Programowanie współbieżne. Iwona Kochańska
|
|
|
- Arkadiusz Mucha
- 6 lat temu
- Przeglądów:
Transkrypt


1 1 Programowanie współbieżne Iwona Kochańska
2 2 Organizacja przedmiotu Wykład: 1 godzina tygodniowo (piątek, 10:15) 2 kolokwia w trakcie semestru Ocena końcowa: 0.5*(średnia z kolokw.)+0.5*projekt Projekt: od połowy semestru (termin wydawania zadań projektowych będzie podany na wykładzie z 2- tygodniowym wyprzedzeniem) Wykład: Iwona Kochańska iwona.kochanska@pg.edu.pl tel pokój EA 745 WETI PG Projekt: Mariusz Rudnicki mariusz.rudnicki@pg.edu.pl tel pokój EA 753 WETI PG
3 3 Historia programowania współbieżnego Początki programowania współbieżnego to lata 60 XX wieku Pojawienie sie kontrolerów dla urządzeń we/wy, które mogły wykonywań operacje równoległe do obliczeń wykonywanych przez CPU Komunikacja miedzy urządzeniami we/wy a CPU za pomocą przerwań przestań wykonywać bieżący program i zacznij wykonywać inną sekwencje instrukcji wielozadaniowość Przerwania mogą zdarzyć sie w dowolnym momencie Początek lat 70 pierwsze komputery wieloprocesorowe (D825 w 1962 r., 4-procesory)









4 4 Programowanie współbieżne Programowanie współbieżne znaczne skrócenie czasu obliczeń rozwiązywanie problemów o większych rozmiarach danych Przykładowe zastosowania:
5 5 Procesory CISC CISC - Complex Instruction Set Computer (np. 6502, 8088) duży zbiór instrukcji o różnej złożoności niektóre kilku-bajtowe, do wykonania wymagają od kilku do kilkunastu cykli zegara, minimalizuje liczbę instrukcji potrzebnych do wykonania zadania (oszczędność RAM) szeroka gama trybów adresowania, rozkazy mogą operować bezpośrednio na pamięci (zamiast przesłania wartości do rejestrów i operowania na nich), dekoder rozkazów jest skomplikowany,
6 6 Procesory CISC Istotą architektury CISC jest to, iż pojedynczy rozkaz mikroprocesora wykonuje kilka operacji niskiego poziomu, jak na przykład pobranie z pamięci, operację arytmetyczną i zapisanie do pamięci. Współczesne procesory zgodne z x86 produkowane przez firmy Intel, AMD i VIA przetwarzają rozkazy procesora x86 na proste mikropolecenia pracujące według idei RISC, często wykonujące się równolegle.
7 7 Procesory RISC RISC - Reducted Instruction Set Computer mały zbiór instrukcji, instrukcje są proste - potrzeba mniej tranzystorów, niż w CISC, do realizacji zadania potrzeba więcej wywołań instrukcji niż w CISC, ale: pamięć jest coraz tańsza i lepiej upakowana kompilatory są coraz bardziej wydajne każda instrukcja mieści sie w pojedynczym słowie binarnym (kod instrukcji + adres + dane) wykonanie każdej instrukcji zajmuje tyle samo czasu przetwarzanie potokowe (Pipelining) - kiedy jedna instrukcja jest wykonywana, następna jest odczytywana z pamięci
8 Procesory SPARC SPARC - Scalable Processor ARChitecture Zaprojektowana przez firmę Sun Microsystems (1985), od 1989 r. rozwijana przez organizacje SPARC International. Wersje: 32-bitowa (SPARC version 8) 64-bitowa (SPARC version 9) Architektura otwarta model programowy mikroprocesora (Instruction Set Architecture, ISA) jest publicznie dostępny (dokumentacja). otwarta implementacja (GNU LGPL) - kod w języku VHDL procesora LEON. Zastosowania: wysokowydajne serwery, stacje robocze, systemy wbudowane 8

9 Przykłady procesorów CISC i RISC 9

10 Rozwój procesorów SPARC 10
11 11
12 12

 opracowana przez firmę Nvidia uniwersalna architektura procesorów wielordzeniowych (głównie kart graficznych) umożliwiająca wykorzystanie")
13 13 Graphics Processing Unit (GPU) Współcześnie możliwości wykonywania obliczeń równoległych nie ograniczają się tylko do CPU od wielu lat możliwe jest wykonywanie obliczeń na GPU Nvidia Tesla K40, moc 1.43TFLOPS, 2880 CUDA cores Tesla P100, 3584 rdzenie CUDA, moc 5.3TFLOPS oraz 10.6 TFLOPS dla obl. zmiennoprzecinkowych pojedynczej precyzji, (zródło Nvidia). CUDA (ang. Compute Unified Device Architecture) opracowana przez firmę Nvidia uniwersalna architektura procesorów wielordzeniowych (głównie kart graficznych) umożliwiająca wykorzystanie ich mocy obliczeniowej do rozwiązywania ogólnych problemów numerycznych w sposób wydajniejszy niż w tradycyjnych, sekwencyjnych procesorach ogólnego zastosowania.

 zajmuje 8 bajtów.")
14 Jednostki w obliczeniach równoległych MIPS liczba milionów operacji stałoprzecinkowych wykonywanych w ciągu sekundy Flop (floating point operation) operacja zmiennoprzecinkowa. Liczba zmiennoprzecinkowa (double) zajmuje 8 bajtów. Flops/s (FLOPS) liczba operacji zmiennoprzecinkowych na sekundę 14

15 15 Superkomputer Superkomputer komputer znacznie przewyższający możliwościami powszechnie używane komputery, w szczególności dysponujący wielokrotnie większą mocą obliczeniową. Określenie to pojawiło się w latach 60. w odniesieniu do komputerów produkowanych przez CDC i później przez przedsiębiorstwo Cray Elementy architektury Blue Gene: chip, karta, węzeł, szafa, system (Wikipedia)

16 16 TOP500 Projekt TOP500 ( od 1993 publikuje listę najszybszych superkomputerów na świecie na podstawie testów wykorzystujących m.in. oprogramowanie do obliczeń numerycznych z dziedziny algebry liniowej. Listopad najszybszym komputerem był Titan wyprodukowany przez Cray i zainstalowany w DOE/SC/Oak Ridge National Laboratory. moc PFLOPS ( ) PFLOPS Architektura: AMD Opteron core CPUs, Nvidia Tesla K20X GPUs zużycie energii 8.2 MW koszt: 97 mln $ powierzchnia 404 m2
 PFLOPS architektura: 16000 węzłów, 3120000 rdzeni - Intel Xeon E5-2692 12C 2.2 zużycie energii 17.")
17 17 TOP500 Czerwiec Tianhe-2 (ang. Skyriver-2) - superkomputer stworzony dla potrzeb Uniwersytetu Technologii Obronnych w Chinach PFLOPS ( ) PFLOPS architektura: węzłów, rdzeni - Intel Xeon E C 2.2 zużycie energii 17.8 MW pamięć GB powierzchnia 404 m2 Czerwiec chiński Sunway TaihuLight moc ok. 93 PFLOPS ( ) węzłów z rdzeni procesory z 256 rdzeniami w architekturze RISC pamięć GB zapotrzebowanie na energie 15.37MW, ok. 6 GFLOPS/W koszt ok. 273 mln. $
18 18 Prawo Moore a W 1965 roku Gordon Moore, szef laboratorium firmy Fairchild Semiconductor, opublikował w branżowym elektronicznym periodyku artykuł, w którym przedstawił prognozę: Liczba dyskretnych komponentów możliwych do upakowania w pojedynczym czipie komputerowym będzie się co rok podwajała, podczas gdy cena tychże czipów pozostanie stała. Gordon Moore stał się później współzałożycielem Intela, a jego prognoza stała się zarówno napędzającą firmy ideą postępu w branży półprzewodników, jak i standardem, którego przestrzeganie jest konieczne, by w tej branży w ogóle przetrwać. Od 1980 podwajanie liczby komponentów chipu co 2 lata
19 19 Prawo Moore a Dave House: choć tempo przyrostu liczby elementów maleje, to same tranzystory stają się szybsze. To zaś powinno oznaczać, że moc obliczeniowa układu scalonego powinna podwajać się co ok. 18 miesięcy. (współczesna postać prawa Moore a). Ten wykładniczy wzrost towarzyszył nam jeszcze do końca lat zerowych XXI wieku a potem zaczęto coraz częściej mówić o tym, że Prawo Moore'a się skończyło. Intel w 2003 roku sugerował, że koniec może nastąpić przed 2018 roku, kiedy to efekty kwantowe sprawią, że tranzystory nie będą mogły już być dalej miniaturyzowane.
20 20 Prawo Moore a Robert Dennard: w miarę zmniejszania tranzystorów ich gęstość energetyczna pozostaje stała tak więc zużycie energii pozostaje proporcjonalne do powierzchni. Mniejsze tranzystory potrzebują mniejszego napięcia i natężenia prądu, tak więc wraz z kolejnymi generacjami czipów o coraz większej liczbie tranzystorów, będą one wydzielały mniej ciepła i zużywały mniej energii. Ta zasada zawiodła! Poniżej pewnych rozmiarów tranzystorów pojawiają się prądy upływu, prowadzące do eskalującego się nagrzewania układu (przez pętlę dodatniego sprzężenia zwrotnego). Kres zasady skalowania Dennarda doprowadził do tego, że zamiast podkręcać zegary, postawiono na zwiększenie liczby rdzeni i optymalizację wydajności pojedyńczych wątków. Dzięki temu udało się utrzymać obowiązywanie Prawa Moore'a w jego współczesnej postaci!

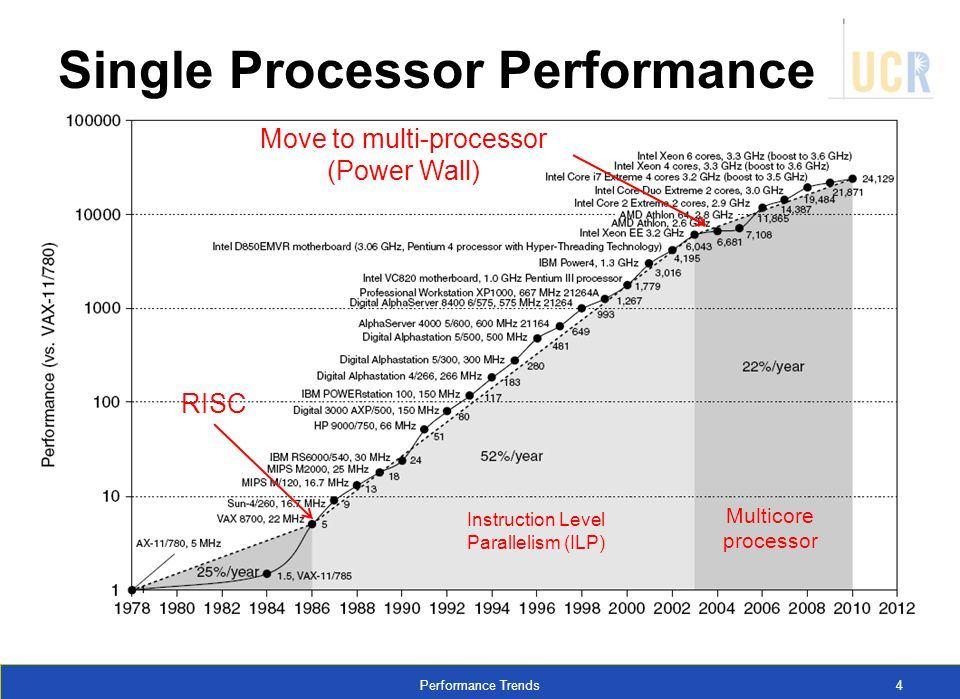
21 Wykładniczy wzrost wydajności obliczeniowej 21
22 22 Zrównoleglenie Gdy nie można skrócić czasu trwania cyklu (zwiększyć taktowania procesora), pozostaje zwiększyć liczbę wykonywanych w tym samym czasie operacji zrównoleglenie. Równoległość na poziomie procesora: równoległość na poziomie bitów: szersze magistrale i liczba bitów w rejestrach procesora (8, 16, 32, 64 bity) równoległość na poziomie instrukcji: równoległe wykonywanie wielu rozkazów w tym samym czasie przetwarzanie potokowe. Procesory wielordzeniowe przetwarzanie wielu wątków w tym samym czasie Komputery równoległe wymagają programów równoległych (współbieżnych)

23 23 Programowanie lata 60 i 70 Programowanie w językach asemblerowych Wzrost mocy obliczeniowej powodował, ze komputery mogły rozwiązywać bardziej złożone zadania konieczność zastosowania bardziej złożonego oprogramowania Problem z przenośnością oprogramowania - potrzeba języków programowania o wyższym stopniu abstrakcji bez utraty wydajności -> języki wysokiego poziomu: Fortran i C





24 24 Programowanie lata 80 i 90 Języki Fortran i C Trudność w tworzeniu i utrzymaniu złożonych aplikacji wymagających milionów linii kodu pisanych przez setki programistów Rozwój komputerów osobistych i ich mocy obliczeniowej Języki obiektowe: C++, Java, C# Lepsze narzędzia: środowiska programistyczne, biblioteki Rozwój metodologii tworzenia oprogramowania: wzorce projektowe, odpowiednie dokumentowanie, testowanie
25 25 Programowanie - współcześnie Programiści mogą tworzyć oprogramowanie bez konieczności dogłębnej znajomości sprzętu, dostępne języki programowania i biblioteki zapewniają wysoki poziom abstrakcji Uzyskania wydajności zgodnej z prawem Moore a wymaga wyjścia poza programowanie sekwencyjne wzrost taktowania procesorów uległ spowolnieniu rośnie liczba rdzeni w procesorach konieczność pisania oprogramowania korzystającego z większej liczby wątków w tym samym czasie
26 Cele programowania współbieżnego 26 Większa wydajność: jeżeli mamy do dyspozycji 4 rdzenie procesora, a program wykorzystuje jedynie jeden, to 75% mocy pozostaje niewykorzystane jeżeli program jest jednowątkowy i korzysta z urządzeń we/wy, to często musi czekać bezczynnie, aż urządzenie przęśle mu dane; program wielowątkowy może w tym czasie pobierać dane z wielu źródeł lub wykonywać inne operacje Prostota modelowania niektóre problemy można podzielić na podzadania, które mogą być wykonywane niezależnie od siebie, np. serwer WWW
27 Cele programowania współbieżnego 27 Większa responsywność (płynność) programu wykonywanie intensywnych obliczeniowo żądań w osobnych watkach, a nie w wątku GUI Uproszczona obsługa asynchronicznych zdarzeń np. komunikacja przez gniazda sieciowe wymaga czekania na odpowiedź (ang. bloking I/O). w aplikacji wielowątkowej każda komunikacja może być obsługiwana w osobnych wątkach, po jednym na połączenie
 Windows Threads boost (Asio, Thread, Interprocess) Źródło: http://www.modernescpp.")
28 28 Narzędzia C/C++ brak obsługi wielowątkowości w standardzie aż do standardu C++11 z 2011 r. biblioteka POSIX Threads (pthreads) Windows Threads boost (Asio, Thread, Interprocess) Źródło:

29 29 Narzędzia Java obsługa wielowątkowości od początku, zdefiniowany model pamięci uwzględniający wykonanie wielowątkowe, bogata biblioteka standardowa
30 Narzędzia MPI Message Passing Interface protokół komunikacyjny przesyłania komunikatów miedzy procesami w programach współbieżnych najpopularniejszy standard dla superkomputerów wysoka wydajność i skalowalność implementacja dla wielu języków programowania (C, C++, Ada, Fortran, C#) mała wygoda użycia w porównaniu do np. OpenMP OpenMP interfejs służący do tworzenia programów równoległych dla komputerów wieloprocesorowych z pamięcią wspólną dostępny dla C, C++, Fortran wygodniejszy w użyciu od MPI często stosowany łącznie z MPI MPI do komunikacji między węzłami klastra, OpenMP do komunikacji wewnątrz węzła Open Computing Language (OpenCL) otwarty standard ułatwiający pisanie programów do równoległego wykonania na różnych urządzeniach obliczeniowych, tj. CPU, GPU, FPGA oraz DSP 30
31 31 Co jeśli nie program równoległy? Uruchomienie wielu instancji tego samego programu dla różnych danych dobre, gdy dane wejściowe można podzielić na niezależne od siebie podzbiory uruchomienie wielu instancji, np. za pomocą skryptów powłoki (np. Bash w Linuxie) Wykorzystanie istniejącego oprogramowania równoległego do wykonania np. zastosowanie baz danych z wbudowaną obsługą równoległości Optymalizacja programu sekwencyjnego, tak by spełniał założenia odnośnie czasu działania Nowe rozkazy procesora umożliwiające przyspieszenie wybranych operacji Zastosowanie algorytmu o mniejszej złożoności obliczeniowej
32 Trudności programowania równoległego 32 Podział pracy obliczenia należy podzielić na zadania, które mogą być wykonywane jednocześnie nierówny podział negatywnie wpływa na wydajność (prawo Amdahla) jak rozdzielić zadania pomiędzy watkami jak Dzielic czas procesora pomiędzy watkami watki o różnych priorytetach Zamiast pojedynczego przepływu sterowania mamy ich wiele dodatkowa logika niezbędna do zarządzania i komunikacji pomiędzy watkami, np. mechanizmy synchronizacji, współbieżne struktury danych
33 33 Trudności programowania równoległego Nowa kategoria bledów możliwych przy współbieżnym wykonywaniu obliczeń: wyścigi w dostępie do danych (ang. data race) sytuacje prowadzące do niepoprawnych wartości zmiennych wynikające z równoczesnego niekontrolowanego dostępu do współdzielonej pamięci zaburzenia poprawnego wykonania zakleszczenia i zagłodzenia Trudniejsze debugowanie: program może działać poprawnie na jednym proc., ale niepoprawnie na większej liczbie błąd może sie objawiać tylko w specyficznych sytuacjach, np. przy dużej liczbie wątków i dla konkretnych danych wejściowych
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Wprowadzenie Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby
Programowanie współbieżne Wykład 1. Rafał Skinderowicz
 Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Programowanie współbieżne Wykład 1 Rafał Skinderowicz Plan wykładu Historia, znaczenie i cele współbieżności w informatyce. Podstawowe pojęcia, prawo Moore a i bariery technologiczne. Sposoby realizacji
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura. 3/26/2018 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Intel Nehalem 4 5 NVIDIA Tesla 6 ATI FireStream 7 NVIDIA Fermi 8 Sprzętowa wielowątkowość 9 Architektury
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Bibliografia: pl.wikipedia.org www.intel.com. Historia i rodzaje procesorów w firmy Intel
 Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
Bibliografia: pl.wikipedia.org www.intel.com Historia i rodzaje procesorów w firmy Intel Specyfikacja Lista mikroprocesorów produkowanych przez firmę Intel 4-bitowe 4004 4040 8-bitowe x86 IA-64 8008 8080
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1
 Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Programowanie z wykorzystaniem technologii CUDA i OpenCL Wykład 1 Organizacja przedmiotu Dr inż. Robert Banasiak Dr inż. Paweł Kapusta 1 2 Nasze kompetencje R n D Tomografia 3D To nie tylko statyczny obraz!
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Projektowanie. Projektowanie mikroprocesorów
 WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
WYKŁAD Projektowanie mikroprocesorów Projektowanie układ adów w cyfrowych - podsumowanie Algebra Boole a Bramki logiczne i przerzutniki Automat skończony System binarny i reprezentacja danych Synteza logiczna
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1
 Wykład nr 1") Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
Programowanie procesorów graficznych NVIDIA (rdzenie CUDA) Wykład nr 1 Wprowadzenie Procesory graficzne GPU (Graphics Processing Units) stosowane są w kartach graficznych do przetwarzania grafiki komputerowej
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego
 Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Porównanie wydajności CUDA i OpenCL na przykładzie równoległego algorytmu wyznaczania wartości funkcji celu dla problemu gniazdowego Mariusz Uchroński 3 grudnia 2010 Plan prezentacji 1. Wprowadzenie 2.
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Kryptografia na procesorach wielordzeniowych
 Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Kryptografia na procesorach wielordzeniowych Andrzej Chmielowiec andrzej.chmielowiec@cmmsigma.eu Centrum Modelowania Matematycznego Sigma Kryptografia na procesorach wielordzeniowych p. 1 Plan prezentacji
Dydaktyka Informatyki budowa i zasady działania komputera
 Dydaktyka Informatyki budowa i zasady działania komputera Instytut Matematyki Uniwersytet Gdański System komputerowy System komputerowy układ współdziałania dwóch składowych: szprzętu komputerowego oraz
Dydaktyka Informatyki budowa i zasady działania komputera Instytut Matematyki Uniwersytet Gdański System komputerowy System komputerowy układ współdziałania dwóch składowych: szprzętu komputerowego oraz
Programowanie procesorów graficznych GPGPU
 Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Programowanie procesorów graficznych GPGPU 1 GPGPU Historia: lata 80 te popularyzacja systemów i programów z graficznym interfejsem specjalistyczne układy do przetwarzania grafiki 2D lata 90 te standaryzacja
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil
 Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
Wykorzystanie architektury Intel MIC w obliczeniach typu stencil Kamil Halbiniak Wydział Inżynierii Mechanicznej i Informatyki Kierunek informatyka, Rok IV Instytut Informatyki Teoretycznej i Stosowanej
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
Raport Hurtownie Danych
 Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
Raport Hurtownie Danych Algorytm Apriori na indeksie bitmapowym oraz OpenCL Mikołaj Dobski, Mateusz Jarus, Piotr Jessa, Jarosław Szymczak Cel projektu: Implementacja algorytmu Apriori oraz jego optymalizacja.
i3: internet - infrastruktury - innowacje
 i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
i3: internet - infrastruktury - innowacje Wykorzystanie procesorów graficznych do akceleracji obliczeń w modelu geofizycznym EULAG Roman Wyrzykowski Krzysztof Rojek Łukasz Szustak [roman, krojek, lszustak]@icis.pcz.pl
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność
 Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
Równoległość i współbieżność Wykonanie sekwencyjne. Poszczególne akcje procesu są wykonywane jedna po drugiej. Dokładniej: kolejna akcja rozpoczyna się po całkowitym zakończeniu poprzedniej. Praca współbieżna
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
Wykład 2. Mikrokontrolery z rdzeniami ARM
 Źródło problemu 2 Wstęp Architektura ARM (Advanced RISC Machine, pierwotnie Acorn RISC Machine) jest 32-bitową architekturą (modelem programowym) procesorów typu RISC. Różne wersje procesorów ARM są szeroko
Źródło problemu 2 Wstęp Architektura ARM (Advanced RISC Machine, pierwotnie Acorn RISC Machine) jest 32-bitową architekturą (modelem programowym) procesorów typu RISC. Różne wersje procesorów ARM są szeroko
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
INSTYTUT INFORMATYKI STOSOWANEJ 2013 INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania Jak? Kto? Kiedy? Co? W jaki sposób? Metodyka Zespół Narzędzia
UTK ARCHITEKTURA PROCESORÓW 80386/ Budowa procesora Struktura wewnętrzna logiczna procesora 80386
 Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa procesora 80386 Struktura wewnętrzna logiczna procesora 80386 Pierwszy prawdziwy procesor 32-bitowy. Zawiera wewnętrzne 32-bitowe rejestry (omówione zostaną w modułach następnych), pozwalające przetwarzać
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f)
 i częstotliwości (f)") Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Zegar Zegar - układ wysyłający regularne impulsy o stałej szerokości (J) i częstotliwości (f) http://en.wikipedia.org/wiki/computer_clock umożliwia kontrolę relacji czasowych w CPU pobieranie, dekodowanie,
Metody optymalizacji soft-procesorów NIOS
 POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
POLITECHNIKA WARSZAWSKA Wydział Elektroniki i Technik Informacyjnych Instytut Telekomunikacji Zakład Podstaw Telekomunikacji Kamil Krawczyk Metody optymalizacji soft-procesorów NIOS Warszawa, 27.01.2011
Od uczestników szkolenia wymagana jest umiejętność programowania w języku C oraz podstawowa znajomość obsługi systemu Linux.
 Kod szkolenia: Tytuł szkolenia: PS/LINUX Programowanie systemowe w Linux Dni: 5 Opis: Adresaci szkolenia Szkolenie adresowane jest do programistów tworzących aplikacje w systemie Linux, którzy chcą poznać
Kod szkolenia: Tytuł szkolenia: PS/LINUX Programowanie systemowe w Linux Dni: 5 Opis: Adresaci szkolenia Szkolenie adresowane jest do programistów tworzących aplikacje w systemie Linux, którzy chcą poznać
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Nazwa przedmiotu: PROGRAMOWANIE WSPÓŁBIEŻNE I ROZPROSZONE I KARTA PRZEDMIOTU CEL PRZEDMIOTU PRZEWODNIK PO PRZEDMIOCIE C1. Uzyskanie przez studentów wiedzy na temat architektur systemów równoległych i rozproszonych,
Zaawansowane programowanie w języku C++
 Kod szkolenia: Tytuł szkolenia: C/ADV Zaawansowane programowanie w języku C++ Dni: 3 Opis: Uczestnicy szkolenia zapoznają się z metodami wytwarzania oprogramowania z użyciem zaawansowanych mechanizmów
Kod szkolenia: Tytuł szkolenia: C/ADV Zaawansowane programowanie w języku C++ Dni: 3 Opis: Uczestnicy szkolenia zapoznają się z metodami wytwarzania oprogramowania z użyciem zaawansowanych mechanizmów
Systemy na Chipie. Robert Czerwiński
 Systemy na Chipie Robert Czerwiński Cel kursu Celem kursu jest zapoznanie słuchaczy ze współczesnymi metodami projektowania cyfrowych układów specjalizowanych, ze szczególnym uwzględnieniem układów logiki
Systemy na Chipie Robert Czerwiński Cel kursu Celem kursu jest zapoznanie słuchaczy ze współczesnymi metodami projektowania cyfrowych układów specjalizowanych, ze szczególnym uwzględnieniem układów logiki
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Podsystem graficzny. W skład podsystemu graficznego wchodzą: karta graficzna monitor
 Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
Plan wykładu 1. Pojęcie podsystemu graficznego i karty graficznej 2. Typy kart graficznych 3. Budowa karty graficznej: procesor graficzny (GPU), pamięć podręczna RAM, konwerter cyfrowo-analogowy (DAC),
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM
 SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
SYSTEMY OPERACYJNE WYKŁAD 1 INTEGRACJA ZE SPRZĘTEM Marcin Tomana marcin@tomana.net SKRÓT WYKŁADU Zastosowania systemów operacyjnych Architektury sprzętowe i mikroprocesory Integracja systemu operacyjnego
Jak ujarzmić hydrę czyli programowanie równoległe w Javie. dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski
 Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Jak ujarzmić hydrę czyli programowanie równoległe w Javie dr hab. Piotr Bała, prof. UW ICM Uniwersytet Warszawski Prawo Moore a Ekonomicznie optymalna liczba tranzystorów w układzie scalonym zwiększa się
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
GRIDY OBLICZENIOWE. Piotr Majkowski
 GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
GRIDY OBLICZENIOWE Piotr Majkowski Wstęp Podział komputerów Co to jest grid? Różne sposoby patrzenia na grid Jak zmierzyć moc? Troszkę dokładniej o gridach Projekt EGEE Klasyfikacja Flynn a (1972) Instrukcje
Zagadnienia egzaminacyjne INFORMATYKA. stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Przetwarzanie wielowątkowe przetwarzanie współbieżne. Krzysztof Banaś Obliczenia równoległe 1
 Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Przetwarzanie wielowątkowe przetwarzanie współbieżne Krzysztof Banaś Obliczenia równoległe 1 Problemy współbieżności wyścig (race condition) synchronizacja realizowana sprzętowo (np. komputery macierzowe)
Technika mikroprocesorowa. Linia rozwojowa procesorów firmy Intel w latach
 mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
mikrokontrolery mikroprocesory Technika mikroprocesorowa Linia rozwojowa procesorów firmy Intel w latach 1970-2000 W krótkim pionierskim okresie firma Intel produkowała tylko mikroprocesory. W okresie
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu
 CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
CUDA Median Filter filtr medianowy wykorzystujący bibliotekę CUDA sprawozdanie z projektu inż. Daniel Solarz Wydział Fizyki i Informatyki Stosowanej AGH 1. Cel projektu. Celem projektu było napisanie wtyczki
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Przygotowanie kilku wersji kodu zgodnie z wymogami wersji zadania,
 Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Przetwarzanie równoległe PROJEKT OMP i CUDA Temat projektu dotyczy analizy efektywności przetwarzania równoległego realizowanego przy użyciu komputera równoległego z procesorem wielordzeniowym z pamięcią
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm
 Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
Wsparcie dla OpenMP w kompilatorze GNU GCC Krzysztof Lamorski Katedra Informatyki, PWSZ Chełm Streszczenie Tematem pracy jest standard OpenMP pozwalający na programowanie współbieŝne w systemach komputerowych
Zał nr 4 do ZW. Dla grupy kursów zaznaczyć kurs końcowy. Liczba punktów ECTS charakterze praktycznym (P)
") Zał nr 4 do ZW WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI KARTA PRZEDMIOTU Nazwa w języku polskim : Architektura Komputerów i Systemy Operacyjne Nazwa w języku angielskim : Computer Architecture and Operating
Zał nr 4 do ZW WYDZIAŁ PODSTAWOWYCH PROBLEMÓW TECHNIKI KARTA PRZEDMIOTU Nazwa w języku polskim : Architektura Komputerów i Systemy Operacyjne Nazwa w języku angielskim : Computer Architecture and Operating
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska
 Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska Zygmunt Kubiak 2 Centralny falownik (ang. central inverter system) Zygmunt Kubiak 3 Micro-Inverter Mikro-przetwornice działają podobnie do systemów
Zygmunt Kubiak Instytut Informatyki Politechnika Poznańska Zygmunt Kubiak 2 Centralny falownik (ang. central inverter system) Zygmunt Kubiak 3 Micro-Inverter Mikro-przetwornice działają podobnie do systemów
Układ wykonawczy, instrukcje i adresowanie. Dariusz Chaberski
 Układ wykonawczy, instrukcje i adresowanie Dariusz Chaberski System mikroprocesorowy mikroprocesor C A D A D pamięć programu C BIOS dekoder adresów A C 1 C 2 C 3 A D pamięć danych C pamięć operacyjna karta
Układ wykonawczy, instrukcje i adresowanie Dariusz Chaberski System mikroprocesorowy mikroprocesor C A D A D pamięć programu C BIOS dekoder adresów A C 1 C 2 C 3 A D pamięć danych C pamięć operacyjna karta
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Systemy operacyjne III
 Systemy operacyjne III Jan Kazimirski 1 Opis zajęć Prezentacja budowy i zasad działania współczesnego systemu operacyjnego Prezentacja podstawowych elementów systemów operacyjnych i zasad ich implementacji
Systemy operacyjne III Jan Kazimirski 1 Opis zajęć Prezentacja budowy i zasad działania współczesnego systemu operacyjnego Prezentacja podstawowych elementów systemów operacyjnych i zasad ich implementacji
MAGISTRALE ZEWNĘTRZNE, gniazda kart rozszerzeń, w istotnym stopniu wpływają na
 , gniazda kart rozszerzeń, w istotnym stopniu wpływają na wydajność systemu komputerowego, m.in. ze względu na fakt, że układy zewnętrzne montowane na tych kartach (zwłaszcza kontrolery dysków twardych,
, gniazda kart rozszerzeń, w istotnym stopniu wpływają na wydajność systemu komputerowego, m.in. ze względu na fakt, że układy zewnętrzne montowane na tych kartach (zwłaszcza kontrolery dysków twardych,
Wykład Ćwiczenia Laboratorium Projekt Seminarium
 WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
WYDZIAŁ ELEKTRONIKI KARTA PRZEDMIOTU Nazwa w języku polskim Języki programowania Nazwa w języku angielskim Programming languages Kierunek studiów (jeśli dotyczy): Informatyka - INF Specjalność (jeśli dotyczy):
Nowinki technologiczne procesorów
 Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Elbląg 22.04.2010 Nowinki technologiczne procesorów Przygotował: Radosław Kubryń VIII semestr PDBiOU 1 Spis treści 1. Wstęp 2. Intel Hyper-Threading 3. Enhanced Intel Speed Technology 4. Intel HD Graphics
Architektura systemów komputerowych. dr Artur Bartoszewski
 Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Architektura systemów komputerowych 1 dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat blokowy CPU 4. Architektura CISC i RISC 2 Jednostka arytmetyczno-logiczna 3 Schemat blokowy
Historia modeli programowania
 Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu
Języki Programowania na Platformie.NET http://kaims.eti.pg.edu.pl/ goluch/ goluch@eti.pg.edu.pl Maszyny z wbudowanym oprogramowaniem Maszyny z wbudowanym oprogramowaniem automatyczne rozwiązywanie problemu
Architektura systemów komputerowych
 Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
Studia stacjonarne inżynierskie, kierunek INFORMATYKA Architektura systemów komputerowych Architektura systemów komputerowych dr Artur Bartoszewski Procesor część I 1. ALU 2. Cykl rozkazowy 3. Schemat
Układ sterowania, magistrale i organizacja pamięci. Dariusz Chaberski
 Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
Układ sterowania, magistrale i organizacja pamięci Dariusz Chaberski Jednostka centralna szyna sygnałow sterowania sygnały sterujące układ sterowania sygnały stanu wewnętrzna szyna danych układ wykonawczy
1 Podstawowe definicje i pojęcia współbieżności
 J. Ułasiewicz Programowanie aplikacji współbieżnych 1 1 Podstawowe definicje i pojęcia współbieżności 1.1 Dlaczego zajmujemy się współbieżnością? W ciągu ostatnich 30 lat wzrost mocy przetwarzania osiągano
J. Ułasiewicz Programowanie aplikacji współbieżnych 1 1 Podstawowe definicje i pojęcia współbieżności 1.1 Dlaczego zajmujemy się współbieżnością? W ciągu ostatnich 30 lat wzrost mocy przetwarzania osiągano
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Architektura komputerów
 Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
Architektura komputerów Wykład 5 Jan Kazimirski 1 Podstawowe elementy komputera. Procesor (CPU) c.d. 2 Architektura CPU Jednostka arytmetyczno-logiczna (ALU) Rejestry Układ sterujący przebiegiem programu
INŻYNIERIA OPROGRAMOWANIA
 INSTYTUT INFORMATYKI STOSOWANEJ 2014 Nowy blok obieralny! Testowanie i zapewnianie jakości oprogramowania INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania
INSTYTUT INFORMATYKI STOSOWANEJ 2014 Nowy blok obieralny! Testowanie i zapewnianie jakości oprogramowania INŻYNIERIA OPROGRAMOWANIA Inżynieria Oprogramowania Proces ukierunkowany na wytworzenie oprogramowania
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia
 Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Kod modułu Język kształcenia Efekty kształcenia dla modułu kształcenia Wydział Matematyki i Informatyki Instytut Informatyki i
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Projektowanie i użytkowanie systemów operacyjnych Rok akademicki: 2013/2014 Kod: EAR-2-324-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek:
Nazwa modułu: Projektowanie i użytkowanie systemów operacyjnych Rok akademicki: 2013/2014 Kod: EAR-2-324-n Punkty ECTS: 5 Wydział: Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Kierunek:
Tesla. Architektura Fermi
 Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Tesla Architektura Fermi Tesla Tesla jest to General Purpose GPU (GPGPU), GPU ogólnego przeznaczenia Obliczenia dotychczas wykonywane na CPU przenoszone są na GPU Możliwości jakie daje GPU dla grafiki
Spis treúci. Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1. Przedmowa... 9. Wstęp... 11
 Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Księgarnia PWN: Krzysztof Wojtuszkiewicz - Urządzenia techniki komputerowej. Cz. 1 Spis treúci Przedmowa... 9 Wstęp... 11 1. Komputer PC od zewnątrz... 13 1.1. Elementy zestawu komputerowego... 13 1.2.
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Opracował: Jan Front
 Opracował: Jan Front Sterownik PLC PLC (Programowalny Sterownik Logiczny) (ang. Programmable Logic Controller) mikroprocesorowe urządzenie sterujące układami automatyki. PLC wykonuje w sposób cykliczny
Opracował: Jan Front Sterownik PLC PLC (Programowalny Sterownik Logiczny) (ang. Programmable Logic Controller) mikroprocesorowe urządzenie sterujące układami automatyki. PLC wykonuje w sposób cykliczny
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Procesory. Schemat budowy procesora
 Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
Procesory Procesor jednostka centralna (CPU Central Processing Unit) to sekwencyjne urządzenie cyfrowe którego zadaniem jest wykonywanie rozkazów i sterowanie pracą wszystkich pozostałych bloków systemu
MIKROKONTROLERY I MIKROPROCESORY
 PLAN... work in progress 1. Mikrokontrolery i mikroprocesory - architektura systemów mikroprocesorów ( 8051, AVR, ARM) - pamięci - rejestry - tryby adresowania - repertuar instrukcji - urządzenia we/wy
PLAN... work in progress 1. Mikrokontrolery i mikroprocesory - architektura systemów mikroprocesorów ( 8051, AVR, ARM) - pamięci - rejestry - tryby adresowania - repertuar instrukcji - urządzenia we/wy
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo