Wielowymiarowa analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok
|
|
|
- Lech Markowski
- 9 lat temu
- Przeglądów:
Transkrypt

1 Wielowymiarowa analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok Adam Kiersztyn Katedra Teorii Prawdopodobieństwa Wydzia Matematyczno - Przyrodniczy Katolicki Uniwersytet Lubelski Jana Paw a II 1

2 1 Wieloczynnikowa analiza wariancji W zasz ym semestrze poznaliśmy jednoczynnikowa¾ analiz ¾e wariancji, teraz poznamy mo zliwości jakie niesie wieloczynnikowa analiza wariancji. Za ó zmy, ze chcemy dokonać analizy p ac dal danych z pliku niedziela.sav ze wzgl ¾edu na wi ¾ecej ni z jeden czynnik. Przypuśćmy, ze chcemy sprawdzić czy średnia p aca ze wzgl ¾edu na p eć zajmowane stanowisko i posiadane wykszta cenie sa¾ równe. W tym celu wybieramy i wybieramy interesujac ¾ a¾ nas zmienna¾ zale zna¾ oraz czynniki 2

3 nast ¾epnie wchodzimy w Opcje i wybieramy jak na poni zszym rysunku. 3

4 Jako wynik otrzymujemy raport zawierajacy ¾ mi ¾edzy innymi podsumowanie 4

5 liczebności poszczególnych grup podstawowe statystyki opisowe dla poszczególnych grup oraz testy efektów mi ¾edzyobiektowych z których mo zemy odczytać dla jakich zmiennych średnia p aca ró zni si ¾e statystycznie. Zastanówmy si ¾e teraz w jaki sposób mo zna dok adniej przeanalizować ró znice pomi ¾edzy poszczególnymi cechami. W tym celu skorzystamy z testów post-hoc w nieco mniej konwencjonalnej formie. Mianowicie na formatce opcje 5

6 wybieramy wszystkie czynniki oraz wybieramy test post-hoc. Jako rezultat otrzymujemy dość interesujacy ¾ raport zawierajacy ¾ bardzo du zo cennych informacji. 2 Regresja liniowa wielu zmiennych Czasami zdarza si ¾e, ze pewna cecha zale zna jest od kilku innych cennych. Dla przyk adu w naszym ostatnio rozwa zanym przyk adzie dodatek sta zowy zale za od czasu pracy oraz od stanowiska. Rozwa zmy nast ¾epujacy ¾ przyk ad: zmienna dorośli zawiera liczb ¾e osób doros ych wyje zd zajacych ¾ na wycieczk¾e, natomiast dzieci oznacza liczb ¾e dzieci, za ka zdego doros ego p aci si ¾e 1200 z otych, zaś za dziecko 800 z otych. Zmienna koszt wycieczki powstaje zatem ze wzoru koszt = 1200 dorosli dzieci 6

7 Zobaczmy w jaki sposób nasza¾ funkcj ¾e liniowa¾ dwóch zmiennych estymuje program SPSS. Wybieramy regresj ¾e liniowa¾ a nast ¾epnie wskazujemy zmienna¾ zale zna¾ oraz zmienne niezale zne jako wynik otrzymujemy raport, 7

8 z którego wynika, ze z = 1200x + 800y czyli program bardzo dobrze oszacowa prosta. ¾ 3 Podsumowanie zdobytej wiedzy Poni zej zamieszczona jest lista poleceń oraz rozwiazania ¾ wybranych poleceń. Dla danych z pliku niedziela.sav wykonać nast ¾epujace ¾ polecenia 1. Obliczyć średnia¾ p ac ¾e kobiet i m ¾e zczyzn oddzielnie, wyznaczyć równie z pozosta e podstawowe statystyki opisowe w podzia em na p eć. Rozwiazanie: ¾ dokonać wymaganych obliczeń skorzystamy z eksploracji danych 8
.")
9 gdzie wybieramy interesujace ¾ nas zmienne oraz statystyki. 2. Wyznaczyć podstawowe statystyki opisowe p acy z podzia em na stanowisko. Rozwiazanie ¾ jest analogiczne jak w powy zszym poleceniu musimy zamienić p eć na stanowisko 3. Wyznaczyć średni czas pracy ze wzgl ¾edu na stanowisko (histogramy dla ka zdego stanowiska). Rozwiazanie ¾ Pierwsza cz ¾eść jest podobna do polecenia 1 musimy tylko 9
 10 Rozwiazanie:")
10 wybrać inne zmienne oraz dodatkowo wybrać histogram w oknie wykresy. 4. Wyznaczyć wielkość dodatku sta zowego za pomoca¾ wzoru dodatek = lata pracy (5 stanowisko) 10 Rozwiazanie: ¾ Tworzymy nowa¾ zmienna¾ poprzez 10

11 a nast ¾epnie wpisujemy stosowna¾ formu ¾e 5. Obliczyć premi ¾e uznaniowa¾ ze wzoru premia = 1500 (suma spóźnień)*100 Rozwiazanie: ¾ analogicznie jak powy zej. 6. Sprawdzić czy wykszta cenie i zajmowane stanowisko sa¾ niezale zne. Rozwiazanie: ¾ wykorzystujemy test niezale zności 2 znajdujacy ¾ si¾e w oknie tabele krzy zowe, gdzie wskazujemy interesujace ¾ nas zmienne (kolumny i wiersze 11

12 mo zna zamienić miejscami) 7. Wyznaczyć prosta¾ regresji stanowisko w zale zności od wykszta cenia. 12

13 Rozwiazanie: ¾ skorzystamy w tym miejscu z estymacji krzywej gdzie wskazujemy zmienna¾ zale zna¾ i zmienna¾ niezale zna¾ oraz wskazujemy rodzaj estymowanej krzywej 8. Obliczyć pensj ¾e końcowa¾ ze wzoru pensja końcowa = pensja+dodatek sta zowy+premia+nadgodziny gdzie za ka zda¾ rozpocz ¾eta¾ godzin¾e nalicza si¾e 5 z dla pracownika, 7 dla asystenta, 8 dla kierownika i 10 dla dyrektora. 13
 sa¾ równe?")
14 Rozwiazanie: ¾ musimy kolejny raz skorzystać z przekszta ceń/ oblicz wartości, przy czym musimy zastosować opisany na wcześniej trik ze stworzeniem funkcji su tu. 9. Czy średnie wolnych dla poszczególnych par miesi ¾ecy (traktowanych jako zmienne zale zne) sa¾ równe? Rozwiazanie: ¾ w tym miejscu musimy kilka razy ( test t-studenta dla prób zale znych 12 2 = 66) zastosować 10. Podzielić na dwie grupy pracowników w zale zności od dni wolnych we wszystkich miesiacach ¾. Rozwiazanie: ¾ skorzystamy z analizy skupień, aby wydzielić interesujace ¾ nas dwie grupy, nale zy w tym miejscu zauwa zyć, ze ka zdego pracownika opisuje zastaw 12 danych (12 miesi ¾ecy) czyli mamy do czynienia z punktami w przestrzeni 12 wymiarowej. Przedstawienie w sposób gra czny naszych punktów mog oby 14

15 być dość problematyczne, ale podzia jest jak najbardziej mo zliwy. jako wynik oprócz raportu tworza¾ nam si¾e dwie nowe zmienne zawierajace ¾ o przynale zności danej obserwacji do danej grupy oraz odleg ości od centrum swojej grupy. 11. Sprawdzić, czy pensja końcowa jest równa we wszystkich grupach stanowisk. 15

16 Rozwiazanie: ¾ nale zy zastosować jednoczynnikowa¾ analiz ¾e wariancji nast ¾epnie wybrać zmienna¾ dla jakiej chcemy porównywać średnia¾ oraz czynnik wed ug którego chcemy dokonać grupowania, oczywiści nale zy pami ¾etać o sprawdzeniu jednorodności wariancji oczywiści mo zemy dokonać dok adniejszej analizy za pomoca¾ testów posthoc 12. Sprawdzić, czy pensje sa¾ równe ze wzgl ¾edu na wykszta cenia. Rozwiazanie: ¾ analogicznie jak powy zej. 13. Opisać za pomoca¾ prostej regresji zale zność pensji od czasu pracy, co mo zna powiedzieć o jakości tej oceny? Rozwiazanie: ¾ Kolejny raz zastosujemy estymacj ¾e krzywej regresji, przy czy w raporcie nale zy zwrócić uwag¾e na wartość wspó czynnika R 2 : 16

17 14. Czy wszystkie grupy pracowników spóźniaja¾ si¾e tak samo cz¾esto, jaka grupa spóźnia si ¾e najcz ¾eściej? Rozwiazanie: ¾ na wst ¾epie tworzymy nowa¾ zmienna, ¾ w której znajduja¾ si¾e zsumowane spóźnienia ze wszystkich kwarta ów a nast ¾epnie dla tej nowej zmiennej nale zy zastosować ANOVE¾ z czynnikiem stanowisko. 15. Czy mo zna stwierdzić, ze pensja na rozk ad normalny, a stanowisko i wykszta cenia maja¾ rozk ad równomierny? Rozwiazanie: ¾ w pierwszej cz ¾eści stosujemy wykres normalności z testami dost ¾epny w eksploracji w drugiej cz¾eści skorzystamy z testu 2 zgodności dost¾epnego w testach niepara- 17

18 metrycznych wskazujemy kolejno odpowiednie zmienne oraz zaznaczamy opcj ¾e, ze wszystkie 18
 sa¾ niezale zne?")
19 wartości sa¾ równe 16. Czy wielkość spóźnienia skategoryzowana do trzech grup kategoria procent udzia u ma e 25% średnie 50% du ze 25% i wykszta cenie (stanowisko) sa¾ niezale zne? Rozwiazanie: ¾ najpierw musimy skategoryzować spóźnienia, w tym celu korzystamy z opcji gdzie wskazujemy jaka¾ zmienna¾ chcemy rekodować oraz na jaka¾ zmienna¾ 19

20 nast ¾epnie ustalamy wartości źród owe i wynikowe i otrzymujemy interesujac ¾ a¾ nas nowa¾ zmienna¾ o trzech wartościach, dla której w zak adce zmienne podajemy mo zliwe wartości. 17. Obliczyć ¾ aczna¾ sum¾e dni wolnych w miesiacach ¾ niewakacyjnych i nast¾epnie opisać za pomoca¾ prostej regresji liczb ¾e dni wolnych w lipcu i sierpniu w zale zności od pozosta ych miesi ¾ecy. Rozwiazanie: ¾ musimy stworzyć nowa¾ zmienna¾ zawierajac ¾a¾ informacje o dniach w wolnych poza lipcem i sierpniem a nast¾epnie wyznaczyć jak to ju z robiliśmy powy zej prosta¾ regresji za pomoca¾ estymacji krzywej. 18. Czy ogólna skategoryzowana liczba spóźnień i liczba dzieci sa¾ niezale zne? Rozwiazanie: ¾ korzystamy z mo zliwości jakie daja¾ tabele krzy zowe, a w szczególności test 2 niezale zności 19. Czy liczba dzieci i p eć sa¾ niezale zne, jaki rozk ad ma liczba dzieci? Rozwiazanie: ¾ jak powy zej dla pierwszej cz ¾eści, w drugiej cz ¾eści najpierw wyznaczamy histogram aby mieć ogólne wyobra zenie o danym rozk adzie, w tym 20

21 celu korzystamy z mo zliwości eksploracji 21

22 i otrzymujemy nast ¾epujacy ¾ histogram który sugeruje nam, ze rozk ad jest troch ¾e zbli zony do rozk adu normalnego, co sprawdzamy za pomoca¾ stosownych testów. Jak si ¾e okazuje nasze przeczucie nie by o s uszne. Kolejnym pomys em jest sprawdzenie, czy rozk ad jest równomierny, albo czy skrajne wartości sa¾ dwa razy mniejsze od pozosta ych. 20. Wygenerować zmienna¾ opisujac ¾ a¾ czas odpoczynku w zale zności od liczby dzieci i nadgodzin przy pomocy wzoru odpoczynek = 12 liczba dzieci suma nadgodzin dla kobiet 2 dla me _zczyzn gdzie jest zmienna¾ losowa¾ o rozk adzie normalnym ze średnia¾ 2 i odchyleniem 1. 1; 5+ 22

23 Rozwiazanie: ¾ stosujemy przekszta cenianoblicz wartości, przy czym musimy pami ¾etać o zastosowaniu warunku je zeli aby wyró znić wartość dla kobiet i m ¾e zczyzn. Ponadto wykorzystujemy funkcj ¾e generujac ¾ a¾ wartość losowa¾ aby wprowadzić czynnik losowości. 4 Wieloczynnikowa analiza wariancji ciag ¾ dalszy Rozwa zmy przyk ad, w którym zbadano wyniki 80 osób z egzaminu ze statystyki. Jak widzimy, dla ka zdej z czterech kombinacji doświadczalnych (p eć i grupa) przebadano po 20 osób. Rozwa zamy wi ¾ec tzw. uk ad zrównowa zony. Przypomnijmy, ze je zeli liczebności w kombinacjach nie sa¾ jednakowe, to do rozwiaza- nia problemu ANOVA musimy stosować inne metody. Omówimy je dok adniej ¾ w dalszej cz ¾eści. Przeprowadzimy obecnie wszechstronna¾ analiz ¾e statystyczna¾ uzyskanych wyników. Aby mo zna by o rozpoczać ¾ wykonywanie analizy wariancji musimy nasze dane zapisać w pewnym pliku, w naszym przypadku b ¾edzie 23

24 to plik wieloczynnikowaanalizawariancji.sta. Pierwsza zmienna opisuje p eć osoby, druga grup ¾e, do której dana osoba ucz ¾eszcza a, zaś ostatnia zmienna przedstawia zdobyte punkty. W celu rozpocz ¾ecia analizy wybieramy z menu statystyka Anova. Wówczas ukazuje nam si¾e okno Opcje znajdujace ¾ si¾e na karcie Podstawowe pozwalaja¾ określić odpowiedni rodzaj analizy. Lista rodzaj analizy umo zliwia wybór jednego z czterech uk adów doświadczalnych ANOVA. Z analiza¾ wieloczynnikowa¾ zwiazane ¾ sa¾ dwa rodzaje 24

25 z nich, Mianowicie ANOVA efektów g ównych oraz ANOVA dla uk adów czynników. Pierwszy rodzaj stosujemy, gdy wiemy, lub zak adamy, ze pomi ¾edzy czynnikami nie wyst ¾epuje interakcja. W takim przypadku ¾ aczne oddzia ywanie czynników jest suma¾ oddzia ywań poszczególnych czynników. Drugi rodzaj jest stosowany w przypadku, gdy analizujemy efekty g ówne i ich interakcje. Nast¾epnie określamy zmienne jak na poni zszym rysunku Jeśli wszystko wykonaliśmy poprawnie to otrzymujemy okno wynikowe, w 25

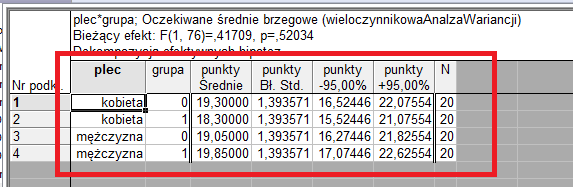
26 którym mamy 8 kart Przyk adowo na karcie podsumowanie mo zemy uzyskać podsumowanie g ównych wyników, takie jak tabela ANOVA, karta średnie pozwala nam obliczyć obserwowane średnie niewa zone, obserwowane średnie wa zone oraz oczekiwane średnie brzegowe. Zak adka porównania pozwala testować szczegó owe hipotezy dotyczace ¾ kombinacji liniowych oczekiwanych średnich brzegowych. Z zak adki podstawowe wybieramy wszystkie efekty i otrzymujemy wynik. Arkusz wynikowy zawiera zestawienie g ównych wyników analizy. Odczytujemy wi¾ec, ze brak podstaw do odrzucenia hipotezy zerowej o braku efektu czynnika p eć (p=0,642244). Zatem nie wyst ¾epuja¾ statystycznie istotne ró znice pomi ¾edzy kobietami a m ¾e zczyznami w wynikach z egzaminu. 26
 o braku interakcji pomi ¾edzy czynnikami p eć oraz grupa.")
27 brak równie z podstaw do odrzucenia hipotezy zerowej o braku wp ywu grupy na końcowy wynik (p=0,942983). Wynika stad, ¾ ze grupa nie mia a istotnego wp ywu na wynik z egzaminu nie ma równie z podstaw do odrzucenia hipotezy (p=0,520339) o braku interakcji pomi ¾edzy czynnikami p eć oraz grupa. Pierwszy wiersz wynikowego arkusza jest ma o istotny i mo zemy nie zwracać na niego uwagi. W prezentowanym powy zej arkuszu wyników nie sa¾ pokazane wszystkie sumy kwadratów, wyświetlone sa¾ tylko średnie kwadraty efektu i b ¾edu. W niektórych sytuacjach mo zemy potrzebować pe nej informacji o obliczonych sumach kwadratów. Korzystamy wówczas z opcji Wyniki jednowymiarowe na karcie Podsumowanie. Aby móc skorzystać z tej opcji musimy postapić ¾ jak na poni zszym rysunku. Wówczas mamy dost ¾ep do pe nego arsena u narz ¾edzi i wybieramy interesujac ¾ a¾ nas opcj¾e. W dalszej cz ¾eści dokonamy jeszcze g ¾ebszej analizy wieloczynnikowej analizy wariancji, omówimy równie z wielowymiarowa¾ analiz ¾e wariancji. 27

28 5 Wieloczynnikowa analiza wariancji ciag ¾ dalszy Wspomnieliśmy wcześniej o mo zliwości g ¾ebszej analizy wyników jednowymiarowych w wieloczynnikowej analizie wariancji. Przypomnijmy, ze w tym celu stosujemy opcj ¾e wyniki jednowymiarowe znajdujac ¾ a¾ si ¾e w rozszerzonej zak adce Podsumowanie w oknie Wyniki Anova. Otrzymane w ten sposób wyniki mo zna przedstawić w dość interesujacy, ¾ gra czny sposób. W tym celu korzystamy z opcji zaznaczonej na powy zszym rysunku strza k a¾ z cyfra¾ 2. Otrzymujemy jako wynik poni zsza¾ tabel ¾e wszystkich efek- 28

29 tów: W oknie tym mo zemy dla wybranego efektu (podświetlonego) otrzymać arkusz zawierajacy ¾ średnie brzegowe (przy wyborze opcji tabela) lub wykres średnich (przy wyborze opcji Wykres). Ponadto mamy mo zliwość określenia kilku rodzajów średnich. Do wyboru mamy: średnie niewa zone. Wyświetlane b ¾eda¾ wówczas obserwowane średnie niewa zone. B ¾edy standardowe dla tych średnich obliczane sa¾ na podstawie średnich kwadratów reszt, odpowiedniej zmiennej. średnie wa zone. Wyświetlane b ¾eda¾ wówczas obserwowane średnie wa zone (wa zone liczebnościami podklas). B ¾edy standardowe dla średnich wa zonych sa¾ obliczane na podstawie odchyleń standardowych, wyliczanych w obr¾ebie odpowiednich komórek brzegowych. oczekiwane średnie brzegowe. Obliczane zostana¾ oczekiwane populacyjne średnie brzegowe dla aktualnie analizowanego modelu. Sa¾ to zazwyczaj średnie b ¾ed ace ¾ przedmiotem zainteresowania przy interpretacji istotnych efektów w tabeli wyników ANOVA. Domyślnie wybrana¾ opcja¾ jest ostatnia z opisanych. Porównamy teraz wyniki otrzymane dla ró znych kombinacji wyborów. W przypadku średnich niewa zonych wykres przyjmuje nast ¾epujac ¾ a¾ postać 29

30 natomiast tabela wyników przyjmuje nast ¾epujac ¾ a¾ postać 30

31 Nieco inne wyniki otrzymujemy dla średnich wa zonych. Mianowicie wykres ma postać natomiast zestawienie wartości ma postać (tabela poni zej). Po g ¾ebszej analizie mo zemy stwierdzić, ze w przypadku średnich wa zonych i niewa zonych ró znica polega na zakresie przedzia ów ufności. 31

32 W ostatnim z mo zliwych przypadków wykres średnich ma postać bardzo zbli zona¾ do zamieszczonych powy zej. Zamieścimy zatem jedynie tabel ¾e z danymi. Tym razem równie z ró znica wyst ¾epuj ¾e w przedzia ach ufności. Powy zej zamieszczono dane dotyczace ¾ odzwierciedlajace ¾ jedynie podzia ze wzgl ¾edu na p eć. Bardziej interesujaca ¾ wydaje si ¾e interakcja obu zmiennych. W tym celu nale zy wybrać (podświetlić) odpowiednia¾ zmienna¾ w tabeli efektów 32

33 g ównych. W takim przypadku zarówno wykresy, jak i tabele z danymi niosa¾ wi¾ecej infor- 33
34 macji. 34

35 Ze wzgl ¾edów praktycznych jest zatem korzystać z opcji umo zliwiajacej ¾ rozdzia ze wzgl ¾edu na kilka zmiennych jednocześnie. Teraz nale za oby przypomnieć, w jaki sposób dokonujemy tej analizy w programie SPSS, omawialiśmy ju z to wcześniej, dlatego nie b ¾edziemy zbytnio si ¾e rozwodzić nad tym problemem. Wybieramy stosowna¾ metod¾e zgodnie z poni zszym rysunkiem 35

36 Nast ¾epnie wskazujemy stosowne zmienne i przychodzimy do opcji 36

37 gdzie wybieramy interesujace ¾ nas pozycje 37

38 Wybierzmy równie z stosowne opcje dla wykresów Po wybraniu interesujacych ¾ nas pozycji i potwierdzeniu naszych wyborów otrzymujemy raport zawierajacy ¾ bardzo du zo interesujacych ¾ informacji. Mi ¾edzy 38

39 innymi wykres pro li 39
.")
40 6 Wielowymiarowe techniki eksploracyjne Opis mo zliwości wielowymiarowych technik eksploracyjnych rozpoczniemy od klasy kacji wielowymiarowej (analizy skupień). Analiza skupień jest metoda s u z aca ¾ do grupowania obiektów podobnych pod wzgledem wielu cech ilosciowych (zmiennych). Wynikiem analizy mo ze być podzia obiektów na kilka lub kilkanaście grup obiektów, które sa do siebie zbli zone pod wzgl ¾edem wielu badanych cech. Metody analizy skupień mo zna podzielić na dwie g ówne grupy: - hierarchiczne (np. najbli zszego sasiedztwa, najdalszego sasiedztwa, ¾ Warda) - niechierarchiczne (np. metoda k-srednich, c-srednich) Inne metody: metoda rozmytej analizy skupień (ang. fuzzy clustering), np. metoda c-średnich (c-means). Aglomeracja obiektów (czyli ¾ aczenie w grupy) odbywa si¾e na podstawie odleg osci miedzy obiektami w przestrzeni wielowymiarowej, najcz ¾eściej u zywana¾ odleg ościa¾ przy grupowaniu obiektów jest odleg ość Eukidesowa lub jej kwadrat, mo zna u zywać równie z innych rodzajów odleg osci np. odleg osci miejskiej (tzw. city block). Cz ¾esto stosuje sie równie z standaryzacje zmiennych dla wyeliminowania wp ywu skali, w której sa¾ wyra zone poszczególne wartości zmiennych. W pakiecie STATISTICA analiza¾ skupień mo zemy przeprowadzić w module Analiza skupień. Modu ten wybieramy w sposób wskazany poni zej W tym oknie na karcie Podstawowe wybieramy metod ¾e grupowania. Mo zemy 40
, prezentujacego ¾ odleg ości mi")
41 wybrać jedna¾ z trzech mo zliwości Poszczególne opcje charakteryzuja¾ si¾e: Aglomeracja. Zastosowanie tej metody pozwala nam na otrzymanie hierarchicznego uporzadkowania ¾ skupień, które mo zna przedstawić w postaci hierarchicznego drzewa (dendrogramu), prezentujacego ¾ odleg ości mi ¾edzy grupowanymi obiektami (zmiennymi lub przypadkami) Grupowanie metoda¾ k-średnich. Grupowanie ta¾ metoda¾ przenosi obiekty mi ¾edzy wskazana¾ przez u zytkownika liczba¾ skupień w celu zminimalizowania zmienności wewnatrzgrupowej ¾ i maksymalizowania zmienności mi ¾edzygrupowej. Grupowanie obiektów i cech. Metoda ta grupuje jednocześnie przypadki i zmienne. Opis mo zliwości programu zaczniemy od hierarchicznych metod aglomeracji (skupienia). Poznamy je, opierajac ¾ si ¾e na danych z przyk adu skupienia.sta. Celem analizy jest próba pogrupowania danych w podgrupy opisujace ¾ ró znice mi¾edzy danymi. Na poczatku ¾ dokonamy standaryzacji danych. Do jej przeprowadzenia wykorzystujemy opcj ¾e standaryzuj. 41

42 Po dokonaniu standaryzacji wybieramy opcj ¾e aglomeracji. Wówczas na 42

43 ekranie otworzy si ¾e okno pokazane na poni zszym rysunku W oknie tym znajduja¾ si¾e dwie karty: Podstawowe i Wi ¾ecej. Korzystajac ¾ z karty Podstawowe mo zemy szybko określić analiz ¾e i uzyskać wyniki, natomiast karta Wi ¾ecej umo zliwia wykonanie dok adniejszej analizy. Rozpoczniemy od określenia zmiennych. W tym celu klikamy przycisk Zmienne i wybieramy zmienne podlegajace ¾ analizie. Zauwa zmy, ze jako plik wejściowy mo zemy wybrać: Dane surowe, je zeli dane do analizy maja¾ postać zwyk ego pliku danych STATISTICA. Macierz odleg ości. Po wybraniu tej opcji analizować mo zemy albo macierz korelacji, albo macierz odleg ości zawierajac ¾ a¾ liczby wskazujace ¾ odleg ości mi ¾edzy obiektami. Je zeli macierz wejściowa jest macierza¾ korelacji (która wskazuje podobieństwa i bliskość obiektów), to zanim rozpocznie si ¾e analiza, zostaje ona przekszta cona na macierz odleg ości. Po wybraniu zmiennych, na podstawie których dokonamy grupowania wskazujemy metod ¾e grupowania. Wybrana metoda aglomeracji steruje bowiem procesem aglomeracji. Określa ona, kiedy dwa skupienia maja¾ zostać po ¾ aczone i jak wyznaczać odleg ości mi ¾edzy skupieniami. Wybory dokonujemy za pomoca¾ rozwijalnej listy Metody aglomeracji. 43
 oraz metod ¾e Warda. Teraz opiszemy mo zliwe do wyboru metody aglomeracji. Metoda pojedynczego wiazania ¾ (single linkage method).")
44 Lista ta oferuje 7 ró znych metod aglomeracyjnych: pojedynczego wiaza- nia, pe nego wiazania, ¾ średnich po ¾ aczeń, średnich po ¾ aczeń wa zonych, środków ¾ ci ¾e zkości, wa zonych środków ci ¾e zkości (mediany) oraz metod ¾e Warda. Teraz opiszemy mo zliwe do wyboru metody aglomeracji. Metoda pojedynczego wiazania ¾ (single linkage method). Metoda ta, nazywana jest równie z metoda¾ najbli zszego sasiedztwa, ¾ zosta a wprowadzona w latach 50-tych we Wroc awiu. W metodzie tej odleg ość mi ¾edzy dwoma skupieniami jest określona przez odleg ość mi ¾edzy dwoma najbli zszymi obiektami (najbli zszymi sasiadami) ¾ nale z acymi ¾ do ró znych skupień. Jest to zatem najmniejsza odleg ość spośród wszystkich odleg ości pomi ¾edzy obiektami nale z acymi ¾ do poszczególnych skupień. Zgodnie z ta¾ zasada¾ obiekty formuja¾ skupienia, ¾ aczac ¾ si¾e w ciagi, ¾ a wynikowe skupienia tworza ¾" ańcuchy". Metoda pe nego wiazania ¾ (complete linkage). Metoda ta, b ¾edaca ¾ prostym przeciwieństwem poprzedniej metody, nazywana jest równie z metoda¾ 44

45 najdalszego sasiedztwa. ¾ W tej metodzie odleg ość mi ¾edzy skupieniami jest odleg ościa¾ mi¾edzy "najdalszymi sasiadami". ¾ Oznacza to, ze odleg ość ta jest równa najwi ¾ekszej odleg ości dwoma dowolnymi obiektami nale z a- ¾ cymi do ró znych skupień. Metoda średnich po ¾ aczeń. Metoda ta jest cz ¾esto oznaczana jako UP- GMA ( unweighted pair-group method using arithmetic averages). W metodzie tej odleg ość mi ¾edzy dwoma skupieniami oblicza si ¾e za pomoca¾ średniej arytmetycznej wyznaczonej ze wszystkich odleg ości obiektów nale z a- ¾ cych do dwóch ró znych skupień. Metoda średnich po ¾ aczeń wa zonych. Metoda ta jest oznaczana jako WPGMA ( weighted pair-group method using arithmetic averages). Metoda ta jest podobna do opisanej powy zej, z ta¾ ró znica, ¾ ze tutaj uwzgl¾ednia si¾e wielkość skupień jako wag¾e. Metoda środków ci ¾e zkości. Metoda ta literaturze cz ¾esto określana jest mianem UPGMC (unweighted pair-group method using the centroid average). Środek ci ¾e zkości skupienia jest średnim punktem w przestrzeni wielowymiarowej zde niowanej przez te wymiary. W metodzie tej odleg ość mi ¾edzy dwoma skupieniami jest równa odleg ości mi ¾edzy ich środkami ci ¾e zkości. 45

46 Metoda wa zonych środków ci ¾e zkości. Znana równie z pod skrótem WMGMC (weighted pair-group method using the centroid average). Jest to pewne uogólnienia powy zsze metody polegajace ¾ na dodaniu wag w zale zności od liczebności skupień. Metoda Warda. Ta metoda ró zni si¾e od pozosta ych, poniewa z do szacowania odleg ości pomi ¾edzy skupieniami stosuje si ¾e analiz ¾e wariancji. Znajac ¾ ju z teoretyczne za o zenia poszczególnych metod mo zemy dokonać analizy za pomoca¾ pakietu STATISTICA. Po określeniu zmiennych oraz metody grupowania przechodzimy dalej i otrzymujemy okno podsumowania, w którym widzimy na górze wybrane przez nas opcje, zaś w dolnej cz ¾eści mamy kilka mo zliwości przedstawienia wyników. Do najciekawszych wyników prezentacji danych nale zy zaliczyć przebieg aglomeracji oraz wykres przebiegu aglomeracji. 46

47 Kolejna¾ z mo zliwych metod grupowania jest metoda k-średnich, w stosownym oknie określamy interesujace ¾ nas zmienne, co chcemy grupować - w naszym przypadku przypadki oraz ile chcemy wyró znić grup i w ilu krokach. G ¾ebszej analizy mo zliwości tego modu u oraz innych mo zliwości wielowymiarowych technik eksploracyjnych omówimy w miar ¾e mo zliwości w dalszej skryptu. 7 Modelowanie i symulacja Celem obecnej sekcji jest zaproponowanie pewnego modelu opisujacego ¾ dynamiczna¾ zmian ¾e pewnego zjawiska i nast ¾epnie zaproponowanie pewnej symulacji przysz ych zmian opisywanego zjawiska. Nasze rozwa zania opiszemy na podstawie przychodów pewnej restauracji. Dane wejściowe znajduja¾ si¾e w pliku restauracja.sta. Na wst ¾epie analizy nasz plik zawiera znikoma¾ liczb ¾e informacji, 47

48 mamy mianowicie jedynie Przychody w kolejnych okresach, lata oraz kwarta y. Na wst ¾epie zapoznajmy si ¾e naszymi danymi sporzadzaj ¾ ac ¾ wykres zmian 48

49 przychodów zgodnie z poni zszy wzorem Jako efekt otrzymujemy poni zszy rysunek, który postaramy si ¾e wspólnie scharak- 49
50 teryzować Liniowy Przychód restuaracja 3v*32c Przychód atwo zauwa zyć pewien trend wzrostowy przychodów w analizowanej restauracji, ponadto nie trudno doszukać si ¾e pewnych kwartalnych wahań oraz jednego bardzo silnego za amania naszego trendu. Jeśli chodzi o zmiany kwartalne do mo zna je dość prosto intuicyjnie wyt umaczyć. Wi ¾ekszy problem mo ze powodować uzasadnienie tego jednorazowego za amania w przychodach. Mo zemy je wyt umaczyć w nast¾epujacy ¾ sposób: w niedalekim otoczeniu otwarto inna¾ restauracj ¾e, która zabra a cz ¾eść klientów naszej restauracji. Oczywiście tworzac ¾ ten zbiór danych mia em taki zamiar, w zyciu codziennym obserwujac ¾ ewaluacj ¾e pewnego procesu cz¾esto napotykamy na tego typu sytuacje. Oczywiści mo ze być równie z nag y skok w gór¾e, albo kilka czynników powodujacych ¾ spadki i wzrosty obserwowanego procesu. Zastanówmy si ¾e teraz jaki sposób mo zna zamodelować przychody rmy. Pierwszym naturalnym sposobem jest opis za pomoca¾ prostej. W tym celu 50

51 korzystamy z W wyniku otrzymujemy na o zona¾ prosta, ¾ która jest najlepiej dopasowana do 51

52 naszych danych Liniowy Przychód restuaracjaobróbka 3v*32c Przychód = 22694, ,7013*x Przychód Zazwyczaj, tak jak w naszym przypadku, prosta ta nie jest zbyt dobrze dopasowana do naszych danych, lepiej jest opisać zale zność za pomoca¾ wielomianu. W tym celu powracamy do wykresu liniowego i wybieramy wielomian, a nast ¾epnie przychodzimy na zak adk¾e Opcje2 i wybieramy interesujacy ¾ nas stopień wielomianu. 52
53 Tym razem otrzymujemy inny wynik, w wi ¾ekszości przypadków funkcja kwadratowa ju z dość dobrze dopasowuje si ¾e do danych surowych. W naszym przypadku jest tak równie z, ale Liniowy Przychód restuaracjaobróbka 3v*32c Przychód = 13379, ,438*x 49,8102*x^ Przychód jak widzimy na powy zszym rysunku funkcja kwadratowa osiagn ¾ ¾e a ju z swoje maksimum i wkrótce zacznie spadać. Nie jest to raczej zgodne z nasza¾ intuicja. ¾ W zwiazku ¾ z tym postapimy ¾ nieco inaczej. Zastosujemy w tym przypadku trend amany. W tym celu dodamy sobie trzy zmienne, w pierwszej b ¾edziemy trzymali czas (t) a w drugiej zmiennej (K) informacje o pojawieniu si ¾e konkurencji, zaś w ostatniej iloczyn dwóch poprzednich. W tym miejscu poznamy przy okazji dość ciekawy sposób oznaczania zmiennej opisujacej ¾ czas 53
 Do oszacowania naszego trendu wykorzystamy regresj ¾e wieloraka¾")
54 polegajacy ¾ na przypisaniu odpowiedniej wartości d ugiej nazwie Przy pomocy nowych zmiennych b ¾edziemy mogli określić nasz model za pomoca¾ nast¾epujacego ¾ wzoru ^Y = a 0 + a 1 t + a 2 k + a 3 (t k) Do oszacowania naszego trendu wykorzystamy regresj ¾e wieloraka¾ 54

55 Wybieramy zmienne objaśniane i zmienne objaśniajace ¾ w nast ¾epnym kroku patrzymy, które z naszych zmiennych objaśniajacych ¾ sa¾ istotne, w tym celu klikamy w podsumowanie i otrzymujemy wynik. W naszym 55

56 przypadku jest on nast¾epujacy: ¾ Natychmiast widzimy, ze zmienna tk jest statystycznie nieistotna i mo zemy ja¾ pominać. ¾ Po usuni ¾eciu stosownej zmiennej z analizy wyznaczamy ponownie nasza¾ regresj ¾e i otrzymane wartości kolumny b kopiujemy sobie. Dodajemy 56

57 sobie nowa¾ zmienna, ¾ która¾ nazwiemy trend amany a w nast ¾epnym kroku porównamy nasz trend z przychodem za pomoca¾ 57

58 na o zonych na siebie dwóch wykresów liniowych. 58

59 I otrzymujemy wynik, który jest dość obiecujacy ¾ Liniowy wiele zmiennych restuaracjaobróbka 7v*32c Przychód trend łamany Teraz spróbujemy jeszcze wychwycić, czy istnieja¾ jakieś sezonowe wahania. Obserwujac ¾ uwa znie wykres mo zemy powiedzieć, ze rzeczywiście w pewnych kwarta ach mamy odst¾epstwa od trendu w dó lub w gór¾e. Postaramy si¾e opisać te zabki ¾ przychodu. W tym celu stworzymy sobie nowa¾ zmienna, ¾ która b ¾edzie ró znica¾ pomi ¾edzy przychodem a trendem amanym. Zmienna¾ ta¾ nazwiemy "sezonowe". Jak widzimy w otrzymanej zmiennej cz ¾eść wartości jest dodatnich a cz ¾eść ujemnych. Nast ¾epnie nale za oby sprawdzić, w których kwarta ach wyst ¾epuje sezonowe wahanie. W tym celu korzystamy z jednoczynnikowej analizy wariancji. 59
60 Wskazujemy zmienne: zale zna ¾: sezonowe i niezale zna¾ i niezale zna¾ kwarta. W wyniku otrzymujemy p = 0 zatem nale zy odrzucić hipotez ¾e o równości średnich wahań w kwarta ach, czyli innymi s owy wyst ¾epuja¾ kwartalne wahania. Mo zemy sobie zobaczyć jak wygladaj ¾ a¾ nasze średnie w poszczególnych kwarta ach na wykresie skategoryzowanym ramka-wasy ¾ lub histogramy. Ten pierwszy jest tutaj chyba bardziej przejrzysty. Mamy zatem: 3000 Skategor. wykres ramka wąsy: sezonowe: =v1 v sezonowe kwartał Mediana 25% 75% Min Maks Widzimy z tego wykresu, ze 1 i 3 kwarta sa¾ poni zej średniej zaś trzeci powy zej. Aby uwzgl ¾ednić sezonowość w naszym modelu dodajmy sobie zmienne kodujace ¾ informacje o poszczególnych kwarta ach. Dodajmy zmienne k2, k3, k4 odpowiadajace ¾ za stwierdzenie czy jest kwarta drugi, trzeci, czy czwarty. Pierwszego kwarta u nie uwzgl ¾edniamy, bo nie ma takiej potrzeby. Tworzac ¾ te zmienne korzystamy z dość ciekawej sztuczki, dla przyk adu w zmiennej k2 w d ugiej nazwie piszemy = (v3 = 2) w ten sposób, gdy kwarta jest rzeczywiście drugi to mamy jedynk¾e a w pozosta ych przypadkach 0. Teraz mo zemy znowu dokonać analizy regresji. Wchodzimy znowu w regresj ¾e 60

61 wieloraka¾ i określamy zmienne i otrzymujemy wyniki regresji. Jak widzimy wszystkie zmienne sa¾ statysty- 61

62 cznie istotne zatem zapami ¾etujemy wszystkie wartości kolumny b i na jej podstawie tworzymy nowa¾ zmienna¾ wpisujac ¾ odpowiednia¾ formu ¾e w d ugiej nazwie, a mianowicie: = 14491; ; 5 t 19415; 6 k ; 6 k ; 6 k ; 4 k4 Teraz mo zemy ju z porównać gra cznie rzeczywiste przychody oraz nasz model. W efekcie otrzymujemy nast ¾epujacy ¾ wykres Liniowy wiele zmiennych restuaracjaobróbka 12v*32c Przychód model Mo zemy jeszcze sprawdzić, czy wyst ¾epujace ¾ u nas ró znice pomi¾edzy stanem faktycznym a modelem sa¾ losowe, czy te z mo ze uda nam si¾e jeszcze wyznaczyć 62
63 pewna¾ zale zność. Cz¾esto zdarza si¾e bowiem, ze w tego typu dynamicznie rozwijajacych ¾ si ¾e zjawiskach spotykamy si ¾e z autokorelacja. ¾ Aby sprawdzić, czy u nas równie z mamy z tym zjawiskiem do czynienia tworzymy nowa¾ zmienna, ¾ w której b ¾edzie ró znica pomi ¾edzy stanem faktycznym a modelem. Dysponujac ¾ ju z nowa¾ zmienna¾ badamy autokorelacj ¾e. Najpierw spróbujemy jakiś zale zności doszukać si ¾e na wykresie naszych reszt 1000 Liniowy reszta restuaracjaobróbka 13v*32c reszta a nast ¾epnie skorzystamy z bardziej fachowego rozwiazania. ¾ W tym celu 63

64 wybieramy stosowna¾ metod¾e z menu Gdzie wskazujemy stosowna¾ zmienna¾ A nast ¾epnie przechodzimy na zak adk¾e autokorelacje, ustawiamy wielkość 64

65 opóźnienia i klikamy w stosowny przycisk W wynikowym rysunku jeśli jeden ze s upków przekroczy by czerwone linie 65

66 to mielibyśmy autokorelacj ¾e. Jednak w naszym przypadku tak nie jest Zatem mo zemy przyjać, ¾ ze nasz model jest ju z w wersji nalnej i na jego podstawie postaramy si ¾e dokonać prognozy przysz ych przychodów danej restauracji. W tym celu musimy odpowiednio przed u zyć sobie wszystkie zmienne wyst¾epujace ¾ w naszym modelu, tj. czas, konkurencj ¾e oraz kwarta y. Oczywiście nie b ¾edziemy wszystkiego wpisywać r ¾ecznie, tylko gdzie to jest mo zliwe 66

67 b ¾edziemy stosowali przeliczanie formu y, jak na poni zszym rysunku Gdy ju z wszystkie formu y zostana¾ przeliczone mo zemy dokonać porównania danych faktycznych z na o zonym modelem, którego ostatnie wartości to ju z nasza symulacja. 1E5 Liniowy wiele zmiennych restuaracjaobróbka 13v*36c Modelowanie i symulacja w programie SPSS Analizie poddamy plik zawierajacy ¾ identyczne jak we wcześniejszym przyk adzie dla programu STATISTICA. Na wst ¾epie dodamy sobie zmienna¾ opisujac ¾ a¾ przyrosty czasu, tak jak ostatnio nazwiemy ja ¾"t", ponadto dodamy zmienna¾ opisujac ¾ a¾ konkurencj¾e "k" oraz zmienna¾ b ¾edac ¾ a¾ iloczynem "t" oraz "k". Wówczas 67

68 mamy nast¾epujace ¾ zmienne, na podstawie których dokonamy dalszej analizy W nast ¾epnym kroku chcemy wyznaczyć prosta¾ regresji opisujac ¾ a¾ przychód na podstawie zmiennych t, k,tk. W tym celu wybieramy z menu regresj¾e liniowa, ¾ wskazujemy w aściwe zmienne W wyniku otrzymujemy raport, z którego o dziwo wynika, ze zmienna "tk" 68

69 jest statystycznie nieistotna Zatem ponawiamy wyszukiwanie prostej regresji, tym razem ju z bez tej zmiennej, w wyniku otrzymujemy raport, 69

70 na podstawie którego tworzymy nowa¾ zmienna, ¾ powiedzmy o nazwie "trend". W nast ¾epnym kroku porównamy nasz pierwszy model ze stanem faktycznym 70
71 rysujac ¾ odpowiednie krzywe na jednym rysunku. Tak jak wcześniej wyznaczamy ró znice pomi ¾edzy przychodem a trendem i otrzymane ró znice zapisujemy w zmiennej "sezonowe", a nast ¾epnie za pomoca¾ jednoczynnikowej ANOVY sprawdzamy, czy średnie dla poszczególnych 71

72 kwarta ów ró znia¾ si¾e mi¾edzy soba. ¾ Jak widzimy z poni zszego wycinka raportu wyst ¾epuje sezonowość, w czym utwierdza nas równie z średnich dla poszczegól- 72

73 nych kwarta ów W zwiazku ¾ z tym analogicznie jak w programie STATISTICA wprowadzamy trzy zmienne przyjmujace ¾ wartości zero i jeden w zale zności od tego czy wyst ¾epuje w aściwy kwarta. A nast ¾epnie wyznaczamy nowa¾ lini¾e regresji zale zna¾ oprócz poprzednich zmiennych jak te z od nowo utworzonych zmiennych k2, k3, 73

74 k4. Jak widzimy z poni zszego wycinka raportu wszystkie zmienne sa¾ statystycznie istotne Tworzymy zatem nasz ostateczny model na podstawie wszystkich tych zmi- 74

75 ennych Nasz ostateczny model przyjmuje wówczas dość obiecujac ¾a¾ postać. Przy pomocy tak utworzonego modelu mo zemy dokonać prognozy dalszych zmian. 75

76 Prognoza przyjmuje nast ¾epujac ¾ a¾ postać wizualna¾ 76
1 Wieloczynnikowa analiza wariancji
 Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Statystyczna analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-02-04 13.00-17.00 1 Wieloczynnikowa analiza wariancji
Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Statystyczna analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-02-04 13.00-17.00 1 Wieloczynnikowa analiza wariancji
1 Wieloczynnikowa analiza wariancji ciag ¾ dalszy
 Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Wielowymiarowa analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-03-18 08.20-12.30 1 Wieloczynnikowa analiza wariancji
Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Wielowymiarowa analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-03-18 08.20-12.30 1 Wieloczynnikowa analiza wariancji
1 Miary asymetrii i koncentracji
 Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Podstawy statystyki opisowej Adam Kiersztyn 3 godziny lekcyjne 2011-10-22 10.10-12.30 1 Miary asymetrii i koncentracji
Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Podstawy statystyki opisowej Adam Kiersztyn 3 godziny lekcyjne 2011-10-22 10.10-12.30 1 Miary asymetrii i koncentracji
1 Analiza wariancji H 1 : 1 6= 2 _ 1 6= 3 _ 1 6= 4 _ 2 6= 3 _ 2 6= 4 _ 3 6= 4
 Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Statystyczna analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-02-04 13.00-17.00 1 Analiza wariancji Na wst¾epie zapoznamy
Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Statystyczna analiza danych Adam Kiersztyn 5 godzin lekcyjnych 2012-02-04 13.00-17.00 1 Analiza wariancji Na wst¾epie zapoznamy
1 Praktyczne metody wyznaczania podstawowych miar przy zastosowaniu programu EXCEL
 Kurs w zakresie zaawansowanych metod komputerowej analizy danych Podstawy statystycznej analizy danych 9.03.2014-3 godziny ćwiczeń autor: Adam Kiersztyn 1 Praktyczne metody wyznaczania podstawowych miar
Kurs w zakresie zaawansowanych metod komputerowej analizy danych Podstawy statystycznej analizy danych 9.03.2014-3 godziny ćwiczeń autor: Adam Kiersztyn 1 Praktyczne metody wyznaczania podstawowych miar
1 Rekodowanie w podgrupach i obliczanie wartości w podgrupach
 1 Rekodowanie w podgrupach i obliczanie wartości w podgrupach Czasami chcemy rekodować jedynie cz ¾eść danych zawartych w pewnym zbiorze. W takim przypadku stosujemy rekodowanie z zastosowaniem warunku
1 Rekodowanie w podgrupach i obliczanie wartości w podgrupach Czasami chcemy rekodować jedynie cz ¾eść danych zawartych w pewnym zbiorze. W takim przypadku stosujemy rekodowanie z zastosowaniem warunku
1 Praktyczne metody wyznaczania podstawowych miar bez zastosowania komputerów
 Kurs w zakresie zaawansowanych metod komputerowej analizy danych Podstawy statystycznej analizy danych 8.03.014 - godziny ćwiczeń autor: Adam Kiersztyn 1 Praktyczne metody wyznaczania podstawowych miar
Kurs w zakresie zaawansowanych metod komputerowej analizy danych Podstawy statystycznej analizy danych 8.03.014 - godziny ćwiczeń autor: Adam Kiersztyn 1 Praktyczne metody wyznaczania podstawowych miar
1 Rozk ad normalny. Szczególnym przypadkiem jest standardowy rozk ad normalny N (0; 1), wartości
, wartości") Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Podstawy statystyki matematycznej Adam Kiersztyn 2 godziny lekcyjne 2011-10-23 8.20-9.50 1 Rozk ad normalny Jednym z najwa
Studia podyplomowe w zakresie technik internetowych i komputerowej analizy danych Podstawy statystyki matematycznej Adam Kiersztyn 2 godziny lekcyjne 2011-10-23 8.20-9.50 1 Rozk ad normalny Jednym z najwa
Wyk ad II. Stacjonarne szeregi czasowe.
 Wyk ad II. Stacjonarne szeregi czasowe. W wi ekszości przypadków poszukiwanie modelu, który dok adnie by opisywa zachowanie sk adnika losowego " t, polega na analizie pewnej klasy losowych ciagów czasowych
Wyk ad II. Stacjonarne szeregi czasowe. W wi ekszości przypadków poszukiwanie modelu, który dok adnie by opisywa zachowanie sk adnika losowego " t, polega na analizie pewnej klasy losowych ciagów czasowych
Przetwarzanie i analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok
 Przetwarzanie i analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok Adam Kiersztyn Katedra Teorii Prawdopodobieństwa Wydzia Matematyczno - Przyrodniczy Katolicki Uniwersytet
Przetwarzanie i analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok Adam Kiersztyn Katedra Teorii Prawdopodobieństwa Wydzia Matematyczno - Przyrodniczy Katolicki Uniwersytet
Równania ró znicowe wg A. Ostoja - Ostaszewski "Matematyka w ekonomii. Modele i metody".
 Równania ró znicowe wg A. Ostoja - Ostaszewski "Matematyka w ekonomii. Modele i metody". Przyk ad. Za ó zmy, ze w chwili t = 0 populacja liczy P 0 osób. Roczny wskaźnik urodzeń wynosi b = 00, a roczna
Równania ró znicowe wg A. Ostoja - Ostaszewski "Matematyka w ekonomii. Modele i metody". Przyk ad. Za ó zmy, ze w chwili t = 0 populacja liczy P 0 osób. Roczny wskaźnik urodzeń wynosi b = 00, a roczna
Pochodne cz ¾astkowe i ich zastosowanie.
 Pochodne cz ¾astkowe i ich zastosowanie. Adam Kiersztyn Lublin 2013 Adam Kiersztyn () Pochodne cz ¾astkowe i ich zastosowanie. maj 2013 1 / 18 Zanim przejdziemy do omawiania pochodnych funkcji wielu zmiennych
Pochodne cz ¾astkowe i ich zastosowanie. Adam Kiersztyn Lublin 2013 Adam Kiersztyn () Pochodne cz ¾astkowe i ich zastosowanie. maj 2013 1 / 18 Zanim przejdziemy do omawiania pochodnych funkcji wielu zmiennych
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Stochastyczne Metody Analizy Danych. PROJEKT: Analiza kluczowych parametrów turbin wiatrowych
 PROJEKT: Analiza kluczowych parametrów turbin wiatrowych Projekt jest wykonywany z wykorzystaniem pakietu statystycznego STATISTICA. Praca odbywa się w grupach 2-3 osobowych. Aby zaliczyć projekt, należy
PROJEKT: Analiza kluczowych parametrów turbin wiatrowych Projekt jest wykonywany z wykorzystaniem pakietu statystycznego STATISTICA. Praca odbywa się w grupach 2-3 osobowych. Aby zaliczyć projekt, należy
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Funkcje dwóch zmiennych
 Funkcje dwóch zmiennych Je zeli ka zdemu punktowi P o wspó rzednych x; y) z pewnego obszaru D na p aszczyźnie R 2 przyporzadkujemy w sposób jednoznaczny liczb e rzeczywista z, to przyporzadkowanie to nazywamy
Funkcje dwóch zmiennych Je zeli ka zdemu punktowi P o wspó rzednych x; y) z pewnego obszaru D na p aszczyźnie R 2 przyporzadkujemy w sposób jednoznaczny liczb e rzeczywista z, to przyporzadkowanie to nazywamy
Dane dotyczące wartości zmiennej (cechy) wprowadzamy w jednej kolumnie. W przypadku większej liczby zmiennych wprowadzamy każdą w oddzielnej kolumnie.
 wprowadzamy w jednej kolumnie. W przypadku większej liczby zmiennych wprowadzamy każdą w oddzielnej kolumnie.") STATISTICA INSTRUKCJA - 1 I. Wprowadzanie danych Podstawowe / Nowy / Arkusz Dane dotyczące wartości zmiennej (cechy) wprowadzamy w jednej kolumnie. W przypadku większej liczby zmiennych wprowadzamy każdą
STATISTICA INSTRUKCJA - 1 I. Wprowadzanie danych Podstawowe / Nowy / Arkusz Dane dotyczące wartości zmiennej (cechy) wprowadzamy w jednej kolumnie. W przypadku większej liczby zmiennych wprowadzamy każdą
Wprowadzenie do analizy dyskryminacyjnej
 Wprowadzenie do analizy dyskryminacyjnej Analiza dyskryminacyjna to zespół metod statystycznych używanych w celu znalezienia funkcji dyskryminacyjnej, która możliwie najlepiej charakteryzuje bądź rozdziela
Wprowadzenie do analizy dyskryminacyjnej Analiza dyskryminacyjna to zespół metod statystycznych używanych w celu znalezienia funkcji dyskryminacyjnej, która możliwie najlepiej charakteryzuje bądź rozdziela
Konkurs Matematyczny, KUL, 30 marca 2012 r.
 Konkurs Matematyczny, KUL, 30 marca 01 r. W pustych kratkach obok liter A) B) C) D) nale zy wpisać s owo TAK lub NIE. Zadanie zostanie uznane za rozwiazane, jeśli wszystkie cztery odpowiedzi sa poprawne.
Konkurs Matematyczny, KUL, 30 marca 01 r. W pustych kratkach obok liter A) B) C) D) nale zy wpisać s owo TAK lub NIE. Zadanie zostanie uznane za rozwiazane, jeśli wszystkie cztery odpowiedzi sa poprawne.
Statystyczna analiza danych w programie STATISTICA. Dariusz Gozdowski. Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW
 Statystyczna analiza danych w programie STATISTICA ( 4 (wykład Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Regresja prosta liniowa Regresja prosta jest
Statystyczna analiza danych w programie STATISTICA ( 4 (wykład Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Regresja prosta liniowa Regresja prosta jest
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 28 listopada 2018 Plan zaj eć 1 Rozk lad estymatora b 2 3 dla parametrów 4 Hipotezy l aczne - test F 5 Dodatkowe za lożenie
Wyznaczniki, macierz odwrotna, równania macierzowe
 Wyznaczniki, macierz odwrotna, równania macierzowe Adam Kiersztyn Katolicki Uniwersytet Lubelski Jana Paw a II Lublin 013 Adam Kiersztyn (KUL) Wyznaczniki, macierz odwrotna, równania macierzowe marzec
Wyznaczniki, macierz odwrotna, równania macierzowe Adam Kiersztyn Katolicki Uniwersytet Lubelski Jana Paw a II Lublin 013 Adam Kiersztyn (KUL) Wyznaczniki, macierz odwrotna, równania macierzowe marzec
1 Poj ¾ecie szeregu czasowego
 Studia podyplomowe w zakresie przetwarzania, zarz¾adzania i statystycznej analizy danych Analiza szeregów czasowych 24.11.2013-2 godziny konwersatorium autor: Adam Kiersztyn 1 Poj ¾ecie szeregu czasowego
Studia podyplomowe w zakresie przetwarzania, zarz¾adzania i statystycznej analizy danych Analiza szeregów czasowych 24.11.2013-2 godziny konwersatorium autor: Adam Kiersztyn 1 Poj ¾ecie szeregu czasowego
Podstawowe operacje i rodzaje analiz dostępne w pakiecie Statistica
 Podstawowe operacje i rodzaje analiz dostępne w pakiecie Statistica 1. Zarządzanie danymi. Pierwszą czynnością w pracy z pakietem Statistica jest zazwyczaj wprowadzenie danych do arkusza. Oprócz możliwości
Podstawowe operacje i rodzaje analiz dostępne w pakiecie Statistica 1. Zarządzanie danymi. Pierwszą czynnością w pracy z pakietem Statistica jest zazwyczaj wprowadzenie danych do arkusza. Oprócz możliwości
Ekstrema funkcji wielu zmiennych.
 Ekstrema funkcji wielu zmiennych. Adam Kiersztyn Lublin 2013 Adam Kiersztyn () Ekstrema funkcji wielu zmiennych. kwiecień 2013 1 / 13 Niech dana b ¾edzie funkcja f (x, y) określona w pewnym otoczeniu punktu
Ekstrema funkcji wielu zmiennych. Adam Kiersztyn Lublin 2013 Adam Kiersztyn () Ekstrema funkcji wielu zmiennych. kwiecień 2013 1 / 13 Niech dana b ¾edzie funkcja f (x, y) określona w pewnym otoczeniu punktu
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Porównanie generatorów liczb losowych wykorzystywanych w arkuszach kalkulacyjnych
 dr Piotr Sulewski POMORSKA AKADEMIA PEDAGOGICZNA W SŁUPSKU KATEDRA INFORMATYKI I STATYSTYKI Porównanie generatorów liczb losowych wykorzystywanych w arkuszach kalkulacyjnych Wprowadzenie Obecnie bardzo
dr Piotr Sulewski POMORSKA AKADEMIA PEDAGOGICZNA W SŁUPSKU KATEDRA INFORMATYKI I STATYSTYKI Porównanie generatorów liczb losowych wykorzystywanych w arkuszach kalkulacyjnych Wprowadzenie Obecnie bardzo
Zadanie 1. Analiza Analiza rozkładu
 Zadanie 1 data lab.zad 1; input czas; datalines; 85 3060 631 819 805 835 955 595 690 73 815 914 ; run; Analiza Analiza rozkładu Ponieważ jesteśmy zainteresowani wyznaczeniem przedziału ufności oraz weryfikacja
Zadanie 1 data lab.zad 1; input czas; datalines; 85 3060 631 819 805 835 955 595 690 73 815 914 ; run; Analiza Analiza rozkładu Ponieważ jesteśmy zainteresowani wyznaczeniem przedziału ufności oraz weryfikacja
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Podstawowe pojęcia: Populacja. Populacja skończona zawiera skończoną liczbę jednostek statystycznych
 Podstawowe pojęcia: Badanie statystyczne - zespół czynności zmierzających do uzyskania za pomocą metod statystycznych informacji charakteryzujących interesującą nas zbiorowość (populację generalną) Populacja
Podstawowe pojęcia: Badanie statystyczne - zespół czynności zmierzających do uzyskania za pomocą metod statystycznych informacji charakteryzujących interesującą nas zbiorowość (populację generalną) Populacja
Testowanie hipotez statystycznych
 round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Dopasowywanie modelu do danych
 Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA
 ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
ANALIZA WARIANCJI - KLASYFIKACJA JEDNOCZYNNIKOWA Na poprzednich zajęciach omawialiśmy testy dla weryfikacji hipotez, że dwie populacje o rozkładach normalnych mają jednakowe wartości średnie. Co jednak
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Analiza Statystyczna
 Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Lekcja 5. Strona 1 z 12 Analiza Statystyczna Do analizy statystycznej wykorzystać można wbudowany w MS Excel pakiet Analysis Toolpak. Jest on instalowany w programie Excel jako pakiet dodatkowy. Oznacza
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji.
 Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Analiza regresji - weryfikacja założeń
 Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Medycyna Praktyczna - portal dla lekarzy Analiza regresji - weryfikacja założeń mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie (Kierownik Zakładu: prof.
Założenia do analizy wariancji. dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW
 Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Moduł. Rama 2D suplement do wersji Konstruktora 4.6
 Moduł Rama 2D suplement do wersji Konstruktora 4.6 110-1 Spis treści 110. RAMA 2D - SUPLEMENT...3 110.1 OPIS ZMIAN...3 110.1.1 Nowy tryb wymiarowania...3 110.1.2 Moduł dynamicznego przeglądania wyników...5
Moduł Rama 2D suplement do wersji Konstruktora 4.6 110-1 Spis treści 110. RAMA 2D - SUPLEMENT...3 110.1 OPIS ZMIAN...3 110.1.1 Nowy tryb wymiarowania...3 110.1.2 Moduł dynamicznego przeglądania wyników...5
Jednoczynnikowa analiza wariancji
 Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Jednoczynnikowa analiza wariancji Zmienna zależna ilościowa, numeryczna Zmienna niezależna grupująca (dzieli próbę na więcej niż dwie grupy), nominalna zmienną wyrażoną tekstem należy w SPSS przerekodować
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Spis treści. Laboratorium III: Testy statystyczne. Inżynieria biomedyczna, I rok, semestr letni 2013/2014 Analiza danych pomiarowych
 1 Laboratorium III: Testy statystyczne Spis treści Laboratorium III: Testy statystyczne... 1 Wiadomości ogólne... 2 1. Krótkie przypomnienie wiadomości na temat testów statystycznych... 2 1.1. Weryfikacja
1 Laboratorium III: Testy statystyczne Spis treści Laboratorium III: Testy statystyczne... 1 Wiadomości ogólne... 2 1. Krótkie przypomnienie wiadomości na temat testów statystycznych... 2 1.1. Weryfikacja
Opis programu do wizualizacji algorytmów z zakresu arytmetyki komputerowej
 Opis programu do wizualizacji algorytmów z zakresu arytmetyki komputerowej 3.1 Informacje ogólne Program WAAK 1.0 służy do wizualizacji algorytmów arytmetyki komputerowej. Oczywiście istnieje wiele narzędzi
Opis programu do wizualizacji algorytmów z zakresu arytmetyki komputerowej 3.1 Informacje ogólne Program WAAK 1.0 służy do wizualizacji algorytmów arytmetyki komputerowej. Oczywiście istnieje wiele narzędzi
Ekonometria, 3 rok. Jerzy Mycielski. Uwniwersytet Warszawski, Wydzia Nauk Ekonomicznych. Jerzy Mycielski (Institute) Ekonometria, 3 rok / 15
 Ekonometria, 3 rok / 15") Ekonometria, 3 rok Jerzy Mycielski Uwniwersytet Warszawski, Wydzia Nauk Ekonomicznych 2009 Jerzy Mycielski (Institute) Ekonometria, 3 rok 2009 1 / 15 Sprawy organizacyjne Dy zur: wtorek godz. 14-15 w sali
Ekonometria, 3 rok Jerzy Mycielski Uwniwersytet Warszawski, Wydzia Nauk Ekonomicznych 2009 Jerzy Mycielski (Institute) Ekonometria, 3 rok 2009 1 / 15 Sprawy organizacyjne Dy zur: wtorek godz. 14-15 w sali
1 Regresja liniowa cz. I
 Regresja liniowa cz. I. Model statystyczny Model statystyczny to zbiór za o zeń. Wprowadzamy model, który mo zliwie najlepiej opisuje ineresujacy ¾ nas fragment rzeczywistość. B ¾edy modelu wynikaja¾ z
Regresja liniowa cz. I. Model statystyczny Model statystyczny to zbiór za o zeń. Wprowadzamy model, który mo zliwie najlepiej opisuje ineresujacy ¾ nas fragment rzeczywistość. B ¾edy modelu wynikaja¾ z
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
1 Przygotowanie ankiety
 1 Przygotowanie ankiety Na dzisiejszych zaj ¾eciach skupimy si ¾e na zasadach tworzenia, wprowadzania oraz wst ¾epnej analizie danych zawartych w ankietach. Za ó zmy, ze ankieta sk ada si ¾e nast¾epujacych
1 Przygotowanie ankiety Na dzisiejszych zaj ¾eciach skupimy si ¾e na zasadach tworzenia, wprowadzania oraz wst ¾epnej analizie danych zawartych w ankietach. Za ó zmy, ze ankieta sk ada si ¾e nast¾epujacych
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
Statystyka w analizie i planowaniu eksperymentu
 31 marca 2014 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
31 marca 2014 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
Regresja linearyzowalna
 1 z 5 2007-05-09 23:22 Medycyna Praktyczna - portal dla lekarzy Regresja linearyzowalna mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie Data utworzenia:
1 z 5 2007-05-09 23:22 Medycyna Praktyczna - portal dla lekarzy Regresja linearyzowalna mgr Andrzej Stanisz z Zakładu Biostatystyki i Informatyki Medycznej Collegium Medicum UJ w Krakowie Data utworzenia:
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Tabele przestawne tabelą przestawną. Sprzedawcy, Kwartały, Wartości. Dane/Raport tabeli przestawnej i wykresu przestawnego.
 Tabele przestawne Niekiedy istnieje potrzeba dokonania podsumowania zawartości bazy danych w formie dodatkowej tabeli. Tabelę taką, podsumowującą wybrane pola bazy danych, nazywamy tabelą przestawną. Zasady
Tabele przestawne Niekiedy istnieje potrzeba dokonania podsumowania zawartości bazy danych w formie dodatkowej tabeli. Tabelę taką, podsumowującą wybrane pola bazy danych, nazywamy tabelą przestawną. Zasady
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
INSTRUKCJA WebPTB 1.0
 INSTRUKCJA WebPTB 1.0 Program WebPTB wspomaga zarządzaniem budynkami w kontekście ich bezpieczeństwa fizycznego. Zawiera zestawienie budynków wraz z ich cechami fizycznymi, które mają wpływ na bezpieczeństwo
INSTRUKCJA WebPTB 1.0 Program WebPTB wspomaga zarządzaniem budynkami w kontekście ich bezpieczeństwa fizycznego. Zawiera zestawienie budynków wraz z ich cechami fizycznymi, które mają wpływ na bezpieczeństwo
Jak sprawdzić normalność rozkładu w teście dla prób zależnych?
 Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
STATYSTYKA I DOŚWIADCZALNICTWO
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Test niezależności chi-kwadrat (χ 2 ) Cel: ocena występowania zależności między dwiema cechami jakościowymi/skategoryzowanymi X- pierwsza cecha; Y druga cecha Przykłady
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Test niezależności chi-kwadrat (χ 2 ) Cel: ocena występowania zależności między dwiema cechami jakościowymi/skategoryzowanymi X- pierwsza cecha; Y druga cecha Przykłady
Inżynieria biomedyczna, I rok, semestr letni 2014/2015 Analiza danych pomiarowych. Laboratorium VIII: Analiza kanoniczna
 1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
Temat: Badanie niezależności dwóch cech jakościowych test chi-kwadrat
 Temat: Badanie niezależności dwóch cech jakościowych test chi-kwadrat Anna Rajfura 1 Przykład W celu porównania skuteczności wybranych herbicydów: A, B, C sprawdzano, czy masa chwastów na poletku zależy
Temat: Badanie niezależności dwóch cech jakościowych test chi-kwadrat Anna Rajfura 1 Przykład W celu porównania skuteczności wybranych herbicydów: A, B, C sprawdzano, czy masa chwastów na poletku zależy
Statystyka. Wykład 7. Magdalena Alama-Bućko. 16 kwietnia Magdalena Alama-Bućko Statystyka 16 kwietnia / 35
 Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 16 kwietnia 2017 Magdalena Alama-Bućko Statystyka 16 kwietnia 2017 1 / 35 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Statystyka w analizie i planowaniu eksperymentu
 29 marca 2011 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
29 marca 2011 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych.
 Laboratorium z ekonometrii (GRETL) 1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych. Okno startowe: Póki nie wczytamy jakiejś bazy danych (lub nie stworzymy własnej), mamy dostęp tylko do dwóch
Laboratorium z ekonometrii (GRETL) 1. Wprowadzenie do oprogramowania gretl. Wprowadzanie danych. Okno startowe: Póki nie wczytamy jakiejś bazy danych (lub nie stworzymy własnej), mamy dostęp tylko do dwóch
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Temat: Funkcje. Własności ogólne. A n n a R a j f u r a, M a t e m a t y k a s e m e s t r 1, W S Z i M w S o c h a c z e w i e 1
 Temat: Funkcje. Własności ogólne A n n a R a j f u r a, M a t e m a t y k a s e m e s t r 1, W S Z i M w S o c h a c z e w i e 1 Kody kolorów: pojęcie zwraca uwagę * materiał nieobowiązkowy A n n a R a
Temat: Funkcje. Własności ogólne A n n a R a j f u r a, M a t e m a t y k a s e m e s t r 1, W S Z i M w S o c h a c z e w i e 1 Kody kolorów: pojęcie zwraca uwagę * materiał nieobowiązkowy A n n a R a
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
AUTOR MAGDALENA LACH
 PRZEMYSŁY KREATYWNE W POLSCE ANALIZA LICZEBNOŚCI AUTOR MAGDALENA LACH WARSZAWA, 2014 Wstęp Celem raportu jest przedstawienie zmian liczby podmiotów sektora kreatywnego na obszarze Polski w latach 2009
PRZEMYSŁY KREATYWNE W POLSCE ANALIZA LICZEBNOŚCI AUTOR MAGDALENA LACH WARSZAWA, 2014 Wstęp Celem raportu jest przedstawienie zmian liczby podmiotów sektora kreatywnego na obszarze Polski w latach 2009
Statystyczna analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok
 Statystyczna analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok Adam Kiersztyn Katedra Teorii Prawdopodobieństwa Wydzia Matematyczno - Przyrodniczy Katolicki Uniwersytet
Statystyczna analiza danych z wykorzystaniem pakietów SPSS i Statistica Skrypt dla studentów 2012 rok Adam Kiersztyn Katedra Teorii Prawdopodobieństwa Wydzia Matematyczno - Przyrodniczy Katolicki Uniwersytet
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowe zasady obliczania wysokości. i pobierania opłat giełdowych. (tekst jednolity)
") Załącznik do Uchwały Nr 1226/2015 Zarządu Giełdy Papierów Wartościowych w Warszawie S.A. z dnia 3 grudnia 2015 r. Szczegółowe zasady obliczania wysokości i pobierania opłat giełdowych (tekst jednolity)
Załącznik do Uchwały Nr 1226/2015 Zarządu Giełdy Papierów Wartościowych w Warszawie S.A. z dnia 3 grudnia 2015 r. Szczegółowe zasady obliczania wysokości i pobierania opłat giełdowych (tekst jednolity)
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Satysfakcja z życia rodziców dzieci niepełnosprawnych intelektualnie
 Satysfakcja z życia rodziców dzieci niepełnosprawnych intelektualnie Zadanie Zbadano satysfakcję z życia w skali 1 do 10 w dwóch grupach rodziców: a) Rodzice dzieci zdrowych oraz b) Rodzice dzieci z niepełnosprawnością
Satysfakcja z życia rodziców dzieci niepełnosprawnych intelektualnie Zadanie Zbadano satysfakcję z życia w skali 1 do 10 w dwóch grupach rodziców: a) Rodzice dzieci zdrowych oraz b) Rodzice dzieci z niepełnosprawnością
ZARZĄDZANIE DANYMI W STATISTICA
 Wprowadzenie do STATISTICA Krzysztof Regulski AGH, WIMiIP ZARZĄDZANIE DANYMI W STATISTICA 1) Zastosowanie: STATISTICA umożliwia w zakresie zarządzania danymi m.in.: scalanie plików sprawdzanie danych sortowanie
Wprowadzenie do STATISTICA Krzysztof Regulski AGH, WIMiIP ZARZĄDZANIE DANYMI W STATISTICA 1) Zastosowanie: STATISTICA umożliwia w zakresie zarządzania danymi m.in.: scalanie plików sprawdzanie danych sortowanie
Rozdział 2: Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów
 Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Rozdział : Metoda największej wiarygodności i nieliniowa metoda najmniejszych kwadratów W tym rozdziale omówione zostaną dwie najpopularniejsze metody estymacji parametrów w ekonometrycznych modelach nieliniowych,
Wykład 5: Analiza dynamiki szeregów czasowych
 Wykład 5: Analiza dynamiki szeregów czasowych ... poczynając od XIV wieku zegar czynił nas najpierw stróżów czasu, następnie ciułaczy czasu, i wreszcie obecnie - niewolników czasu. W trakcie tego procesu
Wykład 5: Analiza dynamiki szeregów czasowych ... poczynając od XIV wieku zegar czynił nas najpierw stróżów czasu, następnie ciułaczy czasu, i wreszcie obecnie - niewolników czasu. W trakcie tego procesu
Grupowanie materiału statystycznego
 Grupowanie materiału statystycznego Materiał liczbowy, otrzymany w wyniku przeprowadzonej obserwacji statystycznej lub pomiaru, należy odpowiednio usystematyzować i pogrupować. Doskonale nadają się do
Grupowanie materiału statystycznego Materiał liczbowy, otrzymany w wyniku przeprowadzonej obserwacji statystycznej lub pomiaru, należy odpowiednio usystematyzować i pogrupować. Doskonale nadają się do
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Statystyka w analizie i planowaniu eksperymentu
 22 marca 2011 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
22 marca 2011 Przestrzeń statystyczna - podstawowe zadania statystyki Zdarzeniom losowym określonym na pewnej przestrzeni zdarzeń elementarnych Ω można zazwyczaj na wiele różnych sposobów przypisać jakieś
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
System zarządzania bazą danych (SZBD) Proces przechodzenia od świata rzeczywistego do jego informacyjnej reprezentacji w komputerze nazywać będziemy
 Proces przechodzenia od świata rzeczywistego do jego informacyjnej reprezentacji w komputerze nazywać będziemy") System zarządzania bazą danych (SZBD) Proces przechodzenia od świata rzeczywistego do jego informacyjnej reprezentacji w komputerze nazywać będziemy modelowaniem, a pewien dobrze zdefiniowany sposób jego
System zarządzania bazą danych (SZBD) Proces przechodzenia od świata rzeczywistego do jego informacyjnej reprezentacji w komputerze nazywać będziemy modelowaniem, a pewien dobrze zdefiniowany sposób jego
5. Model sezonowości i autoregresji zmiennej prognozowanej
 5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
5. Model sezonowości i autoregresji zmiennej prognozowanej 1. Model Sezonowości kwartalnej i autoregresji zmiennej prognozowanej (rząd istotnej autokorelacji K = 1) Szacowana postać: y = c Q + ρ y, t =
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
7.4 Automatyczne stawianie prognoz
 szeregów czasowych za pomocą pakietu SPSS Następnie korzystamy z menu DANE WYBIERZ OBSERWACJE i wybieramy opcję WSZYSTKIE OBSERWACJE (wówczas wszystkie obserwacje są aktywne). Wreszcie wybieramy z menu
szeregów czasowych za pomocą pakietu SPSS Następnie korzystamy z menu DANE WYBIERZ OBSERWACJE i wybieramy opcję WSZYSTKIE OBSERWACJE (wówczas wszystkie obserwacje są aktywne). Wreszcie wybieramy z menu
Opracowywanie wyników doświadczeń
 Podstawy statystyki medycznej Laboratorium Zajęcia 6 Statistica Opracowywanie wyników doświadczeń Niniejsza instrukcja zawiera przykłady opracowywania doświadczeń jednoczynnikowy i wieloczynnikowych w
Podstawy statystyki medycznej Laboratorium Zajęcia 6 Statistica Opracowywanie wyników doświadczeń Niniejsza instrukcja zawiera przykłady opracowywania doświadczeń jednoczynnikowy i wieloczynnikowych w
Analiza sezonowości. Sezonowość może mieć charakter addytywny lub multiplikatywny
 Analiza sezonowości Wiele zjawisk charakteryzuje się nie tylko trendem i wahaniami przypadkowymi, lecz także pewną sezonowością. Występowanie wahań sezonowych może mieć charakter kwartalny, miesięczny,
Analiza sezonowości Wiele zjawisk charakteryzuje się nie tylko trendem i wahaniami przypadkowymi, lecz także pewną sezonowością. Występowanie wahań sezonowych może mieć charakter kwartalny, miesięczny,
Wykład 5: Statystyki opisowe (część 2)
") Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Wykład 5: Statystyki opisowe (część 2) Wprowadzenie Na poprzednim wykładzie wprowadzone zostały statystyki opisowe nazywane miarami położenia (średnia, mediana, kwartyle, minimum i maksimum, modalna oraz
Prognozowanie na podstawie modelu ekonometrycznego
 Prognozowanie na podstawie modelu ekonometrycznego Przykład. Firma usługowa świadcząca usługi doradcze w ostatnich kwartałach (t) odnotowała wynik finansowy (yt - tys. zł), obsługując liczbę klientów (x1t)
Prognozowanie na podstawie modelu ekonometrycznego Przykład. Firma usługowa świadcząca usługi doradcze w ostatnich kwartałach (t) odnotowała wynik finansowy (yt - tys. zł), obsługując liczbę klientów (x1t)
Dokonamy analizy mającej na celu pokazanie czy płeć jest istotnym czynnikiem
 Analiza I Potrzebujesz pomocy? Wypełnij formularz Dokonamy analizy mającej na celu pokazanie czy płeć jest istotnym czynnikiem różnicującym oglądalność w TV meczów piłkarskich. W tym celu zastosujemy test
Analiza I Potrzebujesz pomocy? Wypełnij formularz Dokonamy analizy mającej na celu pokazanie czy płeć jest istotnym czynnikiem różnicującym oglądalność w TV meczów piłkarskich. W tym celu zastosujemy test
ECDL Advanced Moduł AM3 Przetwarzanie tekstu Syllabus, wersja 2.0
 ECDL Advanced Moduł AM3 Przetwarzanie tekstu Syllabus, wersja 2.0 Copyright 2010, Polskie Towarzystwo Informatyczne Zastrzeżenie Dokument ten został opracowany na podstawie materiałów źródłowych pochodzących
ECDL Advanced Moduł AM3 Przetwarzanie tekstu Syllabus, wersja 2.0 Copyright 2010, Polskie Towarzystwo Informatyczne Zastrzeżenie Dokument ten został opracowany na podstawie materiałów źródłowych pochodzących
Instalacja. Zawartość. Wyszukiwarka. Instalacja... 1. Konfiguracja... 2. Uruchomienie i praca z raportem... 4. Metody wyszukiwania...
 Zawartość Instalacja... 1 Konfiguracja... 2 Uruchomienie i praca z raportem... 4 Metody wyszukiwania... 6 Prezentacja wyników... 7 Wycenianie... 9 Wstęp Narzędzie ściśle współpracujące z raportem: Moduł
Zawartość Instalacja... 1 Konfiguracja... 2 Uruchomienie i praca z raportem... 4 Metody wyszukiwania... 6 Prezentacja wyników... 7 Wycenianie... 9 Wstęp Narzędzie ściśle współpracujące z raportem: Moduł
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1
 Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT. Anna Rajfura 1") Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, że 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
Temat: BADANIE ZGODNOŚCI ROZKŁADU CECHY (EMPIRYCZNEGO) Z ROZKŁADEM TEORETYCZNYM TEST CHI-KWADRAT Anna Rajfura 1 Przykład wprowadzający Wiadomo, że 40% owoców ulega uszkodzeniu podczas pakowania automatycznego.
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 8 Regresja wielokrotna Regresja wielokrotna jest metodą statystyczną, w której oceniamy wpływ wielu zmiennych niezależnych (X 1, X 2, X 3,...) na zmienną zależną (Y).