Narzędzia pomiarowe w badaniach społeczno-ekonomicznych. Adam Sagan Uniwersytet Ekonomiczny w Krakowie
|
|
|
- Anna Gajewska
- 8 lat temu
- Przeglądów:
Transkrypt

1 Narzędzia pomiarowe w badaniach społeczno-ekonomicznych Adam Sagan Uniwersytet Ekonomiczny w Krakowie

2 Plan zajęć 1. Budowa narzędzia pomiaru, pytania kwestionariuszowe, skale proste i złożone 2. COARSE, wskaźniki, skale i indeksy, modele pomiarowe 3. Ocena wymiarowości skali (analiza korespondencji, analiza głównych składowych, analiza czynnikowa) 4. Klasyczna teoria testu i rzetelność skal równoległych 5. Konfirmacyjna analiza czynnikowa, modelowe ujęcie rzetelności 6. Teoria reakcji na pozycję, modele Rascha i Birnbauma

3 Literatura 1. Konarski, R., Modelowanie równań strukturalnych, PWN Kline, R., Principles of Structural Equation Modeling, Trafność i rzetelność testów psychologicznych, red. J. Brzeziński, GWP Warszawa 2005

4 Techniki gromadzenia danych w badaniach ankietowych 1. Techniki bezpośrednie - Wywiad kwestionariuszowy: technika standaryzowana, w której badacz otrzymuje dane od respondenta w procesie bezpośredniego komunikowania się (aktywna rola ankieterów) 2. Techniki pośrednie: - Ankieta: technika standaryzowana, w której badacz otrzymuje dane od respondenta w procesie komunikowania się pisemnego (aktywna rola respondentów)


5 Techniki gromadzenia danych
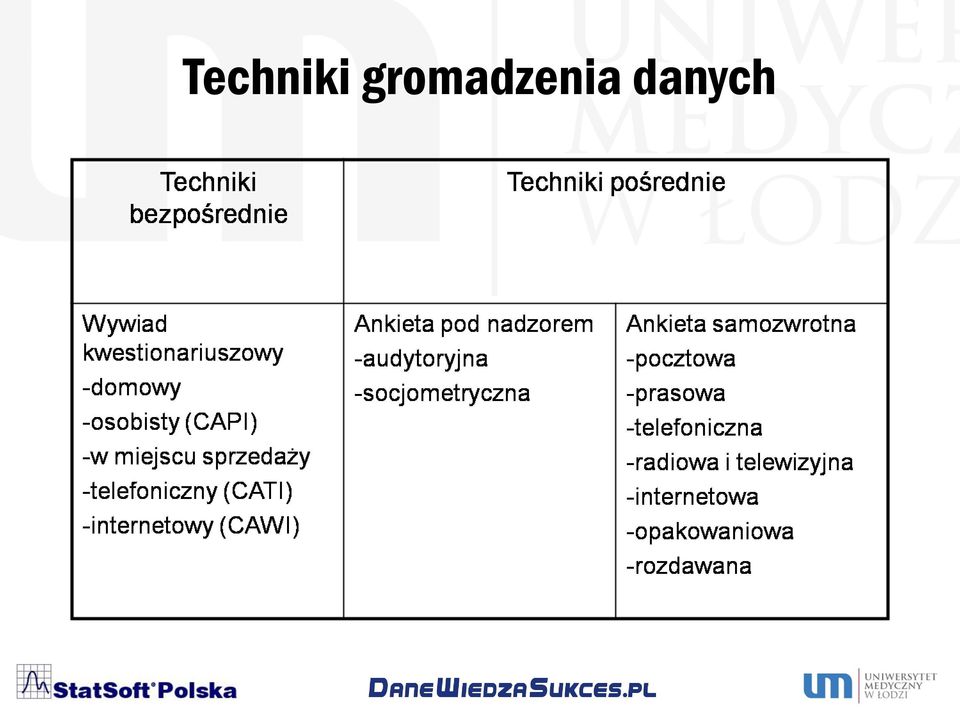
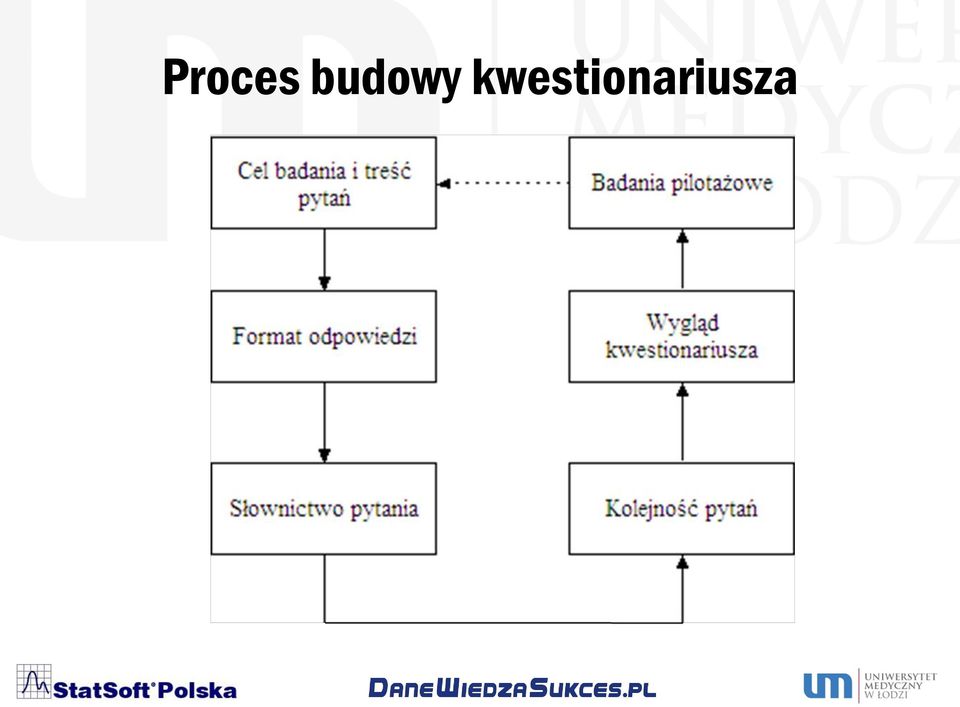
6 Proces budowy kwestionariusza
7 Badania ankietowe - gromadzenie danych 1. Rodzaje pytań - pytania o fakty i pytania o opinie 2. Interakcja respondent - ankieter: 1/ zrozumienie pytania, 2/ odtworzenie istotnych informacji, 3/ zwerbalizowanie odpowiedzi, 4/ wyrażenie intencji udzielenia odpowiedzi na pytanie ) 3. Pytania o fakty: udzielenie informacji na temat faktów i zachowania problem identyfikacji wartości prawdziwej odpowiedzi. 4. Pytania o opinie: udzielenie odpowiedzi na temat postaw i stanów emocjonalnych, sądów wartościujących

8 Błędy w odpowiedziach Two priests, a Dominican and a Jesuit, are discussing whether it is a sin to smoke and pray at the same time. After failing to reach a conclusion, each goes off to consult his respective superior. The next week they meet again. The Dominican says, Well, what did your superior say? The Jesuit responds, He said it was all right. That s funny, the Dominican replies. My superior said it was a sin. The Jesuit says, What did you ask him? The Dominican replies, I asked him if it was all right to smoke while praying. Oh, says the Jesuit. I asked my superior if it was all right to pray while smoking.

9 Błędy w odpowiedziach 1. Założenie wiedzy respondenta - słownictwo w pytaniach powinno być zrozumiałe dla respondentów bez stosowania żargonu badawczego 2. Wieloznaczność pytań - niespójność w interpretacji pytań przez respondentów (np. Czy jesteś zadowolony z urządzeń rekreacyjnych na naszym osiedlu? 3. Pytania sugerujące - ukierunkowywanie odpowiedzi respondentów (np. Większość lekarzy podkreśla, że palenie papierosów jest przyczyną raka. Czy się z tym zgadzasz?, W jakim stopniu jesteś za prawem kobiet do aborcji: a/ w bardzo małym, b/ małym, c/ dużym, d/ bardzo dużym 100% badanych jest za prawem do aborcji. 4. Pytania podwójne - double-barreled requests - pytania dotyczące jednocześnie wielu kwestii (np. Czy uważasz, że ludzie powinni mniej jeść i więcej ćwiczyć? ) 5. Pytania negatywne - pytania zawierające przeczenia (np. Czy jesteś przeciwny zakazowi stosowania nieekologicznych pieców ) 6. Pytania hipotetyczne - pytania o wyobrażeniowe kwestie (np. Jeżeli byłbyś prezydentem Polski, w jaki sposób obniżyłbyś przestępczość?

10 Format odpowiedzi 1. Pytania otwarte - swobodne wyrażanie własnych odpowiedzi, 2. Pytania zamknięte - zawiera listę odpowiedzi, z której respondent wybiera prawidłową odpowiedź, 3. Pytania otwarte logicznie i otwarte formalnie - pytania zadawane w sposób otwarty i mające otwarty zakres odpowiedzi (np. Co sądzisz o wprowadzeniu zakazu jazdy w pasach bezpieczeństwa w samochodzie? ) 4. Pytania otwarte logicznie i zamknięte formalnie - pytania zadawane w sposób zamknięty lecz mające otwarty zakres odpowiedzi (np. Który z poniższych czynników ma największy wpływ na zadowolenie ze studiów: a/ jakość posiłków, b/ uroda wykładowców, c/ czytelność slajdów ) 5. Pytania zamknięte logicznie i zamknięte formalne pytania zadawane w sposób zamknięty i mające zamknięty zakres odpowiedzi (np. Czy masz a/ mniej niż 20 lat, b/ 20 lat i więcej ) 6. Pytania zamknięte logicznie i otwarte formalne - pytania zadawane w sposób otwarty lecz mające zamknięty zakres odpowiedzi (np. Ile masz lat? )
 5.")
11 Błędy w odpowiedziach 1. Błąd zakresu - podanie odpowiedzi spoza zakresu odpowiedzi prawdziwych (np. wiek 324 lata) 2. Błąd spójności - niespójność w odpowiedziach na kilka pytań (np. osoba lat 8 podaje status wdowiec ) 3. Błąd przejścia - pominięcie istotnych pytań z powodu nie uwzględnienia reguł przejść w kwestionariuszu (np. odpowiadanie na pytania przez niepalącego dotyczące palenia papierosów) 4. Efekty pierwszeństwa i świeżości - tendencja do wybierania odpowiedzi na górze (efekt pierwszeństwa) i na dole listy odpowiedzi (efekt świeżości) w kafeteriach 5. Efekt mimikry - tendencja do wybierania odpowiedzi środkowych na listach uporządkowanych mierzących intensywność cech 6. Błąd teleskopii - kompresja czasu - pamiętanie zdarzeń wcześniej niż zdarzyło się to w rzeczywistości. Błąd teleskopii występuje najczęściej w krótkich interwałach czasowych 7. Odpowiedzi fantomowe - pamiętanie zdarzeń, które nigdy nie miały miejsca
 i na dole listy odpowiedzi (efekt świeżości) w kafeteriach 5.")
12 Pytania z nieokreślonym układem odniesienia 1. Do you think the government should give money to workers who are unemployed for a limited length of time until they can find another job? (Yes 63%) 2. It has been proposed that unemployed workers with dependents be given up to $25 per week by the government for as many as 26 weeks during one year while they are out of work and looking for a job. Do you favor or oppose this plan? (Favor 46%) 3. Would you be willing to pay higher taxes to give people up to $25 a week for 26 weeks if they fail to find satisfactory jobs? (Yes 34%)

13 Odpowiedzi na pytania drażliwe Czy zabiłeś swoją żonę? 1. Pytania wprost - Czy zdarzyło Ci się zabić swoją żonę? 2. Sortowanie kart - Z podanych kolejno kart wybierz numer z odpowiedzią prawdziwą: 1/ Naturalna śmierć, 2/ Zabiłem ją z premedytacją 3/ Niechcący zabiłem ją 3. Powszechność zachowań - Jak wiadomo powszechnie zwykle wiele osób zabija swoje żony. Czy zdarzyło się Panu zabić własną również? 4. Uogólniony inny - Czy zna Pan kogoś, kto zabił swoją żonę? A jak to było w Pana przypadku? Czy też tak samo? 5. Technika urny wyborczej - W naszych badaniach szanujemy prywatność i anonimowość odpowiedzi. Proszę zaznaczyć odpowiedź na powyższe pytanie i wrzucić zalakowaną kopertę do urny 6. Technika szczerość za szczerość - Powiem Panu szczerze, ja bym zrobił tak samo, teraz popatrzmy sobie w oczy i szczerze w prostych żołnierskich słowach powiedz stary... zabiłeś swoją żonę?

14 Kolejność odpowiedzi 1. Funneling - określenie logicznej struktury odpowiedzi - od pytań ogólnych, prostych, dotyczących faktów, do pytań szczegółowych złożonych dotyczących opinii i wartości 2. Efekt spójności - dążenie do udzielania spójnych odpowiedzi na poszczególne pytania, blokowanie podobnych zagadnień 3. Efekt nastawienia - priming effect - pozytywna lub negatywna odpowiedź na kluczowe pytanie z bloku ma wpływ na odpowiedzi na kolejne pytania 4. Efekt uczenia się - odpowiedzi na pytania wcześniejsze mają wpływ na odpowiedzi na pytania w dalszej części kwestionariusza: Koszty utrzymania Parlamentu Europejskiego przez przeciętnego Kowalskiego to ok 100 zlotych Pytanie: Czy jesteś za zwiększeniem liczby członków Parlamentu Europejskiego? Liczba członków Parlamentu Europejskiego z Polski wynosi tylko 20 osób Pytanie: Czy jesteś za zwiększeniem liczby członków Parlamentu Europejskiego?

15 Obciążenie odpowiedzi 1. Społecznie pożądane reakcje (Socially Desirable Responses) tendencja do ukazywania siebie w lepszym świetle ze względu na normy kulturowe 2. Wymiary: 1. Zarządzanie wrażeniami (tworzenie obrazu siebie) 2. Podnoszenie obrazu siebie (nadmierne zaufanie dla siebie) 3. Response set (nastawienie odpowiedzi): odpowiedzi na pytania społecznie wrażliwe, gdzie normy społeczne zniekształcają indywidualne opinie (np. relacje rasowe lub płciowe) rola czynników sytuacyjnych 4. Response style (styl odpowiedzi): stabilna psychologiczna tendencja do odpowiadania na wszystkie pytania w kwestionariuszu rola czynników psychologicznych
: odpowiedzi na pytania społecznie wrażliwe, gdzie normy społeczne zniekształcają indywidualne opinie (np.")
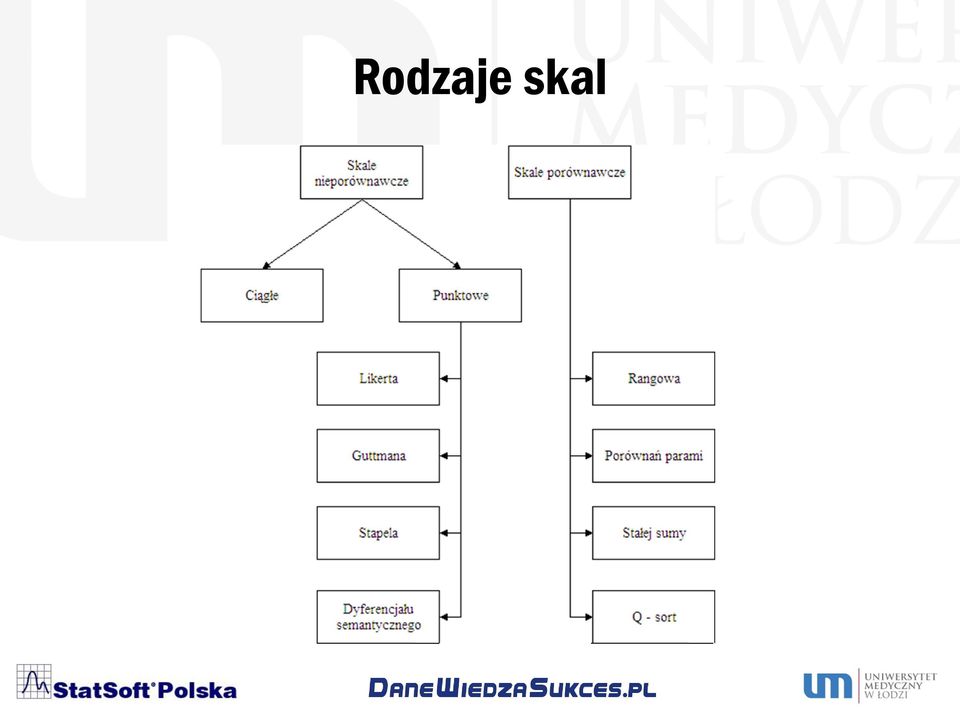
16 Rodzaje skal

17 Budowa narzędzia pomiaru - COARSE Rossitera Construct - Object - Attribute - Rater Scale - Enumeration

18 COARSE 1. Definicja konstruktu opis badanego zjawiska w kontekście: 1. Obiektu 2. Cech 3. Badacza 2. Klasyfikacja obiektów: 1. Konkretny jednostkowy (Cola) 2. Abstrakcyjny kolektywny (napoje) 3. Abstrakcyjny ideacyjny (naród) 3. Klasyfikacja cech: 1. Konkretne (intencje zakupu) 2. Abstrakcyjne /formatywne/ (status) 3. Abstrakcyjne refleksyjne (postawa) 4. Identyfikacja badanych: 1. Indywidualni 2. Grupy 3. Eksperci
 3. Abstrakcyjne refleksyjne (postawa) 4. Identyfikacja badanych: 1.")
19 Etapy budowy skali 1. Refleksywnej (skali) 1. Definicja konstruktu 2. Wybór procedury skalowania 3. Dobór stwierdzeń 4. Analiza dyskryminacji pozycji 5. Ocena wymiarowości i rzetelności 6. Ocena trafności i porównywalności międzykulturowej 2. Formatywnej (indeksu) 1. Określenie dziedziny konstruktu 2. Dobór wskaźników 3. Ocena współliniowości wskaźników 4. Ocena trafności zewnętrznej (korelacji z zewnętrznym kryterium)


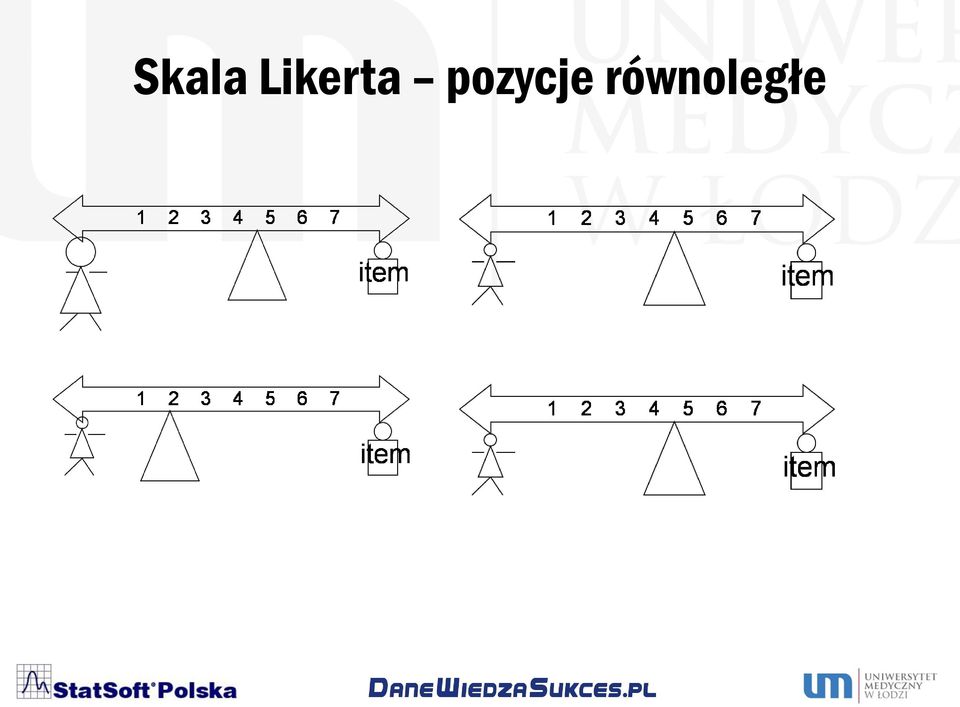
20 Skala Likerta pozycje równoległe

21 Skala Guttmana pozycje skumulowane

22 Model pomiarowy CFA - wskaźniki refleksyjne 1. Model czynnikowy 2. Nadmiarowe 3. Wyjaśniane przez model 4. Jednorodne wewnętrznie 5. Losowy dobór z populacji pozycji 6. Nie ma problemu współliniowości 7. Tworzą skalę

23 Model pomiarowy CFA - wskaźniki refleksyjne 1. Zmienna ukryta: kontrola zależności między zmiennymi obserwowalnymi

24 Model pomiaru ze wskaźnikami refleksywnymi 1. Zmienna ukryta: prawdziwa wartość oczekiwana jest wartością średnią dla zmiennej obserwowalnej w bardzo wielu (nieskończonej liczbie) powtarzalnych prób pomiaru

25 Zmienna ukryta - niedeterministyczna funkcja wskaźników 1. Zmienna ukryta: zmienna w systemie liniowych równań strukturalnych; jeżeli równania nie mogą być w taki sposób przekształcone, że wyrażają w pełni zmienną ukrytą jako wyłącznie kombinację (liniową) zmiennych obserwowalnych
26 Poziomy równoległości wskaźników 1. Ściśle równoległe (strict parallel) 2. Równoległe (parallel) 3. Względnie równoważne (τ - equivalent) 4. Jednorodne (congeneric)

27 Model pomiarowy wskaźników refleksywnych Konfirmacyjna analiza czynnikowa (CFA)
28 Skumulowany charakter skali Guttmana 1. Analiza tabeli Guttmana 1. Współczynnik odtwarzalności: E - liczba błędów w tabeli Guttmana N - liczba wszystkich wyborów na skali. Jest to iloczyn liczby pozycji i liczby respondentów. 2. Współczynnik skalarności: Emax liczba błędów krańcowych 2 Skala Guttmana jest skalą monotoniczną jeżeli współczynnik odtwarzalności jest większy od 0.8 a współczynnik skalarności jest większy od 0.6

29 Analiza błędów skali Guttmana

30 Normalizacja i standaryzacja skali
31 Analiza wymiarowości skali 1. Analiza głównych składowych (Principal Component Analysis), 2. Analiza korespondencji (Correspondence Analysis), 3. Eksploracyjna analiza czynnikowa (Factor Analysis) 4. Konfirmacyjna analiza czynnikowa (Confirmatory Factor Analysis)
32 Ocena wymiarowości skali
33 Metody oceny wymiarowości
34 Analiza głównych składowych 1. Dekompozycja macierzy korelacji lub kowariancji w układzie o mniejszej liczbie wymiarów 2. Wymiar: ważona liniowa kombinacja zmiennych 3. Zastosowanie metody SVD do analizy symetrycznej macierzy korelacji/kowariancji (EVD) 4. Uzyskanie prostej i nie skorelowanej struktury danych 5. Zmienne i przypadki aktywne definiują przestrzeń wielowymiarową a zmienne i przypadki pasywne (dodatkowe) są rzutowane na zredukowaną przestrzeń

35 Procedura analizy głównych składowych
36 Wartości własne 1. Wartości własne są kwadratem wartości osobliwych 2. Wartości własne określają zakres wyjaśnianej wariancji zmiennych pierwotnych 3. Suma wartości własnych jest równa całkowitej wariancji wszystkich zmiennych 4. Wartości własne kolejnych składowych są monotonicznie malejące 5. Liczba składowych (wymiarów) jest równa liczbie zmiennych pierwotnych (W = k)
37 Ładunki czynnikowe 1. Współczynniki korelacji między główną składową a zmienną pierwotną 2. Suma kwadratów ładunków czynnikowych = wartość własna 3. Kwadraty ładunków czynnikowych określają dyskryminację składowej przez zmienną 4. Ładunki czynnikowe stanowią wagi w liniowej kombinacji zmiennych
38 Ładunki czynnikowe 1. Rotacja składowych w PCA jest zawsze ortogonalna 2. Rotacja ma na celu poprawę interpretacji składowych w przekroju zmiennych lub zmiennych w przekroju składowych 3. Typy rotacji: 1. Varimax - maksymalizuje wartości ładunków w przekroju składowych i ułatwia interpretacje składowych 2. Quartimax - maksymalizuje wartości ładunków w przekroju zmiennych i ułatwia interpretację zmiennych 3. Biquartimax - jednocześnie maksymalizuje wartości ładunków w przekroju zmiennych i składowych 4. Equamax - ważona rotacja Biquartimax 4. Rotacja pozwala na uzyskanie prostej struktury danych (wysokich ładunków dla jednych składowych i niskich dla innych w przekroju zmiennych, jednoznaczne przypisanie zmiennych dl składowych bez tzw, ładunków krzyżowych)
39 Wartości czynnikowe 1. Wartości czynnikowe są współrzędnymi obiektów (obserwacji) w przekroju składowych 2. Wartości czynnikowe są podstawą budowy indeksów i skal czynnikowych 3. Wartości czynnikowe są standaryzowanymi ocenami respondentów w przekroju składowych (średnia = 0, wariancja = 1) 4. Wartości czynnikowe są standaryzowanymi wartościami metrycznych danych surowych ważonych ładunkami czynnikowymi 5. Metody obliczania wartości czynnikowych: 1. Regresyjna: (najczęściej stosowana) FS = X(std) λ θ 2. Bartletta 3. Andersona - Rubina: wartości czynnikowe są ortogonalne
40 Analiza korespondencji 1. Analiza głównych składowych danych nominalnych (kategorialnych) 2. Analiza złożonych tabel kontyngencji (n x k) 3. Analiza tabel wielodzielczych (n x k x h x g) 4. Analiza tabel danych wymiarowo jednorodnych (te same jednostki miary) i nieujemnych 5. Dekompozycja według wartości osobliwych macierzy reszt standaryzowanych statystyki χ2 6. Wieloraka analiza korespondencji tabeli Burta 7. Skalowanie optymalne - analiza homogeniczności (HOMALS) 8. Skalowanie dualne wierszy i kolumn tabeli kontyngencji (dual scaling) 9. Analiza skal Guttmana (diagnoza efektu podkowy)

41 Procedura analizy korespondencji
42 Dekompozycja SVD 1. Wartości własne są kwadratem wartości osobliwych 2. Wartości własne określają zakres wyjaśnianej bezwładności tabeli kontyngencji (chi2/n) 3. Suma wartości własnych jest równa całkowitej bezwładności tabeli kontyngencji 4. Wartości własne kolejnych wymiarów są monotonicznie malejące 5. Liczba wymiarów jest równa mniejszej wielkości z liczby kolumn - 1 lub liczby wierszy - 1 (W = min (k - 1, w - 1))

43 Tabela danych

44 Profile wierszy i kolumn
45 Mapa korespondencji
46 Barycentryczny układ współrzędnych
47 Redukcja wymiarowości 1. Dekompozycja całkowitej bezwładności w układzie o małej liczbie wymiarów (2-3), w której wzajemne położenie profili jest jak najbliższe ich położeniu w układzie o k(min) - 1 wymiarach 2. Kryterium redukcji: maksymalizacja bezwładności profili w optymalnej liczbie wymiarów 3. Wartość własna każdej osi głównej jest równa wyjaśnianej bezwładności profili względem tej osi 4. Pierwsza oś główna przechodzi w taki sposób, że maksymalizuje wyjaśnianą bezwładność profili, druga oś jest prostopadła do pierwszej i maksymalizuje bezwładność profili w tym kierunku 5. Bezwładność profili wzdłuż danej osi głównej jest zwana bezwładnością główną. Jest to ważona średnia odległości χ2 od środka ciężkości do projekcji danego profilu na daną oś.
48 Bezwładność względna i kwadrat cosinusa 1. Zakres bezwładności tabeli wyjaśniany przez każdy z wymiarów 2. Suma kwadratów bezwładności = wartość własna 3. Kwadraty bezwładności określają dyskryminację wymiaru przez daną aktywną kategorię wiersza lub kolumny tabeli 1. Korelacja między aktywną lub pasywną kategorią tabeli a wymiarem 2. Suma kwadratów cosinusa = jakość odwzorowania profilu wierszy lub kolumny tabeli przez punkt w układzie współrzędnych
 Wkład absolutny punktu w bezwładność główną osi identyfikacja punktów, które przyciągają osie i mają największy wkład w orientacje osi: wskazuje stopień w jakim geometryczna orientacja osi jest")
49 Analiza wymiarów 1. (1) Wkład absolutny punktu w bezwładność główną osi identyfikacja punktów, które przyciągają osie i mają największy wkład w orientacje osi: wskazuje stopień w jakim geometryczna orientacja osi jest określana przez punkt (wymiar jest definiowany przez punkt) 2. (2) Relatywny wkład osi w bezwładność punktu ocena położenia punktów na osi i stopień reprezentacji na osi (kwadrat cosinusa korelacja punktu i osi głównej): wskazuje stopień, w jakim profil jest opisywany przez wymiar (punkt jest wyjaśniany przez wymiar) 3. W interpretacji wyników analizy korespondencji należy zawsze uwzględnić (1) i (2)
50 Jakość reprezentacji 1. Jakość reprezentacji punktu w zredukowanym układzie współrzędnych 2. Stosunek kwadratu odległości punktu od początku układu współrzędnych w wybranej liczbie wymiarów do kwadratu odległości punktu od początku układu w maksymalnej liczbie wymiarów 3. Suma kwadratów cosinusów w przekroju wymiarów 4. Cosinus kąta między wektorami równa się korelacji tetrachorycznej.
51 Interpretacja osi głównych 1. Kategorie opisujące daną oś mogą należeć do różnych zmiennych, których bezwładność związana z daną osią jest duża, z czego jedna kategoria powinna być związana z półosią wartości dodatnich a druga - z półosią wartości ujemnych 2. Obydwie strony osi są opisane za pomocą różnych kategorii tej samej zmiennej. 3. Wartości własne a kształt układu: 1. (W1 = W2 = W3): sferyczny 2. (W1 = W2) >> W3: soczewkowy 3. W1 >> (W1 = W2): cygara 4. Wariancja osi głównej jest wariancją projekcji punktów kategorii na oś

52 Interpretacja wymiarów w analizie korespondencji

53 Porównanie punktów wierszowych i kolumnowych

54 Analiza korespondencji skal ocen - dublowanie danych
55 Biplot
56 Wieloraka analiza korespondencji 1. Analiza korespondencji wielodzielczych tabel kontyngencji (k x m x n... ) 2. Dane wejściowe w postaci tabeli Burta 3. Liczba wymiarów w MCA = K - Q 4. Wariancja układu: średnia kwadratów odległości od punktów do ich środka ciężkości (punktu średniego) 5. Suma wartości własnych = wariancja układu: (K/ Q) 1
57 Tabela Burta 1. Macierz Burta - symetryczna macierz blokowa na głównej przekątnej znajdują się macierze diagonalne z wartościami brzegowymi. Elementy pozadiagonalne to tablice kontyngencji między parami zmiennych. 2. Analiza korespondencji macierzy Burta
58 Analiza czynnikowa 1. Identyfikacja ukrytych zmiennych (wymiarów) wyjaśniających maksymalną ilość wariancji wspólnej w strukturze macierzy korelacji (kowariancji) 2. Zmienne ukryte (wymiary) mogą być ortogonalne lub skorelowane 3. Zasoby zmienności wspólnej są szacowane na podstawie metody największej wiarygodności (ML) 4. Metoda ML pozwala na ocenę dopasowania modelu czynnikowego do danych
59 Dekompozycja wariancji
60 Wartości własne 1. Wartości własne są szacowane na podstawie zakresu wariancji wspólnej (np. jako kwadrat korelacji wielorakiej) 2. Wartości własne określają zakres wyjaśnianej wariancji wspólnej (kowariancji) zmiennych pierwotnych 3. Suma wartości własnych jest równa wariancji wspólnej zmiennych 4. Wartości własne kolejnych składowych są monotonicznie malejące 5. Liczba czynników jest równa liczbie nieujemnych wartości własnych i zawsze mniejsza od liczby zmiennych pierwotnych
61 Ładunki czynnikowe 1. Współczynniki regresji między czynnikiem a zmienną pierwotną (mogą być większe od jedności) 2. Suma kwadratów ładunków czynnikowych = wartość własna 3. Kwadraty ładunków czynnikowych określają dyskryminację zmiennej przez czynnik 4. Ładunki czynnikowe stanowią wagi w liniowej kombinacji czynników wspólnych wyjaśniających daną zmienną
62 Rotacja czynników 1. Rotacja w FA może być ortogonalna lub ukośna 2. Rotacja ma na celu poprawę interpretacji czynników w przekroju zmiennych lub zmiennych w przekroju czynników 3. Typy rotacji ortogonalnej 1. Varimax 2. Quartimax 3. Biquartimax 4. Equamax 4. Typy rotacji ukośnej 1. Promax 2. Oblimin 3. Geomin 4. Hierarchiczna analiiza czynników ukośnych (STATISTICA) 5. Rotacja w FA pozwala na uzyskanie jednoznacznego rozwiązania czynnikowego w porównaniu do rozwiązania bez rotacji (factor indeterminacy)
63 Analiza wiarygodności skal

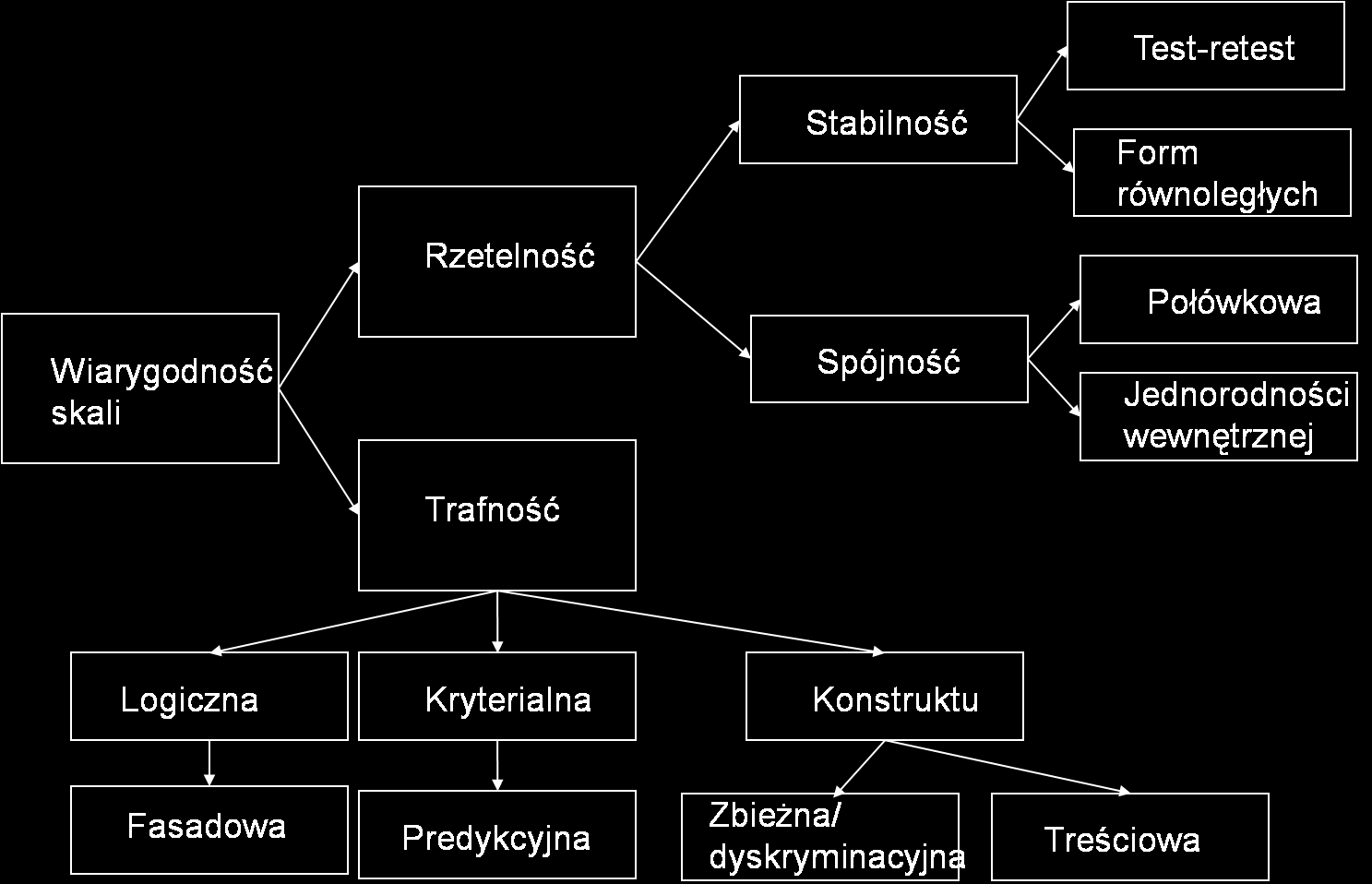
64 Trafność i rzetelność skali

65 Podstawowe równanie teorii testu
66 Przypadkowy błąd pomiaru Ep 1. Ep jest różnicą między X a T 2. Ep jest związany z błędem standardowym pomiaru 3. Gdybyśmy mieli wiele prób to X jest statystyką z próby a T średnią z X w przekroju wszystkich prób (wartością oczekiwaną) 4. Błąd standardowy X jest odchyleniem standardowym X w przekroju wszystkich prób
67 Rzetelność skali 1. Korelacja między skalami równoległymi = rx1,x2 2. Stosunek wariancji wyniku prawdziwego do ogólnej wariancji skali 3. Założenia: 1. cov(t,e) = 0 2. var(e) = 0
68 Rzetelność skali Likerta 1. Wartość prawdziwa odpowiedzi na skali jest to średnia z wartości obserwowanych z nieskończenie wielu powtarzanych pomiarów; 2. Wartości prawdziwe oraz składowe błędu losowego pomiaru z danej populacji są od siebie niezależne 3. Szacowana rzetelność skali jest mierzona, na podstawie wariancji wyników prawdziwych i zależy od charakterystyk próby (lub populacji). Skale te nazywa się często skalami zależnymi od próby/populacji; 4. Składowe błędu dla różnych pozycji są niezależne od siebie; 5. Proces wyboru pozycji do całej skali oparty jest na macierzy korelacji. 6. Relacja pomiędzy X a T jest liniowa.

69 Rzetelność skali Likerta 1. Analiza rzetelności 1. Test-retest 2. Metoda testów równoległych 3. Metoda połówkowa 4. Współczynnik α - Cronbacha 5. Współczynnik KR - 20
70 Alfa Cronbacha 1. Współczynnik ten jest dolną granicą estymatora rzetelności skali, przy założeniu, że: 1. składowe błędu pomiaru są nie skorelowane (skala jest stosowana w tym samym miejscu i czasie i nie istnieje wpływ reakcji na jedne pozycje w skali na odpowiedzi na inne pozycje), 2. skala jest jednowymiarowa, czyli wszystkie pozycje skali są odzwierciedleniem jednego i tego samego czynnika systematycznego oraz źródło błędów losowych jest jedno i to samo, 3. wszystkie współczynniki relacji zmiennych obserwowalnych z wynikiem prawdziwym są dla każdej pozycji takie same
71 Interpretacja alfa Cronbacha 1. Średnia wszystkich rzetelności połówkowych 2. Dolna granica rzetelności skali (GLB) 3. Wskaźnik nasycenia pierwszego czynnika 4. Rzetelność τ - ekwiwalentnych wskaźników 5. Uogólnienie wskaźnika rzetelności KR Miara wewnętrznej spójności skali (nie jednowymiarowości) 1. Skale jednowymiarowe mogą mieć zróżnicowaną wysokość współczynnika Cronbacha (niską) 2. Skale wielowymiarowe mogą mieć wysoką wartość współczynnika Cronbacha

72 Alfa Cronbacha
73 Poprawka na tłumienie 1. Skale o niskiej rzetelności mają niskie obserwowane korelacje nawet jeżeli prawdziwa korelacja między nimi jest wysoka (korelacja jest tłumiona przez niską rzetelność tych skal)
74 Parcels (paczkowanie) 1. Parcels (paczkowanie) suma lub średnia kilku pozycji skal jako wskaźnik zmiennej ukrytej 2. Metody tworzenia: hierarchiczna konfirmacyjna analiza czynnikowa (CFA) 1. Paczka jako czynnik 1 rzędu a zmienna ukryta jako czynnik 2 rzędu 2. Paczka jako suma najwyższych ładunków czynników 1 rzędu 3. Zalety parcelingu: 1. Wyższa rzetelność pomiaru 2. Zmniejszenie liczby wskaźników 3. Rozkład bardziej zbliżony do normalnego w przypadku skośnych rozkładów pozycji indywidualnych
75 CFA - charakter danych wejściowych 1. Macierz kowariancji teoria statystyczna SEM jest oparta na własnościach macierzy kowariancji modelowanie struktur kowariancyjnych (CSA): 1. jeżeli skala pomiaru wskaźników jest interpretowalna, 2. jeżeli model jest wielogrupowy 3. jeżeli występują relacje nieliniowe i interakcje między zmiennymi ukrytymi 2. Macierze kowariancji, w których stosunek maksymalnej do minimalnej wariancji wynosi 10 są źle wyskalowane (ill-scaled matrix?) - należy je przeskalować np. pomnożyć przez stałą 3. Zmienne są inwariantne skalowo jeżeli wartości funkcji rozbieżności są takie same niezależnie od skali pomiaru zmiennej (metoda ML)
76 CFA - charakter danych wejściowych 1. Macierz kowariancji: 1. Jeżeli model jest wolny od skali pomiaru 2. Brak inwariancji skalowej - wyniki estymacji zależą od skali pomiaru; w odtworzonej macierzy korelacji wartości na przekątnej są <1 3. Jeżeli stosowana jest właściwa estymacja statystyczna ( SEPATH Statistica): nieliniowe ograniczenia na parametry modelu w celu uzyskania modelu niezmienniczego skalowo (Browne). Wprowadzenie nieliniowych ograniczeń na parametry modelu i ograniczona optymalizacja Browna prowadzi do modelu inwariantnego skalowo. 4. jeżeli model jest jednogrupowy bez interakcji

77 Skalowanie zmiennej ukrytej
78 Identyfikacja modelu - stopnie swobody 1. Stopnie swobody = liczba danych (nieredundantnych wartości macierzy kowariancji) - liczba estymowanych parametrów modelu 2. Stopnie swobody są jak przeszkody na wyścigach konnych, im więcej stopni swobody, tym więcej ograniczeń (przeszkód) w modelu, stąd jeżeli rozwiązanie modelu jest poprawne dla większej liczby stopni swobody (przeskoczy więcej przeszkód), tym jesteśmy bardziej zadowoleni z wyniku. Rozwiązanie modelu ze stopniami swobody = 0, to bieg po prostej nigdy się nie przewrócimy (model zawsze jest idealny). (Schumacker) 3. Stopnie swobody stanowią odpowiadają stopniom falsyfikowalności modelu. Im większa liczba stopni swobody, tym większe prawdopodobieństwo falsyfikacji ; Sukces brak falsyfikacji przy dużej liczbie stopni swobody
79 Ograniczenia nałożone na parametry modelu 1. Modele nasycone: modele ze zerową liczbą stopni swobody (SS) liczba parametrów jest taka sama jak liczba danych 2. Modele nadidentyfikowane: modele z dodatnią liczbą stopni swobody. Im wyższa liczba SS, tym więcej wolnych parametrów i prostszy model brzytwa Ockhama: brak falsyfikacji modeli z dużą liczbą stopni swobody 3. Ograniczenia: 1. równości parametrów (b1 = b2) 2. równości w grupach (b1a = b1b ) 3. proporcjonalności (b1 = 2 b2) 4. nierówności (b1 >1) 5. nieliniowości (b2 = b1^2)
80 Identyfikacja modelu pomiarowego 1. Niedoidentyfikacja modelu 2. Identyfikacja: 3. Nadidentyfikacja:
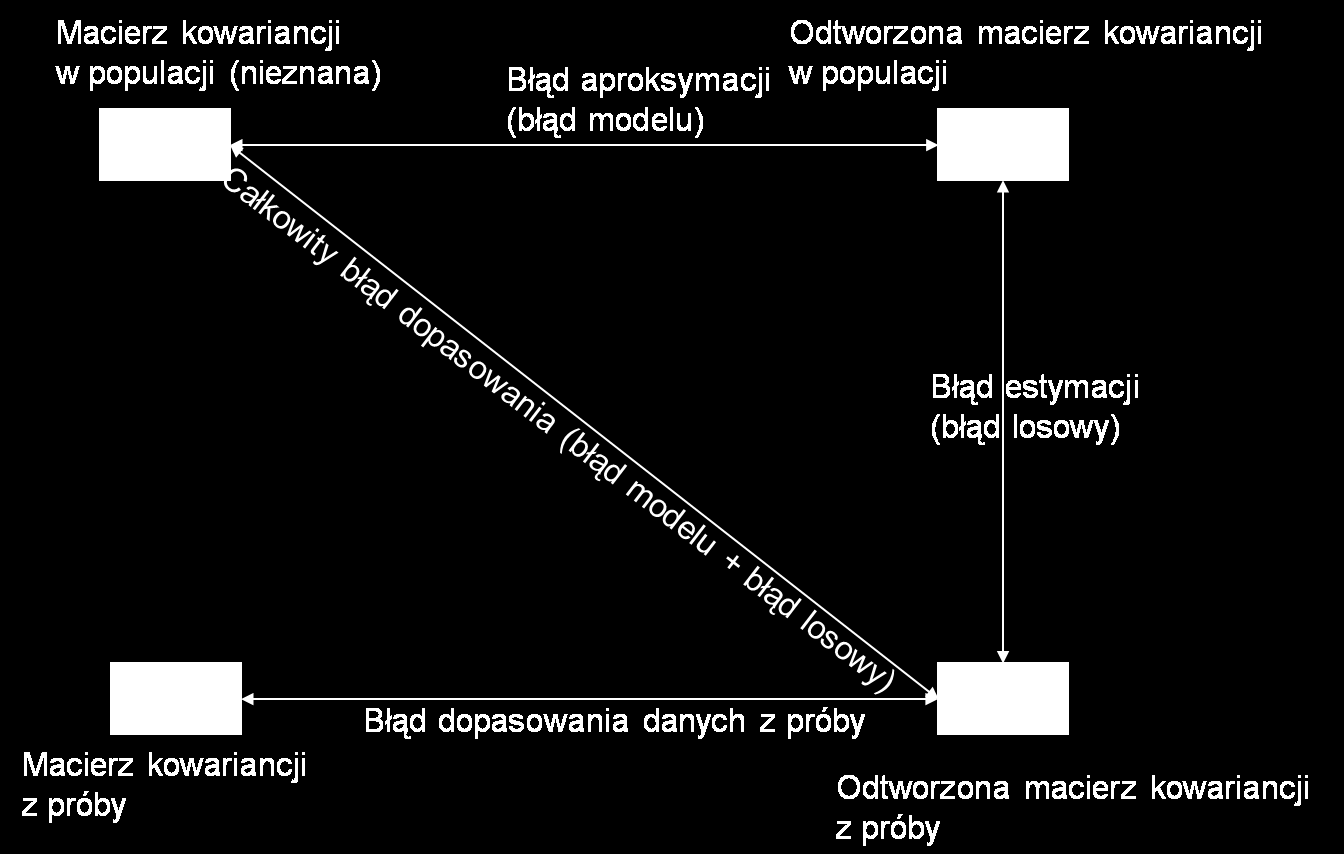
81 Estymacja modelu 1. Celem procedury jest uzyskanie szacunków parametrów, które odtwarzają macierz wariancji-kowariancji zakładaną przez model (Σ(θ)), której wartości są możliwie najbliższe wartościom macierzy wariancji-kowariancji zmiennych obserwowalnych (S). 2. Proces estymacji wykorzystuje odpowiednią funkcję rozbieżności (lub dopasowania) w celu minimalizacji różnicy między (Σ(θ)) a S
82 Dopasowanie modelu

83 Estymacja i ocena modelu

84 Proces estymacji

85 Metody estymacji
86 Dobroć dopasowania 1. Test χ2 hipotezy zerowej, że reszty standaryzowane macierzy empirycznej i teoretycznej (odtworzonej przez model) wynoszą 0, tzn., że ograniczenia nałożone na model teoretyczny są trafne 2. Założenia: 1. Zmienne obserwowane mają rozkład normalny 2. Analizowana jest macierz kowariancji 3. Próba jest duża: przy bardzo dużych próbach nasza ufność, że macierze są równe rośnie, ale istotność różnic może być niewielka; 4. Przy małych próbach nie można poprawnie diagnozować nawet dużych różnic miedzy macierzami 5. Testowane jest doskonałe dopasowanie H0 : S = Σ(θ)
87 Rozkład obserwacji odbiegający od normalnego 1. Założenie wielowymiarowego rozkładu normalnego przy estymacji ML, gdy inny rozkład (kurtoza i skośność): 1. Inflacja statystyki χ 2 (zbyt wysoka wartość) 2. Niedoszacowanie innych wskaźników dopasowania (zbyt niskie) 3. Niedoszacowanie błędów standardowych (zbyt małe - zwiększone ryzyko popełnienia błędu I rodzaju) 2. Inna metoda estymacji: (ADF/WLS/AGLS (SEPATH, AMOS, LISREL/PRELIS EQS), eliptyczna itp 3. Korekta statystyki Chi-Kwadrat (częstsze rozwiązanie): χ 2 Satorry-Bentlera z korekcyjnym czynnikiem skalującym (SCF) (MLM, MLMV Mplus, EQS) 4. Inne procedury: 1. Bootstrapping (empiryczny rozkład z dużej próby losowej) 2. Parceling (sumowanie lub uśrednianie wskaźników zmiennych ukrytych przy założeniu jednowymiarowości) 3. Transformacja danych (np. logarytmiczna przy skośności)
88 Skale Likerta 1. Traktowanie skali Likerta jako skali metrycznej (ciągłej) powoduje: 1. Tłumienie współczynnika korelacji Pearsona (jest niższy niż w przypadku odpowiedniej skali ciągłej), 2. Niedoszacowanie błędów standardowych i 3. Inflację statystyki Chi-Kwadrat gdy skala ma mniej niż 5 kategorii i pozycje mają dużą skośność (opozycyjnie zorientowaną) 2. Jeżeli rozkład odpowiedzi w skali Likerta jest zbliżony do normalnego: 1. liczba kategorii ma niewielki wpływ na dopasowanie modelu 2. ładunki czynnikowe i korelacje między czynnikami są jedynie w małym stopniu niedoszacowane 3. Statystyka Chi-Kwadrat jest najsilniej obciążona przy zastosowaniu binarnych wskaźników (skal typu tak - nie ) 4. Obciążenie parametrów jest znaczne w przypadku efektu podłogi i sufitu przy skalach Likerta (pseudoczynniki ekstremalnych odpowiedzi)
89 Dopasowanie modelu Podstawowa miara dopasowania modelu : χ2 = Fml (N-1) /LISREL/, χ2 = Fml (N) /Mplus/ - F wartość funkcji rozbieżności (suma kwadratów różnic między wejściową macierzą danych a macierzą odtworzoną przez model) N liczebność próby losowej Fml (N) ma rozkład χ2 jeżeli model jest prawidłowy i zmienne mają rozkład normalny 1. Im mniejsza wartość χ2, tym lepsze dopasowanie modelu 2. Im mniejsza wartość p tym większe prawdopodobieństwo odrzucenia Ho: S=Σ 3. Im większa próba, tym większe χ2 i prawdopodobieństwo odrzucenia Ho 4. Χ2 silnie zależy od liczebności próby 5. Założenia wielowymiarowej normalności rozkładu zmiennych nie są często spełniane
90 Dopasowanie modelu 1. Jeżeli model nie ma błędów specyfikacji, to poprawnie odtwarza macierz kowariancji w populacji, stąd: dla poprawnego modelu S = Σ(θ) i S Σ(θ) = 0 2. Jeżeli próba jest duża, to macierz kowariancji z próby S dąży asymptotycznie do macierzy kowariancji w populacji S stąd: S = Σ i S Σ = 0 3. Jeżeli model nie ma błędów specyfikacji, to wzrost próby powoduje wzrost wartości (N) i spadek (F) i tym samym znoszenie się efektów dla (N) x (F) 4. Jeżeli model ma błędy specyfikacji, to błędnie odtwarza macierz kowariancji w populacji, stąd dla niepoprawnego modelu S = Σ(θ) i S Σ(θ) 6= 0 i wzrost próby powoduje silny wzrost (N), lecz nieznaczny spadek (F) i tym samym (F) x (N) rośnie silnie wraz z N
91 Wskaźniki dopasowania modelu 1. Absolutne/resztowe: testują dopasowanie modelu do danych 2. Przyrostowe: testują dopasowanie modelu do modelu bazowego (np. zakładającego brak korelacji między zmiennymi model zerowy lub niezależny) 3. Populacyjne/niecentralne: testują stopień rozbieżności dopasowania modelu do danych populacyjnych 4. Predykcyjne: porównują dopasowanie modelu do innych ekwiwalentnych modeli (najczęściej w nich zagnieżdżonych )

92 Rodzaje wskaźników dopasowania
93 Wskaźniki absolutne 1. Wartość funkcji rozbieżności: 2. Standaryzowane c2 3. Indeks dobroci dopasowania GFI 0 brak dopasowania, 1 doskonałe dopasowanie

94 Wskaźniki przyrostowe
95 Wskaźniki populacyjne (błąd aproksymacji) 1. Średniokwadratowy pierwiastek błędu aproksymacji stopień dopasowania modelu do danych z populacji przy optymalnym doborze parametrów. 2. Pierwiastek z wskaźnika niecentralności populacji przez stopnie swobody = RMSEA 0 doskonałe dopasowanie 0.05 bliskie dopasowanie 0.08 rozsądne dopasowanie >0.1 brak dopasowania

96 Porównanie modeli 1. Modele zagnieżdżone: 1/ podzbiór modeli wynikających z danego modelu, 2/ modele o mniejszej liczbie parametrów, 3/ modele po wyeliminowaniu pewnych ścieżek z modelu podstawowego 2. Modele o mniejszej liczbie parametrów są zawsze gorsze od modeli z większą liczbą parametrów ale za to prostsze 3. Problem? O ile gorsze? Analiza istotności różnic Δ χ2 oraz różnic Δ DF
97 Wskaźniki informacyjne 1. Kryterium informacyjne Akaike 2. Bayesowskie kryterium informacyjne 3. Indeks oceny krzyżowej Browna-Cudecka
98 Parametry modelu 1. Parametry niestandaryzowane: 2. Parametry standaryzowane (wariancjami zmiennych ukrytych (M=0.00, SD=1.00, przy oryginalnej metryce wskaźników): 3. Parametry kompletnie standaryzowane (wariancjami zmiennych ukrytych i wariancjami wskaźników : M=0.00 SD=1.00): 4. Parametry kompletnie standaryzowane z kowariantami (wariancjami zmiennych ukrytych, wskaźników i kowariant ilościowych: M=0.00 SD=1.00):

99 Czynnikowa ocena rzetelności

100 Model czynnikowy a rzetelność skali
101 Teoria reakcji na pozycje (IRT) 1. Probabilistyczna teoria testu: prawdopodobieństwo reakcji na stwierdzenie jest funkcją cechy ukrytej ( zdolności ) i parametrów pozycji ( trudności ) 2. Cecha ukryta jest jednowymiarowa 3. Zasada lokalnej niezależności dla danej wartości cechy ukrytej, każda para pozycji jest statystycznie niezależna reakcje na pozycje zależą tylko od cechy ukrytej (complete latent space) P(U1,U2,...Un θ) = P(U1 θ),p(u2 θ)...p(un θ) 4. Inwariancja parametrów pozycji i osób parametry pozycji nie zależą od poziomu zdolności i parametry osób nie zależą od charakteru pozycji 5. Cecha ukryta jest szacowana na podstawie modelu

102 Teoria reakcji na pozycję
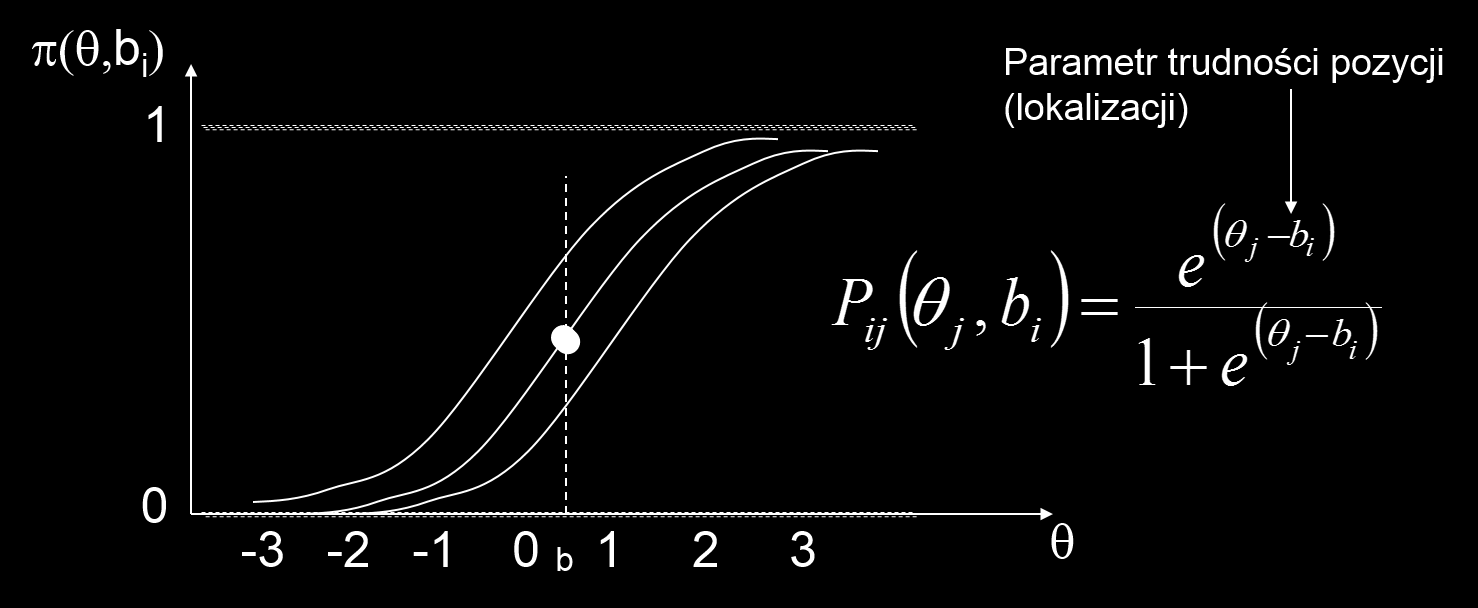
103 Model jednoparametryczny (Rascha)

104 Model dwuparametryczny (Birnbauma)

105 Model trójparametryczny (Birnbauma)
Analiza korespondencji
 Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Analiza korespondencji Kiedy stosujemy? 2 W wielu badaniach mamy do czynienia ze zmiennymi jakościowymi (nominalne i porządkowe) typu np.: płeć, wykształcenie, status palenia. Punktem wyjścia do analizy
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
MODEL POMIAROWY SATYSFAKCJI I LOJALNOŚCI
 MODEL POMIAROWY SATYSFAKCJI I LOJALNOŚCI Adam Sagan Akademia Ekonomiczna w Krakowie, Katedra Analizy Rynku i Badań Marketingowych Wstęp Zaletą stosowania konfirmacyjnej analizy czynnikowej (CFA) w porównaniu
MODEL POMIAROWY SATYSFAKCJI I LOJALNOŚCI Adam Sagan Akademia Ekonomiczna w Krakowie, Katedra Analizy Rynku i Badań Marketingowych Wstęp Zaletą stosowania konfirmacyjnej analizy czynnikowej (CFA) w porównaniu
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Psychometria PLAN NAJBLIŻSZYCH WYKŁADÓW. Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. TEN SLAJD JUŻ ZNAMY
 definicja rzetelności błąd pomiaru: systematyczny i losowy Psychometria Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. rozkład X + błąd losowy rozkład X rozkład X + błąd systematyczny
definicja rzetelności błąd pomiaru: systematyczny i losowy Psychometria Co wyniki testu mówią nam o samym teście? A. Rzetelność pomiaru testem. rozkład X + błąd losowy rozkład X rozkład X + błąd systematyczny
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
5. WNIOSKOWANIE PSYCHOMETRYCZNE
 5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
MODEL STRUKTURALNY RELACJI MIĘDZY SATYSFAKCJĄ
 MODEL STRUKTURALNY RELACJI MIĘDZY SATYSFAKCJĄ I LOJALNOŚCIĄ WOBEC MARKI Adam Sagan Akademia Ekonomiczna w Krakowie, Katedra Analizy Rynku i Badań Marketingowych Wstęp Modelowanie strukturalne ma wielorakie
MODEL STRUKTURALNY RELACJI MIĘDZY SATYSFAKCJĄ I LOJALNOŚCIĄ WOBEC MARKI Adam Sagan Akademia Ekonomiczna w Krakowie, Katedra Analizy Rynku i Badań Marketingowych Wstęp Modelowanie strukturalne ma wielorakie
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
ANALIZA CZYNNIKOWA Przykład 1
 ANALIZA CZYNNIKOWA... stanowi zespół metod i procedur statystycznych pozwalających na badanie wzajemnych relacji między dużą liczbą zmiennych i wykrywanie ukrytych uwarunkowań, ktore wyjaśniają ich występowanie.
ANALIZA CZYNNIKOWA... stanowi zespół metod i procedur statystycznych pozwalających na badanie wzajemnych relacji między dużą liczbą zmiennych i wykrywanie ukrytych uwarunkowań, ktore wyjaśniają ich występowanie.
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Zadanie 1. Za pomocą analizy rzetelności skali i wspólczynnika Alfa- Cronbacha ustalić, czy pytania ankiety stanowią jednorodny zbiór.
 L a b o r a t o r i u m S P S S S t r o n a 1 W zbiorze Pytania zamieszczono odpowiedzi 25 opiekunów dzieci w wieku 8. lat na następujące pytania 1 : P1. Dziecko nie reaguje na bieżące uwagi opiekuna gdy
L a b o r a t o r i u m S P S S S t r o n a 1 W zbiorze Pytania zamieszczono odpowiedzi 25 opiekunów dzieci w wieku 8. lat na następujące pytania 1 : P1. Dziecko nie reaguje na bieżące uwagi opiekuna gdy
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Spis treści 3 SPIS TREŚCI
 Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Spis treści 3 SPIS TREŚCI PRZEDMOWA... 1. WNIOSKOWANIE STATYSTYCZNE JAKO DYSCYPLINA MATEMATYCZNA... Metody statystyczne w analizie i prognozowaniu zjawisk ekonomicznych... Badania statystyczne podstawowe
Przedmowa Wykaz symboli Litery alfabetu greckiego wykorzystywane w podręczniku Symbole wykorzystywane w zagadnieniach teorii
 SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
Idea. Analiza składowych głównych Analiza czynnikowa Skalowanie wielowymiarowe Analiza korespondencji Wykresy obrazkowe.
 Idea (ang. Principal Components Analysis PCA) jest popularnym używanym narzędziem analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości danych. Jest to metoda nieparametryczna,
Idea (ang. Principal Components Analysis PCA) jest popularnym używanym narzędziem analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości danych. Jest to metoda nieparametryczna,
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Oszacowanie i rozkład t
 Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Oszacowanie i rozkład t Marcin Zajenkowski Marcin Zajenkowski () Oszacowanie i rozkład t 1 / 31 Oszacowanie 1 Na podstawie danych z próby szacuje się wiele wartości w populacji, np.: jakie jest poparcie
Importowanie danych do SPSS Eksportowanie rezultatów do formatu MS Word... 22
 Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Kolejna z analiz wielozmiennowych Jej celem jest eksploracja danych, poszukiwanie pewnych struktur, które mogą utworzyć wskaźniki
 Analiza czynnikowa Kolejna z analiz wielozmiennowych Jej celem jest eksploracja danych, poszukiwanie pewnych struktur, które mogą utworzyć wskaźniki Budowa wskaźnika Indeks był banalny I miał wady: o Czy
Analiza czynnikowa Kolejna z analiz wielozmiennowych Jej celem jest eksploracja danych, poszukiwanie pewnych struktur, które mogą utworzyć wskaźniki Budowa wskaźnika Indeks był banalny I miał wady: o Czy
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski
 Kamil Krzysztof Derkowski") Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Projekt zaliczeniowy z przedmiotu Statystyka i eksploracja danych (nr 3) Kamil Krzysztof Derkowski Zadanie 1 Eksploracja (EXAMINE) Informacja o analizowanych danych Obserwacje Uwzględnione Wykluczone Ogółem
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
P: Czy studiujący i niestudiujący preferują inne sklepy internetowe?
 2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice
 Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania analizy wariancji w opracowywaniu wyników badań empirycznych Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki -
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Podstawy statystyki dla psychologów. Podręcznik akademicki. Wydanie drugie poprawione. Wiesław Szymczak
 Podstawy statystyki dla psychologów. Podręcznik akademicki. Wydanie drugie poprawione. Wiesław Szymczak Autor prezentuje spójny obraz najczęściej stosowanych metod statystycznych, dodatkowo omawiając takie
Podstawy statystyki dla psychologów. Podręcznik akademicki. Wydanie drugie poprawione. Wiesław Szymczak Autor prezentuje spójny obraz najczęściej stosowanych metod statystycznych, dodatkowo omawiając takie
Współczynnik korelacji. Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ
 Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Współczynnik korelacji Współczynnik korelacji jest miernikiem zależności między dwiema cechami Oznaczenie: ϱ Własności współczynnika korelacji 1. Współczynnik korelacji jest liczbą niemianowaną 2. ϱ 1,
Prawdopodobieństwo i statystyka
 Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Wykład XV: Zagadnienia redukcji wymiaru danych 2 lutego 2015 r. Standaryzacja danych Standaryzacja danych Własności macierzy korelacji Definicja Niech X będzie zmienną losową o skończonym drugim momencie.
Wprowadzenie (1) Przedmiotem analizy czynnikowej jest badanie wewnętrznych zależności w zbiorze zmiennych. Jest to modelowanie niejawne. Oprócz zmienn
 Przedmiotem analizy czynnikowej jest badanie wewnętrznych zależności w zbiorze zmiennych. Jest to modelowanie niejawne. Oprócz zmienn") Analiza czynnikowa Wprowadzenie (1) Przedmiotem analizy czynnikowej jest badanie wewnętrznych zależności w zbiorze zmiennych. Jest to modelowanie niejawne. Oprócz zmiennych, które są bezpośrednio obserwowalne
Analiza czynnikowa Wprowadzenie (1) Przedmiotem analizy czynnikowej jest badanie wewnętrznych zależności w zbiorze zmiennych. Jest to modelowanie niejawne. Oprócz zmiennych, które są bezpośrednio obserwowalne
Zadania ze statystyki, cz.6
 Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
15. PODSUMOWANIE ZAJĘĆ
 15. PODSUMOWANIE ZAJĘĆ Efekty kształcenia: wiedza, umiejętności, kompetencje społeczne Przedmiotowe efekty kształcenia Pytania i zagadnienia egzaminacyjne EFEKTY KSZTAŁCENIA WIEDZA Wykazuje się gruntowną
15. PODSUMOWANIE ZAJĘĆ Efekty kształcenia: wiedza, umiejętności, kompetencje społeczne Przedmiotowe efekty kształcenia Pytania i zagadnienia egzaminacyjne EFEKTY KSZTAŁCENIA WIEDZA Wykazuje się gruntowną
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Statystyka i eksploracja danych
 Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
Wykład XII: Zagadnienia redukcji wymiaru danych 12 maja 2014 Definicja Niech X będzie zmienną losową o skończonym drugim momencie. Standaryzacją zmiennej X nazywamy zmienną losową Z = X EX Var (X ). Definicja
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
10. Podstawowe wskaźniki psychometryczne
 10. Podstawowe wskaźniki psychometryczne q analiza własności pozycji testowych q metody szacowania mocy dyskryminacyjnej q stronniczość pozycji testowych q własności pozycji testowych a kształt rozkładu
10. Podstawowe wskaźniki psychometryczne q analiza własności pozycji testowych q metody szacowania mocy dyskryminacyjnej q stronniczość pozycji testowych q własności pozycji testowych a kształt rozkładu
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
parametrów strukturalnych modelu = Y zmienna objaśniana, X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających,
 诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
诲 瞴瞶 瞶 ƭ0 ƭ 瞰 parametrów strukturalnych modelu Y zmienna objaśniana, = + + + + + X 1,X 2,,X k zmienne objaśniające, k zmiennych objaśniających, α 0, α 1, α 2,,α k parametry strukturalne modelu, k+1 parametrów
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Wydział Matematyki. Testy zgodności. Wykład 03
 Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia związku pomiędzy dwiema zmiennymi nominalnymi (lub porządkowymi)
 w celu sprawdzenia związku pomiędzy dwiema zmiennymi nominalnymi (lub porządkowymi)") Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia związku pomiędzy dwiema zmiennymi nominalnymi (lub porządkowymi) Czy miejsce zamieszkania różnicuje uprawianie sportu? Mieszkańcy
Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia związku pomiędzy dwiema zmiennymi nominalnymi (lub porządkowymi) Czy miejsce zamieszkania różnicuje uprawianie sportu? Mieszkańcy
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Analiza składowych głównych idea
 Analiza składowych głównych idea Analiza składowych głównych jest najczęściej używanym narzędziem eksploracyjnej analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości
Analiza składowych głównych idea Analiza składowych głównych jest najczęściej używanym narzędziem eksploracyjnej analizy danych. Na metodę tę można spojrzeć jak na pewną technikę redukcji wymiarowości
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz.8. Zadanie 1.
 Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Komputerowa Analiza Danych Doświadczalnych
 Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Komputerowa Analiza Danych Doświadczalnych Prowadząca: dr inż. Hanna Zbroszczyk e-mail: gos@if.pw.edu.pl tel: +48 22 234 58 51 konsultacje: poniedziałek, 10-11, środa: 11-12 www: http://www.if.pw.edu.pl/~gos/students/kadd
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Recenzenci: prof. dr hab. Henryk Domański dr hab. Jarosław Górniak
 Recenzenci: prof. dr hab. Henryk Domański dr hab. Jarosław Górniak Redakcja i korekta Bogdan Baran Projekt graficzny okładki Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2011 ISBN
Recenzenci: prof. dr hab. Henryk Domański dr hab. Jarosław Górniak Redakcja i korekta Bogdan Baran Projekt graficzny okładki Katarzyna Juras Copyright by Wydawnictwo Naukowe Scholar, Warszawa 2011 ISBN
Testowanie hipotez statystycznych.
 Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
Bioinformatyka Wykład 9 Wrocław, 5 grudnia 2011 Temat. Test zgodności χ 2 Pearsona. Statystyka χ 2 Pearsona Rozpatrzmy ciąg niezależnych zmiennych losowych X 1,..., X n o jednakowym dyskretnym rozkładzie
CELE ANALIZY CZYNNIKOWEJ
 ANALIZA CZYNNIKOWA... stanowi zespół metod i procedur statystycznych pozwalających na badanie wzajemnych relacji między dużą liczbą zmiennych i wykrywanie ukrytych uwarunkowań, ktore wyjaśniają ich występowanie.
ANALIZA CZYNNIKOWA... stanowi zespół metod i procedur statystycznych pozwalających na badanie wzajemnych relacji między dużą liczbą zmiennych i wykrywanie ukrytych uwarunkowań, ktore wyjaśniają ich występowanie.
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Ekonometria. Dobór postaci analitycznej, transformacja liniowa i estymacja modelu KMNK. Paweł Cibis 9 marca 2007
 , transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
, transformacja liniowa i estymacja modelu KMNK Paweł Cibis pawel@cibis.pl 9 marca 2007 1 Miary dopasowania modelu do danych empirycznych Współczynnik determinacji Współczynnik zbieżności Skorygowany R
Testowanie hipotez statystycznych
 round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
round Testowanie hipotez statystycznych Wyk lad 9 Natalia Nehrebecka Stanis law Cichocki 13 grudnia 2014 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Testowanie hipotez statystycznych Wyk lad 8 Natalia Nehrebecka Stanis law Cichocki 29 listopada 2015 Plan zajeć 1 Rozk lad estymatora b Rozk lad sumy kwadratów reszt 2 Hipotezy proste - test t Badanie
Założenia do analizy wariancji. dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW
 Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE
 STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
STATYSTYKA - PRZYKŁADOWE ZADANIA EGZAMINACYJNE 1 W trakcie badania obliczono wartości średniej (15,4), mediany (13,6) oraz dominanty (10,0). Określ typ asymetrii rozkładu. 2 Wymień 3 cechy rozkładu Gauss
Statystyczna analiza danych w programie STATISTICA (wykład 2) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
GRUPY NIEZALEŻNE Chi kwadrat Pearsona GRUPY ZALEŻNE (zmienne dwuwartościowe) McNemara Q Cochrana
 McNemara Q Cochrana") GRUPY NIEZALEŻNE Chi kwadrat Pearsona Testy stosujemy w sytuacji, kiedy zmienna zależna mierzona jest na skali nominalnej Liczba porównywanych grup (czyli liczba kategorii zmiennej niezależnej) nie ma
GRUPY NIEZALEŻNE Chi kwadrat Pearsona Testy stosujemy w sytuacji, kiedy zmienna zależna mierzona jest na skali nominalnej Liczba porównywanych grup (czyli liczba kategorii zmiennej niezależnej) nie ma
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 11-12
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
Stanisław Cichocki Natalia Nehrebecka Zajęcia 11-12 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość - Mamy 2 modele: y X u 1 1 (1) y X X 1 1 2 2 (2) - Potencjalnie
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Własności statystyczne regresji liniowej. Wykład 4
 Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Własności statystyczne regresji liniowej Wykład 4 Plan Własności zmiennych losowych Normalna regresja liniowa Własności regresji liniowej Literatura B. Hansen (2017+) Econometrics, Rozdział 5 Własności
Ekonometria. Modele regresji wielorakiej - dobór zmiennych, szacowanie. Paweł Cibis pawel@cibis.pl. 1 kwietnia 2007
 Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Modele regresji wielorakiej - dobór zmiennych, szacowanie Paweł Cibis pawel@cibis.pl 1 kwietnia 2007 1 Współczynnik zmienności Współczynnik zmienności wzory Współczynnik zmienności funkcje 2 Korelacja
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Analiza korespondencji
 Analiza korespondencji Opracował: Damian Wolański Wprowadzenie Analiza korespondencji to opisowa i eksploracyjna technika analizy tablic dwudzielczych i wielodzielczych, zawierających pewne miary charakteryzujące
Analiza korespondencji Opracował: Damian Wolański Wprowadzenie Analiza korespondencji to opisowa i eksploracyjna technika analizy tablic dwudzielczych i wielodzielczych, zawierających pewne miary charakteryzujące
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Inżynieria Środowiska. II stopień ogólnoakademicki. przedmiot podstawowy obowiązkowy polski drugi. semestr zimowy
 Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
Załącznik nr 7 do Zarządzenia Rektora nr../12 z dnia.... 2012r. KARTA MODUŁU / KARTA PRZEDMIOTU Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2017/2018 STATYSTYKA
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
Rozdział 8. Regresja. Definiowanie modelu
 Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność
Rozdział 8 Regresja Definiowanie modelu Analizę korelacji można traktować jako wstęp do analizy regresji. Jeżeli wykresy rozrzutu oraz wartości współczynników korelacji wskazują na istniejąca współzmienność