Agnieszka Nowak Brzezińska Wykład 2 z 5
|
|
|
- Antonina Domańska
- 10 lat temu
- Przeglądów:
Transkrypt
1 Agnieszka Nowak Brzezińska Wykład 2 z 5

2 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja Wszystkie ilościowe Zakłada istnienie podobnych grup Regresja logistyczna Klasyfikacja Wszystkie ilościowe Oblicza prawdopodobieństwo Naiwny klasyfikator Bayesa klasyfikacja Tylko nominalne (jakościowe) Wymaga dużego zbioru danych K-NN Regresja lub klasyfikacja Wszystkie ilościowe Dobre dla nieliniowych zależności, dla odchyleń w danych, i dobrze wyjaśnia dane Sieci neuronowe Regresja lub klasyfikacja Wszystkie ilościowe Model czarnej skrzynki CART Regresja lub klasyfikacja Każde Dobrze wyjaśnia rozumowanie za pomocą drzew klasyfikacji

3 Klasyfikacja to technika, którą wykorzystuje się w takich dziedzinach jak np. statystyka, sztuczna inteligencja i uczenie maszynowe. Oprócz tego znajduje ona zastosowanie w wielu sytuacjach, takich jak: rozpoznawanie obiektów obrazów graficznych, przewidywanie nowości na rynkach finansowych, przy wspomaganiu przeróżnych decyzji opierających się na dużej ilości informacji oraz w medycynie przy diagnozowaniu chorób pacjentów.

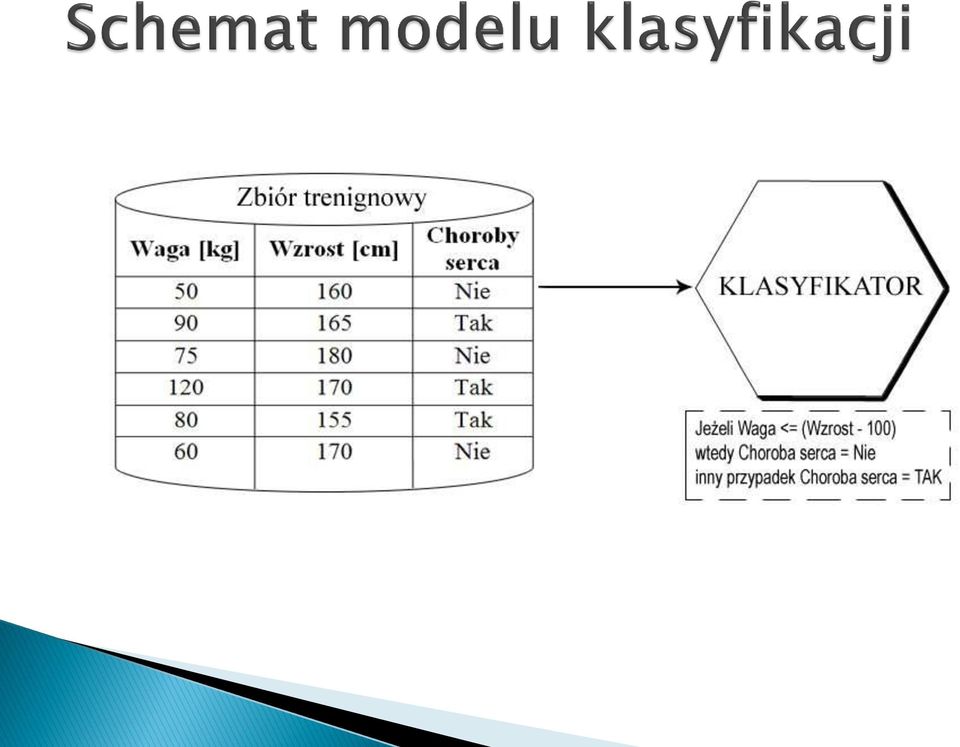
4 Klasyfikacja umożliwia znalezienie w zbiorze predefiniowanych klas odwzorowania nieznanych danych za pomocą stworzonego modelu zwanego klasyfikatorem. Klasyfikowanie nowych obiektów czy też bardziej pełne uświadomienie istniejących podziałów tych obiektów na predefiniowane klasy określonej bazy danych odbywa się za pośrednictwem modelu, który tworzony jest na podstawie danych zawartych w tej bazie. Klasyfikację można podzielić na następujące etapy: 1. Budowa klasyfikatora (modelu). 2. Testowanie modelu. 3. Wykorzystanie zbudowanego modelu do przewidzenia nieznanych wartości.

5 Najistotniejszym zadaniem klasyfikacji jest budowa określonego modelu, który posłuży później do predykcji przydziału do klasy, gdzie jest ona nieznana. W tym przypadku wykorzystuje się do tego część zebranych danych (np. przykłady, doświadczenia, czynniki, wektory itd.) tzw. zbiór treningowy. Zbiór ten wydzielany jest na podstawie podziału całej bazy danych na dwie części, z czego jedna część to właśnie zbiór treningowy, a druga to zbiór testowy. Oba zbiory składają się z listy cech (atrybutów) oraz przyporządkowanych do tych cech klas, będących wartościami decyzyjnymi. Klasyfikator opierając się na zbiorze treningowym uczy się właściwości danych i przypisuje każdemu wektorowi klasę, czyli wartość decyzyjną, będącą wielkością wyjściową modelu.
 oraz przyporządkowanych do tych cech klas, będących wartościami decyzyjnymi.")
6 Testowanie zbudowanego modelu to określenie jakości (dokładności) z jaką dokonuje on predykcji klas. Testowanie to odbywa się z wykorzystaniem zbioru testowego, który jest zbiorem przykładów utworzonym przy wcześniejszym podziale całej bazy danych na dwie części. W zależności od ilości danych (np. przykładów) jakie posiada określona baza danych, podział ten jest dokonywany w różnych proporcjach, gdzie najczęściej zbiór testowy przyjmuje 25-50% danych, a zbiór treningowy pozostałą część. Dokładność danego klasyfikatora wyznaczana jest w następujący sposób: znane wartości decyzyjne przykładów zbioru testowego porównywane są z klasami przewidzianymi przy użyciu tego modelu na tych przykładach. Z dokonanego porównania wyznaczana jest procentowa dokładność poprawnie zakwalifikowanych przykładów do danych klas, co daje wartość współczynnika jakości danego klasyfikatora. Jeżeli jest on akceptowalny można wykorzystać ten model przy klasyfikacji nowych danych i przy predykcji wartości decyzyjnych dla przykładów, w których jest ona utracona bądź niewiadoma.

7
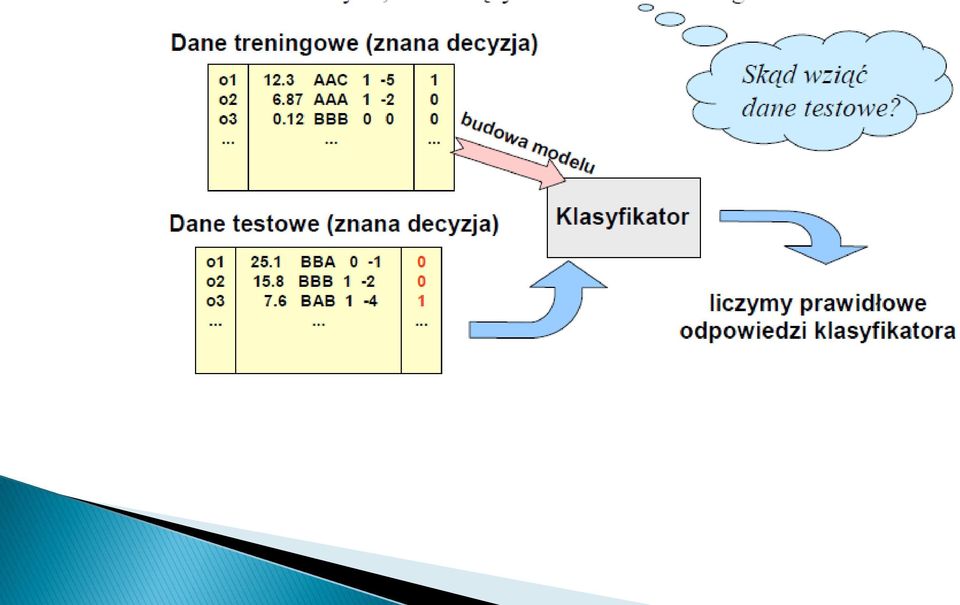
8 Mamy dany zbiór danych podzielony na klasy decyzyjne, oraz pewien algorytm klasyfikujący. Problem: zbadać skuteczność algorytmu na tych danych. Kryterium skuteczności: liczba (procent) prawidłowo rozpoznanych obiektów testowych, niebiorących udziału w treningu
 prawidłowo rozpoznanych")
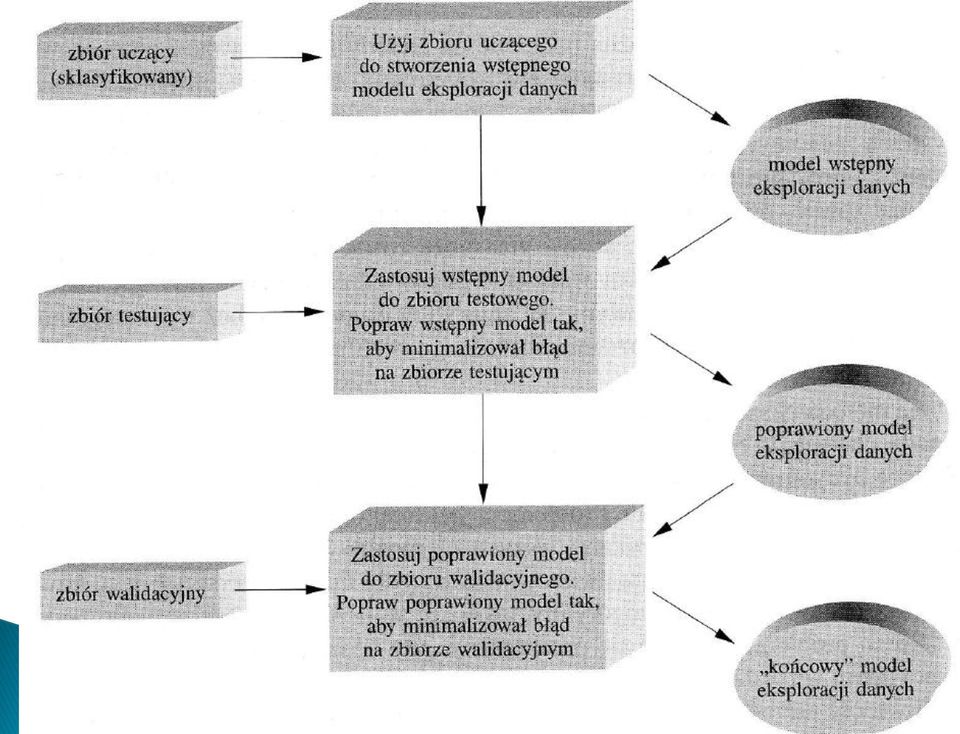
9 W pierwszym kroku budowany jest model opisujący zadany zbiór danych (treningowy zbiór danych) składający się ze zbioru obiektów (krotek) opisanych za pomocą atrybutów. Jeden z atrybutów jest atrybutem klasyfikującym i określa etykietę klasy, do której należy obiekt. Obiekty tworzące zbiór treningowy wybierane są losowo z pewnej populacji. Ten etap klasyfikacji nazywany jest też uczeniem z nadzorem, gdyż podana jest klasyfikacja każdego obiektu (przykładem nauczania bez nadzoru jest tworzenie skupień, clustering)

10 Utworzony model klasyfikacji reprezentowany jest w postaci: reguł klasyfikacji, drzew decyzyjnych, formuł matematycnych. Przykład: mając bazę danych z informacjami o kartach kredytowych klientów można utworzyć reguły klasyfikacyjne określające klientów o dobrej lub słabej zdolności kredytowej. Reguły mogą być wykorzystane do klasyfikacji przyszłych przypadków, jak również do lepszego zrozumienia zawartości bazy danych

11 W drugim kroku model jest używany do klasyfikacji. Najpierw oceniana jest dokładność modelu (klasyfikatora). W tym celu posługujemy się zbiorem testowym, który wybrany jest losowo i jest niezależny od zbioru treningowego. Dokładność modelu na zadanym zbiorze testowym określona jest przez procentową liczbę trafnych klasyfikacji, tzn. jaki procent przypadków testowych został prawidłowo zaklasyfikowany za pomocą modelu. Dla każdego przypadku możemy porównać znaną etykietę klasy z etykietą przypisaną przez model. Jeśli dokładność modelu została oceniona jako wystarczająca, model można użyć do klasyfikacji przyszłych przypadków (obiektów) o nieznanej etykiecie klasy.

12 Predykcja (przewidywanie) może być rozumiana jako wykorzystanie modelu do oszacowania (obliczenia) wartości (lub przedziału wartości), jaką z dużym prawdopodobieństwem może mieć atrybut analizowanego obiektu. Wartością tego atrybutu może być w szczególności etykieta klasy. Z tego punktu widzenia klasyfikacja i regresja są dwoma głównymi rodzajami problemów predykcyjnych; przy czym klasyfikacja jest używana do przewidzenia wartości dyskretnych lub nominalnych, a regresja do oszacowania wartości ciągłych lub uporządkowanych. Umowa: przewidywanie etykiet klas klasyfikacja, przewidywanie wartości ciągłych (technikami regresji) predykacja.

13 Klasyfikacja i predykcja mają wiele zastosowań, na przykład: akceptacja udzielenia kredytu, diagnostyka medyczna, przewidywanie wydajności, selektywny marketing, inne

14 mały Duże ryzyko majątek Średni, duży oszczędności Małe, średnie duże majątek Małe ryzyko duży Średni Małe ryzyko Duże ryzyko


15
16 Techniką bardzo podobną do klasyfikacji jest regresja znajdująca zastosowanie w takich dziedzinach jak np. logistyka, analiza danych finansowych, prognozowanie sprzedaży, medycyna, procesy produkcyjne itp. Głównym celem regresji jest zbudowanie modelu, który podobnie jak wcześniej model klasyfikacji posłuży do predykcji jednej zmiennej na podstawie znanych wartości innych zmiennych. Podstawową różnicą pomiędzy regresją i klasyfikacją, jest to, że w klasyfikacji przewidywana zmienna przyjmuje wartość kategoryczną, natomiast w regresji jej celem jest przewidzenie zmiennej przyjmującej wartość ciągłą (numeryczną).

17
18
19 Błędy w klasyfikacji
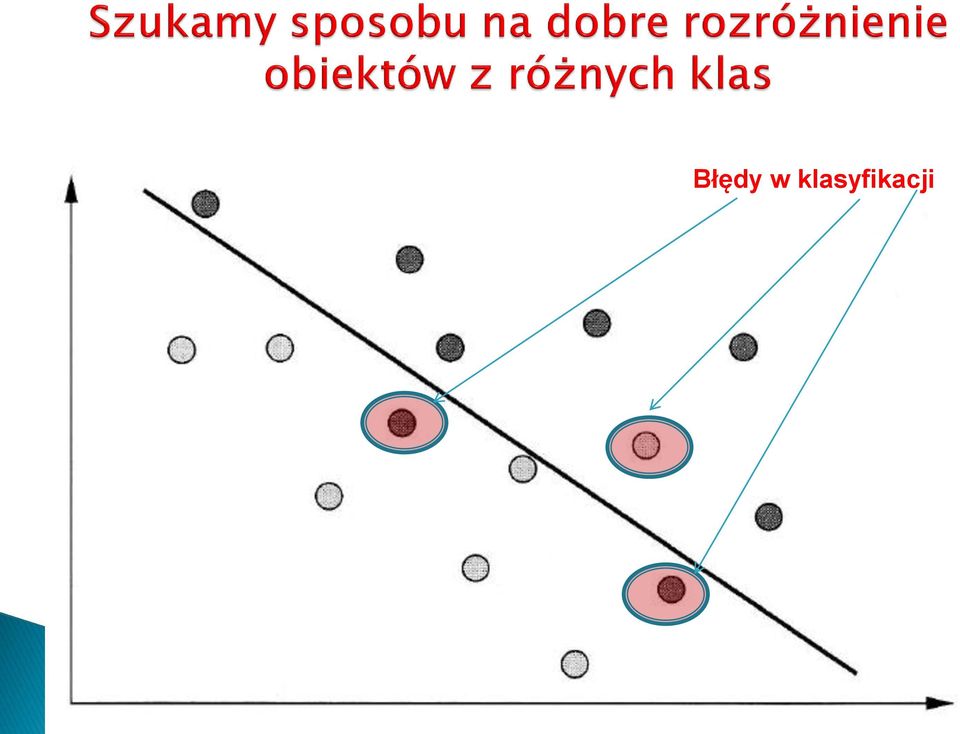
20 Ok.!
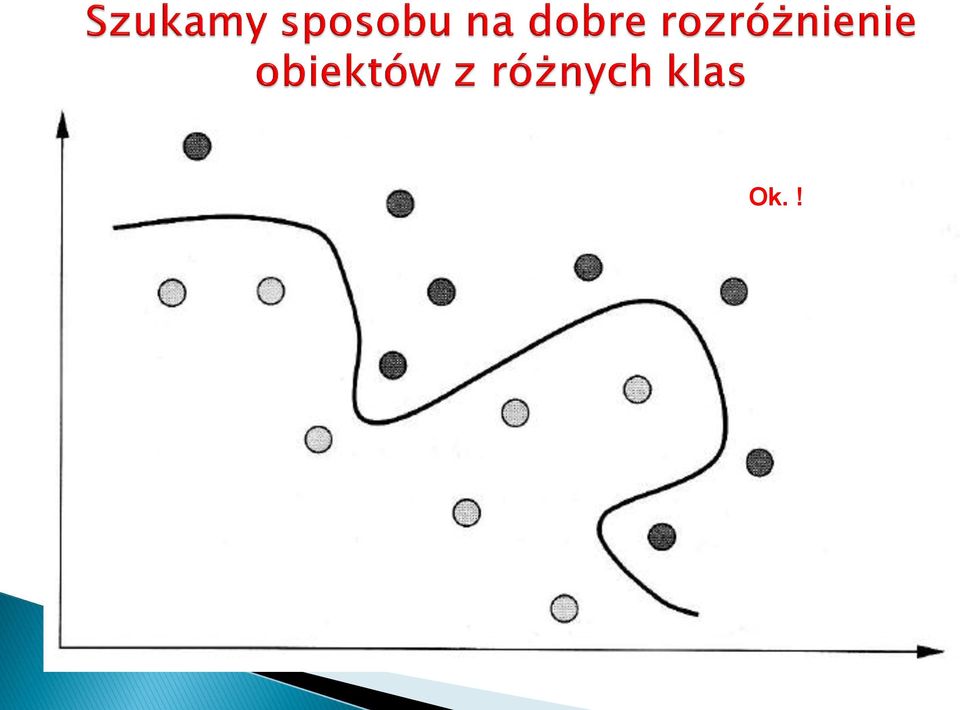
21 Ok.!
22 W praktyce stosowanie regresji tak samo jak w klasyfikacji sprowadza się do trzech etapów: budowy klasyfikatora (modelu), testowania modelu oraz wykorzystania zbudowanego modelu do przewidzenia nieznanych wartości. Budowa modelu regresji odbywa się w podobny sposób do budowy modelu klasyfikacji czyli wykorzystuje się do tego celu zebrane dane podzielone na zbiór testowy i treningowy oraz algorytm regresji. Jedną z różnic występującą między tymi dwoma technikami jest to, iż w danych do nauki modelu regresji wartością decyzyjną nie jest jak w przypadku klasyfikacji kategoria, lecz wartość ciągła. Kolejną różnicą jest to, że w klasyfikacji, decyzja opiera się na przyporządkowaniu nowego przykładu do jednej ze znanych wartości kategorycznych zbioru treningowego, natomiast w regresji predykcja ta zachodzi poprzez obliczenie nowej wartości decyzyjnej dla danego przykładu.
23 Proces regresji służy do ustalenia wartości parametrów tak, by stworzyć funkcję do obliczania wartości decyzyjnej możliwie jak najlepiej odpowiadającą określonemu zbiorowi danych. Modele regresji najczęściej opierają się na funkcji: - regresji liniowej, - regresji nieliniowej (wielorakiej).

24
25 Będziemy dokonywać predykcji, a więc przewidywania wartości zmiennej ilościowej. Przykład będzie dotyczył zbioru 77 płatków śniadaniowych, dla których badane są różne parametry: poziom cukru, tłuszczu, błonnika, a ocena wyrażana jest w postaci tzw. wartości odżywczej płatków.
26
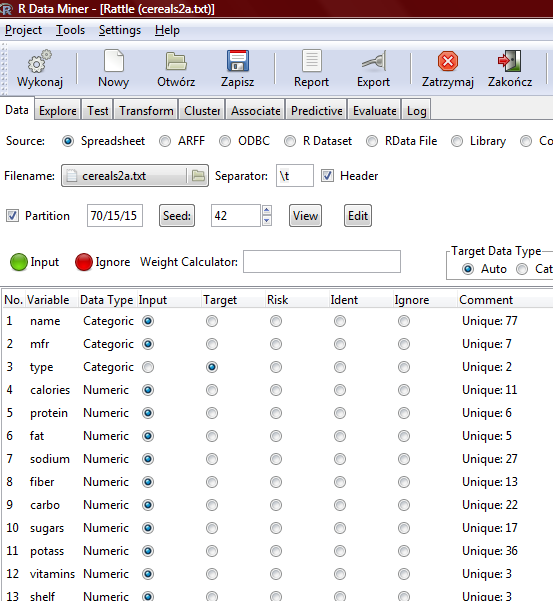
27
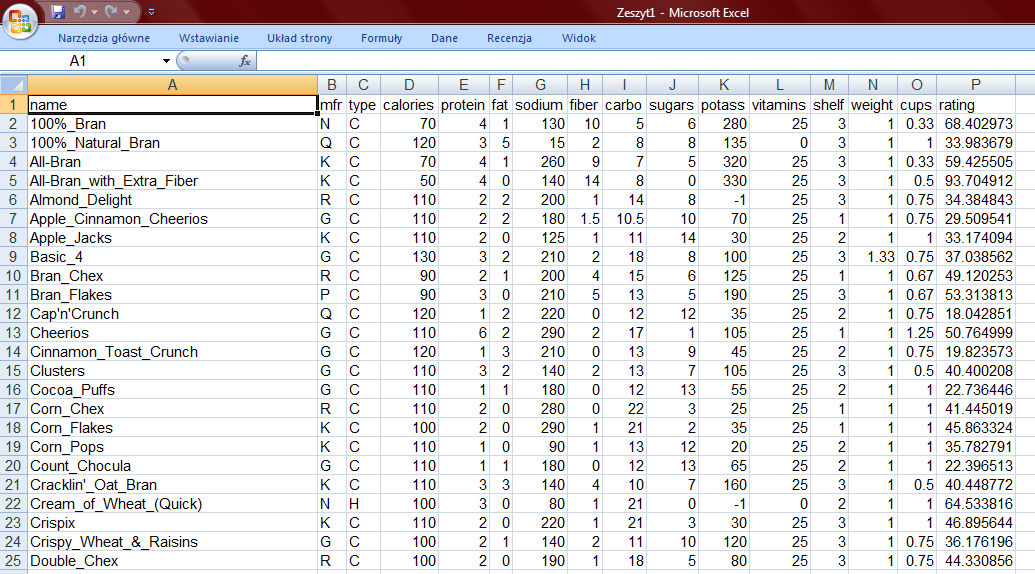
28 Zbiór płatków śniadaniowych (R)
29 Zbiór płatków śniadaniowych (Excel)
30
31
32
33 Szukamy wiedzy o płatkach Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer integer integer double double integer integer integer integer double double double
34 Szukamy wiedzy o płatkach
35 Szukamy wiedzy o płatkach
36 Szukamy wiedzy o płatkach name n missing unique lowest : 100%_Bran 100%_Natural_Bran All-Bran All-Bran_with_Extra_Fiber Almond_Delight highest: Triples Trix Wheat_Chex Wheaties Wheaties_Honey_Gold mfr n missing unique A G K N P Q R Frequency % type n missing unique C (74, 96%), H (3, 4%)
37 Szukamy wiedzy o płatkach calories n missing unique Mean Frequency % protein n missing unique Mean Frequency %
38 Szukamy wiedzy o płatkach carbo n missing unique Mean lowest : , highest: sugars n missing unique Mean Frequency % potass n missing unique Mean lowest : , highest:
39 Szukamy wiedzy o płatkach vitamins n missing unique Mean (8, 10%), 25 (63, 82%), 100 (6, 8%) shelf n missing unique Mean (20, 26%), 2 (21, 27%), 3 (36, 47%) weight n missing unique Mean Frequency %
40 Szukamy wiedzy o płatkach fat n missing unique Mean Frequency % sodium n missing unique Mean lowest : , highest: fiber n missing unique Mean Frequency %
41 Szukamy wiedzy o płatkach cups n missing unique Mean Frequency % rating n missing unique Mean lowest : , highest:
42 Szukamy wiedzy o płatkach
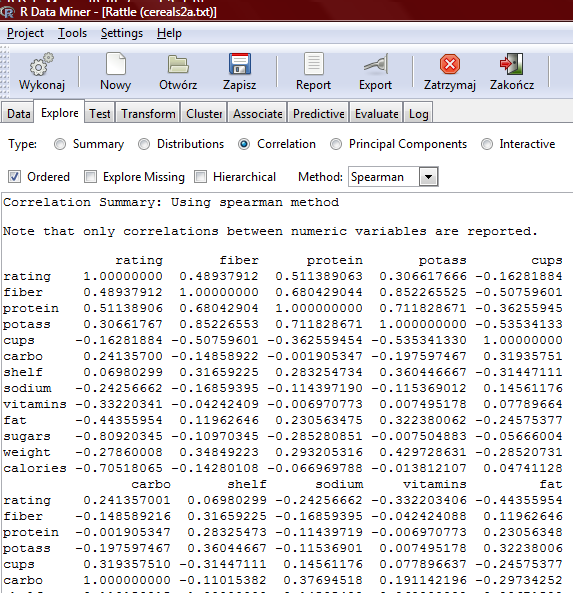
43 Szukamy wiedzy o płatkach
44 Szukamy wiedzy o płatkach
45 Szukamy wiedzy o płatkach
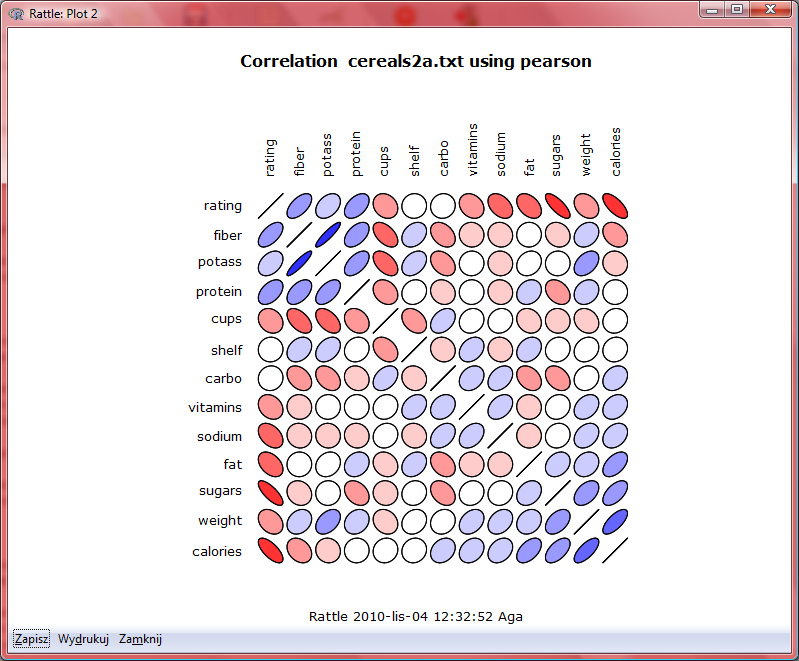
46 Szukamy wiedzy o płatkach sprawdzamy korelację między poziomem cukru w płatkach a ich wartością odżywczą
47 Szukamy wiedzy o płatkach sprawdzamy rozkład wartości odżywczej płatków ze względu na typ
48 Szukamy wiedzy o płatkach histogramy dla danych ilościowych NIE!!!

49 Szukamy wiedzy o płatkach histogramy dla danych jakościowych TAK!!!

50
51
52 rating Korelacja Pearsona w excelu sugars sugars

53 Korelacja Spearmana w excelu
54 The Spearman correlation, called Spearman s rho, is a special case of the Pearson correlation computed on ranked data.
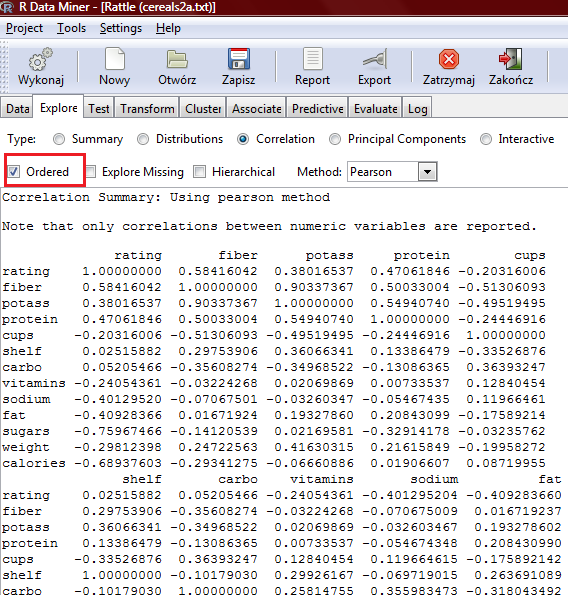
55
56
57
58
59

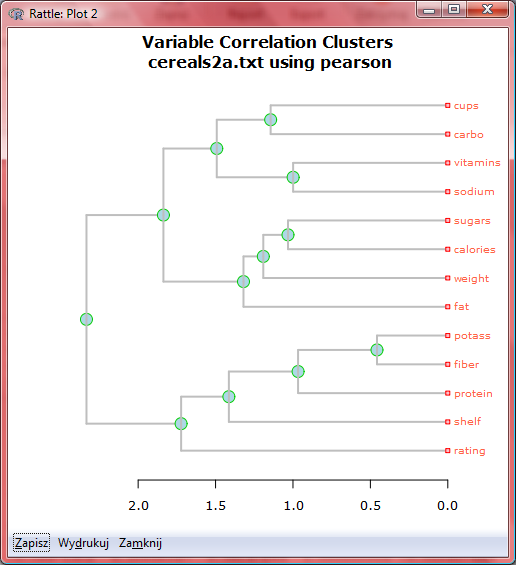
60 Szukamy wiedzy o płatkach korelacja dla wszystkich zmiennych NIE!!!
61 Szukamy wiedzy o płatkach korelacja może być przedstawiona dendrogramem
62
63
64 Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące pomiędzy zmiennymi wejściowymi (objaśniającymi) a wyjściowymi (objaśnianymi). Innymi słowy dokonujemy estymacji jednych danych korzystając z innych. Istnieje wiele różnych technik regresji.
65 Metoda zakłada, że pomiędzy zmiennymi objaśniającymi i objaśnianymi istnieje mniej lub bardziej wyrazista zależność liniowa. Mając zatem zbiór danych do analizy, informacje opisujące te dane możemy podzielić na objaśniane i objaśniające. Wtedy też wartości tych pierwszych będziemy mogli zgadywać znając wartości tych drugich. Oczywiście tak się dzieje tylko w sytuacji, gdy faktycznie między tymi zmiennymi istnieje zależność liniowa. Przewidywanie wartości zmiennych objaśnianych (y) na podstawie wartości zmiennych objaśniających (x) jest możliwe dzięki znalezieniu tzw. modelu regresji. W praktyce polega to na podaniu równania prostej, zwanej prostą regresji o postaci: y = b_0 + b_1 x gdzie: y - jest zmienną objaśnianą, zaś x - objaśniającą. W równaniu tym bardzo istotną rolę odgrywają współczynniki b_0 i b_1, gdzie b_1 jest nachyleniem linii regresji, zaś b_0 punktem przecięcia linii regresji z osią x (wyrazem wolnym) a więc przewidywaną wartością zmiennej objaśnianej gdy zmienna objaśniająca jest równa 0.
66 rating sugars sugars
67 rating sugars Liniowy (sugars) sugars
68
69 y b0 b1 x rating * sugars A więc: b b Oszacowana wartość odżywcza płatków (rating) jest równa 59.4 i 2.42 razy waga cukrów (sugars) w gramach Czyli linia regresji jest liniowym przybliżeniem relacji między zmiennymi x (objaśniającymi, niezależnymi) a y (objaśnianą, zależną) w tym przypadku między zawartością cukrów a wartością odżywczą. Możemy zatem dzięki regresji: SZACOWAĆ, PRZEWIDYWAĆ
70 Gdy np. chcemy oszacować wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=1 gram cukrów. Wówczas za pomocą oszacowanego równania regresji możemy wyestymować wartość odżywczą płatków śniadaniowych zawierającym 1 gram cukrów: y *
71 Gdy np. chcemy oszacować wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=5 gram cukrów. Wówczas za pomocą oszacowanego równania regresji możemy wyestymować wartość odżywczą płatków śniadaniowych zawierającym 5 gram cukrów: y *5 47.3

72 Jak widać, niestety oszacowanie zgodne z równaniem regresji jest nie do końca zgodne z rzeczywistą wartością odżywczą płatków.

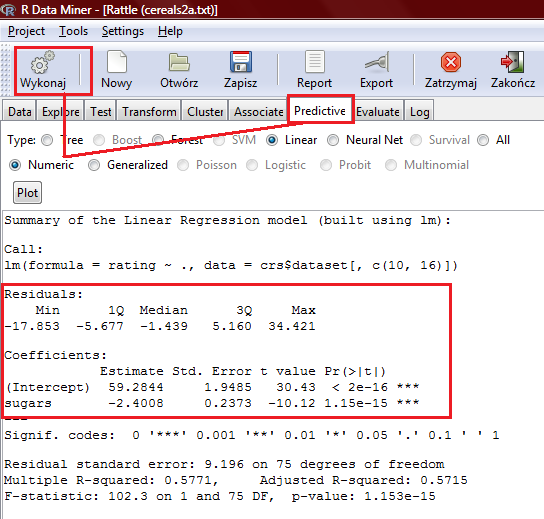
73 Czyli każde płatki mające 1 gram cukru powinny mieć wartość odżywczą równą 56,98 ale jak widać tak nie jest. Płatki Cheerios mają wartość odżywczą równą 50,765. Czyli nastąpiło PRZESACOWANIE wartości odżywczej płatków o 6,215. Graficznie tę odległość widzimy jako odległość punktu reprezentującego te płatki od jego rzutu pionowego na linię regresji.
74 Odległość ta mierzona jako: ( y y) Nazywać będziemy błędem predykcji (błędem oszacowania, wartością resztową, rezyduum). Oczywiście powinno się dążyć do minimalizacji błędu oszacowania. Służy do tego metoda zwana metodą najmniejszych kwadratów. Metoda polega na tym, że wybieramy linię regresji która będzie minimalizować sumę kwadratów reszt dla wszystkich punktów danych.
75
76 Odpowiedź: pewnie NIE. Prawdziwą liniową zależność między wartością odżywczą a zawartością cukrów dla WSZYSTKICH rodzajów płatków reprezentuje równanie: y x Losowy błąd

77 1. Obliczamy wartości x i,y i,x i y i,x i 2
78 1. Obliczamy wartości: x i =534 y i = x i y i = x i2 = Podstawiamy do wzorów: b * / / b0 y b1 x *
79 Wyraz wolny b0 jest miejscem na osi y gdzie linia regresji przecina tę oś czyli jest to przewidywana wartość zmiennej objaśnianej gdy objaśniająca równa się zeru. Współczynnik kierunkowy prostej regresji oznacza szacowaną zmianę wartość y dla jednostkowego wzrostu x wartość b 1 = mówi, że jeśli zawartość cukrów wzrośnie o 1 gram to wartość odżywcza płatków zmniejszy się o 2.42 punktu. Czyli płatki A których zawartość cukrów jest o 5 większa niż w płatkach B powinny mieć oszacowaną wartość odżywczą o 5 razy 2.42 = 12.1 punktów mniejszą niż płatki typu B.
80 Omawiając regresję liniową (prostą) rozpatrywaliśmy dotąd jedynie takie przypadki zależności między zmiennymi objaśniającymi a objaśnianymi gdzie zmienna objaśniana była zależna tylko od jednej konkretnej zmiennej objaśniającej. Jednak w praktyce niezwykle często zmienna objaśniana zależna jest nie od jednej ale od kilku (wielu) zmiennych objaśniających. Będziemy zatem rozważać ogólne równanie regresji postaci: y b 0 b x 1 1 b 2 x 2... b m x m gdzie m oznacza liczbę (najczęściej kilku) zmiennych objaśniających.
81 W środowisku R procedura znajdowania równania regresji dla podanego zbioru danych możliwa jest dzięki wykorzystaniu funkcji lm. Komenda R postaci lm(y ~ x) mówi, że chcemy znaleźć model regresji liniowej dla zmiennej y w zależności od zmiennej x.
82 Wówczas pełny zapis okna dialogu z R-em będzie następujący: > dane<- read.table("c:\\cereals.data", header = TRUE, row.names = 1) > model<-lm(rating~sugars, data=dane) > summary(model) Call: lm(formula = rating ~ sugars, data = dane) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** sugars e-15 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 75 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 75 DF, p-value: 1.153e-15 > równanie regresji, gdy zmienną objaśnianą będzie zmienna rating (wartość odżywcza płatków) zaś objaśniającą sugars (poziom cukrów), będzie następującej postaci: rating = -2.4 * sugars+ 59.3
83 Teraz możemy przewidywać, że gdy poziom cukrów wynosi np 1 to wartość odżywcza płatków będzie wynosić 56.9 zaś gdy poziom cukrów będzie wynosił 10 wówczas wartość odżywcza zmaleje do wartości 35.3 (patrz poniżej). > predict(model,data.frame(sugars=10), level = 0.9, interval = "confidence") fit lwr upr > predict(model,data.frame(sugars=1), level = 0.9, interval = "confidence") fit lwr upr
84
85
86 Widać z nich, że między zmienną objaśniającą sugars a zmienną objaśnianą fiber istnieje pewna zależność (w miarę wzrostu wartości sugars spada wartość rating). Z kolei analizując rozrzut obserwacji ze względu na wartości zmiennej objaśniającej fiber oraz objaśnianej rating już tak silnej zależności nie dostrzegamy. Sprawdźmy jak będzie się zachowywać rozrzut wartości zmiennych objaśnianych w oparciu o te dwie zmienne objaśniające razem.
87 > model<-lm(rating~sugars+fiber, data=dane) > summary(model) Call: lm(formula = rating ~ sugars + fiber, data = dane) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** sugars < 2e-16 *** fiber e-14 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 74 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 74 DF, p-value: < 2.2e-16 W tym przypadku równanie regresji będzie wyglądać następująco: Rating = * sugars * fiber
88 Aby zinterpretować współczynnik nachylenia prostej regresji: Rating = * sugars * fiber b 1 = wartość odżywcza maleje o punktu, jeśli zawartość cukru rośnie o jedną jednostkę. Zakładamy przy tym, że zawartość błonnika (fiber) jest stała. b 2 = wartość odżywcza rośnie o punktu, jeśli zawartość błonnika rośnie o jedną jednostkę a zawartość cukru (sugars) jest stała. Uogólniając będziemy mówić, że dla m zmiennych objaśniających zachodzi reguła, zgodnie z którą: oszacowana zmiana wartości zmiennej odpowiedzi to} b i, jeśli wartość zmiennej x i rośnie o jednostkę i zakładając, że wszystkie pozostałe wartości zmiennych są stałe.
89 Błędy predykcji są mierzone przy użyciu reszt $y - \hat{y}$. Uwaga: w prostej regresji liniowej reszty reprezentują odległość (mierzoną wzdłuż osi pionowej) pomiędzy właściwym punktem danych a linią regresji, zaś w regresji wielokrotnej, reszta jest reprezentowana jako odległość między właściwym punktem danych a płaszczyzną lub hiperpłaszczyzną regresji. Przykładowo płatki Spoon Size Shredded Wheat zawierają x 1 =0 gramów cukru i x 2 = 3 gramy błonnika, a ich wartość odżywcza jest równa podczas gdy wartość oszacowana, podana za pomocą równania regresji: > predict(model, data.frame(sugars=0,fiber=3),level=0.95, interval="confidence") fit lwr upr Zatem dla tych konkretnych płatków reszta jest równa = Zwróćmy uwagę na to, że wyniki, które tutaj zwraca funkcja R: predict są bardzo istotne. Mianowicie, oprócz podanej (oszacowanej, przewidywanej) wartości zmiennej objaśniającej, otrzymujemy również przedział ufności na zadanym poziomie ufności równym 0.95, który to przedział mieści się między wartością (lwr) a (upr).
90 Pozwala stwierdzić czy oszacowane równanie regresji jest przydatne do przewidywania. Określa stopień w jakim linia regresji najmniejszych kwadratów wyjaśnia zmienność obserwowanych danych. 2 x y y y y ( y y)
91 x y y y y 2 ( y y) Całkowita suma kwadratów SST n i 1 ( y y) 2 Regresyjna suma kwadratów SSR n i 1 ( y y) 2 Suma kwadratów błędów oszacowania: SSE n i 1 ( y y) 2 Wówczas współczynnik determinacji r 2 : 2 r SSR SST
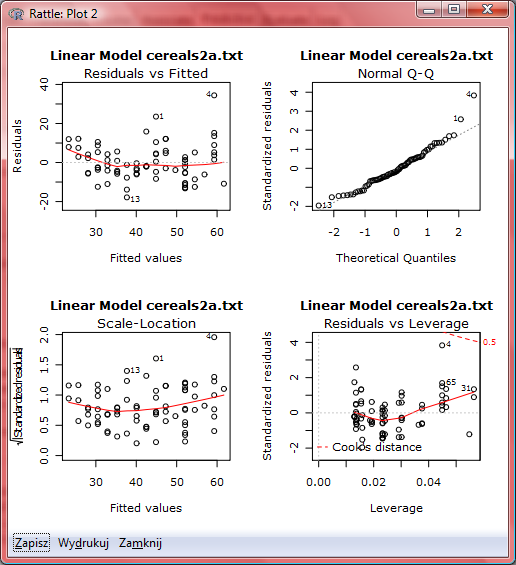
92 Współczynnik determinacji r 2 Współczynnik determinacji r 2 : 2 r SSR SST Mierzy stopień dopasowania regresji jako przybliżenia liniowej zależności pomiędzy zmienną celu a zmienną objaśniającą. Jaka jest wartość maksymalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja idealnie pasuje do danych, co ma miejsce wtedy gdy każdy z punktów danych leży dokładnie na oszacowanej linii regresji. Wówczas nie ma błędów oszacowania, a więc wartości resztowe (rezydua) wynoszą 0, a więc SSE=0 a wtedy SST = SSR a r 2 =1. Jaka jest wartość minimalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja nie wyjaśnia zmienności, wtedy SSR = 0, a więc r 2 =0. Im większa wartość r 2 tym lepsze dopasowanie regresji do zbioru danych.

93 Jak już wspomnieliśmy na początku, często w świecie rzeczywistym mamy do czynienia z zależnościami zmiennej objaśnianej nie od jednej ale raczej od wielu zmiennych objaśniających. Wykonanie tego typu analiz w pakiecie R nie jest rzeczą trudną. Wręcz przeciwnie. Nim przeprowadzimy analizę zależności zmiennej rating od wielu zmiennych objaśniających np. sugars oraz fiber przyjrzyjmy się wykresom rozrzutu dla tych zmiennych osobno. Wykres rozrzutu bowiem doskonale odzwierciedla zależności między pojedynczymi zmiennymi.
94
95
96 Widać z nich, że między zmienną objaśniającą sugars a zmienną objaśnianą fiber istnieje pewna zależność (w miarę wzrostu wartości sugars spada wartość rating). Z kolei analizując rozrzut obserwacji ze względu na wartości zmiennej objaśniającej fiber oraz objaśnianej rating już tak silnej zależności nie dostrzegamy. Sprawdźmy jak będzie się zachowywać rozrzut wartości zmiennych objaśnianych w oparciu o te dwie zmienne objaśniające razem.
97 Niezwykle istotna jest miara nazwana już wcześniej współczynnikiem determinacji R 2 określana za pomocą wzoru: n ^ n 2 SSR ^ 2ˆ 2ˆ SSR ( y ˆ y) i 1 R SST SST ( y ˆ y) gdzie SSR to regresyjna suma kwadratów zaś SST to całkowita suma kwadratów Będziemy go interpetować jako część zmienności zmiennej objaśnianej, która jest wyjaśniana przez liniową zależność ze zbiorem zmiennych objaśniających. Im większa będzie liczba zmiennych objaśniających tym \textbf{nie mniejsza} będzie wartość współczynnika determinacji $R^2$. Możemy wnioskować, że gdy dodajemy nową zmienną objaśniającą do modelu, wartość $R^2$ będzie nie mniejsza niż przy modelu o mniejszej liczbie zmiennych. Oczywiście skala (wielkość) tej różnicy jest bardzo istotna w zależności od tego czy dodamy tę zmienną do modelu czy też nie. Jeśli wzrost jest duży to uznamy tę zmienną za znaczącą (przydatną). i 1
98 Jeśli takie reszty obliczymy dla każdej obserwacji to możliwe będzie wyznaczenie wartości współczynnika determinacji R 2. W naszym przypadku jest on równy czyli %. Oznacza to w naszej analizie, że % zmienności wartości odżywczej jest wyjaśniane przez liniową zależność pomiędzy zmienną wartość odżywcza a zbiorem zmiennych objaśniających - zawartością cukrów i zawartością błonnika. Jeśli popatrzymy jaka była wartość tego współczynnika, gdy badaliśmy na początku zależność zmiennej objaśnianej tylko od jednej zmiennej objaśniającej (cukry) to wartość ta wynosiła R 2 = 57.71%. Dla dwóch zmiennych objaśniających ta wartości wyniosła %. Czyli powiemy, że dodając nową zmienną objaśniającą (w tym przypadku błonnik) możemy wyjaśnić dodatkowe = 22.19% zmienności wartości odżywczej (rating) płatków. Typowy błąd oszacowania jest tu obliczany jako standardowy błąd oszacowania s i wynosi 6.22 punktu. Oznacza to, że estymacja wartości odżywczej płatków na podstawie zawartości cukrów i błonnika zwykle różni się od właściwej wartości o 6.22 punktu. Jeśli nowa zmienna jest przydatna, to błąd ten powinien się zmniejszać po dodaniu nowej zmiennej.
 zaś n oznacza")
99 Najprostszym sposobem na wybór optymalnej liczby zmiennych objaśniających jest współczynnik R 2 adj zwany skorygowanym. Wiedząc, że R 2 = 1 SSE/SST wartość R 2 adj obliczymy jako: 2 R adj 1 SSE n p SST n 1 gdzie p oznacza liczbę parametrów modelu (i jest to zazwyczaj liczba zmiennych objaśniających + 1) zaś n oznacza wielkość próby. Zwykle wartość R 2 adj będzie po prostu nieco mniejsza niż wartość R 2. W środowisku R współczynnik determinacji R 2 wyznaczymy stosując bezpośrednio komendę: summary(model.liniowy)\$r.square Z kolei współczynnik determinacji ale ten tzw. skorygowany (ang. Adjusted) za pomocą komendy: summary(model.liniowy)\$adj.r.squared
100 Chcąc wyznaczyć wartości tych współczynników dla naszego testowego modelu z dwiema zmiennymi objaśniającymi sugars oraz fiber w środowisku R użyjemy odpowiednich komend, jak to pokazuje poniższy kod R wraz z wynikami: > dane<- read.table("c:\\cereals.data", header = TRUE, row.names = 1) > model<-lm(rating~sugars+fiber, data=dane) > summary(model)$r.square [1] > summary(model)$adj.r.squared [1] Jak widzimy współczynnik R 2 wynosi zaś R 2 adj odpowiednio
101 Obserwacja jest wpływowa (ang. influential), jeśli jej obecność wpływa na prostą regresji, w taki sposób, że zmienia się współczynnik kierunkowy tej prostej. Inaczej powiemy, że jeśli obserwacja jest wpływowa to inaczej wygląda prosta regresji w zależności od tego czy ta obserwacja została ujęta w zbiorze, czy też nie (gdyż została usunięta). W praktyce, jeśli obserwowana wartość leży w I-ym kwartylu rozkładu (czyli ma wartość mniejszą niż 25 centyl), to mówimy, że ma ona mały wpływ na regresję. Obserwacje leżące między I a III kwartylem nazywamy wpływowymi. Wykrycie obserwacji wpływowych umożliwia pomiar odległości Cooka, w której wykorzystujemy tzw. modyfikowane rezydua. Usuwając obserwację, którą chcemy uznać za wpływową ze zbioru obserwacji i obliczając różnicę (między tym jak wyglądają równania regresji z tą obserwacją i gdy jej nie ma) uznajemy obserwację za wpływową gdy ta różnica będzie wysoka. Odległość Cooka mierzy poziom wpływu obserwacji i jest obliczana jako: y y j j(i) jest wartością przewidywaną dla j-tej obserwacji obliczoną w modelu z usuniętą obserwacją i-tą jest wartością przewidywaną dla j-tej obserwacji w modelu, w którym nie usunięto i-tej obserwacji (potencjalnie wpływowej).
, main=\"influence Plot\",sub=\"Rozmiar kółka jest proporcjonalny do")
102 Teraz jeśli chcemy poznać obserwacje wpływowe możemy użyć komendy: > influenceplot(lm(b~a), main="influence Plot",sub="Rozmiar kółka jest proporcjonalny do odległości Cooka)
103 Do wykrycia obserwacji wpływowych możemy także użyć funkcji. > influence.measures(lm(b~a)) której efekty będzie następujący > influence.measures(lm(b~a)) Influence measures of lm(formula = b ~ a) : dfb.1_ dfb.a dffit cov.r cook.d hat inf e e e * e e e e e e e e e e e e e e e e e e e e e e e e * e e e > Jak widać, ostatnia kolumna wskazuje na obserwacje wpływowe zaznaczając przy nich symbol *. Z naszych danych wynika, że w zbiorze 10 obserwacji mamy 2 wpływowe. Są to obserwacje 1 i 9.

104 Obserwacje odstające będziemy wykrywać przy użyciu znanego już pakietu car i funkcji outlier.test w ramach tego pakietu. library(car) > outlier.test(model) max rstudent = , degrees of freedom = 73, unadjusted p = , Bonferroni p = Observation: Golden_Crisp Wykryliśmy jedną obserwację odstającą (płatki o nazwie Golden_Crisp).
105 Wartości wpływowe będziemy wykrywać za pomocą fukcji influence.measures. Wyniki takiej analizy widzimy poniżej. influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
106 influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
107 Za wpływowe uznamy 6 obserwacji: 100%_Bran All-Bran All-Bran_with_Extra_Fiber Frosted_Mini-Wheats Golden_Crisp (które zresztą uznaliśmy za obserwację odstającą, outlier) oraz Post_Nat._Raisin_Bran.
108 Gdy zmienne objaśniające są wysoko skorelowane wyniki analizy regresji mogą być niestabilne. Szacowana wartość zmiennej x i może zmienić wielkość a nawet kierunek zależnie od pozostałych zmiennych objaśniających zawartych w tak testowanym modelu regresji. Taka zależność liniowa między zmiennymi objaśniającymi może zagrażać trafności wyników analizy regresji. Do wskaźników oceniających współliniowość należy, m.in. VIF (Variance Inflation Factor) zwany współczynnikiem podbicia (inflacji) wariancji. VIF pozwala wychwycić wzrost wariancji ze względu na współliniowość cechy. Innymi słowy: wskazuje on o ile wariancje współczynników są zawyżone z powodu zależności liniowych w testowanym modelu. Niektóre pakiety statystyczne pozwalają także alternatywnie mierzyć tzw. współczynnik toleracji (TOL - ang. tolerance), który mierzy się jako: 1/VIF VIF i (1 R 2 1 i ) dla modelu x i = f(x 1,., x i-1, x i+1,, x p ) gdzie zmienna x i będzie wyjaśniana przez wszystkie pozostałe zmienne. Gdy VIF > 10 mówimy, że współliniowość wystąpiła i chcąc się jej pozbyć z modelu, usuwamy te cechy, które są liniową kombinacją innych zmiennych niezależnych.
109 Radą na współliniowość jest według niektórych prac zwiększenie zbioru obserwacji o nowe, tak, by zminimalizować istniejące zależności liniowe pomiędzy zmiennymi objaśniającymi. Oczywiście, zwiększenie liczby obserwacji nie gwarantuje poprawy -stąd takie rozwiązanie na pewno nie należy do najlepszych i jedynych. Lepszym wydaje się komponowanie zmiennych zależnych w nowe zmienne (np. waga i wzrost są skorelowane silnie i zamiast nich stworzenie jednej zmiennej stosunek wzrostu do wagi. Taką nową zmienną nazywa się w literaturze kompozytem. Często - dla dużej liczby zmiennych objaśniających - stosuje sie metodę analizy składowych głównych (ang. principal component analysis) dla redukcji liczby zmiennych do jednego lub kilku kompozytów niezależnych.

110 Dla modelu postaci: y i = b 0 + b 1 x 1i + b 2 x 2i + b 3 x 3i + e 1i Gdzie x 3i = 10 * x 1i - 2 * x 2i. Wtedy powiemy, że zmienna x 3 jest kombinacją liniową zmiennych x 1 i x 2. Próba szacowania takiego modelu związana jest ze świadomym popełnianiem błędu, gdyż w modelu tym występuje dokładna współliniowość (jedna ze zmiennych objaśniających jest kombinacją liniową pozostałych).
111 W środowisku R sprawdzanie współliniowości nie jest trudne. Wystarczy skorzystać z funkcji vif której argumentem jest model regresji dla danego zbioru danych. Przykład dotyczący naszego zbioru płatków zbożowych przedstawiamy poniżej: > vif(lm(rating~sugars+fiber, data=dane)) sugars fiber Wartości współczynnika $VIF$ nie są zbyt wysokie toteż uznajemy, że w modelu tym nie występuje zjawisko współliniowości.
112 Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe może być określenie- model cech niezależnych. Model prawdopodobieństwa można wyprowadzić korzystając z twierdzenia Bayesa. W zależności od rodzaju dokładności modelu prawdopodobieństwa, naiwne klasyfikatory bayesowskie można uczyć bardzo skutecznie w trybie uczenia z nadzorem.

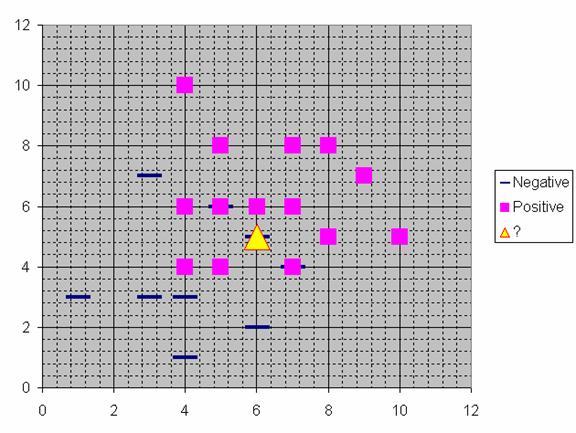
113

114

115

116

117

118

119

120

121
122 Jeśli wiemy, że kulek czerwonych jest 2 razy mniej niż zielonych (bo czerwonych jest 20 a zielonych 40) to prawdopodobieństwo tego, że kolejna (nowa) kulka będzie koloru zielonego jest dwa razy większe niż tego, że kulka będzie czerwona. Dlatego możemy napisać, że znane z góry prawdopodobieństwa:

123 Jeśli więc czerwonych jest 20 a zielonych 40, to razem wszystkich jest 60. Więc Więc teraz gdy mamy do czynienia z nową kulką ( na rysunku biała):
124 To spróbujmy ustalić jaka ona będzie. Dokonujemy po prostu klasyfikacji kulki do jednej z dwóch klas: zielonych bądź czerwonych. Jeśli weźmiemy pod uwagę sąsiedztwo białej kulki takie jak zaznaczono, a więc do 4 najbliższych sąsiadów, to widzimy, że wśród nich są 3 kulka czerwone i 1 zielona. Obliczamy liczbę kulek w sąsiedztwie należących do danej klasy : zielonych bądź czerwonych z wzorów: W naszym przypadku, jest dziwnie, bo akurat w sąsiedztwie kulki X jest więcej kulek czerwonych niż zielonych, mimo, iż kulek zielonych jest ogólnie 2 razy więcej niż czerwonych. Dlatego zapiszemy, że
125 Dlatego ostatecznie powiemy, że Prawdopodobieństwo że kulka X jest zielona = prawdopodobieństwo kulki zielonej * prawdopodobieństwo, że kulka X jest zielona w swoim sąsiedztwie = Prawdopodobieństwo że kulka X jest czerwona = prawdopodobieństwo kulki czerwonej * prawdopodobieństwo, że kulka X jest czerwona w swoim sąsiedztwie = Ostatecznie klasyfikujemy nową kulkę X do klasy kulek czerwonych, ponieważ ta klasa dostarcza nam większego prawdopodobieństwa posteriori.
126 Tylko dla cech jakościowych Tylko dla dużych zbiorów danych
127
128
129
130 Aby obliczyć P(diabetes=1) należy zliczyć liczbę obserwacji dla których spełniony jest warunek diabetes=1. Jest ich dokładnie 9 z 20 wszystkich. Podobnie, aby obliczyć P(diabetes=0) należy zliczyć liczbę obserwacji dla których spełniony jest warunek diabetes=0. Jest ich dokładnie 11 z 20 wszystkich.
131 Zakładając, że zmienne niezależne faktycznie są niezależne, wyliczenie P(X diabetes=1) wymaga obliczenia prawdopodobieństwa warunkowego wszystkich wartości dla X: Np. obliczenie P(BP=high diabetes=1) wymaga znów obliczenia P(BP=high) i P(diabetes=1) co jest odpowiednio równe 4 i 9 zatem prawdopodobieństwo to wynosi 4/9:
132 Zatem: Mając już prawdopodobieństwa P(X diabetes=1) i P(diabetes=1) można wyznaczyć iloczyn tych prawdopodobieństw:
133 Teraz podobnie zrobimy w przypadku P(X diabetes=0)
134 Możemy więc wyznaczyć P(X diabetes=0): Ostatecznie iloczyn prawdopodobieństw jest wyznaczany: Jakoże P(X diabeltes=1)p(diabetes=1) jest większe niż P(X diabetes=0)p(diabetes=0) nowa obserwacja będzie zaklasyfikowana do klasy diabetes=1. Prawdopodobieństwo ostateczne że jeśli obiekt ma opis taki jak X będzie z klasy diabetes=1 jest równe:
135 Jakie będzie prawdopodobieństwo klasyfikacji do klasy diabetes=1 gdy mamy następujące przypadki: X:BP=Average ; weight=above average; FH= yes; age=50+ X:BP=low ; weight=average; FH= no; age=50+ X:BP=high ; weight=average; FH= yes; age=50+

136

137

138
139 jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również być używany do klasyfikacji. - Założenia Dany jest zbiór uczący zawierający obserwacje z których każda ma przypisany wektor zmiennych objaśniających oraz wartość zmiennej objaśnianej Y. Dana jest obserwacja C z przypisanym wektorem zmiennych objaśniających dla której chcemy prognozować wartość zmiennej objaśnianej Y.
140
141
142 Wyznaczanie odległości obiektów: odległość euklidesowa

143 Obiekty są analizowane w ten sposób, że oblicza się odległości bądź podobieństwa między nimi. Istnieją różne miary podobieństwa czy odległości. Powinny być one wybierane konkretnie dla typu danych analizowanych: inne są bowiem miary typowo dla danych binarnych, inne dla danych nominalnych a inne dla danych numerycznych. Nazwa Wzór gdzie: x,y - to wektory wartości cech porównywanych obiektów w przestrzeni p- wymiarowej, gdzie odpowiednio wektory wartości to: oraz. odległość euklidesowa odległość kątowa współczynnik korelacji liniowej Pearsona Miara Gowera
144 Oblicz odległość punktu A o współrzędnych (2,3) do punktu B o współrzędnych (7,8) A B D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07
145 9 8 B A A B C 2 1 C Mając dane punkty: A(2,3), B(7,8) oraz C(5,1) oblicz odległości między punktami: D (A,B) = pierwiastek ((7-2) 2 + (8-3) 2 ) = pierwiastek ( ) = pierwiastek (50) = 7.07 D (A,C) = pierwiastek ((5-2) 2 + (3-1) 2 ) = pierwiastek (9 + 4) = pierwiastek (13) = 3.60 D (B,C) = pierwiastek ((7-5) 2 + (3-8) 2 ) = pierwiastek (4 + 25) = pierwiastek (29) = 5.38
146 1. porównanie wartości zmiennych objaśniających dla obserwacji C z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym. 2. wybór k (ustalona z góry liczba) najbliższych do C obserwacji ze zbioru uczącego. 3. Uśrednienie wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę. Przez "najbliższą obserwację" mamy na myśli, taką obserwację, której odległość do analizowanej przez nas obserwacji jest możliwie najmniejsza.
147
148

149 Najbliższy dla naszego obiektu buźka jest obiekt Więc przypiszemy nowemu obiektowi klasę:

150 Mimo, że najbliższy dla naszego obiektu buźka jest obiekt Metodą głosowania ustalimy, że skoro mamy wziąć pod uwagę 5 najbliższych sąsiadów tego obiektu, a widać, że 1 z nich ma klasę: Zaś 4 pozostałe klasę: To przypiszemy nowemu obiektowi klasę:

151 Obiekt klasyfikowany podany jako ostatni : a = 3, b = 6 Teraz obliczmy odległości poszczególnych obiektów od wskazanego. Dla uproszczenia obliczeń posłużymy sie wzorem:
152
153

154 Znajdujemy więc k najbliższych sąsiadów. Załóżmy, że szukamy 9 najbliższych sąsiadów. Wyróżnimy ich kolorem zielonym. Sprawdzamy, które z tych 9 najbliższych sąsiadów są z klasy + a które z klasy -? By to zrobić musimy znaleźć k najbliższych sąsiadów (funkcja Excela o nazwie MIN.K)
155
156
157 Wyobraźmy sobie, że nie mamy 2 zmiennych opisujących każdy obiekt, ale tych zmiennych jest np. 5: {v1,v2,v3,v4,v5} i że obiekty opisane tymi zmiennymi to 3 punkty: A, B i C: V1 V2 V3 V4 V5 A B C Policzmy teraz odległość między punktami: D (A,B) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.03) = 0.17 D (A,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.69) = 0.83 D (B,C) = pierwiastek (( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 + ( ) 2 ) = pierwiastek ( ) = pierwiastek (0.74) = 0.86 Szukamy najmniejszej odległości, bo jeśli te dwa punkty są najbliżej siebie, dla których mamy najmniejszą odległości! A więc najmniejsza odległość jest między punktami A i B!
158
159
160
161

162
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI
 Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Analiza regresji. Analiza korelacji.
 Analiza regresji. Analiza korelacji. Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer
Analiza regresji. Analiza korelacji. Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer
Analiza regresji część II. Agnieszka Nowak - Brzezińska
 Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Regresja liniowa wprowadzenie
 Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT. Część I: analiza regresji
 Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
Statystyczne metody analizy danych przy użyciu środowiska R
 Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
Rozpoznawanie obrazów
 Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Rozpoznawanie obrazów Laboratorium Python Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, M. Zięba, J. Kaczmar Cel zadania Celem zadania jest implementacja liniowego zadania
Analiza regresji część III. Agnieszka Nowak - Brzezińska
 Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Klasyfikacja metodą Bayesa
 Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
Klasyfikacja metodą Bayesa Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski warunkowe i bezwarunkowe 1. Klasyfikacja Bayesowska jest klasyfikacją statystyczną. Pozwala przewidzieć prawdopodobieństwo
FUNKCJA LINIOWA - WYKRES
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Regresja liniowa w R Piotr J. Sobczyk
 Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Sieci neuronowe w Statistica
 http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Model regresji wielokrotnej Wykład 14 ( ) Przykład ceny domów w Chicago
 Przykład ceny domów w Chicago") Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
Matematyka licea ogólnokształcące, technika
 Matematyka licea ogólnokształcące, technika Opracowano m.in. na podstawie podręcznika MATEMATYKA w otaczającym nas świecie zakres podstawowy i rozszerzony Funkcja liniowa Funkcję f: R R określoną wzorem
Matematyka licea ogólnokształcące, technika Opracowano m.in. na podstawie podręcznika MATEMATYKA w otaczającym nas świecie zakres podstawowy i rozszerzony Funkcja liniowa Funkcję f: R R określoną wzorem
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
3. FUNKCJA LINIOWA. gdzie ; ół,.
 1 WYKŁAD 3 3. FUNKCJA LINIOWA FUNKCJĄ LINIOWĄ nazywamy funkcję typu : dla, gdzie ; ół,. Załóżmy na początek, że wyraz wolny. Wtedy mamy do czynienia z funkcją typu :.. Wykresem tej funkcji jest prosta
1 WYKŁAD 3 3. FUNKCJA LINIOWA FUNKCJĄ LINIOWĄ nazywamy funkcję typu : dla, gdzie ; ół,. Załóżmy na początek, że wyraz wolny. Wtedy mamy do czynienia z funkcją typu :.. Wykresem tej funkcji jest prosta
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna
 Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Funkcja liniowa - podsumowanie
 Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Statystyka. Wykład 9. Magdalena Alama-Bućko. 24 kwietnia Magdalena Alama-Bućko Statystyka 24 kwietnia / 34
 Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 9 Magdalena Alama-Bućko 24 kwietnia 2017 Magdalena Alama-Bućko Statystyka 24 kwietnia 2017 1 / 34 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Analiza współzależności dwóch cech I
 Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Analiza współzależności dwóch cech I Współzależność dwóch cech W tym rozdziale pokażemy metody stosowane dla potrzeb wykrywania zależności lub współzależności między dwiema cechami. W celu wykrycia tych
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH
 Wykład 1 Prosta regresja liniowa - model i estymacja parametrów. Regresja z wieloma zmiennymi - analiza, diagnostyka i interpretacja wyników. Literatura pomocnicza J. Koronacki i J. Ćwik Statystyczne systemy
Wykład 1 Prosta regresja liniowa - model i estymacja parametrów. Regresja z wieloma zmiennymi - analiza, diagnostyka i interpretacja wyników. Literatura pomocnicza J. Koronacki i J. Ćwik Statystyczne systemy
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 1 Regresja liniowa autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się z liniowym zadaniem najmniejszych
FUNKCJA LINIOWA - WYKRES. y = ax + b. a i b to współczynniki funkcji, które mają wartości liczbowe
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (postać kierunkowa) Funkcja liniowa to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości liczbowe Szczególnie ważny w postaci
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych. Regresja logistyczna i jej zastosowanie
 Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Natalia Nehrebecka Stanisław Cichocki. Wykład 13
 Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne.
 Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki