Statystyczne metody analizy danych przy użyciu środowiska R
|
|
|
- Laura Piekarska
- 10 lat temu
- Przeglądów:
Transkrypt

1 Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia

2 Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R. 3. Wybrane metody analizy danych: ˆ Prezentacja danych. ˆ Regresja liniowa, predykcja danych. ˆ Obserwacje odstające a obserwacje wpływowe. 4. Podsumowanie.

3 Środowisko R ˆ Jest to bardzo elastyczne (darmowe) środowisko analityczne o bogatej funkcjonalności, które jest stosowane w wielu badawczych i praktycznych pracach dotyczących analizy danych i odkrywania wiedzy. ˆ R jako język programowania dostarcza wbudowanych operacji ułatwiających przetwarzanie tabelarycznych zbiorów danych, mechanizmów graficznego opisu danych, bogatych bibliotek funkcji analitycznych, obejmujących szeroki zakres metod statystycznych i metod odkrywania wiedzy oraz - co niezwykle ważne - interaktywny interpreter poleceń i (dla niektórych platform) graficzny interfejs użytkownika. ˆ Wszystkie niezbędne informacje o języku R znajdziemy na stronach CRAN (The Comprehensive R Archive Network), gdzie dostępne są pakiety źródłowe, dokumentacja, oraz obszerne zasoby bibliotek.
 graficzny interfejs użytkownika.")

4 Rysunek: Okno główne środowiska R
5 Pomoc w nauce R ˆ Godnym polecenia materiałem umożliwiającym przyswojenie podstawowych zagadnień jest darmowy kurs pt. Wprowadzenie do języka R dostępny na stronie a także źródło anglojęzyczne pt. An Introduction to R do ściągnięcia ze strony ˆ The R Language Definition - źródło: ˆ The R Language A Short Companion - źródło: ˆ R Reference Card - źródło:

6 Pomoc środowiska R

7 Statystyka opisowa za pomocą R-a Wyznaczanie miar rozkładu Bardzo prostą metodą w zakresie statystyki opisowej jest tworzenie opisu zbioru danych za pomocą tzw. emphmiar rozkładu cechy. Miary rozkładu można podzielić na kilka podstawowych kategorii: ˆ miary położenia, np. kwantyl, miary tendencji centralnej (np. średnia arytmetyczna, średnia geometryczna, średnia harmoniczna, średnia kwadratowa, mediana, moda), ˆ miary zróżnicowania, np. odchylenie standardowe, wariancja, rozstęp, rozstęp ćwiartkowy, średnie odchylenie bezwzględne, odchylenie ćwiartkowe, współczynnik zmienności, ˆ miary asymetrii, np. współczynnik skośności, współczynnik asymetrii, trzeci moment centralny, ˆ miary koncentracji, np. współczynnik Giniego, miara kurtozy [2].

8 Funkcja summary: Pakiet Hmisc i komenda library(hmisc)

9 Funkcja describe z pakietu psych otrzymujemy: nazwę zmiennej (kolumny, cechy), jej numer w całym zbiorze danych (var), liczba wartości w zbiorze (n) a także statystyki typu: średnia (mean), odchylenie standardowe (sd), mediana (median), elementy minimalny (min) i maksymalny (max), skośność (skew) oraz kurtoza (kurtosis).
 i maksymalny (max), skośność (skew) oraz kurtoza")
10 Graficzna prezentacja wyników ˆ histogramy i wykresy częstości (ang. density plot)- przedstawiające rozkład empiryczny cechy, ˆ wykresy rozrzutu (ang. scatterplots) - pozwalające wykrywać pewne zależności (i ich typ) między wartościami ciągłymi obserwacji w pewnej mierzonej skali. Każdy punkt wykresu reprezentuje pojedynczą obserwację, ˆ wykresy pudełkowe (ang. boxplot) - prezentowane za pomocą pudełka, którego lewy bok jest wyznaczony przez pierwszy kwartyl, zaś prawy bok przez trzeci kwartyl. Szerokość pudełka odpowiada wartości rozstępu ćwiartkowego. Wewnątrz pudełka znajduje się pionowa linia, określająca wartość mediany. Rysunek uzupełniamy po prawej i lewej stronie odcinkami. Lewy koniec lewego odcinka wyznacza najmniejszą wartość w zbiorze, natomiast prawy koniec prawego odcinka to wartość największa.
 - prezentowane za pomocą pudełka, którego lewy bok jest wyznaczony przez pierwszy kwartyl, zaś prawy bok przez trzeci kwartyl. Szerokość pudełka odpowiada wartości rozstępu ćwiartkowego.")

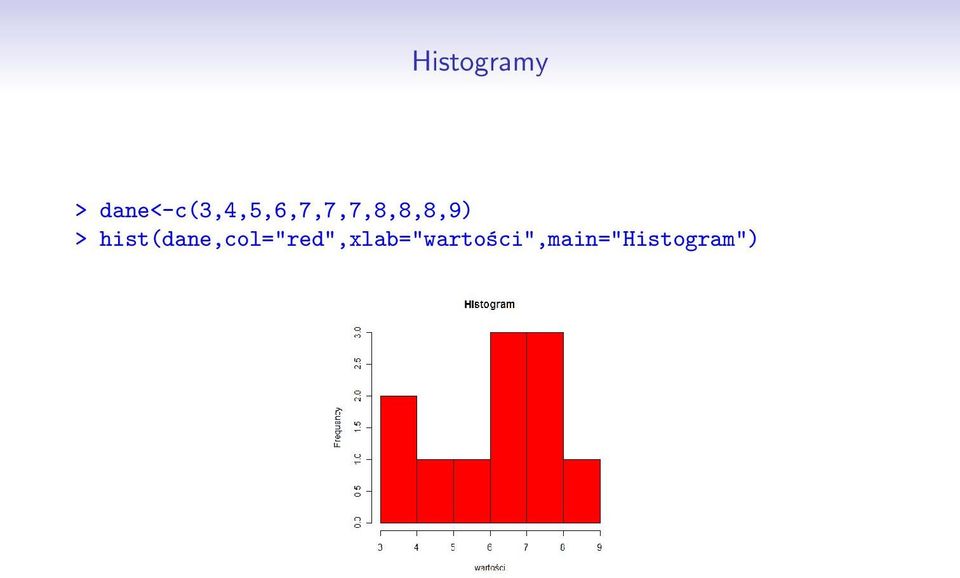
11 Histogramy > dane<-c(3,4,5,6,7,7,7,8,8,8,9) > hist(dane,col="red",xlab="wartości",main="histogram")
12 Wykresy pudełkowe Wykresy pudełkowe spotykane są najczęściej w pakietach komputerowych wspomagających proces analizy i interpretacji danych statystycznych. Oczywiście: ˆ Lower whisker - wartość najmniejsza dla danej zmiennej. ˆ Lower quartile - punkt dokładnie na 25% zbioru obserwacji. ˆ Median - punkt rozgraniczający dokładnie 50% obserwacji. ˆ Upper quartile - Punkt, przed którym jest 75% obserwacji. ˆ Upper whisker - najwyższa wartość w zbiorze. ˆ Mean - wartość średnia w zbiorze obserwacji.

13 Wykres pudełkowy boxplot(dane,col="red",xlab="wartości",main="wykrespudełkowy")

14 Wykresy w R Ogromną zaletą środowiska R jest jego system graficzny i możliwości łatwej wizualizacji danych. Bardzo skrótowo (ale jednocześnie wystarczająco) generowanie wykresów zostało przedstawione w kursie dostępnym pod adresem: Generalizując powiemy, że należy wyróżnić dwa rodzaje funkcji graficznych w R: ˆ wyskopoziomowe funkcje rysują kompletne wykresy ( i usuwające poprzednie), ˆ niskopoziomowe funkcje dodające do wykresów nowe elementy typu legenda, punkty, linie, tekst.

15 Wykres rozrzutu - przykład 1


16 Wykres rozrzutu - przykład 2


17 Wykres mieszany - przykład 3

18

19 Regresja - metoda najmniejszych kwadratów

20 Model regresji liniowej

21 Obserwacje odstające Obserwacja odstająca (ang. outlier) jest obserwacją, która nie spełnia równości regresji czyli nie należy do modelu prostej regresji. Obserwacje odstające mogą znacząco wpłwać na postać prostej regresji: b 0 + b 1x dla której wartość sumy: n i=1 (yi ŷi)2 a więc i sumy n i=1 (yi (b0 + b1xi))2 ma być możliwie najmniejsza. Jeśli analizujemy tylko pojedyncze zmienne objaśniające, to identyfikacja obserwacji odstających jest dość prosta. Wystarczy generować wykresy rozrzutu bądź histogramy. Jeśli zaś chcemy szukać obserwacji odstających globalnie (nie dla pojedynczej zmiennej objaśniającej ale dla wielu) wówczas możemy analizować rezydua lub rezydua studentyzowane i wśród nich szukać wartości odstających.
22 Wyznaczenie obserwacji odstających
23 Wyznaczenie obserwacji odstających 1. Mając wektor wartości resztowych(rezyduów) e = (e 1, e 2,..., e n),gdzie wartość resztowa e i = y i ŷ i (e i = y i (b 0 x i + b 1 ))powiemy, że błąd standardowy rezyduum e i jest równy: = S 1 ( 1 n + (x i x) 2 n i=1 (x i x) ). 2 SE ei Wtedy studentyzowana wartość resztowa będzie odpowiadać wartości: r i = e i SE ei. 2. Sporządzając wykres wartości studentyzowanych rezyduów r i względem ich indeksu będziemy potrafili rozpoznawać te duże wartości, które przypuszczalnie będą odstającymi. Podsumowując powiemy, że nowa obserwacja będzie punktem odstającym jeśli będzie się cechować dużą wartością standaryzowanej reszty. W praktyce, obserwacje odstające to takie, których wartość bezwzględnych standaryzowanych reszt przekracza 2.
24 Wyznaczenie obserwacji odstających w R W środowisku R wykrycie obserwacji odstających możliwe jest na kilka sposobów. Jednym z nich jest użycie funkcji rstudent. Jak widać na poniższym kodzie, w analizowanym przez nas zbiorze występuje obserwacja odstająca. Jest to obserwacja o numerze 8 i wartości
25 Wyznaczenie obserwacji odstających w R Alternatywnie, możemy użyć funkcji outlier.test z biblioteki car.
26 Obserwacje wpływowe Obserwacja jest wpływowa (ang. influential) jeśli jej obecność wpływa na prostą regresji, w taki sposób, że zmienia się współczynnik kierunkowy tej prostej. Inaczej powiemy, że jeśli obserwacja jest wpływowa to inaczej wygląda prosta regresji w zależności od tego czy ta obserwacja została ujęta w zbiorze, czy też nie (gdyż została usunięta). W praktyce, jeśli obserwowana wartość leży w Q 1 (czyli ma wartość mniejszą niż 25 centyl), to mówimy, że ma ona mały wpływ na regresję. Obserwacje leżące między Q 1 a Q 3 kwartylem nazywamy wpływowymi. Wykrycie obserwacji wpływowych umożliwia pomiar odległości Cooka z tzw. modyfikowanymi rezyduami. Usuwamy obserwację potencjalnie wpływową i obliczamy różnicę. Obserwacja jest wpływowa jeśli ta różnica będzie wysoka. Odległość Cooka mierzy poziom wpływu obserwacji i jest obliczana jako: n j=1 (ŷ j y j(i) ˆ ) 2 ps 2 D i = = e2 i h i ps 2 (1 h i ) 2,gdzie ŷ j jest wartością przewidywaną dla j-tej obserwacji obliczoną w modelu z usuniętą obserwacją i-tą zaś y j(i) ˆ jest wartością przewidywaną dla j-tej obserwacji w modelu, w którym nie usunięto i-tej obserwacji (potencjalnie wpływowej).

27 Wyznaczenie obserwacji wpływowych w R Teraz jeśli chcemy poznać obserwacje wpływowe możemy użyć komendy: której efektem będzie wykres:
28 Do wykrycia obserwacji wpływowych możemy także użyć funkcji > influence.measures(lm(b a)), której efekt będzie następujący: Ostatnia kolumna wskazuje na obserwacje wpływowe zaznaczając przy nich symbol. Są to obserwacje 1 i 9.
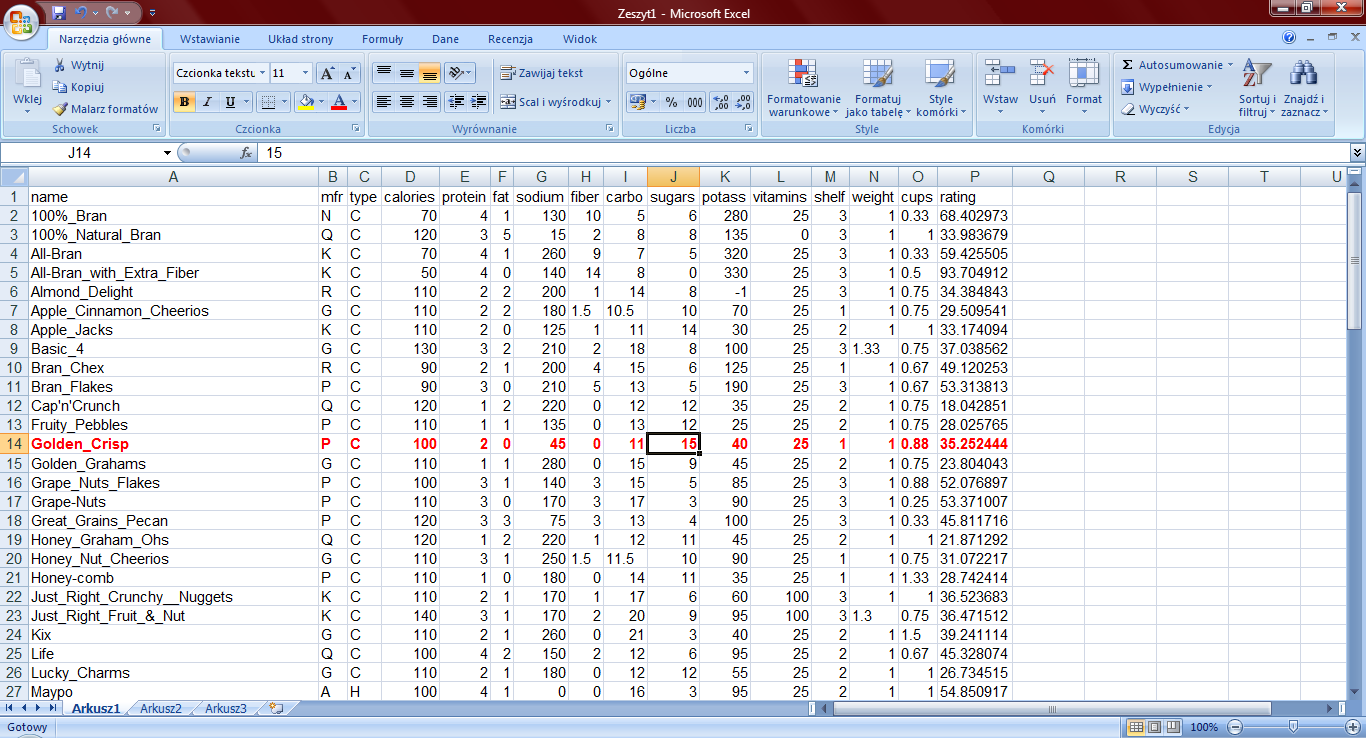
29 Zbiór Cereals.data
30 Zbiór Cereals.data ˆ źródło: ˆ Zbiór zawiera dane 77 rodzajów płatków śniadaniowych,które opisane są 14 atrybutami warunkowymi i jednym atrybutem decyzyjnym rating mówiącym o wartości odżywczej płatków w oparciu o informacje typu: calories, sugars, fiber, sodium, vitamins czy weight (ora zinne).
31 Zbiór Cereals.data
32 Zbiór Cereals.data
33 Wyznaczenie obserwacji odstających w modelu z wieloma zmiennymi objaśniającymi Obserwacje odstające będziemy wykrywać przy użyciu znanego już pakietu car i funkcji outlier.test w ramach tego pakietu. Wykryliśmy jedną obserwację odstającą (płatki o nazwie Golden Crisp).
34
35 Obserwacje wpływowe w zbiorze Cereals Funkcja: influence.measures Za wpływowe uznamy 6 obserwacji: 100% Bran,All-Bran, All-Bran with Extra Fiber czy Frosted Mini-Wheats, Golden Crisp (które zresztą uznaliśmy za obserwację odstającą, outlier) oraz Post Nat. Raisin Bran.

36 Bardzo ważne dla wykrycia obserwacji odstających są tzw. studentyzowane reszty. Wykres dla nich możemy wykonac wywołując komendę: > qq.plot(model, main="qq Plot") Efektem będzie wykres z rozkładem obserwacji między I i III kwartylem, stąd nazwa wykresu międzykwartylny
37 Regresja liniowa dla zbioru Cereals
38 Predykcja dla zbioru Cereals Równanie regresji: gdy zmienną objaśnianą będzie zmienna rating (wartość odżywcza płatków) zaś objaśniającą sugars (poziom cukrów), będzie następującej postaci: rating = -2.4 * sugars Gdy poziom cukrów wynosi np 1 to wartość odżywcza płatków będzie wynosić 56.9 zaś gdy poziom cukrów będzie wynosił np 10 wówczas wartość odżywcza zmaleje do wartości 35.3.
39 Inne metody analizy danych ˆ analizy dyskryminacyjna: ˆ library(mass)i funkcja lda() ˆ analiza skupień: ˆ pam(), kmeans(), pvclust(), hclust(). ˆ drzewa klasyfikacyjne: ˆ rpart(), printcp() ˆ analiza składowych głównych: ˆ princomp(), factanal()
40 Analiza dyskryminacyjna

41 Analiza skupień - statystyki danych

42 Analiza skupień - klasyczny algorytm k-średnich

43 Drzewa klasyfikacyjne

44 Analiza składowych głównych

45 Analiza składowych głównych
46 Podsumowanie ˆ R jest wykorzystywany w badaniach naukowych i dydaktyce na najlepszych uczelniach na świecie, w dziedzinach biologii, socjologii, psychologii, ekonomii. ˆ R to środowisko do obliczeń statystycznych, a jednocześnie język programowania. ˆ R może działać na systemach Windows, Linux i MacOS.
47 Bibliografia Smith L.I.,A tutorial on Principal Components Analysis, Psych-465-Spring-2003/PCA-tutorial.pdf, Redakcja naukowa: Walesiak M. and Gatnar E., Statystyczna analiza danych z wykorzystaniem programu R, PWN, 2009, Warszawa, Polska Larose Daniel T., Metody i modele eksploracji danych. PWN, Warszawa, Polska, Ćwik J. and Mielniczuk J., Statystyczne systemy uczące się. Ćwiczenia w oparciu o pakiet R. Oficyna Wydawnicza Politechniki Warszawskiej, Warszawa, Polska, Koronacki J. and Mielniczuk J., Statystyka dla studentów kierunków technicznych i przyrodniczych. Wydawnictwa Naukowo-Techniczne, Warszawa, Polska, Koronacki J. and Ćwik J., Statystyczne systemy uczące się. EXIT. Warszawa, Polska, 2008.
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Praca z danymi zaczyna się od badania rozkładu liczebności (częstości) zmiennych. Rozkład liczebności (częstości) zmiennej to jakie wartości zmienna
MIARY KLASYCZNE Miary opisujące rozkład badanej cechy w zbiorowości, które obliczamy na podstawie wszystkich zaobserwowanych wartości cechy
 MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
MIARY POŁOŻENIA Opisują średni lub typowy poziom wartości cechy. Określają tą wartość cechy, wokół której skupiają się wszystkie pozostałe wartości badanej cechy. Wśród nich można wyróżnić miary tendencji
-> Średnia arytmetyczna (5) (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak
 (4) ->Kwartyl dolny, mediana, kwartyl górny, moda - analogicznie jak") Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
Wzory dla szeregu szczegółowego: Wzory dla szeregu rozdzielczego punktowego: ->Średnia arytmetyczna ważona -> Średnia arytmetyczna (5) ->Średnia harmoniczna (1) ->Średnia harmoniczna (6) (2) ->Średnia
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY)
") STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
STATYSTYKA OPISOWA. LICZBOWE CHARAKTERYSTYKI(MIARY) Dla opisania rozkładu badanej zmiennej, korzystamy z pewnych charakterystyk liczbowych. Dzielimy je na cztery grupy.. Określenie przeciętnej wartości
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Inteligentna analiza danych
 Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Statystyka w pracy badawczej nauczyciela Wykład 3: Analiza struktury zbiorowości statystycznej. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.
 Statystyka w pracy badawczej nauczyciela Wykład 3: Analiza struktury zbiorowości statystycznej dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Zadania analityczne (1) Analiza przewiduje badanie podobieństw
Statystyka w pracy badawczej nauczyciela Wykład 3: Analiza struktury zbiorowości statystycznej dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Zadania analityczne (1) Analiza przewiduje badanie podobieństw
Laboratorium 3 - statystyka opisowa
 dla szeregu rozdzielczego Laboratorium 3 - statystyka opisowa Agnieszka Mensfelt 11 lutego 2019 dla szeregu rozdzielczego Statystyka opisowa dla szeregu rozdzielczego Przykład wyniki maratonu Wyniki 18.
dla szeregu rozdzielczego Laboratorium 3 - statystyka opisowa Agnieszka Mensfelt 11 lutego 2019 dla szeregu rozdzielczego Statystyka opisowa dla szeregu rozdzielczego Przykład wyniki maratonu Wyniki 18.
1 Podstawy rachunku prawdopodobieństwa
 1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
Statystyka opisowa PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA
 Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
Statystyka opisowa PRZEDMIOT: PODSTAWY STATYSTYKI PROWADZĄCY: DR LUDMIŁA ZA JĄC -LAMPARSKA Statystyka opisowa = procedury statystyczne stosowane do opisu właściwości próby (rzadziej populacji) Pojęcia:
Typy zmiennych. Zmienne i rekordy. Rodzaje zmiennych. Graficzne reprezentacje danych Statystyki opisowe
 Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
Typy zmiennych Graficzne reprezentacje danych Statystyki opisowe Jakościowe charakterystyka przyjmuje kilka możliwych wartości, które definiują klasy Porządkowe: odpowiedzi na pytania w ankiecie ; nigdy,
W kolejnym kroku należy ustalić liczbę przedziałów k. W tym celu należy wykorzystać jeden ze wzorów:
 Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Na dzisiejszym wykładzie omówimy najważniejsze charakterystyki liczbowe występujące w statystyce opisowej. Poszczególne wzory będziemy podawać w miarę potrzeby w trzech postaciach: dla szeregu szczegółowego,
Rok akademicki: 2013/2014 Kod: ZIE n Punkty ECTS: 6. Poziom studiów: Studia I stopnia Forma i tryb studiów: -
 Nazwa modułu: Statystyka opisowa i ekonomiczna Rok akademicki: 2013/2014 Kod: ZIE-1-205-n Punkty ECTS: 6 Wydział: Zarządzania Kierunek: Informatyka i Ekonometria Specjalność: - Poziom studiów: Studia I
Nazwa modułu: Statystyka opisowa i ekonomiczna Rok akademicki: 2013/2014 Kod: ZIE-1-205-n Punkty ECTS: 6 Wydział: Zarządzania Kierunek: Informatyka i Ekonometria Specjalność: - Poziom studiów: Studia I
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)
, które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej)") Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Charakterystyki liczbowe (estymatory i parametry), które pozwalają opisać właściwości rozkładu badanej cechy (zmiennej) 1 Podział ze względu na zakres danych użytych do wyznaczenia miary Miary opisujące
Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.
 znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.") Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Statystyka. Opisowa analiza zjawisk masowych
 Statystyka Opisowa analiza zjawisk masowych Typy rozkładów empirycznych jednej zmiennej Rozkładem empirycznym zmiennej nazywamy przyporządkowanie kolejnym wartościom zmiennej (x i ) odpowiadających im
Statystyka Opisowa analiza zjawisk masowych Typy rozkładów empirycznych jednej zmiennej Rozkładem empirycznym zmiennej nazywamy przyporządkowanie kolejnym wartościom zmiennej (x i ) odpowiadających im
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Pozyskiwanie wiedzy z danych
 Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
Pozyskiwanie wiedzy z danych dr Agnieszka Goroncy Wydział Matematyki i Informatyki UMK PROJEKT WSPÓŁFINANSOWANY ZE ŚRODKÓW UNII EUROPEJSKIEJ W RAMACH EUROPEJSKIEGO FUNDUSZU SPOŁECZNEGO Pozyskiwanie wiedzy
INFORMATYKA W SELEKCJI
 INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
INFORMATYKA W SELEKCJI INFORMATYKA W SELEKCJI - zagadnienia 1. Dane w pracy hodowlanej praca z dużym zbiorem danych (Excel) 2. Podstawy pracy z relacyjną bazą danych w programie MS Access 3. Systemy statystyczne
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Analiza regresji część III. Agnieszka Nowak - Brzezińska
 Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Podstawowe pojęcia. Własności próby. Cechy statystyczne dzielimy na
 Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony zbiór jednostek, które
Wykład 1. Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy
 Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Wykład Podstawowe pojęcia Metody opisowe w analizie rozkładu cechy Zbiorowość statystyczna - zbiór elementów lub wyników jakiegoś procesu powiązanych ze sobą logicznie (tzn. posiadających wspólne cechy
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyczne metody analizy danych. Agnieszka Nowak - Brzezińska
 Statystyczne metody analizy danych Agnieszka Nowak - Brzezińska SZEREGI STATYSTYCZNE SZEREGI STATYSTYCZNE odpowiednio usystematyzowany i uporządkowany surowy materiał statystyczny. Szeregi statystyczne
Statystyczne metody analizy danych Agnieszka Nowak - Brzezińska SZEREGI STATYSTYCZNE SZEREGI STATYSTYCZNE odpowiednio usystematyzowany i uporządkowany surowy materiał statystyczny. Szeregi statystyczne
STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE
 STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE") STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE CECHY mogą być: jakościowe nieuporządkowane - skala nominalna płeć, rasa, kolor oczu, narodowość, marka samochodu,
STATYSTYKA IV SEMESTR ALK (PwZ) STATYSTYKA OPISOWA RODZAJE CECH W POPULACJACH I SKALE POMIAROWE CECHY mogą być: jakościowe nieuporządkowane - skala nominalna płeć, rasa, kolor oczu, narodowość, marka samochodu,
Statystyka opisowa. Literatura STATYSTYKA OPISOWA. Wprowadzenie. Wprowadzenie. Wprowadzenie. Plan. Tomasz Łukaszewski
 Literatura STATYSTYKA OPISOWA A. Aczel, Statystyka w Zarządzaniu, PWN, 2000 A. Obecny, Statystyka opisowa w Excelu dla szkół. Ćwiczenia praktyczne, Helion, 2002. A. Obecny, Statystyka matematyczna w Excelu
Literatura STATYSTYKA OPISOWA A. Aczel, Statystyka w Zarządzaniu, PWN, 2000 A. Obecny, Statystyka opisowa w Excelu dla szkół. Ćwiczenia praktyczne, Helion, 2002. A. Obecny, Statystyka matematyczna w Excelu
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 2 - statystyka opisowa cd
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 2 - statystyka opisowa cd Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 2 1 / 20 MIARY ROZPROSZENIA, Wariancja Wariancją z próby losowej X
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 2 - statystyka opisowa cd Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 2 1 / 20 MIARY ROZPROSZENIA, Wariancja Wariancją z próby losowej X
Przedmiot statystyki. Graficzne przedstawienie danych.
 Przedmiot statystyki. Graficzne przedstawienie danych. dr Mariusz Grządziel 2 marca 2009 Populacja i próba Populacja- zbiorowość skończona lub nieskończona, w stosunku do której mają być formułowane wnioski.
Przedmiot statystyki. Graficzne przedstawienie danych. dr Mariusz Grządziel 2 marca 2009 Populacja i próba Populacja- zbiorowość skończona lub nieskończona, w stosunku do której mają być formułowane wnioski.
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Statystyka. Wykład 5. Magdalena Alama-Bućko. 26 marca Magdalena Alama-Bućko Statystyka 26 marca / 40
 Statystyka Wykład 5 Magdalena Alama-Bućko 26 marca 2018 Magdalena Alama-Bućko Statystyka 26 marca 2018 1 / 40 Uwaga Gdy współczynnik zmienności jest większy niż 70%, czyli V s = s x 100% > 70% (co świadczy
Statystyka Wykład 5 Magdalena Alama-Bućko 26 marca 2018 Magdalena Alama-Bućko Statystyka 26 marca 2018 1 / 40 Uwaga Gdy współczynnik zmienności jest większy niż 70%, czyli V s = s x 100% > 70% (co świadczy
STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych;
 STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych; - badanie skuteczności nowego leku; - badanie stopnia zanieczyszczenia gleb metalami
STATYSTYKA OPISOWA Przykłady problemów statystycznych: - badanie opinii publicznej na temat preferencji wyborczych; - badanie skuteczności nowego leku; - badanie stopnia zanieczyszczenia gleb metalami
Statystyczne metody analizy danych
 Statystyczne metody analizy danych Statystyka opisowa Wykład I-III Agnieszka Nowak - Brzezińska Definicje Statystyka (ang.statistics) - to nauka zajmująca się zbieraniem, prezentowaniem i analizowaniem
Statystyczne metody analizy danych Statystyka opisowa Wykład I-III Agnieszka Nowak - Brzezińska Definicje Statystyka (ang.statistics) - to nauka zajmująca się zbieraniem, prezentowaniem i analizowaniem
Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej
 Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej cechy. Średnia arytmetyczna suma wartości zmiennej wszystkich
Miary położenia wskazują miejsce wartości najlepiej reprezentującej wszystkie wielkości danej zmiennej. Mówią o przeciętnym poziomie analizowanej cechy. Średnia arytmetyczna suma wartości zmiennej wszystkich
Statystyka. Wykład 4. Magdalena Alama-Bućko. 19 marca Magdalena Alama-Bućko Statystyka 19 marca / 33
 Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Statystyka Wykład 4 Magdalena Alama-Bućko 19 marca 2018 Magdalena Alama-Bućko Statystyka 19 marca 2018 1 / 33 Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności (rozproszenia,
Zajęcia nr VII poznajemy Rattle i pakiet R.
 Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Okno główne Rattle wygląda następująco: Zajęcia nr VII poznajemy Rattle i pakiet R. Widzimy główne zakładki: Data pozwala odczytad dane z różnych źródeł danych (pliki TXT, CSV) i inne bazy danych. Jak
Statystyka. Wykład 3. Magdalena Alama-Bućko. 6 marca Magdalena Alama-Bućko Statystyka 6 marca / 28
 Statystyka Wykład 3 Magdalena Alama-Bućko 6 marca 2017 Magdalena Alama-Bućko Statystyka 6 marca 2017 1 / 28 Szeregi rozdzielcze przedziałowe - kwartyle - przypomnienie Po ustaleniu przedziału, w którym
Statystyka Wykład 3 Magdalena Alama-Bućko 6 marca 2017 Magdalena Alama-Bućko Statystyka 6 marca 2017 1 / 28 Szeregi rozdzielcze przedziałowe - kwartyle - przypomnienie Po ustaleniu przedziału, w którym
Statystyka opisowa SYLABUS A. Informacje ogólne
 Statystyka opisowa SYLABUS A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej kierunek Nazwa kierunku studiów Poziom kształcenia Profil studiów Forma studiów Kod Język Rodzaj Rok
Statystyka opisowa SYLABUS A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej kierunek Nazwa kierunku studiów Poziom kształcenia Profil studiów Forma studiów Kod Język Rodzaj Rok
Po co nam charakterystyki liczbowe? Katarzyna Lubnauer 34
 Po co nam charakterystyki liczbowe? Katarzyna Lubnauer 34 Def. Charakterystyki liczbowe to wielkości wyznaczone na podstawie danych statystycznych, charakteryzujące własności badanej cechy. Klasyfikacja
Po co nam charakterystyki liczbowe? Katarzyna Lubnauer 34 Def. Charakterystyki liczbowe to wielkości wyznaczone na podstawie danych statystycznych, charakteryzujące własności badanej cechy. Klasyfikacja
2.Wstępna analiza danych c.d.- wykład z 5.03.2006 Populacja i próba
 2.Wstępna analiza danych c.d.- wykład z 5.03.2006 Populacja i próba Populacja- zbiorowość skończona lub nieskończona, w stosunku do której mają być formułowane wnioski. Próba- skończony podzbiór populacji
2.Wstępna analiza danych c.d.- wykład z 5.03.2006 Populacja i próba Populacja- zbiorowość skończona lub nieskończona, w stosunku do której mają być formułowane wnioski. Próba- skończony podzbiór populacji
Statystyki opisowe i szeregi rozdzielcze
 Statystyki opisowe i szeregi rozdzielcze - ćwiczenia ĆWICZENIA Piotr Ciskowski ramka-wąsy przykład 1. krwinki czerwone Stanisz W eksperymencie farmakologicznym analizowano oddziaływanie pewnego preparatu
Statystyki opisowe i szeregi rozdzielcze - ćwiczenia ĆWICZENIA Piotr Ciskowski ramka-wąsy przykład 1. krwinki czerwone Stanisz W eksperymencie farmakologicznym analizowano oddziaływanie pewnego preparatu
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Wykład 3: Statystyki opisowe - miary położenia, miary zmienności, miary asymetrii
 Wykład 3: Statystyki opisowe - miary położenia, miary zmienności, miary asymetrii Wprowadzenie W przypadku danych liczbowych do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą
Wykład 3: Statystyki opisowe - miary położenia, miary zmienności, miary asymetrii Wprowadzenie W przypadku danych liczbowych do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą
Próba własności i parametry
 Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Próba własności i parametry Podstawowe pojęcia Zbiorowość statystyczna zbiór jednostek (obserwacji) nie identycznych, ale stanowiących logiczną całość Zbiorowość (populacja) generalna skończony lub nieskończony
Ćwiczenia 1-2 Analiza rozkładu empirycznego
 Ćwiczenia 1-2 Zadanie 1. Z kolokwium z ekonometrii studenci otrzymali następujące oceny: 5 osób dostało piątkę, 20 os. dostało czwórkę, 10 os. trójkę, a 3 osoby nie zaliczyły tego kolokwium. Należy w oparciu
Ćwiczenia 1-2 Zadanie 1. Z kolokwium z ekonometrii studenci otrzymali następujące oceny: 5 osób dostało piątkę, 20 os. dostało czwórkę, 10 os. trójkę, a 3 osoby nie zaliczyły tego kolokwium. Należy w oparciu
Statystyka. Wykład 2. Magdalena Alama-Bućko. 5 marca Magdalena Alama-Bućko Statystyka 5 marca / 34
 Statystyka Wykład 2 Magdalena Alama-Bućko 5 marca 2018 Magdalena Alama-Bućko Statystyka 5 marca 2018 1 / 34 Banki danych: Bank danych lokalnych : Główny urzad statystyczny: Baza Demografia : https://bdl.stat.gov.pl/
Statystyka Wykład 2 Magdalena Alama-Bućko 5 marca 2018 Magdalena Alama-Bućko Statystyka 5 marca 2018 1 / 34 Banki danych: Bank danych lokalnych : Główny urzad statystyczny: Baza Demografia : https://bdl.stat.gov.pl/
Plan wykładu. Statystyka opisowa. Statystyka matematyczna. Dane statystyczne miary położenia miary rozproszenia miary asymetrii
 Plan wykładu Statystyka opisowa Dane statystyczne miary położenia miary rozproszenia miary asymetrii Statystyka matematyczna Podstawy estymacji Testowanie hipotez statystycznych Żródła Korzystałam z ksiażek:
Plan wykładu Statystyka opisowa Dane statystyczne miary położenia miary rozproszenia miary asymetrii Statystyka matematyczna Podstawy estymacji Testowanie hipotez statystycznych Żródła Korzystałam z ksiażek:
Statystyka opisowa w wycenie nieruchomości Część I - wyznaczanie miar zbioru danych
 dr Agnieszka Bitner Rzeczoznawca majątkowy Katedra Geodezji Rolnej, Katastru i Fotogrametrii Uniwersytet Rolniczy w Krakowie ul. Balicka 253c 30-198 Kraków, e-mail: rmbitner@cyf-kr.edu.pl WPROWADZENIE
dr Agnieszka Bitner Rzeczoznawca majątkowy Katedra Geodezji Rolnej, Katastru i Fotogrametrii Uniwersytet Rolniczy w Krakowie ul. Balicka 253c 30-198 Kraków, e-mail: rmbitner@cyf-kr.edu.pl WPROWADZENIE
Agata Boratyńska. WYKŁAD 1. Wstępna analiza danych, charakterystyki opisowe. Indeksy statystyczne.
 1 Agata Boratyńska WYKŁAD 1. Wstępna analiza danych, charakterystyki opisowe. Indeksy statystyczne. Agata Boratyńska Wykłady ze statystyki 2 Literatura J. Koronacki i J. Mielniczuk Statystyka WNT 2004
1 Agata Boratyńska WYKŁAD 1. Wstępna analiza danych, charakterystyki opisowe. Indeksy statystyczne. Agata Boratyńska Wykłady ze statystyki 2 Literatura J. Koronacki i J. Mielniczuk Statystyka WNT 2004
KARTA KURSU. (do zastosowania w roku ak. 2015/16) Kod Punktacja ECTS* 4
 Kod Punktacja ECTS* 4") KARTA KURSU (do zastosowania w roku ak. 2015/16) Nazwa Statystyka 1 Nazwa w j. ang. Statistics 1 Kod Punktacja ECTS* 4 Koordynator Dr hab. Tadeusz Sozański (koordynator, wykłady) Dr Paweł Walawender (ćwiczenia)
KARTA KURSU (do zastosowania w roku ak. 2015/16) Nazwa Statystyka 1 Nazwa w j. ang. Statistics 1 Kod Punktacja ECTS* 4 Koordynator Dr hab. Tadeusz Sozański (koordynator, wykłady) Dr Paweł Walawender (ćwiczenia)
Parametry statystyczne
 I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
I. MIARY POŁOŻENIA charakteryzują średni lub typowy poziom wartości cechy, wokół nich skupiają się wszystkie pozostałe wartości analizowanej cechy. I.1. Średnia arytmetyczna x = x 1 + x + + x n n = 1 n
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
author: Andrzej Dudek
 Edytor wprowadzone polecenia zostają w oknie edytora I mogą być uruchamiana poprzez CTRL+R lub Run (tylko zaznaczone linie, z wyświetlaniem wykonywanych linii kodu) lub poprzez Source (zawsze całość, bez
Edytor wprowadzone polecenia zostają w oknie edytora I mogą być uruchamiana poprzez CTRL+R lub Run (tylko zaznaczone linie, z wyświetlaniem wykonywanych linii kodu) lub poprzez Source (zawsze całość, bez
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WYŻSZA SZKOŁA MENEDŻERSKA W WARSZAWIE WYDZIAŁ ZARZĄDZANIA W CIECHANOWIE KARTA PRZEDMIOTU - SYLABUS
 WYŻSZA SZKOŁA MENEDŻERSKA W WARSZAWIE WYDZIAŁ ZARZĄDZANIA W CIECHANOWIE KARTA PRZEDMIOTU - SYLABUS Nazwa przedmiotu: Statystyka opisowa Profil 1 : ogólnoakademicki Cel przedmiotu: Zapoznanie studentów
WYŻSZA SZKOŁA MENEDŻERSKA W WARSZAWIE WYDZIAŁ ZARZĄDZANIA W CIECHANOWIE KARTA PRZEDMIOTU - SYLABUS Nazwa przedmiotu: Statystyka opisowa Profil 1 : ogólnoakademicki Cel przedmiotu: Zapoznanie studentów
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Analiza regresji część II. Agnieszka Nowak - Brzezińska
 Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Wykład 2. Statystyka opisowa - Miary rozkładu: Miary położenia
 Wykład 2 Statystyka opisowa - Miary rozkładu: Miary położenia Podział miar Miary położenia (measures of location): 1. Miary tendencji centralnej (measures of central tendency, averages): Średnia arytmetyczna
Wykład 2 Statystyka opisowa - Miary rozkładu: Miary położenia Podział miar Miary położenia (measures of location): 1. Miary tendencji centralnej (measures of central tendency, averages): Średnia arytmetyczna
Wykład 5. Opis struktury zbiorowości. 1. Miary asymetrii.
 Wykład 5. Opis struktury zbiorowości 1. Miary asymetrii. 2. Miary koncentracji. Przykład Zbadano stawkę godzinową (w zł) pracowników dwóch branŝ, otrzymując następujące charakterysty ki liczbowe: Stawka
Wykład 5. Opis struktury zbiorowości 1. Miary asymetrii. 2. Miary koncentracji. Przykład Zbadano stawkę godzinową (w zł) pracowników dwóch branŝ, otrzymując następujące charakterysty ki liczbowe: Stawka
Wprowadzenie do analizy dyskryminacyjnej
 Wprowadzenie do analizy dyskryminacyjnej Analiza dyskryminacyjna to zespół metod statystycznych używanych w celu znalezienia funkcji dyskryminacyjnej, która możliwie najlepiej charakteryzuje bądź rozdziela
Wprowadzenie do analizy dyskryminacyjnej Analiza dyskryminacyjna to zespół metod statystycznych używanych w celu znalezienia funkcji dyskryminacyjnej, która możliwie najlepiej charakteryzuje bądź rozdziela
Przedmiot statystyki. Graficzne przedstawienie danych. Wykład-26.02.07. Przedmiot statystyki
 Przedmiot statystyki. Graficzne przedstawienie danych. Wykład-26.02.07 Statystyka dzieli się na trzy części: Przedmiot statystyki -zbieranie danych; -opracowanie i kondensacja danych (analiza danych);
Przedmiot statystyki. Graficzne przedstawienie danych. Wykład-26.02.07 Statystyka dzieli się na trzy części: Przedmiot statystyki -zbieranie danych; -opracowanie i kondensacja danych (analiza danych);
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Miary zmienności STATYSTYKA OPISOWA. Dr Alina Gleska. Instytut Matematyki WE PP. 6 marca 2018
 STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 6 marca 2018 1 MIARY ZMIENNOŚCI (inaczej: rozproszenia, rozrzutu, zróżnicowania, dyspersji) informuja o zróżnicowaniu jednostek zbiorowości
STATYSTYKA OPISOWA Dr Alina Gleska Instytut Matematyki WE PP 6 marca 2018 1 MIARY ZMIENNOŚCI (inaczej: rozproszenia, rozrzutu, zróżnicowania, dyspersji) informuja o zróżnicowaniu jednostek zbiorowości
Z-LOGN1-006 Statystyka Statistics
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOGN-006 Statystyka Statistics Obowiązuje od roku akademickiego 0/0 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Z-LOGN-006 Statystyka Statistics Obowiązuje od roku akademickiego 0/0 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW Kierunek
Przedmiot statystyki. Graficzne przedstawienie danych.
 Przedmiot statystyki. Graficzne przedstawienie danych. dr Mariusz Grządziel 23 lutego 2009 Przedmiot statystyki Statystyka dzieli się na trzy części: -zbieranie danych; -opracowanie i kondensacja danych
Przedmiot statystyki. Graficzne przedstawienie danych. dr Mariusz Grządziel 23 lutego 2009 Przedmiot statystyki Statystyka dzieli się na trzy części: -zbieranie danych; -opracowanie i kondensacja danych
Wykład 3. Opis struktury zbiorowości. 1. Parametry opisu rozkładu badanej cechy. 3. Średnia arytmetyczna. 4. Dominanta. 5. Kwantyle.
 Wykład 3. Opis struktury zbiorowości 1. Parametry opisu rozkładu badanej cechy. 2. Miary połoŝenia rozkładu. 3. Średnia arytmetyczna. 4. Dominanta. 5. Kwantyle. W praktycznych zastosowaniach bardzo często
Wykład 3. Opis struktury zbiorowości 1. Parametry opisu rozkładu badanej cechy. 2. Miary połoŝenia rozkładu. 3. Średnia arytmetyczna. 4. Dominanta. 5. Kwantyle. W praktycznych zastosowaniach bardzo często
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU
 WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
WYDZIAŁ MATEMATYKI KARTA PRZEDMIOTU Nazwa w języku polskim: Eksploracja Danych Nazwa w języku angielskim: Data Mining Kierunek studiów (jeśli dotyczy): MATEMATYKA I STATYSTYKA Stopień studiów i forma:
Analiza Statystyczna
 Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013
 KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013 A.
KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013 A.
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013
 0,KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013 A.
0,KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Matematyka stosowana w geomatyce Nazwa modułu w języku angielskim Applied Mathematics in Geomatics Obowiązuje od roku akademickiego 2012/2013 A.
Z-ZIPN1-004 Statystyka. Zarządzanie i Inżynieria Produkcji I stopień Ogólnoakademicki Niestacjonarne Wszystkie Katedra Matematyki dr Zdzisław Piasta
 KARTA MODUŁU / KARTA PRZEDMIOTU Z-ZIPN-004 Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 0/04 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
KARTA MODUŁU / KARTA PRZEDMIOTU Z-ZIPN-004 Statystyka Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Statistics Obowiązuje od roku akademickiego 0/04 A. USYTUOWANIE MODUŁU W SYSTEMIE STUDIÓW
Statystyka opisowa- cd.
 12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa- cd. Wykład 4 Dr inż. Adam Deptuła HISTOGRAM UNORMOWANY Pole słupka = wysokość słupka x długość przedziału Pole słupka = n i n h h,
12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa- cd. Wykład 4 Dr inż. Adam Deptuła HISTOGRAM UNORMOWANY Pole słupka = wysokość słupka x długość przedziału Pole słupka = n i n h h,
Statystyka. Wykład 5. Magdalena Alama-Bućko. 20 marca Magdalena Alama-Bućko Statystyka 20 marca / 26
 Statystyka Wykład 5 Magdalena Alama-Bućko 20 marca 2017 Magdalena Alama-Bućko Statystyka 20 marca 2017 1 / 26 Koncentracja Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności
Statystyka Wykład 5 Magdalena Alama-Bućko 20 marca 2017 Magdalena Alama-Bućko Statystyka 20 marca 2017 1 / 26 Koncentracja Analiza struktury zbiorowości miary położenia ( miary średnie) miary zmienności
Wykład Ćwiczenia Laboratorium Projekt Seminarium 30
 Zał. nr 4 do ZW WYDZIAŁ CHEMICZNY KARTA PRZEDMIOTU Nazwa w języku polskim Wstęp do statystyki praktycznej Nazwa w języku angielskim Intriduction to the Practice of Statistics Kierunek studiów (jeśli dotyczy):
Zał. nr 4 do ZW WYDZIAŁ CHEMICZNY KARTA PRZEDMIOTU Nazwa w języku polskim Wstęp do statystyki praktycznej Nazwa w języku angielskim Intriduction to the Practice of Statistics Kierunek studiów (jeśli dotyczy):
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
3. Modele tendencji czasowej w prognozowaniu
 II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań
 Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Zaawansowana eksploracja danych - sprawozdanie nr 1 Rafał Kwiatkowski 89777, Poznań 6.11.1 1 Badanie współzależności atrybutów jakościowych w wielowymiarowych tabelach danych. 1.1 Analiza współzależności
Statystyka opisowa Opracował: dr hab. Eugeniusz Gatnar, prof. WSBiF
 Statystyka opisowa Opracował: dr hab. Eugeniusz Gatnar, prof. WSBiF 120 I. Ogólne informacje o przedmiocie Cel przedmiotu: Opanowanie podstaw teoretycznych, poznanie przykładów zastosowań metod statystycznych.
Statystyka opisowa Opracował: dr hab. Eugeniusz Gatnar, prof. WSBiF 120 I. Ogólne informacje o przedmiocie Cel przedmiotu: Opanowanie podstaw teoretycznych, poznanie przykładów zastosowań metod statystycznych.
Wykrywanie nietypowości w danych rzeczywistych
 Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
Wykrywanie nietypowości w danych rzeczywistych dr Agnieszka NOWAK-BRZEZIŃSKA, mgr Artur TUROS 1 Agenda 1 2 3 4 5 6 Cel badań Eksploracja odchyleń Metody wykrywania odchyleń Eksperymenty Wnioski Nowe badania
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ (II rok WNE)
") WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ (II rok WNE) Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 1 1 / 33 Warunki zaliczenia 1 Ćwiczenia OBOWIĄZKOWE (max. 3 nieobecności) 2 Zaliczenie
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ (II rok WNE) Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 1 1 / 33 Warunki zaliczenia 1 Ćwiczenia OBOWIĄZKOWE (max. 3 nieobecności) 2 Zaliczenie
2. Wprowadzenie do oprogramowania gretl. Podstawowe operacje na danych.
 Laboratorium z ekonometrii (GRETL) 2. Wprowadzenie do oprogramowania gretl. Podstawowe operacje na danych. 2.1 Zaimportuj dane z pliku zatrudnienie.csv z przecinkiem jako separatorem danych i kropką jako
Laboratorium z ekonometrii (GRETL) 2. Wprowadzenie do oprogramowania gretl. Podstawowe operacje na danych. 2.1 Zaimportuj dane z pliku zatrudnienie.csv z przecinkiem jako separatorem danych i kropką jako
Statystyka Matematyczna Anna Janicka
 Statystyka Matematyczna Anna Janicka wykład I, 22.02.2016 STATYSTYKA OPISOWA, cz. I Kwestie techniczne Kontakt: ajanicka@wne.uw.edu.pl Dyżur: strona z materiałami z przedmiotu: wne.uw.edu.pl/azylicz akson.sgh.waw.pl/~aborata
Statystyka Matematyczna Anna Janicka wykład I, 22.02.2016 STATYSTYKA OPISOWA, cz. I Kwestie techniczne Kontakt: ajanicka@wne.uw.edu.pl Dyżur: strona z materiałami z przedmiotu: wne.uw.edu.pl/azylicz akson.sgh.waw.pl/~aborata
Xi B ni B
 Zadania ze statystyki cz.2 I rok Socjologii lic. Zadanie 1 Ustal dla danych zawartych w tabelach poniżej, prezentujących rozkład liczebności (ni) różnej wielkości gospodarstw domowych w dwóch populacjach,
Zadania ze statystyki cz.2 I rok Socjologii lic. Zadanie 1 Ustal dla danych zawartych w tabelach poniżej, prezentujących rozkład liczebności (ni) różnej wielkości gospodarstw domowych w dwóch populacjach,
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej