Eksploracja Danych. Projekt zaliczeniowy. Marek Lewandowski inf59817
|
|
|
- Ludwika Leśniak
- 9 lat temu
- Przeglądów:
Transkrypt
1 Eksploracja Danych Projekt zaliczeniowy Marek Lewandowski inf59817

2 Spis treści: 1 Zadanie Zadanie Zadanie Zadanie Zadanie Zadanie Zadanie k- Means O Cluster: Zadanie Zadanie Zadanie

3 1 Zadanie 1. Wybierając atrybuty, w których poszukiwałem osobliwości, koncentrowałem się na atrybutach numerycznych, których zakres zmienności określony był jako ciągły. Sądzę, iż tylko w przypadku tych atrybutów jest sens analizy histogramów pod kątem wartości średnich i zakresu atrybutu. Do usuwania osobliwości wybrałem następujące atrybuty: AHRSPAY, DIVVAL, CAPGAIN, CAPLOSS. Są to atrybuty numeryczne, ciągłe. Wartości średnie dla tych atrybutów mogą być mylące, ponieważ zdecydowana większość wartości wymienionych atrybutów to 0 (dla AHRSPAY: , DIVVAL: , CAPGAIN: , CAPLOSS: ). Czy zatem jako osobliwości należy traktować wartości, które są niezerowe? Wniosek taki nasuwa się po analizie histogramów:

4

5 Do oznaczania osobliwości użyłem następujących metod: - dla atrybutu AHRSPAY użyłem opcji value jako min określając 0, a max Odchylenie standardowe było w przypadku tego atrybutu względnie niskie (258,42), a liczba wartości z zakresu duża (ponad czterokrotnie większa niż liczba wszystkich wartości większych niż 1300). Dlatego wartości AHRSPAY większe niż 1300 uznałem za właściwe osobliwości. - dla atrybutów DIVVAL, CAPGAIN i CAPLOSS zastosowałem metodę odchyleń standardowych, która jako osobliwości potraktowała wartości różniące się od średniej o więcej niż trzykrotność odchylenia standardowego. Z histogramów widać, że jako osobliwości zostaną potraktowane tylko wartości wyraźnie różniące się od średniej (bardzo zaburzające wartość średnią a co za tym idzie i odchylenie standardowe). Każdorazowo jako wartości zastępujące (Replace with) wskazywałem wartości graniczne (edge values). Sądzę, iż użycie wartości pustych (NULL) spowodowałoby utratę informacji o wielu wartościach, co mogłoby stanowić zafałszowanie porównywalne z występowaniem osobliwości w danych. Histogramy po operacji wyznaczenia osobliwości wyglądają następująco:

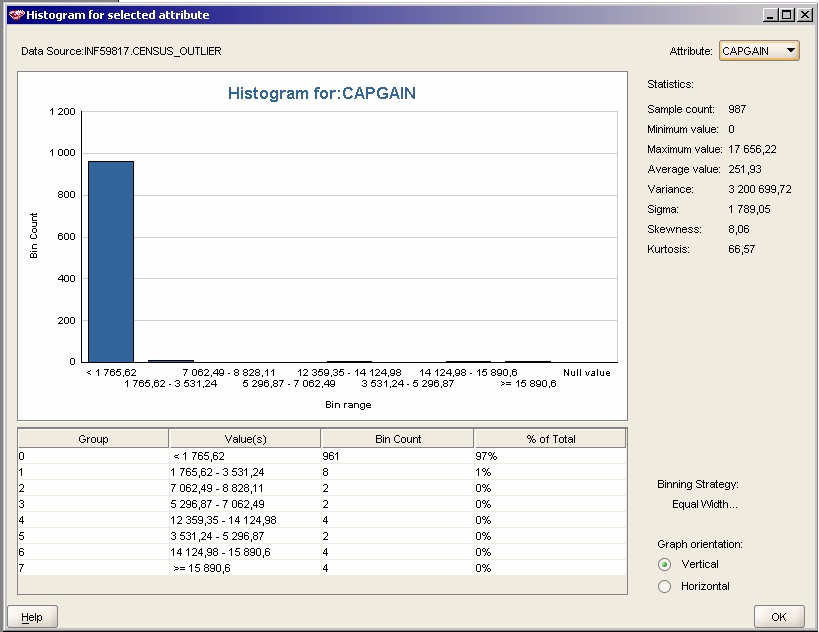
6
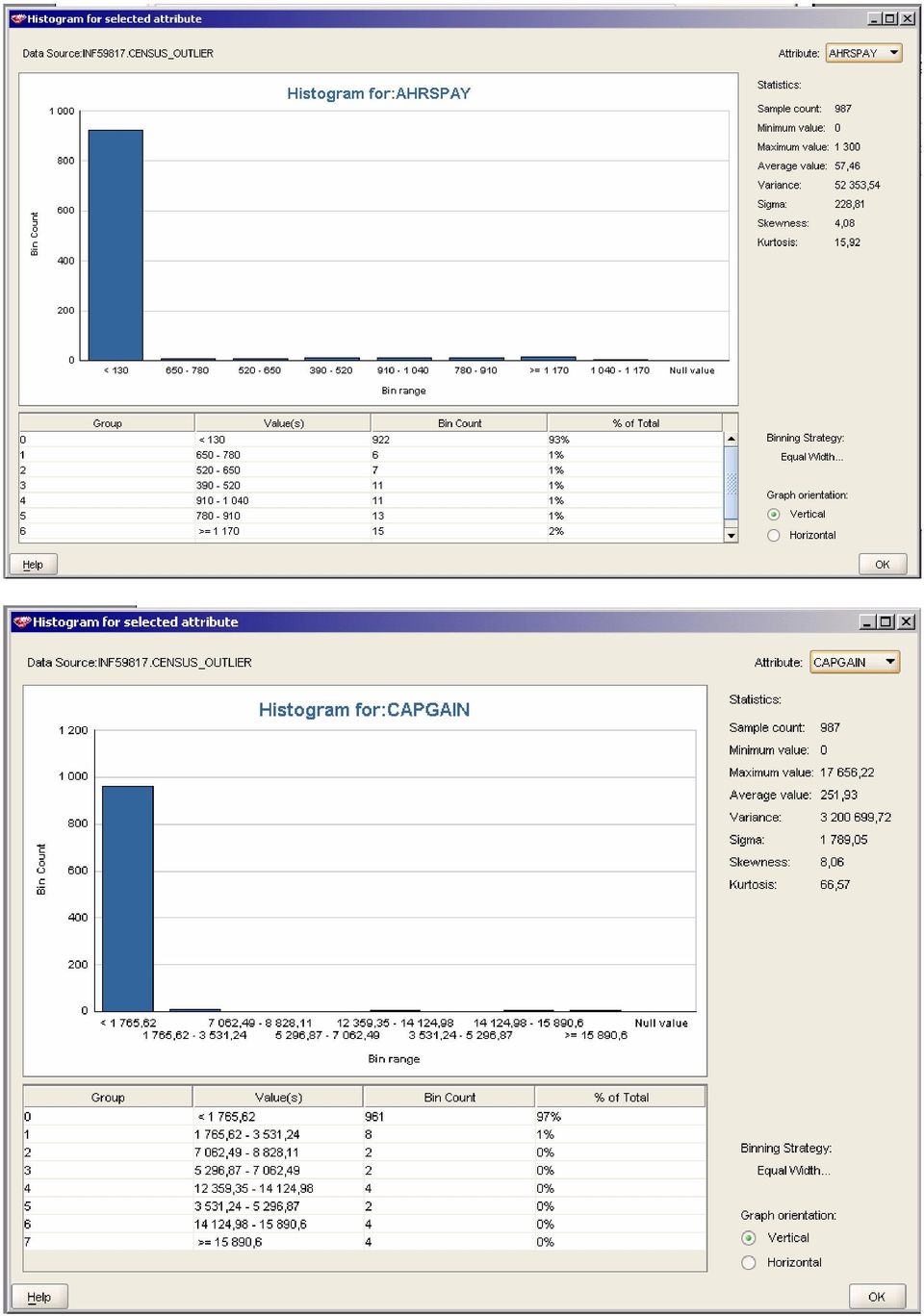
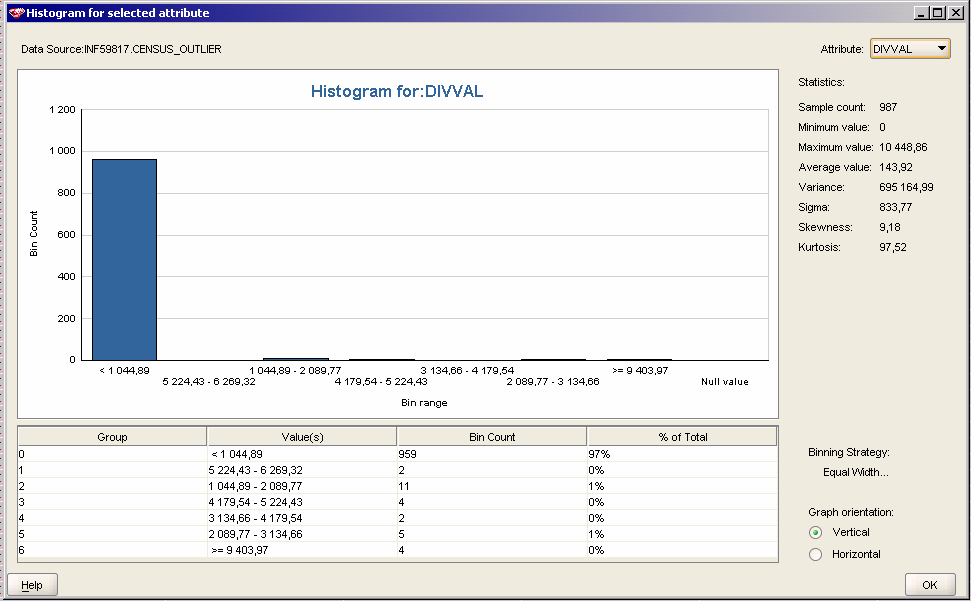
7

8 2 Zadanie 2. Obsługa brakujących wartości Atrybuty zawierające brakujące wartości to: GRINST, MIGMTR1, MIGMTR3, MIGMTR4, MIGSUN, PEMNTVTY, PENATVTY Atrybut Wartość dominująca Zamiana GRINST Not in universe Tak MIGMTR1? Tak MIGMTR3? Tak MIGMTR4? Tak MIGSUN? Tak PENATVTY United States Tak PEMTVTY United States Tak PEFNTVTY United States Tak Wszystkie wartości? dla wszystkich atrybutów udało się zamienić na Not in universe. Zamiany dokonałem za pomocą opcji Recode funkcji Transform menu kontekstowego perspektywy powstałej w wyniku wykonania polecenia do zadania 1.

9 3 Zadanie 3 Do normalizacji wybrałem następujące atrybuty numeryczne: WKSWORK, NOEMP, MARSUWPT, CAPLOSS, CAPGAIN, AHRSPAY, DIVVAL. Jako metodę normalizacji wybrałem skalowanie liniowe, gdzie jako nową wartość maksymalną podałem 1, a nową wartość minimalną 0. Wybierając tę metodę normalizacji sugerowałem się wielkościami średnich i odchyleń standardowych danych. Poza tym większość wartości normalizowanych atrybutów miała wartość 0 (podczas normalizacji metodą skalowania odchyleń standardowych wartości, które oryginalnie wynosiły 0, zmieniały się na wartości ujemne, co powodowało, że uzyskane w wyniku takiej normalizacji rezultaty były mało intuicyjne). W census-income.names atrybut MARSUWPT oznaczony jest jako ignore. Skoro jednak określa on względną wagę instancji reprezentowanej przez każdy wiersz, zatem normalizacja tego atrybutu nie spowoduje żadnej szkody w danych. 4 Zadanie 4 Do dyskretyzacji atrybutów numerycznych wybrałem atrybuty AAGE. Sądzę, że wiek jest idealnym kandydatem do dyskretyzacji (proponuję przedziały o równej szerokości). Dyskretyzacja atrybutów ADTIND, ADTOCC mimo iż pozornie łatwa do przeprowadzenia, nie miałaby większego sensu, chyba że format kodów ADTIND i ADTOCC posiada ukryte informacje (np. w prefiksie datailed industry code zawarta jest informacja o rodzaju przemysłu), założyłem jednak, że tak nie jest. Wybrałem dyskretyzację equal width dla automatycznie obliczonych szerokości przedziałów (co 9 lat). Uważam, że taki podział umożliwi łatwiejszą analizę danych pod kątem poszczególnych grup wiekowych.

10 Histogram przed dyskretyzacją: Histogram po dyskretyzacji:

11 5 Zadanie 5. Poniżej znajduje się kod tworzący perspektywę zawierającą dane po dyskretyzacji, zarówno dla polecenia z zadania 4 jak i 5: SELECT ( CASE WHEN "AAGE" < 9 THEN 1 WHEN "AAGE" >= 9 AND "AAGE" < 18 THEN 2 WHEN "AAGE" >= 18 AND "AAGE" < 27 THEN 3 WHEN "AAGE" >= 27 AND "AAGE" < 36 THEN 4 WHEN "AAGE" >= 36 AND "AAGE" < 45 THEN 5 WHEN "AAGE" >= 45 AND "AAGE" < 54 THEN 6 WHEN "AAGE" >= 54 AND "AAGE" < 63 THEN 7 WHEN "AAGE" >= 63 AND "AAGE" < 72 THEN 8 WHEN "AAGE" >= 72 AND "AAGE" < 81 THEN 9 WHEN "AAGE" >= 81 THEN 10 else null end) "AAGE", "ACLSWKR", "ADTIND", "ADTOCC", "AHGA", "AHRSPAY", "AHSCOL", DECODE ("AMARITL",'Married-A F spouse present','1','married-civilian spouse present','1','married-spouse absent','1',null,null,'2') "AMARITL", "AMJIND", "AMJOCC", "ARACE", "AREORGN", "ASEX", "AUNMEM", "AUNTYPE", "AWKSTAT", "CAPGAIN", "CAPLOSS", "DIVVAL", "FEDTAX", "GRINREG", "GRINST", "HHDFMX", "HHDREL", "INCOME", "MARSUPWT", "MIGMTR1", "MIGMTR3", "MIGMTR4", "MIGSAME", "MIGSUN", "NOEMP", "PARENT", "PEFNTVTY", "PEMNTVTY", "PENATVTY", "PRCITSHP", "SEOTR", "VETQVA", "VETYN", "WKSWORK", "YEAR" FROM "INF59817"."CENSUS_NORMALIZE"
 \"AAGE\", \"ACLSWKR\", \"ADTIND\", \"ADTOCC\", \"AHGA\", \"AHRSPAY\", \"AHSCOL\",")
12 Histogram przed dyskretyzacją: Histogram po dyskretyzacji:

13 6 Zadanie 6 Procedurę określania ważności atrybutów przeprowadziłem z i bez dyskretyzacji atrybutów. Wyniki procedury określania ważności atrybutów dla dyskretyzacji atrybutów numerycznych metodą Quantile Binning i Equal Width Binning nie różniły się znacząco. Krok dyskretyzacja wyłączony: Atrybut Ważność ADTOCC AHGA AMJOCC YEAR GRINST AHRSPAY

14 Krok dyskretyzacja włączony: Atrybut Ważność AHGA AMJOCC AMJIND AHRSPAY 0 WKSWORK 0 GRINST Ujawniły się znaczące różnice w ważności atrybutów w przypadku przeprowadzania procedury określania ważności z dyskretyzacją atrybutów i bez niej. Jednak w obu rankingach wysoko (pierwsza trójka rankingu) zajmuje atrybut AHGA oraz AMJOCC, a nisko AHRSPAY i GRINST (ostatnia trójka). Widać zatem, że atrybut AHGA dosyć czysto klasyfikuje poszczególne krotki: select count(*), income, amjocc from census group by income, amjocc order by amjocc;
 zajmuje atrybut AHGA oraz AMJOCC, a nisko AHRSPAY i GRINST (ostatnia trójka).")
15 Można zatem przyjąć, że niezależnie od szczegółów przeprowadzania klasyfikacji ważności atrybutów, najważniejszymi są: AHGA i AMJOCC, a najmniej ważnymi: GRINST i AHRSPAY. Wpływ na ranking może jednak mieć też liczba różnych wartości poszczególnych atrybutów, która w przypadku AHGA i AMJOCC jest względnie niska. Uzyskany wynik jest zgodny z intuicją. Najważniejsze atrybuty określają poziom wykształcenia i zajmowane stanowisko. Znikoma ważność atrybutów określających liczbę godzin pracy i zarobek uzyskiwany w przeliczeniu na jedną godzinę, może być tłumaczona jako brak danych (trudno uważać zarobek równy 0 jako rzeczywiste dane). 7 Zadanie k- Means Mimo wielu prób nie udało mi się idealnie zbilansować rozkładu instancji pomiędzy skupienia. W każdym eksperymencie jedno ze skupień gromadziło 50% instancji (cluster 3 na rysunku poniżej). Dla 3 skupień i 5 iteracji uzyskałem podział: 50% - 25% - 25%. W miarę zwiększania liczby skupień, malała liczebność klastrów o wyższych id, przy niezmienionej liczebności klastrów o niskich id (zauważalna była tendencja do dążenia do rozkładu: 50% - 25% - 13% - ).

16 Do bliższej analizy postanowiłem wybrać klaster o id = 4 spośród klastrów wyłonionych podczas podziału na 5 skupień w 6 iteracjach. Cecha skupienia Wartość Liczebność Confidence (%) Support Do omawianego skupienia należą dane spełniające poniższy warunek: AAGE <= 9.1 and AAGE >= 1.0 and ACLSWKR in (Not in universe) and ADTIND <= and ADTIND >= 0.0 and ADTOCC <= and ADTOCC >= 0.0 and AHGA in (10th grade, 11th grade, 7th and 8th grade, 9th grade, Children, High school graduate, Some college but no degree) and AHRSPAY <= and AHRSPAY >= 0.0 and AHSCOL in (Not in universe) and AMARITL in (2.0) and AMJIND in (Not in universe or children) and AMJOCC in (Not in universe) and ARACE in (Black, White) and AREORGN in (All other, Mexican-American) and ASEX in (Female, Male) and AUNMEM in (Not in universe) and AUNTYPE in (Not in universe) and AWKSTAT in (Children or Armed Forces) and CAPGAIN <= and CAPGAIN >= 0.0 and CAPLOSS <= and CAPLOSS >= 0.0 and DIVVAL <= and DIVVAL >= 0.0 and FEDTAX in (Nonfiler) and GRINREG in (Not in universe) and GRINST in (California, Not in universe, Utah) and HHDFMX in (Child 18+ never marr Not in a subfamily, Child <18 never marr not in subfamily, Grandchild <18 never marr child of subfamily RP, Householder, Nonfamily householder, Other Rel 18+ ever marr not in subfamily, Secondary individual) and
 and AHRSPAY <= 0.05500000000000001 and AHRSPAY >= 0.")
17 HHDREL in (Child under 18 never married, Householder, Other relative of householder) and INCOME in ( ) and MIGMTR1 in (MSA to MSA, Nonmover) and MIGMTR3 in (Nonmover, Same county) and MIGMTR4 in (Nonmover, Same county) and MIGSAME in (Yes) and MIGSUN in (Not in universe) and NOEMP <= 0.1 and NOEMP >= 0.0 and PARENT in (Both parents present, Mother only present, Not in universe) and PEFNTVTY in (Mexico, 'Not in universe', Puerto-Rico, United-States) and PEMNTVTY in (Mexico, 'Not in universe', Puerto-Rico, United-States) and PENATVTY in (Mexico, United-States) and PRCITSHP in (Native- Born in the United States) and SEOTR in (0.0) and VETQVA in (Not in universe) and VETYN in (0.0,2.0) and WKSWORK <= 0.1 and WKSWORK >= 0.0 and YEAR in (94.0) Poniżej znajduje się tabela wartości środkowych (centroid value) dla każdego atrybutu wybranego przeze mnie skupienia: AAGE ACLSWKR Not in universe ADTIND ADTOCC AHGA Children AHRSPAY E-5 AHSCOL Not in universe AMARITL 2 AMJIND Not in universe or children AMJOCC Not in universe ARACE White AREORGN All other ASEX Female AUNMEM Not in universe AUNTYPE Not in universe AWKSTAT Children or Armed Forces CAPGAIN E-4 CAPLOSS E-5 DIVVAL E-4 FEDTAX Nonfiler GRINREG Not in universe GRINST Not in universe HHDFMX Child <18 never marr not in subfamily HHDREL Child under 18 never married INCOME MIGMTR1 Nonmover MIGMTR3 Nonmover MIGMTR4 Nonmover MIGSAME Yes MIGSUN Not in universe NOEMP PARENT Both parents present PEFNTVTY United-States PEMNTVTY United-States PENATVTY United-States PRCITSHP Native- Born in the United States SEOTR 0 VETQVA Not in universe VETYN 0 WKSWORK YEAR 94
 and PENATVTY in (Mexico, United-States) and PRCITSHP in (Native- Born in the United States) and SEOTR in (0.0) and VETQVA in (Not in universe) and VETYN in (0.0,2.")
18 Na podstawie przeanalizowanych histogramów zakładam, że do wybranego przeze mnie skupienia należą osoby spełniające poniższe warunki: - wiek: do 27 lat (73% instancji w skupieniu ma mniej niż 27 lat) - wykształcenie: children lub high school graduate (łącznie 72% instancji) - płaca na godzinę: bardzo niska płaca, lub jej brak (99% instancji) - stan cywilny: brak współmałżonka (99% instancji przypisanych do kategorii 2 z zadania 5) - major industry code (branża zatrudnienia?): Not in universe or children (99% instancji) - rasa: biała (80% instancji) - typ pracy: children or armed forces (co za opcja...) (99% instancji) - dywidendy oraz zyski i straty na giełdzie: bardzo niskie, lub zerowe. - grupa podatkowa: nonfiler (91% instancji) - status rodzinny: dziecko poniżej 18 roku życia, stan wolny, nie w podrodzinie (66% instancji) - zmiana miejsca zamieszkania: nie (81% instancji) - ten sam dom od zeszłego roku: tak (81% instancji) - miejsce urodzenia rodziców: USA (matki: 80%, ojcowie: 79%) - miejsce urodzenia: USA (92%) Można zatem przyjąć, że sklasyfikowana przez to skupienie grupa ludzi to dzieci (lub młodzież), urodzonych w USA, których oboje rodzice pochodzą z USA. Są to osoby należące do rasy białej, nigdzie niepracujące, niegrające na giełdzie, niebędące w związku małżeńskim. Osobnicy ci maja niskie wykształcenie (najprawdopodobniej są w trakcie edukacji) i w ciągu ostatniego roku nie zmienili miejsca zamieszkania. 7.2 O Cluster: W zaawansowanych ustawieniach podczas definicji zadania podałem liczbę skupień równą 5 (aby uzyskać zgodność z wynikami z poprzedniej części zadania). Algorytm podzielił wejściowy zbiór danych na 5 skupień (przy zastosowaniu domyślnej liczby skupień <10> uzyskałem 10 klastórw). Łatwo zauważyć, że algorytm O Cluster podzielił dane na zbiory o bardzo zbliżonej liczności.
: Not in universe or children (99% instancji) - rasa: biała (80% instancji) - typ pracy: children or armed forces (co za opcja.")
19 Skupienie, które odpowiada klastrowi o id 4 z pierwszej części zadania to skupienie o id = 6. Poniżej znajduje się tabela wartości środkowych (centroid value) dla każdego z atrybutów z klastra o id = 6: AAGE 2.5 ACLSWKR Not in universe ADTIND ADTOCC AHGA Children AHRSPAY AHSCOL Not in universe AMARITL 2 AMJIND Not in universe or children AMJOCC Not in universe ARACE White AREORGN All other ASEX Male AUNMEM Not in universe AUNTYPE Not in universe AWKSTAT Children or Armed Forces CAPGAIN DIVVAL FEDTAX Nonfiler GRINREG Not in universe GRINST Not in universe HHDFMX Child <18 never marr not in subfamily HHDREL Child under 18 never married INCOME MIGMTR1 'Not in universe' MIGMTR3 'Not in universe' MIGMTR4 'Not in universe' MIGSAME Not in universe under 1 year old MIGSUN 'Not in universe' NOEMP PARENT Both parents present PEFNTVTY United-States PEMNTVTY United-States PENATVTY United-States PRCITSHP Native- Born in the United States SEOTR 0 VETQVA Not in universe VETYN 0 WKSWORK YEAR 94 Do tego skupienia należą instancje spełniające poniższy warunek: AAGE <= 3.0 and AAGE >= 1.0 and ACLSWKR equal (Not in universe) and ADTIND = E-45 and ADTOCC = E-45 and AHGA in (10th grade, 9th grade, Children, High school graduate, Some college but no degree) and AHRSPAY = E-45 and AHSCOL equal (Not in universe) and AMARITL = 2.0 and AMJIND equal (Not in universe or children) and AMJOCC equal (Not in universe) and ARACE in (Black, White) and AREORGN in (All other, Mexican-American) and ASEX in (Female, Male) and AUNMEM equal (Not in universe) and AUNTYPE equal (Not in universe) and AWKSTAT in (Children or Armed Forces, Not in labor force) and CAPGAIN = E-45 and

20 DIVVAL = E-45 and FEDTAX equal (Nonfiler) and GRINREG equal (Not in universe) and GRINST equal (Not in universe) and HHDFMX in (Child 18+ never marr Not in a subfamily, Child <18 never marr not in subfamily) and HHDREL in (Child 18 or older, Child under 18 never married) and INCOME equal ( ) and MIGMTR1 in (MSA to MSA, Nonmover, 'Not in universe') and MIGMTR3 in (Nonmover, 'Not in universe') and MIGMTR4 in (Nonmover, 'Not in universe', Same county) and MIGSAME in (Not in universe under 1 year old, Yes) and MIGSUN in ('Not in universe', Not in universe) and NOEMP = E-45 and PARENT in (Both parents present, Mother only present) and PEFNTVTY in (Mexico, 'Not in universe', Puerto-Rico, United-States) and PEMNTVTY in (Mexico, 'Not in universe', Puerto-Rico, United-States) and PENATVTY in (Mexico, United-States) and PRCITSHP equal (Native- Born in the United States) and SEOTR = 0.0 and VETQVA equal (Not in universe) and VETYN in (0.0,2.0) and WKSWORK = E-45 and YEAR in (94.0,95.0) Nie ma znaczących różnic pomiędzy powyższym skupieniem, a tym analizowanym w pierwszej części zadania. Skupienie odnalezione przez algorytm O Cluster różni się od skupienia znalezionego przez k Means dla kilku wartości środkowych (m.in. tych dotyczących historii przeprowadzek w ostatnim roku oraz płci), jednak z histogramów widać, iż różnice, między aktualnymi wartościami środkowymi a wartościami, które są na drugim miejscu pod względem procentowego udziału (a dla danych wynikowych algorytmu k-means są wartościami środkowymi), są nieznaczne. Wiersze puste w tabeli wartości środkowych dla poszczególnych atrybutów, powinny być wypełnione wartościami 0 lub bardzo do nich zbliżonymi. Prawdopodobnie precyzja wyniku, bądź jego długość przekraczały przewidziane dla nich miejsce w tabeli:
 and MIGMTR1 in (MSA to MSA, Nonmover, 'Not in universe') and MIGMTR3 in (Nonmover, 'Not in universe') and MIGMTR4 in (Nonmover, 'Not in universe', Same county) and MIGSAME in (Not in universe under")
21 8 Zadanie 8 Algorytm NNMF znalazł 41 cech. Do porównania z cechami znalezionymi przez k Means / O Cluster wybrałem cechę 26: Wyniki posortowałem malejąco według tabeli współczynników Coefficient. Sądzę, iż wybrana przeze mnie cecha odpowiada skupieniom odnalezionym i analizowanym w zadaniu 7: cecha posiada najwyższe współczynniki dla atrybutów i przyjmowanych przez nich będących niejako wyznacznikami skupień znalezionych zarówno przez k Means jak i O Cluster (przede wszystkim atrybuty określające miejsce urodzenia, pochodzenie, historię zmian miejsc zamieszkania, rasę, grupę podatkową, wykształcenie, pozycję w rodzinie, stan cywilny, itd.).
22 9 Zadanie 9 W skład modelu włączyłem następujące atrybuty: AMJOCC, PENATVTY, AHGA, HHDREL, SEOTR, PRCITSHP, AMARITL, ARACE, ASEX, AWKSTAT, FEDTAX, HHDFMX, AAGE, NOEMP, CAPGAIN. Wybrałem atrybuty, które nie przyjmowały, lub przyjmowały mało wartości Not in universe. Jako parametry singleton threshold i pairwise threshold przyjąłem 0. Macierz pomyłek:
23 Macierz kosztów: 10 Zadanie 10 W skład budowy modelu włączyłem takie same atrybuty jak w zadaniu 9 (AMJOCC, PENATVTY, AHGA, HHDREL, SEOTR, PRCITSHP, AMARITL, ARACE, ASEX, AWKSTAT, FEDTAX, HHDFMX, AAGE, NOEMP, CAPGAIN). Parametry budowy drzewa decyzyjnego wyglądały następująco: - metryka: Gini - maksymalna głębokość: 9 - minimalna liczba rekordów w wierzchołku: 5 - minimalny procent rekordów w wierzchołku: 0,01 - minimalna liczba rekordów dla podziału: 10 - minimalny procent rekordów dla podziału: 0,1 Zauważyłem, że poprawność klasyfikatora jest w znacznym stopniu uzależniona od maksymalnej głębokości drzewa (wzrost poprawności o 400% <29 punktów procentowych> dla głębokości 9 w stosunku do głębokości 8). Niestety system nie pozwolił na przeprowadzenie eksperymentu dla maksymalnej głębokości większej niż 9 (błąd związany z brakiem zasobów pamięciowych).
24 Po zbudowaniu modelu uzyskałem następujące wyniki: Macierz pomyłek:
25 Po zastosowaniu modelu do danych z tabeli CENSUS_TEST: a) wynik klasyfikacji wg rosnącego prawdopodobieństwa: b) wynik klasyfikacji wg malejącego prawdopodobieństwa:
26 Macierz kosztów:
projekt zaliczeniowy Eksploracja Danych
 Ostaszewski Paweł [55566] Piła, 22.02.2006 projekt zaliczeniowy Eksploracja Danych 1. Obejrzyj histogramy dla wszystkich atrybutów, na podstawie wartości średniej i zakresu wartości oceń, dla których atrybutów
Ostaszewski Paweł [55566] Piła, 22.02.2006 projekt zaliczeniowy Eksploracja Danych 1. Obejrzyj histogramy dla wszystkich atrybutów, na podstawie wartości średniej i zakresu wartości oceń, dla których atrybutów
Laboratorium 10. Odkrywanie cech i algorytm Non-Negative Matrix Factorization.
 Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6. Indukcja drzew decyzyjnych.
 Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
SQL (ang. Structured Query Language)
") SQL (ang. Structured Query Language) SELECT pobranie danych z bazy, INSERT umieszczenie danych w bazie, UPDATE zmiana danych, DELETE usunięcie danych z bazy. Rozkaz INSERT Rozkaz insert dodaje nowe wiersze
SQL (ang. Structured Query Language) SELECT pobranie danych z bazy, INSERT umieszczenie danych w bazie, UPDATE zmiana danych, DELETE usunięcie danych z bazy. Rozkaz INSERT Rozkaz insert dodaje nowe wiersze
Laboratorium 12. Odkrywanie osobliwości.
 Laboratorium 12 Odkrywanie osobliwości. Odkrywanie osobliwości (ang. outliers) za pomocą algorytmu SVM zostanie w pierwszej części ćwiczenia przeprowadzone w środowisku SQL, a w drugiej części wykorzystamy
Laboratorium 12 Odkrywanie osobliwości. Odkrywanie osobliwości (ang. outliers) za pomocą algorytmu SVM zostanie w pierwszej części ćwiczenia przeprowadzone w środowisku SQL, a w drugiej części wykorzystamy
Kontekstowe wskaźniki efektywności nauczania - warsztaty
 Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Określanie ważności atrybutów. RapidMiner
 Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Bazy danych 6. Klucze obce. P. F. Góra
 Bazy danych 6. Klucze obce P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2018 Dygresja: Metody przechowywania tabel w MySQL Tabele w MySQL moga być przechowywane na kilka sposobów. Sposób ten (żargonowo:
Bazy danych 6. Klucze obce P. F. Góra http://th-www.if.uj.edu.pl/zfs/gora/ 2018 Dygresja: Metody przechowywania tabel w MySQL Tabele w MySQL moga być przechowywane na kilka sposobów. Sposób ten (żargonowo:
1 n. s x x x x. Podstawowe miary rozproszenia: Wariancja z populacji: Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel:
 Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Wariancja z populacji: Podstawowe miary rozproszenia: 1 1 s x x x x k 2 2 k 2 2 i i n i1 n i1 Czasem stosuje się też inny wzór na wariancję z próby, tak policzy Excel: 1 k 2 s xi x n 1 i1 2 Przykład 38,
Autor: Joanna Karwowska
 Autor: Joanna Karwowska SELECT [DISTINCT] FROM [WHERE ] [GROUP BY ] [HAVING ] [ORDER BY ] [ ] instrukcja może
Autor: Joanna Karwowska SELECT [DISTINCT] FROM [WHERE ] [GROUP BY ] [HAVING ] [ORDER BY ] [ ] instrukcja może
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Autor: Joanna Karwowska
 Autor: Joanna Karwowska SELECT [DISTINCT] FROM [WHERE ] [GROUP BY ] [HAVING ] [ORDER BY ] [ ] instrukcja może
Autor: Joanna Karwowska SELECT [DISTINCT] FROM [WHERE ] [GROUP BY ] [HAVING ] [ORDER BY ] [ ] instrukcja może
Niestandardowa tabela częstości
 raportowanie Niestandardowa tabela częstości Przemysław Budzewski Predictive Solutions Do czego dążymy W Generalnym Sondażu Społecznym USA w 1991 roku badaniu poddano respondentów należących do szeregu
raportowanie Niestandardowa tabela częstości Przemysław Budzewski Predictive Solutions Do czego dążymy W Generalnym Sondażu Społecznym USA w 1991 roku badaniu poddano respondentów należących do szeregu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Podstawy statystyki - ćwiczenia r.
 Zadanie 1. Na podstawie poniższych danych wyznacz i zinterpretuj miary tendencji centralnej dotyczące wysokości miesięcznych zarobków (zł): 1290, 1500, 1600, 2250, 1400, 1600, 2500. Średnia arytmetyczna
Zadanie 1. Na podstawie poniższych danych wyznacz i zinterpretuj miary tendencji centralnej dotyczące wysokości miesięcznych zarobków (zł): 1290, 1500, 1600, 2250, 1400, 1600, 2500. Średnia arytmetyczna
Eksploracja danych. KLASYFIKACJA I REGRESJA cz. 2. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Data Mining podstawy analizy danych Część druga
 Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
S t a t y s t y k a, część 3. Michał Żmihorski
 S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 zajęcia: środa, 9.
 Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 lewandowski.marek@gmail.com zajęcia: środa, 9.00 Spis treści: 1 Wprowadzenie... 4 2 Dostępne dane... 5 3 Przygotowanie
Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 lewandowski.marek@gmail.com zajęcia: środa, 9.00 Spis treści: 1 Wprowadzenie... 4 2 Dostępne dane... 5 3 Przygotowanie
Laboratorium 5. Adaptatywna sieć Bayesa.
 Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Wykład XII. optymalizacja w relacyjnych bazach danych
 Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Optymalizacja wyznaczenie spośród dopuszczalnych rozwiązań danego problemu, rozwiązania najlepszego ze względu na przyjęte kryterium jakości ( np. koszt, zysk, niezawodność ) optymalizacja w relacyjnych
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Projekt Sieci neuronowe
 Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
Projekt Sieci neuronowe Chmielecka Katarzyna Gr. 9 IiE 1. Problem i dane Sieć neuronowa miała za zadanie nauczyć się klasyfikować wnioski kredytowe. W projekcie wykorzystano dane pochodzące z 110 wniosków
dodatkowe operacje dla kopca binarnego: typu min oraz typu max:
 ASD - ćwiczenia IX Kopce binarne własność porządku kopca gdzie dla każdej trójki wierzchołków kopca (X, Y, Z) porządek etykiet elem jest następujący X.elem Y.elem oraz Z.elem Y.elem w przypadku kopca typu
ASD - ćwiczenia IX Kopce binarne własność porządku kopca gdzie dla każdej trójki wierzchołków kopca (X, Y, Z) porządek etykiet elem jest następujący X.elem Y.elem oraz Z.elem Y.elem w przypadku kopca typu
Inteligentna analiza danych
 Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Laboratorium nr Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby:
 dla próby:") Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
PL/SQL. Funkcje wbudowane
 Slajd 1 PL/SQL Opis funkcji SQL PL/SQL(funkcje SQL) M. Rakowski - WSISiZ 1 Slajd 2 Funkcje wbudowane Funkcje wbudowane mają za zadanie umożliwić bardziej zaawansowane operowanie danymi. Funkcje operacji
Slajd 1 PL/SQL Opis funkcji SQL PL/SQL(funkcje SQL) M. Rakowski - WSISiZ 1 Slajd 2 Funkcje wbudowane Funkcje wbudowane mają za zadanie umożliwić bardziej zaawansowane operowanie danymi. Funkcje operacji
Raport z badań preferencji licealistów
 Raport z badań preferencji licealistów Uniwersytet Jagielloński 2011 Raport 2011 1 Szanowni Państwo, definiując misję naszej uczelni napisaliśmy, że Zadaniem Uniwersytetu było i jest wytyczanie nowych
Raport z badań preferencji licealistów Uniwersytet Jagielloński 2011 Raport 2011 1 Szanowni Państwo, definiując misję naszej uczelni napisaliśmy, że Zadaniem Uniwersytetu było i jest wytyczanie nowych
Podstawowe definicje statystyczne
 Podstawowe definicje statystyczne 1. Definicje podstawowych wskaźników statystycznych Do opisu wyników surowych (w punktach, w skali procentowej) stosuje się następujące wskaźniki statystyczne: wynik minimalny
Podstawowe definicje statystyczne 1. Definicje podstawowych wskaźników statystycznych Do opisu wyników surowych (w punktach, w skali procentowej) stosuje się następujące wskaźniki statystyczne: wynik minimalny
Część 2: Data Mining
 Łukasz Przywarty 171018 Wrocław, 18.01.2013 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 2: Data Mining Prowadzący: dr inż. Henryk
Łukasz Przywarty 171018 Wrocław, 18.01.2013 r. Grupa: CZW/N 10:00-13:00 Raport z zajęć laboratoryjnych w ramach przedmiotu Hurtownie i eksploracja danych Część 2: Data Mining Prowadzący: dr inż. Henryk
Wykład 4: Statystyki opisowe (część 1)
") Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Wykład 4: Statystyki opisowe (część 1) Wprowadzenie W przypadku danych mających charakter liczbowy do ich charakterystyki można wykorzystać tak zwane STATYSTYKI OPISOWE. Za pomocą statystyk opisowych można
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
QUERY język zapytań do tworzenia raportów w AS/400
 QUERY język zapytań do tworzenia raportów w AS/400 Dariusz Bober Katedra Informatyki Politechniki Lubelskiej Streszczenie: W artykule przedstawiony został język QUERY, standardowe narzędzie pracy administratora
QUERY język zapytań do tworzenia raportów w AS/400 Dariusz Bober Katedra Informatyki Politechniki Lubelskiej Streszczenie: W artykule przedstawiony został język QUERY, standardowe narzędzie pracy administratora
TRANSFORMACJE I JAKOŚĆ DANYCH
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Uzupełnij pola tabeli zgodnie z przykładem poniżej,
 1. Wykonaj bazę danych biblioteki szkolnej, Otwórz MS Access a następnie z menu plik wybierz przycisk nowy, w oknie nowy plik wybieramy pusta baza danych nadaj jej nazwę Biblioteka i wybierz miejsce w
1. Wykonaj bazę danych biblioteki szkolnej, Otwórz MS Access a następnie z menu plik wybierz przycisk nowy, w oknie nowy plik wybieramy pusta baza danych nadaj jej nazwę Biblioteka i wybierz miejsce w
Podstawowe zapytania SELECT (na jednej tabeli)
") Podstawowe zapytania SELECT (na jednej tabeli) Struktura polecenia SELECT SELECT opisuje nazwy kolumn, wyrażenia arytmetyczne, funkcje FROM nazwy tabel lub widoków WHERE warunek (wybieranie wierszy) GROUP
Podstawowe zapytania SELECT (na jednej tabeli) Struktura polecenia SELECT SELECT opisuje nazwy kolumn, wyrażenia arytmetyczne, funkcje FROM nazwy tabel lub widoków WHERE warunek (wybieranie wierszy) GROUP
Statystyki opisowe i szeregi rozdzielcze
 Statystyki opisowe i szeregi rozdzielcze - ćwiczenia ĆWICZENIA Piotr Ciskowski ramka-wąsy przykład 1. krwinki czerwone Stanisz W eksperymencie farmakologicznym analizowano oddziaływanie pewnego preparatu
Statystyki opisowe i szeregi rozdzielcze - ćwiczenia ĆWICZENIA Piotr Ciskowski ramka-wąsy przykład 1. krwinki czerwone Stanisz W eksperymencie farmakologicznym analizowano oddziaływanie pewnego preparatu
Wykład 5. SQL praca z tabelami 2
 Wykład 5 SQL praca z tabelami 2 Wypełnianie tabel danymi Tabele można wypełniać poprzez standardową instrukcję INSERT INTO: INSERT [INTO] nazwa_tabeli [(kolumna1, kolumna2,, kolumnan)] VALUES (wartosc1,
Wykład 5 SQL praca z tabelami 2 Wypełnianie tabel danymi Tabele można wypełniać poprzez standardową instrukcję INSERT INTO: INSERT [INTO] nazwa_tabeli [(kolumna1, kolumna2,, kolumnan)] VALUES (wartosc1,
Analiza progu rentowności
 Analiza progu rentowności Próg rentowności ( literaturze przedmiotu spotyka się również określenia: punkt równowagi, punkt krytyczny, punkt bez straty punkt zerowy) jest to taki punkt, w którym jednostka
Analiza progu rentowności Próg rentowności ( literaturze przedmiotu spotyka się również określenia: punkt równowagi, punkt krytyczny, punkt bez straty punkt zerowy) jest to taki punkt, w którym jednostka
1: 2: 3: 4: 5: 6: 7: 8: 9: 10:
 Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia
 Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Advanced Tax File Edit
 JDExperts Sp. z o.o. Advanced Tax File Edit Dokumentacja modyfikacji Spis treści 1 Założenia modyfikacji... 2 1.1 Elementy rozwiązania... 2 1.2 Opis rozwiązania... 2 1.3 Ograniczenia rozwiązania... 2 2
JDExperts Sp. z o.o. Advanced Tax File Edit Dokumentacja modyfikacji Spis treści 1 Założenia modyfikacji... 2 1.1 Elementy rozwiązania... 2 1.2 Opis rozwiązania... 2 1.3 Ograniczenia rozwiązania... 2 2
Procedury wyzwalane. (c) Instytut Informatyki Politechniki Poznańskiej 1
 Instytut Informatyki Politechniki Poznańskiej 1") Procedury wyzwalane procedury wyzwalane, cel stosowania, typy wyzwalaczy, wyzwalacze na poleceniach DML i DDL, wyzwalacze typu INSTEAD OF, przykłady zastosowania, zarządzanie wyzwalaczami 1 Procedury wyzwalane
Procedury wyzwalane procedury wyzwalane, cel stosowania, typy wyzwalaczy, wyzwalacze na poleceniach DML i DDL, wyzwalacze typu INSTEAD OF, przykłady zastosowania, zarządzanie wyzwalaczami 1 Procedury wyzwalane
Baza numerów Wersja 1.1
 Baza numerów Wersja 1.1 SPIS TREŚCI 1. Wprowadzenie 1.1 Adresy URL do połączenia z aplikacją 1.2 Informacje zwrotne wysyłane z API w odpowiedzi na odebrane odwołania I. Zarządzanie grupami Bazy Numerów
Baza numerów Wersja 1.1 SPIS TREŚCI 1. Wprowadzenie 1.1 Adresy URL do połączenia z aplikacją 1.2 Informacje zwrotne wysyłane z API w odpowiedzi na odebrane odwołania I. Zarządzanie grupami Bazy Numerów
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
Optymalizacja poleceń SQL Metody dostępu do danych
 Optymalizacja poleceń SQL Metody dostępu do danych 1 Metody dostępu do danych Określają, w jaki sposób dane polecenia SQL są odczytywane z miejsca ich fizycznej lokalizacji. Dostęp do tabeli: pełne przeglądnięcie,
Optymalizacja poleceń SQL Metody dostępu do danych 1 Metody dostępu do danych Określają, w jaki sposób dane polecenia SQL są odczytywane z miejsca ich fizycznej lokalizacji. Dostęp do tabeli: pełne przeglądnięcie,
RAPORT ZBIORCZY z diagnozy Matematyka PP
 RAPORT ZBIORCZY z diagnozy Matematyka PP przeprowadzonej w klasach drugich szkół ponadgimnazjalnych Analiza statystyczna Wskaźnik Wartość wskaźnika Wyjaśnienie Liczba uczniów Liczba uczniów, którzy przystąpili
RAPORT ZBIORCZY z diagnozy Matematyka PP przeprowadzonej w klasach drugich szkół ponadgimnazjalnych Analiza statystyczna Wskaźnik Wartość wskaźnika Wyjaśnienie Liczba uczniów Liczba uczniów, którzy przystąpili
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3
, sprawozdanie z laboratorium 3") Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3 Konrad Miziński, nr albumu 233703 26 maja 2015 Zadanie 1 Wartość krytyczna c, niezbędna wyliczenia mocy testu (1 β) wyznaczono za
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3 Konrad Miziński, nr albumu 233703 26 maja 2015 Zadanie 1 Wartość krytyczna c, niezbędna wyliczenia mocy testu (1 β) wyznaczono za
1. Tworzenie tabeli. 2. Umieszczanie danych w tabeli
 1. Tworzenie tabeli Aby stworzyć tabele w SQL-u należy użyć polecenia CREATE TABLE nazwa_tabeli (nazwa_pola1 właściwości_pola1, nazwa_pola2 właściwości_pola2, itd.) Nazwa_tabeli to wybrana przez nas nazwa
1. Tworzenie tabeli Aby stworzyć tabele w SQL-u należy użyć polecenia CREATE TABLE nazwa_tabeli (nazwa_pola1 właściwości_pola1, nazwa_pola2 właściwości_pola2, itd.) Nazwa_tabeli to wybrana przez nas nazwa
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
AiSD zadanie trzecie
 AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
AiSD zadanie trzecie Gliwiński Jarosław Marek Kruczyński Konrad Marek Grupa dziekańska I5 5 czerwca 2008 1 Wstęp Celem postawionym przez zadanie trzecie było tzw. sortowanie topologiczne. Jest to typ sortowania
Język SQL. Rozdział 2. Proste zapytania
 Język SQL. Rozdział 2. Proste zapytania Polecenie SELECT, klauzula WHERE, operatory SQL, klauzula ORDER BY. 1 Wprowadzenie do języka SQL Język dostępu do bazy danych. Język deklaratywny, zorientowany na
Język SQL. Rozdział 2. Proste zapytania Polecenie SELECT, klauzula WHERE, operatory SQL, klauzula ORDER BY. 1 Wprowadzenie do języka SQL Język dostępu do bazy danych. Język deklaratywny, zorientowany na
Zadania ze statystyki, cz.6
 Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Bazy danych. Plan wykładu. Diagramy ER. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych. Podstawy modeli relacyjnych
 Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
Plan wykładu Bazy danych Wykład 9: Przechodzenie od diagramów E/R do modelu relacyjnego. Definiowanie perspektyw. Diagramy E/R - powtórzenie Relacyjne bazy danych Od diagramów E/R do relacji SQL - perspektywy
2. Ocena dokładności modelu klasyfikacji:
 Spis treści: 1. Klasyfikacja... 1 2. Ocena dokładności modelu klasyfikacji:...1 2.1. Miary dokładności modelu...2 2.2. Krzywe oceny...2 3. Wybrane algorytmy...3 3.1. Naiwny klasyfikator Bayesa...3 3.2.
Spis treści: 1. Klasyfikacja... 1 2. Ocena dokładności modelu klasyfikacji:...1 2.1. Miary dokładności modelu...2 2.2. Krzywe oceny...2 3. Wybrane algorytmy...3 3.1. Naiwny klasyfikator Bayesa...3 3.2.
Sposoby prezentacji problemów w statystyce
 S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
S t r o n a 1 Dr Anna Rybak Instytut Informatyki Uniwersytet w Białymstoku Sposoby prezentacji problemów w statystyce Wprowadzenie W artykule zostaną zaprezentowane podstawowe zagadnienia z zakresu statystyki
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
SQL, LIKE, IN, CASE, EXISTS. Marcin Orchel
 SQL, LIKE, IN, CASE, EXISTS Marcin Orchel Spis treści 1 LIKE 2 2 BETWEEN 4 3 IN 5 4 EXISTS 6 5 WYRAŻENIA CASE 7 6 Zadania 9 1 Rozdział 1 LIKE Predykat LIKE jest testem dopasowującym wzorzec łańcucha. Składnia
SQL, LIKE, IN, CASE, EXISTS Marcin Orchel Spis treści 1 LIKE 2 2 BETWEEN 4 3 IN 5 4 EXISTS 6 5 WYRAŻENIA CASE 7 6 Zadania 9 1 Rozdział 1 LIKE Predykat LIKE jest testem dopasowującym wzorzec łańcucha. Składnia
Za pierwszy niebanalny algorytm uważa się algorytm Euklidesa wyszukiwanie NWD dwóch liczb (400 a 300 rok przed narodzeniem Chrystusa).
.") Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
Algorytmy definicja, cechy, złożoność. Algorytmy napotykamy wszędzie, gdziekolwiek się zwrócimy. Rządzą one wieloma codziennymi czynnościami, jak np. wymiana przedziurawionej dętki, montowanie szafy z
2. Empiryczna wersja klasyfikatora bayesowskiego
 Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Algorytmy rozpoznawania obrazów 2. Empiryczna wersja klasyfikatora bayesowskiego dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Brak pełnej informacji probabilistycznej Klasyfikator bayesowski
Przykładowa baza danych BIBLIOTEKA
 Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Wydział Inżynierii Produkcji. I Logistyki. Statystyka opisowa. Wykład 3. Dr inż. Adam Deptuła
 12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa Wykład 3 Dr inż. Adam Deptuła METODY OPISU DANYCH ILOŚCIOWYCH SKALARNYCH Wykresy: diagramy, histogramy, łamane częstości, wykresy
12.03.2017 Wydział Inżynierii Produkcji I Logistyki Statystyka opisowa Wykład 3 Dr inż. Adam Deptuła METODY OPISU DANYCH ILOŚCIOWYCH SKALARNYCH Wykresy: diagramy, histogramy, łamane częstości, wykresy
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Laboratorium Bazy danych SQL 3 1
 Laboratorium Bazy danych SQL 3 1 F U N K C J E operujące na grupach wierszy: avg([distinct all]kol) oblicza średnią arytmetyczną wartości kolumny kol wszystkich wierszy grupy. count([distinct all]wyr)
Laboratorium Bazy danych SQL 3 1 F U N K C J E operujące na grupach wierszy: avg([distinct all]kol) oblicza średnią arytmetyczną wartości kolumny kol wszystkich wierszy grupy. count([distinct all]wyr)
5 Błąd średniokwadratowy i obciążenie
 5 Błąd średniokwadratowy i obciążenie Przeprowadziliśmy 200 powtórzeń przebiegu próbnika dla tego samego zestawu parametrów modelowych co w Rozdziale 1, to znaczy µ = 0, s = 10, v = 10, n i = 10 (i = 1,...,
5 Błąd średniokwadratowy i obciążenie Przeprowadziliśmy 200 powtórzeń przebiegu próbnika dla tego samego zestawu parametrów modelowych co w Rozdziale 1, to znaczy µ = 0, s = 10, v = 10, n i = 10 (i = 1,...,
Statystyka. Wykład 4. Magdalena Alama-Bućko. 13 marca Magdalena Alama-Bućko Statystyka 13 marca / 41
 Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
Statystyka Wykład 4 Magdalena Alama-Bućko 13 marca 2017 Magdalena Alama-Bućko Statystyka 13 marca 2017 1 / 41 Na poprzednim wykładzie omówiliśmy następujace miary rozproszenia: Wariancja - to średnia arytmetyczna
4.3 Grupowanie według podobieństwa
 4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
4.3 Grupowanie według podobieństwa Przykłady obiektów to coś więcej niż wektory wartości atrybutów. Reprezentują one poszczególne rasy psów. Ważnym pytaniem, jakie można sobie zadać, jest to jak dobrymi
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
STATYSTYKA MATEMATYCZNA WYKŁAD 3. Populacje i próby danych
 STATYSTYKA MATEMATYCZNA WYKŁAD 3 Populacje i próby danych POPULACJA I PRÓBA DANYCH POPULACJA population Obserwacje dla wszystkich osobników danego gatunku / rasy PRÓBA DANYCH sample Obserwacje dotyczące
STATYSTYKA MATEMATYCZNA WYKŁAD 3 Populacje i próby danych POPULACJA I PRÓBA DANYCH POPULACJA population Obserwacje dla wszystkich osobników danego gatunku / rasy PRÓBA DANYCH sample Obserwacje dotyczące
Język SQL. Rozdział 4. Funkcje grupowe Funkcje grupowe, podział relacji na grupy, klauzule GROUP BY i HAVING.
 Język SQL. Rozdział 4. Funkcje grupowe Funkcje grupowe, podział relacji na grupy, klauzule GROUP BY i HAVING. 1 Funkcje grupowe (agregujące) (1) Działają na zbiorach rekordów, nazywanych grupami. Rekordy
Język SQL. Rozdział 4. Funkcje grupowe Funkcje grupowe, podział relacji na grupy, klauzule GROUP BY i HAVING. 1 Funkcje grupowe (agregujące) (1) Działają na zbiorach rekordów, nazywanych grupami. Rekordy
STATYKA Z UWZGLĘDNIENIEM DUŻYCH SIŁ OSIOWYCH
 Część. STATYKA Z UWZGLĘDNIENIEM DUŻYCH SIŁ OSIOWYCH.. STATYKA Z UWZGLĘDNIENIEM DUŻYCH SIŁ OSIOWYCH Rozwiązując układy niewyznaczalne dowolnie obciążone, bardzo często pomijaliśmy wpływ sił normalnych i
Część. STATYKA Z UWZGLĘDNIENIEM DUŻYCH SIŁ OSIOWYCH.. STATYKA Z UWZGLĘDNIENIEM DUŻYCH SIŁ OSIOWYCH Rozwiązując układy niewyznaczalne dowolnie obciążone, bardzo często pomijaliśmy wpływ sił normalnych i
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Podzapytania. Rozdział 5. Podzapytania. Podzapytania wyznaczające wiele krotek (1) Podzapytania wyznaczające jedną krotkę
 Podzapytania wyznaczające jedną krotkę") Podzapytania Rozdział 5 Podzapytania podzapytania proste i skorelowane, podzapytania w klauzuli SELECT i FROM, klauzula WITH, operatory ANY, ALL i EXISTS, zapytania hierarchiczne Podzapytanie jest poleceniem
Podzapytania Rozdział 5 Podzapytania podzapytania proste i skorelowane, podzapytania w klauzuli SELECT i FROM, klauzula WITH, operatory ANY, ALL i EXISTS, zapytania hierarchiczne Podzapytanie jest poleceniem
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Struktura bazy danych
 Bazy danych - MySQL Warunki zaliczenia tych zajęć Rozwiązania zadań domowych proszę zapisać do pliku o nazwie Bazy danych i wysłać do mnie jako załącznik. Ostateczny termin: niedziela, 9.06, godzina 24:00.
Bazy danych - MySQL Warunki zaliczenia tych zajęć Rozwiązania zadań domowych proszę zapisać do pliku o nazwie Bazy danych i wysłać do mnie jako załącznik. Ostateczny termin: niedziela, 9.06, godzina 24:00.
SQL do zaawansowanych analiz danych część 1.
 SQL do zaawansowanych analiz danych część 1. Mechanizmy języka SQL dla agregacji danych Rozszerzenia PIVOT i UNPIVOT Materiały wykładowe Bartosz Bębel Politechnika Poznańska, Instytut Informatyki Plan
SQL do zaawansowanych analiz danych część 1. Mechanizmy języka SQL dla agregacji danych Rozszerzenia PIVOT i UNPIVOT Materiały wykładowe Bartosz Bębel Politechnika Poznańska, Instytut Informatyki Plan
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Dopasowywanie modelu do danych
 Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
Tematyka wykładu dopasowanie modelu trendu do danych; wybrane rodzaje modeli trendu i ich właściwości; dopasowanie modeli do danych za pomocą narzędzi wykresów liniowych (wykresów rozrzutu) programu STATISTICA;
5. Bazy danych Base Okno bazy danych
 5. Bazy danych Base 5.1. Okno bazy danych Podobnie jak inne aplikacje środowiska OpenOffice, program do tworzenia baz danych uruchamia się po wybraniu polecenia Start/Programy/OpenOffice.org 2.4/OpenOffice.org
5. Bazy danych Base 5.1. Okno bazy danych Podobnie jak inne aplikacje środowiska OpenOffice, program do tworzenia baz danych uruchamia się po wybraniu polecenia Start/Programy/OpenOffice.org 2.4/OpenOffice.org
Informatyzacja Przedsiębiorstw
 Informatyzacja Przedsiębiorstw Microsoft Dynamics NAV 2013 Moduł finansowo-księgowy lab6 Strona 1 Plan zajęć 1 Utworzenie kartoteki środka trwałego... 3 2 Zakup środka trwałego... 4 3 Amortyzacja środka
Informatyzacja Przedsiębiorstw Microsoft Dynamics NAV 2013 Moduł finansowo-księgowy lab6 Strona 1 Plan zajęć 1 Utworzenie kartoteki środka trwałego... 3 2 Zakup środka trwałego... 4 3 Amortyzacja środka
RAPORT z diagnozy umiejętności matematycznych
 RAPORT z diagnozy umiejętności matematycznych przeprowadzonej w klasach pierwszych szkół ponadgimnazjalnych 1 Analiza statystyczna Wskaźnik Liczba uczniów Liczba punktów Łatwość zestawu Wyjaśnienie Liczba
RAPORT z diagnozy umiejętności matematycznych przeprowadzonej w klasach pierwszych szkół ponadgimnazjalnych 1 Analiza statystyczna Wskaźnik Liczba uczniów Liczba punktów Łatwość zestawu Wyjaśnienie Liczba