ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA
|
|
|
- Sabina Przybysz
- 6 lat temu
- Przeglądów:
Transkrypt
1 ESTYMACJA BŁĘDU PREDYKCJI I JEJ ZASTOSOWANIA Jan Mielniczuk Wisła, grudzień 2009
2 PLAN Błędy predykcji i ich podstawowe estymatory Estymacja błędu predykcji w modelu liniowym. Funkcje kryterialne Własności predykcyjne estymatorów postselekcyjnych Metoda minimalizacji ryzyka strukturalnego
3 BŁĘDY PREDYKCJI I ICH PODSTAWOWE ESTYMATORY
4 Rozpatrywane problemy (i) Regresja wielokrotna z losowymi zmiennymi objaśniającymi Wektor losowy (X, Y ) R p R o rozkładzie P X,Y takim, że Y = f (X) + ε, ( ) f : R p R, ε zmienna niezależna od X, E(ε) = 0. Uwaga. Założenia implikują f (X) = E(Y X) i ε = Y E(Y X). Dla takich f i ε, ( ) spełniona oczywiście zawsze, tu zakładamy dodatkowo niezależność X i ε.
5 (ii) Klasyfikacja pod nadzorem Tak jak w (i), zakładamy dodatkowo, że Y {1, 2,..., K} (Y - indeks przynależności do populacji). Nie zakładamy niezależności X i ε. Obserwowalna p.p.l. U = {(X 1, Y 1 ),..., (X n, Y n )} z rozkładu P X,Y. Na jej podstawie estymator ˆf (x) używany do prognozy zmiennej Y 0 :. Ŷ 0 = ˆf (X 0 )
6 surface Q Q Q Q QQ Q Q Q Q Q Q Q Q X X XX X X X Q X body
7 (iii) Estymacja gęstości zmiennej losowej Y Y 1,..., Y n p.p.l. z rozkładu P Y o gęstości f. Estymacja f w oparciu o model parametryczny M = {f θ } θ Θ. (iv) Estymacja gęstości warunkowej (X 1, Y 1 ),..., (X n, Y n ) p.p.l. z rozkładu P X,Y na R p R. Estymujemy gęstość warunkową Y pod warunkiem X = x w oparciu o model parametryczny M = {f θ(x) } θ Θ, x R p
8 Problem prognozy (X 0, Y 0 ) P X,Y niezależna od U. - Jak dalece ˆf (X 0 ) różni się od Y 0? (Problem (i) i (ii)) - Jak dalece gęstość fˆθ różni się od gęstości f? (problem (iii)) - Jak dalece gęstość fˆθ(x 0 ) różni się od gęstości f Y 0 X0? (problem (iv)) Błędy rozpatrywane w (iii) i (iv) będą związane z problemem prognozy.
9 Funkcje straty Problemy (i) i (ii): L(y, ˆf (x)) 0 : (y ˆf (x)) 2, y ˆf (x), I {y ˆf (x)} (funkcja straty 0-1 dla problemu (ii)). Problemy (iii) i (iv): L(y, ˆθ(x)) : L(y, ˆθ) = 2 log fˆθ (y) L(y, ˆθ(x)) = 2 log fˆθ(x) (y)
10 Błąd predykcji (uogólnienia) (X 0, Y 0 ) P X,Y niezależna od U. Err U = E(L(Y 0, ˆf (X 0 )) U) Err U = E(L(Y 0, ˆθ(X 0 )) U) (i), (ii) (iii), (iv) Warunkowy błąd predykcji ( w (ii): prawdopodobieństwo błędnej klasyfikacji), Err U = G(U) jest funkcją próby U. Dla ustalonej próby uczącej U konstruujemy predyktor ˆf i oceniamy jego działanie dla nowej obserwacji (X 0, Y 0 ). Miara jakości odpowiadająca faktycznej funkcji predyktora.
11 Bezwarunkowy błąd predykcji Err = E(Err U ) Uśredniamy losowość próby uczącej, na podstawie której skonstruowano predyktor (Hastie et al., ESL). Wewnątrzpróbkowy błąd predykcji (in-sample error) Y 0 i P Y X=Xi niezależne, i = 1, 2,..., n. Y 0 = (Y 0 1,..., Y 0 n ) Err in = 1 n n i=1 E Y 0(L(Y 0 i, ˆf (X i )) U) Losujemy indeks I {1,..., n}, nowa obserwacja Yi 0 i = I, dla niej oczekiwany błąd predykcji. w punkcie X i dla
12 Estymatory błędu predykcji estymator metodą próby testowej estymator metodą powtórnego podstawienia err estymator kroswalidacyjny Err ˆ CV estymator metodą bootstrap Err ˆ boot
13 Estymator metodą próby testowej Oprócz próby uczącej U dysponujemy również w pełni obserwowalną próbą testową T (D = U T, U T = 0), T = m Mamy ˆ Err U = 1 m m I {(X i, Y i ) T : ˆf (X i ) Y i }. i=1 E T ( ˆ Err U U) = Err U Nieobciążone oszacowanie prawdopodobieństwa błędnej klasyfikacji. Ale często w powyższym schemacie będziemy używać estymatora ˆf D a nie ˆf U - wtedy zbyt konserwatywnie z reguły oceniamy prawdopodobieństwo błędnej klasyfikacji tego klasyfikatora.
14 Trudny problem: Err U = 0.05, ErrU (1 Err U ) = m m m 1900!! Dwie możliwości zastąpienia próby testowej: metoda analityczna - uwzględnienie obciążenia estymatora metodą powtórnego podstawienia metoda repróbkowania - efektywne ponowne użycie próby uczącej
15 Estymator metodą powtórnego podstawienia err = 1 n n L(ˆf (X i ), Y i ). i=1 err jest naturalnym estymatorem Err U. Ale: elementy próby U pełnią funkcję niezależnych od U obserwacji (X, Y ). Jest estymatorem optymistycznym w tym sensie, że z reguły możemy sie spodziewać, że Możemy porównać err < Err U. E Y ( err X) z E Y (Err in X) Y = (Y 1,..., Y n ), X = (X 1,..., X n ).
16 Twierdzenie 1. Dla kwadratowej funkcji straty w (i) i 0-1 w (ii) E Y ( err X) = E Y (Err in X) 2 n n Cov(Ŷi, Y i X). Im bardziej elastyczna metoda predykcji (silnej skorelowane Ŷi i Y i ) tym większy optymizm err. Człon kara kowariancyjna. 2 n i=1 n Cov(Ŷi, Y i X) i=1
17 Dowód Porównujemy przy ustalonym X kwadraty wyrażeń (Y i ˆf (X i )) (1) z (Y 0 i ˆf (X i )) (2) (1) = (Y i f (X i )) (ˆf (X i ) E(ˆf (X i ) X) + (f (X i ) E(ˆf (X i ) X) =: A + B + C (2) = A + B + C A := Y 0 i f (X i ) Liczymy E((1) 2 X) i E((2) 2 X) 2E(A B X) 2E(A B X) E(A B X) = E Y (E(A B X, Y)) = E Y (BE(A X, Y)) = 0 E(AB X) = Cov(Y i, Ŷi X)
18 Model liniowy Przypadek szczególny (i): Y i = X iβ + ε i X i = (X i1,..., X ip ), β = (β 1,..., β p ). X = (X 1, X 2,..., X n ) macierz eksperymentu n p z wierszami = X 1, X 2,... X n. Z definicji Err in = n 1 n i=1 E Y 0(Y i 0 ˆf (X i )) 2 U) E Y (Err in X) = σ n E( Xˆβ Xβ 2 X)
19 Fakt Dla modelu liniowego n Cov(Ŷi, Y i X) = pσ 2, i=1 jeśli rząd X = p i σ 2 = Var(ε). Dowód Ŷ = HX, gdzie H = X(X X) 1 X n Cov(Ŷi, Y i X) = E((HY Xβ) ε) X) = i=1 = E(ε Hε) = pσ 2. Tylko w przybliżeniu prawdziwe dla innych modeli i metod!
20 Dla modelu liniowego i kwadratowej funkcji straty estymator E Y (Err in X) ma postać err + 2 p n ˆσ2 = 1 n RSS + 2p n ˆσ2 ( ) Jeśli E ˆσ 2 = σ 2 to ( ) nieobciążony estymator E(Err in X). W takiej sytuacji nieobciążony estymator 1 n E( Xˆβ Xβ 2 X) ma postać Funkcja kryterialna Mallowsa. C p = 1 n RSS + 2p n ˆσ2 ˆσ 2.
21 Estymator kroswalidacyjny (rotacyjny) oczekiwanego błędu prognozy Err Modele (i) i (ii). Próbę U dzielimy na K > 1 w przybliżeniu równych części. κ : {1,..., n} {1,..., K} (funkcja przynależności do elementu podziału). Ŷ i j = ˆf i (X j ) prognoza Y j na podstawie próby z usuniętą i-tą częścią. CV = 1 n L(Y j, Ŷ κ(j) j ). n Y j prognozowana na podstawie próby niezależnej od Y j zgodnie z definicją Err. Co estymujemy? U i : próba z usuniętą i-tą częścią. Oszacowanie błędu j=1 CV = 1 K K Ê(L(X, Y ) U i ) = Ê(Err U 1) i=1
22 Nie estymujemy warunkowego błedu klasyfikatora ˆd U dla danej próby U tylko oczekiwany błąd klasyfikatora ˆd U 1 = Err (n(k 1)/K) Hypothetical learning curve 1 err
23 Uwagi o estymatorze kroswalidacyjnym 1. Liczba podziałów K = 5, 10 i K = n. (leave-one out). W ostatnim przypadku najmniejsze obciążenie estymatora (jako oszacownania Err n dla liczności próby n), największa wariancja (skorelowanie czynników w definicji CV. 2. Obciażenie estymatora kroswalidacyjnego jako estymatora Err n dla K = 5, 10 może być znaczne.
24 cp 3. Niestabilność CV związana z losowością podziału na K części. size of tree X val Relative Error Inf
25 size of tree X val Relative Error Inf cp
26 size of tree X val Relative Error Inf cp
27 size of tree X val Relative Error Inf cp
28 CV jako metoda estymacji Err U i Err Przykład (ESL, rozdział VII) (Y, X) {0, 1} R 20 : Y = 1 jeśli 10 i=1 X i > 5, 0 w przeciwnym przypadku. CV-10 i CV leave-one-out jak estymatory Err U i Err liczone dla 100 prób uczących (n = 80). Metoda estymacji: regresji liniowa dla najlepszego podzbioru predyktorów danej liczności (argmin M: M =p RSS M ) Czerwona linia - Err Czarna linia - ECV 10 i ECV n
29
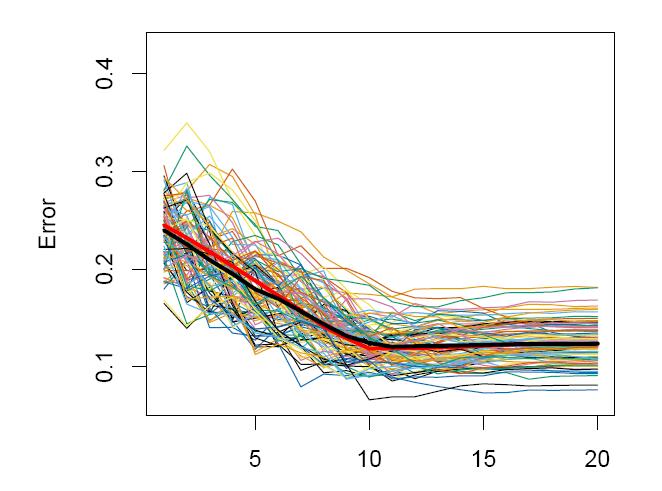
30
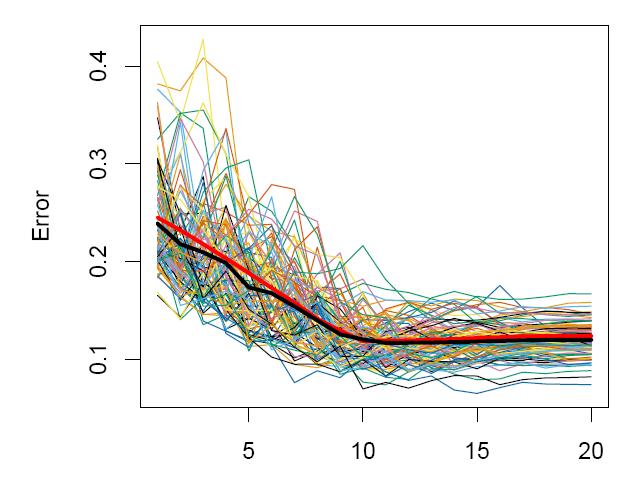
31
32
33
Metoda najmniejszych kwadratów
 Metoda najmniejszych kwadratów Przykład wstępny. W ekonomicznej teorii produkcji rozważa się funkcję produkcji Cobba Douglasa: z = AL α K β gdzie z oznacza wielkość produkcji, L jest nakładem pracy, K
Metoda najmniejszych kwadratów Przykład wstępny. W ekonomicznej teorii produkcji rozważa się funkcję produkcji Cobba Douglasa: z = AL α K β gdzie z oznacza wielkość produkcji, L jest nakładem pracy, K
Stosowana Analiza Regresji
 Stosowana Analiza Regresji Wykład VI... 16 Listopada 2011 1 / 24 Jest to rozkład zmiennej losowej rozkład chi-kwadrat Z = n i=1 X 2 i, gdzie X i N(µ i, 1) - niezależne. Oznaczenie: Z χ 2 (n, λ), gdzie:
Stosowana Analiza Regresji Wykład VI... 16 Listopada 2011 1 / 24 Jest to rozkład zmiennej losowej rozkład chi-kwadrat Z = n i=1 X 2 i, gdzie X i N(µ i, 1) - niezależne. Oznaczenie: Z χ 2 (n, λ), gdzie:
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Wybór modelu i ocena jakości klasyfikatora
 Wybór modelu i ocena jakości klasyfikatora Błąd uczenia i błąd testowania Obciążenie, wariancja i złożoność modelu (klasyfikatora) Dekompozycja błędu testowania Optymizm Estymacja błędu testowania AIC,
Wybór modelu i ocena jakości klasyfikatora Błąd uczenia i błąd testowania Obciążenie, wariancja i złożoność modelu (klasyfikatora) Dekompozycja błędu testowania Optymizm Estymacja błędu testowania AIC,
Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu liniowym, scenariusz p bliskie lub większe od n
 Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu iowym, scenariusz p bliskie lub większe od n Przemyslaw.Biecek@gmail.com, MIM Uniwersytet Warszawski Plan prezentacji: 1 Motywacja;
Porównanie błędu predykcji dla różnych metod estymacji współczynników w modelu iowym, scenariusz p bliskie lub większe od n Przemyslaw.Biecek@gmail.com, MIM Uniwersytet Warszawski Plan prezentacji: 1 Motywacja;
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Prawdopodobieństwo i statystyka
 Wykład VIII: Przestrzenie statystyczne. Estymatory 1 grudnia 2014 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji r(x, Z) = 0, 986 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji
Wykład VIII: Przestrzenie statystyczne. Estymatory 1 grudnia 2014 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji r(x, Z) = 0, 986 Wprowadzenie Przykład: pomiar z błędem Współczynnik korelacji
Estymacja gęstości prawdopodobieństwa metodą selekcji modelu
 Estymacja gęstości prawdopodobieństwa metodą selekcji modelu M. Wojtyś Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Wisła, 7 grudnia 2009 Wstęp Próba losowa z rozkładu prawdopodobieństwa
Estymacja gęstości prawdopodobieństwa metodą selekcji modelu M. Wojtyś Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska Wisła, 7 grudnia 2009 Wstęp Próba losowa z rozkładu prawdopodobieństwa
Estymacja w regresji nieparametrycznej
 Estymacja w regresji nieparametrycznej Jakub Kolecki Politechnika Gdańska 28 listopada 2011 1 Wstęp Co to jest regresja? Przykład regresji 2 Regresja nieparametryczna Założenia modelu Estymacja i jej charakterystyki
Estymacja w regresji nieparametrycznej Jakub Kolecki Politechnika Gdańska 28 listopada 2011 1 Wstęp Co to jest regresja? Przykład regresji 2 Regresja nieparametryczna Założenia modelu Estymacja i jej charakterystyki
Metoda największej wiarogodności
 Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
Wprowadzenie Założenia Logarytm funkcji wiarogodności Metoda Największej Wiarogodności (MNW) jest bardziej uniwersalną niż MNK metodą szacowania wartości nieznanych parametrów Wprowadzenie Założenia Logarytm
STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE
 1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
1 STATYSTYKA MAŁYCH OBSZARÓW I. WPROWADZENIE 1.1 Podejścia w statystyce małych obszarów Randomizacyjne Wektor wartości badanej cechy traktowany jest jako nielosowy. Szacowana charakterystyka jest nielosowa
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/
 Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Matematyka z el. statystyki, # 6 /Geodezja i kartografia II/ Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, bud. CIW, p. 221 e-mail: zdzislaw.otachel@up.lublin.pl
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE. Joanna Sawicka
 Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Szacowanie optymalnego systemu Bonus-Malus przy pomocy Pseudo-MLE Joanna Sawicka Plan prezentacji Model Poissona-Gamma ze składnikiem regresyjnym Konstrukcja optymalnego systemu Bonus- Malus Estymacja
Stopę zbieżności ciagu zmiennych losowych a n, takiego, że E (a n ) < oznaczamy jako a n = o p (1) prawdopodobieństwa szybciej niż n α.
 < oznaczamy jako a n = o p (1) prawdopodobieństwa szybciej niż n α.") Stopy zbieżności Stopę zbieżności ciagu zmiennych losowych a n, takiego, że a n oznaczamy jako a n = o p (1 p 0 a Jeśli n p n α 0, to a n = o p (n α i mówimy a n zbiega według prawdopodobieństwa szybciej
Stopy zbieżności Stopę zbieżności ciagu zmiennych losowych a n, takiego, że a n oznaczamy jako a n = o p (1 p 0 a Jeśli n p n α 0, to a n = o p (n α i mówimy a n zbiega według prawdopodobieństwa szybciej
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Wprowadzenie. Data Science Uczenie się pod nadzorem
 Wprowadzenie Wprowadzenie Wprowadzenie Wprowadzenie Machine Learning Mind Map Historia Wstęp lub uczenie się z przykładów jest procesem budowy, na bazie dostępnych danych wejściowych X i oraz wyjściowych
Wprowadzenie Wprowadzenie Wprowadzenie Wprowadzenie Machine Learning Mind Map Historia Wstęp lub uczenie się z przykładów jest procesem budowy, na bazie dostępnych danych wejściowych X i oraz wyjściowych
STATYSTYKA MATEMATYCZNA WYKŁAD listopada 2009
 STATYSTYKA MATEMATYCZNA WYKŁAD 7 23 listopada 2009 Wykład 6 (16.XI.2009) zakończył się zdefiniowaniem współczynnika korelacji: E X µ x σ x Y µ y σ y = T WSPÓŁCZYNNIK KORELACJI ρ X,Y = ρ Y,X (!) WSPÓŁCZYNNIK
STATYSTYKA MATEMATYCZNA WYKŁAD 7 23 listopada 2009 Wykład 6 (16.XI.2009) zakończył się zdefiniowaniem współczynnika korelacji: E X µ x σ x Y µ y σ y = T WSPÓŁCZYNNIK KORELACJI ρ X,Y = ρ Y,X (!) WSPÓŁCZYNNIK
Zawansowane modele wyborów dyskretnych
 Zawansowane modele wyborów dyskretnych Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Zawansowane modele wyborów dyskretnych grudzien 2013 1 / 16 Model efektów
Zawansowane modele wyborów dyskretnych Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Zawansowane modele wyborów dyskretnych grudzien 2013 1 / 16 Model efektów
Ekonometria egzamin 01/02/ W trakcie egzaminu wolno używać jedynie długopisu o innym kolorze atramentu niż czerwony oraz kalkulatora.
 imię, nazwisko, nr indeksu: Ekonometria egzamin 01/02/2019 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
imię, nazwisko, nr indeksu: Ekonometria egzamin 01/02/2019 1. Egzamin trwa 90 minut. 2. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu.
Wprowadzenie. { 1, jeżeli ˆr(x) > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne
 > 0, pozatym. Regresja liniowa Regresja logistyczne Jądrowe estymatory gęstości. Metody regresyjne") Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
Wprowadzenie Prostym podejściem do klasyfikacji jest estymacja funkcji regresji r(x) =E(Y X =x)zpominięciemestymacjigęstościf k. Zacznijmyodprzypadkudwóchgrup,tj.gdy Y = {1,0}. Wówczasr(x) =P(Y =1 X =x)ipouzyskaniuestymatora
1.1 Statystyka matematyczna Literatura Model statystyczny Preliminaria... 3
 Spis treści Spis treści 1 Wstęp 1 1.1 Statystyka matematyczna...................... 1 1.2 Literatura.............................. 1 1.3 Model statystyczny......................... 2 1.4 Preliminaria.............................
Spis treści Spis treści 1 Wstęp 1 1.1 Statystyka matematyczna...................... 1 1.2 Literatura.............................. 1 1.3 Model statystyczny......................... 2 1.4 Preliminaria.............................
Statystyczna analiza danych 1
 Statystyczna analiza danych 1 Regresja liniowa 1 Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski Ewa Szczurek Regresja liniowa 1 1 / 41 Dane: wpływ reklam produktu na sprzedaż
Statystyczna analiza danych 1 Regresja liniowa 1 Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski Ewa Szczurek Regresja liniowa 1 1 / 41 Dane: wpływ reklam produktu na sprzedaż
1.9 Czasowy wymiar danych
 1.9 Czasowy wymiar danych Do tej pory rozpatrywaliśmy jedynie modele tworzone na podstawie danych empirycznych pochodzących z prób przekrojowych. Teraz zajmiemy się zagadnieniem budowy modeli regresji,
1.9 Czasowy wymiar danych Do tej pory rozpatrywaliśmy jedynie modele tworzone na podstawie danych empirycznych pochodzących z prób przekrojowych. Teraz zajmiemy się zagadnieniem budowy modeli regresji,
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów re
 Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Wykład 4 Wybór najlepszej procedury. Estymacja parametrów regresji z wykorzystaniem metody bootstrap. Wrocław, 22.03.2017r Wybór najlepszej procedury - podsumowanie Co nas interesuje przed przeprowadzeniem
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Mikroekonometria 12. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
STATYSTYKA
 Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Wykład 1 20.02.2008r. 1. ROZKŁADY PRAWDOPODOBIEŃSTWA 1.1 Rozkład dwumianowy Rozkład dwumianowy, 0 1 Uwaga: 1, rozkład zero jedynkowy. 1 ; 1,2,, Fakt: Niech,, będą niezależnymi zmiennymi losowymi o jednakowym
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Metody Ekonometryczne
 Metody Ekonometryczne Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 4 Uogólniona Metoda Najmniejszych Kwadratów (GLS) 1 / 19 Outline 1 2 3 Jakub Mućk Metody Ekonometyczne
Metody Ekonometryczne Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 4 Uogólniona Metoda Najmniejszych Kwadratów (GLS) 1 / 19 Outline 1 2 3 Jakub Mućk Metody Ekonometyczne
Spis treści 3 SPIS TREŚCI
 Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Statystyka w przykładach
 w przykładach Tomasz Mostowski Zajęcia 10.04.2008 Plan Estymatory 1 Estymatory 2 Plan Estymatory 1 Estymatory 2 Własności estymatorów Zazwyczaj w badaniach potrzebujemy oszacować pewne parametry na podstawie
w przykładach Tomasz Mostowski Zajęcia 10.04.2008 Plan Estymatory 1 Estymatory 2 Plan Estymatory 1 Estymatory 2 Własności estymatorów Zazwyczaj w badaniach potrzebujemy oszacować pewne parametry na podstawie
Definicja danych panelowych Typy danych panelowych Modele dla danych panelowych. Dane panelowe. Część 1. Dane panelowe
 Część 1 to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych Czyli obserwujemy te
Część 1 to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych to dane, które jednocześnie posiadają cechy danych przekrojowych i szeregów czasowych Czyli obserwujemy te
1.1 Klasyczny Model Regresji Liniowej
 1.1 Klasyczny Model Regresji Liniowej Klasyczny model Regresji Liniowej jest bardzo użytecznym narzędziem służącym do analizy danych empirycznych. Analiza regresji zajmuje się opisem zależności między
1.1 Klasyczny Model Regresji Liniowej Klasyczny model Regresji Liniowej jest bardzo użytecznym narzędziem służącym do analizy danych empirycznych. Analiza regresji zajmuje się opisem zależności między
Mikroekonometria 3. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 3 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.hedonic.dta przygotuj model oszacowujący wartość kosztów zewnętrznych rolnictwa 1. Przeprowadź regresję objaśniającą
Mikroekonometria 3 Mikołaj Czajkowski Wiktor Budziński Zadanie 1. Wykorzystując dane me.hedonic.dta przygotuj model oszacowujący wartość kosztów zewnętrznych rolnictwa 1. Przeprowadź regresję objaśniającą
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
STATYSTYKA MAŁYCH OBSZARÓW IV. EMPIRYCZNY NAJLEPSZY PREDYKTOR
 1 STATYSTYKA MAŁYCH OBSZARÓW IV. EMPIRYCZNY NAJLEPSZY PREDYKTOR 3.1 Najlepszy predyktor i empiryczny najlepszy predyktor 3.1.1 Najlepszy predyktor i empiryczny najlepszy predyktor Ogólny mieszany model
1 STATYSTYKA MAŁYCH OBSZARÓW IV. EMPIRYCZNY NAJLEPSZY PREDYKTOR 3.1 Najlepszy predyktor i empiryczny najlepszy predyktor 3.1.1 Najlepszy predyktor i empiryczny najlepszy predyktor Ogólny mieszany model
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Ekonometria. Wprowadzenie do modelowania ekonometrycznego Estymator KMNK. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Wprowadzenie do modelowania ekonometrycznego Estymator Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 1 Estymator 1 / 16 Agenda 1 Literatura Zaliczenie przedmiotu 2 Model
Ekonometria Wprowadzenie do modelowania ekonometrycznego Estymator Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 1 Estymator 1 / 16 Agenda 1 Literatura Zaliczenie przedmiotu 2 Model
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Losowe zmienne objaśniające. Rozszerzenia KMRL. Rozszerzenia KMRL
 MNK z losową macierzą obserwacji Równanie modelu y = X β + ε Jeżeli X zawiera elementy losowe to należy sprawdzić czy E(b β) = E[(X X ) 1 X ε]? = E[(X X ) 1 X ]E(ε) Przypomnienie: Nieskorelowane zmienne
MNK z losową macierzą obserwacji Równanie modelu y = X β + ε Jeżeli X zawiera elementy losowe to należy sprawdzić czy E(b β) = E[(X X ) 1 X ε]? = E[(X X ) 1 X ]E(ε) Przypomnienie: Nieskorelowane zmienne
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Ekonometria egzamin 02/02/ W trakcie egzaminu wolno używać jedynie długopisu o innym kolorze atramentu niż czerwony oraz kalkulatora.
 imię, nazwisko, nr indeksu: Ekonometria egzamin 0/0/0. Egzamin trwa 90 minut.. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu. Złamanie
imię, nazwisko, nr indeksu: Ekonometria egzamin 0/0/0. Egzamin trwa 90 minut.. Rozwiązywanie zadań należy rozpocząć po ogłoszeniu początku egzaminu a skończyć wraz z ogłoszeniem końca egzaminu. Złamanie
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Metody systemowe i decyzyjne w informatyce Ćwiczenia lista zadań nr 2 autorzy: A. Gonczarek, J.M. Tomczak Metody estymacji Zad. 1 Pojawianie się spamu opisane jest zmienną losową x o rozkładzie dwupunktowym
Ekonometria. Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
Wykład 5 Estymatory nieobciążone z jednostajnie minimalną war
 Wykład 5 Estymatory nieobciążone z jednostajnie minimalną wariancją Wrocław, 25 października 2017r Statystyki próbkowe - Przypomnienie Niech X = (X 1, X 2,... X n ) będzie n elementowym wektorem losowym.
Wykład 5 Estymatory nieobciążone z jednostajnie minimalną wariancją Wrocław, 25 października 2017r Statystyki próbkowe - Przypomnienie Niech X = (X 1, X 2,... X n ) będzie n elementowym wektorem losowym.
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
1 Modele ADL - interpretacja współczynników
 1 Modele ADL - interpretacja współczynników ZADANIE 1.1 Dany jest proces DL następującej postaci: y t = µ + β 0 x t + β 1 x t 1 + ε t. 1. Wyjaśnić, jaka jest intepretacja współczynników β 0 i β 1. 2. Pokazać
1 Modele ADL - interpretacja współczynników ZADANIE 1.1 Dany jest proces DL następującej postaci: y t = µ + β 0 x t + β 1 x t 1 + ε t. 1. Wyjaśnić, jaka jest intepretacja współczynników β 0 i β 1. 2. Pokazać
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Zależność. przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna),
,") Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna Korelacja brak korelacji korelacja krzywoliniowa korelacja dodatnia korelacja ujemna Szereg korelacyjny numer
Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna Korelacja brak korelacji korelacja krzywoliniowa korelacja dodatnia korelacja ujemna Szereg korelacyjny numer
Ekonometria Wykład 4 Prognozowanie, sezonowość. Dr Michał Gradzewicz Katedra Ekonomii I KAE
 Ekonometria Wykład 4 Prognozowanie, sezonowość Dr Michał Gradzewicz Katedra Ekonomii I KAE Plan wykładu Prognozowanie Założenia i własności predykcji ekonometrycznej Stabilność modelu ekonometrycznego
Ekonometria Wykład 4 Prognozowanie, sezonowość Dr Michał Gradzewicz Katedra Ekonomii I KAE Plan wykładu Prognozowanie Założenia i własności predykcji ekonometrycznej Stabilność modelu ekonometrycznego
Analizowane modele. Dwa modele: y = X 1 β 1 + u (1) y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:
 y = X 1 β 1 + X 2 β 2 + ε (2) Będziemy analizować dwie sytuacje:") Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
Analizowane modele Dwa modele: y = X 1 β 1 + u (1) Będziemy analizować dwie sytuacje: y = X 1 β 1 + X 2 β 2 + ε (2) zmienne pominięte: estymujemy model (1) a w rzeczywistości β 2 0 zmienne nieistotne:
Uogolnione modele liniowe
 Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Uogólniona Metoda Momentów
 Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
Uogólniona Metoda Momentów Momenty z próby daż a do momentów teoretycznych (Prawo Wielkich Liczb) plim 1 n y i = E (y) n i=1 Klasyczna Metoda Momentów (M M) polega na szacowaniu momentów teoretycznych
Wykład z analizy danych: estymacja punktowa
 Wykład z analizy danych: estymacja punktowa Marek Kubiak Instytut Informatyki Politechnika Poznańska Cel wykładu Model statystyczny W pewnej zbiorowości (populacji generalnej) obserwowana jest pewna cecha
Wykład z analizy danych: estymacja punktowa Marek Kubiak Instytut Informatyki Politechnika Poznańska Cel wykładu Model statystyczny W pewnej zbiorowości (populacji generalnej) obserwowana jest pewna cecha
Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX = 4 i EY = 6. Rozważamy zmienną losową Z =.
 Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Prawdopodobieństwo i statystyka 3..00 r. Zadanie Niech X i Y będą niezależnymi zmiennymi losowymi o rozkładach wykładniczych, przy czym Y EX 4 i EY 6. Rozważamy zmienną losową Z. X + Y Wtedy (A) EZ 0,
Stanisław Cichocki. Natalia Nehrebecka. Wykład 12
 Stanisław Cichocki Natalia Nehrebecka Wykład 12 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne 2. Autokorelacja o Testowanie autokorelacji 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne
Stanisław Cichocki Natalia Nehrebecka Wykład 12 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne 2. Autokorelacja o Testowanie autokorelacji 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne
STATYSTYKA MATEMATYCZNA WYKŁAD stycznia 2010
 STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MATEMATYCZNA WYKŁAD 14 18 stycznia 2010 Model statystyczny ROZKŁAD DWUMIANOWY ( ) {0, 1,, n}, {P θ, θ (0, 1)}, n ustalone P θ {K = k} = ( ) n θ k (1 θ) n k, k k = 0, 1,, n Geneza: Rozkład Bernoulliego
STATYSTYKA MAŁYCH OBSZARÓW II.ESTYMATOR HORVITZA-THOMPSONA, ESTYMATOR KALIBROWANY
 STATYSTYKA MAŁYCH OBSZARÓW II.ESTYMATOR HORVITZA-THOMPSONA, ESTYMATOR KALIBROWANY 2.1 Estymator Horvitza-Thompsona 2.1.1 Estymator Horvitza-Thompsona wartości średniej i globalnej w populacji p-nieobciążony
STATYSTYKA MAŁYCH OBSZARÓW II.ESTYMATOR HORVITZA-THOMPSONA, ESTYMATOR KALIBROWANY 2.1 Estymator Horvitza-Thompsona 2.1.1 Estymator Horvitza-Thompsona wartości średniej i globalnej w populacji p-nieobciążony
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Mikroekonometria 6. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
Mikroekonometria 6 Mikołaj Czajkowski Wiktor Budziński Metody symulacyjne Monte Carlo Metoda Monte-Carlo Wykorzystanie mocy obliczeniowej komputerów, aby poznać charakterystyki zmiennych losowych poprzez
WYKŁAD 6. Witold Bednorz, Paweł Wolff. Rachunek Prawdopodobieństwa, WNE, Uniwersytet Warszawski. 1 Instytut Matematyki
 WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
WYKŁAD 6 Witold Bednorz, Paweł Wolff 1 Instytut Matematyki Uniwersytet Warszawski Rachunek Prawdopodobieństwa, WNE, 2010-2011 Własności Wariancji Przypomnijmy, że VarX = E(X EX) 2 = EX 2 (EX) 2. Własności
Prawdopodobieństwo i statystyka r.
 Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Zadanie. Niech (X, Y) ) będzie dwuwymiarową zmienną losową, o wartości oczekiwanej (μ, μ, wariancji każdej ze współrzędnych równej σ oraz kowariancji równej X Y ρσ. Staramy się obserwować niezależne realizacje
Statystyka matematyczna. Wykład III. Estymacja przedziałowa
 Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
Statystyka matematyczna. Wykład III. e-mail:e.kozlovski@pollub.pl Spis treści Rozkłady zmiennych losowych 1 Rozkłady zmiennych losowych Rozkład χ 2 Rozkład t-studenta Rozkład Fischera 2 Przedziały ufności
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 7 i 8 - Efektywność estymatorów, przedziały ufności Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 7 i 8 1 / 9 EFEKTYWNOŚĆ ESTYMATORÓW, próba
Próbkowanie. Wykład 4 Próbkowanie i rozkłady próbkowe. Populacja a próba. Błędy w póbkowaniu, cd, Przykład 1 (Ochotnicy)
") Wykład 4 Próbkowanie i rozkłady próbkowe µ = średnia w populacji, µ=ey, wartość oczekiwana zmiennej Y σ= odchylenie standardowe w populacji, σ =(Var Y) 1/2, pierwiastek kwadratowy wariancji zmiennej Y,
Wykład 4 Próbkowanie i rozkłady próbkowe µ = średnia w populacji, µ=ey, wartość oczekiwana zmiennej Y σ= odchylenie standardowe w populacji, σ =(Var Y) 1/2, pierwiastek kwadratowy wariancji zmiennej Y,
Czasowy wymiar danych
 Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
Problem autokorelacji Model regresji dla szeregów czasowych Model regresji dla szeregów czasowych y t = X t β + ε t Zasadnicze różnice 1 Budowa prognoz 2 Problem stabilności parametrów 3 Problem autokorelacji
Ćwiczenia IV
 Ćwiczenia IV - 17.10.2007 1. Spośród podanych macierzy X wskaż te, których nie można wykorzystać do estymacji MNK parametrów modelu ekonometrycznego postaci y = β 0 + β 1 x 1 + β 2 x 2 + ε 2. Na podstawie
Ćwiczenia IV - 17.10.2007 1. Spośród podanych macierzy X wskaż te, których nie można wykorzystać do estymacji MNK parametrów modelu ekonometrycznego postaci y = β 0 + β 1 x 1 + β 2 x 2 + ε 2. Na podstawie
STATYSTYKA. Rafał Kucharski. Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2
 STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna
STATYSTYKA Rafał Kucharski Uniwersytet Ekonomiczny w Katowicach 2015/16 ROND, Finanse i Rachunkowość, rok 2 Zależność przyczynowo-skutkowa, symptomatyczna, pozorna (iluzoryczna), funkcyjna stochastyczna
Mikroekonometria 9. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 9 Mikołaj Czajkowski Wiktor Budziński Wielomianowy model logitowy Uogólnienie modelu binarnego Wybór pomiędzy 2 lub większą liczbą alternatyw Np. wybór środka transportu, głos w wyborach,
Mikroekonometria 9 Mikołaj Czajkowski Wiktor Budziński Wielomianowy model logitowy Uogólnienie modelu binarnego Wybór pomiędzy 2 lub większą liczbą alternatyw Np. wybór środka transportu, głos w wyborach,
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład I dr inż. 2015/2016
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład I dr inż. Bogumil.Konopka@pwr.edu.pl 2015/2016 1 Wykład I - plan Sprawy organizacyjne Uczenie maszynowe podstawowe pojęcia Proces modelowania
Dane zgrupowane: każda obserwacja należy do jednej grupy i jest tylko jeden czynnik grupujący
 1 Wstęp 1.1 Czym są efekty losowe? Jednokierunkowa ANOVA Na poprzednich zajęciach mówiliśmy o modelach liniowych, o jedno- i dwuczynnikowej analizie wariancji. W tych modelach estymowaliśmy nieznane wartości
1 Wstęp 1.1 Czym są efekty losowe? Jednokierunkowa ANOVA Na poprzednich zajęciach mówiliśmy o modelach liniowych, o jedno- i dwuczynnikowej analizie wariancji. W tych modelach estymowaliśmy nieznane wartości
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Na A (n) rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)
 rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)") MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
Monte Carlo, bootstrap, jacknife
 Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Monte Carlo, bootstrap, jacknife Literatura Bruce Hansen (2012 +) Econometrics, ze strony internetowej: http://www.ssc.wisc.edu/~bhansen/econometrics/ Monte Carlo: rozdział 8.8, 8.9 Bootstrap: rozdział
Komputerowa Analiza Danych Doświadczalnych
 Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Mikroekonometria 13. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 13 Mikołaj Czajkowski Wiktor Budziński Endogeniczność regresja liniowa W regresji liniowej estymujemy następujące równanie: i i i Metoda Najmniejszych Kwadratów zakłada, że wszystkie zmienne
Mikroekonometria 13 Mikołaj Czajkowski Wiktor Budziński Endogeniczność regresja liniowa W regresji liniowej estymujemy następujące równanie: i i i Metoda Najmniejszych Kwadratów zakłada, że wszystkie zmienne
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Rozpoznawanie obrazów Ćwiczenia lista zadań nr 7 autorzy: A. Gonczarek, J.M. Tomczak Przykładowe problemy Klasyfikacja binarna Dla obrazu x zaproponowano dwie cechy φ(x) = (φ 1 (x) φ 2 (x)) T. Na obrazie
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Autokorelacja Konsekwencje Testowanie autokorelacji 2. Metody radzenia sobie z heteroskedastycznością i autokorelacją Uogólniona Metoda Najmniejszych
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Autokorelacja Konsekwencje Testowanie autokorelacji 2. Metody radzenia sobie z heteroskedastycznością i autokorelacją Uogólniona Metoda Najmniejszych
Metoda największej wiarygodności
 Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
Metoda największej wiarygodności Próbki w obecności tła Funkcja wiarygodności Iloraz wiarygodności Pomiary o różnej dokładności Obciążenie Informacja z próby i nierówność informacyjna Wariancja minimalna
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART. MiNI PW
 WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
WYKŁAD: DRZEWA KLASYFIKACYJNE I REGRESYJNE. Metoda CART MiNI PW Drzewa służą do konstrukcji klasyfikatorów prognozujących Y {1, 2,..., g} na podstawie p-wymiarowego wektora atrybutów (dowolne atrybuty:
Wprowadzenie. Metody bayesowskie Drzewa klasyfikacyjne i lasy losowe Sieci neuronowe SVM. Klasyfikacja. Wstęp
 Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Wstęp Problem uczenia się pod nadzorem, inaczej nazywany uczeniem się z nauczycielem lub uczeniem się na przykładach, sprowadza się do określenia przydziału obiektów opisanych za pomocą wartości wielu
Estymacja parametrów rozkładu cechy
 Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Estymacja parametrów rozkładu cechy Estymujemy parametr θ rozkładu cechy X Próba: X 1, X 2,..., X n Estymator punktowy jest funkcją próby ˆθ = ˆθX 1, X 2,..., X n przybliżającą wartość parametru θ Przedział
Mikroekonometria 2. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 2 Mikołaj Czajkowski Wiktor Budziński STATA wczytywanie danych 1. Import danych do Staty Copy-paste z Excela do edytora danych Import z różnych formatów (File -> Import -> ) me.sleep.txt,
Mikroekonometria 2 Mikołaj Czajkowski Wiktor Budziński STATA wczytywanie danych 1. Import danych do Staty Copy-paste z Excela do edytora danych Import z różnych formatów (File -> Import -> ) me.sleep.txt,
Statystyczna analiza danych
 Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Metody Ekonometryczne
 Metody Ekonometryczne Metoda Najmniejszych Kwadratów Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 1 1 / 45 Outline Literatura Zaliczenie przedmiotu 1 Sprawy organizacyjne
Metody Ekonometryczne Metoda Najmniejszych Kwadratów Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Metody Ekonometyczne Wykład 1 1 / 45 Outline Literatura Zaliczenie przedmiotu 1 Sprawy organizacyjne
Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego
 funkcję obserwowalnego wektora losowego") Rozdział 1 Statystyki Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego X = (X 1,..., X n ). Uwaga 1 Statystyka jako funkcja wektora zmiennych losowych jest zmienną losową
Rozdział 1 Statystyki Definicja 1 Statystyką nazywamy (mierzalną) funkcję obserwowalnego wektora losowego X = (X 1,..., X n ). Uwaga 1 Statystyka jako funkcja wektora zmiennych losowych jest zmienną losową
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie