projekt zaliczeniowy Eksploracja Danych
|
|
|
- Antonina Wysocka
- 10 lat temu
- Przeglądów:
Transkrypt
1 Ostaszewski Paweł [55566] Piła, projekt zaliczeniowy Eksploracja Danych 1. Obejrzyj histogramy dla wszystkich atrybutów, na podstawie wartości średniej i zakresu wartości oceń, dla których atrybutów należy zidentyfikować osobliwości. Przeprowadź usuwanie osobliwości. Które atrybuty wybrałaś(eś) do usuwania osobliwości? Jaką metodę oznaczania osobliwości wybrałaś(eś) dla każdego atrybutu? Dlaczego? 2. W bazie danych brakujące dane są oznaczone za pomocą znaku?. Znajdź atrybuty zawierające brakujące dane. Tam, gdzie to możliwe, zamień brakujące dane na wartość Not in universe, w przeciwnym przypadku zamień brakujące dane na dominującą wartość atrybutu. Które atrybuty zawierają brakujące wartości? Jeśli nie można było zamienić brakującej wartości na Not in universe, to jaka była dominująca wartość dla danego atrybutu? 3. Wybierz atrybuty numeryczne, które powinny być Twoim zdaniem znormalizowane. Przeprowadź normalizację atrybutów numerycznych. Które atrybuty numeryczne wybrałaś(eś) do normalizacji? Jaką metodą znormalizowałaś(eś) każdy z atrybutów? Dlaczego? 4. Wybierz atrybuty numeryczne, które powinny Twoim zdaniem podlegać dyskretyzacji. Dla każdego atrybutu wybierz najwłaściwszą Twoim zdaniem metodę dyskretyzacji i przedziały dyskretyzacji. Które atrybuty numeryczne wybrałaś(eś) do dyskretyzacji? Jaką metodę, liczbę przedziałów i granice przedziałów wybrałaś(eś) dla każdego atrybutu? Uzasadnij swój wybór. 5. Dokonaj dyskretyzacji atrybutu kategorycznego AMARITL (marital status) na dwie kategorie: osoby zamężne/żonate (3 wartości) i pozostałe (4 wartości) 1

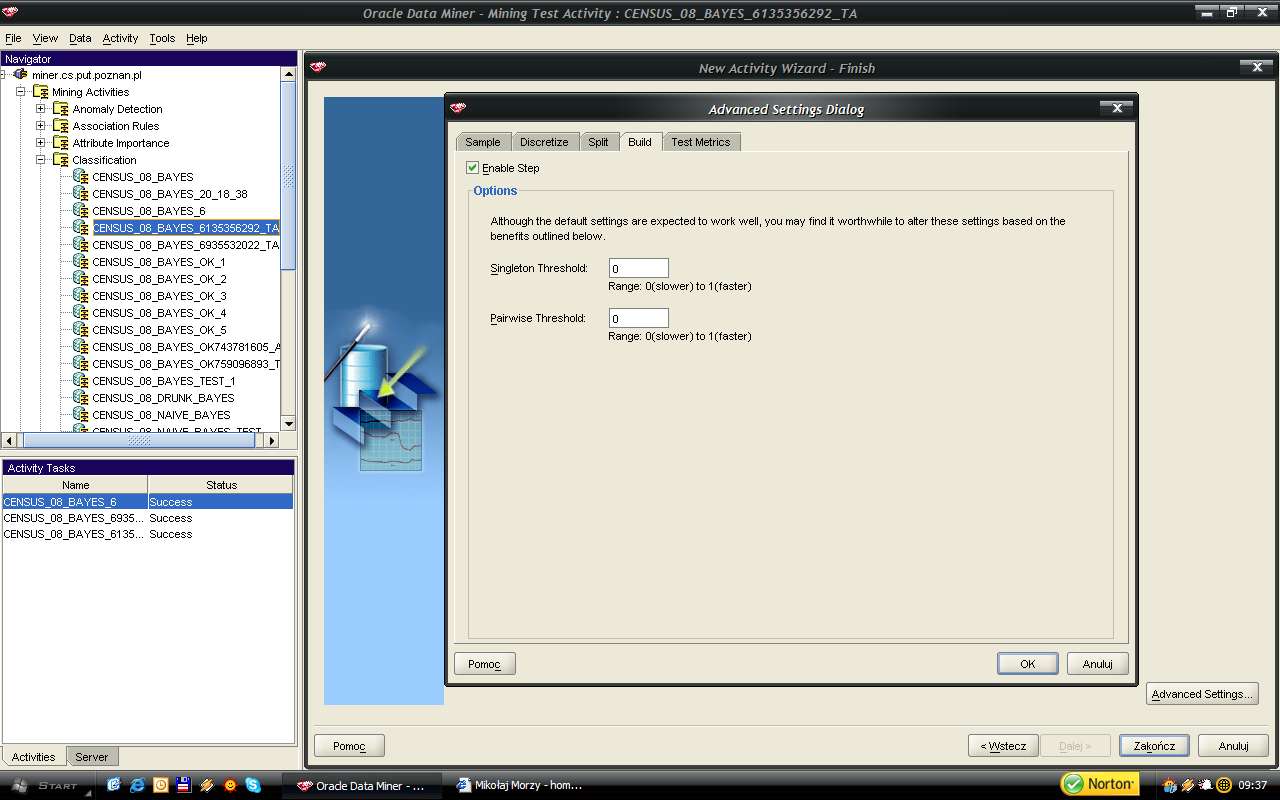
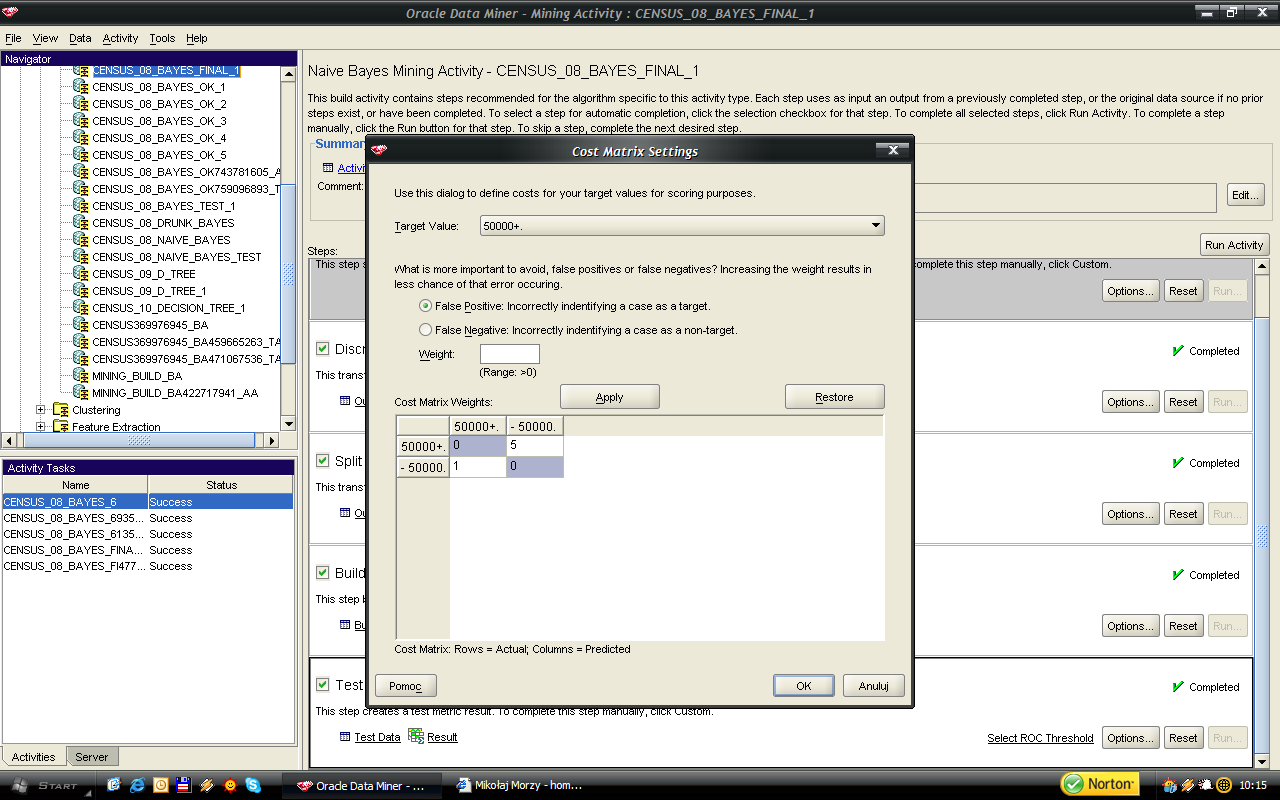
2 Podaj kod perspektywy która umożliwia taką operację 6. Określ ważność atrybutów względem atrybutu decyzyjnego INCOME. W analizie pomiń atrybut MARSUPWT (instance weight) określający względną wagę instancji reprezentowanej przez dany wiersz. Podaj trzy najbardziej przydatne atrybuty do przewidywania wartości atrybutu decyzyjnego. Wytłumacz uzyskany wynik. Podaj trzy najmniej przydatne atrybuty do przewidywania wartości atrybutu decyzyjnego. Wytłumacz uzyskany wynik. 7. Wykorzystaj algorytm k-means do znalezienia najbardziej charakterystycznych skupień cech. Dobierz eksperymentalnie wartość parametru k w taki sposób, aby instancje rozkładały się w miarę równomiernie pośród znalezionych skupień. Podaj wybraną przez siebie wartość parametru k i rozkład instancji w ramach skupień. Wybierz jedno skupienie i starannie je przeanalizuj (obejrzyj histogramy rozkładów wartości poszczególnych atrybutów w skupieniu). Opisz językiem naturalnym instancje przypisane do danego skupienia. Jaka, Twoim zdaniem, grupa/warstwa społeczna jest opisana za pomocą wybranego skupienia? 8. Zbuduj naiwny klasyfikator Bayesa służący do przewidywania wartości atrybutu decyzyjnego INCOME na podstawie wartości pozostałych atrybutów. Wybierz atrybuty, które powinny być włączone do modelu (pozostawienie wszystkich atrybutów skutkuje zbudowaniem modelu niskiej jakości). Jako preferowaną wartość (positive) wybierz Zwróć uwagę, żeby przede wszystkim poprawnie przewidywać preferowaną wartość kosztem ogólnej dokładności modelu (przy sztywnym przewidywaniu klasy dokładność modelu wyniesie i tak 93%). Pamiętaj, żeby zbudowane modele testować z wykorzystaniem tabeli CENSUS_TEST! Które atrybuty weszły w skład modelu? Jak wygląda najlepsza znaleziona przez Ciebie macierz kosztów? Jakie parametry singleton_threshold i pairwise_threshold zostały wykorzystane przy budowie modelu? Jak wyglądała macierz pomyłek? 2

3 3 9. Zbuduj drzewo decyzyjne służące do przewidywania wartości atrybutu decyzyjnego INCOME. Jako preferowaną klasę wybierz Dobierz eksperymentalnie optymalne parametry klasyfikatora (głębokość drzewa, miarę jednorodności, rozmiary węzłów wewnętrznych i liści). Pamiętaj, żeby zbudowane modele testować z wykorzystaniem tabeli CENSUS_TEST. Najważniejszym kryterium jest poprawność przewidywania preferowanej klasy a nie ogólna poprawność klasyfikatora. Które atrybuty weszły w skład modelu? Jak wygląda najlepsza znaleziona przez Ciebie macierz kosztów? Jakie wartości parametrów zostały wykorzystane przy budowie modelu? Jak wyglądała macierz pomyłek? 10. Powiązania między krajem urodzenia ojca, matki i dziecka (atrybuty PEFNTVTY, PEMNTVTY, PENATVTY, odpowiednio) można przedstawić w postaci reguł asocjacyjnych. Stwórz model reprezentujący powiązania między tymi danymi, przykładowa reguła: MOTHER=Mexico FATHER=INDIA SELF=CANADA. Podaj kod polecenia SQL tworzącego perspektywę potrzebną do znalezienia reguł asocjacyjnych o podanym formacie Podaj 5 odkrytych reguł o najwyższym wsparciu i ufności Napisz program w PL/SQL odkrywający i wyświetlający powyższe reguły Napisz program w języku Java odkrywający i wyświetlający powyższe reguły

4 4
5 5
6 6
7 7

8 8

9 9

10 10
11 11
12 12
13 13

14 14
15 15
16 16
17 17
18 18
19 19
20 20
21 21
22 22
23 23
24 24
25 25
26 26
27 27
28 28
29 29
30 30
31 31
32 32
33 33
34 34
35 35
36 36
37 37
38 38
39 39
40 40
41 41
42 42
43 43
44 44
45 45
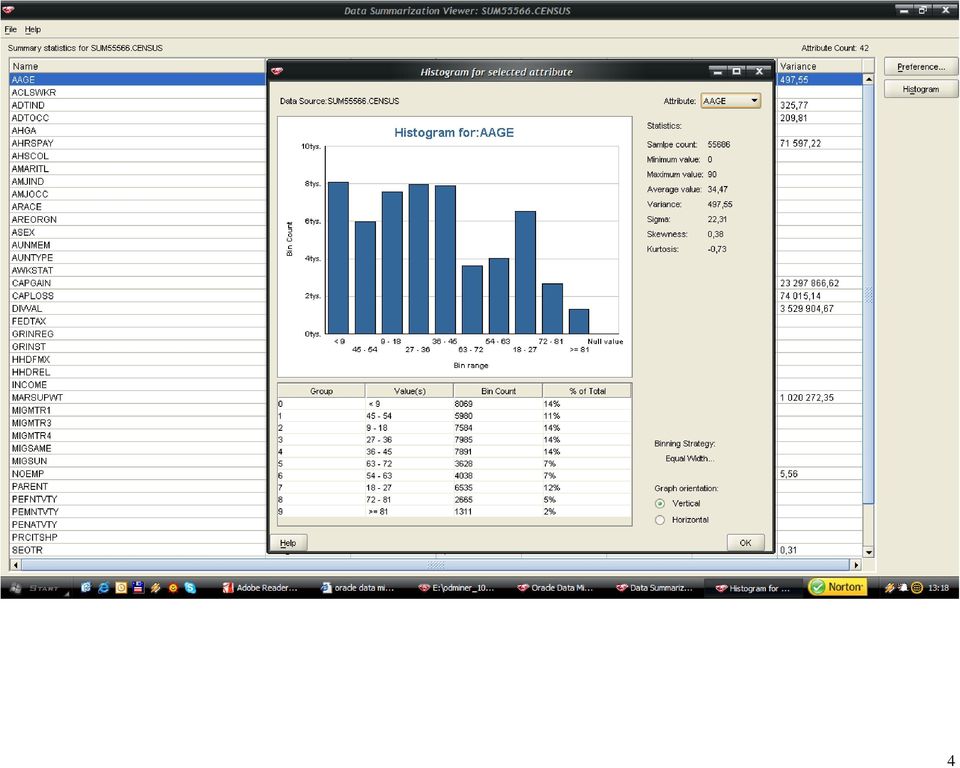
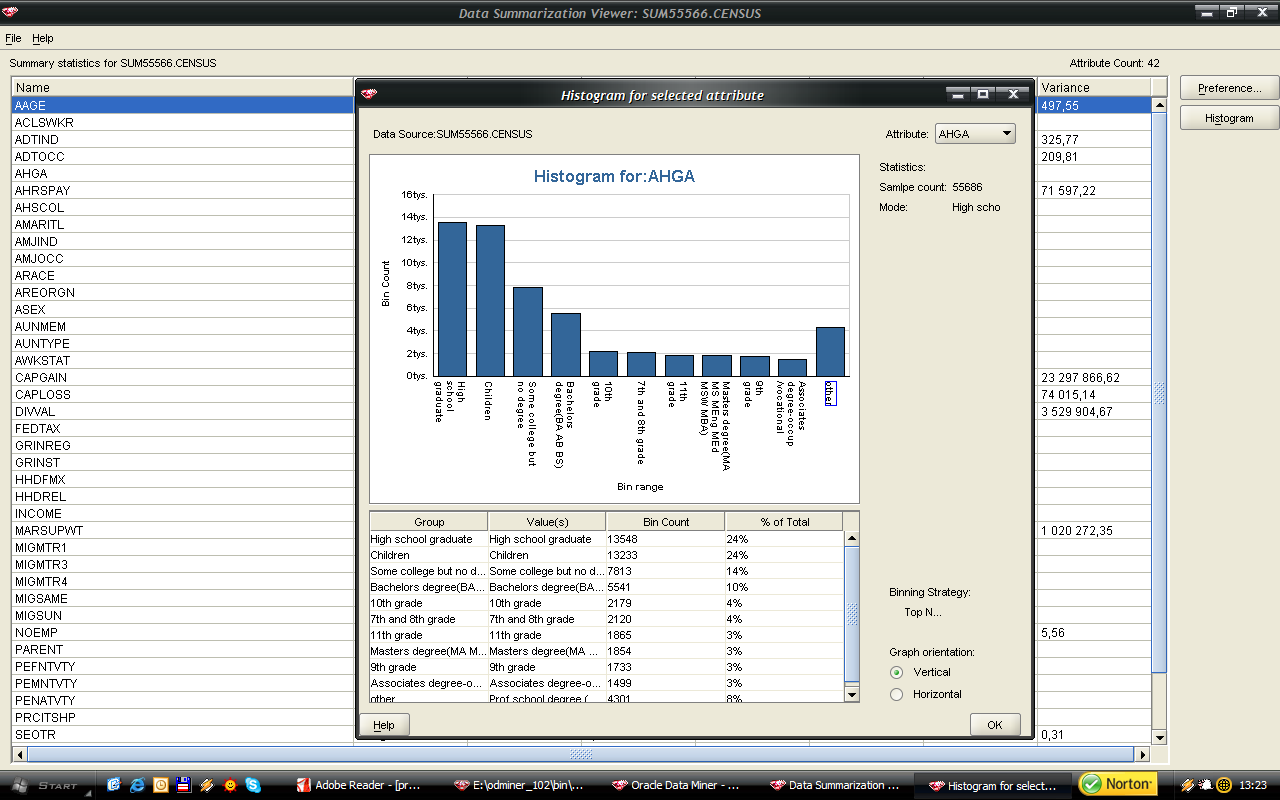
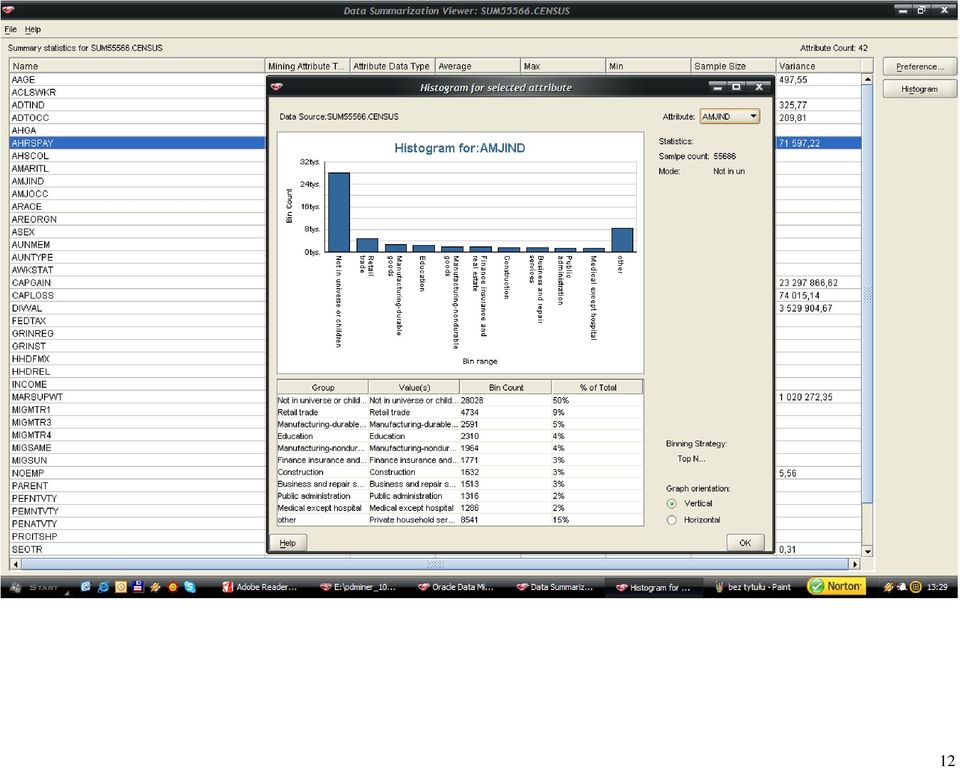
 wytypowałem następujące atrybuty numeryczne do eliminacji osobliwości: wage per hour: 98% próbkowanych wartości")
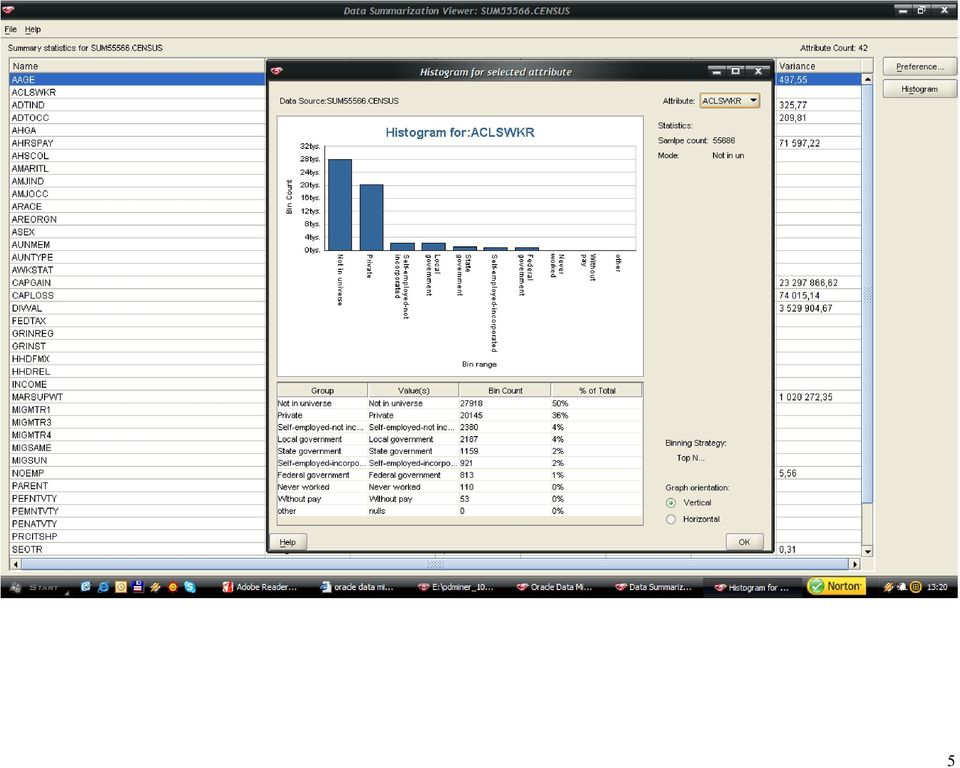
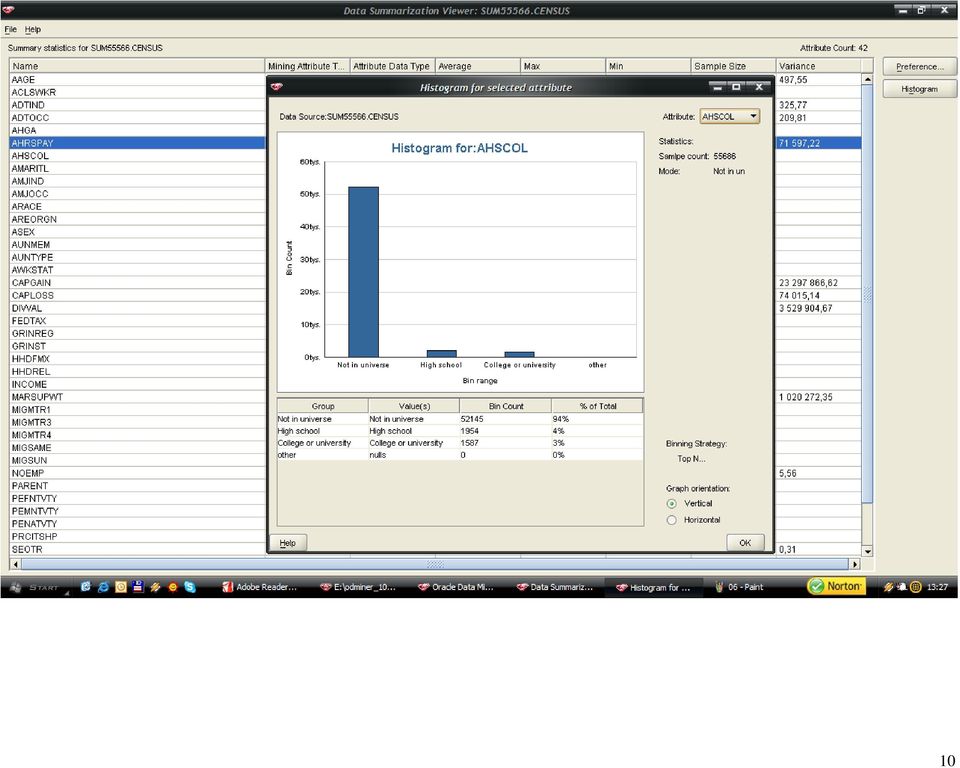
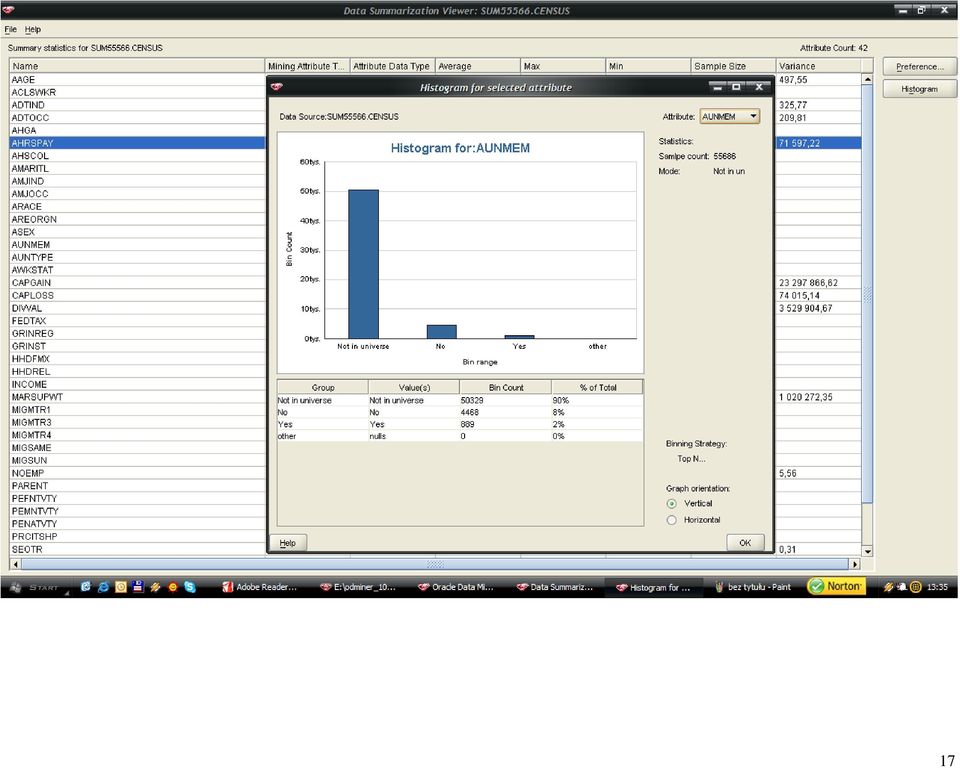
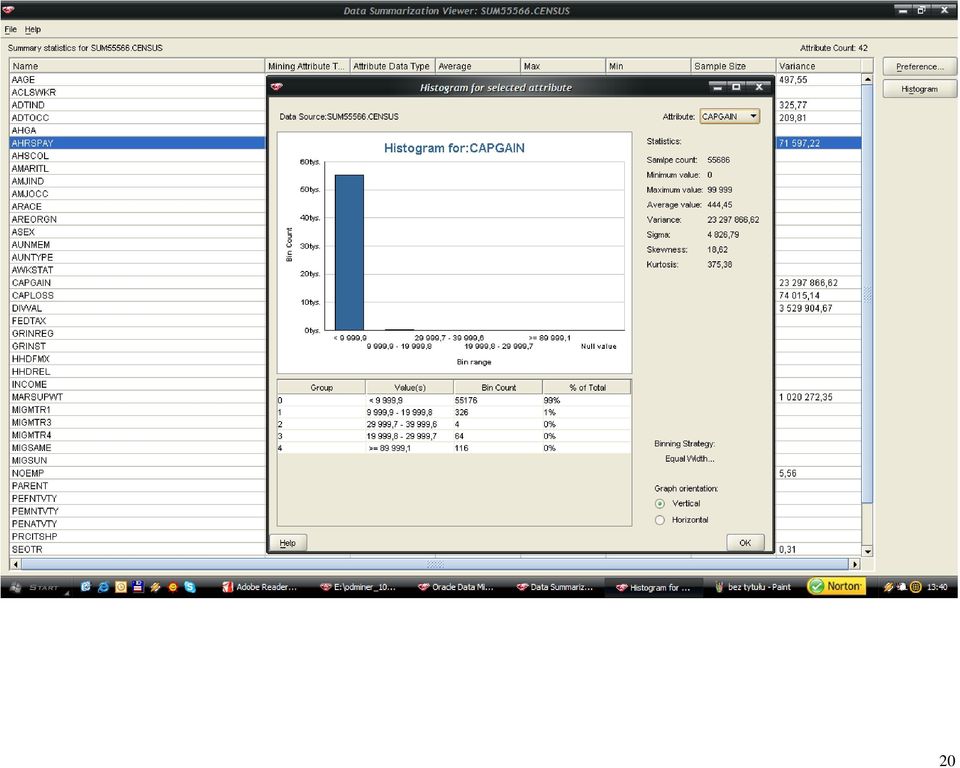
46 46 Histogramy dla każdego z atrybutów zostały wygenerowane dla próbki rekordów. Po analizie wartości średnich, zakresu zmienności oraz współczynnika (variance) wytypowałem następujące atrybuty numeryczne do eliminacji osobliwości: wage per hour: 98% próbkowanych wartości należało to zakresu <0,940>, 2% do przedziału <940,1880>, atrybut przyjmuje wartości z zakresu do <0,9400>, a więc pozostałe pojedyncze rekordy zidentyfikowałem, jako osobliwości; capital gains: 99% wartości jest z zakresu (0,10000), 1% <10000,20000>, pozostałe wartości z zakresu <20000,99999> zidentyfikowałem jako osobliwości; Tożsamy tok myślenia wykorzystałem do nominowania pozostałych dwóch atrybutów: capital losses oraz dividends from stock. Metoda eliminacji osobliwości (Outlier Treatment), która została wybrana przeze mnie to odchylenie standardowe (Std. Deviation). Dla wartości, które odbiegają od trzy odchylenia standardowe od średniej zostaną przypisane wartości progowe. Metoda Std. Deviation została rekomendowana przez środowisko Oracle Data Miner. Po wyeliminowaniu osobliwości dla atrybutów numerycznych, należało zająć się brakującymi danymi dla atrybutów kategorycznych. Atrybuty, w których pojawiała się wartość? to: state of previous residence (GRINST) 708 rekordów migration code-change in msa (MIGMTR1) rekordów migration code-change in reg (MIGMTR3) rekordów
 3393 rekordów Wartości?")
47 47 migration code-move within reg (MIGMTR4) rekordów migration prev res in sunbelt (MIGSUN) rekordów country of birth father (PEFNTVTY) 6713 rekordów country of birth mother (PEMNTVTY) 6119 rekordów country of birth self (PENATVTY) 3393 rekordów Wartości? dla atrybutów: GRINST, MIGMTR1, MIGMTR3, MIGMTR4, MIGSUN zostały zamienione na Not In universe, natomiast: PEFNTVTY, PEMNTVTY, PENATVTY na wartość United- States (wartość dominująca). Kolejnym krokiem była normalizacja wybranych atrybutów numerycznych. Atrybutem, który znormalizowałem jest wage per hour (AHRSPAY), ponieważ w moim odczuciu jest on istotny z punktu późniejszych zadań (wyznaczanie atrybutu INCOME), zakres zmienności jest duży ( przy wartości średniej 54,82), dodatkowo można by się pokusić o dyskretyzację tego atrybutu ponieważ w analizowanej próbce aż 98% przypadków należało do jednej klasy. Wydaję mi się, iż w tym kroku dodatkowo można było uwzględnić atrybuty: capital gains (CAPGAIN), capital losses (CAPLOS), dividends from stock (DIVVAL), ze względu na ich bardzo szeroki zakres zmienności, ale po analizie histogramu doszedłem do wniosku, iż lepszym rozwiązaniem będzie dyskretyzacja, znów ze względu na skupienia.
, weeks worked in year (WKSWORK), capital gains (CAPGAIN), capital losses")
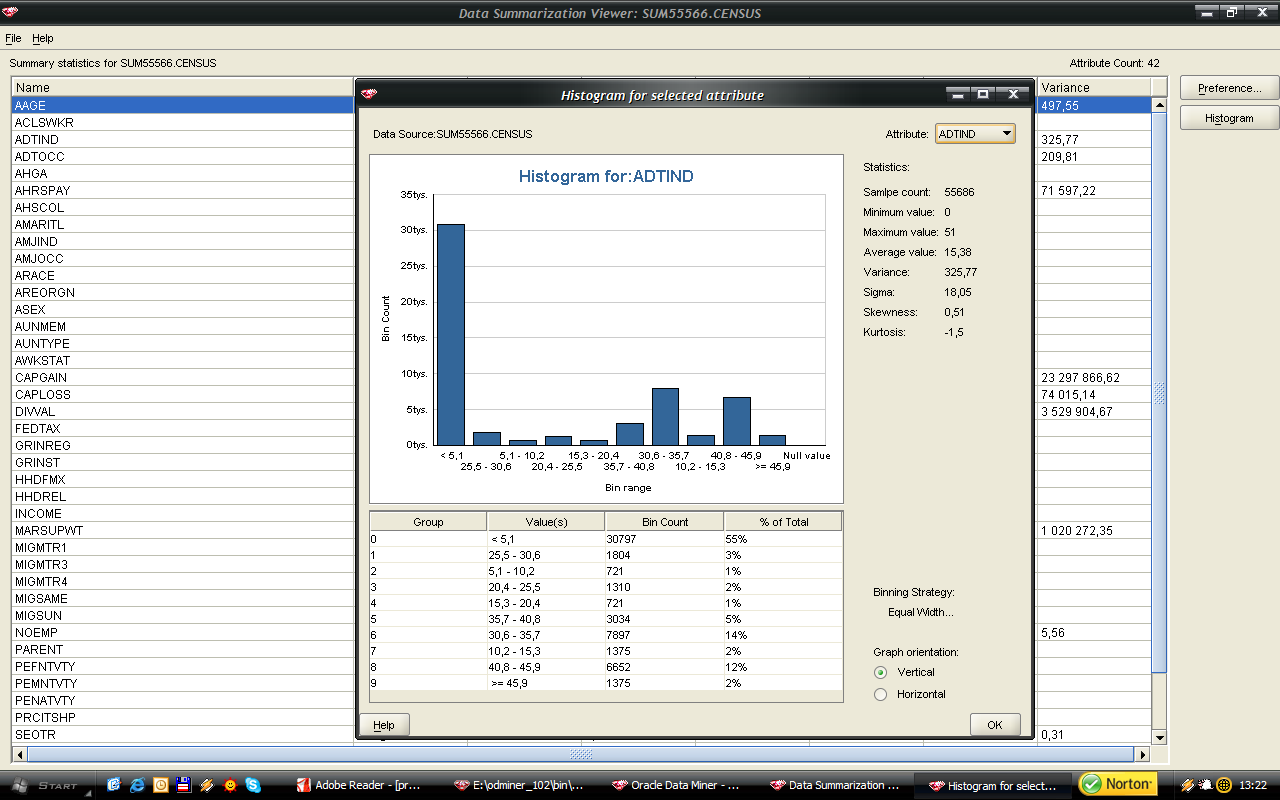
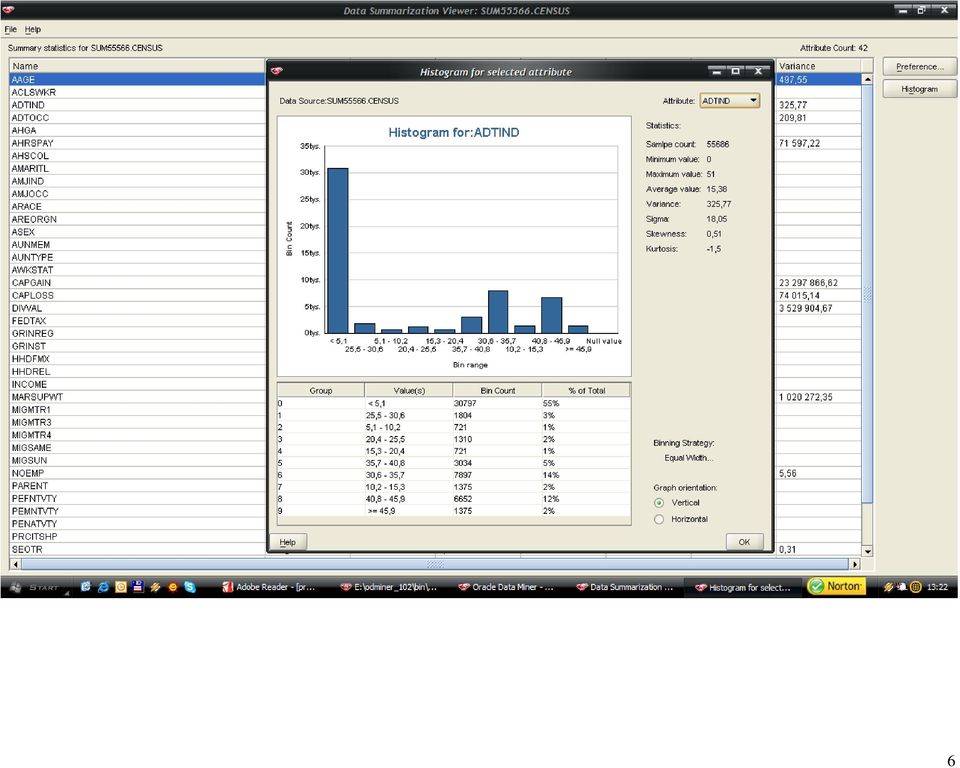
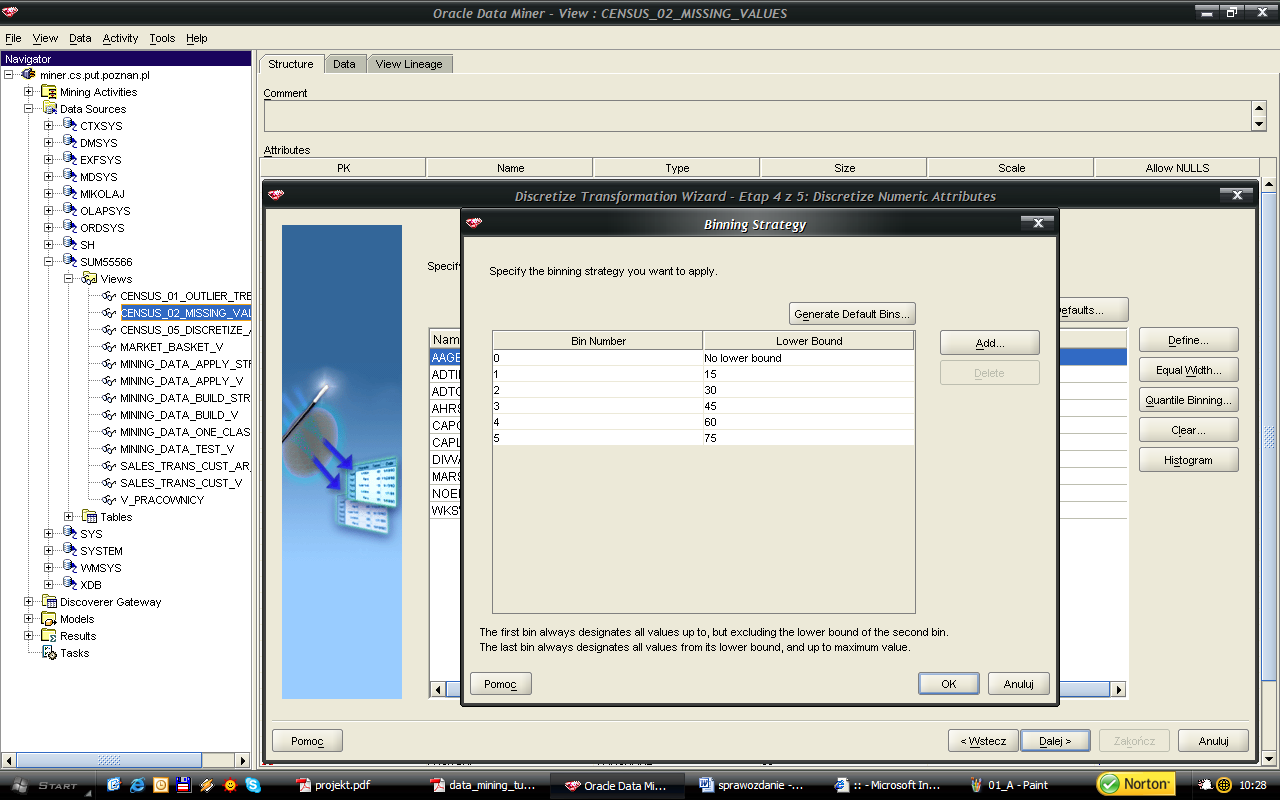
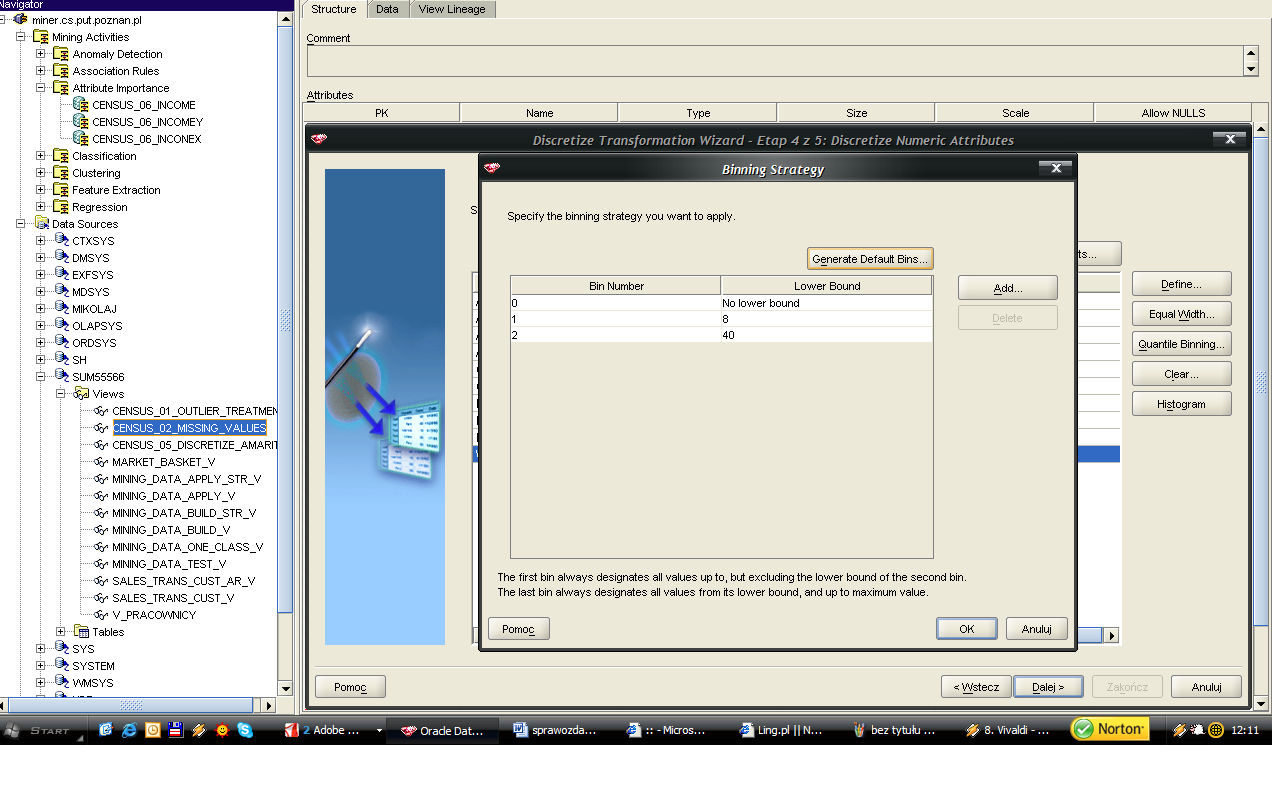
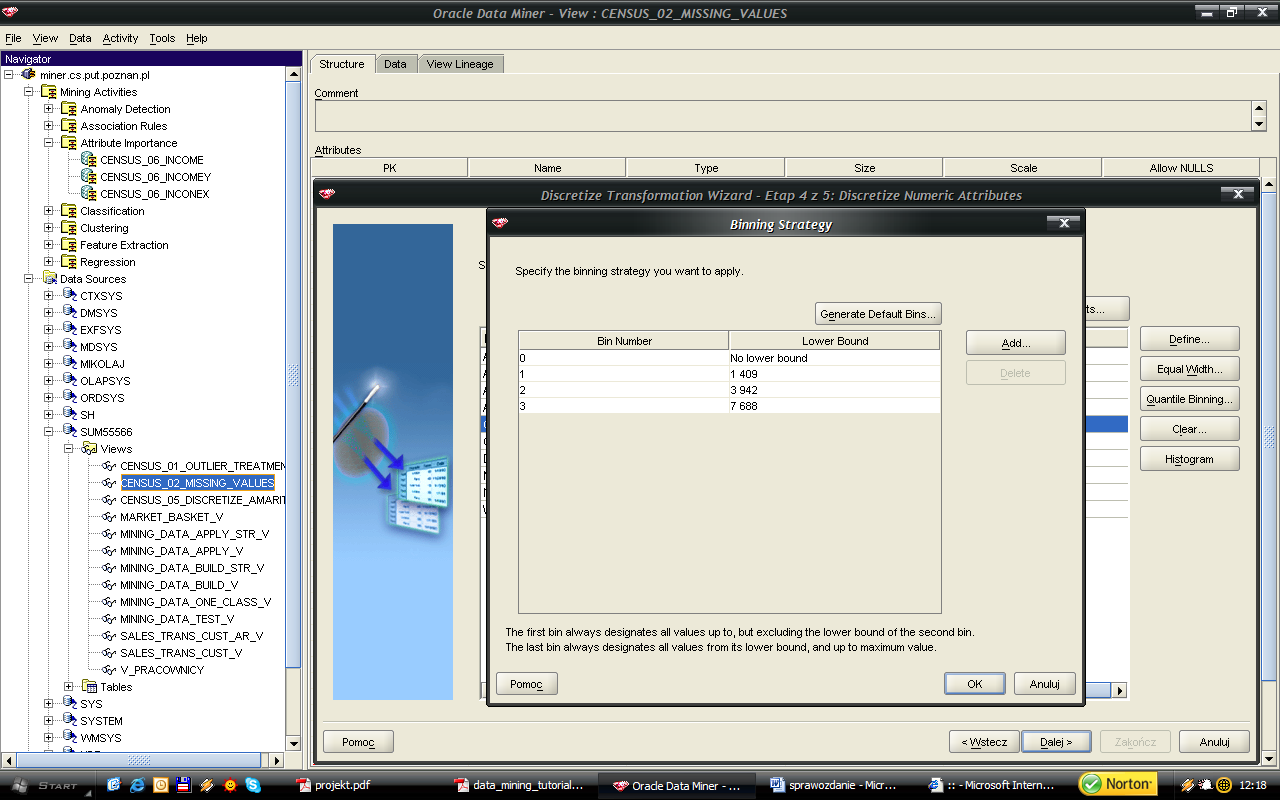
48 48 Kolejnym krokiem była dyskretyzacja wybranych atrybutów numerycznych. Po analizie histogramów, charakteru danych oraz celu eksploracji zdecydowałem, że dyskretyzacja obejmie atrybuty: age (AAGE), weeks worked in year (WKSWORK), capital gains (CAPGAIN), capital losses (CAPLOS), dividends from stock (DIVVAL). Dla atrybutu wiek ustalonych zostało 6 przedziałów - kierowałem się odczuciem, iż wybrane przeze mnie granice odpowiadają nijako etapom życia człowieka. Dla pozostałych atrybutów parametry dyskretyzacji były dobierane samodzielnie na podstawie analiz histogramów: - liczba przepracowanych tygodni w roku 3 - zyski kapitałowe 4 - straty kapitałowe 2 - zyski z gry na giełdzie 9
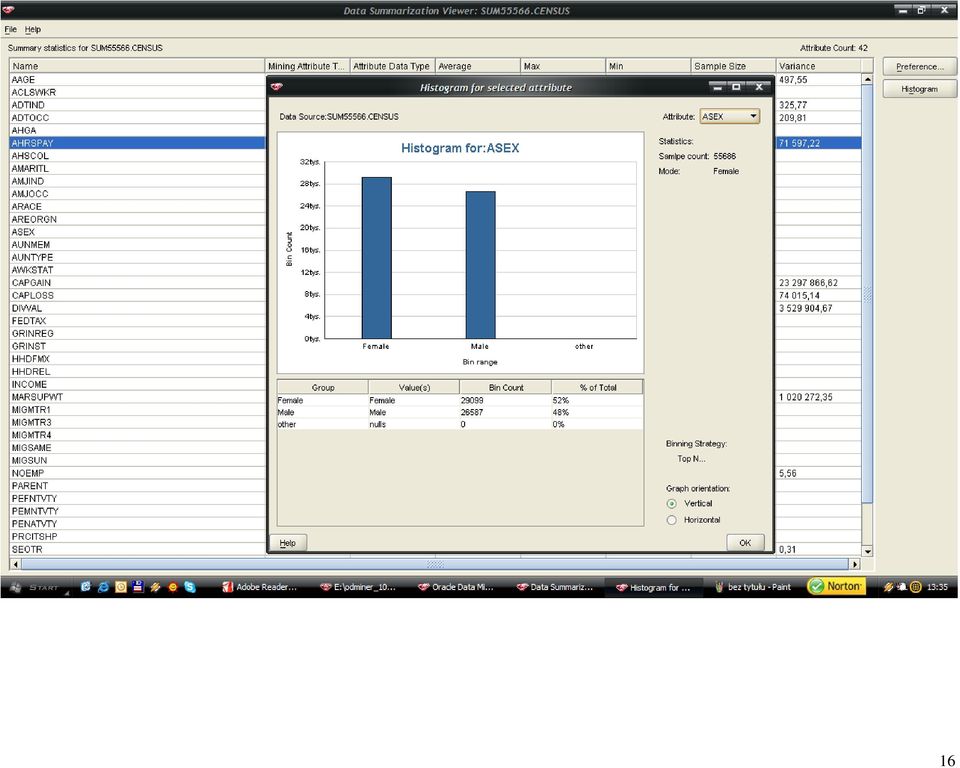
49 49
50 50
51 51
52 52
53 53
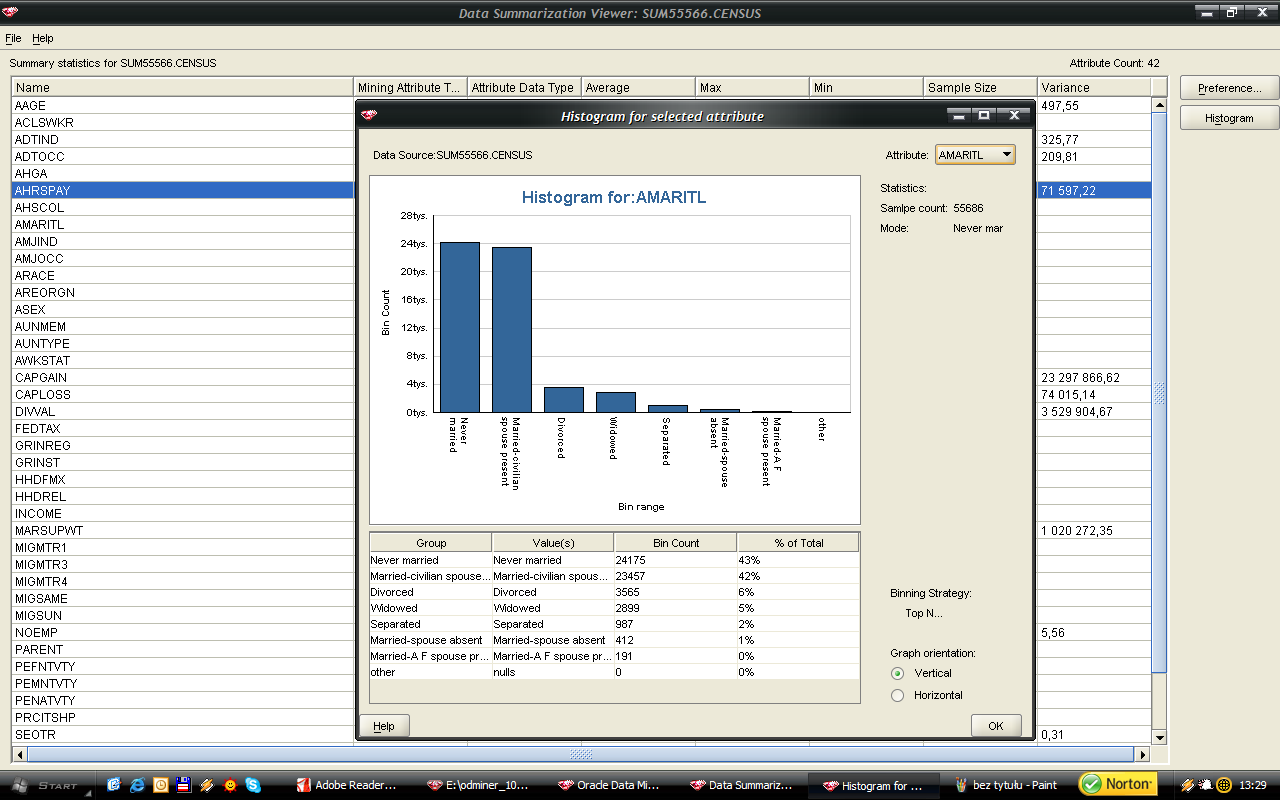
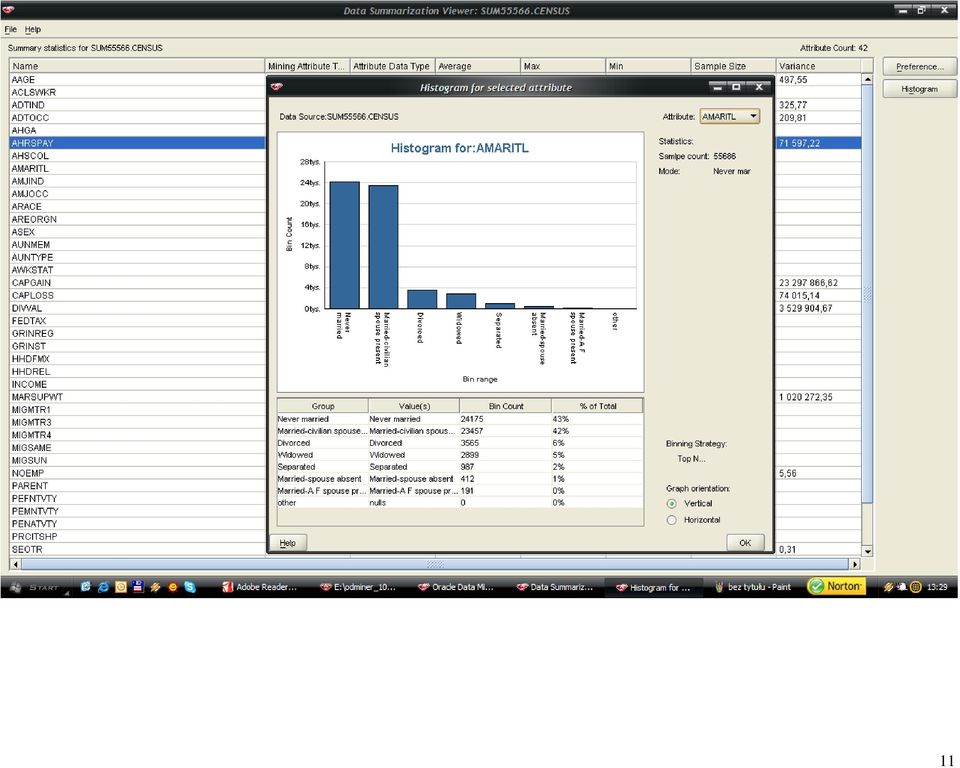
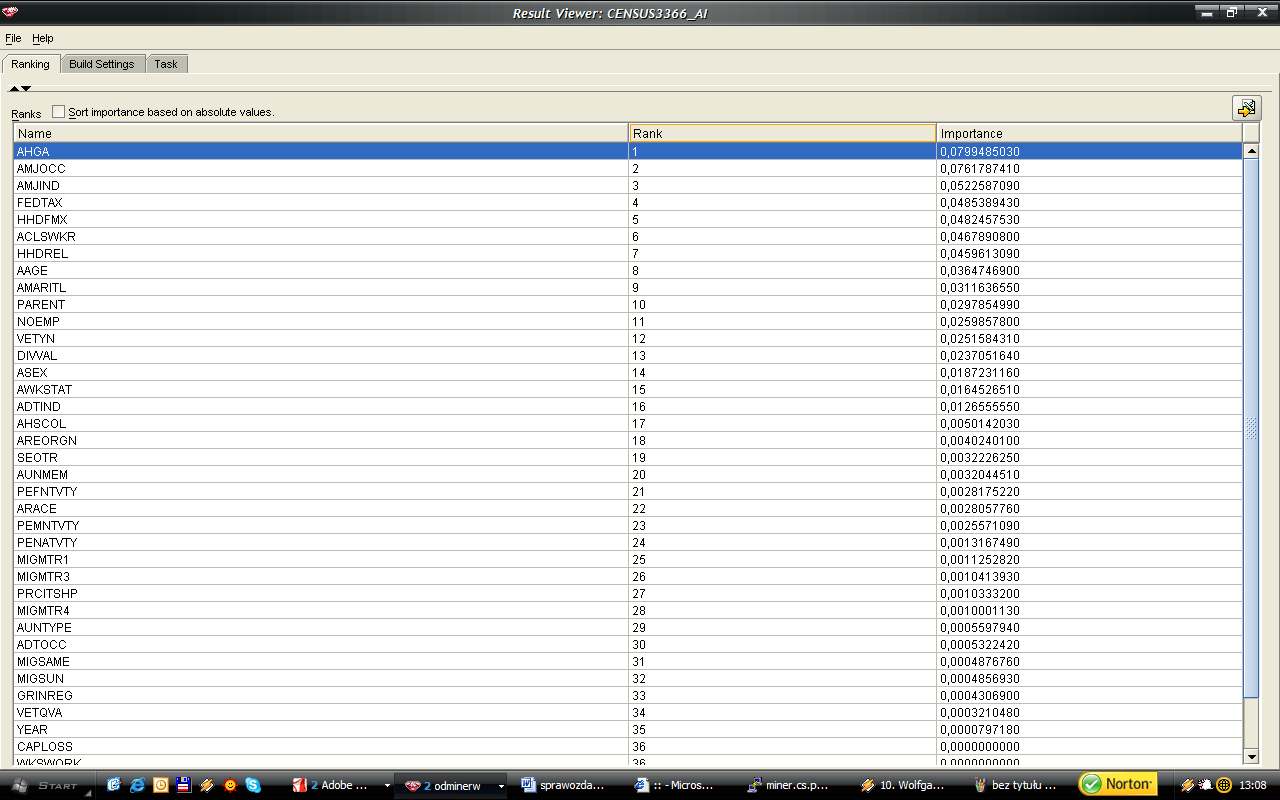
54 54 Kod perspektywy dzięki, której atrybut kategoryczny AMARITL został dyskretyzowany na dwie kategorie: 1 osoby w związku małżeńskim, 0 osoby samotne: CREATE VIEW "SUM55566"."CENSUS_05_DISCRETIZE_AMARITL" AS SELECT "AAGE", "ACLSWKR", "ADTIND", "ADTOCC", "AHGA", "AHRSPAY", "AHSCOL", ( CASE WHEN "AMARITL" = 'Married-civilian spouse present' THEN 1 WHEN "AMARITL" = 'Married-spouse absent' THEN 1 WHEN "AMARITL" = 'Married-A F spouse present' THEN 1 WHEN "AMARITL" = 'Divorced' THEN 0 WHEN "AMARITL" = 'Widowed' THEN 0 WHEN "AMARITL" = 'Never married' THEN 0 WHEN "AMARITL" = 'Separated' THEN 0 END ) "AMARITL", "AMJIND", "AMJOCC", "ARACE", "AREORGN", "ASEX", "AUNMEM", "AUNTYPE", "AWKSTAT", "CAPGAIN", "CAPLOSS", "DIVVAL", "FEDTAX", "GRINREG", "GRINST", "HHDFMX", "HHDREL", "INCOME", "MARSUPWT", "MIGMTR1", "MIGMTR3", "MIGMTR4", "MIGSAME", "MIGSUN", "NOEMP", "PARENT", "PEFNTVTY", "PEMNTVTY", "PENATVTY", "PRCITSHP", "SEOTR", "VETQVA", "VETYN", "WKSWORK", "YEAR" FROM "SUM55566"."CENSUS"; Kolejnym krokiem było określenie ważności atrybutów względem atrybutu decyzyjnego INCOME. Zaprezentuje wyniki obserwacji dla danych źródłowych (A) oraz danych po eliminacji osobliwości, uzupełnieniu brakujących wartości, dyskretyzowanych oraz znormalizowanych (B).
55 (A) 55
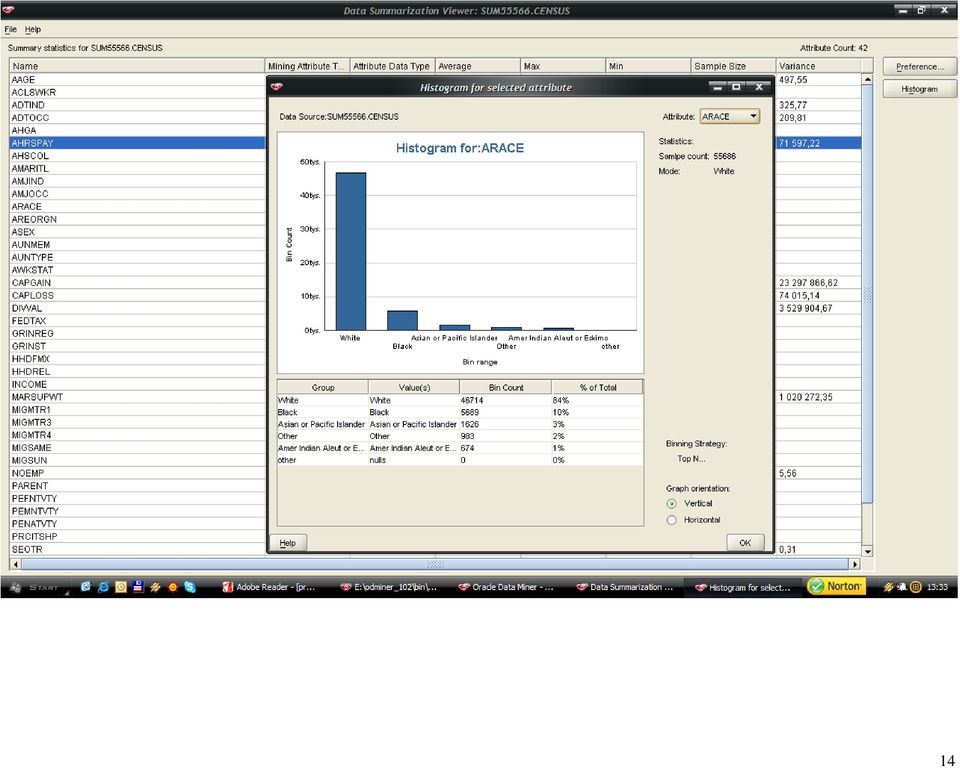
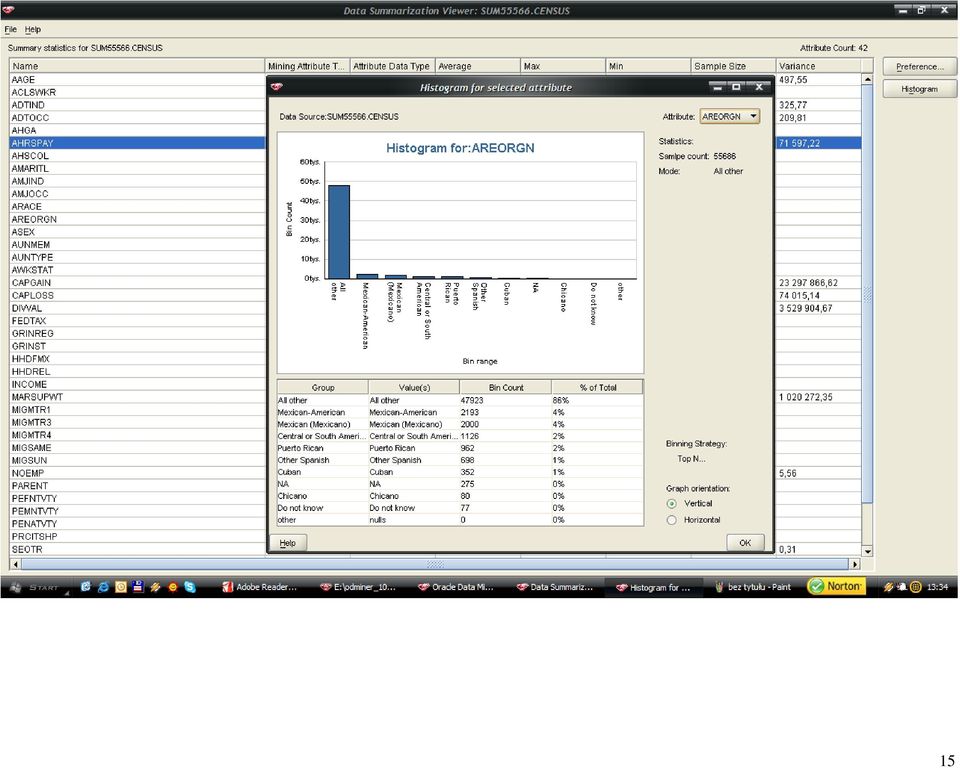
56 (B) 56
57 57 Atrybuty, które w największym stopniu wpływają na wartość atrybutu INCOME w obu przypadkach to: education (AHGA) oraz major occupation code (AMJOCC). Znaleziona prawidłowość jest oczywista, ponieważ uzyskiwany dochód jest w rzeczy samej uzależniony od wykształcenia i etatu, na którym dana osoba jest zatrudniona. Następny sklasyfikowany atrybut to: (A) major industry code (AMJIND) i (B) weeks worked in year (WKSWORK) w przypadku analizy danych po wstępnych modyfikacjach. I tutaj również nie można polemizować nad prawdziwością takiego stwierdzenia, ponieważ te czynniki również w przeważającej większości warunkują wysokość zarobków. Uzyskane wyniki są zgodne z moimi oczekiwaniami. Atrybuty, które w mają najmniejszy wpływ na wartość atrybutu INCOME to w przypadku (A): state of previous residence (GRINST), capital losses (CAPLOS), wage per hour (AHRSPAY), capital gains (CAPGAIN), weeks worked in year (WKSWORK), year (YEAR), natomiast (B): divdends from stocks (DIVVAL), wage per hour (AHRSPAY), year (YEAR) oraz fill inc questionnaire for veteran's admin (VETQVA). Interpretacja tym razem nie jest dla mnie tak czytelna i oczywista. Jeżeli chodzi o atrybuty: year, state of previous residence oraz fill inc questionnaire for veteran's admin to faktycznie nie należy doszukiwać się bliższego związku: natomiast atrybuty: weeks worked in year czy też wage per hour są według mnie skorelowane z wartością zysku ponieważ stawka godzinowa i ilość przepracowanych tygodni w roku nijako wyznaczają zysk. Być może na otrzymany rezultat złożył się rozkład próbkowanych danych (zakres zmienności, ilość wartości unikalnych).

58 58 Kolejnym krokiem było wykorzystanie algorytmu k-means do znalezienia najbardziej charakterystycznych skupień cech.
59 59 Dla wartości parametru k = 6, instancje rozkładały się w miarę równomiernie pośród znalezionych skupień. Do szczegółowej analizy wybrałem skupisko o ID = 6. Po zapoznaniu się z histogramami mogę stwierdzić, iż zakwalifikowano przede wszystkim osoby, które: były w wieku do 15 roku życia nie dotyczą ich pojęcia: klasa pracownika (class of worker), kod branży (industry code), kod zawodu (occupation code) poziom wykształcenia opisany jest jako Children otrzymywały najniższą stawkę godzinową nigdy nie były w związku małżeńskim były białej rasy, płeć bez znaczenia (55% stanowią kobiety) w bardzo małym stopniu udział w ich zarobku stanowią dochody z tytułu lokat lub gry na giełdzie nie dotyczy ich zagadnienie konieczności płacenia podatków Pozostałe atrybuty jak i te, które właśnie opisałem wskazują ewidentnie na to, iż analizowane skupisko to DZIECI. Kolejnym zadaniem było zbudowanie naiwnego klasyfikatora Bayesa, dzięki któremu możliwe będzie przewidywanie wartości atrybutu decyzyjnego INCOME na podstawie wartości pozostałych atrybutów. Atrybuty, które weszły w skład modelu zostały dobrane doświadczalnie.
60 60
61 61
62 62

63 Wyniki otrzymane (Test Matrix) dla danych uczących przy generowaniu modelu: 63
64 Wyniki otrzymane (Test Matrix) dla danych testowych (bez uwzględnienia Cost Matrix) 64
65 65
")
66 Wyniki otrzymane (Test Matrix) dla danych testowych (z uwzględnieniem Cost Matrix) 66
67 67 Macierz kosztów zmodyfikowała rezultat predykcji, polepszając jakość dla preferowanej grupy, ale niestety zaniżyła ogólną jakość klasyfikatora.

68 68 Kolejnym zadaniem było zbudowanie drzewa decyzyjnego, dzięki któremu możliwe będzie przewidywanie wartości atrybutu decyzyjnego INCOME na podstawie wartości pozostałych atrybutów. Atrybuty, które weszły w skład modelu zostały dobrane doświadczalnie.
69 69
70 70

71 Wyniki otrzymane (Test Matrix) dla danych uczących przy generowaniu modelu: 71
72 Wyniki otrzymane (Test Matrix) dla danych testowych (Cost Matrix ustawienie 1) 72
73 73

74 Wyniki otrzymane (Test Matrix) dla danych testowych (Cost Matrix ustawienie 2) 74
75 75
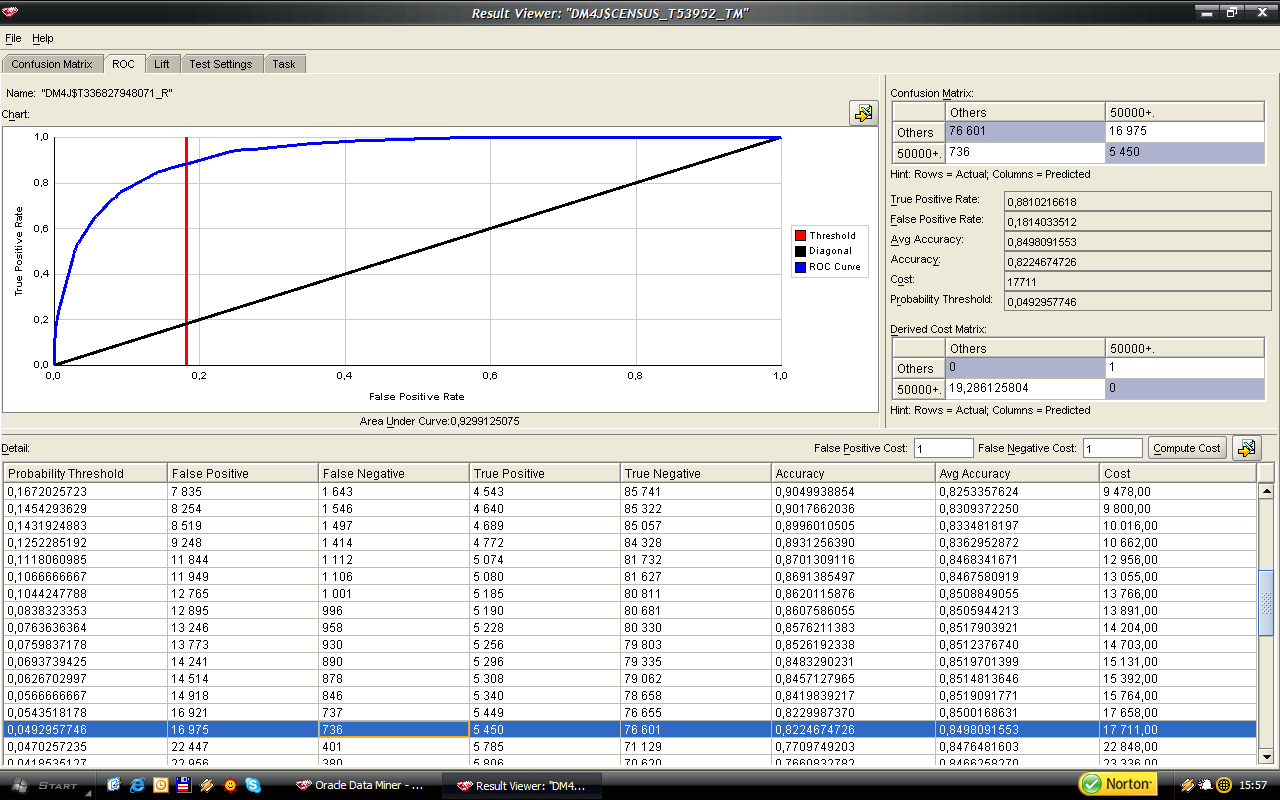
76 76 W przypadku drzewa decyzyjnego zaobserwowałem podobna prawidłowość jak dla naiwnego klasyfikatora Bayesa, a mianowicie dokładność predykcji preferowanej grupy możemy dostrajać modyfikacjami w macierzy kosztów.
Eksploracja Danych. Projekt zaliczeniowy. Marek Lewandowski lewandowski.marek@gmail.com inf59817
 Eksploracja Danych Projekt zaliczeniowy Marek Lewandowski lewandowski.marek@gmail.com inf59817 Spis treści: 1 Zadanie 1... 3 2 Zadanie 2... 8 3 Zadanie 3... 9 4 Zadanie 4... 9 5 Zadanie 5... 11 6 Zadanie
Eksploracja Danych Projekt zaliczeniowy Marek Lewandowski lewandowski.marek@gmail.com inf59817 Spis treści: 1 Zadanie 1... 3 2 Zadanie 2... 8 3 Zadanie 3... 9 4 Zadanie 4... 9 5 Zadanie 5... 11 6 Zadanie
Laboratorium 4. Naiwny klasyfikator Bayesa.
 Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 4 Naiwny klasyfikator Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 11. Regresja SVM.
 Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 11 Regresja SVM. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>. 3. Z
Laboratorium 6. Indukcja drzew decyzyjnych.
 Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 6 Indukcja drzew decyzyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 5. Adaptatywna sieć Bayesa.
 Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Laboratorium 5 Adaptatywna sieć Bayesa. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk Dalej>.
Laboratorium 10. Odkrywanie cech i algorytm Non-Negative Matrix Factorization.
 Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Laboratorium 10 Odkrywanie cech i algorytm Non-Negative Matrix Factorization. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie
Data Mining podstawy analizy danych Część druga
 Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
Data Mining podstawy analizy danych Część druga W części pierwszej dokonaliśmy procesu analizy danych treningowych w oparciu o algorytm drzewa decyzyjnego. Proces analizy danych treningowych może być realizowany
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Laboratorium 12. Odkrywanie osobliwości.
 Laboratorium 12 Odkrywanie osobliwości. Odkrywanie osobliwości (ang. outliers) za pomocą algorytmu SVM zostanie w pierwszej części ćwiczenia przeprowadzone w środowisku SQL, a w drugiej części wykorzystamy
Laboratorium 12 Odkrywanie osobliwości. Odkrywanie osobliwości (ang. outliers) za pomocą algorytmu SVM zostanie w pierwszej części ćwiczenia przeprowadzone w środowisku SQL, a w drugiej części wykorzystamy
WYKŁAD 6. Reguły decyzyjne
 Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Wrocław University of Technology WYKŁAD 6 Reguły decyzyjne autor: Maciej Zięba Politechnika Wrocławska Reprezentacje wiedzy Wiedza w postaci reguł decyzyjnych Wiedza reprezentowania jest w postaci reguł
Przykładowa baza danych BIBLIOTEKA
 Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
Przykładowa baza danych BIBLIOTEKA 1. Opis problemu W ramach zajęć zostanie przedstawiony przykład prezentujący prosty system biblioteczny. System zawiera informację o czytelnikach oraz książkach dostępnych
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Laboratorium nr Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby:
 dla próby:") Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Laboratorium nr 1 CZĘŚĆ I : STATYSTYKA OPISOWA : 1. Wyznaczyć podstawowe statystyki (średnia, mediana, IQR, min, max) dla próby: 6,9,1,2,5,2,6,2,1,0,1,4,5,6,3,7,3,2,2,3,8,5,3,4,8,0,8,0,5,1,6,4,8,0,3,2
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
Metody klasyfikacji danych - część 1 p.1/24
 Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Metody klasyfikacji danych - część 1 Inteligentne Usługi Informacyjne Jerzy Dembski Metody klasyfikacji danych - część 1 p.1/24 Plan wykładu - Zadanie klasyfikacji danych - Przeglad problemów klasyfikacji
Implementacja metod eksploracji danych - Oracle Data Mining
 Implementacja metod eksploracji danych - Oracle Data Mining 395 Plan rozdziału 396 Wprowadzenie do eksploracji danych Architektura Oracle Data Mining Możliwości Oracle Data Mining Etapy procesu eksploracji
Implementacja metod eksploracji danych - Oracle Data Mining 395 Plan rozdziału 396 Wprowadzenie do eksploracji danych Architektura Oracle Data Mining Możliwości Oracle Data Mining Etapy procesu eksploracji
Określanie ważności atrybutów. OracleData Miner
 Określanie ważności atrybutów OracleData Miner Algorytm MDL (intuicja) (1) William of Ockham (1285-1349): Nie należy mnożyć bytów ponad potrzebę Reguła minimalnej długości opisu (Minimum DescriptionLengthMDL)
Określanie ważności atrybutów OracleData Miner Algorytm MDL (intuicja) (1) William of Ockham (1285-1349): Nie należy mnożyć bytów ponad potrzebę Reguła minimalnej długości opisu (Minimum DescriptionLengthMDL)
1: 2: 3: 4: 5: 6: 7: 8: 9: 10:
 Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
Grupa A (LATARNIE) Imię i nazwisko: Numer albumu: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: Nazwisko prowadzącego: 11: 12: Suma: Ocena: Zad. 1 (10 pkt) Dana jest relacja T. Podaj wynik poniższego zapytania (podaj
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
Wprowadzenie do klasyfikacji
 Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Wprowadzenie do klasyfikacji ZeroR Odpowiada zawsze tak samo Decyzja to klasa większościowa ze zbioru uczącego A B X 1 5 T 1 7 T 1 5 T 1 5 F 2 7 F Tutaj jest więcej obiektów klasy T, więc klasyfikator
Laboratorium 3. Odkrywanie reguł asocjacyjnych.
 Laboratorium 3 Odkrywanie reguł asocjacyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Tools SQL Worksheet. W górnym oknie wprowadź i wykonaj
Laboratorium 3 Odkrywanie reguł asocjacyjnych. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Tools SQL Worksheet. W górnym oknie wprowadź i wykonaj
 Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Klasyfikator liniowy Wstęp Klasyfikator liniowy jest najprostszym możliwym klasyfikatorem. Zakłada on liniową separację liniowy podział dwóch klas między sobą. Przedstawia to poniższy rysunek: 5 4 3 2
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
1. Cele eksploracyjnej analizy danych Rapid Miner zasady pracy i wizualizacja danych Oracle Data Miner -zasady pracy.
 Spis treści: 1. Cele eksploracyjnej analizy danych...1 2. Rapid Miner zasady pracy i wizualizacja danych...3 3. Oracle Data Miner -zasady pracy.12 3.1 ODM PL/SQL.......12 3.2 ODM JAVA API......12 3.2.1
Spis treści: 1. Cele eksploracyjnej analizy danych...1 2. Rapid Miner zasady pracy i wizualizacja danych...3 3. Oracle Data Miner -zasady pracy.12 3.1 ODM PL/SQL.......12 3.2 ODM JAVA API......12 3.2.1
2. Ocena dokładności modelu klasyfikacji:
 Spis treści: 1. Klasyfikacja... 1 2. Ocena dokładności modelu klasyfikacji:...1 2.1. Miary dokładności modelu...2 2.2. Krzywe oceny...2 3. Wybrane algorytmy...3 3.1. Naiwny klasyfikator Bayesa...3 3.2.
Spis treści: 1. Klasyfikacja... 1 2. Ocena dokładności modelu klasyfikacji:...1 2.1. Miary dokładności modelu...2 2.2. Krzywe oceny...2 3. Wybrane algorytmy...3 3.1. Naiwny klasyfikator Bayesa...3 3.2.
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Laboratorium 13. Eksploracja danych tekstowych.
 Laboratorium 13 Eksploracja danych tekstowych. Eksploracja danych tekstowych oraz kroki wstępne przetwarzania tekstu zostaną wykonane zarówno w środowisku SQL, jak i za pomocą narzędzia Oracle Data Miner.
Laboratorium 13 Eksploracja danych tekstowych. Eksploracja danych tekstowych oraz kroki wstępne przetwarzania tekstu zostaną wykonane zarówno w środowisku SQL, jak i za pomocą narzędzia Oracle Data Miner.
Rozdział 17. Zarządzanie współbieżnością zadania
 Rozdział 17. Zarządzanie współbieżnością zadania Transakcja DML 1. Uruchom narzędzie Oracle SQL Developer i przyłącz się do bazy danych. Następnie rozpocznij nową transakcję, zmieniając pracownikowi o
Rozdział 17. Zarządzanie współbieżnością zadania Transakcja DML 1. Uruchom narzędzie Oracle SQL Developer i przyłącz się do bazy danych. Następnie rozpocznij nową transakcję, zmieniając pracownikowi o
Metody Eksploracji Danych. Klasyfikacja
 Metody Eksploracji Danych Klasyfikacja w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka
Metody Eksploracji Danych Klasyfikacja w wykładzie wykorzystano: 1. materiały dydaktyczne przygotowane w ramach projektu Opracowanie programów nauczania na odległość na kierunku studiów wyższych Informatyka
RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk
 Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Wprowadzenie RILL - przyrostowy klasyfikator regułowy uczący się ze zmiennych środowisk Magdalena Deckert Politechnika Poznańska, Instytut Informatyki Seminarium ISWD, 21.05.2013 M. Deckert Przyrostowy
Klasyfikacja i regresja Wstęp do środowiska Weka
 Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Klasyfikacja i regresja Wstęp do środowiska Weka 19 listopada 2015 Opis pliku z zadaniami Wszystkie zadania na zajęciach będą przekazywane w postaci plików pdf sformatowanych podobnie do tego dokumentu.
Techniki grupowania danych w środowisku Matlab
 Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Techniki grupowania danych w środowisku Matlab 1. Normalizacja danych. Jedne z metod normalizacji: = = ma ( y =, rσ ( = ( ma ( = min = (1 + e, min ( = σ wartość średnia, r współczynnik, σ odchylenie standardowe
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Wprowadzenie do programu RapidMiner Studio 7.6, część 4 Michał Bereta www.michalbereta.pl W tej części: Zachowanie wytrenowanego modelu w celu późniejszego użytku Filtrowanie danych (brakujące etykiety
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Eksploracja danych. KLASYFIKACJA I REGRESJA cz. 2. Wojciech Waloszek. Teresa Zawadzka.
 Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Eksploracja danych KLASYFIKACJA I REGRESJA cz. 2 Wojciech Waloszek wowal@eti.pg.gda.pl Teresa Zawadzka tegra@eti.pg.gda.pl Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta
 Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Wprowadzenie do programu RapidMiner, część 4 Michał Bereta www.michalbereta.pl 1. Wybór atrybutów (ang. attribute selection, feature selection). Jedną z podstawowych metod analizy współoddziaływania /
Metody probabilistyczne klasyfikatory bayesowskie
 Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Konwersatorium Matematyczne Metody Ekonomii narzędzia matematyczne w eksploracji danych First Prev Next Last Go Back Full Screen Close Quit Metody probabilistyczne klasyfikatory bayesowskie Wykład 8 Marcin
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia
 Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Wyzwalacz - procedura wyzwalana, składowana fizycznie w bazie, uruchamiana automatycznie po nastąpieniu określonego w definicji zdarzenia Składowe wyzwalacza ( ECA ): określenie zdarzenia ( Event ) określenie
Określanie ważności atrybutów. RapidMiner
 Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Określanie ważności atrybutów RapidMiner Klasyfikacja (1/2) TEMP BÓL WYSYPKA GARDŁO DIAGNOZA 36.6 T BRAK NORMA NIESTRAWNOŚĆ 37.5 N MAŁA PRZEKR. ALERGIA 36.0 N BRAK NORMA PRZECHŁODZENIE 39.5 T DUŻA PRZEKR.
Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów
 Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Eksploracja danych Piotr Lipiński Informacje ogólne Informacje i materiały dotyczące wykładu będą publikowane na stronie internetowej wykładowcy, m.in. prezentacje z wykładów UWAGA: prezentacja to nie
Data Mining Wykład 4. Plan wykładu
 Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Data Mining Wykład 4 Klasyfikacja danych Klasyfikacja poprzez indukcje drzew decyzyjnych Plan wykładu Sformułowanie problemu Kryteria oceny metod klasyfikacji Metody klasyfikacji Klasyfikacja poprzez indukcje
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Systemy baz danych 2 laboratorium Projekt zaliczeniowy
 Dany jest następujący logiczny schemat bazy danych Systemy baz danych 2 laboratorium Projekt zaliczeniowy FAKTURY POZYCJE PK f_id_faktury PK p_id_pozycji f_data_wystawienia f_data_płatnosci f_czy_zaplacona
Dany jest następujący logiczny schemat bazy danych Systemy baz danych 2 laboratorium Projekt zaliczeniowy FAKTURY POZYCJE PK f_id_faktury PK p_id_pozycji f_data_wystawienia f_data_płatnosci f_czy_zaplacona
Optymalizacja systemów
 Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Optymalizacja systemów Laboratorium - problem detekcji twarzy autorzy: A. Gonczarek, J.M. Tomczak, S. Zaręba, P. Klukowski Cel zadania Celem zadania jest zapoznanie się z gradientowymi algorytmami optymalizacji
Laboratorium 2. Określanie ważności atrybutów.
 Laboratorium 2 Określanie ważności atrybutów. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
Laboratorium 2 Określanie ważności atrybutów. 1. Uruchom narzędzie Oracle Data Miner i połącz się z serwerem bazy danych. 2. Z menu głównego wybierz Activity Build. Na ekranie powitalnym kliknij przycisk
SQL do zaawansowanych analiz danych część 1.
 SQL do zaawansowanych analiz danych część 1. Mechanizmy języka SQL dla agregacji danych Rozszerzenia PIVOT i UNPIVOT Materiały wykładowe Bartosz Bębel Politechnika Poznańska, Instytut Informatyki Plan
SQL do zaawansowanych analiz danych część 1. Mechanizmy języka SQL dla agregacji danych Rozszerzenia PIVOT i UNPIVOT Materiały wykładowe Bartosz Bębel Politechnika Poznańska, Instytut Informatyki Plan
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
SYSTEMY UCZĄCE SIĘ WYKŁAD 3. DRZEWA DECYZYJNE Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska BUDOWA DRZEW DECYZYJNYCH Drzewa decyzyjne są metodą indukcyjnego
ALGORYTMY SZTUCZNEJ INTELIGENCJI
 ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
ALGORYTMY SZTUCZNEJ INTELIGENCJI Sieci neuronowe 06.12.2014 Krzysztof Salamon 1 Wstęp Sprawozdanie to dotyczy ćwiczeń z zakresu sieci neuronowych realizowanym na przedmiocie: Algorytmy Sztucznej Inteligencji.
Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 zajęcia: środa, 9.
 Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 lewandowski.marek@gmail.com zajęcia: środa, 9.00 Spis treści: 1 Wprowadzenie... 4 2 Dostępne dane... 5 3 Przygotowanie
Analiza Danych Case study Analiza diagnostycznej bazy danych Marek Lewandowski, inf59817 lewandowski.marek@gmail.com zajęcia: środa, 9.00 Spis treści: 1 Wprowadzenie... 4 2 Dostępne dane... 5 3 Przygotowanie
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining"
 Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining" Streszczenie Eksploracja danych znajduje coraz szersze
Mikołaj Morzy, Marek Wojciechowski: "Integracja technik eksploracji danych z systemem zarządzania bazą danych na przykładzie Oracle9i Data Mining" Streszczenie Eksploracja danych znajduje coraz szersze
Język SQL. Rozdział 8. Język manipulowania danymi DML zadania
 Język SQL. Rozdział 8. Język manipulowania danymi DML zadania 1. Wstaw do relacji PRACOWNICY trzy nowe rekordy: Nazwa atrybutu 1. rekord 2. rekord 3. rekord ID_PRAC 250 260 270 KOWALSKI ADAMSKI NOWAK ETAT
Język SQL. Rozdział 8. Język manipulowania danymi DML zadania 1. Wstaw do relacji PRACOWNICY trzy nowe rekordy: Nazwa atrybutu 1. rekord 2. rekord 3. rekord ID_PRAC 250 260 270 KOWALSKI ADAMSKI NOWAK ETAT
Algorytm grupowania danych typu kwantyzacji wektorów
 Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Algorytm grupowania danych typu kwantyzacji wektorów Wstęp Definicja problemu: Typowe, problemem często spotykanym w zagadnieniach eksploracji danych (ang. data mining) jest zagadnienie grupowania danych
Automatyczne wyodrębnianie reguł
 Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Automatyczne wyodrębnianie reguł Jedną z form reprezentacji wiedzy jest jej zapis w postaci zestawu reguł. Ta forma ma szereg korzyści: daje się łatwo interpretować, można zrozumieć sposób działania zbudowanego
Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych. Data Mining Wykład 2
 Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
NAZWA ZMIENNEJ LOSOWEJ PODAJ WARTOŚĆ PARAMETRÓW ROZKŁADU PRAWDOPODOBIEŃSTWA DLA TEJ ZMIENNEJ
 WAŻNE INFORMACJE: 1. Sprawdzane będą wyłącznie wyniki w oznaczonych polach, nie czytam tego co na marginesie, nie sprawdzam pokreślonych i niedbałych pól. 2. Wyniki proszę podawać z dokładnością do dwóch
WAŻNE INFORMACJE: 1. Sprawdzane będą wyłącznie wyniki w oznaczonych polach, nie czytam tego co na marginesie, nie sprawdzam pokreślonych i niedbałych pól. 2. Wyniki proszę podawać z dokładnością do dwóch
Funkcje w PL/SQL Funkcja to nazwany blok języka PL/SQL. Jest przechowywana w bazie i musi zwracać wynik. Z reguły, funkcji utworzonych w PL/SQL-u
 Funkcje w PL/SQL Funkcja to nazwany blok języka PL/SQL. Jest przechowywana w bazie i musi zwracać wynik. Z reguły, funkcji utworzonych w PL/SQL-u będziemy używać w taki sam sposób, jak wbudowanych funkcji
Funkcje w PL/SQL Funkcja to nazwany blok języka PL/SQL. Jest przechowywana w bazie i musi zwracać wynik. Z reguły, funkcji utworzonych w PL/SQL-u będziemy używać w taki sam sposób, jak wbudowanych funkcji
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4
 Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
Metody wykrywania odchyleo w danych. Metody wykrywania braków w danych. Korelacja. PED lab 4 Co z danymi oddalonymi? Błędne dane typu dochód z minusem na początku: to błąd we wprowadzaniu danych, czy faktyczny
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Laboratorium nr 4. Temat: SQL część II. Polecenia DML
 Laboratorium nr 4 Temat: SQL część II Polecenia DML DML DML (Data Manipulation Language) słuŝy do wykonywania operacji na danych do ich umieszczania w bazie, kasowania, przeglądania, zmiany. NajwaŜniejsze
Laboratorium nr 4 Temat: SQL część II Polecenia DML DML DML (Data Manipulation Language) słuŝy do wykonywania operacji na danych do ich umieszczania w bazie, kasowania, przeglądania, zmiany. NajwaŜniejsze
Sprawozdanie z zadania Modele predykcyjne (2)
") Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
Maciej Karpus, 131529 Tomasz Skarżyński, 131618 19.04.2013r. Sprawozdanie z zadania Modele predykcyjne (2) 1. Wprowadzenie 1.1. Informacje wstępne Dane dotyczą wyników badań mammograficznych wykonanych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
Drzewa klasyfikacyjne algorytm podstawowy
 DRZEWA DECYZYJNE Drzewa klasyfikacyjne algorytm podstawowy buduj_drzewo(s przykłady treningowe, A zbiór atrybutów) { utwórz węzeł t (korzeń przy pierwszym wywołaniu); if (wszystkie przykłady w S należą
DRZEWA DECYZYJNE Drzewa klasyfikacyjne algorytm podstawowy buduj_drzewo(s przykłady treningowe, A zbiór atrybutów) { utwórz węzeł t (korzeń przy pierwszym wywołaniu); if (wszystkie przykłady w S należą
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych. Regresja logistyczna i jej zastosowanie
 Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
Ćwiczenie 6 - Hurtownie danych i metody eksploracje danych Regresja logistyczna i jej zastosowanie Model regresji logistycznej jest budowany za pomocą klasy Logistic programu WEKA. Jako danych wejściowych
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Optymalizacja poleceń SQL Wprowadzenie
 Optymalizacja poleceń SQL Wprowadzenie 1 Fazy przetwarzania polecenia SQL 2 Faza parsingu (1) Krok 1. Test składniowy weryfikacja poprawności składniowej polecenia SQL. Krok 2. Test semantyczny m.in. weryfikacja
Optymalizacja poleceń SQL Wprowadzenie 1 Fazy przetwarzania polecenia SQL 2 Faza parsingu (1) Krok 1. Test składniowy weryfikacja poprawności składniowej polecenia SQL. Krok 2. Test semantyczny m.in. weryfikacja
Intellect. Business Intelligence. Interfejsy do systemów zewnętrznych Podręcznik. Business Intelligence od 2Intellect.com Sp. z o.o.
 Intellect Business Intelligence Podręcznik 2 / 19 SPIS TREŚCI 1 Integracja ze systemami zewnętrznymi rycina ogólna 3 2 Sterowniki pobierania danych 3 3 Konfiguracja POŁĄCZENIA 4 4 Konfiguracja sterownika
Intellect Business Intelligence Podręcznik 2 / 19 SPIS TREŚCI 1 Integracja ze systemami zewnętrznymi rycina ogólna 3 2 Sterowniki pobierania danych 3 3 Konfiguracja POŁĄCZENIA 4 4 Konfiguracja sterownika
Metody systemowe i decyzyjne w informatyce
 Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Metody systemowe i decyzyjne w informatyce Laboratorium MATLAB Zadanie nr 2 Detekcja twarzy autorzy: A. Gonczarek, J.M. Tomczak Cel zadania Celem zadania jest zapoznanie się algorytmem gradientu prostego
Indukcja drzew decyzyjnych
 Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Divide et impera
Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Divide et impera
b) Umiejętność wykonania analizy zależności zmiennych i interpretacji uzyskanych wyników.
 Umiejętność wykonania analizy zależności zmiennych i interpretacji uzyskanych wyników.") Cele: a) Umiejętność przeprowadzenia analizy struktury wybranego zbioru obserwacji Obliczanie miar tendencji centralnych, miar rozproszenia, współczynnika skośności i miary spłaszczenia z wykorzystaniem
Cele: a) Umiejętność przeprowadzenia analizy struktury wybranego zbioru obserwacji Obliczanie miar tendencji centralnych, miar rozproszenia, współczynnika skośności i miary spłaszczenia z wykorzystaniem
Inteligentna analiza danych
 Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Numer indeksu 150946 Michał Moroz Imię i nazwisko Numer indeksu 150875 Grzegorz Graczyk Imię i nazwisko kierunek: Informatyka rok akademicki: 2010/2011 Inteligentna analiza danych Ćwiczenie I Wskaźniki
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Metody eksploracji danych Laboratorium 2. Weka + Python + regresja
 Metody eksploracji danych Laboratorium 2 Weka + Python + regresja KnowledgeFlow KnowledgeFlow pozwala na zdefiniowanie procesu przetwarzania danych Komponenty realizujące poszczególne czynności można konfigurować,
Metody eksploracji danych Laboratorium 2 Weka + Python + regresja KnowledgeFlow KnowledgeFlow pozwala na zdefiniowanie procesu przetwarzania danych Komponenty realizujące poszczególne czynności można konfigurować,
www.comarch.pl/szkolenia Operacja PIVOT w języku SQL w środowisku Oracle 21.11.2012
 Operacja PIVOT w języku SQL w środowisku Oracle 21.11.2012 Zakres Wprowadzenie Idea przestawiania danych Możliwe zastosowania Przestawianie danych bez klauzuli PIVOT Konstrukcja klauzuli Korzyści ze stosowania
Operacja PIVOT w języku SQL w środowisku Oracle 21.11.2012 Zakres Wprowadzenie Idea przestawiania danych Możliwe zastosowania Przestawianie danych bez klauzuli PIVOT Konstrukcja klauzuli Korzyści ze stosowania
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji
 Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji Wstęp Systemy automatycznego wyodrębniania reguł pełnią bardzo ważną rolę
Porównanie systemów automatycznej generacji reguł działających w oparciu o algorytm sekwencyjnego pokrywania oraz drzewa decyzji Wstęp Systemy automatycznego wyodrębniania reguł pełnią bardzo ważną rolę
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT. Część I: analiza regresji
 Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
Temat zajęć: ANALIZA DANYCH ZBIORU EKSPORT Część I: analiza regresji Krok 1. Pod adresem http://zsi.tech.us.edu.pl/~nowak/adb/eksport.txt znajdziesz zbiór danych do analizy. Zapisz plik na dysku w dowolnej
OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) Algorytmy i Struktury Danych PIŁA
 PAWLICKI Piotr (55567) Algorytmy i Struktury Danych PIŁA") OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) 16.01.2003 Algorytmy i Struktury Danych PIŁA ALGORYTMY ZACHŁANNE czas [ms] Porównanie Algorytmów Rozwiązyjących problem TSP 100 000 000 000,000 10 000 000
OSTASZEWSKI Paweł (55566) PAWLICKI Piotr (55567) 16.01.2003 Algorytmy i Struktury Danych PIŁA ALGORYTMY ZACHŁANNE czas [ms] Porównanie Algorytmów Rozwiązyjących problem TSP 100 000 000 000,000 10 000 000
OPENMailing.pl - innowacja, efektywność, nieograniczone możliwości kampanii ingowych.
 OPENMailing.pl - innowacja, efektywność, nieograniczone możliwości kampanii e-mailingowych. Bezpłatny system, który umożliwia w bardzo prosty sposób wysyłać maile do wielu osób jednocześnie. Proste i intuicyjne
OPENMailing.pl - innowacja, efektywność, nieograniczone możliwości kampanii e-mailingowych. Bezpłatny system, który umożliwia w bardzo prosty sposób wysyłać maile do wielu osób jednocześnie. Proste i intuicyjne
Złożoność i zagadnienia implementacyjne. Wybierz najlepszy atrybut i ustaw jako test w korzeniu. Stwórz gałąź dla każdej wartości atrybutu.
 Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
Konwersatorium Matematyczne Metody Ekonomii Narzędzia matematyczne w eksploracji danych Indukcja drzew decyzyjnych Wykład 3 - część 2 Marcin Szczuka http://www.mimuw.edu.pl/ szczuka/mme/ Plan wykładu Generowanie
Oracle PL/SQL. Paweł Rajba.
 Paweł Rajba pawel@ii.uni.wroc.pl http://www.kursy24.eu/ Zawartość modułu 2 Kusory Wprowadzenie Kursory użytkownika Kursory domyślne Zmienne kursora Wyrażenia kursora - 2 - Wprowadzenie Co to jest kursor?
Paweł Rajba pawel@ii.uni.wroc.pl http://www.kursy24.eu/ Zawartość modułu 2 Kusory Wprowadzenie Kursory użytkownika Kursory domyślne Zmienne kursora Wyrażenia kursora - 2 - Wprowadzenie Co to jest kursor?
Obiektowe bazy danych Ćwiczenia laboratoryjne (?)
") Obiektowe bazy danych Ćwiczenia laboratoryjne (?) Tworzenie typów obiektowych 1. Zdefiniuj typ obiektowy reprezentujący SAMOCHODY. Każdy samochód powinien mieć markę, model, liczbę kilometrów oraz datę
Obiektowe bazy danych Ćwiczenia laboratoryjne (?) Tworzenie typów obiektowych 1. Zdefiniuj typ obiektowy reprezentujący SAMOCHODY. Każdy samochód powinien mieć markę, model, liczbę kilometrów oraz datę
Optymalizacja parametrów w strategiach inwestycyjnych dla event-driven tradingu dla odczytu Australia Employment Change
 Raport 4/2015 Optymalizacja parametrów w strategiach inwestycyjnych dla event-driven tradingu dla odczytu Australia Employment Change autor: Michał Osmoła INIME Instytut nauk informatycznych i matematycznych
Raport 4/2015 Optymalizacja parametrów w strategiach inwestycyjnych dla event-driven tradingu dla odczytu Australia Employment Change autor: Michał Osmoła INIME Instytut nauk informatycznych i matematycznych
Kontekstowe wskaźniki efektywności nauczania - warsztaty
 Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
Kontekstowe wskaźniki efektywności nauczania - warsztaty Przygotowała: Aleksandra Jasińska (a.jasinska@ibe.edu.pl) wykorzystując materiały Zespołu EWD Czy dobrze uczymy? Metody oceny efektywności nauczania
Podstawy SQL. 1. Wyświetl całość informacji z relacji ZESPOLY. 2. Wyświetl całość informacji z relacji PRACOWNICY
 Podstawy SQL 1. Wyświetl całość informacji z relacji ZESPOLY ID_ZESP NAZWA ADRES ---------- -------------------- -------------------- 10 ADMINISTRACJA PIOTROWO 3A 20 SYSTEMY ROZPROSZONE PIOTROWO 3A 30
Podstawy SQL 1. Wyświetl całość informacji z relacji ZESPOLY ID_ZESP NAZWA ADRES ---------- -------------------- -------------------- 10 ADMINISTRACJA PIOTROWO 3A 20 SYSTEMY ROZPROSZONE PIOTROWO 3A 30
Krzysztof Kawa. empolis arvato. e mail: krzysztof.kawa@empolis.com
 XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
XI Konferencja PLOUG Kościelisko Październik 2005 Zastosowanie reguł asocjacyjnych, pakietu Oracle Data Mining for Java do analizy koszyka zakupów w aplikacjach e-commerce. Integracja ze środowiskiem Oracle
Data Mining w doborze parametrów układu testującego urządzenia EAZ 1
 Rozdział 6 Data Mining w doborze parametrów układu testującego urządzenia EAZ 1 Streszczenie. W rozdziale został zaproponowany sposób doboru parametrów układu testującego urządzenia elektroenergetycznej
Rozdział 6 Data Mining w doborze parametrów układu testującego urządzenia EAZ 1 Streszczenie. W rozdziale został zaproponowany sposób doboru parametrów układu testującego urządzenia elektroenergetycznej
1. Przygotowanie danych do analizy. Transformacja danych
 Spis treści: 1. 2. 3. 3. Przygotowanie danych do analizy. Transformacja danych.1 Rapid Miner transformacja danych.2 Oracle Data Miner - Przygotowanie danych do analizy...5 Transformacja danych w ODM JAVA
Spis treści: 1. 2. 3. 3. Przygotowanie danych do analizy. Transformacja danych.1 Rapid Miner transformacja danych.2 Oracle Data Miner - Przygotowanie danych do analizy...5 Transformacja danych w ODM JAVA
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych
 WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
WEKA klasyfikacja z użyciem sztucznych sieci neuronowych 1 WEKA elementy potrzebne do zadania WEKA (Data mining software in Java http://www.cs.waikato.ac.nz/ml/weka/) jest narzędziem zawierającym zbiór
Przydatne sztuczki - sql. Na przykładzie postgres a.
 Przydatne sztuczki - sql. Na przykładzie postgres a. M. Wiewiórko 05/2014 Plan Uwagi wstępne Przykład Rozwiązanie Tabela testowa Plan prezentacji: Kilka uwag wstępnych. Operacje na typach tekstowych. Korzystanie
Przydatne sztuczki - sql. Na przykładzie postgres a. M. Wiewiórko 05/2014 Plan Uwagi wstępne Przykład Rozwiązanie Tabela testowa Plan prezentacji: Kilka uwag wstępnych. Operacje na typach tekstowych. Korzystanie