Agnieszka Nowak Brzezińska
|
|
|
- Robert Włodarczyk
- 8 lat temu
- Przeglądów:
Transkrypt


1 Agnieszka Nowak Brzezińska

2

3
4
5 jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia Dany jest zbiór uczący zawierający obserwacje z których każda ma przypisany wektor zmiennych objaśniających oraz wartośd zmiennej objaśnianej Y. Dana jest obserwacja C z przypisanym wektorem zmiennych objaśniających dla której chcemy prognozowad wartośd zmiennej objaśnianej Y.
6
7
8 Wyznaczanie odległości obiektów: odległość euklidesowa
9 Obiekty są analizowane w ten sposób, że oblicza się odległości bądź podobieństwa między nimi. Istnieją różne miary podobieństwa czy odległości. Powinny być one wybierane konkretnie dla typu danych analizowanych: inne są bowiem miary typowo dla danych binarnych, inne dla danych nominalnych a inne dla danych numerycznych. Nazwa Wzór gdzie: x,y - to wektory wartości cech porównywanych obiektów w przestrzeni p- wymiarowej, gdzie odpowiednio wektory wartości to: oraz. odległośd euklidesowa odległośd kątowa współczynnik korelacji liniowej Pearsona Miara Gowera
10 Oblicz odległość punktu A o współrzędnych (2,3) do punktu B o współrzędnych (7,8) A B D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07
11 9 8 B A A B C 2 1 C Mając dane punkty: A(2,3), B(7,8) oraz C(5,1) oblicz odległości między punktami: D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07 D (A,C) = pierwiastek ((5-2) 2 + (3-1) 2 ) = pierwiastek (9 + 4) = pierwiastek (13) = 3.60 D (B,C) = pierwiastek ((7-5) 2 + (3-8) 2 ) = pierwiastek (4 + 25) = pierwiastek (29) = 5.38
12 1. porównanie wartości zmiennych objaśniających dla obserwacji C z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym. 2. wybór k (ustalona z góry liczba) najbliższych do C obserwacji ze zbioru uczącego. 3. Uśrednienie wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę. Przez "najbliższą obserwację" mamy na myśli, taką obserwację, której odległośd do analizowanej przez nas obserwacji jest możliwie najmniejsza.

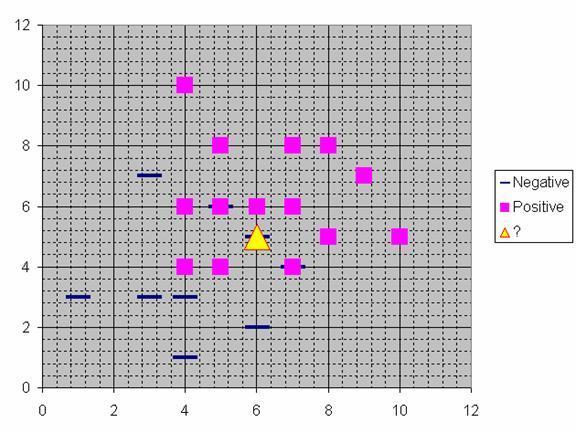
13 Obiekt klasyfikowany podany jako ostatni : a = 3, b = 6 Teraz obliczmy odległości poszczególnych obiektów od wskazanego. Dla uproszczenia obliczeń posłużymy sie wzorem:
14
15

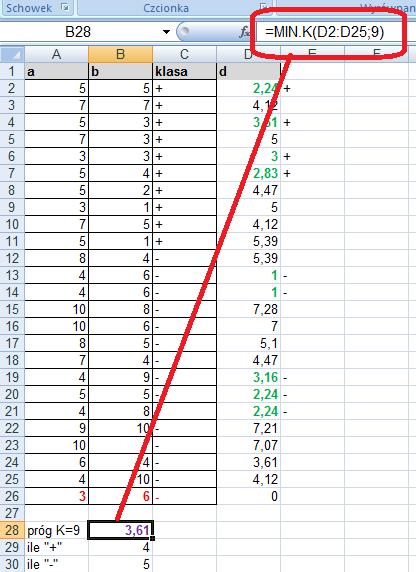
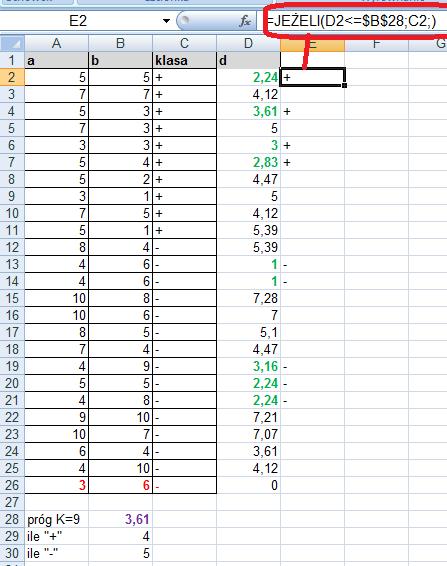
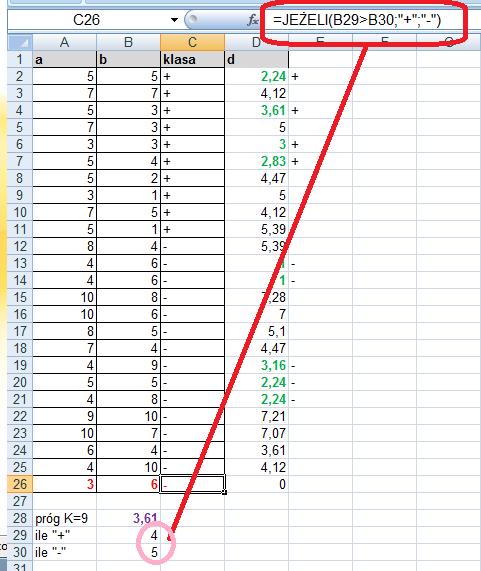
16 Znajdujemy więc k najbliższych sąsiadów. Załóżmy, że szukamy 9 najbliższych sąsiadów. Wyróżnimy ich kolorem zielonym. Sprawdzamy, które z tych 9 najbliższych sąsiadów są z klasy + a które z klasy -? By to zrobić musimy znaleźć k najbliższych sąsiadów (funkcja Excela o nazwie MIN.K)
17
18
19 Wyobraźmy sobie, że nie mamy 2 zmiennych opisujących każdy obiekt, ale tych zmiennych jest np. 5: {v1,v2,v3,v4,v5} i że obiekty opisane tymi zmiennymi to 3 punkty: A, B i C: V1 V2 V3 V4 V5 A B C Policzmy teraz odległość między punktami: D (A,B) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.03) = 0.17 D (A,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.69) = 0.83 D (B,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.74) = 0.86 Szukamy najmniejszej odległości, bo jeśli te dwa punkty są najbliżej siebie, dla których mamy najmniejszą odległości! A więc najmniejsza odległość jest między punktami A i B!
20
21
22
23

24
25
26

27 Schemat algorytmu: Poszukaj obiektu najbliższego w stosunku do obiektu klasyfikowanego. Określenie klasy decyzyjnej na podstawie obiektu najbliższego. Cechy algorytmu: Bardziej odporny na szumy - w poprzednim algorytmie obiekt najbliższy klasyfikowanemu może być zniekształcony - tak samo zostanie zaklasyfikowany nowy obiekt. Konieczność ustalenia liczby najbliższych sąsiadów. Wyznaczenie miary podobieństwa wśród obiektów (wiele miar podobieństwa). Dobór parametru k - liczby sąsiadów: Jeśli k jest małe, algorytm nie jest odporny na szumy jakość klasyfikacji jest niska. Jeśli k jest duże, czas działania algorytmu rośnie - większa złożoność obliczeniowa. Należy wybrać k, które daje najwyższą wartość klasyfikacji.

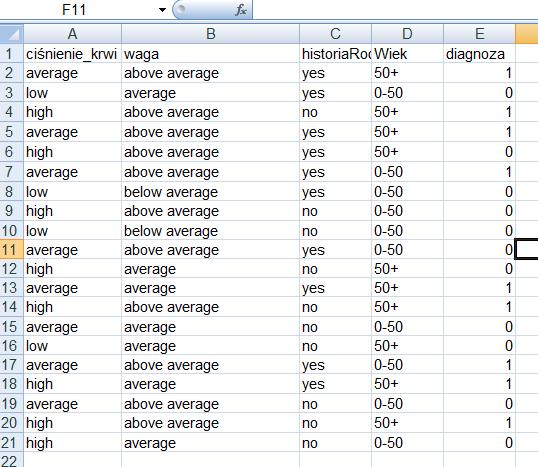
28 Wykonaj algorytm k-nn dla zbioru: Sklasyfikuj przypadek:
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
X Y 4,0 3,3 8,0 6,8 12,0 11,0 16,0 15,2 20,0 18,9
 Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Określanie ważności atrybutów. RapidMiner
 Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Teoria prawdopodobieństwa i elementy kombinatoryki 3. Zmienne losowe 4. Populacje i próby danych 5. Testowanie hipotez i estymacja parametrów 6. Test t 7. Test
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Teoria prawdopodobieństwa i elementy kombinatoryki 3. Zmienne losowe 4. Populacje i próby danych 5. Testowanie hipotez i estymacja parametrów 6. Test t 7. Test
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Rozpoznawanie wzorców. Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki
 Rozpoznawanie wzorców Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Twierzdzenie: Prawdopodobieostwo, że n obserwacji wybranych
Rozpoznawanie wzorców Dr inż. Michał Bereta p. 144 / 10, Instytut Informatyki mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Twierzdzenie: Prawdopodobieostwo, że n obserwacji wybranych
Statystyczna analiza danych
 Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Korelacja krzywoliniowa i współzależność cech niemierzalnych
 Korelacja krzywoliniowa i współzależność cech niemierzalnych Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki Szczecińskiej
Korelacja krzywoliniowa i współzależność cech niemierzalnych Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki Szczecińskiej
Prognozowanie na podstawie modelu ekonometrycznego
 Prognozowanie na podstawie modelu ekonometrycznego Przykład. Firma usługowa świadcząca usługi doradcze w ostatnich kwartałach (t) odnotowała wynik finansowy (yt - tys. zł), obsługując liczbę klientów (x1t)
Prognozowanie na podstawie modelu ekonometrycznego Przykład. Firma usługowa świadcząca usługi doradcze w ostatnich kwartałach (t) odnotowała wynik finansowy (yt - tys. zł), obsługując liczbę klientów (x1t)
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
STATYSTYKA OPISOWA. Dr Alina Gleska. 12 listopada Instytut Matematyki WE PP
 STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 12 listopada 2017 1 Analiza współzależności dwóch cech 2 Jednostka zbiorowości - para (X,Y ). Przy badaniu korelacji nie ma znaczenia, która
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
WYKŁAD 12. Analiza obrazu Wyznaczanie parametrów ruchu obiektów
 WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania
WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania
Projekt Sieci neuronowe
 Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Analiza współzależności dwóch cech I
 Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny 2. Zmienne losowe i teoria prawdopodobieństwa 3. Populacje i próby danych 4. Testowanie hipotez i estymacja parametrów 5. Najczęściej wykorzystywane testy statystyczne
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Uczenie się pojedynczego neuronu. Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z<0 y=1 gdy z>=0. Wówczas: W 1 x 1 + w 2 x 2 + = 0
 Uczenie się pojedynczego neuronu W0 X0=1 W1 x1 W2 s f y x2 Wp xp p x i w i=x w+wo i=0 Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z=0 Wówczas: W 1 x 1 + w 2 x 2 + = 0 Algorytm
Uczenie się pojedynczego neuronu W0 X0=1 W1 x1 W2 s f y x2 Wp xp p x i w i=x w+wo i=0 Jeśli zastosowana zostanie funkcja bipolarna s y: y=-1 gdy z=0 Wówczas: W 1 x 1 + w 2 x 2 + = 0 Algorytm
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
Metody eksploracji danych 2. Metody regresji. Piotr Szwed Katedra Informatyki Stosowanej AGH 2017
 Metody eksploracji danych 2. Metody regresji Piotr Szwed Katedra Informatyki Stosowanej AGH 2017 Zagadnienie regresji Dane: Zbiór uczący: D = {(x i, y i )} i=1,m Obserwacje: (x i, y i ), wektor cech x
Metody eksploracji danych 2. Metody regresji Piotr Szwed Katedra Informatyki Stosowanej AGH 2017 Zagadnienie regresji Dane: Zbiór uczący: D = {(x i, y i )} i=1,m Obserwacje: (x i, y i ), wektor cech x
Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON.
 Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON. Zadanie 6. Dane są punkty A=(5; 2); B=(1; -3); C=(-2; -8). Oblicz odległość punktu A od prostej l przechodzącej
Propozycje rozwiązań zadań otwartych z próbnej matury rozszerzonej przygotowanej przez OPERON. Zadanie 6. Dane są punkty A=(5; 2); B=(1; -3); C=(-2; -8). Oblicz odległość punktu A od prostej l przechodzącej
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo przynależności obiektu do klasy. Opiera się na twierdzeniu Bayesa. Twierdzenia
Agnieszka Nowak Brzezińska Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo przynależności obiektu do klasy. Opiera się na twierdzeniu Bayesa. Twierdzenia
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY
 JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
JEDNORÓWNANIOWY LINIOWY MODEL EKONOMETRYCZNY Będziemy zapisywać wektory w postaci (,, ) albo traktując go jak macierz jednokolumnową (dzięki temu nie będzie kontrowersji przy transponowaniu wektora ) Model
Optymalizacja systemów
 Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Wojciech Skwirz
 1 Regularyzacja jako metoda doboru zmiennych objaśniających do modelu statystycznego. 2 Plan prezentacji 1. Wstęp 2. Część teoretyczna - Algorytm podziału i ograniczeń - Regularyzacja 3. Opis wyników badania
1 Regularyzacja jako metoda doboru zmiennych objaśniających do modelu statystycznego. 2 Plan prezentacji 1. Wstęp 2. Część teoretyczna - Algorytm podziału i ograniczeń - Regularyzacja 3. Opis wyników badania
Sieci neuronowe w Statistica
 http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Wstęp do metod numerycznych Uwarunkowanie Eliminacja Gaussa. P. F. Góra
 Wstęp do metod numerycznych Uwarunkowanie Eliminacja Gaussa P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Uwarunkowanie zadania numerycznego Niech ϕ : R n R m będzie pewna funkcja odpowiednio wiele
Wstęp do metod numerycznych Uwarunkowanie Eliminacja Gaussa P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2012 Uwarunkowanie zadania numerycznego Niech ϕ : R n R m będzie pewna funkcja odpowiednio wiele
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane.
 Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Metodologia badań psychologicznych. Wykład 12. Korelacje
 Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Wykład 12. Korelacje Korelacja Korelacja występuje wtedy gdy dwie różne miary dotyczące tych samych osób, zdarzeń lub obiektów
Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Wykład 12. Korelacje Korelacja Korelacja występuje wtedy gdy dwie różne miary dotyczące tych samych osób, zdarzeń lub obiektów
Podstawy opracowania wyników pomiarów z elementami analizy niepewności pomiarowych
 Podstawy opracowania wyników pomiarów z elementami analizy niepewności pomiarowych dla studentów Biologii A i B dr hab. Paweł Korecki e-mail: pawel.korecki@uj.edu.pl http://www.if.uj.edu.pl/pl/edukacja/pracownia_i/
Podstawy opracowania wyników pomiarów z elementami analizy niepewności pomiarowych dla studentów Biologii A i B dr hab. Paweł Korecki e-mail: pawel.korecki@uj.edu.pl http://www.if.uj.edu.pl/pl/edukacja/pracownia_i/
Mikroekonometria 6. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Regresyjne metody łączenia klasyfikatorów
 Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART. MiNI PW
 WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
WYKŁAD 13 ANALIZA I ROZPOZNANIE OBRAZU. Konstrukcja wektora cech z użyciem współczynników kształtu
 WYKŁAD 13 ANALIZA I ROZPOZNANIE OBRAZU Współczynniki kształtu W1,...,W9 stanowią skalarną miarę kształtu analizowanego obiektu. Konstrukcja wektora cech z użyciem współczynników kształtu Wektor cech: x
WYKŁAD 13 ANALIZA I ROZPOZNANIE OBRAZU Współczynniki kształtu W1,...,W9 stanowią skalarną miarę kształtu analizowanego obiektu. Konstrukcja wektora cech z użyciem współczynników kształtu Wektor cech: x
Optymalizacja konstrukcji
 Optymalizacja konstrukcji Kształtowanie konstrukcyjne: nadanie właściwych cech konstrukcyjnych przeszłej maszynie określenie z jakiego punktu widzenia (wg jakiego kryterium oceny) będą oceniane alternatywne
Optymalizacja konstrukcji Kształtowanie konstrukcyjne: nadanie właściwych cech konstrukcyjnych przeszłej maszynie określenie z jakiego punktu widzenia (wg jakiego kryterium oceny) będą oceniane alternatywne
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Matura próbna 2014 z matematyki-poziom podstawowy
 Matura próbna 2014 z matematyki-poziom podstawowy Klucz odpowiedzi do zadań zamkniętych zad 1 2 3 4 5 6 7 8 9 10 11 12 odp A C C C A A B B C B D A 13 14 15 16 17 18 19 20 21 22 23 24 25 C C A B A D C B
Matura próbna 2014 z matematyki-poziom podstawowy Klucz odpowiedzi do zadań zamkniętych zad 1 2 3 4 5 6 7 8 9 10 11 12 odp A C C C A A B B C B D A 13 14 15 16 17 18 19 20 21 22 23 24 25 C C A B A D C B
Po zapoznaniu się z funkcją liniową możemy przyjśd do badania funkcji kwadratowej.
 Po zapoznaniu się z funkcją liniową możemy przyjśd do badania funkcji kwadratowej. Definicja 1 Jednomianem stopnia drugiego nazywamy funkcję postaci: i a 0. Dziedziną tej funkcji jest zbiór liczb rzeczywistych
Po zapoznaniu się z funkcją liniową możemy przyjśd do badania funkcji kwadratowej. Definicja 1 Jednomianem stopnia drugiego nazywamy funkcję postaci: i a 0. Dziedziną tej funkcji jest zbiór liczb rzeczywistych
SPIS TREŚCI WSTĘP... 8 1. LICZBY RZECZYWISTE 2. WYRAŻENIA ALGEBRAICZNE 3. RÓWNANIA I NIERÓWNOŚCI
 SPIS TREŚCI WSTĘP.................................................................. 8 1. LICZBY RZECZYWISTE Teoria............................................................ 11 Rozgrzewka 1.....................................................
SPIS TREŚCI WSTĘP.................................................................. 8 1. LICZBY RZECZYWISTE Teoria............................................................ 11 Rozgrzewka 1.....................................................
Mgr Kornelia Uczeń. WYMAGANIA na poszczególne oceny-klasa VII-Szkoła Podstawowa
 Mgr Kornelia Uczeń WYMAGANIA na poszczególne oceny-klasa VII-Szkoła Podstawowa Oceny z plusem lub minusem otrzymują uczniowie, których wiadomości i umiejętności znajdują się na pograniczu wymagań danej
Mgr Kornelia Uczeń WYMAGANIA na poszczególne oceny-klasa VII-Szkoła Podstawowa Oceny z plusem lub minusem otrzymują uczniowie, których wiadomości i umiejętności znajdują się na pograniczu wymagań danej
Lista 3 Funkcje. Środkowa częśd podanej funkcji, to funkcja stała. Jej wykresem będzie poziomy odcinek na wysokości 4.
 Lista 3 Funkcje. Zad 1. Narysuj wykres funkcji. Przykład 1:. Zacznijmy od sporządzenia tabelki dla każdej części podanej funkcji, uwzględniając podany zakres argumentów (dziedzinę): Weźmy na początek funkcję,
Lista 3 Funkcje. Zad 1. Narysuj wykres funkcji. Przykład 1:. Zacznijmy od sporządzenia tabelki dla każdej części podanej funkcji, uwzględniając podany zakres argumentów (dziedzinę): Weźmy na początek funkcję,
Wykład 10 Skalowanie wielowymiarowe
 Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY
 MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY WYKORZYSTANIU METOD STATYSTYCZNYCH mgr Małgorzata Pelczar 6 Wprowadzenie Reforma służby zdrowia uwypukliła problem optymalnego ustalania kosztów usług zdrowotnych.
MODELOWANIE KOSZTÓW USŁUG ZDROWOTNYCH PRZY WYKORZYSTANIU METOD STATYSTYCZNYCH mgr Małgorzata Pelczar 6 Wprowadzenie Reforma służby zdrowia uwypukliła problem optymalnego ustalania kosztów usług zdrowotnych.
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych