Machine Learning. KISIM, WIMiIP, AGH
|
|
|
- Aleksander Grzybowski
- 5 lat temu
- Przeglądów:
Transkrypt
1 Machine Learning KISIM, WIMiIP, AGH 1
2 Machine Learning Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i jej praktycznego wdrażania. Algorytmy pozwalają na zautomatyzowanie procesu pozyskiwania i analizy danych do ulepszania i rozwoju własnego systemu. KISIM, WIMiIP, AGH 2
3 Machine Learning Data Mining pozyskiwanie wiedzy przez człowieka Machine Learning odbiorcą jest maszyna, celem usprawnienie działania. Metody (przykładowe): Indukcja drzew decyzyjnych Uczenie Bayesowskie (Bayesian Learning) Uczenie z przykładów (Instance-based Learning) (np. knn) Sieci neuronowe Clustering Support vector machines (SVM) Analiza asocjacji (Association rule learning) Algorytmy genetyczne Wnioskowanie epizodyczne (CBR) Uczenie przez wzmacnianie (Reinforcement Learning) KISIM, WIMiIP, AGH 3
4 Metody eksploracji tekstu Text mining
5 Zadania eksploracji tekstu Wyszukiwanie w oparciu o zapytania (słowa kluczowe) w oparciu o podobne dokumenty Grupowanie dokumentów Klasyfikacja dokumentów Ranking ważności dokumentów Analiza zależności pomiędzy dokumentami (np. analiza sieci cytowań).

6 Problemy: synonimy i polisemia Podstawowe problemy związane z wyszukiwaniem w oparciu o zbiór słów kluczowych: Synonimy: Polisemia: W jaki sposób definiować słowa kluczowe: liczba mnoga czy pojedyncza? Problem odmiany słów w niektórych językach

7 Wyszukiwanie w oparciu o reprezentację wektorową Reprezentacja tekstu - macierz częstości występowania słów kluczowych (Frequency matrix):» Term_Frequency_Matrix(d i, t i ): liczba wystąpień słowa t i, w dokumencie d i. TFM[d i, t i ]» Zbiór słów kluczowych może być bardzo duży ( słów)» Każdy dokument d i, 1 i N, jest reprezentowany w postaci wektora słów» współczynnik d ij - waga słowa d i Reprezentacja boolowska wektora - waga przyjmuje dwie wartości 0 lub 1 Reprezentacja dokumentu w postaci T-wymiarowego wektora słów powoduje utratę informacji o strukturze zdania jak i kolejności występowania słów w zdaniu

8 Zapytania do bazy danych: wagi Podejście, w którym waga słowa przyjmuje wartość różną od 0, jeżeli słowo występuje gdziekolwiek w dokumencie, preferuje duże dokumenty (niekoniecznie relewantne). Różne słowa mają różną wartość dyskryminacyjną. Niektóre słowa występują prawie we wszystkich dokumentach, inne tylko w niektórych. Te drugie, siłą rzeczy, lepiej opisują dany dokument - mówimy, że posiadają większą silę dyskryminacyjną (lepiej rozróżniają dokumenty). Schemat nadawania wag: TF IDF» Waga słowa j (idf j ):» gdzie N łączna liczba dokumentów, n j liczba dokumentów zawierających słowo j
 Zauważmy, że wagi niektórych słów znacząco uległy zmianie.")
9 Wagi TF-IDF Wagi TF-IDF faworyzują słowa, które występują w niewielu dokumentach - mają zatem większą siłę dyskryminacyjną Waga słowa j w wektorze D i jest iloczynem częstości występowania słowa w dokumencie d i i wagi słowa j (idf j ) Zauważmy, że wagi niektórych słów znacząco uległy zmianie. Przykładowo, waga TF-IDF słowa t1 w dokumencie d1, poprzednio wynosząca 24, wynosi 2,54 i jest 6-krotnie mniejsza aniżeli waga TF-IDF słowa t2 w dokumencie d1, która poprzednio wynosiła 21. Wynika to stąd, że słowo t1 występuje praktycznie we wszystkich dokumentach, za wyjątkiem dokumentu d7, stąd jego siła dyskryminacyjna jest stosunkowo mała. Słowo t2 występuje tylko w połowie dokumentów, stąd jego siła dyskryminacyjna jest znacznie większa - stąd większa waga słowa t2.


10 Ukryte indeksowanie semantyczne Latent Semantic Indexing (LSI) Oryginalną macierz TFM o rozmiarze N x T można zastąpić macierzą o rozmiarze N x k, gdzie k << T (z niewielką utratą informacji) LSI odkrywa zależności pomiędzy słowami kluczowymi tworząc nowe pseudosłowa" kluczowe dokładniej wyrażające semantyczną zawartość dokumentów
11 Metody eksploracji WWW WebMining
12 Czym jest eksploracja Web? Eksploracja sieci Web - podstawowe metody:» Eksploracja zawartości sieci (Web content mining)» Eksploracja połączeń sieci (Web linkage mining)» Eksploracja korzystania z sieci (Web usage mining)
13 Przykłady zastosowania metod eksploracji Przeszukiwanie sieci: Google, Yahoo,... Handel elektroniczny: systemy rekomendacyjne (Ceneo, Nokaut), odkrywanie asocjacji, itp.. Reklamy: Google AdSense Wykrywanie oszustw: aukcje internetowe, analiza reputacji kupujących/sprzedających Projektowanie serwerów WWW - personalizacja usług, adaptatywne serwery WWW,... Policja: analizy sieci socjalnych Wiele innych: optymalizacja zapytań,...
14 Taksonomia metod eksploracji Web Eksploracja zawartości sieci (Web Page Content Mining)» Wyszukiwanie stron WWW (języki zapytań do sieci Web (WebSQL, WebOQL, WebML, WebLog, W3QL)» Grupowanie stron WWW (algorytmy grupowania dokumentów XML)» Klasyfikacja stron WWW (algorytmy klasyfikacji dokumentów XML)» Dwie ostatnie grupy metod wymagają zdefiniowania specyficznych miar podobieństwa (odległości) pomiędzy dokumentami XML (XML = struktura grafowa)
15 Eksploracja połączeń Celem eksploracji połączeń sieci Web: Ranking wyników wyszukiwania stron WWW Znajdowanie lustrzanych serwerów Web Problem rankingu - (1970) w ramach systemów IR zaproponowano metody oceny (rankingu) artykułów naukowych w oparciu o cytowania Ranking produktów - ocena jakości produktu w oparciu o opinie innych klientów (zamiast ocen dokonywanych przez producentów) najpopularniejsze algorytmy: Page Rank i H&A

16
 w postaci zapisów w pliku logu; stąd, logi serwerów przechowują olbrzymie ilości informacji dotyczące realizowanych dostępów do stron")
17 Czym jest eksploracja logów? Serwery Web rejestrują każdy dostęp do swoich zasobów (stron) w postaci zapisów w pliku logu; stąd, logi serwerów przechowują olbrzymie ilości informacji dotyczące realizowanych dostępów do stron Metody eksploracji logów:» Charakterystyka danych» Porównywanie klas» Odkrywanie asocjacji» Predykcja» Klasyfikacja» Analiza przebiegów czasowych» Analiza ruchu w sieci» Odkrywanie wzorców sekwencji» Analiza przejść» Analiza trendów
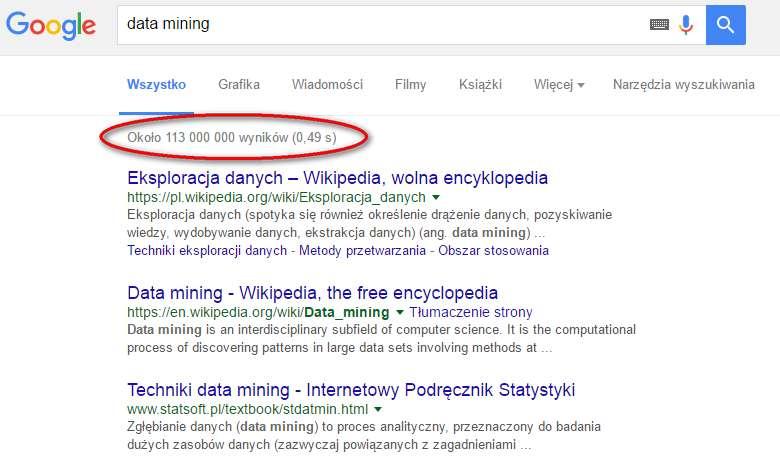
18
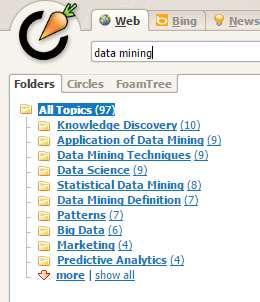
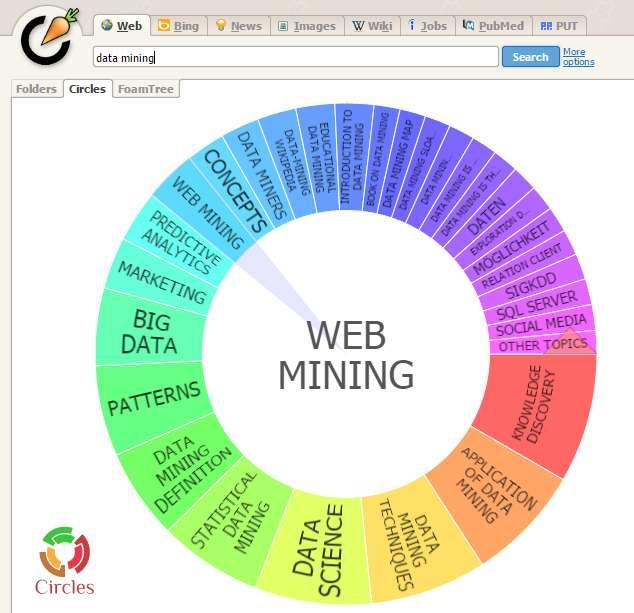
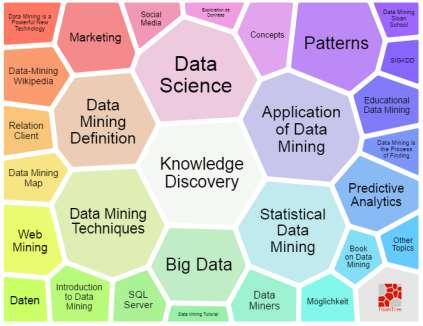
19 Carrot 2 clustering web search results
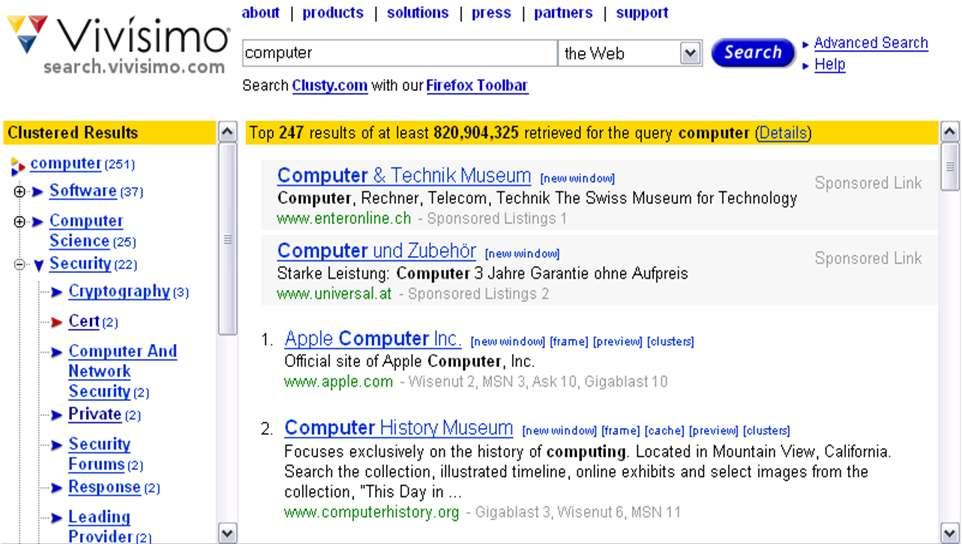
20

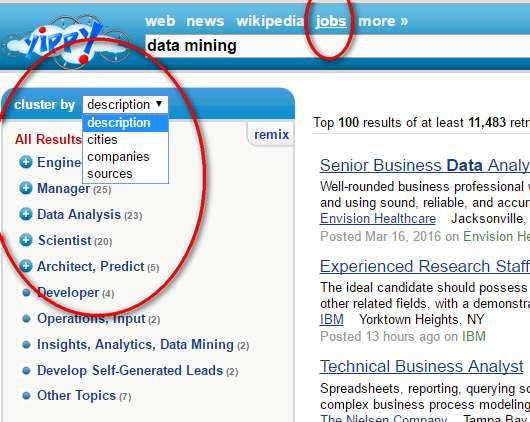
21 KISIM, WIMiIP, AGH 21

22 Analiza koszykowa w sklepie internetowym Cross-selling
23 Metoda wektorów nośnych (wspierających) KISIM, WIMiIP, AGH 23
 na przestrzeń ilustrowaną po prawej. w nowej przestrzeni dwie klasy są liniowo separowalne, co pozwala uniknąć skomplikowanej postaci granicy klas.")
24 Metoda wektorów nośnych (wspierających) stosowane gdy do poprawnego klasyfikowania potrzebne są bardziej skomplikowane struktury niż linia prosta oryginalne obiekty są "mapowane" (transformowane) za pomocą funkcji jądrowych (kernels) na przestrzeń ilustrowaną po prawej. w nowej przestrzeni dwie klasy są liniowo separowalne, co pozwala uniknąć skomplikowanej postaci granicy klas. KISIM, WIMiIP, AGH 24
25 Węższe czy szersze marginesy? Szerszy margines lepsze własności generalizacji, mniejsza podatność na ew. przeuczenie (overfitting) Wąski margines mała zmiana granicy, radykalne zmiany klasyfikacji KISIM, WIMiIP, AGH 25


26 FUNKCJE JĄDRA wielomian 2-stopnia wielomian 3-stopnia wielomian 4-stopnia funkcja radialna σ = 1.0 funkcja radialna σ = 2.0 funkcja radialna σ = 5.0 KISIM, WIMiIP, AGH 26
27 Zbiory przybliżone KISIM, WIMiIP, AGH 27
 danego zbioru.")
28 Aproksymacja elementy bez wątpliwości należą do zbioru elementów nie można wykluczyć cards ( a, U) Dokładność aproksymacji określa wyrażenie: card S gdzie: card symbol określający moc (liczbę elementów) danego zbioru. KISIM, WIMiIP, AGH 28
29 Przykład klasyfikacji KISIM, WIMiIP, AGH 29

30 KISIM, WIMiIP, AGH 30
31 KISIM, WIMiIP, AGH 31
32 Analiza (odkrywanie) Asocjacji Association rule learning
33 Odkrywanie asocjacji Celem procesu odkrywania asocjacji jest znalezienie interesujących zależności lub korelacji, nazywanych ogólnie asocjacjami, pomiędzy danymi w dużych zbiorach danych. Wynikiem procesu odkrywania asocjacji jest zbiór reguł asocjacyjnych opisujących znalezione zależności lub korelacje między danymi. zastosowania odkrytych asocjacji: planowanie kampanii promocyjnych rozmieszczenie stoisk w supermarketach planowanie programów lojalnościowych opracowania koncepcji katalogu
34 Analiza koszykowa Indukcja reguł asocjacyjnych powstała w zastosowaniach analizy danych koszyka sklepowego (MBA market basket analysis) Koszyk sklepowy z zakupami można przedstawić jako macierz o n wierszach (odpowiadających koszykom, nawet miliony zakupów) i p kolumnach (odpowiadających wszystkim produktom, czasem dziesiątki tysięcy) Macierz taka będzie duża i rzadka (sparse), ponieważ typowy koszyk zawiera zazwyczaj kilkanaście produktów. Algorytmy analizy asocjacji służą odnajdowaniu wzorców w sposób sprawny obliczeniowo.
35 Ufność i wsparcie informację o tym, że większość klientów, którzy kupują MS Windows kupują również MS Office można zapisać za pomocą następującej reguły asocjacyjnej: windows office [support = 15%, confidence = 75%]» Wsparcie 15% oznacza, że wśród zbadanych transakcji windows i office występują razem w piętnastu procentach,» wiarygodność 75% oznacza, że wśród klientów kupujących windows 75% klientów również kupuje office.
36 Przykład bazy transakcyjnej i reguły asocjacyjnej

37 Przykład bazy transakcyjnej i reguły asocjacyjnej

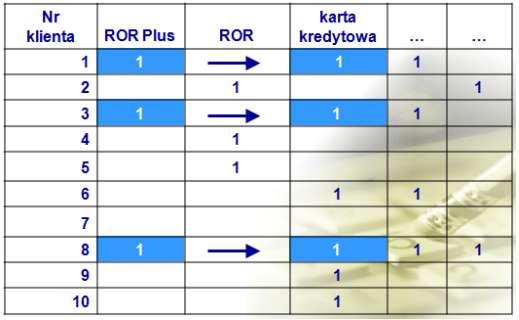
38 Przykład bazy transakcyjnej i reguły asocjacyjnej
39 Ocena reguł kryteria dla reguł interesujących W jaki sposób system eksploracji danych, odkrywając reguły asocjacyjne, może określić, które ze znalezionych reguł są interesujące dla użytkownika? Reguły o dużym wsparciu niekoniecznie muszą okazać się interesujące reguły te są z reguły dobrze znane użytkownikom. Podobnie rzecz ma się w odniesieniu do reguł o wysokim współczynniku ufności. ciąża = 1 płeć = kobieta przetoczenie ponad 2,5 jednostek krwi prowadzi często do komplikacji pooperacyjnych Przydatność reguły potrafi określić tylko i wyłącznie użytkownik.
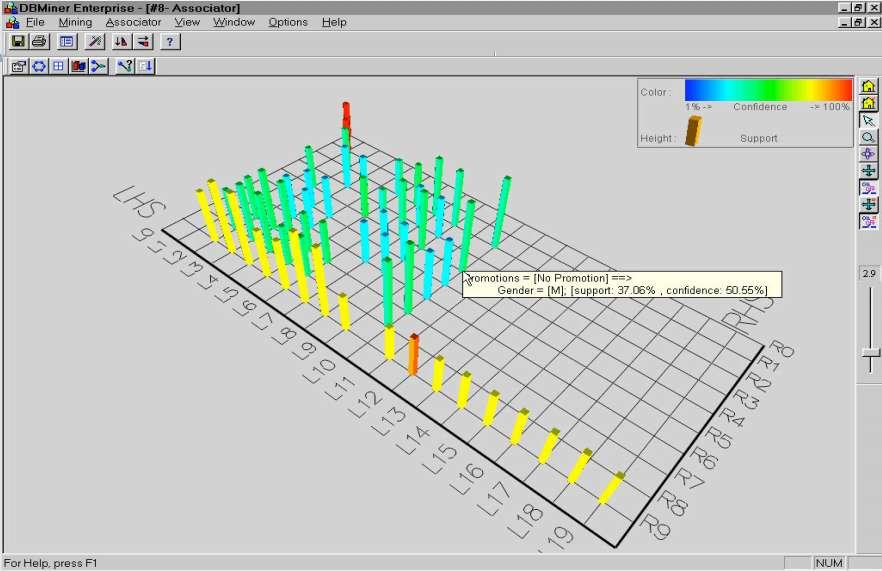
40 Przykłady wizualizacji
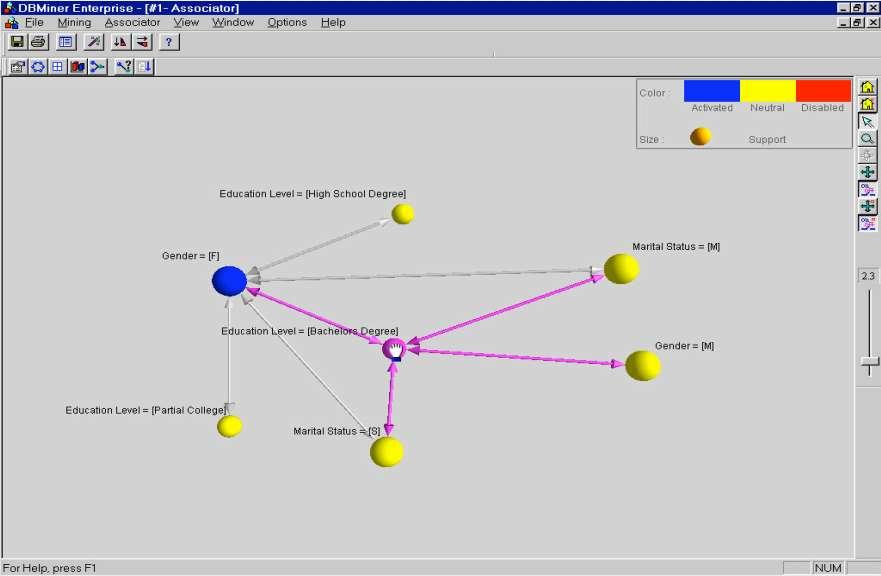
41 Przykłady wizualizacji
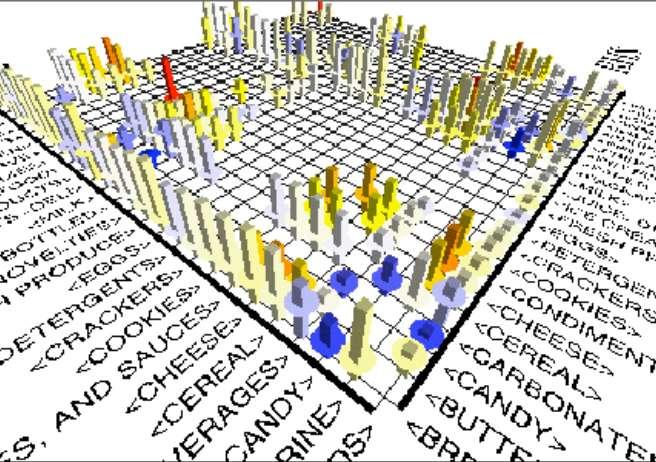
42 Przykłady wizualizacji

43 Zmniejszanie minsup -coraz więcej reguł. -na początku reguły oczywiste i znane, - później ciekawe i wcześniej niezauważane. -Warto zacząć również od reguł najmocniejszych i później zmniejszać poziom minconf

44 Przykład Dane MarketBasket, Ponad 60 tys transakcji, ponad 600 kategorii produktów
. Domyślnie baza ta jest przechowywana w pliku C:\Documents and Settings\USER\My Documents\Default.dbs. 45")
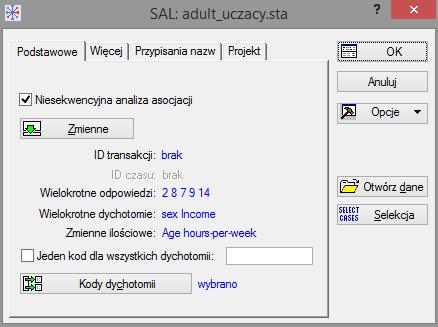
45 Niesekwencyjna analiza asocjacji Wszystkie reguły, a więc też cały model, zapisywane są w bazie danych (.dbs). Domyślnie baza ta jest przechowywana w pliku C:\Documents and Settings\USER\My Documents\Default.dbs. 45


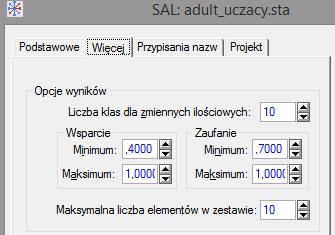
46 minsup 0,1 minconf 0,5 minsup 0,05 minconf 0,5 46

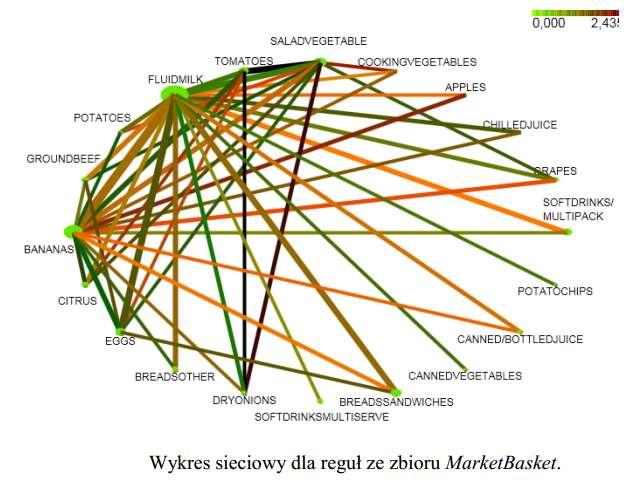
47 47
48 48

49 KISIM, WIMiIP, AGH 49


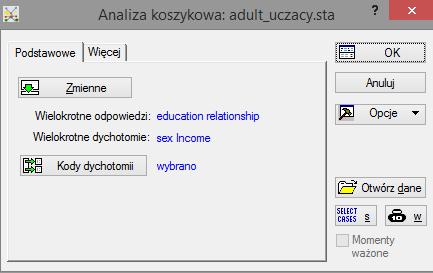
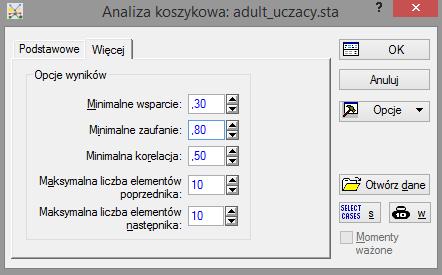
50 Adult KISIM, WIMiIP, AGH 50

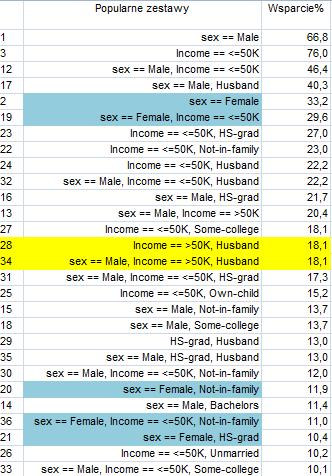
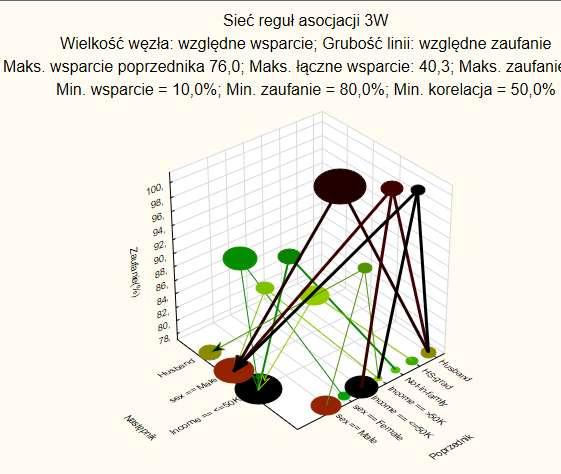
51 KISIM, WIMiIP, AGH 51

52 KISIM, WIMiIP, AGH 52

53 KISIM, WIMiIP, AGH 53




54 minsup = 0,4 minsup = 0,3 brak reguł >50K w konkluzji minsup = 0,2 minconf=0,1 KISIM, WIMiIP, AGH 54

55 minsup = 0,2 minconf=0,1 KISIM, WIMiIP, AGH 55
56 minsup = 0,2 minconf=0,1 KISIM, WIMiIP, AGH 56

57 KISIM, WIMiIP, AGH minsup = 0,1 minconf=0,1 57

58 KISIM, WIMiIP, AGH 58
59 KISIM, WIMiIP, AGH 59

60 KISIM, WIMiIP, AGH 60

61 Algorytm Apriori (R) Apriori wykonane w środowisku R na zbiorze Adult minsup = 0,4 minconf = 0,7 Interesują nas reguły, które w konkluzji mają: race=white lub sex=male


62 Algorytm Apriori (R) sortujemy reguły po wskaźniku lift. wyświetlamy 5 najlepszych reguł
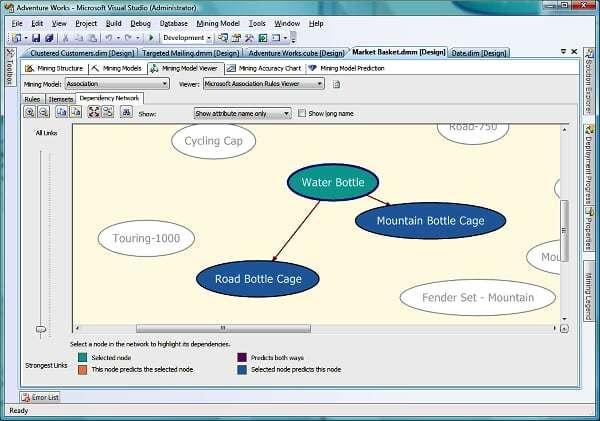
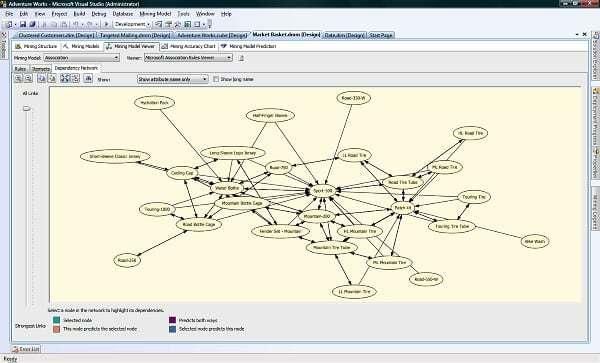
63 Association rules viewers 63

64 arulesviz R library association rule learning with 64

65 Text mining with RapidMiner 65
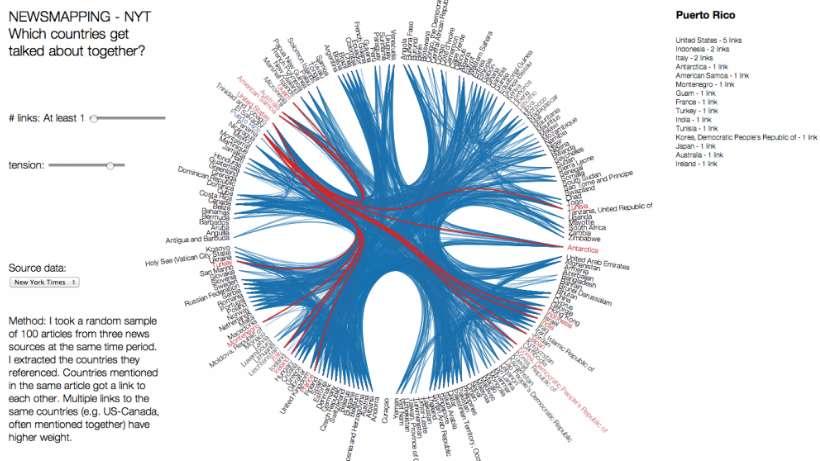
66 NewsMapping 66
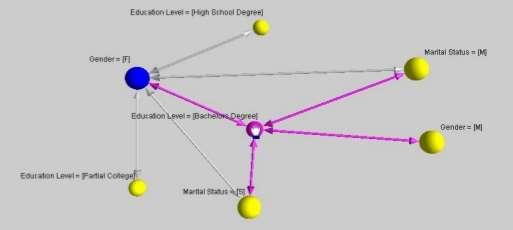
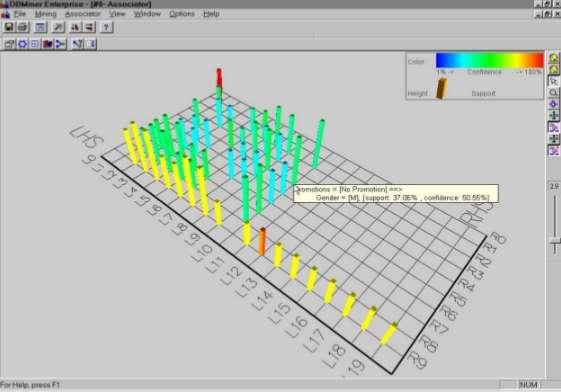
67 67
68 68
69 Odkrywanie wzorców sekwencji Mining Sequential Patterns
70 Eksploracja wzorców sekwencji Wzorce sekwencji stanowią klasę wzorców symbolicznych opisujących zależności występujące pomiędzy zdarzeniami zachodzącymi w pewnym przedziale czasu. W przypadku wzorców symbolicznych zdarzenia są opisane wartościami atrybutów kategorycznych. W przypadku, gdy zdarzenia są opisane wartościami numerycznymi mówimy o przebiegach czasowych lub o analizie trendów. W przypadku analizy trendów, najczęściej stosuje się metody analizy przebiegów czasowych lub metody predykcji. Przykłady:» klient, który wypożyczył tydzień temu film Gwiezdne Wojny, w ciągu tygodnia wypożyczy Imperium Kontratakuje, a następnie, w kolejnym tygodniu Powrót Jedi» użytkownik, który odczytał strony A i B, przejdzie, w kolejnych krokach, do strony D, a następnie, strony F
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe Machine Learning. Krzysztof Regulski, WIMiIP, KISiM, B5, pok.
 Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe Machine Learning Krzysztof Regulski, WIMiIP, KISiM, regulski@agh.edu.pl B5, pok. 408 Inteligencja Czy inteligencja jest jakąś jedną dziedziną, czy
Podstawy Sztucznej Inteligencji Sztuczne Sieci Neuronowe Machine Learning Krzysztof Regulski, WIMiIP, KISiM, regulski@agh.edu.pl B5, pok. 408 Inteligencja Czy inteligencja jest jakąś jedną dziedziną, czy
Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych. Data Mining Wykład 2
 Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Metody eksploracji danych. Reguły asocjacyjne
 Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Wyszukiwanie informacji w internecie. Nguyen Hung Son
 Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Eksploracja tekstu. Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu. Eksploracja danych. Eksploracja tekstu wykład 1
 Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Ewelina Dziura Krzysztof Maryański
 Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Eksploracja sieci Web
 Eksploracja sieci Web Wprowadzenie Klasyfikacja metod Page Rank Hubs & Authorities Eksploracja sieci Web Tematem wykładu są zagadnienia związane z eksploracją sieci Web. Rozpoczniemy od krótkiego wprowadzenia
Eksploracja sieci Web Wprowadzenie Klasyfikacja metod Page Rank Hubs & Authorities Eksploracja sieci Web Tematem wykładu są zagadnienia związane z eksploracją sieci Web. Rozpoczniemy od krótkiego wprowadzenia
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Odkrywanie asocjacji
 Odkrywanie asocjacji Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Odkrywanie asocjacji wykład 1 Wykład jest poświęcony wprowadzeniu i zaznajomieniu się z problemem odkrywania reguł asocjacyjnych.
Odkrywanie asocjacji Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Odkrywanie asocjacji wykład 1 Wykład jest poświęcony wprowadzeniu i zaznajomieniu się z problemem odkrywania reguł asocjacyjnych.
Data Mining Wykład 6. Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa.
 Naiwny klasyfikator Bayesa.") GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
GLM (Generalized Linear Models) Data Mining Wykład 6 Naiwny klasyfikator Bayes a Maszyna wektorów nośnych (SVM) Naiwny klasyfikator Bayesa Naiwny klasyfikator Bayesa jest klasyfikatorem statystycznym -
Odkrywanie wzorców sekwencji
 Odkrywanie wzorców sekwencji Sformułowanie problemu Algorytm GSP Eksploracja wzorców sekwencji wykład 1 Na wykładzie zapoznamy się z problemem odkrywania wzorców sekwencji. Rozpoczniemy od wprowadzenia
Odkrywanie wzorców sekwencji Sformułowanie problemu Algorytm GSP Eksploracja wzorców sekwencji wykład 1 Na wykładzie zapoznamy się z problemem odkrywania wzorców sekwencji. Rozpoczniemy od wprowadzenia
 Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Wydział Elektrotechniki, Informatyki i Telekomunikacji. Instytut Informatyki i Elektroniki. Instrukcja do zajęć laboratoryjnych
 Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. EKSPLORACJA DANYCH Ćwiczenia. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Ćwiczenia Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING EKSPLORACJA DANYCH Ćwiczenia Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Eksploracja danych a serwisy internetowe Przemysław KAZIENKO
 Eksploracja danych a serwisy internetowe Przemysław KAZIENKO Wydział Informatyki i Zarządzania Politechnika Wrocławska kazienko@pwr.wroc.pl Dlaczego eksploracja danych w serwisach internetowych? Kanały
Eksploracja danych a serwisy internetowe Przemysław KAZIENKO Wydział Informatyki i Zarządzania Politechnika Wrocławska kazienko@pwr.wroc.pl Dlaczego eksploracja danych w serwisach internetowych? Kanały
Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining
![Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining](/thumbs/26/8053420.jpg "Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining") Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining 0LNRáDM0RU]\ Marek Wojciechowski Instytut Informatyki PP Eksploracja danych 2GNU\ZDQLHZ]RUFyZZGX*\FK
Integracja technik eksploracji danych ]V\VWHPHP]DU]G]DQLDED]GDQ\FK QDSU]\NáDG]LH2UDFOHi Data Mining 0LNRáDM0RU]\ Marek Wojciechowski Instytut Informatyki PP Eksploracja danych 2GNU\ZDQLHZ]RUFyZZGX*\FK
Ćwiczenie 5. Metody eksploracji danych
 Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
Ćwiczenie 5. Metody eksploracji danych Reguły asocjacyjne (association rules) Badaniem atrybutów lub cech, które są powiązane ze sobą, zajmuje się analiza podobieństw (ang. affinity analysis). Metody analizy
WSTĘP I TAKSONOMIA METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Wyszukiwanie tekstów
 Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Reguły asocjacyjne w programie RapidMiner Michał Bereta
 Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
1. Odkrywanie asocjacji
 1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Wstęp do przetwarzania języka naturalnego
 Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Data Mining Kopalnie Wiedzy
 Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Implementacja metod eksploracji danych - Oracle Data Mining
 Implementacja metod eksploracji danych - Oracle Data Mining 395 Plan rozdziału 396 Wprowadzenie do eksploracji danych Architektura Oracle Data Mining Możliwości Oracle Data Mining Etapy procesu eksploracji
Implementacja metod eksploracji danych - Oracle Data Mining 395 Plan rozdziału 396 Wprowadzenie do eksploracji danych Architektura Oracle Data Mining Możliwości Oracle Data Mining Etapy procesu eksploracji
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Grzegorz Harańczyk, StatSoft Polska Sp. z o.o.
 CO Z CZYM I PO CZYM, CZYLI ANALIZA ASOCJACJI I SEKWENCJI W PROGRAMIE STATISTICA Grzegorz Harańczyk, StatSoft Polska Sp. z o.o. Jednym z zagadnień analizy danych jest wyszukiwanie w zbiorach danych wzorców,
CO Z CZYM I PO CZYM, CZYLI ANALIZA ASOCJACJI I SEKWENCJI W PROGRAMIE STATISTICA Grzegorz Harańczyk, StatSoft Polska Sp. z o.o. Jednym z zagadnień analizy danych jest wyszukiwanie w zbiorach danych wzorców,
Eksploracja Danych. podstawy
 Eksploracja Danych podstawy Bazy danych (1) Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 2/633 Bazy danych (2) Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 3/633
Eksploracja Danych podstawy Bazy danych (1) Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 2/633 Bazy danych (2) Witold Andrzejewski, Politechnika Poznańska, Wydział Informatyki 3/633
METODY INŻYNIERII WIEDZY ASOCJACYJNA REPREZENTACJA POWIĄZANYCH TABEL I WNIOSKOWANIE IGOR CZAJKOWSKI
 METODY INŻYNIERII WIEDZY ASOCJACYJNA REPREZENTACJA POWIĄZANYCH TABEL I WNIOSKOWANIE IGOR CZAJKOWSKI CELE PROJEKTU Transformacja dowolnej bazy danych w min. 3 postaci normalnej do postaci Asocjacyjnej Grafowej
METODY INŻYNIERII WIEDZY ASOCJACYJNA REPREZENTACJA POWIĄZANYCH TABEL I WNIOSKOWANIE IGOR CZAJKOWSKI CELE PROJEKTU Transformacja dowolnej bazy danych w min. 3 postaci normalnej do postaci Asocjacyjnej Grafowej
Analiza danych i data mining.
 Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Eksploracja danych (data mining)
") Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Proces odkrywania wiedzy z baz danych
 Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Bazy dokumentów tekstowych
 Bazy dokumentów tekstowych Bazy dokumentów tekstowych Dziedzina zastosowań Automatyzacja bibliotek Elektroniczne encyklopedie Bazy aktów prawnych i patentów Szukanie informacji w Internecie Dokumenty tekstowe
Bazy dokumentów tekstowych Bazy dokumentów tekstowych Dziedzina zastosowań Automatyzacja bibliotek Elektroniczne encyklopedie Bazy aktów prawnych i patentów Szukanie informacji w Internecie Dokumenty tekstowe
Wielopoziomowe i wielowymiarowe reguły asocjacyjne
 Wielopoziomowe i wielowymiarowe reguły asocjacyjne Wielopoziomowe reguły asocjacyjne Wielowymiarowe reguły asocjacyjne Asocjacje vs korelacja Odkrywanie asocjacji wykład 3 Kontynuując zagadnienia związane
Wielopoziomowe i wielowymiarowe reguły asocjacyjne Wielopoziomowe reguły asocjacyjne Wielowymiarowe reguły asocjacyjne Asocjacje vs korelacja Odkrywanie asocjacji wykład 3 Kontynuując zagadnienia związane
Techniki i algorytmy eksploracji danych. Geneza (1) Geneza (2)
 Geneza (2)") Techniki i algorytmy eksploracji danych Tadeusz Morzy Instytut Informatyki Politechnika Poznańska str. 1 Geneza (1) Dostępność danych Rozwój nowoczesnych technologii przechowywania i przetwarzania danych
Techniki i algorytmy eksploracji danych Tadeusz Morzy Instytut Informatyki Politechnika Poznańska str. 1 Geneza (1) Dostępność danych Rozwój nowoczesnych technologii przechowywania i przetwarzania danych
ID1SII4. Informatyka I stopień (I stopień / II stopień) ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)
 ogólnoakademicki (ogólno akademicki / praktyczny) stacjonarne (stacjonarne / niestacjonarne)") Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu ID1SII4 Nazwa modułu Systemy inteligentne 1 Nazwa modułu w języku angielskim Intelligent
Analiza danych tekstowych i języka naturalnego
 Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Kod szkolenia: Tytuł szkolenia: ANA/TXT Analiza danych tekstowych i języka naturalnego Dni: 3 Opis: Adresaci szkolenia Dane tekstowe stanowią co najmniej 70% wszystkich danych generowanych w systemach
Eksploracja danych - wykład VIII
 I Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 2 grudnia 2016 1/31 1 2 2/31 (ang. affinity analysis) polega na badaniu atrybutów lub cech, które są ze sobą powiązane. Metody
I Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 2 grudnia 2016 1/31 1 2 2/31 (ang. affinity analysis) polega na badaniu atrybutów lub cech, które są ze sobą powiązane. Metody
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Eksploracja danych TADEUSZ MORZY
 NAUKA 3/2007 83-104 TADEUSZ MORZY Eksploracja danych Intensywny rozwój technologii generowania, gromadzenia i przetwarzania danych z jednej strony, z drugiej, upowszechnienie systemów informatycznych,
NAUKA 3/2007 83-104 TADEUSZ MORZY Eksploracja danych Intensywny rozwój technologii generowania, gromadzenia i przetwarzania danych z jednej strony, z drugiej, upowszechnienie systemów informatycznych,
SPOTKANIE 2: Wprowadzenie cz. I
 Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Wrocław University of Technology SPOTKANIE 2: Wprowadzenie cz. I Piotr Klukowski Studenckie Koło Naukowe Estymator piotr.klukowski@pwr.edu.pl 17.10.2016 UCZENIE MASZYNOWE 2/27 UCZENIE MASZYNOWE = Konstruowanie
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Odkrywanie asocjacji
 Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
Odkrywanie asocjacji Cel odkrywania asocjacji Znalezienie interesujących zależności lub korelacji, tzw. asocjacji Analiza dużych zbiorów danych Wynik procesu: zbiór reguł asocjacyjnych Witold Andrzejewski,
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Inteligentne wydobywanie informacji z internetowych serwisów społecznościowych
 Inteligentne wydobywanie informacji z internetowych serwisów społecznościowych AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław
Inteligentne wydobywanie informacji z internetowych serwisów społecznościowych AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław
Sylabus modułu kształcenia na studiach wyższych. Nazwa Wydziału. Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia.
 Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
2
 1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
1 2 3 4 5 Dużo pisze się i słyszy o projektach wdrożeń systemów zarządzania wiedzą, które nie przyniosły oczekiwanych rezultatów, bo mało kto korzystał z tych systemów. Technologia nie jest bowiem lekarstwem
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop Spis treści
 Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Krzysztof Kawa. empolis arvato. e mail: krzysztof.kawa@empolis.com
 XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
W poszukiwaniu sensu w świecie widzialnym
 W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
Odkrywanie reguł asocjacyjnych. Rapid Miner
 Odkrywanie reguł asocjacyjnych Rapid Miner Zbiory częste TS ID_KLIENTA Koszyk 12:57 1123 {mleko, pieluszki, piwo} 13:12 1412 {mleko, piwo, bułki, masło, pieluszki} 13:55 1425 {piwo, wódka, wino, paracetamol}
Odkrywanie reguł asocjacyjnych Rapid Miner Zbiory częste TS ID_KLIENTA Koszyk 12:57 1123 {mleko, pieluszki, piwo} 13:12 1412 {mleko, piwo, bułki, masło, pieluszki} 13:55 1425 {piwo, wódka, wino, paracetamol}
PODSTAWY BAZ DANYCH. 19. Perspektywy baz danych. 2009/2010 Notatki do wykładu "Podstawy baz danych"
 PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
w ekonomii, finansach i towaroznawstwie
 w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
Eksploracja złożonych typów danych Text i Web Mining
 Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
Bazy Danych. Bazy Danych i SQL Podstawowe informacje o bazach danych. Krzysztof Regulski WIMiIP, KISiM,
 Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Oczekiwania? 2 3 Bazy danych Jak przechowywać informacje? Jak opisać rzeczywistość?
Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Oczekiwania? 2 3 Bazy danych Jak przechowywać informacje? Jak opisać rzeczywistość?
7. Maszyny wektorów podpierajacych SVMs
 Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
Algorytmy rozpoznawania obrazów 7. Maszyny wektorów podpierajacych SVMs dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Maszyny wektorów podpierajacych - SVMs Maszyny wektorów podpierających (ang.
Inżynieria Wiedzy i Systemy Ekspertowe. Reguły asocjacyjne
 Inżynieria Wiedzy i Systemy Ekspertowe Reguły asocjacyjne Dr inż. Michał Bereta p. 144 / 10, Instytut Modelowania Komputerowego mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Reguły
Inżynieria Wiedzy i Systemy Ekspertowe Reguły asocjacyjne Dr inż. Michał Bereta p. 144 / 10, Instytut Modelowania Komputerowego mbereta@pk.edu.pl beretam@torus.uck.pk.edu.pl www.michalbereta.pl Reguły
Hurtownie danych. Analiza zachowań użytkownika w Internecie. Ewa Kowalczuk, Piotr Śniegowski. Informatyka Wydział Informatyki Politechnika Poznańska
 Hurtownie danych Analiza zachowań użytkownika w Internecie Ewa Kowalczuk, Piotr Śniegowski Informatyka Wydział Informatyki Politechnika Poznańska 2 czerwca 2011 Wprowadzenie Jak zwiększyć zysk sklepu internetowego?
Hurtownie danych Analiza zachowań użytkownika w Internecie Ewa Kowalczuk, Piotr Śniegowski Informatyka Wydział Informatyki Politechnika Poznańska 2 czerwca 2011 Wprowadzenie Jak zwiększyć zysk sklepu internetowego?
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych
 Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Personalizowane rekomendacje w e-commerce, czyli jak skutecznie zwiększyć przychody w sklepie on-line
 Personalizowane rekomendacje w e-commerce, czyli jak skutecznie zwiększyć przychody w sklepie on-line Paweł Wyborski - Agenda Kim jesteśmy Czym są personalizowane rekomendacje Jak powstają rekomendacje,
Personalizowane rekomendacje w e-commerce, czyli jak skutecznie zwiększyć przychody w sklepie on-line Paweł Wyborski - Agenda Kim jesteśmy Czym są personalizowane rekomendacje Jak powstają rekomendacje,
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Reguły asocjacyjne. 1. Uruchom system weka i wybierz aplikację Knowledge Flow.
 Reguły asocjacyjne Niniejsze ćwiczenie demonstruje działanie implementacji algorytmu apriori w systemie WEKA. Ćwiczenie ma na celu zaznajomienie studenta z działaniem systemu WEKA oraz znaczeniem podstawowych
Reguły asocjacyjne Niniejsze ćwiczenie demonstruje działanie implementacji algorytmu apriori w systemie WEKA. Ćwiczenie ma na celu zaznajomienie studenta z działaniem systemu WEKA oraz znaczeniem podstawowych
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Data Mining Wykład 3. Algorytmy odkrywania binarnych reguł asocjacyjnych. Plan wykładu
 Data Mining Wykład 3 Algorytmy odkrywania binarnych reguł asocjacyjnych Plan wykładu Algorytm Apriori Funkcja apriori_gen(ck) Generacja zbiorów kandydujących Generacja reguł Efektywności działania Własności
Data Mining Wykład 3 Algorytmy odkrywania binarnych reguł asocjacyjnych Plan wykładu Algorytm Apriori Funkcja apriori_gen(ck) Generacja zbiorów kandydujących Generacja reguł Efektywności działania Własności
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Bazy Danych. Bazy Danych i SQL Podstawowe informacje o bazach danych. Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl
 Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Literatura i inne pomoce Silberschatz A., Korth H., S. Sudarshan: Database
Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Literatura i inne pomoce Silberschatz A., Korth H., S. Sudarshan: Database
Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining"
 Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining" Streszczenie Eksploracja danych znajduje coraz szersze
Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining" Streszczenie Eksploracja danych znajduje coraz szersze
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner. rok akademicki 2014/2015
 Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Analiza asocjacji i sekwencji Analiza asocjacji Analiza asocjacji polega na identyfikacji
Zastosowanie metod eksploracji danych Data Mining w badaniach ekonomicznych SAS Enterprise Miner rok akademicki 2014/2015 Analiza asocjacji i sekwencji Analiza asocjacji Analiza asocjacji polega na identyfikacji
Metody Inżynierii Wiedzy
 Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Ćwiczenia z Zaawansowanych Systemów Baz Danych
 Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Ontogeniczne sieci neuronowe. O sieciach zmieniających swoją strukturę
 Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
O szukaniu sensu w stogu siana
 O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
INFORMATYKA Pytania ogólne na egzamin dyplomowy
 INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja
INFORMATYKA Pytania ogólne na egzamin dyplomowy 1. Wyjaśnić pojęcia problem, algorytm. 2. Podać definicję złożoności czasowej. 3. Podać definicję złożoności pamięciowej. 4. Typy danych w języku C. 5. Instrukcja