aby unikać tego problemu jest ustalaniem progu ρ 0, takiego że gdy r(x i, X j ) > ρ 0 (gdzie r jest odpowiednim współczynnikiem korelacji), wyrzucamy jedną z tych zmiennych z modelu. Wyrzucamy zmienną, która jest najsłabiej skorelowana z zmienną zależną (według bezwzględnego współczynnika korelacji). Lepszy sposób jest zastosowaniem regresji krokowej (zob. regresję wielokrotną). 17 / 77

18 Regresja Liniowa z Jedną Ilościową Zmienną Wyjaśniającą Mamy n obserwacji, (Y 1, Y 2,..., Y n ), zmiennej zależnej Y, oraz n obserwacji, (X 1, X 2,..., X n ), zmiennej wyjaśniającej X, gdzie X i Y są zmiennymi ilościowymi. Chcemy tworzyć model regresji postaci Y = β 0 + β 1 X + ɛ. β 0 jest stałą regresji, β 1 jest współczynnikiem regresji odpowiadającym zmiennej X 1, ɛ jest błędem losowym/rezyduum/resztą. 18 / 77

19 Regresja Liniowa z Jedną Ilościową Zmienną Wyjaśniającą Estymatory parametrów β 0, β 1 minimalizują sumę błędów kwadratowych, czyli n i=1 ɛ i, gdzie ɛ i = Y i β 0 β 1 X i = Y i Ŷ i. Ŷ i = β 0 + β 1 X i jest estymatorem (prognozą) wartości obserwacji zmiennej zależnej Y i w oparciu o wartość obserwacji zmiennej wyjaśniającej X i. Wynika z tego że suma rezyduów równa się zeru, czyli nie ma systematycznego błędu gdy przewidujemy wartość obserwacji Y i w oparciu o losowej wybranej obserwacji X i. Uwaga: Ale nie znaczy to prognoza wartości Y przy danej wartości X nie jest obarczona systematycznym błędem. 19 / 77

20 Założenia Regresji Liniowej 1. Błędy mają rozkład normalny z średnią 0 i są niezależne. Czyli ɛ N(0, σ 2 ɛ ). 2. Błędy nie zależą od wartości zmiennych wyjaśniających. Czyli reszty mają się zmienić losowo, a nie systematycznie. 20 / 77
. 2.")
21 Obserwacje Odstające Aby obliczyć standaryzowaną resztę, dzielimy resztę przez odchylenie standardowe reszt. Obserwacja jest odstająca gdy standaryzowana reszta jest większa od 3 (przy założeniach regresji liniowej ok. 1 na 400 obserwacji jest odstająca). Obserwacja odstająca może być błędna, może też być obserwacja w pewnym sensie wyjątkowa (trzeba sprawdzić poszczególne obserwacje odstające). Należy wykonać analizę i z obserwacjami odstającymi i bez nich, aby sprawdzić czy wnioski są odporne na możliwe błędy. 21 / 77
22 Regresja w Excelu - Ceny Mieszkań Dane dotyczące 1170 mieszkań na sprzedaż we Wrocławiu znajdują się w pliku mieszkania.xls na mojej stronie domowej. Chcemy opisać jak cena mieszkania (w kolumnie E) zależy od jego metrażu (w kolumnie B). Wyznaczamy więc model Y = β 0 + β 1 X + ɛ, gdzie Y jest ceną mieszkania i X jego metrażem. 22 / 77
23 Regresja w Excelu - Ceny Mieszkań Dzielnice to 1. Stare Miasto. 2. Śródmieście. 3. Krzyki. 4. Fabryczna. 5. Psie Pole. 23 / 77
24 Regresja w Excelu - Ceny Mieszkań Z menu Dane wybieramy po kolei Analiza Danych i Regresja. Wprowadzamy zakres zmiennej zależnej (e2:e1171). Zaznaczamy poziom ufności (aby wyznaczyć przedziały ufności dla parametrów β 0 i β 1 ). Zacznaczamy standardowe składniki resztowe i rozkład reszt, aby obliczyć standaryzowane reszty oraz rozrzut reszt względem metrażu. 24 / 77
25 Regresja w Excelu - Ceny Mieszkań Otrzymujemy tabelkę podsumującą jak model pasuje do cen mieszkań Wielokrotność R 0, R kwadrat 0, Dopasowany R kwadrat 0, Błąd standardowy 66259,029 Obserwacje / 77
26 Regresja w Excelu - Ceny Mieszkań Najważniejsza statystyka w tej tabelce jest R kwadrat (R 2 ). Jest to tak zwany współczynnik determinacji. Opisuje to proporcję wariancji zmiennej zależnej, która jest wyjaśniona przez zmienną wyjaśniającą. W tym przypadku, około 62% wariancji ceny mieszkania jest wyjaśnione jego metrażem (czyli dosyć dużo). Dopasowany R kwadrat uwzględnia karę opartą na liczbie zmiennych wyjaśniających (gdy k nie jest dużo mniejsze niż n, R 2 zawsze będzie duże nawet przy modelu pozbawionym sensu). 26 / 77
27 Regresja w Excelu - Ceny Mieszkań Następująca tabelka podaje estymatory parametrów tego modelu Współczynniki Błąd standardowy t Stat Wartość-p Dolne 95% Górne 95% Przecięcie 72352,7 6344,15 11,4046 1,22E , ,0 Zmienna X1 4755,60 108,718 43,7426 2,68E , ,91 27 / 77
28 Regresja w Excelu - Ceny Mieszkań Kolumna Współczynniki daje estymatory parametrów tego modelu Czyli mamy Y = 72352, , 6X, gdzie Y jest ceną mieszkania a X jest jego metrażem. Współczynnik zmiennej X określa jak zmienna zależna średnio się zmienia gdy wartość zmiennej X rośnie o jednostkę. Czyli każdy dodatkowy metr kwadratowy średnio kosztuje 4755,60zł. 28 / 77
29 Regresja w Excelu - Ceny Mieszkań Uwaga: Według tego modelu, cena za metr kwadratowy, Y /X, wyraża się wzorem Y X = 72352, , 60. X Czyli im większe jest mieszkanie, tym średnio mniejsza cena za metr kwadratowy. 29 / 77
30 Regresja w Excelu - Ceny Mieszkań Kolumna Wartość-p daje wartości p dla testów typu 1. H 0 : β i = 0 wobec alternatywy 2. H A : β i 0. Dla i > 0, można zinterpretować H 0 jako hipotezę że zmienna wyjaśniająca i nie ma związku z zmienną zależną. Alternatywa mówi że zmienna wyjaśniająca i ma związek z zmienną zależną. 30 / 77
31 Regresja w Excelu - Ceny Mieszkań Wartość p jest miarą wiarygodności hipotezy zerowej H 0 (że nie ma związku). Gdy wartość p spełnia 1. p > 0, 05 - Nie mamy dowodów przeciwko H , 01 < p < 0, 05 - Mamy dowody że H A jest prawidłowe. 3. 0, 001 < p < 0, 01 - Mamy mocne dowody że H A jest prawidłowe. 4. p < 0, Mamy bardzo mocne dowody że H A jest prawidłowe. 31 / 77
32 Regresja w Excelu - Ceny Mieszkań Tutaj E-28 oznacza że pierwsza cyfra niezerowa się pojawia w 28-tym miejscu po przecinku. Z tego widać że mamy bardzo mocne dowody że stała regresji się różni od zera (jest dodatnia). Tak samo, mamy bardzo mocne dowody że β 1 0, czyli cena mieszkania zależy od metrażu (cena rośnie względem metrażu, bo ten współczynnik jest dodatni). 32 / 77
33 Regresja w Excelu - Ceny Mieszkań Kolumny Dolne 95% oraz Górne 95% podają krańce przedziału ufności dla danego parametru. Na przykład przedziałem ufności na poziomie ufności 95% dla kosztu dodatkowego metru kwadratowego we Wrocławiu jest (4542,30; 4968,91). Przedziałem ufności na poziomie ufności 95% dla wartości stałej regresji jest (59905,53; 84800,0). 33 / 77
34 Regresja w Excelu - Rozkład Reszt W Excelu mamy zmienną wyjaśniającą na osi X, a na osi Y reszty. 34 / 77
35 Regresja w Excelu - Diagnostyka Chociaż nie są to reszty standaryzowane, widać że jest parę wyraźnie odstających obserwacji. Gdy obserwacja jest odstająca, reszta jest dodatnia, czyli cena jest większa niż oczekujemy przy danym metrażu. Łatwiej znaleźć i wyrzucić takie obserwacje w pakiecie SPSS. Należy znaleźć te obserwacje odstające i poprawić lub zainterpretować (jak odpowiednio). 35 / 77
36 Regresja w Excelu - Diagnostyka Poza tym rozrzut jest troszkę stożkowaty (czyli średnio bezwzlędna reszta rośnie jak metraż rośnie. Wskazuje na to że model jest błędny (reszty zależą od wartości zmiennej wyjaśniającej). Jeżeli widać że założenia modelu nie są spełnione, wtedy warto się zastanawiać czy inny model byłby bardziej odpowiedni. W tym przypadku, wykres reszt nie obiega strasznie od idealnej chmury i wydaje się sensownie że cena rośnie w miarę liniowo względem metrażu, więc uznaję że model jest błędny, ale przydatny. 36 / 77
37 Regresja w Excelu - Diagnostyka Gdy mamy przydatny model, możemy prognozować w oparciu o ten model. Na przykład, możemy oszacować średnią cenę mieszkania o metrażu 60m za pomocą równania regresji Ŷ = 72352, , 6X. Podstawiając X = 60, otrzymujemy Ŷ = 72352, , 6 60 = , 70zł. Odchylenie standardowe tego estymatora równa się błędowi standardowemu z tabelki Statystyka Regresji czyli ,03zł. Oczywiście cena mieszkania zależy od innych czynników, np. od stanu mieszkania, położenia. Aby to uwzględnić musimy korzystać z regresji wielomiarowej. 37 / 77
38 Regresja w SPSS - Ceny Mieszkań Można łatwo wczytać plik Excelowski do SPSS. Domyślnie nazwy zmiennych znajdują się w pierwszym wierszu. Aby wykonać regresję, należy wybrać opcję Regresja z menu Analiza. Wybieramy opcję Liniowa 38 / 77
39 Regresja w SPSS - Ceny Mieszkań Trzeba umieścić zmienną Y w ramce Zmienna zależna. Zmienną X umieścimy w ramce Zmienne niezależne Aby obliczyć przedziały ufności dla parametrów klikniemy na Statystyki i zaznaczamy Przedziały Ufności. 39 / 77
40 Regresja w SPSS - Analiza reszt Aby narysować rozrzut reszt, klikniemy na wykresy. Na osi X umieścimy *ZPRED - są to standaryzowane wartości zmiennej wyjaśniającej. Na osi Y umieścimy *ZRESID - są to standaryzowane wartości prognozy. Zaznaczamy Histogram aby otrzymać histogram standaryzowanych reszt. Jest to przydatne do sprawdzenia czy reszty pochodzą z rozkładu normalnego. 40 / 77
41 Rozrzut Reszty w SPSS-ie Uwaga: Należy zanotować że na osi X mamy standaryzowane wartości prognozy. Jeżeli istnieje pozytywny związek między zmiennymi X a Y, duże standaryzowane wartości prognozy odpowiadają dużym wartościom zmiennej wyjaśniającej. W tym przypadku rozrzut reszt wygląda identycznie do tego otrzymanego w Excelu (jest tylko przeskalowany). 41 / 77
42 Rozrzut Reszty w SPSS-ie Natomiast, jeżeli istnieje negatywny związek między zmiennymi X a Y, duże standaryzowane wartości prognozy odpowiadają małym wartościom zmiennej wyjaśniającej. W tym przypadku rozrzut reszt jest odbiciem wykresu otrzymanego w Excelu (w prostej pionowej przechodzącej przez środek chmury ). W obu przypadkach, reszty mają tworzyć chmurę równoległą do osi X. 42 / 77
43 Regresja w SPSS - Analiza reszt Klikniemy na OK. Dostajemy te same informacje co w Excelu plus histogram standaryzowanych reszt. Standaryzowane reszty teraz się znajdują w skoroszycie jako zmienna ZRE / 77
44 Regresja w SPSS - Histogram standaryzowanych reszt 44 / 77
45 Regresja w SPSS - Histogram standaryzowanych reszt Widać że rozkład reszt nie pasuje do końca z rozkładem normalnyn z średnią Moda rozkładu (gdzie jest największa gęstość) jest raczej ujemna, a nie Rozkład jest prawostronnie skośny. Jest dosyć dużo obserwacji odstających gdzie cena jest dużo wyższa niż cena przewidywana. 45 / 77
46 Regresja w SPSS - Analiza reszt Aby wyłączyć zmienne odstające z naszej analizy, wybieramy opcję Wybierz obserwacje z menu Dane Zaznaczamy rubrykę Wybierz jeśli spełniony jest warunek. Definiujemy warunek. Tutaj standaryzowana reszta (ZRE 1 ) ma być większa od -3 a mniejsza od 3. Więc wpisujemy warunek ZRE 1 > 3 & ZRE 1 < 3. Obserwacje, które nie spełniają tego warunku, są wyłączone z analizy. 46 / 77
47 Regresja w SPSS - Analiza Reszt Numery obserwacji wyłączonych z analizy są przekreślone w skoroszycie. Łatwo można sprawdzić że jest 15 obserwacji odstających. Każda z tych obserwacji ma dodatnią resztę (czyli cena jest wyższa niż przewidywana przez model). 47 / 77
48 Regresja w SPSS - Analiza Reszt Jeżeli hipoteza o normalności reszt jest spełniona 1. Oczekujemy średnio 3 obserwacji odstających (mamy 1170 obserwacji, i średnio 1 na 400 ma być odstająca). 2. Prawdopodobieństwo że obserwacja odstająca odpowiada dodatniej standaryzowanej reszcie wynosi 0,5. 48 / 77
49 Regresja w SPSS - Analiza Reszt Więc mamy dużo więcej obserwacji odstających niż oczekujemy przy hipotezie o normalności reszt. W dodatku, fakt że każda obserwacja odstająca odpowiada dodatniej standaryzowanej reszcie wskazuje na to, że rozkład reszt jest skośny (czyli nie jest normalny). 49 / 77
50 Regresja w SPSS - Analiza Reszt Wśród tych obserwacji odstających znajduje się w Starym Mieście na Krzykach 3. 1 w Śródmieściu 50 / 77
51 Regresja w SPSS - Analiza Reszt Czyli wszystkie znajdują się w atrakcyjnych dzielnicach. Mając dostęp do źródła tych danych, można sprawdzić że te mieszkania raczej są luksusowymi mieszkaniami w ładnych dzielnicach (czyli raczej nie ma błędów ani w obserwacjach cen, ani w obserwacjach metrażu). 51 / 77
52 Regresja w SPSS - Wyniki po Wyłączeniu Odstających Obserwacji Po wyłączeniu odstających obserwacji, otrzymujemy następujące wyniki dotyczące modelu regresji. Model - podsumowanie R 0,834 R-kwadrat skorygowane 0,695 R-kwadrat 0,695 Błąd standardowy 54771,1 52 / 77
53 Regresja w SPSS - Wyniki po Wyłączeniu Odstających Obserwacji Współczynniki Błąd standardowy t Stat Wartość-p Dolne 95% Górne 95% Przecięcie 74206,1 5281,52 14,050 0, , ,6 Zmienna X1 4648,06 90,715 51,238 0, , ,04 53 / 77
54 Regresja w SPSS - Wyniki po Wyłączeniu Odstających Obserwacji Widać z pierwszej tabelki że po wyłączeniu obserwacji odstających, model lepiej pasuje do danych (wyjaśnia prawie 70% wariancji ceny). Z drugiej tabelki, nasz model wyraża się wzorem Y = 74206, , 06X. Przedziałem ufności dla ceny dodatkowego metra kwadratowego jest (4470,07; 4826,04) Jakościowo, model jest bardzo podobny do oryginalnego (wartości estymatorów są podobne, stała jest trochę większa a estymator ceny dodatkowego metra kwadratowego jest trochę mniejszy). 54 / 77
55 Regresja w SPSS - Wyniki po Wyłączeniu Odstających Obserwacji Podstawiając X = 60, możemy oszacować cenę zwykłego mieszkania o metrażu 60m 2 Ŷ = 74206, , = , 70zł. Estymator ten jest trochę mniejszy niż estymator otrzymany za pomocą oryginalnego modelu (nic dziwnego, skoro teraz baza danych nie zawiera luksusowych mieszkań). 55 / 77
56 Przekształcenie Danych gdy Zależność nie jest Liniowa Rozważamy produkt krajowy Polski w latach w USD. (zob. plik gdppolski.xls - źródło: bank światowy). Rok jest liczbą lat po W tym przypadku, jest to szereg czasowy i GDP wyraźnie zależy od czasu, więc regresja nie jest najlepszą metodą analizy, ale służy to do ilustracji. Gdy mamy szereg czasowy, najpierw rysujemy wykres. Czas jest na osi X a obserwacje zmiennej X t są na osi Y. 56 / 77
57 Wykres dla GDP Polski 57 / 77
58 Wykres dla GDP Polski Wykres sugeruje że GDP rośnie szybciej niż liniowo. Jeżeli średni procentowy wzrost GDP jest stały, wtedy GDP rośnie wykładniczo. Dużo szeregów czasowych (szczególnie ekonomicznych) cechuje się wzrostem wykładniczym 58 / 77
59 Modele Więc rozważamy 2 modele 1. Liniowy: X t = β 0 + β 1 t. 2. Wykładniczy: X t = α 0 e α 1t. 59 / 77
60 Model Liniowy - Podsumowanie Podsumowanie modelu (widać że model wyjaśnia więcej niż 97% wariancji GDP). Wielokrotność R 0, R kwadrat 0, Dopasowany R kwadrat 0, Błąd standardowy 888, Obserwacje / 77
61 Model Liniowy - Parametry Współczynniki Błąd standardowy t Stat Wartość-p Dolne 95% Górne 95% Przecięcie 5150,09 374,451 13,7537 0, , ,82 Zmienna X1 831,039 32, ,9453 0, , , / 77
62 Model Liniowy - Parametry Więc model wyraża się wzorem X t = 5150, , 039t. Czyli oszacujemy że GDP rośnie o $831,039 rocznie [95% przedział (763,998; 898,080)]. Skoro model wyjaśnia więcej niż 97% wariancji GDP, wygląda na to że jest to dobra podstawa do prognozowania przyszłych wartości GDP. Ale parę wyników pokazuje że nie jest to prawda. 62 / 77
63 Model Liniowy - Prognozowanie Stała jest estymatorem GDP w czasie 0 (czyli w roku 1993). 95% przedział ufności (4366,35; 5933,82) nie pokrywa prawdziwego GDP w roku 1993 ($6180). Podstawiając t = 21, otrzymujemy prognozę GDP w roku ˆX 21 = 5150, , 039 = 22601, / 77
64 Model Liniowy - Prognozowanie Jest to mniejsze niż prawdziwe GDP w roku Jest to mało wiarygodne, skoro GDP rosło co roku przez 20 lat. Czyli nawet gdy model wyjaśnia więcej niż 97% wariancji zmiennej zależnej, może być kiepskim narzędziem do prognozowania. 64 / 77
65 Model Wykładniczy Mamy model X t = α 0 e α 1t. Przy takim modelu, α 1 jest średni wzrost (jako proporcja) na jednostkę czasu (tutaj rok). Najpierw, należy wyznaczyć zmienną Z t = f (X t ) taką że Z t zależy od t (zmiennej wyjaśniającej) w sposób liniowy. Weźmiemy funkcję odwrotną do funkcji wykładniczej, czyli Z t = ln X t. W SPSS, aby obliczyć Z t, należy wybrać opcję Oblicz wartości zmiennej z menu Przekształcenia. 65 / 77
66 Model Wykładniczy Mamy X t = α 0 e α 1t. Z t = ln(x t )=ln(α 0 e α 1t ) =ln(α 0 ) + ln(e α 1t ) =ln(α 0 ) + α 1 t Pierwszy krok korzysta z faktu że ln(ab) = ln(a) + ln(b), drugi krok z faktu że logarytmowanie jest funkcją odwrotną do funkcji wykładniczej. 66 / 77
67 Model Wykładniczy Więc w Excelu lub SPSS-ie definiujemy trzecią zmienną Z t = ln(x t ), gdzie X t jest GDP w czasie t. Potem wyznaczamy równanie regresji gdzie zmienna zależna jest Z t i zmienna wyjaśniająca jest t. Ze wzoru na poprzednim slajdzie, stała w tym modelu jest ln(α 0 ) a współczynnik zmiennej Z t jest α / 77
68 Model Wykładniczy - Podsumowanie Podsumowanie modelu (widać że model wyjaśnia więcej niż 99% wariancji Z t (czyli ln(gdp) ). Wielokrotność R 0, R kwadrat 0, Dopasowany R kwadrat 0, Błąd standardowy 0, Obserwacje / 77
69 Model Wykładniczy - Parametry Współczynniki Błąd standardowy t Stat Wartość-p Dolne 95% Górne 95% Przecięcie 8, , ,136 0,0000 8, ,82121 Zmienna X1 0, , ,9663 0,0000 0, , / 77
70 Model Wykładniczy - Parametry Stała 8, = ln(α 0 ). Więc α 0 = e 8,79268 = 6585, 86. Współczynnik Z t 0, = α 1. Jest to średni wzrost (jako proporcja) w okresie (czyli około 6,4%). 70 / 77
71 Model Wykładniczy - Parametry Więc mamy model X t = α 0 e α 1t = 6585, 86e 0,064082t Podstawiając t = 21, otrzymujemy prognozę produktu krajowego w roku ˆX 21 = 6585, 86e 0, = 25296, 02. Prognoza ta lepiej pasuje do naszych danych, choć nie jest idealna (zob. analiza reszt). 71 / 77
72 Model Liniowy - Analiza Reszt 72 / 77
73 Model Liniowy - Analiza Reszt Widać że reszty zmieniają się bardzo systematycznie. Na początku i końcu reszty są dodatnie, a w środku ujemne. Wskazuje na to że wzrost jest szybszy niż liniowy (często w tych przypadkach wzrost jest wyładniczy). 73 / 77
74 Model Liniowy - Analiza Reszt Zakładamy że okazuje się że na początku i końcu reszty są ujemne, a w środku dodatnie. Wskazuje na to że wzrost jest powolniejszy niż liniowy (np. logarytmatyczny). 74 / 77
75 Model Wykładniczy - Analiza Reszt Uwaga: Skoro GDP rośnie względem roku, rozrzuty w SPSS-ie wyglądają identycznie. Duże wartości na osi X odpowiadają dużym wartościom zmiennej wyjaśniającej. 75 / 77
76 Model Wykładniczy - Analiza Reszt W tym przypadku reszty się zmieniają mniej systematycznie, ale widać że sąsiednie reszty mają podobne wartości. Czyli reszty są skorelowane. Wynika to z własności takiego szeregu. Jeśli GDP jest względnie duże (małe) w jednym roku w porównaniu z prognozą, prawdopodobnie będzie względnie duże (odpowiednio, małe) w następnym. Regresja nie uwzględnia tych korelacji, ale analiza szeregów czasowych je uwzględnia. 76 / 77
77 Model Wykładniczy - Analiza Reszt Z ostatniego wykresu, widać że ostatnie dwie reszty są ujemne (czyli GDP jest względnie małe w porównaniu z prognozą). Czyli w 2014 oczekujemy że GDP będzie małe w porównaniu z prognozą opartą na tym modelu. Więc nasza prognoza ($25296,02) raczej przeszacowuje GDP w roku Analogicznie, prognoza oparta na model liniowy ($22 601,91) raczej niedoszacowuje GDP w roku 2014 (ostatnie reszty są dodatnie). 77 / 77
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
7.4 Automatyczne stawianie prognoz
 szeregów czasowych za pomocą pakietu SPSS Następnie korzystamy z menu DANE WYBIERZ OBSERWACJE i wybieramy opcję WSZYSTKIE OBSERWACJE (wówczas wszystkie obserwacje są aktywne). Wreszcie wybieramy z menu
szeregów czasowych za pomocą pakietu SPSS Następnie korzystamy z menu DANE WYBIERZ OBSERWACJE i wybieramy opcję WSZYSTKIE OBSERWACJE (wówczas wszystkie obserwacje są aktywne). Wreszcie wybieramy z menu
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
5.1 Stopa Inflacji - Dyskonto odpowiadające sile nabywczej
 5.1 Stopa Inflacji - Dyskonto odpowiadające sile nabywczej Stopa inflacji, i, mierzy jak szybko ceny się zmieniają jako zmianę procentową w skali rocznej. Oblicza się ją za pomocą średniej ważonej cząstkowych
5.1 Stopa Inflacji - Dyskonto odpowiadające sile nabywczej Stopa inflacji, i, mierzy jak szybko ceny się zmieniają jako zmianę procentową w skali rocznej. Oblicza się ją za pomocą średniej ważonej cząstkowych
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
3. Macierze i Układy Równań Liniowych
 3. Macierze i Układy Równań Liniowych Rozważamy równanie macierzowe z końcówki ostatniego wykładu ( ) 3 1 X = 4 1 ( ) 2 5 Podstawiając X = ( ) x y i wymnażając, otrzymujemy układ 2 równań liniowych 3x
3. Macierze i Układy Równań Liniowych Rozważamy równanie macierzowe z końcówki ostatniego wykładu ( ) 3 1 X = 4 1 ( ) 2 5 Podstawiając X = ( ) x y i wymnażając, otrzymujemy układ 2 równań liniowych 3x
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji.
 Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
3. Modele tendencji czasowej w prognozowaniu
 II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
Analiza Statystyczna
 Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna
 Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Przykład 1 ceny mieszkań
 Przykład ceny mieszkań Przykład ceny mieszkań Model ekonometryczny zaleŝności ceny mieszkań od metraŝu - naleŝy do klasy modeli nieliniowych. - weryfikację empiryczną modelu przeprowadzono na przykładzie
Przykład ceny mieszkań Przykład ceny mieszkań Model ekonometryczny zaleŝności ceny mieszkań od metraŝu - naleŝy do klasy modeli nieliniowych. - weryfikację empiryczną modelu przeprowadzono na przykładzie
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY
 JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
Następnie przypominamy (dla części studentów wprowadzamy) podstawowe pojęcia opisujące funkcje na poziomie rysunków i objaśnień.
 podstawowe pojęcia opisujące funkcje na poziomie rysunków i objaśnień.") Zadanie Należy zacząć od sprawdzenia, co studenci pamiętają ze szkoły średniej na temat funkcji jednej zmiennej. Na początek można narysować kilka krzywych na tle układu współrzędnych (funkcja gładka,
Zadanie Należy zacząć od sprawdzenia, co studenci pamiętają ze szkoły średniej na temat funkcji jednej zmiennej. Na początek można narysować kilka krzywych na tle układu współrzędnych (funkcja gładka,
Przykład 2. Stopa bezrobocia
 Przykład 2 Stopa bezrobocia Stopa bezrobocia. Komentarz: model ekonometryczny stopy bezrobocia w Polsce jest modelem nieliniowym autoregresyjnym. Podobnie jak model podaŝy pieniądza zbudowany został w
Przykład 2 Stopa bezrobocia Stopa bezrobocia. Komentarz: model ekonometryczny stopy bezrobocia w Polsce jest modelem nieliniowym autoregresyjnym. Podobnie jak model podaŝy pieniądza zbudowany został w
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań
 Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Ekonometria. Dobór postaci analitycznej, transformacja liniowa i estymacja modelu KMNK. Paweł Cibis 9 marca 2007
 , transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
, transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
FUNKCJA LINIOWA - WYKRES
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
Stopa Inflacji. W oparciu o zbiór składający się z n towarów, stopa inflacji wyraża się wzorem. n 100w k p k. , p k
 2.1 Stopa Inflacji Stopa inflacji, i, mierzy jak szybko ceny się zmieniają jako zmianę procentową w skali rocznej. Oblicza się ją za pomocą średniej ważonej cząstkowych stóp inflacji, gdzie cząstkowa stopa
2.1 Stopa Inflacji Stopa inflacji, i, mierzy jak szybko ceny się zmieniają jako zmianę procentową w skali rocznej. Oblicza się ją za pomocą średniej ważonej cząstkowych stóp inflacji, gdzie cząstkowa stopa
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
4. Średnia i autoregresja zmiennej prognozowanej
 4. Średnia i autoregresja zmiennej prognozowanej 1. Średnia w próbie uczącej Własności: y = y = 1 N y = y t = 1, 2, T s = s = 1 N 1 y y R = 0 v = s 1 +, 2. Przykład. Miesięczna sprzedaż żelazek (szt.)
4. Średnia i autoregresja zmiennej prognozowanej 1. Średnia w próbie uczącej Własności: y = y = 1 N y = y t = 1, 2, T s = s = 1 N 1 y y R = 0 v = s 1 +, 2. Przykład. Miesięczna sprzedaż żelazek (szt.)
ANALIZA REGRESJI WIELOKROTNEJ. Zastosowanie statystyki w bioinżynierii Ćwiczenia 8
 ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
Metody Ilościowe w Socjologii
 Metody Ilościowe w Socjologii wykład 2 i 3 EKONOMETRIA dr inż. Maciej Wolny AGENDA I. Ekonometria podstawowe definicje II. Etapy budowy modelu ekonometrycznego III. Wybrane metody doboru zmiennych do modelu
Metody Ilościowe w Socjologii wykład 2 i 3 EKONOMETRIA dr inż. Maciej Wolny AGENDA I. Ekonometria podstawowe definicje II. Etapy budowy modelu ekonometrycznego III. Wybrane metody doboru zmiennych do modelu
Ekonometria ćwiczenia 3. Prowadzący: Sebastian Czarnota
 Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Ekonometria ćwiczenia 3 Prowadzący: Sebastian Czarnota Strona - niezbędnik http://sebastianczarnota.com/sgh/ Normalność rozkładu składnika losowego Brak normalności rozkładu nie odbija się na jakości otrzymywanych
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Dopasowywanie modelu do danych
 Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Analiza zależności liniowych
 Narzędzie do ustalenia, które zmienne są ważne dla Inwestora Analiza zależności liniowych Identyfikuje siłę i kierunek powiązania pomiędzy zmiennymi Umożliwia wybór zmiennych wpływających na giełdę Ustala
Narzędzie do ustalenia, które zmienne są ważne dla Inwestora Analiza zależności liniowych Identyfikuje siłę i kierunek powiązania pomiędzy zmiennymi Umożliwia wybór zmiennych wpływających na giełdę Ustala
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne.
 Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki
R-PEARSONA Zależność liniowa
 R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Ekonometria. Dobór postaci analitycznej, transformacja liniowa i estymacja modelu KMNK. Paweł Cibis 23 marca 2006
 , transformacja liniowa i estymacja modelu KMNK Paweł Cibis pcibis@o2.pl 23 marca 2006 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności 2 3 Etapy transformacji
, transformacja liniowa i estymacja modelu KMNK Paweł Cibis pcibis@o2.pl 23 marca 2006 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności 2 3 Etapy transformacji
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Analiza Współzależności
 Statystyka Opisowa z Demografią oraz Biostatystyka Analiza Współzależności Aleksander Denisiuk denisjuk@euh-e.edu.pl Elblaska Uczelnia Humanistyczno-Ekonomiczna ul. Lotnicza 2 82-300 Elblag oraz Biostatystyka
Statystyka Opisowa z Demografią oraz Biostatystyka Analiza Współzależności Aleksander Denisiuk denisjuk@euh-e.edu.pl Elblaska Uczelnia Humanistyczno-Ekonomiczna ul. Lotnicza 2 82-300 Elblag oraz Biostatystyka
Ekonometria. Zajęcia
 Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
W statystyce stopień zależności między cechami można wyrazić wg następującej skali: n 1
 Temat: Wybrane zagadnienia z korelacji i regresji W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00 0,20) Słaba
Temat: Wybrane zagadnienia z korelacji i regresji W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00 0,20) Słaba
Funkcja liniowa - podsumowanie
 Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
FUNKCJA LINIOWA - WYKRES. y = ax + b. a i b to współczynniki funkcji, które mają wartości liczbowe
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY
 MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY WYKORZYSTANIU METOD STATYSTYCZNYCH mgr Małgorzata Pelczar 6 Wprowadzenie Reforma służby zdrowia uwypukliła problem optymalnego ustalania kosztów usług zdrowotnych.
MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY WYKORZYSTANIU METOD STATYSTYCZNYCH mgr Małgorzata Pelczar 6 Wprowadzenie Reforma służby zdrowia uwypukliła problem optymalnego ustalania kosztów usług zdrowotnych.
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego
 Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
Testowanie hipotez statystycznych związanych ą z szacowaniem i oceną ą modelu ekonometrycznego Ze względu na jakość uzyskiwanych ocen parametrów strukturalnych modelu oraz weryfikację modelu, metoda najmniejszych
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Spis treści. LaboratoriumV: Podstawy korelacji i regresji. Inżynieria biomedyczna, I rok, semestr letni 2014/2015 Analiza danych pomiarowych
 1 LaboratoriumV: Podstawy korelacji i regresji Spis treści Laboratorium V: Podstawy korelacji i regresji...1 Wiadomości ogólne...2 1. Wstęp teoretyczny....2 1.1 Korelacja....2 1.2 Funkcja regresji....5
1 LaboratoriumV: Podstawy korelacji i regresji Spis treści Laboratorium V: Podstawy korelacji i regresji...1 Wiadomości ogólne...2 1. Wstęp teoretyczny....2 1.1 Korelacja....2 1.2 Funkcja regresji....5
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Proces modelowania zjawiska handlu zagranicznego towarami
 Załącznik nr 1 do raportu końcowego z wykonania pracy badawczej pt. Handel zagraniczny w województwach (NTS2) realizowanej przez Centrum Badań i Edukacji Statystycznej z siedzibą w Jachrance na podstawie
Załącznik nr 1 do raportu końcowego z wykonania pracy badawczej pt. Handel zagraniczny w województwach (NTS2) realizowanej przez Centrum Badań i Edukacji Statystycznej z siedzibą w Jachrance na podstawie
Inżynieria biomedyczna, I rok, semestr letni 2014/2015 Analiza danych pomiarowych. Laboratorium VIII: Analiza kanoniczna
 1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Narzędzia statystyczne i ekonometryczne. Wykład 1. dr Paweł Baranowski
 Narzędzia statystyczne i ekonometryczne Wykład 1 dr Paweł Baranowski Informacje organizacyjne Wydział Ek-Soc, pok. B-109 pawel@baranowski.edu.pl Strona: baranowski.edu.pl (w tym materiały) Konsultacje:
Narzędzia statystyczne i ekonometryczne Wykład 1 dr Paweł Baranowski Informacje organizacyjne Wydział Ek-Soc, pok. B-109 pawel@baranowski.edu.pl Strona: baranowski.edu.pl (w tym materiały) Konsultacje:
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Statystyka. Wykład 8. Magdalena Alama-Bućko. 23 kwietnia Magdalena Alama-Bućko Statystyka 23 kwietnia / 38
 Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Co to jest analiza regresji?
 Co to jest analiza regresji? Celem analizy regresji jest badanie związków pomiędzy wieloma zmiennymi niezależnymi (objaśniającymi) a zmienną zależną (objaśnianą), która musi mieć charakter liczbowy. W
Co to jest analiza regresji? Celem analizy regresji jest badanie związków pomiędzy wieloma zmiennymi niezależnymi (objaśniającymi) a zmienną zależną (objaśnianą), która musi mieć charakter liczbowy. W
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
4. Postęp arytmetyczny i geometryczny. Wartość bezwzględna, potęgowanie i pierwiastkowanie liczb rzeczywistych.
 Jarosław Wróblewski Matematyka dla Myślących, 008/09. Postęp arytmetyczny i geometryczny. Wartość bezwzględna, potęgowanie i pierwiastkowanie liczb rzeczywistych. 15 listopada 008 r. Uwaga: Przyjmujemy,
Jarosław Wróblewski Matematyka dla Myślących, 008/09. Postęp arytmetyczny i geometryczny. Wartość bezwzględna, potęgowanie i pierwiastkowanie liczb rzeczywistych. 15 listopada 008 r. Uwaga: Przyjmujemy,
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
Analizowane modele. Dwa modele: y = X 1 β 1 + u (1) y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:
 y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:") Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
POLITECHNIKA OPOLSKA
 POLITECHNIKA OPOLSKA WYDZIAŁ MECHANICZNY Katedra Technologii Maszyn i Automatyzacji Produkcji Laboratorium Podstaw Inżynierii Jakości Ćwiczenie nr 4 Temat: Analiza korelacji i regresji dwóch zmiennych
POLITECHNIKA OPOLSKA WYDZIAŁ MECHANICZNY Katedra Technologii Maszyn i Automatyzacji Produkcji Laboratorium Podstaw Inżynierii Jakości Ćwiczenie nr 4 Temat: Analiza korelacji i regresji dwóch zmiennych
LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU
 LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU Tomasz Demski, StatSoft Polska Sp. z o.o. Wprowadzenie Jednym z elementów walidacji metod pomiarowych jest sprawdzenie liniowości
LINIOWOŚĆ METODY OZNACZANIA ZAWARTOŚCI SUBSTANCJI NA PRZYKŁADZIE CHROMATOGRAFU Tomasz Demski, StatSoft Polska Sp. z o.o. Wprowadzenie Jednym z elementów walidacji metod pomiarowych jest sprawdzenie liniowości
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka. Wykład 9. Magdalena Alama-Bućko. 24 kwietnia Magdalena Alama-Bućko Statystyka 24 kwietnia / 34
 Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
t y x y'y x'x y'x x-x śr (x-x śr)^2
^2") Na podstawie:w.samuelson, S.Marks Ekonomia menedżerska Zadanie 1 W przedsiębiorstwie toczy się dyskusja na temat wpływu reklamy na wielkość. Dział marketingu uważa, że reklama daje wysoce pozytywne efekty,
Na podstawie:w.samuelson, S.Marks Ekonomia menedżerska Zadanie 1 W przedsiębiorstwie toczy się dyskusja na temat wpływu reklamy na wielkość. Dział marketingu uważa, że reklama daje wysoce pozytywne efekty,
Ekonometria. Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej
 Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej Paweł Cibis pawel@cibis.pl 23 lutego 2007 1 Regresja liniowa 2 wzory funkcje 3 Korelacja liniowa
Regresja liniowa, współczynnik zmienności, współczynnik korelacji liniowej, współczynnik korelacji wielorakiej Paweł Cibis pawel@cibis.pl 23 lutego 2007 1 Regresja liniowa 2 wzory funkcje 3 Korelacja liniowa
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji
 Ćwiczenie: Wybrane zagadnienia z korelacji i regresji W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Stanisza r xy = 0 zmienne nie są skorelowane 0 < r xy 0,1
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Stanisza r xy = 0 zmienne nie są skorelowane 0 < r xy 0,1
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Zadanie 1. a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1
 Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1") Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów