Zastosowanie metody Cross Entropy Clustering w biometrii Krzysztof Misztal
|
|
|
- Dorota Brzozowska
- 6 lat temu
- Przeglądów:
Transkrypt

1 Zastosowanie metody Cross Entropy Clustering w biometrii Krzysztof Misztal (krzysztofmisztal@ujedupl)
2 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania 1 / 62
3 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania 2 / 62
4 Motywacja R skrypt 1 R skrypt 2 R skrypt 4 3 / 62
5 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania 4 / 62
6 Kompresja danych Zbiór danych do zakodowania x = {x 1, x 2,, x n } Zbiór symboli kodowych C = {c 1, c 2,, c n } Uwaga Zazwyczaj rozważamy C = {0, 1} Zbiór prawdopodobieństw P = {f 1, f 2,, f n } 5 / 62
7 Przykład Przykład ABCDBCDCDD x = {A, B, C, D} P = {01, 02, 03, 04} 6 / 62
8 Przykład Przykład ABCDBCDCDD x = {A, B, C, D} P = {01, 02, 03, 04} 1 A 111 l(a) = 3 2 B 000 l(b) = 3 3 C 1 l(c) = 1 4 D 0 l(d) = 1 6 / 62
9 Przykład Przykład ABCDBCDCDD x = {A, B, C, D} P = {01, 02, 03, 04} 1 A 111 l(a) = 3 2 B 000 l(b) = 3 3 C 1 l(c) = 1 4 D 0 l(d) = AD -?? - CCCD 6 / 62
10 Przykład Przykład ABCDBCDCDD x = {A, B, C, D} P = {01, 02, 03, 04} 1 A 111, l(a) = 4 2 B 000, l(b) = 4 3 C 1, l(c) = 2 4 D 0, l(d) = 2 111,0 1,1,1,0 AD CCCD 6 / 62
11 Jednoznacznie dekodowalny kod Oczekiwana długość kodu to: E(X ) = n f i l(x i ) i=1 Nierówność Krafta-McMillana: warunkiem koniecznym, który musi spełniać kod, aby był jednoznacznie dekodowalny n 2 l i (x i ) 1 i=1 7 / 62
12 Jednoznacznie dekodowalny kod Oczekiwana długość kodu to: E(X ) = n f i l(x i ) i=1 Nierówność Krafta-McMillana: warunkiem koniecznym, który musi spełniać kod, aby był jednoznacznie dekodowalny n 2 l i (x i ) 1 i=1 Przykład (I) = 5 4 > 1 (II) = 5 8 < 1 7 / 62
13 Cel Naszym celem jest minimalizowanie L(l 1,, l n ) := p i l i z warunkiem i=1,,n 2 l i 1 8 / 62
14 Cel Naszym celem jest minimalizowanie L(l 1,, l n ) := p i l i z warunkiem 2 l i 1 i=1,,n Optymalne długości kodów zadane są l i = log 2 f i 8 / 62
15 Cel Naszym celem jest minimalizowanie z warunkiem L(l 1,, l n ) := p i l i i=1,,n 2 l i 1 Optymalne długości kodów zadane są l i = log 2 f i Zatem minimum jest osiągnięte dla kodów o długości zadanej przez entropię h(x ) := i f i l i = i f i ( log 2 f i ) 8 / 62
16 Kodowanie Huffmana Przykład ABCDBCDCDDF S = {A, B, C, D, F } P = {03, 03, 02, 015, 005} 9 / 62

17 Kodowanie Huffmana Przykład ABCDBCDCDDF S = {A, B, C, D, F } P = {03, 03, 02, 015, 005} 9 / 62
18 Kodowanie Huffmana Przykład ABCDBCDCDDF S = {A, B, C, D, F } P = {03, 03, 02, 015, 005} 1 A 00 2 B 01 3 C 10 4 D F / 62
19 Kodowanie Huffmana Przykład ABCDBCDCDDF S = {A, B, C, D, F } P = {03, 03, 02, 015, 005} 1 A 00 2 B 01 3 C 10 4 D F 111 Przykład E(X ) = 22 h(x ) = / 62
20 Entropia krzyżowa (cross entropy) Załóżmy teraz, że chcemy zakodować zmienną losową Y (która przyjmuje takie same wartości jak zmienna X, czyli x 1,, x n, ale zgodnie z innym rozkładem gęstości g i ) kodem zdefiniowanym dla zmienne losowej X (o rozkładzie f i ) Wtedy entropia krzyżowa (cross entropy) h (Y X ) opisująca oczekiwaną długość kodu dana jest przez h (Y X ) := i g i ( log 2 f i ) 10 / 62
21 Entropia krzyżowa (cross entropy) Załóżmy teraz, że chcemy zakodować zmienną losową Y (która przyjmuje takie same wartości jak zmienna X, czyli x 1,, x n, ale zgodnie z innym rozkładem gęstości g i ) kodem zdefiniowanym dla zmienne losowej X (o rozkładzie f i ) Wtedy entropia krzyżowa (cross entropy) h (Y X ) opisująca oczekiwaną długość kodu dana jest przez h (Y X ) := i g i ( log 2 f i ) Entropia krzyżowa jest minimalizowana, gdy X =Y, wtedy uzyskujemy po prostu entropię Zatem entropię krzyżową możemy traktować jako sposób porównywania modeli, im bliżej nam do entropii tym lepszym przybliżeniem Y jest zmienna losowa X 10 / 62
22 Entropia krzyżowa h (Y X ) := i g i ( log 2 f i ) Przykład x = {A, B, C, D} P = {01, 02, 03, 04} G = {025, 025, 025, 025} L = {07, 01, 01, 01} 11 / 62
23 Entropia krzyżowa h (Y X ) := i g i ( log 2 f i ) Przykład x = {A, B, C, D} P = {01, 02, 03, 04} G = {025, 025, 025, 025} L = {07, 01, 01, 01} h(x ) = h (Y X P ) = / 62
24 Entropia krzyżowa h (Y X ) := i g i ( log 2 f i ) Przykład x = {A, B, C, D} P = {01, 02, 03, 04} G = {025, 025, 025, 025} L = {07, 01, 01, 01} h(x ) = h (Y X P ) = h (Y X G ) = 2 11 / 62
25 Entropia krzyżowa h (Y X ) := i g i ( log 2 f i ) Przykład x = {A, B, C, D} P = {01, 02, 03, 04} G = {025, 025, 025, 025} L = {07, 01, 01, 01} h(x ) = h (Y X P ) = h (Y X G ) = 2 h (Y X L ) = / 62
26 Entropia krzyżowa h (Y X ) := i g i ( log 2 f i ) Przykład x = {A, B, C, D} P = {01, 02, 03, 04} G = {025, 025, 025, 025} L = {07, 01, 01, 01} h(x ) = h (Y X P ) = h (Y X G ) = 2 h (Y X L ) = / 62
27 Entropia różniczkowa (differential entropy) Entropia różniczkowa (differential entropy) zadana jest wzorem H(X ) := f (x) ( log 2 f (x))dx, gdzie f oznacza rozkład prawdopodobiestwa zmiennej losowej X 12 / 62
28 Entropia krzyżowa Jeśli chcemy kodować zmienną Y (która opisana jest ciągłym rozkładem g) kodem optymalnym dla zmiennej X (opisanej ciągłym rozkładem f ) to entropia krzyżowa H (Y X ) := g(y) ( ln f (y))dy 13 / 62
29 Entropia krzyżowa Jeśli chcemy kodować zmienną Y (która opisana jest ciągłym rozkładem g) kodem optymalnym dla zmiennej X (opisanej ciągłym rozkładem f ) to entropia krzyżowa H (Y X ) := g(y) ( ln f (y))dy Przez entropię krzyżową zbioru X względem gęstości f rozumiemy H (X f ) = 1 ln(f (x)) X x X 13 / 62
30 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania 14 / 62
31 Algorytm EM (expectation maximization) W ogólnym przypadku algorytm EM znajduje p 1,, p k 0 : k p i = 1, (1) oraz f 1,, f k F, dla ustalonej rodziny F, (zazwyczaj rodzina rozkładów normalnych) tworzących wypukłe kombinacje gęstości postaci f := p 1 f 1 + p k f k (2) najlepiej opisujących rozważany zbiór danych X = {x 1,, x n } i=1 15 / 62
32 Algorytm EM (expectation maximization) Optymalizacja jest rozważana względem funkcji kosztu zadanej przez MLE 1 (maximum likelihood estimation funkcja największej wiarygodności) EM(f, X ) = 1 X n ln ( p 1 f 1 (x j ) + + p k f k (x j ) ), (3) j=1 gdzie X oznacza liczność zbioru X 1 Ponieważ w grupowaniu zazwyczaj minimalizujemy koszt, więc w takich przypadkach funkcja (3) rozważana jest z przeciwnym znakiem 16 / 62
33 Idea algorytmu CEC Celem algorytmu CEC jest minimalizowanie funkcji kosztu (podobnej do tej z równania (3), gdzie wymieniamy sumę na maksimum): CEC(f, X ) := 1 X n ln ( max(p 1 f 1 (x j ),, p k f k (x j )) ), (4) j=1 gdzie p i dla i = 1,, k spełniają warunek R script 3 p 1,, p k 0 : k p i = 1 i=1 17 / 62
34 Idea algorytmu CEC W przypadku podziału X R N na parami rozłączne zbiory X 1,, X k takie, że każdy z nich jest kodowany z wykorzystaniem gęstości f i możemy pokazać, że średnia długość kodu dla losowo wybranego elementu x X wynosi CEC(X 1, f 1 ; ; X k, f k ) = gdzie p i = X i X k p i ( ln(p i ) + H (X i f i ) ), (5) i=1 18 / 62
35 Idea algorytmu CEC Efektywne wyznaczanie mieszaniny modeli w CEC-u wymaga wyznaczenia optymalnej wartości kodowania zmiennej X względem rodziny gęstości F, czyli H (X F) := inf f F H (X f ) 19 / 62
36 Idea algorytmu CEC Warunek optymalności Podsumowując, dla zadanych rodzin gęstości F 1,, F n celem algorytmu CEC jest podział zbioru X na k (zbiory mogą być puste) parami rozłączne zbiory X 1,, X k takie, że wartość CEC(X 1, F 1 ; ; X k, F k ) := k p i ( ln(p i ) + H (X i F i ) ), (6) i=1 jest minimalna (gdzie p i = X i X ) 20 / 62
37 Grupowanie CEC problemy Generalnie są dwa problemy: jak policzyć H ( X i F i ) dla wybranej rodziny rozkładów F i, 21 / 62
38 Grupowanie CEC problemy Generalnie są dwa problemy: jak policzyć H ( X i F i ) dla wybranej rodziny rozkładów F i, jak dobrać rodzinę F i tak, aby spełniała nasze oczekiwania 21 / 62
39 Klastrowanie CEC dobór modelu Twierdzenie ([Tabor and Spurek, 2014]) Niech X R N będzie zbiorem z ustaloną średnią m X oraz macierzą kowariancji Σ X Wtedy H ( ) N X G Σ = 2 ln(2π) tr(σ 1 Σ X ) + 1 ln det(σ), (7) 2 gdzie G Σ oznacza wszystkie rozkłady normalne z macierzą kowariancji Σ Dowód tego twierdzenia znajduje się w artykule [Tabor and Spurek, 2014] 22 / 62
 = Σ H (y G Σ ) = N 2 ln(2π) + 1 2 tr(σ 1 Σ X ) + 1 2 ln det(σ) 23 /")
40 Klastrowanie CEC dobór modelu 1 G Σ rozkłady normalne z ustaloną kowariancją Σ W tym przypadku będziemy mieli tendencję do podziału zbioru na grupy kul zadanych przez odległość Mahalanobisa Σ [Tabor and Spurek, 2014] Σ GΣ (X ) = Σ H (y G Σ ) = N 2 ln(2π) tr(σ 1 Σ X ) ln det(σ) 23 / 62
 = ri H (X G ri ) = N 2 ln(2π) + N 2 ln(r) + 1 2r tr(σ X ) 24")
41 Klastrowanie CEC dobór modelu 2 G ri podrodzina G Σ, dla Σ = ri oraz ustalonego r > 0 Grupowanie będzie zadane przez sferyczne rozkłady normalne zadane przez macierz kowariancji r I, czyli kule o określonym promieniu proporcjonalnym do r [Tabor and Spurek, 2014] Σ GrI (X ) = ri H (X G ri ) = N 2 ln(2π) + N 2 ln(r) + 1 2r tr(σ X ) 24 / 62
 (X ) = tr(σ X ) N I H (X G ( I ) ) = N 2 ln(2πe/n) + N 2 ln(trσ X ) 25")
42 Klastrowanie CEC dobór modelu 3 G ( I ) sferyczne rozkłady normalne Grupowanie będzie zrealizowane przez sferyczne rozkłady normalne, czyli kule o dowolnym promieniu [Tabor and Spurek, 2014] Σ G( I ) (X ) = tr(σ X ) N I H (X G ( I ) ) = N 2 ln(2πe/n) + N 2 ln(trσ X ) 25 / 62
43 Klastrowanie CEC dobór modelu 4 G diag rozkłady normalne o diagonalnej macierzy kowariancji Grupowanie zrealizowane będzie przez elipsy o osiach równoległych do osi układu współrzędnych [Tabor and Spurek, 2014] Σ Gdiag (X ) = diag(σ X ) H (X G diag ) = N 2 ln(2πe) ln(det(diag(σ X ))) 26 / 62
44 Klastrowanie CEC dobór modelu 5 G λ1,,λ N rozkłady normalne o macierzy kowariancji z zadanymi wartościami własnymi λ 1,, λ N takimi, że λ 1 λ N Grupowanie będzie dzieliło zbiór na elipsy o ustalonym kształcie, ale obrócone o dowolny kąt [Tabor and Misztal, 2013] Σ G (X ) = Σ λ1,,λ N ( ) H (X G λ1,,λ N ) = N 2 ln(2π)+ 1 Ni=1 λ X i 2 λ i ln Ni=1 λ i 27 / 62
 = Σ X H (X G) = N 2 ln(2πe) + 1 2 ln det(σ X ) 28 /")
45 Klastrowanie CEC dobór modelu 6 G dowolne rozkłady normalne W tym najbardziej ogólnym przypadku zbiór dzielony będzie na dowolne elipsy [Tabor and Spurek, 2014] Σ G (X ) = Σ X H (X G) = N 2 ln(2πe) ln det(σ X ) 28 / 62
46 CEC przyklady R script 5 R script 6 29 / 62
47 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania Segmentacja tekstu Segmentacja tęczówki vs CEC Cel Algorytm Optymalizacja Rezultat Rozpoznawanie tesktów z wykorzystaniem CEC-a i jego modyfikacji 30 / 62
48 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania Segmentacja tekstu Segmentacja tęczówki vs CEC Rozpoznawanie tesktów z wykorzystaniem CEC-a i jego modyfikacji 31 / 62
 Progowanie CEC [Malik et al, 2016] 32 /")
49 Segmentacja tekstu: Otsu vs CEC (a) Zeskanowany tekst (b) Progowanie Otsu (c) Progowanie CEC [Malik et al, 2016] 32 / 62
50 Segmentacja tekstu: Otsu vs CEC (a) Otsu (b) CEC (c) Otsu (d) CEC 33 / 62
51 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania Segmentacja tekstu Segmentacja tęczówki vs CEC Rozpoznawanie tesktów z wykorzystaniem CEC-a i jego modyfikacji 34 / 62
52 Co chcemy osiągnąć? 35 / 62

53 Co chcemy osiągnąć? 35 / 62
54 Co chcemy osiągnąć? 36 / 62
55 Algorytm [Misztal et al, 2016] 1 Maskowanie Gaussem 2 Regresja 3 Filtrowanie 4 Klastrowanie 5 Optymalizacja 37 / 62
56 Maskowanie Gaussem Cel kroku: Usunięcie zbędnych elementów/obszarów ze zdjęcia Oryginalne zdjęcie 38 / 62

57 Maskowanie Gaussem Oryginalne zdjęcie Gauss ze zdjęcia 38 / 62
 38 /")
58 Maskowanie Gaussem Oryginalne zdjęcie Iris + Gauss ze zdjęcia (w = 03) 38 / 62
59 Maskowanie Gaussem Oryginalne zdjęcie Iris + Gauss ze zdjęcia (w = 03) 39 / 62
60 Maskowanie Gaussem Oryginalne zdjęcie Iris + Gauss ze zdjęcia (w = 03) Cel osiągnięty, bo otrzymałem dużo białego koloru na zdjęciu 39 / 62
61 Po co tutaj regresja? Co chcę znaleźć? 40 / 62
62 Po co tutaj regresja? Co chcę znaleźć? Problem Kolor w źrenicy nie jest równomierny (identyczny) 40 / 62
63 Po co tutaj regresja? Co chcę znaleźć? Problem Kolor w źrenicy nie jest równomierny (identyczny) Nawet maskowanie Gaussem nie pomaga, a wręcz psuje jeszcze bardziej 41 / 62

64 Po co tutaj regresja? Co chcę znaleźć? Rozwiązanie Wyznaczmy płaszczyznę i względem niej poprawmy zdjęcie 41 / 62
65 Jak policzyć regresję? Problem Chcemy wyznaczyć płaszczyznę najlepiej dopasowaną do danych 42 / 62
66 Jak policzyć regresję? Problem Chcemy wyznaczyć płaszczyznę najlepiej dopasowaną do danych Rozwiązanie 1 Należy wyliczyć gdzie X = β = (X T X ) 1 X T y 1 x 1 y 1 1 x n y n y = z i punkty (x i, y i, z i ) to obraz, β = (β 0, β 1, β 2 ) dadzą płaszczyznę z n 42 / 62
67 Jak policzyć regresję? Problem Chcemy wyznaczyć płaszczyznę najlepiej dopasowaną do danych Rozwiązanie 1 Należy wyliczyć gdzie X = β = (X T X ) 1 X T y 1 x 1 y 1 1 x n y n y = z i punkty (x i, y i, z i ) to obraz, β = (β 0, β 1, β 2 ) dadzą płaszczyznę z n 42 / 62

68 Regresja 43 / 62
69 Regresja 43 / 62
70 Filtrowanie 1 Wykonujemy po to aby ograniczyć liczbę szczegółów na zdjęciu 44 / 62
71 Filtrowanie 1 Wykonujemy po to aby ograniczyć liczbę szczegółów na zdjęciu 2 Wykorzystujemy filtry minimalny (Min) i maksymalny (Max) 44 / 62
72 Filtrowanie Przed 45 / 62
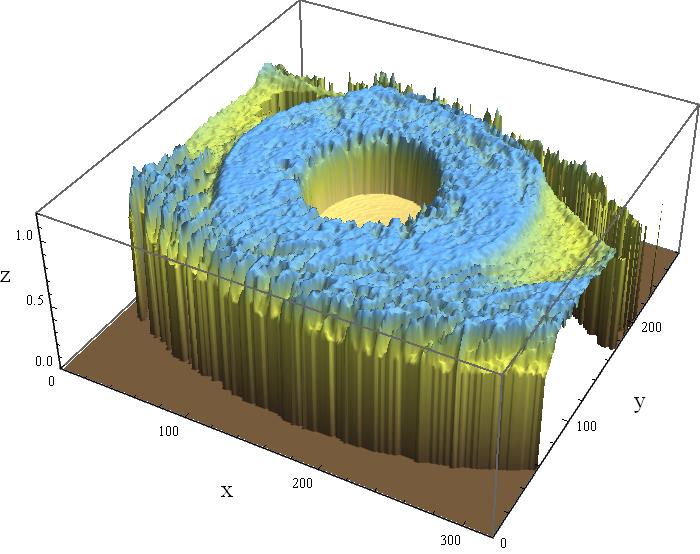
73 Filtrowanie Po 45 / 62
74 Klastrowanie CEC Implementacje CEC-a w R: pakiet CEC, w Javie: 46 / 62
75 Klastrowanie CEC dobór modelu Jaką elipsę chcemy znaleźć? 47 / 62
76 Klastrowanie CEC dobór modelu Jaką elipsę chcemy znaleźć? spłaszczoną, tzn względem osi OX i OY może mieć dowolne wymiary, ale chcemy aby w OZ musi być chuda, 47 / 62
77 Klastrowanie CEC dobór modelu Jaką elipsę chcemy znaleźć? spłaszczoną, tzn względem osi OX i OY może mieć dowolne wymiary, ale chcemy aby w OZ musi być chuda, dodatkowo chcemy aby była ona równoległą do płaszczyzny OXY 47 / 62
78 Klastrowanie CEC dobór modelu Szukana macierz kowariancji: Jaką elipsę chcemy znaleźć? spłaszczoną, tzn względem osi OX i OY może mieć dowolne wymiary, ale chcemy aby w OZ musi być chuda, dodatkowo chcemy aby była ona równoległą do płaszczyzny OXY a 11 a 12 0 a 11 a 12 a 13 Σ ε = a 21 a 22 0, gdzie Σ = a 21 a 22 a ε a 31 a 32 a 33 Σ empiryczna, Σ ε teoretyczna, ε małe, ustalone 47 / 62
79 Klastrowanie Po CEC-u Klastrowanie CEC z 20 klastrami itermax=50, nstart=24, type=c( special ) 48 / 62
")
80 Klastrowanie Po CEC-u Klastrowanie CEC z 20 klastrami itermax=50, nstart=24, type=c( special ) 48 / 62
81 Optymalizacja W tym kroku: wybierzemy klastry tęczówki i źrenicy, usuniemy zbędne punkty z klastrów 49 / 62
82 Optymalizacja dwa klastry Dwa klastry o najmniejszej wariancji w OZ 50 / 62
83 Optymalizacja usuwanie zbędnych punktów Twierdzenie ([Misztal and Tabor, 2013]) Dla rozkładu jednostajnego na elipsie E R N o średniej m E i macierzy kowariancji Σ E zachodzi E = B ΣE (m E, ) N + 2 (8) B ΣE (µ E, r) = {x R N : (x µ E ) T Σ 1 E (x m E ) r 2 } 51 / 62
84 Optymalizacja Do klastra tęczówki dodano punkty z klastra źrenicy cały zbiór będziemy optymalizować 52 / 62

85 Optymalizacja Do klastra tęczówki dodano punkty z klastra źrenicy cały zbiór będziemy optymalizować 52 / 62
86 Optymalizacja Do klastra tęczówki dodano punkty z klastra źrenicy cały zbiór będziemy optymalizować 52 / 62
87 Optymalizacja Do klastra tęczówki dodano punkty z klastra źrenicy cały zbiór będziemy optymalizować 52 / 62
88 Optymalizacja Do klastra tęczówki dodano punkty z klastra źrenicy cały zbiór będziemy optymalizować 52 / 62
89 Wynik końcowy 53 / 62
90 Algorytm 1 Maskowanie Gaussem CEC z jednym klastrem itermax=1, nstart=1, type=c( all ) 2 Regresja 3 Filtrowanie Min, Max x n 4 Klastrowanie CEC z 20 klastrami itermax=50, nstart=24, type=c( special ) 5 Optymalizacja usuwanie wystających części 54 / 62
91 Spis treści 1 Motywacja 2 Entropia 3 Ogólna idea Cross Entropy Clustering 4 Zastosowania Segmentacja tekstu Segmentacja tęczówki vs CEC Rozpoznawanie tesktów z wykorzystaniem CEC-a i jego modyfikacji 55 / 62

92 Zonning podstawowy algorytm 56 / 62
 Uniform-CEC 57 / 62")
93 Prostokątny CEC (a) CEC (b) Uniform-CEC 57 / 62
 Poziomice wygitego rozkładu normalnego 58 /")
94 Wygięty CEC (a) Poziomice rozkładu normalnego (b) Poziomice wygitego rozkładu normalnego 58 / 62
95 Wygięty CEC (a) GMM, k = 8 (b) CEC, k = 7 (c) afcec, k = 5 [Spurek et al, 2017] 59 / 62
96 Dziękuję za uwagę 60 / 62
97 Bibliography I [0] Jain, A K, Ross, A, and Prabhakar, S (2004) An introduction to biometric recognition Circuits and Systems for Video Technology, IEEE Transactions on, 14(1):4 20 [0] Malik, M, Spurek, P, and Tabor, J (2016) Cross-entropy based image thresholding Schedae Informaticae, 24:21 29 [0] Misztal, K, Saeed, E, Saeed, K, Spurek, P, and Tabor, J (2016) Cross entropy clustering approach to iris segmentation for biometrics purpose Schedae Informaticae, 24:31 40 [0] Misztal, K and Tabor, J (2013) Mahalanobis distance-based algorithm for ellipse growing in iris preprocessing In Computer Information Systems and Industrial Management, volume 8104, pages Lecture Notes in Computer Science, Springer Berlin Heidelberg [0] Spurek, P (2017) General split gaussian cross entropy clustering Expert Systems with Applications, 68:58 68 [0] Spurek, P, Kamieniecki, K, Tabor, J, Misztal, K, and Śmieja, M (2016) R package cec Neurocomputing 61 / 62
98 Bibliography II [0] Spurek, P, Tabor, J, and Byrski, K (2017) Active function cross-entropy clustering Expert Systems with Applications, 72:49 66 [0] Spurek, P, Tabor, J, and Zając, E (2013) Detection of disk-like particles in electron microscopy images In Proceedings of the 8th International Conference on Computer Recognition Systems CORES 2013, pages Springer International Publishing [0] Tabor, J and Misztal, K (2013) Detection of elliptical shapes via cross-entropy clustering In Iberian Conference on Pattern Recognition and Image Analysis, pages Springer Berlin Heidelberg [0] Tabor, J and Spurek, P (2014) Cross-entropy clustering Pattern Recognition, 47(9): [0] Tomczyk, A, Spurek, P, Podgórski, M, Misztal, K, and Tabor, J (2016) Detection of elongated structures with hierarchical active partitions and cec-based image representation In Proceedings of the 9th International Conference on Computer Recognition Systems CORES 2015, pages Springer International Publishing 62 / 62
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Prawdopodobieństwo i statystyka
 Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
Statystyka i eksploracja danych
 Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
zadania z rachunku prawdopodobieństwa zapożyczone z egzaminów aktuarialnych
 zadania z rachunku prawdopodobieństwa zapożyczone z egzaminów aktuarialnych 1. [E.A 5.10.1996/zad.4] Funkcja gęstości dana jest wzorem { 3 x + 2xy + 1 y dla (x y) (0 1) (0 1) 4 4 P (X > 1 2 Y > 1 2 ) wynosi:
zadania z rachunku prawdopodobieństwa zapożyczone z egzaminów aktuarialnych 1. [E.A 5.10.1996/zad.4] Funkcja gęstości dana jest wzorem { 3 x + 2xy + 1 y dla (x y) (0 1) (0 1) 4 4 P (X > 1 2 Y > 1 2 ) wynosi:
Metoda momentów i kwantyli próbkowych. Wrocław, 7 listopada 2014
 Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Metoda momentów i kwantyli próbkowych Wrocław, 7 listopada 2014 Metoda momentów Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa. Momenty zmiennych losowych X 1, X 2,..., X n - próba losowa.
Podstawowe modele probabilistyczne
 Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Elementy teorii informacji i kodowania
 i kodowania Entropia, nierówność Krafta, kodowanie optymalne Marcin Jenczmyk m.jenczmyk@knm.katowice.pl 17 kwietnia 2015 M. Jenczmyk Spotkanie KNM i kodowania 1 / 20 Niech S = {x 1,..., x q } oznacza alfabet,
i kodowania Entropia, nierówność Krafta, kodowanie optymalne Marcin Jenczmyk m.jenczmyk@knm.katowice.pl 17 kwietnia 2015 M. Jenczmyk Spotkanie KNM i kodowania 1 / 20 Niech S = {x 1,..., x q } oznacza alfabet,
Prawdopodobieństwo i statystyka r.
 Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Granica kompresji Kodowanie Shannona Kodowanie Huffmana Kodowanie ciągów Kodowanie arytmetyczne. Kody. Marek Śmieja. Teoria informacji 1 / 35
 Kody Marek Śmieja Teoria informacji 1 / 35 Entropia Entropia określa minimalną statystyczną długość kodowania (przyjmijmy dla prostoty że alfabet kodowy A = {0, 1}). Definicja Niech X = {x 1,..., x n }
Kody Marek Śmieja Teoria informacji 1 / 35 Entropia Entropia określa minimalną statystyczną długość kodowania (przyjmijmy dla prostoty że alfabet kodowy A = {0, 1}). Definicja Niech X = {x 1,..., x n }
5. Analiza dyskryminacyjna: FLD, LDA, QDA
 Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Teoria informacji i kodowania Ćwiczenia
 Teoria informacji i kodowania Ćwiczenia Piotr Chołda, Andrzej Kamisiński Katedra Telekomunikacji Akademii Górniczo-Hutniczej Kod źródłowy Kodem źródłowym nazywamy funkcję różnowartościową, która elementom
Teoria informacji i kodowania Ćwiczenia Piotr Chołda, Andrzej Kamisiński Katedra Telekomunikacji Akademii Górniczo-Hutniczej Kod źródłowy Kodem źródłowym nazywamy funkcję różnowartościową, która elementom
Kodowanie i entropia
 Kodowanie i entropia Marek Śmieja Teoria informacji 1 / 34 Kod S - alfabet źródłowy mocy m (np. litery, cyfry, znaki interpunkcyjne), A = {a 1,..., a n } - alfabet kodowy (symbole), Chcemy przesłać tekst
Kodowanie i entropia Marek Śmieja Teoria informacji 1 / 34 Kod S - alfabet źródłowy mocy m (np. litery, cyfry, znaki interpunkcyjne), A = {a 1,..., a n } - alfabet kodowy (symbole), Chcemy przesłać tekst
Matematyka ubezpieczeń majątkowych r.
 Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Komputerowa analiza danych doświadczalnych
 Komputerowa analiza danych doświadczalnych Wykład 9 7.04.09 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 08/09 Metoda największej wiarygodności ierównosć informacyjna Metoda
Komputerowa analiza danych doświadczalnych Wykład 9 7.04.09 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 08/09 Metoda największej wiarygodności ierównosć informacyjna Metoda
WYKŁAD 6. Witold Bednorz, Paweł Wolff. Rachunek Prawdopodobieństwa, WNE, Uniwersytet Warszawski. 1 Instytut Matematyki
 WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
Oznacza to, że chcemy znaleźć minimum, a właściwie wartość najmniejszą funkcji
 Wykład 11. Metoda najmniejszych kwadratów Szukamy zależności Dane są wyniki pomiarów dwóch wielkości x i y: (x 1, y 1 ), (x 2, y 2 ),..., (x n, y n ). Przypuśćmy, że nanieśliśmy je na wykres w układzie
Wykład 11. Metoda najmniejszych kwadratów Szukamy zależności Dane są wyniki pomiarów dwóch wielkości x i y: (x 1, y 1 ), (x 2, y 2 ),..., (x n, y n ). Przypuśćmy, że nanieśliśmy je na wykres w układzie
Kodowanie i kompresja Streszczenie Studia dzienne Wykład 9,
 1 Kody Tunstalla Kodowanie i kompresja Streszczenie Studia dzienne Wykład 9, 14.04.2005 Inne podejście: słowa kodowe mają ustaloną długość, lecz mogą kodować ciągi liter z alfabetu wejściowego o różnej
1 Kody Tunstalla Kodowanie i kompresja Streszczenie Studia dzienne Wykład 9, 14.04.2005 Inne podejście: słowa kodowe mają ustaloną długość, lecz mogą kodować ciągi liter z alfabetu wejściowego o różnej
PEWNE FAKTY Z RACHUNKU PRAWDOPODOBIEŃSTWA
 PEWNE FAKTY Z RACHUNKU PRAWDOPODOBIEŃSTWA 1. Trójkę (Ω, F, P ), gdzie Ω, F jest σ-ciałem podzbiorów Ω, a P jest prawdopodobieństwem określonym na F, nazywamy przestrzenią probabilistyczną. 2. Rodzinę F
PEWNE FAKTY Z RACHUNKU PRAWDOPODOBIEŃSTWA 1. Trójkę (Ω, F, P ), gdzie Ω, F jest σ-ciałem podzbiorów Ω, a P jest prawdopodobieństwem określonym na F, nazywamy przestrzenią probabilistyczną. 2. Rodzinę F
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Kodowanie informacji
 Kodowanie informacji Tomasz Wykład 4: kodowanie arytmetyczne Motywacja Podstawy i własności Liczby rzeczywiste Motywacje 1 średnia długość kodu Huffmana może odbiegać o p max + 0.086 od entropii, gdzie
Kodowanie informacji Tomasz Wykład 4: kodowanie arytmetyczne Motywacja Podstawy i własności Liczby rzeczywiste Motywacje 1 średnia długość kodu Huffmana może odbiegać o p max + 0.086 od entropii, gdzie
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Prawdopodobieństwo i statystyka r.
 Prawdopodobieństwo i statystyka 9.06.999 r. Zadanie. Rzucamy pięcioma kośćmi do gry. Następnie rzucamy ponownie tymi kośćmi, na których nie wypadły szóstki. W trzeciej rundzie rzucamy tymi kośćmi, na których
Prawdopodobieństwo i statystyka 9.06.999 r. Zadanie. Rzucamy pięcioma kośćmi do gry. Następnie rzucamy ponownie tymi kośćmi, na których nie wypadły szóstki. W trzeciej rundzie rzucamy tymi kośćmi, na których
10. Redukcja wymiaru - metoda PCA
 Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych:
 W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
METODY ESTYMACJI PUNKTOWEJ. nieznanym parametrem (lub wektorem parametrów). Przez X będziemy też oznaczać zmienną losową o rozkładzie
. Przez X będziemy też oznaczać zmienną losową o rozkładzie") METODY ESTYMACJI PUNKTOWEJ X 1,..., X n - próbka z rozkładu P θ, θ Θ, θ jest nieznanym parametrem (lub wektorem parametrów). Przez X będziemy też oznaczać zmienną losową o rozkładzie P θ. Definicja. Estymatorem
METODY ESTYMACJI PUNKTOWEJ X 1,..., X n - próbka z rozkładu P θ, θ Θ, θ jest nieznanym parametrem (lub wektorem parametrów). Przez X będziemy też oznaczać zmienną losową o rozkładzie P θ. Definicja. Estymatorem
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU
 ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU obraz dr inż. Jacek Naruniec Analiza Składowych Niezależnych (ICA) Independent Component Analysis Dąży do wyznaczenia zmiennych niezależnych z obserwacji Problem opiera
ANALIZA SEMANTYCZNA OBRAZU I DŹWIĘKU obraz dr inż. Jacek Naruniec Analiza Składowych Niezależnych (ICA) Independent Component Analysis Dąży do wyznaczenia zmiennych niezależnych z obserwacji Problem opiera
Dyskretne procesy stacjonarne o nieskończonej entropii nadwyżkowej
 Dyskretne procesy stacjonarne o nieskończonej entropii nadwyżkowej Łukasz Dębowski ldebowsk@ipipan.waw.pl i Instytut Podstaw Informatyki PAN Co to jest entropia nadwyżkowa? Niech (X i ) i Z będzie procesem
Dyskretne procesy stacjonarne o nieskończonej entropii nadwyżkowej Łukasz Dębowski ldebowsk@ipipan.waw.pl i Instytut Podstaw Informatyki PAN Co to jest entropia nadwyżkowa? Niech (X i ) i Z będzie procesem
Zadanie 1. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k =
 Matematyka ubezpieczeń majątkowych 0.0.006 r. Zadanie. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k 5 Pr( N = k) =, k = 0,,,... 6 6 Wartości kolejnych szkód Y, Y,, są i.i.d.,
Matematyka ubezpieczeń majątkowych 0.0.006 r. Zadanie. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k 5 Pr( N = k) =, k = 0,,,... 6 6 Wartości kolejnych szkód Y, Y,, są i.i.d.,
Teoria Informacji - wykład. Kodowanie wiadomości
 Teoria Informacji - wykład Kodowanie wiadomości Definicja kodu Niech S={s 1, s 2,..., s q } oznacza dany zbiór elementów. Kodem nazywamy wówczas odwzorowanie zbioru wszystkich możliwych ciągów utworzonych
Teoria Informacji - wykład Kodowanie wiadomości Definicja kodu Niech S={s 1, s 2,..., s q } oznacza dany zbiór elementów. Kodem nazywamy wówczas odwzorowanie zbioru wszystkich możliwych ciągów utworzonych
Kwantyle. Kwantyl rzędu p rozkładu prawdopodobieństwa to taka liczba x p. , że. Możemy go obliczyć z dystrybuanty: P(X x p.
 Kwantyle Kwantyl rzędu p rozkładu prawdopodobieństwa to taka liczba x p, że P(X x p ) p P(X x p ) 1 p Możemy go obliczyć z dystrybuanty: Jeżeli F(x p ) = p, to x p jest kwantylem rzędu p Jeżeli F(x p )
Kwantyle Kwantyl rzędu p rozkładu prawdopodobieństwa to taka liczba x p, że P(X x p ) p P(X x p ) 1 p Możemy go obliczyć z dystrybuanty: Jeżeli F(x p ) = p, to x p jest kwantylem rzędu p Jeżeli F(x p )
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Komputerowa analiza danych doświadczalnych
 Komputerowa analiza danych doświadczalnych Wykład 9 27.04.2018 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 2017/2018 Metoda największej wiarygodności ierównosć informacyjna
Komputerowa analiza danych doświadczalnych Wykład 9 27.04.2018 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 2017/2018 Metoda największej wiarygodności ierównosć informacyjna
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 autorzy: A. Gonczarek, J.M. Tomczak Zbiory i funkcje wypukłe Zad. 1 Pokazać, że następujące zbiory są wypukłe: a) płaszczyzna S = {x
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 autorzy: A. Gonczarek, J.M. Tomczak Zbiory i funkcje wypukłe Zad. 1 Pokazać, że następujące zbiory są wypukłe: a) płaszczyzna S = {x
Szkice do zajęć z Przedmiotu Wyrównawczego
 Szkice do zajęć z Przedmiotu Wyrównawczego Matematyka Finansowa sem. letni 2011/2012 Spis treści Zajęcia 1 3 1.1 Przestrzeń probabilistyczna................................. 3 1.2 Prawdopodobieństwo warunkowe..............................
Szkice do zajęć z Przedmiotu Wyrównawczego Matematyka Finansowa sem. letni 2011/2012 Spis treści Zajęcia 1 3 1.1 Przestrzeń probabilistyczna................................. 3 1.2 Prawdopodobieństwo warunkowe..............................
KADD Minimalizacja funkcji
 Minimalizacja funkcji Poszukiwanie minimum funkcji Foma kwadratowa Metody przybliżania minimum minimalizacja Minimalizacja w n wymiarach Metody poszukiwania minimum Otaczanie minimum Podział obszaru zawierającego
Minimalizacja funkcji Poszukiwanie minimum funkcji Foma kwadratowa Metody przybliżania minimum minimalizacja Minimalizacja w n wymiarach Metody poszukiwania minimum Otaczanie minimum Podział obszaru zawierającego
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Metoda największej wiarygodności
 Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Prawdopodobieństwo i statystyka
 Wykład VII: Metody specjalne Monte Carlo 24 listopada 2014 Transformacje specjalne Przykład - symulacja rozkładu geometrycznego Niech X Ex(λ). Rozważmy zmienną losową [X ], która przyjmuje wartości naturalne.
Wykład VII: Metody specjalne Monte Carlo 24 listopada 2014 Transformacje specjalne Przykład - symulacja rozkładu geometrycznego Niech X Ex(λ). Rozważmy zmienną losową [X ], która przyjmuje wartości naturalne.
Metody Obliczeniowe w Nauce i Technice
 Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Statystyka matematyczna
 Statystyka matematyczna Wykład 6 Magdalena Alama-Bućko 8 kwietnia 019 Magdalena Alama-Bućko Statystyka matematyczna 8 kwietnia 019 1 / 1 Rozkłady ciagłe Magdalena Alama-Bućko Statystyka matematyczna 8
Statystyka matematyczna Wykład 6 Magdalena Alama-Bućko 8 kwietnia 019 Magdalena Alama-Bućko Statystyka matematyczna 8 kwietnia 019 1 / 1 Rozkłady ciagłe Magdalena Alama-Bućko Statystyka matematyczna 8
WYKŁAD 2 i 3. Podstawowe pojęcia związane z prawdopodobieństwem. Podstawy teoretyczne. autor: Maciej Zięba. Politechnika Wrocławska
 Wrocław University of Technology WYKŁAD 2 i 3 Podstawowe pojęcia związane z prawdopodobieństwem. Podstawy teoretyczne autor: Maciej Zięba Politechnika Wrocławska Pojęcie prawdopodobieństwa Prawdopodobieństwo
Wrocław University of Technology WYKŁAD 2 i 3 Podstawowe pojęcia związane z prawdopodobieństwem. Podstawy teoretyczne autor: Maciej Zięba Politechnika Wrocławska Pojęcie prawdopodobieństwa Prawdopodobieństwo
Teoria informacji i kodowania Ćwiczenia Sem. zimowy 2016/2017
 Kody źródłowe jednoznacznie dekodowalne Zadanie Ile najwięcej słów kodowych może liczyć kod binarny jednoznacznie dekodowalny, którego najdłuższe słowo ma siedem liter? (Odp. 28) Zadanie 2 Zbiór sześciu
Kody źródłowe jednoznacznie dekodowalne Zadanie Ile najwięcej słów kodowych może liczyć kod binarny jednoznacznie dekodowalny, którego najdłuższe słowo ma siedem liter? (Odp. 28) Zadanie 2 Zbiór sześciu
12DRAP - parametry rozkładów wielowymiarowych
 DRAP - parametry rozkładów wielowymiarowych Definicja.. Jeśli h : R R, a X, Y ) jest wektorem losowym o gęstości fx, y) to EhX, Y ) = hx, y)fx, y)dxdy. Jeśli natomiast X, Y ) ma rozkład dyskretny skupiony
DRAP - parametry rozkładów wielowymiarowych Definicja.. Jeśli h : R R, a X, Y ) jest wektorem losowym o gęstości fx, y) to EhX, Y ) = hx, y)fx, y)dxdy. Jeśli natomiast X, Y ) ma rozkład dyskretny skupiony
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład Kody liniowe - kodowanie w oparciu o macierz parzystości
 Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Wykład 3 Momenty zmiennych losowych.
 Wykład 3 Momenty zmiennych losowych. Wrocław, 19 października 2016r Momenty zmiennych losowych Wartość oczekiwana - przypomnienie Definicja 3.1: 1 Niech X będzie daną zmienną losową. Jeżeli X jest zmienną
Wykład 3 Momenty zmiennych losowych. Wrocław, 19 października 2016r Momenty zmiennych losowych Wartość oczekiwana - przypomnienie Definicja 3.1: 1 Niech X będzie daną zmienną losową. Jeżeli X jest zmienną
Wstęp do Rachunku Prawdopodobieństwa, IIr. WMS
 Wstęp do Rachunku Prawdopodobieństwa, IIr. WMS przykładowe zadania na. kolokwium czerwca 6r. Poniżej podany jest przykładowy zestaw zadań. Podczas kolokwium na ich rozwiązanie przeznaczone będzie ok. 85
Wstęp do Rachunku Prawdopodobieństwa, IIr. WMS przykładowe zadania na. kolokwium czerwca 6r. Poniżej podany jest przykładowy zestaw zadań. Podczas kolokwium na ich rozwiązanie przeznaczone będzie ok. 85
Rachunek prawdopodobieństwa i statystyka
 Rachunek prawdopodobieństwa i statystyka Momenty Zmienna losowa jest wystarczająco dokładnie opisana przez jej rozkład prawdopodobieństwa. Względy praktyczne dyktują jednak potrzebę znalezienia charakterystyk
Rachunek prawdopodobieństwa i statystyka Momenty Zmienna losowa jest wystarczająco dokładnie opisana przez jej rozkład prawdopodobieństwa. Względy praktyczne dyktują jednak potrzebę znalezienia charakterystyk
Wykład 3 Momenty zmiennych losowych.
 Wykład 3 Momenty zmiennych losowych. Wrocław, 18 października 2017r Momenty zmiennych losowych Wartość oczekiwana - przypomnienie Definicja 3.1: 1 Niech X będzie daną zmienną losową. Jeżeli X jest zmienną
Wykład 3 Momenty zmiennych losowych. Wrocław, 18 października 2017r Momenty zmiennych losowych Wartość oczekiwana - przypomnienie Definicja 3.1: 1 Niech X będzie daną zmienną losową. Jeżeli X jest zmienną
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE. Joanna Sawicka
 Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Generowanie liczb o zadanym rozkładzie. ln(1 F (y) λ
 λ") Wprowadzenie Generowanie liczb o zadanym rozkładzie Generowanie liczb o zadanym rozkładzie wejście X U(0, 1) wyjście Y z zadanego rozkładu F (y) = 1 e λy y = ln(1 F (y) λ = ln(1 0,1563 0, 5 0,34 Wprowadzenie
Wprowadzenie Generowanie liczb o zadanym rozkładzie Generowanie liczb o zadanym rozkładzie wejście X U(0, 1) wyjście Y z zadanego rozkładu F (y) = 1 e λy y = ln(1 F (y) λ = ln(1 0,1563 0, 5 0,34 Wprowadzenie
N ma rozkład Poissona z wartością oczekiwaną równą 100 M, M M mają ten sam rozkład dwupunktowy o prawdopodobieństwach:
 Zadanie. O niezależnych zmiennych losowych N, M M, M 2, 3 wiemy, że: N ma rozkład Poissona z wartością oczekiwaną równą 00 M, M M mają ten sam rozkład dwupunktowy o prawdopodobieństwach: 2, 3 Pr( M = )
Zadanie. O niezależnych zmiennych losowych N, M M, M 2, 3 wiemy, że: N ma rozkład Poissona z wartością oczekiwaną równą 00 M, M M mają ten sam rozkład dwupunktowy o prawdopodobieństwach: 2, 3 Pr( M = )
Stosowana Analiza Regresji
 Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Kody blokowe Wykład 5a;
 Kody blokowe Wykład 5a; 31.03.2011 1 1 Kolorowanie hiperkostki Definicja. W teorii grafów symbol Q n oznacza kostkę n-wymiarową, czyli graf o zbiorze wierzchołków V (Q n ) = {0, 1} n i zbiorze krawędzi
Kody blokowe Wykład 5a; 31.03.2011 1 1 Kolorowanie hiperkostki Definicja. W teorii grafów symbol Q n oznacza kostkę n-wymiarową, czyli graf o zbiorze wierzchołków V (Q n ) = {0, 1} n i zbiorze krawędzi
Kompresja bezstratna. Entropia. Kod Huffmana
 Kompresja bezstratna. Entropia. Kod Huffmana Kodowanie i bezpieczeństwo informacji - Wykład 10 29 kwietnia 2013 Teoria informacji Jeśli P(A) jest prawdopodobieństwem wystapienia informacji A to niech i(a)
Kompresja bezstratna. Entropia. Kod Huffmana Kodowanie i bezpieczeństwo informacji - Wykład 10 29 kwietnia 2013 Teoria informacji Jeśli P(A) jest prawdopodobieństwem wystapienia informacji A to niech i(a)
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Matematyka II. Bezpieczeństwo jądrowe i ochrona radiologiczna Semestr letni 2018/2019 wykład 13 (27 maja)
") Matematyka II Bezpieczeństwo jądrowe i ochrona radiologiczna Semestr letni 208/209 wykład 3 (27 maja) Całki niewłaściwe przedział nieograniczony Rozpatrujemy funkcje ciągłe określone na zbiorach < a, ),
Matematyka II Bezpieczeństwo jądrowe i ochrona radiologiczna Semestr letni 208/209 wykład 3 (27 maja) Całki niewłaściwe przedział nieograniczony Rozpatrujemy funkcje ciągłe określone na zbiorach < a, ),
WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 4 Przekształcenia zmiennej losowej, momenty
 WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 4 Przekształcenia zmiennej losowej, momenty Agata Boratyńska Agata Boratyńska Rachunek prawdopodobieństwa, wykład 4 / 9 Przekształcenia zmiennej losowej X
WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 4 Przekształcenia zmiennej losowej, momenty Agata Boratyńska Agata Boratyńska Rachunek prawdopodobieństwa, wykład 4 / 9 Przekształcenia zmiennej losowej X
Wykład 6 Estymatory efektywne. Własności asymptotyczne estym. estymatorów
 Wykład 6 Estymatory efektywne. Własności asymptotyczne estymatorów Wrocław, 30 listopada 2016r Powtórzenie z rachunku prawdopodobieństwa Zbieżność Definicja 6.1 Niech ciąg {X } n ma rozkład o dystrybuancie
Wykład 6 Estymatory efektywne. Własności asymptotyczne estymatorów Wrocław, 30 listopada 2016r Powtórzenie z rachunku prawdopodobieństwa Zbieżność Definicja 6.1 Niech ciąg {X } n ma rozkład o dystrybuancie
Kody blokowe Wykład 2, 10 III 2011
 Kody blokowe Wykład 2, 10 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding
Kody blokowe Wykład 2, 10 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding
IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. - funkcja dwóch zmiennych,
 IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. Definicja 1.1. Niech D będzie podzbiorem przestrzeni R n, n 2. Odwzorowanie f : D R nazywamy
IX. Rachunek różniczkowy funkcji wielu zmiennych. 1. Funkcja dwóch i trzech zmiennych - pojęcia podstawowe. Definicja 1.1. Niech D będzie podzbiorem przestrzeni R n, n 2. Odwzorowanie f : D R nazywamy
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Kodowanie i kompresja Streszczenie Studia dzienne Wykład 12,
 1 Kompresja stratna Kodowanie i kompresja Streszczenie Studia dzienne Wykład 12, 5.05.2005 Algorytmy kompresji bezstratnej oceniane są ze względu na: stopień kompresji; czas działania procesu kodowania
1 Kompresja stratna Kodowanie i kompresja Streszczenie Studia dzienne Wykład 12, 5.05.2005 Algorytmy kompresji bezstratnej oceniane są ze względu na: stopień kompresji; czas działania procesu kodowania
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Metody Rozmyte i Algorytmy Ewolucyjne
 mgr inż. Wydział Matematyczno-Przyrodniczy Szkoła Nauk Ścisłych Uniwersytet Kardynała Stefana Wyszyńskiego Podstawowe operatory genetyczne Plan wykładu Przypomnienie 1 Przypomnienie Metody generacji liczb
mgr inż. Wydział Matematyczno-Przyrodniczy Szkoła Nauk Ścisłych Uniwersytet Kardynała Stefana Wyszyńskiego Podstawowe operatory genetyczne Plan wykładu Przypomnienie 1 Przypomnienie Metody generacji liczb
Matematyka ubezpieczeń majątkowych r.
 Zadanie. W pewnej populacji kierowców każdego jej członka charakteryzują trzy zmienne: K liczba przejeżdżanych kilometrów (w tysiącach rocznie) NP liczba szkód w ciągu roku, w których kierowca jest stroną
Zadanie. W pewnej populacji kierowców każdego jej członka charakteryzują trzy zmienne: K liczba przejeżdżanych kilometrów (w tysiącach rocznie) NP liczba szkód w ciągu roku, w których kierowca jest stroną
Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe
 Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe Nierówność Czebyszewa Niech X będzie zmienną losową o skończonej wariancji V ar(x). Wtedy wartość oczekiwana E(X) też jest skończona i
Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe Nierówność Czebyszewa Niech X będzie zmienną losową o skończonej wariancji V ar(x). Wtedy wartość oczekiwana E(X) też jest skończona i
Uogólniona Metoda Momentów
 Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 6 Wrocław, 7 listopada 2011 Temat. Weryfikacja hipotez statystycznych dotyczących proporcji. Test dla proporcji. Niech X 1,..., X n będzie próbą statystyczną z 0-1. Oznaczmy odpowiednio
Bioinformatyka Wykład 6 Wrocław, 7 listopada 2011 Temat. Weryfikacja hipotez statystycznych dotyczących proporcji. Test dla proporcji. Niech X 1,..., X n będzie próbą statystyczną z 0-1. Oznaczmy odpowiednio
Postać Jordana macierzy
 Rozdział 8 Postać Jordana macierzy Niech F = R lub F = C Macierz J r λ) F r r postaci λ 1 0 0 0 λ 1 J r λ) = 0 λ 1 0 0 λ gdzie λ F nazywamy klatką Jordana stopnia r Oczywiście J 1 λ) = [λ Definicja 81
Rozdział 8 Postać Jordana macierzy Niech F = R lub F = C Macierz J r λ) F r r postaci λ 1 0 0 0 λ 1 J r λ) = 0 λ 1 0 0 λ gdzie λ F nazywamy klatką Jordana stopnia r Oczywiście J 1 λ) = [λ Definicja 81
Metoda największej wiarygodności
 Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
Estymacja gęstości prawdopodobieństwa metodą selekcji modelu
 Estymacja gęstości prawdopodobieństwa metodą selekcji modelu M. Wojtyś Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Wisła, 7 grudnia 2009 Wstęp Próba losowa z rozkładu prawdopodobieństwa
Estymacja gęstości prawdopodobieństwa metodą selekcji modelu M. Wojtyś Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Wisła, 7 grudnia 2009 Wstęp Próba losowa z rozkładu prawdopodobieństwa
Stacjonarne procesy gaussowskie, czyli o zwiazkach pomiędzy zwykła
 Stacjonarne procesy gaussowskie, czyli o zwiazkach pomiędzy zwykła autokorelacji Łukasz Dębowski ldebowsk@ipipan.waw.pl Instytut Podstaw Informatyki PAN autokorelacji p. 1/25 Zarys referatu Co to sa procesy
Stacjonarne procesy gaussowskie, czyli o zwiazkach pomiędzy zwykła autokorelacji Łukasz Dębowski ldebowsk@ipipan.waw.pl Instytut Podstaw Informatyki PAN autokorelacji p. 1/25 Zarys referatu Co to sa procesy
Według raportu ISO z 1988 roku algorytm JPEG składa się z następujących kroków: 0.5, = V i, j. /Q i, j
 Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 2 i 3 Zmienna losowa
 WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 2 i 3 Zmienna losowa Agata Boratyńska Agata Boratyńska Rachunek prawdopodobieństwa, wykład 2 i 3 1 / 19 Zmienna losowa Definicja Dana jest przestrzeń probabilistyczna
WYKŁADY Z RACHUNKU PRAWDOPODOBIEŃSTWA I wykład 2 i 3 Zmienna losowa Agata Boratyńska Agata Boratyńska Rachunek prawdopodobieństwa, wykład 2 i 3 1 / 19 Zmienna losowa Definicja Dana jest przestrzeń probabilistyczna
Modele DSGE. Jerzy Mycielski. Maj Jerzy Mycielski () Modele DSGE Maj / 11
 Modele DSGE Maj / 11") Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
SIMR 2017/18, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania
 SIMR 7/8, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania. Dana jest gęstość prawdopodobieństwa zmiennej losowej ciągłej X : { a( x) dla x [, ] f(x) = dla pozostałych x Znaleźć: i) Wartość parametru
SIMR 7/8, Statystyka, Przykładowe zadania do kolokwium - Rozwiązania. Dana jest gęstość prawdopodobieństwa zmiennej losowej ciągłej X : { a( x) dla x [, ] f(x) = dla pozostałych x Znaleźć: i) Wartość parametru
Lista zadania nr 7 Metody probabilistyczne i statystyka studia I stopnia informatyka (rok 2) Wydziału Ekonomiczno-Informatycznego Filia UwB w Wilnie
 Wydziału Ekonomiczno-Informatycznego Filia UwB w Wilnie") Lista zadania nr 7 Metody probabilistyczne i statystyka studia I stopnia informatyka (rok 2) Wydziału Ekonomiczno-Informatycznego Filia UwB w Wilnie Jarosław Kotowicz Instytut Matematyki Uniwersytet w
Lista zadania nr 7 Metody probabilistyczne i statystyka studia I stopnia informatyka (rok 2) Wydziału Ekonomiczno-Informatycznego Filia UwB w Wilnie Jarosław Kotowicz Instytut Matematyki Uniwersytet w
dla t ściślejsze ograniczenie na prawdopodobieństwo otrzymujemy przyjmując k = 1, zaś dla t > t ściślejsze ograniczenie otrzymujemy przyjmując k = 2.
 Zadanie. Dla dowolnej zmiennej losowej X o wartości oczekiwanej μ, wariancji momencie centralnym μ k rzędu k zachodzą nierówności (typu Czebyszewa): ( X μ k Pr > μ + t σ ) 0. k k t σ *
Zadanie. Dla dowolnej zmiennej losowej X o wartości oczekiwanej μ, wariancji momencie centralnym μ k rzędu k zachodzą nierówności (typu Czebyszewa): ( X μ k Pr > μ + t σ ) 0. k k t σ *
Rozdział 1. Wektory losowe. 1.1 Wektor losowy i jego rozkład
 Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
1. Pokaż, że estymator MNW parametru β ma postać β = nieobciążony. Znajdź estymator parametru σ 2.
 Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
RACHUNEK PRAWDOPODOBIEŃSTWA WYKŁAD 3.
 RACHUNEK PRAWDOPODOBIEŃSTWA WYKŁAD 3. ZMIENNA LOSOWA JEDNOWYMIAROWA. Zmienną losową X nazywamy funkcję (praktycznie każdą) przyporządkowującą zdarzeniom elementarnym liczby rzeczywiste. X : Ω R (dokładniej:
RACHUNEK PRAWDOPODOBIEŃSTWA WYKŁAD 3. ZMIENNA LOSOWA JEDNOWYMIAROWA. Zmienną losową X nazywamy funkcję (praktycznie każdą) przyporządkowującą zdarzeniom elementarnym liczby rzeczywiste. X : Ω R (dokładniej:
P (A B) = P (A), P (B) = P (A), skąd P (A B) = P (A) P (B). P (A)
 = P (A), P (B) = P (A), skąd P (A B) = P (A) P (B). P (A)") Wykład 3 Niezależność zdarzeń, schemat Bernoulliego Kiedy dwa zdarzenia są niezależne? Gdy wiedza o tym, czy B zaszło, czy nie, NIE MA WPŁYWU na oszacowanie prawdopodobieństwa zdarzenia A: P (A B) = P
Wykład 3 Niezależność zdarzeń, schemat Bernoulliego Kiedy dwa zdarzenia są niezależne? Gdy wiedza o tym, czy B zaszło, czy nie, NIE MA WPŁYWU na oszacowanie prawdopodobieństwa zdarzenia A: P (A B) = P
Kompresja danych DKDA (7)
") Kompresja danych DKDA (7) Marcin Gogolewski marcing@wmi.amu.edu.pl Uniwersytet im. Adama Mickiewicza w Poznaniu Poznań, 22 listopada 2016 1 Kwantyzacja skalarna Wprowadzenie Analiza jakości Typy kwantyzatorów
Kompresja danych DKDA (7) Marcin Gogolewski marcing@wmi.amu.edu.pl Uniwersytet im. Adama Mickiewicza w Poznaniu Poznań, 22 listopada 2016 1 Kwantyzacja skalarna Wprowadzenie Analiza jakości Typy kwantyzatorów
Biostatystyka, # 3 /Weterynaria I/
 Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Przykład 1 W przypadku jednokrotnego rzutu kostką przestrzeń zdarzeń elementarnych
 Rozdział 1 Zmienne losowe, ich rozkłady i charakterystyki 1.1 Definicja zmiennej losowej Niech Ω będzie przestrzenią zdarzeń elementarnych. Definicja 1 Rodzinę S zdarzeń losowych (zbiór S podzbiorów zbioru
Rozdział 1 Zmienne losowe, ich rozkłady i charakterystyki 1.1 Definicja zmiennej losowej Niech Ω będzie przestrzenią zdarzeń elementarnych. Definicja 1 Rodzinę S zdarzeń losowych (zbiór S podzbiorów zbioru
Rachunek prawdopodobieństwa Rozdział 5. Rozkłady łączne
 Rachunek prawdopodobieństwa Rozdział 5. Rozkłady łączne 5.2. Momenty rozkładów łącznych. Katarzyna Rybarczyk-Krzywdzińska rozkładów wielowymiarowych Przypomnienie Jeśli X jest zmienną losową o rozkładzie
Rachunek prawdopodobieństwa Rozdział 5. Rozkłady łączne 5.2. Momenty rozkładów łącznych. Katarzyna Rybarczyk-Krzywdzińska rozkładów wielowymiarowych Przypomnienie Jeśli X jest zmienną losową o rozkładzie
KADD Metoda najmniejszych kwadratów funkcje nieliniowe
 Metoda najmn. kwadr. - funkcje nieliniowe Metoda najmniejszych kwadratów Funkcje nieliniowe Procedura z redukcją kroku iteracji Przykłady zastosowań Dopasowanie funkcji wykładniczej Dopasowanie funkcji
Metoda najmn. kwadr. - funkcje nieliniowe Metoda najmniejszych kwadratów Funkcje nieliniowe Procedura z redukcją kroku iteracji Przykłady zastosowań Dopasowanie funkcji wykładniczej Dopasowanie funkcji
Centralne twierdzenie graniczne
 Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 4 Ważne uzupełnienie Dwuwymiarowy rozkład normalny N (µ X, µ Y, σ X, σ Y, ρ): f XY (x, y) = 1 2πσ X σ Y 1 ρ 2 { [ (x ) 1
Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 4 Ważne uzupełnienie Dwuwymiarowy rozkład normalny N (µ X, µ Y, σ X, σ Y, ρ): f XY (x, y) = 1 2πσ X σ Y 1 ρ 2 { [ (x ) 1
SPOTKANIE 3: Regresja: Regresja liniowa
 Wrocław University of Technology SPOTKANIE 3: Regresja: Regresja liniowa Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 22.11.2013 Rozkład normalny Rozkład normalny (ang. normal
Wrocław University of Technology SPOTKANIE 3: Regresja: Regresja liniowa Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 22.11.2013 Rozkład normalny Rozkład normalny (ang. normal