CLUSTERING. Metody grupowania danych
|
|
|
- Karolina Markiewicz
- 9 lat temu
- Przeglądów:
Transkrypt
1 CLUSTERING Metody grupowania danych

2 Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means clustering) Grupowanie hierarchiczne (hierarchical clustering) Probabilistyczne grupowanie (probability-based clustering)
 Grupowanie hierarchiczne (hierarchical")
3 Co to jest klastrowanie Klastrowanie (clustering): problem grupowania obiektów o podobnych właściwościach. Klaster: grupa (lub klasa) obiektów podobnych (powstająca w wyniku grupowania danych)
 obiektów podobnych")
4 Clustering i Klasyfikacja Clustering = uczenie bez nadzoru Znaleźć naturalne skupienia dla zbioru obiektów nie etykietowanych Klasyfikacja=uczenie z nadzorem Uczenie metod przewidywania przynależności obiektów do klas decyzyjnych (dane etykietowane)

5 Dziedziny zastosowania Medycyna Grupowania chorób Grupowanie objaw u pacjentów np. paranoja, schizophrenia -> właściwa terapia Archeologia: taksonomie wydobytych narzędzi... Text Mining Grupowanie podobnych dokumentów -> lepsze wyniki wyszukiwań dokumentów

6 Opis klastrów d e d e a k g j h i f c b a k g j h i f c b a b c d e f g h g a c i e d k b j f h

7 Problem grupowania (clustering) Dane są: liczba klastrów k funkcja odległości d określona na zbiorze obiektów P. funkcja oceny jakości klastrów F (objective function) Problem: Podzielić zbiór P na k klastrów tak aby funkcja F przyjmowała maksymalną wartość.

8 Klasyfikacja metody Unsupervised learning: grupowanie obiektów bez wiedzy o ich kategorii (klasach decyzyjnych). Metody klasyfikują się według postaci generowanych klastrów: Czy są one rozłączne czy nierozłączne Czy mają strukturę hierarchiczną czy płaską Czy są określone deterministycznie czy probabilistycznie.

9 Podstawowe metody clusteringu k-centroidów (k-mean): Klastry mają strukturę płaską są określone deterministycznie Grupowanie hierarchiczne: Klastry mają strukturę drzewiastą są określone deterministycznie Grupowanie w oparciu o prawdopodobieństwo: Klastry mają strukturę płaską są określone probabilistycznie

10 Miary odległości


11 Grupowanie hierarchiczne Przykład grupowania profili danych ekspresji RNA (Nugoli et al. BMC Cancer :13)

12 Algorytm Cel: Budować drzewo klastrów dla zbioru n obiektów. Jakość klastra: suma odległości pomiędzy obiektami w klastrze. 1. Na najniższym poziomie drzewa: n liści. Każdy liść (zawierający 1 obiekt) jest klastrem 2. Repeat Znajdź najbliższą parę klastrów (parę poddrzew) Połącz te klastry (poddrzewa) w jeden większy until STOP
 jest klastrem 2.")
13 Przykład
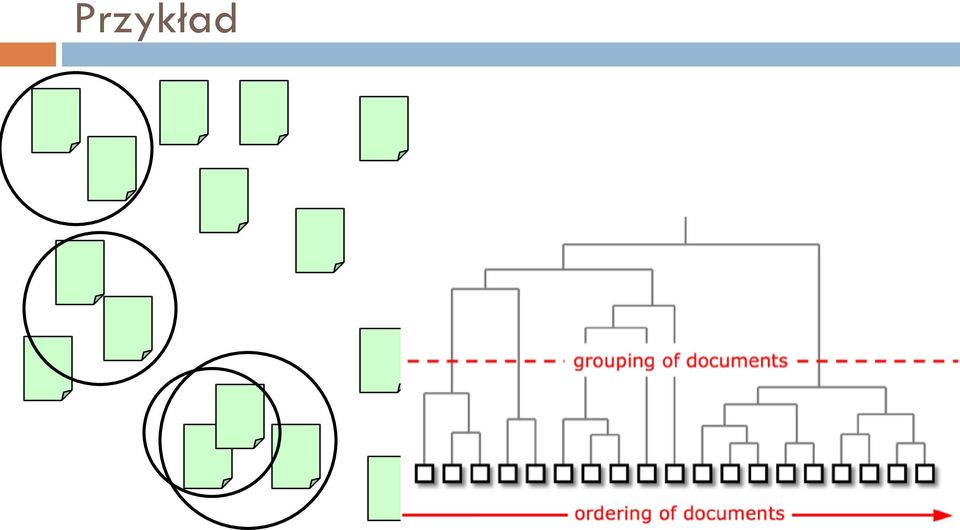
14 Odległość między klastrami 1. Single linkage (nearest neighbor) 2. Complete linkage (furthest neighbor) 3. Unweighted pair-group average 4. Weighted pair-group average 5. Unweighted pair-group centroid 6. Weighted pair-group centroid (median).

15 Metoda k-centroidów (k-means, MacQueen, 1967) Dane: N punktów x 1, x 2 x N w przestrzeni R n Parametr k < N Szukane: k punktów c 1 c k (zwanych środkami lub centroidami) będących optymalnymi punktami ze względu na funkcję: F( c N 1,..., ck ) min d xi, j1,.., k i1 c j
 min d xi, j1,.., k i1 c j")
 Jeśli zdołamy reprezentować ten obraz używając jedynie k=32 kolorów => możemy kodować każdy punkt za pomocą 5 bitów =>")
16 Przykład: kwantyzacja wektorowa Mały 100x100 obraz kolorowy wymaga 10000*24 = 29.3 kb; (N=10000) Jeśli zdołamy reprezentować ten obraz używając jedynie k=32 kolorów => możemy kodować każdy punkt za pomocą 5 bitów => redukcja pamięci do 6.1 kb + 32*24 bitów na książkę kodową

17 Algorytm Znaleźć k środków tak, aby suma odległości punktów do najbliższego centroida była minimalna. Krok 1. Wybierz losowo dowolnych k centrum klastrów (centroidów) Krok 2. Przydziel każdy obiekt do najbliższego centroida. Krok 3. Wyznacz nowy układ centroidów Krok 4. Powtórz krok 2 dopóty, póki poprawa jakości będzie mała.

18 Metoda k centroidów (c.d.) Wyznaczanie nowego układu centroidów Idea: Nowy centroid jest środkiem ciężkości powstającego (w poprzednim przebiegu algorytmu) klastra. Współrzędne nowego centroida c: p1( xi )... pk ( xi ) c( xi ) gdzie k p 1,p 2,...,p k punkty należące do klastra. c(x i ), p 1 (x i ),..., p k (x i ) i-ta współrzędna.
 Wyznaczanie nowego układu centroidów Idea: Nowy centroid jest środkiem ciężkości")
19 Własciwości metody k - centroidów Jakości klastrów zależą od wyboru początkowego układu centroidów. Algorytm może trafić w lokalne minimum Aby unikać lokalne minimum: startować z różnymi układami losowo wybieranych centroidów.

20 Przykład k=3, Krok 1 Y Wybierz losowo 3 punkty jako początkowy zbiór środków. k 2 k 1 k 3 X

21 Przykład k=3, Krok 2 Y k 1 Przypisanie każdego z punktów do najbliższego środka k 2 k 3 X
22 Przykład k=3, Krok 3 Y k 1 k 1 Przesuwanie centroidów do środków klastrów. k 2 k 2 k 3 k 3 X
23 Przykład k=3, Krok 4 Znów przypisać punkty do najbliższych środków Y Pyt.: Które z tych punktów zmienia grupę? k 1 k 2 k 3 X
24 Przykład k=3, Krok 4a A: 3 zmiany Y k 1 k 2 k 3 X
25 Przykład k=3, Krok 4b re-compute cluster means Y k 2 k 1 k 3 X
26 Przykład k=3, Krok 5 k 1 Y Przesuwanie centroidów do środków nowych klastrów k 2 X k 3

27 Anomalie metody centroidów
28 Probabilistyczne grupowanie Obiekt należy do klastra z pewnym stopniem prawdopodobieństwa. Idea: Każdy klaster jest opisany jednym rozkładem prawdopodobieństwa. Założenie: Wszystkie rozkłady są rozkładami normalnymi. Rozkłady różnią się wartoścami oczekiwanymi () i odchyleniami standardowymi ().
29 Przykład: Trzy probabilistyczne klastry
30 Stopień należności obiektu do klastra Obiekt x należy do klastra A z prawdopodobieństwem: gdzie f(x; A ; A ) - rozkład normalny ] [ ). ; ; ( ] [ ] [ ]. [ ] [ x P p x f x P A P A x P x A P A A A ) ( 2 1 ) ; ; ( x e x f
31 Algorytm EM EM Expection - Maximization Dana jest liczba klastrów k. Cel: Dla każdego atrybutu rzeczywistego znaleźć k układów parametrów ( i, i, p i ) dla i =1,..,k (opisów k klastrów). Dla uproszczenia opisu, niech k = 2 Algorytm jest opisany dla wybranego atrybutu.
32 Algorytm EM Idea: adoptować algorytm k centroidów. Krok 1. Wybierz losowo 2 układy parametrów ( A, A, p A ) i ( B, B, p B ); Krok 2. Oblicz oczekiwane stopnie przynależności obiektów do klastrów ( expectation step) Krok 3. Wyznacz nowe układy parametrów w celu maksymalizacji funkcji jakości likelihood ( maximization step); Krok 4. Powtórz krok 2 dopóty, póki poprawa jakości będzie mała.
33 Funkcja oceny jakości Funkcja dopasowania likelihood : dla dwóch klastrów A i B: i ( p. P[ x A] p. P[ x B]) A i B i
34 Wyznaczanie nowych parametrów Szuka się dwóch układów parametrów: ( A, A, p A ) i ( B, B, p B ) Jeśli w i jest stopniem przynależności i tego obiektu do klastra A to : n n n A w w w x w x w w x n A n n A A A w w w x w x w x w... ) (... ) ( ) (
35 Bibliografia Brian S. Everitt (1993). Cluster analysis. Oxford University Press Inc. Ian H. Witten, Eibe Frank (1999). Data Mining. Practical ML Tools and Techniques with Java Implementations. Morgan Kaufmann Publishers.
CLUSTERING METODY GRUPOWANIA DANYCH
 CLUSTERING METODY GRUPOWANIA DANYCH Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING METODY GRUPOWANIA DANYCH Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Algorytmy rozpoznawania obrazów. 11. Analiza skupień. dr inż. Urszula Libal. Politechnika Wrocławska
 Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Algorytmy rozpoznawania obrazów 11. Analiza skupień dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Analiza skupień Określenia: analiza skupień (cluster analysis), klasteryzacja (clustering), klasyfikacja
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
4.3 Grupowanie według podobieństwa
 4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Techniki grupowania danych w środowisku Matlab
 Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Wyszukiwanie informacji w internecie. Nguyen Hung Son
 Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
CLUSTERING II. Efektywne metody grupowania danych
 CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Metody analizy skupień Wprowadzenie Charakterystyka obiektów Metody grupowania Ocena poprawności grupowania
 Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Wielowymiarowe metody segmentacji CHAID Metoda Automatycznej Detekcji Interakcji CHAID Cele CHAID Dane CHAID Przebieg analizy CHAID Parametry CHAID Wyniki Metody analizy skupień Wprowadzenie Charakterystyka
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Przestrzeń algorytmów klastrowania
 20 listopada 2008 Plan prezentacji 1 Podstawowe pojęcia Przykłady algorytmów klastrowania 2 Odległość algorytmów klastrowania Odległość podziałów 3 Dane wejściowe Eksperymenty Praca źródłowa Podstawowe
20 listopada 2008 Plan prezentacji 1 Podstawowe pojęcia Przykłady algorytmów klastrowania 2 Odległość algorytmów klastrowania Odległość podziałów 3 Dane wejściowe Eksperymenty Praca źródłowa Podstawowe
Metody teorii gier. ALP520 - Wykład z Algorytmów Probabilistycznych p.2
 Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasteryzacja danych
 Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Klasteryzacja danych na podstawie: Leszek Rutkowski. Metody i techniki
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Klasteryzacja danych na podstawie: Leszek Rutkowski. Metody i techniki
1. Grupowanie Algorytmy grupowania:
 1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
 : idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
: idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Analiza Skupień Cluster analysis
 Metody Eksploracji Danych w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka http://wazniak.mimuw.edu.pl
Metody Eksploracji Danych w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka http://wazniak.mimuw.edu.pl
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Czym jest analiza skupień?
 Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
Statystyczna analiza danych z pakietem SAS Analiza skupień metody hierarchiczne Czym jest analiza skupień? wielowymiarowa technika pozwalająca wykrywać współzależności między obiektami; ściśle związana
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Algorytmy zrandomizowane
 Algorytmy zrandomizowane www.qed.pl/ai/nai2003 PLAN WYKŁADU Inne zadania optymalizacyjne grupowanie Generowanie liczb losowych Metody Monte Carlo i Las Vegas przykłady zastosowa Przeszukiwanie losowe metoda
Algorytmy zrandomizowane www.qed.pl/ai/nai2003 PLAN WYKŁADU Inne zadania optymalizacyjne grupowanie Generowanie liczb losowych Metody Monte Carlo i Las Vegas przykłady zastosowa Przeszukiwanie losowe metoda
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Wykrywanie nietypowości w danych rzeczywistych
 Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Algorytmy zrandomizowane
 Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Monitorowanie i Diagnostyka w Systemach Sterowania
 Monitorowanie i Diagnostyka w Systemach Sterowania Katedra Inżynierii Systemów Sterowania Dr inż. Michał Grochowski Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności:
Monitorowanie i Diagnostyka w Systemach Sterowania Katedra Inżynierii Systemów Sterowania Dr inż. Michał Grochowski Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności:
Zagadnienie klasyfikacji (dyskryminacji)
") Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana II stopień studiów Wykład 13b 2 Eksploracja danych Co rozumiemy pod pojęciem eksploracja danych Algorytmy grupujące (klajstrujące) Graficzna
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana II stopień studiów Wykład 13b 2 Eksploracja danych Co rozumiemy pod pojęciem eksploracja danych Algorytmy grupujące (klajstrujące) Graficzna
Wstęp do grupowania danych
 Eksploracja zasobów internetowych Wykład 5 Wstęp do grupowania danych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Istnieją dwie podstawowe metody klasyfikowania obiektów: metoda z nauczycielem, metoda
Eksploracja zasobów internetowych Wykład 5 Wstęp do grupowania danych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Istnieją dwie podstawowe metody klasyfikowania obiektów: metoda z nauczycielem, metoda
Metoda największej wiarygodności
 Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Rozdział Metoda największej wiarygodności Ogólnie w procesie estymacji na podstawie prób x i (każde x i może być wektorem) wyznaczamy parametr λ (w ogólnym przypadku również wektor) opisujący domniemany
Kwantyzacja wektorowa. Kodowanie różnicowe.
 Kwantyzacja wektorowa. Kodowanie różnicowe. Kodowanie i kompresja informacji - Wykład 7 12 kwietnia 2010 Kwantyzacja wektorowa wprowadzenie Zamiast kwantyzować pojedyncze elementy kwantyzujemy całe bloki
Kwantyzacja wektorowa. Kodowanie różnicowe. Kodowanie i kompresja informacji - Wykład 7 12 kwietnia 2010 Kwantyzacja wektorowa wprowadzenie Zamiast kwantyzować pojedyncze elementy kwantyzujemy całe bloki
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Przykładowa analiza danych
 Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Kryteria stopu algorytmu grupowania reguł a efektywność systemu wspomagania decyzji
 Kryteria stopu algorytmu grupowania reguł a efektywność systemu wspomagania decyzji Agnieszka Nowak Alicja Wakulicz-Deja Zakład Systemów Informatycznych Instytut Informatyki Uniwersytetu Śląskiego Sosnowiec,
Kryteria stopu algorytmu grupowania reguł a efektywność systemu wspomagania decyzji Agnieszka Nowak Alicja Wakulicz-Deja Zakład Systemów Informatycznych Instytut Informatyki Uniwersytetu Śląskiego Sosnowiec,
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd.
 Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane cd. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 2013-11-26 Projekt pn. Wzmocnienie potencjału
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Analiza danych tekstowych i języka naturalnego
 Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Uczenie nienadzorowane
 Uczenie nienadzorowane Nadzorowane, klasyfikacja: Nienadzorowane, analiza skupień (clustering): Zbiór uczacy: { (x 1 1,x1 2 ),c1, (x 2 1,x2 2 ),c2,... (x N 1,xN 2 ),cn } Zbiór uczacy: { (x 1 1,x1 2 ),
Uczenie nienadzorowane Nadzorowane, klasyfikacja: Nienadzorowane, analiza skupień (clustering): Zbiór uczacy: { (x 1 1,x1 2 ),c1, (x 2 1,x2 2 ),c2,... (x N 1,xN 2 ),cn } Zbiór uczacy: { (x 1 1,x1 2 ),
PRZYSPIESZENIE KNN. Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo.
 PRZYSPIESZENIE KNN Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo. Plan wykładu Klasyfikacja w oparciu o przykładach Problem indeksowania przestrzeni obiektów
PRZYSPIESZENIE KNN Ulepszone metody indeksowania przestrzeni danych: R-drzewo, R*-drzewo, SS-drzewo, SR-drzewo. Plan wykładu Klasyfikacja w oparciu o przykładach Problem indeksowania przestrzeni obiektów
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
WYKŁAD 4. Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie. autor: Maciej Zięba. Politechnika Wrocławska
 Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Wymagania egzaminacyjne z matematyki. Klasa 3C. MATeMATyka. Nowa Era. Klasa 3
 Wymagania egzaminacyjne z matematyki. lasa 3C. MATeMATyka. Nowa Era. y są ze sobą ściśle powiązane ( + P + R + D + W), stanowiąc ocenę szkolną, i tak: ocenę dopuszczającą (2) otrzymuje uczeń, który spełnił
Wymagania egzaminacyjne z matematyki. lasa 3C. MATeMATyka. Nowa Era. y są ze sobą ściśle powiązane ( + P + R + D + W), stanowiąc ocenę szkolną, i tak: ocenę dopuszczającą (2) otrzymuje uczeń, który spełnił
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
WYKŁAD 3. Klasyfikacja: modele probabilistyczne
 Wrocław University of Technology WYKŁAD 3 Klasyfikacja: modele probabilistyczne Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification): Dysponujemy obserwacjami z etykietami
Wrocław University of Technology WYKŁAD 3 Klasyfikacja: modele probabilistyczne Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification): Dysponujemy obserwacjami z etykietami
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Eksploracja danych w środowisku R
 Eksploracja danych w środowisku R Moi drodzy, niniejszy konspekt nie omawia eksploracji danych samej w sobie. Nie dowiecie się tutaj o co chodzi w generowaniu drzew decyzyjnych czy grupowaniu danych. Te
Eksploracja danych w środowisku R Moi drodzy, niniejszy konspekt nie omawia eksploracji danych samej w sobie. Nie dowiecie się tutaj o co chodzi w generowaniu drzew decyzyjnych czy grupowaniu danych. Te
Klasteryzacja i klasyfikacja danych spektrometrycznych
 Klasteryzacja i klasyfikacja danych spektrometrycznych Współpraca: Janusz Dutkowski, Anna Gambin, Krzysztof Kowalczyk, Joanna Reda, Jerzy Tiuryn, Michał Dadlez z zespołem (IBB PAN) Instytut Informatyki
Klasteryzacja i klasyfikacja danych spektrometrycznych Współpraca: Janusz Dutkowski, Anna Gambin, Krzysztof Kowalczyk, Joanna Reda, Jerzy Tiuryn, Michał Dadlez z zespołem (IBB PAN) Instytut Informatyki
Analiza skupień (Cluster analysis)
") Analiza skupień (Cluster analysis) Analiza skupień jest to podział zbioru obserwacji na podzbiory (tzw. klastry) tak, że obiekty (obserwacje) w tym samym klastrze były podobne (w pewnym sensie). Jest to
Analiza skupień (Cluster analysis) Analiza skupień jest to podział zbioru obserwacji na podzbiory (tzw. klastry) tak, że obiekty (obserwacje) w tym samym klastrze były podobne (w pewnym sensie). Jest to
Instytut Automatyki i Inżynierii Informatycznej Politechniki Poznańskiej. Adam Meissner. Elementy uczenia maszynowego
 Instytut Automatyki i Inżynierii Informatycznej Politechniki Poznańskiej Adam Meissner Adam.Meissner@put.poznan.pl http://www.man.poznan.pl/~ameis Elementy uczenia maszynowego Literatura [1] Bolc L., Zaremba
Instytut Automatyki i Inżynierii Informatycznej Politechniki Poznańskiej Adam Meissner Adam.Meissner@put.poznan.pl http://www.man.poznan.pl/~ameis Elementy uczenia maszynowego Literatura [1] Bolc L., Zaremba
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
Analiza skupień (Cluster Analysis)
") Rozdział 8 Analiza skupień (Cluster Analysis) 8.1 Wstęp Analiza skupień jest techniką statystyczną i neuronową mającą na celu porównywanie i klasyfikowanie obiektów, opisywanych za pomocą wielu atrybutów.
Rozdział 8 Analiza skupień (Cluster Analysis) 8.1 Wstęp Analiza skupień jest techniką statystyczną i neuronową mającą na celu porównywanie i klasyfikowanie obiektów, opisywanych za pomocą wielu atrybutów.
Przybliżone algorytmy analizy ekspresji genów.
 Przybliżone algorytmy analizy ekspresji genów. Opracowanie i implementacja algorytmu analizy danych uzyskanych z eksperymentu biologicznego. 20.06.04 Seminarium - SKISR 1 Wstęp. Dane wejściowe dla programu
Przybliżone algorytmy analizy ekspresji genów. Opracowanie i implementacja algorytmu analizy danych uzyskanych z eksperymentu biologicznego. 20.06.04 Seminarium - SKISR 1 Wstęp. Dane wejściowe dla programu
Seminarium IO. Zastosowanie wielorojowej metody PSO w Dynamic Vehicle Routing Problem. Michał Okulewicz
 Seminarium IO Zastosowanie wielorojowej metody PSO w Dynamic Vehicle Routing Problem Michał Okulewicz 26.02.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm PSO Podejścia DAPSO, MAPSO 2PSO, 2MPSO
Seminarium IO Zastosowanie wielorojowej metody PSO w Dynamic Vehicle Routing Problem Michał Okulewicz 26.02.2013 Plan prezentacji Przypomnienie Problem DVRP Algorytm PSO Podejścia DAPSO, MAPSO 2PSO, 2MPSO
Poznań, 14 grudnia 2002. Case Study 2 Analiza skupień
 Poznań, 14 grudnia 2002 Case Study 2 Analiza skupień Celem ćwiczenia jest przeprowadzenie procesu grupowania / analizy skupień dla jednego z wybranych zbiorów danych (tj. dostarczonych przez prowadzącego).
Poznań, 14 grudnia 2002 Case Study 2 Analiza skupień Celem ćwiczenia jest przeprowadzenie procesu grupowania / analizy skupień dla jednego z wybranych zbiorów danych (tj. dostarczonych przez prowadzącego).
Wrocław University of Technology. Wprowadzenie cz. I. Adam Gonczarek. Rozpoznawanie Obrazów, Lato 2015/2016
 Wrocław University of Technology Wprowadzenie cz. I Adam Gonczarek adam.gonczarek@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2015/2016 ROZPOZNAWANIE OBRAZÓW / WZORCÓW Definicja z Wikipedii 2/39 ROZPOZNAWANIE
Wrocław University of Technology Wprowadzenie cz. I Adam Gonczarek adam.gonczarek@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2015/2016 ROZPOZNAWANIE OBRAZÓW / WZORCÓW Definicja z Wikipedii 2/39 ROZPOZNAWANIE
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Katalog wymagań programowych na poszczególne stopnie szkolne. Matematyka. Poznać, zrozumieć
 Katalog wymagań programowych na poszczególne stopnie szkolne Matematyka. Poznać, zrozumieć Kształcenie w zakresie podstawowym. Klasa 3 Poniżej podajemy umiejętności, jakie powinien zdobyć uczeń z każdego
Katalog wymagań programowych na poszczególne stopnie szkolne Matematyka. Poznać, zrozumieć Kształcenie w zakresie podstawowym. Klasa 3 Poniżej podajemy umiejętności, jakie powinien zdobyć uczeń z każdego
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Wymagania kl. 3. Zakres podstawowy i rozszerzony
 Wymagania kl. 3 Zakres podstawowy i rozszerzony Temat lekcji Zakres treści Osiągnięcia ucznia 1. RACHUNEK PRAWDOPODOBIEŃSTWA 1. Reguła mnożenia reguła mnożenia ilustracja zbioru wyników doświadczenia za
Wymagania kl. 3 Zakres podstawowy i rozszerzony Temat lekcji Zakres treści Osiągnięcia ucznia 1. RACHUNEK PRAWDOPODOBIEŃSTWA 1. Reguła mnożenia reguła mnożenia ilustracja zbioru wyników doświadczenia za
Algorytmy genetyczne w interpolacji wielomianowej
 Algorytmy genetyczne w interpolacji wielomianowej (seminarium robocze) Seminarium Metod Inteligencji Obliczeniowej Warszawa 22 II 2006 mgr inż. Marcin Borkowski Plan: Przypomnienie algorytmu niszowego
Algorytmy genetyczne w interpolacji wielomianowej (seminarium robocze) Seminarium Metod Inteligencji Obliczeniowej Warszawa 22 II 2006 mgr inż. Marcin Borkowski Plan: Przypomnienie algorytmu niszowego
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO
 SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Porównanie szeregów czasowych z wykorzystaniem algorytmu DTW
 Zlot użytkowników R Porównanie szeregów czasowych z wykorzystaniem algorytmu DTW Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk 21 września 2010 Miary podobieństwa między szeregami
Zlot użytkowników R Porównanie szeregów czasowych z wykorzystaniem algorytmu DTW Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk 21 września 2010 Miary podobieństwa między szeregami
STATYSTYKA I DOŚWIADCZALNICTWO
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 9 Analiza skupień wielowymiarowa klasyfikacja obiektów Metoda, a właściwie to zbiór metod pozwalających na grupowanie obiektów pod względem wielu cech jednocześnie.
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 9 Analiza skupień wielowymiarowa klasyfikacja obiektów Metoda, a właściwie to zbiór metod pozwalających na grupowanie obiektów pod względem wielu cech jednocześnie.
ALGORYTMY GENETYCZNE ćwiczenia
 ćwiczenia Wykorzystaj algorytmy genetyczne do wyznaczenia minimum globalnego funkcji testowej: 1. Wylosuj dwuwymiarową tablicę 100x2 liczb 8-bitowych z zakresu [-100; +100] reprezentujących inicjalną populację
ćwiczenia Wykorzystaj algorytmy genetyczne do wyznaczenia minimum globalnego funkcji testowej: 1. Wylosuj dwuwymiarową tablicę 100x2 liczb 8-bitowych z zakresu [-100; +100] reprezentujących inicjalną populację
voxele o wartości >0 to voxele stopy (kości, mięśnie, skóra), voxele o wartości > 70 to voxele kości.
, voxele o wartości > 70 to voxele kości.") Zadanie 1: Stopa Autor: dr Krzysztof Nowiński Zbiór danych stopa.dat (do ściągnięcia stąd: http://www.icm.edu.pl/~bolo/kfnrd2013/know/) zawiera tomogram komputerowy stopy człowieka. Dane są zawarte w kostce
Zadanie 1: Stopa Autor: dr Krzysztof Nowiński Zbiór danych stopa.dat (do ściągnięcia stąd: http://www.icm.edu.pl/~bolo/kfnrd2013/know/) zawiera tomogram komputerowy stopy człowieka. Dane są zawarte w kostce
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Indukowane Reguły Decyzyjne I. Wykład 8
 Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Indukowane Reguły Decyzyjne I Wykład 8 IRD Wykład 8 Plan Powtórka Krzywa ROC = Receiver Operating Characteristic Wybór modelu Statystyka AUC ROC = pole pod krzywą ROC Wybór punktu odcięcia Reguły decyzyjne
Zadania domowe. Ćwiczenie 2. Rysowanie obiektów 2-D przy pomocy tworów pierwotnych biblioteki graficznej OpenGL
 Zadania domowe Ćwiczenie 2 Rysowanie obiektów 2-D przy pomocy tworów pierwotnych biblioteki graficznej OpenGL Zadanie 2.1 Fraktal plazmowy (Plasma fractal) Kwadrat należy pokryć prostokątną siatką 2 n
Zadania domowe Ćwiczenie 2 Rysowanie obiektów 2-D przy pomocy tworów pierwotnych biblioteki graficznej OpenGL Zadanie 2.1 Fraktal plazmowy (Plasma fractal) Kwadrat należy pokryć prostokątną siatką 2 n
SPOTKANIE 2: Wprowadzenie cz. I
 Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
WYKŁAD 12. Analiza obrazu Wyznaczanie parametrów ruchu obiektów
 WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania
WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania