Obliczenia równoległe. Wojciech Kwedlo Wydział Informatyki PB pokój 205
|
|
|
- Artur Niewiadomski
- 9 lat temu
- Przeglądów:
Transkrypt
1 Obliczenia równoległe Wojciech Kwedlo Wydział Informatyki PB pokój 205

2 Plan wykładu (1) Wstęp (2) Programowanie systemów z przesyłaniem komunikatów przy pomocy MPI. (3) Programowanie systemów ze wspólną pamięcią przy pomocy OpenMP (4) Techniki projektowania i modelowania wydajności algorytmów równoległych (5) Wybrane algorytmy równoległe
 Techniki projektowania i modelowania wydajności algorytmów")
3 Literatura Niestety tylko po angielsku. Przygotowując wykład opierałem się na książkach: A. Grama, A. Gupta, G. Karypis, V. Kumar, Introduction to Parallel Computing, Addison Wesley, B. Wilkinson, M. Allen. Parallel programming: Techniques and Applications Using Networked Workstations and Parallel Computers, Prentice Hall, 1999 W. Gropp, E. Lusk, A. Skjellum, Using MPI, Mit Press, 2 nd edition, M. Snir, S. Otto, S. Huss-Lederman, D. Walker, J. Dongarra, MPI: The Complete Reference, Mit Press, dostępna legalnie w Internecie. B. Chapman, G. Jost, R. v. d. Pas, Using OpenMP: Portable Shared Memory Parallel Programming, MIT Press, M.J. Quinn, Parallel Programming in C with MPI and OpenMP, McGraw Hill, 2003.

4 Jednostki i skale w obliczeniach równoległych Flop (floating point operation) operacja zmiennoprzecinkowa. Liczba zmiennoprzcinkowa (double) zajmuje 8 bajtów. Flops/s liczba operacji zmiennopozycyjnych na sekundę Mega Mflop/s = 10 6 flop/sec Mbyte = 2 20 = ~ 10 6 bytes Giga Gflop/s = 10 9 flop/sec Gbyte = 2 30 ~ 10 9 bytes Tera Tflop/s = flop/sec Tbyte = 2 40 ~ bytes Peta Pflop/s = flop/sec Pbyte = 2 50 ~ bytes Exa Eflop/s = flop/sec Ebyte = 2 60 ~ bytes

5 Zaliczenie Wykład: Egzamin składający się z o.k. 20 pytań testowych. Pracownia specjalistyczna: rozgrzewka (zapoznanie się z laboratorium gridowym). 1 lub 2 projekty (jeszcze się zastanawiamy). Zaliczenie pracowni specjalistycznej nie jest warunkiem dopuszczenia do egzaminu.

6 Miary wydajności komputerów Peak performance (Peak advertised performence). Maksymalna teoretyczna wydajność, w praktyce bardzo trudna do osiągnięcia. Przykład. Pentium IV 3 Ghz ma przepustowość dwóch operacji zmiennoprzecinkowych w jednym takcie zegara. Peak peformance = 6 Gflops/s Komputer składający się z 1000 takich procesorów 6 Teraflops/s W praktyce osiągnięcie takiej wydajności nie jest możliwe Benchmark Linpack Hello world obliczeń równoległych Rozwiązanie (eliminacja Gaussa dekompozycja LU) układu równań Ax=b, gdzie A macierz nxn; x,b wektory n -wymiarowe Stosowany przy rankingu komputerów na liście Top500.
 układu równań Ax=b, gdzie A macierz nxn; x,b wektory n")
7 System równoległy Na wykładzie skupimy się wyłącznie na systemach wieloprocesorowych, zawierających więcej niż jeden procesor. Pomijamy równoległość wewnątrz pojedynczego procesora (super skalarność, VLIW), architektury specjalne (np. sieci systoliczne) Idea jest prosta: Skoro jeden procesor rozwiązuje problem w N godzin, może warto użyć N procesorów, aby rozwiązać problem w (powiedzmy) jedną godzinę Pytanie 1: Czy nie można poczekać i kupić N razy szybszy procesor. Innymi słowy dlaczego bardzo szybki komputer musi być komputerem równoległym. Pytanie 2: Do jakich zagadnień potrzebujemy tak szybkich komputerów.

8 Symulacja trzeci filar nauki Tradycyjny paradygmat w nauce i inżynierii. Stwórz teorię lub projekt na papierze. Wykonaj eksperyment lub zbuduj system. Ograniczenia zbyt trudne (np. duże tunele aerodynamiczne) zbyt drogie (test zderzeniowy jumbo jeta, odwiert w poszukiwaniu ropy) zbyt powolne (ewolucja galaktyk, klimatu) zbyt niebezpieczne (broń jądrowa, farmaceutyki, wpływ człowieka na klimat) Trzecia droga: wykorzystaj bardzo szybki komputer do symulacji zjawiska. Bazując na prawach fizyki i metodach numerycznych Trudne (ang. grand challenge) problemy wymagają naprawdę szybkich komputerów
 Trzecia droga: wykorzystaj bardzo szybki komputer do symulacji zjawiska.")
9 Przykład pierwszy modelowanie klimatu Atmosfera jest dzielona na trójwymiarowe komórki. Obliczenia w każdej komórce wykonywane wielokrotnie (upływ czasu). Podzielmy globalną atmosferę ziemską na komórki o wymiarze 1mila x 1mila x 1 mila. Wysokość atmosfery to 10 komórek. Łącznie około 5*10 8 komórek. Niech jedna komórka wymaga 200 flopów (typowa wartość dla równań Naviera- Stokesa). W jednym kroku = 100 Gflops Prognoza pogody na 7 dni zakładając krok czasowy 1 minutę przez komputer o szybkości 1 Gflop/s wymaga 10 dni. Jeżeli chcemy zakończyć obliczenia w 5 minut potrzebujemy komputera o szybkości 3.4 Tflop/s Rzeczywiste modele są dużo bardziej skomplikowane. (np. modelowanie klimatu w skali dziesiątków, setek lat).

10 Przykład drugi: ewolucja galaktyki Problem N ciał. Modelowanie polega na obliczeniu sił grawitacji działających na każde z ciał. Po obliczeniu nowej pozycji obliczenia są ponawiane (upływ czasu). Naiwny algorytm ma złożoność O(N*N) (każde ciało przyciąga wszystkie pozostałe), algorytmy zaawansowane O(NlogN). Galaktyka zawiera około gwiazd (potrzeba pamięci rzędu TB) Zakładając że obliczenie łącznej siły grawitacji działającej na jedną gwiazdę zajmuje 1ms (bardzo optymistyczne dla szeregowego komputera), to potrzebujemy ponad jednego roku na jedną iterację, zakładając algorytm O(NlogN).
 Zakładając że obliczenie łącznej siły grawitacji działającej na jedną gwiazdę")
11 Zagadnienia wymagające dużych mocy obliczeniowych Badania naukowe Globalne modelowanie klimatu Biologia: genomika, prognozowanie struktury białka Modelowanie zjawisk astrofizycznych (ewolucja galaktyk, czarne dziury) Chemia obliczeniowa Inżynieria Projektowanie układów scalonych Dynamika płynów (projektowanie samolotów, rakiet) Symulacja zderzeń Biznes Modelowanie finansowe i ekonomiczne Data mining Wojsko Symulacje broni jądrowej Kryptografia
 Symulacja zderzeń Biznes Modelowanie finansowe i ekonomiczne Data mining Wojsko Symulacje broni")
12 Ograniczenia szybkości komputerów szeregowych Prawo Moore'a (G. More współzałożyciel Intela). Liczba tranzystorów i szybkość mikroprocesora podwaja się co 18 miesięcy. Prawo Moore'a przestało działać!!! Ograniczenia związane z odprowadzaniem ciepła ze struktury utrudniają dalszy wzrost prędkości zegara. (Moc tracona jest proporcjonalna do prędkości zegara). Dalszy wzrost prędkości zegara prowadzi do innych barier fizycznych. Np. Istnieją tranzystory działające z prędkością 1THz, ale w czasie jednego cyklu światło pokonuje 0.3mm!!!. Predykcja: nastąpi wzrost liczby tranzystorów na strukturze, ale wzrost szybkości zegara będzie bardzo powolny. Gdzie zainwestować dodatkowe tranzystory? Inwestycja w wieksze pamięci cache, więcej jednostek funkcjonalnych przestaje się opłacać. (typowy program nie jest w stanie ich wykorzystać) Albo zupełnie nowy paradygmat (kwantowy?? biologiczny??) albo wiele procesorów na jednym chipie.

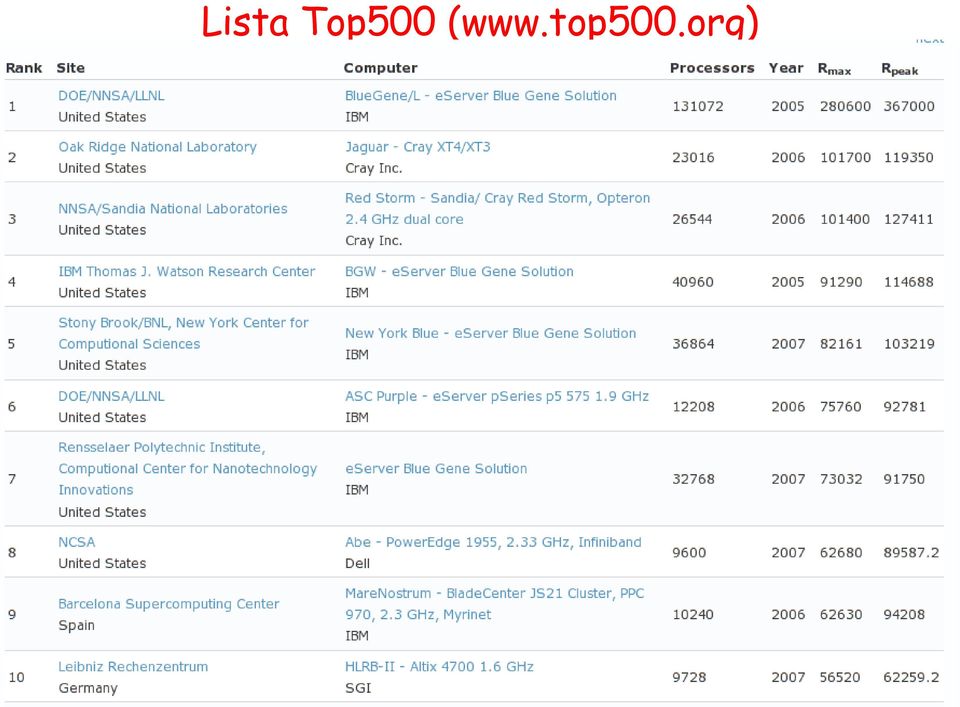
13 Lista Top500 (
14 Miary skalowalności algorytmu równoległego Zakładamy stały rozmiar danych N T(1) czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) czas obliczeń dla algorytmu równoległego przy pomocy p procesorów Przyspieszenie (ang. speedup) S(p) Idealnie S(p)=p (przyspieszenie liniowe), w niektórych sytuacjach (rzadko) S(p)>p (przyspieszenie superliniowe ang. superlinear). W praktycznych algorytmach S(p)<p. Wydajność E(p) S p = T 1 T p E p = S p p = T 1 p T p Wydajność jest stosunkiem osiągniętego przyspieszenia do idealnego przyspieszenia liniowego. Wydajność równa 1 oznacza przyspieszenie liniowe.
<p.")
15 Prawo Amdahla G. Amdahl pracownik IBM, założyciel firmy Amdahl. Zakładamy że pewna część programu w ogóle nie ulega przyspieszeniu przez równoległe przetwarzanie danych. Pozostała część jest przyspieszona p-krotnie na p procesorach. t S czas sekwencyjnego wykonania programu. Niech f jest stosunkiem czasu fragmentu nie dającego się przyspieszyć (równego f*t S ) do całkowitego czasu t S. t s (a) jeden procesor ft s Sekcja szeregowa (1 - f)t s Sekcje zrównoleglone
 do całkowitego czasu t S.")
16 Prawo Amdahla t p czas obliczeń na p procesorach. (a) jeden procesor (b) p procesorów ft s Sekcja szeregowa t s (1 - f)t s Sekcje zrównoleglone ` p procesorów t p (1 - f)t s /p
t s Sekcje")
17 Prawo Amdahla przyspieszenie Przyspieszenie S(p) dane jest wzorem: S(p) t s p ft s (1 f )t s /p 1 (p 1)f zwanym prawem Amdahla. Uwaga: lim S p =1/ f A zatem dysponując nawet nieskończoną liczbą procesorów, nie przekroczymy przyspieszenia 1/f

18 Prawo Amdahla maksymalne przyspieszenie dla f=0 S(p)=p 20 f = 0% 16 przyspieszenie S(p) f = 5% f = 10% f = 20% Liczba procesorów p

19 Prawo Amdahla - wnioski Na pierwszy rzut oka wnioski wydają się pesymistyczne: maksymalne przyspieszenie jest ograniczone z góry. W rzeczywistych problemach skalowalność jest gorsza od wynikającej z prawa Amdahla. Koszty komunikacji procesorów (rosną wraz ze wzrostem ich liczby) Niezrównoważenie obciążenia (ang. load imbalance) Potrzeba duplikacji obliczeń na różnych procesorach. Istotnym założeniem w prawie Amdahla jest stały rozmiar problemu. To założenie nie jest spełnione. Szybkie komputery buduje się po to aby rozwiązywać coraz bardziej skomplikowane problemy (np. budować złożone modele symulacyjne, grać w bardziej złożone gry) Dlatego też dziedzina obliczeń równoległych rozwija się dynamicznie..

20 Klasyfikacja Flynn'a (1966) Flynn oparł swoją klasyfikację na liczbie przetwarzanych strumieni danych i rozkazów. Zdefiniował cztery kategorie SISD, MISD, SIMD, MIMD. Warto się z nimi zapoznać, bo występują w literaturze. SISD (single instruction single data) klasyczny komputer sekwencyjny. MISD (multiple instruction single data) nie występuje, niektórzy zaliczają architektury oparte na przetwarzaniu potokowym. SIMD (single instruction multiple data) głównie wektorowe rozszerzenia procesorów 3DNOW, SSE, SSE2 Intel i AMD AltiVec Motorola/IBM/Apple (już bez Apple) MIMD (multiple instruction multiple data) wszystkie obecne maszyny wieloprocesorowe wpadają do tej kategorii, co ogranicza użyteczność klasyfikacji. Jednak z grubsza możemy podzielić je na: Systemy wieloprocesorowe ze wspólną pamięcią Systemy wieloprocesorowe z pamięcią rozproszoną
 głównie wektorowe rozszerzenia procesorów 3DNOW, SSE, SSE2 Intel i AMD AltiVec Motorola/IBM/Apple (już bez Apple) MIMD (multiple instruction multiple data)")
21 System ze wspólną (ang. shared) pamięcią
22 Konwencjonalny komputer Składa się z procesora wykonującego program przechowywany w pamięci operacyjnej. Pamięć operacyjna instrukcje (z pamięci) dane (z i do pamięci) Procesor Każdy bajt pamięci głównej ma swój adres. 2 D adresów, gdzie D jest długością słowa w bitach.
23 System wieloprocesorowy ze wspólną pamięcią Każdy procesor ma dostęp do dowolnego modułu pamięci Bajt pamięci widoczny przez wszystkie procesory pod tym samym adresem Pamięci cache (indywidualne dla poszczególnych procesorów) komplikują sytuację. Procesory wielordzeniowe (ang. multi-core) należą do tej klasy Wspólna przestrzeń adresów Moduły pamięci Sieć połączeń Procesory
24 System wieloprocesorowy ze wspólną pamięcią - programowanie Generalnie stosuje się mechanizmy programowania wielowątkowego. System operacyjny (Linuks, Windows) dba o to, aby uruchomić różne wątki na różnych procesorach. Jeżeli uda się dobrze podzielić zadanie pomiędzy wątki=> uzyskamy skrócenie czasu obliczeń. Standardy dla wątków (niskopoziomowe): POSIX threads => znane z systemów operacyjnych Windows threads => pomijamy Java threads => być może znane z programowania obiektowego; raczej nie nadaje się do obliczeń o wysokiej wydajności Nasz standard: OpenMP ( wysokopoziomowy, wygodny (powiedzmy wygodniejsz niż PThreads i WinThreads). w postaci dyrektyw #pragma omp dla kompilatora. Wymaga odpowiedniego kompilatora (np. gcc 4.2 albo icc Intel C/C++ compiller) gcc 4.2 do pobrania z internetu i zainstalowania na Linuksie (kompilacja ze źródeł trochę trwa; gcc.gnu.org)
25 Procesory wielordzeniowe Szczególnym przypadkiem systemu ze wspólną pamięcią jest system z procesorem wielordzeniowym (ang. multicore). Procesor wielordzeniowy to układ scalony zawierający kilka niezależnych procesorów. Niedługo wszystkie komputery biurkowe będą systemami równoległymi. Zaprogramowanie dobrej gry 3D będzie wymagało wiadomości z tej dziedziny. Jest to kolejna powód, dla którego warto zainwestować w ten przedmiot.
26 System z pamięcią rozproszoną (ang. distributed)
27 System z przesyłaniem komunikatów (ang. message passing) Również zwany systemem z przesyłaniem komunikatów (ang. message passing). Często klastry (ang. cluster) niezależnych systemów komputerowych. Każdy procesor ma dostęp wyłącznie do swojej lokalnej pamięci. Współpraca z innymi procesorami odbywa się poprzez wymianę komunikatów Sieć połączeń: dziś co najmniej Gigabit Ethernet (1Gb/s), często Infiniband (10 Gb/s lub 20 Gb/s) lub wyspecjalizowane rozwiązania. Możliwe rozwiązanie hybrydowe: każdy komputer jest systemem wieloprocesorowym ze wspólną pamięcią. Sieć połączeń Komunikaty Procesor Pamięć lokalna Komputery (często całkowicie autonomiczne)
28 Architektura klastra obliczeniowego Mordor Węzeł zarządzający (mordor) publiczny Internet mordor.wi.pb.edu.pl sieć wewnętrzna n1 n2... n16 2xXeon MHz, 2 GB RAM macierz RAID 1 sieciowy system plików (NFS) system kolejkowy monitoring klastra (Ganglia) logowanie użytkowników Węzły obliczeniowe: (n1,n2,..., n16) 2xXeon 2.8GHz, 2 GB RAM komputer ze wspólną pamięcią!!! 64-bitowy Linux Sieć wewnętrzna Gigabit Ethernet (protokół TCP/IP) Infiniband 4x (10 Gb/s, tylko dla aplikacji równoległych MPI)
29 System z przesyłaniem komunikatów - programowanie Proces P0 Proces P1... oblicz x; send (P1,x) receive (P1,x) wykorzystaj x;... W programie umieszcza się wywołania powodujące wysyłanie i odbiór danych do/z innych procesów. Komunikacja jest jawna upraszcza to projektowania wydajnych algorytmów (łatwiej jest minimalizować komunikację) Na zajęciach: standard MPI (ang. message passing interface) wzbogacający standardowy język programowania (C/C++/Fortran) o funkcje służące do przesyłania komunikatów. Darmowe implementacje można pobrać ze stron:
30 Model programowania a model maszyny Należy odróżnić model programowania od modelu maszyny Maszynę ze wspólną pamięcią jest bardzo łatwo programować przy pomocy modelu z przesyłaniem komunikatów. Wystarczy przeznaczyć część pamięci na bufor, w którym przechowywane są komunikaty. Dlatego też klastry maszyn ze wspólną pamięcią programowane są przy pomocy przesyłania komunikatów, chociaż możliwe jest programowanie hybrydowe MPI + OpenMP. Sytuacja odwrotna, w której maszyna z przesyłaniem komunikatów jest programowana przy pomocy modelu ze wspólną pamięcią jest bardzo trudna (niemożliwa bez specjalnego hardware'u) do realizacji.
31 Podsumowanie Programowanie maszyn równoległych jest trudną sztuką. Należy znaleźć dostatecznie dużo równoległości w algorytmie (prawo Amdahla) Należy zapewnić koordynację, komunikację i synchronizację (to ostatnie zagadnienie znane z systemów operacyjnych) wszystko to kosztuje. Należy zadbać o maksymalnie lokalny wzorzec odwołań do pamięci aby zmaksymalizować wykorzystanie pamięci cache. Należy zadbać aby wszystkie procesory były zajęte rozwiązując problem (zagadnienie równoważenia obciążenia load balancing)
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Poziom kwalifikacji: I stopnia. Liczba godzin/tydzień: 2W E, 2L PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE ROZPROSZONE I RÓWNOLEGŁE Distributed and parallel programming Kierunek: Forma studiów: Informatyka Stacjonarne Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe
Nazwa przedmiotu: PROGRAMOWANIE ROZPROSZONE I RÓWNOLEGŁE Distributed and parallel programming Kierunek: Forma studiów: Informatyka Stacjonarne Rodzaj przedmiotu: moduł specjalności obowiązkowy: Sieci komputerowe
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE APLIKACJI RÓWNOLEGŁYCH I ROZPROSZONYCH Programming parallel and distributed applications Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach specjalności: Inżynieria
Nazwa przedmiotu: PROGRAMOWANIE APLIKACJI RÓWNOLEGŁYCH I ROZPROSZONYCH Programming parallel and distributed applications Kierunek: Informatyka Rodzaj przedmiotu: obowiązkowy w ramach specjalności: Inżynieria
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Wykorzystanie klastra Wydziału Informatyki PB do prowadzenia własnych obliczeń. Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.
 Wykorzystanie klastra Wydziału Informatyki PB do prowadzenia własnych obliczeń Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl Cele prezentacji Zapoznanie potencjalnych użytkowników z
Wykorzystanie klastra Wydziału Informatyki PB do prowadzenia własnych obliczeń Wojciech Kwedlo Wydział Informatyki PB wkwedlo@ii.pb.bialystok.pl Cele prezentacji Zapoznanie potencjalnych użytkowników z
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f)
 i częstotliwości (f)") Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie współbieżne. Iwona Kochańska
 1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
1 Programowanie współbieżne Iwona Kochańska 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt:
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM. Juliusz Pukacki,PCSS
 DLA FIRM. Juliusz Pukacki,PCSS") USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
USŁUGI HIGH PERFORMANCE COMPUTING (HPC) DLA FIRM Juliusz Pukacki,PCSS Co to jest HPC (High Preformance Computing)? Agregowanie dużych zasobów obliczeniowych w sposób umożliwiający wykonywanie obliczeń
Wydajność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
System obliczeniowy laboratorium oraz. mnożenia macierzy
 System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
System obliczeniowy laboratorium.7. oraz przykładowe wyniki efektywności mnożenia macierzy opracował: Rafał Walkowiak Materiały dla studentów informatyki studia niestacjonarne październik 1 SYSTEMY DLA
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Analityczne modelowanie systemów równoległych
 Analityczne modelowanie systemów równoległych 1 Modelowanie wydajności Program szeregowy jest modelowany przez czas wykonania. Na ogół jest to czas asymptotyczny w notacji O. Czas wykonania programu szeregowego
Analityczne modelowanie systemów równoległych 1 Modelowanie wydajności Program szeregowy jest modelowany przez czas wykonania. Na ogół jest to czas asymptotyczny w notacji O. Czas wykonania programu szeregowego
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
GRIDY OBLICZENIOWE. Piotr Majkowski
 GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Systemy operacyjne III
 Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Systemy operacyjne III WYKŁAD 7 Jan Kazimirski 1 Komputery równoległe 2 Wydajność komputerów Rozwój technologii wiąże się z ciągłym wzrostem wydajności komputerów Pierwsze komputery 1-100 operacji/sek.
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW)
") Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Program Obliczeń Wielkich Wyzwań Nauki i Techniki (POWIEW) Maciej Cytowski, Maciej Filocha, Maciej E. Marchwiany, Maciej Szpindler Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Wprowadzenie. Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra.
 N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
N Wprowadzenie Co to jest klaster? Podział ze względu na przeznaczenie. Architektury klastrów. Cechy dobrego klastra. Wprowadzenie (podział ze względu na przeznaczenie) Wysokiej dostępności 1)backup głównego
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Obliczenia równoległe na klastrze opartym na procesorze CELL/B.E.
 Obliczenia równoległe na klastrze opartym na procesorze CELL/B.E. Łukasz Szustak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V szustak.lukasz@gmail.com Streszczenie W artykule
Obliczenia równoległe na klastrze opartym na procesorze CELL/B.E. Łukasz Szustak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok V szustak.lukasz@gmail.com Streszczenie W artykule
Porównaj CISC, RISC, EPIC.
 Porównaj CISC, RISC, EPIC. CISC Complex Instruction Set duża liczba rozkazów (instrukcji) mała optymalizacja niektóre rozkazy potrzebują dużej liczby cykli procesora do wykonania występowanie złożonych,
Porównaj CISC, RISC, EPIC. CISC Complex Instruction Set duża liczba rozkazów (instrukcji) mała optymalizacja niektóre rozkazy potrzebują dużej liczby cykli procesora do wykonania występowanie złożonych,
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Kierunek Informatyka stosowana Studia stacjonarne Studia pierwszego stopnia
 Studia pierwszego stopnia I rok Matematyka dyskretna 30 30 Egzamin 5 Analiza matematyczna 30 30 Egzamin 5 Algebra liniowa 30 30 Egzamin 5 Statystyka i rachunek prawdopodobieństwa 30 30 Egzamin 5 Opracowywanie
Studia pierwszego stopnia I rok Matematyka dyskretna 30 30 Egzamin 5 Analiza matematyczna 30 30 Egzamin 5 Algebra liniowa 30 30 Egzamin 5 Statystyka i rachunek prawdopodobieństwa 30 30 Egzamin 5 Opracowywanie
HPC na biurku. Wojciech De bski
 na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
na biurku Wojciech De bski 22.01.2015 - co to jest? High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki
 Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Autor: inż. Wojciech Zatorski Opiekun pracy: dr inż. Krzysztof Małecki Cel Konfiguracja i testowanie serwera WWW Apache w celu optymalizacji wydajności. 2/25 Zakres Konfigurowanie serwera Apache jako wydajnego
Jacek Naruniec. lato 2014, Politechnika Warszawska, Wydział Elektroniki i Technik Informacyjnych
 lato 2014,, Wydział Elektroniki i Technik Informacyjnych Wykład (poniedziałek 10:15) dr inż. Jacek Naruniec, dr inż. Maciej Sypniewski Laboratoria (3-godzinne) w 08 Środy 12:15 Projekt Punktacja: Laboratorium
lato 2014,, Wydział Elektroniki i Technik Informacyjnych Wykład (poniedziałek 10:15) dr inż. Jacek Naruniec, dr inż. Maciej Sypniewski Laboratoria (3-godzinne) w 08 Środy 12:15 Projekt Punktacja: Laboratorium
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Rola superkomputerów i modelowania numerycznego we współczesnej fzyce. Gabriel Wlazłowski
 Rola superkomputerów i modelowania numerycznego we współczesnej fzyce Gabriel Wlazłowski Podział fizyki historyczny Fizyka teoretyczna Fizyka eksperymentalna Podział fizyki historyczny Ogólne równania
Rola superkomputerów i modelowania numerycznego we współczesnej fzyce Gabriel Wlazłowski Podział fizyki historyczny Fizyka teoretyczna Fizyka eksperymentalna Podział fizyki historyczny Ogólne równania
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP.
 P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
P O L I T E C H N I K A S Z C Z E C I Ń S K A Wydział Informatyki PRZETWARZANIE RÓWNOLEGŁE I ROZPROSZONE. Mnożenie macierzy kwadratowych metodą klasyczną oraz blokową z wykorzystaniem OpenMP. Autor: Wojciech
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH
 ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
ZESZYTY NAUKOWE 41-53 Dariusz CHAŁADYNIAK 1 WYBRANE ZAGADNIENIA PRZETWARZANIA RÓWNOLEGŁEGO I ROZPROSZONEGO ORAZ KLASTRÓW KOMPUTEROWYCH Streszczenie W artykule przedstawiono wprowadzenie do zagadnień przetwarzania
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Programowanie Równoległe i Rozproszone. Algorytm Kung a. Algorytm Kung a. Programowanie Równoległe i Rozproszone Wykład 8. Przygotował: Lucjan Stapp
 Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/34 PRiR Algorytm Kunga Dany jest odcinek [a,b] i ciągła funkcja
Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/34 PRiR Algorytm Kunga Dany jest odcinek [a,b] i ciągła funkcja
Zagadnienia egzaminacyjne INFORMATYKA. Stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii