Stanisław Cichocki. Natalia Nehrebecka
|
|
|
- Maciej Biernacki
- 6 lat temu
- Przeglądów:
Transkrypt

1 Stanisław Cichocki Natalia Nehrebecka 1
 Interpretacja współczynników b) Miary dopasowania 4.")
2 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 2
3 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 3
4 - zmienne zero-jedynkowe nazywane są także zmiennymi binarnymi - dla wielu interesujących modeli ekonomicznych zmienna zależna jest zmienną zero-jedynkową - zmienna zero-jedynkowa opisuje stan w jakim znajdują się badane obiekty 4
5 - Przykład: W badaniach na danych przekrojowych dotyczących aktywności zawodowej ludności może nas interesować jakie są przyczyny bezrobocia. Zmienną objaśnianą w tym przypadku będzie status zawodowy respondenta opisany zmienną zero-jedynkową (0 nie pracuje, 1 pracuje). 5
6 - przy kodowaniu zmiennej przyjmuje się konwencję: 0 - porażka 1 - sukces - czym jest sukces a czym porażka zależy od badania 6
7 - Przykład: 0 - brak pracy, porażka 1 - wykonywanie pracy, sukces 7
8 - w modelach dla zmiennych binarnych wyjaśniamy, za pomocą zmiennych niezależnych, prawdopodobieństwa stanów - by sformułować model musimy opisać prawdopodobieństwa zdarzeń dla poszczególnych obserwacji - na największym poziomie ogólności: gdzie px ( i ) opisuje zależność prawdopodobieństwa sukcesu od wielkości zmiennych niezależnych x i 8
9 - modele dla zmiennych binarnych nie są modelami liniowymi 9
10 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 10
11 - rozpatrujemy różne formy funkcyjne dla zależności między prawdopodobieństwem sukcesu a wielkością zmiennych objaśniających - najprostszy model liniowy model prawdopodobieństwa (LPM) - p( x ) F( x ) x i i i gdzie: px ( i ) F() - prawdopodobieństwo sukcesu - dystrybuanta 11
12 - liniowy w tym sensie, że warunkowa wartość oczekiwana jest dana funkcją liniową: E y x x i i i 12
13 - zalety LPM: a) łatwy do wyestymowania b) współczynniki = efekty cząstkowe - wady LPM: a) wartości dopasowane spoza [0;1] nieinterpretowalne (prawdopodobieństwo sukcesu) b) heteroscedastyczność 13
14 - problemu z punktu a) nie da się w prosty sposób rozwiązać - w przypadku heteroscedastyczności stosujemy SUMNK lub odporne macierze wariancji i kowariancji 14
15 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 15
16 - w liniowym modelu prawdopodobieństwa interpretuje się współczynniki - interpretacja: a) dla zmiennych objaśniających ciągłych: wpływ jednostkowej zmiany zmiennej niezależnej na wielkość prawdopodobieństwa sukcesu b) dla zmiennych objaśniających zero-jedynkowych: różnica między prawdopodobieństwem sukcesu dla zmiennej zero-jedynkowej równej 0 i równej 1, przy pozostałych zmiennych ustalonych na poziomie średnich 16
17 - Przykład: Modelowano odpowiedź na pytanie: czy ubiegał się o zasiłek? Zmienna zależna y: 0 nie ubiegał się, 1 ubiegał się. Zmienne niezależne: wiek, płeć (0-kobieta, 1 mężczyzna), stan cywilny (0 - pozostałe stany, 1 zamężna/zamężny), głowa (0 nie jest głową rodziny, 1 jest głową rodziny) 17
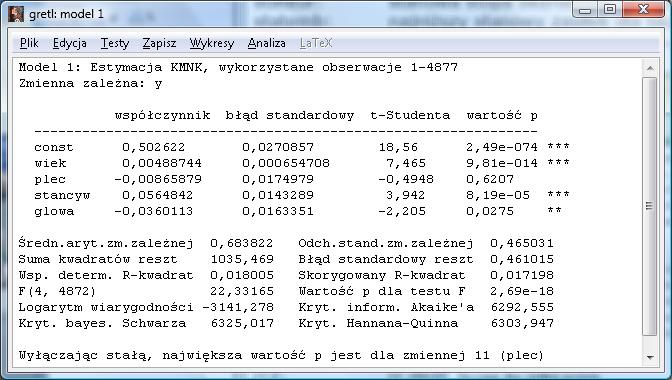
18 18
19 - interpretacja współczynników: a) wiek: wzrost wieku o rok powoduje wzrost prawdopodobieństwa ubiegania się o zasiłek o 0,4 punktu procentowego b) plec: mężczyźni mają o 0,8 punktu procentowego mniejsze prawdopodobieństwo ubiegania się o zasiłek niż kobiety c) stancyw: osoby zamężne mają o 5,6 punktów procentowych większe prawdopodobieństwo ubiegania się o zasiłek niż pozostałe osoby d) glowa: osoba będąca głową rodziny ma o 3,6 punktów procentowych mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoby nie będące głowami rodzin

20 Heteroscedastyczność 20
21 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 21
22 F() - w modelu probitowym zakładamy, że jest dystrybuantą rozkładu normalnego 22
23 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 23
24 - nie interpretuje się współczynników w modelu probitowym - interpretuje się efekty cząstkowe (krańcowe): a) dla zmiennych objaśniających ciągłych: wpływ jednostkowej zmiany zmiennej niezależnej na wielkość prawdopodobieństwa sukcesu b) dla zmiennych objaśniających zero-jedynkowych: różnica między prawdopodobieństwem sukcesu dla zmiennej zero-jedynkowej równej 0 i równej 1, przy pozostałych zmiennych ustalonych na poziomie średnich
25 - efekty cząstkowe dla zmiennych objaśniających ciągłych liczymy zwykle dla średnich wartości tych zmiennych (efekty cząstkowe zależą od wielkości zmiennych objaśniających) - znak efektu cząstkowego dla danej zmiennej jest taki sam jak znak współczynnika przy tej zmiennej - możemy zatem interpretować znaki przy współczynnikach: dodatni znak zmienna wpływa dodatnio na prawdopodobieństwo sukcesu ujemny znak zmienna wpływa ujemnie na prawdopodbieństwo sukcesu 25
26 - Przykład: Modelowano odpowiedź na pytanie: czy ubiegał się o zasiłek? Zmienna zależna y: 0 nie ubiegał się, 1 ubiegał się. Zmienne niezależne: wiek, płeć (0-kobieta, 1 mężczyzna), stan cywilny (0 - pozostałe stany, 1 zamężna/zamężny), głowa (0 nie jest głową rodziny, 1 jest głową rodziny) 26
27 27
28 - interpretacja znaków: a) wiek: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, im większy wiek tym większe prawdopodobieństwo ubiegania się o zasiłek b) plec: wpływa ujemnie na prawdopodobieństwo ubiegania się o zasiłek, mężczyźni mają mniejsze prawdopodobieństwo ubiegania się o zasiłek niż kobiety c) stancyw: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, osoby zamężne mają większe prawdopodobieństwo ubiegania się o zasiłek niż pozostałe osoby
29 d) glowa: wpływa ujemnie na prawdopodobieństwo ubiegania się o zasiłek, osoba będąca głową rodziny ma mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoby nie będące głowami rodzin e) rasa: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, osoby innych ras mają większe prawdopodobieństwo ubiegania się o zasiłek niż osoby rasy białej
30 30
31 - Interpretacja efektów cząstkowych (krańcowych) a) wiek: wzrost wieku o rok powoduje wzrost prawdopodobieństwa ubiegania się o zasiłek o 0,5 punktu procentowego b) plec: mężczyźni mają o 0,8 punktu procentowego mniejsze prawdopodobieństwo ubiegania się o zasiłek niż kobiety c) stancyw: osoby zamężne mają o 5,8 punktów procentowych większe prawdopodobieństwo ubiegania się o zasiłek niż pozostałe osoby d) glowa: osoba będąca głową rodziny ma o 3,6 punktów procentowych mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoby nie będące głowami rodzin
32 e) rasa: osoba rasy innej niż biała ma o 1,9 punktów procentowych większe prawdopodobieństwo ubiegania się o zasiłek niż osoby rasy białej


33 Łączna istotność zmiennych 33
34 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 34
35 - tablica klasyfikacyjna: y i * - analiza częstości wartości zaobserwowanych i przewidzianych - zakładamy, ze model przewiduje sukces, jeśli dopasowane z modelu prawdopodobieństwo sukcesu jest większe o progowego * prawdopodobieństwa p y i 35
36 - tablica klasyfikacyjna: Przewidywane (Predicted) 0 1 Empiryczne (Actual) 0 N 00 N 01 1 N 10 N 11 Prognozujemy porażkę i obserwujemy sukces Prognozujemy porażkę i obserwujemy porażkę 36
37 - na podstawie tablicy klasyfikacyjnej można ustalić na ile model trafnie przewiduje sukcesy i porażki - liczebnościowe R²: proporcja zdarzeń (sukcesów bądź porażek) prawidłowo przewidywanych przez model N00 N11 R 2 liczebnosciowe N00 N01 N10 N11 37
38 - wielkość liczebnościowego R² może być myląca w przypadku zmiennej binarnej można zawsze uzyskać co najmniej 50% trafności przewidywań prognozując dla wszystkich obserwacji wartość, która jest najczęściej obserwowana w próbie y i - skorygowane liczebnościowe R²: 2 N00 N11 N max R liczebnosciowe N00 N01 N10 N11 N max - Gdzie Nmax - liczba obserwacji dla zdarzenia - (sukces/porażka), którą obserwowano częściej 38
39 - skorygowane liczebnościowe R² zawsze <=1 ale >0 tylko wtedy, gdy udział prawidłowo przewidzianych zdarzeń przekracza udział zdarzenia, które było najczęściej obserwowane w próbie - skorygowane liczebnościowe R²: jest to procent prawidłowych przewidywań uzyskany poprzez zastosowanie w modelu zmiennych objaśniających 39
40 40
41 - liczebnościowe R²: R liczebnosciowe ,697 - skorygowane liczebnościowe R²: R ( ) ( ) 0,035 41
42 - tablica klasyfikacyjna może być użyta do zdefiniowania jeszcze 2 miar: a) wrażliwość prawdopodobieństwo przewidzenia sukcesu dla obserwacji, dla której zaobserwowano sukces wrazliwosc N11 N10 N11 42
43 - b) specyficzność prawdopodobieństwo przewidzenia porażki dla obserwacji, dla której zaobserwowano porażkę specyficznosc N00 N00 N01 43

44 - Przykład: 44
45 - dodatkowo: c) 1- wrażliwość prawdopodobieństwo przewidzenia porażki dla obserwacji, dla której zaobserwowano sukces 1 wrazliwosc N10 N10 N11 45
46 d) 1- specyficzność prawdopodobieństwo przewidzenia sukcesu dla obserwacji, dla której zaobserwowano porażkę 1 specyficznosc N01 N00 N01 46
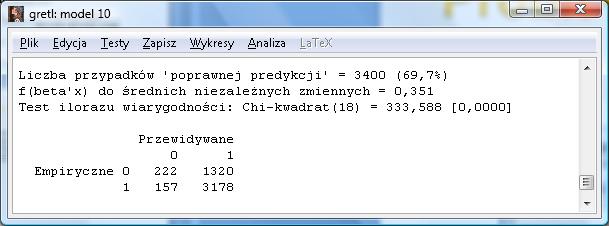
47 47
48 wrazliwosc ,95 specyficznosc , wrazliwosc 0, specyficznosc 0,
49 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 49
 F( x ) 1 e i i x i")
50 F() - w modelu logitowym zakładamy, że jest dystrybuantą rozkładu logistycznego - xi e p( x ) F( x ) 1 e i i x i 50
51 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 51
52 - nie interpretuje się współczynników w modelu probitowym - interpretuje się efekty cząstkowe (krańcowe): a) dla zmiennych objaśniających ciągłych: wpływ jednostkowej zmiany zmiennej niezależnej na wielkość prawdopodobieństwa sukcesu b) dla zmiennych objaśniających zero-jedynkowych: różnica między prawdopodobieństwem sukcesu dla zmiennej zero-jedynkowej równej 0 i równej 1, przy pozostałych zmiennych ustalonych na poziomie średnich
53 - efekty cząstkowe dla zmiennych objaśniających ciągłych liczymy zwykle dla średnich wartości tych zmiennych (efekty cząstkowe zależą od wielkości zmiennych objaśniających) - znak efektu cząstkowego dla danej zmiennej jest taki sam jak znak współczynnika przy tej zmiennej - możemy zatem interpretować znaki przy współczynnikach: dodatni znak zmienna wpływa dodatnio na prawdopodobieństwo sukcesu ujemny znak zmienna wpływa ujemnie na prawdopodbieństwo sukcesu 53
54 - Przykład: Modelowano odpowiedź na pytanie: czy ubiegał się o zasiłek? Zmienna zależna y: 0 nie ubiegał się, 1 ubiegał się. Zmienne niezależne: wiek, płeć (0-kobieta, 1 mężczyzna), stan cywilny (0 - pozostałe stany, 1 zamężna/zamężny), głowa (0 nie jest głową rodziny, 1 jest głową rodziny) 54
55 55
56 - interpretacja znaków: a) wiek: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, im większy wiek tym większe prawdopodobieństwo ubiegania się o zasiłek b) plec: wpływa ujemnie na prawdopodobieństwo ubiegania się o zasiłek, mężczyźni mają mniejsze prawdopodobieństwo ubiegania się o zasiłek niż kobiety c) stancyw: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, osoby zamężne mają większe prawdopodobieństwo ubiegania się o zasiłek niż pozostałe osoby
57 d) glowa: wpływa ujemnie na prawdopodobieństwo ubiegania się o zasiłek, osoba będąca głową rodziny ma mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoby nie będące głowami rodzin e) rasa: wpływa dodatnio na prawdopodobieństwo ubiegania się o zasiłek, osoby innych ras mają większe prawdopodobieństwo ubiegania się o zasiłek niż osoby rasy białej f) miasto: wpływa ujemnie na prawdopodobieństwo ubiegania się o zasiłek, osoby mieszkające w miastach mają mniejsze prawdopodobieństwo ubiegania się o zasiłek niż mieszkające poza miastem

58 58
59 - Interpretacja efektów cząstkowych (krańcowych) a) wiek: wzrost wieku o rok powoduje wzrost prawdopodobieństwa ubiegania się o zasiłek o 0,5 punktu procentowego b) plec: mężczyźni mają o 0,6 punktu procentowego mniejsze prawdopodobieństwo ubiegania się o zasiłek niż kobiety c) stancyw: osoby zamężne mają o 5,6 punktów procentowych większe prawdopodobieństwo ubiegania się o zasiłek niż pozostałe osoby d) glowa: osoba będąca głową rodziny ma o 3,8 punktów procentowych mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoby nie będące głowami rodzin
60 e) rasa: osoba rasy innej niż biała ma o 1,9 punktów procentowych większe prawdopodobieństwo ubiegania się o zasiłek niż osoby rasa białej e) miasto: osoba mieszkająca w mieście ma o 2,7 punktów procentowych mniejsze prawdopodobieństwo ubiegania się o zasiłek niż osoba mieszkająca poza miastem

61 Łączna istotność zmiennych 61
62 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary dopasowania 4. Logit a) Interpretacja współczynników b) Miary dopasowania 62
63 - takie same jak w modelu probitowym 63
64 1. Co jest modelowane w przypadku jeśli zmienna zależna jest zmienna binarną (zero-jedynkową)? 2. Jakie są wady liniowego modelu prawdopodobieństwa? 3. Wyjaśnić czym jest wrażliwość i specyficzność. 64
65 Dziękuję za uwagę 65
Stanisław Cichocki. Natalia Neherebecka. Zajęcia 15-17
 Stanisław Cichocki Natalia Neherebecka Zajęcia 15-17 1 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary
Stanisław Cichocki Natalia Neherebecka Zajęcia 15-17 1 1. Binarne zmienne zależne 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników 3. Probit a) Interpretacja współczynników b) Miary
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Stanisław Cichocki Natalia Nehrebecka 1 1. Wstęp a) Binarne zmienne zależne b) Interpretacja ekonomiczna c) Interpretacja współczynników 2. Liniowy model prawdopodobieństwa a) Interpretacja współczynników
Model 1: Estymacja KMNK z wykorzystaniem 4877 obserwacji Zmienna zależna: y
 Zadanie 1 Rozpatrujemy próbę 4877 pracowników fizycznych, którzy stracili prace w USA miedzy rokiem 1982 i 1991. Nie wszyscy bezrobotni, którym przysługuje świadczenie z tytułu ubezpieczenia od utraty
Zadanie 1 Rozpatrujemy próbę 4877 pracowników fizycznych, którzy stracili prace w USA miedzy rokiem 1982 i 1991. Nie wszyscy bezrobotni, którym przysługuje świadczenie z tytułu ubezpieczenia od utraty
Ekonometria. Modelowanie zmiennej jakościowej. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Modelowanie zmiennej jakościowej Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Ćwiczenia 8 Zmienna jakościowa 1 / 25 Zmienna jakościowa Zmienna ilościowa może zostać zmierzona
Ekonometria Modelowanie zmiennej jakościowej Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Ćwiczenia 8 Zmienna jakościowa 1 / 25 Zmienna jakościowa Zmienna ilościowa może zostać zmierzona
Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna
 Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
Regresja wieloraka Regresja wieloraka Ogólny problem obliczeniowy: dopasowanie linii prostej do zbioru punktów. Najprostszy przypadek - jedna zmienna zależna i jedna zmienna niezależna (można zobrazować
1. Pokaż, że estymator MNW parametru β ma postać β = nieobciążony. Znajdź estymator parametru σ 2.
 Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
Zadanie 1 Niech y t ma rozkład logarytmiczno normalny o funkcji gęstości postaci [ ] 1 f (y t ) = y exp (ln y t β ln x t ) 2 t 2πσ 2 2σ 2 Zakładamy, że x t jest nielosowe a y t są nieskorelowane w czasie.
WSTĘP DO REGRESJI LOGISTYCZNEJ. Dr Wioleta Drobik-Czwarno
 WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
WSTĘP DO REGRESJI LOGISTYCZNEJ Dr Wioleta Drobik-Czwarno REGRESJA LOGISTYCZNA Zmienna zależna jest zmienną dychotomiczną (dwustanową) przyjmuje dwie wartości, najczęściej 0 i 1 Zmienną zależną może być:
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Stanisław Cichocki. Natalia Nehrebecka. Wykład 4
 Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Stanisław Cichocki Natalia Nehrebecka Wykład 4 1 1. Własności hiperpłaszczyzny regresji 2. Dobroć dopasowania równania regresji. Współczynnik determinacji R 2 Dekompozycja wariancji zmiennej zależnej Współczynnik
Zawansowane modele wyborów dyskretnych
 Zawansowane modele wyborów dyskretnych Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Zawansowane modele wyborów dyskretnych grudzien 2013 1 / 16 Model efektów
Zawansowane modele wyborów dyskretnych Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Zawansowane modele wyborów dyskretnych grudzien 2013 1 / 16 Model efektów
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska. Anna Stankiewicz Izabela Słomska
 Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Adam Kirpsza Zastosowanie regresji logistycznej w studiach nad Unią Europejska Anna Stankiewicz Izabela Słomska Wstęp- statystyka w politologii Rzadkie stosowanie narzędzi statystycznych Pisma Karla Poppera
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
gdzie. Dla funkcja ma własności:
 Ekonometria, 21 listopada 2011 r. Modele ściśle nieliniowe Funkcja logistyczna należy do modeli ściśle nieliniowych względem parametrów. Jest to funkcja jednej zmiennej, zwykle czasu (t). Dla t>0 wartośd
Ekonometria, 21 listopada 2011 r. Modele ściśle nieliniowe Funkcja logistyczna należy do modeli ściśle nieliniowych względem parametrów. Jest to funkcja jednej zmiennej, zwykle czasu (t). Dla t>0 wartośd
Stanisław Cichocki. Natalia Nehrebecka. Wykład 14
 Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Współliniowość 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji Metody radzenia sobie z heteroskedastycznością
Stanisław Cichocki Natalia Nehrebecka Wykład 14 1 1.Problemy z danymi Współliniowość 2. Heteroskedastyczność i autokorelacja Konsekwencje heteroskedastyczności i autokorelacji Metody radzenia sobie z heteroskedastycznością
Natalia Nehrebecka Stanisław Cichocki. Wykład 6
 Natalia Nehrebecka Stanisław Cichocki Wykład 6 1 1. Zmienne dyskretne Zmienne zero-jedynkowe 2. Modele z interakcjami 2 Zmienne dyskretne Zmienne nominalne Zmienne uporządkowane 3 4 1 podstawowe i 0 podstawowe
Natalia Nehrebecka Stanisław Cichocki Wykład 6 1 1. Zmienne dyskretne Zmienne zero-jedynkowe 2. Modele z interakcjami 2 Zmienne dyskretne Zmienne nominalne Zmienne uporządkowane 3 4 1 podstawowe i 0 podstawowe
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Stanisław Cichocki Natalia Nehrebecka. Wykład 7
 Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki Natalia Nehrebecka Wykład 7 1 1. Metoda Największej Wiarygodności MNW 2. Założenia MNW 3. Własności estymatorów MNW 4. Testowanie hipotez w MNW 2 1. Metoda Największej Wiarygodności
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka - adres mailowy: scichocki@o2.pl - strona internetowa: www.wne.uw.edu.pl/scichocki - dyżur: po zajęciach lub po umówieniu mailowo - 80% oceny: egzaminy - 20% oceny:
Stanisław Cichocki Natalia Nehrebecka - adres mailowy: scichocki@o2.pl - strona internetowa: www.wne.uw.edu.pl/scichocki - dyżur: po zajęciach lub po umówieniu mailowo - 80% oceny: egzaminy - 20% oceny:
Stanisław Cichocki. Natalia Nehrebecka. Wykład 12
 Stanisław Cichocki Natalia Nehrebecka Wykład 12 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne 2. Autokorelacja o Testowanie autokorelacji 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne
Stanisław Cichocki Natalia Nehrebecka Wykład 12 1 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne 2. Autokorelacja o Testowanie autokorelacji 1.Problemy z danymi Zmienne pominięte Zmienne nieistotne
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka - adres mailowy: nnehrebecka@wne.uw.edu.pl - strona internetowa: www.wne.uw.edu.pl/nnehrebecka - dyżur: wtorek 18.30-19.30 sala 302 lub 303 - 80% oceny: egzaminy -
Stanisław Cichocki Natalia Nehrebecka - adres mailowy: nnehrebecka@wne.uw.edu.pl - strona internetowa: www.wne.uw.edu.pl/nnehrebecka - dyżur: wtorek 18.30-19.30 sala 302 lub 303 - 80% oceny: egzaminy -
PODSTAWOWE ROZKŁADY PRAWDOPODOBIEŃSTWA. Piotr Wiącek
 PODSTAWOWE ROZKŁADY PRAWDOPODOBIEŃSTWA Piotr Wiącek ROZKŁAD PRAWDOPODOBIEŃSTWA Jest to miara probabilistyczna określona na σ-ciele podzbiorów borelowskich pewnej przestrzeni metrycznej. σ-ciało podzbiorów
PODSTAWOWE ROZKŁADY PRAWDOPODOBIEŃSTWA Piotr Wiącek ROZKŁAD PRAWDOPODOBIEŃSTWA Jest to miara probabilistyczna określona na σ-ciele podzbiorów borelowskich pewnej przestrzeni metrycznej. σ-ciało podzbiorów
Stanisław Cichocki Natalia Nehrebecka. Zajęcia 8
 Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Stanisław Cichocki Natalia Nehrebecka Zajęcia 8 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia.
 Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia. D A R I U S Z P I W C Z Y Ń S K I 2 2 ROZKŁAD ZMIENNEJ LOSOWEJ Polega na przyporządkowaniu
Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia. D A R I U S Z P I W C Z Y Ń S K I 2 2 ROZKŁAD ZMIENNEJ LOSOWEJ Polega na przyporządkowaniu
Mikroekonometria 12. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
Mikroekonometria 12 Mikołaj Czajkowski Wiktor Budziński Dane panelowe Co jeśli mamy do dyspozycji dane panelowe? Kilka obserwacji od tych samych respondentów, w różnych punktach czasu (np. ankieta realizowana
Wnioskowanie statystyczne Weryfikacja hipotez. Statystyka
 Wnioskowanie statystyczne Weryfikacja hipotez Statystyka Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
Wnioskowanie statystyczne Weryfikacja hipotez Statystyka Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
Biostatystyka, # 3 /Weterynaria I/
 Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Biostatystyka, # 3 /Weterynaria I/ dr n. mat. Zdzisław Otachel Uniwersytet Przyrodniczy w Lublinie Katedra Zastosowań Matematyki i Informatyki ul. Głęboka 28, p. 221 bud. CIW, e-mail: zdzislaw.otachel@up.lublin.pl
Natalia Nehrebecka Stanisław Cichocki. Wykład 13
 Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Natalia Nehrebecka Stanisław Cichocki Wykład 13 1 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje nietypowe i błędne 4. Współliniowość 2 1. Zmienne pominięte 2. Zmienne nieistotne 3. Obserwacje
Mikroekonometria 14. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 14 Mikołaj Czajkowski Wiktor Budziński Symulacje Analogicznie jak w przypadku ciągłej zmiennej zależnej można wykorzystać metody Monte Carlo do analizy różnego rodzaju problemów w modelach
Mikroekonometria 14 Mikołaj Czajkowski Wiktor Budziński Symulacje Analogicznie jak w przypadku ciągłej zmiennej zależnej można wykorzystać metody Monte Carlo do analizy różnego rodzaju problemów w modelach
WERYFIKACJA MODELI MODELE LINIOWE. Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno
 WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
WERYFIKACJA MODELI MODELE LINIOWE Biomatematyka wykład 8 Dr Wioleta Drobik-Czwarno ANALIZA KORELACJI LINIOWEJ to NIE JEST badanie związku przyczynowo-skutkowego, Badanie współwystępowania cech (czy istnieje
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Natalia Neherbecka. 11 czerwca 2010
 Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Natalia Neherbecka 11 czerwca 2010 1 1. Konsekwencje heteroskedastyczności i autokorelacji 2. Uogólniona MNK 3. Stosowalna Uogólniona MNK 4. Odporne macierze wariancji i kowariancji b 2 1. Konsekwencje
Stanisław Cichocki. Natalia Neherbecka. Zajęcia 13
 Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki Natalia Neherbecka Zajęcia 13 1 1. Kryteria informacyjne 2. Testowanie autokorelacji 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Stanisław Cichocki Natalia Nehrebecka 1 2 3 1. Wprowadzenie do danych panelowych a) Charakterystyka danych panelowych b) Zalety i ograniczenia 2. Modele ekonometryczne danych panelowych a) Model efektów
Regresja liniowa wprowadzenie
 Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Regresja liniowa wprowadzenie a) Model regresji liniowej ma postać: gdzie jest zmienną objaśnianą (zależną); są zmiennymi objaśniającymi (niezależnymi); natomiast są parametrami modelu. jest składnikiem
Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego. Łukasz Kończyk WMS AGH
 Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego Łukasz Kończyk WMS AGH Plan prezentacji Model regresji liniowej Uogólniony model liniowy (GLM) Ryzyko ubezpieczeniowe Przykład
Zastosowanie modelu regresji logistycznej w ocenie ryzyka ubezpieczeniowego Łukasz Kończyk WMS AGH Plan prezentacji Model regresji liniowej Uogólniony model liniowy (GLM) Ryzyko ubezpieczeniowe Przykład
Dwuczynnikowa ANOVA dla prób niezależnych w schemacie 2x2
 Dwuczynnikowa ANOVA dla prób niezależnych w schemacie 2x2 Poniżej prezentujemy przykładowe pytania z rozwiązaniami dotyczącymi dwuczynnikowej analizy wariancji w schemacie 2x2. Wszystkie rozwiązania są
Dwuczynnikowa ANOVA dla prób niezależnych w schemacie 2x2 Poniżej prezentujemy przykładowe pytania z rozwiązaniami dotyczącymi dwuczynnikowej analizy wariancji w schemacie 2x2. Wszystkie rozwiązania są
Wybór formy funkcyjnej modelu (cz. II)
") Wybór formy funkcyjnej modelu (cz. II) Wyk lad 6 Natalia Nehrebecka Stanis law Cichocki 19 listopada 2014 Plan zaj eć 1 w modelu liniowym w modelu logliniowym i semielastyczność - przyk lad 2 Zastosowania
Wybór formy funkcyjnej modelu (cz. II) Wyk lad 6 Natalia Nehrebecka Stanis law Cichocki 19 listopada 2014 Plan zaj eć 1 w modelu liniowym w modelu logliniowym i semielastyczność - przyk lad 2 Zastosowania
Statystyka. Wykład 8. Magdalena Alama-Bućko. 23 kwietnia Magdalena Alama-Bućko Statystyka 23 kwietnia / 38
 Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 23 kwietnia 2017 Magdalena Alama-Bućko Statystyka 23 kwietnia 2017 1 / 38 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
ANALIZA REGRESJI SPSS
 NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
NLIZ REGRESJI SPSS Metody badań geografii społeczno-ekonomicznej KORELCJ REGRESJ O ile celem korelacji jest zmierzenie siły związku liniowego między (najczęściej dwoma) zmiennymi, o tyle w regresji związek
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Stanisław Cichocki. Natalia Nehrebecka Katarzyna Rosiak-Lada
 Stanisław Cichocki Natalia Nehrebecka Katarzyna Rosiak-Lada 1. Sprawy organizacyjne Zasady zaliczenia 2. Czym zajmuje się ekonometria? 3. Formy danych statystycznych 4. Model ekonometryczny 2 1. Sprawy
Stanisław Cichocki Natalia Nehrebecka Katarzyna Rosiak-Lada 1. Sprawy organizacyjne Zasady zaliczenia 2. Czym zajmuje się ekonometria? 3. Formy danych statystycznych 4. Model ekonometryczny 2 1. Sprawy
Wybrane rozkłady zmiennych losowych. Statystyka
 Wybrane rozkłady zmiennych losowych Statystyka Rozkład dwupunktowy Zmienna losowa przyjmuje tylko dwie wartości: wartość 1 z prawdopodobieństwem p i wartość 0 z prawdopodobieństwem 1- p x i p i 0 1-p 1
Wybrane rozkłady zmiennych losowych Statystyka Rozkład dwupunktowy Zmienna losowa przyjmuje tylko dwie wartości: wartość 1 z prawdopodobieństwem p i wartość 0 z prawdopodobieństwem 1- p x i p i 0 1-p 1
Zadanie 1. a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1
 Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1") Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Zadanie 1 a) Przeprowadzono test RESET. Czy model ma poprawną formę funkcyjną? 1 b) W naszym przypadku populacja są inżynierowie w Tajlandii. Czy można jednak przypuszczać, że na zarobki kobiet-inżynierów
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna
 Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Wielowymiarowa analiza regresji. Regresja wieloraka, wielokrotna Badanie współzależności zmiennych Uwzględniając ilość zmiennych otrzymamy 4 odmiany zależności: Zmienna zależna jednowymiarowa oraz jedna
Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb
 Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Współzależność Załóżmy, że obserwujemy nie jedną lecz dwie cechy, które oznaczymy symbolami X i Y. Wyniki obserwacji obu cech w i-tym obiekcie oznaczymy parą liczb (x i, y i ). Geometrycznie taką parę
Analiza współzależności zjawisk. dr Marta Kuc-Czarnecka
 Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
Analiza współzależności zjawisk dr Marta Kuc-Czarnecka Wprowadzenie Prawidłowości statystyczne mają swoje przyczyny, w związku z tym dla poznania całokształtu badanego zjawiska potrzebna jest analiza z
1.6 Zmienne jakościowe i dyskretne w modelu regresji
 1.6 Zmienne jakościowe i dyskretne w modelu regresji 1.6.1 Zmienne dyskretne i zero-jedynkowe (Dummy Variables) W badaniach ekonometrycznych bardzo często występują zjawiska, które opisujemy zmiennymi
1.6 Zmienne jakościowe i dyskretne w modelu regresji 1.6.1 Zmienne dyskretne i zero-jedynkowe (Dummy Variables) W badaniach ekonometrycznych bardzo często występują zjawiska, które opisujemy zmiennymi
Uogolnione modele liniowe
 Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Uogolnione modele liniowe Jerzy Mycielski Uniwersytet Warszawski grudzien 2013 Jerzy Mycielski (Uniwersytet Warszawski) Uogolnione modele liniowe grudzien 2013 1 / 17 (generalized linear model - glm) Zakładamy,
Statystyka. Wykład 7. Magdalena Alama-Bućko. 3 kwietnia Magdalena Alama-Bućko Statystyka 3 kwietnia / 36
 Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 7 Magdalena Alama-Bućko 3 kwietnia 2017 Magdalena Alama-Bućko Statystyka 3 kwietnia 2017 1 / 36 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
METODY BADAŃ NA ZWIERZĘTACH ze STATYSTYKĄ wykład 3-4. Parametry i wybrane rozkłady zmiennych losowych
 METODY BADAŃ NA ZWIERZĘTACH ze STATYSTYKĄ wykład - Parametry i wybrane rozkłady zmiennych losowych Parametry zmiennej losowej EX wartość oczekiwana D X wariancja DX odchylenie standardowe inne, np. kwantyle,
METODY BADAŃ NA ZWIERZĘTACH ze STATYSTYKĄ wykład - Parametry i wybrane rozkłady zmiennych losowych Parametry zmiennej losowej EX wartość oczekiwana D X wariancja DX odchylenie standardowe inne, np. kwantyle,
Rozdział 1. Wektory losowe. 1.1 Wektor losowy i jego rozkład
 Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Rozdział 1 Wektory losowe 1.1 Wektor losowy i jego rozkład Definicja 1 Wektor X = (X 1,..., X n ), którego każda współrzędna jest zmienną losową, nazywamy n-wymiarowym wektorem losowym (krótko wektorem
Wybrane rozkłady zmiennych losowych. Statystyka
 Wybrane rozkłady zmiennych losowych Statystyka Rozkład dwupunktowy Zmienna losowa przyjmuje tylko dwie wartości: wartość 1 z prawdopodobieństwem p i wartość 0 z prawdopodobieństwem 1- p x i p i 0 1-p 1
Wybrane rozkłady zmiennych losowych Statystyka Rozkład dwupunktowy Zmienna losowa przyjmuje tylko dwie wartości: wartość 1 z prawdopodobieństwem p i wartość 0 z prawdopodobieństwem 1- p x i p i 0 1-p 1
Stanisław Cichocki. Natalia Nehrebecka
 Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Stanisław Cichocki Natalia Nehrebecka 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów 5. Testowanie
Egzamin z ekonometrii wersja IiE, MSEMAT
 Egzamin z ekonometrii wersja IiE, MSEMAT 04-02-2016 Pytania teoretyczne 1. Za pomocą jakiego testu weryfikowana jest normalność składnika losowego? Jakiemu założeniu KMRL odpowiada w tym teście? Jakie
Egzamin z ekonometrii wersja IiE, MSEMAT 04-02-2016 Pytania teoretyczne 1. Za pomocą jakiego testu weryfikowana jest normalność składnika losowego? Jakiemu założeniu KMRL odpowiada w tym teście? Jakie
Modelowanie zależności. Matematyczne podstawy teorii ryzyka i ich zastosowanie R. Łochowski
 Modelowanie zależności pomiędzy zmiennymi losowymi Matematyczne podstawy teorii ryzyka i ich zastosowanie R. Łochowski P Zmienne losowe niezależne - przypomnienie Dwie rzeczywiste zmienne losowe X i Y
Modelowanie zależności pomiędzy zmiennymi losowymi Matematyczne podstawy teorii ryzyka i ich zastosowanie R. Łochowski P Zmienne losowe niezależne - przypomnienie Dwie rzeczywiste zmienne losowe X i Y
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Statystyka matematyczna
 Statystyka matematyczna Wykład 6 Magdalena Alama-Bućko 8 kwietnia 019 Magdalena Alama-Bućko Statystyka matematyczna 8 kwietnia 019 1 / 1 Rozkłady ciagłe Magdalena Alama-Bućko Statystyka matematyczna 8
Statystyka matematyczna Wykład 6 Magdalena Alama-Bućko 8 kwietnia 019 Magdalena Alama-Bućko Statystyka matematyczna 8 kwietnia 019 1 / 1 Rozkłady ciagłe Magdalena Alama-Bućko Statystyka matematyczna 8
Wyk lad 3. Natalia Nehrebecka Dariusz Szymański. 13 kwietnia, 2010
 Wyk lad 3 Natalia Nehrebecka Dariusz Szymański 13 kwietnia, 2010 N. Nehrebecka, D.Szymański Plan zaj eć 1 Sprowadzenie modelu nieliniowego do liniowego 2 w modelu liniowym Elastyczność Semielastyczność
Wyk lad 3 Natalia Nehrebecka Dariusz Szymański 13 kwietnia, 2010 N. Nehrebecka, D.Szymański Plan zaj eć 1 Sprowadzenie modelu nieliniowego do liniowego 2 w modelu liniowym Elastyczność Semielastyczność
Wprowadzenie do teorii ekonometrii. Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe
 Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Wprowadzenie do teorii ekonometrii Wykład 1 Warunkowa wartość oczekiwana i odwzorowanie liniowe Zajęcia Wykład Laboratorium komputerowe 2 Zaliczenie EGZAMIN (50%) Na egzaminie obowiązują wszystkie informacje
Stanisław Cihcocki. Natalia Nehrebecka
 Stanisław Cihcocki Natalia Nehrebecka 1 1. Kryteria informacyjne 2. Testowanie autokorelacji w modelu 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych opóźnieniach
Stanisław Cihcocki Natalia Nehrebecka 1 1. Kryteria informacyjne 2. Testowanie autokorelacji w modelu 3. Modele dynamiczne: modele o rozłożonych opóźnieniach (DL) modele autoregresyjne o rozłożonych opóźnieniach
Statystyka I. Regresja dla zmiennej jakościowej - wykład dodatkowy (nieobowiązkowy)
") Statystyka I Regresja dla zmiennej jakościowej - wykład dodatkowy (nieobowiązkowy) 1 Zmienne jakościowe qzmienne jakościowe niemierzalne kategorie: np. pracujący / bezrobotny qzmienna binarna Y=0,1 qczasami
Statystyka I Regresja dla zmiennej jakościowej - wykład dodatkowy (nieobowiązkowy) 1 Zmienne jakościowe qzmienne jakościowe niemierzalne kategorie: np. pracujący / bezrobotny qzmienna binarna Y=0,1 qczasami
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
3. Modele tendencji czasowej w prognozowaniu
 II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
II Modele tendencji czasowej w prognozowaniu 1 Składniki szeregu czasowego W teorii szeregów czasowych wyróżnia się zwykle następujące składowe szeregu czasowego: a) składowa systematyczna; b) składowa
Ekonometria Ćwiczenia 19/01/05
 Oszacowano regresję stopy bezrobocia (unemp) na wzroście realnego PKB (pkb) i stopie inflacji (cpi) oraz na zmiennych zero-jedynkowych związanymi z kwartałami (season). Regresję przeprowadzono na danych
Oszacowano regresję stopy bezrobocia (unemp) na wzroście realnego PKB (pkb) i stopie inflacji (cpi) oraz na zmiennych zero-jedynkowych związanymi z kwartałami (season). Regresję przeprowadzono na danych
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych:
 W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
W rachunku prawdopodobieństwa wyróżniamy dwie zasadnicze grupy rozkładów zmiennych losowych: Zmienne losowe skokowe (dyskretne) przyjmujące co najwyżej przeliczalnie wiele wartości Zmienne losowe ciągłe
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
Etapy modelowania ekonometrycznego
 Etapy modelowania ekonometrycznego jest podstawowym narzędziem badawczym, jakim posługuje się ekonometria. Stanowi on matematyczno-statystyczną formę zapisu prawidłowości statystycznej w zakresie rozkładu,
Etapy modelowania ekonometrycznego jest podstawowym narzędziem badawczym, jakim posługuje się ekonometria. Stanowi on matematyczno-statystyczną formę zapisu prawidłowości statystycznej w zakresie rozkładu,
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ
 REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ Korelacja oznacza fakt współzależności zmiennych, czyli istnienie powiązania pomiędzy nimi. Siłę i kierunek powiązania określa się za pomocą współczynnika korelacji
PODSTAWY STATYSTYCZNEJ ANALIZY DANYCH
 Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
Wykład 3 Liniowe metody klasyfikacji. Wprowadzenie do klasyfikacji pod nadzorem. Fisherowska dyskryminacja liniowa. Wprowadzenie do klasyfikacji pod nadzorem. Klasyfikacja pod nadzorem Klasyfikacja jest
REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ. Analiza regresji i korelacji
 Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Statystyka i opracowanie danych Ćwiczenia 5 Izabela Olejarczyk - Wożeńska AGH, WIMiIP, KISIM REGRESJA I KORELACJA MODEL REGRESJI LINIOWEJ MODEL REGRESJI WIELORAKIEJ MODEL REGRESJI LINIOWEJ Analiza regresji
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
STUDIA I STOPNIA EGZAMIN Z EKONOMETRII
 NAZWISKO IMIĘ Nr albumu Nr zestawu Zadanie 1. Dana jest macierz Leontiefa pewnego zamkniętego trzygałęziowego układu gospodarczego: 0,64 0,3 0,3 0,6 0,88 0,. 0,4 0,8 0,85 W okresie t stosunek zuŝycia środków
NAZWISKO IMIĘ Nr albumu Nr zestawu Zadanie 1. Dana jest macierz Leontiefa pewnego zamkniętego trzygałęziowego układu gospodarczego: 0,64 0,3 0,3 0,6 0,88 0,. 0,4 0,8 0,85 W okresie t stosunek zuŝycia środków
Przykład 1 W przypadku jednokrotnego rzutu kostką przestrzeń zdarzeń elementarnych
 Rozdział 1 Zmienne losowe, ich rozkłady i charakterystyki 1.1 Definicja zmiennej losowej Niech Ω będzie przestrzenią zdarzeń elementarnych. Definicja 1 Rodzinę S zdarzeń losowych (zbiór S podzbiorów zbioru
Rozdział 1 Zmienne losowe, ich rozkłady i charakterystyki 1.1 Definicja zmiennej losowej Niech Ω będzie przestrzenią zdarzeń elementarnych. Definicja 1 Rodzinę S zdarzeń losowych (zbiór S podzbiorów zbioru
Statystyka matematyczna dla kierunku Rolnictwo w SGGW. BADANIE WSPÓŁZALEśNOŚCI DWÓCH CECH. ANALIZA KORELACJI PROSTEJ.
 BADANIE WSPÓŁZALEśNOŚCI DWÓCH CECH. ANALIZA KORELACJI PROSTEJ. IDEA OPISU WSPÓŁZALEśNOŚCI CECH X, Y cechy obserwowane w doświadczeniu, n liczba jednostek doświadczalnych, Wyniki doświadczenia: wartości
BADANIE WSPÓŁZALEśNOŚCI DWÓCH CECH. ANALIZA KORELACJI PROSTEJ. IDEA OPISU WSPÓŁZALEśNOŚCI CECH X, Y cechy obserwowane w doświadczeniu, n liczba jednostek doświadczalnych, Wyniki doświadczenia: wartości
Metodologia badań psychologicznych. Wykład 12. Korelacje
 Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Wykład 12. Korelacje Korelacja Korelacja występuje wtedy gdy dwie różne miary dotyczące tych samych osób, zdarzeń lub obiektów
Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Wykład 12. Korelacje Korelacja Korelacja występuje wtedy gdy dwie różne miary dotyczące tych samych osób, zdarzeń lub obiektów
Wyk lad 5. Natalia Nehrebecka Stanis law Cichocki. 7 listopada 2015
 Wyk lad 5 Natalia Nehrebecka Stanis law Cichocki 7 listopada 2015 N. Nehrebecka Plan zaj eć 1 Sprowadzenie modelu nieliniowego do liniowego 2 w modelu liniowym Elastyczność w modelu logliniowym Semielastyczność
Wyk lad 5 Natalia Nehrebecka Stanis law Cichocki 7 listopada 2015 N. Nehrebecka Plan zaj eć 1 Sprowadzenie modelu nieliniowego do liniowego 2 w modelu liniowym Elastyczność w modelu logliniowym Semielastyczność
Ćwiczenia 3 ROZKŁAD ZMIENNEJ LOSOWEJ JEDNOWYMIAROWEJ
 Ćwiczenia 3 ROZKŁAD ZMIENNEJ LOSOWEJ JEDNOWYMIAROWEJ Zadanie 1. Zmienna losowa przyjmuje wartości -1, 0, 1 z prawdopodobieństwami równymi odpowiednio: ¼, ½, ¼. Należy: a. Wyznaczyć rozkład prawdopodobieństwa
Ćwiczenia 3 ROZKŁAD ZMIENNEJ LOSOWEJ JEDNOWYMIAROWEJ Zadanie 1. Zmienna losowa przyjmuje wartości -1, 0, 1 z prawdopodobieństwami równymi odpowiednio: ¼, ½, ¼. Należy: a. Wyznaczyć rozkład prawdopodobieństwa
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja) założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)
 założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)") PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
Mikroekonometria 9. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 9 Mikołaj Czajkowski Wiktor Budziński Wielomianowy model logitowy Uogólnienie modelu binarnego Wybór pomiędzy 2 lub większą liczbą alternatyw Np. wybór środka transportu, głos w wyborach,
Mikroekonometria 9 Mikołaj Czajkowski Wiktor Budziński Wielomianowy model logitowy Uogólnienie modelu binarnego Wybór pomiędzy 2 lub większą liczbą alternatyw Np. wybór środka transportu, głos w wyborach,
Przykład 2. Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku
 Przykład 2 Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku Sondaż sieciowy analiza wyników badania sondażowego dotyczącego motywacji w drodze do sukcesu Cel badania: uzyskanie
Przykład 2 Na podstawie książki J. Kowal: Metody statystyczne w badaniach sondażowych rynku Sondaż sieciowy analiza wyników badania sondażowego dotyczącego motywacji w drodze do sukcesu Cel badania: uzyskanie
Na A (n) rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)
 rozważamy rozkład P (n) , który na zbiorach postaci A 1... A n określa się jako P (n) (X n, A (n), P (n)") MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
MODELE STATYSTYCZNE Punktem wyjścia w rozumowaniu statystycznym jest zmienna losowa (cecha) X i jej obserwacje opisujące wyniki doświadczeń bądź pomiarów. Zbiór wartości zmiennej losowej X (zbiór wartości
Mikroekonometria 13. Mikołaj Czajkowski Wiktor Budziński
 Mikroekonometria 13 Mikołaj Czajkowski Wiktor Budziński Endogeniczność regresja liniowa W regresji liniowej estymujemy następujące równanie: i i i Metoda Najmniejszych Kwadratów zakłada, że wszystkie zmienne
Mikroekonometria 13 Mikołaj Czajkowski Wiktor Budziński Endogeniczność regresja liniowa W regresji liniowej estymujemy następujące równanie: i i i Metoda Najmniejszych Kwadratów zakłada, że wszystkie zmienne
Binarne zmienne zależne
 Binarne zmienne zależne Zmienna zależna nie jest ciagła ale przyjmuje zero lub jeden Przykład: szukanie determinant bezrobocia (próba przekrojowa) zmienna objaśniana: zerojedynkowa (pracujacy, bezrobotny)
Binarne zmienne zależne Zmienna zależna nie jest ciagła ale przyjmuje zero lub jeden Przykład: szukanie determinant bezrobocia (próba przekrojowa) zmienna objaśniana: zerojedynkowa (pracujacy, bezrobotny)
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji.
 Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
Ćwiczenie: Wybrane zagadnienia z korelacji i regresji. W statystyce stopień zależności między cechami można wyrazić wg następującej skali: Skala Guillforda Przedział Zależność Współczynnik [0,00±0,20)
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Uogólniony model liniowy
 Uogólniony model liniowy Ogólny model liniowy y = Xb + e Każda obserwacja ma rozkład normalny Każda obserwacja ma tą samą wariancję Dane nienormalne Rozkład binomialny np. liczba chorych krów w stadzie
Uogólniony model liniowy Ogólny model liniowy y = Xb + e Każda obserwacja ma rozkład normalny Każda obserwacja ma tą samą wariancję Dane nienormalne Rozkład binomialny np. liczba chorych krów w stadzie
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Ekonometria. Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych. Jakub Mućk. Katedra Ekonomii Ilościowej
 Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
Ekonometria Prognozowanie ekonometryczne, ocena stabilności oszacowań parametrów strukturalnych Jakub Mućk Katedra Ekonomii Ilościowej Jakub Mućk Ekonometria Wykład 4 Prognozowanie, stabilność 1 / 17 Agenda
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
TEST STATYSTYCZNY. Jeżeli hipotezę zerową odrzucimy na danym poziomie istotności, to odrzucimy ją na każdym większym poziomie istotności.
 TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
TEST STATYSTYCZNY Testem statystycznym nazywamy regułę postępowania rozstrzygająca, przy jakich wynikach z próby hipotezę sprawdzaną H 0 należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
Natalia Nehrebecka Stanisław Cichocki. Wykład 10
 Natalia Nehrebecka Stanisław Cichocki Wykład 10 1 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Natalia Nehrebecka Stanisław Cichocki Wykład 10 1 1. Testy diagnostyczne 2. Testowanie prawidłowości formy funkcyjnej modelu 3. Testowanie normalności składników losowych 4. Testowanie stabilności parametrów
Rozkłady dwóch zmiennych losowych
 Rozkłady dwóch zmiennych losowych Uogólnienie pojęć na rozkład dwóch zmiennych Dystrybuanta i gęstość prawdopodobieństwa Rozkład brzegowy Prawdopodobieństwo warunkowe Wartości średnie i odchylenia standardowe
Rozkłady dwóch zmiennych losowych Uogólnienie pojęć na rozkład dwóch zmiennych Dystrybuanta i gęstość prawdopodobieństwa Rozkład brzegowy Prawdopodobieństwo warunkowe Wartości średnie i odchylenia standardowe