Wprowadzenie do programu RapidMiner, część 4 Michał Bereta
|
|
|
- Judyta Sikora
- 7 lat temu
- Przeglądów:
Transkrypt

 x i y.")
1 Wprowadzenie do programu RapidMiner, część 4 Michał Bereta 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania / zależności atrybutów jest analiza korelacji. Możemy sprawdzid czy atrybuty nie niosą w pewnym sensie podobnej informacji. Współczynnik korelacji między atrybutem x oraz y można wyliczyd ze wzoru gdzie s x oraz s y to odchylenia standardowe, n to liczba przykładów. Powyższy współczynnik to współczynnik Pearsona i przyjmuje wartości z przedziału *-1, 1+. Duże bezwzględne wartości tego współczynnika wskazują na dużą korelację (dodatnią lub ujemną) x i y. Takie atrybuty często są nadmiarowe. Wykorzystaj operator Correlation Matrix i bazę danych Indian Pima. W wyniku otrzymamy macierz korelacji, gdzie możemy sprawdzid korelację pomiędzy dowolną parą atrybutów. 1




2 Wartości te mogą służyd do określenia wartości wag atrybutów (większa wartośd wagi oznacza większe znaczenie atrybutu). Sprawdź, że jeśli w opcjach operatora CorrelationMatrix nie jest zaznaczone normalize weights to wagi te nie są tak wyraźnie oceniające atrybuty. Wagi atrybutów mogą posłużyd do decyzji, które z nich odrzucid, np. wykorzystując operator Select by Weights by wybrad tylko te atrybuty, które mają wagę większą niż np


3 Wynik: z oryginalnego zestawu ośmiu atrybutów pozostały jedynie trzy atrybuty (att9 jest tu etykietą klasy): 3
 W przypadku liczby klas większej niż dwa, procedura ta nie jest wskazana (dlaczego?). c.")


4 Zadanie: Jak sprawdzid korelację każdego z atrybutów z etykietą klasy? a.) W przypadku dwóch klas należy zakodowad etykiety klas numerycznie, np. jako 0 i 1 b.) W przypadku liczby klas większej niż dwa, procedura ta nie jest wskazana (dlaczego?). c.) Czy atrybuty, które są w tym przykładzie najbardziej skorelowane z etykietą klasy (att9) są tymi samymi, które zostały najlepiej ocenione (otrzymały najwyższe wagi) w poprzednim przykładzie? (Dlaczego?) Wynik (pamiętaj, że istotna jest bezwzględna wartośd): Uwaga: operator Weight by Correlation umożliwia oszacowanie wag dla atrybutów na podstawie ich korelacji z etykietą klasy. Wypróbuj go i porównaj z wynikami z powyższej tabli. Z dokumentacji: This operator calculates the relevance of the attributes by computing the value of correlation for each attribute of the input ExampleSet with respect to the label attribute. This weighting scheme is based upon correlation and it returns the absolute or squared value of correlation as attribute weight. 4


5 Zadanie: Porównaj działanie Select by Weights z Correlation Matrix z poprzedniego przykładu z operatorem Remove Correlated Attributes : Zwród uwagę na znaczenie wartości 0.5 oraz 0.3 w poniższych ustawieniach: 5



6 Przykładowy wynik: Select by Weights z Correlation Matrix : Remove Correlated Attributes : Powyższą tabelkę porównaj z Correlation Matrix : 6

7 Zadanie: Zbadaj korzyści płynące z wykorzystania powyższych metod analizy istotności atrybutów a problemie klasyfikacji szkła. Dodatkowo zastosuj operator Weight by Relief oraz jeden dodatkowy z zestawu dostępnego w RM. Zwród uwagę, że nie wszystkie nadają się do problemów klasyfikacji z wieloma klasami. 7

8 2. Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora. Przy ocenie wartości atrybutu kierowad można się empiryczną oceną jakości działania konkretnego klasyfikatora, który wykorzystuje dany atrybut, a raczej cały zestaw atrybutów. Istnieją dwa główne podejścia: a.) Forward selection - dodawaj kolejne atrybuty jeśli ich dodanie poprawia działanie klasyfikatora danego typu b.) Backward elimination - usuwaj po kolei kolejne atrybuty, i akceptuj usunięcie, jeśli wytrenowany na pozostających atrybutach klasyfikator danego typu poprawia się / nie pogarsza swojego działania Porównaj działanie tych dwóch operatorów czy jest duża różnica w ostatecznym wyborze? : Dla ForwardSelection : 8

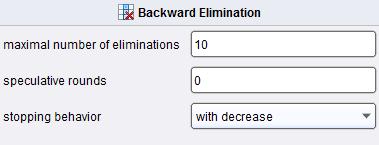

9 Dla Backward Elimination : Przykładowe wybrane atrybuty: Dla ForwardSelection : 9


10 Dla Backward Elimination : 10
Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Reguły asocjacyjne w programie RapidMiner Michał Bereta
 Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Reguły asocjacyjne w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Reguły asocjacyjne mają na celu odkrycie związków współwystępowania pomiędzy atrybutami. Stosuje się je często do danych
Określanie ważności atrybutów. RapidMiner
 Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Data Mining z wykorzystaniem programu Rapid Miner
 Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Data Mining z wykorzystaniem programu Rapid Miner Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community
Podstawy grupowania danych w programie RapidMiner Michał Bereta
 Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Podstawy grupowania danych w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Grupowanie hierarchiczne Grupowanie (analiza skupieo, ang. clustering) ma na celu automatyczne wykrycie grup istniejących
Rozpoznawanie twarzy metodą PCA Michał Bereta 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów
 Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Rozpoznawanie twarzy metodą PCA Michał Bereta www.michalbereta.pl 1. Testowanie statystycznej istotności różnic między jakością klasyfikatorów Wiemy, że możemy porównywad klasyfikatory np. za pomocą kroswalidacji.
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
KURS STATYSTYKA. Lekcja 5 Analiza współzależności ZADANIE DOMOWE. Strona 1
 KURS STATYSTYKA Lekcja 5 Analiza współzależności ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 W analizie współzależności a) badamy
KURS STATYSTYKA Lekcja 5 Analiza współzależności ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 W analizie współzależności a) badamy
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Wprowadzenie do programu RapidMiner, część 5 Michał Bereta www.michalbereta.pl 1. Przekształcenia atrybutów (ang. attribute reduction / transformation, feature extraction). Zamiast wybierad częśd atrybutów
Laboratorium 10. Odkrywanie cech i algorytm Non-Negative Matrix Factorization.
 Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów
 Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Wprowadzenie do programu RapidMiner, część 2 Michał Bereta www.michalbereta.pl 1. Wykorzystanie wykresu ROC do porównania modeli klasyfikatorów Zaimportuj dane pima-indians-diabetes.csv. (Baza danych poświęcona
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
1. Zbadać liniową niezależność funkcji x, 1, x, x 2 w przestrzeni liniowej funkcji ciągłych na przedziale [ 1, ).
.") B 2 Suma Zbadać, czy liniowo niezależne wektory u, v, w stanowią bazę przestrzeni liniowej lin { u + 2 v + w, u v + 2 w, 3 u + 5 w } 2 Współrzędne wektora (, 4, 5, 4 ) w pewnej bazie podprzestrzeni U R
B 2 Suma Zbadać, czy liniowo niezależne wektory u, v, w stanowią bazę przestrzeni liniowej lin { u + 2 v + w, u v + 2 w, 3 u + 5 w } 2 Współrzędne wektora (, 4, 5, 4 ) w pewnej bazie podprzestrzeni U R
1. Eliminuje się ze zbioru potencjalnych zmiennych te zmienne dla których korelacja ze zmienną objaśnianą jest mniejsza od krytycznej:
 Metoda analizy macierzy współczynników korelacji Idea metody sprowadza się do wyboru takich zmiennych objaśniających, które są silnie skorelowane ze zmienną objaśnianą i równocześnie słabo skorelowane
Metoda analizy macierzy współczynników korelacji Idea metody sprowadza się do wyboru takich zmiennych objaśniających, które są silnie skorelowane ze zmienną objaśnianą i równocześnie słabo skorelowane
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Java Podstawy. Michał Bereta
 Prezentacja współfinansowana przez Unię Europejską ze środków Europejskiego Funduszu Społecznego w ramach projektu Wzmocnienie znaczenia Politechniki Krakowskiej w kształceniu przedmiotów ścisłych i propagowaniu
Prezentacja współfinansowana przez Unię Europejską ze środków Europejskiego Funduszu Społecznego w ramach projektu Wzmocnienie znaczenia Politechniki Krakowskiej w kształceniu przedmiotów ścisłych i propagowaniu
Y = α 1 Z α k Z k + e. (1) (k 1)[ktrA2 (tra) 2 ] (4) d = 1 k. (por. np. Kolupa, 2006). Wówczas jak to wynika ze wzorów (2) i (3) mamy:
![Y = α 1 Z α k Z k + e. (1) (k 1)[ktrA2 (tra) 2 ] (4) d = 1 k. (por. np. Kolupa, 2006). Wówczas jak to wynika ze wzorów (2) i (3) mamy:](/thumbs/92/110279918.jpg "Y = α 1 Z α k Z k + e. (1) (k 1)[ktrA2 (tra) 2 ] (4) d = 1 k. (por. np. Kolupa, 2006). Wówczas jak to wynika ze wzorów (2) i (3) mamy:") PRZEGLĄD STATYSTYCZNY R. LVIII ZESZYT 3-4 2011 MICHAŁ KOLUPA, JOANNA PLEBANIAK KILKA UWAG O WARTOŚCIACH WŁASNYCH MACIERZY KORELACJI W niniejszej pracy, w nawiązaniu do pracy Kolupa, 2006, podajemy konstrukcję
PRZEGLĄD STATYSTYCZNY R. LVIII ZESZYT 3-4 2011 MICHAŁ KOLUPA, JOANNA PLEBANIAK KILKA UWAG O WARTOŚCIACH WŁASNYCH MACIERZY KORELACJI W niniejszej pracy, w nawiązaniu do pracy Kolupa, 2006, podajemy konstrukcję
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Wprowadzenie do programu RapidMiner, część 3 Michał Bereta www.michalbereta.pl 1. W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych jako operatory: a. LDA Linear Discriminant
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
x y
 Tym razem pominę wstęp teoretyczny i skupię się na praktycznym aspekcie sprawy, czyli jak szybko policzyć korelację oraz ocenić jej istotność. Bardzo zachęcam do przejrzenia książki autorstwa Adama wspomnianej
Tym razem pominę wstęp teoretyczny i skupię się na praktycznym aspekcie sprawy, czyli jak szybko policzyć korelację oraz ocenić jej istotność. Bardzo zachęcam do przejrzenia książki autorstwa Adama wspomnianej
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Wycena nieruchomości za pomocą wyboru wielokryterialnego w warunkach niepewności rozmytej oraz klasycznie: metodą pp i kcś
 Wycena nieruchomości za pomocą wyboru wielokryterialnego w warunkach niepewności rozmytej oraz klasycznie: metodą pp i kcś Materiały reklamowe ZAWAM-Marek Zawadzki Wybór wielokryterialny jako jadna z metod
Wycena nieruchomości za pomocą wyboru wielokryterialnego w warunkach niepewności rozmytej oraz klasycznie: metodą pp i kcś Materiały reklamowe ZAWAM-Marek Zawadzki Wybór wielokryterialny jako jadna z metod
Ekonometria. Zajęcia
 Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych. Regresja logistyczna i jej zastosowanie
 Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Statystyka podstawowe wzory i definicje
 1 Statystyka podstawowe wzory i definicje Średnia arytmetyczna to suma wszystkich liczb (a 1, a 2,, a n) podzielona przez ich ilość (n) Przykład 1 Dany jest zbiór liczb {6, 8, 11, 2, 5, 3}. Oblicz średnią
1 Statystyka podstawowe wzory i definicje Średnia arytmetyczna to suma wszystkich liczb (a 1, a 2,, a n) podzielona przez ich ilość (n) Przykład 1 Dany jest zbiór liczb {6, 8, 11, 2, 5, 3}. Oblicz średnią
Regresja logistyczna (LOGISTIC)
") Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Zmienna zależna: Wybór opcji zachodniej w polityce zagranicznej (kodowana jako tak, 0 nie) Zmienne niezależne: wiedza o Unii Europejskiej (WIEDZA), zamieszkiwanie w regionie zachodnim (ZACH) lub wschodnim
Metody klasyfikacji i rozpoznawania wzorców. Najważniejsze rodzaje klasyfikatorów
 Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
Metody klasyfikacji i rozpoznawania wzorców www.michalbereta.pl Najważniejsze rodzaje klasyfikatorów Dla określonego problemu klasyfikacyjnego (tzn. dla danego zestawu danych) należy przetestować jak najwięcej
PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
Analiza korelacji i regresji KORELACJA zależność liniowa Obserwujemy parę cech ilościowych (X,Y). Doświadczenie jest tak pomyślane, aby obserwowane pary cech X i Y (tzn i ta para x i i y i dla różnych
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 7 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi
 Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska D syst D śr m 1 3 5 2 4 6 śr j D 1
Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska D syst D śr m 1 3 5 2 4 6 śr j D 1
Bioinformatyka Laboratorium, 30h. Michał Bereta
 Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Filogenetyka molekularna wykorzystuje informację zawartą w sekwencjach aminokwasów lub nukleotydów do kontrukcji drzew
Analiza korelacji
 Analiza korelacji Zakres szkolenia Wstęp Podstawowe pojęcia korelacji Współczynnik korelacji liniowej Pearsona Współczynnik korelacji rang Spearmana Test istotności Zadania 2 Wstęp Do czego służy korelacja:
Analiza korelacji Zakres szkolenia Wstęp Podstawowe pojęcia korelacji Współczynnik korelacji liniowej Pearsona Współczynnik korelacji rang Spearmana Test istotności Zadania 2 Wstęp Do czego służy korelacja:
Zestaw C-11: Organizacja plików: Oddajemy tylko źródła programów (pliki o rozszerzeniach.cpp i.h)!!! Zad. 1: Zad. 2:
!!! Zad. 1: Zad. 2:") Zestaw C-11: funkcję usun rozpatrującą rozłączne trójki elementów sznura i usuwającą te z elementów trójki, które nie zawierają wartości najmniejszej w obrębie takiej trójki (w każdej trójce pozostaje
Zestaw C-11: funkcję usun rozpatrującą rozłączne trójki elementów sznura i usuwającą te z elementów trójki, które nie zawierają wartości najmniejszej w obrębie takiej trójki (w każdej trójce pozostaje
Strategic planning. Jolanta Żyśko University of Physical Education in Warsaw
 Strategic planning Jolanta Żyśko University of Physical Education in Warsaw 7S Formula Strategy 5 Ps Strategy as plan Strategy as ploy Strategy as pattern Strategy as position Strategy as perspective Strategy
Strategic planning Jolanta Żyśko University of Physical Education in Warsaw 7S Formula Strategy 5 Ps Strategy as plan Strategy as ploy Strategy as pattern Strategy as position Strategy as perspective Strategy
X Y 4,0 3,3 8,0 6,8 12,0 11,0 16,0 15,2 20,0 18,9
 Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
Zadanie W celu sprawdzenia, czy pipeta jest obarczona błędem systematycznym stałym lub zmiennym wykonano szereg pomiarów przy różnych ustawieniach pipety. Wyznacz równanie regresji liniowej, które pozwoli
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI REGRESJA LINIOWA Powtórka Powtórki Kowiariancja cov xy lub c xy - kierunek zależności Współczynnik korelacji liniowej Pearsona r siła liniowej zależności Istotność
b) Umiejętność wykonania analizy zależności zmiennych i interpretacji uzyskanych wyników.
 Umiejętność wykonania analizy zależności zmiennych i interpretacji uzyskanych wyników.") Cele: a) Umiejętność przeprowadzenia analizy struktury wybranego zbioru obserwacji Obliczanie miar tendencji centralnych, miar rozproszenia, współczynnika skośności i miary spłaszczenia z wykorzystaniem
Cele: a) Umiejętność przeprowadzenia analizy struktury wybranego zbioru obserwacji Obliczanie miar tendencji centralnych, miar rozproszenia, współczynnika skośności i miary spłaszczenia z wykorzystaniem
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Sieci neuronowe w Statistica
 http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
1. Grupowanie Algorytmy grupowania:
 1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
1. 1.1. 2. 3. 3.1. 3.2. Grupowanie...1 Algorytmy grupowania:...1 Grupowanie metodą k-średnich...3 Grupowanie z wykorzystaniem Oracle Data Miner i Rapid Miner...3 Grupowanie z wykorzystaniem algorytmu K-Means
System wizyjny OMRON Xpectia FZx
 Ogólna charakterystyka systemu w wersji FZ3 w zależności od modelu można dołączyć od 1 do 4 kamer z interfejsem CameraLink kamery o rozdzielczościach od 300k do 5M pikseli możliwość integracji oświetlacza
Ogólna charakterystyka systemu w wersji FZ3 w zależności od modelu można dołączyć od 1 do 4 kamer z interfejsem CameraLink kamery o rozdzielczościach od 300k do 5M pikseli możliwość integracji oświetlacza
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Badanie zależności skala nominalna
 Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
Badanie zależności skala nominalna I. Jak kształtuje się zależność miedzy płcią a wykształceniem? II. Jak kształtuje się zależność między płcią a otyłością (opis BMI)? III. Jak kształtuje się zależność
author: Andrzej Dudek
 Edytor wprowadzone polecenia zostają w oknie edytora I mogą być uruchamiana poprzez CTRL+R lub Run (tylko zaznaczone linie, z wyświetlaniem wykonywanych linii kodu) lub poprzez Source (zawsze całość, bez
Edytor wprowadzone polecenia zostają w oknie edytora I mogą być uruchamiana poprzez CTRL+R lub Run (tylko zaznaczone linie, z wyświetlaniem wykonywanych linii kodu) lub poprzez Source (zawsze całość, bez
Inteligentna analiza danych
 Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Tworzenie prostej etykiety i synchronizacja etykiet z wagą. AXIS Sp. z o.o. Kod produktu:
 Tworzenie prostej etykiety i synchronizacja etykiet z wagą Współpraca wagi z etykieciarką wymaga zaprojektowania formy (szablonu) etykiety na komputerze i zapisania jej w pamięci etykieciarki. Następnie
Tworzenie prostej etykiety i synchronizacja etykiet z wagą Współpraca wagi z etykieciarką wymaga zaprojektowania formy (szablonu) etykiety na komputerze i zapisania jej w pamięci etykieciarki. Następnie
Bioinformatyka. Program UGENE
 Bioinformatyka Program UGENE www.michalbereta.pl UGENE jest darmowym programem do zadań bioinformatycznych. Można go pobrać ze strony http://ugene.net/. 1 1. Wczytanie rekordu z bazy ENA do programu UGENE
Bioinformatyka Program UGENE www.michalbereta.pl UGENE jest darmowym programem do zadań bioinformatycznych. Można go pobrać ze strony http://ugene.net/. 1 1. Wczytanie rekordu z bazy ENA do programu UGENE
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 5 Analiza korelacji - współczynnik korelacji Pearsona Cel: ocena współzależności między dwiema zmiennymi ilościowymi Ocenia jedynie zależność liniową. r = cov(x,y
12/30/2018. Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie. Estymacja Testowanie hipotez
 Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie Wyznaczanie przedziału 95%CI oznaczającego, że dla 95% prób losowych następujące nierówności są prawdziwe: X t s 0.025 n < μ < X + t s
Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie Wyznaczanie przedziału 95%CI oznaczającego, że dla 95% prób losowych następujące nierówności są prawdziwe: X t s 0.025 n < μ < X + t s
Pomoc do programu Kalkulacje Budowlane NS.
 Pomoc do programu Kalkulacje Budowlane NS. 1. Produkty i usługi Dodaj guzik służący do dodawania do bazy produktów lub usług 1 Tak jak na obrazku powyżej widad, okno służy do wprowadzania nowych produktów
Pomoc do programu Kalkulacje Budowlane NS. 1. Produkty i usługi Dodaj guzik służący do dodawania do bazy produktów lub usług 1 Tak jak na obrazku powyżej widad, okno służy do wprowadzania nowych produktów
Laboratorium 5. Adaptatywna sieć Bayesa.
 Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Python wstęp. Michał Bereta www.michalbereta.pl
 Python wstęp Michał Bereta www.michalbereta.pl Wprowadzenie... 1 Źródła wiedzy... 1 Uruchomienie interpretera Pythona... 2 Python jako kalkulator użycie interaktyne... 2 Uruchamianie skryptów z plików...
Python wstęp Michał Bereta www.michalbereta.pl Wprowadzenie... 1 Źródła wiedzy... 1 Uruchomienie interpretera Pythona... 2 Python jako kalkulator użycie interaktyne... 2 Uruchamianie skryptów z plików...
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu
 Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu Niniejszy mini poradnik ma na celu pomóc Państwu jak najszybciej uruchomić Wasz nowy sklep internetowy i uchronić od popełniania najczęstszych
Podstawowe informacje potrzebne do szybkiego uruchomienia e-sklepu Niniejszy mini poradnik ma na celu pomóc Państwu jak najszybciej uruchomić Wasz nowy sklep internetowy i uchronić od popełniania najczęstszych
Regresja wielokrotna. PDF created with FinePrint pdffactory Pro trial version http://www.fineprint.com
 Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Regresja wielokrotna Model dla zależności liniowej: Y=a+b 1 X 1 +b 2 X 2 +...+b n X n Cząstkowe współczynniki regresji wielokrotnej: b 1,..., b n Zmienne niezależne (przyczynowe): X 1,..., X n Zmienna
Programowanie celowe #1
 Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Programowanie celowe #1 Problem programowania celowego (PC) jest przykładem problemu programowania matematycznego nieliniowego, który można skutecznie zlinearyzować, tzn. zapisać (i rozwiązać) jako problem
Zjawisko dopasowania w sytuacji komunikacyjnej. Patrycja Świeczkowska Michał Woźny
 Zjawisko dopasowania w sytuacji komunikacyjnej Patrycja Świeczkowska Michał Woźny 0.0.0 pomiar nastroju Przeprowadzone badania miały na celu ustalenie, w jaki sposób rozmówcy dopasowują się do siebie nawzajem.
Zjawisko dopasowania w sytuacji komunikacyjnej Patrycja Świeczkowska Michał Woźny 0.0.0 pomiar nastroju Przeprowadzone badania miały na celu ustalenie, w jaki sposób rozmówcy dopasowują się do siebie nawzajem.
Korelacja, autokorelacja, kowariancja, trendy. Korelacja określa stopień asocjacji między zmiennymi
 Korelacja, autokorelacja, kowariancja, trendy Korelacja określa stopień asocjacji między zmiennymi Kowariancja Wady - ograniczenia. Wartość kowariancji zależy od rozmiarów zmienności zmiennej.. W konsekwencji
Korelacja, autokorelacja, kowariancja, trendy Korelacja określa stopień asocjacji między zmiennymi Kowariancja Wady - ograniczenia. Wartość kowariancji zależy od rozmiarów zmienności zmiennej.. W konsekwencji
K wartość kapitału zaangażowanego w proces produkcji, w tys. jp.
 Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Sprawdzian 2. Zadanie 1. Za pomocą KMNK oszacowano następującą funkcję produkcji: Gdzie: P wartość produkcji, w tys. jp (jednostek pieniężnych) K wartość kapitału zaangażowanego w proces produkcji, w tys.
Podzapytania. SELECT atrybut_1, atrybut_2,... FROM relacja WHERE atrybut_n operator (SELECT atrybut_1, FROM relacja WHERE warunek
 Podzapytania Podzapytanie jest poleceniem SELECT zagnieżdżonym w innym poleceniu SELECT. Podzapytanie może wystąpić wszędzie tam, gdzie system spodziewa się zbioru wartości, czyli w klauzulach SELECT,
Podzapytania Podzapytanie jest poleceniem SELECT zagnieżdżonym w innym poleceniu SELECT. Podzapytanie może wystąpić wszędzie tam, gdzie system spodziewa się zbioru wartości, czyli w klauzulach SELECT,
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
STATYSTYKA MATEMATYCZNA ZESTAW 0 (POWT. RACH. PRAWDOPODOBIEŃSTWA) ZADANIA
 ZADANIA") STATYSTYKA MATEMATYCZNA ZESTAW 0 (POWT. RACH. PRAWDOPODOBIEŃSTWA) ZADANIA Zadanie 0.1 Zmienna losowa X ma rozkład określony funkcją prawdopodobieństwa: x k 0 4 p k 1/3 1/6 1/ obliczyć EX, D X. (odp. 4/3;
STATYSTYKA MATEMATYCZNA ZESTAW 0 (POWT. RACH. PRAWDOPODOBIEŃSTWA) ZADANIA Zadanie 0.1 Zmienna losowa X ma rozkład określony funkcją prawdopodobieństwa: x k 0 4 p k 1/3 1/6 1/ obliczyć EX, D X. (odp. 4/3;
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 23 maja 2018 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji
 Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Wykład 12 Testowanie hipotez dla współczynnika korelacji Wrocław, 24 maja 2017 Współczynnik korelacji Niech będą dane dwie próby danych X = (X 1, X 2,..., X n ) oraz Y = (Y 1, Y 2,..., Y n ). Współczynnikiem
Recenzja rozprawy doktorskiej mgr Łukasza Gadomera pt. Rozmyte lasy losowe oparte na modelach klastrowych drzew decyzyjnych w zadaniach klasyfikacji
 Prof. dr hab. inż. Eulalia Szmidt Instytut Badań Systemowych Polskiej Akademii Nauk ul. Newelska 6 01-447 Warszawa E-mail: szmidt@ibspan.waw.pl Warszawa, 30.04.2019r. Recenzja rozprawy doktorskiej mgr
Prof. dr hab. inż. Eulalia Szmidt Instytut Badań Systemowych Polskiej Akademii Nauk ul. Newelska 6 01-447 Warszawa E-mail: szmidt@ibspan.waw.pl Warszawa, 30.04.2019r. Recenzja rozprawy doktorskiej mgr
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Estymacja parametrów modeli liniowych oraz ocena jakości dopasowania modeli do danych empirycznych
 Estymacja parametrów modeli liniowych oraz ocena jakości dopasowania modeli do danych empirycznych 3.1. Estymacja parametrów i ocena dopasowania modeli z jedną zmienną 23. Właściciel komisu w celu zbadania
Estymacja parametrów modeli liniowych oraz ocena jakości dopasowania modeli do danych empirycznych 3.1. Estymacja parametrów i ocena dopasowania modeli z jedną zmienną 23. Właściciel komisu w celu zbadania
Ekonometria, lista zadań nr 6 Zadanie 5 H X 1, X 2, X 3
 Ekonometria, lista zadań nr 6 Zadanie 5 Poniższy diagram przedstawia porządek między rozważanymi modelami oparty na relacji zawierania pomiędzy podzbiorami zbioru zmiennych objaśniających: H, X 2, X 3
Ekonometria, lista zadań nr 6 Zadanie 5 Poniższy diagram przedstawia porządek między rozważanymi modelami oparty na relacji zawierania pomiędzy podzbiorami zbioru zmiennych objaśniających: H, X 2, X 3
... (środowisko) ... ... 60 minut
 ... ... 60 minut") EGZAMIN MATURALNY OD ROKU SZKOLNEGO 2014/2015 INFORMATYKA POZIOM ROZSZERZONY ARKUSZ I PRZYKŁADOWY ZESTAW ZADAŃ DLA OSÓB Z AUTYZMEM, W TYM Z ZESPOŁEM ASPERGERA (A2) WYBRANE:... (środowisko)... (kompilator)...
EGZAMIN MATURALNY OD ROKU SZKOLNEGO 2014/2015 INFORMATYKA POZIOM ROZSZERZONY ARKUSZ I PRZYKŁADOWY ZESTAW ZADAŃ DLA OSÓB Z AUTYZMEM, W TYM Z ZESPOŁEM ASPERGERA (A2) WYBRANE:... (środowisko)... (kompilator)...
Raport Testy Trenerskie. Kadr Makroregionalnych Polskiego Związku Podnoszenia Ciężarów
 Raport Testy Trenerskie Kadr Makroregionalnych Polskiego Związku Podnoszenia Ciężarów W trakcie zgrupowań Kadr Makroregionalnych Polskiego Związku Podnoszenia Ciężarów, poddano zawodników Testom Trenerskim.
Raport Testy Trenerskie Kadr Makroregionalnych Polskiego Związku Podnoszenia Ciężarów W trakcie zgrupowań Kadr Makroregionalnych Polskiego Związku Podnoszenia Ciężarów, poddano zawodników Testom Trenerskim.
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y. 2. Współczynnik korelacji Pearsona
 KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
KORELACJA 1. Wykres rozrzutu ocena związku między zmiennymi X i Y 2. Współczynnik korelacji Pearsona 3. Siła i kierunek związku między zmiennymi 4. Korelacja ma sens, tylko wtedy, gdy związek między zmiennymi
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta
 Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Algorytm wstecznej propagacji błędów dla sieci RBF Michał Bereta www.michalbereta.pl Sieci radialne zawsze posiadają jedną warstwę ukrytą, która składa się z neuronów radialnych. Warstwa wyjściowa składa
Ćwiczenie 12. Metody eksploracji danych
 Ćwiczenie 12. Metody eksploracji danych Modelowanie regresji (Regression modeling) 1. Zadanie regresji Modelowanie regresji jest metodą szacowania wartości ciągłej zmiennej celu. Do najczęściej stosowanych
Ćwiczenie 12. Metody eksploracji danych Modelowanie regresji (Regression modeling) 1. Zadanie regresji Modelowanie regresji jest metodą szacowania wartości ciągłej zmiennej celu. Do najczęściej stosowanych
Czas pracy: 60 minut
 EGZAMIN MATURALNY OD ROKU SZKOLNEGO 2014/2015 INFORMATYKA POZIOM ROZSZERZONY ARKUSZ I PRZYKŁADOWY ZESTAW ZADAŃ DLA OSÓB SŁABOSŁYSZĄCYCH (A3) WYBRANE:... (środowisko)... (kompilator)... (program użytkowy)
EGZAMIN MATURALNY OD ROKU SZKOLNEGO 2014/2015 INFORMATYKA POZIOM ROZSZERZONY ARKUSZ I PRZYKŁADOWY ZESTAW ZADAŃ DLA OSÓB SŁABOSŁYSZĄCYCH (A3) WYBRANE:... (środowisko)... (kompilator)... (program użytkowy)
Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta www.michalbereta.pl Modele liniowe W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych
Wprowadzenie do programu RapidMiner Studio 7.6, część 9 Modele liniowe Michał Bereta www.michalbereta.pl Modele liniowe W programie RapidMiner mamy do dyspozycji kilka dyskryminacyjnych modeli liniowych
Bioinformatyka Laboratorium, 30h. Michał Bereta
 Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Wyszukiwanie sekwencji Jak wyszukad z baz danych bioinformatycznych sekwencje podobne do sekwencji zadanej (ang. query
Bioinformatyka Laboratorium, 30h Michał Bereta mbereta@pk.edu.pl www.michalbereta.pl 1 Wyszukiwanie sekwencji Jak wyszukad z baz danych bioinformatycznych sekwencje podobne do sekwencji zadanej (ang. query
Przypomnienie: Ćwiczenie 1.
 Strona1 Przypomnienie: Zmienne statystyczne można podzielić na: 1. Ilościowe, czyli mierzalne (przedstawiane liczbowo) w tym: skokowe inaczej dyskretne (przyjmują skończoną lub co najwyżej przeliczalną
Strona1 Przypomnienie: Zmienne statystyczne można podzielić na: 1. Ilościowe, czyli mierzalne (przedstawiane liczbowo) w tym: skokowe inaczej dyskretne (przyjmują skończoną lub co najwyżej przeliczalną
Spis treści. LaboratoriumV: Podstawy korelacji i regresji. Inżynieria biomedyczna, I rok, semestr letni 2014/2015 Analiza danych pomiarowych
 1 LaboratoriumV: Podstawy korelacji i regresji Spis treści Laboratorium V: Podstawy korelacji i regresji...1 Wiadomości ogólne...2 1. Wstęp teoretyczny....2 1.1 Korelacja....2 1.2 Funkcja regresji....5
1 LaboratoriumV: Podstawy korelacji i regresji Spis treści Laboratorium V: Podstawy korelacji i regresji...1 Wiadomości ogólne...2 1. Wstęp teoretyczny....2 1.1 Korelacja....2 1.2 Funkcja regresji....5
Tworzenie prostej etykiety i synchronizacja etykiet z wagą. AXIS Sp. z o.o. Kod produktu:
 Tworzenie prostej etykiety i synchronizacja etykiet z wagą Współpraca wagi z etykieciarką wymaga zaprojektowania formy (szablonu) etykiety na komputerze i zapisania jej w pamięci etykieciarki. Następnie
Tworzenie prostej etykiety i synchronizacja etykiet z wagą Współpraca wagi z etykieciarką wymaga zaprojektowania formy (szablonu) etykiety na komputerze i zapisania jej w pamięci etykieciarki. Następnie
Bazy danych TERMINOLOGIA
 Bazy danych TERMINOLOGIA Dane Dane są wartościami przechowywanymi w bazie danych. Dane są statyczne w tym sensie, że zachowują swój stan aż do zmodyfikowania ich ręcznie lub przez jakiś automatyczny proces.
Bazy danych TERMINOLOGIA Dane Dane są wartościami przechowywanymi w bazie danych. Dane są statyczne w tym sensie, że zachowują swój stan aż do zmodyfikowania ich ręcznie lub przez jakiś automatyczny proces.
KORELACJE I REGRESJA LINIOWA
 KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
KORELACJE I REGRESJA LINIOWA Korelacje i regresja liniowa Analiza korelacji: Badanie, czy pomiędzy dwoma zmiennymi istnieje zależność Obie analizy się wzajemnie przeplatają Analiza regresji: Opisanie modelem
1: 2: 3: 4: 5: 6: 7: 8: 9: 10:
 Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
Podstawowe definicje statystyczne
 Podstawowe definicje statystyczne 1. Definicje podstawowych wskaźników statystycznych Do opisu wyników surowych (w punktach, w skali procentowej) stosuje się następujące wskaźniki statystyczne: wynik minimalny
Podstawowe definicje statystyczne 1. Definicje podstawowych wskaźników statystycznych Do opisu wyników surowych (w punktach, w skali procentowej) stosuje się następujące wskaźniki statystyczne: wynik minimalny
Inżynieria biomedyczna, I rok, semestr letni 2014/2015 Analiza danych pomiarowych. Laboratorium VIII: Analiza kanoniczna
 1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
1 Laboratorium VIII: Analiza kanoniczna Spis treści Laboratorium VIII: Analiza kanoniczna... 1 Wiadomości ogólne... 2 1. Wstęp teoretyczny.... 2 Przykład... 2 Podstawowe pojęcia... 2 Założenia analizy
Przygotowanie materiału uczącego dla OCR w oparciu o aplikację Wycinanki.
 Przygotowanie materiału uczącego dla OCR w oparciu o aplikację Wycinanki. Zespół bibliotek cyfrowych PCSS 6 maja 2011 1 Cel aplikacji Aplikacja wspomaga przygotowanie poprawnego materiału uczącego dla
Przygotowanie materiału uczącego dla OCR w oparciu o aplikację Wycinanki. Zespół bibliotek cyfrowych PCSS 6 maja 2011 1 Cel aplikacji Aplikacja wspomaga przygotowanie poprawnego materiału uczącego dla
Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl. Program RapidMiner (RM) ma trzy główne widoki (perspektywy):
 ma trzy główne widoki (perspektywy):") Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community Edition.
Wprowadzenie do programu RapidMiner, częśd 1 Michał Bereta www.michalbereta.pl Program Rapid Miner jest dostępny na stronie: http://rapid-i.com/ Korzystamy z bezpłatnej wersji RapidMiner Community Edition.
opisuje nazwy kolumn, wyrażenia arytmetyczne, funkcje nazwy tabel lub widoków warunek (wybieranie wierszy)
") Zapytania SQL. Polecenie SELECT jest używane do pobierania danych z bazy danych (z tabel lub widoków). Struktura polecenia SELECT SELECT FROM WHERE opisuje nazwy kolumn, wyrażenia arytmetyczne, funkcje
Zapytania SQL. Polecenie SELECT jest używane do pobierania danych z bazy danych (z tabel lub widoków). Struktura polecenia SELECT SELECT FROM WHERE opisuje nazwy kolumn, wyrażenia arytmetyczne, funkcje
Wartośd aktywów w analizie ryzyka bezpieczeostwa informacji
 Strona1 Wartośd aktywów w analizie ryzyka bezpieczeostwa informacji Spis treści I Wstęp... 2 II. W jakim celu określa się wartośd aktywów?... 2 III. Wartościowanie aktywów... 3 IV. Powiązanie istotności
Strona1 Wartośd aktywów w analizie ryzyka bezpieczeostwa informacji Spis treści I Wstęp... 2 II. W jakim celu określa się wartośd aktywów?... 2 III. Wartościowanie aktywów... 3 IV. Powiązanie istotności
Techniki grupowania danych w środowisku Matlab
 Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów
 LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
LEMRG algorytm generowania pokoleń reguł decyzji dla baz danych z dużą liczbą atrybutów Łukasz Piątek, Jerzy W. Grzymała-Busse Katedra Systemów Ekspertowych i Sztucznej Inteligencji, Wydział Informatyki
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny