Systemy wieloprocesorowe i wielokomputerowe
|
|
|
- Tomasz Szymczak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Systemy wieloprocesorowe i wielokomputerowe
2 Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą JP Moduł pamięci MP
3 Taksonomia Flynna Skrót Nazwa Liczba strumieni instrukcji Liczba strumieni danych SISD Single Instruction Single Data 1 1 SIMD Single Instruction Multiplie Data 1 wiele MISD Multiplie Instruction Single Data wiele 1 MIMD Multiplie Instruction Multiplie Data wiele wiele
4 SISD - Single Instruction, Single Data Przykład: urządzenia jednoprocesorowe Elementy równoległości: przetwarzanie potokowe i super skalarne;
5 Single Instruction Multiplie Data Przykład: komputery wektorowe i macierzowe. takie same instrukcje na oddzielnych danych.
6 Procesory macierzowe Procesor macierzowy składa się z siatki (dwu lub trzy wymiarowej) jednakowych procesorów posiadających pamięci lokalne wykonujących jeden program.
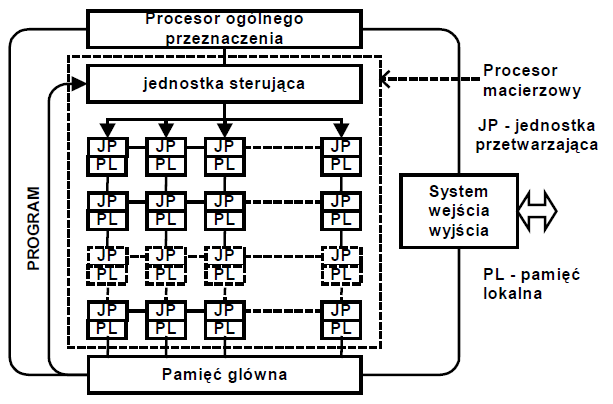
7 Procesory macierzowe
8 Procesory macierzowe Przykład: Za pierwszy komputer macierzowy zbudowany według architektury SIMD źródła podają komputer ILLIAC IV. Projekt z lat 60 w University of Illinois a maszyna weszła do eksploatacji w roku Maszyna składała się z jednostki sterującej rozgłaszającej rozkazy do 64 jednostek przetwarzających (w rzeczywistości zbudowano tylko 16 jednostek). Każda z tych jednostek operowała na pamięci lokalnej zawierającej 2K słów 64 bitowych i mogła komunikować się bezpośrednio z czterema innymi procesorami. Wydajność maszyny sięgnęła 15 Mflop i była daleko poniżej zakładanej wydajności 1000 Mflop.
9 Procesory wektorowe Procesor wektorowy operuje na wektorach czyli wielu wielkościach skalarnych naraz. Komputer wektorowy składa się z części zawierającej procesor konwencjonalny i uzupełniony jest o procesor wektorowy będący jednostką wykonującą operacje na długich rejestrach danych. Procesory wektorowe są elementami wielu superkomputerów (DCD Cyber 205, Cray 1, Cray 2, Cray 3, Fujitsu VPX 2000, Hitachi S3600). W procesorach Pentium zastosowano po raz pierwszy mechanizmy MMX (ang. MultiMedia extension) i SSE (ang. Streaming SIMD Extensions). Mechanizm MMX - wykonywanie operacji stałoprzecinkowych na wektorach 64 bitowych. Mechanizm SSE - wykonywaniu operacji zmiennoprzecinkowych na wektorach zawierających 4 liczby zmiennoprzecinkowe (każda zajmuje 32 bity).
10 Single Instruction Multiplie Data Współcześnie wg koncepcji SIMD budowane są akceleratory graficzne wykorzystywane w komputerach PC. Nvidia - GeForce GTX TITAN liczba rdzeni CUDA 2688: 5 GPCs Graphics Processor Clasters; 14 SMx Streaming Multi-processors; stream processors;
11 Nvidia GeForce KEPLER
12 Single Instruction Multiplie Data Własności komputerów SIMD: Większość systemów składa się z wielu (często prostych) procesorów. Wszystkie procesory wykonują tę samą instrukcję ale dla różnych zestawów danych. Każdy z procesorów posiada pamięć lokalną ale istnieje też pamięć wspólna. Często istnieje połączenie pomiędzy sąsiednimi (lub innymi) procesorami. Implementują równoległość drobnoziarnistą (ang. finegrained parallelism.)
13 MISD - Multiple Instruction Single Data
14 MISD - Multiple Instruction Single Data Przykład: komputery wysokiej dyspozycyjności; w pojedynczym strumieniu wyznaczane są beamformery w różnych pasmach; zaszyfrowane dane są dekodowane wg różnych algorytmów.
15 MIMD - Multiple Instruction Multiple Data
16 MIMD - Multiple Instruction Multiple Data Do grupy systemów MIMD zalicza się całe spektrum komputerów poczynając do stacji roboczych (procesory wielordzeniowe) po superkomputery. Systemy MIMD mają bardzo zróżnicowaną architekturę, a przez to wymagają odrębnych metod programowania. Z uwagi na te właściwości powstały metody dalszego ich klasyfikowania.
17 TITAN Supercomputer
18 TITAN Supercomputer
19 Taksonomia Tanneubauma Kryterium sposób komunikacji pomiędzy procesorami. Komunikacja może być realizowany poprzez: wspólną pamięć; system wejścia wyjścia.
20 Taksonomia Tanneubauma Konstrukcja, w której procesory komunikują się poprzez pamięć dzieloną nazywa się wieloprocesorem (ang. Multiprocessor). Gdy procesory komunikują się poprzez urządzenia wejścia wyjścia mamy do czynienia z wielokomputerem (ang. Multicomputer).
21 Taksonomia Tanneubauma
22 Multiprocesory Przestrzeń adresowa współdzielona pomiędzy wszystkie procesory
23 Multiprocesory Własności multiprocesora: Dostęp do pamięci jest wąskim gardłem ograniczającym wydajność systemu. Komunikacja procesów odbywa się przez wspólną pamięć nie trzeba specjalnych mechanizmów komunikacyjnych. Konieczność synchronizacji dostępu do zmiennych dzielonych.
24 Multikomputery ang. multicomputers
25 Multikomputery Własności: Każdy z procesorów ma swoją lokalną pamięć. Komunikacja procesów odbywa się przez system wejścia/wyjścia przy wykorzystaniu abstrakcji komunikatów.
26 Taksonomia Johnsona Modyfikacja klasyfikacji Flynna kategoria systemów MIMD podzielona została na cztery podkategorie w zależności od zastosowanej w nich struktury pamięci. Typ pamięci: GM pamięć globalna, ang. Global Memory. DM pamięć rozproszona, ang. Distributed Memory. Sposób dostępu do pamięci: SV współdzielone zmienne, ang. Shared Veriables. MP przekazywanie komunikatów, ang. Message Passing.
27 Taksonomia Johnsona Pamięć globalna GM Pamięć rozproszona DM Komunikacja poprzez zmienne dzielone SV Shared Veriables GMSV DMSV Komunikacja poprzez przekazywanie komunikatów MP Message Passing GMMP DMMP
28 Taksonomia Johnsona Komputery należące do grupy GMSV są ściśle powiązanymi ze sobą wieloprocesorami, których liczba w większości rozwiązań nie przekracza 20. Dostęp do pamięci realizowany jest przy użyciu współdzielonej magistrali. DMMP wysoko skalowalne wielokomputery: wyposażone w pamięć rozproszoną; wykorzystujące różnorodne mechanizmy dostępu do pamięci; posiadające kilka przestrzeni adresowych; wykorzystujące mechanizm przesyłania komunikatów. Ze względu na różnorodność rozwiązań zgodnych z architekturą DMMP wydziela się wśród nich mniejsze klasy.
29 Taksonomia Johnsona DMSV skalowalne wieloprocesory wykorzystujące: współdzielenie zmiennych zamiast przesyłania komunikatów; zastosowanie globalnej przestrzeni adresowej. Ilość procesorów nie przekracza 256, a wykorzystywane topologie ich połączeń to hipersześcian i kratownica. GMMP wykorzystują: pamięć globalną oraz mechanizm przesyłania komunikatów. Brak praktycznej implementacje tej kategorii.
30 Klasyfikacja równoległości: Procesory superskalarne i procesory wektorowe; Procesory wielordzeniowe; Systemy SMP / Systemy NUMA; Klastry; Systemy masywnie równoległe; Gridy.
31 Systemy z pamięcią dzieloną Zwiększanie mocy obliczeniowej poprzez zrównoleglanie na poziomie instrukcji ma swoje granice wynikające z ograniczeń technologicznych. Dalsze przyspieszenie może być osiągnięte poprzez wskazanie części kodu, która może być wykonywana równolegle. Nazwane jest to zrównolegleniem na poziomie wątków, ang. Thread Level Parallelism.

32 Multiprocesory z siecią w pełni połączoną Wieloprocesor z przełącznicą krzyżową
33 Multiprocesory Rozwiązaniem wąskiego gardła przy dostępie do wspólnej pamięci było zastosowanie tak zwanej przełącznicy krzyżowej (ang. Crossbar Switch), która jest przykładem sieci w pełni połączonych (ang. Fully Connected Networks). Zalety - jednoczesny dostęp wielu procesorów do wielu modułów pamięci (pod warunkiem że dany moduł nie jest zajęty), sieci nieblokujące. Wady - znaczna liczba magistral i przełączników co przy większej liczbie modułów pociąga za sobą znaczne koszty. Przy n procesorach i k modułach pamięci liczba przełączników proporcjonalna do k n. Komputer Sun Fire E25K wykorzystuje przełącznicę krzyżową wymiaru 18x18
 stanowią kompromis pomiędzy kosztami a wydajnością.")
34 Wieloprocesory z siecią wielostopniową Sieci wielostopniowe (ang. Multistage Networks) stanowią kompromis pomiędzy kosztami a wydajnością. Wykazują większą wydajność niż konstrukcje ze wspólną magistralą i mniejszy koszt niż rozwiązania z przełącznicą krzyżową.
35 Wieloprocesory z siecią wielostopniową Przykład sieci wielostopniowej sieć omega Sieć omega zawierająca n procesorów i n modułów pamięci składała się będzie z log 2 n stopni a w każdym stopniu będzie n przełączników. 2 n 2 log 2 n W całej sieci będzie przełączników. W przełącznicy krzyżowej n 2. Przełącznica krzyżowa dla 8 procesorów i 8 pamięci zawierała będzie 64 przełączniki podczas gdy sieć omega tylko 12.
36 Wieloprocesory z pamięcią wieloportową Przeniesienie układów logicznych, odpowiedzialnych za obsługę transmisji i zgłoszeń dostępu, z punktów krzyżowych (w przełącznicy krzyżowej) do wnętrza modułów pamięci, prowadzi do organizacji zwanej pamięcią wieloportową, ang. multiport memory. Właściwości systemów opartych na pamięciach wieloportowych: - skomplikowany druk, - kosztowna pamięć, - ograniczenie konfiguracji i maksymalnej przepustowości systemu przez liczbę portów do modułu pamięci

37
38 Klastry Wyróżnia się trzy podstawowe rodzaje klastrów: klastry wysokiej dostępności (ang. high availability clusters HA), klastry zrównoważonego obciążenia (ang. load balancing clusters LB), klastry wysokiej wydajności (ang. high performance clusters HPC).
39 Klaster wysokiej dostępności Klastry HA = gwarancja dostępności usług oferowanych poprzez klaster. Najprostszy klaster tego typu składa się z dwóch węzłów, węzła aktywnego, aktualnie oferującego daną usługę oraz węzła oczekującego i monitorującego pracę węzła aktywnego. W przypadku awarii węzła aktywnego, węzeł będący w spoczynku przechodzi w stan aktywności - przejmuje adres IP odchodzącego węzła, uzyskuje dostęp do współdzielonych zasobów a następnie uruchamia odpowiednie usługi - umożliwiając dalszą pracę. Współdzielenie danych pomiędzy węzłami może odbywać się za sprawą replikacji programowej (np. DRBD) bądź też dzięki rozwiązaniu sprzętowemu. Przykładem dosyć popularnego oprogramowania typu OpenSource oferującego funkcjonalność wysokiej dostępności jest projekt Linux-HA
40 Klaster zrównoważonego obciążenia Klastry LB = gwarancja zrównoważonego obciążenia na wszystkie węzły klastra. Przekierowanie żądania do innego węzła odbywa się na podstawie analizy obciążenia (wykorzystania procesora, pamięci) węzłów. Nie dopuszcza się do sytuacji, w której niektóre z węzłów są w stanie pełnej zajętości, a inne wolne od wykonywania jakichkolwiek zadań. Zadaniem mechanizmu LB jest pełne wykorzystanie mocy klastra. Umożliwia on również wykrywanie awarii węzłów bądź też wykrycie całkowitego wyłączenia węzła. Przykładem projektów realizujących założenia klastra zrównoważonego obciążenia jest LVS (Linux Virtual Server) oraz openmosix.
41 Klaster wysokiej wydajności Poprzez klaster wysokiej wydajności (ang. high performance computing - HPC) rozumie się grupę komputerów wykorzystywaną do wykonywania obliczeń. Klastry tego typu ze względu na oferowaną dużą moc obliczeniową są szczególnie popularne w środowiskach naukowych. Używa się ich do uruchamiania programów wykonujących obliczenia.
42 Klaster wysokiej wydajności Poniżej kilka przykładowych zastosowań systemów HPC: analiza danych pochodzących z sejsmogramów w poszukiwaniu złóż ropy naftowej czy też gazu ziemnego (do rekonstrukcji niewielkich obszarów potrzebne są terabajty danych), symulacje aerodynamiczne przy projektowaniu silników oraz samolotów, projektowanie systemów do przewidywania trzęsień ziemi, w naukach biomedycznych np. symulacja procesu fałdowania białek, który w przyrodzie zachodzi bardzo szybko tj. około jednej milionowej części sekundy (zaburzenie tego procesu może prowadzić do choroby Alzheimera) - symulacja tego procesu na zwykłym komputerze zajęłaby dekady, modelowanie farmaceutyczne, modelowanie wyników finansowych, symulacje astrofizyczne, symulacje klimatu Ziemi (modelowanie aktualnie zachodzących zjawisk klimatycznych oraz ich przewidywanie), zastosowanie w kinematografii przy tworzeniu efektów specjalnych w filmach; renderowanie graficzne przy manipulowaniu obrazem wysokiej rozdzielczości.
43 Klasyfikacja klastrów Kryterium sprzęt i sieć Klastry heterogeniczne: uruchamiane w środowiskach heterogenicznych, czyli niejednorodnych; zbudowane z komputerów pochodzących od różnych producentów; komputery pracują na różnych systemach operacyjnych; elementy klastra wykorzystują różne protokoły sieciowe. Klastry homogeniczne: uruchamiane w środowiskach homogenicznych, czyli jednorodnych; zbudowane w oparciu o sprzęt tego samego, lub kompatybilnego producenta. komputery pracują pod kontrolą tego samego systemu operacyjnego.
44 Klastry
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
SSE (Streaming SIMD Extensions)
") SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
SSE (Streaming SIMD Extensions) Zestaw instrukcji wprowadzony w 1999 roku po raz pierwszy w procesorach Pentium III. SSE daje przede wszystkim możliwość wykonywania działań zmiennoprzecinkowych na 4-elementowych
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH
 ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
SPRZĘT SYSTEMÓW ROWNOLEGŁYCH
 Jędrzej Ułasiewicz - Komputery i systemy równoległe 1 SPRZĘT SYSTEMÓW ROWNOLEGŁYCH 1. Podstawy...2 1.1 Klasyfikacja systemów równoległych...3 1.1.1 Taksonomia Flynna...3 1.1.2 Maszyna SISD - Single Instruction,
Jędrzej Ułasiewicz - Komputery i systemy równoległe 1 SPRZĘT SYSTEMÓW ROWNOLEGŁYCH 1. Podstawy...2 1.1 Klasyfikacja systemów równoległych...3 1.1.1 Taksonomia Flynna...3 1.1.2 Maszyna SISD - Single Instruction,
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wprowadzenie do architektury komputerów. Taksonomie architektur Podstawowe typy architektur komputerowych
 Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Przetwarzanie równoległesprzęt. Rafał Walkowiak Wybór
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Systemy rozproszone System rozproszony
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
współbieżność - zdolność do przetwarzania wielu zadań jednocześnie
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową.
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
Spis treści. 1 Wprowadzenie. 1.1 Podstawowe pojęcia. 1 Wprowadzenie Podstawowe pojęcia Sieci komunikacyjne... 3
 Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Spis treści 1 Wprowadzenie 1 1.1 Podstawowe pojęcia............................................ 1 1.2 Sieci komunikacyjne........................................... 3 2 Problemy systemów rozproszonych
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Klasyfikacja systemów komputerowych. Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Wprowadzenie do systemów wieloprocesorowych
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Wprowadzenie do systemów wieloprocesorowych Wstęp Do tej pory mówiliśmy głównie o systemach z jednym procesorem Coraz trudniej wycisnąć
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Wprowadzenie do systemów wieloprocesorowych Wstęp Do tej pory mówiliśmy głównie o systemach z jednym procesorem Coraz trudniej wycisnąć
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Wstęp. Historia i przykłady przetwarzania współbieżnego, równoległego i rozproszonego 1 Historia i pojęcia wstępne Przetwarzanie współbieżne realizacja wielu programów (procesów) w taki sposób, że ich
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Architektura mikroprocesorów z rdzeniem ColdFire
 Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Porównaj CISC, RISC, EPIC.
 Porównaj CISC, RISC, EPIC. CISC Complex Instruction Set duża liczba rozkazów (instrukcji) mała optymalizacja niektóre rozkazy potrzebują dużej liczby cykli procesora do wykonania występowanie złożonych,
Porównaj CISC, RISC, EPIC. CISC Complex Instruction Set duża liczba rozkazów (instrukcji) mała optymalizacja niektóre rozkazy potrzebują dużej liczby cykli procesora do wykonania występowanie złożonych,
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Informatyka 1. Wykład nr 5 ( ) Politechnika Białostocka. - Wydział Elektryczny. dr inŝ. Jarosław Forenc
 Politechnika Białostocka. - Wydział Elektryczny. dr inŝ. Jarosław Forenc") Informatyka Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 28/29 Wykład nr 5 (6.5.29) Rok akademicki 28/29, Wykład nr 5 2/43 Plan
Informatyka Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 28/29 Wykład nr 5 (6.5.29) Rok akademicki 28/29, Wykład nr 5 2/43 Plan
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Przetwarzanie Rozproszone i Równoległe
 WYDZIAŁ INŻYNIERII ELEKTRYCZNEJ I KOMPUTEROWEJ KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Przetwarzanie Rozproszone i Równoległe www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński
WYDZIAŁ INŻYNIERII ELEKTRYCZNEJ I KOMPUTEROWEJ KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Przetwarzanie Rozproszone i Równoległe www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński
Przetwarzanie Równoległe i Rozproszone
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNOLOGII INFORMACYJNYCH Przetwarzanie Równoległe i Rozproszone www.pk.edu.pl/~zk/prir_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Architektura Systemów Komputerowych 2
 Architektura Systemów Komputerowych 2 Pytania egzaminacyjne z części pisemnej mgr inż. Leszek Ciopiński Wykład I 1. Historia i ewolucja architektur komputerowych 1.1. Czy komputer Z3 jest zgodny z maszyną
Architektura Systemów Komputerowych 2 Pytania egzaminacyjne z części pisemnej mgr inż. Leszek Ciopiński Wykład I 1. Historia i ewolucja architektur komputerowych 1.1. Czy komputer Z3 jest zgodny z maszyną
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Informatyka I stopień (I stopień / II stopień) Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)
 Ogólnoakademicki (ogólno akademicki / praktyczny) niestacjonarne (stacjonarne / niestacjonarne)") KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Architektura systemów komputerowych 2 Nazwa modułu w języku angielskim Computer
Architektura komputerów. Układy wejścia-wyjścia komputera
 Architektura komputerów Układy wejścia-wyjścia komputera Wspópraca komputera z urządzeniami zewnętrznymi Integracja urządzeń w systemach: sprzętowa - interfejs programowa - protokół sterujący Interfejs
Architektura komputerów Układy wejścia-wyjścia komputera Wspópraca komputera z urządzeniami zewnętrznymi Integracja urządzeń w systemach: sprzętowa - interfejs programowa - protokół sterujący Interfejs
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Równoległe i Rozproszone
 Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
Pojęcia podstawowe. Oprogramowanie systemów równoległych i rozproszonych. Wykład 1. Klasyfikacja komputerów równoległych I
 Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
Pojęcia podstawowe Oprogramowanie systemów równoległych i rozproszonych Dr inż. Tomasz Olas olas@icis.pcz.pl Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Obliczenia równoległe
Magistrala. Magistrala (ang. Bus) służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.
 służy do przekazywania danych, adresów czy instrukcji sterujących w różne miejsca systemu komputerowego.") Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
Plan wykładu Pojęcie magistrali i jej struktura Architektura pamięciowo-centryczna Architektura szynowa Architektury wieloszynowe Współczesne architektury z połączeniami punkt-punkt Magistrala Magistrala
Klasyfikacja systemów komputerowych. Architektura von Neumanna i architektura harwardzka Budowa komputera: dr inż. Jarosław Forenc
 Rok akademicki 2015/2016, Wykład nr 4 2/51 Plan wykładu nr 4 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
Rok akademicki 2015/2016, Wykład nr 4 2/51 Plan wykładu nr 4 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2015/2016
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura Systemów Komputerowych. Architektura potokowa Klasyfikacja architektur równoległych
 Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Podstawy programowania obliczeń równoległych
 Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Podstawy programowania obliczeń równoległych Uniwersytet Marii Curie-Skłodowskiej Wydział Matematyki, Fizyki i Informatyki Instytut Informatyki Podstawy programowania obliczeń równoległych Przemysław
Architektura komputerów
 Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
System operacyjny System operacyjny
 System operacyjny System operacyjny (ang. operating system) jest programem (grupą programów), który pośredniczy między użytkownikiem komputera a sprzętem komputerowym. Jest on niezbędny do prawidłowej
System operacyjny System operacyjny (ang. operating system) jest programem (grupą programów), który pośredniczy między użytkownikiem komputera a sprzętem komputerowym. Jest on niezbędny do prawidłowej
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Wprowadzenie do systemów operacyjnych
 SOE - Systemy Operacyjne Wykład 1 Wprowadzenie do systemów operacyjnych dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW System komputerowy Podstawowe pojęcia System operacyjny
SOE - Systemy Operacyjne Wykład 1 Wprowadzenie do systemów operacyjnych dr inż. Andrzej Wielgus Instytut Mikroelektroniki i Optoelektroniki WEiTI PW System komputerowy Podstawowe pojęcia System operacyjny