Wprowadzenie. Data Science Uczenie się pod nadzorem
|
|
|
- Roman Kruk
- 5 lat temu
- Przeglądów:
Transkrypt
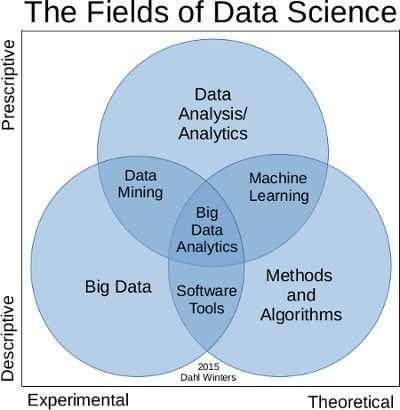
1 Wprowadzenie
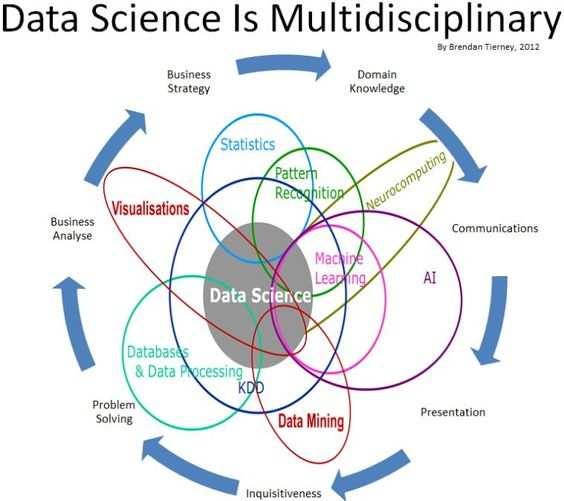
2 Wprowadzenie
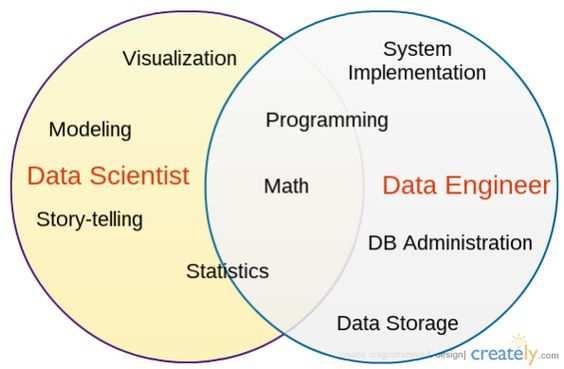
3 Wprowadzenie
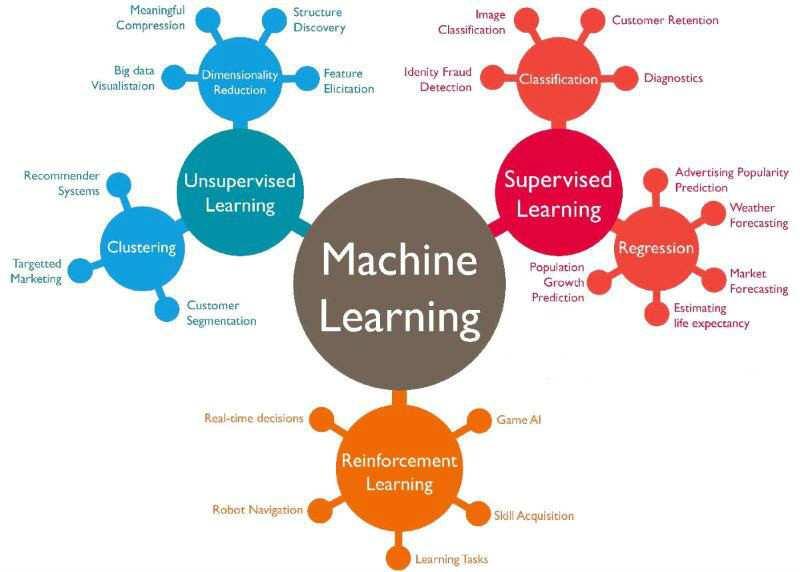
4 Wprowadzenie
5 Machine Learning Mind Map
6 Historia
7 Wstęp lub uczenie się z przykładów jest procesem budowy, na bazie dostępnych danych wejściowych X i oraz wyjściowych Y i, i = 1, 2,...,n, regułyklasyfikacyjnejzwanej inaczej klasyfikatorem, służącejdopredykcjietykietyy grupy, do której należy obserwacja X.
8 Wstęp Załóżmy, że dysponujemy K niezależnymi, prostymi próbami losowymi o liczebnościach, odpowiednio, n 1, n 2,...,n K,pobranymi z K różnych populacji (klas, grup): X 11, X 12,...,X 1n1 z populacji 1 X 21, X 22,...,X 2n2 z populacji 2 X K1, X K2,...,X KnK z populacji K, gdzie X ij =(X ij1, X ij2,...,x ijp ) jest j-tą obserwacją z i-tej populacji zawierającą p obserwowanych cech, i = 1, 2,...,K, j = 1, 2,...,n i.
9 Wstęp Powyższe dane można wygodniej zapisać w innej postaci, a mianowicie w postaci jednego ciągu n uporządkowanych par losowych (X 1, Y 1 ),...,(X n, Y n ), gdzie X i =(X i1, X i2,...,x ip ) X R p jest i-tą obserwacją, natomiast Y i jest etykietą populacji, do której ta obserwacja należy, przyjmującą wartości w pewnym skończonym zbiorze Y, i = 1, 2,...,n, n = n 1 + n n K. Składowe wektora X i =(X i1, X i2,...,x ip ) nazywać będziemy cechami, zmiennymi lub atrybutami. Próbę L n = {(X 1, Y 1 ),...,(X n, Y n )} nazywać będziemy próbą uczącą.
10 Wstęp Interesuje nas problem predykcji etykiety Y na podstawie wektora cech X. Problem ten nazywany jest klasyfikacją, dyskryminacją, uczeniem się pod nadzorem lub rozpoznawaniem wzorców. Reguła klasyfikacyjna, zwana krótko klasyfikatorem, jestfunkcją d : X Y.GdyobserwujemynowywektorX,toprognozą etykiety Y jest d(x ).
11 Wstęp Na poniższym rysunku pokazanych jest 20 punktów. Wektor cech X =(X 1, X 2 ) jest dwuwymiarowy a etykieta Y Y= {1, 0}. Wartości cechy X dla Y = 0reprezentowanesąprzeztrójkąty,a dla Y = 1przezkwadraty.Liniaprzerywanareprezentujeliniową regułę klasyfikacyjną postaci { 1, jeżeli a + b1 x d(x) = 1 + b 2 x 2 > 0, 0, poza tym. Każdy punkt leżący poniżej tej linii klasyfikowany jest do grupy o etykiecie 0 oraz każdy punkt leżący powyżej tej linii klasyfikowany jest do grupy o etykiecie 1.
12 Wstęp
13 Rzeczywisty poziom błędu Klasyczny problem klasyfikacji polega na predykcji nieznanej etykiety Y Y na podstawie wektora cech X X R p klasyfikowanego obiektu. Naszym celem jest znalezienie takiego klasyfikatora d : X Y,który daje dokładnąpredykcję. Miarą jakości klasyfikatora jest jego rzeczywisty poziom błędu. Definicja Rzeczywisty poziom błędu klasyfikatora d jest równy e(d) =P(d(X ) Y ). (1)
14 Klasyfikator bayesowski Weźmy wpierw pod uwagę przypadek dwóch klas, tj. gdy Y = {1, 0}. Wcelustworzeniamodeluklasyfikacjizałóżmy,że (X, Y ) jest parą losową o wartościach w R p {1, 0} oraz, że jej rozkład prawdopodobieństwa opisuje para (µ, r), gdzie µ jest miarą probabilistyczną wektora X oraz r jest regresją Y względem X. Bardziej precyzyjnie, dla zbioru A R p, oraz dla każdego x R p, µ(a) =P(X A) r(x) =E(Y X = x) =1 P(Y = 1 X = x)+0 P(Y = 0 X = x) = P(Y = 1 X = x) Zatem r(x) jest prawdopodobieństwem warunkowym, że Y = 1, gdy X = x. Rozkładprawdopodobieństwapary(X, Y ) wyznacza para (µ, r). Funkcja r(x) nazywa się prawdopodobieństwem a posteriori.
15 Klasyfikator bayesowski ZtwierdzeniaBayes amamy gdzie r(x) =P(Y = 1 X = x) f (x Y = 1)P(Y = 1) = f (x Y = 1)P(Y = 1)+f (x Y = 0)P(Y = 0) π 1 f 1 (x) = π 1 f 1 (x)+π 0 f 0 (x), π 1 = P(Y = 1), π 0 = P(Y = 0), π 1 + π 0 = 1 są prawdopodobieństwami a priori.
16 Klasyfikator bayesowski Definicja Klasyfikator postaci d B (x) = { 1, jeżeli r(x) > 1 2, 0, poza tym. nazywać będziemy klasyfikatorem bayesowskim
17 Klasyfikator bayesowski Klasyfikator bayesowski zapisać można w innych równoważnych postaciach: { 1, jeżeli P(Y = 1 X = x) > P(Y = 0 X = x), d B (x) = 0, poza tym. lub { 1, jeżeli π1 f d B (x) = 1 (x) >π 0 f 0 (x), 0, poza tym.
18 Klasyfikator bayesowski Twierdzenie Klasyfikator bayesowski jest optymalny, tj. jeżeli d jest jakimkolwiek innym klasyfikatorem, to e(d B ) e(d), gdziee(d) jest rzeczywistym poziomem błędu klasyfikatora d.
19 Aktualny poziom błędu Niestety, klasyfikator bayesowski zależy od rozkładu prawdopodobieństwa pary (X, Y ). Najczęściej rozkład ten nie jest znany i stąd również nie jest znany klasyfikator bayesowski d B. Pojawia się zatem problem skonstruowania klasyfikatora ˆd(x) = ˆd(x; L n ) opartego na próbie uczącej L n = {(X 1, Y 1 ),...,(X n, Y n )} zaobserwowanej w przeszłości. Proces konstruowania klasyfikatora ˆd nazywany jest uczeniem się, uczeniem pod nadzorem lub uczeniem się z nauczycielem. Chcemy znaleźć taki klasyfikator ˆd, dlaktóregoe( ˆd) jest bliskie e(d B ).Jednakżee( ˆd) jest zmienną losową, ponieważ zależy od losowej próby uczącej L n.
20 Aktualny poziom błędu Wnaszymmodeluklasyfikacyjnymzakładamy,żepróbaucząca L n = {(X 1, Y 1 ),...,(X n, Y n )} jest ciągiem niezależnych par losowych o identycznym rozkładzie prawdopodobieństwa takim, jak rozkład pary (X, Y ). Jakośćklasyfikatoraˆd mierzona jest za pomocą warunkowego prawdopodobieństwa błędu e( ˆd) =P( ˆd(X ) Y L n ), gdzie para losowa (X, Y ) jest niezależna od próby uczącej L n. Wielkość e( ˆd) nazywamy aktualnym poziomem błędu klasyfikatora. Chcemy znaleźć taki klasyfikator ˆd, dlaktóregoe( ˆd) jest bliskie e(d B ).Jednakżee( ˆd) jest zmienną losową, ponieważ zależy od losowej próby uczącej L n.
21 Estymacja aktualnego poziomu błędu Niech ˆd(x) = ˆd(x; L n ) oznacza klasyfikator skonstruowany przy pomocy próby uczącej L n.niechê ê( ˆd) oznacza ocenę aktualnego poziomu błędu klasyfikatora ˆd. Ocenętęnazywać będziemy błędem klasyfikacji. Wsytuacjach,kiedynapopulacje nie narzuca się żadnej konkretnej rodziny rozkładów, jedyną drogą oceny prawdopodobieństwa e( ˆd) jest użycie metod estymacji nieparamerycznej.
22 Estymacja aktualnego poziomu błędu Wnajlepszejsytuacjijesteśmywtedy,gdydysponujemy m-elementową próbą testową T m niezależną od próby uczącej L n. Niech zatem T m = {(X t 1, Y t 1 ),...,(X t m, Y t m)}. Wtedyza estymator aktualnego poziomu błędu klasyfikatora ˆd przyjmujemy: ê T = 1 m m j=1 I ( ˆd(X t j ; L n) Y t j ). Wprzypadkugdyniedysponujemyniezależnąpróbątestową,do estymacji używamy jedynie próby uczącej.
23 Estymacja aktualnego poziomu błędu Naturalną oceną aktualnego poziomu błędu jest wtedy wartość estymatora ponownego podstawienia (resubstytucji) ê R = 1 n n I ( ˆd(X j ; L n ) Y j ). j=1 Wartość tego estymatora uzyskuje się poprzez klasyfikację regułą ˆd tych samych obserwacji, które służyły do jej konstrukcji. Oznacza to, iż próba ucząca jest zarazem próbą testową. Estymator ten jest więc obciążonym estymatorem wielkości e( ˆd) i zaniża jej rzeczywistą wartość. Uwidacznia się to szczególnie w przypadku złożonych klasyfikatorów opartych na relatywnie małych próbach uczących. Redukcję obciążenia można uzyskać stosując poniższe metody estymacji.
24 Estymacja aktualnego poziomu błędu Jednym ze sposobów redukcji obciążenia estymatora ê R jest tzw. metoda podziału próby na dwa podzbiory: próbę uczącą ipróbętestową. Wówczasklasyfikatorkonstruujesięzapomocą pierwszego z nich, drugi natomiast służy do konstrukcji estymatora. Wykorzystanie tylko części informacji w celu uzyskania reguły klasyfikacyjnej prowadzi jednak często do zawyżenia wartości estymatora błędu. Rozwiązaniem tego problemu jest metoda sprawdzania krzyżowego. Oznaczmy przez L ( j) n próbę uczącą L n zktórejusunięto obserwację Z j =(X j, Y j ).Klasyfikatorkonstruujesię wykorzystując próbę L ( j) n,anastępnietestujesięgona pojedynczej obserwacji Z j.czynnośćtępowtarzasięn razy, dla każdej obserwacji Z j zosobna.odpowiedniestymatormapostać: ê CV = 1 n n j=1 I ( ˆd(X j ; L ( j) n ) Y j ).
25 Estymacja aktualnego poziomu błędu Procedura ta w każdym z n etapów jest w rzeczywistości metodą podziału próby dla przypadku jednoelementowego zbioru testowego. Każda obserwacja próby jest użyta do konstrukcji klasyfikatora ˆd. Każdaznichjestteż(dokładniejedenraz) elementem testowym. Estymator ten, choć granicznie nieobciążony, ma większą wariancję. Ponadto wymaga on konstrukcji n klasyfikatorów, co dla dużych n oznacza znaczący wzrost obliczeń. Rozwiązaniem pośrednim jest metoda rotacyjna, zwana często v-krokową metodą sprawdzania krzyżowego. Polegaonanalosowympodzialepróby na v podzbiorów, przy czym v 1znichtworzypróbęuczącą, natomiast pozostały próbę testową. Procedurę tę powtarza się v razy, dla każdego podzbioru rozpatrywanego kolejno jako zbiór testowy.

26 Estymacja aktualnego poziomu błędu
27 Estymacja aktualnego poziomu błędu Odpowiedni estymator jest postaci: ê vcv = 1 n v n i=1 j=1 I (Z j L (i) n )I ( ˆd(X j ; L ( i) n ) Y j ), gdzie L (1) n, L (2) n,..., L (v) n jest losowym v-podziałem próby L n na równoliczne podzbiory, a L ( i) n = L n \ L (i) n, i = 1, 2,...,v.
28 Estymacja aktualnego poziomu błędu Metoda ta daje mniejsze obciążenie błędu niż metoda podziału próby i wymaga mniejszej liczby obliczeń w porównaniu ze sprawdzaniem krzyżowym (jeśli tylko v < n). W zagadnieniu estymacji aktualnego poziomu błędu zalecane jest obranie wartości v = 10. Metoda sprawdzania krzyżowego jest powszechnie wykorzystywana w zagadnieniu wyboru modelu. Z rodziny klasyfikatorów opisanej parametrycznie wybieramy wtedy klasyfikator, dla którego błąd klasyfikacji ma wartość najmniejszą.
29 Estymacja aktualnego poziomu błędu Definicja Próbą bootstrapową nazywamy próbę n-elementową pobraną z n-elementowej próby uczącej w procesie n-krotnego losowania pojedynczych obserwacji ze zwracaniem. Niech L 1 n, L 2 n,...,l B n będzie ciągiem kolejno pobranych B prób bootstrapowych. Bootstrapowa ocena aktualnego poziomu błędu ma postać ê B = 1 B B b=1 n j=1 I (Z j L b n )I ( ˆd(X j ; L b n ) Y j ) n j=1 I (Z j L b n ). Widać, że powyższa ocena aktualnego poziomu błędu jest uzyskana metodą sprawdzania krzyżowego zastosowaną do prób bootstrapowych.
30 Estymacja aktualnego poziomu błędu Wceludalszejredukcjiobciążeniategoestymatorazaproponowano estymator postaci: ê.632 = 0,368 ê R + 0,632 ê B. Waga 0,368 jest przybliżoną wartością wielkości e 1 =lim n (1 1/n) n,ijestgranicznąwartością prawdopodobieństwa nie wylosowania obserwacji z próby uczącej do próby bootstrapowej.
31 Macierz pomyłek Sam błąd klasyfikacji nie wystarczy aby stwierdzić, czy klasyfikator działa dobrze. Po zakonczeniu procedury oceny błędu klasyfikacji naszego modelu zostajemy z lista obserwacji testowych, gdzie dla kazdej z nich znamy klasę obserwowaną oraz klasę przewidywaną przez nasz model. Zliczając liczbe przypadkow dla kazdej z kombinacji tych dwóch klas (obserwowanej i przewidywanej) możemy stworzyć tzw. macierz pomyłek (ang. confusion matrix). Możemy na jej podstawie ocenić błąd modelu: musimy zsumować wartości na głównej przekątnej (obserwacje poprawnie rozpoznane) ipodzielićjeprzezliczbęwszystkichobserwacjitestowych.

32 Przeuczenie i niedouczenie modelu
33 ZeroR najprostszy klasyfikator Algorytm ZeroR (Zero Rule) ignoruje wszystkie cechy, oprócz etykiet. Na ich podstawie, sprawdza najczęściej występującą klasę i tworzy klasyfikator który zawsze będzie ją zwracać. Zatem algorytm ZeroR zawsze przypisuje nowe obserwacje do tej samej klasy (klasy większościowej), niezależnie od wartości cech.

34 OneR Algorytm OneR (One Rule) jest tylko nieco bardziej wyrafinowany niz ZeroR. Podczas gdy ZeroR ignoruje wszystkie cechy, OneR wybiera tylko jedną i ignoruje pozostałe. Wybierając najlepszą cechę sprawdza on błąd na danych uczących dla klasyfikatorow zbudowanych na kazdej z cech osobno i wybiera tą z nich, która minimalizuje błąd. Dla każdej cechy dzieli on dane uczące na podzbiory ze względu na wartość tej cechy. Następnie, na każdym znichużywaalgorytmuzeror.pokazano,żepomimoprostotyjest to metoda jedynie nieznacznie ustępująca najlepszym klasyfikatorom. R.C. Holte. (1993). Very simple classification rules perform well on most commonly used datasets. MachineLearning 11(1):63 90.
35 OneR Day Outlook Temperature Humidity PlayTennis D1 sunny hot high NO D2 sunny hot high NO D3 overcast hot high YES D4 overcast hot normal YES D5 rain mild high NO Skonstruujmy klasyfikatory dla różnych atrybutów: Outlook YES NO trafność sunny 0 2 5/5 = 100% overcast 2 0 rain 0 1 Temperature YES NO trafność hot 2 2 3/5 = 60% mild 0 1 Humidity YES NO trafność high 1 3 4/5 = 80% normal 1 0 Jak widzimy, najwyższą trafność osiągamy korzystając z atrybutu Outlook. Algorytm stworzy więc następujący klasyfikator: IF Outlook = sunny THEN PlayTennis = NO IF Outlook = overcast THEN PlayTennis = YES IF Outook = rain THEN PlayTennis = NO
Wprowadzenie. { 1, jeżeli ˆr(x) > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne
 > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne") Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Prawdopodobieństwo i statystyka
 Wykład VIII: Przestrzenie statystyczne. Estymatory 1 grudnia 2014 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji r(x, Z) = 0, 986 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji
Wykład VIII: Przestrzenie statystyczne. Estymatory 1 grudnia 2014 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji r(x, Z) = 0, 986 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Regresyjne metody łączenia klasyfikatorów
 Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
Regresyjne metody łączenia klasyfikatorów Tomasz Górecki, Mirosław Krzyśko Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza XXXV Konferencja Statystyka Matematyczna Wisła 7-11.12.2009
Wprowadzenie. Metody bayesowskie Drzewa klasyfikacyjne i lasy losowe Sieci neuronowe SVM. Klasyfikacja. Wstęp
 Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Drzewa klasyfikacyjne Lasy losowe. Wprowadzenie
 Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Wprowadzenie Konstrukcja binarnych drzew klasyfikacyjnych polega na sekwencyjnym dzieleniu podzbiorów przestrzeni próby X na dwa rozłączne i dopełniające się podzbiory, rozpoczynając od całego zbioru X.
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak
 Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak 1 Wprowadzenie. Zmienne losowe Podczas kursu interesować nas będzie wnioskowanie o rozpatrywanym zjawisku. Poprzez wnioskowanie rozumiemy
Wstęp do Metod Systemowych i Decyzyjnych Opracowanie: Jakub Tomczak 1 Wprowadzenie. Zmienne losowe Podczas kursu interesować nas będzie wnioskowanie o rozpatrywanym zjawisku. Poprzez wnioskowanie rozumiemy
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Metody systemowe i decyzyjne w informatyce Laboratorium JAVA Zadanie nr 2 Rozpoznawanie liter autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z problemem klasyfikacji
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
WYKŁAD 4. Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie. autor: Maciej Zięba. Politechnika Wrocławska
 Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Wrocław University of Technology WYKŁAD 4 Podejmowanie decyzji dla modeli probabilistycznych Modelowanie Gaussowskie autor: Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification):
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap
 Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Wykład 1 Próba i populacja. Estymacja parametrów z wykorzystaniem metody bootstrap Magdalena Frąszczak Wrocław, 21.02.2018r Tematyka Wykładów: Próba i populacja. Estymacja parametrów z wykorzystaniem metody
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH
 Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX = 4 i EY = 6. Rozważamy zmienną losową Z =.
 Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 3 Metody estymacji. Estymator największej wiarygodności Zad. 1 Pojawianie się spamu opisane jest zmienną losową y o rozkładzie zero-jedynkowym
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Rozkłady statystyk z próby. Statystyka
 Rozkłady statystyk z próby tatystyka Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających ten
Rozkłady statystyk z próby tatystyka Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających ten
Estymacja parametrów w modelu normalnym
 Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Estymacja parametrów w modelu normalnym dr Mariusz Grządziel 6 kwietnia 2009 Model normalny Przez model normalny będziemy rozumieć rodzine rozkładów normalnych N(µ, σ), µ R, σ > 0. Z Centralnego Twierdzenia
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Jądrowe klasyfikatory liniowe
 Jądrowe klasyfikatory liniowe Waldemar Wołyński Wydział Matematyki i Informatyki UAM Poznań Wisła, 9 grudnia 2009 Waldemar Wołyński () Jądrowe klasyfikatory liniowe Wisła, 9 grudnia 2009 1 / 19 Zagadnienie
Jądrowe klasyfikatory liniowe Waldemar Wołyński Wydział Matematyki i Informatyki UAM Poznań Wisła, 9 grudnia 2009 Waldemar Wołyński () Jądrowe klasyfikatory liniowe Wisła, 9 grudnia 2009 1 / 19 Zagadnienie
LABORATORIUM Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz.
 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz.") LABORATORIUM 4 1. Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz. I) WNIOSKOWANIE STATYSTYCZNE (STATISTICAL INFERENCE) Populacja
LABORATORIUM 4 1. Populacja Generalna (PG) 2. Próba (P n ) 3. Kryterium 3σ 4. Błąd Średniej Arytmetycznej 5. Estymatory 6. Teoria Estymacji (cz. I) WNIOSKOWANIE STATYSTYCZNE (STATISTICAL INFERENCE) Populacja
Metody probabilistyczne
 Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Metody probabilistyczne 13. Elementy statystki matematycznej I Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 17.01.2019 1 / 30 Zagadnienia statystki Przeprowadzamy
Metoda reprezentacyjna
 Metoda reprezentacyjna Stanisław Jaworski Katedra Ekonometrii i Statystyki Zakład Statystyki Populacja, cecha, parametr, próba Metoda reprezentacyjna Przedmiotem rozważań metody reprezentacyjnej są metody
Metoda reprezentacyjna Stanisław Jaworski Katedra Ekonometrii i Statystyki Zakład Statystyki Populacja, cecha, parametr, próba Metoda reprezentacyjna Przedmiotem rozważań metody reprezentacyjnej są metody
Statystyka i eksploracja danych
 Wykład II: i charakterystyki ich rozkładów 24 lutego 2014 Wartość oczekiwana Dystrybuanty Słowniczek teorii prawdopodobieństwa, cz. II Wartość oczekiwana Dystrybuanty Słowniczek teorii prawdopodobieństwa,
Wykład II: i charakterystyki ich rozkładów 24 lutego 2014 Wartość oczekiwana Dystrybuanty Słowniczek teorii prawdopodobieństwa, cz. II Wartość oczekiwana Dystrybuanty Słowniczek teorii prawdopodobieństwa,
Wykład 4. Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym. 2. Rozkłady próbkowe. 3. Centralne twierdzenie graniczne
 Wykład 4 Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym 2. Rozkłady próbkowe 3. Centralne twierdzenie graniczne Przybliżenie rozkładu dwumianowego rozkładem normalnym Niech Y ma rozkład
Wykład 4 Plan: 1. Aproksymacja rozkładu dwumianowego rozkładem normalnym 2. Rozkłady próbkowe 3. Centralne twierdzenie graniczne Przybliżenie rozkładu dwumianowego rozkładem normalnym Niech Y ma rozkład
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Indukowane Reguły Decyzyjne I. Wykład 3
 Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
Indukowane Reguły Decyzyjne I Wykład 3 IRD Wykład 3 Plan Powtórka Grafy Drzewa klasyfikacyjne Testy wstęp Klasyfikacja obiektów z wykorzystaniem drzewa Reguły decyzyjne generowane przez drzewo 2 Powtórzenie
STATYSTYKA wykład 5-6
 TATYTYKA wykład 5-6 Twierdzenia graniczne Rozkłady statystyk z próby Wanda Olech Twierdzenia graniczne Jeżeli rozpatrujemy ciąg zmiennych losowych {X ; X ;...; X n }, to zdarza się, że ich rozkłady przy
TATYTYKA wykład 5-6 Twierdzenia graniczne Rozkłady statystyk z próby Wanda Olech Twierdzenia graniczne Jeżeli rozpatrujemy ciąg zmiennych losowych {X ; X ;...; X n }, to zdarza się, że ich rozkłady przy
Dokładne i graniczne rozkłady statystyk z próby
 Dokładne i graniczne rozkłady statystyk z próby Przypomnijmy Populacja Próba Wielkość N n Średnia Wariancja Odchylenie standardowe 4.2 Rozkład statystyki Mówimy, że rozkład statystyki (1) jest dokładny,
Dokładne i graniczne rozkłady statystyk z próby Przypomnijmy Populacja Próba Wielkość N n Średnia Wariancja Odchylenie standardowe 4.2 Rozkład statystyki Mówimy, że rozkład statystyki (1) jest dokładny,
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Na A (n) rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)
 rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)") MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
WYKŁAD 8 ANALIZA REGRESJI
 WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
WYKŁAD 8 ANALIZA REGRESJI Regresja 1. Metoda najmniejszych kwadratów-regresja prostoliniowa 2. Regresja krzywoliniowa 3. Estymacja liniowej funkcji regresji 4. Testy istotności współczynnika regresji liniowej
Estymacja przedziałowa - przedziały ufności dla średnich. Wrocław, 5 grudnia 2014
 Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
Estymacja przedziałowa - przedziały ufności dla średnich Wrocław, 5 grudnia 2014 Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja Przedziałem ufności dla paramertu
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Ważne rozkłady i twierdzenia c.d.
 Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Ważne rozkłady i twierdzenia c.d. Funkcja charakterystyczna rozkładu Wielowymiarowy rozkład normalny Elipsa kowariacji Sploty rozkładów Rozkłady jednostajne Sploty z rozkładem normalnym Pobieranie próby
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
5. Analiza dyskryminacyjna: FLD, LDA, QDA
 Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
Algorytmy rozpoznawania obrazów 5. Analiza dyskryminacyjna: FLD, LDA, QDA dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Liniowe funkcje dyskryminacyjne Liniowe funkcje dyskryminacyjne mają ogólną
STATYSTYKA MATEMATYCZNA WYKŁAD stycznia 2010
 STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Komputerowa analiza danych doświadczalnych
 Komputerowa analiza danych doświadczalnych Wykład 9 27.04.2018 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 2017/2018 Metoda największej wiarygodności ierównosć informacyjna
Komputerowa analiza danych doświadczalnych Wykład 9 27.04.2018 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 2017/2018 Metoda największej wiarygodności ierównosć informacyjna
... i statystyka testowa przyjmuje wartość..., zatem ODRZUCAMY /NIE MA POD- STAW DO ODRZUCENIA HIPOTEZY H 0 (właściwe podkreślić).
.") Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Egzamin ze Statystyki Matematycznej, WNE UW, wrzesień 016, zestaw B Odpowiedzi i szkice rozwiązań 1. Zbadano koszt 7 noclegów dla 4-osobowej rodziny (kwatery) nad morzem w sezonie letnim 014 i 015. Wylosowano
Zagadnienie klasyfikacji (dyskryminacji)
") Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Zagadnienie klasyfikacji (dyskryminacji) Przykład Bank chce klasyfikować klientów starających się o pożyczkę do jednej z dwóch grup: niskiego ryzyka (spłacających pożyczki terminowo) lub wysokiego ryzyka
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średn
 Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
Wykład 10 Estymacja przedziałowa - przedziały ufności dla średniej Wrocław, 21 grudnia 2016r Przedział ufności Niech będzie dana próba X 1, X 2,..., X n z rozkładu P θ, θ Θ. Definicja 10.1 Przedziałem
STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE
 1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori.
 Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
Analiza danych Reguły decyzyjne, algorytm AQ i CN2. Reguły asocjacyjne, algorytm Apriori. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ REGUŁY DECYZYJNE Metoda reprezentacji wiedzy (modelowania
), którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0
, którą będziemy uważać za prawdziwą jeżeli okaże się, że hipoteza H 0") Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Testowanie hipotez Każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy nazywamy hipotezą statystyczną. Hipoteza określająca jedynie wartości nieznanych parametrów liczbowych badanej cechy
Biostatystyka, # 3 /Weterynaria I/
 Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu liniowym, scenariusz p bliskie lub większe od n
 Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu iowym, scenariusz p bliskie lub większe od n Przemyslaw.Biecek@gmail.com, MIM Uniwersytet Warszawski Plan prezentacji: 1 Motywacja;
Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu iowym, scenariusz p bliskie lub większe od n Przemyslaw.Biecek@gmail.com, MIM Uniwersytet Warszawski Plan prezentacji: 1 Motywacja;
Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału.
 Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału Wiktor Miszuris 2 czerwca 2004 Przepustowość kanału Zacznijmy od wprowadzenia równości IA, B HB HB A HA HA B Można ją intuicyjnie
Przepustowość kanału, odczytywanie wiadomości z kanału, poprawa wydajności kanału Wiktor Miszuris 2 czerwca 2004 Przepustowość kanału Zacznijmy od wprowadzenia równości IA, B HB HB A HA HA B Można ją intuicyjnie
WYKŁAD 3. Klasyfikacja: modele probabilistyczne
 Wrocław University of Technology WYKŁAD 3 Klasyfikacja: modele probabilistyczne Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification): Dysponujemy obserwacjami z etykietami
Wrocław University of Technology WYKŁAD 3 Klasyfikacja: modele probabilistyczne Maciej Zięba Politechnika Wrocławska Klasyfikacja Klasyfikacja (ang. Classification): Dysponujemy obserwacjami z etykietami
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Prawdopodobieństwo i statystyka
 Wykład IV: 27 października 2014 Współczynnik korelacji Brak korelacji a niezależność Definicja współczynnika korelacji Współczynnikiem korelacji całkowalnych z kwadratem zmiennych losowych X i Y nazywamy
Wykład IV: 27 października 2014 Współczynnik korelacji Brak korelacji a niezależność Definicja współczynnika korelacji Współczynnikiem korelacji całkowalnych z kwadratem zmiennych losowych X i Y nazywamy
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
Podstawowe modele probabilistyczne
 Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Wrocław University of Technology Podstawowe modele probabilistyczne Maciej Zięba maciej.zieba@pwr.edu.pl Rozpoznawanie Obrazów, Lato 2018/2019 Pojęcie prawdopodobieństwa Prawdopodobieństwo reprezentuje
Stan dotychczasowy. OCENA KLASYFIKACJI w diagnostyce. Metody 6/10/2013. Weryfikacja. Testowanie skuteczności metody uczenia Weryfikacja prosta
 Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Stan dotychczasowy OCENA KLASYFIKACJI w diagnostyce Wybraliśmy metodę uczenia maszynowego (np. sieć neuronowa lub drzewo decyzyjne), która będzie klasyfikować nieznane przypadki Na podzbiorze dostępnych
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji ML Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
1 Klasyfikator bayesowski
 Klasyfikator bayesowski Załóżmy, że dane są prawdopodobieństwa przynależności do klasp( ),P( 2 ),...,P( L ) przykładów z pewnego zadania klasyfikacji, jak również gęstości rozkładów prawdopodobieństw wystąpienia
Klasyfikator bayesowski Załóżmy, że dane są prawdopodobieństwa przynależności do klasp( ),P( 2 ),...,P( L ) przykładów z pewnego zadania klasyfikacji, jak również gęstości rozkładów prawdopodobieństw wystąpienia
STATYSTYKA wykład 1. Wanda Olech. Katedra Genetyki i Ogólnej Hodowli Zwierząt
 STTYSTYK wykład 1 Wanda Olech Katedra Genetyki i Ogólnej Hodowli Zwierząt Plan wykładów Data WYKŁDY 1.X rachunek prawdopodobieństwa; 8.X zmienna losowa jednowymiarowa, funkcja rozkładu, dystrybuanta 15.X
STTYSTYK wykład 1 Wanda Olech Katedra Genetyki i Ogólnej Hodowli Zwierząt Plan wykładów Data WYKŁDY 1.X rachunek prawdopodobieństwa; 8.X zmienna losowa jednowymiarowa, funkcja rozkładu, dystrybuanta 15.X
Komputerowa analiza danych doświadczalnych
 Komputerowa analiza danych doświadczalnych Wykład 9 7.04.09 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 08/09 Metoda największej wiarygodności ierównosć informacyjna Metoda
Komputerowa analiza danych doświadczalnych Wykład 9 7.04.09 dr inż. Łukasz Graczykowski lukasz.graczykowski@pw.edu.pl Semestr letni 08/09 Metoda największej wiarygodności ierównosć informacyjna Metoda
Podstawy metod probabilistycznych. dr Adam Kiersztyn
 Podstawy metod probabilistycznych dr Adam Kiersztyn Przestrzeń zdarzeń elementarnych i zdarzenia losowe. Zjawiskiem lub doświadczeniem losowym nazywamy taki proces, którego przebiegu i ostatecznego wyniku
Podstawy metod probabilistycznych dr Adam Kiersztyn Przestrzeń zdarzeń elementarnych i zdarzenia losowe. Zjawiskiem lub doświadczeniem losowym nazywamy taki proces, którego przebiegu i ostatecznego wyniku
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne
 WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
WYKŁAD 11 Uczenie maszynowe drzewa decyzyjne Reprezentacja wiedzy w postaci drzew decyzyjnych entropia, przyrost informacji algorytmy ID3, C4.5 problem przeuczenia wyznaczanie reguł rzykładowe drzewo decyzyjne
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotn. istotności, p-wartość i moc testu
 Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
Metody Sztucznej Inteligencji II
 17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Prawdopodobieństwo i statystyka
 Wykład XIII: Prognoza. 26 stycznia 2015 Wykład XIII: Prognoza. Prognoza (predykcja) Przypuśćmy, że mamy dany ciąg liczb x 1, x 2,..., x n, stanowiących wyniki pomiaru pewnej zmiennej w czasie wielkości
Wykład XIII: Prognoza. 26 stycznia 2015 Wykład XIII: Prognoza. Prognoza (predykcja) Przypuśćmy, że mamy dany ciąg liczb x 1, x 2,..., x n, stanowiących wyniki pomiaru pewnej zmiennej w czasie wielkości
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
1.1 Wstęp Literatura... 1
 Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
Spis treści Spis treści 1 Wstęp 1 1.1 Wstęp................................ 1 1.2 Literatura.............................. 1 2 Elementy rachunku prawdopodobieństwa 2 2.1 Podstawy..............................
Centralne twierdzenie graniczne
 Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 4 Ważne uzupełnienie Dwuwymiarowy rozkład normalny N (µ X, µ Y, σ X, σ Y, ρ): f XY (x, y) = 1 2πσ X σ Y 1 ρ 2 { [ (x ) 1
Instytut Sterowania i Systemów Informatycznych Universytet Zielonogórski Wykład 4 Ważne uzupełnienie Dwuwymiarowy rozkład normalny N (µ X, µ Y, σ X, σ Y, ρ): f XY (x, y) = 1 2πσ X σ Y 1 ρ 2 { [ (x ) 1
WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ
 WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ Dana jest populacja generalna, w której dwuwymiarowa cecha (zmienna losowa) (X, Y ) ma pewien dwuwymiarowy rozk lad. Miara korelacji liniowej dla zmiennych (X, Y
WNIOSKOWANIE W MODELU REGRESJI LINIOWEJ Dana jest populacja generalna, w której dwuwymiarowa cecha (zmienna losowa) (X, Y ) ma pewien dwuwymiarowy rozk lad. Miara korelacji liniowej dla zmiennych (X, Y
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ