Główne cechy metody Saltona
|
|
|
- Weronika Czajkowska
- 8 lat temu
- Przeglądów:
Transkrypt
1 Metoda Saltona
2 Słowem wstępu Rozszerzenie metody list prostych. Dokumenty są dzielone na grupy tematyczne (klasteryzowane). Każda grupa jest opisana koniunkcją deskryptorów (z wagami). Wyszukiwanie najpierw interesującą nas grupę dokumentów, a następnie jak w MLP.
3 Główne cechy metody Saltona Metoda Saltona - opracowana dla dokumentów i pytao zadawanych w języku naturalnym, dlatego też podstawowy moduł stanowi moduł analizy językowej, którego opracowanie jest niezwykle pracochłonne i wymaga rozwiązania szeregu problemów natury lingwistycznej. Zrealizowany system SMART oparty na metodzie Saltona zajmuje się wyszukiwaniem dokumentów opisanych w języku angielskim. W metodzie Saltona opisy obiektów są tekstami w języku naturalnym. Metoda polega na podziale wszystkich obiektów na grupy o podobnym opisie. Istnieje wiele sposobów takiego grupowania. Każda grupa obiektów jest poprzedzona określonym wektorem pojęd charakterystycznych dla danej grupy (wektor centriodalny, profil). Wyszukiwanie odpowiedzi polega na porównaniu pytania z wektorami pojęd charakteryzujących poszczególne grupy obiektów, a następnie wybraniu grup o wektorze najbardziej zbliżonym do pytania. Obiekty występujące w tych grupach stanowią tzw. odpowiedź przybliżoną na pytanie. Następnie dokonuje się przeglądu zupełnego wybranych obiektów dla znalezienia odpowiedzi dokładnej, tzn. obiektów, których opisy dokładnie odpowiadają pytaniu (zawierają identyczne pojęcia jak w pytaniu). W przypadku otrzymania dużej liczby grup w BD stosuje się dalsze ich łączenie w grupy większe, tworząc strukturę drzewiastą. Pojęcia charakteryzujące duże grupy (pnie) zawierają zbiory wektorów pojęd grup, a te dopiero - zbiory obiektów. *- automatyczny system wyszukiwania dokumentów zaprojektowany na Uniwersytecie Harvarda w latach System przyjmuje dokumenty i żądania usług sformułowane w języku naturalnym, dokonuje automatycznej analizy tekstów przy użyciu jednej z kilkudziesięciu metod analizy językowej, kojarzy przeanalizowane dokumenty z kwerendami i wyszukuje dla użytkownika te pozycje, które uzna za najbardziej odpowiadające zgłoszonym kwerendom.
4 PROCES WYSZUKIWANIA Proces wyszukiwania w systemie Smart można podzielid na 5 etapów: wprowadzenie tekstu drukowanego grupowanie dokumentów dla celów przeszukiwania (wiązanie w grupy) wybranie grupy dokumentów do wyszukiwania przeszukiwanie grupy dokumentów ocena wyszukiwania.
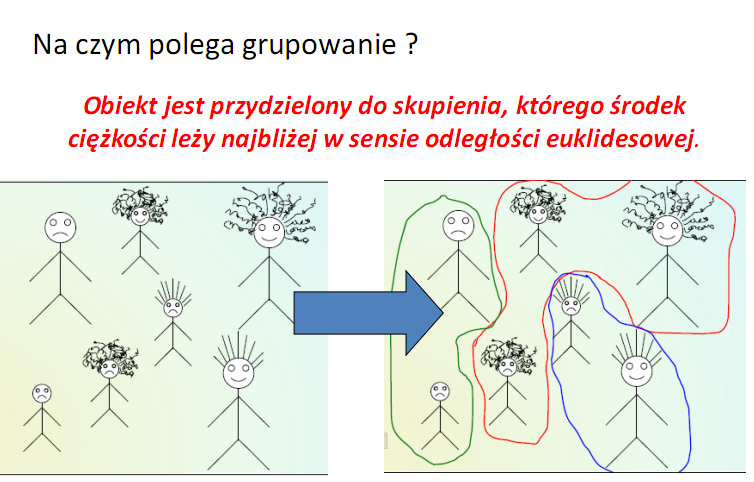
5
6 Cel grupowania dokumentów Grupowanie polega na umieszczeniu w tej samej grupie dokumentów zawierających podobne pojęcia, oraz na określeniu dla każdej grupy reprezentatywnej pozycji centralnej (CENTROID). Po utworzeniu kartoteki dokumentów powiązanych w grupy, przeszukiwanie grup polega na uprzednim dobieraniu kwerend do centroidów każdej grupy. Następnie dokonuje się wyboru grup, które prawdopodobnie zawierają najwłaściwsze dokumenty, po czym następuje przeszukiwanie grup przy użyciu normalnej procedury - pozycja za pozycją.
7 Algorytmy grupowania dokumentów Istnieje wiele sposobów grupowania. My poznamy 2 metody: algorymt Rocchia algorytm Doyle'a Zarówno proces grupowania, jak i proces porównywania pytania z pniami czy wektorami pojęd odbywa się poprzez znajdowanie współczynników korelacji (podobieostwa) pomiędzy pojęciami występującymi w pytaniu lub pojęciami występującymi w wektorze pojęd danej grupy.
8 Miary korelacji (podobieostwa) Współczynnik korelacji to wartośd z przedziału <0,1>. Im bardziej podobne są do siebie obiekty tym wyższy jest dla nich współczynnik korelacji. Jeżeli dwa obiekty są identyczne to współczynnik korelacji = 1. Dla obiektów w ogóle nie podobnych współczynnik korelacji = 0. I tak dla dwóch obiektów x1 i x2 poniżej przedstawione są typowe miary korelacji:
9 W systemie Smart W systemie SMART Saltona istnieją dwie miary korelacji: korelacja cosinusowa korelacja nakładania gdzie: d i q to n-wymiarowe wektory terminów reprezentujących analizowaną kwerendę q i analizowany dokument d.
10 Struktura kartoteki Czyli mamy system S = <X, A, V, q>. Opisy obiektów pogrupowane są w BD w grupy Xi, gdzie i=1,..,m przy czym spełniony jest warunek: X m i 1 X i Struktura kartoteki ma więc formę drzewiastą (hierarchię) w której dokumenty podobne do siebie łączone są w grupy, dla których tworzy reprezentantów (centroid bądź profil). Jeśli grup tak utworzonych jest dużo, traktowane są one jak dokumenty i ponownie grupowane w grupy a kolejnym poziomie hierarchii (pnie). Każda grupa Xi poprzedzona jest identyfikatorem grupy, który jest nazywany CENTROIDEM (Ci) lub PROFILEM (Pi): Xi = (Ci, {t{xi}}). Centroid - Ci to wektor pojęd opisujących dokumenty danej grupy. Stosowany do opisu grupy w algorytmie Rocchio'a. Profil - Pi to wektor wartości pozycyjnych pojęd opisujących dokumenty danej grupy. Stosowany do opisu grupy w algorytmie Doyle'a.

11 Przyporządkowanie dokumentów do kategorii (grup)
12 Struktura hierarchiczna dokumentów, grup i pni Grupa 1: Doc_1, Doc_5, Doc_4 Centroid: A,b Pieo I A,b,f Pieo II C,d,e gr_1 A,b Gr_2 a,f Gr_3 C,d gr_4 C, e Doc_1 A,b,c Doc_5 A,b Doc_4 A,b,d Doc_2 a,e,f Doc_6 a,f Doc_7 a,f,g Doc_3 b,c,d Doc_8 d,e,c
13 Wyszukiwanie obliczanie podobieostw Szukamy dokumentów zawierających słowa: a i f Pieo I A,b,f 2/3 0/5 Pieo II C,d,e gr_1 A,b Gr_2 a,f Gr_3 C,d gr_4 C, e Doc_1 A,b,c Doc_5 A,b Doc_4 A,b,d Doc_2 a,e,f Doc_6 a,f Doc_7 a,f,g Doc_3 b,c,d Doc_8 d,e,c
14 Wyszukiwanie obliczanie podobieostw Szukamy dokumentów zawierających słowa: a i f Wybieramy pieo najbardziej obiecujący czyli pieo I Pieo I A,b,f 2/3 0/5 Pieo II C,d,e gr_1 A,b Gr_2 a,f Gr_3 C,d gr_4 C, e Doc_1 A,b,c Doc_5 A,b Doc_4 A,b,d Doc_2 a,e,f Doc_6 a,f Doc_7 a,f,g Doc_3 b,c,d Doc_8 d,e,c
15 Wyszukiwanie obliczanie podobieostw Szukamy dokumentów zawierających słowa: a i f Wybieramy pieo najbardziej obiecujący czyli pieo I Pieo I A,b,f 2/3 0/5 Pieo II C,d,e 1/2 2/2 gr_1 A,b Gr_2 a,f Gr_3 C,d gr_4 C, e Doc_1 A,b,c Doc_5 A,b Doc_4 A,b,d Doc_2 a,e,f Doc_6 a,f Doc_7 a,f,g Doc_3 b,c,d Doc_8 d,e,c
16 Wyszukiwanie obliczanie podobieostw Szukamy dokumentów zawierających słowa: a i f Wybieramy pieo najbardziej obiecujący czyli pieo I Pieo I A,b,f 2/3 0/5 Pieo II C,d,e 1/2 2/2 gr_1 A,b Gr_2 a,f Grupa wyszkana Gr_3 C,d gr_4 C, e Doc_1 A,b,c Doc_5 A,b Doc_4 A,b,d Doc_2 a,e,f Doc_6 a,f Doc_7 a,f,g Doc_3 b,c,d Doc_8 d,e,c

17 Przykłady takich systemów Identyfikatory dokumentów w skupieniu nr 5 Reprezentant skupienia nr 5

18 Dokumenty w danej grupie powinny zawierad wspólne cechy (słowa)
19 Test gęstości Na początku zakłada się, że wszystkie dokumenty są niezwiązane, a każdy jest poddany testowi gęstości dla określenia, czy dostatecznie duża liczba dokumentów znajduje się w sąsiedztwie badanego. Ponad n1 dokumentów powinno mied współczynnik korelacji z dokumentem badanym, wyższy od pewnego parametru p1, a więcej niż n2 dokumentów wyższy od p2 np. co najmniej 5 dokumentów ma mieć korelację z centrum grupy większą bądź równą 0.5 i co najmniej 3 dokumenty większą bądź równą 0.7. Dzięki testowi mamy pewnośd, że elementy z brzegu dużych grup nie będą centrami i że regiony, gdzie dokumenty są skupione w kształcie pierścienia nie będą akceptowane jako grupy. Elementy nie spełniające testu gęstości nazywamy swobodnymi. Nie mogą byd one potem wybierane jako potencjalne centra grup. Jeśli dokument przejdzie test gęstości to wybiera się wartośd progową jako funkcję minimalnie i maksymalnie dopuszczalnej liczby elementów w grupie. Grupę wtedy tworzą dokumenty, które mają z elementem centralnym korelację większą od wybranego progu.
20 Wartośd progowa Wartośd progowa jest wybierana jako maksymalna różnica korelacji dwóch kolejnych dokumentów, tak, aby odległośd pomiędzy tworzonym zbiorem a sąsiednimi nie związanymi elementami była możliwie najmniejsza.
21 Wyszukiwanie strukturalne Po powiązaniu dokumentów w zbiorze wyjściowym przeprowadza się dwuetapową operację wyszukiwania. Nadchodzącą kwerendę najpierw porównuje się z wektorami centroidalnymi wszystkich grup. Jeśli np. 82 dokumenty rozdzielono między 7 grup, to trzeba dla danej kwerendy dokonad jej porównania z opisem każdej z 7 grup (opisem grupy: centroidem) i następnie porównad ją z dokumentami z n grup o najwyższym współczynniku korelacji, lub alternatywnie z dokumentami wszystkich grup takich, że współczynnik korelacji ich centroidu z kwerendą przekracza zadany próg.
22 1. Pobranie opisów obiektów. 2. Ustalenie parametrów: Algorytm Rocchia P1,P2,N1,N2 - dla centrum grupy, P1p,P2p,N1p,N2p - dla centroidu. 3. Wybranie potencjalnego centrum grupy: xc 4. Przeprowadzamy test gęstości dla centrum grupy xc,(co najmniej N1 dokumentów ma współczynnik większy bądź równy od P1 a N2 dokumentów ma współczynnik większy bądź równy P2). W tym celu obliczamy współczynniki korelacji dokumentów z potencjalnym centrum grupy. Jeżeli założenia nie są spełnione to konieczny jest wybór innego potencjalnego centrum grupy lub zmiana parametrów tekstu gęstości (punkt 3). Jeśli potencjalne centrum grupy przeszło test gęstości: przechodzimy do punktu Określamy rangę obiektów. 6. Wyznaczamy M1 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P2), M2 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P1). Jeśli M1=M2 to Pmin równa się najmniejszemu współczynnikowi korelacji obiektu należącego do M1,przechodzimy do punktu 7. Jeśli M1 M2 to: Obliczamy różnicę pomiędzy współczynnikami korelacji obiektów sąsiednich w grupie maksymalnej M2,bez obiektów grupy minimalnej M1 i określamy największą różnicę. Minimalny współczynnik korelacji Pmin jest równy odjemnej z największej różnicy. Jeśli największa różnica powtarza się to za Pmin przyjmujemy odjemną o większej wartości. 7. Tworzymy wstępną grupę do której należą elementy o współczynniku korelacji większym bądź równym P min. 8. Tworzymy wektor centroidalny, który stanowi sumę opisów obiektów należących do grupy wstępnej.
23 II-ga iteracja algorytmu - dla tworzenia tzw. grupy poprawionej 1. Przeprowadzamy test gęstości dla centroidu, (co najmniej N1p dokumentów ma współczynnik większy bądź równy od P1p a N2p dokumentów ma współczynnik większy bądź równy P2p). 2. Obliczamy współczynniki korelacji dokumentów z centroidem. 3. Określamy rangę obiektów. 4. Wyznaczamy M1p (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P2p), M2p (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P1p). Jeśli M1p=M2p to Pmin równa się najmniejszemu współczynnikowi korelacji obiektu należącego do M1p,przechodzimy do punktu 5. Jeśli M1p M2p to: 1. Obliczamy różnicę pomiędzy współczynnikami korelacji obiektów sąsiednich w grupie maksymalnej M2p,bez obiektów grupy minimalnej M1p. 2. Określamy największą różnicę. 3. Minimalny współczynnik korelacji Pmin jest równy odjemnej z największej różnicy. 4. Jeśli największa różnica powtarza się to za Pmin przyjmujemy odjemną o większej wartości. 5. Tworzymy grupę poprawioną do której należą elementy o współczynniku korelacji większym bądź równym Pmin. 6. Tworzymy wektor centroidalny, który stanowi sumę opisów obiektów należących do grupy poprawionej. 7. Obiekty nie należące do grupy poprawionej (swobodne),traktujemy jako wejściowe opisy obiektów i generujemy kolejne grupy dokumentów.
24 Przykład Wykorzystując opis (poniżej) algorytmu Rocchia przeprowadź grupowanie 10 obiektów o następujących opisach: x1=a1 b1 c1 d1 e1 x2=a1 b1 c1 d1 e2 x3=a1 b1 c2 d1 e3 x4=a1 b1 c3 d1 e1 x5=a1 b1 c1 d1 e3 x6=a2 b1 c2 d1 e2 x7=a2 b1 c3 d1 e3 x8=a2 b2 c3 d3 e3 x9=a3 b3 c2 d2 e2 x10=a3 b3 c2 d3 e2 Dla podanego wyżej zbioru obiektów dane są następujące parametry: a) Dla centrum grupy: N1=5, N2=3, p1=0,2, p2=0,3 b) Dla centroidu: N1c=5, N2c=3, p1c=0,25, p2c=0,35 Wybór potencjalnego centrum grupy xc Jako potencjalne centrum grupy 1 przyjmij obiekt x1. Wybór miary podobieostwa (korelacji) każdego dokumentu z centrum grupy xc: p( x c, x i ) x x c c x x i i
25 Przeprowadzamy test gęstości dla centrum grupy: x c Test ten mówi, że co najmniej N1 dokumentów ma współczynnik większy bądź równy od P1, a N2 dokumentów ma współczynnik większy bądź równy P2. W tym celu obliczamy współczynniki korelacji (podobieostwa każdego dokumentu (x i ) z wybranym centrum grupy x c ) stosując wybraną wcześniej miarę korelacji. Gdy mamy 10 dokumentów w systemie to po kolei dla każdego dokumentu wyliczamy taki współczynnik: p(x1,xc)=?... p(x10,xc)=? W liczniku podajemy liczbę pojęd wspólnym danego dokumentu z centrum grupy x c W mianowniku podajemy sumę pojęd, którymi są opisane obydwa dokumenty: dany dokument x i i dokument stanowiący centrum grupy.
26 zatem: Aby obliczyd współczynnik korelacji obiektu 1 z centrum grupy który jest jednocześnie obiektem 1 wykonujemy następujące czynności. x1=a1 b1 c1 d1 e1 xc=a1 b1 c1 d1 e1 Liczba pojęd wspólnych = 5, bo są to pojęcia: (a1,b1,c1,d1,e1) Suma wszystkich pojęd = 5, bo są to pojęcia: (a1,b1,c1,d1,e1) Zatem: p(xc,x1) = 5/5 = 1.0 p(xc,x2) = 4/6 = 0.67 p(xc,x3) = 3/7 = 0.43 p(xc,x4) = 4/6 = 0.67 p(xc,x5) = 4/6 = 0.67 p(xc,x6) = 2/8 = 0.25 p(xc,x7) = 2/8 = 0.25 p(xc,x8) = 0/10 = 0 p(xc,x9) = 0/10 = 0 p(xc,x10) = 0/10 = 0
27 Określamy rangę dokumentów, czyli porządkujemy dokumenty malejąco według obliczonych w kroku 5 współczynników korelacji i nadajemy tak ułożonym wartościom rangi od 1 do n. Ranga 1: Ranga 2: Ranga 3: Ranga 4: Ranga 5: Ranga 6: Ranga 7: Ranga 8: Ranga 9: Ranga 10: p(x1,xc)=1.0 p(x2,xc)=0.67 p(x4,xc)=0.67 p(x5,xc)=0.67 p(x3,xc)=0.43 p(x6,xc)=0.25 p(x7,xc)=0.25 p(x8,xc)=0.0 p(x9,xc)=0.0 p(x10,xc)=0.0 Przeprowadzamy test gęstości czyli sprawdzamy, czy na pewno: N1 dokumentów ma podobieostwo >= p1? Tak N2 dokumentów ma podobieostwo >=p2? Nie wybrane centrum grupy przeszedł test gęstości wybieramy inny obiekt jako centrum grupy (x c ).
28 Obliczamy faktyczne rozmiary grupy: M1 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P2) M2 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P1. M1 = 5 zaś M2 = 7 Obliczamy minimalny współczynnik korelacji p min : Jeśli M1=M2 to p min równa się najmniejszemu współczynnikowi korelacji obiektu należącego do M1 Jeśli M1 < M2 to: Obliczamy różnicę pomiędzy współczynnikami korelacji obiektów sąsiednich w grupie maksymalnej M2,bez obiektów grupy minimalnej M1. Wybieramy największą różnicę i obliczamy minimalny współczynnik korelacji p min jako odjemną z tej największej różnicy. Jeśli największa różnica powtarza się to za p min przyjmujemy odjemną o większej wartości.
29 Ranga 1: p(x1,xc)=1.0 Ranga 2: p(x2,xc)=0.67 Ranga 3: p(x4,xc)=0.67 Ranga 4: p(x5,xc)=0.67 Ranga 5: p(x3,xc)=0.43 Ranga 6: p(x6,xc)=0.25 Ranga 7: p(x7,xc)=0.25 Ranga 8: p(x8,xc)=0.0 Ranga 9: p(x9,xc)=0.0 Ranga 10:p(x10,xc)=0.0 M1 większe od 0.3 Ranga 1: p(x1,xc)=1.0 Ranga 2: p(x2,xc)=0.67 Ranga 3: p(x4,xc)=0.67 Ranga 4: p(x5,xc)=0.67 Ranga 5: p(x3,xc)=0.43 M2 większe od 0.2 Ranga 1: p(x1,xc)=1.0 Ranga 2: p(x2,xc)=0.67 Ranga 3: p(x4,xc)=0.67 Ranga 4: p(x5,xc)=0.67 Ranga 5: p(x3,xc)=0.43 Ranga 6: p(x6,xc)=0.25 Ranga 7: p(x7,xc)=0.25
30 Ranga 1: p(x1,xc)=1.0 Ranga 2: p(x2,xc)=0.67 Ranga 3: p(x4,xc)=0.67 Ranga 4: p(x5,xc)=0.67 Ranga 5: p(x3,xc)=0.43 Ranga 6: p(x6,xc)=0.25 Ranga 7: p(x7,xc)=0.25 Ranga 8: p(x8,xc)=0.0 Ranga 9: p(x9,xc)=0.0 Ranga 10:p(x10,xc)=0.0 5 różnica z 6: 0,43 0,25 = 0, 18 6 różnica z 7: 0,25 0,25 = 0 7 różnica z 8: 0,25 0 = 0,25 M1=5 M2=7 W naszym przypadku: M1 = 5 a M2 = 7, zatem są to różne wartości, więc, aby obliczyd współczynnik korelacji p min obliczamy różnicę między dokumentami na granicy tych grup. 5: 6: 7: 8:
31 Szukamy p min Minimalny współczynnik korelacji p min jest równy odjemnej z największej różnicy. p min = p7(x7) = 0,25
32 Tworzymy grupę wstępną (X 1W ) Do grupy wstępnej będą należały wszystkie te dokumenty, które miały wyliczony współczynnik korelacji większy lub równy p min. p(x1,xc)=1.0 p(x2,xc)=0.67 p(x4,xc)=0.67 p(x5,xc)=0.67 p(x3,xc)=0.43 p(x6,xc)=0.25 p(x7,xc)=0.25 p(x8,xc)=0.0 p(x9,xc)=0.0 p(x10,xc)=0.0 Są to wszystkie obiekty grupy maksymalnej M2: x1, x2, x3, x4, x5, x6 i x7.
33 Grupa wstępna to dokumenty: x1, x2, x3, x4, x5, x6 i x7. Wyznaczamy wstępnego reprezentanta grupy X 1 czyli centroid: Centroid to zbiór wszystkich pojęd, którymi są opisane dokumenty grupy minimalnej M1 (x1,x2,x3,x4,x5): x1=a1 b1 c1 d1 e1 x2=a1 b1 c1 d1 e2 x3=a1 b1 c2 d1 e3 x4=a1 b1 c3 d1 e1 x5=a1 b1 c1 d1 e3 x6=a2 b1 c2 d1 e2 x7=a2 b1 c3 d1 e3 x8=a2 b2 c3 d3 e3 x9=a3 b3 c2 d2 e2 x10=a3 b3 c2 d3 e2 czyli:c W1 : = {a1, b1, c1, c2, c3, d1, e1, e2, e3}
34 Generujemy grupę poprawioną: DRUGA ITERACJA W tym celu powtarzamy raz jeszcze cały algorytm, z tym, że teraz centrum grupy stanowi teraz CENTROID C1. Ustalenie parametrów testu gęstości dla centroidu: p1c = 0,25 ;p2c = 0,35 ;N1c = 5 ;N2c = 3 Test gęstości dla centroidu: W tym celu obliczamy współczynniki korelacji (podobieostwa) dokumentów grupy maksymalnej M2 z centroidem C1 P(x1,c1)=5/9 = 0.55 P(x2,c1)=5/9 = 0.55 P(x3,c1)=5/9 = 0.55 P(x4,c1)=5/9= 0.55 P(x5,c1)=5/9 = 0.55 P(x6,c1)=4/10 = 0.4 P(x7,c1)=4/10 = 0.4 Określamy rangę dokumentów: Ranga 1 p(x1,xc)=0.55 Ranga 2 p(x2,xc)= 0.55 Ranga 3 p(x4,xc)=0.55 Ranga 4 p(x5,xc)=0.55 Ranga 5 p(x3,xc)=0.55 Ranga 6 p(x6,xc)=0.4 Ranga 7 p(x7,xc)=0.4
35 Sprawdzamy, czy na pewno: N1c dokumentów ma p>= p1c i N2c dokumentów ma współczynnik p>=p2c Jeśli tak to znaczy, że wybrane centrum grupy przeszedł test gęstości. Jeśli nie to zmieniamy parametry testu gęstości dla centroidu, bądź zaczynamy cały algorytm od nowa łącznie z wyborem nowego potencjalnego centrum grupy x_c. Obliczamy faktyczne rozmiary grupy poprawionej: Wyznaczamy M1 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P2), M2 (liczebnośd zbioru obiektów dla których elementy są większe bądź równe P1). Jeśli M1=M2 to p min równa się najmniejszemu współczynnikowi korelacji obiektu należącego do M1 czyli p min = p7(x7) = 0,4 m1=m2= 7 Wyznaczamy grupę poprawioną X_1 Do tej grupy będą należały wszystkie te dokumenty, które miały wyliczony współczynnik korelacji większy lub równy pmin. Są to wszystkie obiekty grupy maksymalnej M2: X1= {x1, x2, x3, x4, x5, x6,x7} Wyznaczamy reprezentanta grupy X_1 czyli centroid Centroid to zbiór wszystkich pojęd, którymi są opisane wszystkie dokumenty grupy X_1, czyli... C_1 = {a1, a2, b1, c1, c2, c3, d1, e1, e2, e3 KONIEC GENEROWANIA PIERWSZEJ GRUPY.
36 Rezultat Zatem jedna iteracja algorytmu doprowadziła do powstania grupy: X1 = {X1, x2, x3, x4, x5, x6, x7} Na jej czele stoi centroid C1 = {a1, a2, b1, c1, c2, c3, d1, e1, e2, e3} Co dalej? Są 2 możliwości: LUB Z dokumentów pozostałych: X X1 = {x8,x9, x10} powinniśmy tworzyd kolejne grupy. Jednakże jak łatwo zauważyd patrząc na ustalone na początku parametry testu gęstości nie możliwe będzie utworzenie następnych grup, gdyż test ten wymaga aby...grupa maksymalna liczyła co najmniej N2=5 dokumentów...a nam zostały już tylko 3... Zatem na tym kooczy się algorytm. Z wszystkich dokumentów X = {X1, x2, x3, x4, x5, x6, x7,x8,x9, x10} powinniśmy tworzyd kolejne grupy. Tyle że wybieramy teraz inne potencjalne centrum grupy (a więc nie obiektu x1) i próbujemy wokół niego związad grupę. Zatem na tym kooczy się algorytm.
37 Algorytm Doyle a Zakładamy następujące wartości: m - liczba grup T - wartośd progowa a - współczynnik skalujący z przedziału - <0,1> Dokonujemy wstępnego podziału zbioru dokumentów na m grup. Dla każdej grupy wyznaczamy: Wektor Sj- wektor dokumentów Wektor Cj - wektor pojęć występujących w j-tej grupie Wektor Fj- wektor częstości występowania pojęć Wektor Rj - wektor rang przyporządkowanych pojęciom grupy Wektor Pj - wektor wartości pozycyjnych (PROFIL) gdzie: pi = ( b - ri ) * wcześniej wyznaczamy wartośd bazową "b". dla każdego di wyliczamy wartośd funkcji punktującej g(di,pj) w każdej grupie zawierającej wszystkie pojęcia opisujące obiekt di wybieramy wartośd maksymalną!!! Zazwyczaj b wybiera się jako wartośd całkowitą o 1 większą od maksymalnej liczby cech w danej grupie Sj.
38 Dla przykładowej grupy: Sj Cj Fj Rj Pj Doc_1 Kobieta 4 2 B-r(kobieta) Doc_2 Niska 3 3 B-r(niska) Oczy niebieskie 5 1 B-r(oczy niebieskie) Jakie dokumenty Należą do Grupy? Jakie cechy (pojęcia) opisują dokumenty danej grupy? Jaka jest częstośd wystąpienia cechy kobieta we wszystkich dokumentach danej grupy? Tam gdzie jest największa częstośd wpiszemy najwyższą rangę ( 1 ) i potem mniejszym częstościom przypiszemy niższe rangi Wartość pozycyjna dla każdego pojęcia, obliczana jako różnica między wartością bazową b a rangą danej cechy
39 Potem obliczamy funkcję punktującą: Dla każdego dokumentu obliczamy wartośd funkcji punktującej. Nazywamy ją g(di,pj) i obliczamy ją dla każdego profilu Pj (więc jeśli mamy 3 grupy: S1,S2i S3 to mamy 3 profile grup: P1,P2 i P3) wartośd funkcji punktującej. Funkcja punktująca oblicza dla każdego dokumentu di sumę wartości pozycyjnych pojęć opisujących ten dokument w Profilu Pj. Opis dokumentu x1: tx1=(pł,k)(ty,dr)(sp,5)(oz,c) Suma=34 Wartości pozycyjne pojęd opisujących ten dokument to: cecha K 8 DR c 9 Wartość pozycyjna
40 Na podstawie wyznaczonych wartości funkcji punktującej dokonaj wstępnego podziału dokumentów do grup tak, że: gdy Gdzie: Hj = max(g (di,pj)) A więc maksymalna wartośd funkcji punktującej w każdej grupie: Hj = max(g (di,pj)) * z reguły powstaje m+1 grup (bo m grup + grupa dokumentów swobodnych) Jeśli podział w i+1-ej iteracji jest identyczny jak w i-tej to KONIEC algorytmu. REZULTAT: m- grup dokumentów (na czele każdej grupy stoi PROFIL) i ewentualnie grupa dokumentów swobodnych (L).
41 Przydział dokumentów do grup Sj to będzie wektor tych wszystkich dokumentów (każdy taki dokument di ) dla którego wartość funkcji punktującej (g(di,pj)) jest większa niż ustalona wartość Tj
42 Przykład algorytmu Doyle'a Dla podanego zbioru obiektów przeprowadź jedną iterację grupowania algorytmem Doyle'a przy założeniach: liczba grup wynosi m=3, współczynnik a= 0,5 tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d)
43 I iteracja Tworzymy wektory opisujące każdą grupę: tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d)
44 Obliczamy wartośd funkcji punktującej g(di,pj) dla każdego dokumentu di i profilu Pj:
45 Dla każdej grupy ustalamy wartośd progową Tj, którą muszą spełnid dokumenty aby wejśd do danej grupy. Wartośd progową obliczamy wg jednego z poniższych wzorów: Przyjmijmy więc, że T = 37. Nowy podział na grupy ustalamy zgodnie ze wzorem podanym poniżej. Do nowych grup będą należed obiekty, których wartości funkcji punktującej będą Tj czyli większe bądź równe od wartości progowej j-tej grupy.
46 Wyznaczamy maksymalną wartośd funkcji punktującej j-tej grupy: H1= 37 H2= 40 H3= 39
47 Następnie wartości progowe danych grup (Tj), przy założeniu, że a = 0.5. T1= H1- a(h1 - T) = 37 T2= H2- a(h2 - T) = 40-0,5*(40-37) = 38,5 T3= H3- a(h3 - T) = 39-0,5*(39-37) = 38 OTRZYMANE GRUPY: Porównując wartości funkcji punktującej z wartościami progowymi według wzoru Otrzymujemy nowe grupy których jest m+1 ponieważ tworzy się jeszcze jedna grupa, grupa obiektów swobodnych (niesklasyfikowanych). tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d) Co zapiszemy następująco: Grupa I Grupa II Grupa III Grupa IV tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d) tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) X1={x3} X2={x2,x7} X3={x5,x9,x10} Grupa obiektów swobodnych: L={x1,x4,x6,x8}
48 Dlaczego parametr a wpływa na moc wiązania dokumentów w grupy? Jeśli: a = 0.5 Wówczas: T1= H1- a(h1 - T) = 37 T2= H2- a(h2 - T) = 40-0,5*(40-37) = 38,5 T3= H3- a(h3 - T) = 39-0,5*(39-37) = 38 Wtedy przydział do grup jest następujący: Grupa I Grupa II Grupa III Grupa IV tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d) tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a)
49 Dlaczego parametr a wpływa na moc wiązania dokumentów w grupy? Jeśli: a = 0 Wówczas: T1= H1- a(h1 - T) = 37 T2= H2- a(h2 - T) = 40 0*(40-37) = 40 T3= H3- a(h3 - T) = 39-0*(39-37) = 40 Wtedy przydział do grup jest następujący: Grupa I Grupa II tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) Grupa III Grupa IV Brak dokumentów spełniających kryteria tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx10=(pł,k)(ty,pr)(sp,2)(oz,d)
50 Dlaczego parametr a wpływa na moc wiązania dokumentów w grupy? Jeśli: a = 1 Wówczas: T1= H1- a(h1 - T) = 37 T2= H2- a(h2 - T) = 40-1*(40-37) = 37 T3= H3- a(h3 - T) = 39-1*(39-37) = 37 Wtedy przydział do grup jest następujący: Grupa I Grupa II Grupa III Grupa IV tx3=(pł,m)(ty,mgr)(sp,5)(oz,c) tx2=(pł,m)(ty,pr)(sp,2)(oz,b) tx6=(pł,m)(ty,dr)(sp,5)(oz,b) tx7=(pł,k)(ty,dr)(sp,2)(oz,b) tx5=(pł,m)(ty,pr)(sp,12)(oz,d) tx9=(pł,m)(ty,pr)(sp,5)(oz,d) tx8=(pł,m)(ty,mgr)(sp,12)(oz,c) tx10=(pł,k)(ty,pr)(sp,2)(oz,d) tx1=(pł,k)(ty,dr)(sp,5)(oz,c) tx4=(pł,m)(ty,mgr)(sp,2)(oz,a)
51 Wnioski? Gdy a wówczas Tj dzięki czemu zdolność wiązania dokumentów w grupy jest większa I odwrotnie: Gdy a wówczas Tj dzięki czemu zdolność wiązania dokumentów w grupy jest mniejsza
52 II ITERACJA Aby wykonad kolejną iterację algorytmu przyporządkujemy obiekty swobodne do grup ale innych niż występowały w poprzedniej iteracji, wtedy otrzymujemy nowy podział grup. Cała operacja kolejnych iteracji się kooczy, kiedy otrzymujemy po raz kolejny ten sam podział.
53 Obliczamy wartośd funkcji punktującej g(di,pj) dla każdego dokumentu di i profilu Pj:
54
55 Kiedy kooczymy algorytm? Kiedy w dwóch kolejnych iteracjach nie ma już zmian w przydziale dokumentów do grup: Iteracja i Iteracja i+1 X1={x3} X2={x2,x7} X3={x5,x9,x10} L={x1,x4,x6,x8} X1={x3} X2={x2,x7} X3={x5,x9,x10} L={x1,x4,x6,x8}
56 Wyszukiwanie w systemie Saltona Najpierw formułujemy kwerendę, posługując się oryginalnym żądaniem autora albo jego modyfikacją w postaci numerycznego wektora pojęd. Jedną z najważniejszych metod modyfikacji kwerend źródłowych jest korzystanie z dokumentów, które autor ocenił jako relewantne. Z chwilą sformułowania kwerendy selekcjonuje się zbiór dokumentów, które będą z nią korelowane.
57 Metody wyszukiwania sekwencyjna - pełna ( full search) strukturalna (tree search)
58 Metoda sekwencyjna Metoda ta jest niezależna od klasyfikacji dokumentów w grupie. Polega ona na tym, że pytanie kierowane do systemu jest korelowane z każdym dokumentem. Jest liczony współczynnik korelacji - podobieostwa pytania z każdym dokumentem. Wybiera się te dokumenty, w których współczynnik jest większy od założonej wartości progowej (p min ). Dla wszystkich dokumentów robiony jest przegląd zupełny. Czyli nie grupujemy dokumentów. Odpowiedź na zadane pytanie otrzymujemy przez przegląd wszystkich, po kolei dokumentów znajdujących się w kartotece wyszukiwawczej. Im więcej będzie dokumentów tym dłuższy będzie czas obliczenia współczynników korelacji. Wada: bardzo wiele zależy od przyjętego współczynnika progowego, im on będzie mniejszy tym więcej obiektów zaliczymy do grupy będącej odpowiedzią na pytanie. Jeśli będzie za wysoki - to może się okazad, ze mało dokumentów spełni warunek wymagalny (tzn. mało będzie miało współczynnik korelacji z pytaniem temu założonemu współczynnikowi progowemu).
59 P(pytanie,x1) = 5/5 = 1.0 P(pytanie,x2) = 4/6 = 0.67 p(pytanie,x3) = 3/7 = 0.43 p(pytanie,x4) = 4/6 = 0.67 p(pytanie,x5) = 4/6 = 0.67 p(pytanie,x6) = 2/8 = 0.25 P(pytanie,x7) = 2/8 = 0.25 p(pytanie,x8) = 0/10 = 0 p(pytanie,x9) = 0/10 = 0 p(pytanie,x10) = 0/10 = 0 Przykład dla p min = Obliczamy podobieostwo pytania do każdego dokumentu: 2. Wybieramy jako odpowiedź tylko te dokumenty, które mają podobieostwo z pytaniem większe lub równe p min : P(pytanie,x1) = 5/5 = 1.0 P(pytanie,x2) = 4/6 = 0.67 p(pytanie,x3) = 3/7 = 0.43 p(pytanie,x4) = 4/6 = 0.67 p(pytanie,x5) = 4/6 = 0.67 p(pytanie,x6) = 2/8 = 0.25 P(pytanie,x7) = 2/8 = 0.25 p(pytanie,x8) = 0/10 = 0 p(pytanie,x9) = 0/10 = 0 p(pytanie,x10) = 0/10 = 0 (pytanie) = {x1,x2,x4,x5}
60 Metoda strukturalna Ta metoda jest ściśle związana ze strukturą bazy danych. Polega na obliczeniu współczynnika korelacji pytania z pniami i wybór pni najbardziej obiecujących, czyli tych o najwyższych współczynnikach korelacji. Wybrane pnie zostają usunięte i następuje obliczanie współczynników korelacji pytania z centroidami (w tych wybranych grupach). Ponownie wybiera się poziomy najbardziej obiecujące na poziomie centroidów i dla tych centroidów, usuwamy je i liczymy współczynniki korelacji dokumentów (tzn. pytania z dokumentami zbioru). Ostatecznie odpowiedzią na pytanie jest zbiór dokumentów, dla których współczynniki korelacji są większe od założonego pmin.
61

62 PARAMETRY EFEKTYWNOŚCI SYSTEMÓW INFORMACYJNYCH Dokument jest relewantny względem pytania Q wtedy i tylko wtedy jeżeli w opisie dokumentu występują wszystkie niezaprzeczone deskryptory pytania Q i w opisie tym nie występuje żaden z deskryptorów zaprzeczonych pytaniem.
63 Kompletnośd Kompletność określa zdolność systemu do wyszukiwania wszystkich dokumentów, które mogą okazać się relewantnymi gdzie: a - liczba dokumentów relewantnych wyszukanych c - liczba dokumentów relewantnych niewyszukanych
64 Dokładnośd Dokładność określa zdolność systemu do nie wyznaczania dokumentów nierelewantnych względem danego pytania Q. gdzie: a - liczba wyszukanych dokumentów relewantnych b - liczba wyszukanych. dokumentów nierelewantnych
65 Pozostałe parametry efektywności
66 Przykład badania efektywności W systemie zorganizowanym zgodnie z metodą Saltona występują dokumenty o następujących opisach: d1: abe d2: acef d3: abec d4: ab d5: cde d6: def d7: aef d8: f d9: efg d10: ceg Na pytanie t=ab+f, odpowiedź systemu była następująca: {d1, d2, d7,d9}.
67 Pytanie do systemu: T = t1 + t2 ab + f ab f d1: abe d2: acef d3: abec d4: ab d5: cde d6: def d7: aef d8: f d9: efg d10: ceg d1,d3,d4 + d1: abe d2: acef d3: abec d4: ab d5: cde d6: def d7: aef d8: f d9: efg d10: ceg d2,d6,d7,d8,d9 Dokumenty relewantne: d1,d3,d4,d2,d6,d7,d8,d9
68 Zapis formalny Pytanie do systemu: T = ab + f T1 = ab T2 = f (t1)={d1,d3,d4} (t2)={d2,d6,d7,d8,d9} (t)= (t1) (t2) (t)={d1,d3,d4} {d2,d6,d7,d8,d9} = {d1,d3,d4,d2,d6,d7,d8,d9}
69 Dokumenty relewantne: d1,d3,d4,d2,d6,d7,d8,d9 Dokumenty Wyszukane przez system: d1,d2,d7,d9 Parametry oceny efektywności wyszukiwania takiego systemu kształtują się zatem następująco: wyszukane Niewyszukane Relewantne d1,d2,d7,d9 d3,d4,d6,d8 nierelewantne brak d5,d10
70 wyszukane Niewyszukane wyszukane Niewyszukane Relewantne a c Relewantne d1,d2,d7,d9 d3,d4,d6,d8 nierelewantne b d nierelewantne brak d5,d10 Kompletnośd K = a/(a+c) = 4/(4+4) = 1/2 Dokładnośd: D = a/(a+b) = 4/(4+0) = 1 Uzyskaliśmy pełną dokładnośd (D), gdyż nie wyszukano nierelewantnych dokumentów. Kompletnośd wyniosła jedynie 0.5 gdyż spośród 8 relewantnych dokumentów znaleziono jedynie połowę.
71 Relacja między kompletnością a dokładnością Dokładność Wysokiej dokładności towarzyszy niska kompletnośd i odwrotnie: wysokiej kompletności niska dokładnośd.
Metoda Saltona - wyszukiwanie informacji w strukturach drzewiastych
 Metoda Saltona - wyszukiwanie informacji w strukturach drzewiastych 2 grudnia 2008 1 Główne cechy metody Saltona Metoda Saltona - opracowana dla dokumentów i pytań zadawanych w języku naturalnym, dlatego
Metoda Saltona - wyszukiwanie informacji w strukturach drzewiastych 2 grudnia 2008 1 Główne cechy metody Saltona Metoda Saltona - opracowana dla dokumentów i pytań zadawanych w języku naturalnym, dlatego
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Metoda list prostych Wykład II. Agnieszka Nowak - Brzezińska
 Metoda list prostych Wykład II Agnieszka Nowak - Brzezińska Wprowadzenie Przykładowa KW Inna wersja KW Wyszukiwanie informacji Metoda I 1. Przeglądamy kolejne opisy obiektów i wybieramy te, które zawierają
Metoda list prostych Wykład II Agnieszka Nowak - Brzezińska Wprowadzenie Przykładowa KW Inna wersja KW Wyszukiwanie informacji Metoda I 1. Przeglądamy kolejne opisy obiektów i wybieramy te, które zawierają
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Metoda List Łańcuchowych
 Metoda List Łańcuchowych mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2010 Celem metody jest utrzymanie zalet MLI (dobre czasy wyszukiwania), ale wyeliminowanie jej wad (wysoka
Metoda List Łańcuchowych mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2010 Celem metody jest utrzymanie zalet MLI (dobre czasy wyszukiwania), ale wyeliminowanie jej wad (wysoka
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Metody indeksowania dokumentów tekstowych
 Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Metoda list inwersyjnych. Wykład III
 Metoda list inwersyjnych Wykład III Plan wykładu Cele metody Tworzenie kartoteki wyszukiwawczej Redundancja i zajętość pamięci Wyszukiwanie informacji Czasy wyszukiwania Ocena metody: wady i zalety Modyfikacje
Metoda list inwersyjnych Wykład III Plan wykładu Cele metody Tworzenie kartoteki wyszukiwawczej Redundancja i zajętość pamięci Wyszukiwanie informacji Czasy wyszukiwania Ocena metody: wady i zalety Modyfikacje
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
KADD Minimalizacja funkcji
 Minimalizacja funkcji Poszukiwanie minimum funkcji Foma kwadratowa Metody przybliżania minimum minimalizacja Minimalizacja w n wymiarach Metody poszukiwania minimum Otaczanie minimum Podział obszaru zawierającego
Minimalizacja funkcji Poszukiwanie minimum funkcji Foma kwadratowa Metody przybliżania minimum minimalizacja Minimalizacja w n wymiarach Metody poszukiwania minimum Otaczanie minimum Podział obszaru zawierającego
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Treść wykładu. Pierścienie wielomianów. Dzielenie wielomianów i algorytm Euklidesa Pierścienie ilorazowe wielomianów
 Treść wykładu Pierścienie wielomianów. Definicja Niech P będzie pierścieniem. Wielomianem jednej zmiennej o współczynnikach z P nazywamy każdy ciąg f = (f 0, f 1, f 2,...), gdzie wyrazy ciągu f są prawie
Treść wykładu Pierścienie wielomianów. Definicja Niech P będzie pierścieniem. Wielomianem jednej zmiennej o współczynnikach z P nazywamy każdy ciąg f = (f 0, f 1, f 2,...), gdzie wyrazy ciągu f są prawie
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Program MC. Obliczyć radialną funkcję korelacji. Zrobić jej wykres. Odczytać z wykresu wartość radialnej funkcji korelacji w punkcie r=
 Program MC Napisać program symulujący twarde kule w zespole kanonicznym. Dla N > 100 twardych kul. Gęstość liczbowa 0.1 < N/V < 0.4. Zrobić obliczenia dla 2,3 różnych wartości gęstości. Obliczyć radialną
Program MC Napisać program symulujący twarde kule w zespole kanonicznym. Dla N > 100 twardych kul. Gęstość liczbowa 0.1 < N/V < 0.4. Zrobić obliczenia dla 2,3 różnych wartości gęstości. Obliczyć radialną
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych
 Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Automatyczne tworzenie trójwymiarowego planu pomieszczenia z zastosowaniem metod stereowizyjnych autor: Robert Drab opiekun naukowy: dr inż. Paweł Rotter 1. Wstęp Zagadnienie generowania trójwymiarowego
Bukiety matematyczne dla szkoły podstawowej http://www.mat.uni.torun.pl/~kolka/
 Bukiety matematyczne dla szkoły podstawowej http://www.mat.uni.torun.pl/~kolka/ 12 IX rok 2003/2004 Bukiet 1 O pewnych liczbach A, B i C wiadomo, że: A + B = 32, B + C = 40, C + A = 26. 1. Ile wynosi A
Bukiety matematyczne dla szkoły podstawowej http://www.mat.uni.torun.pl/~kolka/ 12 IX rok 2003/2004 Bukiet 1 O pewnych liczbach A, B i C wiadomo, że: A + B = 32, B + C = 40, C + A = 26. 1. Ile wynosi A
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Metody numeryczne. dr Artur Woike. Ćwiczenia nr 2. Rozwiązywanie równań nieliniowych metody połowienia, regula falsi i siecznych.
 Ćwiczenia nr 2 metody połowienia, regula falsi i siecznych. Sformułowanie zagadnienia Niech będzie dane równanie postaci f (x) = 0, gdzie f jest pewną funkcją nieliniową (jeżeli f jest liniowa to zagadnienie
Ćwiczenia nr 2 metody połowienia, regula falsi i siecznych. Sformułowanie zagadnienia Niech będzie dane równanie postaci f (x) = 0, gdzie f jest pewną funkcją nieliniową (jeżeli f jest liniowa to zagadnienie
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
FUNKCJA LINIOWA - WYKRES
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
ROZWIĄZYWANIE RÓWNAŃ NIELINIOWYCH
 Transport, studia I stopnia Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym
Transport, studia I stopnia Instytut L-5, Wydział Inżynierii Lądowej, Politechnika Krakowska Ewa Pabisek Adam Wosatko Postać ogólna równania nieliniowego Często występującym, ważnym problemem obliczeniowym
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Metoda List Prostych mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2012
 Metoda List Prostych mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2012 Najprostsza metoda wyszukiwania informacji. Nazywana również Metodą Przeglądu Zupełnego (bo w procesie wyszukiwania
Metoda List Prostych mgr Tomasz Xięski, Instytut Informatyki, Uniwersytet Śląski Sosnowiec, 2012 Najprostsza metoda wyszukiwania informacji. Nazywana również Metodą Przeglądu Zupełnego (bo w procesie wyszukiwania
Liczby rzeczywiste. Działania w zbiorze liczb rzeczywistych. Robert Malenkowski 1
 Robert Malenkowski 1 Liczby rzeczywiste. 1 Liczby naturalne. N {0, 1,, 3, 4, 5, 6, 7, 8...} Liczby naturalne to liczby używane powszechnie do liczenia i ustalania kolejności. Liczby naturalne można ustawić
Robert Malenkowski 1 Liczby rzeczywiste. 1 Liczby naturalne. N {0, 1,, 3, 4, 5, 6, 7, 8...} Liczby naturalne to liczby używane powszechnie do liczenia i ustalania kolejności. Liczby naturalne można ustawić
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Rozdział 1 PROGRAMOWANIE LINIOWE
 Wprowadzenie do badań operacyjnych z komputerem Opisy programów, ćwiczenia komputerowe i zadania. T. Trzaskalik (red.) Rozdział 1 PROGRAMOWANIE LINIOWE 1.1 Opis programów Do rozwiązania zadań programowania
Wprowadzenie do badań operacyjnych z komputerem Opisy programów, ćwiczenia komputerowe i zadania. T. Trzaskalik (red.) Rozdział 1 PROGRAMOWANIE LINIOWE 1.1 Opis programów Do rozwiązania zadań programowania
R-PEARSONA Zależność liniowa
 R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
R-PEARSONA Zależność liniowa Interpretacja wyników: wraz ze wzrostem wartości jednej zmiennej (np. zarobków) liniowo rosną wartości drugiej zmiennej (np. kwoty przeznaczanej na wakacje) czyli np. im wyższe
5.5. Wybieranie informacji z bazy
 5.5. Wybieranie informacji z bazy Baza danych to ogromny zbiór informacji, szczególnie jeśli jest odpowiedzialna za przechowywanie danych ogromnych firm lub korporacji. Posiadając tysiące rekordów trudno
5.5. Wybieranie informacji z bazy Baza danych to ogromny zbiór informacji, szczególnie jeśli jest odpowiedzialna za przechowywanie danych ogromnych firm lub korporacji. Posiadając tysiące rekordów trudno
Luty 2001 Algorytmy (4) 2000/2001
 2000/2001") Mając dany zbiór elementów, chcemy znaleźć w nim element największy (maksimum), bądź najmniejszy (minimum). We wszystkich naturalnych metodach znajdywania najmniejszego i największego elementu obecne jest
Mając dany zbiór elementów, chcemy znaleźć w nim element największy (maksimum), bądź najmniejszy (minimum). We wszystkich naturalnych metodach znajdywania najmniejszego i największego elementu obecne jest
RAPORT SPRAWDZIAN 2012 SZKOŁA PODSTAWOWA IM. KSIĘDZA TEODORA KORCZA W TOPOLI MAŁEJ
 SPRAWDZIAN 2012 RAPORT SZKOŁA PODSTAWOWA IM. KSIĘDZA TEODORA KORCZA W TOPOLI MAŁEJ Spis treści: 1. Prezentacja wyników. 2. Analiza wyników umiejętności w kategoriach: czytanie, pisanie, rozumowanie, korzystanie
SPRAWDZIAN 2012 RAPORT SZKOŁA PODSTAWOWA IM. KSIĘDZA TEODORA KORCZA W TOPOLI MAŁEJ Spis treści: 1. Prezentacja wyników. 2. Analiza wyników umiejętności w kategoriach: czytanie, pisanie, rozumowanie, korzystanie
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Priorytetyzacja przypadków testowych za pomocą macierzy
 Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Algorytm genetyczny (genetic algorithm)-
-") Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
Optymalizacja W praktyce inżynierskiej często zachodzi potrzeba znalezienia parametrów, dla których system/urządzenie będzie działać w sposób optymalny. Klasyczne podejście do optymalizacji: sformułowanie
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
KADD Minimalizacja funkcji
 Minimalizacja funkcji n-wymiarowych Forma kwadratowa w n wymiarach Procedury minimalizacji Minimalizacja wzdłuż prostej w n-wymiarowej przestrzeni Metody minimalizacji wzdłuż osi współrzędnych wzdłuż kierunków
Minimalizacja funkcji n-wymiarowych Forma kwadratowa w n wymiarach Procedury minimalizacji Minimalizacja wzdłuż prostej w n-wymiarowej przestrzeni Metody minimalizacji wzdłuż osi współrzędnych wzdłuż kierunków
Materiały dla finalistów
 Materiały dla finalistów Malachoviacus Informaticus 2016 11 kwietnia 2016 Wprowadzenie Poniższy dokument zawiera opisy zagadnień, które będą niezbędne do rozwiązania zadań w drugim etapie konkursu. Polecamy
Materiały dla finalistów Malachoviacus Informaticus 2016 11 kwietnia 2016 Wprowadzenie Poniższy dokument zawiera opisy zagadnień, które będą niezbędne do rozwiązania zadań w drugim etapie konkursu. Polecamy
Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami
 Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami Przykład 1. Napisz program, który dla podanej liczby n wypisze jej rozkład na czynniki pierwsze. Oblicz asymptotyczną złożoność
Wstęp do Informatyki zadania ze złożoności obliczeniowej z rozwiązaniami Przykład 1. Napisz program, który dla podanej liczby n wypisze jej rozkład na czynniki pierwsze. Oblicz asymptotyczną złożoność
METODA LIST PROSTYCH. Marcin Jaskuła
 METODA LIST PROSTYCH Marcin Jaskuła DEFINIOWANIE SYSTEMU S= Gdzie: X- zbiór obiektów systemu A- zbiór atrybutów systemu V- zbiór wartości atrybutów Q- funkcja informacji Zdefiniowany system
METODA LIST PROSTYCH Marcin Jaskuła DEFINIOWANIE SYSTEMU S= Gdzie: X- zbiór obiektów systemu A- zbiór atrybutów systemu V- zbiór wartości atrybutów Q- funkcja informacji Zdefiniowany system
II. FUNKCJE WIELU ZMIENNYCH
 II. FUNKCJE WIELU ZMIENNYCH 1. Zbiory w przestrzeni R n Ustalmy dowolne n N. Definicja 1.1. Zbiór wszystkich uporzadkowanych układów (x 1,..., x n ) n liczb rzeczywistych, nazywamy przestrzenią n-wymiarową
II. FUNKCJE WIELU ZMIENNYCH 1. Zbiory w przestrzeni R n Ustalmy dowolne n N. Definicja 1.1. Zbiór wszystkich uporzadkowanych układów (x 1,..., x n ) n liczb rzeczywistych, nazywamy przestrzenią n-wymiarową
Metody numeryczne I Równania nieliniowe
 Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Metody numeryczne I Równania nieliniowe Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/66 Równania nieliniowe 1. Równania nieliniowe z pojedynczym pierwiastkiem
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
3. Macierze i Układy Równań Liniowych
 3. Macierze i Układy Równań Liniowych Rozważamy równanie macierzowe z końcówki ostatniego wykładu ( ) 3 1 X = 4 1 ( ) 2 5 Podstawiając X = ( ) x y i wymnażając, otrzymujemy układ 2 równań liniowych 3x
3. Macierze i Układy Równań Liniowych Rozważamy równanie macierzowe z końcówki ostatniego wykładu ( ) 3 1 X = 4 1 ( ) 2 5 Podstawiając X = ( ) x y i wymnażając, otrzymujemy układ 2 równań liniowych 3x
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
W kolejnym kroku należy ustalić liczbę przedziałów k. W tym celu należy wykorzystać jeden ze wzorów:
 Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 6.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
Temat: Algorytm kompresji plików metodą Huffmana
 Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
WARTOŚCIOWANIE STANOWISK PRACY
 WARTOŚCIOWANIE STANOWISK PRACY 1 Wartościowanie stanowisk korzyści Przegląd organizacji pracy w przedsiębiorstwie, Lepsze wzajemne poznanie treści pracy na stanowiskach Uporządkowanie, lub sporządzenie
WARTOŚCIOWANIE STANOWISK PRACY 1 Wartościowanie stanowisk korzyści Przegląd organizacji pracy w przedsiębiorstwie, Lepsze wzajemne poznanie treści pracy na stanowiskach Uporządkowanie, lub sporządzenie
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
LISTA 1 ZADANIE 1 a) 41 x =5 podnosimy obustronnie do kwadratu i otrzymujemy: 41 x =5 x 5 x przechodzimy na system dziesiętny: 4x 1 1=25 4x =24
 41 x =5 podnosimy obustronnie do kwadratu i otrzymujemy: 41 x =5 x 5 x przechodzimy na system dziesiętny: 4x 1 1=25 4x =24") LISTA 1 ZADANIE 1 a) 41 x =5 podnosimy obustronnie do kwadratu i otrzymujemy: 41 x =5 x 5 x przechodzimy na system dziesiętny: 4x 1 1=25 4x =24 x=6 ODP: Podstawą (bazą), w której spełniona jest ta zależność
LISTA 1 ZADANIE 1 a) 41 x =5 podnosimy obustronnie do kwadratu i otrzymujemy: 41 x =5 x 5 x przechodzimy na system dziesiętny: 4x 1 1=25 4x =24 x=6 ODP: Podstawą (bazą), w której spełniona jest ta zależność
Klasa 1 technikum. Poniżej przedstawiony został podział wymagań na poszczególne oceny szkolne:
 Klasa 1 technikum Przedmiotowy system oceniania wraz z wymaganiami edukacyjnymi Wyróżnione zostały następujące wymagania programowe: konieczne (K), podstawowe (P), rozszerzające (R), dopełniające (D) i
Klasa 1 technikum Przedmiotowy system oceniania wraz z wymaganiami edukacyjnymi Wyróżnione zostały następujące wymagania programowe: konieczne (K), podstawowe (P), rozszerzające (R), dopełniające (D) i
Politechnika Gdańska Wydział Elektrotechniki i Automatyki Katedra Inżynierii Systemów Sterowania
 Politechnika Gdańska Wydział Elektrotechniki i Automatyki Katedra Inżynierii Systemów Sterowania KOMPUTEROWE SYSTEMY STEROWANIA I WSPOMAGANIA DECYZJI Rozproszone programowanie produkcji z wykorzystaniem
Politechnika Gdańska Wydział Elektrotechniki i Automatyki Katedra Inżynierii Systemów Sterowania KOMPUTEROWE SYSTEMY STEROWANIA I WSPOMAGANIA DECYZJI Rozproszone programowanie produkcji z wykorzystaniem
5c. Sieci i przepływy
 5c. Sieci i przepływy Grzegorz Kosiorowski Uniwersytet Ekonomiczny w Krakowie zima 2016/2017 rzegorz Kosiorowski (Uniwersytet Ekonomiczny w Krakowie) 5c. Sieci i przepływy zima 2016/2017 1 / 40 1 Definicje
5c. Sieci i przepływy Grzegorz Kosiorowski Uniwersytet Ekonomiczny w Krakowie zima 2016/2017 rzegorz Kosiorowski (Uniwersytet Ekonomiczny w Krakowie) 5c. Sieci i przepływy zima 2016/2017 1 / 40 1 Definicje
ZAGADNIENIA PROGRAMOWE I WYMAGANIA EDUKACYJNE DO TESTU PRZYROSTU KOMPETENCJI Z MATEMATYKI DLA UCZNIA KLASY II
 ZAGADNIENIA PROGRAMOWE I WYMAGANIA EDUKACYJNE DO TESTU PRZYROSTU KOMPETENCJI Z MATEMATYKI DLA UCZNIA KLASY II POZIOM ROZSZERZONY Równania i nierówności z wartością bezwzględną. rozwiązuje równania i nierówności
ZAGADNIENIA PROGRAMOWE I WYMAGANIA EDUKACYJNE DO TESTU PRZYROSTU KOMPETENCJI Z MATEMATYKI DLA UCZNIA KLASY II POZIOM ROZSZERZONY Równania i nierówności z wartością bezwzględną. rozwiązuje równania i nierówności
Algorytmy wyznaczania centralności w sieci Szymon Szylko
 Algorytmy wyznaczania centralności w sieci Szymon Szylko Zakład systemów Informacyjnych Wrocław 10.01.2008 Agenda prezentacji Cechy sieci Algorytmy grafowe Badanie centralności Algorytmy wyznaczania centralności
Algorytmy wyznaczania centralności w sieci Szymon Szylko Zakład systemów Informacyjnych Wrocław 10.01.2008 Agenda prezentacji Cechy sieci Algorytmy grafowe Badanie centralności Algorytmy wyznaczania centralności
FUNKCJA LINIOWA - WYKRES. y = ax + b. a i b to współczynniki funkcji, które mają wartości liczbowe
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. - funkcja dwóch zmiennych,
 IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. Definicja 1.1. Niech D będzie podzbiorem przestrzeni R n, n 2. Odwzorowanie f : D R nazywamy
IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. Definicja 1.1. Niech D będzie podzbiorem przestrzeni R n, n 2. Odwzorowanie f : D R nazywamy
Algorytmy sortujące i wyszukujące
 Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Wyszukiwanie binarne
 Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Wyszukiwanie binarne Wyszukiwanie binarne to technika pozwalająca na przeszukanie jakiegoś posortowanego zbioru danych w czasie logarytmicznie zależnym od jego wielkości (co to dokładnie znaczy dowiecie
Rozwiązania zadań. Arkusz Maturalny z matematyki nr 1 POZIOM ROZSZERZONY. Aby istniały dwa różne pierwiastki równania kwadratowego wyróżnik
 Rozwiązania zadań Arkusz Maturalny z matematyki nr 1 POZIOM ROZSZERZONY Zadanie 1 (5pkt) Równanie jest kwadratowe, więc Aby istniały dwa różne pierwiastki równania kwadratowego wyróżnik /:4 nierówności
Rozwiązania zadań Arkusz Maturalny z matematyki nr 1 POZIOM ROZSZERZONY Zadanie 1 (5pkt) Równanie jest kwadratowe, więc Aby istniały dwa różne pierwiastki równania kwadratowego wyróżnik /:4 nierówności
D. Miszczyńska, M.Miszczyński KBO UŁ 1 GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO
 D. Miszczyńska, M.Miszczyński KBO UŁ GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO Gra w sensie niżej przedstawionym to zasady którymi kierują się decydenci. Zakładamy, że rezultatem gry jest wypłata,
D. Miszczyńska, M.Miszczyński KBO UŁ GRY KONFLIKTOWE GRY 2-OSOBOWE O SUMIE WYPŁAT ZERO Gra w sensie niżej przedstawionym to zasady którymi kierują się decydenci. Zakładamy, że rezultatem gry jest wypłata,
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Algorytmy i struktury danych
 Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
Algorytmy i struktury danych Proste algorytmy sortowania Witold Marańda maranda@dmcs.p.lodz.pl 1 Pojęcie sortowania Sortowaniem nazywa się proces ustawiania zbioru obiektów w określonym porządku Sortowanie
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Wielokryteriowa optymalizacja liniowa cz.2
 Wielokryteriowa optymalizacja liniowa cz.2 Metody poszukiwania końcowych rozwiązań sprawnych: 1. Metoda satysfakcjonujących poziomów kryteriów dokonuje się wyboru jednego z kryteriów zadania wielokryterialnego
Wielokryteriowa optymalizacja liniowa cz.2 Metody poszukiwania końcowych rozwiązań sprawnych: 1. Metoda satysfakcjonujących poziomów kryteriów dokonuje się wyboru jednego z kryteriów zadania wielokryterialnego
Spośród licznych filtrów nieliniowych najlepszymi właściwościami odznacza się filtr medianowy prosty i skuteczny.
 Filtracja nieliniowa może być bardzo skuteczną metodą polepszania jakości obrazów Filtry nieliniowe Filtr medianowy Spośród licznych filtrów nieliniowych najlepszymi właściwościami odznacza się filtr medianowy
Filtracja nieliniowa może być bardzo skuteczną metodą polepszania jakości obrazów Filtry nieliniowe Filtr medianowy Spośród licznych filtrów nieliniowych najlepszymi właściwościami odznacza się filtr medianowy
1 Całki funkcji wymiernych
 Całki funkcji wymiernych Definicja. Funkcją wymierną nazywamy iloraz dwóch wielomianów. Całka funkcji wymiernej jest więc postaci: W (x) W (x) = an x n + a n x n +... + a x + a 0 b m x m + b m x m +...
Całki funkcji wymiernych Definicja. Funkcją wymierną nazywamy iloraz dwóch wielomianów. Całka funkcji wymiernej jest więc postaci: W (x) W (x) = an x n + a n x n +... + a x + a 0 b m x m + b m x m +...
A. Arkusz standardowy GM-A1, B1, C1 oraz arkusze przystosowane: GM-A4, GM-A5, GM-A6 1.
 GM Charakterystyka arkuszy egzaminacyjnych A. Arkusz standardowy GM-A1, B1, C1 oraz arkusze przystosowane: GM-A4, GM-A5, GM-A6 1. Zestaw egzaminacyjny z zakresu przedmiotów matematyczno-przyrodniczych
GM Charakterystyka arkuszy egzaminacyjnych A. Arkusz standardowy GM-A1, B1, C1 oraz arkusze przystosowane: GM-A4, GM-A5, GM-A6 1. Zestaw egzaminacyjny z zakresu przedmiotów matematyczno-przyrodniczych
Dr inż. Robert Wójcik, p. 313, C-3, tel Katedra Informatyki Technicznej (K-9) Wydział Elektroniki (W-4) Politechnika Wrocławska
 Wydział Elektroniki (W-4) Politechnika Wrocławska") Dr inż. Robert Wójcik, p. 313, C-3, tel. 320-27-40 Katedra Informatyki Technicznej (K-9) Wydział Elektroniki (W-4) Politechnika Wrocławska E-mail: Strona internetowa: robert.wojcik@pwr.edu.pl google: Wójcik
Dr inż. Robert Wójcik, p. 313, C-3, tel. 320-27-40 Katedra Informatyki Technicznej (K-9) Wydział Elektroniki (W-4) Politechnika Wrocławska E-mail: Strona internetowa: robert.wojcik@pwr.edu.pl google: Wójcik
5. Bazy danych Base Okno bazy danych
 5. Bazy danych Base 5.1. Okno bazy danych Podobnie jak inne aplikacje środowiska OpenOffice, program do tworzenia baz danych uruchamia się po wybraniu polecenia Start/Programy/OpenOffice.org 2.4/OpenOffice.org
5. Bazy danych Base 5.1. Okno bazy danych Podobnie jak inne aplikacje środowiska OpenOffice, program do tworzenia baz danych uruchamia się po wybraniu polecenia Start/Programy/OpenOffice.org 2.4/OpenOffice.org
Systemy Wyszukiwania Informacji
 Systemy Wyszukiwania Informacji METODA LIST INWERSYJNYCH OPRACOWALI: Filip Kuliński Adam Pokoleńczuk Sprawozdanie zawiera: Przedstawienie kartoteki wtórnej Przedstawienie kartoteki wyszukiwawczej (inwersyjne)
Systemy Wyszukiwania Informacji METODA LIST INWERSYJNYCH OPRACOWALI: Filip Kuliński Adam Pokoleńczuk Sprawozdanie zawiera: Przedstawienie kartoteki wtórnej Przedstawienie kartoteki wyszukiwawczej (inwersyjne)
Przedmiotowy system oceniania wraz z określeniem wymagań edukacyjnych klasa druga zakres rozszerzony
 Przedmiotowy system oceniania wraz z określeniem wymagań edukacyjnych klasa druga zakres rozszerzony Wymagania konieczne (K) dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, zatem
Przedmiotowy system oceniania wraz z określeniem wymagań edukacyjnych klasa druga zakres rozszerzony Wymagania konieczne (K) dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, zatem
Dekompozycja w systemach wyszukiwania informacji
 METODY DEKOMPOZYCJI: Dekompozycja w systemach wyszukiwania informacji ATRYBUTOWA OBIEKTOWA HIERARCHICZNA (zależna i wymuszona) Dekompozycje mają cel wtedy kiedy zachodzi któryś z poniższych warunków: Duża
METODY DEKOMPOZYCJI: Dekompozycja w systemach wyszukiwania informacji ATRYBUTOWA OBIEKTOWA HIERARCHICZNA (zależna i wymuszona) Dekompozycje mają cel wtedy kiedy zachodzi któryś z poniższych warunków: Duża
Kurs ZDAJ MATURĘ Z MATEMATYKI - MODUŁ 11 Teoria planimetria
 1 Pomimo, że ten dział, to typowa geometria wydawałoby się trudny dział to paradoksalnie troszkę tu odpoczniemy, jeśli chodzi o teorię. Dlaczego? Otóż jak zapewne doskonale wiesz, na maturze otrzymasz
1 Pomimo, że ten dział, to typowa geometria wydawałoby się trudny dział to paradoksalnie troszkę tu odpoczniemy, jeśli chodzi o teorię. Dlaczego? Otóż jak zapewne doskonale wiesz, na maturze otrzymasz
Programowanie liniowe metoda sympleks
 Programowanie liniowe metoda sympleks Mirosław Sobolewski Wydział Matematyki, Informatyki i Mechaniki UW wykład z algebry liniowej Warszawa, styczeń 2009 Mirosław Sobolewski (UW) Warszawa, 2009 1 / 13
Programowanie liniowe metoda sympleks Mirosław Sobolewski Wydział Matematyki, Informatyki i Mechaniki UW wykład z algebry liniowej Warszawa, styczeń 2009 Mirosław Sobolewski (UW) Warszawa, 2009 1 / 13
Wykrywanie twarzy na zdjęciach przy pomocy kaskad
 Wykrywanie twarzy na zdjęciach przy pomocy kaskad Analiza i przetwarzanie obrazów Sebastian Lipnicki Informatyka Stosowana,WFIIS Spis treści 1. Wstęp... 3 2. Struktura i funkcjonalnośd... 4 3. Wyniki...
Wykrywanie twarzy na zdjęciach przy pomocy kaskad Analiza i przetwarzanie obrazów Sebastian Lipnicki Informatyka Stosowana,WFIIS Spis treści 1. Wstęp... 3 2. Struktura i funkcjonalnośd... 4 3. Wyniki...
Wykład 4 Przebieg zmienności funkcji. Badanie dziedziny oraz wyznaczanie granic funkcji poznaliśmy na poprzednich wykładach.
 Wykład Przebieg zmienności funkcji. Celem badania przebiegu zmienności funkcji y = f() jest poznanie ważnych własności tej funkcji na podstawie jej wzoru. Efekty badania pozwalają naszkicować wykres badanej
Wykład Przebieg zmienności funkcji. Celem badania przebiegu zmienności funkcji y = f() jest poznanie ważnych własności tej funkcji na podstawie jej wzoru. Efekty badania pozwalają naszkicować wykres badanej
Automatyczna klasyfikacja zespołów QRS
 Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
WYRAŻENIA ALGEBRAICZNE
 WYRAŻENIA ALGEBRAICZNE Wyrażeniem algebraicznym nazywamy wyrażenie zbudowane z liczb, liter, nawiasów oraz znaków działań, na przykład: Symbole literowe występujące w wyrażeniu algebraicznym nazywamy zmiennymi.
WYRAŻENIA ALGEBRAICZNE Wyrażeniem algebraicznym nazywamy wyrażenie zbudowane z liczb, liter, nawiasów oraz znaków działań, na przykład: Symbole literowe występujące w wyrażeniu algebraicznym nazywamy zmiennymi.
Algorytm. Krótka historia algorytmów
 Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Algorytm znaczenie cybernetyczne Jest to dokładny przepis wykonania w określonym porządku skończonej liczby operacji, pozwalający na rozwiązanie zbliżonych do siebie klas problemów. znaczenie matematyczne
Efektywność Projektów Inwestycyjnych. 1. Mierniki opłacalności projektów inwestycyjnych Metoda Wartości Bieżącej Netto - NPV
 Efektywność Projektów Inwestycyjnych Jednym z najczęściej modelowanych zjawisk przy użyciu arkusza kalkulacyjnego jest opłacalność przedsięwzięcia inwestycyjnego. Skuteczność arkusza kalkulacyjnego w omawianym
Efektywność Projektów Inwestycyjnych Jednym z najczęściej modelowanych zjawisk przy użyciu arkusza kalkulacyjnego jest opłacalność przedsięwzięcia inwestycyjnego. Skuteczność arkusza kalkulacyjnego w omawianym
FUNKCJA WYMIERNA. Poziom podstawowy
 FUNKCJA WYMIERNA Poziom podstawowy Zadanie Wykonaj działania i podaj niezbędne założenia: a+ a) + ; ( pkt.) a+ a a b) + + ; ( pkt.) + m m m c) :. ( pkt.) m m+ Zadanie ( pkt.) Oblicz wartość liczbową wyrażenia
FUNKCJA WYMIERNA Poziom podstawowy Zadanie Wykonaj działania i podaj niezbędne założenia: a+ a) + ; ( pkt.) a+ a a b) + + ; ( pkt.) + m m m c) :. ( pkt.) m m+ Zadanie ( pkt.) Oblicz wartość liczbową wyrażenia
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
Scenariusz zajęć. Moduł VI. Projekt Gra logiczna zgadywanie liczby
 Scenariusz zajęć Moduł VI Projekt Gra logiczna zgadywanie liczby Moduł VI Projekt Gra logiczna zgadywanie liczby Cele ogólne: przypomnienie i utrwalenie poznanych wcześniej poleceń i konstrukcji języka
Scenariusz zajęć Moduł VI Projekt Gra logiczna zgadywanie liczby Moduł VI Projekt Gra logiczna zgadywanie liczby Cele ogólne: przypomnienie i utrwalenie poznanych wcześniej poleceń i konstrukcji języka
CMAES. Zapis algorytmu. Generacja populacji oraz selekcja Populacja q i (t) w kroku t generowana jest w następujący sposób:
 w kroku t generowana jest w następujący sposób:") CMAES Covariance Matrix Adaptation Evolution Strategy Opracowanie: Lidia Wojciechowska W algorytmie CMAES, podobnie jak w algorytmie EDA, adaptowany jest rozkład prawdopodobieństwa generacji punktów, opisany
CMAES Covariance Matrix Adaptation Evolution Strategy Opracowanie: Lidia Wojciechowska W algorytmie CMAES, podobnie jak w algorytmie EDA, adaptowany jest rozkład prawdopodobieństwa generacji punktów, opisany
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
ERGODESIGN - Podręcznik użytkownika. Wersja 1.0 Warszawa 2010
 ERGODESIGN - Podręcznik użytkownika Wersja 1.0 Warszawa 2010 Spis treści Wstęp...3 Organizacja menu nawigacja...3 Górne menu nawigacyjne...3 Lewe menu robocze...4 Przestrzeń robocza...5 Stopka...5 Obsługa
ERGODESIGN - Podręcznik użytkownika Wersja 1.0 Warszawa 2010 Spis treści Wstęp...3 Organizacja menu nawigacja...3 Górne menu nawigacyjne...3 Lewe menu robocze...4 Przestrzeń robocza...5 Stopka...5 Obsługa
PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II
 PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II Szkic wykładu 1 Wprowadzenie 2 3 4 5 Weryfikacja hipotez statystycznych Obok estymacji drugim działem wnioskowania statystycznego jest weryfikacja hipotez
PODSTAWY WNIOSKOWANIA STATYSTYCZNEGO czȩść II Szkic wykładu 1 Wprowadzenie 2 3 4 5 Weryfikacja hipotez statystycznych Obok estymacji drugim działem wnioskowania statystycznego jest weryfikacja hipotez