Analiza regresji. Analiza korelacji.
|
|
|
- Krystyna Olszewska
- 6 lat temu
- Przeglądów:
Transkrypt
1 Analiza regresji. Analiza korelacji.
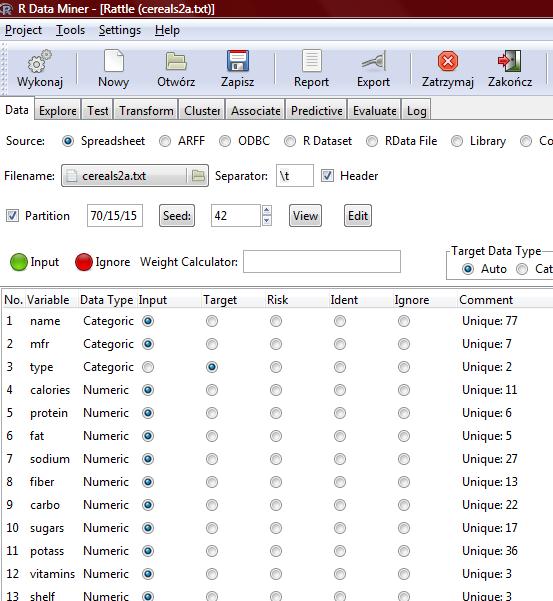
2
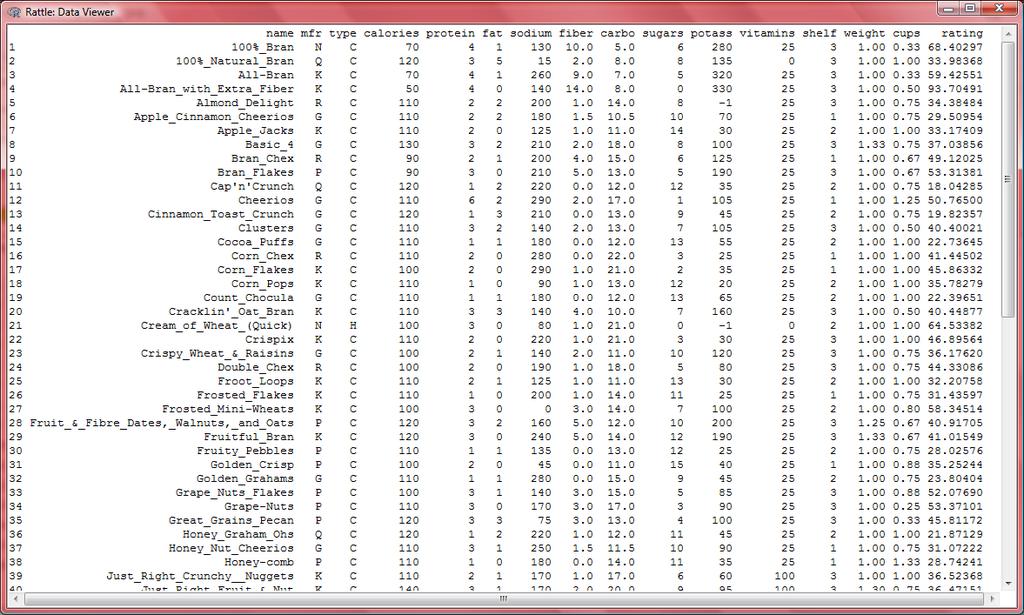
3
4
5

6 Levels name mfr type calories protein fat sodium fiber carbo sugars potass vitamins shelf weight cups rating Storage 77 integer 7 integer 2 integer integer integer integer integer double double integer integer integer integer double double double
7
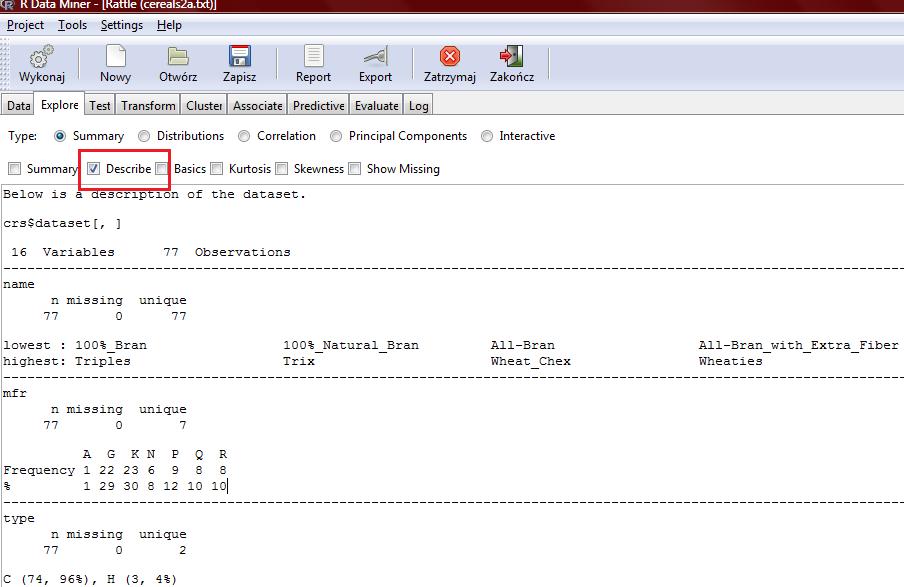
8
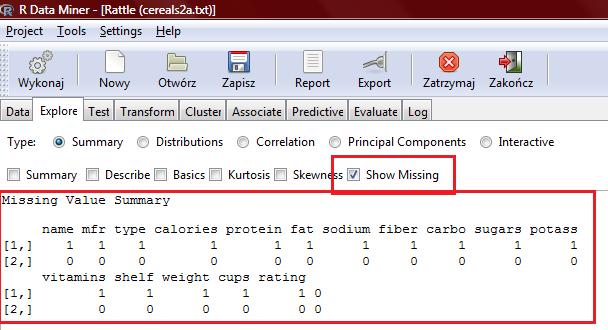
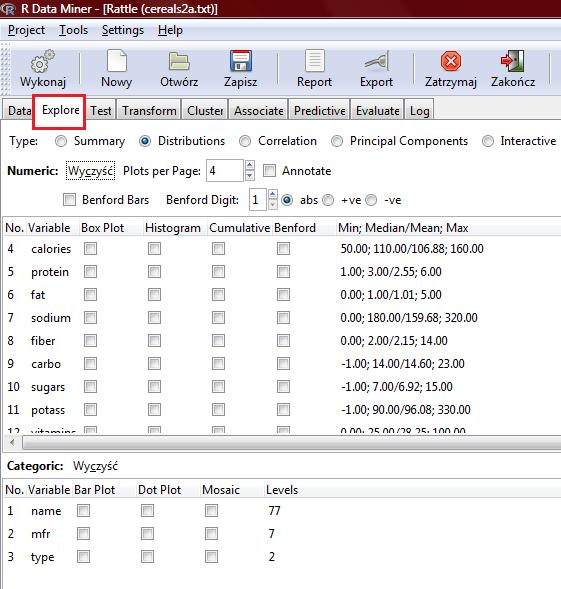
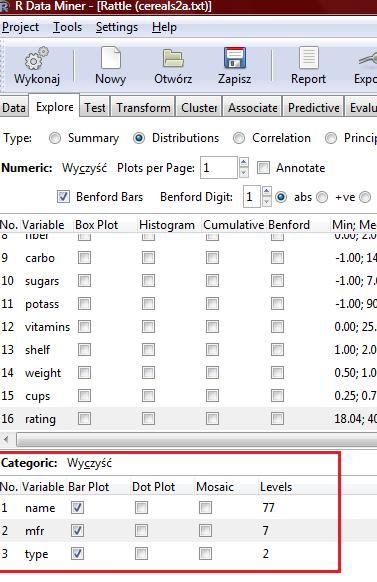
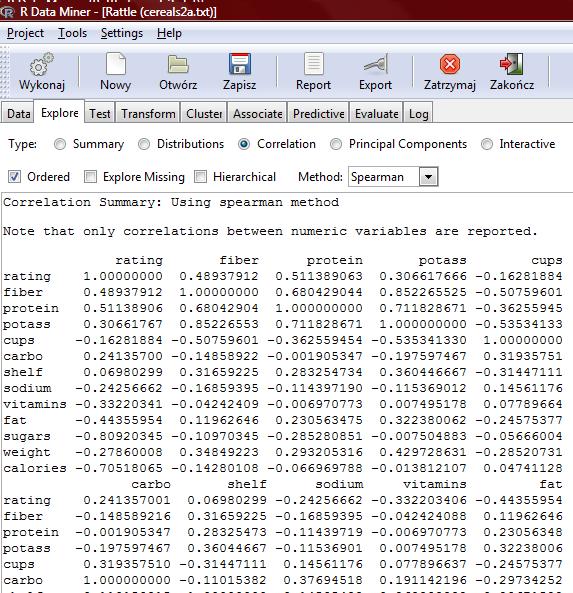
9 name n missing unique lowest : 100%_Bran 100%_Natural_Bran All-Bran All-Bran_with_Extra_Fiber Almond_Delight highest: Triples Trix Wheat_Chex Wheaties Wheaties_Honey_Gold mfr n missing unique A G K N P Q R Frequency % type n missing unique C (74, 96%), H (3, 4%)
10 calories n missing unique Mean Frequency % protein n missing unique Mean Frequency %
11 carbo n missing unique Mean lowest : , highest: sugars n missing unique Mean Frequency % potass n missing unique Mean lowest : , highest:
12 vitamins n missing unique Mean (8, 10%), 25 (63, 82%), 100 (6, 8%) shelf n missing unique Mean (20, 26%), 2 (21, 27%), 3 (36, 47%) weight n missing unique Mean Frequency %
13 fat n missing unique Mean Frequency % sodium n missing unique Mean lowest : , highest: fiber n missing unique Mean Frequency %
14 cups n missing unique Mean Frequency % rating n missing unique Mean lowest : , highest:
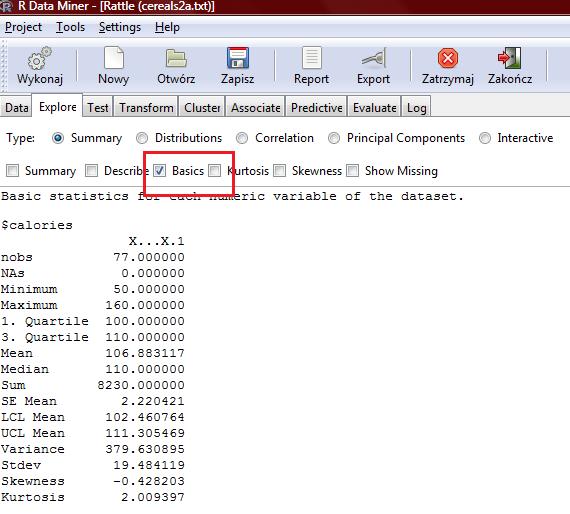
15
16
17

18
19
20
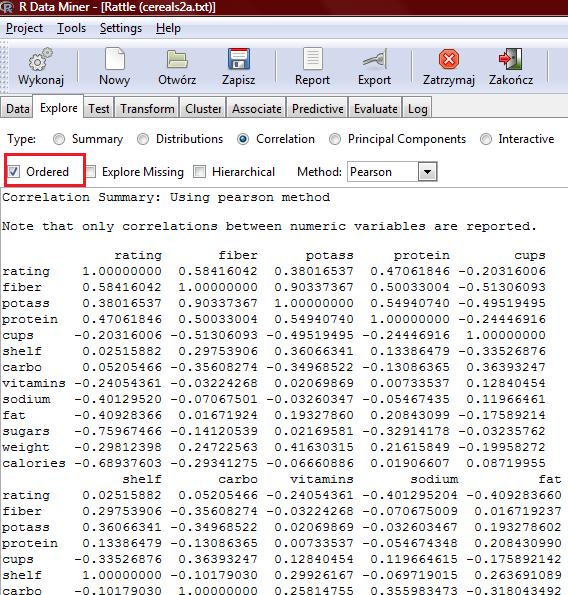
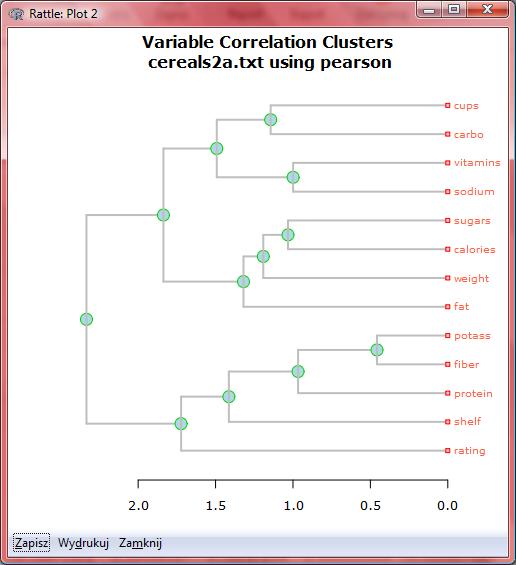
21
22
23
24
25

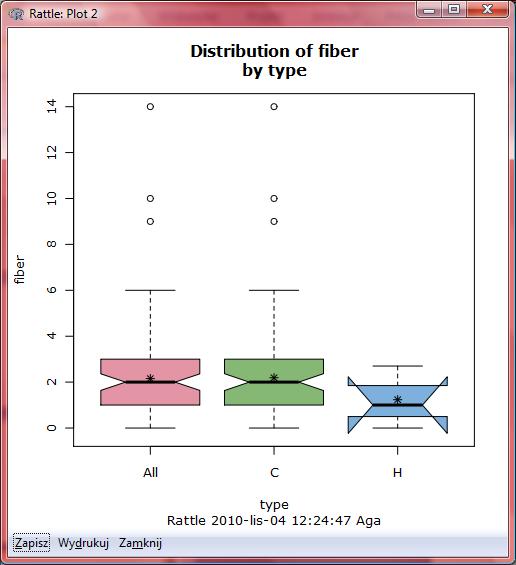
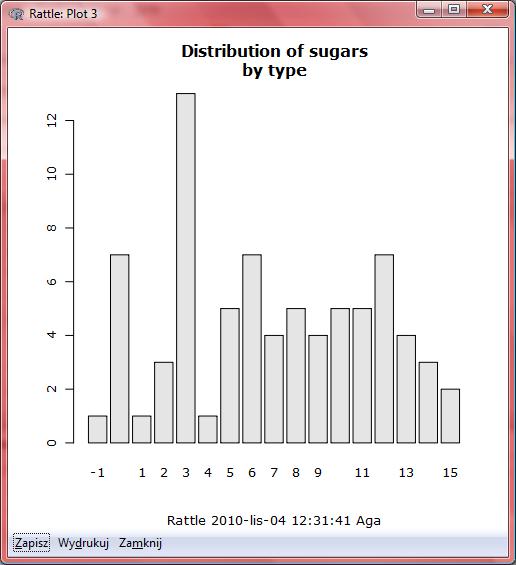
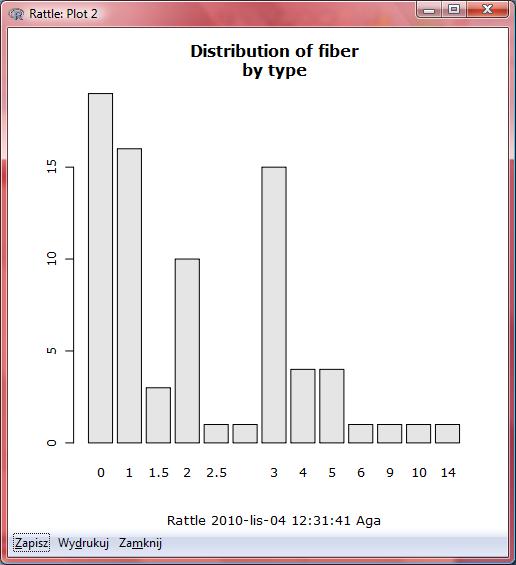
26 Kompletnie nieczytelny!!!
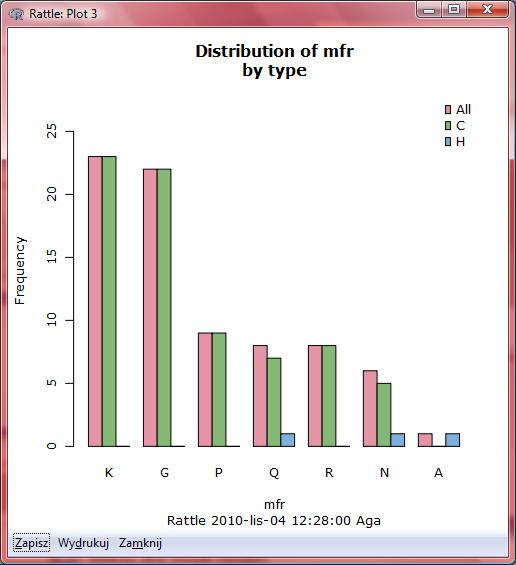
27
28 Korelacja
29 Korelacja Pearsona w excelu
30 rating Korelacja Pearsona w excelu sugars sugars

31 Korelacja Spearmana w excelu
32 The Spearman correlation, called Spearman s rho, is a special case of the Pearson correlation computed on ranked data.
33
34

35
36
37
38
39
40 Porównanie miar korelacji Pearsona i Spearmana
41 Porównanie miar korelacji Pearsona i Spearmana
42 Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywad związki zachodzące pomiędzy zmiennymi wejściowymi (objaśniającymi) a wyjściowymi (objaśnianymi). Innymi słowy dokonujemy estymacji jednych danych korzystając z innych. Istnieje wiele różnych technik regresji.
43 Regresja liniowa Metoda zakłada, że pomiędzy zmiennymi objaśniającymi i objaśnianymi istnieje mniej lub bardziej wyrazista zależnośd liniowa. Mając zatem zbiór danych do analizy, informacje opisujące te dane możemy podzielid na objaśniane i objaśniające. Wtedy też wartości tych pierwszych będziemy mogli zgadywad znając wartości tych drugich. Oczywiście tak się dzieje tylko w sytuacji, gdy faktycznie między tymi zmiennymi istnieje zależnośd liniowa. Przewidywanie wartości zmiennych objaśnianych (y) na podstawie wartości zmiennych objaśniających (x) jest możliwe dzięki znalezieniu tzw. modelu regresji. W praktyce polega to na podaniu równania prostej, zwanej prostą regresji o postaci: y = b_0 + b_1 x gdzie: y - jest zmienną objaśnianą, zaś x - objaśniającą. W równaniu tym bardzo istotną rolę odgrywają współczynniki b_0 i b_1, gdzie b_1 jest nachyleniem linii regresji, zaś b_0 punktem przecięcia linii regresji z osią x (wyrazem wolnym) a więc przewidywaną wartością zmiennej objaśnianej gdy zmienna objaśniająca jest równa 0.
44 rating sugars sugars
45 rating sugars Liniowy (sugars) sugars
46
47 y b0 b1 x rating * sugars A więc: b b Jak to czytad? Oszacowana wartość odżywcza płatków (rating) jest równa 59.4 i 2.42 razy waga cukrów (sugars) w gramach Czyli linia regresji jest liniowym przybliżeniem relacji między zmiennymi x (objaśniającymi, niezależnymi) a y (objaśnianą, zależną) w tym przypadku między zawartością cukrów a wartością odżywczą. Możemy zatem dzięki regresji: SZACOWAD, PRZEWIDYWAD
48 Po co przewidywad? Gdy np. chcemy oszacowad wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=1 gram cukrów. Wówczas za pomocą oszacowanego równania regresji możemy wyestymowad wartośd odżywczą płatków śniadaniowych zawierającym 1 gram cukrów: y *
49 Po co przewidywad? Gdy np. chcemy oszacowad wartości odżywcze nowego rodzaju płatków (nieuwzględnionych dotąd w tej próbie 77 różnym badanych płatków śniadaniowych), które zawierają x=5 gram cukrów. Wówczas za pomocą oszacowanego równania regresji możemy wyestymowad wartośd odżywczą płatków śniadaniowych zawierającym 5 gram cukrów: y *5 47.3

50 Jak widad, niestety oszacowanie zgodne z równaniem regresji jest nie do kooca zgodne z rzeczywistą wartością odżywczą płatków.

51 Czyli każde płatki mające 1 gram cukru powinny mied wartośd odżywczą równą 56,98 ale jak widad tak nie jest. Płatki Cheerios mają wartośd odżywczą równą 50,765. Czyli nastąpiło PRZESACOWANIE wartości odżywczej płatków o 6,215. Graficznie tę odległośd widzimy jako odległośd punktu reprezentującego te płatki od jego rzutu pionowego na linię regresji.
52 Co wówczas? Odległośd ta mierzona jako: ( y y) Nazywad będziemy błędem predykcji (błędem oszacowania, wartością resztową, rezyduum). Oczywiście powinno się dążyd do minimalizacji błędu oszacowania. Służy do tego metoda zwana metodą najmniejszych kwadratów. Metoda polega na tym, że wybieramy linię regresji która będzie minimalizowad sumę kwadratów reszt dla wszystkich punktów danych.
53
54 Czy to równanie będzie spełnione dla innych płatów niż te z badanego zbioru? Odpowiedź: pewnie NIE. Prawdziwą liniową zależnośd między wartością odżywczą a zawartością cukrów dla WSZYSTKICH rodzajów płatków reprezentuje równanie: y x Losowy błąd
55 Dla n obserwacji y x i 0 1 i i i=1,,n Linia najmniejszych kwadratów minimalizuje sumę kwadratów błędów SSE (population sum of squared errors): SSE p n R i n i1 i1 ( y x ) i 0 1 i 2
56 Co dalej? 1. Różniczkujemy to równanie by oszacowad 0 1 i ) ( * i n i i p x y SSE ) ( * i n i i i p x y x SSE 2. Przyrównujemy wynik do zera: 0 ) ( i n i i x b b y 0 ) ( i n i i i x b b y x
57 Co dalej? 3. Rozbijamy sumę: 4. Powstaje n i i n i i x b nb y n i i n i i n i i i x b x b y x n i i n i x i y b nb n i i i n i i n i i y x x b x b
58 Co dalej? 5. Rozwiązując te równania otrzymujemy: x i yi ( xi )( yi ) / n b1 2 2 x ( x ) / n b0 y b1 x n liczba obserwacji x y A sumy są od i=1 do n. b i 1 0 i - Średnia wartośd zmiennej objaśniającej - Średnia wartośd zmiennej objaśnianej b i -estymatory najmniejszych kwadratów dla 0i 1 Czyli wartości które minimalizują sumę kwadratów błędów.

59 Jak znaleźd wartości b 0 =59.4 i b 1 =-2.42 z tych równao? 1. Obliczamy wartości x i,y i,x i y i,x i 2
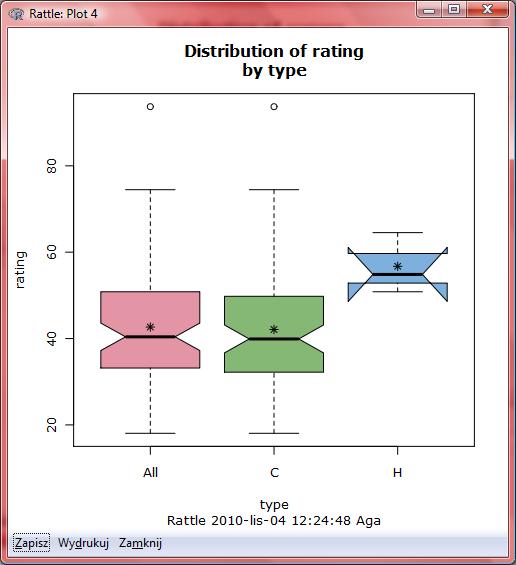
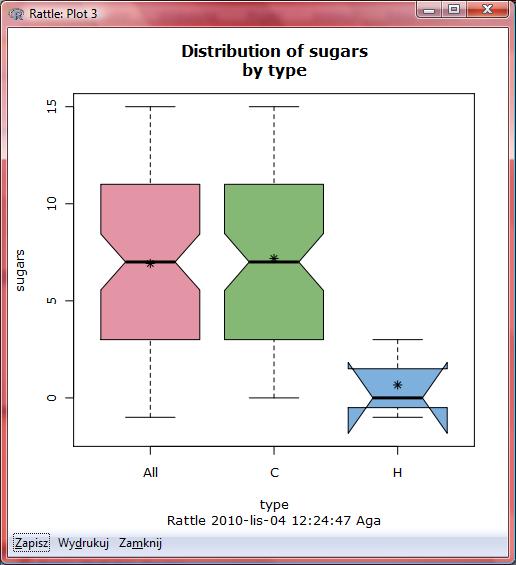
60 1. Obliczamy wartości: x i =534 y i = x i y i = x i2 = Podstawiamy do wzorów: b * / / b0 y b1 x *
61 Wnioski Wyraz wolny b0 jest miejscem na osi y gdzie linia regresji przecina tę oś czyli jest to przewidywana wartośd zmiennej objaśnianej gdy objaśniająca równa się zeru. Współczynnik kierunkowy prostej regresji oznacza szacowaną zmianę wartośd y dla jednostkowego wzrostu x wartośd b 1 =-2.42 mówi, że jeśli zawartośd cukrów wzrośnie o 1 gram to wartośd odżywcza płatków zmniejszy się o 2.42 punktu. Czyli płatki A których zawartośd cukrów jest o 5 większa niż w płatkach B powinny mied oszacowaną wartośd odżywczą o 5 razy 2.42 = 12.1 punktów mniejszą niż płatki typu B.
62 Regresja wielokrotna Omawiając regresję liniową (prostą) rozpatrywaliśmy dotąd jedynie takie przypadki zależności między zmiennymi objaśniającymi a objaśnianymi gdzie zmienna objaśniana była zależna tylko od jednej konkretnej zmiennej objaśniającej. Jednak w praktyce niezwykle często zmienna objaśniana zależna jest nie od jednej ale od kilku (wielu) zmiennych objaśniających. Będziemy zatem rozważad ogólne równanie regresji postaci: y b 0 b x 1 1 b 2 x 2... gdzie m oznacza liczbę (najczęściej kilku) zmiennych objaśniających. b m x m
63 W środowisku R W środowisku R procedura znajdowania równania regresji dla podanego zbioru danych możliwa jest dzięki wykorzystaniu funkcji lm. Komenda R postaci lm(y ~ x) mówi, że chcemy znaleźd model regresji liniowej dla zmiennej y w zależności od zmiennej x.
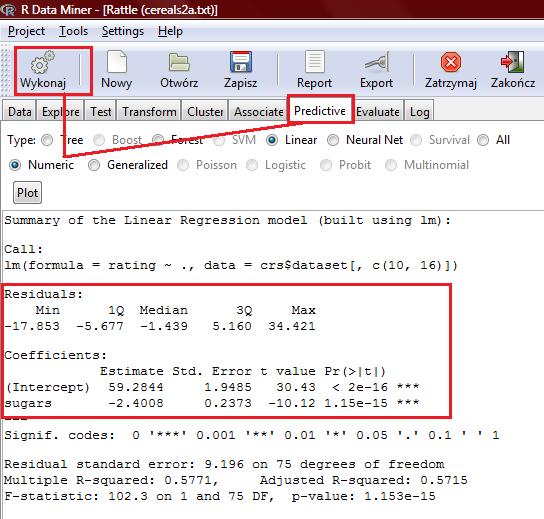
64 Wówczas pełny zapis okna dialogu z R-em będzie następujący: > dane<- read.table("c:\\cereals.data", header = TRUE, row.names = 1) > model<-lm(rating~sugars, data=dane) > summary(model) Call: lm(formula = rating ~ sugars, data = dane) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** sugars e-15 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 75 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 1 and 75 DF, p-value: 1.153e-15 > równanie regresji, gdy zmienną objaśnianą będzie zmienna rating (wartośd odżywcza płatków) zaś objaśniającą sugars (poziom cukrów), będzie następującej postaci: rating = -2.4 * sugars+ 59.3
65 Teraz możemy przewidywad, że gdy poziom cukrów wynosi np 1 to wartośd odżywcza płatków będzie wynosid 56.9 zaś gdy poziom cukrów będzie wynosił 10 wówczas wartośd odżywcza zmaleje do wartości 35.3 (patrz poniżej). > predict(model,data.frame(sugars=10), level = 0.9, interval = "confidence") fit lwr upr > predict(model,data.frame(sugars=1), level = 0.9, interval = "confidence") fit lwr upr
66 Wykres rozrzutu dla zmiennej sugars
67 Wykres rozrzutu dla zmiennej fiber
68 Interpretacja Widad z nich, że między zmienną objaśniającą sugars a zmienną objaśnianą fiber istnieje pewna zależnośd (w miarę wzrostu wartości sugars spada wartośd rating). Z kolei analizując rozrzut obserwacji ze względu na wartości zmiennej objaśniającej fiber oraz objaśnianej rating już tak silnej zależności nie dostrzegamy. Sprawdźmy jak będzie się zachowywad rozrzut wartości zmiennych objaśnianych w oparciu o te dwie zmienne objaśniające razem.
69 > model<-lm(rating~sugars+fiber, data=dane) > summary(model) Call: lm(formula = rating ~ sugars + fiber, data = dane) Residuals: Min 1Q Median 3Q Max Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) < 2e-16 *** sugars < 2e-16 *** fiber e-14 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: on 74 degrees of freedom Multiple R-squared: , Adjusted R-squared: F-statistic: on 2 and 74 DF, p-value: < 2.2e-16 W tym przypadku równanie regresji będzie wyglądad następująco: Rating = * sugars * fiber
70 Aby zinterpretowad współczynnik nachylenia prostej regresji: Rating = * sugars * fiber b 1 = wartośd odżywcza maleje o punktu, jeśli zawartośd cukru rośnie o jedną jednostkę. Zakładamy przy tym, że zawartośd błonnika (fiber) jest stała. b 2 = wartośd odżywcza rośnie o punktu, jeśli zawartośd błonnika rośnie o jedną jednostkę a zawartośd cukru (sugars) jest stała. Uogólniając będziemy mówid, że dla m zmiennych objaśniających zachodzi reguła, zgodnie z którą: oszacowana zmiana wartości zmiennej odpowiedzi to} b i, jeśli wartość zmiennej x i rośnie o jednostkę i zakładając, że wszystkie pozostałe wartości zmiennych są stałe.
71 Błędy predykcji są mierzone przy użyciu reszt $y - \hat{y}$. Uwaga: w prostej regresji liniowej reszty reprezentują odległośd (mierzoną wzdłuż osi pionowej) pomiędzy właściwym punktem danych a linią regresji, zaś w regresji wielokrotnej, reszta jest reprezentowana jako odległośd między właściwym punktem danych a płaszczyzną lub hiperpłaszczyzną regresji. Przykładowo płatki Spoon Size Shredded Wheat zawierają x 1 =0 gramów cukru i x 2 = 3 gramy błonnika, a ich wartośd odżywcza jest równa podczas gdy wartośd oszacowana, podana za pomocą równania regresji: > predict(model, data.frame(sugars=0,fiber=3),level=0.95, interval="confidence") fit lwr upr Zatem dla tych konkretnych płatków reszta jest równa = Zwródmy uwagę na to, że wyniki, które tutaj zwraca funkcja R: predict są bardzo istotne. Mianowicie, oprócz podanej (oszacowanej, przewidywanej) wartości zmiennej objaśniającej, otrzymujemy również przedział ufności na zadanym poziomie ufności równym 0.95, który to przedział mieści się między wartością (lwr) a (upr).
72 Współczynnik determinacji r 2 Pozwala stwierdzid czy oszacowane równanie regresji jest przydatne do przewidywania. Określa stopieo w jakim linia regresji najmniejszych kwadratów wyjaśnia zmiennośd obserwowanych danych. x y y y y 2 ( y y)
73 x y y y y 2 ( y y) Całkowita suma kwadratów SST n i1 ( y y) 2 Regresyjna suma kwadratów SSR n i1 ( y y) 2 Suma kwadratów błędów oszacowania: SSE n i1 ( y y) 2 Wówczas współczynnik determinacji r 2 : 2 r SSR SST
74 Współczynnik determinacji r 2 Współczynnik determinacji r 2 : 2 r SSR SST Mierzy stopieo dopasowania regresji jako przybliżenia liniowej zależności pomiędzy zmienną celu a zmienną objaśniającą. Jaka jest wartośd maksymalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja idealnie pasuje do danych, co ma miejsce wtedy gdy każdy z punktów danych leży dokładnie na oszacowanej linii regresji. Wówczas nie ma błędów oszacowania, a więc wartości resztowe (rezydua) wynoszą 0, a więc SSE=0 a wtedy SST = SSR a r 2 =1. Jaka jest wartośd minimalna współczynnika determinacji r 2? Jest ona osiągana wtedy, gdy regresja nie wyjaśnia zmienności, wtedy SSR = 0, a więc r 2 =0. Im większa wartość r 2 tym lepsze dopasowanie regresji do zbioru danych.
75 Przykład analizy współczynnika R 2 dla wielu zmiennych objaśniających Jak już wspomnieliśmy na początku, często w świecie rzeczywistym mamy do czynienia z zależnościami zmiennej objaśnianej nie od jednej ale raczej od wielu zmiennych objaśniających. Wykonanie tego typu analiz w pakiecie R nie jest rzeczą trudną. Wręcz przeciwnie. Nim przeprowadzimy analizę zależności zmiennej rating od wielu zmiennych objaśniających np. sugars oraz fiber przyjrzyjmy się wykresom rozrzutu dla tych zmiennych osobno. Wykres rozrzutu bowiem doskonale odzwierciedla zależności między pojedynczymi zmiennymi.
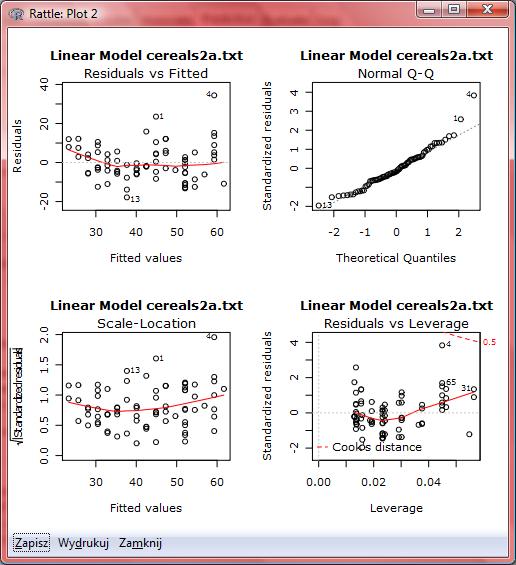
76 Wykres rozrzutu dla zmiennej sugars
77 Wykres rozrzutu dla zmiennej fiber
78 Interpretacja Widad z nich, że między zmienną objaśniającą sugars a zmienną objaśnianą fiber istnieje pewna zależnośd (w miarę wzrostu wartości sugars spada wartośd rating). Z kolei analizując rozrzut obserwacji ze względu na wartości zmiennej objaśniającej fiber oraz objaśnianej rating już tak silnej zależności nie dostrzegamy. Sprawdźmy jak będzie się zachowywad rozrzut wartości zmiennych objaśnianych w oparciu o te dwie zmienne objaśniające razem.
79 Współczynnik determinacji Niezwykle istotna jest miara nazwana już wcześniej współczynnikiem determinacji R 2 określana za pomocą wzoru: n ^ n 2 SSR ^ 2ˆ 2ˆ SSR ( y ˆ y) i1 R SST SST ( y ˆ y) gdzie SSR to regresyjna suma kwadratów zaś SST to całkowita suma kwadratów Będziemy go interpetowad jako częśd zmienności zmiennej objaśnianej, która jest wyjaśniana przez liniową zależnośd ze zbiorem zmiennych objaśniających. Im większa będzie liczba zmiennych objaśniających tym \textbf{nie mniejsza} będzie wartość współczynnika determinacji $R^2$. Możemy wnioskowad, że gdy dodajemy nową zmienną objaśniającą do modelu, wartośd $R^2$ będzie nie mniejsza niż przy modelu o mniejszej liczbie zmiennych. Oczywiście skala (wielkośd) tej różnicy jest bardzo istotna w zależności od tego czy dodamy tę zmienną do modelu czy też nie. Jeśli wzrost jest duży to uznamy tę zmienną za znaczącą (przydatną). i1
80 Jeśli takie reszty obliczymy dla każdej obserwacji to możliwe będzie wyznaczenie wartości współczynnika determinacji R 2. W naszym przypadku jest on równy czyli %. Oznacza to w naszej analizie, że % zmienności wartości odżywczej jest wyjaśniane przez liniową zależnośd pomiędzy zmienną wartośd odżywcza a zbiorem zmiennych objaśniających - zawartością cukrów i zawartością błonnika. Jeśli popatrzymy jaka była wartośd tego współczynnika, gdy badaliśmy na początku zależnośd zmiennej objaśnianej tylko od jednej zmiennej objaśniającej (cukry) to wartośd ta wynosiła R 2 = 57.71%. Dla dwóch zmiennych objaśniających ta wartości wyniosła %. Czyli powiemy, że dodając nową zmienną objaśniającą (w tym przypadku błonnik) możemy wyjaśnid dodatkowe = 22.19% zmienności wartości odżywczej (rating) płatków. Typowy błąd oszacowania jest tu obliczany jako standardowy błąd oszacowania s i wynosi 6.22 punktu. Oznacza to, że estymacja wartości odżywczej płatków na podstawie zawartości cukrów i błonnika zwykle różni się od właściwej wartości o 6.22 punktu. Jeśli nowa zmienna jest przydatna, to błąd ten powinien się zmniejszad po dodaniu nowej zmiennej.
81 Ile zmiennych objaśniających w modelu regresji? Najprostszym sposobem na wybór optymalnej liczby zmiennych objaśniających jest współczynnik R 2 adj zwany skorygowanym. Wiedząc, że R 2 = 1 SSE/SST wartośd R 2 adj obliczymy jako: 2 R adj 1 SSE n p SST n 1 gdzie p oznacza liczbę parametrów modelu (i jest to zazwyczaj liczba zmiennych objaśniających + 1) zaś n oznacza wielkośd próby. Zwykle wartośd R 2 adj będzie po prostu nieco mniejsza niż wartośd R 2. W środowisku R współczynnik determinacji R 2 wyznaczymy stosując bezpośrednio komendę: summary(model.liniowy)\$r.square Z kolei współczynnik determinacji ale ten tzw. skorygowany (ang. Adjusted) za pomocą komendy: summary(model.liniowy)\$adj.r.squared
82 Chcąc wyznaczyd wartości tych współczynników dla naszego testowego modelu z dwiema zmiennymi objaśniającymi sugars oraz fiber w środowisku R użyjemy odpowiednich komend, jak to pokazuje poniższy kod R wraz z wynikami: > dane<- read.table("c:\\cereals.data", header = TRUE, row.names = 1) > model<-lm(rating~sugars+fiber, data=dane) > summary(model)$r.square [1] > summary(model)$adj.r.squared [1] Jak widzimy współczynnik R 2 wynosi zaś R 2 adj odpowiednio
83 Obserwacje wpływowe Obserwacja jest wpływowa (ang. influential), jeśli jej obecnośd wpływa na prostą regresji, w taki sposób, że zmienia się współczynnik kierunkowy tej prostej. Inaczej powiemy, żejeśli obserwacja jest wpływowa to inaczej wygląda prosta regresji w zależności od tego czy ta obserwacja została ujęta w zbiorze, czy też nie (gdyż została usunięta). W praktyce, jeśli obserwowana wartośd leży w I-ym kwartylu rozkładu (czyli ma wartośd mniejszą niż 25 centyl), to mówimy, żema ona mały wpływ na regresję. Obserwacje leżące między I a III kwartylem nazywamy wpływowymi. Wykrycie obserwacji wpływowych umożliwia pomiar odległości Cooka, w której wykorzystujemy tzw. modyfikowane rezydua. Usuwając obserwację, którą chcemy uznad za wpływową ze zbioru obserwacji i obliczając różnicę (między tym jak wyglądają równania regresji z tą obserwacją i gdy jej nie ma) uznajemy obserwację za wpływową gdy ta różnica będzie wysoka. Odległośd Cooka mierzy poziom wpływu obserwacji i jest obliczana jako: y y j j(i) jest wartością przewidywaną dla j-tej obserwacji obliczoną w modelu z usuniętą obserwacją i-tą jest wartością przewidywaną dla j-tej obserwacji w modelu, w którym nie usunięto i-tej obserwacji (potencjalnie wpływowej).
, main=\"influence Plot\",sub=\"Rozmiar kółka jest proporcjonalny do odległości")
84 Wykres obserwacji wpływowych z zaznaczeniem odległości Cooka Teraz jeśli chcemy poznad obserwacje wpływowe możemy użyd komendy: > influenceplot(lm(b~a), main="influence Plot",sub="Rozmiar kółka jest proporcjonalny do odległości Cooka)
85 Do wykrycia obserwacji wpływowych możemy także użyd funkcji. > influence.measures(lm(b~a)) której efekty będzie następujący > influence.measures(lm(b~a)) Influence measures of lm(formula = b ~ a) : dfb.1_ dfb.a dffit cov.r cook.d hat inf e e e * e e e e e e e e e e e e e e e e e e e e e e e e * e e e > Jak widad, ostatnia kolumna wskazuje na obserwacje wpływowe zaznaczając przy nich symbol *. Z naszych danych wynika, że w zbiorze 10 obserwacji mamy 2 wpływowe. Są to obserwacje 1 i 9.
86 Wyznaczenie obserwacji odstających w modelu z wieloma zmiennymi objaśniającymi Obserwacje odstające będziemy wykrywad przy użyciu znanego już pakietu car i funkcji outlier.test w ramach tego pakietu. library(car) > outlier.test(model) max rstudent = , degrees of freedom = 73, unadjusted p = , Bonferroni p = Observation: Golden_Crisp Wykryliśmy jedną obserwację odstającą (płatki o nazwie Golden_Crisp).
87 Wyznaczenie obserwacji wpływowych w modelu z wieloma zmiennymi objaśniającymi Wartości wpływowe będziemy wykrywad za pomocą fukcji influence.measures. Wyniki takiej analizy widzimy poniżej. influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
88 influence.measures(model) Influence measures of lm(formula = rating ~ sugars + fiber, data = dane) : dfb.1_ dfb.sgrs dfb.fibr dffit 100\%_Bran e \%_Natural_Bran e All-Bran e All-Bran_with_Extra_Fiber e Frosted_Flakes e Frosted_Mini-Wheats e Golden_Crisp e Golden_Grahams e Grape_Nuts_Flakes e Grape-Nuts e Shredded_Wheat_'n'Bran e Shredded_Wheat_spoon_size e Wheaties_Honey_Gold e cov.r cook.d hat inf 100\%_Bran e * 100\%_Natural_Bran e All-Bran e * All-Bran_with_Extra_Fiber e *... Frosted_Flakes e Frosted_Mini-Wheats e *... Golden_Crisp e *... Post_Nat._Raisin_Bran e *
89 Zawpływowe uznamy 6 obserwacji: 100%_Bran All-Bran All-Bran_with_Extra_Fiber Frosted_Mini-Wheats Golden_Crisp (które zresztą uznaliśmy za obserwację odstającą, outlier) oraz Post_Nat._Raisin_Bran.
90 Współliniowośd Gdy zmienne objaśniające są wysoko skorelowane wyniki analizy regresji mogą byd niestabilne. Szacowana wartośd zmiennej x i może zmienid wielkośd a nawet kierunek zależnie od pozostałych zmiennych objaśniających zawartych w tak testowanym modelu regresji. Taka zależnośd liniowa między zmiennymi objaśniającymi może zagrażad trafności wyników analizy regresji. Do wskaźników oceniających współliniowośd należy, m.in. VIF (Variance Inflation Factor) zwany współczynnikiem podbicia (inflacji) wariancji. VIF pozwala wychwycid wzrost wariancji ze względu na współliniowośd cechy. Innymi słowy: wskazuje on o ile wariancje współczynników są zawyżone z powodu zależności liniowych w testowanym modelu. Niektóre pakiety statystyczne pozwalają także alternatywnie mierzyd tzw. współczynnik toleracji (TOL - ang. tolerance), który mierzy się jako: 1/VIF VIF i (1 R 2 1 i ) dla modelu x i = f(x 1,., x i-1, x i+1,, x p ) gdzie zmienna x i będzie wyjaśniana przez wszystkie pozostałe zmienne. Gdy VIF > 10 mówimy, że współliniowośd wystąpiła i chcąc się jej pozbyd z modelu, usuwamy te cechy, które są liniową kombinacją innych zmiennych niezależnych.
91 Radą na współliniowośd jest według niektórych prac zwiększenie zbioru obserwacji o nowe, tak, by zminimalizowad istniejące zależności liniowe pomiędzy zmiennymi objaśniającymi. Oczywiście, zwiększenie liczby obserwacji nie gwarantuje poprawy -stąd takie rozwiązanie na pewno nie należy do najlepszych i jedynych. Lepszym wydaje się komponowanie zmiennych zależnych w nowe zmienne (np. waga i wzrost są skorelowane silnie i zamiast nich stworzenie jednej zmiennej stosunek wzrostu do wagi. Taką nową zmienną nazywa się w literaturze kompozytem. Często - dla dużej liczby zmiennych objaśniających - stosuje sie metodę analizy składowych głównych (ang. principal component analysis) dla redukcji liczby zmiennych do jednego lub kilku kompozytów niezależnych.
92 Przykład modelu ze współliniowością Dla modelu postaci: y i = b 0 + b 1 x 1i + b 2 x 2i + b 3 x 3i + e 1i Gdzie x 3i = 10 * x 1i - 2 * x 2i. Wtedy powiemy, że zmienna x 3 jest kombinacją liniową zmiennych x 1 i x 2. Próba szacowania takiego modelu związana jest ze świadomym popełnianiem błędu, gdyż w modelu tym występuje dokładna współliniowośd (jedna ze zmiennych objaśniających jest kombinacją liniową pozostałych).
93 W środowisku R sprawdzanie współliniowości nie jest trudne. Wystarczy skorzystad z funkcji vif której argumentem jest model regresji dla danego zbioru danych. Przykład dotyczący naszego zbioru płatków zbożowych przedstawiamy poniżej: > vif(lm(rating~sugars+fiber, data=dane)) sugars fiber Wartości współczynnika $VIF$ nie są zbyt wysokie toteż uznajemy, że w modelu tym nie występuje zjawisko współliniowości.
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI
 Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Regresja liniowa oraz regresja wielokrotna w zastosowaniu zadania predykcji danych. Agnieszka Nowak Brzezińska Wykład III-VI Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną
Agnieszka Nowak Brzezińska Wykład 2 z 5
 Agnieszka Nowak Brzezińska Wykład 2 z 5 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja
Agnieszka Nowak Brzezińska Wykład 2 z 5 metoda typ Zmienna niezależna Regresja liniowa Regresja Wszystkie ilościowe Zakłada liniową zależność, prosta w implementacji Analiza dyskryminacyjna klasyfikacja
Analiza regresji część III. Agnieszka Nowak - Brzezińska
 Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Analiza regresji część III Agnieszka Nowak - Brzezińska Są trzy typy obserwacji, które mogą ale nie muszą wywierać nadmiernego nacisku na wyniki regresji: Obserwacje oddalone (outlier) Obserwacje wysokiej
Regresja liniowa, klasyfikacja metodą k-nn. Agnieszka Nowak Brzezińska
 Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Regresja liniowa, klasyfikacja metodą k-nn Agnieszka Nowak Brzezińska Analiza regresji Analiza regresji jest bardzo popularną i chętnie stosowaną techniką statystyczną pozwalającą opisywać związki zachodzące
Analiza regresji część II. Agnieszka Nowak - Brzezińska
 Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Analiza regresji część II Agnieszka Nowak - Brzezińska Niebezpieczeństwo ekstrapolacji Analitycy powinni ograniczyć predykcję i estymację, które są wykonywane za pomocą równania regresji dla wartości objaśniającej
Analiza zależności cech ilościowych regresja liniowa (Wykład 13)
") Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Analiza zależności cech ilościowych regresja liniowa (Wykład 13) dr Mariusz Grządziel semestr letni 2012 Przykład wprowadzajacy W zbiorze danych homedata (z pakietu R-owskiego UsingR) można znaleźć ceny
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT. Część I: analiza regresji
 Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Regresja liniowa wprowadzenie
 Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y. 2. Współczynnik korelacji Pearsona
 KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka w analizie i planowaniu eksperymentu
 23 kwietnia 2014 Korelacja - wspó lczynnik korelacji 1 Gdy badamy różnego rodzaju rodzaju zjawiska (np. przyrodnicze) możemy stwierdzić, że na każde z nich ma wp lyw dzia lanie innych czynników; Korelacja
23 kwietnia 2014 Korelacja - wspó lczynnik korelacji 1 Gdy badamy różnego rodzaju rodzaju zjawiska (np. przyrodnicze) możemy stwierdzić, że na każde z nich ma wp lyw dzia lanie innych czynników; Korelacja
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Regresja liniowa w R Piotr J. Sobczyk
 Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Regresja liniowa w R Piotr J. Sobczyk Uwaga Poniższe notatki mają charakter roboczy. Mogą zawierać błędy. Za przesłanie mi informacji zwrotnej o zauważonych usterkach serdecznie dziękuję. Weźmy dane dotyczące
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
Model regresji wielokrotnej Wykład 14 ( ) Przykład ceny domów w Chicago
 Przykład ceny domów w Chicago") Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
Model regresji wielokrotnej Wykład 14 (4.06.2007) Przykład ceny domów w Chicago Poniżej są przedstawione dane dotyczące cen domów w Chicago (źródło: Sen, A., Srivastava, M., Regression Analysis, Springer,
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Stosowana Analiza Regresji
 prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
prostej Stosowana Wykład I 5 Października 2011 1 / 29 prostej Przykład Dane trees - wyniki pomiarów objętości (Volume), średnicy (Girth) i wysokości (Height) pni drzew. Interesuje nas zależność (o ile
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych
 Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych 1 Wprowadzenie Agnieszka Nowak-Brzezi«ska 17 listopada 2009 Niech ogólne równanie regresji ma posta
Zagadnienia regresji. Cz ± III Regresja wielokrotna Konspekt do zaj : Statystyczne metody analizy danych 1 Wprowadzenie Agnieszka Nowak-Brzezi«ska 17 listopada 2009 Niech ogólne równanie regresji ma posta
Stanisław Cichocki. Natalia Nehrebecka. Wykład 4
 Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Statystyczne metody analizy danych przy użyciu środowiska R
 Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
Statystyczne metody analizy danych przy użyciu środowiska R Agnieszka Nowak - Brzezińska Instytut Informatyki, Uniwersytet Śląski Wybrane zagadnienia Plan wystąpienia 1. Wprowadzenie. 2. Środowisko R.
Funkcja liniowa - podsumowanie
 Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
Funkcja liniowa - podsumowanie 1. Funkcja - wprowadzenie Założenie wyjściowe: Rozpatrywana będzie funkcja opisana w dwuwymiarowym układzie współrzędnych X. Oś X nazywana jest osią odciętych (oś zmiennych
Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X1, X2, X3,...) na zmienną zależną (Y).
 na zmienną zależną (Y).") Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
Statystyka i opracowanie danych Ćwiczenia 12 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA WIELORAKA Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
Pracownia Astronomiczna. Zapisywanie wyników pomiarów i niepewności Cyfry znaczące i zaokrąglanie Przenoszenie błędu
 Pracownia Astronomiczna Zapisywanie wyników pomiarów i niepewności Cyfry znaczące i zaokrąglanie Przenoszenie błędu Każdy pomiar obarczony jest błędami Przyczyny ograniczeo w pomiarach: Ograniczenia instrumentalne
Pracownia Astronomiczna Zapisywanie wyników pomiarów i niepewności Cyfry znaczące i zaokrąglanie Przenoszenie błędu Każdy pomiar obarczony jest błędami Przyczyny ograniczeo w pomiarach: Ograniczenia instrumentalne
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH
 Wykład 1 Prosta regresja liniowa - model i estymacja parametrów. Regresja z wieloma zmiennymi - analiza, diagnostyka i interpretacja wyników. Literatura pomocnicza J. Koronacki i J. Ćwik Statystyczne systemy
Wykład 1 Prosta regresja liniowa - model i estymacja parametrów. Regresja z wieloma zmiennymi - analiza, diagnostyka i interpretacja wyników. Literatura pomocnicza J. Koronacki i J. Ćwik Statystyczne systemy
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Regresja logistyczna. Regresja logistyczna. Przykłady DV. Wymagania
 Regresja logistyczna analiza relacji między zbiorem zmiennych niezależnych (ilościowych i dychotomicznych) a dychotomiczną zmienną zależną wyniki wyrażone są w prawdopodobieństwie przynależności do danej
Regresja logistyczna analiza relacji między zbiorem zmiennych niezależnych (ilościowych i dychotomicznych) a dychotomiczną zmienną zależną wyniki wyrażone są w prawdopodobieństwie przynależności do danej
ANALIZA REGRESJI WIELOKROTNEJ. Zastosowanie statystyki w bioinżynierii Ćwiczenia 8
 ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
ANALIZA REGRESJI WIELOKROTNEJ Zastosowanie statystyki w bioinżynierii Ćwiczenia 8 ZADANIE 1A 1. Irysy: Sprawdź zależność długości płatków korony od ich szerokości Utwórz wykres punktowy Wyznacz współczynnik
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna
 Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Natalia Nehrebecka Stanisław Cichocki. Wykład 13
 Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Ekonometria dla IiE i MSEMat Z7
 Ekonometria dla IiE i MSEMat Z7 Rafał Woźniak Faculty of Economic Sciences, University of Warsaw Warszawa, 21-11-2016 Na podstawie zbioru danych cps_small.dat z książki Principles of Econometrics oszacowany
Ekonometria dla IiE i MSEMat Z7 Rafał Woźniak Faculty of Economic Sciences, University of Warsaw Warszawa, 21-11-2016 Na podstawie zbioru danych cps_small.dat z książki Principles of Econometrics oszacowany
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Regresja liniowa Korelacja Modelowanie Analiza modelu Wnioskowanie Korelacja 3 Korelacja R: charakteryzuje
FUNKCJA LINIOWA - WYKRES
 FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
FUNKCJA LINIOWA - WYKRES Wzór funkcji liniowej (Postać kierunkowa) Funkcja liniowa jest podstawowym typem funkcji. Jest to funkcja o wzorze: y = ax + b a i b to współczynniki funkcji, które mają wartości
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Wykład Centralne twierdzenie graniczne. Statystyka matematyczna: Estymacja parametrów rozkładu
 Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Wykład 11-12 Centralne twierdzenie graniczne Statystyka matematyczna: Estymacja parametrów rozkładu Centralne twierdzenie graniczne (CTG) (Central Limit Theorem - CLT) Centralne twierdzenie graniczne (Lindenberga-Levy'ego)
Stanisław Cichocki. Natalia Nehrebecka. Wykład 14
 Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne Obserwacje nietypowe i błędne Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2)
Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne Obserwacje nietypowe i błędne Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2)
Permutacyjna metoda oceny istotności regresji
 Permutacyjna metoda oceny istotności regresji (bez założenia normalności) f
Permutacyjna metoda oceny istotności regresji (bez założenia normalności) f
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
BADANIE ZALEśNOŚCI CECHY Y OD CECHY X - ANALIZA REGRESJI PROSTEJ
 WYKŁAD 3 BADANIE ZALEśNOŚCI CECHY Y OD CECHY X - ANALIZA REGRESJI PROSTEJ Było: Przykład. Z dziesięciu poletek doświadczalnych zerano plony ulw ziemniaczanych (cecha X) i oznaczono w nich procentową zawartość
WYKŁAD 3 BADANIE ZALEśNOŚCI CECHY Y OD CECHY X - ANALIZA REGRESJI PROSTEJ Było: Przykład. Z dziesięciu poletek doświadczalnych zerano plony ulw ziemniaczanych (cecha X) i oznaczono w nich procentową zawartość
Regresja i Korelacja
 Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Regresja i Korelacja Regresja i Korelacja W przyrodzie często obserwujemy związek między kilkoma cechami, np.: drzewa grubsze są z reguły wyższe, drewno iglaste o węższych słojach ma większą gęstość, impregnowane
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Problemy z danymi Obserwacje nietypowe i błędne Współliniowość. Heteroskedastycznośd i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Problemy z danymi Obserwacje nietypowe i błędne Współliniowość. Heteroskedastycznośd i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Stanisław Cichocki. Natalia Nehrebecka. Wykład 9
 Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Stanisław Cichocki Natalia Nehrebecka Wykład 9 1 1. Dodatkowe założenie KMRL 2. Testowanie hipotez prostych Rozkład estymatora b Testowanie hipotez prostych przy użyciu statystyki t 3. Przedziały ufności
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH. Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa
 Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa Obserwacje nietypowe i wpływowe Obserwacje nietypowe i wpływowe Obserwacje nietypowe w analizie regresji: nietypowe wartości zmiennej Y - prowadzące
Wykład 2 Obserwacje nietypowe i wpływowe Regresja nieliniowa Obserwacje nietypowe i wpływowe Obserwacje nietypowe i wpływowe Obserwacje nietypowe w analizie regresji: nietypowe wartości zmiennej Y - prowadzące
Wprowadzenie do technik analitycznych Metoda najmniejszych kwadratów
 Wprowadzenie do technik analitycznych Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski Wykład 2 Korelacja i regresja Przykład: Temperatura latem średnia liczba napojów sprzedawanych
Wprowadzenie do technik analitycznych Instytut Sterowania i Systemów Informatycznych Uniwersytet Zielonogórski Wykład 2 Korelacja i regresja Przykład: Temperatura latem średnia liczba napojów sprzedawanych
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Wstęp do teorii niepewności pomiaru. Danuta J. Michczyńska Adam Michczyński
 Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
Wstęp do teorii niepewności pomiaru Danuta J. Michczyńska Adam Michczyński Podstawowe informacje: Strona Politechniki Śląskiej: www.polsl.pl Instytut Fizyki / strona własna Instytutu / Dydaktyka / I Pracownia
Statystyka opisowa. Wykład V. Regresja liniowa wieloraka
 Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
Statystyka opisowa. Wykład V. e-mail:e.kozlovski@pollub.pl Spis treści 1 Prosta regresji cechy Y względem cech X 1,..., X k. 2 3 Wyznaczamy zależność cechy Y od cech X 1, X 2,..., X k postaci Y = α 0 +
FUNKCJA LINIOWA, RÓWNANIA I UKŁADY RÓWNAŃ LINIOWYCH
 FUNKCJA LINIOWA, RÓWNANIA I UKŁADY RÓWNAŃ LINIOWYCH PROPORCJONALNOŚĆ PROSTA Proporcjonalnością prostą nazywamy zależność między dwoma wielkościami zmiennymi x i y, określoną wzorem: y = a x Gdzie a jest
FUNKCJA LINIOWA, RÓWNANIA I UKŁADY RÓWNAŃ LINIOWYCH PROPORCJONALNOŚĆ PROSTA Proporcjonalnością prostą nazywamy zależność między dwoma wielkościami zmiennymi x i y, określoną wzorem: y = a x Gdzie a jest
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
5. Model sezonowości i autoregresji zmiennej prognozowanej
 5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
Regresja logistyczna. Regresja logistyczna. Wymagania. Przykłady DV
 Regresja logistyczna analiza relacji między zbiorem zmiennych niezależnych (ilościowych i dychotomicznych) a dychotomiczną zmienną zależną wyniki wyrażone są w prawdopodobieństwie przynależności do danej
Regresja logistyczna analiza relacji między zbiorem zmiennych niezależnych (ilościowych i dychotomicznych) a dychotomiczną zmienną zależną wyniki wyrażone są w prawdopodobieństwie przynależności do danej
Metoda najmniejszych kwadratów
 Własności algebraiczne Model liniowy Zapis modelu zarobki = β 0 + β 1 plec + β 2 wiek + ε Oszacowania wartości współczynników zarobki = b 0 + b 1 plec + b 2 wiek + e Model liniowy Tabela: Oszacowania współczynników
Własności algebraiczne Model liniowy Zapis modelu zarobki = β 0 + β 1 plec + β 2 wiek + ε Oszacowania wartości współczynników zarobki = b 0 + b 1 plec + b 2 wiek + e Model liniowy Tabela: Oszacowania współczynników
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.
 znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej.") Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Temat: WYKRYWANIE ODCHYLEO W DANYCH Outlier to dana (punkt, obiekt, wartośd w zbiorze) znacznie odstająca od reszty. prezentacji punktów odstających jest rysunek poniżej. Przykładem Box Plot wygodną metodą
Projekt Nowa oferta edukacyjna Uniwersytetu Wrocławskiego odpowiedzią na współczesne potrzeby rynku pracy i gospodarki opartej na wiedzy
 Projekt Nowa oferta edukacyjna Uniwersytetu Wrocławskiego odpowiedzią na współczesne potrzeby rynku pracy i gospodarki opartej na wiedzy Dane: Eksploracja (mining) Problemy: Jedna zmienna 2000 najwi ększych
Projekt Nowa oferta edukacyjna Uniwersytetu Wrocławskiego odpowiedzią na współczesne potrzeby rynku pracy i gospodarki opartej na wiedzy Dane: Eksploracja (mining) Problemy: Jedna zmienna 2000 najwi ększych
Ekonometria. Dobór postaci analitycznej, transformacja liniowa i estymacja modelu KMNK. Paweł Cibis 9 marca 2007
 , transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
, transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
Lista 2 logika i zbiory. Zad 1. Dane są zbiory A i B. Sprawdź, czy zachodzi któraś z relacji:. Wyznacz.
 Lista 2 logika i zbiory. Zad 1. Dane są zbiory A i B. Sprawdź, czy zachodzi któraś z relacji:. Wyznacz. Na początek wypiszmy elementy obu zbiorów: A jest zbiorem wszystkich liczb całkowitych, które podniesione
Lista 2 logika i zbiory. Zad 1. Dane są zbiory A i B. Sprawdź, czy zachodzi któraś z relacji:. Wyznacz. Na początek wypiszmy elementy obu zbiorów: A jest zbiorem wszystkich liczb całkowitych, które podniesione
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Stanisław Cichocki. Natalia Nehrebecka. Wykład 14
 Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Współliniowość 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji Metody radzenia sobie z heteroskedastycznością
Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Współliniowość 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji Metody radzenia sobie z heteroskedastycznością
Statystyczna analiza danych
 Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Statystyczna analiza danych Korelacja i regresja Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/30 Ostrożnie z interpretacją p wartości p wartości zależą od dwóch rzeczy
Analiza współzależności zjawisk
 Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Analiza współzależności zjawisk Informacje ogólne Jednostki tworzące zbiorowość statystyczną charakteryzowane są zazwyczaj za pomocą wielu cech zmiennych, które nierzadko pozostają ze sobą w pewnym związku.
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Matematyka licea ogólnokształcące, technika
 Matematyka licea ogólnokształcące, technika Opracowano m.in. na podstawie podręcznika MATEMATYKA w otaczającym nas świecie zakres podstawowy i rozszerzony Funkcja liniowa Funkcję f: R R określoną wzorem
Matematyka licea ogólnokształcące, technika Opracowano m.in. na podstawie podręcznika MATEMATYKA w otaczającym nas świecie zakres podstawowy i rozszerzony Funkcja liniowa Funkcję f: R R określoną wzorem
gdzie. Dla funkcja ma własności:
 Ekonometria, 21 listopada 2011 r. Modele ściśle nieliniowe Funkcja logistyczna należy do modeli ściśle nieliniowych względem parametrów. Jest to funkcja jednej zmiennej, zwykle czasu (t). Dla t>0 wartośd
Ekonometria, 21 listopada 2011 r. Modele ściśle nieliniowe Funkcja logistyczna należy do modeli ściśle nieliniowych względem parametrów. Jest to funkcja jednej zmiennej, zwykle czasu (t). Dla t>0 wartośd
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
3. FUNKCJA LINIOWA. gdzie ; ół,.
 1 WYKŁAD 3 3. FUNKCJA LINIOWA FUNKCJĄ LINIOWĄ nazywamy funkcję typu : dla, gdzie ; ół,. Załóżmy na początek, że wyraz wolny. Wtedy mamy do czynienia z funkcją typu :.. Wykresem tej funkcji jest prosta
1 WYKŁAD 3 3. FUNKCJA LINIOWA FUNKCJĄ LINIOWĄ nazywamy funkcję typu : dla, gdzie ; ół,. Załóżmy na początek, że wyraz wolny. Wtedy mamy do czynienia z funkcją typu :.. Wykresem tej funkcji jest prosta
Stanisław Cichocki. Natalia Nehrebecka. Wykład 13
 Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Testowanie autokorelacji 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji 3.Problemy z danymi Zmienne pominięte
Stanisław Cichocki Natalia Nehrebecka Wykład 13 1 1. Testowanie autokorelacji 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji 3.Problemy z danymi Zmienne pominięte
Analiza statystyczna trudności tekstu
 Analiza statystyczna trudności tekstu Łukasz Dębowski ldebowsk@ipipan.waw.pl Problem badawczy Chcielibyśmy mieć wzór matematyczny,...... który dla dowolnego tekstu...... na podstawie pewnych statystyk......
Analiza statystyczna trudności tekstu Łukasz Dębowski ldebowsk@ipipan.waw.pl Problem badawczy Chcielibyśmy mieć wzór matematyczny,...... który dla dowolnego tekstu...... na podstawie pewnych statystyk......
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Regresja - zadania i przykłady.
 Regresja - zadania i przykłady. W5 e0 Zadanie 1. Poniżej zamieszczono fragmenty wydruków dotyczących dopasowania modelu regresji do zmiennej ozone w oparciu o promieniowanie (radiation), oraz w oparciu
Regresja - zadania i przykłady. W5 e0 Zadanie 1. Poniżej zamieszczono fragmenty wydruków dotyczących dopasowania modelu regresji do zmiennej ozone w oparciu o promieniowanie (radiation), oraz w oparciu
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).
Wykład 4 Związki i zależności
 Wykład 4 Związki i zależności Rozważmy: Dane z dwiema lub więcej zmiennymi Zagadnienia do omówienia: Zmienne objaśniające i zmienne odpowiedzi Wykres punktowy Korelacja Prosta regresji Słownictwo: Zmienna
Wykład 4 Związki i zależności Rozważmy: Dane z dwiema lub więcej zmiennymi Zagadnienia do omówienia: Zmienne objaśniające i zmienne odpowiedzi Wykres punktowy Korelacja Prosta regresji Słownictwo: Zmienna