Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
|
|
|
- Mirosław Michalak
- 7 lat temu
- Przeglądów:
Transkrypt
1 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, Seminarium Metody Inteligencji Obliczeniowej 1/46
2 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja Wygląd funkcji błędu Zalety i wady algorytmu Testy 2/46
3 Działanie algorytmu 1.Uczenie na zbiorze uczącym: stwórz estymator gęstości dla każdej z klas 2.Odtwarzanie/klasyfikacja punktu testowego: oblicz prawd. przynależności do każdej z klas za pomocą wzoru Bayes'a 3/46
4 Jądra Dokonujemy estymacji jądrowej dla różnych szerokości jądra i uśredniamy 4/46
5 Jądra a preprocessing Jeśli punkty poddaliśmy preprocessingowi, to jest to równoważne zmianie kształtu jąder (które oryginalnie są kulami) Standardyzacja PCA Elipsoida o osiach równoległych do osi układu współrzędnych Elipsoida Dzięki temu (teoretycznie) możemy lepiej dopasować model do danych 5/46
6 Estymacja gęstości Estymacje gęstości dla różnych szerokości jąder 6/46
7 Wzór Bayesa Gdy mamy estymacje gęstości dla każdej z klas, korzystamy ze wzoru Bayesa 7/46
8 Uczenie Uczenie/dopasowywanie modelu do zbioru uczącego X 8/46
9 Obliczanie przedziału h Metoda opisana w [Ghosh06]: Badamy rozkład odległości w zbiorze danych h_max = odległość między dwoma najbardziej oddalonymi punktami h_min = 1/3 odległości między najbliższymi punktami, a jeśli to jest =0, to 1/3 pierwszego percentyla odległości między punktami Metoda stosowana w KDEC: h_max = jw. h_min = jw. tylko, że zamiast 1/3 stosuję wielkość zależną od przedziału, w którym znajduje się większość masy prawd. jądra 9/46
10 Optymalizacja błędu h values h value 8 h0 h1 h2 h3 h4 h5 h6 h Chcemy dobrać odpowiednią szybkość (parametr a) zmniejszania się jąder w sensownym przedziale szerokości jąder (h_min, h_max) a /46
11 Optymalizacja błędu Optymalizujemy błąd, który dla danego a obliczany za pomocą 10-fold cross-validation (używanie zbiorów walidujących jest konieczne ze względu na budowę algorytmu) Wzór dla jednego fold-a : 11/46
12 Błąd dla estymacji z 10 estymatorami dla różnych zbiorów danych 12/46
13 Wygląd funkcji błędu 13/46
14 14/46
15 15/46
16 16/46
17 17/46
18 18/46
19 19/46
20 20/46
21 21/46
22 22/46
23 Błąd estymacji z 10 estymatorami oddzielne a dla każdej z klas (z przedziałami h dopasowywanymi dla każdej z klas oddzielnie oraz wspólnie) 23/46
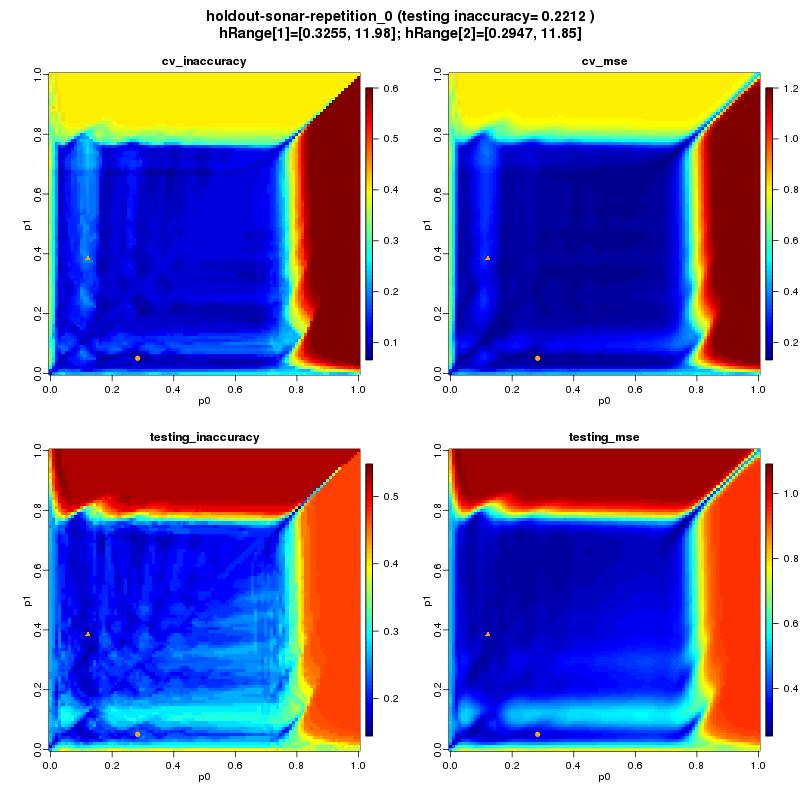
24 24/46
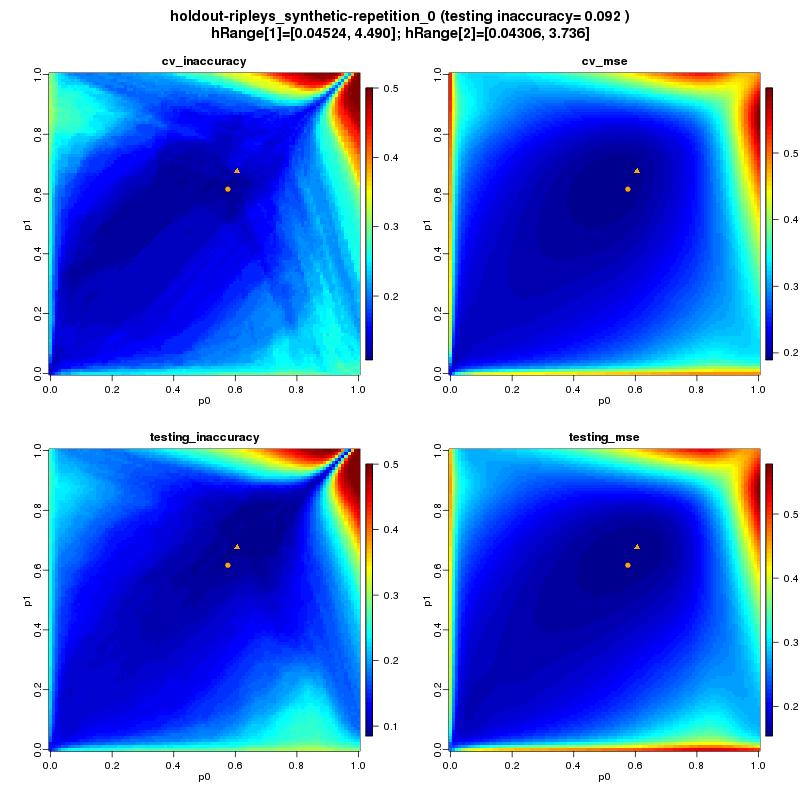
25 25/46
26 26/46
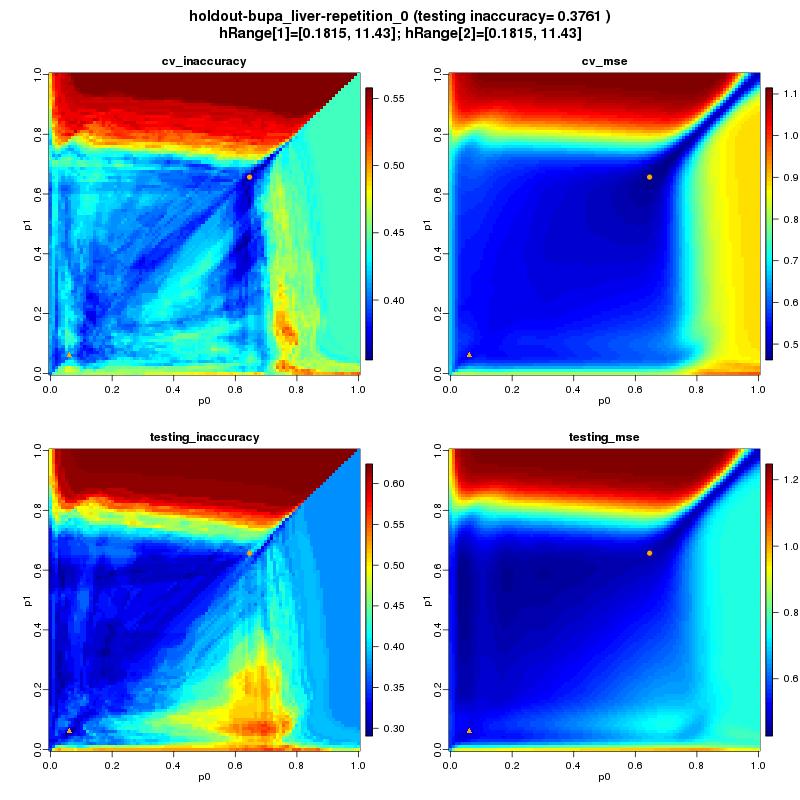
27 27/46
28 28/46
29 Zalety i wady algorytmu Zalety Spojrzenie na dane z różnych odległości Klasyfikacja z wieloma klasami Zwraca bezpośrednio prawdopodobieństwa przynależności punktu testowego do każdej z klas Wady Powolna klasyfikacja - wymaga iteracji po wszystkich elementach ze zbioru uczącego Nie jest tworzony żaden model danych Działa tylko na zbiorach danych z atrybutami numerycznymi 29/46
30 Testy Zbiory danych: Sposób testowania: Źródło: z literatury w wersji używanej w jednym z 2 artykułów ([Lim00], [Ghosh06]) Holdout: zbiór ze zdefiniowanym zbiorem testowym: 10 powtórzeń i uśrednienie Cv: Bez zdefiniowanego zbioru testowego: 10 x 10-fold cross-validation Wersja algorytmu: Transformacja: standardyzacja Co optymalizujemy: parametr a (taki sam dla każdej klasy) 30/46
31 Testy - wyniki Dataset name Boston housing BUPA liver disorders Glass Glass reduced iris PIMA indians diabetes StatLog vehicle silhouettes ripleys synthetic sonar averaged StatLog satellite image test type cv cv cv cv cv cv cv holdout holdout holdout source [Lim00] [Lim00] Dataset name Boston housing BUPA liver disorders Glass Glass reduced iris PIMA indians diabetes StatLog vehicle silhouettes ripleys synthetic sonar averaged StatLog satellite image 10 estimators 1 estimator MSE opt errorquantile inaccuracy opt error quantile MSE opt errorinaccuracy opt error lit. Min: B. min: lit. Min:0.098 [Ghosh06] [Lim00] [Lim00] [Ghosh06] [Ghosh06] [Lim00] classes attributes instances /46
32 Testy - spostrzeżenia Generalnie wyniki są poniżej średniej w porównaniu z innymi klasyfikatorami (kolor czerwony) Dla 2 zbiorów udało się uzyskać wyniki (trochę) lepsze niż te literaturowe MSE jest dobrym przybliżeniem błędu klasyfikacji Wyniki dla liczby jąder =10 są podobne do dla jednego jądra ale trochę lepsze (chociaż nieznacznie) a nauka dla 10 jąder trwa 10-krotnie dłużej! 32/46
33 Testy - uwagi Dziwne wyniki dla zbioru StatLog satellite image (dokładnie taki sam błąd inaccuracy za każdym razem (różnice w błędzie MSE też bliskie 0)) Zła postać funkcji błędu dla estymacji z 1 estymatorem: Minimum zazwyczaj na brzegu przedziału Na dużej części przedziału funkcja jest płaska 33/46
34 Błąd dla estymacji z 1 estymatorem dla różnych zbiorów danych 34/46
35 35/46
36 36/46
37 37/46
38 38/46
39 39/46
40 40/46
41 41/46
42 42/46
43 Co należy zrobić Zastosować metody optymalizacyjne Lepsze określanie przedziału h Rozwiązać problem z jednym ze zbiorów (breast_cancer) zbyt duża liczba przykładów o tych samych współrzędnych? Sprawdzić: Preprocessing: PCA Sprawdzić wersję ze stratified cross-validation Inna liczba estymacji 43/46
44 Pomysły/modyfikacje Średnie zmiany Używać innej funkcji zmniejszania się jąder Używać innego jądra (np. p-gaussian) B. duże zmiany Dopasowywać wielkość/kształt jądra w zależności od położenia w przestrzeni 44/46
45 Literatura [Lim00] Tjen-Sien Lin, Wei-Yin Loh, A Comparison of Prediction Accuracy, Complexity, and Training Time of Thirty-Three Old and New Classification Algorithms, Machine Learning, 2000 [Ghosh06] Anil K. Ghosh, Probal Chaudhuri, and Debasis Sengupta, Classification Using Kernel Density Estimates: Multi-scale Analysis and Visualization, Technometrics, /46
46 Dziękuję za uwagę! 46/46
Kombinacja jądrowych estymatorów gęstości w klasyfikacji kontynuacja prac
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji kontynuacja prac Mateusz Kobos, 25.03.2009 Seminarium Metody Inteligencji Obliczeniowej 1/26 Spis treści Opis algorytmu Testy wersji z optymalizacją
Kombinacja jądrowych estymatorów gęstości w klasyfikacji kontynuacja prac Mateusz Kobos, 25.03.2009 Seminarium Metody Inteligencji Obliczeniowej 1/26 Spis treści Opis algorytmu Testy wersji z optymalizacją
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - zastosowanie na sztucznym zbiorze danych Mateusz Kobos, 07.04.2010 Seminarium Metody Inteligencji Obliczeniowej Spis treści Opis algorytmu i zbioru
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - testy na sztucznych danych Mateusz Kobos, 25.11.2009 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Dolne ograniczenie na wsp.
Mateusz Kobos Seminarium z Metod Inteligencji Obliczeniowej, MiNI PW
 Klasyfikacja za pomocą kombinacji estymatorów jądrowych: dobór szerokości jądra w zależności od lokalizacji w przestrzeni cech, stosowanie różnych przekształceń przestrzeni, funkcja błędu oparta na information
Klasyfikacja za pomocą kombinacji estymatorów jądrowych: dobór szerokości jądra w zależności od lokalizacji w przestrzeni cech, stosowanie różnych przekształceń przestrzeni, funkcja błędu oparta na information
Kombinacja jądrowych estymatorów gęstości w klasyfikacji - przegląd literatury
 1/37 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - przegląd literatury Mateusz Kobos, 22.10.2008 Seminarium Metody Inteligencji Obliczeniowej 2/37 Spis treści Klasyfikator Bayesowski Estymatory
1/37 Kombinacja jądrowych estymatorów gęstości w klasyfikacji - przegląd literatury Mateusz Kobos, 22.10.2008 Seminarium Metody Inteligencji Obliczeniowej 2/37 Spis treści Klasyfikator Bayesowski Estymatory
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Jakość uczenia i generalizacja
 Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Jakość uczenia i generalizacja Dokładność uczenia Jest koncepcją miary w jakim stopniu nasza sieć nauczyła się rozwiązywać określone zadanie Dokładność mówi na ile nauczyliśmy się rozwiązywać zadania które
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
9. Praktyczna ocena jakości klasyfikacji
 Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań
 w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań") Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym, kontynuacja badań Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym
 w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym") Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW 17 XII 2013 Jan Karwowski
Zastosowanie optymalizacji rojem cząstek (PSO) w procesie uczenia wielowarstwowej sieci neuronowej w problemie lokalizacyjnym Jan Karwowski Wydział Matematyki i Nauk Informacyjnych PW 17 XII 2013 Jan Karwowski
Metody klasyfikacji i rozpoznawania wzorców. Najważniejsze rodzaje klasyfikatorów
 Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych
 inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
inż. Marek Duczkowski Metoda określania pozycji wodnicy statków na podstawie pomiarów odległości statku od głowic laserowych słowa kluczowe: algorytm gradientowy, optymalizacja, określanie wodnicy W artykule
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner
 Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Problem eliminacji nieprzystających elementów w zadaniu rozpoznania wzorca Marcin Luckner Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Elementy nieprzystające Definicja odrzucania Klasyfikacja
Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ
 IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
Wybór modelu i ocena jakości klasyfikatora
 Wybór modelu i ocena jakości klasyfikatora Błąd uczenia i błąd testowania Obciążenie, wariancja i złożoność modelu (klasyfikatora) Dekompozycja błędu testowania Optymizm Estymacja błędu testowania AIC,
Wybór modelu i ocena jakości klasyfikatora Błąd uczenia i błąd testowania Obciążenie, wariancja i złożoność modelu (klasyfikatora) Dekompozycja błędu testowania Optymizm Estymacja błędu testowania AIC,
Przewidywanie cen akcji z wykorzystaniem artykułów prasowych
 Przewidywanie cen akcji z wykorzystaniem artykułów prasowych Mateusz Kobos, 05.12.2007 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Ogólna budowa programu Pobieranie danych Budowa bazy
Przewidywanie cen akcji z wykorzystaniem artykułów prasowych Mateusz Kobos, 05.12.2007 Seminarium Metody Inteligencji Obliczeniowej 1/25 Spis treści Ogólna budowa programu Pobieranie danych Budowa bazy
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych. Regresja logistyczna i jej zastosowanie
 Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Metody oceny podobieństwa
 [1] Algorytmy Rozpoznawania Wzorców Metody oceny podobieństwa dr inż. Paweł Forczmański pforczmanski@wi.zut.edu.pl Spis treści: [2] Podstawowe pojęcia Odległość Metryka Klasyfikacja Rodzaje metryk Przykłady
[1] Algorytmy Rozpoznawania Wzorców Metody oceny podobieństwa dr inż. Paweł Forczmański pforczmanski@wi.zut.edu.pl Spis treści: [2] Podstawowe pojęcia Odległość Metryka Klasyfikacja Rodzaje metryk Przykłady
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Regresja nieparametryczna series estimator
 Regresja nieparametryczna series estimator 1 Literatura Bruce Hansen (2018) Econometrics, rozdział 18 2 Regresja nieparametryczna Dwie główne metody estymacji Estymatory jądrowe Series estimators (estymatory
Regresja nieparametryczna series estimator 1 Literatura Bruce Hansen (2018) Econometrics, rozdział 18 2 Regresja nieparametryczna Dwie główne metody estymacji Estymatory jądrowe Series estimators (estymatory
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji
 Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Analiza składników podstawowych - wprowadzenie (Principal Components Analysis
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Analiza składników podstawowych - wprowadzenie (Principal Components Analysis
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Eksploracja danych OCENA KLASYFIKATORÓW. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych OCENA KLASYFIKATORÓW Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika
Eksploracja danych OCENA KLASYFIKATORÓW Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Machine learning Lecture 5
 Machine learning Lecture 5 Marcin Wolter IFJ PAN 21 kwietnia 2017 Uczenie -sprawdzanie krzyżowe (cross-validation). Optymalizacja parametrów metod uczenia maszynowego. Deep learning 1 Uczenie z nauczycielem
Machine learning Lecture 5 Marcin Wolter IFJ PAN 21 kwietnia 2017 Uczenie -sprawdzanie krzyżowe (cross-validation). Optymalizacja parametrów metod uczenia maszynowego. Deep learning 1 Uczenie z nauczycielem
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Uczenie sieci typu MLP
 Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
Uczenie sieci typu MLP Przypomnienie budowa sieci typu MLP Przypomnienie budowy neuronu Neuron ze skokową funkcją aktywacji jest zły!!! Powszechnie stosuje -> modele z sigmoidalną funkcją aktywacji - współczynnik
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni
 Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
Mikroekonometria 5. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Mikroekonometria 5 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.medexp3.dta przygotuj model regresji kwantylowej 1. Przygotuj model regresji kwantylowej w którym logarytm wydatków
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład II 2017/2018
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład II bogumil.konopka@pwr.edu.pl 2017/2018 Określenie rzeczywistej dokładności modelu Zbiór treningowym vs zbiór testowy Zbiór treningowy
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
10. Redukcja wymiaru - metoda PCA
 Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
Algorytmy rozpoznawania obrazów 10. Redukcja wymiaru - metoda PCA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. PCA Analiza składowych głównych: w skrócie nazywana PCA (od ang. Principle Component
Metody eksploracji danych Laboratorium 2. Weka + Python + regresja
 Metody eksploracji danych Laboratorium 2 Weka + Python + regresja KnowledgeFlow KnowledgeFlow pozwala na zdefiniowanie procesu przetwarzania danych Komponenty realizujące poszczególne czynności można konfigurować,
Metody eksploracji danych Laboratorium 2 Weka + Python + regresja KnowledgeFlow KnowledgeFlow pozwala na zdefiniowanie procesu przetwarzania danych Komponenty realizujące poszczególne czynności można konfigurować,
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I
 Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Wprowadzenie. Data Science Uczenie się pod nadzorem
 Wprowadzenie Wprowadzenie Wprowadzenie Wprowadzenie Machine Learning Mind Map Historia Wstęp lub uczenie się z przykładów jest procesem budowy, na bazie dostępnych danych wejściowych X i oraz wyjściowych
Wprowadzenie Wprowadzenie Wprowadzenie Wprowadzenie Machine Learning Mind Map Historia Wstęp lub uczenie się z przykładów jest procesem budowy, na bazie dostępnych danych wejściowych X i oraz wyjściowych
Wstęp do metod numerycznych Zadania numeryczne 2016/17 1
 Wstęp do metod numerycznych Zadania numeryczne /7 Warunkiem koniecznym (nie wystarczającym) uzyskania zaliczenia jest rozwiązanie co najmniej 3 z poniższych zadań, przy czym zadania oznaczone literą O
Wstęp do metod numerycznych Zadania numeryczne /7 Warunkiem koniecznym (nie wystarczającym) uzyskania zaliczenia jest rozwiązanie co najmniej 3 z poniższych zadań, przy czym zadania oznaczone literą O
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej. Adam Żychowski
 Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
Zastosowanie sieci neuronowych w problemie klasyfikacji wielokategorialnej Adam Żychowski Definicja problemu Każdy z obiektów może należeć do więcej niż jednej kategorii. Alternatywna definicja Zastosowania
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH. Wykład 5 Kwadratowa analiza dyskryminacyjna QDA. Metody klasyfikacji oparte na rozkładach prawdopodobieństwa.
 Wykład 5 Kwadratowa analiza dyskryminacyjna QDA. Metody klasyfikacji oparte na rozkładach prawdopodobieństwa. Kwadratowa analiza dyskryminacyjna Przykład analizy QDA Czasem nie jest możliwe rozdzielenie
Wykład 5 Kwadratowa analiza dyskryminacyjna QDA. Metody klasyfikacji oparte na rozkładach prawdopodobieństwa. Kwadratowa analiza dyskryminacyjna Przykład analizy QDA Czasem nie jest możliwe rozdzielenie
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY WALIDACJA KRZYŻOWA dla ZAAWANSOWANEGO KLASYFIKATORA KNN ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji
 Kierunek: Informatyka Zastosowania Informatyki w Medycynie Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji 1. WSTĘP AUTORZY Joanna Binczewska gr. I3.1
Kierunek: Informatyka Zastosowania Informatyki w Medycynie Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji 1. WSTĘP AUTORZY Joanna Binczewska gr. I3.1
METODY NUMERYCZNE. Wykład 4. Numeryczne rozwiązywanie równań nieliniowych z jedną niewiadomą. prof. dr hab.inż. Katarzyna Zakrzewska
 METODY NUMERYCZNE Wykład 4. Numeryczne rozwiązywanie równań nieliniowych z jedną niewiadomą prof. dr hab.inż. Katarzyna Zakrzewska Met.Numer. Wykład 4 1 Rozwiązywanie równań nieliniowych z jedną niewiadomą
METODY NUMERYCZNE Wykład 4. Numeryczne rozwiązywanie równań nieliniowych z jedną niewiadomą prof. dr hab.inż. Katarzyna Zakrzewska Met.Numer. Wykład 4 1 Rozwiązywanie równań nieliniowych z jedną niewiadomą
Wstęp do sieci neuronowych, wykład 09, Walidacja jakości uczenia. Metody statystyczne.
 Wstęp do sieci neuronowych, wykład 09, Walidacja jakości uczenia. Metody statystyczne. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-12-06 1 Przykład
Wstęp do sieci neuronowych, wykład 09, Walidacja jakości uczenia. Metody statystyczne. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-12-06 1 Przykład
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład III 2016/2017
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Sprawozdanie z zadania Modele predykcyjne (2)
") Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Zastosowanie Excela w obliczeniach inżynierskich.
 Zastosowanie Excela w obliczeniach inżynierskich. Część I Różniczkowanie numeryczne. Cel ćwiczenia: Zapoznanie się z ilorazami różnicowymi do obliczania wartości pochodnych. Pochodna jest miarą szybkości
Zastosowanie Excela w obliczeniach inżynierskich. Część I Różniczkowanie numeryczne. Cel ćwiczenia: Zapoznanie się z ilorazami różnicowymi do obliczania wartości pochodnych. Pochodna jest miarą szybkości
Wykład 9. Terminologia i jej znaczenie. Cenzurowanie wyników pomiarów.
 Wykład 9. Terminologia i jej znaczenie. Cenzurowanie wyników pomiarów.. KEITHLEY. Practical Solutions for Accurate. Test & Measurement. Training materials, www.keithley.com;. Janusz Piotrowski: Procedury
Wykład 9. Terminologia i jej znaczenie. Cenzurowanie wyników pomiarów.. KEITHLEY. Practical Solutions for Accurate. Test & Measurement. Training materials, www.keithley.com;. Janusz Piotrowski: Procedury
Dobór parametrów algorytmu ewolucyjnego
 Dobór parametrów algorytmu ewolucyjnego 1 2 Wstęp Algorytm ewolucyjny posiada wiele parametrów. Przykładowo dla algorytmu genetycznego są to: prawdopodobieństwa stosowania operatorów mutacji i krzyżowania.
Dobór parametrów algorytmu ewolucyjnego 1 2 Wstęp Algorytm ewolucyjny posiada wiele parametrów. Przykładowo dla algorytmu genetycznego są to: prawdopodobieństwa stosowania operatorów mutacji i krzyżowania.
7. Maszyny wektorów podpierajacych SVMs
 Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
WYKŁAD 9 METODY ZMIENNEJ METRYKI
 WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
WYKŁAD 9 METODY ZMIENNEJ METRYKI Kierunki sprzężone. Metoda Newtona Raphsona daje dobre przybliżenie najlepszego kierunku poszukiwań, lecz jest to okupione znacznym kosztem obliczeniowym zwykle postać
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
W4 Eksperyment niezawodnościowy
 W4 Eksperyment niezawodnościowy Henryk Maciejewski Jacek Jarnicki Jarosław Sugier www.zsk.iiar.pwr.edu.pl Badania niezawodnościowe i analiza statystyczna wyników 1. Co to są badania niezawodnościowe i
W4 Eksperyment niezawodnościowy Henryk Maciejewski Jacek Jarnicki Jarosław Sugier www.zsk.iiar.pwr.edu.pl Badania niezawodnościowe i analiza statystyczna wyników 1. Co to są badania niezawodnościowe i
Konferencja Statystyka Matematyczna Wisła 2013
 Konferencja Statystyka Matematyczna Wisła 2013 Wykorzystanie metod losowych podprzestrzeni do predykcji i selekcji zmiennych Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre
Konferencja Statystyka Matematyczna Wisła 2013 Wykorzystanie metod losowych podprzestrzeni do predykcji i selekcji zmiennych Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre
NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Wprowadzenie do teorii ekonometrii. Część A
 NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Autor: 1. Dobromił Serwa 2. Tytuł przedmiotu Sygnatura (będzie nadana, po akceptacji przez Senacką Komisję Programową) Wprowadzenie do teorii
NOWY PROGRAM STUDIÓW 2016/2017 SYLABUS PRZEDMIOTU AUTORSKIEGO: Autor: 1. Dobromił Serwa 2. Tytuł przedmiotu Sygnatura (będzie nadana, po akceptacji przez Senacką Komisję Programową) Wprowadzenie do teorii
Modelowanie rynków finansowych z wykorzystaniem pakietu R
 Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
Modelowanie rynków finansowych z wykorzystaniem pakietu R Metody numeryczne i symulacje stochastyczne Mateusz Topolewski woland@mat.umk.pl Wydział Matematyki i Informatyki UMK Plan działania 1 Całkowanie
Seminarium IO. Zastosowanie metody PSO w Dynamic Vehicle Routing Problem (kontynuacja) Michał Okulewicz
 Michał Okulewicz") Seminarium IO Zastosowanie metody PSO w Dynamic Vehicle Routing Problem (kontynuacja) Michał Okulewicz 26.10.2012 Plan prezentacji Problem VRP+DR Algorytm PSO Podejścia MAPSO + 2-Opt 2-phase PSO Wyniki
Seminarium IO Zastosowanie metody PSO w Dynamic Vehicle Routing Problem (kontynuacja) Michał Okulewicz 26.10.2012 Plan prezentacji Problem VRP+DR Algorytm PSO Podejścia MAPSO + 2-Opt 2-phase PSO Wyniki
Optymalizacja systemów
 Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
MOŻLIWOŚCI ZASTOSOWANIA METOD WTÓRNEGO PRÓBKOWANIA DO WERYFIKACJI EFEKTYWNOŚCI INWESTYCJI PORTFELOWYCH
 Studia Ekonomiczne. Zeszyty Naukowe Uniwersytetu Ekonomicznego w Katowicach ISSN 2083-8611 Nr 242 2015 Ekonomia 3 Maciej Pichura Uniwersytet Ekonomiczny w Katowicach Wydział Ekonomii Katedra Metod Statystyczno-Matematycznych
Studia Ekonomiczne. Zeszyty Naukowe Uniwersytetu Ekonomicznego w Katowicach ISSN 2083-8611 Nr 242 2015 Ekonomia 3 Maciej Pichura Uniwersytet Ekonomiczny w Katowicach Wydział Ekonomii Katedra Metod Statystyczno-Matematycznych
Metoda cyfrowej korelacji obrazu w badaniach geosyntetyków i innych materiałów drogowych
 Metoda cyfrowej korelacji obrazu w badaniach geosyntetyków i innych materiałów drogowych Jarosław Górszczyk Konrad Malicki Politechnika Krakowska Instytut Inżynierii Drogowej i Kolejowej Wprowadzenie Dokładne
Metoda cyfrowej korelacji obrazu w badaniach geosyntetyków i innych materiałów drogowych Jarosław Górszczyk Konrad Malicki Politechnika Krakowska Instytut Inżynierii Drogowej i Kolejowej Wprowadzenie Dokładne
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Stan dotychczasowy. OCENA KLASYFIKACJI w diagnostyce. Metody 6/10/2013. Weryfikacja. Testowanie skuteczności metody uczenia Weryfikacja prosta
 Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów. Wit Jakuczun
 Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Konstrukcja biortogonalnych baz dyskryminacyjnych dla problemu klasyfikacji sygnałów Politechnika Warszawska Strona 1 Podstawowe definicje Politechnika Warszawska Strona 2 Podstawowe definicje Zbiór treningowy
Fuzja sygnałów i filtry bayesowskie
 Fuzja sygnałów i filtry bayesowskie Roboty Manipulacyjne i Mobilne dr inż. Janusz Jakubiak Katedra Cybernetyki i Robotyki Wydział Elektroniki, Politechnika Wrocławska Wrocław, 10.03.2015 Dlaczego potrzebna
Fuzja sygnałów i filtry bayesowskie Roboty Manipulacyjne i Mobilne dr inż. Janusz Jakubiak Katedra Cybernetyki i Robotyki Wydział Elektroniki, Politechnika Wrocławska Wrocław, 10.03.2015 Dlaczego potrzebna