Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
|
|
|
- Marcin Filipiak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem sposobu zrównoleglenia obliczeń 4. Złożoność algorytmów obliczeniowych

2 Klasyfikacja Flynna systemów komputerowych Przy rozpatrywaniu architektury systemów komputerowych rozważane są następujące podstawowe elementy tych systemów: procesory składające się z bloków wykonawczych i układu sterowania, pamięci układy wejścia/wyjścia. Dla rozważenia sposobu wykonywania obliczeń w systemie komputerowym, prof. Michael Flynn (wtedy pracownik IBM) zaproponował w 1972 roku rozpatrzenie liczby strumieni rozkazów i liczby strumieni strumieni danych istniejących przy wykonywaniu programów w systemie. Na podstawie takich rozważań, M. Flynn podał klasyfikację systemów komputerowych, która jest używana powszechnie do dzisiaj dla określenia ogólnych cech systemu.

3 Systemy z pojedynczym strumieniem rozkazów i danych - SISD Pierwszym typem systemu jest system z pojedynczym strumieniem rozkazów i danych (ang. Single Instruction Stream Single Data Stream SISD). Odpowiada on systemowi z jednym procesorem. Układ sterowania R Procesor danych D Pamięć główna R System z pojedynczym strumieniem rozkazów i danych SISD

4 Systemy z pojedynczym strumieniem rozkazów i wieloma strumieniami danych - SIMD Drugim typem systemu jest system z pojedynczym strumieniem rozkazów i wieloma strumieniami danych (ang. Single Instruction Stream Multiple Data Streams SIMD). W systemie SIMD ten sam strumień rozkazów (program) jest wykonywany na wielu różnych strumieniach danych. Aby to zrealizować, system musi zawierać wiele procesorów wykonujących rozkazy przetwarzające dane procesory danych. Wspólny dla wszystkich procesorów układ sterowania pobiera rozkazy z pamięci i rozsyła je do wykonania we wszystkich procesorach danych. Każdy procesor pobiera swoje dane do wykonania.

5 System SIMD - z pojedynczym strumieniem rozkazów i wieloma strumieniami danych Procesor danych 1 D 1 Pamięć lokalna 1 Pamięć główna R Układ sterowania R Procesor danych 2 D 2 Pamięć lokalna 2 Procesor danych n D n Pamięć lokalna n Rysunek przedstawia realizację takiego modelu wykonania programu w systemie ze wspólną pamięcią rozkazów i rozdzielnymi pamięciami danych. Systemy SIMD są stosowane przede wszystkim dla wydajnego wykonania programów, w których nastąpiło zrównoleglenie metodą dekompozycji danych. Systemy te są popularne w centrach dla intensywnych obliczeń numerycznych.

6 Systemy z wieloma strumieniami rozkazów i pojedynczym strumieniem danych- MISD Trzecim typem systemu jest system z wieloma strumieniami rozkazów i pojedynczym strumieniem danych (ang. Multiple Instruction Streams Single Data Stream MISD). W systemie MISD następuje wykonanie wielu strumieni rozkazów na tym samym strumieniu danych. System, który ma realizować taki model przetwarzania, zawiera wiele procesorów, przez który przesuwa się strumień danych, na których te procesory wykonują ciągi rozkazów. Występuje tu podobieństwo do potokowego przetwarzania danych, z tym, że stopnie potoku wykonują nie pojedyncze operacje a strumienie rozkazów programy.

7 System z wieloma strumieniami rozkazów i pojedynczym strumieniem danych - MISD D Układ sterowania 1 R 1 Procesor danych 1 Pamięć główna Układ sterowania 2 R 2 Procesor danych 2 Układ sterowania n R n Procesor danych n

8 Kolejne procesory przekazują wyniki obliczeń do następnych procesorów. Optymalnym sposobem działania jest przekazywanie wyników między procesorami w tym samym momencie. Wymaga to jednak, aby długości czasu wykonywania rozkazów w procesorach były identyczne lub bardzo zbliżone. Wtedy procesory wzajemnie nie opóźniają swego działania. System MISD może pracować jako serwer, który wykonuje ten sam zestaw programów na stale dostarczanych zbiorach danych. Serwer MISD wykonuje swoje usługi n razy szybciej niż serwer zawierający tylko jeden procesor wykonujący sewkwencyjnie cały zbiór rozkazów wykonywanych na danych (programy wszystkich procesorów od 1 do n). Warunkiem powodzenie jest aby nowe dane były stale dostarczane do procesora 1, w takt przesunięć wyników między wszystkimi procesorami. Systemy typu MISD nie są dostępne na rynku. Można je zbudować z sytemu wieloprocesorowego z rozproszoną lub wspólną pamięcią i wydajnym systemem komunikacji między procesorami, np. opartym na przełączniku krzyżowym.

9 Systemy z wieloma strumieniami rozkazów i danych - MIMD Ostatnim typem systemu w klasyfikacji Flynna jest system z wieloma strumieniami rozkazów i danych (ang. Multiple Instruction Stream Multiple Data Streams MIMD). W systemie MIMD wykonywanych jest wiele strumieni rozkazów (programów) działających na własnych różnych danych. System, który może zrealizować taki model wykonywania programu musi zawierać wiele procesorów, które niezależnie pobierają rozkazy i dane z pamięci.

10 Schemat systemu z wieloma strumieniami rozkazów i danych MIMD, opartego na systemie wieloprocesorowym ze wspólną pamięcią Układ sterowania 1 R 1 Procesor danych 1 D 1 Pamięć główna Układ sterowania 2 R 2 Procesor danych 2 D 2 Układ sterowania n R n Procesor danych n D n

11 Taki model wykonania programu MIMD odpowiada zrównolegleniu programu poprzez dekompozycję kodu na równoległe procesory. Dla takich więc zastosowań systemy MIMD są optymalne. Przy dekompozycji programu tą metodą, należy zwrócić uwagę, by czas wykonania fragmentów programów był w przybliżeniu jednakowy. Tylko wtedy uzyska się dobre przyspieszenie obliczeń. Można to osiągnąć analizując obciążenia procesorów wykonujących fragmenty programu i stosować strategię przypisywania zadań obliczeniowych (programów) na procesory (ang. task allocation) zapewniającą zrównoważenie obciążeń procesorów w systemie (ang. load balancing). Systemy MIMD są obecnie najbardziej popularnym typem systemu równoległego. Najbardziej popularnym systemem łączącym elementy systemu MIMD są przełącznice krzyżowe lub układy wieloszynowe. Stosowane są też statyczne sieci połączeń np. hipersześcian, torus trójwymiarowy. W systemach MIMD są stosowane wszystkie znane rozwiązania pamięci w systemach wieloprocesorowych: pamięć wspólna, rozproszona i wirtualna pamięć wspólna
 zapewniającą zrównoważenie obciążeń procesorów w systemie (ang. load balancing). Systemy MIMD są obecnie najbardziej popularnym typem systemu równoległego.")
12

13 Klasyfikacja Skillicorna systemów komputerowych Klasyfikacja Davida Skillicorna, profesora Queens University w Kanadzie, służy do opisy struktur systemów równoległych. Klasyfikacja ta jest oparta na modelu zbudowanym z następujących elementów: układy sterujące (procesory instrukcji) - IP (ang. instruction processor) hierachiczna pamięć instrukcji - IM (ang. instruction memory hierarchy) procesory danych (bloki wykonawcze) - DP (ang. data processor) hierachia pamięć danych - DM (ang. data memory hierarchy) układy łączące powyższe elementy.
 hierachiczna pamięć instrukcji - IM (ang.")
14 Hierarchiczna pamięć danych zawiera: pamięć podręczną danych, pamięć operacyjną pamięć dodatkową (np. dyskową). Procesor realizuje dostęp najpierw do pamięci podręcznej. Jeśli potrzebnej danej (adresu) nie ma w pamięci podręcznej, następuje poszukiwanie danej w pamięci operacyjnej. Jeśli dana tam jest, to następuje odczyt potrzebnego bloku do pamięci podręcznej a stamtąd następuje odczyt słowa do procesora. Jeśli danej nie ma w pamięci operacyjnej, bo np. brak jest w niej potrzebnej strony przy stronicowaniu, strona jest sprowadzona do pamięci operacyjnej a następnie blok tej strony jest sprowadzany do pamięci podręcznej, skąd potrzebne słowo (bajt) trafia do procesora.

15 Hierachiczna pamięć instrukcji jest zbudowana podobnie jak pamięć danych. Pamięć instrukcji zawiera: pamięć podręczną instrukcji, pamięć operacyjną pamięć dodatkową (np. dyskową). Pamięć operacyjna oraz pamięć dodatkowa może być wspólna dla danych i instrukcji lub oddzielna. Tego problemu klasyfikacja Skilicorna nie rozstrzyga i nie przedstawia tego na schematach systemów.

16 Zadania układu sterującego - procesora instrukcji: wyznaczenie adresu następnej instrukcji do wykonania sterowanie adresacją pamięci instrukcji (ang. addresses) odczyt i dekodowanie instrukcji sterowanie procesorem danych - wysłanie mu instrukcji (ang. instructions) do wykonania wyznaczanie adresów operandów (ang. operand addresses) odbieranie informacji stanu (ang. state) od procesorów danych
 do wykonania wyznaczanie adresów operandów (ang.")
17 Zadania układu wykonawczego - procesora danych: odbiór od układu sterującego instrukcji i adresów dotyczących operandów odczyt operandów z pamięci danych wykonanie instrukcji dotyczących obliczeń na operandach (ang. operands) wyznaczenie informacji stanu dla układu sterującego zapamiętywanie wyników obliczeń w pamięci danych
 wyznaczenie informacji stanu dla układu sterującego zapamiętywanie")
18

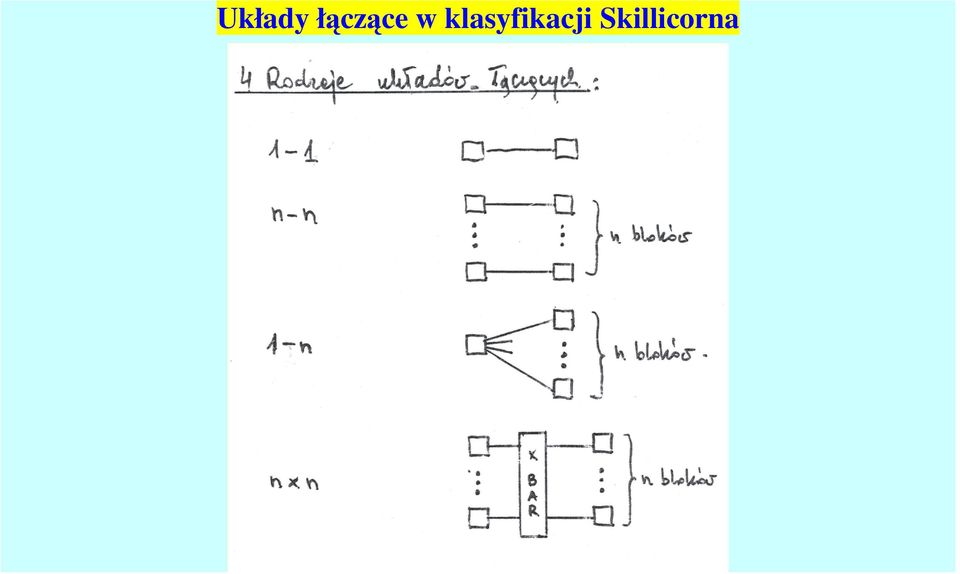
19 Układy łączące obejmują następujące typy: połączenia 1 do 1, pojedyncze połączenie, ( oznaczenie 1-1) połączenia n do n, n połączeń pojedynczych idących równolegle (oznaczenie n - n) połączenia 1 do n, rozesłanie informacji do n odbiorców ( rozgłaszanie, ang. broadcast) (oznaczenie 1 - n) połączenia n na n, przełącznik krzyżowy łączący w sobie n wejść z n wyjściami (oznaczenie n x n).
 (oznaczenie 1 - n) połączenia n na n, przełącznik krzyżowy łączący w sobie n wejść z")
20 Układy łączące w klasyfikacji Skillicorna
21 Schemat jednoprocesorowego komputera o modelu von Neumana Para IP-DP z wzajemnymi połączeniami odpowiada procesorowi o harwardzkim modelu architekturalnym. IP to uklad sterujący tego procesora a DP to jego bloki wykonawcze. IP pobiera instrukcje z pamięci instrukcji, dekoduje je i przesyla do wykonania do DP. DP pobiera dane z własnej pamięci danych. DP przesyla informacje o stanie obliczeń do IP, potrzebne dla sterowania w instrukcjach warunkowych.
22 Schemat systemu wieloprocesorowego SIMD z pamięcią danych wspólną n x n SW to przełącznik krzyżowy. 1 n SW to układ rozgłaszania instrukcji z IP do DP. Strzałki dwukierunkowe oznaczają przesyłanie adresów do pamięci i danych (instrukcji) w potrzebnym kierunku. IP to uklad sterowania pobierający instrukcje dla procesorów wykonawczych DP. Procesory DP mają dostęp poprzez n x n SW do bloków wspólnej pamięci danych.
23 Schemat systemu wieloprocesorowego SIMD z rozproszoną pamięcią danych. W tym systemie SIMD wymiana danych (częściowych wyników obliczeń) między procesorami DP odbywa się przez przełącznik krzyżowy SW. Kazdy DP ma wlasną lokalną pamięć danych
24
25 Schemat systemu wieloprocesorowego MIMD z rozproszoną pamięcią instrukcji i wspólną pamięcią danych. Każda para IP-DP z połączeniem odpowiada klasycznemu procesorowi o modelu von Neumanna. Każdy IP ma własną pamięć instrukcji.wymiana danych (częściowych wyników obliczeń) między procesorami odbywa się przez dostęp DP do wspólnych zmiennych przechowywanych we wspólnej pamięci danych. Wiele modułów tej pamięci, podłączonych do procesorów przez przełącznik krzyżowy SW, jest umieszczonych we wspólnej przestrzeni adresowej.
26 Schemat systemu wieloprocesorowego MIMD z rozproszonymi pamięciami danych i instrukcji. Każda para IP-DP z połączeniem odpowiada klasycznemu procesorowi o modelu von Neumanna. Każdy IP ma własną pamięć instrukcji. Każdy DP ma własną pamięć danych. Wymiana danych (częściowych wynikow obliczeń) między procesorami danych odbywa się przez przesyłanie komunikatów poprzez przełącznik krzyżowy.
27 Tabela możliwych architektur według klasyfikacji Skilicorna Kolumny przedstawiają od lewej: numer architektury (Cat), liczbę układów sterujących (IP) w systemie, liczbę procesorów danych (DP) w systemie, typ układów łączących: uklad sterujący z procesorem danych (IP DP), układ sterujący z pamięcią instrukcji (IP IM), procesor danych z pamięcią danych (DP DM), procesory wzajemnie miedzy sobą (DP DP) typ systemu w j. angielskim (Name).
28
29 Klasyfikacja architektury systemów pod względem sposobu zrównoleglenia obliczeń Zrównoleglenie funkcjonalne (geometryczne) polega na logicznej dekompozycji kodu programu na równoległe fragmenty wykonywane w różnych procesorach. Taka dekompozycja jest przeważnie nieregularna w sensie kodu i danych. Zrównoleglenie przez dekompozycję danych polega na dekompozycji danych programu miedzy różne procesory w celu wykonania na nich obliczen. Często takie same części kodu programu są różnych procesorach na różnych częściach danych. Dane są tutaj często regularne i regularna jest ich dekompozycja. Odpowiadaja temu dwa typy architektury systemów równoległych: architektura oparta na równoleglości danych (ang. data-parallel architecture), architektura oparta na równoległości funkcjonalnej (ang. function-parallel architecture).
30 Klasyfikacja architektur systemow rownoleglych ze względu na spoób zrownoleglenia obliczeń
31 Złożoność obliczeniowa algorytmów Złożoność algorytmu (programu) jest określona przez szybkość wzrostu czasu obliczeń i zajętości pamięci przy realizacji algorytmu w funkcji wzrostu rozmiaru problemu do rozwiązania. Np. w algorytmie sortowania elementów zbioru, rozmiar problemu jest wyznaczony przez liczbę elementów n w zbiorze. W algorytmie mnożenia macierzy, rozmiar problemu to łączna liczba wierszy i kolumn macierzy.
32 Jeśli przez T(n) oznaczymy maksymalną liczbę kroków obliczeniowych użytych przez algorytm dla rozwiązania problemu rozmiaru n, to funkcja T(n) jest złożonością czasową (time complexity) algorytmu. Jeśli przez S(n) oznaczymy maksymalną liczbę słów pamięci użytych przez algorytm dla rozwiązania problemu rozmiaru n, to funkcja S(n) jest złożonością pamięciową (przestrzenną) (space complexity) algorytmu.
33 Złożoność asymptotyczna jest to ograniczenie funkcji S lub T, gdy rozmiar problemu zdąża do bardzo dużych wartości. Jeśli dla dużych x, f(x) nie przekracza C g(x), gdzie C jest stałą, to mówimy, że: f jest co najwyżej równa O(g) i piszemy f = O(g) oraz mówimy, że: g jest co najmniej równa Ω(f) i piszemy g = Ω(f). Jeśli dla dużych x, zachodzi jednocześnie f = O(g) i f = Ω(g) to mówimy, że f równa się (jest równoważne) g i piszemy f = Θ(g). Np. dla f(x) = 2x oraz g(x) = x zachodzi, że dla x 3 f(x) 2 g(x) oraz g(x) 2 f(x). Stąd f = Θ( x 2 ) oraz g = Θ( x 2 ). W powyższych porównaniach rozważamy jedynie charakter zachowania się funkcji f i g dla bardzo dużych x, wyznaczając ich wartości z dokładnością do tzw. stałej multiplikatywnej C.
34 Powyższe notacje są używane do określania dolnych lub górnych ograniczeń asymptotycznych złożoności algorytmów. Jeśli np. wiemy, że T (złożoność czasowa pewnego algorytmu) spełnia T = Ω(f), czyli T jest co najmniej równa Ω(f) to mówimy, że ten algorytm ma złożoność asymptotyczną Ω(f). Często słowo asymptotyczny jest pomijane, i mówimy T ma złożoność Ω(f).
35 Złożoność problemu obliczeniowego jest to minimalna złożoność znaleziona w zbiorze wszystkich znanych algorytmów dla rozwiązania tego problemu. Złożoność wielomianowa problemu wielkość problemu n występuje w podstawie potęg wielomianu określającego złożoność asymptotyczną, np. Θ( n 2 ). Złożoność wykładnicza problemu wielkość problemu n występuje w wykładniku potęgi określającej złożoność asymptotyczną, np. Θ(x n ). Złożoność logarytmiczna problemu wielkość problemu n występuje w logarytmie określającym złożoność asymptotyczną, np. Θ(log n).
36 Złożoność przykładowych problemów (algorytmy sekwencyjne) Problem Złożoność czasowa Złożoność pamięciowa Sumowanie N P Permutacje N P Sortowanie NlogN P Obliczanie N P mediany FFT NlogN P Mnożenie N 1.5 P 2/3 macierzy Eliminacja Gaussa N 1.5 P 2/lg7 gdzie N i P są odpowiednimi rozmiarami problemu.
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Wprowadzenie do architektury komputerów. Taksonomie architektur Podstawowe typy architektur komputerowych
 Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
Logiczny model komputera i działanie procesora. Część 1.
 Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Logiczny model komputera i działanie procesora. Część 1. Klasyczny komputer o architekturze podanej przez von Neumana składa się z trzech podstawowych bloków: procesora pamięci operacyjnej urządzeń wejścia/wyjścia.
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Architektura Systemów Komputerowych. Architektura potokowa Klasyfikacja architektur równoległych
 Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Archiekura Sysemów Kompuerowych Archiekura pookowa Klasyfikacja archiekur równoległych 1 Archiekura pookowa Sekwencyjne wykonanie programu w mikroprocesorze o archiekurze von Neumanna Insr.1 Φ1 Insr.1
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Wstęp do informatyki. Architektura co to jest? Architektura Model komputera. Od układów logicznych do CPU. Automat skończony. Maszyny Turinga (1936)
") Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Wstęp doinformatyki Architektura co to jest? Architektura Model komputera Dr inż Ignacy Pardyka Slajd 1 Slajd 2 Od układów logicznych do CPU Automat skończony Slajd 3 Slajd 4 Ile jest automatów skończonych?
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Mikroprocesory rodziny INTEL 80x86
 Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Mikroprocesory rodziny INTEL 80x86 Podstawowe wła ciwo ci procesora PENTIUM Rodzina procesorów INTEL 80x86 obejmuje mikroprocesory Intel 8086, 8088, 80286, 80386, 80486 oraz mikroprocesory PENTIUM. Wprowadzając
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Za pierwszy niebanalny algorytm uważa się algorytm Euklidesa wyszukiwanie NWD dwóch liczb (400 a 300 rok przed narodzeniem Chrystusa).
.") Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Organizacja typowego mikroprocesora
 Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Organizacja typowego mikroprocesora 1 Architektura procesora 8086 2 Architektura współczesnego procesora 3 Schemat blokowy procesora AVR Mega o architekturze harwardzkiej Wszystkie mikroprocesory zawierają
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Architektura mikroprocesorów z rdzeniem ColdFire
 Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Architektura mikroprocesorów z rdzeniem ColdFire 1 Rodzina procesorów z rdzeniem ColdFire Rdzeń ColdFire V1: uproszczona wersja rdzenia ColdFire V2. Tryby adresowania, rozkazy procesora oraz operacje MAC/EMAC/DIV
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2013/14 Znajdowanie maksimum w zbiorze
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Architektura komputera
 Architektura komputera Architektura systemu komputerowego O tym w jaki sposób komputer wykonuje program i uzyskuje dostęp do pamięci i danych, decyduje architektura systemu komputerowego. Określa ona sposób
Architektura komputera Architektura systemu komputerowego O tym w jaki sposób komputer wykonuje program i uzyskuje dostęp do pamięci i danych, decyduje architektura systemu komputerowego. Określa ona sposób
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Układ sterowania, magistrale i organizacja pamięci. Dariusz Chaberski
 Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Budowa i zasada działania komputera. dr Artur Bartoszewski
 Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Budowa i zasada działania komputera 1 dr Artur Bartoszewski Jednostka arytmetyczno-logiczna 2 Pojęcie systemu mikroprocesorowego Układ cyfrowy: Układy cyfrowe służą do przetwarzania informacji. Do układu
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Przetwarzanie potokowe pipelining
 Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
Przetwarzanie potokowe pipelining (część A) Przypomnienie - implementacja jednocyklowa 4 Add Add PC Address memory ister # isters Address ister # ister # memory Wstęp W implementacjach prezentowanych tydzień
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Wykład I. Podstawowe pojęcia. Studia Podyplomowe INFORMATYKA Architektura komputerów
 Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
Studia Podyplomowe INFORMATYKA Architektura komputerów Wykład I Podstawowe pojęcia 1, Cyfrowe dane 2 Wewnątrz komputera informacja ma postać fizycznych sygnałów dwuwartościowych (np. dwa poziomy napięcia,
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
ANALIZA EFEKTYWNOŚCI MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A,B,C są tablicami nxn for (int j = 0 ; j
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych
 Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Algorytmy równoległe: ocena efektywności prostych algorytmów dla systemów wielokomputerowych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2014/15 Znajdowanie maksimum w zbiorze
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ
 EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
EFEKTYWNOŚĆ MNOŻENIA MACIERZY W SYSTEMACH Z PAMIĘCIĄ WSPÓŁDZIELONĄ 1 Mnożenie macierzy dostęp do pamięci podręcznej [język C, kolejność - j,i,k][1] A[i][*] lokalność przestrzenna danych rózne A,B,C są
Technologie Informacyjne
 POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 3: Wprowadzenie do algorytmów i ich
POLITECHNIKA KRAKOWSKA - WIEiK - KATEDRA AUTOMATYKI Technologie Informacyjne www.pk.edu.pl/~zk/ti_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 3: Wprowadzenie do algorytmów i ich
Wprowadzenie do złożoności obliczeniowej
 problemów Katedra Informatyki Politechniki Świętokrzyskiej Kielce, 16 stycznia 2007 problemów Plan wykładu 1 2 algorytmów 3 4 5 6 problemów problemów Plan wykładu 1 2 algorytmów 3 4 5 6 problemów problemów
problemów Katedra Informatyki Politechniki Świętokrzyskiej Kielce, 16 stycznia 2007 problemów Plan wykładu 1 2 algorytmów 3 4 5 6 problemów problemów Plan wykładu 1 2 algorytmów 3 4 5 6 problemów problemów
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM
 Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
ARCHITEKTURA PROCESORA,
 ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
ARCHITEKTURA PROCESORA, poza blokami funkcjonalnymi, to przede wszystkim: a. formaty rozkazów, b. lista rozkazów, c. rejestry dostępne programowo, d. sposoby adresowania pamięci, e. sposoby współpracy
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 3 2 Złożoność obliczeniowa algorytmów Notacja wielkie 0 Notacja Ω i Θ Algorytm Hornera Przykłady rzędów
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 3 2 Złożoność obliczeniowa algorytmów Notacja wielkie 0 Notacja Ω i Θ Algorytm Hornera Przykłady rzędów
Architektura potokowa RISC
 Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Architektura potokowa RISC Podział zadania na odrębne części i niezależny sprzęt szeregowe Brak nawrotów" podczas pracy potokowe Przetwarzanie szeregowe i potokowe Podział instrukcji na fazy wykonania
Technologie informacyjne (2) Zdzisław Szyjewski
 Zdzisław Szyjewski") Technologie informacyjne (2) Zdzisław Szyjewski Technologie informacyjne Technologie pracy z komputerem Funkcje systemu operacyjnego Przykłady systemów operacyjnych Zarządzanie pamięcią Zarządzanie danymi
Technologie informacyjne (2) Zdzisław Szyjewski Technologie informacyjne Technologie pracy z komputerem Funkcje systemu operacyjnego Przykłady systemów operacyjnych Zarządzanie pamięcią Zarządzanie danymi
Zrównoleglenie i przetwarzanie potokowe
 Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Zrównoleglenie i przetwarzanie potokowe Zrównoleglenie wysoka wydajność pozostaje osiągnięta w efekcie jednoczesnego wykonania różnych części zagadnienia. Przetwarzanie potokowe proces jest rozdzielony
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych
 Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Algorytmy równoległe: prezentacja i ocena efektywności prostych algorytmów dla systemów równoległych Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2018/19 Problem: znajdowanie
Budowa systemów komputerowych
 Budowa systemów komputerowych Krzysztof Patan Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski k.patan@issi.uz.zgora.pl Współczesny system komputerowy System komputerowy składa
Budowa systemów komputerowych Krzysztof Patan Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski k.patan@issi.uz.zgora.pl Współczesny system komputerowy System komputerowy składa
Algorytmy równoległe. Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka 2010
 Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Algorytmy równoległe Rafał Walkowiak Politechnika Poznańska Studia inżynierskie Informatyka Znajdowanie maksimum w zbiorze n liczb węzły - maksimum liczb głębokość = 3 praca = 4++ = 7 (operacji) n - liczność
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Wstęp. Przetwarzanie współbieżne, równoległe i rozproszone
 Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Wstęp. 1 Cel zajęć Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów równoległych Przedstawienie sprzętu wykorzystywanego do obliczeń równoległych Nauczenie sposobów
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
LEKCJA TEMAT: Współczesne procesory.
 LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
LEKCJA TEMAT: Współczesne procesory. 1. Wymagania dla ucznia: zna pojęcia: procesor, CPU, ALU, potrafi podać typowe rozkazy; potrafi omówić uproszczony i rozszerzony schemat mikroprocesora; potraf omówić
Wstęp do informatyki. Maszyna RAM. Schemat logiczny komputera. Maszyna RAM. RAM: szczegóły. Realizacja algorytmu przez komputer
 Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
Realizacja algorytmu przez komputer Wstęp do informatyki Wykład UniwersytetWrocławski 0 Tydzień temu: opis algorytmu w języku zrozumiałym dla człowieka: schemat blokowy, pseudokod. Dziś: schemat logiczny
Algorytmy numeryczne 1
 Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Algorytmy numeryczne 1 Wprowadzenie Obliczenie numeryczne są najważniejszym zastosowaniem komputerów równoległych. Przykładem są symulacje zjawisk fizycznych, których przeprowadzenie sprowadza się do rozwiązania
Projektowanie i Analiza Algorytmów
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Projektowanie i Analiza Algorytmów www.pk.edu.pl/~zk/piaa_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI I TECHNIK INFORMACYJNYCH Projektowanie i Analiza Algorytmów www.pk.edu.pl/~zk/piaa_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład
WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH
 ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
Efektywność algorytmów
 Efektywność algorytmów Algorytmika Algorytmika to dział informatyki zajmujący się poszukiwaniem, konstruowaniem i badaniem własności algorytmów, w kontekście ich przydatności do rozwiązywania problemów
Efektywność algorytmów Algorytmika Algorytmika to dział informatyki zajmujący się poszukiwaniem, konstruowaniem i badaniem własności algorytmów, w kontekście ich przydatności do rozwiązywania problemów
Zarządzanie pamięcią operacyjną
 Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
Dariusz Wawrzyniak Plan wykładu Pamięć jako zasób systemu komputerowego hierarchia pamięci przestrzeń owa Wsparcie dla zarządzania pamięcią na poziomie architektury komputera Podział i przydział pamięci
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Zarządzanie pamięcią w systemie operacyjnym
 Zarządzanie pamięcią w systemie operacyjnym Cele: przydział zasobów pamięciowych wykonywanym programom, zapewnienie bezpieczeństwa wykonywanych procesów (ochrona pamięci), efektywne wykorzystanie dostępnej
Zarządzanie pamięcią w systemie operacyjnym Cele: przydział zasobów pamięciowych wykonywanym programom, zapewnienie bezpieczeństwa wykonywanych procesów (ochrona pamięci), efektywne wykorzystanie dostępnej
Programowanie Współbieżne. Wstęp
 Programowanie Współbieżne Wstęp Literatura M. Ben-Ari, Podstawy programowania współbieżnego i rozproszonego, WNT W. Richard Stevens Programowanie zastosowań sieciowych A.S. Tanenbaum, Rozproszone systemy
Programowanie Współbieżne Wstęp Literatura M. Ben-Ari, Podstawy programowania współbieżnego i rozproszonego, WNT W. Richard Stevens Programowanie zastosowań sieciowych A.S. Tanenbaum, Rozproszone systemy
Zadania jednorodne 5.A.Modele przetwarzania równoległego. Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011
 Zadania jednorodne 5.A.Modele przetwarzania równoległego Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011 Zadanie podzielne Zadanie podzielne (ang. divisible task) może zostać
Zadania jednorodne 5.A.Modele przetwarzania równoległego Rafał Walkowiak Przetwarzanie równoległe Politechnika Poznańska 2010/2011 Zadanie podzielne Zadanie podzielne (ang. divisible task) może zostać
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Technologie cyfrowe. Artur Kalinowski. Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15
 Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Zadanie algorytmiczne: wyszukiwanie dane wejściowe:
Technologie cyfrowe Artur Kalinowski Zakład Cząstek i Oddziaływań Fundamentalnych Pasteura 5, pokój 4.15 Artur.Kalinowski@fuw.edu.pl Semestr letni 2014/2015 Zadanie algorytmiczne: wyszukiwanie dane wejściowe:
Architektura komputerów II - opis przedmiotu
 Architektura komputerów II - opis przedmiotu Informacje ogólne Nazwa przedmiotu Architektura komputerów II Kod przedmiotu 11.3-WI-INFP-AK-II Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki
Architektura komputerów II - opis przedmiotu Informacje ogólne Nazwa przedmiotu Architektura komputerów II Kod przedmiotu 11.3-WI-INFP-AK-II Wydział Kierunek Wydział Informatyki, Elektrotechniki i Automatyki
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Architektura komputerów
 Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
Architektura komputerów Tydzień 11 Wejście - wyjście Urządzenia zewnętrzne Wyjściowe monitor drukarka Wejściowe klawiatura, mysz dyski, skanery Komunikacyjne karta sieciowa, modem Urządzenie zewnętrzne
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Mikroinformatyka. Koprocesory arytmetyczne 8087, 80187, 80287, i387
 Mikroinformatyka Koprocesory arytmetyczne 8087, 80187, 80287, i387 Koprocesor arytmetyczny 100 razy szybsze obliczenia numeryczne na liczbach zmiennoprzecinkowych. Obliczenia prowadzone równolegle z procesorem
Mikroinformatyka Koprocesory arytmetyczne 8087, 80187, 80287, i387 Koprocesor arytmetyczny 100 razy szybsze obliczenia numeryczne na liczbach zmiennoprzecinkowych. Obliczenia prowadzone równolegle z procesorem
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Wydajność obliczeń Dla wielu programów wydajność obliczeń można traktować jako wydajność pobierania z pamięci
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura komputerów
 Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
Przykładem jest komputer z procesorem 4 rdzeniowym dostępny w laboratorium W skład projektu wchodzi:
 Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Przetwarzanie równoległe PROJEKT OMP Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego w komputerze równoległym z procesorem wielordzeniowym z pamięcią współdzieloną.
Introduction to Computer Science
 Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Introduction to Computer Science Grzegorz J. Nalepa Katedra Automatyki AGH spring 2011 c by G.J.Nalepa, 2004-11 (AGH) Introduction to Computer Science spring 2011 1 / 55 c by G.J.Nalepa,
Mikroprocesor Operacje wejścia / wyjścia
 Definicja Mikroprocesor Operacje wejścia / wyjścia Opracował: Andrzej Nowak Bibliografia: Urządzenia techniki komputerowej, K. Wojtuszkiewicz Operacjami wejścia/wyjścia nazywamy całokształt działań potrzebnych
Definicja Mikroprocesor Operacje wejścia / wyjścia Opracował: Andrzej Nowak Bibliografia: Urządzenia techniki komputerowej, K. Wojtuszkiewicz Operacjami wejścia/wyjścia nazywamy całokształt działań potrzebnych
Wykład 1_2 Algorytmy sortowania tablic Sortowanie bąbelkowe
 I. Struktury sterujące.bezpośrednie następstwo (A,B-czynności) Wykład _2 Algorytmy sortowania tablic Sortowanie bąbelkowe Elementy języka stosowanego do opisu algorytmu Elementy Poziom koncepcji Poziom
I. Struktury sterujące.bezpośrednie następstwo (A,B-czynności) Wykład _2 Algorytmy sortowania tablic Sortowanie bąbelkowe Elementy języka stosowanego do opisu algorytmu Elementy Poziom koncepcji Poziom