Wyszukiwanie informacji w internecie. Nguyen Hung Son
|
|
|
- Jacek Michalak
- 8 lat temu
- Przeglądów:
Transkrypt
1 Wyszukiwanie informacji w internecie Nguyen Hung Son
2 Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy główne moduły Zarządzanie pająków; Serwer indeksowania; Interfejs użytkownika Wyniki wyszukiwania: Lista rankingowa


3 Architektura Menedżer indeksów Serwer indeksowania Wstępne przetwarza nie i tworzenie indeksów Adresy url Wyniki Wyszukiwarka Internetowa Menedżer pająków zapytania Zawartość strony Pająki

4 Lista rankingowa nie jest doskonała!

5 Lista rankingowa nie jest doskonała!

6 Grupowanie wyników wyszukiwania (ang. SRC: Search Result Clustering)

7 SRC korzysta z krótkich fragmentów tekstu (snippets)
, itp.")
8 SRC czy grupowanie dokumentów? Grupowanie dokumentów: Miliardy stron; Ich treści ciągle się zmieniają; Skalowalność wzg. liczby dokumentów Są to niestrukturalne i różnorodne dane; dodatkowe informacje: hiperłącze, przejścia między stronami (click-through data), itp. SRC Próba 100~400 wyników wyszukiwania Informacje są aktualne Działa na bieżąco Skalowalność wzg. potrzeby użytkownika Zbyt mała, zaszumiona informacja gorsza jakość grup

9 Problemy w SRC

10 Wymagania Kryteria oceniania jakości metod SRC: Semantyczność: dokumenty w jednej grupie powinny dotyczyć tego samego tematu Znaczenie etykiet grup: powinny one dobrze opisać zawartość całej grupy. Mała liczba grup: należy pokryć jak najwięcej dokumentów używając przy tym jak najmniej grup. Te kryteria są raczej subiektywne aniżeli obiektywne.
![Model wektorowy dokumentów T={t 1,,t n } zbiór wybranych wyrazów (słów, fraz) Dokument d i = [w i,1,,w i,n ] gdzie w i,j jest wagą wyrazu t j w dokumencie d i Schemat](/docs-images/53/32916977/images/11-0.png "ważenia wyrazów TFxIDF w i, j fi, j log N df t j w i,j : częstość występowania wyrazu t j w dokumencie d i N : liczba dokumentów df(t j ): liczba dokumentów zawierających")
11 Model wektorowy dokumentów T={t 1,,t n } zbiór wybranych wyrazów (słów, fraz) Dokument d i = [w i,1,,w i,n ] gdzie w i,j jest wagą wyrazu t j w dokumencie d i Schemat ważenia wyrazów TFxIDF w i, j fi, j log N df t j w i,j : częstość występowania wyrazu t j w dokumencie d i N : liczba dokumentów df(t j ): liczba dokumentów zawierających t j
12 Podobieństwo dokumentów Miara cosinusa: n i k i n i j i n i k i j i k j k j k j w w w w d d d d d d sim 1 2, 1 2, 1,, ), ( t 1 d 2 d 1 t 3 t 2 θ
13 Istniejące metody
14 Klasyfikacja algorytmów grupowania Płaska struktura czy hierarchiczna? Czy grupy są rozłączne? Ostry czy miękki podział? Przyrostowa metoda? Czy liczba grup jest z góry zadana? Czy miary odległości lub podobieństwa muszą być zadane z góry? Z użyciem odległości Hierarchiczna struktura Agglomerative Hierarchical Clustering (AHC) Płaska struktura K-centroidów (możliwe rozmycie) Inkrementalna (Single-pass) Inne Suffix Tree Clustering (Grouper) SOM (Kohonen) Latent Semantic Indexing (LSI) (zmniejsza wymiar)
15 Grupowanie hierarchiczne (AHC)

16 Wynik grupowania: hierarchia pojęć
 Minimum (single-link) Średnia")
17 Różne wersje AHC Istnieją różne metody mierzenia podobieństwa grup Maksymum (complete-link) Minimum (single-link) Średnia (average)
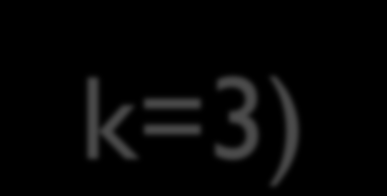
18 K-centroidów (k=3)

19 Metoda inkrementalna (single-pass)
 Czas liniowy Metoda inkrementalna Grupy nie są rozłączne Może być")
20 Grouper (Zamir and Etzioni 1997, 1999) Działa na bieżąco (online) Grupuje wyniki wyszukiwania (snippets) Grupuje dokumenty, które mają wiele wspólnych fraz Grupowanie drzewem sufiksowym (STC - Suffix Tree Clustering) Czas liniowy Metoda inkrementalna Grupy nie są rozłączne Może być hierarchiczna.
21 Algorytm STC (Suffix Tree Clustering) Krok 1: Czyszczenie danych: Normalizacja (stemming, stop-words elimination) Identyfikacja fraz i zdań. Eliminacja znaków interpunkcyjnych. Krok 2: Budowa drzewa sufiksowego: Stworzenie grup bazowych Ocena grup bazowych za pomocą ich rozmiaru i ocen fraz Krok 3: Łączenie grup bazowych: Grupy mające dużą część wspólną są połączone.

22 Drzewo sufiksowe = minimalne drzewo zawierające sufiksy wszystkich napisów 1. cat ate cheese 2. mouse ate cheese too 3. cat ate mouse too Odwrotny indeks fraz
23 Krok 2 Identyfikacja grup bazowych Wierzchołki reprezentują grupy dokumentów mających wspólną frazę Każda grupa B definiowana przez frazę P jest oceniona przez S(B) = B f( P )
24 Krok 3 Łączenie grup bazowych Podobieństwo między grupami bazowymi: 1 sim 0 Łączymy grupy algorytmem przyrostowym B n B B n m 0.5 oraz wpp. B n B B m m 0.5
25 Lingo (S.Osiński, D. Weiss) Korzysta z rozkładu macierzy wzg. wartości osobliwych (SVD) Reprezentacja zbioru dokumentów (snippets) w przestrzeni rzutowej o małym wymiarze Wektory osobliwe wyznaczają etykiety grup Dokumenty są dopisane do grup według miary cosinusa. Implementacja: Carrot2: Search Results Clustering Framework
 A macierz m x n A =U V T Kolumny U wektory własne AA T Kolumny V wektory własne A T A =")
26 Rozkład wzg. wartości osobliwych (ang. SVD - Singular Value Decomposition) A macierz m x n A =U V T Kolumny U wektory własne AA T Kolumny V wektory własne A T A = diag( 1,, n ): 1,, n wartości osobliwe A 1 > > k > n Aproksymacja: A U k k V kt = U k C k

27 SVD Współrzędne dokumentów w przestrzeni rzutowej Wektory własne wektory własne A U k C k
28 SVD wyznacza etykiety grup Możliwa etykieta
29 Konkluzje SRC próba przyśpieszania procesu wyszukiwania informacji w internecie i w bibliotekach elektronicznych. Temat atrakcyjny również dla dużych graczy Problemy: Brak obiektywnego kryterium oceny Brak personalizacji Źródła informacji: Historie procesów wyszukiwania w przeszłości Publiczne katalogi internetowe Leksykon semantycznych powiązań, np. Wordnet Profil użytkownika
O szukaniu sensu w stogu siana
 O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
4.3 Grupowanie według podobieństwa
 4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
Grupowanie opisowe dużych repozytoriów danych tekstowych. Grupowanie opisowe
 Grupowanie opisowe dużych repozytoriów danych tekstowych Stanisław Osiński, Dawid Weiss, Carrot Search info@carrotsearch.com https://carrotsearch.com Stanisław Osiński, Dawid Weiss Grupowanie opisowe to
Grupowanie opisowe dużych repozytoriów danych tekstowych Stanisław Osiński, Dawid Weiss, Carrot Search info@carrotsearch.com https://carrotsearch.com Stanisław Osiński, Dawid Weiss Grupowanie opisowe to
CLUSTERING. Metody grupowania danych
 CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
CLUSTERING Metody grupowania danych Plan wykładu Wprowadzenie Dziedziny zastosowania Co to jest problem klastrowania? Problem wyszukiwania optymalnych klastrów Metody generowania: k centroidów (k - means
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Analiza danych tekstowych i języka naturalnego
 Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Wydział Elektrotechniki, Informatyki i Telekomunikacji. Instytut Informatyki i Elektroniki. Instrukcja do zajęć laboratoryjnych
 Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wyszukiwanie dokumentów/informacji
 Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Semantyczne podobieństwo stron internetowych
 Uniwersytet Mikołaja Kopernika Wydział Matematyki i Informatyki Marcin Lamparski Nr albumu: 184198 Praca magisterska na kierunku Informatyka Semantyczne podobieństwo stron internetowych Praca wykonana
Uniwersytet Mikołaja Kopernika Wydział Matematyki i Informatyki Marcin Lamparski Nr albumu: 184198 Praca magisterska na kierunku Informatyka Semantyczne podobieństwo stron internetowych Praca wykonana
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Analiza korespondencji
 Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Kodowanie transformacyjne. Plan 1. Zasada 2. Rodzaje transformacji 3. Standard JPEG
 Kodowanie transformacyjne Plan 1. Zasada 2. Rodzaje transformacji 3. Standard JPEG Zasada Zasada podstawowa: na danych wykonujemy transformacje która: Likwiduje korelacje Skupia energię w kilku komponentach
Kodowanie transformacyjne Plan 1. Zasada 2. Rodzaje transformacji 3. Standard JPEG Zasada Zasada podstawowa: na danych wykonujemy transformacje która: Likwiduje korelacje Skupia energię w kilku komponentach
Grupowanie wyników zapytań do wyszukiwarek internetowych
 Grupowanie wyników zapytań do wyszukiwarek internetowych oraz propozycje usprawnień algorytmów przy pomocy fraz poprawnych językowo Dawid Weiss Instytut Informatyki Politechnika Poznańska Seminarium Instytut
Grupowanie wyników zapytań do wyszukiwarek internetowych oraz propozycje usprawnień algorytmów przy pomocy fraz poprawnych językowo Dawid Weiss Instytut Informatyki Politechnika Poznańska Seminarium Instytut
Eksploracja złożonych typów danych Text i Web Mining
 Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
Machine Learning. KISIM, WIMiIP, AGH
 Machine Learning KISIM, WIMiIP, AGH 1 Machine Learning Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i jej praktycznego wdrażania. Algorytmy pozwalają na zautomatyzowanie procesu
Machine Learning KISIM, WIMiIP, AGH 1 Machine Learning Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i jej praktycznego wdrażania. Algorytmy pozwalają na zautomatyzowanie procesu
Wyszukiwanie boolowskie i strukturalne. Adam Srebniak
 Wyszukiwanie boolowskie i strukturalne Adam Srebniak Wyszukiwanie boolowskie W wyszukiwaniu boolowskim zapytanie traktowane jest jako zdanie logiczne. Zwracane są dokumenty, dla których to zdanie jest
Wyszukiwanie boolowskie i strukturalne Adam Srebniak Wyszukiwanie boolowskie W wyszukiwaniu boolowskim zapytanie traktowane jest jako zdanie logiczne. Zwracane są dokumenty, dla których to zdanie jest
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych
 Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Wstęp do przetwarzania języka naturalnego
 Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Egzamin z Metod Numerycznych ZSI, Egzamin, Gr. A
 Egzamin z Metod Numerycznych ZSI, 06.2007. Egzamin, Gr. A Imię i nazwisko: Nr indeksu: Section 1. Test wyboru, max 33 pkt Zaznacz prawidziwe odpowiedzi literą T, a fałszywe N. Każda prawidłowa odpowiedź
Egzamin z Metod Numerycznych ZSI, 06.2007. Egzamin, Gr. A Imię i nazwisko: Nr indeksu: Section 1. Test wyboru, max 33 pkt Zaznacz prawidziwe odpowiedzi literą T, a fałszywe N. Każda prawidłowa odpowiedź
Pobieranie i przetwarzanie treści stron WWW
 Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne
 E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
E: Rekonstrukcja ewolucji. Algorytmy filogenetyczne Przypominajka: 152 drzewo filogenetyczne to drzewo, którego liśćmi są istniejące gatunki, a węzły wewnętrzne mają stopień większy niż jeden i reprezentują
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami.
 zależności pomiędzy gatunkami.") 181 Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami. 3. D T(D) poprzez algorytm łączenia sąsiadów 182 D D* : macierz łącząca sąsiadów n Niech TotDist i = k=1 D i,k Definiujemy
181 Filogeneza: problem konstrukcji grafu (drzewa) zależności pomiędzy gatunkami. 3. D T(D) poprzez algorytm łączenia sąsiadów 182 D D* : macierz łącząca sąsiadów n Niech TotDist i = k=1 D i,k Definiujemy
Forma. Główny cel kursu. Umiejętności nabywane przez studentów. Wymagania wstępne:
 WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
WYDOBYWANIE I WYSZUKIWANIE INFORMACJI Z INTERNETU Forma wykład: 30 godzin laboratorium: 30 godzin Główny cel kursu W ramach kursu studenci poznają podstawy stosowanych powszechnie metod wyszukiwania informacji
Hybrydowa metoda rekomendacji dokumentów w środowisku hipertekstowym
 Hybrydowa metoda rekomendacji dokumentów w środowisku hipertekstowym Paweł Szołtysek 09 listopada 2009 1/46 metod metod 2/46 metod 199 stron, 2 cytowania własne 7rozdziałów Promotor: NT Nguyen 3/46 metod
Hybrydowa metoda rekomendacji dokumentów w środowisku hipertekstowym Paweł Szołtysek 09 listopada 2009 1/46 metod metod 2/46 metod 199 stron, 2 cytowania własne 7rozdziałów Promotor: NT Nguyen 3/46 metod
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
METODY INDEKSOWANIA DOKUMENTÓW TEKSTOWYCH W SYSTEMACH WEBOWYCH
 Indeksowanie, Indeks Inwersyjny Grupowanie, Pliki Podpisu Daniel Halikowski METODY INDEKSOWANIA DOKUMENTÓW TEKSTOWYCH W SYSTEMACH WEBOWYCH Zasoby sieci Internet to miliardy plików zlokalizowanych na całym
Indeksowanie, Indeks Inwersyjny Grupowanie, Pliki Podpisu Daniel Halikowski METODY INDEKSOWANIA DOKUMENTÓW TEKSTOWYCH W SYSTEMACH WEBOWYCH Zasoby sieci Internet to miliardy plików zlokalizowanych na całym
Grupowanie dokumentów tekstowych z wykorzystaniem technik NLP
 Uniwersytet im. Adama Mickiewicza w Poznaniu Wydział Matematyki i Informatyki Krzysztof Sielski nr albumu: 301650 Grupowanie dokumentów tekstowych z wykorzystaniem technik NLP Praca magisterska na kierunku:
Uniwersytet im. Adama Mickiewicza w Poznaniu Wydział Matematyki i Informatyki Krzysztof Sielski nr albumu: 301650 Grupowanie dokumentów tekstowych z wykorzystaniem technik NLP Praca magisterska na kierunku:
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Techniki grupowania danych w środowisku Matlab
 Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Projektowanie architektury informacji katalogu biblioteki w oparciu o badania użytkowników Analiza przypadku
 Projektowanie architektury informacji katalogu biblioteki w oparciu o badania użytkowników Analiza przypadku dr Stanisław Skórka Biblioteka Główna Instytut Informacji Naukowej i Bibliotekoznawstwa Uniwersytet
Projektowanie architektury informacji katalogu biblioteki w oparciu o badania użytkowników Analiza przypadku dr Stanisław Skórka Biblioteka Główna Instytut Informacji Naukowej i Bibliotekoznawstwa Uniwersytet
Metody teorii gier. ALP520 - Wykład z Algorytmów Probabilistycznych p.2
 Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Metody teorii gier ALP520 - Wykład z Algorytmów Probabilistycznych p.2 Metody teorii gier Cel: Wyprowadzenie oszacowania dolnego na oczekiwany czas działania dowolnego algorytmu losowego dla danego problemu.
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe.
 Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
Lingwistyczny system definicyjny wykorzystujący korpusy tekstów oraz zasoby internetowe. Autor: Mariusz Sasko Promotor: dr Adrian Horzyk Plan prezentacji 1. Wstęp 2. Cele pracy 3. Rozwiązanie 3.1. Robot
1. Dane punkty na płaszczyźnie. Trzeba narysować dendrogram centroidu
 1. Dane punkty na płaszczyźnie. Trzeba narysować dendrogram centroidu Dendrogram obrazuje powiązania między klastrami. Liście obiekty Korzeń wynik grupowania Linia odcinająca pokazuje, w którym momencie
1. Dane punkty na płaszczyźnie. Trzeba narysować dendrogram centroidu Dendrogram obrazuje powiązania między klastrami. Liście obiekty Korzeń wynik grupowania Linia odcinająca pokazuje, w którym momencie
Zad. 3: Układ równań liniowych
 1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
1 Cel ćwiczenia Zad. 3: Układ równań liniowych Wykształcenie umiejętności modelowania kluczowych dla danego problemu pojęć. Definiowanie właściwego interfejsu klasy. Zwrócenie uwagi na dobór odpowiednich
Wyszukiwanie tekstów
 Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Ontologie, czyli o inteligentnych danych
 1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
POZYCJONOWANIE STRONY SKLEPU
 . Wszystko O Pozycjonowaniu I Marketingu. >>>POZYCJONOWANIE STRON LEGNICA POZYCJONOWANIE STRONY SKLEPU >>>WIĘCEJ
. Wszystko O Pozycjonowaniu I Marketingu. >>>POZYCJONOWANIE STRON LEGNICA POZYCJONOWANIE STRONY SKLEPU >>>WIĘCEJ
Algorytmy i struktury danych. Drzewa: BST, kopce. Letnie Warsztaty Matematyczno-Informatyczne
 Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
W poszukiwaniu sensu w świecie widzialnym
 W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
< K (2) = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >
 = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >") Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Sortowanie. Bartman Jacek Algorytmy i struktury
 Sortowanie Bartman Jacek jbartman@univ.rzeszow.pl Algorytmy i struktury danych Sortowanie przez proste wstawianie przykład 41 56 17 39 88 24 03 72 41 56 17 39 88 24 03 72 17 41 56 39 88 24 03 72 17 39
Sortowanie Bartman Jacek jbartman@univ.rzeszow.pl Algorytmy i struktury danych Sortowanie przez proste wstawianie przykład 41 56 17 39 88 24 03 72 41 56 17 39 88 24 03 72 17 41 56 39 88 24 03 72 17 39
Badanie struktury sieci WWW
 Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
Eksploracja zasobów internetowych Wykład 1 Badanie struktury sieci WWW mgr inż. Maciej Kopczyński Białystok 214 Rys historyczny Idea sieci Web stworzona została w 1989 przez Tima BernersaLee z CERN jako
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Wstęp do przetwarzania języka naturalnego. Wykład 10 Zaawansowana wektoryzacja i klasyfikacja
 Wstęp do przetwarzania języka naturalnego Wykład 10 Zaawansowana wektoryzacja i klasyfikacja Wojciech Czarnecki 8 stycznia 2014 Section 1 Wektoryzacja tfidf document x y z Antony and Cleopatra 5.25 1.21
Wstęp do przetwarzania języka naturalnego Wykład 10 Zaawansowana wektoryzacja i klasyfikacja Wojciech Czarnecki 8 stycznia 2014 Section 1 Wektoryzacja tfidf document x y z Antony and Cleopatra 5.25 1.21
ang. file) Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku
 Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku") System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
Metody indeksowania dokumentów tekstowych
 Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Metody iteracyjne rozwiązywania układów równań liniowych (5.3) Normy wektorów i macierzy (5.3.1) Niech. x i. i =1
 Normy wektorów i macierzy (5.3.1) Niech. x i. i =1") Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Przykładowa analiza danych
 Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Grupowanie danych. Wprowadzenie. Przykłady
 Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
EmotiWord, semantyczne powiązanie i podobieństwo, odległość znaczeniowa
 , semantyczne powiązanie i podobieństwo, odległość Projekt przejściowy ARR Politechnika Wrocławska Wydział Elektroniki Wrocław, 22 października 2013 Spis treści 1 językowa 2, kryteria 3 Streszczenie artykułu
, semantyczne powiązanie i podobieństwo, odległość Projekt przejściowy ARR Politechnika Wrocławska Wydział Elektroniki Wrocław, 22 października 2013 Spis treści 1 językowa 2, kryteria 3 Streszczenie artykułu
Uczenie sieci radialnych (RBF)
") Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Uczenie sieci radialnych (RBF) Budowa sieci radialnej Lokalne odwzorowanie przestrzeni wokół neuronu MLP RBF Budowa sieci radialnych Zawsze jedna warstwa ukryta Budowa neuronu Neuron radialny powinien
Kolejny krok iteracji polega na tym, że przechodzimy do następnego wierzchołka, znajdującego się na jednej krawędzi z odnalezionym już punktem, w
 Metoda Simpleks Jak wiadomo, problem PL z dowolną liczbą zmiennych można rozwiązać wyznaczając wszystkie wierzchołkowe punkty wielościanu wypukłego, a następnie porównując wartości funkcji celu w tych
Metoda Simpleks Jak wiadomo, problem PL z dowolną liczbą zmiennych można rozwiązać wyznaczając wszystkie wierzchołkowe punkty wielościanu wypukłego, a następnie porównując wartości funkcji celu w tych
Macierze. Rozdział Działania na macierzach
 Rozdział 5 Macierze Funkcję, która każdej parze liczb naturalnych (i, j) (i 1,..., n; j 1,..., m) przyporządkowuje dokładnie jedną liczbę a ij F, gdzie F R lub F C, nazywamy macierzą (rzeczywistą, gdy
Rozdział 5 Macierze Funkcję, która każdej parze liczb naturalnych (i, j) (i 1,..., n; j 1,..., m) przyporządkowuje dokładnie jedną liczbę a ij F, gdzie F R lub F C, nazywamy macierzą (rzeczywistą, gdy
Wyszukiwanie strukturalne
 Wyszukiwanie strukturalne Wprowadzenie Wyszukiwanie indeksowe (Wyszukiwanie strukturalne)- podejście tradycyjne Każdy dokument jest opatrzony w opis strukturalny dokumentu (właściwości indeksu / właściwości
Wyszukiwanie strukturalne Wprowadzenie Wyszukiwanie indeksowe (Wyszukiwanie strukturalne)- podejście tradycyjne Każdy dokument jest opatrzony w opis strukturalny dokumentu (właściwości indeksu / właściwości
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
dodatkowe operacje dla kopca binarnego: typu min oraz typu max:
 ASD - ćwiczenia IX Kopce binarne własność porządku kopca gdzie dla każdej trójki wierzchołków kopca (X, Y, Z) porządek etykiet elem jest następujący X.elem Y.elem oraz Z.elem Y.elem w przypadku kopca typu
ASD - ćwiczenia IX Kopce binarne własność porządku kopca gdzie dla każdej trójki wierzchołków kopca (X, Y, Z) porządek etykiet elem jest następujący X.elem Y.elem oraz Z.elem Y.elem w przypadku kopca typu
Wykład 6. Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym
 1 Wykład 6 Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym ELIMINACJA GAUSSA Z WYBOREM CZĘŚCIOWYM ELEMENTÓW PODSTAWOWYCH 2 Przy pomocy klasycznego algorytmu eliminacji
1 Wykład 6 Metoda eliminacji Gaussa: Eliminacja z wyborem częściowym Eliminacja z wyborem pełnym ELIMINACJA GAUSSA Z WYBOREM CZĘŚCIOWYM ELEMENTÓW PODSTAWOWYCH 2 Przy pomocy klasycznego algorytmu eliminacji
Klasteryzacja danych
 Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Klasteryzacja danych na podstawie: Leszek Rutkowski. Metody i techniki
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Klasteryzacja danych na podstawie: Leszek Rutkowski. Metody i techniki
Część I Rozpoczęcie pracy z usługami Reporting Services
 Spis treści Podziękowania... xi Wprowadzenie... xiii Część I Rozpoczęcie pracy z usługami Reporting Services 1 Wprowadzenie do usług Reporting Services... 3 Platforma raportowania... 3 Cykl życia raportu...
Spis treści Podziękowania... xi Wprowadzenie... xiii Część I Rozpoczęcie pracy z usługami Reporting Services 1 Wprowadzenie do usług Reporting Services... 3 Platforma raportowania... 3 Cykl życia raportu...
Eksploracja danych a serwisy internetowe Przemysław KAZIENKO
 Eksploracja danych a serwisy internetowe Przemysław KAZIENKO Wydział Informatyki i Zarządzania Politechnika Wrocławska kazienko@pwr.wroc.pl Dlaczego eksploracja danych w serwisach internetowych? Kanały
Eksploracja danych a serwisy internetowe Przemysław KAZIENKO Wydział Informatyki i Zarządzania Politechnika Wrocławska kazienko@pwr.wroc.pl Dlaczego eksploracja danych w serwisach internetowych? Kanały
CLUSTERING II. Efektywne metody grupowania danych
 CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
CLUSTERING II Efektywne metody grupowania danych Plan wykładu Wstęp: Motywacja i zastosowania Metody grupowania danych Algorytmy oparte na podziałach (partitioning algorithms) PAM Ulepszanie: CLARA, CLARANS
Zastosowanie wartości własnych macierzy
 Uniwersytet Warszawski 15 maja 2008 Agenda Postawienie problemu 1 Postawienie problemu Motywacja Jak zbudować wyszukiwarkę? Dlaczego to nie jest takie trywialne? Możliwe rozwiazania Model 2 3 4 Motywacja
Uniwersytet Warszawski 15 maja 2008 Agenda Postawienie problemu 1 Postawienie problemu Motywacja Jak zbudować wyszukiwarkę? Dlaczego to nie jest takie trywialne? Możliwe rozwiazania Model 2 3 4 Motywacja
Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, Spis treści
 Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, 2016 Spis treści Przedmowa XI I Podstawy języka Python 1. Wprowadzenie 3 1.1. Język i środowisko
Przetwarzanie i analiza danych w języku Python / Marek Gągolewski, Maciej Bartoszuk, Anna Cena. Warszawa, 2016 Spis treści Przedmowa XI I Podstawy języka Python 1. Wprowadzenie 3 1.1. Język i środowisko
Transformaty. Kodowanie transformujace
 Transformaty. Kodowanie transformujace Kodowanie i kompresja informacji - Wykład 10 10 maja 2009 Szeregi Fouriera Każda funkcję okresowa f (t) o okresie T można zapisać jako f (t) = a 0 + a n cos nω 0
Transformaty. Kodowanie transformujace Kodowanie i kompresja informacji - Wykład 10 10 maja 2009 Szeregi Fouriera Każda funkcję okresowa f (t) o okresie T można zapisać jako f (t) = a 0 + a n cos nω 0
dr Mariusz Grządziel 15,29 kwietnia 2014 Przestrzeń R k R k = R R... R k razy Elementy R k wektory;
 Wykłady 8 i 9 Pojęcia przestrzeni wektorowej i macierzy Układy równań liniowych Elementy algebry macierzy dodawanie, odejmowanie, mnożenie macierzy; macierz odwrotna dr Mariusz Grządziel 15,29 kwietnia
Wykłady 8 i 9 Pojęcia przestrzeni wektorowej i macierzy Układy równań liniowych Elementy algebry macierzy dodawanie, odejmowanie, mnożenie macierzy; macierz odwrotna dr Mariusz Grządziel 15,29 kwietnia
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Kompresja bezstratna. Entropia. Kod Huffmana
 Kompresja bezstratna. Entropia. Kod Huffmana Kodowanie i bezpieczeństwo informacji - Wykład 10 29 kwietnia 2013 Teoria informacji Jeśli P(A) jest prawdopodobieństwem wystapienia informacji A to niech i(a)
Kompresja bezstratna. Entropia. Kod Huffmana Kodowanie i bezpieczeństwo informacji - Wykład 10 29 kwietnia 2013 Teoria informacji Jeśli P(A) jest prawdopodobieństwem wystapienia informacji A to niech i(a)
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2
 Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Ekstrakcja informacji oraz stylometria na usługach psychologii Część 2 ws.clarin-pl.eu/websty.shtml Tomasz Walkowiak, Maciej Piasecki Politechnika Wrocławska Grupa Naukowa G4.19 Katedra Inteligencji Obliczeniowej
Układy równań i nierówności liniowych
 Układy równań i nierówności liniowych Wiesław Krakowiak 1 grudnia 2010 1 Układy równań liniowych DEFINICJA 11 Układem równań m liniowych o n niewiadomych X 1,, X n, nazywamy układ postaci: a 11 X 1 + +
Układy równań i nierówności liniowych Wiesław Krakowiak 1 grudnia 2010 1 Układy równań liniowych DEFINICJA 11 Układem równań m liniowych o n niewiadomych X 1,, X n, nazywamy układ postaci: a 11 X 1 + +
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych
 Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Grupowanie Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633
 Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Grupowanie Grupowanie 7 6 5 4 y 3 2 1 0-3 -2-1 0 1 2 3 4 5-1 -2-3 -4 x Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 201/633 Wprowadzenie Celem procesu grupowania jest podział zbioru
Monitorowanie i Diagnostyka w Systemach Sterowania
 Monitorowanie i Diagnostyka w Systemach Sterowania Katedra Inżynierii Systemów Sterowania Dr inż. Michał Grochowski Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności:
Monitorowanie i Diagnostyka w Systemach Sterowania Katedra Inżynierii Systemów Sterowania Dr inż. Michał Grochowski Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności:
Wykład X. Programowanie. dr inż. Janusz Słupik. Gliwice, Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2016 Janusz Słupik
 Wykład X Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2016 c Copyright 2016 Janusz Słupik Drzewa binarne Drzewa binarne Drzewo binarne - to drzewo (graf spójny bez cykli) z korzeniem (wyróżnionym
Wykład X Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2016 c Copyright 2016 Janusz Słupik Drzewa binarne Drzewa binarne Drzewo binarne - to drzewo (graf spójny bez cykli) z korzeniem (wyróżnionym
Internet, jako ocean informacji. Technologia Informacyjna Lekcja 2
 Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Internet, jako ocean informacji Technologia Informacyjna Lekcja 2 Internet INTERNET jest rozległą siecią połączeń, między ogromną liczbą mniejszych sieci komputerowych na całym świecie. Jest wszechstronnym
Numeryczna algebra liniowa. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Numeryczna algebra liniowa Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak
Alicja Marszałek Różne rodzaje baz danych
 Alicja Marszałek Różne rodzaje baz danych Rodzaje baz danych Bazy danych można podzielić wg struktur organizacji danych, których używają. Można podzielić je na: Bazy proste Bazy złożone Bazy proste Bazy
Alicja Marszałek Różne rodzaje baz danych Rodzaje baz danych Bazy danych można podzielić wg struktur organizacji danych, których używają. Można podzielić je na: Bazy proste Bazy złożone Bazy proste Bazy
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
Ogólne wiadomości o grafach
 Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
Ogólne wiadomości o grafach Algorytmy i struktury danych Wykład 5. Rok akademicki: / Pojęcie grafu Graf zbiór wierzchołków połączonych za pomocą krawędzi. Podstawowe rodzaje grafów: grafy nieskierowane,
 Metody getter https://www.python-course.eu/python3_object_oriented_programming.php 0_class http://interactivepython.org/runestone/static/pythonds/index.html https://www.cs.auckland.ac.nz/compsci105s1c/lectures/
Metody getter https://www.python-course.eu/python3_object_oriented_programming.php 0_class http://interactivepython.org/runestone/static/pythonds/index.html https://www.cs.auckland.ac.nz/compsci105s1c/lectures/
Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
 : idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
: idea Indeksowanie: Drzewo decyzyjne, przeszukiwania binarnego: F = {5, 7, 10, 12, 13, 15, 17, 30, 34, 35, 37, 40, 45, 50, 60} 30 12 40 7 15 35 50 Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Sieci Kohonena Sieci Kohonena Sieci Kohonena zostały wprowadzone w 1982 przez fińskiego
KATEGORIA OBSZAR WIEDZY
 Moduł 3 - Przetwarzanie tekstów - od kandydata wymaga się zaprezentowania umiejętności wykorzystywania programu do edycji tekstu. Kandydat powinien wykonać zadania o charakterze podstawowym związane z
Moduł 3 - Przetwarzanie tekstów - od kandydata wymaga się zaprezentowania umiejętności wykorzystywania programu do edycji tekstu. Kandydat powinien wykonać zadania o charakterze podstawowym związane z
Zadania. Przygotowanie zbiorów danych. 1. Sposób 1: 2. Sposób 2:
 Wstęp Jednym z typowych zastosowań metod sztucznej inteligencji i uczenia maszynowego jest przetwarzanie języka naturalnego (ang. Natural Language Processing, NLP), której typowych przykładem jest analiza
Wstęp Jednym z typowych zastosowań metod sztucznej inteligencji i uczenia maszynowego jest przetwarzanie języka naturalnego (ang. Natural Language Processing, NLP), której typowych przykładem jest analiza
Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych
 Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe (maneo@man.poznan.pl) I Konferencja Polskie Biblioteki
Systemy organizacji wiedzy i ich rola w integracji zasobów europejskich bibliotek cyfrowych Adam Dudczak Poznańskie Centrum Superkomputerowo-Sieciowe (maneo@man.poznan.pl) I Konferencja Polskie Biblioteki
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Analiza obrazów - sprawozdanie nr 2
 Analiza obrazów - sprawozdanie nr 2 Filtracja obrazów Filtracja obrazu polega na obliczeniu wartości każdego z punktów obrazu na podstawie punktów z jego otoczenia. Każdy sąsiedni piksel ma wagę, która
Analiza obrazów - sprawozdanie nr 2 Filtracja obrazów Filtracja obrazu polega na obliczeniu wartości każdego z punktów obrazu na podstawie punktów z jego otoczenia. Każdy sąsiedni piksel ma wagę, która
Drzewa spinające MST dla grafów ważonych Maksymalne drzewo spinające Drzewo Steinera. Wykład 6. Drzewa cz. II
 Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem
Wykład 6. Drzewa cz. II 1 / 65 drzewa spinające Drzewa spinające Zliczanie drzew spinających Drzewo T nazywamy drzewem rozpinającym (spinającym) (lub dendrytem) spójnego grafu G, jeżeli jest podgrafem