(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
|
|
|
- Maciej Sawicki
- 6 lat temu
- Przeglądów:
Transkrypt
 G01N 37/00 (06.01) Urząd Patentowy Rzeczypospolitej Polskiej (97) O udzieleniu patentu europejskiego ogłoszono: 17.12.")
1 RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego: (13) (1) T3 Int.Cl. C12Q 1/68 (06.01) G01N 37/00 (06.01) Urząd Patentowy Rzeczypospolitej Polskiej (97) O udzieleniu patentu europejskiego ogłoszono: Europejski Biuletyn Patentowy 14/1 EP B1 (4) Tytuł wynalazku: Sposoby określania dokładnych danych dotyczących sekwencji i pozycji zmodyfikowanej zasady () Pierwszeństwo: US P US P US (43) Zgłoszenie ogłoszono: w Europejskim Biuletynie Patentowym nr /44 (4) O złożeniu tłumaczenia patentu ogłoszono: Wiadomości Urzędu Patentowego 1/0 (73) Uprawniony z patentu: Industrial Technology Research Institute, Chutung, TW (72) Twórca(y) wynalazku: PL/EP T3 CHAO-CHI PAN, Hsinchu City, TW JENN-YEH FANN, Guanxi Township, TW CHUNG-FAN CHIOU, Hsinchu, TW HUNG-CHI CHIEN, Hsinchu City, TW HUI-LING CHEN, Hsinchu City, TW (74) Pełnomocnik: rzecz. pat. Marta Kawczyńska POLSERVICE KANCELARIA RZECZNIKÓW PATENTOWYCH SP. Z O.O. ul. Bluszczańska Warszawa Uwaga: W ciągu dziewięciu miesięcy od publikacji informacji o udzieleniu patentu europejskiego, każda osoba może wnieść do Europejskiego Urzędu Patentowego sprzeciw dotyczący udzielonego patentu europejskiego. Sprzeciw wnosi się w formie uzasadnionego na piśmie oświadczenia. Uważa się go za wniesiony dopiero z chwilą wniesienia opłaty za sprzeciw (Art. 99 (1) Konwencji o udzielaniu patentów europejskich).
2 17P3622PL00 EP B1 Opis DZIEDZINA WYNALAZKU [0001] Niniejszy wynalazek dotyczy sposobów określania sekwencji kwasów nukleinowych oraz identyfikacji pozycji zasad zmodyfikowanych w kwasach nukleinowych. TŁO WYNALAZKU 1 2 [0002] Niedawne postępy w technologii sekwencjonowania DNA stworzyły możliwość, aby medycyna prewencyjna na poziomie genomowym była wysoce spersonalizowana. Ponadto możliwość szybkiego uzyskiwania dużych ilości danych dotyczących sekwencji od wielu osobników w jednej lub większej liczbie populacji może oznaczać nową fazę rewolucji w genomice w ramach nauk biomedycznych. [0003] Różnice pojedynczych zasad między genotypami mogą mieć znaczące efekty fenotypowe. Na przykład zidentyfikowano ponad 0 mutacji w genie kodującym hydroksylazę fenyloalaniny (PAH, ang. phenylalanine hydroxylase), enzym przekształcający fenyloalaninę w tyrozynę w ramach katabolizmu fenyloalaniny oraz biosyntezy białek i neuroprzekaźników, co prowadzi do niedoboru aktywności enzymu oraz do zaburzeń: hiperfenyloalaninemii i fenyloketonurii. Patrz np. Jennings i wsp., Eur J Hum Genet 8, (00). [0004] Dane dotyczące sekwencji można uzyskać za pomocą
3 2 1 2 metody sekwencjonowania Sangera, w której w masowej reakcji wydłużania startera wprowadza się analogi dideoksy nukleotydów kończące łańcuch i produkty o różnych długościach rozdziela się i analizuje w celu określenia tożsamości wprowadzonego terminatora. Patrz np. Sanger i wsp., Proc Natl Acad Sci USA 74, (1997). Istotnie, za pomocą tej technologii wyznaczono wiele sekwencji genomowych. Jednak koszt i szybkość uzyskiwania danych dotyczących sekwencji metodą sekwencjonowania Sangera może stanowić ograniczenie. [000] Nowe technologie sekwencjonowania mogą dostarczyć danych dotyczących sekwencji z niezwykłą szybkością setek megazasad na dobę, przy kosztach na zasadę niższych niż w przypadku sekwencjonowania Sangera. Patrz np. Kato, Int J Clin Exp Med 2, (09). Jednak dane nieprzetworzone otrzymane za pomocą tych technologii sekwencjonowania mogą być bardziej narażone na błędy niż tradycyjne sekwencjonowanie Sangera. Może to wynikać z tego, że informacje uzyskuje się z pojedynczych cząsteczek DNA, a nie z dużej populacji. [0006] Na przykład w przypadku sekwencjonowania pojedynczej cząsteczki za pomocą syntezy zasada może zostać pominięta wskutek nie dostrzeżenia słabego sygnału przez urządzenie lub wskutek braku sygnału w związku z odbarwieniem barwnika fluorescencyjnego lub wskutek zbyt szybkiego działania polimerazy, aby urządzenie mogło przeprowadzić detekcję. Wszystkie powyższe zdarzenia prowadzą do powstania błędu (delecji) w nieprzetworzonej sekwencji. Ponadto z prostych przyczyn: potencjalnie słabszych sygnałów i
4 3 1 2 większej szybkości reakcji niż w metodach konwencjonalnych mogą z większą częstością powstać błędy-mutacje i błędy-insercje. [0007] Dane dotyczące sekwencji o niskiej dokładności trudniej jest złożyć. Przy sekwencjonowaniu na dużą skalę, na przykład sekwencjonowaniu pełnego genomu eukariotycznego, cząsteczki DNA ulegają fragmentacji na krótsze odcinki. Odcinki te sekwencjonuje się równolegle, a następnie otrzymane odczytane odcinki składa się, aby odtworzyć pełną sekwencję cząsteczek DNA z pierwotnej próbki. Fragmentację można przeprowadzić na przykład za pomocą rozdrabniania mechanicznego lub trawienia enzymatycznego. [0008] Składanie niewielkich odczytanych odcinków sekwencji w duży genom wymaga, aby odczytane odcinki po fragmentacji były wystarczająco dokładne, aby poprawnie je razem zgrupować. Jest tak zasadniczo w przypadku danych nieprzetworzonych z sekwencjonowania uzyskanych metodą Sangera, w której dokładność danych nieprzetworzonych może przekraczać 9%. Do wykrywania modyfikacji lub mutacji pojedynczych zasad w próbkach kwasu nukleinowego można zastosować dokładną technologię sekwencjonowania pojedynczych cząsteczek. Jednak dokładność danych nieprzetworzonych w przypadku technologii sekwencjonowania pojedynczych cząsteczek może być niższa wskutek ograniczeń omawianych powyżej. Dokładność pojedynczych odczytów w danych nieprzetworzonych dotyczących sekwencji może wynosić zaledwie 60 do 80%. Patrz np. Harris i wsp., Science 3:6-9 (08). Oznacza to, że przydatne byłoby dostarczenie dokładnych sposobów sekwencjonowania
5 4 1 2 pojedynczych cząsteczek. [0009] Ponadto metylacja DNA ma podstawowe znaczenie dla regulacji ekspresji genów; na przykład metylacja promotorów często prowadzi do wyciszenia na poziomie transkrypcji. Wiadomo ponadto, że metylacja jest istotnym mechanizmem w piętnowaniu genomowym i inaktywacji chromosomu X. Jednak postępy w odczytywaniu złożonych profili metylacji pełnych genomów są ograniczone. W związku z tym użyteczne mogłyby być sposoby wyznaczania profili metylacji DNA z dużą wydajnością, które byłyby jeszcze bardziej przydatne, gdyby sposoby te zapewniały także dokładność wyznaczania sekwencji. [00] US 04/ A1 ujawnia sposób sekwencjonowania kwasu nukleinowego. Sposób ten obejmuje dostarczenie kompleksu startera kotwiczącego przyłączonego do kolistej matrycy i połączenie kompleksu z polimerazą i nukleotydami, aby uzyskać połączone, liniowe kopie komplementarne kolistej matrycy. [0011] US 06/06174 A1 ujawnia sposób sekwencjonowania docelowych cząsteczek DNA. Reakcja sekwencjonowania obejmuje pojedynczy kompleks enzymu polimeryzującego z wymianą nici i kolistego DNA docelowego, unieruchomionego w przestrzeni zamkniętej optycznie. STRESZCZENIE WYNALAZKU [0012] Wynalazek jest ograniczony zastrzeżeniami [0013] W niektórych wykonaniach dostarczony jest sposób
6 1 2 określania sekwencji próbki kwasu nukleinowego obejmujący (a) dostarczanie kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, gdzie wstawka ma znaną sekwencję; (b) uzyskanie danych dotyczących sekwencji zawierających sekwencję co najmniej dwóch jednostek wstawka-próbka, gdzie wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; (c) obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (b) przez porównanie sekwencji ze znaną sekwencją wstawki; (d) zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (b) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego; (e) zebranie zestawu zaakceptowanych sekwencji zawierających co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego zaakceptowanej w etapie (d); oraz (f) określanie sekwencji próbki kwasu nukleinowego przy wykorzystaniu zestawu zaakceptowanych sekwencji. Ujawniony jest tu układ zawierający aparat do sekwencjonowania połączony w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika, gdzie w pamięci zakodowany jest program zawierający system operacyjny, oprogramowanie interfejsu użytkownika i instrukcje, które po wykonaniu przez procesor, ewentualnie przy udziale użytkownika,
7 6 1 2 przeprowadzają sposób obejmujący: (a) uzyskanie danych dotyczących sekwencji z kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, gdzie: (i) wstawka ma znaną sekwencję, (ii) dane dotyczące sekwencji zawierają sekwencję co najmniej dwóch jednostek wstawka-próbka i (iii) wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; (b) obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (a) przez porównanie sekwencji ze znaną sekwencją wstawki; (c) zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (a) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego; (d) zebranie zestawu zaakceptowanych sekwencji zawierającego co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego zaakceptowanej w etapie (c); oraz (e) określanie sekwencji próbki kwasu nukleinowego przy wykorzystaniu zestawu zaakceptowanych sekwencji, przy czym sygnał wyjściowy z układu wykorzystuje się do wytworzenia co najmniej jednego spośród: (i) sekwencji próbki kwasu nukleinowego lub (ii) wskazania, że w co najmniej jednej pozycji w próbce kwasu nukleinowego znajduje się zasada zmodyfikowana. [0014] Wynalazek jest ograniczony zastrzeżeniami [001] W niektórych wykonaniach dostarczona jest pamięć, w której zakodowany jest program zawierający
8 7 1 2 system operacyjny, oprogramowanie interfejsu użytkownika i instrukcje, które po wykonaniu przez procesor w układzie zawierającym aparat do sekwencjonowania połączone w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika, ewentualnie przy udziale użytkownika, przeprowadzają sposób obejmujący: (a) uzyskanie danych dotyczących sekwencji z kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, gdzie: (i) wstawka ma znaną sekwencję, (ii) dane dotyczące sekwencji zawierają sekwencję co najmniej dwóch jednostek wstawka-próbka oraz (iii) wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; (b) obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (a) przez porównanie sekwencji ze znaną sekwencją wstawki; (c) zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (a) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego; (d) zebranie zestawu zaakceptowanych sekwencji zawierającego co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego przyjętej w etapie (c); oraz (e) określanie sekwencji próbki kwasu nukleinowego przy wykorzystaniu zestawu zaakceptowanych sekwencji, przy
9 8 1 2 czym sposób daje w rezultacie sygnał wyjściowy wykorzystywany do wytworzenia co najmniej jednego spośród: (i) sekwencji próbki kwasu nukleinowego lub (ii) wskazania, że w co najmniej jednej pozycji w próbce kwasu nukleinowego znajduje się zasada zmodyfikowana. [0016] W niektórych wykonaniach opisany jest sposób określania sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji, obejmujący: (a) zamknięcie razem nici w przód (ang. forward) i w tył (ang. reverse), z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) uzyskanie danych dotyczących sekwencji z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym dane dotyczące sekwencji zawierają sekwencje nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; (c) określanie sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; (d) zmianę swoistości tworzenia par zasad dla zasad określonego rodzaju w kolistej cząsteczce z zamkniętymi w niej parami z wytworzeniem zmienionej kolistej cząsteczki z zamkniętymi w niej parami; (e) uzyskanie danych dotyczących sekwencji dla zmienionej kolistej cząsteczki z zamkniętymi w niej parami, przy czym dane dotyczące sekwencji zawierają sekwencje zmienionej nici w przód i w tył; oraz (f) określanie pozycji zasad zmodyfikowanych w sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji zmienionej nici
10 9 1 2 w przód i w tył. [0017] W niektórych wykonaniach ujawnienie dostarcza sposobu określania sekwencji próbki dwuniciowego kwasu nukleinowego obejmującego: (a) zamknięcie razem nici w przód i w tył w próbce kwasu nukleinowego z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) uzyskanie danych dotyczących sekwencji dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym dane dotyczące sekwencji zawierają sekwencje nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; oraz (c) określanie sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami. [0018] W niektórych wykonaniach ujawnienie dostarcza sposobu określania sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji, obejmującego: (a) zamknięcie razem nici w przód i w tył w próbce kwasu nukleinowego z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) uzyskanie danych dotyczących sekwencji dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, gdzie dane dotyczące sekwencji zawierają sekwencje nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; oraz (c) określenie sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji zmienionej nici
11 1 2 w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami. [0019] W niektórych wykonaniach ujawnienie dostarcza sposobu określania sekwencji próbki dwuniciowego kwasu nukleinowego i położenia co najmniej jednej zasady zmodyfikowanej w sekwencji, obejmującego: (a) zamknięcie razem nici w przód i w tył w próbce kwasu nukleinowego z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) zmianę swoistości tworzenia par zasad dla zasad określonego rodzaju w kolistej cząsteczce z zamkniętymi w niej parami; (c) uzyskanie danych dotyczących sekwencji dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym dane dotyczące sekwencji zawierają sekwencje nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; oraz (d) określanie sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji zmienionej nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami. [00] W niektórych wykonaniach ujawnienie dostarcza sposobu określania sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji, obejmującego: (a) zamknięcie razem nici w przód i w tył z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) uzyskanie danych dotyczących sekwencji dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym dane
12 dotyczące sekwencji zawierają sekwencje nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; (c) określanie sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami; (d) uzyskanie danych z sekwencjonowania dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym wykorzystuje się co najmniej jeden analog nukleotydu rozróżniający między zasadą a jej formą zmodyfikowaną do uzyskania danych dotyczących sekwencji zawierających co najmniej jedną pozycję, gdzie wprowadzono co najmniej jeden analog nukleotydu znakowany w sposób różnicujący; oraz (e) określanie pozycji zasad zmodyfikowanych w sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji nici w przód i w tył. [0021] W niektórych wykonaniach ujawnienie dostarcza sposobu określania sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji, obejmującego: (a) zamknięcie razem nici w przód i w tył w próbce kwasu nukleinowego z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami; (b) uzyskanie danych dotyczących sekwencji dla kolistej cząsteczki z zamkniętymi w niej parami poprzez sekwencjonowanie pojedynczej cząsteczki, przy czym wykorzystuje się co najmniej jeden analog nukleotydu rozróżniający między zasadą a jej formą zmodyfikowaną do uzyskania danych dotyczących sekwencji zawierających co najmniej jedną pozycję, gdzie wprowadzono co najmniej jeden analog
13 12 1 nukleotydu znakowany w sposób różnicujący; oraz (c) określanie sekwencji próbki dwuniciowego kwasu nukleinowego i pozycji co najmniej jednej zasady zmodyfikowanej w sekwencji próbki dwuniciowego kwasu nukleinowego przez porównanie sekwencji zmienionej nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami. [0022] Dodatkowe przedmioty i korzyści wynikające z wynalazku zostaną częściowo przedstawione w poniższym opisie, a po części będą oczywiste na podstawie opisu. Przedmioty i korzyści wynikające z wynalazku zostaną zrealizowane i uzyskane dzięki elementom i kombinacjom wymienionym w dołączonych zastrzeżeniach. [0023] Należy rozumieć, że zarówno powyższy opis ogólny, jak i poniższy opis szczegółowy mają charakter jedynie przykładowy i objaśniający i nie mają ograniczać zastrzeganego wynalazku. [0024] Dołączone do dokumentu rysunki, które zostały włączone do niniejszego opisu i stanowią jego część, ilustrują szereg wykonań ujawnienia i wraz z opisem służą wyjaśnieniu zasad wynalazku zdefiniowanych w zastrzeżeniach KRÓTKI OPIS RYSUNKÓW 2 [002] Powyższe aspekty i korzyści wynikające z niniejszego ujawnienia mogą stać się oczywiste na podstawie poniższego opisu szczegółowego w odniesieniu do dołączonych rysunków, na których: Fig. 1. Otrzymywanie kolistej cząsteczki DNA zgodnie z niektórymi opisanymi tu wykonaniami. Próbkę
14 DNA nr 1 poddaje się fragmentacji; fragment 2 poddaje się ligacji na jego końcu (romb) z łącznikiem 3 oraz na jego końcu 3 (strzałka) z innym łącznikiem 4. Łączniki 3 i 4 są komplementarne wobec przylegających do siebie segmentów oligonukleotydu. Przyłączenie do 3 i 4 daje substrat do cyrkularyzacji przez ligację, która to reakcja daje cząsteczkę kolistą 6 zawierającą wstawkę kwasu nukleinowego (z sekwencji łączników 3 i 4) oraz próbkę kwasu nukleinowego (z sekwencji fragmentu 2). Fig. 2. Amplifikacja metodą toczącego się koła. Oligonukleotyd przyłączony do kolistej cząsteczki 6 wytworzonej jak na Fig. 1 jest wiązany przez polimerazę 7 zakotwiczoną na powierzchni 8. Wydłużenie oligonukleotydu daje komplementarną kopię liniową 9 cząsteczki kolistej. Kontynuowane wydłużanie powoduje wymianę nici i syntezę cząsteczki zawierającej wiele kopii cząsteczki kolistej. Fig. 3. Kolista cząsteczka z zamkniętymi w niej parami; (A) Cząsteczkę dwuniciową zawierającą nić w przód 11 i nić w tył 12 można połączyć ze wstawkami tworzącymi spinki 13 i 14, które mogą być identyczne lub nieidentyczne, z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami. W niektórych wykonaniach łączniki mają wystające końce i cofnięte końce (37 i 38). Można je wypełnić wykorzystując polimerazę lub mogą one być komplementarne wobec wystających końców cząsteczki dwuniciowej (nie pokazano). W pełnej kolistej cząsteczce z zamkniętymi w niej parami, 37 i 38 wypełnia się i zamyka tak, że cząsteczka zawiera ciągły, jednoniciowy, kolisty szkielet. (B) Po
15 odpowiednim wypełnieniu przerw i połączeniu końców tworzy się kolisty DNA zawierający nić w przód 11, łącznik 14, nić w tył 12 i łącznik 13, pokazane tutaj w postaci stopionej. Cząsteczkę można przekształcić w formę dwuniciową na przykład przez przyłączenie startera do jednego z łączników i wydłużanie go za pomocą polimerazy niemającej aktywności wymiany nici, na przykład polimerazy DNA I E. coli, a następnie ligację. Fig. 4. Schematy określania sekwencji oraz określania sekwencji i profilu metylacji przy zastosowaniu kolistych cząsteczek z zamkniętymi w niej parami. (Po lewej) Kolistą cząsteczkę z zamkniętymi w niej parami można sekwencjonować dla co najmniej jednej pełnej długości cząsteczki, aby uzyskać odczytane odcinki sekwencji komplementarnej; aby uzyskać dodatkową nadmiarowość, można zastosować dalsze sekwencjonowanie. Dane dotyczące sekwencji można przyrównać i ocenić na podstawie sekwencji wstawek kwasów nukleinowych, dzięki czemu uzyskuje się dokładną sekwencję badanego kwasu nukleinowego. (Po prawej) Przekształcenie określonego rodzaju nukleotydu, na przykład za pomocą reakcji z wodorosiarczynem lub przemiany fotochemicznej, a następnie sekwencjonowanie, przyrównanie i porównanie zmodyfikowanej sekwencji i niezmodyfikowanej sekwencji do niej komplementarnej można wykorzystać do uzyskania dokładnych danych dotyczących sekwencji i profili metylacji. Wydłużone odczyty sekwencji zawierające wielokrotne powtórzenia badanej sekwencji kwasu nukleinowego można wykorzystać do zwiększenia dokładności.
16 1 1 2 Fig.. Przekształcenie nukleotydów. (A) Kolistą cząsteczkę z zamkniętymi w niej parami zawierającą wstawki 13 i 14, nić w przód 1 zawierającą co najmniej jedną resztę -metylocytozyny ( m C) i nić w tył 16 poddaje się reakcji, na przykład przemianie fotochemicznej, aby przekształcić m C w T, otrzymując przekształconą nić w przód 17. Nie ma to wpływu na nukleotyd komplementarny w nici w tył, co daje parę chwiejną (ang. wobble) G-T. (Reszty m C w nici w tył, jeśli występują, także zostają przekształcone w tej reakcji.) (B) Kolistą cząsteczkę z zamkniętymi w niej parami zawierającą wstawki 13 i 14, nić w przód 1 zawierającą co najmniej jedną resztę -metylocytozyny ( m C) i nić w tył 16 poddaje się reakcji, na przykład reakcji z wodorosiarczynem, aby przekształcić C (ale nie m C) w U, otrzymując przekształconą nić w przód 39 i przekształconą nić w tył 40. Nie ma to wpływu na nukleotydy komplementarne wobec nukleotydów przekształconych, co daje pary chwiejne G-U. Fig. 6. Uzyskanie danych dotyczących sekwencji i profilu metylacji dla kolistej cząsteczki z zamkniętymi w niej parami. (A) Starter 18 przyłącza się do przekształconej kolistej cząsteczki z zamkniętymi w niej parami z Fig. A i jest wydłużany za pomocą polimerazy, w wyniku czego następuje synteza nici z segmentami19, i 21, komplementarnymi, odpowiednio, wobec sekwencji 16, 14 i 17. (B) Uzyskuje się sekwencję zawierającą co najmniej dwa powtórzenia: co najmniej jedno powtórzenie próbki 17 i powtórzenie nowo zsyntetyzowanej nici komplementarnej do nici w przód 21 oraz co najmniej jedno spośród powtórzenia nowo
17 zsyntetyzowanej nici komplementarnej do nici w tył 19 i powtórzenia nici w tył 16. Te powtórzenia przyrównuje się; pozycja 41, w której występuje niezgodność między powtórzeniami, oznacza, że zasada w tej pozycji została zmodyfikowana. W zależności od rodzaju zastosowanej modyfikacji można określić zasady występujące pierwotnie w odpowiedniej pozycji w próbce kwasu nukleinowego. W tym przykładzie, w którym kolistą cząsteczkę z zamkniętymi w niej parami zmodyfikowano przez przekształcenie m C w T (patrz Fig. A), niezgodność wskazuje, że w próbce kwasu nukleinowego w nici w przód w pozycji 41 znajdowała się m C; wynika to logicznie z tego, że w pozycji, w której sekwencje są niezgodne, zasada będąca produktem reakcji przekształcania (T) zastąpiła substrat reakcji przekształcania ( m C) występujący w próbce kwasu nukleinowego. Fig. 7. Nieprzetworzone i przetworzone dane dotyczące sekwencji uzyskane z matrycy kolistej cząsteczki kwasu nukleinowego. (A) Schematycznie przedstawiono zawartość sekwencji, którą można uzyskać z matrycy kolistej. Sekwencję próbki kwasu nukleinowego przedstawiono kreskami, zaś sekwencję wstawki kwasu nukleinowego przedstawiono za pomocą kółek. Przedstawiona sekwencja rozpoczyna się od częściowej sekwencji 22 próbki kwasu nukleinowego, po czym następuje sekwencja wstawki 23 kwasu nukleinowego; po nich następuje sekwencja 24 próbki kwasu nukleinowego, sekwencja 2 wstawki kwasu nukleinowego, sekwencja 26 próbki kwasu nukleinowego i sekwencja 27 wstawki kwasu nukleinowego. 28 stanowi
18 dodatkową sekwencję niepokazaną na tym rysunku, po której następuje sekwencja 29 wstawki kwasu nukleinowego, sekwencja próbki kwasu nukleinowego, sekwencja 31 wstawki kwasu nukleinowego i sekwencja częściowa 32 próbki kwasu nukleinowego. Jeśli matryca kolista zawiera pojedynczą próbkę kwasu nukleinowego i pojedynczą wstawkę kwasu nukleinowego, wtedy zarówno 22, jak i 24, wraz z późniejszymi sekwencjami 26, i 32 próbki kwasu nukleinowego, stanowią sekwencje tej samej pojedynczej próbki kwasu nukleinowego; podobnie w tym przypadku 23, 2, 27, 29 i 31 stanowią sekwencje tej samej pojedynczej wstawki kwasu nukleinowego. Jeśli matryca kolista zawiera powtórzenia w przód i w tył sekwencji próbki kwasu nukleinowego i dwóch wstawek kwasu nukleinowego o znanych sekwencjach, które mogą być identyczne lub nieidentyczne, jak w przypadku kolistej cząsteczki z zamkniętymi w niej parami, wtedy sekwencje próbki kwasu nukleinowego mają naprzemienne orientacje i odpowiadają dwóm powtórzeniom próbki kwasu nukleinowego w sposób naprzemienny (np. 22 może mieć orientację w przód, co oznacza, że jest to sekwencja powtórzenia w tył, zaś 24 może mieć orientację w tył, co oznacza, że jest to sekwencja powtórzenia w przód i odwrotnie). Podobnie sekwencje 23, 2 itd. wstawki kwasu nukleinowego także odpowiadają dwóm wstawkom kwasu nukleinowego, które mogą być identyczne lub nieidentyczne, w matrycy kolistej w sposób naprzemienny. (B) Sekwencję przedstawioną na Fig. 7A można rozłożyć na segmenty tak, że każdy zawiera powtórzenie
19 sekwencji próbki kwasu nukleinowego, np. 24; segmenty zawierają ponadto co najmniej jedno powtórzenie wstawki kwasu nukleinowego, na przykład dwa powtórzenia wstawki kwasu nukleinowego, np. 23 i 2. Niektóre segmenty mogą zawierać jedynie sekwencję częściową, np. 33, lub sekwencję nietypowo długą, np. 34. Takie segmenty mogą wytworzyć się wskutek błędów przy sekwencjonowaniu. W niektórych wykonaniach takie segmenty wyklucza się z dalszej analizy. Fig. 8. Schemat etapów przy przetwarzaniu sekwencji. W niektórych wykonaniach bada się, przetwarza oraz przyjmuje lub odrzuca dane nieprzetworzone dotyczące sekwencji w pokazany sposób. Fig. 9. Produkty amplifikacji metodą toczącego się koła. Produkty reakcji opisanych w Przykładzie 1 poddano elektroforezie i żel wizualizowano zgodnie z opisem. C1 i C2 od lewej stanowią ścieżki z kontrolą ujemną. Ścieżka Mr najbardziej po lewej zawiera drabinkę FERMENTAS GENERULER 1 kb, nr kat. SM0311, przy czym wielkości prążków mają zakres od do 000 p.z. Następnych dziesięć ścieżek zawiera produkty reakcji amplifikacji metodą toczącego się koła zgodnie z opisem, uzyskane za pomocą dwóch starterów lub jednego startera (kontrola amplifikacji) i produkty L0 (kontrola ujemna ligacji) lub reakcji ligacji L3 pobrane w podanych punktach czasowych; patrz Przykład 1. Następna ścieżka Mr zawiera drabinkę FERMENTAS GENERULER 0 bp Plus, nr kat. SM0321, przy czym wielkości prążków mają zakres od 0 do 00 p.z. Następnych dziesięć ścieżek zawiera te same produkty co w poprzednich dziesięciu ścieżkach z produktami, z tą
20 różnicą, że produkty te wymieszano z barwnikiem obciążającym zawierającym 1% SDS. Fig.. Przyrównania pokazujące sekwencje powtórzeń i wyprowadzoną sekwencję pierwotną symulowanej próbki kwasu nukleinowego. Położenia, w których wszystkie dopasowane sekwencje są zgodne, oznaczono gwiazdkami. (A) Odczyty a i b z Przykładu 2 pokazano wraz z wyprowadzoną sekwencją pierwotną oznaczoną o nici w przód próbki kwasu nukleinowego. Sekwencję pierwotną wyprowadzono za pomocą reguł podanych w Tabeli. Pozycje, w których wszystkie trzy sekwencje zawierają C, stanowią pozycje, w których symulowana próbka kwasu nukleinowego zawierała metylowaną cytozynę w nici w przód. Pozycje, w których wszystkie trzy sekwencje zawierają G, stanowią pozycje, w których symulowana próbka kwasu nukleinowego zawierała metylowaną cytozynę w nici w tył. (B) Odczyty a i b z Przykładu 3 pokazano wraz z wyprowadzoną sekwencją pierwotną nici w przód oznaczoną r_a. Sekwencję pierwotną wyprowadzono za pomocą reguł podanych w Tabeli 6. Pozycje, w których wyprowadzona sekwencja pierwotna zawiera C niezgodną z odczytem a, stanowią pozycje, w których symulowana próbka kwasu nukleinowego zawierała metylowaną cytozynę w nici w przód. Pozycje, w których wyprowadzona sekwencja pierwotna zawiera G niezgodną z odczytem b, stanowią pozycje, w których symulowana próbka kwasu nukleinowego zawierała metylowaną cytozynę w nici w tył. Fig. 11. Urządzenie obliczające i pamięć. (A) W niektórych wykonaniach ujawnienie dotyczy aparatu 1 do sekwencjonowania połączonego w sposób funkcjonalny z
21 1 2 urządzeniem obliczeniowym 2 zawierającym co najmniej jeden element interfejsu użytkownika wybrany spośród wyświetlacza 7, klawiatury 8 i myszy 9 oraz co najmniej jeden komputer 3 zawierający pamięć 4 (patrz panel B), magistralę danych i procesor 6. (B) W niektórych wykonaniach opisano pamięć 4 zawierającą system operacyjny 60, oprogramowanie interfejsu użytkownika 61 i oprogramowanie przetwarzające 62. Pamięć może ponadto zawierać dane 63 dotyczące sekwencji zarejestrowane przez aparat do sekwencjonowania (1 na Fig. 11 A). Fig. 12. Schemat ogólny określania sekwencji i pozycji -metylocytozyny przy użyciu reakcji z wodorosiarczynem w przypadku liniowej cząsteczki z zamkniętymi w niej parami Uzyskuje się próbkę dwuniciowego kwasu nukleinowego zawierającą - metylocytozynę (u góry). Liniową cząsteczkę z zamkniętymi w niej parami otrzymuje się w wyniku ligacji wstawki w postaci spinki z jednym końcem dwuniciowym cząsteczki (pod pierwszą strzałką, po prawej), dzięki czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Ponadto do drugiego końca podwójnej nici dołącza się liniowe przedłużenia (po lewej). Przeprowadza się reakcję z wodorosiarczynem, w wyniku której reszty cytozyny przekształcają się w reszty uracylu, ale nie obejmuje ona reszt -metylocytozyny. Cząsteczkę kopiuje się dostarczając starter wiążący się z liniowym przedłużeniem dołączonym na końcu 3 liniowej cząsteczki z zamkniętymi w niej parami i wydłużając starter za pomocą polimerazy. Końce można zmodyfikować
22 np. przez trawienie restrykcyjne, dzięki czemu uzyskuje się cząsteczkę do późniejszego klonowania i/lub sekwencjonowania. Fig. 13. Schemat ogólny określania sekwencji i pozycji -metylocytozyny przy użyciu przemiany fotochemicznej w przypadku liniowej cząsteczki z zamkniętymi w niej parami. Uzyskuje się próbkę dwuniciowego kwasu nukleinowego zawierającą - metylocytozynę (u góry). Liniową cząsteczkę z zamkniętymi w niej parami otrzymuje się w wyniku ligacji wstawki w postaci spinki z jednym końcem dwuniciowym cząsteczki (pod pierwszą strzałką, po prawej), dzięki czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Ponadto do drugiego końca podwójnej nici dołącza się liniowe przedłużenia (po lewej). Przeprowadza się przemianę fotochemiczną przekształcając reszty -metylocytozyny w reszty tyminy, ale nie obejmuje ona niezmodyfikowanych reszt cytozyny. Cząsteczkę kopiuje się, dostarczając starter wiążący się z liniowym przedłużeniem dołączonym na końcu 3 liniowej cząsteczki z zamkniętymi w niej parami i wydłużając starter za pomocą polimerazy. Końce można zmodyfikować np. przez trawienie restrykcyjne, dzięki czemu uzyskuje się cząsteczkę do późniejszego klonowania i/lub sekwencjonowania. Fig. 14. Schemat ogólny określania sekwencji z zastosowaniem kolistej cząsteczki z zamkniętymi w niej parami. Uzyskuje się próbkę dwuniciowego kwasu nukleinowego (u góry). Kolistą cząsteczkę z zamkniętymi w niej parami otrzymuje się w wyniku ligacji wstawki w postaci spinki z oboma dwuniciowymi końcami cząsteczki
23 (pod pierwszą strzałką, po prawej i po lewej), dzięki czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Przeprowadza się sekwencjonowanie i dane dotyczące sekwencji analizuje się, aby określić sekwencję próbki; patrz np. Przykład. Fig. 1. Schemat ogólny określania sekwencji i pozycji -metylocytozyny przy użyciu reakcji z wodorosiarczynem i kolistej cząsteczki z zamkniętymi w niej parami. Uzyskuje się próbkę dwuniciowego kwasu nukleinowego zawierającą -metylocytozynę (u góry). Kolistą cząsteczkę z zamkniętymi w niej parami otrzymuje się w wyniku ligacji wstawki w postaci spinki z oboma końcami dwuniciowymi cząsteczki (pod pierwszą strzałką, po prawej i po lewej), dzięki czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Przeprowadza się reakcję z wodorosiarczynem, w wyniku której reszty cytozyny przekształcają się w reszty uracylu, ale nie obejmuje ona reszt -metylocytozyny. Przeprowadza się sekwencjonowanie i dane dotyczące sekwencji analizuje się, aby określić sekwencję próbki i pozycje reszt - metylocytozyny; patrz np. Przykład 6. Fig. 16. Schemat ogólny określania sekwencji i pozycji -metylocytozyny przy użyciu przemiany fotochemicznej i kolistej cząsteczki z zamkniętymi w niej parami. Uzyskuje się próbkę dwuniciowego kwasu nukleinowego zawierającą -metylocytozynę (u góry). Kolistą cząsteczkę z zablokowanymi w niej parami zablokowaną otrzymuje się w wyniku ligacji wstawki w postaci spinki z oboma końcami dwuniciowymi cząsteczki (pod pierwszą strzałką, po prawej i po lewej), dzięki
24 23 1 czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Przeprowadza się przemianę fotochemiczną przekształcając reszty -metylocytozyny w reszty tyminy, ale nie obejmuje ona niezmodyfikowanych reszt cytozyny. Przeprowadza się sekwencjonowanie i dane dotyczące sekwencji analizuje się, aby określić sekwencję próbki i pozycje reszt -metylocytozyny; patrz np. Przykład 7. Fig. 17. Schemat ogólny określania sekwencji i pozycji reszt -bromouracylu za pomocą kolistej cząsteczki z zamkniętymi w niej parami. Uzyskuje się próbkę dwuniciowego kwasu nukleinowego zawierającą - bromouracyl (u góry). Kolistą cząsteczkę z zamkniętymi w niej parami otrzymuje się w wyniku ligacji wstawki w postaci spinki z oboma końcami dwuniciowymi cząsteczki (pod pierwszą strzałką, po prawej i po lewej), dzięki czemu następuje zamknięcie razem nici w przód i w tył w próbce dwuniciowej. Przeprowadza się sekwencjonowanie i dane dotyczące sekwencji analizuje się, aby określić sekwencję próbki i pozycje reszt -bromouracylu; patrz np. Przykład 8. SZCZEGÓŁOWY OPIS WYNALAZKU 2 Definicje [0026] Aby ułatwić zrozumienie niniejszego wynalazku, poniżej zdefiniowano szereg określeń. Określenia, których tu nie zdefiniowano, mają znaczenie zwyczajowo rozumiane przez specjalistę w dziedzinach, których dotyczy niniejszy wynalazek. Określenia, takie jak a,
25 an i the, w tekście w języku angielskim, nie mają oznaczać wyłącznie liczby pojedynczej, ale obejmują także ogólną klasę, do której zilustrowania można wykorzystać dany przykład. Terminologię w niniejszym dokumencie wykorzystuje się do opisu konkretnych wykonań wynalazku, ale jej stosowanie nie ogranicza wynalazku, chyba że dokonano tego w zastrzeżeniach [0027] Termin kwas nukleinowy obejmuje oligonukleotydy i polinukleotydy. [0028] Warunki wysokiej ostrości przy hybrydyzacji oznaczają warunki, w których dwa kwasy nukleinowe muszą mieć wysoki stopień homologii względem siebie, aby nastąpiła hybrydyzacja. Przykłady warunków wysokiej ostrości przy hybrydyzacji obejmują hybrydyzację w 4X chlorek sodowy/cytrynian sodowy (SSC), w 6 lub 70 C, lub hybrydyzację w 4X SSC z 0% formamidem w około 42 lub 0 C, a następnie co najmniej jedno, co najmniej dwa lub co najmniej trzy płukania w 1X SSC, w 6 lub 70 C. [0029] Temperatura topnienia oznacza temperaturę, w której połowa kwasu nukleinowego występuje w roztworze w stanie stopionym i połowa występuje w stanie niestopionym, zakładając obecność wystarczającej ilości komplementarnego kwasu nukleinowego. Jeśli oligonukleotyd występuje w nadmiarze względem sekwencji komplementarnej, temperatura topnienia oznacza temperaturę, w której połowa sekwencji komplementarnej jest przyłączona do oligonukleotydu. W przypadku wstawki kwasu nukleinowego, która może tworzyć spinkę, temperatura topnienia oznacza temperaturę, w
26 2 1 2 której połowa wstawki występuje w postaci spinki częściowo zhybrydyzowanej z samą sobą. Ponieważ temperatura topnienia zależy od warunków, temperatura topnienia oligonukleotydów tu omawianych oznacza temperaturę topnienia w 0 mm roztworze wodnym chlorku sodowego o stężeniu oligonukleotydu 0, μm. Temperaturę topnienia można oszacować za pomocą różnych metod znanych w tej dziedzinie, na przykład stosując parametry termodynamiczne dla najbliższych sąsiadów podane w Allawi i wsp., Biochemistry, 36, (1997) wraz ze standardowymi równaniami termodynamicznymi. [00] Miejsce w cząsteczce kwasu nukleinowego jest odpowiednie do związania startera, jeśli zawiera unikatową sekwencję w cząsteczce kwasu nukleinowego i ma długość i skład takie, że oligonukleotyd komplementarny ma dopuszczalną temperaturę topnienia, na przykład temperaturę topnienia w zakresie od 4 C do 70 C, od 0 C do 70 C, od 4 C do 6 C, od 0 C do 6 C, od C do 70 C, od 60 C do 70 C, od C do 60 C, od 60 C do 6 C lub od 0 C do C. [0031] Wydłużenie startera, oligonukleotydu lub kwasu nukleinowego oznacza dodanie co najmniej jednego nukleotydu do startera, oligonukleotydu lub kwasu nukleinowego. Obejmuje to reakcje katalizowane aktywnością polimerazy lub ligazy. [0032] Starter do sekwencjonowania stanowi oligonukleotyd, który może wiązać się z miejscem w cząsteczce kwasu nukleinowego odpowiednim do związania startera i który można wydłużać w reakcji sekwencjonowania uzyskując dane dotyczące sekwencji.
27 [0033] Wstawka kwasu nukleinowego jest zdolna do utworzenia spinki, jeśli może ulec częściowej hybrydyzacji z samą sobą i forma zhybrydyzowana z samą sobą ma temperaturę topnienia co najmniej 1 C. [0034] Wystający koniec jest to segment jednoniciowy na końcu dwuniciowej cząsteczki kwasu nukleinowego lub spinki. [003] Powtórzenie lub sekwencja powtórzenia stanowi sekwencję, która występuje w kwasie nukleinowym więcej niż raz. Jeśli powtórzenia występują w cząsteczce kwasu nukleinowego, wszystkie wystąpienia sekwencji, także wystąpienie pierwsze, uznaje się za powtórzenia. Powtórzenia obejmują sekwencje stanowiące odwrócone sekwencje komplementarne względem siebie, które na przykład występują w kolistej cząsteczce z zamkniętymi w niej parami. Powtórzenia obejmują ponadto sekwencje nie dokładnie identyczne, ale pochodzące od tej samej sekwencji, np. sekwencje różniące się wskutek błędnego wprowadzenia nukleotydu lub innych błędów polimerazy podczas syntezy, bądź sekwencje, które początkowo były identyczne lub stanowiły idealne odwrócone sekwencje komplementarne, ale różnią się wskutek modyfikacji w procesie, takim jak przemiana fotochemiczna lub reakcja z wodorosiarczynem. [0036] Wstawka kwasu nukleinowego i próbka kwasu nukleinowego znajdują się bezpośrednio powyżej i poniżej względem siebie, jeśli między wstawką a próbką nie ma innych wtrąconych powtórzeń wstawki lub próbki. W cząsteczce jednoniciowej powyżej oznacza w kierunku, zaś poniżej oznacza w kierunku 3. W cząsteczce dwuniciowej polarność można określić arbitralnie lub
28 można ją określić na podstawie polarności elementów kierunkowych, takich jak promotory, sekwencje kodujące itd., jeśli większość takich elementów ma identyczną orientację. Polarność promotora jest taka, że kierunek inicjacji syntezy przez polimerazę RNA jest kierunkiem w dół. Polarność sekwencji kodującej jest taka, że kierunek od kodonu start do kodonu stop jest poniżej. [0037] Dwa powtórzenia znajdują się w orientacji w przód i w tył względem siebie i mają orientacje przeciwne, jeśli stanowią odwrócone sekwencje komplementarne względem siebie bądź jedna lub obydwie stanowią pochodne odwróconych sekwencji komplementarnych względem siebie. To, które powtórzenie uznaje się za w przód, może być arbitralne lub może zostać określone na podstawie polarności elementów w powtórzeniu, omawianych w akapicie poprzednim. [0038] Zasada zmodyfikowana stanowi zasadę inną niż adenina, tymina, guanina, cytozyna lub uracyl, którą można wprowadzić w miejsce jednej lub większej liczby zasad wymienionych wcześniej w kwasie nukleinowym lub nukleotydzie. [0039] Kody niejednoznaczne stanowią kody odpowiadające kombinacji zasad w sekwencji w sensie takim, że może występować dowolna z odpowiednich zasad, na przykład: Y = pirymidyna (C, U lub T); R = puryna (A lub G); W = słaba (A, T lub U); S = silna (G lub C); K = keto (T, U lub G); M = amino (C lub A); D = nie C (A, G, T lub U); V = nie T lub U (A, C lub G); H = nie G (A, C, T lub U); B = nie A (C, G, T lub U). [0040] Macierz wagi pozycji jest to macierz, w której rzędy odpowiadają pozycjom w sekwencji kwasu
29 nukleinowego, zaś kolumny odpowiadają zasadom, lub odwrotnie, i każdy element w macierzy stanowi wagę dla danej zasady w określonej pozycji. Można obliczyć wynik dla sekwencji na podstawie macierzy wagi pozycji sumując wagi odpowiadające każdej zasadzie w sekwencji; na przykład, jeśli sekwencja to ACG, wynik jest sumą wagi A w pierwszej kolumnie macierzy, wagi C w drugiej kolumnie i wagi G w trzeciej kolumnie, zakładając, że kolumny odpowiadają pozycjom. Macierz wagi pozycji można wyznaczyć dla sekwencji o długości większej od liczby pozycji w macierzy za pomocą iteracyjnego obliczania wyników dla sekwencji w macierzy, przy czym pozycja początkowa zwiększa się w każdym cyklu o jedno miejsce. W ten sposób można określić pozycję w sekwencji dającą wynik maksymalny lub minimalny w macierzy. [0041] Pamięć oznacza magazyn informacji cyfrowych dostępny dla komputera. Obejmuje ona RAM, ROM, dyski twarde, nieulotną pamięć półprzewodnikową, dyski optyczne, dyski magnetyczne i ich odpowiedniki. [0042] Struktura danych stanowi obiekt lub zmienną w pamięci, które zawierają dane. Struktura danych może zawierać dane skalarne (np. pojedynczy znak, liczbę lub ciąg), zespół danych skalarnych (np. macierz lub matrycę skalarów) lub zespół rekursywny (np. listę, która może być wielowymiarowa, zawierać podlisty, macierze, matryce i/lub skalary jako elementy, przy czym podlisty same mogą zawierać podlisty, macierze, matryce i/lub skalary jako elementy).
30 29 Próbka kwasu nukleinowego 1 2 [0043] Sposoby obejmują określenie sekwencji próbki kwasu nukleinowego i/lub określenie pozycji zasad zmodyfikowanych w próbce kwasu nukleinowego. Określenie próbka kwasu nukleinowego oznacza kwas nukleinowy, którego sekwencję i/lub pozycje zasad zmodyfikowanych należy określić za pomocą opisywanych tu sposobów. [0044] Próbkę kwasu nukleinowego można uzyskać ze źródeł obejmujących między innymi DNA (w tym między innymi DNA genomowy, cdna, mtdna, DNA chloroplastów i DNA pozachromosomowy lub pozakomórkowy) lub RNA (w tym między innymi mrna, pierwotny transkrypt RNA, trna, rrna, mirna, sirna i snorna). Próbka kwasu nukleinowego może pochodzić od osobnika, pacjenta, z innej próbki, hodowli komórkowej, biofilmu, narządu, tkanki, komórki, zarodnika, zwierzęcia, rośliny, grzyba, pierwotniaka, bakterii, archeona, wirusa lub wiriona. W niektórych wykonaniach próbka kwasu nukleinowego stanowi próbkę środowiskową, np. z gleby lub wód; próbkę kwasu nukleinowego można uzyskać w postaci próbki środowiskowej nie mając konkretnej wiedzy o tym, czy kwas nukleinowy jest pochodzenia komórkowego, pozakomórkowego czy wirusowego. Ponadto kwas nukleinowy można otrzymać za pomocą reakcji chemicznej lub enzymatycznej, w tym reakcji, w których kwas nukleinowy syntetyczny, rekombinowany lub występujący naturalnie modyfikuje się za pomocą enzymu, na przykład metylotransferazy. [004] W niektórych wykonaniach próbka kwasu nukleinowego stanowi próbkę przetworzoną ze źródła, na
31 1 przykład jednego z wymienionych powyżej. Na przykład izolowany kwas nukleinowy można poddać fragmentacji poprzez cięcie, na przykład przez sonikację lub pipetowanie przez wąski otwór, lub trawienia enzymatycznego, na przykład za pomocą endonukleazy, która może być endonukleazą restrykcyjną. W niektórych wykonaniach próbka kwasu nukleinowego zawiera co najmniej jeden wystający koniec. Wyizolowany kwas nukleinowy można wpierw klonować i namnażać w komórce gospodarza i/lub wektorze, np. w postaci sztucznego chromosomu bakteryjnego lub drożdżowego, minichromosomu, plazmidu, kosmidu, elementu pozachromosomowego lub konstruktu zintegrowanego z chromosomem. Dostarczanie kolistej cząsteczki kwasu nukleinowego 2 [0046] W niektórych wykonaniach sposoby obejmują dostarczanie kolistej cząsteczki kwasu nukleinowego zawierającej jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, gdzie wstawka ma znaną sekwencję. Kolista cząsteczka kwasu nukleinowego może być jedno- lub dwuniciowa. [0047] W niektórych wykonaniach kolistą cząsteczkę kwasu nukleinowego uzyskuje się przez wyizolowanie formy kolistej ze źródła, jeśli część jej sekwencji jest znana, a zatem może stanowić wstawkę kwasu nukleinowego (np. motyw konserwowany w obrębie sekwencji genu zawartego w cząsteczce kolistej może być znany lub może być wiadome, że cząsteczka zawiera daną sekwencję na podstawie jej zdolności do hybrydyzacji w
32 warunkach wysokiej ostrości z innym kwasem nukleinowym o znanej sekwencji). W niektórych wykonaniach sekwencja wstawki kwasu nukleinowego jest znana jedynie niedokładnie, jak w przypadku, gdy znajomość sekwencji wynika z właściwości hybrydyzacji w warunkach ostrych. W niektórych wykonaniach sekwencja wstawki kwasu nukleinowego jest znana dokładnie, jak w przypadku, gdy kolista cząsteczka kwasu nukleinowego ma znaną sekwencję szkieletową lub została zmodyfikowana tak, że zawiera znaną sekwencję. [0048] W niektórych wykonaniach kolistą cząsteczkę kwasu nukleinowego uzyskuje się przeprowadzając reakcję lub reakcje in vitro, aby wprowadzić próbkę kwasu nukleinowego do cząsteczki kolistej wraz ze wstawką kwasu nukleinowego. W niektórych wykonaniach reakcja lub reakcje in vitro obejmują ligację za pomocą ligazy i/lub innych reakcji łączenia nici, które mogą na przykład być katalizowane przez różne enzymy, w tym rekombinazy i topoizomerazy. Do połączenia enzymatycznego dwóch końców matrycy liniowej można zastosować ligazę DNA lub ligazę RNA z cząsteczką adaptorową lub łącznikami bądź bez nich, tworząc koło. Na przykład ligaza RNA T4 łączy jednoniciowy DNA lub RNA, zgodnie z opisem w Tessier i wsp., Anal Biochem, 18: (1986). Do katalizy ligacji jednoniciowego kwasu nukleinowego można ponadto zastosować CIRCLIGASE(TM) (Epicentre, Madison, Wis.). Alternatywnie, do przeprowadzenia reakcji cyrkularyzacji można zastosować ligazę dwuniciową, na przykład ligazę DNA E. coli lub T4. [0049] W niektórych wykonaniach dostarczenie kolistej
33 cząsteczki kwasu nukleinowego obejmuje amplifikację matrycy kwasu nukleinowego z zastosowaniem starterów(które mogą stanowić startery losowe z przedłużeniami o znanej sekwencji służące jako wstawka kwasu nukleinowego) zawierających regiony komplementarne i cyrkularyzację zamplifikowanego kwasu nukleinowego, na przykład katalizowaną przez ligazę lub rekombinazę; zamplifikowany kwas nukleinowy może w niektórych wykonaniach zostać zmodyfikowany na końcach, np. za pomocą trawienia enzymem restrykcyjnym lub fosforylacji, przed cyrkularyzacją. [000] W niektórych wykonaniach kolistą cząsteczkę kwasu nukleinowego uzyskuje się prowadząc cyrkularyzację chemiczną. W metodach chemicznych wykorzystuje się znane odczynniki sprzęgające, na przykład BrCN z imidazolem i metalem dwuwartościowym, N-cyjanoimidazol z ZnCl 2, chlorowodorek 1-(3- dimetyloaminopropylo)-3-etylokarbodiimidu oraz inne karbodiimidy i karbonylodiimidazole. Końce matrycy liniowej można także połączyć przez kondensację - fosforanu i 3 -hydroksylu lub -hydroksylu i 3 - fosforanu. [001] W niektórych wykonaniach kolista cząsteczka kwasu nukleinowego jest kolistą cząsteczką z zamkniętymi w niej parami (cplm, ang. circular pairlocked molecule). Ten rodzaj cząsteczki omówiono dokładnie poniżej.
34 33 Dostarczanie powtórzeń w przód i w tył próbki kwasu nukleinowego; koliste cząsteczki z zamkniętymi w niej parami 1 2 [002] W niektórych wykonaniach sposoby obejmują dostarczenie powtórzeń w przód i w tył próbki kwasu nukleinowego i zamknięcie razem nici w przód i w tył z utworzeniem cplm. Strukturę ogólną cplm przedstawiono na Fig. 3A. cplm jest jednoniciową kolistą cząsteczką kwasu nukleinowego, która zawiera powtórzenia w przód i w tył próbki kwasu nukleinowego; powtórzenia te są obramowane wstawkami kwasu nukleinowego, co pokazano na Fig. 3A. Wstawki kwasu nukleinowego mogą być identyczne lub nieidentyczne. W niektórych wykonaniach wstawki mają długość co najmniej 0 nt lub co najmniej 0 nt. W niektórych wykonaniach wstawki mają długość w zakresie od 0 lub 0 nt do 000 lub 0000 nt. [003] Nici liniowej dwuniciowej próbki kwasu nukleinowego można zamknąć razem z utworzeniem cplm, na przykład w wyniku ligacji wstawek kwasu nukleinowego tworzących spinki na obu końcach cząsteczki. W niektórych wykonaniach wstawki kwasu nukleinowego tworzące spinki mają temperaturę topnienia co najmniej C, 2 C, C, 3 C, 40 C, 4 C, 0 C, C, 60 C, 6 C lub 70 C. Można przeprowadzić ligację z tępymi końcami lub z lepkimi końcami. Struktury spinek mają regiony trzonka ze sparowanymi zasadami i niesparowane regiony pętli. W niektórych wykonaniach wstawka kwasu nukleinowego zawiera region pętli o długości co najmniej, 22, 2, lub 3 nukleotydów. W niektórych wykonaniach region pętli nadaje się do
35 wiązania startera. W niektórych wykonaniach region pętli wiąże się ze starterem przy temperaturze topnienia co najmniej 4 C, 0 C, C, 60 C, 6 C lub 70 C. [004] W niektórych wykonaniach próbka kwasu nukleinowego zawiera różne końce lepkie, na przykład wytworzone w wyniku trawienia za pomocą enzymów restrykcyjnych dla różnych miejsc restrykcyjnych, przy czym takie końce lepkie są korzystne dla ligacji różnych wstawek kwasu nukleinowego. W niektórych wykonaniach dwuniciowy kwas nukleinowy, który ma zostać w ten sposób przekształcony, można otrzymać wydłużając starter losowy zawierający przedłużenie o znanej sekwencji wzdłuż matrycy zawierającej pożądaną sekwencję próbki. [00] Nici dwuniciowego kwasu nukleinowego można ponadto zamknąć razem z utworzeniem cplm działając enzymem przekształcającym końce dwuniciowe w spinki, na przykład rekombinazami tworzącymi wiązanie fosfotyrozynowe z jedną nicią cząsteczki dwuniciowej, po czym w wyniku ataku nukleofilowego drugiej nici na wiązanie fosfotyrozynowe tworzy się spinka. Przykładami takich rekombinaz są przedstawiciele tej rodziny, na przykład integraza λ i rekombinaza Flp. Patrz np. Chen i wsp., Cell 69, (1992); Roth i wsp., Proc Natl Acad Sci USA 90, (1993). W niektórych wykonaniach próbka kwasu nukleinowego zawiera sekwencje rozpoznawane przez enzym przekształcający końce dwuniciowe w spinki. W niektórych wykonaniach sekwencje rozpoznawane przez enzym przekształcający końce dwuniciowe w spinki są dołączone do próbki kwasu
36 3 nukleinowego, np. przez ligację. [006] W niektórych wykonaniach próbkę kwasu nukleinowego otrzymuje się początkowo w formie jednoniciowej i przekształca w formę dwuniciową przed utworzeniem cplm. Można tego dokonać na przykład przez ligację spinki z wystającym końcem z końcem 3 badanego kwasu nukleinowego, a następnie wydłużając od końca 3 spinki przyłączonej poprzez ligację w celu syntezy nici komplementarnej. Drugą spinkę można następnie połączyć z cząsteczką tworząc cplm. Wstawka kwasu nukleinowego 1 2 [007] Opisywane tu sposoby obejmują dostarczanie i/lub wykorzystywanie kolistych cząsteczek kwasu nukleinowego, w tym cplm, zawierających co najmniej jedną wstawkę kwasu nukleinowego. W niektórych wykonaniach co najmniej jedna wstawka kwasu nukleinowego ma sekwencję częściowo, niedokładnie lub całkowicie znaną, co omówiono powyżej. W niektórych wykonaniach sekwencja co najmniej jednej wstawki kwasu nukleinowego jest całkowicie znana. W niektórych wykonaniach co najmniej jedna wstawka kwasu nukleinowego zawiera odpowiednie miejsce wiązania oligonukleotydu, w tym startera do sekwencjonowania. W niektórych wykonaniach co najmniej jedna wstawka kwasu nukleinowego tworzy spinkę. [008] W niektórych wykonaniach co najmniej jedna wstawka kwasu nukleinowego ma długość w zakresie od do 0, 1 do, do 0 lub do 0 reszt nukleotydowych. W niektórych wykonaniach co najmniej
37 36 jedna wstawka kwasu nukleinowego ma temperaturę topnienia w zakresie od 4 C do 70 C lub od 0 C do 6 C. [009] W niektórych wykonaniach co najmniej jedna wstawka kwasu nukleinowego zawiera promotor, na przykład promotor polimerazy RNA T7. Patrz np. Guo i wsp., J Biol Chem 280, (0). Promotor jest rozpoznawany przez polimerazę RNA jako miejsce inicjacji syntezy RNA. Dodatkowe promotory także są znane w tej dziedzinie. Jednostka wstawka-próbka 1 2 [0060] Koliste cząsteczki kwasu nukleinowego wykorzystywane w opisywanych tu sposobach zawierają co najmniej jedną próbkę kwasu nukleinowego i co najmniej jedną wstawkę kwasu nukleinowego zgrupowane w co najmniej jednej jednostce wstawka- próbka. Jednostka wstawka-próbka jest to segment kwasu nukleinowego, w którym wstawka kwasu nukleinowego znajduje się bezpośrednio powyżej lub poniżej próbki kwasu nukleinowego. [0061] W niektórych wykonaniach kolistą cząsteczką kwasu nukleinowego jest cplm zawierająca dwie jednostki wstawka-próbka; próbki kwasu nukleinowego w tych dwóch jednostkach znajdują się w orientacjach przeciwnych względem siebie, czyli jedna stanowi powtórzenie w przód próbki kwasu nukleinowego, zaś druga stanowi powtórzenie w tył. Należy zauważyć, że można uznać, iż cplm zawiera dwie jednostki wstawka-próbka, jeśli wstawki znajdują się powyżej lub poniżej próbek;
38 37 1 oznacza to, że cplm przyjmująca strukturę pokazaną na Fig. 3B zawiera, kolejno, elementy 11 (powtórzenie w przód), 14 (wstawkę), 12 (powtórzenie w tył) i 13 (wstawkę), gdzie 13 łączy się ponownie z 11 zamykając koło. Niezależnie od tego, czy uznaje się, że jednostki wstawka-próbka stanowią 11 z 14 i 12 z 13 czy 13 z 11 i 14 z 12, cząsteczka zawiera dwie jednostki wstawkapróbka. W wykonaniach, w których orientacja wstawki i/lub jej położenie względem próbki są istotne funkcjonalnie, np. wstawka zawiera promotor lub miejsce wiązania startera, najwydajniejsze może być zgrupowanie jednostek wstawka-próbka tak, że wstawka zostaje zgrupowana z próbką, wobec której zorientowane jest miejsce wiązania startera lub promotor, tzn. próbką, która zostanie skopiowana najpierw przez polimerazę z inicjacją od miejsca wiązania startera lub promotora. Uzyskanie danych dotyczących sekwencji Metoda sekwencjonowania 2 [0062] Opisywane tu sposoby obejmują uzyskiwanie danych dotyczących sekwencji. W niektórych wykonaniach w etapie uzyskiwania danych dotyczących sekwencji wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka. W niektórych wykonaniach cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka można wytworzyć syntetyzując ją z dostarczonej kolistej cząsteczki kwasu nukleinowego. W niektórych wykonaniach cząsteczkę kwasu nukleinowego zawierającą co najmniej
39 dwie jednostki wstawka-próbka można wytworzyć modyfikując dostarczoną kolistą cząsteczkę kwasu nukleinowego, np. przekształcając kolistą cząsteczkę kwasu nukleinowego w liniową cząsteczkę kwasu nukleinowego, która w niektórych wykonaniach może być jednoniciowa. W niektórych wykonaniach w etapie uzyskiwania danych dotyczących sekwencji tworzy się lub rozrywa co najmniej jedno wiązanie fosfodiestrowe w cząsteczce kwasu nukleinowego, którą może być dostarczona kolista cząsteczka kwasu nukleinowego lub produkt syntezy z użyciem jej jako matrycy. [0063] W niektórych wykonaniach dane dotyczące sekwencji uzyskuje się przez sekwencjonowanie metodą syntezy. W niektórych wykonaniach dane dotyczące sekwencji uzyskuje się metodą sekwencjonowania pojedynczej cząsteczki. W niektórych wykonaniach metodę sekwencjonowania pojedynczej cząsteczki wybiera się spośród pirosekwencjonowania, sekwencjonowania z terminatorem odwracalnym, sekwencjonowania z ligacją, sekwencjonowania w nanoporach i sekwencjonowania trzeciej generacji. [0064] W niektórych wykonaniach dane dotyczące sekwencji uzyskuje się metodą sekwencjonowania masowego, na przykład sekwencjonowania Sangera lub sekwencjonowania Maxama-Gilberta. [006] Metody sekwencjonowania pojedynczej cząsteczki odróżnia się od metod sekwencjonowania masowego tym, czy w ramach procedury sekwencjonowania izoluje się pojedynczą cząsteczkę kwasu nukleinowego. Cząsteczka kwasu nukleinowego może być jedno- lub dwuniciowa; do tych celów dwie połączone nici kwasu nukleinowego
40 uznaje się za pojedynczą cząsteczkę. Wyizolowanie pojedynczej cząsteczki może nastąpić w mikrostudzience, poprzez zastosowanie nanoporów, dołączenia bezpośredniego lub pośredniego w sposób umożliwiający rozdział optyczny do podłoża, na przykład szkiełka mikroskopowego, lub w dowolny inny sposób umożliwiający uzyskanie danych dotyczących sekwencji dla pojedynczej cząsteczki. W przypadku dołączania pośredniego pojedynczą cząsteczkę dołącza się do podłoża poprzez strukturę łączącą, która wiąże się z pojedynczą cząsteczką, na przykład białka lub oligonukleotydu. Należy zaznaczyć, że metody, w których izoluje się pojedynczą cząsteczkę, następnie amplifikuje i dane dotyczące sekwencji uzyskuje się bezpośrednio na podstawie produktu lub produktów amplifikacji, nadal uznaje się za metody z pojedynczą cząsteczką, ponieważ pojedynczą cząsteczkę wyizolowano i stanowi ona ostateczne źródło danych dotyczących sekwencji. (W przeciwieństwie do tego w metodach sekwencjonowania masowego wykorzystuje się próbkę kwasu nukleinowego zawierającą wiele cząsteczek i uzyskuje się dane zawierające sygnał pochodzący od wielu cząsteczek.) W niektórych wykonaniach przeprowadza się sekwencjonowanie pojedynczej cząsteczki, w którym z tej samej cząsteczki uzyskuje się sekwencję nadmiarową. Sekwencję nadmiarową można uzyskać przez sekwencjonowanie co najmniej dwóch prostych lub odwróconych powtórzeń w cząsteczce lub przez sekwencjonowanie tego samego segmentu cząsteczki więcej niż raz. Sekwencja nadmiarowa może być całkowicie nadmiarowa lub częściowo nadmiarowa z pewną
41 zmiennością, np. wynikającą z różnic wprowadzonych przez zmianę swoistości parowania zasad w przypadku zasad pewnego rodzaju lub wskutek błędów, które mogą wystąpić w procesie sekwencjonowania. W niektórych wykonaniach zmiana swoistości parowania zasad może zajść przed sekwencjonowaniem. W niektórych wykonaniach tę samą cząsteczkę sekwencjonuje się wielokrotnie, ewentualnie stosując między powtórzeniami sekwencjonowania postępowanie powodujące selektywną zmianę swoistości parowania zasad w przypadku zasad pewnego rodzaju. [0066] Sekwencjonowanie Sangera obejmujące zastosowanie znakowanych terminatorów łańcucha dideoksy jest dobrze znane w tej dziedzinie; patrz np. Sanger i wsp., Proc Natl Acad Sci USA 74, (1997). Sekwencjonowanie Maxama-Gilberta obejmujące przeprowadzenie wielokrotnych reakcji częściowej degradacji chemicznej na frakcjach próbki kwasu nukleinowego, a następnie wykrywanie i analizę fragmentów w celu wyprowadzenia sekwencji, jest także dobrze znane w tej dziedzinie; patrz np. Maxam i wsp., Proc Natl Acad Sci USA 74, (1977). Inną metodą sekwencjonowania masowego jest sekwencjonowanie przez hybrydyzację, polegające na wydedukowaniu sekwencji próbki na podstawie właściwości hybrydyzacji z wieloma cząsteczkami, np. na mikromacierzy lub chipie genowym; patrz np. Drmanac i wsp., Nat Biotechnol 16, 4-8 (1998). [0067] Metody sekwencjonowania pojedynczej cząsteczki omówiono ogólnie na przykład w Kato, Int J Clin Exp Med 2, (09) i w podanych tam odnośnikach.
42 [0068] Uznaje się, że pirosekwencjonowanie, sekwencjonowanie z terminatorem odwracalnym i sekwencjonowanie z ligacją stanowią metody sekwencjonowania drugiej generacji. Generalnie, w metodach tych wykorzystuje się produkty amplifikacji wytworzone z jednej cząsteczki, które rozdziela się przestrzennie od produktów amplifikacji wytworzonych z innych cząsteczek. Oddzielenie przestrzenne można przeprowadzić wykorzystując emulsję, studzienkę o objętości rzędu pikolitrów lub przez dołączenie do szkiełka nakrywkowego. Informacje dotyczące sekwencji otrzymuje się na podstawie fluorescencji po wprowadzeniu nukleotydu; po rejestracji danych fluorescencję nowo wprowadzonego nukleotydu eliminuje się i proces powtarza z następnym nukleotydem. [0069] W przypadku pirosekwencjonowania jon pirofosforanowy uwalniany w reakcji polimeryzacji reaguje z -fosfosiarczanem adenozyny pod działaniem sulfurylazy ATP i wytwarza się ATP; ATP następnie powoduje przekształcenie lucyferyny w oksylucyferynę i światło pod działaniem lucyferazy. Ponieważ fluorescencja jest przemijająca, w tej metodzie nie jest konieczny oddzielny etap eliminacji fluorescencji. W danej chwili dodaje się jeden rodzaj trifosforanu deoksyrybonukleotydu (dntp), zaś informacje dotyczące sekwencji uzyskuje się na podstawie tego, który dntp generuje znaczny sygnał w miejscu reakcji. Dostępny w sprzedaży aparat Roche GS FLX odczytuje sekwencję przy wykorzystaniu tej metody. Tę metodę oraz jej zastosowania omówiono szczegółowo na przykład w Ronaghi i wsp., Anal Biochem 242, (1996) oraz w Margulies
43 i wsp., Nature 437, (0) (sprostowanie: Nature 441, 1 (06)). [0070] W przypadku sekwencjonowania z terminatorem odwracalnym w reakcji wydłużania o pojedynczą zasadę wprowadza się analog nukleotydu znakowany barwnikiem fluorescencyjnym stanowiący odwracalny terminator łańcucha dzięki obecności grupy blokującej. Tożsamość zasady określa się na podstawie fluoroforu; inaczej mówiąc każda zasada tworzy parę z innym fluoroforem. Po uzyskaniu danych dotyczących fluorescencji/sekwencji fluorofor i grupę blokującą usuwa się chemicznie i cykl powtarza aby uzyskać informacje dotyczące sekwencji dla kolejnej zasady. Tę metodę wykorzystuje aparat Illumina GA. Tę metodę oraz jej zastosowania omówiono szczegółowo na przykład w Ruparel i wsp., Proc Natl Acad Sci USA 2, (0) oraz w Harris i wsp., Science 3, 6-9 (08). [0071] W przypadku sekwencjonowania za pomocą ligacji do połączenia częściowo dwuniciowego oligonukleotydu z wystającym końcem z kwasem nukleinowym poddawanym sekwencjonowaniu zawierającym wystający koniec wykorzystuje się enzym ligazę; aby nastąpiła ligacja, wystające końce muszą być komplementarne. Zasady w wystającym końcu częściowo dwuniciowego oligonukleotydu można zidentyfikować na podstawie fluoroforu sprzężonego z częściowo dwuniciowym oligonukleotydem i/lub z dodatkowym oligonukleotydem, który hybrydyzuje z inną częścią częściowo dwuniciowego oligonukleotydu. Po zarejestrowaniu danych dotyczących fluorescencji kompleks poddany ligacji odcina się przed miejscem ligacji, na przykład za pomocą enzymu restrykcyjnego
44 typu II, na przykład BbvI, który trawi w miejscu w stałej odległości od miejsca, które rozpoznaje (które było zawarte w częściowo dwuniciowym oligonukleotydzie). Ta reakcja cięcia powoduje powstanie nowego wystającego końca bezpośrednio przed poprzednim wystającym końcem i proces jest powtarzany. Tę technikę oraz jej zastosowania omówiono szczegółowo na przykład w Brenner i wsp., Nat Biotechnol 18, (00). W niektórych wykonaniach sekwencjonowanie z ligacją dostosowuje się do opisywanych tu sposobów, otrzymując produkt amplifikacji metodą toczącego się koła kolistej cząsteczki kwasu nukleinowego i wykorzystując taki produkt amplifikacji metodą toczącego się koła jako matrycę do sekwencjonowania z ligacją. [0072] W przypadku sekwencjonowania w nanoporach cząsteczkę jednoniciowego kwasu nukleinowego przetyka się przez por, np. wykorzystując elektroforetyczną siłę napędową, i dedukuje się sekwencję analizując dane otrzymane, kiedy cząsteczka jednoniciowego kwasu nukleinowego przechodzi przez por. Dane mogą stanowić dane dotyczące prądu jonowego, przy czym każda zasada zmienia prąd, np. wskutek częściowego blokowania przepływu prądu przez por w różnym, rozróżnialnym stopniu. [0073] W przypadku sekwencjonowania trzeciej generacji jako falowód z wartością modalną zerową wykorzystuje się szkiełko z powłoką z glinu zawierającą wiele małych (~0 nm) otworów (patrz np. Levene i wsp., Science 299, (03)). Powierzchnia glinu jest chroniona przed dołączeniem polimerazy DNA poprzez
45 44 1 przeprowadzenie reakcji chemicznej z polifosfonianem, np. reakcji chemicznej z poliwinylofosfonianem (patrz np. Korlach i wsp., Proc Natl Acad Sci USA, (08)). Powoduje to preferencyjne przyłączanie cząsteczek polimerazy DNA do eksponowanej krzemionki w otworach powłoki glinowej. Taka konfiguracja umożliwia wykorzystanie zjawisk fal zanikających do zmniejszania tła fluorescencji, co pozwala zastosować wyższe stężenia dntp znakowanych fluorescencyjnie. Fluorofor zostaje dołączony do końcowego fosforanu dntp tak, że po wprowadzeniu dntp następuje emisja fluorescencji, jednak fluorofor nie pozostaje dołączony do nowo wprowadzanego nukleotydu, co oznacza, że kompleks jest natychmiast gotowy do kolejnej rundy wprowadzania. Dzięki tej metodzie można wykrywać włączanie się dntp do pojedynczych kompleksów starter-matryca znajdujących się w otworach powłoki glinowej. Patrz np. Eid i wsp., Science 323, (09). Matryca do sekwencjonowania; ilość otrzymywanych danych dotyczących sekwencji 2 [0074] W niektórych wykonaniach dane dotyczące sekwencji otrzymuje się bezpośrednio z kolistej cząsteczki kwasu nukleinowego, czyli wykorzystując kolistą cząsteczkę kwasu nukleinowego jako matrycę. Kolistą cząsteczką kwasu nukleinowego wykorzystywaną jako matryca może być kolista cząsteczka z zamkniętymi w niej parami. W niektórych wykonaniach dane dotyczące sekwencji otrzymuje się z wytworzonej cząsteczki kwasu nukleinowego, którą zsyntetyzowano wykorzystując
46 4 1 2 kolistą cząsteczkę kwasu nukleinowego jako matrycę; oznacza to, że matrycą, z której otrzymuje się dane dotyczące sekwencji, może stanowić wytworzona cząsteczka kwasu nukleinowego zsyntetyzowana z matrycy będącej kolistą cząsteczką kwasu nukleinowego. W niektórych wykonaniach dane dotyczące sekwencji otrzymuje się zarówno z matrycy będącej kolistą cząsteczką kwasu nukleinowego, jak i z wytworzonej cząsteczki kwasu nukleinowego zsyntetyzowanej z matrycy będącej kolistą cząsteczką kwasu nukleinowego. [007] W niektórych wykonaniach przeprowadza się amplifikację metodą toczącego się koła obejmującą syntezę wytworzonej cząsteczki kwasu nukleinowego zawierającej co najmniej dwie jednostki wstawka-próbka przy zastosowaniu kolistej cząsteczki kwasu nukleinowego jako matrycy. W niektórych wykonaniach amplifikacja metodą toczącego się koła obejmuje zsyntetyzowanie produktu - cząsteczki kwasu nukleinowego zawierającej co najmniej 3, 4,,, 1,, 2, 0 lub 0 jednostek wstawka-próbka. Zastosowanie amplifikacji metodą toczącego się koła do wytworzenia wielu kopii matrycy jest dobrze znane w tej dziedzinie; patrz np. Blanco i wsp., J Biol Chem 264, (1989) oraz Banér i wsp., Nucleic Acids Res 26, (1998). Amplifikację metodą toczącego się koła można przeprowadzić w ramach sekwencjonowania, w którym matrycą do sekwencjonowania jest kolista cząsteczka kwasu nukleinowego, lub w celu zsyntetyzowania produktu - cząsteczki kwasu nukleinowego, którą wykorzystuje się jako matrycę do sekwencjonowania.
47 46 1 [0076] Niezależnie od matrycy dane dotyczące sekwencji otrzymane według opisywanych tu sposobów obejmują co najmniej dwa powtórzenia sekwencji próbki kwasu nukleinowego; te co najmniej dwa powtórzenia mogą w niektórych wykonaniach obejmować co najmniej jedno powtórzenie w przód sekwencji próbki kwasu nukleinowego i co najmniej jedno powtórzenie w tył sekwencji próbki kwasu nukleinowego. W niektórych wykonaniach dane dotyczące sekwencji zawierają co najmniej 3, 4,,, 1,, 2, 0 lub 0 powtórzeń sekwencji próbki kwasu nukleinowego. W niektórych wykonaniach dane dotyczące sekwencji zawierają co najmniej 2, 3, 4,,, 1,, 2, 0 lub 0 powtórzeń w przód sekwencji próbki kwasu nukleinowego. W niektórych wykonaniach dane dotyczące sekwencji zawierają co najmniej 2, 3, 4,,, 1,, 2, 0 lub 0 powtórzeń w tył sekwencji próbki kwasu nukleinowego. W niektórych wykonaniach dane dotyczące sekwencji zawierają co najmniej 2, 3, 4,,, 1,, 2, 0 lub 0 każdego spośród powtórzeń w przód i w tył sekwencji próbki kwasu nukleinowego. Obliczanie wyników 2 [0077] W niektórych wykonaniach sposoby obejmują obliczenie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji przez porównanie sekwencji ze znaną sekwencją wstawki. W wykonaniach, w których sekwencja wstawki jest jedynie częściowo lub niedokładnie znana, znana sekwencja wstawki kwasu nukleinowego może zawierać pozycje niejednoznaczne lub nieznane, na przykład wskutek zastosowania kodów
48 niejednoznacznych lub macierzy wagi pozycji. [0078] Porównanie sekwencji ze znaną sekwencją wstawki obejmuje identyfikację sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji. Identyfikację sekwencji można w niektórych wykonaniach przeprowadzić za pomocą analizy wizualnej, tzn. osoba przegląda dane dotyczące sekwencji i znajduje zawarte w nich sekwencje wstawki kwasu nukleinowego, lub metodą dopasowania z pomocą komputera. Patrz np. publikacja międzynarodowego zgłoszenia patentowego WO 09/ Identyfikację sekwencji można w niektórych wykonaniach przeprowadzić za pomocą skanowania danych dotyczących sekwencji z użyciem algorytmu rozpoznającego sekwencję, na przykład przez obliczanie wyników iteracyjnie lub heurystycznie dla wielu pozycji w obrębie danych dotyczących sekwencji w celu identyfikacji ekstremów lokalnych odpowiadających najlepiej znanej sekwencji wstawki kwasu nukleinowego. W niektórych wykonaniach identyfikację sekwencji co najmniej dwóch wstawek kwasu nukleinowego przeprowadza się jednocześnie z obliczaniem wyników, ponieważ w obu procesach można wykorzystać ten sam wynik. [0079] W niektórych wykonaniach obliczanie wyników obejmuje przeprowadzenie przyrównania za pomocą odpowiedniego algorytmu do przyrównania, których wiele jest znanych w tej dziedzinie i są one łatwo dostępne, na przykład BLAST, MEGABLAST, przyrównanie Smitha- Watermana i przyrównanie Needlemana-Wunscha. Patrz np. Altschul i wsp., J Mol Biol 21, (1990). Odpowiednie algorytmy do dprzyrównywania obejmują zarówno algorytmy zezwalające na przerwy, jak i
49 algorytmy niezezwalające na przerwy. Alternatywnie, w niektórych wykonaniach obliczanie wyników obejmuje analizę sekwencji za pomocą algorytmu, na przykład wyznaczenie macierzy wagi pozycji dla sekwencji i obliczenie elementów macierzy odpowiadających sekwencji. W ten sposób wynik można obliczyć jako maksimum lokalne określone dzięki zastosowaniu macierzy do sekwencji odczytywanej krokowo. [0080] W niektórych wykonaniach wyniki wykazują dodatnią korelację z bliskością co najmniej dwóch sekwencji wstawki kwasu nukleinowego do znanej sekwencji (np. maksymalny możliwy wynik oznacza dokładne dopasowanie). Takie wyniki z korelacją dodatnią obejmują między innymi identyczność procentową, wyniki bitowe i liczbę pasujących zasad. [0081] W niektórych wykonaniach wyniki wykazują ujemną korelację z bliskością co najmniej dwóch sekwencji wstawki kwasu nukleinowego do znanej sekwencji (np. minimalny możliwy wynik oznacza dokładne dopasowanie). Takie wyniki z korelacją ujemną obejmują między innymi wartość e, liczbę niedopasowań, liczbę niedopasowań i przerw, niedopasowanie procentowe i procent niedopasowań/przerw. [0082] W niektórych wykonaniach wyniki oblicza się procentowo. Możliwy zakres wyników obliczanych procentowo nie zmienia się w zależności od długości porównywanych sekwencji. Do przykładów wskaźników obliczanych procentowo należą między innymi identyczność procentowa i procent niedopasowań/przerw. [0083] W niektórych wykonaniach wyniki oblicza się liczbowo. Możliwy zakres wyników obliczanych liczbowo
50 49 zmienia się w zależności od długości porównywanych sekwencji. Do przykładów wyników obliczanych liczbowo należą między innymi wyniki bitowe, liczba niedopasowań, liczba niedopasowań i przerw oraz liczba pasujących zasad. Akceptowanie lub odrzucanie powtórzeń sekwencji próbki kwasu nukleinowego; zestaw zaakceptowanych sekwencji 1 2 [0084] W niektórych wykonaniach sposoby obejmują akceptowanie lub odrzucenie powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio poniżej i powyżej powtórzenia sekwencji próbki kwasu nukleinowego. Dlatego w różnych wykonaniach wyniki dla obydwu wstawek kwasu nukleinowego, znajdujących się bezpośrednio powyżej i bezpośrednio poniżej wstawek kwasu nukleinowego, wynik dla jednej z nich lub wynik, konkretnie, dla jednej lub drugiej wykorzystuje się, aby zdecydować o zaakceptowaniu lub odrzuceniu sekwencji próbki kwasu nukleinowego w danych dotyczących sekwencji. [008] W niektórych wykonaniach, w których wyniki wykazują dodatnią korelację z bliskością co najmniej dwóch sekwencji wstawki kwasu nukleinowego do znanej sekwencji, wyniki takie muszą być większe bądź większe lub równe wartości progowej, aby zaakceptować sekwencję. Wybór odpowiedniej wartości progowej zależy od wielu czynników, w tym od rodzaju wykorzystywanego wyniku, częstości błędów metody sekwencjonowania oraz
51 0 1 2 uwarunkowań dotyczących czasu i nadmiarowości. [0086] Zaakceptowania i odrzucenia powtórzeń sekwencji próbki kwasu nukleinowego można dokonywać w różny sposób tak, że wykorzystuje się co najmniej jedno zaakceptowane powtórzenie, zaś nie wykorzystuje się żadnego powtórzenia odrzuconego, w celu określenia sekwencji próbki kwasu nukleinowego. Zaakceptowanie i odrzucenie powtórzeń można przeprowadzać lub nie przeprowadzać w sposób jednoczesny z gromadzeniem zestawu zaakceptowanych sekwencji. Na przykład sekwencje zaakceptowanych powtórzeń można skopiować po ich przyjęciu do nowej struktury danych, która staje się zestawem zaakceptowanych sekwencji. Ewentualnie sekwencje odrzuconych powtórzeń można usunąć lub zastąpić (np. znakami 0 lub X oznaczającymi brak danych lub dane wykluczone) po ich odrzuceniu; w tym przypadku po usunięciu lub zastąpieniu odrzuconych sekwencji pierwotną strukturę danych modyfikuje się, tak by stanowiła zestaw zaakceptowanych sekwencji. W tych przykładach uznaje się, że zaakceptowanie i odrzucenie powtórzeń prowadzi się w sposób jednoczesny z określaniem zestawu zaakceptowanych sekwencji. [0087] W niektórych wykonaniach powtórzenia sekwencji próbki kwasu nukleinowego mogą zostać odrzucone według dodatkowych reguł, jeśli na przykład mają długość odbiegającą od długości innych powtórzeń sekwencji próbki kwasu nukleinowego (patrz np. Fig. 7B). Na przykład, powtórzenie sekwencji próbki kwasu nukleinowego można odrzucić, jeśli odbiega o wartość progową od średniej lub mediany długości innych sekwencji próbki kwasu nukleinowego lub wersji wstępnej
52 1 1 2 zestawu zaakceptowanych sekwencji zawierającego powtórzenia sekwencji próbki kwasu nukleinowego zaakceptowane na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego, zgodnie z opisem powyżej, które może zawierać lub nie zawierać powtórzenia rozpatrywanej sekwencji próbki kwasu nukleinowego, aby ewentualnie usunąć tymczasowo odrzuconą sekwencję przy obliczaniu średniej lub mediany długości. Wartość progową można wyrazić względem długości bezwzględnej, na przykład 1, 2,,, lub 0 nukleotydów; długości względnej, na przykład 1%, 2%, %, %, % lub 0%, lub za pomocą miary statystycznej, takiej jak odchylenie standardowe, na przykład 0,, 1, 1,, 2, 2,, 3, 3,, 4 lub odchyleń standardowych. [0088] Ewentualnie sekwencje można oznaczyć jako zaakceptowane lub odrzucone, a następnie po zakończeniu procesu oznaczania sekwencje zaakceptowane można skopiować do nowej struktury danych lub sekwencje odrzucone można usunąć lub zastąpić, dzięki czemu tworzy się zestaw zaakceptowanych sekwencji w sposób niejednoczesny. [0089] Zestaw zaakceptowanych sekwencji można wybrać z postaci obejmujących ciąg danych pojedynczych, który zawiera co najmniej jedno powtórzenie zaakceptowane sekwencji próbki kwasu nukleinowego oraz wszelkie dodatkowe zaakceptowane powtórzenia w formie połączonej, a także zmienną wieloelementową, w przypadku której każdy element oznacza powtórzenie zaakceptowane sekwencji próbki kwasu nukleinowego lub
53 2 1 jego część. W niektórych wykonaniach zmienną wieloelementową wybiera się spośród listy, uporządkowanego zestawu, skrótu i macierzy. Do zastosowania nadaje się dowolna postać struktury danych umożliwiająca zapisanie co najmniej jednego przyjętego powtórzenia sekwencji próbki kwasu nukleinowego i późniejsze określenie sekwencji próbki kwasu nukleinowego. [0090] W wykonaniach, w których postać zestawu zaakceptowanych sekwencji różni się od postaci danych nieprzetworzonych dotyczących sekwencji (np. dane nieprzetworzone dotyczące sekwencji mają postać ciągu, zaś zestaw zaakceptowanych sekwencji ma postać wieloelementowej struktury danych, na przykład uporządkowanego zestawu), dane nieprzetworzone dotyczące sekwencji można rozebrać na elementy zawierające powtórzenia, jednostki wstawka-próbka lub powtórzenia próbki ograniczone wstawkami bezpośrednio powyżej i poniżej w etapie sposobu po uzyskaniu danych nieprzetworzonych dotyczących sekwencji i przed wytworzeniem ostatecznego zestawu zaakceptowanych sekwencji. Etap rozbioru może nastąpić przed lub po etapie obliczania wyników omawianym powyżej. 2 Określanie sekwencji próbki kwasu nukleinowego; sekwencje konsensusowe; poziomy ufności [0091] W niektórych wykonaniach sposoby obejmują określanie sekwencji próbki kwasu nukleinowego. [0092] Sposób określania sekwencji próbki kwasu nukleinowego można wybrać warunkowo na podstawie liczby
54 3 powtórzeń próbki kwasu nukleinowego w zestawie zaakceptowanych sekwencji. Na przykład, jeśli zestaw zaakceptowanych sekwencji zawiera tylko jedno zaakceptowane powtórzenie, można stwierdzić, że sekwencja próbki kwasu nukleinowego stanowi sekwencję przyjętego powtórzenia. Jeśli zestaw zaakceptowanych sekwencji zawiera tylko dwa lub co najmniej trzy zaakceptowane powtórzenia, można stwierdzić, że sekwencja próbki kwasu nukleinowego stanowi sekwencję konsensusową (patrz poniżej) zaakceptowanych powtórzeń. Więcej możliwości określania sekwencji konsensusowej jest dostępnych, jeśli zestaw zaakceptowanych sekwencji zawiera co najmniej trzy zaakceptowane powtórzenia. 1 Sekwencja konsensusowa 2 [0093] Sekwencję konsensusową określa się na podstawie przyrównania (przeprowadzanego zgodnie z opisem powyżej w punkcie Obliczanie wyników ) dla zaakceptowanych powtórzeń; w pozycjach w przyrównaniu, w których zaakceptowane powtórzenia zawierają tę samą zasadę, sekwencja konsensusowa zawiera tę zasadę. W niektórych wykonaniach w pozycjach w przyrównaniu, w których zaakceptowane powtórzenia nie zawierają tej samej zasady, sekwencja konsensusowa zawiera odpowiedni kod niejednoznaczny (np. R, kiedy zaakceptowane powtórzenia zawierają A i G w tej pozycji). W niektórych wykonaniach w pozycjach w przyrównaniu, w których zaakceptowane powtórzenia nie zawierają tej samej zasady, sekwencja konsensusowa zawiera N lub inny symbol oznaczający nieznaną zasadę. W niektórych
55 4 1 2 wykonaniach w pozycjach w przyrównaniu, w których zaakceptowane powtórzenia nie zawierają tej samej zasady, sekwencja konsensusowa zawiera zasadę występującą w przyjętym powtórzeniu, która daje silniejszy lub odporniejszy sygnał podczas ustalania sekwencji (np. jeśli dane nieprzetworzone były w postaci fluorescencji, do sekwencji konsensusowej wstawia się zasadę na podstawie jaśniejszej emisji fluorescencji (w niektórych wykonaniach po odpowiedniej normalizacji i/lub standaryzacji). [0094] Jeśli sekwencję konsensusową określa się na podstawie zestawu zaakceptowanych sekwencji zawierającego co najmniej trzy zaakceptowane powtórzenia, zasadę w każdej pozycji sekwencji konsensusowej można w niektórych wykonaniach określać większościowo; tzn. do sekwencji konsensusowej wstawia się zasadę znajdującą się w danej pozycji w więcej niż połowie zaakceptowanych powtórzeń. Jeśli zaakceptowane powtórzenia są niezgodne w danej pozycji tak, że w tej pozycji nie można ustalić zasady za pomocą reguły większości, zasadę w tej pozycji sekwencji konsensusowej określa się inną metodą, na przykład można zastosować względną większość (tzn. do sekwencji konsensusowej wstawia się zasadę znajdującą się najczęściej w danej pozycji w zaakceptowanych powtórzeniach) lub można zastosować jedną z procedur omawianych w poprzednim akapicie. [009] W niektórych wykonaniach, jeśli sekwencję konsensusową określa się na podstawie zestawu zaakceptowanych sekwencji zawierającego co najmniej trzy zaakceptowane powtórzenia, zasadę w każdej pozycji
56 1 2 sekwencji konsensusowej można w niektórych wykonaniach określać na podstawie częstości występowania każdej zasady w danej pozycji w zaakceptowanych powtórzeniach. Oznacza to, że sekwencja konsensusowa może stanowić reprezentację probabilistyczną prawdopodobieństwa wystąpienia każdej zasady w każdej pozycji w próbce kwasu nukleinowego. Taka reprezentacja może mieć postać macierzy wagi pozycji. W niektórych wykonaniach elementy macierzy wagi pozycji stanowią częstości, z którymi każdą zasadę stwierdzono w każdej pozycji przy przyrównaniu zaakceptowanych powtórzeń. [0096] W niektórych wykonaniach elementy macierzy wagi pozycji można obliczyć na podstawie częstości, z którymi każdą zasadę stwierdzono w każdej pozycji przy przyrównaniu zaakceptowanych powtórzeń; w tych obliczeniach można także zastosować inne czynniki, na przykład, jeśli dla niektórych zaakceptowanych sekwencji powtórzeń zarejestrowano silniejszy lub odporniejszy sygnał podczas ustalania sekwencji niż w przypadku innych powtórzeń, przyjętym sekwencjom powtórzeń można nadać większą wagę i/lub innym powtórzeniom można nadać mniejszą wagę. Stopień modyfikacji wag można określić ilościowo na podstawie na przykład natężenia sygnału lub może stanowić modyfikację stałą; na przykład wagę zasad rejestrowanych przy stosunkowo silnym sygnale można zwiększyć o wartość, na przykład 0% lub 0%, i/lub wagę zasad rejestrowanych przy stosunkowo słabym sygnale można zmniejszyć o wartość, na przykład 33% lub 0%. [0097] W niektórych wykonaniach elementy macierzy wagi
57 6 1 pozycji stanowią wartości uzyskane na podstawie przekształconych częstości występowania każdej zasady w każdej pozycji (ewentualnie ważonych zgodnie z opisem powyżej). Częstości można przekształcić na przykład logarytmicznie lub wykładniczo; W niektórych wykonaniach przekształcenie prowadzi do zmniejszenia wagi zasad rzadko stwierdzanych w danej pozycji i/lub do zwiększenia wagi zasady lub zasad często stwierdzanych w danej pozycji. Na przykład, jeśli T występuje w danej pozycji przy przyrównaniu N zaakceptowanych sekwencji powtórzeń M-krotnie, gdzie N > 2 i M < N/2, zaś C występuje zawsze w innym przypadku (tzn. (N-M)-krotnie), w niektórych wykonaniach przekształcenie tych częstości daje wagę T w macierzy wagi pozycji mniejszą niż M/N (lub odpowiadającą jej wartość procentową) i/lub wagę C większą niż (N-M)/N (lub odpowiadającą jej wartość procentową). W niektórych wykonaniach przekształcenie wybiera się tak, aby jedynie zwiększyć wagę zasady stwierdzanej najczęściej (lub zasad w przypadku tej samej częstości). Poziomy ufności 2 [0098] W niektórych wykonaniach dla co najmniej jednej pozycji w sekwencji próbki kwasu nukleinowego określa się poziom ufności. Poziom ufności można wyrazić na wiele sposobów, na przykład jako ogólną wartość dokładności odczytania zasady, wyrazić procentowo lub w postaci wyniku Phred lub częstości błędów. W niektórych wykonaniach poziom ufności określa się na podstawie
58 7 częstości zasady lub zasad występujących najczęściej w danej pozycji lub połączonej częstości zasad, które nie występują najczęściej. W niektórych wykonaniach te częstości przekształca się, zwiększa wagę i/lub zmniejsza wagę, jak omówiono powyżej. Określanie poziomu ufności sekwencji jako całości; określanie sekwencji próbki kwasu nukleinowego i poziomów ufności w czasie rzeczywistym i/lub na pożądanym poziomie ufności 1 2 [0099] W niektórych wykonaniach sposoby obejmują określanie poziomu ufności dla sekwencji jako całości. Poziom ufności dla sekwencji jako całości można wyrazić na wiele sposobów, na przykład jako ogólną wartość dokładności odczytania zasady, wyrazić procentowo lub w postaci wyniku Phred, jako częstość błędów lub jako oczekiwaną liczbę błędów w sekwencji. [00] Poziomy ufności dla pojedynczych pozycji (omawiane w punkcie powyżej) można wykorzystać do obliczenia poziomu ufności dla sekwencji jako całości. Na przykład ogólny poziom ufności można wyznaczyć w postaci średniej arytmetycznej, średniej geometrycznej, mediany lub modalnego poziomu ufności w populacji statystycznej poziomów ufności w każdej pozycji sekwencji próbki kwasu nukleinowego. W niektórych wykonaniach populację statystyczną poziomów ufności w każdej pozycji sekwencji próbki kwasu nukleinowego przetwarza się przed obliczeniem poziomu ufności dla sekwencji jako całości, na przykład aby odrzucić wartości oddalone.
59 8 1 [01] W niektórych wykonaniach sposoby obejmują określanie sekwencji próbki kwasu nukleinowego i poziomów ufności w czasie rzeczywistym. W tych wykonaniach dane uzyskane w etapie sekwencjonowania przetwarza się, aby określić sekwencję i poziomy ufności jednocześnie z uzyskiwaniem dodatkowych danych dotyczących sekwencji, np. na podstawie dodatkowych powtórzeń produktu amplifikacji metodą toczącego się koła. W miarę uzyskiwania dodatkowych danych dotyczących sekwencji uaktualnia się zarówno określaną sekwencję, jak i poziomy ufności. W niektórych wykonaniach proces w czasie rzeczywistym prowadzi się nadal do uzyskania wstępnie wybranego poziomu ufności. Wstępnie wybrany poziom ufności może na przykład stanowić dokładność odczytu zasad wynosząca 90%, 9%, 99%, 99,%, 99,9%, 99,9% lub 99,99%. Wstępnie wybrany poziom ufności może dotyczyć sekwencji jako całości lub ułamka pozycji w sekwencji i można go wybrać z wartości, takich jak na przykład 0%, 67%, 7%, 80%, 8%, 90%, 9%, 98%, 99%, 99,% i 99,9%. Próbki wielokrotne; składanie kontigu 2 [02] W niektórych wykonaniach sposób obejmuje powtórzenie etapów sposobu z zastosowaniem co najmniej jednej innej próbki z tego samego źródła, gatunku lub szczepu co próbka kwasu nukleinowego, która ma sekwencję częściowo nakładającą się na sekwencję próbki kwasu nukleinowego, dzięki czemu określa się co najmniej jedną inną sekwencję i składa się tę co najmniej jedną inną sekwencję z sekwencją pierwotnej
60 9 próbki tworząc kontig. W niektórych wykonaniach sposób obejmuje powtórzenie etapów sposobu z zastosowaniem wielu próbek, dzięki czemu tworzy się kontigi o długości powyżej 0,, 1, 2,, lub 0 kb, albo 1, 2,,, 0 lub 00 Mb. W niektórych wykonaniach kontig reprezentuje sekwencję pełną lub sekwencję pełną oprócz regionów heterochromatycznych lub opornych cząsteczki kwasu nukleinowego, którą może być na przykład i bez ograniczania chromosom, minichromosom, chromosom sztuczny, genom wirusowy lub element pozachromosomowy. Składanie kontigów można przeprowadzić stosując metody znane w tej dziedzinie. Zasady zmodyfikowane 1 2 [03] W niektórych wykonaniach próbka kwasu nukleinowego zawiera co najmniej jedną zasadę zmodyfikowaną, na przykład -metylocytozynę, - bromouracyl, uracyl,,6-dihydrouracyl, rybotyminę, 7- metyloguaninę, hipoksantynę lub ksantynę. Uracyl można uznać za zasadę zmodyfikowaną w nici DNA, zaś rybotyminę można uznać za zasadę zmodyfikowaną w nici RNA. W niektórych wykonaniach co najmniej jedna zasada zmodyfikowana w próbce dwuniciowego kwasu nukleinowego tworzy parę przy swoistości parowania zasad różnej od jej preferowanej zasady-partnera. Dochodzi do tego na przykład, kiedy jedna zasada w cząsteczce dwuniciowej przereagowała (np. wskutek sporadycznego utleniania lub ekspozycji na czynnik mutagenny, na przykład promieniowanie lub mutagen chemiczny), w wyniku czego została przekształcona z jednej z zasad standardowych w
61 zasadę zmodyfikowaną, która nie ma tych samych preferowanych zasad-partnerów. [04] Preferowane zasady-partnerów określa się na podstawie reguł parowania zasad Watsona-Cricka. Na przykład preferowaną zasadą-partnerem dla adeniny jest tymina (lub uracyl) i odwrotnie; preferowaną zasadąpartnerem dla cytozyny jest guanina i odwrotnie. Preferowane zasady-partnerzy zasad zmodyfikowanych są zasadniczo znane specjalistom w tej dziedzinie lub można je przewidzieć na podstawie występowania donorów i akceptorów wiązania wodorowego w pozycjach analogicznych wobec występujących w zasadach standardowych. Na przykład hipoksantyna zawiera akceptor wiązania wodorowego (tlen z wiązaniem podwójnym) w pozycji 6 pierścienia purynowego, podobnie jak guanina, dlatego jej preferowaną zasadą-partnerem jest cytozyna, która zawiera akceptor wiązania wodorowego (grupę aminową) w pozycji 6 pierścienia pirymidynowego. Ponadto hipoksantyna może się utworzyć w wyniku deaminowania adeniny. Ponieważ adenina tworzy normalnie w DNA parę z tyminą, reakcja deaminowania da parę hipoksantyna-tymina, w której zasada zmodyfikowana (hipoksantyna) nie tworzy pary z preferowaną zasadąpartnerem. Cytozyna także może ulec deaminowaniu tworząc uracyl. W odniesieniu do DNA uracyl można uznać za zasadę zmodyfikowaną i, jeśli tworzy parę z guaniną (która może powstać z cytozyny w wyniku deaminowania w normalnym dwuniciowym DNA), także dochodzi do sytuacji, w której zasada zmodyfikowana (uracyl) nie tworzy pary z preferowaną zasadą-partnerem.
62 61 Wykrywanie zasad zmodyfikowanych; zmiana swoistości parowania zasad w przypadku zasad określonego rodzaju 1 2 [0] W niektórych wykonaniach sposoby obejmują zmianę swoistości parowania zasad w przypadku zasad określonego rodzaju. Zmiana swoistości tworzenia par zasad w przypadku zasad określonego rodzaju może obejmować konkretnie zmianę swoistości tworzenia par zasad dla odmiany niezmodyfikowanej zasady, np. cytozyny. W tym przypadku nie zmienia się swoistość parowania zasad w przypadku co najmniej jednej formy zmodyfikowanej zasady, na przykład -metylocytozyny. [06] Alternatywnie, zmiana swoistości tworzenia par zasad w przypadku zasad określonego rodzaju może obejmować konkretnie zmianę swoistości tworzenia par zasad dla odmiany zmodyfikowanej zasady (np. - metylocytozyny), ale nie odmiany niezmodyfikowanej zasady (cytozyna). [07] W niektórych wykonaniach zmiana swoistości parowania zasad w przypadku zasad określonego rodzaju obejmuje przemianę fotochemiczną, w wyniku której - metylocytozyna (ale nie niezmodyfikowana cytozyna) przekształca się w tyminę. Patrz np. Matsumura i wsp., Nucleic Acids Symp Ser No. 1, (07). Reakcja ta powoduje zmianę swoistości parowania zasad ulegających przemianie fotochemicznej z guaniny na adeninę (guanina tworzy parę z -metylocytozyną, zaś adenina tworzy parę z tyminą). [08] W innych wykonaniach zmiana swoistości parowania zasad w przypadku zasad określonego rodzaju obejmuje reakcję z wodorosiarczynem, w wyniku której cytozyna
63 62 1 (ale nie -metylocytozyna) przekształca się w uracyl. Patrz np. Laird i wsp., Proc Natl Acad Sci USA 1, 4-9 (04) oraz Zilberman i wsp., Development 134, (07). Reakcja ta powoduje zmianę swoistości parowania zasad ulegających reakcji z wodorosiarczynem z guaniny na adeninę (guanina tworzy parę z cytozyną, zaś adenina tworzy parę z uracylem). [09] W jeszcze innych wykonaniach zasady zmodyfikowane można wykrywać bez etapu zmiany, na przykład w przypadkach, w których zasada zmodyfikowana charakteryzuje się zmienioną swoistością parowania zasad względem odmiany niezmodyfikowanej zasady. Do przykładów takich zasad mogą należeć -bromouracyl, uracyl,,6-dihydrouracyl, rybotymina, 7-metyloguanina, hipoksantyna i ksantyna. Patrz np. Brown, Genomes, wyd. 2., John Wiley & Sons, Inc., New York, NY, 02, rozdział 14, Mutation, Repair, and Recombination, w którym omawia się podatność -bromouracylu na tautomeryzację keto-enolową, co powoduje wzrost tendencji do tworzenia pary z guaniną względem adeniny, i tworzenie hipoksantyny (która preferencyjnie tworzy parę z cytozyną względem tyminy) w wyniku deaminowania adeniny. 2 Analog nukleotydu rozróżniający między zasadą a jej formą zmodyfikowaną [01] W niektórych wykonaniach dane dotyczące sekwencji uzyskuje się wykorzystując co najmniej jeden analog nukleotydu rozróżniający między zasadą a jej formą zmodyfikowaną ( analog rozróżniający ; tworzy on
64 parę preferencyjnie z jedną, ale nie z drugą spośród zasady i jej formy zmodyfikowanej). Analog nukleotydu można wykorzystywać i wykrywać, jak gdyby stanowił piątą zasadę oprócz standardowych czterech zasad, na przykład stosując znaczniki różnicujące w sekwencjonowaniu z terminatorem odwracalnym lub sekwencjonowaniu z ligacją, bądź, jeśli zostaje wprowadzony podczas pirosekwencjonowania, w ramach którego nukleotydy można wprowadzać po jednym, a następnie odmywać. W niektórych wykonaniach analog rozróżniający dodaje się przed odpowiednim nukleotydem naturalnym (np. podczas pirosekwencjonowania) lub podaje się go w stężeniu w zakresie od - do 0- krotnie wyższego od stężenia jego odpowiedniego nukleotydu naturalnego (np. podczas sekwencjonowania z terminatorem odwracalnym). Na przykład analog rozróżniający może stanowić analog trifosforanu deoksyguanozyny, który rozróżnia między cytozyną a - metylocytozyną (np. tworzy parę z cytozyną, ale nie z -metylocytozyną); analog można podać w stężeniu w zakresie od - do 0-krotnie wyższego od stężenia trifosforanu deoksyguanozyny. W ten sposób analog należy zasadniczo wprowadzać naprzeciwko odmiany zasady, z którą tworzy on preferencyjnie parę, jednak zasadę naturalną należy zasadniczo wprowadzać naprzeciwko odmiany zasady, z którą analog nie tworzy preferencyjnie pary. [0111] Przykłady analogów rozróżniających podano w patencie USA 7,399,614 i obejmują one na przykład poniższe cząsteczki rozróżniające między niezmodyfikowaną cytozyną a -metylocytozyną, ponieważ
65 64 tworzą preferencyjnie parę z tą pierwszą: i Te cząsteczki określa się odpowiednio jako analog rozróżniający 1 i analog rozróżniający 2. Określanie pozycji zasad zmodyfikowanych w próbce kwasu nukleinowego 1 [0112] W niektórych wykonaniach sposoby obejmują określanie pozycji zasad zmodyfikowanych w próbce kwasu nukleinowego. Te wykonania obejmują (i) dostarczenie próbki kwasu nukleinowego w postaci dwuniciowej; (ii) przekształcenie próbki kwasu nukleinowego w kolistą cząsteczkę z zamkniętymi w niej parami, gdzie kolista cząsteczka z zamkniętymi w niej parami zawiera powtórzenia w przód i w tył sekwencji próbki kwasu nukleinowego i dwie wstawki kwasu nukleinowego o znanych sekwencjach, które mogą być identyczne lub nieidentyczne; (iii) ewentualnie zmianę swoistości tworzenia par zasad w przypadku zasad określonego rodzaju w kolistej cząsteczce z zamkniętymi w niej parami; (iv) następnie uzyskanie danych dotyczących sekwencji z matrycy w postaci powtórzeń w przód i w tył
66 6 1 2 w kolistej cząsteczce z zamkniętymi w niej parami lub sekwencji do nich komplementarnej; oraz (v) określenie pozycji zasad zmodyfikowanych w próbce kwasu nukleinowego z wykorzystaniem danych dotyczących sekwencji co najmniej powtórzeń w przód i w tył lub ich kopii. Należy zaznaczyć, że sekwencja z matrycy w postaci powtórzenia w przód ma ten sam sens co powtórzenie w tył (i odwrotnie), ale może być lub nie być całkowicie identyczna względem powtórzenia w tył; różnice mogą wynikać z tego, że powtórzenie w przód może zawierać zasady, które mogą tworzyć pary z zasadą inną niż odpowiednia zasada w powtórzeniu w tył. Przykładem takiej sytuacji jest, kiedy powtórzenie w przód w cplm zawiera -bromouracyl, który utworzył parę z adeniną w nici w tył, jednak w reakcji sekwencjonowania przez syntezę stanowi matrycę dla wprowadzania guaniny. [0113] Uzyskuje się dane dotyczące sekwencji zawierające co najmniej dwa powtórzenia: co najmniej jedno powtórzenie próbki (np. powtórzenie oznaczone numerem 17 na Fig. A) i powtórzenie nowo zsyntetyzowanej nici komplementarnej do nici w przód (np. powtórzenie oznaczone numerem 21 na Fig. 6A) oraz co najmniej jedno powtórzenie nowo zsyntetyzowanej nici komplementarnej do nici w tył (np. powtórzenie oznaczone numerem 19 na Fig. 6A) i powtórzenie nici w tył (np. powtórzenie oznaczone numerem 16 na Fig. 6A). Te powtórzenia przyrównuje się. Przyrównanie można przeprowadzić za pomocą dowolnego odpowiedniego algorytmu, co omówiono powyżej. Pozycja, w której występuje niezgodność między powtórzeniami (np.
67 położenie oznaczone numerem 41 na Fig. 6B), oznacza, że nastąpiła zmiana swoistości parowania zasady w przypadku zasady w próbce kwasu nukleinowego w tej pozycji. W zależności od rodzaju modyfikacji, zasady zmodyfikowanej i/lub analogu rozróżniającego wykorzystanego w procesie lub występującego w próbce można określić zasady występujące pierwotnie w odpowiedniej pozycji próbki kwasu nukleinowego. [0114] Na przykład, jeśli kolistą cząsteczkę z zamkniętymi w niej parami zmieniono przez przekształcenie m C w T (patrz Fig. A), niezgodność wskazuje, że w próbce kwasu nukleinowego w pozycji, stanowiącej T lub komplementarnej do A w jednym odczycie i stanowiącej C lub komplementarnej do G w innym odczycie, znajdowała się m C; wynika to logicznie z tego, że w pozycji, w której sekwencje są niezgodne, zasada będąca produktem reakcji przekształcania (T) zastąpiła substrat reakcji przekształcania ( m C) występujący w próbce kwasu nukleinowego. [011] W innym przykładzie, jeśli kolistą cząsteczkę z zamkniętymi w niej parami zmieniono przez przekształcenie C w U, niezgodność wskazuje, że w próbce kwasu nukleinowego w pozycji zajętej obecnie przez U lub T bądź komplementarnej do A w jednym odczycie i stanowiącej C lub komplementarnej do G w innym odczycie, znajdowała się C; wynika to logicznie z tego, że w pozycji, w której sekwencje są niezgodne, zasada będąca produktem reakcji przekształcania (U, który może być odczytywany przez system sekwencjonowania jako T) zastąpiła substrat reakcji przekształcania (C) występujący w próbce kwasu
68 67 nukleinowego. Ponieważ reszty m C nie są zmieniane przy przekształcaniu C w U, pozycje, w których odczyty są zgodne i pokazują C w danej pozycji i/lub G jako komplementarną do niej, wskazują, że w próbce pierwotnej w tej pozycji znajdowała się m C. [0116] W wykonaniach, w których zastosowano analog rozróżniający, zgodnie z omówieniem powyżej, o występowaniu zasady, z którą wiąże się on preferencyjnie, można wywnioskować dla sekwencji pierwotnej w pozycji w sekwencji pierwotnej odpowiadającej pozycji, w której występuje analog rozróżniający. Nośnik odczytywany przez system/komputer 1 2 [0117] W niektórych wykonaniach ujawnienie dotyczy systemu zawierającego aparat do sekwencjonowania połączony w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika. Element interfejsu użytkownika można wybrać spośród wyświetlacza, klawiatury i myszy. W niektórych wykonaniach system zawiera co najmniej jeden obwód scalony i/lub co najmniej jeden półprzewodnik. [0118] W niektórych wykonaniach aparat do sekwencjonowania wybiera się spośród aparatów do sekwencjonowania w konfiguracji do wykonywania co najmniej jednej spośród metod sekwencjonowania omawianych powyżej. [0119] W niektórych wykonaniach wyświetlaczem może być ekran dotykowy służący jako jedyny element interfejsu
69 użytkownika. W pamięci jest kodowany program zawierający system operacyjny, oprogramowanie interfejsu użytkownika i instrukcje, które po wykonaniu przez procesor w systemie zawierającym aparat do sekwencjonowania połączony w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika, ewentualnie przy udziale użytkownika, wykonują sposób według wynalazku opisany powyżej. W niektórych wykonaniach pamięć zawiera ponadto dane dotyczące sekwencji, które mogą mieć dowolną postać omawianą powyżej, na przykład stanowić dane nieprzetworzone dotyczące sekwencji, zestaw zaakceptowanych sekwencji, sekwencję konsensusową itd. [01] W niektórych wykonaniach pamięć i cała jej zawartość znajdują się w pojedynczym komputerze. W innych wykonaniach pamięć jest podzielona między co najmniej dwa komputery, na przykład komputery połączone w sieć. W niektórych wykonaniach interfejs użytkownika jest częścią jednego komputera komunikującego się z co najmniej jednym innym komputerem zawierającym co najmniej jeden element systemu, na przykład oprogramowanie do przetwarzania. [0121] W niektórych wykonaniach sygnał wyjściowy z systemu lub metoda wykonywana przez procesor daje wskazanie, że w co najmniej jednej pozycji w próbce kwasu nukleinowego znajduje się zasada zmodyfikowana. Wskazanie to może występować w dowolnej liczbie postaci, na przykład liście zmodyfikowanych pozycji w sekwencji, reprezentacji tekstowej lub graficznej sekwencji, gdzie pozycje zmodyfikowane podkreślono lub
70 69 zaznaczono, na przykład gwiazdką lub podobnym znakiem bądź czcionką pogrubioną, pochyłą lub podkreśloną, tekstem kolorowym lub przez opisanie struktury chemicznej kwasu nukleinowego, w tym struktury zasady zmodyfikowanej. PRZYKŁADY [0122] Następujące dalej konkretne przykłady należy interpretować jako jedynie ilustrujące, a nie w jakikolwiek sposób ograniczające pozostałą część ujawnienia. 1 PRZYKŁAD 1: Amplifikacja metodą toczącego się koła syntetycznej kolistej cząsteczki z zamkniętymi w niej parami [0123] Uzyskano cztery oligodeoksyrybonukleotydy przedstawione w Tabeli 1. Tabela 1. Sekwencje oligonukleotydów Nazwa Sekwencja NR ID. SEKW. CPLM-1 CGACTTATGCATTTGGTATCTGCGCTCTGCA 1 TATTTAAATGGAAGGAGATAGTTAAGGATA AGGGCAGAGCGCAGATAC CPLM-2 CAAATGCATAAGTCGTGTCTTACCGGGTTGA 2 TAGCGGCCGCTCGGAGAAAAGAAGTTGGAT GATGCAACCCGGTAAGACA ps-t1 CCTTATCCTTAACTATCTCCTT 3 ps-t2 TAGCGGCCGCTCGGAGAAAAG 4
71 70 [0124] CPLM-1 i CPLM-2 poddano fosforylacji w oddzielnych reakcjach w objętości 0 μl, w których μl i μl oligodeoksyrybonukleotydu (stężenie końcowe) poddano działaniu 1 μl j./μl kinazy polinukleotydowej T4 (New England Biolabs ( NEB ), nr kat. M01S), w obecności μl X buforu do ligazy T4 (NEB; X bufor podstawowy zawiera mm ATP). Dodano 14 μl ddh 2 O uzyskując objętość końcową 0 μl (patrz Tabela 2). Reakcje inkubowano w 37 C przez min, a następnie przeprowadzono inaktywację enzymu w 6 C przez min. Tabela 2. Warunki reakcji fosforylacji (objętości w μl) Odczynnik P-CALM-1 P-CPLM-2 μm CPLM-1 0 μm CPLM-2 0 j./μl PNK T4 1 1 X bufor do ligazy T4 ddh 2 O Objętość całkowita [012] Stężenie fosforylowanych CPLM-1 i CPLM-2 (odpowiednio, P-CPLM-1 i P-CPLM-2) z powyższych reakcji doprowadzono do 6 μm. [0126] Oczyszczone, fosforylowane CPLM-1 i CPLM-2 zdenaturowano następnie w 9 C przez min, a później wstawiono na lód i wymieszano z buforem, ddh 2 O i ligazą T4 (NEB, nr kat. M02S) otrzymując koliste cząsteczki z zamkniętymi w nich parami pokazane w Tabeli 3. Ligacja następowała w 2 C, a po, i 60 min pobrano próbki o wielkości 18 μl. Równolegle wykonano kontrolę ujemną bez ligazy (kolumna L0 w Tabeli 3).
72 71 Tabela 3. Warunki reakcji ligacji Odczynnik L0 L3 6 μm P-CPLM μm P-CPLM j./μl ligazy T4 0 3 Bufor X 6 6 ddh 2 O Objętość całkowita [0127] Produkty ligacji połączono ze starterami ps-t1 i/lub ps-t2, dntp, polimerazą DNA Phi29 RepliPHI (Epicentre, nr kat. PP03) i odpowiednim X buforem do reakcji polimerazy DNA Phi29 RepliPHI, zgodnie z Tabelą 4. Tabela 4. Amplifikacja Kontrole 2 1 starter metodą toczącego się startery koła kolistych cząsteczek z zamkniętymi w nich parami Odczynnik C1 C2 L0 L3 L0 L3 mm dntp μm startera ps-t μm startera ps-t X L0_,, 60 min X L3_,, 60 min j./μl polimerazy Phi29 Bufor X ddh 2 O Objętość całkowita
73 [0128] Mieszaniny reakcyjne sporządzono bez polimerazy Phi29, zdenaturowano w 9 C przez min i wstawiono na lód na min. Dodano polimerazę Phi29, a następnie inkubowano w C przez 18 godzin. [0129] Próbki 1 μl produktów reakcji wymieszano z 1 μl 6X barwnika obciążającego (0,03% błękit bromofenolowy, 0,03% cyjanol ksylenu FF, 60% glicerol, 0 mm Tris- EDTA (ph 7,6)), ogrzewano w 9 C przez min, a następnie natychmiast wstawiono na lód. Drugi zestaw próbek produktów reakcji traktowano identycznie, z tą różnicą, że dodano ponadto 1% SDS. [01] Próbki nałożono na 0,7% żel agarozowy w 1X buforze TAE i rozdzielono elektroforetycznie przy 13 V przez 28 min. DNA wizualizowano przez barwienie wstępnie wylanych żeli za pomocą GelRed (Biotium, nr kat. 403, barwnik do żeli z kwasami nukleinowymi GelRed, rozcieńczony 000 razy w wodzie). Żel pokazano na Fig. 9. Produkty amplifikacji metodą toczącego się koła mające widoczną masę cząsteczkową przekraczającą kb obserwowano w próbkach z reakcji, w których zastosowano produkty reakcji ligacji L3 i obydwa startery ps-t1 i ps-t2, ale nie w próbkach z użyciem kontroli L0 lub próbkach bez startera. Próbki, w których wykorzystano produkty reakcji ligacji L3 oraz obydwa startery ps-t1 i ps-t2, poddane działaniu SDS wykazywały większą retencję produktu w studzienkach, zgodną z denaturacją struktury drugorzędowej w produktach RCA (ang. rolling circle amplification, amplifikacji metodą toczącego się koła).
74 73 PRZYKŁAD 2. Symulacja wykrywania metylacji przez przekształcenie C w U w reakcji z wodorosiarczynem w liniowej cząsteczce z zamkniętymi w niej parami [0131] Określenie sekwencji i pozycji -metylocytozyny w hipotetycznym fragmencie DNA dwuniciowego za pomocą przekształcenia reszt C w reszty U w reakcji z wodorosiarczynem symulowano w następujący sposób. Schemat ogólny tego przykładu pokazano na figurze 12. Sekwencję DNA przedstawiono poniżej. Próbka DNA (metylowane C oznaczono jako m C) NR ID. SEKW.: NR ID. SEKW.: 6 1 [0132] Dwie nici połączono poprzez ligację z sekwencją łącznika (pokazanego jako nnnn ) otrzymując następujący produkt. Sekwencja łącznika nadaje się do zastosowania jako starter do sekwencjonowania. NR ID. SEKW.: 7 2 [0133] Ponadto do obu końców cząsteczki z NR ID. SEKW. dołączono liniowe przedłużenie o znanej sekwencji (nie pokazano). Przedłużenie na końcu 3 jest odpowiednie do wiązania startera do sekwencjonowania lub replikacji. Sekwencja komplementarna do przedłużenia na końcu jest odpowiednia do wiązania startera do sekwencjonowania lub replikacji. [0134] Na produkt działa się wodorosiarczynem sodu, co powoduje przekształcenie reszt cytozyny (ale nie -
75 74 metylocytozyny) w uracyl i uzyskuje się następujący produkt. Nowo utworzone reszty uracylu zaznaczono czcionką pogrubioną i gwiazdkami nad zasadami. NR ID. SEKW.: 8 [013] Nić komplementarną (oznaczoną poniżej jako NR ID. SEKW.: 9) syntetyzuje się poprzez replikację DNA obejmującą przyłączanie startera do przedłużenia wprowadzonego na końcu 3. NR ID. SEKW.: 8 NR ID. SEKW.: 9 1 [0136] Powyższą podwójną nić sekwencjonuje się w obu kierunkach; produkty pośrednie sekwencjonowania pokazano poniżej. Powstająca nić, której sekwencję się otrzymuje, to NR ID. SEKW.: w reakcji a i NR ID. SEKW.: 11 w reakcji b. Reakcja sekwencjonowania a NR ID. SEKW.: 9 NR ID. SEKW.:
76 7 Reakcja sekwencjonowania b NR ID. SEKW.: 11 NR ID. SEKW.: 8 [0137] W związku z tym odczyty, które, jak się przewiduje, uzyska się w tych reakcjach, zawierają następujące sekwencje. a: -AGATGTGGACGGGGTGGGCGGAGGTGGGTTGGGGTnnnn-3 (NR ID. SEKW.: ) b: -AAATATAAACGAAATAAACGAAAATAAATTAAAACnnnn-3 (NR ID. SEKW.: 11) 1 2 [0138] Sekwencję próbki pierwotnej, w tym stan metylacji cytozyny, określa się stosując następujące reguły, które podsumowano w Tabeli. Nić w przód sekwencji pierwotnej stanowi nić mającą ten sam sens co dwie nici odczytane. [0139] W pozycjach, w których zarówno odczyt a, jak i odczyt b zawierają A, nić w przód sekwencji pierwotnej także zawiera A, zaś nić w tył zawiera T. W pozycjach, w których zarówno odczyt a, jak i odczyt b zawierają T, nić w przód sekwencji pierwotnej także zawiera T, zaś nić w tył zawiera A. [0140] Jeśli zarówno odczyt a, jak i odczyt b zawierają C, nić w przód sekwencji pierwotnej zawiera m C, zaś nić w tył zawiera G. Jeśli zarówno odczyt a, jak i odczyt b zawierają G, nić w przód sekwencji pierwotnej zawiera G, zaś nić w tył zawiera m C.
77 76 [0141] Jeśli jeden odczyt zawiera G w pozycji, w której drugi odczyt zawiera A, nić w przód sekwencji pierwotnej zawiera G, zaś nić w tył zawiera C. [0142] Jeśli jeden odczyt zawiera T w pozycji, w której drugi odczyt zawiera C, nić w przód sekwencji pierwotnej zawiera C, zaś nić w tył zawiera G. [0143] Odczyty a i b uszeregowano w kolumnie 1 i 2 w Tabeli w zależności od tego, który odczyt zawiera reszty G i T w pozycjach, w których odczyty się różnią; w tym przykładzie odczyt a odpowiada kolumnie 1. Tabela : Reguły wyznaczania stanu metylacji w wyniku reakcji z wodorosiarczynem Odczyty Sekwencja pierwotna sekwencji 1 2 Nić w przód ( => Nić w tył (3 => 3 ) ) A A A T T T T A C C C metylowana G G G G C metylowana G A G C T C C G 1 [0144] Zastosowanie powyższych reguł do NR ID. SEKW.: i 11 pozwala odtworzyć (po usunięciu sekwencji łącznika nnnn) sekwencje pierwotne, tzn. sekwencje NR ID. SEKW.: i 6. Przyrównanie odczytów a i b z nicią w przód sekwencji pierwotnej pokazano na Fig. A.
78 77 PRZYKŁAD 3. Symulacja wykrywania metylacji przez przekształcenie m C w T za pomocą przemiany fotochemicznej w liniowej cząsteczce z zamkniętymi w niej parami [014] Określenie sekwencji i pozycji -metylocytozyny w hipotetycznym fragmencie DNA dwuniciowego za pomocą przekształcenia reszt m C w reszty T poprzez przemianę fotochemiczną symulowano w następujący sposób. Schemat ogólny tego Przykładu pokazano na Fig. 13. Sekwencję DNA przedstawiono poniżej. Próbka DNA (metylowaną C oznaczono jako m C) NR ID. SEKW.: NR ID. SEKW.: 6 1 [0146] Dwie nici są połączone poprzez ligację z sekwencją łącznika (pokazanego jako nnnn ) z otrzymaniem następującego produktu. Sekwencja łącznika nadaje się do zastosowania jako starter do sekwencjonowania. Do końców 3 i tej cząsteczki są dołączone ponadto liniowe przedłużenia (nie pokazano). NR ID. SEKW.: 7 2 [0147] Na produkt działa się światłem, co powoduje przekształcenie fotochemiczne reszt -metylocytozyny (ale nie cytozyny) w tyminę i uzyskuje się następujący produkt. Nowo utworzone reszty tyminy są zaznaczone czcionką pogrubioną i gwiazdkami nad lub pod zasadami.
79 78 NR ID. SEKW.: 12 [0148] Nić komplementarną (oznaczoną poniżej jako NR ID. SEKW.: 13) syntetyzuje się za pomocą replikacji DNA z użyciem startera, który wiąże się z przedłużeniem dołączonym na końcu 3 cząsteczki. [0149] Powyższą podwójną nić poddaje się sekwencjonowaniu w obu kierunkach jak w przykładzie 2 powyżej otrzymując następujące odczyty. Odczyt a: -AGATGTGGATGGGGTGGGTGGAGGTGGGTTGGGGC-3 (NR ID. SEKW.: 14) 1 Odczyt b: -AGATGTGGACAGGGTGGGCAGAGGTGGGTTGGGGC-3 (NR ID. SEKW.: 1) 2 [0] Sekwencję próbki pierwotnej, w tym stan metylacji cytozyny, określa się stosując następujące reguły, które podsumowano w Tabeli 6. Nić w przód sekwencji pierwotnej stanowi nić mająca ten sam sens co dwie nici odczytane. [011] W pozycjach, w których zarówno odczyt a, jak i odczyt b zawierają A, nić w przód sekwencji pierwotnej także zawiera A, zaś nić w tył zawiera T. W pozycjach, w których zarówno odczyt a, jak i odczyt b zawierają T, nić w przód sekwencji pierwotnej także zawiera T, zaś
80 79 1 nić w tył zawiera A. [012] Jeśli zarówno odczyt a, jak i odczyt b zawierają C, nić w przód sekwencji pierwotnej zawiera C, zaś nić w tył zawiera G. Jeśli zarówno odczyt a, jak i odczyt b zawierają G, nić w przód sekwencji pierwotnej zawiera G, zaś nić w tył zawiera C. [013] Jeśli jeden odczyt zawiera G w pozycji, w której drugi odczyt zawiera A, nić w przód sekwencji pierwotnej zawiera G, zaś nić w tył zawiera m C. [014] Jeśli jeden odczyt zawiera T w pozycji, w którym drugi odczyt zawiera C, nić w przód sekwencji pierwotnej zawiera m C, zaś nić w tył zawiera G. [01] Odczyty a i b uszeregowano w kolumnie 1 i 2 w Tabeli 6 w zależności od tego, który odczyt zawiera reszty G i T w pozycjach, w których odczyty się różnią; w tym przykładzie odczyt a odpowiada kolumnie 1. Tabela 6: Reguły wyznaczania stanu metylacji w wyniku przemiany fotochemicznej Odczyty Sekwencja pierwotna sekwencji 1 2 Nić w przód Nić w tył (3 ( => 3 ) => ) A A A T T T T A C C C G G G G C G A G C metylowana T C C metylowana G [016] Zastosowanie powyższych reguł do sekwencji o nr ident. 14 i 1 pozwala odtworzyć (po usunięciu
81 80 sekwencji łącznika nnnn) sekwencje pierwotne, tzn. NR ID. SEKW.: do 6. Dopasowanie odczytów a i b z nicią w przód sekwencji pierwotnej pokazano na Fig. B. a => -AGATGTGGATGGGGTGGGTGGAGGTGGGTTGGGGC-3 (NR ID. SEKW.: 14) b => -AGATGTGGACAGGGTGGGCAGAGGTGGGTTGGGGC-3 (NR ID. SEKW.: 1) r => -AGATGTGGA m CGGGGTGGG m CGGAGGTGGGTTGGGGC-3 (r_a) (NR ID. SEKW.: ) 3 -TCTACACCTG m CCCCACCCG m CCTCCACCCAACCCCG- (r_b) (NR ID. SEKW.: 6) 1 PRZYKŁAD 4: Porównanie dokładności sekwencjonowania symulowanego odczytu pojedynczego i odczytu wielokrotnego 2 [017] Sekwencję złożonego genomu Escherichia coli, nr dostępu w GenBank U00096, o długości p.z. pobrano z bazy GenBank. Z tej sekwencji wyodrębniono wybierane w sposób losowy fragmenty o długości w zakresie od 00 p.z. do 00 p.z. Fragmenty te oznaczono jako sekwencje główne. [018] Z sekwencji głównych wygenerowano pięć podsekwencji wprowadzając z określoną częstością komputerowo błędy delecyjne i odczytu jak pokazano w Tabeli 7. [019] Tych pięć podsekwencji zawierających błędy poddano analizie porównania wielu sekwencji za pomocą algorytmu CLUSTALW (przy ustawieniach domyślnych). Wyniki analizy za pomocą CLUSTALW wykorzystano jako
82 81 1 dane wejściowe do programu cons w pakiecie EMBOSS, aby uzyskać sekwencję konsensusową. Program cons opisano w Rice i wsp., Trends Genet 16, (00) oraz w Mullan i wsp., Brief Bioinform 3, (02). [0160] Pierwszą podsekwencję i sekwencję konsensusową porównano z sekwencją główną i częstości przerw oraz błędów odczytu opracowano w formie tabelarycznej; patrz Tabela 7. Wyniki pokazują, że uzyskanie sekwencji konsensusowej za pomocą wielu odczytów zmniejszyło częstość błędów odczytu i przerw w przypadku każdego z różnych badanych wyników błędów. Dla każdego zestawu wyników błędów delecyjnych i odczytu pojedynczy symulowany odczyt i sekwencję konsensusową określoną na podstawie symulowanych odczytów dopasowano do sekwencji głównej. Liczbę i odsetek pozycji z błędami odczytu i przerwami określono jako ułamek pozycji w przyrównaniu. 2
83 82 Tabela 7. Dokładność sekwencji konsensusowych określonych na podstawie symulowanych odczytów w porównaniu do pojedynczych odczytów przy różnych wynikach błędów. Częstość Długość Pojedyncza wobec Konsensusowa wobec wprowadzony sekwenc głównej głównej ch błędów ji głównej Błędy odczytu Błędy odczytu (nt) Przerwy Przerwy % delecji 816 3/816 47/816 8/817 /817 1% błędów odczytu (6,%) (,8%) (1,0%) (0,6%) % delecji 16 90/16 74/16 9/16 4/16 2% błędów odczytu (,8%) (4,7%) (1,0%) (0,3%) 1% delecji / / /193 /193 % błędów odczytu (2,0%) (2,6%) (,6%) (0,3%) 1% delecji /764 11/764 47/761 1/861 % błędów (23,8%) (1,4%) (6,2%) (0,1%) odczytu PRZYKŁAD. Symulacja określania sekwencji przy zastosowaniu cplm [0161] Uzyskano próbkę dwuniciowego kwasu nukleinowego jak w Przykładzie 2. Zamknięto razem nić w przód i w tył w próbce dołączającpoprzez ligację wstawkę tworzącą spinkę na obydwu końcach cząsteczki, jak
84 83 pokazano w etapie konstruowania cplm na Figurze 14, z utworzeniem kolistej cząsteczki z zamkniętymi w niej parami. Przeprowadzono sekwencjonowanie pojedynczej cząsteczki w reakcji syntezy z zastosowaniem startera, który wiąże się z jedną z wstawek. Uzyskuje się dane dotyczące sekwencji zawierające co najmniej jedną sekwencję nici w przód próbki i co najmniej jedną sekwencję nici w tył próbki. Dane dotyczące sekwencji analizuje się przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami w celu określenia sekwencji próbki kwasu nukleinowego według Tabeli 8. Tabela 8. Reguły określania sekwencji cplm Uzyskana sekwencja Sekwencja pierwotna Matryca z Matryca z nici Nić w przód Nić w tył (3 nici w przód w tył ( => 3 ) => ) A T A T T A T A C G C G G C G C 1 [0162] Uwaga: w Tabeli 8 i Tabelach 9-11, poniżej, sekwencja uzyskana z matrycą z nici w przód odpowiada górnemu wierszowi danych dotyczących sekwencjonowania (tzn. sekwencja podana pod strzałką oznaczoną Sekwencjonowanie i nad strzałką oznaczoną Analiza sekwencji ), odpowiednio, na Fig Podobnie sekwencja uzyskana z matrycą z nici w tył odpowiada dolnemu wierszowi danych dotyczących sekwencjonowania, odpowiednio, na Fig
85 84 PRZYKŁAD 6. Symulacja wykrywania metylacji przez przekształcenie C w U w reakcji z wodorosiarczynem w kolistej cząsteczce z zamkniętymi w niej parami 1 [0163] Schemat ogólny tego Przykładu pokazano na Fig. 1. Uzyskano próbkę dwuniciowego kwasu nukleinowego zawierającą co najmniej jedną -metylocytozynę, jak w Przykładzie 2. Wytworzono kolistą cząsteczkę z zamkniętymi w niej parami, jak w Przykładzie. Reakcję z wodorosiarczynem przeprowadzono jak w Przykładzie 2. Dane dotyczące sekwencji uzyskano jak w Przykładzie. Dane dotyczące sekwencji analizuje się przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami w celu określenia sekwencji próbki kwasu nukleinowego i pozycji co najmniej jednej -metylocytozyny według reguł podanych w Tabeli 9. Tabela 9. Reguły określania sekwencji cplm po reakcji z wodorosiarczynem Sekwencja uzyskana Sekwencja pierwotna Matryca z nici Matryca z Nić w przód Nić w tył (3 w tył nici w przód ( => 3 ) => ) A T A T T A T A C A C G A C G C C G G C metylowana G C C G metylowana
86 8 PRZYKŁAD 7. Symulacja wykrywania metylacji przez przekształcenie m C w T za pomocą przemiany fotochemicznej w kolistej cząsteczce z zamkniętymi w niej parami 1 [0164] Schemat ogólny tego Przykładu pokazano na Fig. 16. Uzyskano próbkę dwuniciowego kwasu nukleinowego zawierającą co najmniej jedną -metylocytozynę, jak w Przykładzie 3. Wytworzono kolistą cząsteczkę z zamkniętymi w niej parami jak w Przykładzie. Przeprowadzono przemianę fotochemiczną jak w Przykładzie 3. Dane dotyczące sekwencji uzyskano jak w Przykładzie. Dane dotyczące sekwencji analizuje się przez porównanie sekwencji nici w przód i w tył w kolistej cząsteczce z zamkniętymi w niej parami w celu określenia sekwencji próbki kwasu nukleinowego i pozycji co najmniej jednej -metylocytozyny według reguł podanych w Tabeli. Tabela. Reguły określania sekwencji cplm po przemianie fotochemicznej Sekwencja uzyskana Sekwencja pierwotna Matryca z nici Matryca z nici Nić w Nić w tył (3 w tył w przód przód ( => ) => 3 ) A T A T T A T A C G C G G C G C C A G C metylowana A C C G metylowana
87 86 PRZYKŁAD 8. Symulacja wykrywania -bromouracylu w kolistej cząsteczce z zamkniętymi w niej parami 1 [016] Schemat ogólny tego Przykładu pokazano na Fig. 17. Uzyskano próbkę dwuniciowego kwasu nukleinowego zawierającą co najmniej jeden -bromouracyl. Wytworzono kolistą cząsteczkę z zamkniętymi w niej parami, jak w Przykładzie. Dane dotyczące sekwencji uzyskano jak w Przykładzie. Dane dotyczące sekwencji analizuje się przez porównanie sekwencji nici w przód i w tył w kolistej z zamkniętymi w niej parami w celu określenia sekwencji próbki kwasu nukleinowego i pozycji co najmniej jednego -bromouracylu według reguł podanych w Tabeli 11. Tabela 11. Reguły określania sekwencji cplm/- bromouracylu Sekwencja uzyskana Sekwencja pierwotna Matryca z nici Matryca z Nić w przód Nić w tył (3 w tył nici w przód ( => 3 ) => ) A T A T T A T A C G C G G C G C G T A -bromouracyl T G - A bromouracyl [0166] Opis jest najlepiej zrozumiały przy uwzględnieniu treści odnośników cytowanych w opisie. Wykonania w opisie stanowią ilustrację wykonań wynalazku i nie należy ich interpretować jako
88 ograniczenia zakresu wynalazku. Specjalista w tej dziedzinie z łatwością stwierdzi, że wynalazek obejmuje wiele innych wykonań. Cytowanie jakichkolwiek odnośników w niniejszym dokumencie nie oznacza, że takie odnośniki są stanem techniki w odniesieniu do niniejszego wynalazku. [0167] Jeśli nie zaznaczono, że jest inaczej, wszystkie liczby wyrażające ilości składników, warunki reakcji i tak dalej wykorzystywane w opisie, w tym w zastrzeżeniach, należy rozumieć tak, że we wszystkich przypadkach są zmodyfikowane określeniem około. W związku z tym, jeśli nie zaznaczono, że jest inaczej, parametry liczbowe stanowią przybliżenie i mogą się zmieniać. Na koniec i nie w sensie próby ograniczenia zastosowania doktryny o odpowiednikach do zakresu zastrzeżeń, każdy parametr liczbowy należy interpretować w świetle liczby cyfr znaczących i typowych metod zaokrąglania. Jeśli w opisie wymienia się szereg liczb różniących się liczbą cyfr znaczących, nie należy tego interpretować jako sugestii, że liczby z mniejszą liczbą cyfr znaczących mają tę samą precyzję co liczby z większą liczbą cyfr znaczących. [0168] Zastosowanie w tekście w języku angielskim rodzajników a lub an w połączeniu z określeniem zawierający w zastrzeżeniach i/lub w opisie może oznaczać jeden, ale jest także zgodne ze znaczeniem jeden lub więcej, co najmniej jeden oraz jeden lub więcej niż jeden. Zastosowanie określenia lub w zastrzeżeniach ma oznaczać i/lub, chyba że zaznaczono wyraźnie, że dotyczy ono wyłącznie alternatywy lub że ujęcia alternatywne wzajemnie się wykluczają, mimo że
89 88 1 ujawnienie wspiera definicję odnoszącą się wyłącznie do alternatywy oraz i/lub. [0169] Jeśli nie zaznaczono, że jest inaczej, określenie co najmniej poprzedzające ciąg elementów należy rozumieć tak, że odnosi się do każdego elementu w ciągu. [0170] Jeśli nie zaznaczono, że jest inaczej, wszystkie terminy techniczne i naukowe wykorzystywane w niniejszym dokumencie mają znaczenie zwyczajowo rozumiane przez specjalistę w dziedzinie, do której należy niniejszy wynalazek. Jakkolwiek przy wykonywaniu lub testowaniu niniejszego wynalazku można wykorzystać dowolne metody i materiały podobne lub równoważne wobec omawianych w niniejszym dokumencie, w jego treści omówiono korzystne metody i materiały. Industrial Technology Research Institute Pełnomocnik:
90 89 Zastrzeżenia patentowe Sposób określania sekwencji próbki kwasu nukleinowego obejmujący: a. dostarczanie kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, przy czym wstawka ma znaną sekwencję; b. uzyskanie danych dotyczących sekwencji zawierających sekwencję co najmniej dwóch jednostek wstawka-próbka, przy czym wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; c. obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (b) przez porównanie sekwencji ze znaną sekwencją wstawki; d. zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (b) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego; e. zebranie zestawu zaakceptowanych sekwencji zawierającego co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego zaakceptowanej w etapie (d); oraz f. określanie sekwencji próbki kwasu nukleinowego z wykorzystaniem zestawu zaakceptowanych sekwencji,
91 90 przy czym zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (b) obejmuje zaakceptowanie tych spośród co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego, które znajdują się bezpośrednio powyżej lub poniżej sekwencji wstawki próbki i mają wynik większy lub równy wcześniej określonej wartości progowej, oraz odrzucenie tych, które tego warunku nie spełniają. 2. Sposób według zastrz. 1, w którym uzyskanie danych dotyczących sekwencji obejmuje sekwencjonowanie pojedynczej cząsteczki Sposób według zastrz. 1, w którym dostarczanie kolistej cząsteczki kwasu nukleinowego obejmuje ligację próbki kwasu nukleinowego ze wstawką kwasu nukleinowego z utworzeniem kolistej cząsteczki kwasu nukleinowego. 4. Sposób według zastrz. 1, w którym kolista cząsteczka kwasu nukleinowego zawiera co najmniej dwie jednostki wstawka-próbka. 2. Sposób według zastrz. 1, w którym wstawka kwasu nukleinowego zawiera promotor, zaś synteza produktu - cząsteczki kwasu nukleinowego obejmuje doprowadzenie do kontaktu promotora z polimerazą RNA rozpoznającą promotor, a następnie syntezę produktu - cząsteczki kwasu nukleinowego zawierającej reszty rybonukleotydowe.
92 91 6. Sposób według zastrz. 1, w którym wstawka kwasu nukleinowego ma długość w zakresie od 14 do 0 reszt nukleotydowych. 7. Sposób według zastrz. 1, w którym zestaw zaakceptowanych sekwencji ma postać wybraną spośród zmiennej wieloelementowej i ciągu pojedynczych danych zawierających dane dotyczące sekwencji z etapu (b), które poddano przetwarzaniu w celu usunięcia, zastąpienia lub pominięcia powtórzeń sekwencji próbki kwasu nukleinowego odrzuconych w etapie (e) Sposób według zastrz. 1, w którym zestaw zaakceptowanych sekwencji ma postać zmiennej wieloelementowej typu wybranego spośród listy, uporządkowanego zestawu, hash i macierzy Sposób według zastrz. 1, w którym co najmniej dwa powtórzenia sekwencji próbki kwasu nukleinowego są zaakceptowane w etapie (d), zaś określanie sekwencji próbki kwasu nukleinowego obejmuje określanie sekwencji konsensusowej na podstawie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego zaakceptowanych w etapie (d).. Sposób według zastrz. 9, w którym sekwencja konsensusowa zawiera zasady z reprezentacją probabilistyczną w co najmniej jednej pozycji, w której co najmniej dwa powtórzenia sekwencji próbki kwasu nukleinowego zaakceptowanej w etapie (d) się różnią.
93 Sposób według zastrz. 9, w którym co najmniej trzy powtórzenia sekwencji próbki kwasu nukleinowego są zaakceptowane w etapie (d), zaś określanie sekwencji konsensusowej obejmuje ustalanie większości na podstawie co najmniej trzech powtórzeń sekwencji próbki kwasu nukleinowego zaakceptowanych w etapie (d). 12. Sposób według zastrz. 9, w którym sekwencja konsensusowa obejmuje poziomy ufności. 13. Sposób według zastrz. 12, w którym poziomy ufności wyraża się w postaci wybranej spośród częstości zasad, zawartości informacji i wyniku jakości Phred Sposób według zastrz. 12, w którym etapy (b)- (f) według zastrz. 1 przeprowadza się w czasie rzeczywistym i sekwencję konsensusową oraz poziomy ufności uaktualnia się w czasie rzeczywistym. 1. Sposób według zastrz. 14, który to sposób wykonuje się do momentu uzyskania określonego minimalnego poziomu ufności dla wstępnie określonego odsetka pozycji w sekwencji konsensusowej Sposób według zastrz. 1, który obejmuje ponadto wydanie ostrzeżenia, kiedy wstępnie określony odsetek pozycji osiąga określony minimalny poziom ufności. 17. Sposób według zastrz. 1, który obejmuje ponadto powtarzanie etapów według zastrz. 1 przy użyciu
94 93 co najmniej jednej innej próbki kwasu nukleinowego z tego samego źródła, gatunku lub szczepu co próbka kwasu nukleinowego według zastrz. 1, która ma sekwencję częściowo nakładającą się na sekwencję próbki kwasu nukleinowego według zastrz. 1, dzięki czemu określa się co najmniej jedną inną sekwencję i składa się tę co najmniej jedną inną sekwencję z sekwencją według etapu (f) tworząc kontig. 18. Sposób według zastrz. 1, w którym wyniki z etapu (c) wykorzystuje się do oszacowania poziomu ufności dla danych dotyczących sekwencji z etapu (b) jako całości Sposób według zastrz. 1, w którym obliczanie wyników obejmuje określenie liczby niedopasowań między co najmniej dwiema wstawkami z danych dotyczących sekwencji i znanej sekwencji wstawki.. Sposób według zastrz. 1, w którym obliczanie wyników obejmuje określanie identyczności procentowej między co najmniej dwiema wstawkami z danych dotyczących sekwencji i znanej sekwencji wstawki Sposób według zastrz. 1, w którym obliczanie wyników obejmuje przeprowadzanie przyrównania między co najmniej dwiema wstawkami z danych dotyczących sekwencji i znanej sekwencji wstawki. 22. Sposób według zastrz. 1, w którym wyniki generuje się na podstawie wybranej spośród podstawy
95 94 zliczeniowej i podstawy częstości System obejmujący aparat do sekwencjonowania połączony w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika, przy czym w pamięci jest zakodowany program zawierający system operacyjny, oprogramowanie interfejsu użytkownika i instrukcje, które po wykonaniu przez procesor, ewentualnie przy udziale użytkownika, wykonują sposób obejmujący: a. uzyskanie danych dotyczących sekwencji z kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, przy czym: (i) wstawka ma znaną sekwencję, (ii) dane dotyczące sekwencji zawierają sekwencję co najmniej dwóch jednostek wstawka-próbka i (iii) wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; b. obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (a) przez porównanie sekwencji ze znaną sekwencją wstawki; c. zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (a) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego;
96 9 1 d. zebranie zestawu zaakceptowanych sekwencji zawierającego co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego zaakceptowanej w etapie (c); oraz e. określanie sekwencji próbki kwasu nukleinowego przy wykorzystaniu zestawu zaakceptowanych sekwencji, przy czym zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (b) obejmuje zaakceptowanie tych spośród co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego, które znajdują się bezpośrednio powyżej lub poniżej sekwencji wstawki próbki i mają wynik większy lub równy wcześniej określonej wartości progowej, oraz odrzucenie tych, które tego warunku nie spełniają, i przy czym sygnał wyjściowy z układu wykorzystuje się do wytworzenia co najmniej jednego spośród: (i) sekwencji próbki kwasu nukleinowego lub (ii) wskazania, że w co najmniej jednej pozycji w próbce kwasu nukleinowego znajduje się zasada zmodyfikowana Pamięć, w której jest zakodowany program zawierający system operacyjny, oprogramowanie interfejsu użytkownika i instrukcje, które po wykonaniu przez procesor w systemie zawierającym aparat do sekwencjonowania połączony w sposób funkcjonalny z urządzeniem obliczeniowym zawierającym procesor, pamięć, magistralę danych i co najmniej jeden element interfejsu użytkownika, ewentualnie przy udziale użytkownika, wykonują sposób obejmujący:
97 a. uzyskanie danych dotyczących sekwencji z kolistej cząsteczki kwasu nukleinowego zawierającej co najmniej jedną jednostkę wstawka-próbka zawierającą wstawkę kwasu nukleinowego i próbkę kwasu nukleinowego, przy czym: (i) wstawka ma znaną sekwencję, (ii) dane dotyczące sekwencji zawierają sekwencję co najmniej dwóch jednostek wstawka-próbka oraz (iii) wytwarza się cząsteczkę kwasu nukleinowego zawierającą co najmniej dwie jednostki wstawka-próbka; b. obliczanie wyników dla sekwencji co najmniej dwóch wstawek z danych dotyczących sekwencji z etapu (a) przez porównanie sekwencji ze znaną sekwencją wstawki; c. zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (a) na podstawie wyników dla jednej lub obydwu sekwencji wstawek znajdujących się bezpośrednio powyżej i poniżej powtórzenia sekwencji próbki kwasu nukleinowego; d. zebranie zestawu zaakceptowanych sekwencji zawierającego co najmniej jedno powtórzenie sekwencji próbki kwasu nukleinowego przyjętej w etapie (c); i e. określanie sekwencji próbki kwasu nukleinowego przy wykorzystaniu zestawu zaakceptowanych sekwencji, przy czym zaakceptowanie lub odrzucenie co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego z danych dotyczących sekwencji z etapu (b) obejmuje zaakceptowanie tych spośród co najmniej dwóch powtórzeń sekwencji próbki kwasu nukleinowego, które znajdują się bezpośrednio powyżej lub poniżej sekwencji
98 97 wstawki próbki i mają wynik większy lub równy wcześniej określonej wartości progowej, oraz odrzucenie tych, które tego warunku nie spełniają, i przy czym sposób daje sygnał wyjściowy wykorzystywany do wytworzenia co najmniej jednego spośród: (i) sekwencji próbki kwasu nukleinowego lub (ii) wskazania, że w co najmniej jednej pozycji w próbce kwasu nukleinowego znajduje się zasada zmodyfikowana. 1 Industrial Technology Research Institute Pełnomocnik:
99 98
100 99
101 0
102 1
103 2
104 3
105 4
106
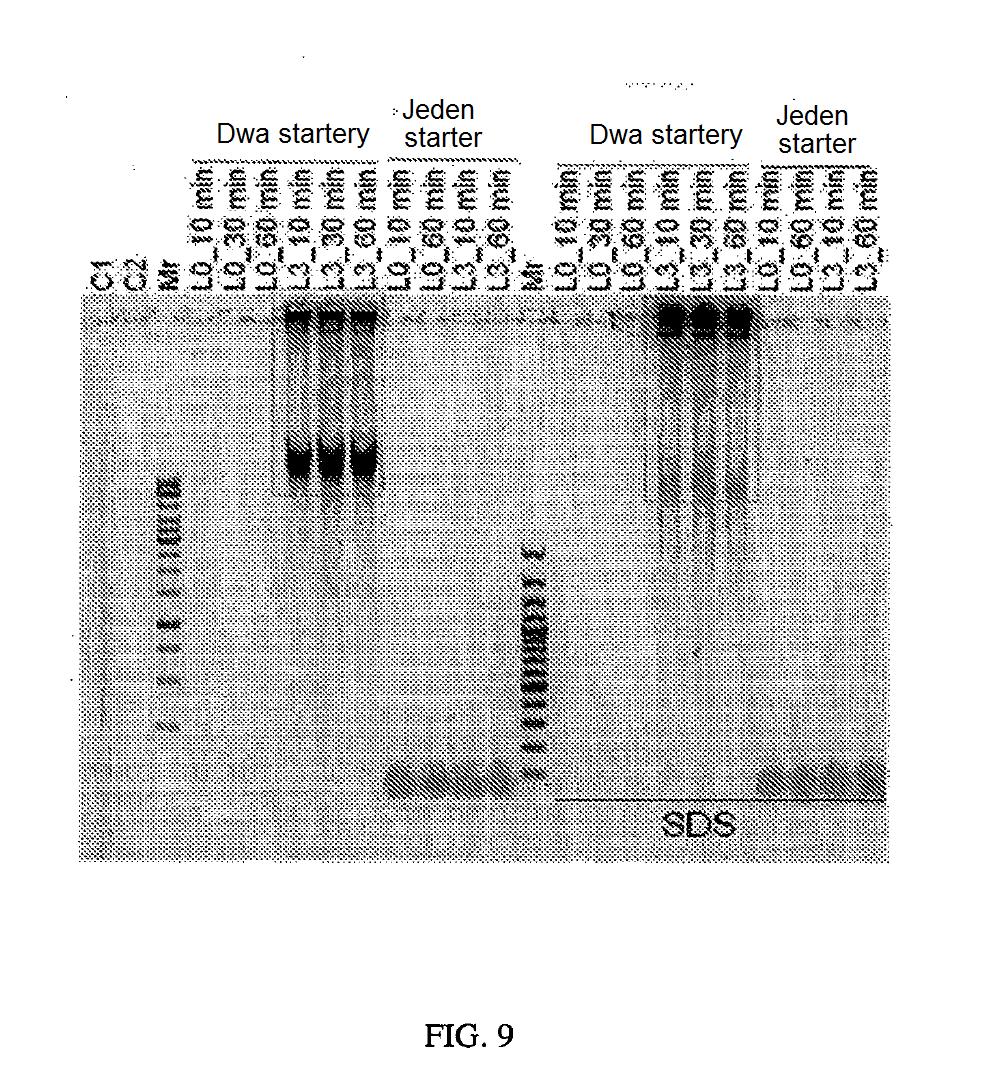
107 6
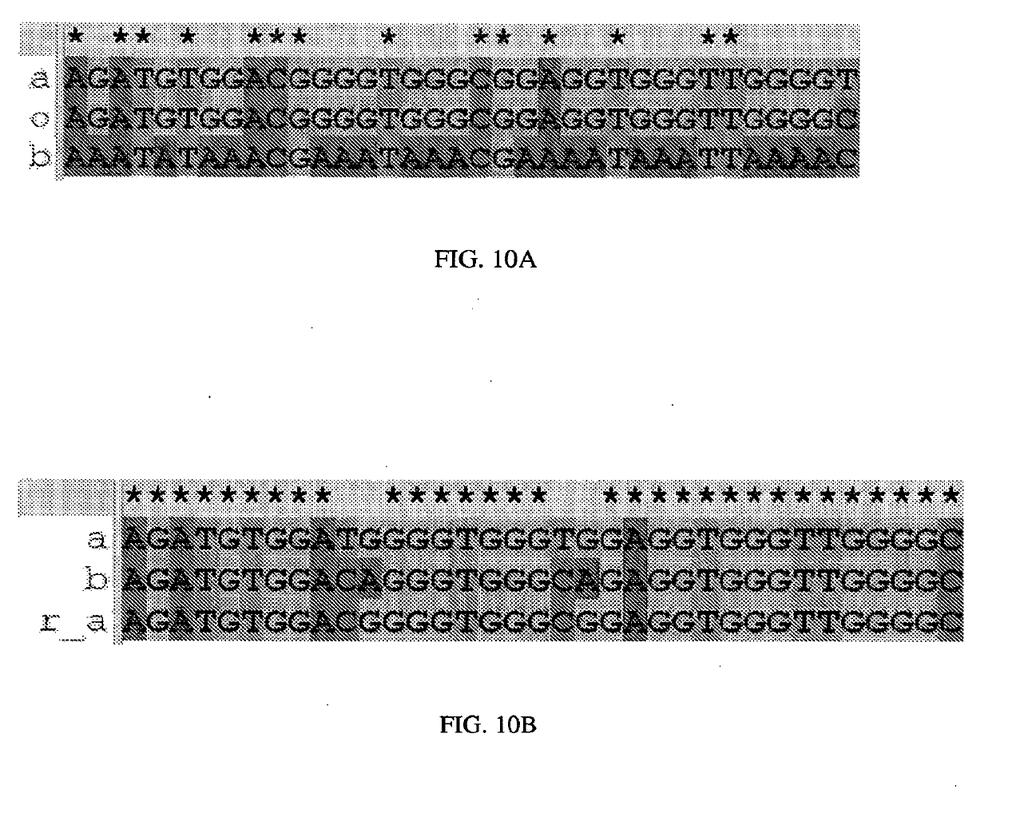
108 7
Klonowanie molekularne Kurs doskonalący. Zakład Geriatrii i Gerontologii CMKP
 Klonowanie molekularne Kurs doskonalący Zakład Geriatrii i Gerontologii CMKP Etapy klonowania molekularnego 1. Wybór wektora i organizmu gospodarza Po co klonuję (do namnożenia DNA [czy ma być metylowane
Klonowanie molekularne Kurs doskonalący Zakład Geriatrii i Gerontologii CMKP Etapy klonowania molekularnego 1. Wybór wektora i organizmu gospodarza Po co klonuję (do namnożenia DNA [czy ma być metylowane
Metody odczytu kolejności nukleotydów - sekwencjonowania DNA
 Metody odczytu kolejności nukleotydów - sekwencjonowania DNA 1. Metoda chemicznej degradacji DNA (metoda Maxama i Gilberta 1977) 2. Metoda terminacji syntezy łańcucha DNA - klasyczna metoda Sangera (Sanger
Metody odczytu kolejności nukleotydów - sekwencjonowania DNA 1. Metoda chemicznej degradacji DNA (metoda Maxama i Gilberta 1977) 2. Metoda terminacji syntezy łańcucha DNA - klasyczna metoda Sangera (Sanger
Ćwiczenia 1 Wirtualne Klonowanie Prowadzący: mgr inż. Joanna Tymeck-Mulik i mgr Lidia Gaffke. Część teoretyczna:
 Uniwersytet Gdański, Wydział Biologii Katedra Biologii Molekularnej Przedmiot: Biologia Molekularna z Biotechnologią Biologia II rok ===============================================================================================
Uniwersytet Gdański, Wydział Biologii Katedra Biologii Molekularnej Przedmiot: Biologia Molekularna z Biotechnologią Biologia II rok ===============================================================================================
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1505553. (96) Data i numer zgłoszenia patentu europejskiego: 05.08.2004 04018511.
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1505553. (96) Data i numer zgłoszenia patentu europejskiego: 05.08.2004 04018511.") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 3 (96) Data i numer zgłoszenia patentu europejskiego: 0.08.04 0401811.8 (13) (1) T3 Int.Cl. G08C 17/00 (06.01) Urząd Patentowy
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 3 (96) Data i numer zgłoszenia patentu europejskiego: 0.08.04 0401811.8 (13) (1) T3 Int.Cl. G08C 17/00 (06.01) Urząd Patentowy
Wykład 14 Biosynteza białek
 BIOCHEMIA Kierunek: Technologia Żywności i Żywienie Człowieka semestr III Wykład 14 Biosynteza białek WYDZIAŁ NAUK O ŻYWNOŚCI I RYBACTWA CENTRUM BIOIMMOBILIZACJI I INNOWACYJNYCH MATERIAŁÓW OPAKOWANIOWYCH
BIOCHEMIA Kierunek: Technologia Żywności i Żywienie Człowieka semestr III Wykład 14 Biosynteza białek WYDZIAŁ NAUK O ŻYWNOŚCI I RYBACTWA CENTRUM BIOIMMOBILIZACJI I INNOWACYJNYCH MATERIAŁÓW OPAKOWANIOWYCH
Nowoczesne systemy ekspresji genów
 Nowoczesne systemy ekspresji genów Ekspresja genów w organizmach żywych GEN - pojęcia podstawowe promotor sekwencja kodująca RNA terminator gen Gen - odcinek DNA zawierający zakodowaną informację wystarczającą
Nowoczesne systemy ekspresji genów Ekspresja genów w organizmach żywych GEN - pojęcia podstawowe promotor sekwencja kodująca RNA terminator gen Gen - odcinek DNA zawierający zakodowaną informację wystarczającą
Wybrane techniki badania białek -proteomika funkcjonalna
 Wybrane techniki badania białek -proteomika funkcjonalna Proteomika: umożliwia badanie zestawu wszystkich (lub prawie wszystkich) białek komórkowych Zalety analizy proteomu np. w porównaniu z analizą trankryptomu:
Wybrane techniki badania białek -proteomika funkcjonalna Proteomika: umożliwia badanie zestawu wszystkich (lub prawie wszystkich) białek komórkowych Zalety analizy proteomu np. w porównaniu z analizą trankryptomu:
Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii
 Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii 1. Technologia rekombinowanego DNA jest podstawą uzyskiwania genetycznie zmodyfikowanych organizmów 2. Medycyna i ochrona zdrowia
Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii 1. Technologia rekombinowanego DNA jest podstawą uzyskiwania genetycznie zmodyfikowanych organizmów 2. Medycyna i ochrona zdrowia
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego: 06.09.2005 05788867.9
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego: 06.09.2005 05788867.9") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1786660 (96) Data i numer zgłoszenia patentu europejskiego: 06.09.2005 05788867.9 (13) T3 (51) Int. Cl. B62D25/08 B60G15/06
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1786660 (96) Data i numer zgłoszenia patentu europejskiego: 06.09.2005 05788867.9 (13) T3 (51) Int. Cl. B62D25/08 B60G15/06
TECHNIKI ANALIZY RNA TECHNIKI ANALIZY RNA TECHNIKI ANALIZY RNA
 DNA 28SRNA 18/16S RNA 5SRNA mrna Ilościowa analiza mrna aktywność genów w zależności od wybranych czynników: o rodzaju tkanki o rodzaju czynnika zewnętrznego o rodzaju upośledzenia szlaku metabolicznego
DNA 28SRNA 18/16S RNA 5SRNA mrna Ilościowa analiza mrna aktywność genów w zależności od wybranych czynników: o rodzaju tkanki o rodzaju czynnika zewnętrznego o rodzaju upośledzenia szlaku metabolicznego
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 223771 (96) Data i numer zgłoszenia patentu europejskiego: 06.12.08 0886773.1 (13) (1) T3 Int.Cl. A47L 1/42 (06.01) Urząd
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 223771 (96) Data i numer zgłoszenia patentu europejskiego: 06.12.08 0886773.1 (13) (1) T3 Int.Cl. A47L 1/42 (06.01) Urząd
(96) Data i numer zgłoszenia patentu europejskiego:
 Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1690978 (96) Data i numer zgłoszenia patentu europejskiego: 11.02.2005 05101042.9 (13) T3 (51) Int. Cl. D06F81/08 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1690978 (96) Data i numer zgłoszenia patentu europejskiego: 11.02.2005 05101042.9 (13) T3 (51) Int. Cl. D06F81/08 (2006.01)
TATA box. Enhancery. CGCG ekson intron ekson intron ekson CZĘŚĆ KODUJĄCA GENU TERMINATOR. Elementy regulatorowe
 Promotory genu Promotor bliski leży w odległości do 40 pz od miejsca startu transkrypcji, zawiera kasetę TATA. Kaseta TATA to silnie konserwowana sekwencja TATAAAA, występująca w większości promotorów
Promotory genu Promotor bliski leży w odległości do 40 pz od miejsca startu transkrypcji, zawiera kasetę TATA. Kaseta TATA to silnie konserwowana sekwencja TATAAAA, występująca w większości promotorów
Powodzenie reakcji PCR wymaga właściwego doboru szeregu parametrów:
 Powodzenie reakcji PCR wymaga właściwego doboru szeregu parametrów: dobór warunków samej reakcji PCR (temperatury, czas trwania cykli, ilości cykli itp.) dobór odpowiednich starterów do reakcji amplifikacji
Powodzenie reakcji PCR wymaga właściwego doboru szeregu parametrów: dobór warunków samej reakcji PCR (temperatury, czas trwania cykli, ilości cykli itp.) dobór odpowiednich starterów do reakcji amplifikacji
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1730054 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 22.03.2005 05731932.9 (51) Int. Cl. B65G17/06 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1730054 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 22.03.2005 05731932.9 (51) Int. Cl. B65G17/06 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1732433 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 27.01.2005 05702820.1
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1732433 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 27.01.2005 05702820.1
Dr. habil. Anna Salek International Bio-Consulting 1 Germany
 1 2 3 Drożdże są najprostszymi Eukariontami 4 Eucaryota Procaryota 5 6 Informacja genetyczna dla każdej komórki drożdży jest identyczna A zatem każda komórka koduje w DNA wszystkie swoje substancje 7 Przy
1 2 3 Drożdże są najprostszymi Eukariontami 4 Eucaryota Procaryota 5 6 Informacja genetyczna dla każdej komórki drożdży jest identyczna A zatem każda komórka koduje w DNA wszystkie swoje substancje 7 Przy
października 2013: Elementarz biologii molekularnej. Wykład nr 2 BIOINFORMATYKA rok II
 10 października 2013: Elementarz biologii molekularnej www.bioalgorithms.info Wykład nr 2 BIOINFORMATYKA rok II Komórka: strukturalna i funkcjonalne jednostka organizmu żywego Jądro komórkowe: chroniona
10 października 2013: Elementarz biologii molekularnej www.bioalgorithms.info Wykład nr 2 BIOINFORMATYKA rok II Komórka: strukturalna i funkcjonalne jednostka organizmu żywego Jądro komórkowe: chroniona
TaqNova-RED. Polimeraza DNA RP20R, RP100R
 TaqNova-RED Polimeraza DNA RP20R, RP100R RP20R, RP100R TaqNova-RED Polimeraza DNA Rekombinowana termostabilna polimeraza DNA Taq zawierająca czerwony barwnik, izolowana z Thermus aquaticus, o przybliżonej
TaqNova-RED Polimeraza DNA RP20R, RP100R RP20R, RP100R TaqNova-RED Polimeraza DNA Rekombinowana termostabilna polimeraza DNA Taq zawierająca czerwony barwnik, izolowana z Thermus aquaticus, o przybliżonej
Ćwiczenia 1 Wirtualne Klonowanie. Prowadzący: mgr Anna Pawlik i mgr Maciej Dylewski. Część teoretyczna:
 Uniwersytet Gdański, Wydział Biologii Biologia i Biologia Medyczna II rok Katedra Biologii Molekularnej Przedmiot: Biologia Molekularna z Biotechnologią ===============================================================================================
Uniwersytet Gdański, Wydział Biologii Biologia i Biologia Medyczna II rok Katedra Biologii Molekularnej Przedmiot: Biologia Molekularna z Biotechnologią ===============================================================================================
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 161679 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 24.06.0 064.7 (1) Int. Cl. B60R21/01 (06.01) (97) O udzieleniu
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 161679 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 24.06.0 064.7 (1) Int. Cl. B60R21/01 (06.01) (97) O udzieleniu
Wybrane techniki badania białek -proteomika funkcjonalna
 Wybrane techniki badania białek -proteomika funkcjonalna Proteomika: umożliwia badanie zestawu wszystkich (lub prawie wszystkich) białek komórkowych Zalety analizy proteomu w porównaniu z analizą trankryptomu:
Wybrane techniki badania białek -proteomika funkcjonalna Proteomika: umożliwia badanie zestawu wszystkich (lub prawie wszystkich) białek komórkowych Zalety analizy proteomu w porównaniu z analizą trankryptomu:
Przetarg nieograniczony na zakup specjalistycznej aparatury laboratoryjnej Znak sprawy: DZ-2501/6/17
 Część nr 2: SEKWENATOR NASTĘPNEJ GENERACJI Z ZESTAWEM DEDYKOWANYCH ODCZYNNIKÓW Określenie przedmiotu zamówienia zgodnie ze Wspólnym Słownikiem Zamówień (CPV): 38500000-0 aparatura kontrolna i badawcza
Część nr 2: SEKWENATOR NASTĘPNEJ GENERACJI Z ZESTAWEM DEDYKOWANYCH ODCZYNNIKÓW Określenie przedmiotu zamówienia zgodnie ze Wspólnym Słownikiem Zamówień (CPV): 38500000-0 aparatura kontrolna i badawcza
2015-11-18. DNA i RNA ENZYMY MODYFIKUJĄCE KOŃCE CZĄSTECZEK. DNA i RNA. DNA i RNA
 Fosfataza alkaliczna CIP Calf Intestine Phosphatase- pochodzenie: jelito cielęce BAP Bacterial Alcaline Phosphatase- pochodzenie: E. coli SAP Shrimp Alcaline Phosphatase- pochodzenie: krewetki Pandalus
Fosfataza alkaliczna CIP Calf Intestine Phosphatase- pochodzenie: jelito cielęce BAP Bacterial Alcaline Phosphatase- pochodzenie: E. coli SAP Shrimp Alcaline Phosphatase- pochodzenie: krewetki Pandalus
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2321656 (96) Data i numer zgłoszenia patentu europejskiego:.08.09 09807498.2 (13) (51) T3 Int.Cl. G01R /18 (06.01) G01R 19/
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2321656 (96) Data i numer zgłoszenia patentu europejskiego:.08.09 09807498.2 (13) (51) T3 Int.Cl. G01R /18 (06.01) G01R 19/
Definicje. Białka rekombinowane (ang. recombinant proteins, r-proteins) Ukierunkowana mutageneza (ang. site-directed/site-specific mutagenesis)
 Ukierunkowana mutageneza (ang. site-directed/site-specific mutagenesis)") Definicje Białka rekombinowane (ang. recombinant proteins, r-proteins) Białka, które powstały w żywych organizmach (lub liniach komórkowych) w wyniku ekspresji rekombinowanego DNA. Rekombinowany DNA jest
Definicje Białka rekombinowane (ang. recombinant proteins, r-proteins) Białka, które powstały w żywych organizmach (lub liniach komórkowych) w wyniku ekspresji rekombinowanego DNA. Rekombinowany DNA jest
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1799953 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 18.08.2005 05770398.5
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1799953 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 18.08.2005 05770398.5
Biologia medyczna, materiały dla studentów
 Zasada reakcji PCR Reakcja PCR (replikacja in vitro) obejmuje denaturację DNA, przyłączanie starterów (annealing) i syntezę nowych nici DNA (elongacja). 1. Denaturacja: rozplecenie nici DNA, temp. 94 o
Zasada reakcji PCR Reakcja PCR (replikacja in vitro) obejmuje denaturację DNA, przyłączanie starterów (annealing) i syntezę nowych nici DNA (elongacja). 1. Denaturacja: rozplecenie nici DNA, temp. 94 o
KLONOWANIE DNA REKOMBINACJA DNA WEKTORY
 KLONOWANIE DNA Klonowanie DNA jest techniką powielania fragmentów DNA DNA można powielać w komórkach (replikacja in vivo) W probówce (PCR) Do przeniesienia fragmentu DNA do komórek gospodarza potrzebny
KLONOWANIE DNA Klonowanie DNA jest techniką powielania fragmentów DNA DNA można powielać w komórkach (replikacja in vivo) W probówce (PCR) Do przeniesienia fragmentu DNA do komórek gospodarza potrzebny
Metody badania polimorfizmu/mutacji DNA. Aleksandra Sałagacka Pracownia Diagnostyki Molekularnej i Farmakogenomiki Uniwersytet Medyczny w Łodzi
 Metody badania polimorfizmu/mutacji DNA Aleksandra Sałagacka Pracownia Diagnostyki Molekularnej i Farmakogenomiki Uniwersytet Medyczny w Łodzi Mutacja Mutacja (łac. mutatio zmiana) - zmiana materialnego
Metody badania polimorfizmu/mutacji DNA Aleksandra Sałagacka Pracownia Diagnostyki Molekularnej i Farmakogenomiki Uniwersytet Medyczny w Łodzi Mutacja Mutacja (łac. mutatio zmiana) - zmiana materialnego
Dane mikromacierzowe. Mateusz Markowicz Marta Stańska
 Dane mikromacierzowe Mateusz Markowicz Marta Stańska Mikromacierz Mikromacierz DNA (ang. DNA microarray) to szklana lub plastikowa płytka (o maksymalnych wymiarach 2,5 cm x 7,5 cm) z naniesionymi w regularnych
Dane mikromacierzowe Mateusz Markowicz Marta Stańska Mikromacierz Mikromacierz DNA (ang. DNA microarray) to szklana lub plastikowa płytka (o maksymalnych wymiarach 2,5 cm x 7,5 cm) z naniesionymi w regularnych
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1968711 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 05.01.2007 07712641.5
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1968711 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 05.01.2007 07712641.5
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2003466 (96) Data i numer zgłoszenia patentu europejskiego: 12.06.2008 08460024.6 (13) (51) T3 Int.Cl. G01S 5/02 (2010.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2003466 (96) Data i numer zgłoszenia patentu europejskiego: 12.06.2008 08460024.6 (13) (51) T3 Int.Cl. G01S 5/02 (2010.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1890471 (96) Data i numer zgłoszenia patentu europejskiego: 19.10.2006 06791271.7 (13) (51) T3 Int.Cl. H04M 3/42 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1890471 (96) Data i numer zgłoszenia patentu europejskiego: 19.10.2006 06791271.7 (13) (51) T3 Int.Cl. H04M 3/42 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 71811 (96) Data i numer zgłoszenia patentu europejskiego: 29.09.06 06791167.7 (13) (1) T3 Int.Cl. H04Q 11/00 (06.01) Urząd
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 71811 (96) Data i numer zgłoszenia patentu europejskiego: 29.09.06 06791167.7 (13) (1) T3 Int.Cl. H04Q 11/00 (06.01) Urząd
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2326237 (96) Data i numer zgłoszenia patentu europejskiego: 07.07.2009 09780285.4 (13) (51) T3 Int.Cl. A47L 15/50 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2326237 (96) Data i numer zgłoszenia patentu europejskiego: 07.07.2009 09780285.4 (13) (51) T3 Int.Cl. A47L 15/50 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2913207 (96) Data i numer zgłoszenia patentu europejskiego: 08.05.2014 14167514.0 (13) (51) T3 Int.Cl. B60C 23/04 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2913207 (96) Data i numer zgłoszenia patentu europejskiego: 08.05.2014 14167514.0 (13) (51) T3 Int.Cl. B60C 23/04 (2006.01)
TRANSKRYPCJA - I etap ekspresji genów
 Eksparesja genów TRANSKRYPCJA - I etap ekspresji genów Przepisywanie informacji genetycznej z makrocząsteczki DNA na mniejsze i bardziej funkcjonalne cząsteczki pre-mrna Polimeraza RNA ETAP I Inicjacja
Eksparesja genów TRANSKRYPCJA - I etap ekspresji genów Przepisywanie informacji genetycznej z makrocząsteczki DNA na mniejsze i bardziej funkcjonalne cząsteczki pre-mrna Polimeraza RNA ETAP I Inicjacja
Inżynieria Genetyczna ćw. 3
 Materiały do ćwiczeń z przedmiotu Genetyka z inżynierią genetyczną D - blok Inżynieria Genetyczna ćw. 3 Instytut Genetyki i Biotechnologii, Wydział Biologii, Uniwersytet Warszawski, rok akad. 2018/2019
Materiały do ćwiczeń z przedmiotu Genetyka z inżynierią genetyczną D - blok Inżynieria Genetyczna ćw. 3 Instytut Genetyki i Biotechnologii, Wydział Biologii, Uniwersytet Warszawski, rok akad. 2018/2019
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2334863. (96) Data i numer zgłoszenia patentu europejskiego: 31.08.2009 09782381.
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2334863. (96) Data i numer zgłoszenia patentu europejskiego: 31.08.2009 09782381.") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2334863 (96) Data i numer zgłoszenia patentu europejskiego: 31.08.2009 09782381.9 (13) (51) T3 Int.Cl. D06F 39/08 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2334863 (96) Data i numer zgłoszenia patentu europejskiego: 31.08.2009 09782381.9 (13) (51) T3 Int.Cl. D06F 39/08 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1701111 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 11.03.2005 05090064.6 (51) Int. Cl. F24H9/20 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1701111 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 11.03.2005 05090064.6 (51) Int. Cl. F24H9/20 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 02.05.2005 05747547.
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 02.05.2005 05747547.") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1747298 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 02.05.2005 05747547.7 (51) Int. Cl. C22C14/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1747298 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 02.05.2005 05747547.7 (51) Int. Cl. C22C14/00 (2006.01)
2. Enzymy pozwalające na manipulację DNA a. Polimerazy DNA b. Nukleazy c. Ligazy
 Metody analizy DNA 1. Budowa DNA. 2. Enzymy pozwalające na manipulację DNA a. Polimerazy DNA b. Nukleazy c. Ligazy 3. Klonowanie in vivo a. w bakteriach, wektory plazmidowe b. w fagach, kosmidy c. w drożdżach,
Metody analizy DNA 1. Budowa DNA. 2. Enzymy pozwalające na manipulację DNA a. Polimerazy DNA b. Nukleazy c. Ligazy 3. Klonowanie in vivo a. w bakteriach, wektory plazmidowe b. w fagach, kosmidy c. w drożdżach,
Proteomika: umożliwia badanie zestawu wszystkich lub prawie wszystkich białek komórkowych
 Proteomika: umożliwia badanie zestawu wszystkich lub prawie wszystkich białek komórkowych Zalety w porównaniu z analizą trankryptomu: analiza transkryptomu komórki identyfikacja mrna nie musi jeszcze oznaczać
Proteomika: umożliwia badanie zestawu wszystkich lub prawie wszystkich białek komórkowych Zalety w porównaniu z analizą trankryptomu: analiza transkryptomu komórki identyfikacja mrna nie musi jeszcze oznaczać
Dominika Stelmach Gr. 10B2
 Dominika Stelmach Gr. 10B2 Czym jest DNA? Wielkocząsteczkowy organiczny związek chemiczny z grupy kwasów nukleinowych Zawiera kwas deoksyrybonukleoinowy U organizmów eukariotycznych zlokalizowany w jądrze
Dominika Stelmach Gr. 10B2 Czym jest DNA? Wielkocząsteczkowy organiczny związek chemiczny z grupy kwasów nukleinowych Zawiera kwas deoksyrybonukleoinowy U organizmów eukariotycznych zlokalizowany w jądrze
Biologia Molekularna Podstawy
 Biologia Molekularna Podstawy Budowa DNA Budowa DNA Zasady: Purynowe: adenina i guanina Pirymidynowe: cytozyna i tymina 2 -deoksyryboza Grupy fosforanowe Budowa RNA Budowa RNA Zasady: purynowe: adenina
Biologia Molekularna Podstawy Budowa DNA Budowa DNA Zasady: Purynowe: adenina i guanina Pirymidynowe: cytozyna i tymina 2 -deoksyryboza Grupy fosforanowe Budowa RNA Budowa RNA Zasady: purynowe: adenina
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 240040 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 09.07. 007077.0 (97)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 240040 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 09.07. 007077.0 (97)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1854925 (96) Data i numer zgłoszenia patentu europejskiego: 16.12.2005 05826699.0 (13) (51) T3 Int.Cl. E03D 1/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1854925 (96) Data i numer zgłoszenia patentu europejskiego: 16.12.2005 05826699.0 (13) (51) T3 Int.Cl. E03D 1/00 (2006.01)
WYNALAZKI BIOTECHNOLOGICZNE W POLSCE. Ewa Waszkowska ekspert UPRP
 WYNALAZKI BIOTECHNOLOGICZNE W POLSCE Ewa Waszkowska ekspert UPRP Źródła informacji w biotechnologii projekt SLING Warszawa, 9-10.12.2010 PLAN WYSTĄPIENIA Umocowania prawne Wynalazki biotechnologiczne Statystyka
WYNALAZKI BIOTECHNOLOGICZNE W POLSCE Ewa Waszkowska ekspert UPRP Źródła informacji w biotechnologii projekt SLING Warszawa, 9-10.12.2010 PLAN WYSTĄPIENIA Umocowania prawne Wynalazki biotechnologiczne Statystyka
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2949485 (96) Data i numer zgłoszenia patentu europejskiego: 06.10.2014 14187774.6 (13) (51) T3 Int.Cl. B60C 23/04 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2949485 (96) Data i numer zgłoszenia patentu europejskiego: 06.10.2014 14187774.6 (13) (51) T3 Int.Cl. B60C 23/04 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2528702 (96) Data i numer zgłoszenia patentu europejskiego: 03.12.2010 10796315.9 (13) (51) T3 Int.Cl. B21D 53/36 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2528702 (96) Data i numer zgłoszenia patentu europejskiego: 03.12.2010 10796315.9 (13) (51) T3 Int.Cl. B21D 53/36 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2259949 (96) Data i numer zgłoszenia patentu europejskiego: 11.02.2009 09727379.1 (13) (51) T3 Int.Cl. B60L 11/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2259949 (96) Data i numer zgłoszenia patentu europejskiego: 11.02.2009 09727379.1 (13) (51) T3 Int.Cl. B60L 11/00 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2555663 (96) Data i numer zgłoszenia patentu europejskiego: 06.04.2011 11730434.5 (13) (51) T3 Int.Cl. A47L 15/42 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2555663 (96) Data i numer zgłoszenia patentu europejskiego: 06.04.2011 11730434.5 (13) (51) T3 Int.Cl. A47L 15/42 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1680075 (13) T3 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 11.10.2004
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1680075 (13) T3 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 11.10.2004
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2210706 (96) Data i numer zgłoszenia patentu europejskiego: 21.01.2010 10000580.0 (13) (51) T3 Int.Cl. B24B 21/20 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2210706 (96) Data i numer zgłoszenia patentu europejskiego: 21.01.2010 10000580.0 (13) (51) T3 Int.Cl. B24B 21/20 (2006.01)
Hybrydyzacja kwasów nukleinowych
 Hybrydyzacja kwasów nukleinowych Jaka jest lokalizacja genu na chromosomie? Jakie jest jego sąsiedztwo? Hybrydyzacja - powstawanie stabilnych struktur dwuniciowych z cząsteczek jednoniciowych o komplementarnych
Hybrydyzacja kwasów nukleinowych Jaka jest lokalizacja genu na chromosomie? Jakie jest jego sąsiedztwo? Hybrydyzacja - powstawanie stabilnych struktur dwuniciowych z cząsteczek jednoniciowych o komplementarnych
Biologia Molekularna z Biotechnologią ===============================================================================================
 Uniwersytet Gdański, Wydział Biologii Biologia i Biologia Medyczna II rok Katedra Genetyki Molekularnej Bakterii Katedra Biologii i Genetyki Medycznej Przedmiot: Katedra Biologii Molekularnej Biologia
Uniwersytet Gdański, Wydział Biologii Biologia i Biologia Medyczna II rok Katedra Genetyki Molekularnej Bakterii Katedra Biologii i Genetyki Medycznej Przedmiot: Katedra Biologii Molekularnej Biologia
Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu
 Ćwiczenie 4 Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu Wstęp CYP2D6 kodowany przez gen występujący w co najmniej w 78 allelicznych formach związanych ze zmniejszoną
Ćwiczenie 4 Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu Wstęp CYP2D6 kodowany przez gen występujący w co najmniej w 78 allelicznych formach związanych ze zmniejszoną
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2445326 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 24.10.2011 11186353.6
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2445326 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 24.10.2011 11186353.6
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1449961 (96) Data i numer zgłoszenia patentu europejskiego: 14.04.2004 04405227.2 (13) T3 (51) Int. Cl. E01B9/14 F16B13/00
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1449961 (96) Data i numer zgłoszenia patentu europejskiego: 14.04.2004 04405227.2 (13) T3 (51) Int. Cl. E01B9/14 F16B13/00
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1624265 (96) Data i numer zgłoszenia patentu europejskiego: 06.07.2005 05106119.0 (13) T3 (51) Int. Cl. F25D23/06 F25D25/02
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1624265 (96) Data i numer zgłoszenia patentu europejskiego: 06.07.2005 05106119.0 (13) T3 (51) Int. Cl. F25D23/06 F25D25/02
POLIMERAZY DNA- PROCARYOTA
 Enzymy DNA-zależne, katalizujące syntezę DNA wykazują aktywność polimerazy zawsze w kierunku 5 3 wykazują aktywność polimerazy zawsze wobec jednoniciowej cząsteczki DNA do utworzenia kompleksu z ssdna
Enzymy DNA-zależne, katalizujące syntezę DNA wykazują aktywność polimerazy zawsze w kierunku 5 3 wykazują aktywność polimerazy zawsze wobec jednoniciowej cząsteczki DNA do utworzenia kompleksu z ssdna
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 213136 (96) Data i numer zgłoszenia patentu europejskiego: 14.03.2008 08723469.6 (13) (1) T3 Int.Cl. F24D 19/ (2006.01) Urząd
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 213136 (96) Data i numer zgłoszenia patentu europejskiego: 14.03.2008 08723469.6 (13) (1) T3 Int.Cl. F24D 19/ (2006.01) Urząd
Substancje stosowane do osadzania enzymu na stałym podłożu Biotyna (witamina H, witamina B 7 ) Tworzenie aktywnej powierzchni biosensorów
 Tworzenie aktywnej powierzchni biosensorów") SEKWECJWAIE ASTĘPEJ GEERACJI- GS Losowa fragmentacja nici DA Dołączanie odpowiednich linkerów (konstrukcja biblioteki) Amplifikacja biblioteki na podłożu szklanym lub plastikowym biosensory Wielokrotnie
SEKWECJWAIE ASTĘPEJ GEERACJI- GS Losowa fragmentacja nici DA Dołączanie odpowiednich linkerów (konstrukcja biblioteki) Amplifikacja biblioteki na podłożu szklanym lub plastikowym biosensory Wielokrotnie
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2127498 (96) Data i numer zgłoszenia patentu europejskiego: 14.02.2008 08716843.1 (13) (51) T3 Int.Cl. H05B 41/288 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2127498 (96) Data i numer zgłoszenia patentu europejskiego: 14.02.2008 08716843.1 (13) (51) T3 Int.Cl. H05B 41/288 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1802536 (96) Data i numer zgłoszenia patentu europejskiego: 20.09.2004 04774954.4 (13) T3 (51) Int. Cl. B65D77/20 B65D85/72
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1802536 (96) Data i numer zgłoszenia patentu europejskiego: 20.09.2004 04774954.4 (13) T3 (51) Int. Cl. B65D77/20 B65D85/72
Metody badania ekspresji genów
 Metody badania ekspresji genów dr Katarzyna Knapczyk-Stwora Warunki wstępne: Proszę zapoznać się z tematem Metody badania ekspresji genów zamieszczonym w skrypcie pod reakcją A. Lityńskiej i M. Lewandowskiego
Metody badania ekspresji genów dr Katarzyna Knapczyk-Stwora Warunki wstępne: Proszę zapoznać się z tematem Metody badania ekspresji genów zamieszczonym w skrypcie pod reakcją A. Lityńskiej i M. Lewandowskiego
Najważniejsze z nich to: enzymy restrykcyjne wektory DNA inne enzymy np. ligazy, fosfatazy, polimerazy, nukleazy
 Aby manipulować genami niezbędne są odpowiednie narzędzia molekularne, które pozwalają uzyskać tzw. zrekombinowane DNA (umożliwiają rekombinację materiału genetycznego in vitro czyli w próbówce) Najważniejsze
Aby manipulować genami niezbędne są odpowiednie narzędzia molekularne, które pozwalają uzyskać tzw. zrekombinowane DNA (umożliwiają rekombinację materiału genetycznego in vitro czyli w próbówce) Najważniejsze
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1810954 (96) Data i numer zgłoszenia patentu europejskiego: 06.12.2006 06025226.9 (13) (51) T3 Int.Cl. C03B 9/41 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1810954 (96) Data i numer zgłoszenia patentu europejskiego: 06.12.2006 06025226.9 (13) (51) T3 Int.Cl. C03B 9/41 (2006.01)
wykład dla studentów II roku biotechnologii Andrzej Wierzbicki
 Genetyka ogólna wykład dla studentów II roku biotechnologii Andrzej Wierzbicki Uniwersytet Warszawski Wydział Biologii andw@ibb.waw.pl http://arete.ibb.waw.pl/private/genetyka/ Ekspresja genów jest regulowana
Genetyka ogólna wykład dla studentów II roku biotechnologii Andrzej Wierzbicki Uniwersytet Warszawski Wydział Biologii andw@ibb.waw.pl http://arete.ibb.waw.pl/private/genetyka/ Ekspresja genów jest regulowana
DNA musi współdziałać z białkami!
 DNA musi współdziałać z białkami! Specyficzność oddziaływań między DNA a białkami wiążącymi DNA zależy od: zmian konformacyjnych wzdłuż cząsteczki DNA zróżnicowania struktury DNA wynikającego z sekwencji
DNA musi współdziałać z białkami! Specyficzność oddziaływań między DNA a białkami wiążącymi DNA zależy od: zmian konformacyjnych wzdłuż cząsteczki DNA zróżnicowania struktury DNA wynikającego z sekwencji
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1561894 (96) Data i numer zgłoszenia patentu europejskiego: 25.01.2005 05001385.3 (13) (51) T3 Int.Cl. E06B 3/66 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1561894 (96) Data i numer zgłoszenia patentu europejskiego: 25.01.2005 05001385.3 (13) (51) T3 Int.Cl. E06B 3/66 (2006.01)
wykład dla studentów II roku biotechnologii Andrzej Wierzbicki
 Genetyka ogólna wykład dla studentów II roku biotechnologii Andrzej Wierzbicki Uniwersytet Warszawski Wydział Biologii andw@ibb.waw.pl http://arete.ibb.waw.pl/private/genetyka/ 1. Gen to odcinek DNA odpowiedzialny
Genetyka ogólna wykład dla studentów II roku biotechnologii Andrzej Wierzbicki Uniwersytet Warszawski Wydział Biologii andw@ibb.waw.pl http://arete.ibb.waw.pl/private/genetyka/ 1. Gen to odcinek DNA odpowiedzialny
Analizy wielkoskalowe w badaniach chromatyny
 Analizy wielkoskalowe w badaniach chromatyny Analizy wielkoskalowe wykorzystujące mikromacierze DNA Genotypowanie: zróżnicowane wewnątrz genów RNA Komórka eukariotyczna Ekspresja genów: Które geny? Poziom
Analizy wielkoskalowe w badaniach chromatyny Analizy wielkoskalowe wykorzystujące mikromacierze DNA Genotypowanie: zróżnicowane wewnątrz genów RNA Komórka eukariotyczna Ekspresja genów: Które geny? Poziom
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") PL/EP 1699990 T3 RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1699990 (96) Data i numer zgłoszenia patentu europejskiego: 09.11.2004 04800186.1 (13) (51) T3 Int.Cl. E04G
PL/EP 1699990 T3 RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1699990 (96) Data i numer zgłoszenia patentu europejskiego: 09.11.2004 04800186.1 (13) (51) T3 Int.Cl. E04G
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1999308 (96) Data i numer zgłoszenia patentu europejskiego: 28.03.2007 07727422.3 (13) (51) T3 Int.Cl. D06F 35/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1999308 (96) Data i numer zgłoszenia patentu europejskiego: 28.03.2007 07727422.3 (13) (51) T3 Int.Cl. D06F 35/00 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2074843. (96) Data i numer zgłoszenia patentu europejskiego: 27.09.2007 07818485.
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2074843. (96) Data i numer zgłoszenia patentu europejskiego: 27.09.2007 07818485.") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 74843 (96) Data i numer zgłoszenia patentu europejskiego: 27.09.07 0781848.0 (13) (1) T3 Int.Cl. H04W 4/12 (09.01) Urząd
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 74843 (96) Data i numer zgłoszenia patentu europejskiego: 27.09.07 0781848.0 (13) (1) T3 Int.Cl. H04W 4/12 (09.01) Urząd
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2086467 (96) Data i numer zgłoszenia patentu europejskiego: 26.11.2007 07824706.1 (13) (51) T3 Int.Cl. A61F 2/16 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2086467 (96) Data i numer zgłoszenia patentu europejskiego: 26.11.2007 07824706.1 (13) (51) T3 Int.Cl. A61F 2/16 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 8294 (96) Data i numer zgłoszenia patentu europejskiego: 2.01.08 08001421.0 (13) (1) T3 Int.Cl. B62D /04 (06.01) Urząd Patentowy
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 8294 (96) Data i numer zgłoszenia patentu europejskiego: 2.01.08 08001421.0 (13) (1) T3 Int.Cl. B62D /04 (06.01) Urząd Patentowy
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1912546. (96) Data i numer zgłoszenia patentu europejskiego: 11.08.2006 06761852.
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1912546. (96) Data i numer zgłoszenia patentu europejskiego: 11.08.2006 06761852.") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1912546 (96) Data i numer zgłoszenia patentu europejskiego: 11.08.2006 06761852.0 (13) (51) T3 Int.Cl. A47J 41/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1912546 (96) Data i numer zgłoszenia patentu europejskiego: 11.08.2006 06761852.0 (13) (51) T3 Int.Cl. A47J 41/00 (2006.01)
Scenariusz lekcji przyrody/biologii (2 jednostki lekcyjne)
") Joanna Wieczorek Scenariusz lekcji przyrody/biologii (2 jednostki lekcyjne) Strona 1 Temat: Budowa i funkcje kwasów nukleinowych Cel ogólny lekcji: Poznanie budowy i funkcji: DNA i RNA Cele szczegółowe:
Joanna Wieczorek Scenariusz lekcji przyrody/biologii (2 jednostki lekcyjne) Strona 1 Temat: Budowa i funkcje kwasów nukleinowych Cel ogólny lekcji: Poznanie budowy i funkcji: DNA i RNA Cele szczegółowe:
Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii
 Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii 1. Transgeneza - genetycznie zmodyfikowane oraganizmy 2. Medycyna i ochrona zdrowia 3. Genomika poznawanie genomów Przełom XX i
Możliwości współczesnej inżynierii genetycznej w obszarze biotechnologii 1. Transgeneza - genetycznie zmodyfikowane oraganizmy 2. Medycyna i ochrona zdrowia 3. Genomika poznawanie genomów Przełom XX i
SCENARIUSZ LEKCJI BIOLOGII Z WYKORZYSTANIEM FILMU PCR sposób na DNA.
 SCENARIUSZ LEKCJI BIOLOGII Z WYKORZYSTANIEM FILMU PCR sposób na DNA. SPIS TREŚCI: 1. Wprowadzenie. 2. Części lekcji. 1. Część wstępna. 2. Część realizacji. 3. Część podsumowująca. 3. Karty pracy. 1. Karta
SCENARIUSZ LEKCJI BIOLOGII Z WYKORZYSTANIEM FILMU PCR sposób na DNA. SPIS TREŚCI: 1. Wprowadzenie. 2. Części lekcji. 1. Część wstępna. 2. Część realizacji. 3. Część podsumowująca. 3. Karty pracy. 1. Karta
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2353894 (96) Data i numer zgłoszenia patentu europejskiego: 19.02.2010 10001703.7 (13) (51) T3 Int.Cl. B60D 5/00 (2006.01)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2353894 (96) Data i numer zgłoszenia patentu europejskiego: 19.02.2010 10001703.7 (13) (51) T3 Int.Cl. B60D 5/00 (2006.01)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) (13) T3 (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1689214 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 19.01.06 06091.4 (1) Int. Cl. H0B37/02 (06.01) (97) O
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1689214 (13) T3 (96) Data i numer zgłoszenia patentu europejskiego: 19.01.06 06091.4 (1) Int. Cl. H0B37/02 (06.01) (97) O
RT31-020, RT , MgCl 2. , random heksamerów X 6
 RT31-020, RT31-100 RT31-020, RT31-100 Zestaw TRANSCRIPTME RNA zawiera wszystkie niezbędne składniki do przeprowadzenia syntezy pierwszej nici cdna na matrycy mrna lub całkowitego RNA. Uzyskany jednoniciowy
RT31-020, RT31-100 RT31-020, RT31-100 Zestaw TRANSCRIPTME RNA zawiera wszystkie niezbędne składniki do przeprowadzenia syntezy pierwszej nici cdna na matrycy mrna lub całkowitego RNA. Uzyskany jednoniciowy
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2828428 (96) Data i numer zgłoszenia patentu europejskiego: 12.03.13 13731877.0 (13) (1) T3 Int.Cl. D0B 19/12 (06.01) D0B
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 2828428 (96) Data i numer zgłoszenia patentu europejskiego: 12.03.13 13731877.0 (13) (1) T3 Int.Cl. D0B 19/12 (06.01) D0B
TaqNovaHS. Polimeraza DNA RP902A, RP905A, RP910A, RP925A RP902, RP905, RP910, RP925
 TaqNovaHS RP902A, RP905A, RP910A, RP925A RP902, RP905, RP910, RP925 RP902A, RP905A, RP910A, RP925A RP902, RP905, RP910, RP925 TaqNovaHS Polimeraza TaqNovaHS jest mieszaniną termostabilnej polimerazy DNA
TaqNovaHS RP902A, RP905A, RP910A, RP925A RP902, RP905, RP910, RP925 RP902A, RP905A, RP910A, RP925A RP902, RP905, RP910, RP925 TaqNovaHS Polimeraza TaqNovaHS jest mieszaniną termostabilnej polimerazy DNA
47 Olimpiada Biologiczna
 47 Olimpiada Biologiczna Pracownia biochemiczna zasady oceniania rozwia zan zadan Część A. Identyfikacja zawartości trzech probówek zawierających cukry (0 21 pkt) Zadanie A.1 (0 13 pkt) Tabela 1 (0 7 pkt)
47 Olimpiada Biologiczna Pracownia biochemiczna zasady oceniania rozwia zan zadan Część A. Identyfikacja zawartości trzech probówek zawierających cukry (0 21 pkt) Zadanie A.1 (0 13 pkt) Tabela 1 (0 7 pkt)
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 197092 (96) Data i numer zgłoszenia patentu europejskiego: 22.11.06 06824279.1 (13) (1) T3 Int.Cl. A61K 3/36 (06.01) A61P
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 197092 (96) Data i numer zgłoszenia patentu europejskiego: 22.11.06 06824279.1 (13) (1) T3 Int.Cl. A61K 3/36 (06.01) A61P
POLIMERAZY DNA- PROCARYOTA
 Enzymy DNA-zależne, katalizujące syntezę DNA wykazują aktywność polimerazy zawsze w kierunku 5 3 wykazują aktywność polimerazy zawsze wobec jednoniciowej cząsteczki DNA do utworzenia kompleksu z ssdna
Enzymy DNA-zależne, katalizujące syntezę DNA wykazują aktywność polimerazy zawsze w kierunku 5 3 wykazują aktywność polimerazy zawsze wobec jednoniciowej cząsteczki DNA do utworzenia kompleksu z ssdna
Kwasy Nukleinowe. Rys. 1 Struktura typowego dinukleotydu
 Kwasy Nukleinowe Kwasy nukleinowe są biopolimerami występującymi w komórkach wszystkich organizmów. Wyróżnia się dwa główne typy kwasów nukleinowych: Kwas deoksyrybonukleinowy (DNA) Kwasy rybonukleinowe
Kwasy Nukleinowe Kwasy nukleinowe są biopolimerami występującymi w komórkach wszystkich organizmów. Wyróżnia się dwa główne typy kwasów nukleinowych: Kwas deoksyrybonukleinowy (DNA) Kwasy rybonukleinowe
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1591364 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 22.04.2005 05103299.3
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1591364 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 22.04.2005 05103299.3
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 18761 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 31.03.06 06726163.6 (97)
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 18761 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 31.03.06 06726163.6 (97)
Biotechnologia i inżynieria genetyczna
 Wersja A Test podsumowujący rozdział II i inżynieria genetyczna..................................... Imię i nazwisko.............................. Data Klasa oniższy test składa się z 16 zadań. rzy każdym
Wersja A Test podsumowujący rozdział II i inżynieria genetyczna..................................... Imię i nazwisko.............................. Data Klasa oniższy test składa się z 16 zadań. rzy każdym
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1837599 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 07.03.2007 07004628.9
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 1837599 Urząd Patentowy Rzeczypospolitej Polskiej (96) Data i numer zgłoszenia patentu europejskiego: 07.03.2007 07004628.9
Najważniejsze z nich to: enzymy restrykcyjne wektory DNA inne enzymy np. ligazy, fosfatazy, polimerazy, nukleazy
 Aby manipulować genami niezbędne są odpowiednie narzędzia molekularne, które pozwalają uzyskać tzw. zrekombinowane DNA (umożliwiają rekombinację materiału genetycznego in vitro czyli w próbówce) Najważniejsze
Aby manipulować genami niezbędne są odpowiednie narzędzia molekularne, które pozwalają uzyskać tzw. zrekombinowane DNA (umożliwiają rekombinację materiału genetycznego in vitro czyli w próbówce) Najważniejsze
Zakład Biologii Molekularnej Materiały do ćwiczeń z przedmiotu: BIOLOGIA MOLEKULARNA
 Zakład Biologii Molekularnej Materiały do ćwiczeń z przedmiotu: BIOLOGIA MOLEKULARNA Zakład Biologii Molekularnej Wydział Farmaceutyczny, WUM ul. Banacha 1, 02-097 Warszawa IZOLACJA DNA Z HODOWLI KOMÓRKOWEJ.
Zakład Biologii Molekularnej Materiały do ćwiczeń z przedmiotu: BIOLOGIA MOLEKULARNA Zakład Biologii Molekularnej Wydział Farmaceutyczny, WUM ul. Banacha 1, 02-097 Warszawa IZOLACJA DNA Z HODOWLI KOMÓRKOWEJ.
(12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:
 TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP (96) Data i numer zgłoszenia patentu europejskiego:") RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 221611 (96) Data i numer zgłoszenia patentu europejskiego: 19.01. 000481.1 (13) (1) T3 Int.Cl. B28C /42 (06.01) B60P 3/16
RZECZPOSPOLITA POLSKA (12) TŁUMACZENIE PATENTU EUROPEJSKIEGO (19) PL (11) PL/EP 221611 (96) Data i numer zgłoszenia patentu europejskiego: 19.01. 000481.1 (13) (1) T3 Int.Cl. B28C /42 (06.01) B60P 3/16
Transformacja pośrednia składa się z trzech etapów:
 Transformacja pośrednia składa się z trzech etapów: 1. Otrzymanie pożądanego odcinka DNA z materiału genetycznego dawcy 2. Wprowadzenie obcego DNA do wektora 3. Wprowadzenie wektora, niosącego w sobie
Transformacja pośrednia składa się z trzech etapów: 1. Otrzymanie pożądanego odcinka DNA z materiału genetycznego dawcy 2. Wprowadzenie obcego DNA do wektora 3. Wprowadzenie wektora, niosącego w sobie