Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
|
|
|
- Małgorzata Czerwińska
- 5 lat temu
- Przeglądów:
Transkrypt
1 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
2 Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów ciągłych (wartości z R) na dyskretne (przyjmujące jedną ze z góry ustalonych możliwych wartości). Terminu używa się także w przypadku agregacji atrybutów porządkowych, tzn. rzutowaniu atrybutów przyjmujących wartości całkowite na mniejszą liczbę reprezentantów.
3 Dyskretyzacja - cele Dyskretyzacja umożliwia zastosowanie klasyfikatorów, które nie obsługują wartości ciągłych. W przypadku klasyfikatorów obsługujących atrybuty ciągłe, dyskretyzacja pozwala na uproszczenie modelu klasyfikatora, a także pozwala osiągnąć lepsze wyniki klasyfikacji.
4 Pomysł Algorytmy klasteryzacji dzielą zbiór danych na grupy (klasy), w taki sposób, żeby zmaksymalizować podobieństwo próbek w ramach jednej klasy i zminimalizować podobieństwo grup między sobą. Pozwala to na: równomierne pokrycie próbek reprezentantami klas, uproszczenie rozwiązywanego problemu dzięki użyciu reprezentantów zamiast pełnego zakresu danych. Dlaczego więc nie zastosować klasteryzacji jako metody dyskretyzacji?
5 Ogólny algorytm 1. Posiadamy macierz M (n,m+1) z próbkami uczącymi. W n wierszach znajdują się kolejne próbki, które opisane są m atrybutami i klasą decyzyjną. 2. Dla każdego i=1,,m: 1. Przypisz do X i-tą kolumnę z M; 2. Przeprowadź dyskretyzacje dla X; 3. Wyznacz przedziały dyskretyzacji na podstawie wyniku dyskretyzacji; 4. Rzutuj wartości z X na odpowiadające im przedziały dyskretyzacji. 3. Uruchom algorytm klasyfikacji na zdyskretyzowanych danych.
6 Korzyści Wartości, których występuje więcej mają większy wpływ na wynik klasyfikacji. Pokrywamy zakres danych przedziałami dyskretyzacji w taki sposób, że: Każda liczna grupa posiada swojego reprezentanta; Grupy o małej liczbie próbek także posiadają swoich reprezentantów*; Duże grupy mogą zostać rozdzielone na wiele przedziałów dyskretyzacji. *w zależności od maksymalnej liczby przedziałów dyskretyzacji;
7 Badane algorytmy i ich warianty Dyskretyzacja równych przedziałów; Dyskretyzacja równych częstotliwości; Rosnący gaz neuronowy: Warunek stopu: liczba spójnych składowych topologii równa zadanej liczbie przedziałów dyskretyzacji -1; Warunek stopu: liczba neuronów równa zadanej liczbie przedziałów dyskretyzacji -1; Algorytm k-średnich: Klasyczne rzutowanie próbek na przedziały dyskretyzacji wykorzystując diagramy Woronoja; Ważone rzutowanie próbek.

8 Klasyfikacja metod dyskretyzacji
9 Algorytm k-średnich 1. Wybierz k początkowych środków i przyporządkuj każda próbkę do najbliższego środka. 2. Oblicz środki ciężkości dla każdej z grup. 3. Przyporządkuj każdą próbkę do najbliższego środka ciężkości. 4. Powtarzaj punkty 2 i 3 tak długo, póki występują zmiany przyporządkowania.
10 Dyskretyzacja na podstawie algorytmu k-średnich
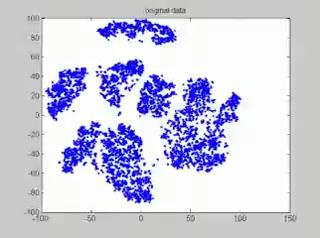
11 Algorytm k-średnich
12 Pozostałe algorytmy (1) Dyskretyzacja równych przedziałów Dzieli dziedzinę atrybutu na zadaną liczbę przedziałów o równej długości. Dyskretyzacja równych częstotliwości Sortuje wartości atrybutu, a następnie przydziela kolejno do przedziałów dyskretyzacji tak długo, aż liczba wartości w przedziale nie przekroczy (liczba próbek/liczba przedziałów).
 graf, który posiada spójne składowe w obszarach, na których gęstość P przyjmuje")
13 Pozostałe algorytmy (2) Rosnący gaz neuronowy Dla rozkładu P tworzy indukowaną triangulacje Delaunay (ang. induced Delaunay triangulation) graf, który posiada spójne składowe w obszarach, na których gęstość P przyjmuje wysokie wartości.
14 Histogram
15 Dyskretyzacja równoczęstotliwościowa
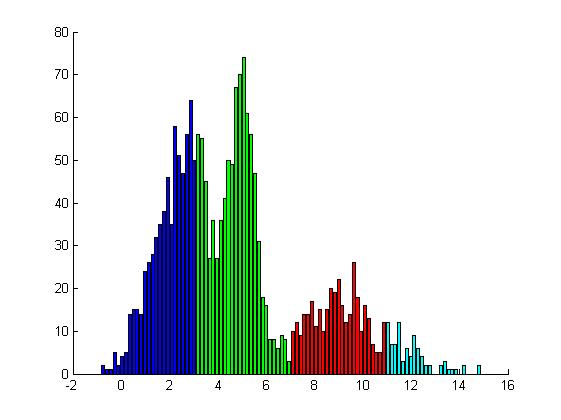
16 Dyskretyzacja równoprzedziałowa
17 Pożądany wynik dyskretyzacji wykorzystującej klasteryzację
18 Miara efektów (1) Nie istnieje jedna właściwa miara efektów dyskretyzacji. Często używa się miar bazujących na entropii. Pozwala to na szybką ocenę podziału i jest możliwe do zastosowania np. w k krotnej walidacji krzyżowej.
19 Miara efektów (2) Miary bazujące na entropii nie są jednak idealne. Stosowanie ich oznacza przyjęcie założenia o niezależności zmiennych, podobnego jak w naiwnym klasyfikatorze Bayesa. W przypadku klasyfikatorów regułowych może to utrudniać budowę poprawnego modelu.
20 Miara efektów (3) Celem przeprowadzenia dyskretyzacji jest skorzystanie z klasyfikatora. Z tego też względu jako najbardziej rzetelną miarę efektów dyskretyzacji postanowiliśmy przyjąć procent poprawnie sklasyfikowanych próbek przy użyciu różnych klasyfikatorów, jednocześnie budując model klasyfikatora przy użyciu 10 krotnej walidacji krzyżowej.
21 Metodyka badań i wyniki (1) Testy przeprowadziliśmy dla zbiorów danych: Ionosphere, iris, wheather Użyliśmy klasyfikatorów: Tabele decyzyjne, PART, Ridor Zbadaliśmy następujące liczby przedziałów: 5,6,7 I wykonaliśmy 10-krotną walidację krzyżową dla każdego możliwego zestawienia parametrów.
22 Metodyka badań i wyniki (2) Poskutkowało to przeprowadzeniem 270 testów. Badania zostały wykonane przy użyciu środowiska Weka, zaś testowane algorytmy dyskretyzacji zostały zaimplementowane jako filtry danych.
23 Wyniki: Rosnący gaz neuronowy (1) Wyniki pokazują, że rosnący gaz neuronowy nie nadaje się do zastosowania jako metoda jednowymiarowej klasteryzacji. W żadnym z wariantów nie udało się uzyskać satysfakcjonujących wyników. Wariant pierwszy aby uzyskać zadaną liczbę spójnych składowych musiał korzystać z takich wartości parametrów, które powodowały, że spójne składowe były wyznaczone losowo.
24 Wyniki: Rosnący gaz neuronowy (2) Wariant drugi także nie przyniósł pożądanych efektów. Sąsiedztwo topologiczne w jednowymiarowej przestrzeni powodowało, że wszystkie neurony były skupione w jednym obszarze, nie pokrywając równomiernie całego przedziału. W wyniku otrzymywaliśmy histogram z wysoką wartością w jednym przedziale i bliskimi zeru wartościami w pozostałych.

25 Tabela wyników zbiorczych
26 Średni wynik w zależności od algorytmu i zbioru danych ionosphere iris weather EqualFrequency EqualWidth KMeans KMeansWeighted
27 Praktyczne zastosowania
28 Dalsze możliwości rozwoju Dyskretyzacja wieloatrybutowa dyskretyzacja połączona z redukcją wymiarowości. Uruchamia się proces klasteryzacji dla większej liczby wymiarów, przeprowadza klasteryzacje i na podstawie uzyskanych klastrów przeprowadza dyskretyzacje wielu atrybutów w jeden.
29 Dziękuję za uwagę
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Sprawozdanie z zadania Modele predykcyjne (2)
") Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji
 Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Identyfikacja istotnych atrybutów za pomocą Baysowskich miar konfirmacji Jacek Szcześniak Jerzy Błaszczyński Roman Słowiński Poznań, 5.XI.2013r. Konspekt Wstęp Wprowadzenie Metody typu wrapper Nowe metody
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Co to znaczy eksploracja danych Klastrowanie (grupowanie) hierarchiczne Klastrowanie
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Co to jest grupowanie
 Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Grupowanie danych Co to jest grupowanie 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Szukanie grup, obszarów stanowiących lokalne gromady punktów Co to jest grupowanie
Systemy uczące się wykład 1
 Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
Systemy uczące się wykład 1 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 5 X 2018 e-mail: przemyslaw.juszczuk@ue.katowice.pl Konsultacje: na stronie katedry + na stronie domowej
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Sieci Kohonena Grupowanie
 Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
Sieci Kohonena Grupowanie http://zajecia.jakubw.pl/nai UCZENIE SIĘ BEZ NADZORU Załóżmy, że mamy za zadanie pogrupować następujące słowa: cup, roulette, unbelievable, cut, put, launderette, loveable Nie
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Ontogeniczne sieci neuronowe. O sieciach zmieniających swoją strukturę
 Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Norbert Jankowski Ontogeniczne sieci neuronowe O sieciach zmieniających swoją strukturę Warszawa 2003 Opracowanie książki było wspierane stypendium Uniwersytetu Mikołaja Kopernika Spis treści Wprowadzenie
Asocjacyjna reprezentacja danych i wnioskowanie
 Asocjacyjna reprezentacja danych i wnioskowanie Wykorzystane technologie JetBrains PyCharm 504 Python 35 Struktura drzewa GRAPH PARAM PARAM ID1 ID2 ID_N params params params param_name_1: param_value_1
Asocjacyjna reprezentacja danych i wnioskowanie Wykorzystane technologie JetBrains PyCharm 504 Python 35 Struktura drzewa GRAPH PARAM PARAM ID1 ID2 ID_N params params params param_name_1: param_value_1
Kurs Chemometrii Poznań 28 listopad 2006
 Komisja Nauk Chemicznych Polskiej Akademii Nauk Oddział w Poznaniu Wydział Technologii Chemicznej Politechniki Poznańskiej w Poznaniu GlaxoSmithKline Pharmaceuticals S.A. w Poznaniu Stowarzyszenie ISPE
Komisja Nauk Chemicznych Polskiej Akademii Nauk Oddział w Poznaniu Wydział Technologii Chemicznej Politechniki Poznańskiej w Poznaniu GlaxoSmithKline Pharmaceuticals S.A. w Poznaniu Stowarzyszenie ISPE
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Obliczenia iteracyjne
 Lekcja Strona z Obliczenia iteracyjne Zmienne iteracyjne (wyliczeniowe) Obliczenia iteracyjne wymagają zdefiniowania specjalnej zmiennej nazywanej iteracyjną lub wyliczeniową. Zmienną iteracyjną od zwykłej
Lekcja Strona z Obliczenia iteracyjne Zmienne iteracyjne (wyliczeniowe) Obliczenia iteracyjne wymagają zdefiniowania specjalnej zmiennej nazywanej iteracyjną lub wyliczeniową. Zmienną iteracyjną od zwykłej
Drzewa decyzyjne i lasy losowe
 Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Drzewa decyzyjne i lasy losowe Im dalej w las tym więcej drzew! ML Gdańsk http://www.mlgdansk.pl/ Marcin Zadroga https://www.linkedin.com/in/mzadroga/ 20 Czerwca 2017 WPROWADZENIE DO MACHINE LEARNING CZYM
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Sieci neuronowe w Statistica
 http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
http://usnet.us.edu.pl/uslugi-sieciowe/oprogramowanie-w-usk-usnet/oprogramowaniestatystyczne/ Sieci neuronowe w Statistica Agnieszka Nowak - Brzezińska Podstawowym elementem składowym sztucznej sieci neuronowej
Plan wykładu. Przykład. Przykład 3/19/2011. Przykład zagadnienia transportowego. Optymalizacja w procesach biznesowych Wykład 2 DECYZJA?
 /9/ Zagadnienie transportowe Optymalizacja w procesach biznesowych Wykład --9 Plan wykładu Przykład zagadnienia transportowego Sformułowanie problemu Własności zagadnienia transportowego Metoda potencjałów
/9/ Zagadnienie transportowe Optymalizacja w procesach biznesowych Wykład --9 Plan wykładu Przykład zagadnienia transportowego Sformułowanie problemu Własności zagadnienia transportowego Metoda potencjałów
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
KURS PRAWDOPODOBIEŃSTWO
 KURS PRAWDOPODOBIEŃSTWO Lekcja 6 Ciągłe zmienne losowe ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 Zmienna losowa ciągła jest
KURS PRAWDOPODOBIEŃSTWO Lekcja 6 Ciągłe zmienne losowe ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 Zmienna losowa ciągła jest
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Przykładowa analiza danych
 Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Sieci neuronowe w Statistica. Agnieszka Nowak - Brzezioska
 Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Sieci neuronowe w Statistica Agnieszka Nowak - Brzezioska Podstawowym elementem składowym sztucznej sieci neuronowej jest element przetwarzający neuron. Schemat działania neuronu: x1 x2 w1 w2 Dendrites
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek
 Bożena Kostek") Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
Sztuczna Inteligencja w medycynie projekt (instrukcja) Bożena Kostek Cel projektu Celem projektu jest przygotowanie systemu wnioskowania, wykorzystującego wybrane algorytmy sztucznej inteligencji; Nabycie
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Prawdopodobieństwo czerwonych = = 0.33
 Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
Temat zajęć: Naiwny klasyfikator Bayesa a algorytm KNN Część I: Naiwny klasyfikator Bayesa Naiwny klasyfikator bayerowski jest prostym probabilistycznym klasyfikatorem. Naiwne klasyfikatory bayesowskie
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Sztuczna inteligencja : Algorytm KNN
 Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Instytut Informatyki Uniwersytetu Śląskiego 23 kwietnia 2012 1 Algorytm 1 NN 2 Algorytm knn 3 Zadania Klasyfikacja obiektów w oparciu o najbliższe obiekty: Algorytm 1-NN - najbliższego sąsiada. Parametr
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury. Paweł Kobojek, prof. dr hab. inż. Khalid Saeed
 Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Algorytm do rozpoznawania człowieka na podstawie dynamiki użycia klawiatury Paweł Kobojek, prof. dr hab. inż. Khalid Saeed Zakres pracy Przegląd stanu wiedzy w dziedzinie biometrii, ze szczególnym naciskiem
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, rozważane dotychczas problemy koncentrowały się na nauczeniu na podstawie zbioru treningowego i zbioru etykiet klasyfikacji
Wybór / ocena atrybutów na podstawie oceny jakości działania wybranego klasyfikatora.
 Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
Wprowadzenie do programu RapidMiner Studio 7.6, część 7 Podstawy metod wyboru atrybutów w problemach klasyfikacyjnych, c.d. Michał Bereta www.michalbereta.pl Wybór / ocena atrybutów na podstawie oceny
2. Reprezentacje danych wielowymiarowych sposoby sobie radzenia z nimi. a. Wprowadzenie, aspekt psychologiczny, wady statystyki
 1. Wstęp 2. Reprezentacje danych wielowymiarowych sposoby sobie radzenia z nimi a. Wprowadzenie, aspekt psychologiczny, wady statystyki b. Metody graficzne i. Wykres 1.zmiennej ii. Rzut na 2 współrzędne
1. Wstęp 2. Reprezentacje danych wielowymiarowych sposoby sobie radzenia z nimi a. Wprowadzenie, aspekt psychologiczny, wady statystyki b. Metody graficzne i. Wykres 1.zmiennej ii. Rzut na 2 współrzędne
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane.
 Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
WSTĘP I TAKSONOMIA METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Wstęp do sieci neuronowych, wykład 12 Łańcuchy Markowa
 Wstęp do sieci neuronowych, wykład 12 Łańcuchy Markowa M. Czoków, J. Piersa 2012-01-10 1 Łańcucha Markowa 2 Istnienie Szukanie stanu stacjonarnego 3 1 Łańcucha Markowa 2 Istnienie Szukanie stanu stacjonarnego
Wstęp do sieci neuronowych, wykład 12 Łańcuchy Markowa M. Czoków, J. Piersa 2012-01-10 1 Łańcucha Markowa 2 Istnienie Szukanie stanu stacjonarnego 3 1 Łańcucha Markowa 2 Istnienie Szukanie stanu stacjonarnego
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Wstęp do sieci neuronowych, wykład 8 Uczenie nienadzorowane.
 Wstęp do sieci neuronowych, wykład 8. M. Czoków, J. Piersa, A. Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 1-811-6 Projekt pn. Wzmocnienie potencjału dydaktycznego
Wstęp do sieci neuronowych, wykład 8. M. Czoków, J. Piersa, A. Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 1-811-6 Projekt pn. Wzmocnienie potencjału dydaktycznego
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Metody iteracyjne rozwiązywania układów równań liniowych (5.3) Normy wektorów i macierzy (5.3.1) Niech. x i. i =1
 Normy wektorów i macierzy (5.3.1) Niech. x i. i =1") Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
Normy wektorów i macierzy (5.3.1) Niech 1 X =[x x Y y =[y1 x n], oznaczają wektory przestrzeni R n, a yn] niech oznacza liczbę rzeczywistą. Wyrażenie x i p 5.3.1.a X p = p n i =1 nosi nazwę p-tej normy
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ
 IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
IMPLEMENTACJA SIECI NEURONOWYCH MLP Z WALIDACJĄ KRZYŻOWĄ Celem ćwiczenia jest zapoznanie się ze sposobem działania sieci neuronowych typu MLP (multi-layer perceptron) uczonych nadzorowaną (z nauczycielem,
RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk
 Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
1. Eliminuje się ze zbioru potencjalnych zmiennych te zmienne dla których korelacja ze zmienną objaśnianą jest mniejsza od krytycznej:
 Metoda analizy macierzy współczynników korelacji Idea metody sprowadza się do wyboru takich zmiennych objaśniających, które są silnie skorelowane ze zmienną objaśnianą i równocześnie słabo skorelowane
Metoda analizy macierzy współczynników korelacji Idea metody sprowadza się do wyboru takich zmiennych objaśniających, które są silnie skorelowane ze zmienną objaśnianą i równocześnie słabo skorelowane
Spis treści 377 379 WSTĘP... 9
 Spis treści 377 379 Spis treści WSTĘP... 9 ZADANIE OPTYMALIZACJI... 9 PRZYKŁAD 1... 9 Założenia... 10 Model matematyczny zadania... 10 PRZYKŁAD 2... 10 PRZYKŁAD 3... 11 OPTYMALIZACJA A POLIOPTYMALIZACJA...
Spis treści 377 379 Spis treści WSTĘP... 9 ZADANIE OPTYMALIZACJI... 9 PRZYKŁAD 1... 9 Założenia... 10 Model matematyczny zadania... 10 PRZYKŁAD 2... 10 PRZYKŁAD 3... 11 OPTYMALIZACJA A POLIOPTYMALIZACJA...
Programowanie dynamiczne. Tadeusz Trzaskalik
 Programowanie dynamiczne Tadeusz Trzaskalik 9.. Wprowadzenie Słowa kluczowe Wieloetapowe procesy decyzyjne Zmienne stanu Zmienne decyzyjne Funkcje przejścia Korzyści (straty etapowe) Funkcja kryterium
Programowanie dynamiczne Tadeusz Trzaskalik 9.. Wprowadzenie Słowa kluczowe Wieloetapowe procesy decyzyjne Zmienne stanu Zmienne decyzyjne Funkcje przejścia Korzyści (straty etapowe) Funkcja kryterium
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
Metody Sztucznej Inteligencji II
 17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
17 marca 2013 Neuron biologiczny Neuron Jest podstawowym budulcem układu nerwowego. Jest komórką, która jest w stanie odbierać i przekazywać sygnały elektryczne. Neuron działanie Jeżeli wartość sygnału
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Klasyfikacja LDA + walidacja
 Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
Klasyfikacja LDA + walidacja Dr hab. Izabela Rejer Wydział Informatyki Zachodniopomorski Uniwersytet Technologiczny w Szczecinie Plan wykładu 1. Klasyfikator 2. LDA 3. Klasyfikacja wieloklasowa 4. Walidacja
9. Praktyczna ocena jakości klasyfikacji
 Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Algorytmy rozpoznawania obrazów 9. Praktyczna ocena jakości klasyfikacji dr inż. Urszula Libal Politechnika Wrocławska 2015 1 1. Zbiór uczacy i zbiór testowy 1. Zbiór uczacy służy do konstrukcji (treningu)
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
CZEŚĆ PIERWSZA. Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III I. POTĘGI
 Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III CZEŚĆ PIERWSZA I. POTĘGI Zamienia potęgi o wykładniku całkowitym ujemnym na odpowiednie potęgi o wykładniku naturalnym. Oblicza wartości
Wymagania na poszczególne oceny,,matematyka wokół nas Klasa III CZEŚĆ PIERWSZA I. POTĘGI Zamienia potęgi o wykładniku całkowitym ujemnym na odpowiednie potęgi o wykładniku naturalnym. Oblicza wartości
METODY INŻYNIERII WIEDZY
 METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY Metoda K Najbliższych Sąsiadów K-Nearest Neighbours (KNN) ĆWICZENIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization
 Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wrocław University of Technology SPOTKANIE 6: Klasteryzacja: K-Means, Expectation Maximization Jakub M. Tomczak Studenckie Koło Naukowe Estymator jakub.tomczak@pwr.wroc.pl 4.1.213 Klasteryzacja Zmienne
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Matematyczne Podstawy Informatyki
 Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Matematyczne Podstawy Informatyki dr inż. Andrzej Grosser Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Rok akademicki 2013/2014 Informacje podstawowe 1. Konsultacje: pokój
Parametryzacja obrazu na potrzeby algorytmów decyzyjnych
 Parametryzacja obrazu na potrzeby algorytmów decyzyjnych Piotr Dalka Wprowadzenie Z reguły nie stosuje się podawania na wejście algorytmów decyzyjnych bezpośrednio wartości pikseli obrazu Obraz jest przekształcany
Parametryzacja obrazu na potrzeby algorytmów decyzyjnych Piotr Dalka Wprowadzenie Z reguły nie stosuje się podawania na wejście algorytmów decyzyjnych bezpośrednio wartości pikseli obrazu Obraz jest przekształcany
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
ZeroR. Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F
 ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 5 T 7 T 5 T 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator ZeroR będzie zawsze odpowiadał T niezależnie
INSTRUKCJA DO ĆWICZENIA NR 4
 KATEDRA MECHANIKI STOSOWANEJ Wydział Mechaniczny POLITECHNIKA LUBELSKA INSTRUKCJA DO ĆWICZENIA NR 4 PRZEDMIOT TEMAT Wybrane zagadnienia z optymalizacji elementów konstrukcji Zastosowanie optymalizacji
KATEDRA MECHANIKI STOSOWANEJ Wydział Mechaniczny POLITECHNIKA LUBELSKA INSTRUKCJA DO ĆWICZENIA NR 4 PRZEDMIOT TEMAT Wybrane zagadnienia z optymalizacji elementów konstrukcji Zastosowanie optymalizacji
Zagadnienie transportowe
 9//9 Zagadnienie transportowe Optymalizacja w procesach biznesowych Wykład Plan wykładu Przykład zagadnienia transportowego Sformułowanie problemu Własności zagadnienia transportowego Metoda potencjałów
9//9 Zagadnienie transportowe Optymalizacja w procesach biznesowych Wykład Plan wykładu Przykład zagadnienia transportowego Sformułowanie problemu Własności zagadnienia transportowego Metoda potencjałów
Analiza głównych składowych- redukcja wymiaru, wykł. 12
 Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Reprezentacja i analiza obszarów
 Cechy kształtu Topologiczne Geometryczne spójność liczba otworów liczba Eulera szkielet obwód pole powierzchni środek ciężkości ułożenie przestrzenne momenty wyższych rzędów promienie max-min centryczność
Cechy kształtu Topologiczne Geometryczne spójność liczba otworów liczba Eulera szkielet obwód pole powierzchni środek ciężkości ułożenie przestrzenne momenty wyższych rzędów promienie max-min centryczność
Algorytmy i struktury danych. Wykład 4
 Wykład 4 Różne algorytmy - obliczenia 1. Obliczanie wartości wielomianu 2. Szybkie potęgowanie 3. Algorytm Euklidesa, liczby pierwsze, faktoryzacja liczby naturalnej 2017-11-24 Algorytmy i struktury danych
Wykład 4 Różne algorytmy - obliczenia 1. Obliczanie wartości wielomianu 2. Szybkie potęgowanie 3. Algorytm Euklidesa, liczby pierwsze, faktoryzacja liczby naturalnej 2017-11-24 Algorytmy i struktury danych
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Na podstawie dokonanych obserwacji:
 PODSTAWOWE PROBLEMY STATYSTYKI MATEMATYCZNEJ Niech mamy próbkę X 1,..., X n oraz przestrzeń prób X n, i niech {X i } to niezależne zmienne losowe o tym samym rozkładzie P θ P. Na podstawie obserwacji chcemy
PODSTAWOWE PROBLEMY STATYSTYKI MATEMATYCZNEJ Niech mamy próbkę X 1,..., X n oraz przestrzeń prób X n, i niech {X i } to niezależne zmienne losowe o tym samym rozkładzie P θ P. Na podstawie obserwacji chcemy
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Laboratorium 6. Indukcja drzew decyzyjnych.
 Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Techniki uczenia maszynowego nazwa przedmiotu SYLABUS
 Techniki uczenia maszynowego nazwa SYLABUS Obowiązuje od cyklu kształcenia: 2014/20 Część A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej studiów Poziom kształcenia Profil studiów
Techniki uczenia maszynowego nazwa SYLABUS Obowiązuje od cyklu kształcenia: 2014/20 Część A. Informacje ogólne Elementy składowe sylabusu Nazwa jednostki prowadzącej studiów Poziom kształcenia Profil studiów
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO
 SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
SCHEMAT ROZWIĄZANIA ZADANIA OPTYMALIZACJI PRZY POMOCY ALGORYTMU GENETYCZNEGO. Rzeczywistość (istniejąca lub projektowana).. Model fizyczny. 3. Model matematyczny (optymalizacyjny): a. Zmienne projektowania
Algorytmy zrandomizowane
 Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Algorytmy zrandomizowane http://zajecia.jakubw.pl/nai ALGORYTMY ZRANDOMIZOWANE Algorytmy, których działanie uzależnione jest od czynników losowych. Algorytmy typu Monte Carlo: dają (po pewnym czasie) wynik
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova
 Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu