Metody oparte na logicznej regresji. zastosowaniu do wykrywania interakcji SNPów
|
|
|
- Dagmara Grzybowska
- 8 lat temu
- Przeglądów:
Transkrypt
1 w zastosowaniu do wykrywania interakcji SNPów Instytut Matematyczny, Uniwersytet Wrocławski Wisła, 9 grudnia 2009
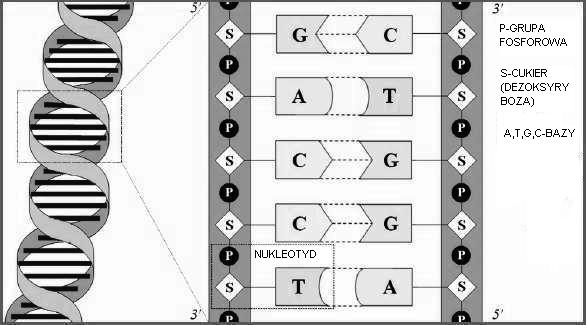
2 DNA
3 Zmienność genetyczna Polimorfizm to zmiana w strukturze DNA, obecna u co najmniej 1% populacji Polimorfizm pojedynczego nukleotydu SNP(Single Nucleotide Polimorphism-zmiany dotycza różnicy na pojedynczej bazie GŁÓWNY CEL: znalezienie mutacji w ciągu DNA, mających wpływ na badaną cechę. METODY: regresja logiczna (Ruczinski, Kooperberg, LeBlanc ( zmiennymi objaśniającymi są wyrażenia logiczne otrzymane ze zmiennych binarnych regresja logiczna z algorytmem Monte Carlo (Ruczinski, Kooperberg (2005 w pełni bayesowska wersja logicznej regresji (Fritsch(2006 bayesowska wersja regresji logistycznej, w której zmiennymi objaśniającymi są iloczyny binarnych predykatorów
4 Regresja Logiczna z predykatorami genetycznymi Predykatorami są SNPy o możliwych trzech wartościach: 0, 1 lub 2. Zmienne pomocnicze (Kooperberg et.al(2001: { 0, SNP = 0 X d - efekt dominujący, X d = 1, SNP = 1, 2, { 0, SNP = 0, 1 X r -efekt recesywny, X r =. 1, SNP = 2 SNP X d X r Genotyp Homozygota (reference Heterozygota Homozygota (variant
5 Wyrażenia logiczne Niech X 1, X 2,..., X m będą predykatorami binarnymi. Wówczas: wyrażeniem logicznym jest każda kombinacja zmiennych X i, uzyskana przez zastosowanie operatorów logicznych (AND, (OR oraz C (NOT Każde wyrażenie logiczne może być przedstawione za pomocą drzewa binarnego, np: L = (A B c C możemy przedstawić w postaci drzewa
6 Model regresji logicznej Dopasowujemy model regresji g(e[y ] = β 0 + t β j L j, gdzie L j są wyrażeniami logicznymi otrzymanymi ze zmiennych binarnych X i, i = 1, 2,..., m. Rozmiar modelu to liczba liści w modelu; ustalany w oparciu o zbiór testowy i treningowy metodę kroswalidacji Przykład: X = (X 1, X 2,..., X m - macierz zmiennych binarnych; Y - status chory/zdrowy j=1 Model Regresji Logicznej: log( E[Y ] = X1 (X2 X3 1 E[Y ] Model Regresji Logistycznej z iloczynami : = X1 + X2 X3 X1 X2 X3 log( E[Y ] 1 E[Y ]
7 W pełni bayesowska wersja Logicznej Regresji (FBLR Fritsch (2006 zaproponował wersję bayesowską logicznej regresji (FBLR wyrażenia logiczne tylko ze spójnikiem AND w jednoznacznej reprezentacji np.: X 4 X C 1 X 7 jako (1C, 4, 7 Rozkłady a priori: k - liczba predykatorów, p(k U({0, 1,..., k max }, β - wektor parametrów regresji, p(β v, k N (0, v I k+1, p(v InvGamma(τ = 0.001; ν = 0.1, (Holmes, Denison(2003. s i - liczba zmiennych binarnych w wyrażeniu logicznym L i, p(s i (a si, (a = 0.7 bin - wektor indeksów zmiennych binarnych włączonych do modelu p(bin s i = ( 1 2m s i p(θ = p(k p(v p(β v, k k p(s i p(bin s i, i=1
8 Rozważany model Rozważamy prosty model z jedną zmienną objaśniającą: i = 1, 2,..., n; x ij b(1, p, p znane, M 1 : y i = β 0 + β 1 x ij + ε i, j = 1, 2,..., m,, ε i N (0, σ 2, σ jest znane. β = (β 0, β 1, ˆβ - estymator największej wiarogodności dla β, f (β M 1 = p(vp(β v - gęstość a priori rozkładu β w modelu M 1, p(β v = 1 2πv exp( 1 2v (β2 0 + β 2 1, p(v = ντ exp( ν v I v τ+1 Γ(τ (0,+ (v. π(m K a K 1 m K - prawdopodobieństwo a priori modelu M K, K = 0, 1, m K - liczba modeli rozmiaru K. prawdopodobieństwo a posteriori modelu M K : P(M K Y L(Y M K π(m K
9 Rozważany model Testujemy hipotezę H0 : β 1 = 0 przy alternatywie H1 : β 1 0. metoda FBLR odrzuca hipotezę H0, gdy P(M 1 Y > P(M 0 Y. funkcja wiarogodności w K-tym modelu: L(Y M K = L(Y M K, βf (β M K dβ czyli L(Y M 1 = ντ τ2 τ+1 ( 2πσ n 2π + + ( exp (2ν + β β 2 1 (τ+1 dβ 0 dβ 1 n i=1 (y i (β 0 + β 1 x ij 2 2σ 2
10 Stosując aproksymację Laplace a otrzymujemy oszacowanie log(l(y M 1 = log(l(y M 1, ˆβ log(n + log(r 1, gdzie i podobnie R 1 = ν τ τ2 τ+1 σ 2 S(2ν + ˆβ ˆβ 2 1 τ+1, gdzie log(l(y M 0 = log(l(y M 0, ˆβ + log(r 0, R 0 = ντ τ2 τ+1 σ 2 2πS(2ν τ+1. A więc odrzucamy hipotezę H 0 gdy ( L(Y M 1, log ˆβ ( m1 L(Y M 0, ˆβ > log(n + log log(r 1 + log(r 0. a
11 Oszacowanie prawdopodobieństwa błędu I rodzaju Przy założeniu, że X T X = ni (m+1 (m+1, mamy ( L(Y M 1, log ˆβ L(Y M 0, ˆβ = n ˆβ 2 1 2σ 2. Przy c = 2(log(n + log ( m 1 a log(r1 + log(r 0, prawdopodobieństwo błędu I rodzaju α n,m1 wynosi (n P ˆβ 2 1 > c σ 2 n ˆβ1 = 2P( > c, gdzie σ n ˆβ1 N (0, 1. σ Stosując oszacowanie : P( n ˆβ 1 σ > c 1 2πc exp ( c 2 dostajemy a α n,m1 = n m 1 π(log(n + log( m 1 a log(r. 1 + log(r 0 R 0 R 1
12 Korekta na wielokrotne testowanie W modelu z interakcjami rzędu 2 α int,n,m2 = n m 2 π(log(n + log( m 2. a log(r log(r 0 R 0 Przy pominięciu składników resztowych R 0, R 1 : α n,m1 = α int,n,m2 = a 2 a n m 1 π(log(n + log( m 1 a, a 2 n m 2 π(log(n + log( m 2 a 2. - automatyczna korekta na wielokrotne testowanie. R 1
13 Całkowity błąd I rodzaju - oszacowanie Laplace a Liczba obserwacji n rośnie od 50 do 2500:
14 Badanie wpływu czynników R 0 i R 1 Badamy wartości α n i α int,n z włączeniem czynników R 0, R 1 i z ich pominięciem. Liczba obserwacji n rośnie od 50 do 2500:
15 Uwzględnienie rozkładu składników resztowych Gdy R 0, R 1 uwzględniamy jako mające wpływ na rozkład Prawdopodobieństwo błędu I rodzaju dla FBLR: ( ( m1 ( (2ν (τ+1 α n,m1 = P Z > log(n + log log, a 2π gdzie Z = n ˆβ 1 2 σ 2 (τ + 1 log(2ν + ˆβ ˆβ1 2. Konsekwencją asymptotycznej normalności estymatorów największej wiarogodności ˆβ jest, że ( n ˆβ 2 nν + (τ + 1σ 2 n 2 p 2 ν 0 σ 2 ν σ 2 (nνp + (τ + 1σ 2 χ 2 (1 oraz ( n ˆβ 2 nνp + (τ + 1σ 2 n 2 p 2 ν 1 σ 2 ν σ 2 (nν + (τ + 1σ 2 χ 2 (1
16 Uwzględnienie rozkładu składników resztowych Stąd i z dwustronnego oszacowania logarytmu ˆβ ( 2 p 2 +1 ( ( 1 2ν ˆβ ( log 1 + ˆβ 2 p 2 ( p ν ˆβ 2 p ν 1 2ν otrzymujemy ( t R następujące oszacowanie rozkładu zmiennej Z ( ( c 1 (t + (τ + 1 log(2ν c 1 (t + (τ + 1 log(2ν F χ2 (1 F 1 2σ (τ + 1 p2 +1 Z (t F χ2 (1, 1 2 2νn 2σ (τ + 1 p νn gdzie F χ 2 (1( oznacza dystrybuantę centralnego rozkładu χ 2 (1 z jednym stopniem swobody i ( nνp + (τ + 1σ 2 n 2 p 2 ν c 1 = σ 2 ν σ 2 (nν + (τ + 1σ 2.
17 Oszacowanie prawdopodobieństwa błędu I rodzaju Twierdzenie: Dla testowania hipotezy H 0 : β 1 = 0 przy alternatywie H 1 : β 1 0 w metodzie FBLR dla pojedynczych zmiennych prawdopodobieństwo błędu pierwszego rodzaju dla pojedynczego testu α n,m1 spełnia warunek ( c1 log ( ( 2πm 1 c1 log ( 2πm 1 1 F χ2 (1 1 2σ (τ + 1 p νn a α n,m1 1 F χ2 (1 1 2σ (τ + 1 p νn gdzie F χ 2 (1( oznacza dystrybuantę centralnego rozkładu χ 2 (1 z jednym stopniem swobody i ( nνp + (τ + 1σ 2 n 2 p 2 ν c 1 = σ 2 ν σ 2 (nν + (τ + 1σ 2. a
18 Literatura [1]Ruczinski I., Kooperberg C., LeBlanc M., Logic regression, J. Comput. Graphical Statist. 12 (3,(2003, , [2]Kooperberg C., Ruczinski I., Identifying Interacting SNPs Using Monte Carlo Logic Regression, Genetic Epidemiology 28, (2005 [3]Fritsch A., Ickstadt K., Comparing Logic Regression Based Methods for Identifying SNP Interactions, Springer Berlin / Heidelberg, Lecture Notes in Computer Science, Volume 4414/2007, pp [4]Fritsch A., A Full Bayesian Version of Logic regression for SNP Data, Diploma Thesis, (2006 [5]Scott J.G. and Berger J.O., Bayes and empirical-bayes multiplicity adjustment in the variable-selection problem., Duke University Department of Statistical Science Technical Report (2008. [6]Holmes,C.C and Denison D.G.T, Classification with Bayesian MARS, Mach. Learn.50(2003, [7]Green, P.J. (1995. Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 82,
19 Symulacje DANE: Uproszczona wersja danych SNP-owych: po 1000 osób, z 50, 200 i 300 SNP-ami; METODY: FBLR: logit(p(y = 1 = β 0 + k j=1 βjlj, - w L i możliwe dopełnienia Bayesowska wersja regresji logistycznej dla interakcji: logit(p(y = 1 = γ 0 + t γjij, j=1 - I j proste iloczyny zmiennych, bez dopełnień Dla każdego modelu tworzymy 20 zbiorów danych Dla każdego zbioru danych obliczamy liczbę właściwie i niewłaściwie klasyfikowanych interakcji SNPów Wynik uśredniony przez 20 zbiorów danych Pojedynczy SNP reprezentowany przez dwie zmienne X i z rozkładu b(1, 0.25
20 Liczba interakcji SNPów w prawdziwym modelu=1 Model 1. Z = X 1d X 2d + X 11d + ε, ε N (0, 1 #SNP Poprawne Niepoprawne FBLR Bayesowska Regresja Logistyczna Model 2. Z = X7d C X 9d C X 11d C + ε, ε N (0, 1 #SNP Poprawne Poprawne Niepoprawne rzędu 2 lub 3 rzędu 1 FBLR Bayesowska Regresja Logistyczna
21 Wyniki symulacji (Fritsch, Ickstadt( zbiorów danych dla każdego modelu Dla każdego zbioru danych obliczamy liczbę właściwie i niewłaściwie klasyfikowanych interakcji SNPów Wynik uśredniony przez 10 zbiorów danych Pojedynczy SNP reprezentowany przez dwie zmienne X i z rozkładu b(1, 0.3 P(Y =1 η = log( P(Y =0 1. η = (X 1d X C 2d (X 3d X 4d (X 5d X 6d Liczba interakcji SNPów w prawdziwym modelu= 3 MODEL 1 poprawne niepoprawne Regresja Logiczna MCLR t = 2, a = MCLR t = 3, a = FBLR
22 Wyniki symulacji(fritsch, Ickstadt( η = (X 1d X C 2d (X 3d X 4d (X 5d X 6d Liczba interakcji SNPów w prawdziwym modelu= 3 MODEL 2 poprawne niepoprawne Regresja Logiczna MCLR t = 2, a = MCLR t = 3, a = FBLR η = (X 1d (X C 2d X 3d Liczba interakcji SNPów w prawdziwym modelu= 3 MODEL 3 poprawne niepoprawne Regresja Logiczna MCLR t = 2, a = MCLR t = 3, a = FBLR
Porównanie modeli regresji. klasycznymi modelami regresji liniowej i logistycznej
 Porównanie modeli logicznej regresji z klasycznymi modelami regresji liniowej i logistycznej Instytut Matematyczny, Uniwersytet Wrocławski Małgorzata Bogdan Instytut Matematyki i Informatyki, Politechnika
Porównanie modeli logicznej regresji z klasycznymi modelami regresji liniowej i logistycznej Instytut Matematyczny, Uniwersytet Wrocławski Małgorzata Bogdan Instytut Matematyki i Informatyki, Politechnika
Algorytmy MCMC i ich zastosowania statystyczne
 Algorytmy MCMC i ich zastosowania statystyczne Wojciech Niemiro Uniwersytet Mikołaja Kopernika, Toruń i Uniwersytet Warszawski Statystyka Matematyczna Wisła, grudzień 2010 Wykład 1 1 Co to jest MCMC? 2
Algorytmy MCMC i ich zastosowania statystyczne Wojciech Niemiro Uniwersytet Mikołaja Kopernika, Toruń i Uniwersytet Warszawski Statystyka Matematyczna Wisła, grudzień 2010 Wykład 1 1 Co to jest MCMC? 2
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE. Joanna Sawicka
 Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Regresyjne metody łączenia klasyfikatorów
 Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
Ekonometria. Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Kolokwium ze statystyki matematycznej
 Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Kolokwium ze statystyki matematycznej 28.05.2011 Zadanie 1 Niech X będzie zmienną losową z rozkładu o gęstości dla, gdzie 0 jest nieznanym parametrem. Na podstawie pojedynczej obserwacji weryfikujemy hipotezę
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Imputacja brakujacych danych binarnych w modelu autologistycznym 1
 Imputacja brakujacych danych binarnych w modelu autologistycznym 1 Marta Zalewska Warszawski Uniwesytet Medyczny Statystyka Matematyczna Wisła, grudzień 2009 1 Współautorzy: Wojciech Niemiro, UMK Toruń
Imputacja brakujacych danych binarnych w modelu autologistycznym 1 Marta Zalewska Warszawski Uniwesytet Medyczny Statystyka Matematyczna Wisła, grudzień 2009 1 Współautorzy: Wojciech Niemiro, UMK Toruń
Metoda najmniejszych kwadratów
 Metoda najmniejszych kwadratów Przykład wstępny. W ekonomicznej teorii produkcji rozważa się funkcję produkcji Cobba Douglasa: z = AL α K β gdzie z oznacza wielkość produkcji, L jest nakładem pracy, K
Metoda najmniejszych kwadratów Przykład wstępny. W ekonomicznej teorii produkcji rozważa się funkcję produkcji Cobba Douglasa: z = AL α K β gdzie z oznacza wielkość produkcji, L jest nakładem pracy, K
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Testowanie hipotez statystycznych
 round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wykład 10 Testy jednorodności rozkładów
 Wykład 10 Testy jednorodności rozkładów Wrocław, 16 maja 2018 Test Znaków test jednorodności rozkładów nieparametryczny odpowiednik testu t-studenta dla prób zależnych brak normalności rozkładów Test Znaków
Wykład 10 Testy jednorodności rozkładów Wrocław, 16 maja 2018 Test Znaków test jednorodności rozkładów nieparametryczny odpowiednik testu t-studenta dla prób zależnych brak normalności rozkładów Test Znaków
1. Pokaż, że estymator MNW parametru β ma postać β = nieobciążony. Znajdź estymator parametru σ 2.
 Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Hipotezy proste. (1 + a)x a, dla 0 < x < 1, 0, poza tym.
x a, dla 0 < x < 1, 0, poza tym.") Hipotezy proste Zadanie 1. Niech X ma funkcję gęstości f a (x) = (1 + a)x a, dla 0 < x < 1, Testujemy H 0 : a = 1 przeciwko H 1 : a = 2. Dysponujemy pojedynczą obserwacją X. Wyznaczyć obszar krytyczny
Hipotezy proste Zadanie 1. Niech X ma funkcję gęstości f a (x) = (1 + a)x a, dla 0 < x < 1, Testujemy H 0 : a = 1 przeciwko H 1 : a = 2. Dysponujemy pojedynczą obserwacją X. Wyznaczyć obszar krytyczny
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Testy adaptacyjne dla problemu k prób
 Instytut Matematyczny Polskiej Akademii Nauk Oddział Wrocław Problem testowania Problem Testowania Weryfikacja hipotezy Notacja Pomocnicza statystyka rangowa Załóżmy, że X l1,..., X lnl, l = 1,..., k,
Instytut Matematyczny Polskiej Akademii Nauk Oddział Wrocław Problem testowania Problem Testowania Weryfikacja hipotezy Notacja Pomocnicza statystyka rangowa Załóżmy, że X l1,..., X lnl, l = 1,..., k,
Wprowadzenie. { 1, jeżeli ˆr(x) > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne
 > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne") Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Ekonometria. Ćwiczenia nr 3. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Ćwiczenia nr 3 Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Ćwiczenia 3 Własności składnika losowego 1 / 18 Agenda KMNK przypomnienie 1 KMNK przypomnienie 2 3 4 Jakub Mućk
Ekonometria Ćwiczenia nr 3 Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Ćwiczenia 3 Własności składnika losowego 1 / 18 Agenda KMNK przypomnienie 1 KMNK przypomnienie 2 3 4 Jakub Mućk
Stosowana Analiza Regresji
 Stosowana Analiza Regresji Wykład VI... 16 Listopada 2011 1 / 24 Jest to rozkład zmiennej losowej rozkład chi-kwadrat Z = n i=1 X 2 i, gdzie X i N(µ i, 1) - niezależne. Oznaczenie: Z χ 2 (n, λ), gdzie:
Stosowana Analiza Regresji Wykład VI... 16 Listopada 2011 1 / 24 Jest to rozkład zmiennej losowej rozkład chi-kwadrat Z = n i=1 X 2 i, gdzie X i N(µ i, 1) - niezależne. Oznaczenie: Z χ 2 (n, λ), gdzie:
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Ekonometria. Własności składnika losowego. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Własności składnika losowego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 3 Własności składnika losowego 1 / 31 Agenda KMNK przypomnienie 1 KMNK przypomnienie 2 3 4
Ekonometria Własności składnika losowego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 3 Własności składnika losowego 1 / 31 Agenda KMNK przypomnienie 1 KMNK przypomnienie 2 3 4
Prawdopodobieństwo i statystyka r.
 Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Metody klasyfikacji dla nielicznej próbki wektorów o wielkim wymiarze
 Metody klasyfikacji dla nielicznej próbki wektorów o wielkim wymiarze Small n large p problem Problem w analizie wielu zbiorów danych biologicznych: bardzo mała liczba obserwacji (rekordów, próbek) rzędu
Metody klasyfikacji dla nielicznej próbki wektorów o wielkim wymiarze Small n large p problem Problem w analizie wielu zbiorów danych biologicznych: bardzo mała liczba obserwacji (rekordów, próbek) rzędu
Metody Obliczeniowe w Nauce i Technice
 Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Metody Obliczeniowe w Nauce i Technice 15. Obliczanie całek metodami Monte Carlo Marian Bubak Department of Computer Science AGH University of Science and Technology Krakow, Poland bubak@agh.edu.pl dice.cyfronet.pl
Statystyka Matematyczna Anna Janicka
 Statystyka Matematyczna Anna Janicka wykład X, 9.05.206 TESTOWANIE HIPOTEZ STATYSTYCZNYCH II: PORÓWNYWANIE TESTÓW Plan na dzisiaj 0. Przypomnienie potrzebnych definicji. Porównywanie testów 2. Test jednostajnie
Statystyka Matematyczna Anna Janicka wykład X, 9.05.206 TESTOWANIE HIPOTEZ STATYSTYCZNYCH II: PORÓWNYWANIE TESTÓW Plan na dzisiaj 0. Przypomnienie potrzebnych definicji. Porównywanie testów 2. Test jednostajnie
Modele DSGE. Jerzy Mycielski. Maj Jerzy Mycielski () Modele DSGE Maj / 11
 Modele DSGE Maj / 11") Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Modele DSGE Jerzy Mycielski Maj 2008 Jerzy Mycielski () Modele DSGE Maj 2008 1 / 11 Modele DSGE DSGE - Dynamiczne, stochastyczne modele równowagi ogólnej (Dynamic Stochastic General Equilibrium Model)
Statystyka matematyczna. Wykład III. Estymacja przedziałowa
 Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
STATYSTYKA MATEMATYCZNA WYKŁAD października 2009
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 26 października 2009 Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ (X µ) 2 { (x µ) 2 exp 1 ( ) } x µ 2 dx 2 σ Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ
STATYSTYKA MATEMATYCZNA WYKŁAD 4 26 października 2009 Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ (X µ) 2 { (x µ) 2 exp 1 ( ) } x µ 2 dx 2 σ Rozkład N(µ, σ). Estymacja σ σ 2 = 1 σ 2π + = E µ,σ
Wykład 7 Testowanie zgodności z rozkładem normalnym
 Wykład 7 Testowanie zgodności z rozkładem normalnym Wrocław, 05 kwietnia 2017 Rozkład normalny Niech X = (X 1, X 2,..., X n ) będzie próbą z populacji o rozkładzie normalnym określonym przez dystrybuantę
Wykład 7 Testowanie zgodności z rozkładem normalnym Wrocław, 05 kwietnia 2017 Rozkład normalny Niech X = (X 1, X 2,..., X n ) będzie próbą z populacji o rozkładzie normalnym określonym przez dystrybuantę
Ekonometria. Weryfikacja liniowego modelu jednorównaniowego. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Weryfikacja liniowego modelu jednorównaniowego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 2 Weryfikacja liniowego modelu jednorównaniowego 1 / 28 Agenda 1 Estymator
Ekonometria Weryfikacja liniowego modelu jednorównaniowego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 2 Weryfikacja liniowego modelu jednorównaniowego 1 / 28 Agenda 1 Estymator
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni
 Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
Selekcja modelu liniowego i predykcja metodami losowych podprzestrzeni Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre Selekcja modelu liniowego i predykcja 1 / 29 Plan
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 5 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 5 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Metody Ekonometryczne
 Metody Ekonometryczne Goodness of fit i wprowadzenie do wnioskowania statystycznego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 2 Goodness of fit i wprowadzenie do wnioskowania
Metody Ekonometryczne Goodness of fit i wprowadzenie do wnioskowania statystycznego Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 2 Goodness of fit i wprowadzenie do wnioskowania
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba Cel zadania Celem zadania jest implementacja klasyfikatorów
SPOTKANIE 3: Regresja: Regresja liniowa
 Wrocław University of Technology SPOTKANIE 3: Regresja: Regresja liniowa Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 22.11.2013 Rozkład normalny Rozkład normalny (ang. normal
Wrocław University of Technology SPOTKANIE 3: Regresja: Regresja liniowa Adam Gonczarek Studenckie Koło Naukowe Estymator adam.gonczarek@pwr.wroc.pl 22.11.2013 Rozkład normalny Rozkład normalny (ang. normal
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotn. istotności, p-wartość i moc testu
 Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 11 i 12 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 11 i 12 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 11 i 12 1 / 41 TESTOWANIE HIPOTEZ - PORÓWNANIE
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 11 i 12 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 11 i 12 1 / 41 TESTOWANIE HIPOTEZ - PORÓWNANIE
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 2 κ-nn i Naive Bayes autorzy: M. Zięba, J.M. Tomczak, A. Gonczarek, S. Zaręba, J. Kaczmar Cel zadania Celem zadania jest implementacja klasyfikatorów
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 13 i 14 1 / 15 MODEL BAYESOWSKI, przykład wstępny Statystyka
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 13 i 14 - Statystyka bayesowska Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 13 i 14 1 / 15 MODEL BAYESOWSKI, przykład wstępny Statystyka
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1
 Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1") Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, Ŝe 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, Ŝe 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
WYKŁAD 4. Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie. autor: Maciej Zięba. Politechnika Wrocławska
 Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Konferencja Statystyka Matematyczna Wisła 2013
 Konferencja Statystyka Matematyczna Wisła 2013 Wykorzystanie metod losowych podprzestrzeni do predykcji i selekcji zmiennych Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre
Konferencja Statystyka Matematyczna Wisła 2013 Wykorzystanie metod losowych podprzestrzeni do predykcji i selekcji zmiennych Paweł Teisseyre Instytut Podstaw Informatyki, Polska Akademia Nauk Paweł Teisseyre
Elementy statystyki STA - Wykład 5
 STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Czasowy wymiar danych
 Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
Przyczynowość Kointegracja. Kointegracja. Kointegracja
 korelacja a związek o charakterze przyczynowo-skutkowym korelacja a związek o charakterze przyczynowo-skutkowym Przyczynowość w sensie Grangera Zmienna x jest przyczyną w sensie Grangera zmiennej y jeżeli
korelacja a związek o charakterze przyczynowo-skutkowym korelacja a związek o charakterze przyczynowo-skutkowym Przyczynowość w sensie Grangera Zmienna x jest przyczyną w sensie Grangera zmiennej y jeżeli
Stosowana Analiza Regresji
 Model jako : Stosowana Analiza Regresji Wykład XI 21 Grudnia 2011 1 / 11 Analiza kowariancji Model jako : Oprócz czynnika o wartościach nominalnych chcemy uwzględnić wpływ predyktora o wartościach ilościowych
Model jako : Stosowana Analiza Regresji Wykład XI 21 Grudnia 2011 1 / 11 Analiza kowariancji Model jako : Oprócz czynnika o wartościach nominalnych chcemy uwzględnić wpływ predyktora o wartościach ilościowych
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład V. Parametryczne testy istotności
 Statystyka matematyczna. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Weryfikacja hipotezy o równości wartości średnich w dwóch populacjach 2 3 Weryfikacja hipotezy o równości wartości średnich
Statystyka matematyczna. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Weryfikacja hipotezy o równości wartości średnich w dwóch populacjach 2 3 Weryfikacja hipotezy o równości wartości średnich
REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO. Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój
 1 REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój 2 DOTYCHCZASOWE MODELE Regresja liniowa o postaci: y
1 REGRESJA LINIOWA Z UOGÓLNIONĄ MACIERZĄ KOWARIANCJI SKŁADNIKA LOSOWEGO Aleksander Nosarzewski Ekonometria bayesowska, prowadzący: dr Andrzej Torój 2 DOTYCHCZASOWE MODELE Regresja liniowa o postaci: y
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metoda największej wiarogodności
 Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Stopę zbieżności ciagu zmiennych losowych a n, takiego, że E (a n ) < oznaczamy jako a n = o p (1) prawdopodobieństwa szybciej niż n α.
 < oznaczamy jako a n = o p (1) prawdopodobieństwa szybciej niż n α.") Stopy zbieżności Stopę zbieżności ciagu zmiennych losowych a n, takiego, że a n oznaczamy jako a n = o p (1 p 0 a Jeśli n p n α 0, to a n = o p (n α i mówimy a n zbiega według prawdopodobieństwa szybciej
Stopy zbieżności Stopę zbieżności ciagu zmiennych losowych a n, takiego, że a n oznaczamy jako a n = o p (1 p 0 a Jeśli n p n α 0, to a n = o p (n α i mówimy a n zbiega według prawdopodobieństwa szybciej
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1
 Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1") Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, że 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, że 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
Metody statystyczne w lokalizacji genów
 Metody statystyczne w lokalizacji genów Instytut Matematyki Uniwersytet Wrocławski Zakopane, 06/09/2016 Plan Lokalizacja genów Plan Lokalizacja genów Wielokrotne testowanie Plan Lokalizacja genów Wielokrotne
Metody statystyczne w lokalizacji genów Instytut Matematyki Uniwersytet Wrocławski Zakopane, 06/09/2016 Plan Lokalizacja genów Plan Lokalizacja genów Wielokrotne testowanie Plan Lokalizacja genów Wielokrotne
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średn
 Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
2.1 Przykład wstępny Określenie i konstrukcja Model dwupunktowy Model gaussowski... 7
 Spis treści Spis treści 1 Przedziały ufności 1 1.1 Przykład wstępny.......................... 1 1.2 Określenie i konstrukcja...................... 3 1.3 Model dwupunktowy........................ 5 1.4
Spis treści Spis treści 1 Przedziały ufności 1 1.1 Przykład wstępny.......................... 1 1.2 Określenie i konstrukcja...................... 3 1.3 Model dwupunktowy........................ 5 1.4
TESTOWANIE HIPOTEZ STATYSTYCZNYCH
 TETOWANIE HIPOTEZ TATYTYCZNYCH HIPOTEZA TATYTYCZNA przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia jest oceniana na
TETOWANIE HIPOTEZ TATYTYCZNYCH HIPOTEZA TATYTYCZNA przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia jest oceniana na
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Matematyka ubezpieczeń majątkowych r.
 Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Matematyka ubezpieczeń majątkowych 3..007 r. Zadanie. Każde z ryzyk pochodzących z pewnej populacji charakteryzuje się tym że przy danej wartości λ parametru ryzyka Λ rozkład wartości szkód z tego ryzyka
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Ekonometryczne modele nieliniowe
 Ekonometryczne modele nieliniowe Wykład 10 Modele przełącznikowe Markowa Literatura P.H.Franses, D. van Dijk (2000) Non-linear time series models in empirical finance, Cambridge University Press. R. Breuning,
Ekonometryczne modele nieliniowe Wykład 10 Modele przełącznikowe Markowa Literatura P.H.Franses, D. van Dijk (2000) Non-linear time series models in empirical finance, Cambridge University Press. R. Breuning,
Dynamiczne stochastyczne modele równowagi ogólnej
 Dynamiczne stochastyczne modele równowagi ogólnej mgr Anna Sulima Instytut Matematyki UJ 8 maja 2012 mgr Anna Sulima (Instytut Matematyki UJ) Dynamiczne stochastyczne modele równowagi ogólnej 8 maja 2012
Dynamiczne stochastyczne modele równowagi ogólnej mgr Anna Sulima Instytut Matematyki UJ 8 maja 2012 mgr Anna Sulima (Instytut Matematyki UJ) Dynamiczne stochastyczne modele równowagi ogólnej 8 maja 2012
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Dane zgrupowane: każda obserwacja należy do jednej grupy i jest tylko jeden czynnik grupujący
 1 Wstęp 1.1 Czym są efekty losowe? Jednokierunkowa ANOVA Na poprzednich zajęciach mówiliśmy o modelach liniowych, o jedno- i dwuczynnikowej analizie wariancji. W tych modelach estymowaliśmy nieznane wartości
1 Wstęp 1.1 Czym są efekty losowe? Jednokierunkowa ANOVA Na poprzednich zajęciach mówiliśmy o modelach liniowych, o jedno- i dwuczynnikowej analizie wariancji. W tych modelach estymowaliśmy nieznane wartości
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA
 analiza wariancji ANOVA") Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
Statystyczna analiza danych (molekularnych) analiza wariancji ANOVA Anna Gambin 19 maja 2013 Spis treści 1 Przykład: Model liniowy dla ekspresji genów 1 2 Jednoczynnikowa analiza wariancji 3 2.1 Testy
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 4 - zagadnienie estymacji, metody wyznaczania estymatorów Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 4 1 / 23 ZAGADNIENIE ESTYMACJI Zagadnienie
Estymacja przedziałowa - przedziały ufności dla średnich. Wrocław, 5 grudnia 2014
 Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
STATYSTYKA. Rafał Kucharski. Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2
 STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Karl Popper... no matter how many instances of white swans we may have observed, this does not
STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Karl Popper... no matter how many instances of white swans we may have observed, this does not
Mikroekonometria 12. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
Instytut Matematyczny Uniwersytet Wrocławski. Zakres egzaminu magisterskiego. Wybrane rozdziały anazlizy i topologii 1 i 2
 Instytut Matematyczny Uniwersytet Wrocławski Zakres egzaminu magisterskiego Wybrane rozdziały anazlizy i topologii 1 i 2 Pojęcia, fakty: Definicje i pojęcia: metryka, iloczyn skalarny, norma supremum,
Instytut Matematyczny Uniwersytet Wrocławski Zakres egzaminu magisterskiego Wybrane rozdziały anazlizy i topologii 1 i 2 Pojęcia, fakty: Definicje i pojęcia: metryka, iloczyn skalarny, norma supremum,
Statystyczna analiza danych
 Statystyczna analiza danych Testowanie hipotez statystycznych Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/23 Testowanie hipotez średniej w R Test istotności dla wartości
Statystyczna analiza danych Testowanie hipotez statystycznych Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/23 Testowanie hipotez średniej w R Test istotności dla wartości
Wykład 8 Dane kategoryczne
 Wykład 8 Dane kategoryczne Wrocław, 19.04.2017r Zmienne kategoryczne 1 Przykłady zmiennych kategorycznych 2 Zmienne nominalne, zmienne ordynalne (porządkowe) 3 Zmienne dychotomiczne kodowanie zmiennych
Wykład 8 Dane kategoryczne Wrocław, 19.04.2017r Zmienne kategoryczne 1 Przykłady zmiennych kategorycznych 2 Zmienne nominalne, zmienne ordynalne (porządkowe) 3 Zmienne dychotomiczne kodowanie zmiennych
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Analiza wariancji w analizie regresji - weryfikacja prawdziwości przyjętego układu ograniczeń Problem Przykłady
 Analiza wariancji w analizie regresji - weryfikacja prawdziwości przyjętego układu ograniczeń 1. Problem ozwaŝamy zjawisko (model): Y = β 1 X 1 X +...+ β k X k +Z Ηβ = w r Hipoteza alternatywna: Ηβ w r
Analiza wariancji w analizie regresji - weryfikacja prawdziwości przyjętego układu ograniczeń 1. Problem ozwaŝamy zjawisko (model): Y = β 1 X 1 X +...+ β k X k +Z Ηβ = w r Hipoteza alternatywna: Ηβ w r
Stosowana Analiza Regresji
 Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Stosowana Analiza Regresji Wykład VIII 30 Listopada 2011 1 / 18 gdzie: X : n p Q : n n R : n p Zał.: n p. X = QR, - macierz eksperymentu, - ortogonalna, - ma zera poniżej głównej diagonali. [ R1 X = Q
Wykład 11: Dane jakościowe. Rozkład χ 2. Test zgodności chi-kwadrat
 Wykład 11: Dane jakościowe Obserwacje klasyfikujemy do klas Zliczamy liczbę obserwacji w każdej klasie Jeżeli są tylko dwie klasy, to jedną z nich możemy nazwać sukcesem, a drugą porażką. Generalnie, liczba
Wykład 11: Dane jakościowe Obserwacje klasyfikujemy do klas Zliczamy liczbę obserwacji w każdej klasie Jeżeli są tylko dwie klasy, to jedną z nich możemy nazwać sukcesem, a drugą porażką. Generalnie, liczba
Prawdopodobieństwo i statystyka
 Wykład XI: Testowanie hipotez statystycznych 12 stycznia 2015 Przykład Motywacja X 1, X 2,..., X N N (µ, σ 2 ), Y 1, Y 2,..., Y M N (ν, δ 2 ). Chcemy sprawdzić, czy µ = ν i σ 2 = δ 2, czyli że w obu populacjach
Wykład XI: Testowanie hipotez statystycznych 12 stycznia 2015 Przykład Motywacja X 1, X 2,..., X N N (µ, σ 2 ), Y 1, Y 2,..., Y M N (ν, δ 2 ). Chcemy sprawdzić, czy µ = ν i σ 2 = δ 2, czyli że w obu populacjach
Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX = 4 i EY = 6. Rozważamy zmienną losową Z =.
 Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
... i statystyka testowa przyjmuje wartość..., zatem ODRZUCAMY /NIE MA POD- STAW DO ODRZUCENIA HIPOTEZY H 0 (właściwe podkreślić).
.") Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Statystyka matematyczna. Wykład VI. Zesty zgodności
 Statystyka matematyczna. Wykład VI. e-mail:e.kozlovski@pollub.pl Spis treści 1 Testy zgodności 2 Test Shapiro-Wilka Test Kołmogorowa - Smirnowa Test Lillieforsa Test Jarque-Bera Testy zgodności Niech x
Statystyka matematyczna. Wykład VI. e-mail:e.kozlovski@pollub.pl Spis treści 1 Testy zgodności 2 Test Shapiro-Wilka Test Kołmogorowa - Smirnowa Test Lillieforsa Test Jarque-Bera Testy zgodności Niech x
1 Gaussowskie zmienne losowe
 Gaussowskie zmienne losowe W tej serii rozwiążemy zadania dotyczące zmiennych o rozkładzie normalny. Wymagana jest wiedza na temat własności rozkładu normalnego, CTG oraz warunkowych wartości oczekiwanych..
Gaussowskie zmienne losowe W tej serii rozwiążemy zadania dotyczące zmiennych o rozkładzie normalny. Wymagana jest wiedza na temat własności rozkładu normalnego, CTG oraz warunkowych wartości oczekiwanych..