Wyszukiwanie i Przetwarzanie Informacji Information Retrieval & Search
|
|
|
- Robert Grzelak
- 6 lat temu
- Przeglądów:
Transkrypt




1 Wyszukiwanie i Przetwarzanie Informacji Information Retrieval & Search dr hab. inż. Miłosz Kadziński dr inż. Irmina Masłowska {milosz.kadzinski, irmina.maslowska}@cs.put.poznan.pl
2 Document representation Document representation Podstawowe sposoby reprezentacji dokumentów tekstowych d 1 : Paul is quicker than John. Paul is quicker than George, too. d 2 : John is quicker than George. index terms: george, john, paul, quicker Boolean representation (BIN - binary vectors) d 1 = (1, 1, 1, 1) d 2 = (1, 1, 0, 1) Bag-of words-representations (np. TF, TF-IDF) d 1 = (1, 1, 2, 2) d 2 = (1, 1, 0, 1) Reprezentacja pełna
3 Jaccard Coecient Jaccard Coefficient Do wyznaczania podobieństwa między dwoma dokumentami w binarnej reprezentacji BIN można stosować współczynnik (indeks) Jaccarda Jest to statystyka używana do porównywania zbiorów. Współczynnik Jaccarda mierzy podobieństwo między dwoma zbiorami i jest zdefiniowany jako iloraz mocy części wspólnej zbiorów i mocy sumy tych zbiorów W kontekście zbioru termów występujących w dokumencie T(dj)
4 Jaccard Coecient Jaccard Coefficient
5 Jaccard Coecient Jaccard Coefficient = 2/5 Rozważa tylko niezerowe współrzędne wektorów Wystarczy porównywać pary jedynie tych dokumentów, które posiadają co najmniej jedną wspólną niezerową współrzędną
6 Jaccard Coecient Jaccard Coefficient = 2/5 Rozważa tylko niezerowe współrzędne wektorów Wystarczy porównywać pary jedynie tych dokumentów, które posiadają co najmniej jedną wspólną niezerową współrzędną Stosowany m.in. w wykrywaniu prawie-duplikatów (plagiatów) algorytmem W-shingling wykorzystującym reprezentację dokumentów opartą na n-gramach, czy w korekcji literówek przy wykorzystaniu reprezentacji słów opartej na k-gramach
7 Information Retrieval models Information Retrieval models Niech T będzie liczbą termów indeksujących (rozmiarem słownika), k i i-tym słowem kluczowym, D kolekcją, czyli zbiorem wszystkich dostępnych dokumentów, Q zbiorem zapytań K= k 1, k 2,..., k T jest zbiorem wszystkich termów indeksujących Z każdym słowem kluczowym k i dokumentu d j związana jest waga a ij > 0 (ew. a ij 0), dla słów kluczowych niewystępujących w tekście dokumentu a ij = 0 Stąd każdemu dokumentowi przyporządkowany jest wektor d j = (a 1j, a 2j,..., a Tj) Niech g i będzie funkcją, która zwraca wagę związaną ze słowem kluczowym k i dowolnego T-wymiarowego wektora, np.: g i(d j) = a ij sim(q, d j ) jest funkcją rangującą, która przyporządkowuje wartości rzeczywiste parom (q, d j ): q Q, d j D Funkcja sim definiuje uporządkowanie (ranking) dokumentów względem zapytania
8 TF term weighting scheme TF term weighting scheme term frequency waga termu k i K w dokumencie d j D rośnie wraz ze wzrostem liczby wystąpień tego słowa w tym dokumencie Hans Peter Luhn (1957)
9 TF term weighting scheme TF term weighting scheme zwykła liczność wystąpień częstość znormalizowana długością d j znormalizowana względem najczęstszego termu w d j inne, np.: 0 0, 1 1, 2 1.3, 10 2,
10 TF-IDF term weighting scheme TF-IDF term weighting scheme term frequency inverse document frequency waga termu k i K w dokumencie d j D rośnie wraz ze wzrostem jego liczby wystąpień w tym dokumencie Hans Peter Luhn (1957) waga termu k i K w każdym dokumencie kolekcji D maleje wraz ze wzrostem liczby dokumentów kolekcji, które zawierają term k i Karen Spärck Jones (1972) a ij = tf ij. idf i
11 TF-IDF term weighting scheme TF-IDF term weighting scheme
12 TF-IDF term weighting scheme TF-IDF term weighting scheme TF dokument d j 100 liczba wystąpień najczęstszego termu 4 wystąpienia termu k i =wieloryb IDF 10 mln dokumentów w kolekcji D 10 zawierających term k i =wieloryb (d j i jeszcze 9 innych) idf i log N N i
13 TF-IDF term weighting scheme TF-IDF term weighting scheme TF dokument d j 100 liczba wystąpień najczęstszego termu 4 wystąpienia termu k i =wieloryb 4/100 = 0.04 IDF 10 mln dokumentów w kolekcji D 10 zawierających term k i =wieloryb log( /10) = 6 (d j i jeszcze 9 innych) a ij = 0,04*6 = 0.24 idf i log N N i
14 TF-IDF term weighting scheme TF-IDF term weighting scheme Wysoką wagę osiąga term, który w danym dokumencie występuje stosunkowo wiele razy, natomiast występuje w małym odsetku dokumentów kolekcji dokumentów, 1 zawiera słowo wieloryb 4/100 * log (10000 / 1) = dokumentów, 100 zawiera słowo wieloryb 4/100 * log (10000 / 100) = dokumentów, zawiera słowo wieloryb 4/100 * log (10000 / 10000) = 0
15 Information Retrieval models Information Retrieval models Klasyczne modele IR model Boole owski model wektorowy (VSM Vector Space Model) model probabilistyczny (BIR Binary Independence Model) Nieklasyczne modele IR model oparty na zbiorach rozmytych (fuzzy sets) rozszerzony model Boole owski model LSI (Latent Semantic Indexing) model oparty na sieciach neuronowych (NN) uogólniony model wektorowy (Generalized VSM) modele probabilistyczne (sieci Bayesowskie, belief networks, inference networks...)
16 VSM - Vector Space Model VSM Vector Space Model Model wektorowy VSM może bazować na reprezentacji BIN, TF, lecz najczęściej TF-IDF Gerard Salton, 1975 Dokumenty i zapytania reprezentowane są w przestrzeni T-wymiarowej, gdzie T jest rozmiarem słownika (liczbą wszystkich jednostek indeksujących) Dalej będziemy zwykle zakładać, że wagi a ij poszczególnych słów kluczowych k i dla danego dokumentu dj są wyznaczane miarą tf-idf
17 Vector Space Model Vector Space Model A jak wyznaczyć ranking dokumentów względem q?
18 Vector Space Model Vector Space Model
19 Vector Space Model Vector Space Model W modelu wektorowym dokumenty są wektorami w T-wymiarowej przestrzeni euklidesowej, gdzie osie reprezentują poszczególne termy Każdy wektor reprezentujący dokument ma początek w początku układu współrzędnych, a koniec w punkcie o współrzędnych wyznaczonych wagami tf-idf Zapytania q i są reprezentowane analogicznie Wagi q i mogą być binarne {0;1}, lepiej idf lub tf-idf
20 Vector Space Model Vector Space Model A jak wyznaczyć ranking dokumentów względem q? miara kosinusowa:
21 Cosine Similarity Cosine Similarity Wektory d j i q w T-wymiarowej przestrzeni euklidesowej Licznik: suma iloczynów odpowiadających sobie współrzędnych Mianownik: iloczyn długości wektorów dokumentu i zapytania (długość to pierwiastek z sumy kwadratów współrzędnych) Miara kosinusowa nadaje się również do wyznaczania podobieństwa między dwoma dokumentami
22 VSM ranking VSM ranking Przedstaw zapytanie w postaci wektora tf-idf Przedstaw każdy dokument w postaci wektora tf-idf Oblicz kosinus kąta między wektorem zapytania a wektorami poszczególnych dokumentów Utwórz ranking dokumentów wg wartości miary kosinusowej (największe wartości na górze) Zwróć ustaloną liczbę najwyżej sklasyfikowanych dokumetów jako odpowiedź dla zadanego zapytania
23 Example Boolean Search Example Boolean Search q: Brutus AND Caesar AND NOT Calpurnia Źródło: An Introduction to Information Retrieval, Cambridge Univ. P
24 Example Boolean Search Example Boolean Search Odpowiedź: Antony and Cleopatra, Hamlet
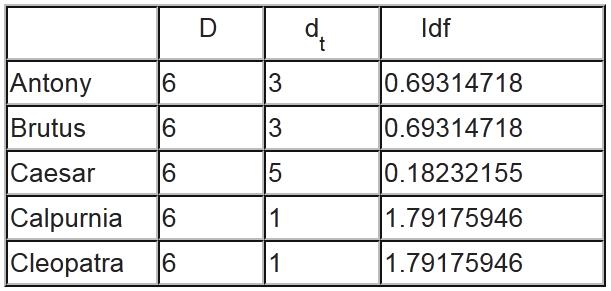
25 Example VSM Search Example VSM Search

26 Example VSM Search Example VSM Search q: Brutus AND Caesar AND NOT Calpurnia
27 Example VSM Search Example VSM Search q: Brutus Caesar Ranking: 1. Hamlet 2. Antony and Cleopatra
28 Vector Space Model Vector Space Model Czy IDF będzie miał wpływ na wyniki zapytań składających się z pojedynczego termu indeksującego - np. bitcoin?
29 Vector Space Model Vector Space Model Czy IDF będzie miał wpływ na wyniki zapytań składających się z pojedynczego termu indeksującego - np. bitcoin? IDF nie ma wpływu na takie zapytania Wpływ IDF objawia się przy zapytaniach składających się z 2 lub więcej termów Przykładowo, dla zapytania święta wielkanocne waga IDF spowoduje, że wystąpienia słowa wielkanocne w dokumentach będą liczyły się dużo bardziej niż wystąpienia słowa święta
30 Vector Space Model Vector Space Model Zalety modelu wektorowego prostota i szybkość uwzględnienie wag tf-idf poprawia wyniki kosinusowa miara podobieństwa umożliwia uszeregowanie dokumentów zgodnie z malejącą adekwatnością (możliwość kontroli rozmiarów zbioru wyników) częściowe dopasowanie umożliwia odnajdowanie dokumentów w przybliżeniu spełniających warunki zapytania popularność ;) Wady modelu wektorowego założenie o niezależności słów kluczowych
31 Information Retrieval models Information Retrieval models Klasyczne modele IR model Boole owski model wektorowy (VSM Vector Space Model) model probabilistyczny (BIR Binary Independence Model) Nieklasyczne modele IR model oparty na zbiorach rozmytych (fuzzy sets) rozszerzony model Boole owski model LSI (Latent Semantic Indexing) model oparty na sieciach neuronowych (NN) uogólniony model wektorowy (Generalized VSM) modele probabilistyczne (sieci Bayesowskie, belief networks, inference networks...)
32 Binary Independence Model Binary Independence Model Probabilistyczny model BIR bazuje na binarnej reprezentacji dokumentów i zapytań (BIN) Dla danego zapytania q Q i dokumentu z kolekcji d j D, model probabilistyczny usiłuje oszacować prawdopodobieństwo, że użytkownik uzna dokument d j za interesujący (adekwatny) Prawdopodobieństwo adekwatności zależy wyłącznie od reprezentacji zapytania q i reprezentacji dokumentu d j Istnieje pewien zbiór R - podzbiór dokumentów, które użytkownik preferuje jako odpowiedź na zapytanie q. Zbiór R ma maksymalizować całkowite prawdopodobieństwo adekwatności dla użytkownika. Dokumenty z R są uznawane za adekwatne, dokumenty spoza R (oznacz. R ) za nieadekwatne
33 Binary Independence Model Binary Independence Model Funkcja rangująca modelu BIR w iq waga termu k i w zapytaniu q a ij waga termu k i w dokumencie d j P(k i R) prawdopodobieństwo, że term k i występuje w losowo wybranym dokumencie ze zbioru dokumentów interesujących R P(k i R ) prawdopodobieństwo, że term k i występuje w losowo wybranym dokumencie ze zbioru dokumentów nieinteresujących R
34 Binary Independence Model Binary Independence Model Początkowe szacowanie prawdopodobieństw prawdopodobieństwo występowania k i w dokumencie losowo wybranym z R jest równe dla wszystkich słów kluczowych rozkład termów w dokumentach z R jest taki jak w całej kolekcji dokumentów D P(k i R) = 0,5 P(k i R ) = Dla takich wartości można otrzymać wstępny ranking
35 Binary Independence Model Binary Independence Model Dokładniejsze szacowanie prawdopodobieństw następuje na podstawie pierwszego (wstępnego) rankingu: Pewna liczba dokumentów z początku wstępnego rankingu czołowych zostaje uznana za adekwatne V, reszta za nieadekwatne Niech V będzie podzbiorem dokumentów wybranych jako adekwatne, a V i jego podzbiorem złożonym tylko z tych dokumentów, które zawierają term k i, wówczas prawdopodobieństwa można oszacować następująco:
36 Binary Independence Model Binary Independence Model Zalety probabilistycznego modelu BIR prostota i szybkość dokumenty są porządkowane zgodnie z malejącym prawdopodobieństwem ich adekwatności (możliwość kontroli rozmiarów zbioru wyników) Wady modelu BIR ignorowanie informacji o częstości wystąpienia słów kluczowych w dokumentach (binarne wagi) konieczność zgadywania początkowego podziału zbioru dokumentów na adekwatne i nieadekwatne założenie o niezależności słów kluczowych
37 Term Independence Assumption Term Independence Assumption Wszystkie klasyczne modele IR bazują na założeniu, że termy indeksujące są niezależne, czyli na podstawie znajomości wagi a ij przyporządkowanej parze (k i, d j ) nie możemy nic powiedzieć o wadze a lj dla pary (k l, d j ): i l Założenie o niezależności słów kluczowych jest uproszczeniem dyktowanym: efektywnością i prostotą obliczeń trudnością w modelowaniu związków między słowami (zależność od konkretnych kontekstów) zadowalającymi wynikami mimo tego założenia
38 Information Retrieval models Information Retrieval models Klasyczne modele IR model Boole owski model wektorowy (VSM Vector Space Model) model probabilistyczny (BIR Binary Independence Model) Nieklasyczne modele IR model oparty na zbiorach rozmytych (fuzzy sets) rozszerzony model Boole owski model LSI (Latent Semantic Indexing) model oparty na sieciach neuronowych (NN) uogólniony model wektorowy (Generalized VSM) modele probabilistyczne (sieci Bayesowskie, belief networks, inference networks...)
39 Bayesian Network IR model Bayesian Network IR model Turtle and Croft (1989, 1991) Model formalnie oparty na mechanizmie wnioskowania w sieciach bayesowskich Sieć bayesowska to skierowany graf acykliczny kodujący prawdopodobieństwa warunkowe dla zdarzeń losowych. Wierzchołki grafu reprezentują zdarzenia, a łuki związki przyczynowe pomiędzy tymi zdarzeniami
40 Neural Network IR model Neural Network IR model Wilkinson and Hingston (1991)
41 IR Evaluation Measures IR Evaluation Measures Oceniając system IR należy brać pod uwagę różne aspekty jego działania: złożoność przetwarzania (time & space efficiency) jakość wyników wyszukiwania zadowolenie użytkowników rozszerzalność i adaptacyjność skalowalność
42 IR Evaluation Measures IR Evaluation Measures D Dla każdego zapytania q przedstawionego systemowi mamy: R q zbiór dokumentów zwróconych (Retrieved) przez system D q zbiór dokumentów adekwatnych (Relevant) obecnych w całej kolekcji dokumentów
43 IR Evaluation Measures IR Evaluation Measures Podstawowe miary oceny jakości dopasowania odpowiedzi systemu dla zapytania q: miara dokładności (precision) miara kompletności (recall) precision odsetek wyszukanych dokumentów, które rzeczywiście są adekwatne do zapytania recall odsetek dokumentów adekwatnych do zapytania, które zostały wyszukane
44 IR Evaluation Measures IR Evaluation Measures R q R q D q D q R q D q D q R q
45 IR Evaluation Measures IR Evaluation Measures Dokładność i kompletność a konkretne zastosowania Typowy użytkownik chciałby, aby w czołówce zwróconego rankingu były tyko dokumenty adekwatne, ale zwykle nie zechce przeglądać wszystkich dokumentów adekwatnych Przeszukując dysk twardy, użytkownik jest zwykle zainteresowany znalezieniem wszystkich dokumentów pasujących do zapytania A filtr antyspamowy?
46 IR Evaluation Measures IR Evaluation Measures Badania rzeczywistych systemów IR pokazują, że jeśli polepsza się precision to degraduje się recall jeśli polepsza się recall to degraduje się precision
47 IR Evaluation Measures IR Evaluation Measures F-measure ważona średnia harmoniczna dokładności (P) i kompletności (R)
48 IR Evaluation Measures IR Evaluation Measures F-measure ważona średnia harmoniczna dokładności (P) i kompletności (R) to parametr ustalany tak, że > 1 nacisk na kompletność, < 1 nacisk na dokładność Średnia harmoniczna jest bliższa minimum dwóch wartości niż średnia arytmetyczna lub geometryczna
49 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results precision at rank k (P@k) i recall at rank k (R@k) Miary oceniające ranking dokumentów liczone są dla pewnej liczby k początkowych dokumentów Niech r i = 1 gdy dokument d i stojący na i-tej pozycji w rankingu jest adekwatny (0 w przeciwnym razie) Niech k >= 0 Dokładność oraz kompletność dla k początkowych dokumentów definiujemy jako:
50 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results 1/1 1/2 1/3 2/4 2/5 3/6 3/7 4/8 1/10 1/10 1/10 2/10 2/10 3/10 3/10 4/10 * *) w tym przykładzie założono, że D q =10)

51 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results
52 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results 11-point interpolated average precision interpolowana dokładność mierzona dla 11 poziomów kompletności: 0.0, 0.1, 0.2,..., 1.0 uśredniana po wszystkich badanych zapytaniach miara używana m.in. dla oceny 1-8 TREC Ad Hoc Tasks kolekcje TREC (Text Retrieval Conference) kolekcje testowe do ewaluacji różnych zadań w ramach tematów konferencji najpopularniejsze: Ad Hoc Track z lat ,89mln docs (głównie artykuły prasowe), częściowe oceny adekwatności dla 450 zapytań; TRECs 6 8: 528 tys. artykułów newswire i Foreign Broadcast Information Service zapytań
53 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results Averaged 11-point precision/recall graph across 50 queries for a representative TREC system (MAP=0.2553)
54 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results Mean average precision (MAP) gdzie m j to minimalna liczba dokumentów od początku rankingu, które zawierają dokładnie j adekwatnych dokumentów wymaga znajomości liczności zbioru dokumentów adekwatnych D q
55 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results Mean average precision (MAP) gdzie m j to minimalna liczba dokumentów od początku rankingu, które zawierają dokładnie j adekwatnych dokumentów MAP = ¼ (1+2/4+3/6+4/8) = 5/8
56 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results Mean average precision (MAP) Oceny MAP obliczone dla danego systemu zwykle wykazują bardzo duże zróżnicowanie w zależności od badanego zapytania, przykładowo dla typowego systemu z TREC mogą to być wartości rozrzucone pomiędzy 0.1 and 0.7. Stąd powszechnie miarę tę uznaje się za miarodajną dla porównywania różnych systemów na danym zapytaniu Zbiór testowy zapytań musi więc być bardzo duży i różnorodny, aby mógł służyć za podstawę oceny jakości systemu wyszukującego i stanowić bazę do porównania różnych systemów
57 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results R-precision R-dokładność to dokładność zbioru pierwszych D q dokumentów w rankingu zwróconym przez system wyszukujący (czyli P@k dla k= D q ) Miara ta w praktyce silnie koreluje z miarą MAP Obliczenie miary R-dokładność także wymaga znajomości zbioru dokumentów adekwatnych D q lub choćby oszacowania jego liczności D q
58 Evaluation of Ranked Retrieval Results Evaluation of Ranked Retrieval Results R-precision R-dokładność to dokładność zbioru pierwszych D q dokumentów w rankingu zwróconym przez system wyszukujący R-precision = 2/4 = 0.5


59 Other IR Evaluation Measures Other IR Evaluation Measures Miary badające zadowolenie/frustrację użytkownika, coverage ratio, novelty ratio, relative recall, recall effort
Wyszukiwanie i Przetwarzanie Informacji Information Retrieval & Search
 Wyszukiwanie i Przetwarzanie Informacji Information Retrieval & Search Irmina Masłowska irmina.maslowska@cs.put.poznan.pl www.cs.put.poznan.pl/imaslowska/wipi/ Document representation Document representation
Wyszukiwanie i Przetwarzanie Informacji Information Retrieval & Search Irmina Masłowska irmina.maslowska@cs.put.poznan.pl www.cs.put.poznan.pl/imaslowska/wipi/ Document representation Document representation
Wstęp do przetwarzania języka naturalnego
 Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Wyszukiwanie dokumentów/informacji
 Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji. Instytut Informatyki i Elektroniki. Instrukcja do zajęć laboratoryjnych
 Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych
 Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Wyszukiwanie tekstów
 Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Bazy dokumentów tekstowych
 Bazy dokumentów tekstowych Bazy dokumentów tekstowych Dziedzina zastosowań Automatyzacja bibliotek Elektroniczne encyklopedie Bazy aktów prawnych i patentów Szukanie informacji w Internecie Dokumenty tekstowe
Bazy dokumentów tekstowych Bazy dokumentów tekstowych Dziedzina zastosowań Automatyzacja bibliotek Elektroniczne encyklopedie Bazy aktów prawnych i patentów Szukanie informacji w Internecie Dokumenty tekstowe
Wyszukiwanie informacji w internecie. Nguyen Hung Son
 Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Eksploracja tekstu. Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu. Eksploracja danych. Eksploracja tekstu wykład 1
 Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene
 2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Zastosowanie metod statystycznych do ekstrakcji słów kluczowych w kontekście projektu LT4eL. Łukasz Degórski
 Zastosowanie metod statystycznych do ekstrakcji słów kluczowych w kontekście projektu LT4eL Łukasz Degórski LT4eL Language Technology for e-learning Wykorzystanie narzędzi językowych oraz technik sieci
Zastosowanie metod statystycznych do ekstrakcji słów kluczowych w kontekście projektu LT4eL Łukasz Degórski LT4eL Language Technology for e-learning Wykorzystanie narzędzi językowych oraz technik sieci
Wykład 10 Skalowanie wielowymiarowe
 Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
Wykład 10 Skalowanie wielowymiarowe Wrocław, 30.05.2018r Skalowanie wielowymiarowe (Multidimensional Scaling (MDS)) Główne cele MDS: przedstawienie struktury badanych obiektów przez określenie treści wymiarów
WYSZUKIWANIE I PRZETWARZANIE INFORMACJI LISTA KONTROLNA PYTAŃ, WSKAZÓWEK I PODPOWIEDZI PRZED KOLOKWIUM ZALICZENIOWYM
 WYSZUKIWANIE I PRZETWARZANIE INFORMACJI LISTA KONTROLNA PYTAŃ, WSKAZÓWEK I PODPOWIEDZI PRZED KOLOKWIUM ZALICZENIOWYM Termin i miejsce: wtorek 28 maja 2019r. 9:45 (BT 122) Liczba zadań: ok. 15 (wiele z
WYSZUKIWANIE I PRZETWARZANIE INFORMACJI LISTA KONTROLNA PYTAŃ, WSKAZÓWEK I PODPOWIEDZI PRZED KOLOKWIUM ZALICZENIOWYM Termin i miejsce: wtorek 28 maja 2019r. 9:45 (BT 122) Liczba zadań: ok. 15 (wiele z
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych
 Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Analiza zawartości dokumentów za pomocą probabilistycznych modeli graficznych Probabilistic Topic Models Jakub M. TOMCZAK Politechnika Wrocławska, Instytut Informatyki 30.03.2011, Wrocław Plan 1. Wstęp
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Spacery losowe generowanie realizacji procesu losowego
 Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Spacery losowe generowanie realizacji procesu losowego Michał Krzemiński Streszczenie Omówimy metodę generowania trajektorii spacerów losowych (błądzenia losowego), tj. szczególnych procesów Markowa z
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
W poszukiwaniu sensu w świecie widzialnym
 W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
W poszukiwaniu sensu w świecie widzialnym Andrzej Śluzek Nanyang Technological University Singapore Uniwersytet Mikołaja Kopernika Toruń AGH, Kraków, 28 maja 2010 1 Podziękowania Przedstawione wyniki powstały
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II
 Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część V - Model PRAM II Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Wymagania kl. 3. Zakres podstawowy i rozszerzony
 Wymagania kl. 3 Zakres podstawowy i rozszerzony Temat lekcji Zakres treści Osiągnięcia ucznia 1. RACHUNEK PRAWDOPODOBIEŃSTWA 1. Reguła mnożenia reguła mnożenia ilustracja zbioru wyników doświadczenia za
Wymagania kl. 3 Zakres podstawowy i rozszerzony Temat lekcji Zakres treści Osiągnięcia ucznia 1. RACHUNEK PRAWDOPODOBIEŃSTWA 1. Reguła mnożenia reguła mnożenia ilustracja zbioru wyników doświadczenia za
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Zastosowanie rozmytych map kognitywnych do badania scenariuszy rozwoju jednostek naukowo-dydaktycznych
 Konferencja Systemy Czasu Rzeczywistego 2012 Kraków, 10-12 września 2012 Zastosowanie rozmytych map kognitywnych do badania scenariuszy rozwoju jednostek naukowo-dydaktycznych Piotr Szwed AGH University
Konferencja Systemy Czasu Rzeczywistego 2012 Kraków, 10-12 września 2012 Zastosowanie rozmytych map kognitywnych do badania scenariuszy rozwoju jednostek naukowo-dydaktycznych Piotr Szwed AGH University
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
REPREZENTACJA I WYSZUKIWANIE DOKUMENTÓW TEKSTOWYCH W BAZACH DANYCH
 STUDIA INFORMATICA 2009 Volume 30 Number 2A (83) Jakub CIEŚLEWICZ, Adam PELIKANT Politechnika Łódzka, Instytut Mechatroniki i Systemów Informatycznych REPREZENTACJA I WYSZUKIWANIE DOKUMENTÓW TEKSTOWYCH
STUDIA INFORMATICA 2009 Volume 30 Number 2A (83) Jakub CIEŚLEWICZ, Adam PELIKANT Politechnika Łódzka, Instytut Mechatroniki i Systemów Informatycznych REPREZENTACJA I WYSZUKIWANIE DOKUMENTÓW TEKSTOWYCH
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
P(F=1) F P(C1 = 1 F = 1) P(C1 = 1 F = 0) P(C2 = 1 F = 1) P(C2 = 1 F = 0) P(R = 1 C2 = 1) P(R = 1 C2 = 0)
 F P(C1 = 1 F = 1) P(C1 = 1 F = 0) P(C2 = 1 F = 1) P(C2 = 1 F = 0) P(R = 1 C2 = 1) P(R = 1 C2 = 0)") Sieci bayesowskie P(F=) F P(C = F = ) P(C = F = 0) C C P(C = F = ) P(C = F = 0) M P(M = C =, C = ) P(M = C =, C = 0) P(M = C = 0, C = ) P(M = C = 0, C = 0) R P(R = C = ) P(R = C = 0) F pali papierosy C
Sieci bayesowskie P(F=) F P(C = F = ) P(C = F = 0) C C P(C = F = ) P(C = F = 0) M P(M = C =, C = ) P(M = C =, C = 0) P(M = C = 0, C = ) P(M = C = 0, C = 0) R P(R = C = ) P(R = C = 0) F pali papierosy C
EmotiWord, semantyczne powiązanie i podobieństwo, odległość znaczeniowa
 , semantyczne powiązanie i podobieństwo, odległość Projekt przejściowy ARR Politechnika Wrocławska Wydział Elektroniki Wrocław, 22 października 2013 Spis treści 1 językowa 2, kryteria 3 Streszczenie artykułu
, semantyczne powiązanie i podobieństwo, odległość Projekt przejściowy ARR Politechnika Wrocławska Wydział Elektroniki Wrocław, 22 października 2013 Spis treści 1 językowa 2, kryteria 3 Streszczenie artykułu
Indukcja matematyczna. Zasada minimum. Zastosowania.
 Indukcja matematyczna. Zasada minimum. Zastosowania. Arkadiusz Męcel Uwagi początkowe W trakcie zajęć przyjęte zostaną następujące oznaczenia: 1. Zbiory liczb: R - zbiór liczb rzeczywistych; Q - zbiór
Indukcja matematyczna. Zasada minimum. Zastosowania. Arkadiusz Męcel Uwagi początkowe W trakcie zajęć przyjęte zostaną następujące oznaczenia: 1. Zbiory liczb: R - zbiór liczb rzeczywistych; Q - zbiór
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
MODELOWANIE STANÓW CZYNNOŚCIOWYCH W JĘZYKU SIECI BAYESOWSKICH
 Inżynieria Rolnicza 7(105)/2008 MODELOWANIE STANÓW CZYNNOŚCIOWYCH W JĘZYKU SIECI BAYESOWSKICH Katedra Podstaw Techniki, Uniwersytet Przyrodniczy w Lublinie Streszczenie. Zastosowanie sieci bayesowskiej
Inżynieria Rolnicza 7(105)/2008 MODELOWANIE STANÓW CZYNNOŚCIOWYCH W JĘZYKU SIECI BAYESOWSKICH Katedra Podstaw Techniki, Uniwersytet Przyrodniczy w Lublinie Streszczenie. Zastosowanie sieci bayesowskiej
TEORETYCZNE PODSTAWY INFORMATYKI
 1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
1 TEORETYCZNE PODSTAWY INFORMATYKI WFAiS UJ, Informatyka Stosowana I rok studiów, I stopień Wykład 16 2 Data Science: Uczenie maszynowe Uczenie maszynowe: co to znaczy? Metody Regresja Klasyfikacja Klastering
Eksploracja złożonych typów danych Text i Web Mining
 Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
Eksploracja złożonych typów danych Text i Web Mining Jerzy Stefanowski Instytut Informatyki Politechniki Poznańskiej Wykład AiED, Poznań 2002 Co będzie? Eksploracja danych tekstowych Wyszukiwanie informacji
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Eksploracja danych Algorytmy klastujące Problem 3 Mając daną chmurę punktów chcielibyśmy zrozumieć ich
Priorytetyzacja przypadków testowych za pomocą macierzy
 Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Priorytetyzacja przypadków testowych za pomocą macierzy W niniejszym artykule przedstawiony został problem przyporządkowania priorytetów do przypadków testowych przed rozpoczęciem testów oprogramowania.
Modelowanie motywów łańcuchami Markowa wyższego rzędu
 Modelowanie motywów łańcuchami Markowa wyższego rzędu Uniwersytet Warszawski Wydział Matematyki, Informatyki i Mechaniki 23 października 2008 roku Plan prezentacji 1 Źródła 2 Motywy i ich znaczenie Łańcuchy
Modelowanie motywów łańcuchami Markowa wyższego rzędu Uniwersytet Warszawski Wydział Matematyki, Informatyki i Mechaniki 23 października 2008 roku Plan prezentacji 1 Źródła 2 Motywy i ich znaczenie Łańcuchy
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Uczeń: -podaje przykłady ciągów liczbowych skończonych i nieskończonych oraz rysuje wykresy ciągów
 Wymagania edukacyjne PRZEDMIOT: Matematyka KLASA: III Th ZAKRES: zakres podstawowy Poziom wymagań Lp. Dział programu Konieczny-K Podstawowy-P Rozszerzający-R Dopełniający-D Uczeń: 1. Ciągi liczbowe. -zna
Wymagania edukacyjne PRZEDMIOT: Matematyka KLASA: III Th ZAKRES: zakres podstawowy Poziom wymagań Lp. Dział programu Konieczny-K Podstawowy-P Rozszerzający-R Dopełniający-D Uczeń: 1. Ciągi liczbowe. -zna
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Metody selekcji cech
 Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Metody selekcji cech A po co to Często mamy do dyspozycji dane w postaci zbioru cech lecz nie wiemy które z tych cech będą dla nas istotne. W zbiorze cech mogą wystąpić cechy redundantne niosące identyczną
Postać Jordana macierzy
 Rozdział 8 Postać Jordana macierzy Niech F = R lub F = C Macierz J r λ) F r r postaci λ 1 0 0 0 λ 1 J r λ) = 0 λ 1 0 0 λ gdzie λ F nazywamy klatką Jordana stopnia r Oczywiście J 1 λ) = [λ Definicja 81
Rozdział 8 Postać Jordana macierzy Niech F = R lub F = C Macierz J r λ) F r r postaci λ 1 0 0 0 λ 1 J r λ) = 0 λ 1 0 0 λ gdzie λ F nazywamy klatką Jordana stopnia r Oczywiście J 1 λ) = [λ Definicja 81
Metody numeryczne. materiały do wykładu dla studentów
 Metody numeryczne materiały do wykładu dla studentów 4. Wartości własne i wektory własne 4.1. Podstawowe definicje, własności i twierdzenia 4.2. Lokalizacja wartości własnych 4.3. Metoda potęgowa znajdowania
Metody numeryczne materiały do wykładu dla studentów 4. Wartości własne i wektory własne 4.1. Podstawowe definicje, własności i twierdzenia 4.2. Lokalizacja wartości własnych 4.3. Metoda potęgowa znajdowania
O szukaniu sensu w stogu siana
 O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
O szukaniu sensu w stogu siana Algorytmy grupowania wyników z wyszukiwarek internetowych i propozycje ich ulepszenia przy wykorzystaniu wiedzy lingwistycznej. Dawid Weiss Instytut Informatyki Politechnika
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
Wstęp do sieci neuronowych, wykład 07 Uczenie nienadzorowane.
 Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
Wstęp do sieci neuronowych, wykład 7. M. Czoków, J. Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika w Toruniu 212-11-28 Projekt pn. Wzmocnienie potencjału dydaktycznego UMK w Toruniu
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
WYMAGANIE EDUKACYJNE Z MATEMATYKI W KLASIE II GIMNAZJUM. dopuszczającą dostateczną dobrą bardzo dobrą celującą
 1. Statystyka odczytać informacje z tabeli odczytać informacje z diagramu 2. Mnożenie i dzielenie potęg o tych samych podstawach 3. Mnożenie i dzielenie potęg o tych samych wykładnikach 4. Potęga o wykładniku
1. Statystyka odczytać informacje z tabeli odczytać informacje z diagramu 2. Mnożenie i dzielenie potęg o tych samych podstawach 3. Mnożenie i dzielenie potęg o tych samych wykładnikach 4. Potęga o wykładniku
Przedmiotowe zasady oceniania i wymagania edukacyjne z matematyki dla klasy drugiej gimnazjum
 Przedmiotowe zasady oceniania i wymagania edukacyjne z matematyki dla klasy drugiej gimnazjum I. POTĘGI I PIERWIASTKI oblicza wartości potęg o wykładnikach całkowitych liczb różnych od zera zapisuje liczbę
Przedmiotowe zasady oceniania i wymagania edukacyjne z matematyki dla klasy drugiej gimnazjum I. POTĘGI I PIERWIASTKI oblicza wartości potęg o wykładnikach całkowitych liczb różnych od zera zapisuje liczbę
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I
 Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Techniki Optymalizacji: Stochastyczny spadek wzdłuż gradientu I Wojciech Kotłowski Instytut Informatyki Politechniki Poznańskiej email: imię.nazwisko@cs.put.poznan.pl pok. 2 (CW) tel. (61)665-2936 konsultacje:
Wymagania na poszczególne oceny w klasie II gimnazjum do programu nauczania MATEMATYKA NA CZASIE
 Wymagania na poszczególne oceny w klasie II gimnazjum do programu nauczania MATEMATYKA NA CZASIE Wymagania konieczne K dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, powinien je
Wymagania na poszczególne oceny w klasie II gimnazjum do programu nauczania MATEMATYKA NA CZASIE Wymagania konieczne K dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, powinien je
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład Kody liniowe - kodowanie w oparciu o macierz parzystości
 Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Machine Learning. KISIM, WIMiIP, AGH
 Machine Learning KISIM, WIMiIP, AGH 1 Machine Learning Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i jej praktycznego wdrażania. Algorytmy pozwalają na zautomatyzowanie procesu
Machine Learning KISIM, WIMiIP, AGH 1 Machine Learning Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i jej praktycznego wdrażania. Algorytmy pozwalają na zautomatyzowanie procesu
ROK SZKOLNY 2017/2018 WYMAGANIA EDUKACYJNE NA POSZCZEGÓLNE OCENY:
 ROK SZKOLNY 2017/2018 WYMAGANIA EDUKACYJNE NA POSZCZEGÓLNE OCENY: KLASA II GIMNAZJUM Wymagania konieczne K dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, powinien je zatem opanować
ROK SZKOLNY 2017/2018 WYMAGANIA EDUKACYJNE NA POSZCZEGÓLNE OCENY: KLASA II GIMNAZJUM Wymagania konieczne K dotyczą zagadnień elementarnych, stanowiących swego rodzaju podstawę, powinien je zatem opanować
dr Mariusz Grządziel 15,29 kwietnia 2014 Przestrzeń R k R k = R R... R k razy Elementy R k wektory;
 Wykłady 8 i 9 Pojęcia przestrzeni wektorowej i macierzy Układy równań liniowych Elementy algebry macierzy dodawanie, odejmowanie, mnożenie macierzy; macierz odwrotna dr Mariusz Grządziel 15,29 kwietnia
Wykłady 8 i 9 Pojęcia przestrzeni wektorowej i macierzy Układy równań liniowych Elementy algebry macierzy dodawanie, odejmowanie, mnożenie macierzy; macierz odwrotna dr Mariusz Grządziel 15,29 kwietnia
Systemy liczbowe. 1. Przedstawić w postaci sumy wag poszczególnych cyfr liczbę rzeczywistą R = (10).
.") Wprowadzenie do inżynierii przetwarzania informacji. Ćwiczenie 1. Systemy liczbowe Cel dydaktyczny: Poznanie zasad reprezentacji liczb w systemach pozycyjnych o różnych podstawach. Kodowanie liczb dziesiętnych
Wprowadzenie do inżynierii przetwarzania informacji. Ćwiczenie 1. Systemy liczbowe Cel dydaktyczny: Poznanie zasad reprezentacji liczb w systemach pozycyjnych o różnych podstawach. Kodowanie liczb dziesiętnych
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Zastosowania obliczeń inteligentnych do wyszukiwania w obrazowych bazach danych
 Zastosowania obliczeń inteligentnych do wyszukiwania w obrazowych bazach danych Tatiana Jaworska Jaworska@ibspan.waw.pl www.ibspan.waw.pl/~jaworska Istniejące systemy - Google Istniejące systemy - Google
Zastosowania obliczeń inteligentnych do wyszukiwania w obrazowych bazach danych Tatiana Jaworska Jaworska@ibspan.waw.pl www.ibspan.waw.pl/~jaworska Istniejące systemy - Google Istniejące systemy - Google
Algebra Liniowa 2 (INF, TIN), MAP1152 Lista zadań
, MAP1152 Lista zadań") Algebra Liniowa 2 (INF, TIN), MAP1152 Lista zadań Przekształcenia liniowe, diagonalizacja macierzy 1. Podano współrzędne wektora v w bazie B. Znaleźć współrzędne tego wektora w bazie B, gdy: a) v = (1,
Algebra Liniowa 2 (INF, TIN), MAP1152 Lista zadań Przekształcenia liniowe, diagonalizacja macierzy 1. Podano współrzędne wektora v w bazie B. Znaleźć współrzędne tego wektora w bazie B, gdy: a) v = (1,
Wykład 1: Przestrzeń probabilistyczna. Prawdopodobieństwo klasyczne. Prawdopodobieństwo geometryczne.
 Rachunek prawdopodobieństwa MAP1151 Wydział Elektroniki, rok akad. 2011/12, sem. letni Wykładowca: dr hab. A. Jurlewicz Wykład 1: Przestrzeń probabilistyczna. Prawdopodobieństwo klasyczne. Prawdopodobieństwo
Rachunek prawdopodobieństwa MAP1151 Wydział Elektroniki, rok akad. 2011/12, sem. letni Wykładowca: dr hab. A. Jurlewicz Wykład 1: Przestrzeń probabilistyczna. Prawdopodobieństwo klasyczne. Prawdopodobieństwo
Elementy inteligencji obliczeniowej
 Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
Elementy inteligencji obliczeniowej Paweł Liskowski Institute of Computing Science, Poznań University of Technology 9 October 2018 1 / 19 Perceptron Perceptron (Rosenblatt, 1957) to najprostsza forma sztucznego
MATeMAtyka 3. Propozycja przedmiotowego systemu oceniania wraz z określeniem wymagań edukacyjnych. Zakres podstawowy i rozszerzony
 Agnieszka Kamińska, Dorota Ponczek MATeMAtyka 3 Propozycja przedmiotowego systemu oceniania wraz z określeniem wymagań edukacyjnych Zakres podstawowy i rozszerzony Wyróżnione zostały następujące wymagania
Agnieszka Kamińska, Dorota Ponczek MATeMAtyka 3 Propozycja przedmiotowego systemu oceniania wraz z określeniem wymagań edukacyjnych Zakres podstawowy i rozszerzony Wyróżnione zostały następujące wymagania
Wnioskowanie bayesowskie
 Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Wnioskowanie bayesowskie W podejściu klasycznym wnioskowanie statystyczne oparte jest wyłącznie na podstawie pobranej próby losowej. Możemy np. estymować punktowo lub przedziałowo nieznane parametry rozkładów,
Dekompozycje prostej rzeczywistej
 Dekompozycje prostej rzeczywistej Michał Czapek michal@czapek.pl www.czapek.pl 26 X AD MMXV Streszczenie Celem pracy jest zwrócenie uwagi na ciekawą różnicę pomiędzy klasami zbiorów pierwszej kategorii
Dekompozycje prostej rzeczywistej Michał Czapek michal@czapek.pl www.czapek.pl 26 X AD MMXV Streszczenie Celem pracy jest zwrócenie uwagi na ciekawą różnicę pomiędzy klasami zbiorów pierwszej kategorii
Data Mining Wykład 5. Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny. Indeks Gini. Indeks Gini - Przykład
 Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Data Mining Wykład 5 Indukcja drzew decyzyjnych - Indeks Gini & Zysk informacyjny Indeks Gini Popularnym kryterium podziału, stosowanym w wielu produktach komercyjnych, jest indeks Gini Algorytm SPRINT
Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa
 Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
Spis treści Elementy Modelowania Matematycznego Wykład 4 Regresja i dyskryminacja liniowa Romuald Kotowski Katedra Informatyki Stosowanej PJWSTK 2009 Spis treści Spis treści 1 Wstęp Bardzo często interesujący
KRYTERIA OCENIANIA ODPOWIEDZI Próbna Matura z OPERONEM. Matematyka Poziom podstawowy
 KRYTERIA OCENIANIA ODPOWIEDZI Matematyka Poziom podstawowy Marzec 09 Zadania zamknięte Za każdą poprawną odpowiedź zdający otrzymuje punkt. Poprawna odpowiedź. D 8 9 8 7. D. C 9 8 9 8 8 9 8 9 8 ( 89 )
KRYTERIA OCENIANIA ODPOWIEDZI Matematyka Poziom podstawowy Marzec 09 Zadania zamknięte Za każdą poprawną odpowiedź zdający otrzymuje punkt. Poprawna odpowiedź. D 8 9 8 7. D. C 9 8 9 8 8 9 8 9 8 ( 89 )
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS. wersja 9.2 i 9.3. Szkoła Główna Handlowa w Warszawie
 STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
STATYSTYKA OD PODSTAW Z SYSTEMEM SAS wersja 9.2 i 9.3 Szkoła Główna Handlowa w Warszawie Spis treści Wprowadzenie... 6 1. Podstawowe informacje o systemie SAS... 9 1.1. Informacje ogólne... 9 1.2. Analityka...
Kompresja danych Streszczenie Studia Dzienne Wykład 10,
 1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
1 Kwantyzacja wektorowa Kompresja danych Streszczenie Studia Dzienne Wykład 10, 28.04.2006 Kwantyzacja wektorowa: dane dzielone na bloki (wektory), każdy blok kwantyzowany jako jeden element danych. Ogólny
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Średnie. Średnie. Kinga Kolczyńska - Przybycień
 Czym jest średnia? W wielu zagadnieniach praktycznych, kiedy mamy do czynienia z jakimiś danymi, poszukujemy liczb, które w pewnym sensie charakteryzują te dane. Na przykład kiedy chcielibyśmy sklasyfikować,
Czym jest średnia? W wielu zagadnieniach praktycznych, kiedy mamy do czynienia z jakimiś danymi, poszukujemy liczb, które w pewnym sensie charakteryzują te dane. Na przykład kiedy chcielibyśmy sklasyfikować,
MATLAB Neural Network Toolbox przegląd
 MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
MATLAB Neural Network Toolbox przegląd WYKŁAD Piotr Ciskowski Neural Network Toolbox: Neural Network Toolbox - zastosowania: przykłady zastosowań sieci neuronowych: The 1988 DARPA Neural Network Study
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Sterowanie procesem i jego zdolność. Zbigniew Wiśniewski
 Sterowanie procesem i jego zdolność Zbigniew Wiśniewski Wybór cech do kart kontrolnych Zaleca się aby w pierwszej kolejności były brane pod uwagę cechy dotyczące funkcjonowania wyrobu lub świadczenia usługi
Sterowanie procesem i jego zdolność Zbigniew Wiśniewski Wybór cech do kart kontrolnych Zaleca się aby w pierwszej kolejności były brane pod uwagę cechy dotyczące funkcjonowania wyrobu lub świadczenia usługi
Ciągi liczbowe. Zbigniew Koza. Wydział Fizyki i Astronomii
 Ciągi liczbowe Zbigniew Koza Wydział Fizyki i Astronomii Wrocław, 2015 Co to są ciągi? Ciąg skończony o wartościach w zbiorze A to dowolna funkcja f: 1,2,, n A Ciąg nieskończony o wartościach w zbiorze
Ciągi liczbowe Zbigniew Koza Wydział Fizyki i Astronomii Wrocław, 2015 Co to są ciągi? Ciąg skończony o wartościach w zbiorze A to dowolna funkcja f: 1,2,, n A Ciąg nieskończony o wartościach w zbiorze
dr inż. Jacek Naruniec email: J.Naruniec@ire.pw.edu.pl
 dr inż. Jacek Naruniec email: J.Naruniec@ire.pw.edu.pl Coraz większa ilość danych obrazowych How much information, University of California Berkeley, 2002: przyrost zdjęć rentgenowskich to 17,2 PB rocznie
dr inż. Jacek Naruniec email: J.Naruniec@ire.pw.edu.pl Coraz większa ilość danych obrazowych How much information, University of California Berkeley, 2002: przyrost zdjęć rentgenowskich to 17,2 PB rocznie
EGZAMIN MATURALNY Z MATEMATYKI
 Miejsce na naklejkę z kodem szkoły dysleksja MMA-R1_1P-07 EGZAMIN MATURALNY Z MATEMATYKI POZIOM ROZSZERZONY Czas pracy 180 minut Instrukcja dla zdającego 1 Sprawdź, czy arkusz egzaminacyjny zawiera 15
Miejsce na naklejkę z kodem szkoły dysleksja MMA-R1_1P-07 EGZAMIN MATURALNY Z MATEMATYKI POZIOM ROZSZERZONY Czas pracy 180 minut Instrukcja dla zdającego 1 Sprawdź, czy arkusz egzaminacyjny zawiera 15
Przykładowe rozwiązania
 Przykładowe rozwiązania (E. Ludwikowska, M. Zygora, M. Walkowiak) Zadanie 1. Rozwiąż równanie: w przedziale. ( ) ( ) ( )( ) ( ) ( ) ( ) Uwzględniając, że x otrzymujemy lub lub lub. Zadanie. Dany jest czworokąt
Przykładowe rozwiązania (E. Ludwikowska, M. Zygora, M. Walkowiak) Zadanie 1. Rozwiąż równanie: w przedziale. ( ) ( ) ( )( ) ( ) ( ) ( ) Uwzględniając, że x otrzymujemy lub lub lub. Zadanie. Dany jest czworokąt
Pobieranie i przetwarzanie treści stron WWW
 Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
Eksploracja zasobów internetowych Wykład 2 Pobieranie i przetwarzanie treści stron WWW mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Jedną z funkcji silników wyszukiwania danych, a właściwie ich modułów
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne.
 Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki
Funkcje wymierne. Funkcja homograficzna. Równania i nierówności wymierne. Funkcja homograficzna. Definicja. Funkcja homograficzna jest to funkcja określona wzorem f() = a + b c + d, () gdzie współczynniki
WYMAGANIA Z WIEDZY I UMIEJĘTNOŚCI NA POSZCZEGÓLNE STOPNIE SZKOLNE DLA KLASY CZWARTEJ H. zakres rozszerzony. Wiadomości i umiejętności
 WYMAGANIA Z WIEDZY I UMIEJĘTNOŚCI NA POSZCZEGÓLNE STOPNIE SZKOLNE DLA KLASY CZWARTEJ H. zakres rozszerzony Funkcja wykładnicza i funkcja logarytmiczna. Stopień Wiadomości i umiejętności -definiować potęgę
WYMAGANIA Z WIEDZY I UMIEJĘTNOŚCI NA POSZCZEGÓLNE STOPNIE SZKOLNE DLA KLASY CZWARTEJ H. zakres rozszerzony Funkcja wykładnicza i funkcja logarytmiczna. Stopień Wiadomości i umiejętności -definiować potęgę
Sponsorem wydruku schematu odpowiedzi jest wydawnictwo
 Kujawsko-Pomorskie Centrum Edukacji Nauczycieli w Bydgoszczy PLACÓWKA AKREDYTOWANA Sponsorem wydruku schematu odpowiedzi jest wydawnictwo KRYTERIA OCENIANIA POZIOM ROZSZERZONY Katalog zadań poziom rozszerzony
Kujawsko-Pomorskie Centrum Edukacji Nauczycieli w Bydgoszczy PLACÓWKA AKREDYTOWANA Sponsorem wydruku schematu odpowiedzi jest wydawnictwo KRYTERIA OCENIANIA POZIOM ROZSZERZONY Katalog zadań poziom rozszerzony
Uczenie sieci neuronowych i bayesowskich
 Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
Wstęp do metod sztucznej inteligencji www.mat.uni.torun.pl/~piersaj 2009-01-22 Co to jest neuron? Komputer, a mózg komputer mózg Jednostki obliczeniowe 1-4 CPU 10 11 neuronów Pojemność 10 9 b RAM, 10 10
Testy post-hoc. Wrocław, 6 czerwca 2016
 Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
Testy post-hoc Wrocław, 6 czerwca 2016 Testy post-hoc 1 metoda LSD 2 metoda Duncana 3 metoda Dunneta 4 metoda kontrastów 5 matoda Newman-Keuls 6 metoda Tukeya Metoda LSD Metoda Least Significant Difference
KURS MATURA ROZSZERZONA część 1
 KURS MATURA ROZSZERZONA część 1 LEKCJA Wyrażenia algebraiczne ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 Wyrażenie 3 a 8 a +
KURS MATURA ROZSZERZONA część 1 LEKCJA Wyrażenia algebraiczne ZADANIE DOMOWE www.etrapez.pl Strona 1 Część 1: TEST Zaznacz poprawną odpowiedź (tylko jedna jest prawdziwa). Pytanie 1 Wyrażenie 3 a 8 a +
Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe
 Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe Nierówność Czebyszewa Niech X będzie zmienną losową o skończonej wariancji V ar(x). Wtedy wartość oczekiwana E(X) też jest skończona i
Wykład 6 Centralne Twierdzenie Graniczne. Rozkłady wielowymiarowe Nierówność Czebyszewa Niech X będzie zmienną losową o skończonej wariancji V ar(x). Wtedy wartość oczekiwana E(X) też jest skończona i
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych
 Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Interaktywne wyszukiwanie informacji w repozytoriach danych tekstowych Marcin Deptuła Julian Szymański, Henryk Krawczyk Politechnika Gdańska Wydział Elektroniki, Telekomunikacji i Informatyki Katedra Architektury
Osiągnięcia ponadprzedmiotowe
 W rezultacie kształcenia matematycznego uczeń potrafi: Osiągnięcia ponadprzedmiotowe Umiejętności konieczne i podstawowe KONIECZNE PODSTAWOWE ROZSZERZAJĄCE DOPEŁNIAJACE WYKRACZAJĄCE czytać teksty w stylu
W rezultacie kształcenia matematycznego uczeń potrafi: Osiągnięcia ponadprzedmiotowe Umiejętności konieczne i podstawowe KONIECZNE PODSTAWOWE ROZSZERZAJĄCE DOPEŁNIAJACE WYKRACZAJĄCE czytać teksty w stylu
Zadanie 1. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k =
 Matematyka ubezpieczeń majątkowych 0.0.006 r. Zadanie. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k 5 Pr( N = k) =, k = 0,,,... 6 6 Wartości kolejnych szkód Y, Y,, są i.i.d.,
Matematyka ubezpieczeń majątkowych 0.0.006 r. Zadanie. Liczba szkód N w ciągu roku z pewnego ryzyka ma rozkład geometryczny: k 5 Pr( N = k) =, k = 0,,,... 6 6 Wartości kolejnych szkód Y, Y,, są i.i.d.,
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova
 Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu
Wstęp do sieci neuronowych, wykład 11 Łańcuchy Markova M. Czoków, J. Piersa 2010-12-21 1 Definicja Własności Losowanie z rozkładu dyskretnego 2 3 Łańcuch Markova Definicja Własności Losowanie z rozkładu
WYMAGANIA EDUKACYJNE Z MATEMATYKI W KLASIE II W PUBLICZNYM GIMNAZJUM NR 2 W ZESPOLE SZKÓŁ W RUDKACH
 WYMAGANIA EDUKACYJNE Z MATEMATYKI W KLASIE II W PUBLICZNYM GIMNAZJUM NR 2 W ZESPOLE SZKÓŁ W RUDKACH Marzena Zbrożyna DOPUSZCZAJĄCY: Uczeń potrafi: odczytać informacje z tabeli odczytać informacje z diagramu
WYMAGANIA EDUKACYJNE Z MATEMATYKI W KLASIE II W PUBLICZNYM GIMNAZJUM NR 2 W ZESPOLE SZKÓŁ W RUDKACH Marzena Zbrożyna DOPUSZCZAJĄCY: Uczeń potrafi: odczytać informacje z tabeli odczytać informacje z diagramu
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
SZTUCZNA INTELIGENCJA SYSTEMY ROZMYTE Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra Automatyki i Inżynierii Biomedycznej Laboratorium
Arytmetyka. Działania na liczbach, potęga, pierwiastek, logarytm
 Arytmetyka Działania na liczbach, potęga, pierwiastek, logarytm Zbiory liczbowe Zbiór liczb naturalnych N = {1,2,3,4, }. Zbiór liczb całkowitych Z = {, 3, 2, 1,0,1,2,3, }. Zbiory liczbowe Zbiór liczb wymiernych
Arytmetyka Działania na liczbach, potęga, pierwiastek, logarytm Zbiory liczbowe Zbiór liczb naturalnych N = {1,2,3,4, }. Zbiór liczb całkowitych Z = {, 3, 2, 1,0,1,2,3, }. Zbiory liczbowe Zbiór liczb wymiernych