R. Zdunek: Autoreferat Załącznik 2 AUTOREFERAT
|
|
|
- Ksawery Tomaszewski
- 10 lat temu
- Przeglądów:
Transkrypt
1 1. Dane personalne AUTOREFERAT Imię i Nazwisko: Data i miejsce urodzenia: Rafał Zdunek 26 czerwca 1972r., Brzesko 2. Posiadane dyplomy, stopnie naukowe z podaniem nazwy, miejsca i roku ich uzyskania oraz tytułu rozprawy doktorskiej Stopień naukowy: Doktor Nauk Technicznych Dyscyplina: Telekomunikacja Specjalność: Metody numeryczne Jednostka: Instytut Telekomunikacji i Akustyki Politechnika Wrocławska Temat pracy: Optymalizacja metod rekonstrukcji obrazu rozkładu współczynnika tłumienia fal elektromagnetycznych w ziemi Data obrony: 6 lutego 2002 r. (praca obroniona z wyróżnieniem) Promotor: Recenzenci: Dr hab. inż. Andrzej Prałat Instytut Telekomunikacji i Akustyki, Politechnika Wrocławska Prof. dr hab. inż. Jan Sikora Instytut Elektrotechniki, Politechnika Warszawska Dr hab. Krystyna Ziętak Instytut Matematyki i Informatyki, Politechnika Wrocławska Tytuł: Magister inżynier Kierunek: Elektronika i Telekomunikacja Specjalność: Telekomunikacja rozsiewcza Jednostka: Wydział Elektroniki, Politechnika Wrocławska Temat pracy: Podatność systemu ochrony przeciwpożarowej wrocławskiego Ratusza na wyładowania piorunowe Data obrony: 29 września 1997 Promotor: Dr inż. Andrzej Sowa Instytut Telekomunikacji i Akustyki, Politechnika Wrocławska Tytuł: Technik elektronik Specjalność: Elektronika ogólna Szkoła: Technikum Elektroniczne Zespół Szkół Mechaniczno-Elektrycznych w Tarnowie Data obrony: Czerwiec
 Promotor: Recenzenci: Dr hab. inż.")
2 3. Informacje o dotychczasowym zatrudnieniu w jednostkach naukowych 3.1. Przebieg pracy zawodowej: Miejsce pracy: Katedra Teorii Pola, Układów Elektronicznych i Optoelektroniki (K-4), Wydział Elektroniki, Politechnika Wrocławska Stanowisko: Adiunkt Okres zatrudnienia: od 1 czerwca 2013 do obecnie Miejsce pracy: Instytut Telekomunikacji, Teleinformatyki i Akustyki, Wydział Elektroniki, Politechnika Wrocławska Stanowisko: Adiunkt Okres zatrudnienia: od 1 października 2002 do 31 maja 2013 Miejsce pracy: Instytut Telekomunikacji i Akustyki, Wydział Elektroniki, Politechnika Wrocławska Stanowisko: Asystent Okres zatrudnienia: od 1 października 2001 do 30 września Doświadczenie zawodowe zdobyte za granicą: Miejsce pracy: Laboratory for Advanced Brain Signal Processing Brain Science Institute, RIKEN 2-1 Hirosawa, Wako-shi, Saitama, Japonia Stanowisko: Visiting Researcher Okres zatrudnienia: Miejsce pracy: Laboratory for Advanced Brain Signal Processing Brain Science Institute, RIKEN 2-1 Hirosawa, Wako-shi, Saitama, Japonia Stanowisko: Visiting Researcher Okres zatrudnienia: Miejsce pracy: Laboratory for Advanced Brain Signal Processing Brain Science Institute, RIKEN 2-1 Hirosawa, Wako-shi, Saitama, Japonia Stanowisko: Research Scientist Okres zatrudnienia: Miejsce pracy: The Institute of Statistical Mathematics Minami-Azabu, Minato-ku, Tokio , Japonia Stanowisko: Visiting Associate Professor Okres zatrudnienia:

3 4. Wskazanie osiągnięcia wynikającego z art. 16 ust. 2 ustawy z dnia 14 marca 2003 r. o stopniach naukowych i tytule naukowym oraz o stopniach i tytule w zakresie sztuki (Dz. U. nr 65, poz. 595 ze zm.) Moim osiągnięciem naukowym stanowiącym znaczny wkład w rozwój dyscypliny naukowej Elektronika jest jednotematyczny cykl publikacji pt.: Nieujemna faktoryzacja macierzy i tensorów: zastosowanie do klasyfikacji i przetwarzania sygnałów Cykl publikacji składa się z dwunastu prac naukowych, w tym dwie monografie, osiem artykułów w czasopismach z listy filadelfijskiej, posiadających Impact Factor, jednego artykułu w czasopiśmie międzynarodowym (aktualnie na liście filadelfijskiej) oraz jednego artykułu w serii LNAI (Springer). [1] Zdunek R., Nieujemna faktoryzacja macierzy i tensorów: zastosowanie do klasyfikacji i przetwarzania sygnałów, Oficyna Wydawnicza Politechniki Wrocławskiej, Wroclaw 2014, 362 stron, ISBN: Udział własny: 100% [2] Cichocki A., Zdunek R., Phan A. H., Amari S.-I., Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-way Data Analysis and Blind Source Separation, Wiley and Sons, Chichester, UK, 2009, Liczba cytowań (według Web of Science bez autocytowań): 221 Udział własny: 25% [3] Zdunek R., Regularized Nonnegative Matrix Factorization: Geometrical Interpretation and Application to Spectral Unmixing, International Journal of Applied Mathematics and Computer Science, Vol. 24, No. 2, pp , 2014, Punkty MNiSW (2013): 25, IF (2013): 1,008 Udział własny: 100% [4] Zdunek R., Improved Convolutive and Under-determined Blind Audio Source Separation with MRF Smoothing, Cognitive Computation, Vol. 5, No. 4, pp , 2013, Punkty MNiSW (2013): 20, IF (2013): 0,867 Udział własny: 100% [5] Zdunek R., Cichocki A., Nonnegative Matrix Factorization with Constrained Second-Order Optimization, Signal Processing, Vol. 87, pp , 2007, Punkty MNiSW (2010): 27, IF (2007): 0,737, IF(2013): 1,851 Liczba cytowań (według Web of Science bez autocytowań): 26 Udział własny: 70% 3
 oraz jednego artykułu w serii LNAI (Springer).")
4 [6] Zdunek R., Cichocki A., Nonnegative Matrix Factorization with Quadratic Programming, Neurocomputing, Vol. 71, No , pp , 2008, Punkty MNiSW (2010): 20, IF (2008): 1,234 Liczba cytowań (według Web of Science bez autocytowań): 7 Udział własny: 70% [7] Zdunek R., Cichocki A., Fast Nonnegative Matrix Factorization Algorithms Using Projected Gradient Approaches for Large-Scale Problems, Computational Intelligence and Neuroscience, Vol. 2008, No , 13 pages, 2008, To czasopismo jest już na liście filadelfijskiej ( Master Journal List ) oraz indeksowane w bazie JCR ( Punkty MNiSW (2010): 2, Liczba cytowań (według Web of Science bez autocytowań): 16 Udział własny: 70% [8] Cichocki A., Zdunek R., Multilayer Nonnegative Matrix Factorization Using Projected Gradient Approaches, International Journal of Neural Systems, Vol. 17, No. 6, pp , 2007, Punkty MNiSW (2010): 20, IF (2007): 0,488, IF(2013): 5,054 Liczba cytowań (według Web of Science bez autocytowań): 18 Udział własny: 30% [9] Cichocki A., Zdunek R., Multilayer Nonnegative Matrix Factorization, Electronics Letters, Vol. 42, No. 16, pp , 2006, Punkty MNiSW (2010): 27, IF (2006): 1,063 Liczba cytowań (według Web of Science bez autocytowań): 9 Udział własny: 30% [10] Cichocki A., Zdunek R., Amari S.-I., Nonnegative Matrix and Tensor Factorization, IEEE Signal Processing Magazine, Vol. 25, No. 1, pp , 2008, Punkty MNiSW (2013): 32, IF (2008): 3,758 Liczba cytowań (według Web of Science bez autocytowań): 44 Udział własny: 30% [11] He Z., Xie S., Zdunek R., Zhou G., Cichocki A., Symmetric nonnegative matrix factorization: algorithms and applications to probabilistic clustering, IEEE Transactions on Neural Networks, Vol. 22, No. 12, pp , 2011, Punkty MNiSW (2010): 32, IF (2011): 2,952 Liczba cytowań (według Web of Science bez autocytowań): 9 Udział własny: 15% [12] Zdunek R., Initialization of nonnegative matrix factorization with vertices of convex polytope, In: 11th International Conference on Artificial Intelligence and Soft 4
 oraz indeksowane w bazie JCR (http://www.hindawi.")
5 Computing (ICAISC 2012), Zakopane, Poland, April 29 - May 3, 2012, Lecture Notes in Artificial Intelligence, Vol. 7267, pp , 2012, Punkty MNiSW (2010): 13, Liczba cytowań (według Web of Science bez autocytowań): 2 Udział własny: 100% Omówienie celu naukowego ww. prac i osiągniętych wyników wraz z omówieniem ich ewentualnego wykorzystania Nieujemna faktoryzacja macierzy (NMF ang.: Nonnegative Matrix Factorization) jest metodą redukcji wymiarowości danych nieujemnych oraz ekstrakcji cech rzadkich. Stosuje się ją w wielu obszarach sztucznej inteligencji, analizie danych oraz w przetwarzaniu sygnałów i obrazów. Stanowi istotne narzędzie w rozwoju multidyscyplinarnych badań naukowych, łączących wiele dyscyplin nauk technicznych, zwłaszcza informatykę z elektroniką czy telekomunikacją. Podstawowa wersja metody NMF zakłada przybliżoną i liniową dekompozycję macierzy nieujemnej (np. macierzy nieujemnych danych pomiarowych) na macierze (faktory) o nieujemnych elementach i zwykle mniejszym rzędzie. Nieujemne i częstokroć rzadkie faktory mają pewne właściwości charakterystyczne, znaczeniowe i na ogół dość łatwą interpretację: każdy wektor kolumnowy nieujemnej macierzy danych można przedstawić jako liniową i addytywną kombinację pewnych wektorów nieujemnych cech rzadkich. Przykładowo, metoda NMF dekomponuje obrazy twarzy na obrazy części składowych (cech), takich jak: oczy, usta, włosy, uszy, itp. Lokalność, rzadkość, a przede wszystkim nieujemność wektorów reprezentacji i możliwość ich statystycznej zależności są właściwościami, które odróżniają NMF od znanych metod dekompozycji danych, takich jak, np. analiza składowych głównych lub analiza składowych niezależnych. Dodatkowo, duża elastyczność modelu NMF w dostosowaniu do charakteru estymowanych faktorów (rzadkość, gładkość, ortogonalność, unimodalność, itp.), rozkładu i mocy spektralnej zakłóceń danych pomiarowych, wymiaru dekomponowanej macierzy, stopnia dokładności aproksymacji modelu, a także struktury modelu, znajduje odzwierciedlenie w rosnącej popularności tej metody w różnych dziedzinach nauki. Opublikowany w czasopiśmie,,nature'' w 1999 roku artykuł autorstwa Lee i Seunga, który tak znacząco spopularyzował metodę NMF, ma już ponad 5000 cytowań według Google Scholar. Tematyka mojego osiągnięcia naukowego jest zatem aktualna i istotna dla rozwoju badań naukowych. Nieujemna faktoryzacja tensora (NTF ang.: Nonnegative Tensor Factorization) jest metodą, którą można interpretować jako rozszerzenie nieujemnej faktoryzacji macierzy do reprezentowania danych zebranych w postaci tensora (wielowymiarowej tablicy liczb). Jest szczególnie przydatna do ekstrakcji dwuwymiarowych rzadkich i nieujemnych cech ze zbioru obrazów. W podstawowej wersji może być opisana znanym modelem CP z narzuconą nieujemnością na estymowane faktory. Do estymacji faktorów w metodzie NTF można stosować te same lub podobne narzędzia jak w metodzie NMF, a zatem w podejściu algorytmicznym obie metody faktoryzacji są blisko ze sobą związane. Cel pracy: Nadrzędnym celem moich badań jest poszukiwanie takich narzędzi do redukcji wymiarowości danych nieujemnych lub ekstrakcji nieujemnych cech, które byłyby efektywniejsze od obecnie istniejących, w danym obszarze zastosowań. Pojęcie efektywności należy rozumieć w szerokim sensie najczęściej jednak jako stosunek jakości estymacji do 5
 jest metodą redukcji wymiarowości danych nieujemnych oraz ekstrakcji cech rzadkich.")
6 czasu obliczeń. Ze względu na założenie nieujemności danych obserwowanych lub estymowanych cech, zakres moich badań ograniczyłem do metod nieujemnej faktoryzacji macierzy lub tensorów. Zajmuję się aktualnym i bardzo dynamicznie rozwijającym się obszarem badań naukowych, a zatem moje lokalne (krótkoczasowe) kierunki działań zmieniają się w zależności od stanu wiedzy i wyników badań publikowanych przez konkurencyjne zespoły badawcze. Podczas mojej pracy podejmowałem próby poszukiwania odpowiedzi na następujące pytania: Jaki algorytm numeryczny zastosować do estymacji faktorów w danym modelu NMF/NTF, zwłaszcza w kontekście zastosowania do ślepej separacji sygnałów nieujemnych, grupowania lub klasyfikacji danych? Kiedy model NMF ma jednoznaczne faktory? Jak modelować obserwowane dane w różnych zastosowaniach? Jak minimalizować ryzyko zatrzymywania się procesu naprzemiennej aktualizacji faktorów w lokalnych minimach funkcji celu? Jaką metodę wybrać do inicjalizacji faktorów? Jak wykorzystać wiedzę aprioryczną o charakterze estymowanych faktorów w procesie ich estymacji i jak dobierać parametry kar lub regularyzacji? Jaką funkcję celu przyjąć do estymacji faktorów w modelu NMF lub NTF w kontekście danego zastosowania? Jak estymować liczbę komponentów ukrytych? Odpowiedzi na powyższe pytania poszukiwałem na różnych etapach realizacji mojej pracy i można je odnaleźć w przedstawionym cyklu publikacji [1]-[12]. Są to jednak w znacznej mierze pytania nadal otwarte i będą stanowiły wyzwania badawcze jeszcze przez wiele lat. Omówienie osiągniętych wyników: Prace [2, 5 10] zawierają wyniki badań, które prowadziłem w Laboratory for Advanced Brain Signal Processing w RIKEN Brain Science Institute w Japonii. Celem tych badań było opracowanie skutecznych narzędzi do ślepej separacji obrazów i sygnałów nieujemnych. Moje zainteresowania koncentrowały się zatem na różnych aspektach metod NMF/NTF. Dużo uwagi poświęcałem tematyce algorytmów estymacji nieujemnych faktorów. Początkowo zajmowałem się algorytmami multiplikatywnymi. Były one dość często stosowane w początkowym okresie rozwoju metody NMF, głównie ze względu na ich prostotę w implementacji, niską złożoność obliczeniową i monotoniczną zbieżność. Niestety ich wady, takie jak bardzo powolna zbieżność i to w dodatku do niekoniecznie optymalnego rozwiązania w sensie warunków optymalności KKT (Karush-Kuhn-Tucker), niestabilność numeryczna w estymacji bardzo rzadkich rozwiązań oraz dość duża podatność na zatrzymywanie się w lokalnych minimach funkcji celu, znacznie ograniczają ich użyteczność w wielu zastosowaniach modelu NMF. Istniała więc potrzeba opracowania skuteczniejszych narzędzi do realizacji postawionego celu. Praca [5] ukazuje potencjał obliczeniowy projekcyjnych algorytmów quasi-newtona w zadaniach estymacji faktorów w modelu NMF. Algorytmy te charakteryzują się znacznie większą szybkością zbieżności niż wspomniane algorytmy multiplikatywne. Do najważniejszych moich osiągnięć naukowych przedstawionych w tej pracy należy zaliczyć: Koncepcję i opracowanie różnych wersji algorytmów quasi-newtona do naprzemiennej minimalizacji zregularyzowanej funkcji odległości euklidesowej oraz dywergencji alfa. Są to algorytmy przeznaczone do głębokiej eksploracji funkcji celu. Pozwalają uzyskać bardzo dobrą jakość estymacji faktorów, jeśli model jest 6

7 dokładny. Znalazły różnorodne zastosowania w wielu dziedzinach nauki, o czym świadczą liczne cytowania tej pracy (26 cytowań według bazy WoS). Zastosowanie uogólnionej miary różnorodności, inspirowanej funkcją celu w algorytmie FOCUSS (ang. FOCal Underdetermined System Solver), do wymuszania rzadkości w estymowanym faktorze. W pracy pokazano, że taką funkcję łatwo zaimplementować i prowadzi ona do znacznej poprawy jakości estymowanych faktorów, jeśli charakteryzują się one dużą rzadkością. Zaproponowanie reguły zmniejszającej parametr regularyzacji stopniowo z postępującymi iteracjami naprzemiennymi, poczynając od dużej wartości początkowej. Reguła ta pozwala łatwiej kontrolować ilość wprowadzanej informacji apriorycznej i jest obecnie stosowana w wielu metodach NMF. W pracy [6] przedstawiono nową koncepcję estymacji faktorów w modelu NMF. Zaproponowałem aby zadania naprzemiennej optymalizacji nieliniowej funkcji Lagrange a (z logarytmicznym członem kary) sprowadzić do zadań programowania kwadratowego, aproksymując tę funkcję za pomocą szeregu Taylora do stopnia drugiego. Zadania te są następnie rozwiązywane za pomocą zmodyfikowanego algorytmu IPTR (ang. Interior- Point Trust-Region). Takie podejście okazało się szczególnie efektywne w przypadku występowania niejednoznaczności rotacyjnej. Zaproponowany algorytm QP-NMF najlepiej bowiem radził sobie z problemem zatrzymywania się procesu naprzemiennej optymalizacji funkcji celu w jej lokalnych minimach. Niestety pomimo niewątpliwych zalet tego algorytmu, jego koszt obliczeniowy w zadaniach o dużych rozmiarach jest znaczący. Problem dużej złożoności obliczeniowej udało się częściowo rozwiązać w pracy [7], stosując algorytmy gradientów rzutowanych. Charakteryzują się one znacznie lepszymi właściwościami numerycznymi niż znane algorytmy multiplikatywne oraz mogą być zastosowane do rozwiązywania zadań o dużych rozmiarach (są skalowalne). Ten wniosek potwierdzono eksperymentalnie, a zaproponowane narzędzia już znalazły liczne zastosowania (praca cytowana 16 razy). Metodę NMF bazującą na algorytmach gradientów rzutowanych można dodatkowo usprawnić, jeśli zaimplementuje się ją w tzw. wielowarstwowej strukturze modelu NMF. Takie podejście zaproponowano w pracy [8] i jest ono szczególnie użyteczne, gdy nadmiarowość obserwacji nie jest zbyt duża. Ponadto, taka struktura modelu NMF jest też przydatna w estymacji komponentów ukrytych w modelu źle uwarunkowanym. W pracy [9] pokazano, że możliwa jest ślepa separacja nieujemnych i nieskalowanych sygnałów źródłowych na podstawie ich liniowych mieszanin, uzyskanych za pomocą mieszającej macierzy Hilbera o wskaźniku uwarunkowania ok W testach przeprowadzonych w tej pracy, zaproponowana metoda zwiększa znacząco jakość estymowanych sygnałów. Artykuł [10] syntezuje otrzymane wcześniej wyniki badań w zakresie zastosowania metod NMF do ślepej separacji sygnałów nieujemnych oraz pokazuje, że opracowane narzędzia mogą być wykorzystane do estymacji faktorów w modelu NTF. Rozdziały 5, 6 i 8 monografii [2] są mojego autorstwa. Zawarto w nich podsumowujące wyniki badań w zakresie wykorzystania projekcyjnych algorytmów gradientów rzutowanych oraz quasi-newtona. Porównano opracowane narzędzia pod względem ich efektywności dla różnych zbiorów danych. Zamieszczono również m-pliki funkcyjne Matlaba, zawierające implementacje zoptymalizowanych algorytmów. Przegląd wybranych zastosowań metody NMF przedstawiono w Rozdziale 8. Najwięcej uwagi poświęcono grupowaniu danych, klasyfikacji obrazów, spektroskopii oraz analizie mikromacierzy DNA. Praca [2] liczy obecnie ponad 220 cytowań w bazie WoS. Metoda NMF znalazła także liczne zastosowania w ślepej separacji sygnałów spektralnych, zwłaszcza w obrazowaniu hiperspektralnym. W pracy [3] zaproponowano zmodyfikowaną wersję algorytmu FC-NNLS (ang. Fast Combinatorial Nonnegative Least 7

8 Square) oraz stosując podejście geometryczne wyjaśniono dlaczego parametr regularyzacji powinien zmniejszać się stopniowo z iteracjami naprzemiennymi. Z badań przeprowadzonych na różnych sygnałach spektralnych wynika, że zaproponowany algorytm jest efektywniejszy niż znane z literatury algorytmy VCA (ang. Vertex Component Analysis), MVSA (ang. Minimum Volume Simplex Analysis) i SISAL (ang. Simplex Identification via Split Augmented Lagrangian). Praca [4] dotyczy splotowego i podokreślonego modelu ślepej separacji sygnałów akustycznych z nagrań rejestrowanych stereofonicznie. Model NMF zastosowano do opisu komponentów ukrytych w spektrogramach źródeł. Założono, że estymowane sygnały źródłowe charakteryzują się lokalnie gładkim profilem zarówno w dziedzinie czasu jak i częstotliwości. Modelując lokalną gładkość losowym polem Markowa oraz stosując podejście bayesowskie, uzyskano znaczącą poprawę jakości estymowanych sygnałów akustycznych (mowy i dźwięków instrumentów nieperkusyjnych) w stosunku do innych badanych metod. Szczególnym przypadkiem modelu NMF jest jego symetryczna struktura, która znalazła zastosowanie w zadaniu grupowania probabilistycznego, niekoniecznie nieujemnych danych. Do realizacji takiego zadania można zastosować narzędzia zaproponowane w pracy [11]. Są to usprawnione algorytmy multiplikatywne, które gwarantują monotoniczną zbieżność do punktu granicznego, określonego warunkami optymalności KKT i można je implementować w konfiguracji równoległej. W pracy tej zastosowano je do grupowania obrazów twarzy, dokumentów tekstowych oraz ekspresji genów. Jeśli w standardowym modelu NMF, jeden z estymowanych faktorów jest wystarczająco rzadki a drugi całkowicie gęsty, wówczas nieujemna faktoryzacja takich danych jest niejednoznaczna. Jeśli jednak, obserwowane dane są dokładne, możliwa jest jednoznaczna estymacja faktorów (z pominięciem niejednoznaczności skali i permutacji) stosując algorytm przedstawiony w pracy [12]. Bazuje on na podejściu geometrycznym. Wyszukuje rekurencyjnie promienie ekstremalne stożka wielościanowego, generowanego wektorami danych. Dla danych dokładnych, promienie te są poszukiwanymi wektorami cech. Uwzględniając jednak słabe zaburzenia modelu, algorytm ten może być stosowny do inicjalizacji faktorów w modelu NMF. Monografia [1] stanowi syntezę wyników moich badań przeprowadzonych od 2005 r. do 2013 r. Zawiera zarówno gruntowne porównanie opracowanych algorytmów i modeli, jak i nowe, niepublikowane wcześniej wyniki badań. Przedstawiłem różne zagadnienia związane z nieujemną faktoryzacją macierzy, takie jak: funkcje celu, algorytmy optymalizacji z ograniczeniami nieujemności, niejednoznaczność faktoryzacji oraz strategie wymuszania określonych cech faktorów, struktury modeli, modele nieujemnej faktoryzacji tensora oraz przykładowe zastosowania omawianych modeli. Omawiane metody znajdują liczne zastosowania w wielu dziedzinach nauki i technikach inżynieryjnych. W pracy dokonano oceny efektywności wybranych metod i modeli dla zadań ślepej separacji sygnałów, grupowania oraz klasyfikacji danych. Prognozowane kierunki rozwoju metod NMF i NTF przedstawiłem w rozdziale podsumowującym monografię. Najważniejsze osiągnięcia naukowe: Prowadzone przeze mnie badania zaowocowały powstaniem wielu nowych i efektywnych algorytmów dla modeli NMF/NTF. Monografie [1], [2] i artykuł [10] syntezują otrzymane wyniki badań i zawierają porównanie efektywności opracowanych algorytmów dla danych o różnych właściwościach. Liczne wyniki badań pokazują, że algorytm Fast HALS (rozdział w [1]) jest jednym z najefektywniejszych algorytmów do estymacji nieujemnych faktorów w wielu zastosowaniach modeli NMF/NTF, zwłaszcza jeśli obserwowane dane są 8

9 faktoryzowalne. Badania te były prowadzone przez niezależnych badaczy z zagranicznych ośrodków naukowych i publikowane w renomowanych czasopismach zagranicznych. Wyniki badań przedstawione w tej monografii również potwierdzają ten wniosek. Algorytm ten powstał na bazie algorytmu HALS (ang. Hierarchical Alternating Least Squares), którego jestem współautorem. Liczne cytowania moich prac z lat oraz komentarze w literaturze pokazują, że mój pomysł zastosowania projekcyjnych algorytmów quasi-newtona ([5, 6] oraz rozdział 6 w [2]) do metody NMF stał się bardzo trafny i zainspirował wielu badaczy do rozwijania tej tematyki. Obecnie algorytmy quasi-newtona są dość popularne w rozwiązywaniu zadań nieujemnej faktoryzacji macierzy. Opracowałem nowe i bardzo skuteczne algorytmy quasi-newtona dla symetrycznej struktury modelu NMF (rozdział w [1]). Algorytmy te dla danych dokładnych lub słabo zaburzonych są znacznie skuteczniejsze niż istniejące w literaturze algorytmy multiplikatywne. Współpracując z wieloma światowymi ekspertami w dziedzinie metod NMF, brałem udział w opracowaniu efektywnych algorytmów multiplikatywnych do grupowania probabilistycznego [11]. Zaproponowałem wymuszanie rzadkości w estymowanym faktorze przez uogólnioną miarę różnorodności [5], inspirowaną funkcją celu w algorytmie FOCUSS. Takie podejście znacząco poprawia jakość estymacji faktorów o dużej rzadkości. Zauważyłem, że parametr kary lub regularyzacji w członie wymuszającego gładkość estymowanego faktora powinien zmniejszać się stopniowo z iteracjami naprzemiennymi, poczynając od dużej wartości początkowej. Takie rozwiązanie jest szczególnie przydatne, gdy zadanie faktoryzacji jest niejednoznaczne (z pominięciem niejednoznaczności skali i permutacji), bowiem zmniejsza ryzyko zatrzymywania się procesu zbieżności w niekorzystnym punkcie lokalnego minimum funkcji celu. Analiza geometryczna i badania empiryczne potwierdzają tę tezę ([3] i rozdział 4 w [1]). Do wymuszania lokalnej gładkości estymowanych faktorów zastosowałem wygładzanie oparte na rozkładzie Gibbsa z losowym polem Markowa. Takie rozwiązanie okazało się bardzo efektywne, zwłaszcza w podokreślonym modelu ślepej separacji sygnałów akustycznych [4]. Zaproponowałem różne metody inicjalizacji faktorów ([12] i rozdział 4.1 w [1]). Na szczególne wyróżnienie zasługuje metoda SimplexMax [12], która wyszukuje promienie ekstremalne w stożku wielościanowym tworzonym przez zbiór wektorów obserwacji. Umożliwia ona znalezienie rozwiązania dokładnego, jeśli obserwowane dane są niesprzeczne i co najmniej jeden z estymowanych faktorów jest wystarczająco rzadki. W przypadku danych zaburzonych, algorytm ten znajduje rozwiązanie przybliżone, które jest zwykle lepszym inicjalizatorem iteracyjnych metod aktualizacji faktorów niż inicjalizacja całkowicie losowa. Opracowałem nową strukturę modelu NMF (rozdział w [1]), która zakłada, że jeden z estymowanych faktorów można wyrazić za pomocą liniowej kombinacji jednomodalnych funkcji bazowych, nieujemnych i lokalnie gładkich. Takie podejście jest szczególnie użyteczne w estymacji sygnałów spektralnych. Udowodniłem monotoniczną zbieżność algorytmów MUE i beta-nmf, stosując bardziej rygorystyczne podejście niż w pracach Lee i Seunga (rozdział 4.4 w [1]). Zaproponowałem usprawnioną wersję algorytmu spektralnego rzutowania gradientu (rozdział w [1]), służącą do minimalizacji funkcji odległości euklidesowej, regularyzowanej członem wymuszającym założone profile cech lub profile 9
![Liczne cytowania moich prac z lat 2006 2007 oraz komentarze w literaturze pokazują, że mój pomysł zastosowania projekcyjnych algorytmów quasi-newtona ([5, 6] oraz rozdział 6 w [2]) do metody NMF stał](/docs-images/46/2183810/images/page_9.jpg "się bardzo trafny i zainspirował wielu badaczy do rozwijania tej tematyki. Obecnie algorytmy quasi-newtona są dość popularne w rozwiązywaniu zadań nieujemnej faktoryzacji macierzy.")
10 wektorów wierszowych w macierzy kodującej. Jest to wersja przeznaczona do nadzorowanej klasyfikacji lub estymacji sygnałów o lokalnej gładkości. Usprawniłem algorytm punktów wewnętrznych (rozdział 4.8 w [1]). W wyniku zastosowania faktoryzacji Choleskiego do rozwiązywania zadania odwrotnego, uzyskano pokaźne zmniejszenie kosztu obliczeniowego. Do minimalizacji uogólnionych funkcji celu zastosowałem algorytm obszaru zaufania (rozdział i w [1]). Dla dywergencji alfa i beta pokazano, że punkt Cauchy ego może być relatywnie łatwo obliczany i przy niskim koszcie obliczeniowym. Finalna postać algorytmu może być wyrażona w wersji zwektoryzowanej. Bazując na modelu Tweedie, przedstawiłem związek funkcji celu z rozkładami gęstości prawdopodobieństwa zmiennych obserwowanych (rozdział 2 w [1]). Opracowałem półortogonalny model dekompozycji Tuckera, który jest szczególnie przydatny w klasyfikacji obrazów (rozdział w [1]). Zaproponowałem półbinarną metodę NMF do twardego grupowania danych (rozdział w [1]). Najistotniejsze wnioski: Z przeprowadzonych badań wynika konkluzja, że nie istnieje taki algorytm, który byłby bezkonkurencyjny we wszystkich zastosowaniach modelu NMF. W wielu przypadkach algorytmem pierwszego wyboru może być HALS lub RNNLS (ang. Regularized Nonnegative Least Squares). Jednakże precyzyjny wybór algorytmu powinien być zależny od wielu czynników, zwłaszcza własności obserwowanych danych i charakteru poszukiwanych faktorów. Jeśli dane są dokładne, opisane modelem faktoryzowalnym, a funkcja celu należy do klasy C 1,1, z pewnością najlepszym wyborem będą algorytmy quasi-newtona. Jeśli jednak model faktoryzacji jest tylko przybliżony lub silnie zaburzony, szybkość zbieżności danego algorytmu nie jest aż tak istotna. W takim przypadku, należy bardziej brać pod uwagę inne czynniki, takie jak charakter zbieżności, stabilność numeryczną algorytmu oraz łatwość przystosowania go do włączenia informacji apriorycznej. W trzecim rozdziale monografii [1] przedstawiono warunki jednoznaczności faktorów w modelu NMF. Dotyczą one modelu dokładnego i są przydatne głównie w rozważaniach teoretycznych, bowiem zastosowanie ich do oceny faktorów w przestrzeniach wielowymiarowych sprowadza się do zadania klasy NP. Co więcej, metody te umożliwiają ocenę jednoznaczności już istniejących faktorów, a nie dają odpowiedzi na pytanie czy dana macierz obserwacji posiada jednoznaczną nieujemną faktoryzację. Można przypuszczać, że ten aspekt modelu NMF będzie jeszcze silnie rozwijany w przyszłości. Niejednoznaczność faktorów w pewnych zastosowaniach modelu NMF nie jest jednak istotnym problemem. Przykładowo, w nadzorowanej klasyfikacji metodę NMF najczęściej stosuje się do ekstrakcji cech o określonym charakterze. Nie jest więc szczególnie istotne czy cechy te są jednoznaczne czy nie, a jedynie to czy prowadzą do właściwej reguły dyskryminacyjnej. Inaczej jest jednak w grupowaniu danych czy ślepej separacji źródeł. W tych zastosowaniach, niejednoznaczności inne niż skalowanie lub permutacja faktorów mogą poważnie zaburzyć interpretację estymowanych faktorów. Problem niejednoznaczności faktorów można też łagodzić przez odpowiedni dobór informacji apriorycznej. Zadanie to nie jest łatwe, ale pokazuje ogromną elastyczność modelu NMF w dostosowaniu do danych obserwowanych. Przykładowo, jeśli NMF stosowany jest do grupowania 10
![Do minimalizacji uogólnionych funkcji celu zastosowałem algorytm obszaru zaufania (rozdział 4.10.2 i 4.10.4 w [1]).](/docs-images/46/2183810/images/page_10.jpg "Dla dywergencji alfa i beta pokazano, że punkt Cauchy ego może być relatywnie łatwo obliczany i przy niskim koszcie obliczeniowym. Finalna postać algorytmu może być wyrażona w wersji zwektoryzowanej.")
11 twardego, wówczas wymuszanie binarności w jednym z estymowanych faktorów jest celowe i prowadzi do większej stabilizacji i powtarzalności rezultatów grupowania. Badania eksperymentalne potwierdzają, że jeśli zadanie nieujemnej faktoryzacji macierzy jest jednoznaczne (z wyłączeniem niejednoznaczności skali i permutacji), dobrze uwarunkowane i bez zaburzeń modelu, możliwa jest ekstrakcja nawet bardzo dużej liczby komponentów ukrytych (cech). W przeciwnym razie, nawet przy silnej nadmiarowości obserwacji mogą wystąpić problemy z estymacją kilku komponentów. W takim przypadku, informacje aprioryczne o charakterze poszukiwanych faktorów mają istotne znaczenie. Jeśli oczekuje się, że co najmniej jeden z faktorów modelu NMF nie będzie wystarczająco rzadki, jego estymacja powinna być wspomagana regularyzacją w normie l 2, a współczynnik regularyzacji powinien zmniejszać się stopniowo z liczbą iteracji naprzemiennych, poczynając od dużej wartości. Do estymacji faktorów w modelu NMF można stosować różne funkcje celu. Funkcja odległości euklidesowej jest prawdopodobnie najczęściej stosowana, ponieważ zwykle zakłada się, że błąd residualny ma rozkład gaussowski. Nie we wszystkich zastosowaniach funkcja ta jest najlepszym wyborem. Przykładowo, w klasyfikacji obrazów twarzy lepsze rezultaty uzyskano stosując uogólnioną dywergencję Kullbacka Leiblera. Podobnie jest w grupowaniu dokumentów tekstowych. Stosując model NMF do ślepej separacji sygnałów akustycznych efektywniej jest modelować podobieństwo między zbiorem komponentów ukrytych a modelem NMF przez dywergencję Itakura Saito. Liczne przykłady z literatury również potwierdzają, że w wielu zastosowaniach modelu NMF lepsze wyniki uzyskuje się innymi miarami podobieństwa niż odległość euklidesowa. Nieujemna faktoryzacja tensora może być realizowana za pomocą algorytmów NMF, ale nie są to jednak metody równoważne z punktu widzenia właściwości estymowanych cech. Przykładowo, cechy estymowane metodą NMF z macierzy zwektoryzowanych obrazów twarzy mogą charakteryzować się odmienną lokalnością niż cechy estymowane podstawową metodą NTF z tensora obrazów uporządkowanych wzdłuż jednego z modów. Komponenty ukryte otrzymane metodą NTF wzdłuż modu uporządkowania obrazów mogą posiadać lepsze właściwości dyskryminacyjne niż wektory macierzy kodującej w modelu NMF. Badania przedstawione w pracy [1] pokazują, że algorytm UO-NTD pozwala uzyskać trochę większą dokładność klasyfikacji obrazów twarzy z bazy ORL niż metody NMF. Można więc przypuszczać, że metoda NTF jest bardziej odpowiednia do klasyfikacji obrazów wielowymiarowych. Można nią ekstrahować cechy multiliniowe z danych wielomodalnych. Przykładowo, stosując NTF do wielomodalnego tensora zbioru spektrogramów, każda estymowana cecha reprezentowana jest wielomodalnym tensorem rzędu pierwszego, gdzie każdy mod odpowiada jednej dziedzinie obserwacji. Przy odpowiedniej informacji apriorycznej o własnościach cech względem dowolnego modu, łatwiej realizować ich selekcję oraz interpretację. Aspekt praktyczny i zastosowanie: Prowadzone badania zaowocowały powstaniem wielu algorytmów numerycznych oraz narzędzi programistycznych, które mogą znaleźć zastosowania w obszarach sztucznej inteligencji, uczeniu maszyn oraz przetwarzaniu sygnałów i obrazów. Poniżej przedstawiono listę najważniejszych zastosowań: 11

12 Ślepa separacja sygnałów spektralnych. W wielu metodach analizy spektralnej, zwłaszcza w obrazowaniu hiperspektralnym oraz różnego rodzaju spektroskopiach, np. Ramana lub masowej, przyjmuje się liniowy i addytywny model mieszania sygnałów czystych spektralnie. Są to sygnały nieujemne i częstokroć rzadkie, a proces mieszania wyrażony przez superpozycję. Do estymacji takich sygnałów oraz macierzy mieszającej opracowano różne narzędzia bazujące na modelach NMF lub NTF (rozdział 7.1 w [1]). Ślepa separacja sygnałów akustycznych (mowy lub muzyki) z nagrań rejestrowanych stereofonicznie. Opracowane narzędzia bazują na podokreślonym modelu jednoczesnego lub splotowego mieszania niestacjonarnych sygnałów źródłowych z możliwymi stacjonarnymi zaburzeniami obserwacji [4]. Umożliwiają więc separację większej liczby sygnałów źródłowych niż liczba sygnałów obserwowanych. Analiza skupień różnego rodzaju danych. Na szczególne wyróżnienie zasługują narzędzia do grupowania dokumentów tekstowych, a także do twardego grupowania danych nieujemnych, grupowania probabilistycznego oraz miękkiego grupowania dwustronnego (rozdział 7.2 w [1]). Klasyfikacja obrazów (rozdział 7.3 w [1]), w szczególności obrazów twarzy, tekstury, cyfr ręcznie pisanych, oraz spektrogramów różnych sygnałów. Opracowane narzędzia mogą być zastosowane w różnych dziedzinach nauki, np. w inżynierii biomedycznej (analiza ekspresji genów, analiza sygnałów EEG), medycynie (ekstrakcja cech z obrazów rezonansu magnetycznego), a także w przemyśle (w zautomatyzowanej ocenie jakości produkcji przemysłowej różnego rodzaju materiałów na podstawie obrazów ich tekstury). 5. Omówienie pozostałych osiągnięć naukowo badawczych (artystycznych) 5.1. Działalność naukowa prowadzona przed uzyskaniem stopnia doktora Pierwsze badania naukowe rozpocząłem podczas realizacji pracy magisterskiej. Moim celem było wyjaśnienie przyczyny uszkadzania się systemu ochrony przeciwpożarowej wieży wrocławskiego Ratusza podczas wyładowań atmosferycznych występujących w bezpośredniej jego bliskości. Zadanie badawcze zakończyło się sukcesem opracowano równoważny model obwodowy opisujący zjawisko indukowania się sygnałów zakłócających w obwodach elektrycznych instalacji przeciwpożarowej, których źródłem jest prąd impulsowy w kanale burzowym. Model ten został zweryfikowany przez porównanie zmierzonych i obliczonych wyników. Następnie, na podstawie modelu opracowano skuteczne sposoby zwiększenia odporności tego systemu na wyładowania atmosferyczne. Wyniki badań opublikowano w materiałach konferencji EMC98 (Zał. 4: [H.12]). Moje pierwsze osiągnięcia naukowo-badawcze oraz leżąca u podstaw pasja poznawania świata motywowały mnie do dalszych działań w kierunku rozwoju nauki. W 1997 roku rozpocząłem studia doktoranckie w Zakładzie Układów Elektronicznych Instytutu Telekomunikacji i Akustyki Politechniki Wrocławskiej pod opieką dra hab. inż. A. Prałata. Zaangażowałem się w badania geofizyczne struktury skał osadowych metodami elektromagnetycznymi. Badania te miały na celu poszukiwanie niejednorodności takiej struktury w rejonie występowania szkód górniczych. Moje zainteresowania naukowe koncentrowały się na zadaniu tzw. inwersji modelu, tzn. jak z danych zmierzonych zrekonstruować obraz rozkładu poszukiwanej cechy, niosącej istotną informację o badanych szkodach górniczych. W moich rozważaniach tą cechą jest współczynnik tłumienia fali elektromagnetycznej, propagowanej w ziemi między odwiertami, a metodą badań tzw. geotomografia 12
![Do estymacji takich sygnałów oraz macierzy mieszającej opracowano różne narzędzia bazujące na modelach NMF lub NTF (rozdział 7.1 w [1]).](/docs-images/46/2183810/images/page_12.jpg "Ślepa separacja sygnałów akustycznych (mowy lub muzyki) z nagrań rejestrowanych stereofonicznie.")
13 elektromagnetyczna. Celem mojej pracy doktorskiej było znalezienie optymalnej metody rekonstrukcji obrazu w geotomografii elektromagnetycznej. Po przyjęciu pewnych uproszczeń modelu opisującego propagację fali elektromagnetycznej w ziemi oraz przy założeniu dyskretnej reprezentacji transformaty Radona, zadanie rekonstrukcji obrazu w analizowanej geotomografii sprowadza się do zregularyzowanego liniowego zadania najmniejszych kwadratów z macierzą systemową niepełnego rzędu. W pracy badałem różne metody rozwiązywania takich zadań, zarówno w podejściu algebraicznym jak i statystycznym. Do największych moich osiągnięć naukowo-badawczych uzyskanych podczas realizacji pracy doktorskiej należy zaliczyć: przetestowanie ok. 100 (iteracyjnych) metod stosowanych do rozwiązywania liniowego zadania najmniejszych kwadratów i zadań rekonstrukcji obrazów w innych zastosowaniach tomografii oraz ocenę ich przydatności do rekonstrukcji obrazu w geotomografii elektromagnetycznej usprawnienie wieloparametrowej metody gradientów sprzężonych przez włączenie regularyzacji Tichonowa modyfikacja ta okazała się innowacyjna i kluczowa do osiągnięcia wysokiej jakości rekonstruowanego obrazu, zastosowanie wygładzania obrazu rekonstruowanego filtracją Wienera lub regularyzacją losowymi polami Markowa. Osiągnięcia te pokazały jak ważna jest regularyzacja zadań rekonstrukcji obrazów w tego rodzaju tomografii oraz jakie funkcje kary należy zastosować. W wyniku realizacji tej pracy powstały efektywne narzędzia do interpretacji danych pomiarowych w geotomografii elektromagnetycznej. Mogą one być przydatne w badaniach geofizycznych zarówno naukowych jak i inżynierskich. W okresie realizacji doktoratu wyniki badań opublikowano w dwóch czasopismach o zasięgu międzynarodowym oraz dziewięciu raportach konferencyjnych (Zał. 4: [H.1 H.11]) Działalność naukowa prowadzona po uzyskaniu stopnia doktora Moja działalność naukowa prowadzona po doktoracie dotyczy następujących obszarów badań: Rekonstrukcja obrazu w geotomografii elektromagnetycznej Po obronie doktoratu kontynuowałem badania w zakresie metod rekonstrukcji obrazu w geotomografii elektromagnetycznej. Motywowany konstruktywnymi uwagami recenzentów mojej pracy doktorskiej, znacznie usprawniłem opracowane narzędzia i metody. W latach moje badania prowadzone były w kierunku statystycznych metod rekonstrukcji obrazu, a zwłaszcza metod estymacji parametrów regularyzacji i innych hiperparametrów, występujących w bayesowskim podejściu do rekonstrukcji obrazu. Bazowałem zarówno na metodach walidacji krzyżowej, jak i na metodach maksymalizacji wielowymiarowych rozkładów granicznych. Zaproponowałem narzędzia statystyczne do estymacji wspomnianych parametrów, a zwłaszcza hiperparametrów w rozkładzie Gibbsa. W kontekście wspomnianych zastosowań zajmowałem się też wielosiatkową metodą rekonstrukcji obrazu. Wyniki badań zostały opublikowane w różnych pracach: artykuł z listy filadelfijskiej (Zał. 4: [B.4]), inne artykuły (Zał. 4: [C.3, C.8]) i raporty konferencyjne (Zał. 4: [E.16 E.20, E.22, E.23]). W 2002 roku nawiązałem współpracę z Prof. C. Popa z Wydziału Matematyki i Informatyki, OVIDIUS University of Constanta w Rumunii w zakresie rozwoju i zastoso- 13

14 wania algorytmu Kaczmarza do rekonstrukcji obrazu w geotomografii elektromagnetycznej. Wspólne analizy pokazały, że podstawowa wersja tego algorytmu, stosowanego w różnych metodach obrazowania tomograficznego, jest wrażliwa na zaburzenia szumowe, należące do ortogonalnego uzupełnienia obrazu przekształcenia przestrzeni rozwiązań w przestrzeń obserwacji. Zaproponowano więc wersję usprawnioną i eksperymentalnie pokazano, że takie podejście pozwala uzyskać lepsze rekonstrukcje. Wyniki badań opublikowano w czasopiśmie z listy filadelfijskiej (Zał. 4: [B.5]). Mój udział w tych badaniach oceniam na 50 %. Kolejne wspólne badania zaowocowały dalszym rozwojem algorytmu Kaczmarza. Wprowadzono regularyzację losowym polem Markowa oraz ograniczenia nieujemności. Takie podejścia pozwalają znacząco zredukować pionowe smużenia w obrazie, powodowane ograniczonym zakresem kątowym promieni sondujących badany obszar. Rezultaty badań przedstawiane były na wielu konferencjach międzynarodowych (Zał. 4: [E.6, E.11, E.12, E.14, E.15]). Wprowadzanie informacji apriorycznej o cechach rekonstruowanego obrazu jest bardzo istotne w tomografii o ograniczonym zakresie pomiarowym. Celem stosowania geotomografii do badań obszarów ze szkodami górniczymi było poszukiwanie tzw. pustek w górotworze. Obiekty te charakteryzują się znacznie odmienną wartością współczynnika tłumienia fali elektromagnetycznej niż obszar tła stąd wniosek, że taki obraz tomograficzny można modelować obrazem binarnym. Rekonstrukcja obrazu w tomografii binarnej jest numerycznie trudniejsza niż obrazu o cechach ciągłych, ponieważ zadanie optymalizacji binarnej jest zwykle niewypukłe. Mimo to, tomografia binarna umożliwia zrekonstruowanie obrazu dokładnego nawet z danych niekompletnych oraz jest znacznie bardziej odporna na zakłócenia szumowe. Takie podejście do geotomografii przedstawiłem na warsztatach naukowych pt. Workshop on Discrete Tomography and Its Applications, które odbyły się w Nowym Jorku w 2005 r. Mój referat spotkał się z akceptacją światowych ekspertów w dziedzinie tomografii dyskretnej. Zostałem zaproszony przez Prof. G. Hermana i Prof. A. Kuba do współpracy. W efekcie dalszych badań w zakresie tej tematyki, powstały nowe algorytmy do geotomografii binarnej. Zaproponowałem zregularyzowany algorytm rekonstrukcji obrazu oparty na maksymalizacji statystyki Gibbsa- Boltzmanna oraz algorytm rzutowania gradientu z binarnym wymuszaniem. Efektywność zaproponowanych rozwiązań została potwierdzona zarówno w testach z danymi syntetycznymi jak i rzeczywistymi. Wyniki badań opublikowano w czasopiśmie z listy filadelfijskiej (Zał. 4: [B.3]) oraz w Zał. 4: [C.5, F.3]. Nieparametryczna estymacja rozkładu gęstości prawdopodobieństwa Podczas pobytu w Institute of Statistical Mathematics w Tokio włączyłem się aktywnie w realizację jednego z projektów badawczych tego instytutu. Podjąłem współpracę z Prof. K. Tanabe. Zajmowałem się bayesowską metodą nieparametrycznej estymacji rozkładu gęstości prawdopodobieństwa wielowymiarowych zmiennych losowych. W tej metodzie estymator jest formułowany podobnie jak w modelu jądrowej regresji logistycznej. Funkcja jądrowa może być wyrażona w bazie wielomianów, zwłaszcza wielomianów ortogonalnych. Do wyznaczenia współczynników liniowej kombinacji funkcji bazowych zastosowałem metodę Newtona. W moim podejściu wszystkie hiperparametry estymowane były na podstawie maksymalizacji rozkładów granicznych, wyznaczanych za pomocą próbkowania ważonego, stosując metodę MCMC lub przez aproksymację funkcji podcałkowej szeregiem Taylora do stopnia drugiego. Moja praca z tej tematyki zakończyła się opracowaniem skutecznych narzędzi w Matlabie do wyznaczania poszukiwanego estymatora. Dla wielu zbiorów testowych, estymator ten okazał się efektywniejszy niż np. znane estymatory jądrowe. Wyniki badań przedstawiono podczas warsztatów naukowych 14
. Mój udział w tych badaniach oceniam na 50 %. Kolejne wspólne badania zaowocowały dalszym rozwojem algorytmu Kaczmarza.")
15 Workshop on Nonparametric Density Estimation Methods, które odbyły się w Kioto w 2004 r. Wiedzę i doświadczenie jakie zdobyłem podczas realizacji tego projektu nadal wykorzystuję do rozwijania metod nieujemnej faktoryzacji macierzy, którymi zajmuję się obecnie. Optymalizacja sieci telefonii komórkowej UMTS W 2004 roku podjąłem współpracę z ówczesnym Zakładem Radiokomunikacji w Instytucie Telekomunikacji i Akustyki Politechniki Wrocławskiej. Uczestniczyłem w trzech projektach badawczych związanych z planowaniem i optymalizacją sieci telefonii komórkowej trzeciej generacji UMTS. Zajmowałem się algorytmami numerycznymi w zastosowaniu do zadania poszukiwania optymalnych położeń stacji bazowych oraz optymalnych wartości kątów pochylenia wiązki głównej promieniowania w antenach stacji bazowych, czyli tzw. tiltów. Są to zadania klasy NP-trudnej i zwykle rozwiązywane za pomocą algorytmów heurystycznych. Stosując dane syntetyczne oraz model propagacyjny Okumura- Hata, badałem różne strategie ewolucyjne, algorytmy genetyczne oraz algorytm inwazyjnych chwastów w kontekście wspomnianych zastosowań. Pod moją opieką powstały również dwie prace magisterskie o tej tematyce. Wyniki badań zostały opublikowane w Zał. 4: [B.7] (w roku publikacji czasopismo to znajdowało się na liście filadelfijskiej). Efektywność optymalizacji heurystycznej znacząco zależy od szybkości oceny dopasowania osobników w populacji. W rozważanym zastosowaniu, zadanie optymalizacji wiąże się z koniecznością estymacji mocy sygnałów wysyłanych przez anteny nadawcze (zarówno w terminalach jak i stacjach bazowych). Moce te można wyznaczyć z układu równań liniowych, otrzymanych z przekształcenia modelu sterowania mocą w systemie UMTS. W tym kontekście badałem różne metody iteracyjne, zwłaszcza bazujące na podprzestrzeni Kryłowa. Ponadto zajmowałem się również metodami redukcji wymiarowości analizowanego układu równań oraz warunkami jakie muszą być spełnione, aby rozwiązania były nieujemne (moce sygnałów nie mogą mieć ujemnych wartości). Wyniki badań opublikowano w następujących pracach w Zał. 4: [C.6, C.7, E.10, E.13, E.21, F.5]. Metoda FOCUSS dla podokreślonych układów równań Podokreślony układ równań to taki, w którym liczba niewiadomych jest większa niż liczba równań. Aby jego rozwiązanie było jednoznaczne, muszą być spełnione odpowiednie warunki jednoznaczności, dotyczące zarówno macierzy systemowej, jak i profilu rzadkości wektora rozwiązań. Najrzadsze rozwiązanie uzyskuje się, wyrażając zadanie optymalizacji w normie l 0. Jednak w wielu zastosowaniach, wystarczająco dobre wyniki uzyskuje się już w normie l 1. Do rozwiązania takiego zadania można zastosować różne algorytmy, jak np. poszukiwanie dopasowujące (ang. matching pursuit), ortogonalne poszukiwanie dopasowujące, algorytmy LASSO, itp. Moje zainteresowania w tym zakresie koncentrowały się wokół algorytmu FOCUSS. Jest to iteracyjny algorytm ważonych najmniejszych kwadratów, który jest podobny do reguły aktualizacji pierwszego kroku iteracyjnego w zregularyzowanej wieloparametrowej metodzie gradientów sprzężonych. Metodą tą zajmowałem się podczas doktoratu. Charakteryzuje się znacznie mniejszą złożonością obliczeniową niż wspomniane poszukiwania dopasowujące i już znalazł szerokie spektrum zastosowań, m.in. w rzadkiej rekonstrukcji sygnałów, próbkowaniu oszczędnym (ang. compressed sensing), rzadkim bayesowskim uczeniu, estymacji spektralnej oraz analizie sygnałów EEG/MEG. Obecnie istnieje wiele jego modyfikacji lub usprawnień. Moje badania dotyczyły głównie algorytmu M-FOCUSS, który jest szczególnie użyteczny do estymacji sygnałów złożonych z wielu próbek lub grupy sekwencyjnych wektorów. 15

16 Sygnały źródłowe (w dziedzinie bezpośredniej lub transformowanej) w pewnych zastosowaniach, np. w EEG lub MEG, mogą być zarówno rzadkie jak i lokalnie gładkie. Celowe wydaje się zatem włączenie do procesu ich estymacji nie tylko funkcji wymuszających rzadkość ale też lokalną gładkość. Takie podejście badałem przy współpracy z Prof. A. Cichockim (RIKEN Brain Science Institute, Japonia). W wyniku tych badań powstał nowy algorytm SOB-M-FOCUSS do estymacji sygnałów o wspomnianych właściwościach. W algorytmie tym parametr regularyzacji estymowany jest automatycznie z danych pomiarowych, wykorzystując uogólnioną metodę walidacji krzyżowej. Wyniki badań opublikowano w czasopiśmie z listy filadelfijskiej (Zał. 4: [B.2]). Kolejne moje prace naukowe o tej tematyce dotyczą innego (rygorystycznego) sposobu wyprowadzenia formuł iteracyjnych algorytmu FOCUSS oraz usprawnień obliczeniowych w algorytmach FOCUSS i M-FOCUSS (Zał. 4: [B.1, D.17]). W pracach pokazano, że operacja odwrotności macierzy w podstawowej formule iteracyjnej algorytmu FOCUSS może być realizowana za pomocą algorytmu gradientów sprzężonych, co znacznie przyśpiesza procedurę aktualizacji rozwiązania. Opublikowane prace są cytowane wielokrotnie w czasopismach z listy filadelfijskiej. Algorytm FOCUSS w połączeniu z filtracją Wienera znalazł również zastosowanie do rekonstrukcji obrazu w geotomografii elektromagnetycznej (Zał. 4: [E.5]). Nieujemna faktoryzacja macierzy i tensorów W 2005 r. wyjechałem do Laboratory for Advanced Brain Signal Processing w RI- KEN Brain Science Institute, podejmując współpracę z Prof. A. Cichockim w zakresie rozwoju metod nieujemnej faktoryzacji macierzy. Początkowo moja praca dotyczyła głównie implementacji algorytmów numerycznych w pakiecie narzędziowym ICALAB. Jednakże dzięki wiedzy nt. algorytmów rekonstrukcji obrazu i doświadczeniu w posługiwaniu się algorytmami numerycznymi mogłem szybko włączyć się w nurt zaawansowanych prac naukowo-badawczych wspomnianego laboratorium. Przy współpracy z innymi pracownikami tego laboratorium opracowałem nowy pakiet narzędziowy NMFLAB, w którym zaimplementowałem bardzo wiele badanych algorytmów i modeli NMF. Są to narzędzia służące do ślepej separacji obrazów lub sygnałów nieujemnych, udostępniane niekomercyjnie na stronie Obecnie narzędzia te stosowane są w wielu dziedzinach nauki, a liczba pobrań tego pakietu już dawno przekroczyła tysiąc. We wspomnianym laboratorium zajmowałem się różnymi aspektami nieujemnej faktoryzacji macierzy, ale w obszarze zastosowań do przetwarzania sygnałów. Początkowo pracowałem nad regularyzacją algorytmów multiplikatywnych (Zał. 4: [E.9]) oraz analizowałem właściwości statystycznych miar podobieństwa (Zał. 4: [D.22, D.23]). W kolejnym etapie moje badania koncentrowały się wokół zastosowań metod quasi-newtona. Opracowałem bardzo efektywne algorytmy bazujące na metodzie Newtona do minimalizacji różnych funkcji celu, zwłaszcza dywergencji alfa i beta (Zał. 4: [D.21]). Miary te stosowałem również do oceny nieujemnych faktorów w modelach dekompozycji tensorach (Zał. 4: [D.20, E.8]). Jestem autorem pomysłu zastosowania wygładzania estymowanych cech w modelu NMF za pomocą losowego pola Markowa (Zał. 4: [D.14, E.7]). Jest to koncepcja inspirowana bayesowskimi metodami rekonstrukcji obrazów tomograficznych. Uczestniczyłem w badaniach nad wielowarstwową strukturą modelu NMF. Rozwiązanie technologiczne oparte na takiej strukturze zostało opatentowane przez US Patent and Trademark Office (Zał. 4: [G.1]). Po powrocie do jednostki macierzystej nadal rozwijałem metody NMF ale w szerszym spektrum ich zastosowań. Opracowałem bardziej specyficzne algorytmy NMF, przeznaczone do konkretnych zastosowań, np. takich jak twarde grupowanie danych, grupowanie dokumentów tekstowych, klasyfikacja obrazów twarzy oraz sygnałów akustycznych (Zał. 16

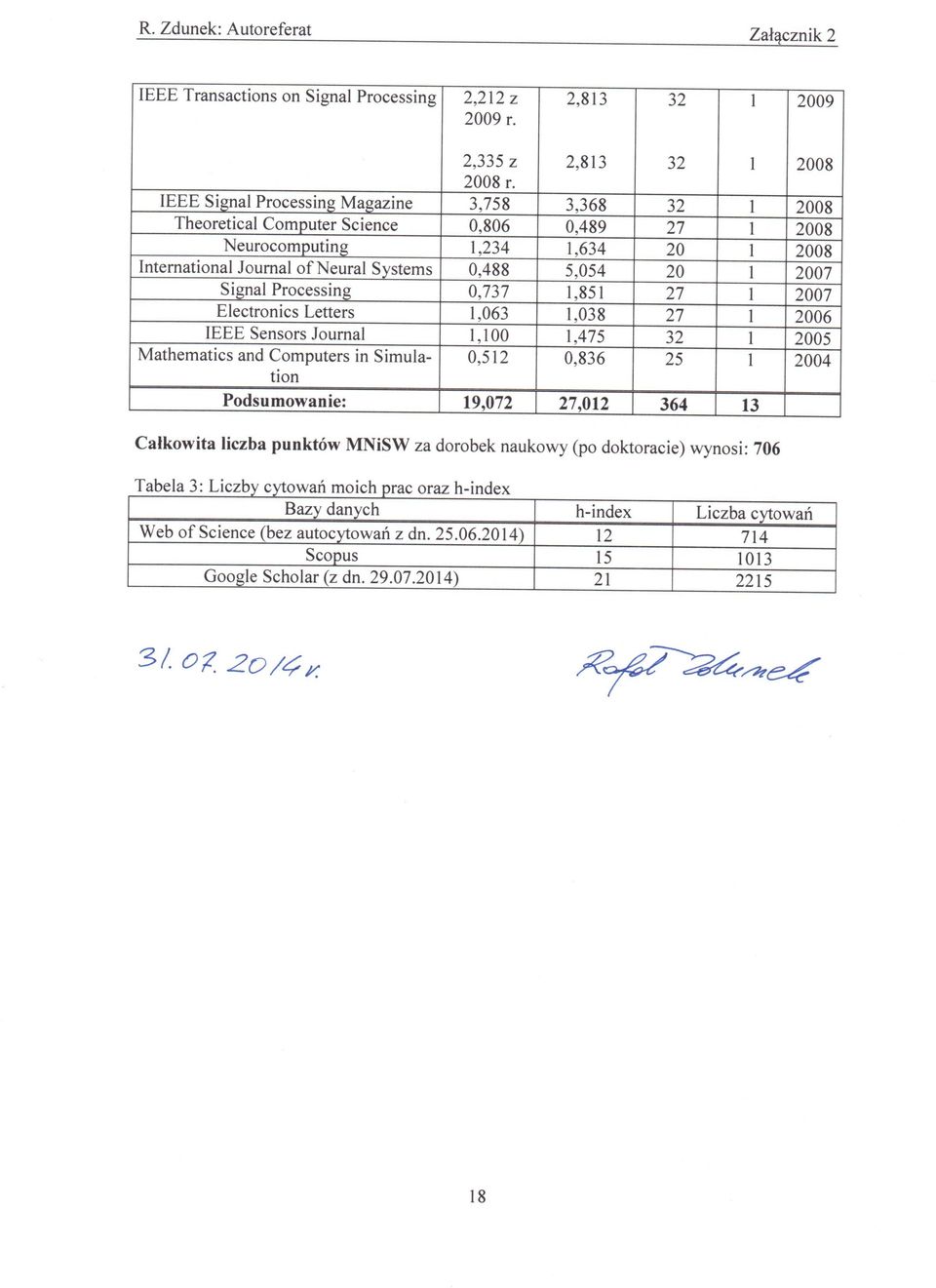
17 4: [C1, D.3 D.13, E.2 E.4, F.1, F.2, F.4]). Zaproponowałem nową strukturę modelu NMF, w której wektory cech wyrażone są przez liniową kombinację funkcji bazowych (Zał. 4: [D.4]). Jest to model szczególnie użyteczny do estymacji sygnałów lokalnie gładkich i o małej rzadkości. Model ten był rozwijany i usprawniany w kolejnych pracach (Zał. 4: [D.2, E.1]), które powstały już po zredagowaniu monografii habilitacyjnej. Jedna z ostatnich moich prac (Zał. 4: [D.1]) dotyczy również tzw. modelu online NMF, przeznaczonego przede wszystkim do dynamicznej estymacji wektorów cech. Takie modele potrzebne są do opisu splotowego mieszania niestacjonarnych sygnałów, propagowanych wielodrogowo. 6. Podsumowanie dorobku naukowego Tabela 1: Zestawienie dorobku naukowego: Kategoria Publikacje z tzw. listy filadelfijskiej, w tym: artykuły z bazy Journal Citation Reports (JCR): o autor o współautor pozostałe artykuły (źródło: Web of Science): Liczba publikacji Przed doktoratem Po doktoracie Razem Artykuły w czasopismach spoza listy filadelfijskiej: Książki: monografie w jęz. polskim podręczniki/monografie w jęz. angielskim Rozdziały w książkach: Referaty konferencyjne: w tym: publikowane w serii Springer LNCS/LNAI (do 2010 r. dokumentowane jako artykuł o zasięgu międzynarodowym, a obecnie jako referat konferencyjny) publikowane w IEEE Xplore pozostałe Patenty: Publikacje popularno-naukowe: Prace przyjęte do druku: 3 3 Podsumowanie: Tabela 2: Informacje o publikacjach z bazy JCR. Czasopismo Impact Factor (IF) Impact Factor (IF) Pkt. MNiSW Liczba publ. Rok publ. (rok publ.) z 2013 r. z 2013 r. International Journal of Applied Mathematics 1,008 1, and Computer Science Cognitive Computation 0,867 0, IEEE Transactions on Neural Networks 2,952 3,

18
Nieujemna faktoryzacja macierzy i tensorów
 Rafał Zdunek Nieujemna faktoryzacja macierzy i tensorów Zastosowanie do klasyfikacji i przetwarzania sygnałów Oficyna Wydawnicza Politechniki Wrocławskiej Wrocław 2014 Recenzenci Andrzej CICHOCKI Ewaryst
Rafał Zdunek Nieujemna faktoryzacja macierzy i tensorów Zastosowanie do klasyfikacji i przetwarzania sygnałów Oficyna Wydawnicza Politechniki Wrocławskiej Wrocław 2014 Recenzenci Andrzej CICHOCKI Ewaryst
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Opinia o dorobku naukowym dr inż. Ireneusz Dominik w związku z wystąpieniem o nadanie stopnia naukowego doktora habilitowanego.
 Prof. dr hab. inż. Tadeusz Uhl Katedra Robotyki i Mechatroniki Wydział Inżynierii Mechanicznej i Robotyki Akademia Górniczo Hutnicza w Krakowie Kraków 01.07.2018 Opinia o dorobku naukowym dr inż. Ireneusz
Prof. dr hab. inż. Tadeusz Uhl Katedra Robotyki i Mechatroniki Wydział Inżynierii Mechanicznej i Robotyki Akademia Górniczo Hutnicza w Krakowie Kraków 01.07.2018 Opinia o dorobku naukowym dr inż. Ireneusz
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metody kierunków poparwy (metoda Newtona-Raphsona, metoda gradientów sprzężonych) Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 28.03.2019 1
Optymalizacja ciągła 5. Metody kierunków poparwy (metoda Newtona-Raphsona, metoda gradientów sprzężonych) Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 28.03.2019 1
Analiza korespondencji
 Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Opis efektów kształcenia dla programu kształcenia (kierunkowe efekty kształcenia) WIEDZA. rozumie cywilizacyjne znaczenie matematyki i jej zastosowań
 WIEDZA. rozumie cywilizacyjne znaczenie matematyki i jej zastosowań") TABELA ODNIESIEŃ EFEKTÓW KSZTAŁCENIA OKREŚLONYCH DLA PROGRAMU KSZTAŁCENIA DO EFEKTÓW KSZTAŁCENIA OKREŚLONYCH DLA OBSZARU KSZTAŁCENIA I PROFILU STUDIÓW PROGRAM KSZTAŁCENIA: POZIOM KSZTAŁCENIA: PROFIL KSZTAŁCENIA:
TABELA ODNIESIEŃ EFEKTÓW KSZTAŁCENIA OKREŚLONYCH DLA PROGRAMU KSZTAŁCENIA DO EFEKTÓW KSZTAŁCENIA OKREŚLONYCH DLA OBSZARU KSZTAŁCENIA I PROFILU STUDIÓW PROGRAM KSZTAŁCENIA: POZIOM KSZTAŁCENIA: PROFIL KSZTAŁCENIA:
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
KIERUNKOWE EFEKTY KSZTAŁCENIA
 KIERUNKOWE EFEKTY KSZTAŁCENIA Wydział: Matematyki Kierunek studiów: Matematyka i Statystyka (MiS) Studia w j. polskim Stopień studiów: Pierwszy (1) Profil: Ogólnoakademicki (A) Umiejscowienie kierunku
KIERUNKOWE EFEKTY KSZTAŁCENIA Wydział: Matematyki Kierunek studiów: Matematyka i Statystyka (MiS) Studia w j. polskim Stopień studiów: Pierwszy (1) Profil: Ogólnoakademicki (A) Umiejscowienie kierunku
Podsumowanie wyników ankiety
 SPRAWOZDANIE Kierunkowego Zespołu ds. Programów Kształcenia dla kierunku Informatyka dotyczące ankiet samooceny osiągnięcia przez absolwentów kierunkowych efektów kształcenia po ukończeniu studiów w roku
SPRAWOZDANIE Kierunkowego Zespołu ds. Programów Kształcenia dla kierunku Informatyka dotyczące ankiet samooceny osiągnięcia przez absolwentów kierunkowych efektów kształcenia po ukończeniu studiów w roku
ZADANIA OPTYMALIZCJI BEZ OGRANICZEŃ
 ZADANIA OPTYMALIZCJI BEZ OGRANICZEŃ Maciej Patan Uniwersytet Zielonogórski WSTEP Zadanie minimalizacji bez ograniczeń f(ˆx) = min x R nf(x) f : R n R funkcja ograniczona z dołu Algorytm rozwiazywania Rekurencyjny
ZADANIA OPTYMALIZCJI BEZ OGRANICZEŃ Maciej Patan Uniwersytet Zielonogórski WSTEP Zadanie minimalizacji bez ograniczeń f(ˆx) = min x R nf(x) f : R n R funkcja ograniczona z dołu Algorytm rozwiazywania Rekurencyjny
UCHWAŁA. Wniosek o wszczęcie przewodu doktorskiego
 UCHWAŁA 30 czerwiec 2011 r. Uchwała określa minimalne wymagania do wszczęcia przewodu doktorskiego i przewodu habilitacyjnego jakimi powinny kierować się Komisje Rady Naukowej IPPT PAN przy ocenie składanych
UCHWAŁA 30 czerwiec 2011 r. Uchwała określa minimalne wymagania do wszczęcia przewodu doktorskiego i przewodu habilitacyjnego jakimi powinny kierować się Komisje Rady Naukowej IPPT PAN przy ocenie składanych
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
ROZWIĄZYWANIE RÓWNAŃ NIELINIOWYCH
 Transport, studia I stopnia Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym
Transport, studia I stopnia Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym
WYKŁAD 9 METODY ZMIENNEJ METRYKI
 WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
Metody numeryczne I Równania nieliniowe
 Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Podstawy Sztucznej Inteligencji (PSZT)
") Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Podstawy Sztucznej Inteligencji (PSZT) Paweł Wawrzyński Uczenie maszynowe Sztuczne sieci neuronowe Plan na dziś Uczenie maszynowe Problem aproksymacji funkcji Sieci neuronowe PSZT, zima 2013, wykład 12
Dobór parametrów algorytmu ewolucyjnego
 Dobór parametrów algorytmu ewolucyjnego 1 2 Wstęp Algorytm ewolucyjny posiada wiele parametrów. Przykładowo dla algorytmu genetycznego są to: prawdopodobieństwa stosowania operatorów mutacji i krzyżowania.
Dobór parametrów algorytmu ewolucyjnego 1 2 Wstęp Algorytm ewolucyjny posiada wiele parametrów. Przykładowo dla algorytmu genetycznego są to: prawdopodobieństwa stosowania operatorów mutacji i krzyżowania.
OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI
 Autoreferat do rozprawy doktorskiej OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI Michał Mazur Gliwice 2016 1 2 Montaż samochodów na linii w
Autoreferat do rozprawy doktorskiej OPTYMALIZACJA HARMONOGRAMOWANIA MONTAŻU SAMOCHODÓW Z ZASTOSOWANIEM PROGRAMOWANIA W LOGICE Z OGRANICZENIAMI Michał Mazur Gliwice 2016 1 2 Montaż samochodów na linii w
Metody Optymalizacji: Przeszukiwanie z listą tabu
 Metody Optymalizacji: Przeszukiwanie z listą tabu Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje: wtorek
Metody Optymalizacji: Przeszukiwanie z listą tabu Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje: wtorek
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych
 Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO
 Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Zał. nr 4 do ZW WYDZIAŁ BUDOWNICTWA LĄDOWEGO I WODNEGO KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA STOSOWANA Nazwa w języku angielskim APPLIED STATISTICS Kierunek studiów (jeśli dotyczy): Specjalność
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Zał nr 4 do ZW. Dla grupy kursów zaznaczyć kurs końcowy. Liczba punktów ECTS charakterze praktycznym (P)
") Zał nr 4 do ZW WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI KARTA PRZEDMIOTU Nazwa w języku polskim : Algebra numeryczna Nazwa w języku angielskim : Numerical algebra Kierunek studiów : Informatyka Specjalność
Zał nr 4 do ZW WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI KARTA PRZEDMIOTU Nazwa w języku polskim : Algebra numeryczna Nazwa w języku angielskim : Numerical algebra Kierunek studiów : Informatyka Specjalność
KARTA PRZEDMIOTU. Techniki przetwarzania sygnałów, D1_3
 KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
KARTA PRZEDMIOTU 1. Informacje ogólne Nazwa przedmiotu i kod (wg planu studiów): Nazwa przedmiotu (j. ang.): Kierunek studiów: Specjalność/specjalizacja: Poziom kształcenia: Profil kształcenia: Forma studiów:
Opinia o pracy doktorskiej pt. On active disturbance rejection in robotic motion control autorstwa mgr inż. Rafała Madońskiego
 Prof. dr hab. inż. Tadeusz Uhl Katedra Robotyki i Mechatroniki Akademia Górniczo Hutnicza Al. Mickiewicza 30 30-059 Kraków Kraków 09.06.2016 Opinia o pracy doktorskiej pt. On active disturbance rejection
Prof. dr hab. inż. Tadeusz Uhl Katedra Robotyki i Mechatroniki Akademia Górniczo Hutnicza Al. Mickiewicza 30 30-059 Kraków Kraków 09.06.2016 Opinia o pracy doktorskiej pt. On active disturbance rejection
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
przetworzonego sygnału
 Synteza falek ortogonalnych na podstawie oceny przetworzonego sygnału Instytut Informatyki Politechnika Łódzka 28 lutego 2012 Plan prezentacji 1 Sformułowanie problemu 2 3 4 Historia przekształcenia falkowego
Synteza falek ortogonalnych na podstawie oceny przetworzonego sygnału Instytut Informatyki Politechnika Łódzka 28 lutego 2012 Plan prezentacji 1 Sformułowanie problemu 2 3 4 Historia przekształcenia falkowego
Układy równań liniowych. Krzysztof Patan
 Układy równań liniowych Krzysztof Patan Motywacje Zagadnienie kluczowe dla przetwarzania numerycznego Wiele innych zadań redukuje się do problemu rozwiązania układu równań liniowych, często o bardzo dużych
Układy równań liniowych Krzysztof Patan Motywacje Zagadnienie kluczowe dla przetwarzania numerycznego Wiele innych zadań redukuje się do problemu rozwiązania układu równań liniowych, często o bardzo dużych
Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym
 do sterowania i diagnostyki procesów w przemyśle spożywczym") POLITECHNIKA WARSZAWSKA Instytut Technik Wytwarzania Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym Marcin Perzyk Dlaczego eksploracja danych?
POLITECHNIKA WARSZAWSKA Instytut Technik Wytwarzania Zastosowanie metod eksploracji danych (data mining) do sterowania i diagnostyki procesów w przemyśle spożywczym Marcin Perzyk Dlaczego eksploracja danych?
Zagadnienia optymalizacji Problems of optimization
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 0/04 Zagadnienia optymalizacji Problems of optimization A. USYTUOWANIE MODUŁU W
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 0/04 Zagadnienia optymalizacji Problems of optimization A. USYTUOWANIE MODUŁU W
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015
 Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Laboratorium 5 Przybliżone metody rozwiązywania równań nieliniowych
 Uniwersytet Zielonogórski Wydział Informatyki, Elektrotechniki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych Elektrotechnika niestacjonarne-zaoczne pierwszego stopnia z tyt. inżyniera
Uniwersytet Zielonogórski Wydział Informatyki, Elektrotechniki i Telekomunikacji Instytut Sterowania i Systemów Informatycznych Elektrotechnika niestacjonarne-zaoczne pierwszego stopnia z tyt. inżyniera
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
EFEKTY KSZTAŁCENIA DLA KIERUNKU STUDIÓW INFORMATYKA
 EFEKTY KSZTAŁCENIA DLA KIERUNKU STUDIÓW INFORMATYKA poziom kształcenia profil kształcenia tytuł zawodowy uzyskiwany przez absolwenta studia drugiego stopnia ogólnoakademicki magister inżynier 1. Umiejscowienie
EFEKTY KSZTAŁCENIA DLA KIERUNKU STUDIÓW INFORMATYKA poziom kształcenia profil kształcenia tytuł zawodowy uzyskiwany przez absolwenta studia drugiego stopnia ogólnoakademicki magister inżynier 1. Umiejscowienie
Odniesienie symbol I [1] [2] [3] [4] [5] Efekt kształcenia
![Odniesienie symbol I [1] [2] [3] [4] [5] Efekt kształcenia](/thumbs/92/110361306.jpg "Odniesienie symbol I [1] [2] [3] [4] [5] Efekt kształcenia") Efekty dla studiów pierwszego stopnia profil ogólnoakademicki, prowadzonych na kierunku Matematyka, na Wydziale Matematyki i Nauk Informacyjnych Użyte w poniższej tabeli: 1) w kolumnie 4 określenie Odniesienie
Efekty dla studiów pierwszego stopnia profil ogólnoakademicki, prowadzonych na kierunku Matematyka, na Wydziale Matematyki i Nauk Informacyjnych Użyte w poniższej tabeli: 1) w kolumnie 4 określenie Odniesienie
Prof. dr hab. Krzysztof Dems Łódź, dn. 28 grudnia 2014 r. ul. Dywizjonu 303 nr Łódź
 Prof. dr hab. Krzysztof Dems Łódź, dn. 28 grudnia 2014 r. ul. Dywizjonu 303 nr 9 94-237 Łódź R E C E N Z J A osiągnięć naukowo-badawczych, dorobku dydaktycznego i popularyzatorskiego oraz współpracy międzynarodowej
Prof. dr hab. Krzysztof Dems Łódź, dn. 28 grudnia 2014 r. ul. Dywizjonu 303 nr 9 94-237 Łódź R E C E N Z J A osiągnięć naukowo-badawczych, dorobku dydaktycznego i popularyzatorskiego oraz współpracy międzynarodowej
Miejsce pracy Okres pracy Stanowisko
 ŻYCIORYS NAUKOWY z wykazem prac naukowych, twórczych prac zawodowych oraz informacją o działalności popularyzującej naukę Dane osobowe Imię i nazwisko Data i miejsce urodzenia Adres zamieszkania Telefon,
ŻYCIORYS NAUKOWY z wykazem prac naukowych, twórczych prac zawodowych oraz informacją o działalności popularyzującej naukę Dane osobowe Imię i nazwisko Data i miejsce urodzenia Adres zamieszkania Telefon,
Praca dyplomowa magisterska
 Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
Praca dyplomowa magisterska Implementacja algorytmów filtracji adaptacyjnej o strukturze transwersalnej na platformie CUDA Dyplomant: Jakub Kołakowski Opiekun pracy: dr inż. Michał Meller Plan prezentacji
efekty kształcenia dla kierunku Elektronika studia stacjonarne drugiego stopnia, profil ogólnoakademicki
 Opis efektów dla kierunku Elektronika Studia stacjonarne drugiego stopnia, profil ogólnoakademicki Objaśnienie oznaczeń: K kierunkowe efekty W kategoria wiedzy U kategoria umiejętności K (po podkreślniku)
Opis efektów dla kierunku Elektronika Studia stacjonarne drugiego stopnia, profil ogólnoakademicki Objaśnienie oznaczeń: K kierunkowe efekty W kategoria wiedzy U kategoria umiejętności K (po podkreślniku)
Dopasowywanie modelu do danych
 Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Wprowadzenie Metoda bisekcji Metoda regula falsi Metoda siecznych Metoda stycznych RÓWNANIA NIELINIOWE
 Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Zazwyczaj nie można znaleźć
Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Zazwyczaj nie można znaleźć
PROGRAM KSZTAŁCENIA NA STUDIACH III STOPNIA Informatyka (nazwa kierunku)
") PROGRAM KSZTAŁCENIA NA STUDIACH III STOPNIA Informatyka (nazwa kierunku) 1. OPIS ZAKŁADANYCH EFEKTÓW KSZTAŁCENIA: 1) Tabela odniesień kierunkowych efektów kształcenia (EKK) do obszarowych efektów kształcenia
PROGRAM KSZTAŁCENIA NA STUDIACH III STOPNIA Informatyka (nazwa kierunku) 1. OPIS ZAKŁADANYCH EFEKTÓW KSZTAŁCENIA: 1) Tabela odniesień kierunkowych efektów kształcenia (EKK) do obszarowych efektów kształcenia
Uchwała Nr 34/2012/V Senatu Politechniki Lubelskiej z dnia 21 czerwca 2012 r.
 Uchwała Nr 34/2012/V Senatu Politechniki Lubelskiej z dnia 21 czerwca 2012 r. w sprawie określenia efektów kształcenia dla studiów drugiego stopnia na kierunku mechatronika, prowadzonych wspólnie przez
Uchwała Nr 34/2012/V Senatu Politechniki Lubelskiej z dnia 21 czerwca 2012 r. w sprawie określenia efektów kształcenia dla studiów drugiego stopnia na kierunku mechatronika, prowadzonych wspólnie przez
Efekty kształcenia dla kierunku studiów informatyka i agroinżynieria i ich odniesienie do efektów obszarowych
 Załącznik do uchwały nr 376/2012 Senatu UP Efekty kształcenia dla kierunku studiów informatyka i agroinżynieria i ich odniesienie do efektów obszarowych Wydział prowadzący kierunek: Wydział Rolnictwa i
Załącznik do uchwały nr 376/2012 Senatu UP Efekty kształcenia dla kierunku studiów informatyka i agroinżynieria i ich odniesienie do efektów obszarowych Wydział prowadzący kierunek: Wydział Rolnictwa i
Egzamin / zaliczenie na ocenę*
 Zał. nr do ZW /01 WYDZIAŁ / STUDIUM KARTA PRZEDMIOTU Nazwa w języku polskim Identyfikacja systemów Nazwa w języku angielskim System identification Kierunek studiów (jeśli dotyczy): Inżynieria Systemów
Zał. nr do ZW /01 WYDZIAŁ / STUDIUM KARTA PRZEDMIOTU Nazwa w języku polskim Identyfikacja systemów Nazwa w języku angielskim System identification Kierunek studiów (jeśli dotyczy): Inżynieria Systemów
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
UKŁADY ALGEBRAICZNYCH RÓWNAŃ LINIOWYCH
 Transport, studia I stopnia rok akademicki 2011/2012 Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Uwagi wstępne Układ liniowych równań algebraicznych można
Transport, studia I stopnia rok akademicki 2011/2012 Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Uwagi wstępne Układ liniowych równań algebraicznych można
STATYSTYKA MATEMATYCZNA
 Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
Zał. nr 4 do ZW WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim STATYSTYKA MATEMATYCZNA Nazwa w języku angielskim Mathematical Statistics Kierunek studiów (jeśli dotyczy): Specjalność (jeśli
INTERPOLACJA I APROKSYMACJA FUNKCJI
 Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Wprowadzenie Na czym polega interpolacja? Interpolacja polega
Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Wprowadzenie Na czym polega interpolacja? Interpolacja polega
Matryca weryfikacji efektów kształcenia - studia III stopnia
 Ocena publicznej obrony pracy doktorskiej Ocena rozprawy doktorskiej Ocena opublikowanych prac naukowych Ocena uzyskanych projektów badawczych Ocena przygotowania referatu na konferencję Ocena wystąpienia
Ocena publicznej obrony pracy doktorskiej Ocena rozprawy doktorskiej Ocena opublikowanych prac naukowych Ocena uzyskanych projektów badawczych Ocena przygotowania referatu na konferencję Ocena wystąpienia
Uniwersytet Śląski. Wydział Informatyki i Nauki o Materiałach PROGRAM KSZTAŁCENIA. Studia III stopnia (doktoranckie) kierunek Informatyka
 kierunek Informatyka") Uniwersytet Śląski Wydział Informatyki i Nauki o Materiałach PROGRAM KSZTAŁCENIA Studia III stopnia (doktoranckie) kierunek Informatyka (przyjęty przez Radę Wydziału Informatyki i Nauki o Materiałach w
Uniwersytet Śląski Wydział Informatyki i Nauki o Materiałach PROGRAM KSZTAŁCENIA Studia III stopnia (doktoranckie) kierunek Informatyka (przyjęty przez Radę Wydziału Informatyki i Nauki o Materiałach w
zna metody matematyczne w zakresie niezbędnym do formalnego i ilościowego opisu, zrozumienia i modelowania problemów z różnych
 Grupa efektów kierunkowych: Matematyka stosowana I stopnia - profil praktyczny (od 17 października 2014) Matematyka Stosowana I stopień spec. Matematyka nowoczesnych technologii stacjonarne 2015/2016Z
Grupa efektów kierunkowych: Matematyka stosowana I stopnia - profil praktyczny (od 17 października 2014) Matematyka Stosowana I stopień spec. Matematyka nowoczesnych technologii stacjonarne 2015/2016Z
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
Z-ZIP2-303z Zagadnienia optymalizacji Problems of optimization
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 0/03 Z-ZIP-303z Zagadnienia optymalizacji Problems of optimization A. USYTUOWANIE
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 0/03 Z-ZIP-303z Zagadnienia optymalizacji Problems of optimization A. USYTUOWANIE
Przekształcenia widmowe Transformata Fouriera. Adam Wojciechowski
 Przekształcenia widmowe Transformata Fouriera Adam Wojciechowski Przekształcenia widmowe Odmiana przekształceń kontekstowych, w których kontekstem jest w zasadzie cały obraz. Za pomocą transformaty Fouriera
Przekształcenia widmowe Transformata Fouriera Adam Wojciechowski Przekształcenia widmowe Odmiana przekształceń kontekstowych, w których kontekstem jest w zasadzie cały obraz. Za pomocą transformaty Fouriera
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody komputerowe statystyki Computer Methods in Statistics. Matematyka. Poziom kwalifikacji: II stopnia. Liczba godzin/tydzień: 2W, 3L
 Nazwa przedmiotu: Kierunek: Metody komputerowe statystyki Computer Methods in Statistics Matematyka Rodzaj przedmiotu: przedmiot obowiązkowy dla specjalności matematyka przemysłowa Rodzaj zajęć: wykład,
Nazwa przedmiotu: Kierunek: Metody komputerowe statystyki Computer Methods in Statistics Matematyka Rodzaj przedmiotu: przedmiot obowiązkowy dla specjalności matematyka przemysłowa Rodzaj zajęć: wykład,
EFEKTY UCZENIA SIĘ DLA KIERUNKU INŻYNIERIA DANYCH W ODNIESIENIU DO EFEKTÓW UCZENIA SIĘ PRK POZIOM 6
 EFEKTY UCZENIA SIĘ DLA KIERUNKU INŻYNIERIA DANYCH W ODNIESIENIU DO EFEKTÓW UCZENIA SIĘ PRK POZIOM 6 studia pierwszego stopnia o profilu ogólnoakademickim Symbol K_W01 Po ukończeniu studiów pierwszego stopnia
EFEKTY UCZENIA SIĘ DLA KIERUNKU INŻYNIERIA DANYCH W ODNIESIENIU DO EFEKTÓW UCZENIA SIĘ PRK POZIOM 6 studia pierwszego stopnia o profilu ogólnoakademickim Symbol K_W01 Po ukończeniu studiów pierwszego stopnia
KADD Minimalizacja funkcji
 Minimalizacja funkcji n-wymiarowych Forma kwadratowa w n wymiarach Procedury minimalizacji Minimalizacja wzdłuż prostej w n-wymiarowej przestrzeni Metody minimalizacji wzdłuż osi współrzędnych wzdłuż kierunków
Minimalizacja funkcji n-wymiarowych Forma kwadratowa w n wymiarach Procedury minimalizacji Minimalizacja wzdłuż prostej w n-wymiarowej przestrzeni Metody minimalizacji wzdłuż osi współrzędnych wzdłuż kierunków
Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach to Feature Selection and Machine Learning
 Warszawa, 30.01.2017 Prof. Dr hab. Henryk Rybinski Instytut Informatyki Politechniki Warszawskiej hrb@ii.pw.edu.pl Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach
Warszawa, 30.01.2017 Prof. Dr hab. Henryk Rybinski Instytut Informatyki Politechniki Warszawskiej hrb@ii.pw.edu.pl Recenzja rozprawy doktorskiej mgr Mirona Bartosza Kursy p/t. Robust and Efficient Approach
WYZNACZANIE NIEPEWNOŚCI POMIARU METODAMI SYMULACYJNYMI
 WYZNACZANIE NIEPEWNOŚCI POMIARU METODAMI SYMULACYJNYMI Stefan WÓJTOWICZ, Katarzyna BIERNAT ZAKŁAD METROLOGII I BADAŃ NIENISZCZĄCYCH INSTYTUT ELEKTROTECHNIKI ul. Pożaryskiego 8, 04-703 Warszawa tel. (0)
WYZNACZANIE NIEPEWNOŚCI POMIARU METODAMI SYMULACYJNYMI Stefan WÓJTOWICZ, Katarzyna BIERNAT ZAKŁAD METROLOGII I BADAŃ NIENISZCZĄCYCH INSTYTUT ELEKTROTECHNIKI ul. Pożaryskiego 8, 04-703 Warszawa tel. (0)
Wstęp do metod numerycznych Zadania numeryczne 2016/17 1
 Wstęp do metod numerycznych Zadania numeryczne /7 Warunkiem koniecznym (nie wystarczającym) uzyskania zaliczenia jest rozwiązanie co najmniej 3 z poniższych zadań, przy czym zadania oznaczone literą O
Wstęp do metod numerycznych Zadania numeryczne /7 Warunkiem koniecznym (nie wystarczającym) uzyskania zaliczenia jest rozwiązanie co najmniej 3 z poniższych zadań, przy czym zadania oznaczone literą O
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
R-PEARSONA Zależność liniowa
 R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
UKŁADY ALGEBRAICZNYCH RÓWNAŃ LINIOWYCH
 Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać układu równań liniowych Układ liniowych równań algebraicznych
Transport, studia niestacjonarne I stopnia, semestr I Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać układu równań liniowych Układ liniowych równań algebraicznych
II - EFEKTY KSZTAŁCENIA
 II - EFEKTY KSZTAŁCENIA 1. Opis zakładanych efektów kształcenia Nazwa wydziału Nazwa studiów Określenie obszaru wiedzy, dziedziny nauki i dyscypliny naukowej Wydział Matematyczno-Fizyczny studia III stopnia
II - EFEKTY KSZTAŁCENIA 1. Opis zakładanych efektów kształcenia Nazwa wydziału Nazwa studiów Określenie obszaru wiedzy, dziedziny nauki i dyscypliny naukowej Wydział Matematyczno-Fizyczny studia III stopnia
Teoria sygnałów Signal Theory. Elektrotechnika I stopień (I stopień / II stopień) ogólnoakademicki (ogólno akademicki / praktyczny)
 ogólnoakademicki (ogólno akademicki / praktyczny)") . KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013 Teoria sygnałów Signal Theory A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013 Teoria sygnałów Signal Theory A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Instytut Politechniczny Państwowa Wyższa Szkoła Zawodowa. Diagnostyka i niezawodność robotów
 Instytut Politechniczny Państwowa Wyższa Szkoła Zawodowa Diagnostyka i niezawodność robotów Laboratorium nr 6 Model matematyczny elementu naprawialnego Prowadzący: mgr inż. Marcel Luzar Cele ćwiczenia:
Instytut Politechniczny Państwowa Wyższa Szkoła Zawodowa Diagnostyka i niezawodność robotów Laboratorium nr 6 Model matematyczny elementu naprawialnego Prowadzący: mgr inż. Marcel Luzar Cele ćwiczenia:
Życiorys. Wojciech Paszke. 04/2005 Doktor nauk technicznych w dyscyplinie Informatyka. Promotor: Prof. Krzysztof Ga lkowski
 Życiorys Wojciech Paszke Dane Osobowe Data urodzin: 20 luty, 1975 Miejsce urodzin: Zielona Góra Stan Cywilny: Kawaler Obywatelstwo: Polskie Adres domowy pl. Cmentarny 1 67-124 Nowe Miasteczko Polska Telefon:
Życiorys Wojciech Paszke Dane Osobowe Data urodzin: 20 luty, 1975 Miejsce urodzin: Zielona Góra Stan Cywilny: Kawaler Obywatelstwo: Polskie Adres domowy pl. Cmentarny 1 67-124 Nowe Miasteczko Polska Telefon:
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Metody matematyczne w elektroenergetyce Rok akademicki: 2013/2014 Kod: EEL-2-101-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek: Elektrotechnika
Nazwa modułu: Metody matematyczne w elektroenergetyce Rok akademicki: 2013/2014 Kod: EEL-2-101-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek: Elektrotechnika
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Rok akademicki: 2012/2013 Kod: JFM s Punkty ECTS: 3. Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne
 Nazwa modułu: Statystyka inżynierska Rok akademicki: 2012/2013 Kod: JFM-1-210-s Punkty ECTS: 3 Wydział: Fizyki i Informatyki Stosowanej Kierunek: Fizyka Medyczna Specjalność: Poziom studiów: Studia I stopnia
Nazwa modułu: Statystyka inżynierska Rok akademicki: 2012/2013 Kod: JFM-1-210-s Punkty ECTS: 3 Wydział: Fizyki i Informatyki Stosowanej Kierunek: Fizyka Medyczna Specjalność: Poziom studiów: Studia I stopnia
Załącznik nr 1 Łódź, 21 grudnia 2016 r.
 Załącznik nr 1 Łódź, 21 grudnia 2016 r. Uzasadnienie uchwały komisji habilitacyjnej w sprawie wniosku o nadanie dr. Dariuszowi Bukacińskiemu stopnia doktora habilitowanego w dziedzinie nauk biologicznych
Załącznik nr 1 Łódź, 21 grudnia 2016 r. Uzasadnienie uchwały komisji habilitacyjnej w sprawie wniosku o nadanie dr. Dariuszowi Bukacińskiemu stopnia doktora habilitowanego w dziedzinie nauk biologicznych
1 Równania nieliniowe
 1 Równania nieliniowe 1.1 Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym jest numeryczne poszukiwanie rozwiązań równań nieliniowych, np. algebraicznych (wielomiany),
1 Równania nieliniowe 1.1 Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym jest numeryczne poszukiwanie rozwiązań równań nieliniowych, np. algebraicznych (wielomiany),
WNIOSEK O FINANSOWANIE PROJEKTU BADAWCZEGO REALIZOWANEGO PRZEZ OSOBĘ ROZPOCZYNAJĄCĄ KARIERĘ NAUKOWĄ, NIEPOSIADAJĄCĄ STOPNIA NAUKOWEGO DOKTORA 1
 Załącznik nr 2 WNIOSEK O FINANSOWANIE PROJEKTU BADAWCZEGO REALIZOWANEGO PRZEZ OSOBĘ ROZPOCZYNAJĄCĄ KARIERĘ NAUKOWĄ, NIEPOSIADAJĄCĄ STOPNIA NAUKOWEGO DOKTORA 1 WYPEŁNIA NARODOWE CENTRUM NAUKI 1. Nr rejestracyjny
Załącznik nr 2 WNIOSEK O FINANSOWANIE PROJEKTU BADAWCZEGO REALIZOWANEGO PRZEZ OSOBĘ ROZPOCZYNAJĄCĄ KARIERĘ NAUKOWĄ, NIEPOSIADAJĄCĄ STOPNIA NAUKOWEGO DOKTORA 1 WYPEŁNIA NARODOWE CENTRUM NAUKI 1. Nr rejestracyjny
Podstawy metodologiczne symulacji
 Sławomir Kulesza kulesza@matman.uwm.edu.pl Symulacje komputerowe (05) Podstawy metodologiczne symulacji Wykład dla studentów Informatyki Ostatnia zmiana: 26 marca 2015 (ver. 4.1) Spirala symulacji optymistycznie
Sławomir Kulesza kulesza@matman.uwm.edu.pl Symulacje komputerowe (05) Podstawy metodologiczne symulacji Wykład dla studentów Informatyki Ostatnia zmiana: 26 marca 2015 (ver. 4.1) Spirala symulacji optymistycznie
WYMAGANIA WSTĘPNE W ZAKRESIE WIEDZY, UMIEJĘTNOŚCI I INNYCH KOMPETENCJI
 WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
WYDZIAŁ GEOINŻYNIERII, GÓRNICTWA I GEOLOGII KARTA PRZEDMIOTU Nazwa w języku polskim: Statystyka matematyczna Nazwa w języku angielskim: Mathematical Statistics Kierunek studiów (jeśli dotyczy): Górnictwo
Recenzja osiągnięcia naukowego oraz całokształtu aktywności naukowej dr inż. Agnieszki Ozgi
 Prof. dr hab. inż. Jerzy Warmiński Lublin 08.09.2019 Katedra Mechaniki Stosowanej Wydział Mechaniczny Politechnika Lubelska Recenzja osiągnięcia naukowego oraz całokształtu aktywności naukowej dr inż.
Prof. dr hab. inż. Jerzy Warmiński Lublin 08.09.2019 Katedra Mechaniki Stosowanej Wydział Mechaniczny Politechnika Lubelska Recenzja osiągnięcia naukowego oraz całokształtu aktywności naukowej dr inż.
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Teoria i przetwarzanie sygnałów Rok akademicki: 2013/2014 Kod: EEL-1-524-s Punkty ECTS: 6 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek: Elektrotechnika
Nazwa modułu: Teoria i przetwarzanie sygnałów Rok akademicki: 2013/2014 Kod: EEL-1-524-s Punkty ECTS: 6 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek: Elektrotechnika
Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki
 Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki dr inż. Marek Wojtyra Instytut Techniki Lotniczej
Projekt współfinansowany przez Unię Europejską w ramach Europejskiego Funduszu Społecznego Rozszerzony konspekt preskryptu do przedmiotu Podstawy Robotyki dr inż. Marek Wojtyra Instytut Techniki Lotniczej
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
5. Analiza dyskryminacyjna: FLD, LDA, QDA
 Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
KIERUNKOWE EFEKTY KSZTAŁCENIA
 WYDZIAŁ INFORMATYKI I ZARZĄDZANIA Kierunek studiów: INFORMATYKA Stopień studiów: STUDIA II STOPNIA Obszar Wiedzy/Kształcenia: OBSZAR NAUK TECHNICZNYCH Obszar nauki: DZIEDZINA NAUK TECHNICZNYCH Dyscyplina
WYDZIAŁ INFORMATYKI I ZARZĄDZANIA Kierunek studiów: INFORMATYKA Stopień studiów: STUDIA II STOPNIA Obszar Wiedzy/Kształcenia: OBSZAR NAUK TECHNICZNYCH Obszar nauki: DZIEDZINA NAUK TECHNICZNYCH Dyscyplina
KIERUNKOWE EFEKTY KSZTAŁCENIA
 Załącznik do Uchwały Senatu Politechniki Krakowskiej z dnia 28 czerwca 2017 r. nr 58/d/06/2017 Politechnika Krakowska im. Tadeusza Kościuszki w Krakowie Nazwa wydziału Wydział Inżynierii Środowiska Dziedzina
Załącznik do Uchwały Senatu Politechniki Krakowskiej z dnia 28 czerwca 2017 r. nr 58/d/06/2017 Politechnika Krakowska im. Tadeusza Kościuszki w Krakowie Nazwa wydziału Wydział Inżynierii Środowiska Dziedzina
Katedra Chemii Analitycznej
 Katedra Chemii Analitycznej Gdańsk, 13 kwietnia 2014 Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska e-mail: piotr.konieczka@pg.gda.pl Ocena dorobku naukowego dr inż. Mariusza Ślachcińskiego
Katedra Chemii Analitycznej Gdańsk, 13 kwietnia 2014 Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska e-mail: piotr.konieczka@pg.gda.pl Ocena dorobku naukowego dr inż. Mariusza Ślachcińskiego
tel. (+4861) fax. (+4861)
 fax. (+4861)") dr hab. inż. Michał Nowak prof. PP Politechnika Poznańska, Instytut Silników Spalinowych i Transportu Zakład Inżynierii Wirtualnej ul. Piotrowo 3 60-965 Poznań tel. (+4861) 665-2041 fax. (+4861) 665-2618
dr hab. inż. Michał Nowak prof. PP Politechnika Poznańska, Instytut Silników Spalinowych i Transportu Zakład Inżynierii Wirtualnej ul. Piotrowo 3 60-965 Poznań tel. (+4861) 665-2041 fax. (+4861) 665-2618
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Nazwa przedmiotu: Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach treści kierunkowych, moduł kierunkowy oólny Rodzaj zajęć: wykład, laboratorium I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
WNIOSEK OSOBY FIZYCZNEJ
 Załącznik nr 2a WNIOSEK OSOBY FIZYCZNEJ niezatrudnionej w podmiotach, o których mowa w art. 10 pkt. 1-8 i pkt. 10 ustawy z dnia 30 kwietnia 2010 r. o zasadach finansowania nauki (Dz.U. Nr 96 poz. 615),
Załącznik nr 2a WNIOSEK OSOBY FIZYCZNEJ niezatrudnionej w podmiotach, o których mowa w art. 10 pkt. 1-8 i pkt. 10 ustawy z dnia 30 kwietnia 2010 r. o zasadach finansowania nauki (Dz.U. Nr 96 poz. 615),
Uczenie sieci typu MLP
 Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
Estymacja wektora stanu w prostym układzie elektroenergetycznym
 Zakład Sieci i Systemów Elektroenergetycznych LABORATORIUM INFORMATYCZNE SYSTEMY WSPOMAGANIA DYSPOZYTORÓW Estymacja wektora stanu w prostym układzie elektroenergetycznym Autorzy: dr inż. Zbigniew Zdun
Zakład Sieci i Systemów Elektroenergetycznych LABORATORIUM INFORMATYCZNE SYSTEMY WSPOMAGANIA DYSPOZYTORÓW Estymacja wektora stanu w prostym układzie elektroenergetycznym Autorzy: dr inż. Zbigniew Zdun