Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
|
|
|
- Franciszek Stankiewicz
- 6 lat temu
- Przeglądów:
Transkrypt
1 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora. Przy ocenie wartości atrybutu kierować można się empiryczną oceną jakości działania konkretnego klasyfikatora, który wykorzystuje dany atrybut, a raczej cały zestaw atrybutów. Istnieją dwa główne podejścia: a.) Forward selection - dodawaj kolejne atrybuty jeśli ich dodanie poprawia działanie klasyfikatora danego typu b.) Backward elimination - usuwaj po kolei kolejne atrybuty, i akceptuj usunięcie, jeśli wytrenowany na pozostających atrybutach klasyfikator danego typu poprawia się / nie pogarsza swojego działania Porównaj działanie tych dwóch operatorów. Wykorzystują one wewnętrzny operator walidacji (kros- lub splitwalidacja) jako sposób oceny aktualnie wybranego zestawu atrybutów. Charakter przeszukiwania przestrzeni wszystkich możliwych podzbiorów atrybutów pozwala stwierdzić, że oba te algorytmy (forward i backward) są przykładami optymalizacji zachłannej. Metody takie charakteryzują się tym, że kolejne rozwiązania generowane są przez stosunkowo niewielkie modyfikacje aktualnego rozwiązania. Otrzymane nowe rozwiązanie jest akceptowane jeśli jest lepsze od aktualnego. Jako że ocena każdego kolejnego rozważanego podzbioru atrybutów wymaga wykonania np. kroswalidacji, metoda ta może szybko stać się wymagająca obliczeniowo. Z drugiej strony, zestaw atrybutów jest optymalizowany pod kątem konkretnego modelu klasyfikacyjnego. Jako metodę ewaluacji użyjemy 10-krotnej kroswalidacji dla naiwnego klasyfikatora Bayesa, który jest stosunkowo szybkim modelem klasyfikacyjnym, co ma tu duże znaczenie. 1
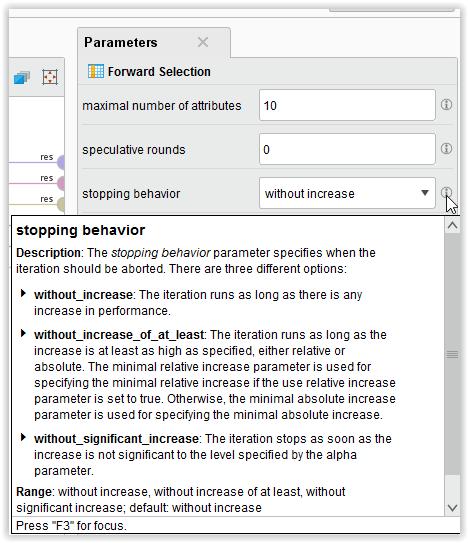
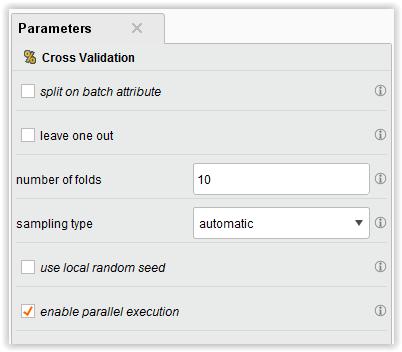
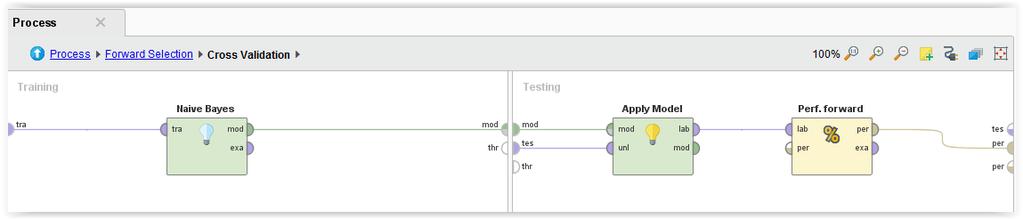
2 Dla ForwardSelection : 2

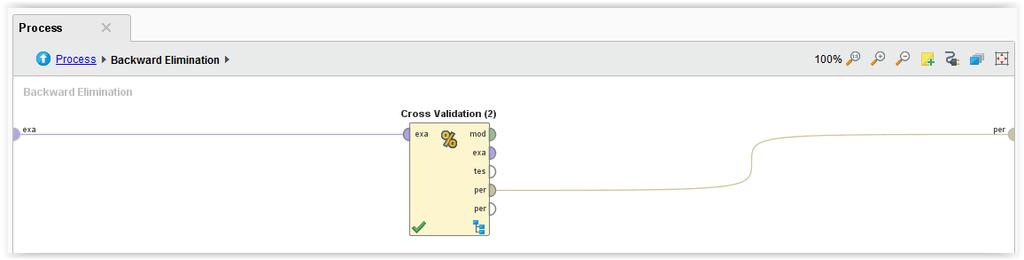
3 Dla Backward Elimination : 3


4 Przykładowe wyniki osiągnięte przez obie metody: Dla ForwardSelection: Dla BackwardElimination: Przykładowe wybrane atrybuty: Dla ForwardSelection : / Dla Backward Elimination : Jak widać, wyniki są zbliżone, jednak metody różnią się wybranym zestawem atrybutów. Czy metody te poprawiają działanie modelu w stosunku do sytuacji, gdy wszystkie atrybuty zostały użyte? Wykonaj poniższy projekt. 4
. Obu metodom udało się pozbyć części atrybutów i zachować średnią jakość działania.")
5 Przykładowe wyniki dla naiwnego klasyfikatora Bayesa z wykorzystaniem wszystkich atrybutów: Średnia jest niższa niż dla Forward oraz Backward, jednak według testu ANOVA, nie ma podstaw by twierdzić, że różnice są znaczące (Prob=0.519 > 0.05). Obu metodom udało się pozbyć części atrybutów i zachować średnią jakość działania. 5

6 Uwaga: Użycie wymagającego obliczeniowo klasyfikatora (np. sieci neuronowej) jako bazowego modelu dla metod forward oraz backward, może być zbyt wymagające i czasochłonne. Można jednak próbować użyć szybszego modelu w środku operatora forward i backward, a zoptymalizowane przez te metody zestawy atrybutów użyć do trenowania wolniejszego klasyfikatora. Liczymy przy tym, że zestaw atrybutów, który dobrze działał dla np. naiwnego klasyfikatora Bayesa, będzie również całkiem niezły dla np. sieci neuronowej. Wypróbuj poniższe podejście dla bazy ionosphery. W trzech widocznych operatorach kroswalidacji używamy sieci neuronowej 6
.")


7 natomiast w operatorach forward i backward, używamy kroswalidacji, ale z naiwnym klasyfikatorem Bayesa (szybki klasyfikator). Aby przyspieszyć obliczenia, można spróbować użyć splitwalidacji zamiast kroswalidacji. Należy jednak pamiętać, że oszacowanie kroswalidacyjne jest ogólnie dokładniejsze. Przykładowe wyniki sieci neuronowej: Dla wszystkich atrybutów: Dla ForwardSelection: Dla BackwardElimination: 7

8 Wyniki testu ANOVA: Według testu ANOVA, różnice nie są znaczące, nawet spadek do 88% dla metody forward nie jest statystycznie istotny. Ile atrybutów usunęły metody forward oraz backward w tym przypadku? Przypomnijmy, że w bazie ionosphere są 33 atrybuty + 1 atrybut klasy. Atrybuty wybrane (podgląd): Forward (4 wybrane) / Backward (3 odrzucone) Biorąc pod uwagę, że różnice nie są statystycznie istotne, metoda forward zadziałała tu bardzo dobrze. 8

9 Uwaga: Kosztem zwiększenia ilości obliczeń, można skorzystać z opcji speculative rounds. Pozwala to kontynuować obliczenia metodom forward oraz backward, mimo braku poprawy przez kilka dodatkowych iteracji. Czasami pozwala to algorytmowi uciec z tzw. lokalnego minimum. 9
 oraz Optimize Weights (Backward) do bazy sonar.")
10 Generowanie wag atrybutów za pomocą metod ForwardSelection oraz BackwardElimination Podobne procedury mogą być wykorzystane do generowania wag atrybutów. Przykładowo, wypróbuj operatory Optimize Weights (Forward) oraz Optimize Weights (Backward) do bazy sonar. Operatory te również wymagają zdefiniowania podprocesu (w tym przykładzie jest to kroswalidacja z klasyfikatorem k-nn). Z dokumentacji RMS: Synopsis This operator calculates the relevance of the attributes of the given ExampleSet by calculating the attribute weights. This operator assumes that the attributes are independent and optimizes the weights of the attributes with a linear search. 10
11 Przykładowe wagi otrzymane z tych operatorów: Forward / Backward Sposób postępowania z tak otrzymanymi wagami jest taki sam jak w przypadku wag otrzymanych z metod wykorzystujących analizę korelacji omawianych na poprzednim laboratorium. 11
12 Zadanie Wykorzystując poznane metody wyboru atrybutów oraz optymalizacji parametrów algorytmów, zaprojektuj jak najlepszy (dobre wyniki klasyfikacji i jak najmniej atrybutów) klasyfikator SVM dla bazy messidor (ostatnia kolumna jest etykietą klasy). 12
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Metody klasyfikacji i rozpoznawania wzorców. Najważniejsze rodzaje klasyfikatorów
 Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Zadania laboratoryjne i projektowe - wersja β
 Zadania laboratoryjne i projektowe - wersja β 1 Laboratorium Dwa problemy do wyboru (jeden do realizacji). 1. Water Jug Problem, 2. Wieże Hanoi. Water Jug Problem Ograniczenia dla każdej z wersji: pojemniki
Zadania laboratoryjne i projektowe - wersja β 1 Laboratorium Dwa problemy do wyboru (jeden do realizacji). 1. Water Jug Problem, 2. Wieże Hanoi. Water Jug Problem Ograniczenia dla każdej z wersji: pojemniki
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów
 Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Testowanie modeli predykcyjnych
 Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Testowanie modeli predykcyjnych Wstęp Podczas budowy modelu, którego celem jest przewidywanie pewnych wartości na podstawie zbioru danych uczących poważnym problemem jest ocena jakości uczenia i zdolności
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Reguły asocjacyjne w programie RapidMiner Michał Bereta
 Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta
 Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Rozpoznawanie twarzy metodą PCA Michał Bereta 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów
 Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Data Mining z wykorzystaniem programu Rapid Miner
 Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta www.michalbereta.pl Modele liniowe W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych
Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta www.michalbereta.pl Modele liniowe W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Bioinformatyka. Ocena wiarygodności dopasowania sekwencji.
 Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
Bioinformatyka Ocena wiarygodności dopasowania sekwencji www.michalbereta.pl Załóżmy, że mamy dwie sekwencje, które chcemy dopasować i dodatkowo ocenić wiarygodność tego dopasowania. Interesujące nas pytanie
 ń ż Ą Ł ż ć ż ć ż ć Ś Ż ć ć ż ć ż ż ż Ą ż ż Ź ń Ą ź ń ź ń Ą ż Ń ż ń Ą ń ż ń Ź ć ń ż Ń Ą ż ż ż ć ń ń Ł ż ż ż ń Ź ź Ą ż Ł ż ż ć ń Ś ć Ó ż ć Ś ż ż Ą ń ż ń Ł ż Ż ń Ą Ł ć ż ń ż ń Ż ń ń Ą ż ż Ł ż ż ż ż ć ż Ń
ń ż Ą Ł ż ć ż ć ż ć Ś Ż ć ć ż ć ż ż ż Ą ż ż Ź ń Ą ź ń ź ń Ą ż Ń ż ń Ą ń ż ń Ź ć ń ż Ń Ą ż ż ż ć ń ń Ł ż ż ż ń Ź ź Ą ż Ł ż ż ć ń Ś ć Ó ż ć Ś ż ż Ą ń ż ń Ł ż Ż ń Ą Ł ć ż ń ż ń Ż ń ń Ą ż ż Ł ż ż ż ż ć ż Ń
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
WYKŁAD 6. Reguły decyzyjne
 Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) Algorytmy i Struktury Danych PIŁA
 PAWLICKI Piotr (55567) Algorytmy i Struktury Danych PIŁA") OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) 16.01.2003 Algorytmy i Struktury Danych PIŁA ALGORYTMY ZACHŁANNE czas [ms] Porównanie Algorytmów Rozwiązyjących problem TSP 100 000 000 000,000 10 000 000
OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) 16.01.2003 Algorytmy i Struktury Danych PIŁA ALGORYTMY ZACHŁANNE czas [ms] Porównanie Algorytmów Rozwiązyjących problem TSP 100 000 000 000,000 10 000 000
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki
 Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Kombinacja jądrowych estymatorów gęstości w klasyfikacji wstępne wyniki Mateusz Kobos, 10.12.2008 Seminarium Metody Inteligencji Obliczeniowej 1/46 Spis treści Działanie algorytmu Uczenie Odtwarzanie/klasyfikacja
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
A Zadanie
 where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
where a, b, and c are binary (boolean) attributes. A Zadanie 1 2 3 4 5 6 7 8 9 10 Punkty a (maks) (2) (2) (2) (2) (4) F(6) (8) T (8) (12) (12) (40) Nazwisko i Imiȩ: c Uwaga: ta część zostanie wypełniona
Optymalizacja optymalizacji
 7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
7 maja 2008 Wstęp Optymalizacja lokalna Optymalizacja globalna Algorytmy genetyczne Badane czasteczki Wykorzystane oprogramowanie (Algorytm genetyczny) 2 Sieć neuronowa Pochodne met-enkefaliny Optymalizacja
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
1. Należy zalogować się w systemie podając identyfikator oraz hasło
 1. Należy zalogować się w systemie http://usosweb.wpia.uw.edu.pl podając identyfikator oraz hasło 2. Po wybraniu z menu głównego opcji Rejestracja > Rejestracja bezpośrednia do grup >Rejestracja do grup
1. Należy zalogować się w systemie http://usosweb.wpia.uw.edu.pl podając identyfikator oraz hasło 2. Po wybraniu z menu głównego opcji Rejestracja > Rejestracja bezpośrednia do grup >Rejestracja do grup
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych
 Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
Zrównoleglona optymalizacja stochastyczna na dużych zbiorach danych mgr inż. C. Dendek prof. nzw. dr hab. J. Mańdziuk Politechnika Warszawska, Wydział Matematyki i Nauk Informacyjnych Outline 1 Uczenie
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2012-10-10 Projekt pn. Wzmocnienie
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2012-10-10 Projekt pn. Wzmocnienie
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji
 Kierunek: Informatyka Zastosowania Informatyki w Medycynie Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji 1. WSTĘP AUTORZY Joanna Binczewska gr. I3.1
Kierunek: Informatyka Zastosowania Informatyki w Medycynie Klasyfikacja publikacji biomedycznych w konkursie JRS 2012 Data Mining Competition - Szkic koncepcji 1. WSTĘP AUTORZY Joanna Binczewska gr. I3.1
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Systemy uczące się wykład 1
 Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
TOUCAN Team Evaluator OPIS FUNKCJONALNOŚCI
 TOUCAN Team Evaluator OPIS FUNKCJONALNOŚCI SPIS TREŚCI Funkcje... 4 Ocena celów... 4 Definicja celów... 4 Procesowy model akceptacji -... 5 Ocena stopnia realizacji celu... 5 Ocena kompetencji... 5 Definicja
TOUCAN Team Evaluator OPIS FUNKCJONALNOŚCI SPIS TREŚCI Funkcje... 4 Ocena celów... 4 Definicja celów... 4 Procesowy model akceptacji -... 5 Ocena stopnia realizacji celu... 5 Ocena kompetencji... 5 Definicja
Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa
 Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa Odkrywanie asocjacji Wzorce sekwencji Analiza koszykowa Podobieństwo szeregów temporalnych Klasyfikacja Wykrywanie odchyleń
Co to jest klasyfikacja? Klasyfikacja a grupowanie Naiwny klasyfikator Bayesa Odkrywanie asocjacji Wzorce sekwencji Analiza koszykowa Podobieństwo szeregów temporalnych Klasyfikacja Wykrywanie odchyleń
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Sieci obliczeniowe poprawny dobór i modelowanie
 Sieci obliczeniowe poprawny dobór i modelowanie 1. Wstęp. Jednym z pierwszych, a zarazem najważniejszym krokiem podczas tworzenia symulacji CFD jest poprawne określenie rozdzielczości, wymiarów oraz ilości
Sieci obliczeniowe poprawny dobór i modelowanie 1. Wstęp. Jednym z pierwszych, a zarazem najważniejszym krokiem podczas tworzenia symulacji CFD jest poprawne określenie rozdzielczości, wymiarów oraz ilości
Machine learning Lecture 6
 Machine learning Lecture 6 Marcin Wolter IFJ PAN 11 maja 2017 Deep learning Convolution network Zastosowanie do poszukiwań bozonu Higgsa 1 Deep learning Poszczególne warstwy ukryte uczą się rozpoznawania
Machine learning Lecture 6 Marcin Wolter IFJ PAN 11 maja 2017 Deep learning Convolution network Zastosowanie do poszukiwań bozonu Higgsa 1 Deep learning Poszczególne warstwy ukryte uczą się rozpoznawania
Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny
 Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny AiRIII gr. 2TI sekcja 1 Autorzy: Tomasz Bizon Józef Wawrzyczek 2 1. Wstęp Celem projektu było stworzenie sklepu
Technologie Internetowe Raport z wykonanego projektu Temat: Internetowy sklep elektroniczny AiRIII gr. 2TI sekcja 1 Autorzy: Tomasz Bizon Józef Wawrzyczek 2 1. Wstęp Celem projektu było stworzenie sklepu
Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości
 Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości część 2 Zaprojektowaliśmy stronę dodaj_dzial.aspx proszę jednak spróbować dodać nowy dział nie podając jego nazwy
Budowa aplikacji ASP.NET współpracującej z bazą dany do obsługi przesyłania wiadomości część 2 Zaprojektowaliśmy stronę dodaj_dzial.aspx proszę jednak spróbować dodać nowy dział nie podając jego nazwy
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
LABORATORIUM 7: Problem komiwojażera (TSP) cz. 2
 cz. 2") Instytut Mechaniki i Inżynierii Obliczeniowej Wydział Mechaniczny Technologiczny, Politechnika Śląska www.imio.polsl.pl OBLICZENIA EWOLUCYJNE LABORATORIUM 7: Problem komiwojażera (TSP) cz. 2 opracował:
Instytut Mechaniki i Inżynierii Obliczeniowej Wydział Mechaniczny Technologiczny, Politechnika Śląska www.imio.polsl.pl OBLICZENIA EWOLUCYJNE LABORATORIUM 7: Problem komiwojażera (TSP) cz. 2 opracował:
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl. Program RapidMiner (RM) ma trzy główne widoki (perspektywy):
 ma trzy główne widoki (perspektywy):") Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community Edition.
Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community Edition.
Automatyczna klasyfikacja zespołów QRS
 Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Przetwarzanie sygnałów w systemach diagnostycznych Informatyka Stosowana V Automatyczna klasyfikacja zespołów QRS Anna Mleko Tomasz Kotliński AGH EAIiE 9 . Opis zadania Tematem projektu było zaprojektowanie
Algorytmy i struktury danych. Drzewa: BST, kopce. Letnie Warsztaty Matematyczno-Informatyczne
 Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Hierarchia cen w systemie humansoft HermesSQL
 Wersja: 3.15 Aktualizacja: 04.08.2009 Humansoft Sp. z o.o. 26-600 Radom, ul. Wernera 29/31 http://www.humansoft.pl tel./fax (048) 360 89 58, 360 89 09 e-mail: biuro@humansoft.pl 1 Promocje... 2 Gazetki
Wersja: 3.15 Aktualizacja: 04.08.2009 Humansoft Sp. z o.o. 26-600 Radom, ul. Wernera 29/31 http://www.humansoft.pl tel./fax (048) 360 89 58, 360 89 09 e-mail: biuro@humansoft.pl 1 Promocje... 2 Gazetki
Bioinformatyka Laboratorium, 30h. Michał Bereta
 Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ROZWIĄZYWANIE UKŁADÓW RÓWNAŃ NIELINIOWYCH PRZY POMOCY DODATKU SOLVER PROGRAMU MICROSOFT EXCEL. sin x2 (1)
") ROZWIĄZYWANIE UKŁADÓW RÓWNAŃ NIELINIOWYCH PRZY POMOCY DODATKU SOLVER PROGRAMU MICROSOFT EXCEL 1. Problem Rozważmy układ dwóch równań z dwiema niewiadomymi (x 1, x 2 ): 1 x1 sin x2 x2 cos x1 (1) Nie jest
ROZWIĄZYWANIE UKŁADÓW RÓWNAŃ NIELINIOWYCH PRZY POMOCY DODATKU SOLVER PROGRAMU MICROSOFT EXCEL 1. Problem Rozważmy układ dwóch równań z dwiema niewiadomymi (x 1, x 2 ): 1 x1 sin x2 x2 cos x1 (1) Nie jest
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Oprogramowanie Systemów Obrazowania SIECI NEURONOWE
 SIECI NEURONOWE Przedmiotem laboratorium jest stworzenie algorytmu rozpoznawania zwierząt z zastosowaniem sieci neuronowych w oparciu o 5 kryteriów: ile zwierzę ma nóg, czy żyje w wodzie, czy umie latać,
SIECI NEURONOWE Przedmiotem laboratorium jest stworzenie algorytmu rozpoznawania zwierząt z zastosowaniem sieci neuronowych w oparciu o 5 kryteriów: ile zwierzę ma nóg, czy żyje w wodzie, czy umie latać,
Technologie Informacyjne
 Systemy Uczące się Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności January 16, 2017 1 Wprowadzenie 2 Uczenie nadzorowane 3 Uczenie bez nadzoru 4 Uczenie ze wzmocnieniem Uczenie się - proces
Systemy Uczące się Szkoła Główna Służby Pożarniczej Zakład Informatyki i Łączności January 16, 2017 1 Wprowadzenie 2 Uczenie nadzorowane 3 Uczenie bez nadzoru 4 Uczenie ze wzmocnieniem Uczenie się - proces
Ontogeniczne sieci neuronowe. O sieciach zmieniających swoją strukturę
 Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
PROGRAM SZKOLENIA. Excel w Analizach danych.
 PROGRAM SZKOLENIA Excel w Analizach danych SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, w codziennej pracy wykorzystują Excel jako narzędzie analizy danych i chcą zgłębić posiadaną
PROGRAM SZKOLENIA Excel w Analizach danych SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, w codziennej pracy wykorzystują Excel jako narzędzie analizy danych i chcą zgłębić posiadaną
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Uczenie sieci neuronowych i bayesowskich
 Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
Strategie VIP. Opis produktu. Tworzymy strategie oparte o systemy transakcyjne wyłącznie dla Ciebie. Strategia stworzona wyłącznie dla Ciebie
 Tworzymy strategie oparte o systemy transakcyjne wyłącznie dla Ciebie Strategie VIP Strategia stworzona wyłącznie dla Ciebie Codziennie sygnał inwestycyjny na adres e-mail Konsultacje ze specjalistą Opis
Tworzymy strategie oparte o systemy transakcyjne wyłącznie dla Ciebie Strategie VIP Strategia stworzona wyłącznie dla Ciebie Codziennie sygnał inwestycyjny na adres e-mail Konsultacje ze specjalistą Opis
Mateusz Kobos Seminarium z Metod Inteligencji Obliczeniowej, MiNI PW
 Klasyfikacja za pomocą kombinacji estymatorów jądrowych: dobór szerokości jądra w zależności od lokalizacji w przestrzeni cech, stosowanie różnych przekształceń przestrzeni, funkcja błędu oparta na information
Klasyfikacja za pomocą kombinacji estymatorów jądrowych: dobór szerokości jądra w zależności od lokalizacji w przestrzeni cech, stosowanie różnych przekształceń przestrzeni, funkcja błędu oparta na information
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Metody Optymalizacji: Przeszukiwanie z listą tabu
 Metody Optymalizacji: Przeszukiwanie z listą tabu Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje: wtorek
Metody Optymalizacji: Przeszukiwanie z listą tabu Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje: wtorek
Optymalizacja. Przeszukiwanie lokalne
 dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Maciej Hapke Idea sąsiedztwa Definicja sąsiedztwa x S zbiór N(x) S rozwiązań, które leżą blisko rozwiązania x
dr hab. inż. Instytut Informatyki Politechnika Poznańska www.cs.put.poznan.pl/mkomosinski, Maciej Hapke Idea sąsiedztwa Definicja sąsiedztwa x S zbiór N(x) S rozwiązań, które leżą blisko rozwiązania x
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować?
 Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
Algorytm k-nn Naiwny klasyfikator Bayesa brał pod uwagę jedynie najbliższe otoczenie. Lecz czym jest otoczenie? Jak je zdefiniować? Jak daleko są położone obiekty od siebie? knn k nearest neighbours jest
8. Neuron z ciągłą funkcją aktywacji.
 8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
8. Neuron z ciągłą funkcją aktywacji. W tym ćwiczeniu zapoznamy się z modelem sztucznego neuronu oraz przykładem jego wykorzystania do rozwiązywanie prostego zadania klasyfikacji. Neuron biologiczny i
Program szkolenia EXCEL ŚREDNIOZAAWANSOWANY.
 Program szkolenia EXCEL ŚREDNIOZAAWANSOWANY SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, chcą przyspieszyć i usprawnić pracę oraz poszerzyć posiadaną już wiedzę z zakresu wprowadzania
Program szkolenia EXCEL ŚREDNIOZAAWANSOWANY SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, chcą przyspieszyć i usprawnić pracę oraz poszerzyć posiadaną już wiedzę z zakresu wprowadzania
EKONOMETRIA STOSOWANA PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 EKONOMETRIA STOSOWANA PRZYKŁADOWE ZADANIA EGZAMINACYJNE ZADANIE 1 Oszacowano zależność między luką popytowa a stopą inflacji dla gospodarki niemieckiej. Wyniki estymacji są następujące: Estymacja KMNK,
EKONOMETRIA STOSOWANA PRZYKŁADOWE ZADANIA EGZAMINACYJNE ZADANIE 1 Oszacowano zależność między luką popytowa a stopą inflacji dla gospodarki niemieckiej. Wyniki estymacji są następujące: Estymacja KMNK,
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Program szkolenia EXCEL W ANALIZACH DANYCH.
 Program szkolenia EXCEL W ANALIZACH DANYCH SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, w codziennej pracy wykorzystują Excel jako narzędzie analizy danych i chcą zgłębić posiadaną
Program szkolenia EXCEL W ANALIZACH DANYCH SZKOLENIE JEST DLA OSÓB, KTÓRE: znają podstawy programu Microsoft Excel, w codziennej pracy wykorzystują Excel jako narzędzie analizy danych i chcą zgłębić posiadaną
Program Qmak Podręcznik użytkownika
 Program Qmak Podręcznik użytkownika Krzysztof Mroczek Leszek Tur Damian Wójcik 2 lipca 2007 Maciej Zuchniak 1 Spis treści 1 Wprowadzenie do Qmaka 3 1.1 Informacje techniczne................................
Program Qmak Podręcznik użytkownika Krzysztof Mroczek Leszek Tur Damian Wójcik 2 lipca 2007 Maciej Zuchniak 1 Spis treści 1 Wprowadzenie do Qmaka 3 1.1 Informacje techniczne................................
Metody eksploracji danych w odkrywaniu wiedzy (MED) projekt, dokumentacja końcowa
 projekt, dokumentacja końcowa") Metody eksploracji danych w odkrywaniu wiedzy (MED) projekt, dokumentacja końcowa Konrad Miziński 14 stycznia 2015 1 Temat projektu Grupowanie hierarchiczne na podstawie algorytmu k-średnich. 2 Dokumenty
Metody eksploracji danych w odkrywaniu wiedzy (MED) projekt, dokumentacja końcowa Konrad Miziński 14 stycznia 2015 1 Temat projektu Grupowanie hierarchiczne na podstawie algorytmu k-średnich. 2 Dokumenty
Propensity score matching (PSM)
") Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
Propensity score matching (PSM) Jerzy Mycielski Uniwersytet Warszawski Maj 2010 Jerzy Mycielski (Uniwersytet Warszawski) Propensity score matching (PSM) Maj 2010 1 / 18 Badania ewaluacyjne Ocena wpływu
E-REZERWACJE24.PL. Internetowy System Rezerwacji Online. Konfiguracja usług dodatkowych w systemie rezerwacji online
 Konfiguracja usług dodatkowych w systemie rezerwacji online Opis i zasady działania modułu usług dodatkowych System rezerwacji online e-rezerwacje24.pl umożliwia, oprócz klasycznego procesu rezerwacji
Konfiguracja usług dodatkowych w systemie rezerwacji online Opis i zasady działania modułu usług dodatkowych System rezerwacji online e-rezerwacje24.pl umożliwia, oprócz klasycznego procesu rezerwacji
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Sprawozdanie z zadania Modele predykcyjne (2)
") Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Obsługa Programu Operacyjnego Pomoc Żywnościowa w POMOST Std
 Obsługa Programu Operacyjnego Pomoc Żywnościowa 2014-2020 w POMOST Std W odpowiedzi na zgłoszenia Ośrodków Pomocy Społecznej, POMOST Std w wersji 3-10.0 został rozszerzony o możliwość wydruku skierowania
Obsługa Programu Operacyjnego Pomoc Żywnościowa 2014-2020 w POMOST Std W odpowiedzi na zgłoszenia Ośrodków Pomocy Społecznej, POMOST Std w wersji 3-10.0 został rozszerzony o możliwość wydruku skierowania
Problemy z ograniczeniami
 Problemy z ograniczeniami 1 2 Dlaczego zadania z ograniczeniami Wiele praktycznych problemów to problemy z ograniczeniami. Problemy trudne obliczeniowo (np-trudne) to prawie zawsze problemy z ograniczeniami.
Problemy z ograniczeniami 1 2 Dlaczego zadania z ograniczeniami Wiele praktycznych problemów to problemy z ograniczeniami. Problemy trudne obliczeniowo (np-trudne) to prawie zawsze problemy z ograniczeniami.
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Selekcja cech. Wprowadzenie Metody selekcji cech. Przykład zastosowania. Miary niepodobieństwa. Algorytmy przeszukiwania
 Selekcja cech Wprowadzenie Metody selekcji cech Miary niepodobieństwa Algorytmy przeszukiwania Przykład zastosowania Wprowadzenie 2 Cel selekcji: dobór cech obiektu, na których opierać się będzie klasyfikacja
Selekcja cech Wprowadzenie Metody selekcji cech Miary niepodobieństwa Algorytmy przeszukiwania Przykład zastosowania Wprowadzenie 2 Cel selekcji: dobór cech obiektu, na których opierać się będzie klasyfikacja
Zasady wystawiania ocen klasyfikacyjnych szkoła podstawowa.
 Zasady wystawiania ocen klasyfikacyjnych szkoła podstawowa. Oceny klasyfikacyjne śródroczne i końcoworoczne ustalone są według skali: stopień niedostateczny 1 stopień dopuszczający 2 stopień dostateczny
Zasady wystawiania ocen klasyfikacyjnych szkoła podstawowa. Oceny klasyfikacyjne śródroczne i końcoworoczne ustalone są według skali: stopień niedostateczny 1 stopień dopuszczający 2 stopień dostateczny
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Online Workbook Przewodnik dla nauczycieli
 Online Workbook Przewodnik dla nauczycieli Ćwiczenia w Online Workbook odpowiadają tym w drukowanej wersji zeszytu ćwiczeń, ale pozwalają uczniom otrzymać natychmiastową informację zwrotną oraz zapisać
Online Workbook Przewodnik dla nauczycieli Ćwiczenia w Online Workbook odpowiadają tym w drukowanej wersji zeszytu ćwiczeń, ale pozwalają uczniom otrzymać natychmiastową informację zwrotną oraz zapisać
METODA SYMPLEKS. Maciej Patan. Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski
 METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
METODA SYMPLEKS Maciej Patan Uniwersytet Zielonogórski WSTĘP Algorytm Sympleks najpotężniejsza metoda rozwiązywania programów liniowych Metoda generuje ciąg dopuszczalnych rozwiązań x k w taki sposób,
LEGISLATOR. Data dokumentu:24 maja 2013 Wersja: 1.3 Autor: Paweł Jankowski, Piotr Jegorow
 LEGISLATOR Dokument zawiera opis sposobu tworzenia podpisów pod aktami dla celów wizualizacji na wydrukach Data dokumentu:24 maja 2013 Wersja: 1.3 Autor: Paweł Jankowski, Piotr Jegorow Zawartość Wprowadzenie...
LEGISLATOR Dokument zawiera opis sposobu tworzenia podpisów pod aktami dla celów wizualizacji na wydrukach Data dokumentu:24 maja 2013 Wersja: 1.3 Autor: Paweł Jankowski, Piotr Jegorow Zawartość Wprowadzenie...