Bazy dokumentów tekstowych
|
|
|
- Bogumił Leśniak
- 8 lat temu
- Przeglądów:
Transkrypt
1 Bazy dokumentów tekstowych
2 Bazy dokumentów tekstowych Dziedzina zastosowań Automatyzacja bibliotek Elektroniczne encyklopedie Bazy aktów prawnych i patentów Szukanie informacji w Internecie Dokumenty tekstowe Ksiązki e-book Artykuły naukowe, gazetowe Dokumenty urzędowe Artykuły prawne e Strony WWW Specyfika Dane są niestrukturalne lub semistrukturalne Wyszukiwanie przybliżone (niejednoznaczne) Ranking znalezionych dokumentów Pokrewne technologie informatyczne Wyszukiwanie informacji Wyszukiwanie tekstów Wyszukiwanie dokumentów Wyszukiwanie danych Wyszukiwarki Internetowe
3 Miary wyszukiwania dokumentów W przeciwieństwie do systemów baz danych wyszukiwanie dokumentów zazwyczaj nie jest dokładne. Jakość wyszukiwania dokumentu jest zależna od jakości modelu reprezentacji dokumentów tekstowych, algorytmów wyszukiwania oraz od jakości zapytania. Spełnienie warunków wyszukiwania dokumentów tekstowych, nie jest binarne. Wyniki wyszukiwania dokumentów: Nie znalezione, poprawne Znalezione, ale niepoprawne Poprawne dokumenty Znalezione, poprawne Znalezione dokumenty Ustalenie poprawności znalezionych dokumentów należy do osoby wyszukującej. Termin poprawność oznacza jedynie potencjalną użyteczność dokumentów.
4 Miary jakości wyszukiwania Powszechnie przyjęte jest stosowanie trzech miar jakości wyszukiwania w bazie dokumentów tekstowych. Precyzja: jaki procent znalezionych dokumentów jest poprawnych Precision = { poprawne} { znalezione} { znalezione} Czułość: jaki procent poprawnych dokumentów zostało znalezionych Recall = { poprawne} { znalezione} { poprawne} Fall-out: jaki procent znalezionych dokumentów jest niepoprawny { niepoprawne} { znalezione} Fall-out = { znalezione} Fall-out = 1 - Precision
5 Metody wyszukiwania tekstów Reprezentacja tekstu goły tekst dane niestrukturalne metadane opisujące tekst: zbiór słów kluczowych, klasyfikacja tekstów, wyróżnione fragmenty tekstu (tytuły, śródtytuły, czcionka tekstu), wskazania na dokument tekstowy reprezentacja tekstów przez ich sygnatury reprezentacja tekstów jako punktów w przestrzeni wielowymiarowej Klasy zapytań Szukanie za pomocą zapytania o wyrażenia logiczne (and or not) na słowach kluczowych o wagi przypisywane poszczególnym słowom o wyrażenia regularne Problemy: fleksja, liczba mnoga, synonimy, polisemia, brak naturalnej miary odległości (brak rankingu), słowa neutralne Szukanie za pomocą wzorcowych dokumentów tekstowych Metody wyszukiwania Pełny przegląd tekstu Pliki odwrócone na tekście lub na opisie tekstu Pliki sygnaturowe NN w przestrzeni wielowymiarowej
6 Pełny przegląd tekstu Wydajne metody wyszukiwania wzorcowego tekstu (w ogólności wyrażenia regularnego) w łańcuchu znaków: Algorytmy: Knutha-Morrisa-Pratta lub Boyera i Moora o liniowej złożoności obliczeniowej: length(pattern) + length(string); Złożoność algorytmu podstawowego to: length(pattern) * length(string) tekst: ALGORYTMY I STRUKTURY DANYCH wzorzec: TUR ALGORYTMY I STRUKTURY DANYCH TUR TUR TUR TUR TUR TUR TUR W danym kroku, przy braku dopasowania wyznaczane jest przesunięcie dla następnego kroku algorytmu.
7 Pełny przegląd tekstu Równoległe wyszukiwanie wielu słów; Tolerowanie błędów typowania słów wzorca poprzez wyszukiwanie wielu słów różniących się minimalnie od wzorca (ang. editing distance). Odległość Hamminga określająca odległość między dwoma ciągami o tej samej długości, jako liczbę różniących się symboli. HD(mama, tata) = 2 Odległość edycji dla dwóch tekstów jest minimalną liczbą operacji insert i delete, które pozwolą przekształcić jeden tekst w drugi. Dla dwóch tekstów x i y o długościach x i y odległość edycji wynosi: de(x,y)= x + y -2* LCS(x,y) gdzie LCS(x,y) jest najdłuższym wspólnym łańcuchem symboli zawartym w tekstach x i y. Na przykład, niech x='abcdefg', y='bcefh'. Wtedy: LCS(x,y) = bcef. de(x,y) = * 4 = 4 Odległość Levenshteina - dla dwóch tekstów jest minimalna liczbą operacji insert, delete i update które pozwolą przekształcić jeden tekst w drugi.
8 Własności metody brak narzutu dodatkowych struktur danych brak narzutu dla operacji modyfikacji tekstów mała wydajność dla dużych zbiorów dokumentów
9 Pliki odwrócone Pliki/indeksy odwrócone (ang. inverted files/indexes) są specyficznym rodzajem indeksów pomocniczych (ang. secondary indices) zakładanych na poszczególnych słowach tekstów. Słownik Abisynia Listy wskaźników Baza tekstów Żegota Różne rozszerzenia i wariacje: liczniki częstości występowania słów; pomijanie słów pospolitych; listy synonimów w słowniku; uproszczony indeks (ang. coarse index) dwupoziomowy Glimps adresuje zbiory tekstów (mniej i krótsze wskaźniki); rozmiar indeksu jest równy 2-4% wielkości bazy danych tekstów Własności metody bardzo wydajne wyszukiwanie duży narzut na dodatkowe struktury danych (50-300%) duży narzut na operacje modyfikacji
10 Typy plików odwróconych Typy plików odwróconych Ze względu na typ używanych wskaźników nie-pozycyjne wskazania na dokumenty, jeden wskaźnik na cały dokument zawierający dane słowo częstościowy - wskazania na dokumenty poszerzone o liczbę wystąpień słowa, jeden wskaźnik na cały dokument zawierający dane słowo pozycyjne wskazania na wystąpienia słowa w tekście, wiele wskaźników na różne pozycje tego samego słowa Ze względu na sposób konstrukcji słownika słownikowe predefiniowany słownik dla bazy dokumentów tekstowych nie-słownikowe słowa występujące w indeksowanych tekstach


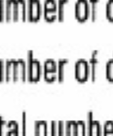
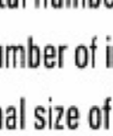



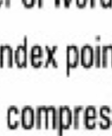







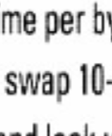








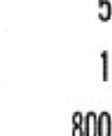



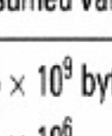



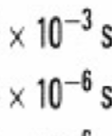
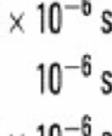

11 Przykładowa charakterystyka pliku odwró óconego (5GB)
12 Sygnatury tekstów Sygnatury są uproszczoną numeryczną reprezentacją tekstów. Dzięki temu zajmują mniej miejsca i koszt ich przeszukiwania jest znacznie mniejszy, niż pełny przegląd bazy danych tekstów. Wartość sygnatury jest zależna od słów występujących w tekście, natomiast nie jest zależna od kolejności i częstości ich występowania. Sygnatura tekstu jest generowana na podstawie sygnatur wszystkich różnych słów występujących w tekście. Dokładność odwzorowanie tekstu przez sygnaturę jest ograniczona. Różne teksty, zawierające różne słowa, mogą mieć takie same sygnatury. Pliki sygnatur reprezentujące zbiory tekstów są wykorzystywane jako filtr ograniczający rozmiar przeszukiwanego zbioru tekstów. Sposoby generowania sygnatur tekstu Konkatenacja sygnatur Sygnatura dokumentu jest tworzona jako sklejenie sygnatur wszystkich różnych słów występujących w dokumencie. dokument Ala ma małego kota sygnatury słów: sygnatura dokumentu: Szukanie dokumentów zawierających określone słowo polega na znalezieniu w pliku sygnatur wszystkich dokumentów, których sygnatura zawiera sygnaturę szukanego słowa.
13 Sygnatury tekstów Sposoby generowania sygnatur Kodowanie nałożone (ang. superimposed coding) Każdy tekst dzielony jest na logiczne bloki o tej samej liczbie różnych niepospolitych słów. Sygnatury słów mają stałą długość F. Każde słowo zajmuje w sygnaturze m bitów. Ustawione bity różnych słów mogą się pokrywać, unikalna jedynie jest ich kompozycja. Sygnatura bloków danego tekstu jest tworzona przez zastosowanie operacji OR na sygnaturach wszystkich słów w bloku. Sygnatura dokumentów jest tworzona przez konkatenację sygnatur bloków dokumentu. słowo sygnatura Ala ma kota blok Ala Szukanie polega na porównywaniu sygnatur podanych słów z sygnaturami bloków dokumentów. Znalezione dokumenty są w ogólności nadzbiorem szukanego zbioru. Zwrócony zbiór dokumentów może zawierać również niewłaściwe dokumenty (ang. false drops).
14 Optymalizacja parametrów plików sygnatur Jakość szukania za pomocą plików sygnatur jest określona przez skuteczność ograniczenia rozmiaru przeszukiwanego zbioru dokumentów. Można ją oszacować jako proporcję rozmiaru szukanego zbioru dokumentów do rozmiaru znalezionego zbioru. Jakość szukania jest zależna od przyjętych parametrów sygnatur. Koszt szukania: Koszt = Funkcja(F, m, D blok ) gdzie: F - rozmiar sygnatur słów; m - liczba jedynek w pojedynczym słowie; D blok rozmiar bloków mierzony liczbą różnych słów. Prawdopodobieństwo false-drops Liczba jedynek w pojedynczym słowie Własności metody wydajne wyszukiwanie mały narzut na dodatkowe struktury danych ( 10%) mały narzut na operacje modyfikacji wymaga umiejętnego zaprojektowania
15 Wektorowa reprezentacja tekstów Dokumenty są reprezentowane jako N-wymiarowe wektory, gdzie N jest liczbą wszystkich pojęć (słów kluczowych) znajdujących się w bazie dokumentów. Wektory mogą być mapami bitowymi; 1 oznacza występowanie, a 0 brak danego pojęcia w dokumencie; lub wektorami liczbowymi, gdzie poszczególne wartości reprezentują liczbę wystąpień danego słowa w dokumencie. Przykład: Dana jest przestrzeń wielowymiarowa MD = <algorytmy, analizy, metody, grupowanie> Tekst: Algorytmy analizy skupień dzieli się na szereg kategorii: Większość metod analizy skupień to metody iteracyjne, wśród których najczęściej używane to metody kombinatoryczne: aglomeracyjne i deglomeracyjne. jest reprezentowany przez wektor logiczny: <1, 1, 1, 0 > lub wektor liczbowy: <1, 2, 2, 0 >
16 Własności reprezentacji wektorowej Nie oddaje kolejności występowania poszczególnych słów w tekście Dla dużej liczby wymiarów wektory reprezentujące teksty są bardzo rzadkie, tzn. większość składowych wektorów ma wartość równą zero. Pozwala na wyszukiwanie za pomocą zapytania i za pomocą wzorcowych tekstów. Zapytania muszą być reprezentowane za pomocą wektorów. Reprezentacja wektorowa charakteryzuje się naturalną miarą odległości między tekstami. Pozwala to na ustalenie rankingu znalezionych tekstów oraz na wyszukiwanie przybliżone.
17 Miary odległości tekstów Odległość kosinusowa Poszczególne teksty są punktami w przestrzeni wielowymiarowej określonej przez słowa występujące w tekstach. Kąt między wektorami tekstów reprezentuje ich podobieństwo. cos(v1, v2) = v v1 v Jeżeli kąt między wektorem zapytania i wektorem danego dokumentu lub między wektorami dwóch dokumentów są równe zero, to odległość kosinusowa jest równa 1. Zapytanie o teksty o algorytmach grupowania przetransformowane do postaci wektorowej: Q = <1,0,0,1> Wyszukiwane są teksty, o najmniejszej odległości kosinusowej od wektora zapytania. Teksty mogą zostać uporządkowane ze względu na zmniejszającą się odległość kosinusową. v Słowo 3 tekst 2 tekst 1 α Słowo 2 Słowo 1
18 Wagi słów Baza danych jest dużą kolekcją danych. Ania jest dużą dziewczynką. Które współdzielone słowa są istotne dla podobieństwa tekstów? Waga TF (term frequency) reprezentuje częstość występowania słowa w tekście. Waga TF preferuje długie teksty i nie oddaje siły dyskryminacji poszczególnych słów. Waga IDF (inverse document frequency) - reprezentuje siłę dyskryminacji tekstów przez dane słowo. IDF = log (N/n j ) gdzie: N jest liczbą wszystkich tekstów, a n j liczbą tekstów, w których występuje dane słowo. Waga słowa w wektorze reprezentującym dany tekst jest iloczynem wag TF i IDF. Baza danych jest dużą kolekcją danych <Ania, baza, dana, duża, dziewczyna, jest, kolekcja> <0*0.3, 1*0.3, 2*0.3, 1*0, 0*0.3, 1*0, 1*0.3> <0, 0.3, 0.6, 0, 0, 0, 0.3>
Wyszukiwanie tekstów
 Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Wyszukiwanie tekstów Dziedzina zastosowań Elektroniczne encyklopedie Wyszukiwanie aktów prawnych i patentów Automatyzacja bibliotek Szukanie informacji w Internecie Elektroniczne teksy Ksiązki e-book Artykuły
Eksploracja tekstu. Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu. Eksploracja danych. Eksploracja tekstu wykład 1
 Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
Eksploracja tekstu Wprowadzenie Wyszukiwanie dokumentów Reprezentacje tekstu Eksploracja tekstu wykład 1 Tematem wykładu są zagadnienia związane z eksploracją tekstu. Rozpoczniemy od krótkiego wprowadzenia
Wydział Elektrotechniki, Informatyki i Telekomunikacji. Instytut Informatyki i Elektroniki. Instrukcja do zajęć laboratoryjnych
 Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wydział Elektrotechniki, Informatyki i Telekomunikacji Instytut Informatyki i Elektroniki Instrukcja do zajęć laboratoryjnych wersja: 1.0 Nr ćwiczenia: 12, 13 Temat: Cel ćwiczenia: Wymagane przygotowanie
Wyszukiwanie dokumentów/informacji
 Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Wyszukiwanie dokumentów/informacji Wyszukiwanie dokumentów (ang. document retrieval, text retrieval) polega na poszukiwaniu dokumentów tekstowych z pewnego zbioru, które pasują do zapytania. Wyszukiwanie
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Systemy liczbowe. 1. Przedstawić w postaci sumy wag poszczególnych cyfr liczbę rzeczywistą R = (10).
.") Wprowadzenie do inżynierii przetwarzania informacji. Ćwiczenie 1. Systemy liczbowe Cel dydaktyczny: Poznanie zasad reprezentacji liczb w systemach pozycyjnych o różnych podstawach. Kodowanie liczb dziesiętnych
Wprowadzenie do inżynierii przetwarzania informacji. Ćwiczenie 1. Systemy liczbowe Cel dydaktyczny: Poznanie zasad reprezentacji liczb w systemach pozycyjnych o różnych podstawach. Kodowanie liczb dziesiętnych
S O M SELF-ORGANIZING MAPS. Przemysław Szczepańczyk Łukasz Myszor
 S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
S O M SELF-ORGANIZING MAPS Przemysław Szczepańczyk Łukasz Myszor Podstawy teoretyczne Map Samoorganizujących się stworzył prof. Teuvo Kohonen (1982 r.). SOM wywodzi się ze sztucznych sieci neuronowych.
Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene
 2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
2..22 Zaglądamy pod maskę: podstawy działania silnika wyszukiwawczego na przykładzie Lucene Dominika Puzio Indeks Podstawy: dokument Dokument: jednostka danych, pojedynczy element na liście wyników wyszukiwania,
Algorytmy i struktury danych. wykład 8
 Plan wykładu: Kodowanie. : wyszukiwanie wzorca w tekście, odległość edycyjna. Kodowanie Kodowanie Kodowanie jest to proces przekształcania informacji wybranego typu w informację innego typu. Kod: jest
Plan wykładu: Kodowanie. : wyszukiwanie wzorca w tekście, odległość edycyjna. Kodowanie Kodowanie Kodowanie jest to proces przekształcania informacji wybranego typu w informację innego typu. Kod: jest
Eksploracja danych. Grupowanie. Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne. Grupowanie wykład 1
 Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Grupowanie Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Grupowanie wykład 1 Sformułowanie problemu Dany jest zbiór obiektów (rekordów). Znajdź naturalne pogrupowanie
Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych
 Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Eksploracja zasobów internetowych Wykład 3 Wyszukiwanie dokumentów WWW bazujące na słowach kluczowych mgr inż. Maciej Kopczyński Białystok 2014 Wstęp Wyszukiwanie dokumentów za pomocą słów kluczowych bazujące
Algorytmy przeszukiwania wzorca
 Algorytmy i struktury danych Instytut Sterowania i Systemów Informatycznych Wydział Elektrotechniki, Informatyki i Telekomunikacji Uniwersytet Zielonogórski Algorytmy przeszukiwania wzorca 1 Wstęp Algorytmy
Algorytmy i struktury danych Instytut Sterowania i Systemów Informatycznych Wydział Elektrotechniki, Informatyki i Telekomunikacji Uniwersytet Zielonogórski Algorytmy przeszukiwania wzorca 1 Wstęp Algorytmy
Wstęp do przetwarzania języka naturalnego
 Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Wstęp do przetwarzania języka naturalnego Wykład 9 Wektoryzacja dokumentów i podstawowe miary podobieństwa Wojciech Czarnecki 17 grudnia 2013 Section 1 Przypomnienie Bag of words model Podejście Przypomnienie
Multi-wyszukiwarki. Mediacyjne Systemy Zapytań wprowadzenie. Architektury i technologie integracji danych Systemy Mediacyjne
 Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
Architektury i technologie integracji danych Systemy Mediacyjne Multi-wyszukiwarki Wprowadzenie do Mediacyjnych Systemów Zapytań (MQS) Architektura MQS Cechy funkcjonalne MQS Cechy implementacyjne MQS
Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas)
") Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas) Bazy danych podstawowe pojęcia Baza danych jest to zbiór danych zorganizowany zgodnie ze ściśle określonym modelem danych. Model danych to zbiór ścisłych
Dr Michał Tanaś(http://www.amu.edu.pl/~mtanas) Bazy danych podstawowe pojęcia Baza danych jest to zbiór danych zorganizowany zgodnie ze ściśle określonym modelem danych. Model danych to zbiór ścisłych
Indeksy w hurtowniach danych
 Indeksy w hurtowniach danych Hurtownie danych 2011 Łukasz Idkowiak Tomasz Kamiński Bibliografia Zbyszko Królikowski, Hurtownie danych. Logiczne i fizyczne struktury danych, Wydawnictwo Politechniki Poznańskiej,
Indeksy w hurtowniach danych Hurtownie danych 2011 Łukasz Idkowiak Tomasz Kamiński Bibliografia Zbyszko Królikowski, Hurtownie danych. Logiczne i fizyczne struktury danych, Wydawnictwo Politechniki Poznańskiej,
Definicja pliku kratowego
 Pliki kratowe Definicja pliku kratowego Plik kratowy (ang grid file) jest strukturą wspierająca realizację zapytań wielowymiarowych Uporządkowanie rekordów, zawierających dane wielowymiarowe w pliku kratowym,
Pliki kratowe Definicja pliku kratowego Plik kratowy (ang grid file) jest strukturą wspierająca realizację zapytań wielowymiarowych Uporządkowanie rekordów, zawierających dane wielowymiarowe w pliku kratowym,
1.1. Pozycyjne systemy liczbowe
 1.1. Pozycyjne systemy liczbowe Systemami liczenia nazywa się sposób tworzenia liczb ze znaków cyfrowych oraz zbiór reguł umożliwiających wykonywanie operacji arytmetycznych na liczbach. Dla dowolnego
1.1. Pozycyjne systemy liczbowe Systemami liczenia nazywa się sposób tworzenia liczb ze znaków cyfrowych oraz zbiór reguł umożliwiających wykonywanie operacji arytmetycznych na liczbach. Dla dowolnego
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Teoria informacji i kodowania Ćwiczenia Sem. zimowy 2016/2017
 Algebra liniowa Zadanie 1 Czy jeśli wektory x, y i z, należące do binarnej przestrzeni wektorowej nad ciałem Galois GF (2), są liniowo niezależne, to można to samo orzec o następujących trzech wektorach:
Algebra liniowa Zadanie 1 Czy jeśli wektory x, y i z, należące do binarnej przestrzeni wektorowej nad ciałem Galois GF (2), są liniowo niezależne, to można to samo orzec o następujących trzech wektorach:
Metody numeryczne I. Janusz Szwabiński. Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/61
 2004 Janusz Szwabiński p.1/61") Metody numeryczne I Dokładność obliczeń numerycznych. Złożoność obliczeniowa algorytmów Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/61 ... the purpose of
Metody numeryczne I Dokładność obliczeń numerycznych. Złożoność obliczeniowa algorytmów Janusz Szwabiński szwabin@ift.uni.wroc.pl Metody numeryczne I (C) 2004 Janusz Szwabiński p.1/61 ... the purpose of
Kody blokowe Wykład 2, 10 III 2011
 Kody blokowe Wykład 2, 10 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding
Kody blokowe Wykład 2, 10 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015
 Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Metody numeryczne Technika obliczeniowa i symulacyjna Sem. 2, EiT, 2014/2015 1 Metody numeryczne Dział matematyki Metody rozwiązywania problemów matematycznych za pomocą operacji na liczbach. Otrzymywane
Wprowadzenie do uczenia maszynowego
 Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Wprowadzenie do uczenia maszynowego Agnieszka Ławrynowicz 12 stycznia 2017 Co to jest uczenie maszynowe? dziedzina nauki, która zajmuje się sprawianiem aby komputery mogły uczyć się bez ich zaprogramowania
Sztuczne sieci neuronowe. Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335
 Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Sztuczne sieci neuronowe Krzysztof A. Cyran POLITECHNIKA ŚLĄSKA Instytut Informatyki, p. 335 Wykład 10 Mapa cech Kohonena i jej modyfikacje - uczenie sieci samoorganizujących się - kwantowanie wektorowe
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Systemy OLAP II. Krzysztof Dembczyński. Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska
 Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr letni 2006/07 Plan wykładu Systemy baz
Krzysztof Dembczyński Instytut Informatyki Zakład Inteligentnych Systemów Wspomagania Decyzji Politechnika Poznańska Technologie Wytwarzania Oprogramowania Semestr letni 2006/07 Plan wykładu Systemy baz
Założenia i obszar zastosowań. JPEG - algorytm kodowania obrazu. Geneza algorytmu KOMPRESJA OBRAZÓW STATYCZNYCH - ALGORYTM JPEG
 Założenia i obszar zastosowań KOMPRESJA OBRAZÓW STATYCZNYCH - ALGORYTM JPEG Plan wykładu: Geneza algorytmu Założenia i obszar zastosowań JPEG kroki algorytmu kodowania obrazu Założenia: Obraz monochromatyczny
Założenia i obszar zastosowań KOMPRESJA OBRAZÓW STATYCZNYCH - ALGORYTM JPEG Plan wykładu: Geneza algorytmu Założenia i obszar zastosowań JPEG kroki algorytmu kodowania obrazu Założenia: Obraz monochromatyczny
Systemy GIS Tworzenie zapytań w bazach danych
 Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
Systemy GIS Tworzenie zapytań w bazach danych Wykład nr 6 Analizy danych w systemach GIS Jak pytać bazę danych, żeby otrzymać sensowną odpowiedź......czyli podstawy języka SQL INSERT, SELECT, DROP, UPDATE
WYKŁAD 12. Analiza obrazu Wyznaczanie parametrów ruchu obiektów
 WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania
WYKŁAD 1 Analiza obrazu Wyznaczanie parametrów ruchu obiektów Cel analizy obrazu: przedstawienie każdego z poszczególnych obiektów danego obrazu w postaci wektora cech dla przeprowadzenia procesu rozpoznania
Metody indeksowania dokumentów tekstowych
 Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
Metody indeksowania dokumentów tekstowych Paweł Szołtysek 21maja2009 Metody indeksowania dokumentów tekstowych 1/ 19 Metody indeksowania dokumentów tekstowych 2/ 19 Czym jest wyszukiwanie informacji? Wyszukiwanie
ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia
 ZP/ITS/11/2012 Załącznik nr 1a do SIWZ ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych
ZP/ITS/11/2012 Załącznik nr 1a do SIWZ ZMODYFIKOWANY Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych
operacje porównania, a jeśli jest to konieczne ze względu na złe uporządkowanie porównywanych liczb zmieniamy ich kolejność, czyli przestawiamy je.
 Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Problem porządkowania zwanego również sortowaniem jest jednym z najważniejszych i najpopularniejszych zagadnień informatycznych. Dane: Liczba naturalna n i ciąg n liczb x 1, x 2,, x n. Wynik: Uporządkowanie
Spis treści. Część I Metody reprezentowania informacji oraz struktury danych...9. Wprowadzenie Rozdział 1. Reprezentacja liczb całkowitych...
 Spis treści Wprowadzenie... 7 Część I Metody reprezentowania informacji oraz struktury danych...9 Rozdział 1. Reprezentacja liczb całkowitych... 11 Wprowadzenie...11 System binarny...11 System oktalny...12
Spis treści Wprowadzenie... 7 Część I Metody reprezentowania informacji oraz struktury danych...9 Rozdział 1. Reprezentacja liczb całkowitych... 11 Wprowadzenie...11 System binarny...11 System oktalny...12
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
ang. file) Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku
 Pojęcie pliku (ang( Typy plików Atrybuty pliku Fragmentacja wewnętrzna w systemie plików Struktura pliku") System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
System plików 1. Pojęcie pliku 2. Typy i struktury plików 3. etody dostępu do plików 4. Katalogi 5. Budowa systemu plików Pojęcie pliku (ang( ang. file)! Plik jest abstrakcyjnym obrazem informacji gromadzonej
Systemy liczbowe używane w technice komputerowej
 Systemy liczbowe używane w technice komputerowej Systemem liczenia nazywa się sposób tworzenia liczb ze znaków cyfrowych oraz zbiór reguł umożliwiających wykonywanie operacji arytmetycznych na liczbach.
Systemy liczbowe używane w technice komputerowej Systemem liczenia nazywa się sposób tworzenia liczb ze znaków cyfrowych oraz zbiór reguł umożliwiających wykonywanie operacji arytmetycznych na liczbach.
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl
 Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Text mining w programie RapidMiner Michał Bereta www.michalbereta.pl 1. Wstęp Aby skorzystać z możliwości RapidMinera w zakresie analizy tekstu, należy zainstalować Text Mining Extension. Wybierz: 1 Po
Wyszukiwanie informacji w internecie. Nguyen Hung Son
 Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Wyszukiwanie informacji w internecie Nguyen Hung Son Jak znaleźć informację w internecie? Wyszukiwarki internetowe: Potężne machiny wykorzystujące najnowsze metody z różnych dziedzin Architektura: trzy
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11,
 1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
1 Kwantyzacja skalarna Kodowanie i kompresja Streszczenie Studia Licencjackie Wykład 11, 10.05.005 Kwantyzacja polega na reprezentowaniu dużego zbioru wartości (być może nieskończonego) za pomocą wartości
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład Kody liniowe - kodowanie w oparciu o macierz parzystości
 Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Kodowanie i kompresja Tomasz Jurdziński Studia Wieczorowe Wykład 13 1 Kody liniowe - kodowanie w oparciu o macierz parzystości Przykład Różne macierze parzystości dla kodu powtórzeniowego. Co wiemy z algebry
Oracle11g: Wprowadzenie do SQL
 Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Oracle11g: Wprowadzenie do SQL OPIS: Kurs ten oferuje uczestnikom wprowadzenie do technologii bazy Oracle11g, koncepcji bazy relacyjnej i efektywnego języka programowania o nazwie SQL. Kurs dostarczy twórcom
Metody numeryczne. Janusz Szwabiński. nm_slides.tex Metody numeryczne Janusz Szwabiński 2/10/ :02 p.
 Metody numeryczne Janusz Szwabiński szwabin@ift.uni.wroc.pl nm_slides.tex Metody numeryczne Janusz Szwabiński 2/10/2002 23:02 p.1/63 Plan wykładu 1. Dokładność w obliczeniach numerycznych 2. Złożoność
Metody numeryczne Janusz Szwabiński szwabin@ift.uni.wroc.pl nm_slides.tex Metody numeryczne Janusz Szwabiński 2/10/2002 23:02 p.1/63 Plan wykładu 1. Dokładność w obliczeniach numerycznych 2. Złożoność
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa, Andrzej Rutkowski Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2018-10-15 Projekt
< K (2) = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >
 = ( Adams, John ), P (2) = adres bloku 2 > < K (1) = ( Aaron, Ed ), P (1) = adres bloku 1 >") Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Typy indeksów Indeks jest zakładany na atrybucie relacji atrybucie indeksowym (ang. indexing field). Indeks zawiera wartości atrybutu indeksowego wraz ze wskaźnikami do wszystkich bloków dyskowych zawierających
Grupowanie danych. Wprowadzenie. Przykłady
 Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Grupowanie danych str. 1 Wprowadzenie Celem procesu grupowania jest podział zbioru obiektów, fizycznych lub abstrakcyjnych, na klasy obiektów o podobnych cechach, nazywane klastrami lub skupieniami Klaster
Kodowanie informacji
 Kodowanie informacji Tomasz Wykład 4: kodowanie arytmetyczne Motywacja Podstawy i własności Liczby rzeczywiste Motywacje 1 średnia długość kodu Huffmana może odbiegać o p max + 0.086 od entropii, gdzie
Kodowanie informacji Tomasz Wykład 4: kodowanie arytmetyczne Motywacja Podstawy i własności Liczby rzeczywiste Motywacje 1 średnia długość kodu Huffmana może odbiegać o p max + 0.086 od entropii, gdzie
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego.
 77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
77. Modelowanie bazy danych rodzaje połączeń relacyjnych, pojęcie klucza obcego. Przy modelowaniu bazy danych możemy wyróżnić następujące typy połączeń relacyjnych: jeden do wielu, jeden do jednego, wiele
Wprowadzenie do informatyki - ć wiczenia
 Stałoprzecinkowy zapis liczb wymiernych dr inż. Izabela Szczęch WSNHiD Ćwiczenia z wprowadzenia do informatyki Reprezentacja liczb wymiernych Stałoprzecinkowa bez znaku ze znakiem Zmiennoprzecinkowa pojedynczej
Stałoprzecinkowy zapis liczb wymiernych dr inż. Izabela Szczęch WSNHiD Ćwiczenia z wprowadzenia do informatyki Reprezentacja liczb wymiernych Stałoprzecinkowa bez znaku ze znakiem Zmiennoprzecinkowa pojedynczej
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Wykład X. Programowanie. dr inż. Janusz Słupik. Gliwice, Wydział Matematyki Stosowanej Politechniki Śląskiej. c Copyright 2016 Janusz Słupik
 Wykład X Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2016 c Copyright 2016 Janusz Słupik Drzewa binarne Drzewa binarne Drzewo binarne - to drzewo (graf spójny bez cykli) z korzeniem (wyróżnionym
Wykład X Wydział Matematyki Stosowanej Politechniki Śląskiej Gliwice, 2016 c Copyright 2016 Janusz Słupik Drzewa binarne Drzewa binarne Drzewo binarne - to drzewo (graf spójny bez cykli) z korzeniem (wyróżnionym
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Haszowanie. dr inż. Urszula Gałązka
 Haszowanie dr inż. Urszula Gałązka Problem Potrzebujemy struktury do Wstawiania usuwania wyszukiwania Liczb, napisów, rekordów w Bazach danych, sieciach komputerowych, innych Rozwiązanie Tablice z haszowaniem
Haszowanie dr inż. Urszula Gałązka Problem Potrzebujemy struktury do Wstawiania usuwania wyszukiwania Liczb, napisów, rekordów w Bazach danych, sieciach komputerowych, innych Rozwiązanie Tablice z haszowaniem
0 + 0 = 0, = 1, = 1, = 0.
 5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
5 Kody liniowe Jak już wiemy, w celu przesłania zakodowanego tekstu dzielimy go na bloki i do każdego z bloków dodajemy tak zwane bity sprawdzające. Bity te są w ścisłej zależności z bitami informacyjnymi,
Algorytmy, które estymują wprost rozkłady czy też mapowania z nazywamy algorytmami dyskryminacyjnymi.
 Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Spis treści 1 Wstęp: generatywne algorytmy uczące 2 Gaussowska analiza dyskryminacyjna 2.1 Gaussowska analiza dyskryminacyjna a regresja logistyczna 3 Naiwny Klasyfikator Bayesa 3.1 Wygładzanie Laplace'a
Temat: Algorytmy wyszukiwania wzorca w tekście
 Temat: Algorytmy wyszukiwania wzorca w tekście 1. Sformułowanie problemu Dany jest tekst T oraz wzorzec P, będące ciągami znaków o długości równej odpowiednio n i m (n m 1), nad pewnym ustalonym i skończonym
Temat: Algorytmy wyszukiwania wzorca w tekście 1. Sformułowanie problemu Dany jest tekst T oraz wzorzec P, będące ciągami znaków o długości równej odpowiednio n i m (n m 1), nad pewnym ustalonym i skończonym
Java Podstawy. Michał Bereta
 Prezentacja współfinansowana przez Unię Europejską ze środków Europejskiego Funduszu Społecznego w ramach projektu Wzmocnienie znaczenia Politechniki Krakowskiej w kształceniu przedmiotów ścisłych i propagowaniu
Prezentacja współfinansowana przez Unię Europejską ze środków Europejskiego Funduszu Społecznego w ramach projektu Wzmocnienie znaczenia Politechniki Krakowskiej w kształceniu przedmiotów ścisłych i propagowaniu
WYMAGANIA EGZAMINACYJNE Egzamin maturalny z INFORMATYKI
 WYMAGANIA EGZAMINACYJNE Egzamin maturalny z INFORMATYKI 1. Cele ogólne Podstawowym celem kształcenia informatycznego jest przekazanie wiadomości i ukształtowanie umiejętności w zakresie analizowania i
WYMAGANIA EGZAMINACYJNE Egzamin maturalny z INFORMATYKI 1. Cele ogólne Podstawowym celem kształcenia informatycznego jest przekazanie wiadomości i ukształtowanie umiejętności w zakresie analizowania i
Stan wysoki (H) i stan niski (L)
 i stan niski (L)") PODSTAWY Przez układy cyfrowe rozumiemy układy, w których w każdej chwili występują tylko dwa (zwykle) możliwe stany, np. tranzystor, jako element układu cyfrowego, może być albo w stanie nasycenia, albo
PODSTAWY Przez układy cyfrowe rozumiemy układy, w których w każdej chwili występują tylko dwa (zwykle) możliwe stany, np. tranzystor, jako element układu cyfrowego, może być albo w stanie nasycenia, albo
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Adrian Horzyk
 Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Metody Inteligencji Obliczeniowej Metoda K Najbliższych Sąsiadów (KNN) Adrian Horzyk horzyk@agh.edu.pl AGH Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Modelowanie hierarchicznych struktur w relacyjnych bazach danych
 Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Modelowanie hierarchicznych struktur w relacyjnych bazach danych Wiktor Warmus (wiktorwarmus@gmail.com) Kamil Witecki (kamil@witecki.net.pl) 5 maja 2010 Motywacje Teoria relacyjnych baz danych Do czego
Pojęcie bazy danych. Funkcje i możliwości.
 Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
1 abbbaabaaabaa -wzorzec: aaba
 Algorytmy i złożoność obliczeniowa Laboratorium 14. Algorytmy tekstowe. 1. Algorytmy tekstowe Algorytmy tekstowe mają decydujące znaczenie przy wyszukiwaniu informacji typu tekstowego, ten typ informacji
Algorytmy i złożoność obliczeniowa Laboratorium 14. Algorytmy tekstowe. 1. Algorytmy tekstowe Algorytmy tekstowe mają decydujące znaczenie przy wyszukiwaniu informacji typu tekstowego, ten typ informacji
LABORATORIUM PROCESORY SYGNAŁOWE W AUTOMATYCE PRZEMYSŁOWEJ. Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q
 LABORAORIUM PROCESORY SYGAŁOWE W AUOMAYCE PRZEMYSŁOWEJ Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q 1. Zasady arytmetyki stałoprzecinkowej. Kody stałopozycyjne mają ustalone
LABORAORIUM PROCESORY SYGAŁOWE W AUOMAYCE PRZEMYSŁOWEJ Zasady arytmetyki stałoprzecinkowej oraz operacji arytmetycznych w formatach Q 1. Zasady arytmetyki stałoprzecinkowej. Kody stałopozycyjne mają ustalone
Języki formalne i automaty Ćwiczenia 6
 Języki formalne i automaty Ćwiczenia 6 Autor: Marcin Orchel Spis treści Spis treści... 1 Wstęp teoretyczny... 2 Wyrażenia regularne... 2 Standardy IEEE POSIX Basic Regular Expressions (BRE) oraz Extended
Języki formalne i automaty Ćwiczenia 6 Autor: Marcin Orchel Spis treści Spis treści... 1 Wstęp teoretyczny... 2 Wyrażenia regularne... 2 Standardy IEEE POSIX Basic Regular Expressions (BRE) oraz Extended
Algorytmy i struktury danych. Drzewa: BST, kopce. Letnie Warsztaty Matematyczno-Informatyczne
 Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Algorytmy i struktury danych Drzewa: BST, kopce Letnie Warsztaty Matematyczno-Informatyczne Drzewa: BST, kopce Definicja drzewa Drzewo (ang. tree) to nieskierowany, acykliczny, spójny graf. Drzewo może
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych
 PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych 2005/2006 Wykład "Podstawy baz danych" 1 Statyczny model pamiętania bazy danych 1. Dane przechowywane są w pamięci zewnętrznej podzielonej
PODSTAWY BAZ DANYCH Wykład 6 4. Metody Implementacji Baz Danych 2005/2006 Wykład "Podstawy baz danych" 1 Statyczny model pamiętania bazy danych 1. Dane przechowywane są w pamięci zewnętrznej podzielonej
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Optymalizacja ciągła
 Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Optymalizacja ciągła 5. Metoda stochastycznego spadku wzdłuż gradientu Wojciech Kotłowski Instytut Informatyki PP http://www.cs.put.poznan.pl/wkotlowski/ 04.04.2019 1 / 20 Wprowadzenie Minimalizacja różniczkowalnej
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa.
 Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
Wstęp do sieci neuronowych, wykład 02 Perceptrony c.d. Maszyna liniowa. Maja Czoków, Jarosław Piersa Wydział Matematyki i Informatyki, Uniwersytet Mikołaja Kopernika 2011-10-11 1 Modelowanie funkcji logicznych
16MB - 2GB 2MB - 128MB
 FAT Wprowadzenie Historia FAT jest jednym z najstarszych spośród obecnie jeszcze używanych systemów plików. Pierwsza wersja (FAT12) powstała w 1980 roku. Wraz z wzrostem rozmiaru dysków i nowymi wymaganiami
FAT Wprowadzenie Historia FAT jest jednym z najstarszych spośród obecnie jeszcze używanych systemów plików. Pierwsza wersja (FAT12) powstała w 1980 roku. Wraz z wzrostem rozmiaru dysków i nowymi wymaganiami
Podstawy Informatyki. Inżynieria Ciepła, I rok. Wykład 5 Liczby w komputerze
 Podstawy Informatyki Inżynieria Ciepła, I rok Wykład 5 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie
Podstawy Informatyki Inżynieria Ciepła, I rok Wykład 5 Liczby w komputerze Jednostki informacji Bit (ang. bit) (Shannon, 948) Najmniejsza ilość informacji potrzebna do określenia, który z dwóch równie
Kodowanie i kompresja Streszczenie Studia dzienne Wykład 6
 Kodowanie i kompresja Streszczenie Studia dzienne Wykład 6 1 Kody cykliczne: dekodowanie Definicja 1 (Syndrom) Niech K będzie kodem cyklicznym z wielomianem generuja- cym g(x). Resztę z dzielenia słowa
Kodowanie i kompresja Streszczenie Studia dzienne Wykład 6 1 Kody cykliczne: dekodowanie Definicja 1 (Syndrom) Niech K będzie kodem cyklicznym z wielomianem generuja- cym g(x). Resztę z dzielenia słowa
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0
 ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
ECDL/ICDL Użytkowanie baz danych Moduł S1 Sylabus - wersja 5.0 Przeznaczenie Sylabusa Dokument ten zawiera szczegółowy Sylabus dla modułu ECDL/ICDL Użytkowanie baz danych. Sylabus opisuje zakres wiedzy
Przykładowe B+ drzewo
 Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Przykładowe B+ drzewo 3 8 1 3 7 8 12 Jak obliczyć rząd indeksu p Dane: rozmiar klucza V, rozmiar wskaźnika do bloku P, rozmiar bloku B, liczba rekordów w indeksowanym pliku danych r i liczba bloków pliku
Instrukcja przygotowania pliku do deponowania
 Instrukcja przygotowania pliku do deponowania Etapy przygotowania pliku Przygotowanie pliku w formacie PDF Uzupełnienie metadanych w dokumencie Nadanie nazwy pliku PDF Format tekstowy pliku PDF Uporządkowanie
Instrukcja przygotowania pliku do deponowania Etapy przygotowania pliku Przygotowanie pliku w formacie PDF Uzupełnienie metadanych w dokumencie Nadanie nazwy pliku PDF Format tekstowy pliku PDF Uporządkowanie
Algorytmy genetyczne w interpolacji wielomianowej
 Algorytmy genetyczne w interpolacji wielomianowej (seminarium robocze) Seminarium Metod Inteligencji Obliczeniowej Warszawa 22 II 2006 mgr inż. Marcin Borkowski Plan: Przypomnienie algorytmu niszowego
Algorytmy genetyczne w interpolacji wielomianowej (seminarium robocze) Seminarium Metod Inteligencji Obliczeniowej Warszawa 22 II 2006 mgr inż. Marcin Borkowski Plan: Przypomnienie algorytmu niszowego
Algorytmy genetyczne. Paweł Cieśla. 8 stycznia 2009
 Algorytmy genetyczne Paweł Cieśla 8 stycznia 2009 Genetyka - nauka o dziedziczeniu cech pomiędzy pokoleniami. Geny są czynnikami, które decydują o wyglądzie, zachowaniu, rozmnażaniu każdego żywego organizmu.
Algorytmy genetyczne Paweł Cieśla 8 stycznia 2009 Genetyka - nauka o dziedziczeniu cech pomiędzy pokoleniami. Geny są czynnikami, które decydują o wyglądzie, zachowaniu, rozmnażaniu każdego żywego organizmu.
Kody blokowe Wykład 1, 3 III 2011
 Kody blokowe Wykład 1, 3 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding Theory
Kody blokowe Wykład 1, 3 III 2011 Literatura 1. R.M. Roth, Introduction to Coding Theory, 2006 2. W.C. Huffman, V. Pless, Fundamentals of Error-Correcting Codes, 2003 3. D.R. Hankerson et al., Coding Theory
Zaawansowane algorytmy i struktury danych
 Zaawansowane algorytmy i struktury danych u dr Barbary Marszał-Paszek Opracowanie pytań teoretycznych z egzaminów. Strona 1 z 12 Pytania teoretyczne z egzaminu pisemnego z 25 czerwca 2014 (studia dzienne)
Zaawansowane algorytmy i struktury danych u dr Barbary Marszał-Paszek Opracowanie pytań teoretycznych z egzaminów. Strona 1 z 12 Pytania teoretyczne z egzaminu pisemnego z 25 czerwca 2014 (studia dzienne)
Charakterystyki oraz wyszukiwanie obrazów cyfrowych
 Algorytmy Graficzne Charakterystyki oraz wyszukiwanie obrazów cyfrowych Autor: Mateusz Nostitz-Jackowski 1 / 7 Działanie programu: Do poprawnego działania projektu potrzeba programu Mathematica 5.2 (możliwe
Algorytmy Graficzne Charakterystyki oraz wyszukiwanie obrazów cyfrowych Autor: Mateusz Nostitz-Jackowski 1 / 7 Działanie programu: Do poprawnego działania projektu potrzeba programu Mathematica 5.2 (możliwe
Algorytmy przeszukiwania
 Algorytmy przeszukiwania Przeszukiwanie liniowe Algorytm stosowany do poszukiwania elementu w zbiorze, o którym nic nie wiemy. Aby mieć pewność, że nie pominęliśmy żadnego elementu zbioru przeszukujemy
Algorytmy przeszukiwania Przeszukiwanie liniowe Algorytm stosowany do poszukiwania elementu w zbiorze, o którym nic nie wiemy. Aby mieć pewność, że nie pominęliśmy żadnego elementu zbioru przeszukujemy
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING NEURONOWE MAPY SAMOORGANIZUJĄCE SIĘ Self-Organizing Maps SOM Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki,
Kodowanie informacji. Kody liczbowe
 Wykład 2 2-1 Kodowanie informacji PoniewaŜ komputer jest urządzeniem zbudowanym z układów cyfrowych, informacja przetwarzana przez niego musi być reprezentowana przy pomocy dwóch stanów - wysokiego i niskiego,
Wykład 2 2-1 Kodowanie informacji PoniewaŜ komputer jest urządzeniem zbudowanym z układów cyfrowych, informacja przetwarzana przez niego musi być reprezentowana przy pomocy dwóch stanów - wysokiego i niskiego,
Algorytmy sortujące i wyszukujące
 Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Algorytmy sortujące i wyszukujące Zadaniem algorytmów sortujących jest ułożenie elementów danego zbioru w ściśle określonej kolejności. Najczęściej wykorzystywany jest porządek numeryczny lub leksykograficzny.
Tablice z haszowaniem
 Tablice z haszowaniem - efektywna metoda reprezentacji słowników (zbiorów dynamicznych, na których zdefiniowane są operacje Insert, Search i Delete) - jest uogólnieniem zwykłej tablicy - przyspiesza operacje
Tablice z haszowaniem - efektywna metoda reprezentacji słowników (zbiorów dynamicznych, na których zdefiniowane są operacje Insert, Search i Delete) - jest uogólnieniem zwykłej tablicy - przyspiesza operacje
Zarządzanie pamięcią. Od programu źródłowego do procesu. Dołączanie dynamiczne. Powiązanie programu z adresami w pamięci
 Zarządzanie pamięcią Przed wykonaniem program musi być pobrany z dysku i załadowany do pamięci. Tam działa jako proces. Podczas wykonywania, proces pobiera rozkazy i dane z pamięci. Większość systemów
Zarządzanie pamięcią Przed wykonaniem program musi być pobrany z dysku i załadowany do pamięci. Tam działa jako proces. Podczas wykonywania, proces pobiera rozkazy i dane z pamięci. Większość systemów
Od programu źródłowego do procesu
 Zarządzanie pamięcią Przed wykonaniem program musi być pobrany z dysku i załadowany do pamięci. Tam działa jako proces. Podczas wykonywania, proces pobiera rozkazy i dane z pamięci. Większość systemów
Zarządzanie pamięcią Przed wykonaniem program musi być pobrany z dysku i załadowany do pamięci. Tam działa jako proces. Podczas wykonywania, proces pobiera rozkazy i dane z pamięci. Większość systemów
Temat: Algorytm kompresji plików metodą Huffmana
 Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Temat: Algorytm kompresji plików metodą Huffmana. Wymagania dotyczące kompresji danych Przez M oznaczmy zbiór wszystkich możliwych symboli występujących w pliku (alfabet pliku). Przykład M = 2, gdy plik
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Wykład II. Reprezentacja danych w technice cyfrowej. Studia Podyplomowe INFORMATYKA Podstawy Informatyki
 Studia Podyplomowe INFORMATYKA Podstawy Informatyki Wykład II Reprezentacja danych w technice cyfrowej 1 III. Reprezentacja danych w komputerze Rodzaje danych w technice cyfrowej 010010101010 001010111010
Studia Podyplomowe INFORMATYKA Podstawy Informatyki Wykład II Reprezentacja danych w technice cyfrowej 1 III. Reprezentacja danych w komputerze Rodzaje danych w technice cyfrowej 010010101010 001010111010
Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I
 Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I Rozkład zgodny
Zespół TI Instytut Informatyki Uniwersytet Wrocławski ti@ii.uni.wroc.pl http://www.wsip.com.pl/serwisy/ti/ Rozkład materiału do nauczania informatyki w liceum ogólnokształcącym Wersja I Rozkład zgodny
Według raportu ISO z 1988 roku algorytm JPEG składa się z następujących kroków: 0.5, = V i, j. /Q i, j
 Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Kompresja transformacyjna. Opis standardu JPEG. Algorytm JPEG powstał w wyniku prac prowadzonych przez grupę ekspertów (ang. Joint Photographic Expert Group). Prace te zakończyły się w 1991 roku, kiedy
Podstawy Informatyki dla Nauczyciela
 Podstawy Informatyki dla Nauczyciela Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 2 Bożena Woźna-Szcześniak (AJD) Podstawy Informatyki dla Nauczyciela Wykład 2 1 / 1 Informacja
Podstawy Informatyki dla Nauczyciela Bożena Woźna-Szcześniak bwozna@gmail.com Jan Długosz University, Poland Wykład 2 Bożena Woźna-Szcześniak (AJD) Podstawy Informatyki dla Nauczyciela Wykład 2 1 / 1 Informacja
Platforma e-learnigowa Moodle Testy i oceny
 Platforma e-learnigowa Moodle Testy i oceny 02.02.2011 Przygotowanie quizu - baza pytań Pytania Baza pytań niezależna od quizów Struktura bazy: kategorie obejmujące określoną część materiału, np. pytania
Platforma e-learnigowa Moodle Testy i oceny 02.02.2011 Przygotowanie quizu - baza pytań Pytania Baza pytań niezależna od quizów Struktura bazy: kategorie obejmujące określoną część materiału, np. pytania