Miary efektywności zrównleglenia
|
|
|
- Patryk Krystian Rosiński
- 8 lat temu
- Przeglądów:
Transkrypt
1 Zagadnienia Miary efektywności zrównoleglenia Trendy rynku maszyn równoległych Klasyfikacja maszyn równoległych Przegląd topologii architektur równoległych
2 Miary efektywności zrównleglenia Oszacowanie wzrostu wydajności obliczeń realizowanych w sposób równoległy w stosunku do rozwiązania sekwencyjnego Oznaczenia: n wielkość zadania, p liczba procesorów, T(n,p) czas wykonania programu realizującego ten sam algorytm dla zadania o wielkości n na maszynie równoległej z p procesorami.
3 Współczynnik przyspieszenia Współczynnik przyspieszenia (Speedup) zadania o wielkości n dzięki zrównolegleniu na p procesorów: S n, p = T n,1 T n, p Zachodzi nierówność: S n, p p
4 Założenia modelowe Zakładamy, że program składa się z kilku części wykonywanych równolegle poprzedzielanych częściami, które muszą być wykonywane sekwencyjnie. Oznaczenia: β(n) udział części sekwencyjnej (część T(n,1), która nie da się zrównoleglić), Część sekwencyjna (czas): σ(n) = β(n) T(n,1). Część równoległa: ϕ(n) = (1 β(n)) T(n,1), może być zrównoleglona idealnie (rozłożona na dowolną ilość procesorów). κ(n,p) czas zużyty na narzuty na synchronizację i komunikację międzyprocesową.
5 Efekt zrównoleglenia β t s (1-β)t s p (1-β)t s /p
6 Efekt zrównoleglenia Czas wykonania zadania o rozmiarze n na maszynie równoległej o p procesorach: T n, 1 =σ n ϕ n T n, p =σ n ϕ n p κ n, p Zdefiniujmy udział sekwencyjny: σ n β n = σ n ϕ n
7 Prawo Amdahla Czas wykonania na maszynie równoległej o p procesorach (założenie: κ(n,p) = 0): 1 β n T n,1 T n, p =β n T n,1 p lub S n, p = T n,1 T n, p = 1 1 β n β n p
8 Speedup β=0% Speedup, S(p) β=5% β=10% β=20% liczba procesorów, p
9 p=256 Speedup Speedup, S(p) p=16 udział części sekwencyjnej, β
10 Prawo Amdahla S n, p 1 p β n Nawet przy użyciu dowolnie wielu procesorów, obliczeń nie da się przyspieszyć bardziej, niż wynosi odwrotność udziału części sekwencyjnej w programie wykonywanym na jednym procesorze.
11 Prawo Amdahla Jeżeli czas części sekwencyjnych jest stały i równy β s T(1,1), a czas części równoległej jest proporcjonalny do rozmiaru n zadania, to: β n = β s β s n 1 β s = 1 1 n 1 β s 1
12 Prawo Amdahla Jeżeli czas wykonania części sekwencyjnej jest proporcjonalny do wielkości zadania (np. n β s ), a czas części równoległej ~ n 2 (np. n 2 (1- β s )), to: β n n 0 czyli S n, p p
13 Efekt Amdahla Zwykle narzut komunikacyjny ma mniejszą złożoność obliczeniową niż część idealnie dająca się zrównoleglić. Zwiększenie rozmiaru zadania powoduje wzrost czasu obliczeń szybciej niż czas komunikacji. Dla stałej ilości procesorów, przyśpieszenie jest rosnącą funkcją rozmiaru zadania.
14 Wniosek Powodem stosowania obliczeń równoległych jest chęć rozwiązywania dużych (o dużej wymiarowości) przykładów tego samego zadania niż szybszego uzyskania wyników małego wymiaru.
15 Prawo Gustafsona-Barsisa Niech s (małe) oznacza udział części sekwencyjnej rozwiązania równoległego, wtedy: s= σ n σ n ϕ n / p Definicja przyspieszenia: 1 s = ϕ n / p σ n ϕ n / p S n, p = σ n ϕ n σ n ϕ n / p κ n, p =0
16 Prawo Gustafsona-Barsisa Po podstawieniu s do wyrażenia na Speedup: S n, p = σ n σ n n / p n σ n n / p S n, p =s p 1 s = p s p 1 Współczynnik s jest funkcją rozmiaru problemu, a więc rozwiązywanie większych problemów pozwala ominąć ograniczenie wynikające z prawa Amdahla.
17 Metryka Karpa-Flatta Uwzględnia wpływ narzutu komunikacyjnego. Niech e oznacza tzw. eksperymentalnie określony udział części sekwencyjnej rozwiązania równoległego: e=[ σ n κ n, p ]/T n,1 T n, p =T n,1 e T n,1 1 e / p T n, p =T n, p S n, p e T n, p S n, p 1 e / p e= 1/ S n, p 1 / p 1 1/ p
18 Metryka Karpa-Flatta Umożliwia oszacowanie czy spadek wydajności zrównoleglenia zachodzi na skutek: ograniczonego potencjału zrównoleglenia, wzrostu narzutów algorytmicznych.
19 Przykład e nie rośnie ze wzrostem p brak potencjału zrównoleglenia duża część obliczeń jest immanentnie sekwencyjna. p S e e rośnie ze wzrostem p przyczyną słabego przyspieszenia jest narzut (na inicjalizację, komunikację, synchronizację, itp.). p S e
20 Uwaga Osłabieniem ograniczenia narzucanego przez prawo Amdahla jest stosowanie obliczeń asynchronicznych. Nie ma w nich sztywnego podziału na część dającą się zrównoleglić i nie.
21 Skalowalność i sprawność Właściwość systemu (sprzętu i oprogramowania) polegająca na elastycznym dostosowywaniu się do zwiększonej liczby procesorów tj. zachowującym tę samą sprawność. η(n,p) sprawność programu o wielkości n na maszynie o p procesorach: η n, p = S n, p 100 p
22 Metryka stałej sprawności Speedup: σ n ϕ n S n, p = σ n ϕ n / p κ n, p = p σ n ϕ n σ n ϕ n p 1 σ n pκ n, p Niech T 0 (n,p) całkowity czas zużyty przez wszystkie procesy wykonujące operacje nie wchodzące w skład algorytmu sekwencyjnego (narzut). Wtedy: T 0 n, p = p 1 σ n pκ n, p p σ n ϕ n σ n ϕ n S n, p = η n, p = σ n ϕ n T 0 n, p σ n ϕ n T 0 n, p η n, p = 1 1 T 0 n, p σ n ϕ n
23 Relacja stałej sprawności Skoro T(n,1) czas zużyty wykonania sekwencyjnego, wtedy: 1 η n, p η n, p = T n,1 = 1 T 0 n, p /T n,1 1 η n, p T 0 n, p Niech system równoległy ma sprawność η(n,p). Aby zachować ten sam poziom sprawności ze wzrostem liczby procesorów, n musi wzrosnąć w stopniu spełniającym zależność (isoefficiency relation): T n,1 =CT 0 n, p
24 Funkcja skalowalności Aby utrzymać tę samą sprawność, po zwiększeniu liczby procesorów p należy zwiększyć wielkość n zadania; Dla danej liczby p można wyznaczyć wielkość zadania przy której jest zachowana ta sama sprawność; Związek ten określa funkcję stałej sprawności (isoefficiency function), monotonicznie rosnącą. Jeśli dany system ma relację stałej sprawności n = f(p), a M(n) oznacza ilość pamięci niezbędnej dla problemu o rozmiarze n, to zależność M(f(p))/p, wyznaczającą ilość pamięci na procesor, nazywamy funkcją skalowalności. Dana architektura jest bardziej skalowalna gdy funkcja ta rośnie wolniej: np. jeśli M(f(n)/p = Θ(1), to system jest w pełni skalowalny.
25 Funkcja skalowalności 10 8 Pojemność pamięci procesora magana pamięć, M 6 4
26 Przykłady Równoległa redukcja: złoż. sekw.: Θ(n), złoż. redukcji: Θ(log p) T 0 (n,p) = Θ(p log p) rel. isoeff.: n = C p log p, M(n) = n M(C p log p )/p = C log p Algorytm Floyda (najkrótszej ścieżki): złoż. sekw.: Θ(n 3 ), złoż. komunikacji p procesorów: Θ(n 2 log p) rel. isoeff.: n 3 = C (p n 2 log p), M(n) = n 2 M(C p log p )/p = C 2 p log 2 p Metoda elementów skończonych (PDE): złoż. sekw.: Θ(n 3 ), złoż. komunikacji p procesorów: Θ(n / p) rel. isoeff.: n 2 = C p (n / p)), M(n) = n 2 M(C p )/p = (C p) 2 /p = C 2
27 Trendy rynku maszyn równoległych Rynek komputerów równoległych podlega dynamicznym zmianom. Wiele systemów jest obecnych na rynku przez dość krótki okres (2-3 lata). Wiele znaczących firm zdążyło przestać istnieć (np. Kendall Square Research, Thinking Machines, Parsytec, Meiko).
28 Producenci sprzętu superkomputerowego Cray Research Inc. przejęty przez SGI, część odsprzedana firmie Sun, reszta firmie Tera Computer (obecnie przywrócono nazwę Cray) Convex przejęty przez Hewlett-Packard Digital Equipment Corp. (DEC) przejęty przez Compaq (obecnie HP) Silicon Graphics (SGI) International Business Machines (IBM) Hewlett-Packard (HP) Intel Corp. Sun Microsystems NEC, Fujitsu, Hitachi Control Data Corp. (CDC), NCR NVidia
29 Klastery (grona) Prawo Moore'a wydajność komputerów osobistych (zegar procesora, wielkość pamięci) podwaja się co 18 miesięcy. Powstanie wydajnych sieci: Fast/Gigabit Ethernet, Myrinet, SCI, QsNet, Infiniband (prędkości 1 10 Gbps i więcej). Zakup grupy szybkich PC + sieć co najmniej rząd wielkości tańszy, niż dedykowany komputer wieloprocesorowy. Postępująca dominacja klastrów wśród systemów komputerowych.
30 Lista TOP500 jesień 2003 Earth Simulator, Yokohama (NEC) Tflops 5120 (8-way nodes) 500 MHz SX-5 CPUs LANL ASCI Q (HP AlphaServer) Tflops 4096 (4-way nodes) EV GHz CPUs, Quadrics Virginia Tech s X cluster (Apple G5) Tflops 2200 (2-way nodes) PowerPC GHz CPU, Infiniband NCSA Tungsten cluster (Dell PowerEdge) 9.82 Tflops 2500 (2-way nodes) Intel Xeon 3.04 GHz CPU, Myrinet PNNL MPP2 (HP Integrity rx) 8.64 Tflops 1936 (2-way nodes) Intel Itanium GHz CPU, Quadrics
31 Lista TOP500 jesień 2004 DOE BlueGene/L DD2, Rochester (IBM) Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs NASA Columbia, Mountain View (SGI) Tflops (512-way nodes) 1.5 GHz Intel Itanium-2 CPUs, Infiniband Earth Simulator, Yokohama (NEC) Tflops 5120 (8-way nodes) 500 MHz SX-5 CPUs BSC MareNostrum, Barcelona (IBM) Tflops 3564 (2-way blades) 2.2 GHz PowerPC 970 CPUs, Myrinet LLNL Thunder (Intel/Calif. Digital Corp.) Tflops 4096 (4-way nodes) 1.4 GHz Intel Itanium-2 CPUs, Quadrics
 700 MHz PowerPC 440 CPUs, GE DOE ASC Purple, LLNL (IBM p575) 63.39 Tflops 10240 (8-way nodes) 1.")
32 Lista TOP500 jesień 2005 DOE BlueGene/L, LLNL (IBM) Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs, GE IBM BGW BlueGene, Yorktown Heights Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs, GE DOE ASC Purple, LLNL (IBM p575) Tflops (8-way nodes) 1.9 GHz Power5 575 CPUs, IBM Federation NASA Columbia, Mountain View (SGI Altix) Tflops (512-way nodes) 1.5 GHz Intel Itanium-2 CPUs, Infiniband DOE Thunderbird, Sandia NL (Dell) Tflops 8000 (2-way nodes) 3.6 GHz Intel Xeon EM64T CPUs, Infiniband
 700 MHz PowerPC 440 CPUs, GE DOE ASC Purple, LLNL (IBM p575) 75.")
33 Lista TOP500 jesień 2006 DOE BlueGene/L, LLNL (IBM) Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs, GE DOE Red Storm, Sandia (Cray) Tflops Opteron 2.4 GHz dual core CPUs, Cray SeaStar, HT IBM BGW BlueGene, Yorktown Heights Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs, GE DOE ASC Purple, LLNL (IBM p575) Tflops (8-way nodes) 1.9 GHz Power5 575 CPUs, IBM Federation BSC MareNostrum, Barcelona (IBM) Tflops (2-way blades) 2.3 GHz PowerPC 970 CPUs, Myrinet
 850 MHz PowerPC 450 CPUs, torus + 10GE NMCAC ICE, Rio Rancho (SGI Altix 8200) 126.")
34 Lista TOP500 jesień 2007 DOE BlueGene/L, LLNL (IBM) Tflops (2-way nodes) 700 MHz PowerPC 440 CPUs, torus + GE JSC JUGENE, fz Jülich (IBM) Tflops (4-way nodes) 850 MHz PowerPC 450 CPUs, torus + 10GE NMCAC ICE, Rio Rancho (SGI Altix 8200) Tflops (2-way blades) 3 GHz Xeon 53xx CPUs, Infiniband Tata CRL EKA, Pune (HP Cluster BL460c) Tflops (2-way blades) 3 GHz Xeon 53xx CPUs, Infiniband Swedish Gov t Cluster Platform (HP BL460c) Tflops (2-way blades) 3 GHz Xeon 53xx CPUs, Infiniband 428. P1 BladeCenter, Poland (IBM HS21 Cluster) 6.36 Tflops 1288 (2-way blades) 3 GHz Xeon 51xx CPUs, GE

35 Lista TOP500
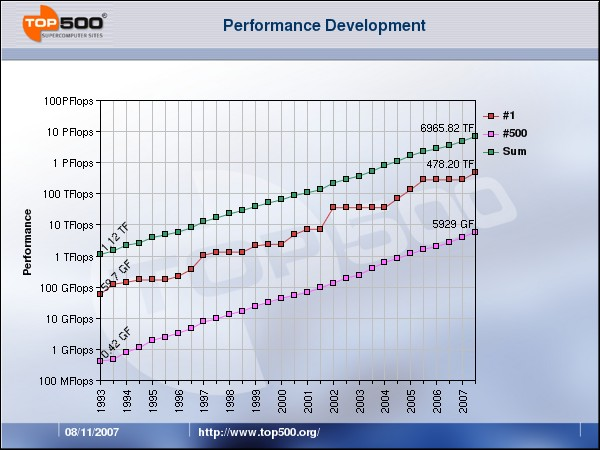
36 TOP 500
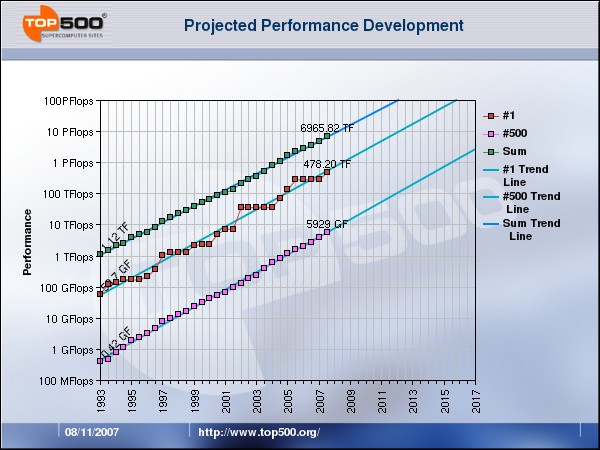
37 TOP 500

38 Lista TOP500
39 Lista TOP500

40 Lista TOP500
41 Klasyfikacja maszyn równoległych Taksonomia Flynna: SISD (Single Instruction Single Data) SIMD (Single Instruction Multiple Data) MISD (Multiple Instruction Single Data) MIMD (Multiple Instruction Multiple Data)
42 SISD Klasyczne maszyny sekwencyjne zbudowane wg architektury von Neumanna Zawierają jeden procesor i jeden blok pamięci operacyjnej Program ciąg instrukcji wykonywanych sekwencyjnie
43 SIMD Te same operacje wykonywane jednocześnie na różnych danych Komputery wektorowe jeden procesor operujący na tablicy danych Tablice procesorów wiele (do kilkunastu tysięcy) prostych procesorów wykonujących te same operacje skalarne
44 MISD Maszyny wykonujące różne operacje na pojedynczym strumieniu danych Systolic arrays (szeregi tętniące) układy kolejek priorytetowych Architektura występująca sporadycznie w układach DSP (digital signal processing) Brak naturalnego mapowania popularnych konstrukcji programistycznych na MISD
45 MIMD Poszczególne procesory wykonują różne operacje na różnych danych, stanowiących różne części tego samego zadania obliczeniowego Najważniejszy typ architektury komputerów równoległych
46 Architektury pamięci SM (Shared Memory) maszyny z pamięcią wspólną (współdzieloną, globalną); wszystkie procesory mają tę samą przestrzeń adresową; dostęp do danych zgodnie z regułami zasięgu danego języka programowania; SMP wariant: Symmetric Multi Processing.
47 Architektury pamięci DM (Distributed Memory) maszyny z pamięcią rozproszoną (lokalną); maszyny z procesorami posiadającymi każdy odrębną pamięć (przestrzeń adresową); także systemy połączone przez sieć (klastery); Programista musi dokonać explicite podziału danych między procesory; większa skalowalność.
48 Maszyny typu SISD Występują w nich pewne elementy równoległości pipelining przetwarzanie potokowe, SSE rozszerzenia streaming SIMD extensions. Systemy wieloprocesorowe wykonujące niezależne programy sekwencyjne.
49 Maszyny typu SIMD SM-SIMD maszyny wektorowe: w sposób równoległy (po współrzędnych) wykonywane są ciągi tych samych operacji, zrównoleglanie wykonywane automatycznie poprzez kompilator, przykłady: CDC Cyber 205, Cray 1, Cray 2.
50 SM-SIMD Pamięć I/O procesor Cache instrukcji/danych Cache danych Rejestry wektorowe Urządzenia peryferyjne IP/ALU FPU VPU IP/ALU: procesor całkowitoliczbowy FPU: skalarna jednostka zmiennoprzecinkowa VPU: wektorowa jednostka zmiennoprzecinkowa
51 Maszyny typu SIMD DM-SIMD tablice procesorów: jeden procesor sterujący, duża ilość prostych procesorów z pamięcią lokalną połączonych tylko z sąsiadami, ta sama instrukcja wykonywana na lokalnych danych przez wszystkie procesory, wymiana danych tylko z sąsiadami (routing), specjalistyczne i historyczne (lata 80-te XX w.), przykłady: Thinking Machines CM-2, MasPar MP-1.
52 DM-SIMD Terminal Procesor sterujący Połączenia z terminalem oraz procesorem I/O Tablica procesorów Płaszczyzna rejestrów Sieć połączeń Płaszczyzna wymiany danych Pamięć
53 Maszyny typu MIMD SM-MIMD pamięć wspólna umiarkowana liczba działających niezależnie procesorów, globalna pamięć, jednorodnie adresowana, teoretyczny model PRAM (Parallel Random Access Memory), SMP (Symmetric Multi-Processing) oznaczenie marketingowe, przykłady: Cray T90, SGI Challenge, Sun 690.
54 Model PRAM Każdy procesor może uzyskać dostęp do dowolnej komórki pamięci w tym samym czasie. Dostęp do danych: EREW (exclusive read, exclusive write), CREW (concurrent read, exclusive write), CRCW (concurrent read, concurrent write).
55 SM-MIMD Procesor Procesor Procesor Sieć połączeń Pamięć
56 SM-MIMD W praktyce dostęp do pamięci nie jest całkowicie jednolity: przełącznica krzyżowa (crossbar switch) zapewnia ten sam czas dostępu, wspólna magistrala danych (bus) najtańsze rozwiązanie, wielostopniowa przełącznica krzyżowa (np. typu Ω).

57 Crossbar wejście wyjście
58 Bus wejście wyjście
59 Pamięć cache Procesor Procesor Procesor Cache Cache Cache Sieć połączeń Pamięć

60 Omega switch
61 Koszty połączeń Przełącznica krzyżowa O(p 2 ) czas odczytu średnio jak dla 1-go procesora Magistrala O(p) pamięć cache buforująca często używane dane, czas dostępu może rosnąć aż do p Przełącznica Omega O(p log 2 p) elementy łączą we z wy na wprost gdy i-ty bit adresu źródła jest równy i-temu bitowi adresu celu, w kolejnych warstwach adresy przesunięte o jeden z zapętleniem, jednocześnie można przesłać p pakietów
62 Cechy maszyn SM-MIMD Zaletę stanowi względna łatwość realizacji oraz programowania: jednolita przestrzeń adresowa, zbędne specjalne mechanizmy komunikacji, konieczny mechanizm synchronizacji. Słaba skalowalność liczby procesorów: brak możliwości proporcjonalnego wzrostu przepustowości dostępu do pamięci.
63 Maszyny typu MIMD DM-MIMD pamięć rozproszona duża liczba procesorów działających niezależnie, każdy procesor dysponuje pamięcią lokalną przechowującą bezpośrednio dostępne obiekty danych, nie dostępną dla innych procesorów, wymiana informacji między procesorami za pomocą komunikatów, MPP (Massive Parallel Processing) łączenie bardzo dużej (tysiące) liczby procesorów, przykłady: Thinking Machines CM-5, Cray T3E, Fujitsu VPP5000, Meiko CS-2, Intel Paragon.
64 DM-MIMD Pamięć Pamięć Pamięć Procesor Procesor Procesor Sieć połączeń
65 DM-MIMD Parametry maszyn DM: topologia połączeń między procesorami, średnica d największa odległość między procesorami tj. liczba kanałów do pokonania, Rozpiętość przekroju połówkowego RPP (bisection bandwidth) maksymalna liczba komunikatów, jakie mogą być wysłane jednocześnie przez jedną połowę procesorów do drugiej, inaczej minimalna liczba kanałów, po usunięciu których sieć będzie podzielona na dwie równe części.
66 Parametry... Maszyny SM (liczba procesorów p): przełącznica krzyżowa, d=1, RPP=0.5p, magistrala, d=1, RPP=1, sieć Ω, d=log 2 p, RPP=p. Maszyny DM (p = n n): siatka 2D, d=2n-2, RPP=n, torus 2D, d=n, RPP=2n, pierścień (torus 1D), d=p-1(1-kier.), RPP=2, drzewo, np. binarne, d=2log 2 [(p+1)/2], RPP=1, hipersześcian (n-wym., p=2 n ), d=n, RPP=p/2=2 n-1.
67 Topologie maszyn DM Siatka 2D Drzewo binarne Pierścień (torus 1D)

68 Topologie maszyn DM przełączniki m = 4 węzły m-fat Tree, d=log m n, RPP=p/2 gdzie: m ilość potomków, n ilość warstw, ilość węzłów p=m n, ilość przełączników s=n m n-1, niewielka średnica, dobra skalowalność, niewielka ilość przełączników
69 rank 0 Butterfly >101 rank 1 > 01 > 1 rank 2 > rank 3
70 Topologie maszyn DM Hipersześcian 3D Hipersześcian 4D
71 Drzewo Hypercube Pierścień Fizyczna architektura hipersześcianu pozwala tworzyć różne topologie logiczne Siatka 2D
72 Atrybuty topologii sieciowych Processor nodes Switch nodes Diameter Bisection width Edges/ nodes Constant edge length 2-D mesh n=d 2 n 2( n 1) n 4 Yes Binary tree n=2 d 2n 1 2 log n 1 3 No 4-Fat tree n=4 2 2n n log n n / 2 6 No Butterfly n=d 2 n (log n+1) log n n / 2 4 No Hypercube n=d 2 n log n n / 2 log n No Omega n=2 k n 2 log n 1 n / log n 2 No
73 Routing kanalikowy Wormhole routing Rozwiązanie zastępujące hypercube Radykalne skrócenie czasu transmisji Wcześniejsze rozwiązania zakładały przesyłanie komunikatów od węzła do węzła maszyny równoległej (procesor+ pamięć) store and forward.
74 Store-and-Forward Opóźnienie komunikacyjne: Δt s f = L B D gdzie: L długość pakietu, B przepustowość kanału (channel bandwidth), D długość ścieżki między nadawcą i odbiorcą (liczba odcinków między procesorami).
75 Wormhole routing Pakiet jest dzielony na bardzo małe części tzw. flity (flow-control digit). Pierwszy flit otwiera drogę pozostałym; na bazie ustalonego algorytmu routingu. Po przesłaniu pierwszego flitu, pozostałe podążają za nim; jeżeli kanał jest zajęty, flity są buforowane w węźle pośrednim, aż do odblokowania. Transmisja ma charakter potokowy: przypomina ruch dżdżownicy (wormhole kanalik).
76 Wormhole routing Opóźnienie komunikacyjne (brak blokad): Δt whr = L f B D L B = 1 B L f D L gdzie: L f długość flitu. Jeśli L f D<<L, czyli flity są b. krótkie, a odległość między procesorami niezbyt duża, to długość ścieżki D nie wpływa znacząco na opóźnienie.
77 Sieci komputerów Zaliczane są do kategorii DM-MIMD. COW (Cluster of Workstations) klastery Linux: Beowulf ( NOW (Network of Workstations) połączone ad hoc ogólnodostępną siecią lokalną. Zbudowane z komponentów off-the-shelf: niższa o rząd wielkości cena. Problemy: niezawodność, bezpieczeństwo, heterogeniczność sprzętu i oprogramowania.
78 Systemy hybrydowe Zespoły wieloprocesorowych węzłów SM-MIMD połączone wewnętrzną szybką siecią. Dominujące podejście w nowszych systemach superkomputerowych. Traktowanie jako maszyn DM nieefektywne komunikaty lokalne w węzłach SM. Trudność programowego odwzorowania hierarchicznej budowy. Przykłady: IBM RS/6000 SP, SGI Origin, Cray SV1, HP AlphaServer SC, HP Exemplar.
79 System hybrydowy Proc. Proc. Proc. Proc. Pamięć Pamięć Proc. Proc. Proc. Proc. Sieć połączeń Urządzenia peryferyjne
80 Distributed Shared Memory Maszyny hybrydowe z mechanizmem przedstawiającym pamięć rozproszoną fizycznie jako współdzieloną adresowo. Asymetryczny dostęp szybszy do pamięci lokalnej: NUMA (non-uniform memory access), sprzętowe przyspieszanie za pomocą pamięci cache wymaga zachowania spójności danych w całym systemie: ccnuma (cache coherent) Przykład: SGI Origin, HP Exemplar
81 Single System Image Systemy klastrowe wzorowane na architekturze ccnuma, posiadające jedną kopię systemu operacyjnego zarządzającego wszystkimi węzłami naraz. Upodabnia to funkcjonalnie działanie klastera do systemu typu SMP. Przykład: SGI Altix (klaster Linux, Itanium-2)
82 Rozwiązania programowe Wirtualna maszyna z pamięcią wspólną ukrywa hybrydową naturę sprzętu High Performance Fortran dyrektywy zrównoleglające Linda przestrzeń krotek
16. Taksonomia Flynn'a.
 16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
16. Taksonomia Flynn'a. Taksonomia systemów komputerowych według Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine
 - Parallel Random Access Machine") 21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
21 Model z pamięcią współdzieloną (model PRAM) - Parallel Random Access Machine Model PRAM zapewnia możliwość jednoczesnego dostępu każdego spośród n procesorów o architekturze RAM do wspólnej pamięci
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD. Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej
 Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Podstawy Techniki Mikroprocesorowej wykład 13: MIMD Dr inż. Jacek Mazurkiewicz Katedra Informatyki Technicznej e-mail: Jacek.Mazurkiewicz@pwr.edu.pl Kompjuter eta jest i klasyfikacja jednostka centralna
Nowoczesne technologie przetwarzania informacji
 Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Projekt Nowe metody nauczania w matematyce Nr POKL.09.04.00-14-133/11 Nowoczesne technologie przetwarzania informacji Mgr Maciej Cytowski (ICM UW) Lekcja 2: Podstawowe mechanizmy programowania równoległego
Programowanie równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Programowanie równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 23 października 2009 Spis treści Przedmowa...................................................
Obliczenia równoległe i rozproszone. Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz
 Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Obliczenia równoległe i rozproszone Praca zbiorowa pod redakcją Andrzeja Karbowskiego i Ewy Niewiadomskiej-Szynkiewicz 15 czerwca 2001 Spis treści Przedmowa............................................
Architektura komputerów
 Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
Architektura komputerów Wykład 13 Jan Kazimirski 1 KOMPUTERY RÓWNOLEGŁE 2 Klasyfikacja systemów komputerowych SISD Single Instruction, Single Data stream SIMD Single Instruction, Multiple Data stream MISD
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012 Wykład nr 6 (27.04.2012) dr inż. Jarosław Forenc Rok akademicki
Klasyfikacja systemów komputerowych. Architektura von Neumanna Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż.
 Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
Rok akademicki 2011/2012, Wykład nr 6 2/46 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2011/2012
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH
 1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
1. ARCHITEKTURY SYSTEMÓW KOMPUTEROWYCH 1 Klasyfikacje komputerów Podstawowe architektury używanych obecnie systemów komputerowych można podzielić: 1. Komputery z jednym procesorem 2. Komputery równoległe
Architektura mikroprocesorów TEO 2009/2010
 Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Architektura mikroprocesorów TEO 2009/2010 Plan wykładów Wykład 1: - Wstęp. Klasyfikacje mikroprocesorów Wykład 2: - Mikrokontrolery 8-bit: AVR, PIC Wykład 3: - Mikrokontrolery 8-bit: 8051, ST7 Wykład
Przetwarzanie równoległesprzęt
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 4.0.204 7.0.2 Sieci połączeń komputerów równoległych () Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi Parametry: liczba wejść, wyjść,
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 4.0.204 7.0.2 Sieci połączeń komputerów równoległych () Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi Parametry: liczba wejść, wyjść,
Programowanie współbieżne Wstęp do obliczeń równoległych. Rafał Skinderowicz
 Programowanie współbieżne Wstęp do obliczeń równoległych Rafał Skinderowicz Plan wykładu Modele obliczeń równoległych Miary oceny wydajności algorytmów równoległych Prawo Amdahla Prawo Gustavsona Modele
Programowanie współbieżne Wstęp do obliczeń równoległych Rafał Skinderowicz Plan wykładu Modele obliczeń równoległych Miary oceny wydajności algorytmów równoległych Prawo Amdahla Prawo Gustavsona Modele
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2009/2010 Wykład nr 6 (15.05.2010) dr inż. Jarosław Forenc Rok akademicki
Architektury komputerów Architektury i wydajność. Tomasz Dziubich
 Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektury komputerów Architektury i wydajność Tomasz Dziubich Przetwarzanie potokowe Przetwarzanie sekwencyjne Przetwarzanie potokowe Architektura superpotokowa W przetwarzaniu potokowym podczas niektórych
Architektura komputerów
 Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
Architektura komputerów Tydzień 14 Procesory równoległe Klasyfikacja systemów wieloprocesorowych Luźno powiązane systemy wieloprocesorowe Każdy procesor ma własną pamięć główną i kanały wejścia-wyjścia.
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 24 stycznia 2009 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych
 Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Wykład 5 Klasyfikacje systemów komputerowych, modele złożoności algorytmów obliczeniowych Spis treści: 1. Klasyfikacja Flynna 2. Klasyfikacja Skillicorna 3. Klasyfikacja architektury systemów pod względem
Przetwarzanie równoległesprzęt. Rafał Walkowiak Wybór
 Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Przetwarzanie równoległesprzęt 2 Rafał Walkowiak Wybór 17.01.2015 1 1 Sieci połączeń komputerów równoległych (1) Zadanie: przesyłanie danych pomiędzy węzłami przetwarzającymi, pomiędzy pamięcią a węzłami
Podstawy Informatyki Systemy sterowane przepływem argumentów
 Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Podstawy Informatyki alina.momot@polsl.pl http://zti.polsl.pl/amomot/pi Plan wykładu 1 Komputer i jego architektura Taksonomia Flynna 2 Komputer i jego architektura Taksonomia Flynna Komputer Komputer
Wydajność komunikacji grupowej w obliczeniach równoległych. Krzysztof Banaś Obliczenia wysokiej wydajności 1
 Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Wydajność komunikacji grupowej w obliczeniach równoległych Krzysztof Banaś Obliczenia wysokiej wydajności 1 Sieci połączeń Topologie sieci statycznych: Sieć w pełni połączona Gwiazda Kraty: 1D, 2D, 3D
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności i łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (28.03.2011) Rok akademicki 2010/2011, Wykład
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Analiza ilościowa w przetwarzaniu równoległym
 Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Komputery i Systemy Równoległe Jędrzej Ułasiewicz 1 Analiza ilościowa w przetwarzaniu równoległym 10. Analiza ilościowa w przetwarzaniu równoległym...2 10.1 Kryteria efektywności przetwarzania równoległego...2
Skalowalność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Skalowalność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Skalowalność Przy rozważaniu wydajności przetwarzania (obliczeń, komunikacji itp.) często pojawia się pojęcie skalowalności
Wydajność obliczeń równoległych. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Wydajność obliczeń równoległych Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność obliczeń równoległych Podobnie jak w obliczeniach sekwencyjnych, gdzie celem optymalizacji wydajności było maksymalne
Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system.
 Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Wstęp Zapoznanie z technikami i narzędziami programistycznymi służącymi do tworzenia programów współbieżnych i obsługi współbieżności przez system. Przedstawienie architektur sprzętu wykorzystywanych do
Algorytmy i Struktury Danych
 POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
POLITECHNIKA KRAKOWSKA - WIEiK KATEDRA AUTOMATYKI i TECHNIK INFORMACYJNYCH Algorytmy i Struktury Danych www.pk.edu.pl/~zk/aisd_hp.html Wykładowca: dr inż. Zbigniew Kokosiński zk@pk.edu.pl Wykład 12: Wstęp
Architektura Komputerów
 1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
1/3 Architektura Komputerów dr inż. Robert Jacek Tomczak Uniwersytet Przyrodniczy w Poznaniu Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne dla programisty, atrybuty
Wprowadzenie. Klastry komputerowe. Superkomputery. informatyka +
 Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Klastry komputerowe Superkomputery Wprowadzenie Filozofia przetwarzania równoległego polega na podziale programu na fragmenty, z których każdy
Klasyfikacja systemów komputerowych. Architektura von Neumanna. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2010/2011
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Część teoretyczna Informacje i wstępne wymagania Cel przedmiotu i zakres materiału Zasady wydajnego
dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia i ich zastosowań w przemyśle" POKL
 Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Architektura komputerów wprowadzenie materiał do wykładu 3/3 dr inż. Rafał Klaus Zajęcia finansowane z projektu "Rozwój i doskonalenie kształcenia na Politechnice Poznańskiej w zakresie technologii informatycznych
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Architektura von Neumanna
 Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
Architektura von Neumanna Klasyfikacja systemów komputerowych (Flynna) SISD - Single Instruction Single Data SIMD - Single Instruction Multiple Data MISD - Multiple Instruction Single Data MIMD - Multiple
3.Przeglądarchitektur
 Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Materiały do wykładu 3.Przeglądarchitektur Marcin Peczarski Instytut Informatyki Uniwersytet Warszawski 17 marca 2014 Architektura a organizacja komputera 3.1 Architektura komputera: atrybuty widzialne
Budowa komputera. Magistrala. Procesor Pamięć Układy I/O
 Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Budowa komputera Magistrala Procesor Pamięć Układy I/O 1 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący przetwarzanie informacji Zmiana stanu tranzystorów wewnątrz
Algorytmy dla maszyny PRAM
 Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Instytut Informatyki 21 listopada 2015 PRAM Podstawowym modelem służącym do badań algorytmów równoległych jest maszyna typu PRAM. Jej głównymi składnikami są globalna pamięć oraz zbiór procesorów. Do rozważań
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Architektura Systemów Komputerowych. Rozwój architektury komputerów klasy PC
 Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
Architektura Systemów Komputerowych Rozwój architektury komputerów klasy PC 1 1978: Intel 8086 29tys. tranzystorów, 16-bitowy, współpracował z koprocesorem 8087, posiadał 16-bitową szynę danych (lub ośmiobitową
High Performance Computers in Cyfronet. Andrzej Oziębło Zakopane, marzec 2009
 High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
High Performance Computers in Cyfronet Andrzej Oziębło Zakopane, marzec 2009 Plan Podział komputerów dużej mocy Podstawowe informacje użytkowe Opis poszczególnych komputerów Systemy składowania danych
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne.
 Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Wykład 8 Systemy komputerowe ze współdzieloną pamięcią operacyjną, struktury i cechy funkcjonalne. Części wykładu: 1. Ogólny podział struktur systemów równoległych 2. Rodzaje systemów komputerowych z pamięcią
Analiza efektywności przetwarzania współbieżnego. Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak Grudzień 2015 Źródła kosztów przetwarzania współbieżnego interakcje między procesami
Obliczenia Wysokiej Wydajności
 Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Obliczenia wysokiej wydajności 1 Wydajność obliczeń Wydajność jest (obok poprawności, niezawodności, bezpieczeństwa, ergonomiczności oraz łatwości stosowania i pielęgnacji) jedną z najważniejszych charakterystyk
Projektowanie algorytmów równoległych. Zbigniew Koza Wrocław 2012
 Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
Projektowanie algorytmów równoległych Zbigniew Koza Wrocław 2012 Spis reści Zadniowo-kanałowy (task-channel) model algorytmów równoległych Projektowanie algorytmów równoległych metodą PACM Task-channel
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011 Wykład nr 6 (06.05.2011) Rok akademicki 2010/2011, Wykład
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami
 Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Równoległy algorytm wyznaczania bloków dla cyklicznego problemu przepływowego z przezbrojeniami dr inż. Mariusz Uchroński Wrocławskie Centrum Sieciowo-Superkomputerowe Agenda Cykliczny problem przepływowy
Komputery równoległe. Zbigniew Koza. Wrocław, 2012
 Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Komputery równoległe Zbigniew Koza Wrocław, 2012 Po co komputery równoległe? Przyspieszanie obliczeń np. diagnostyka medyczna; aplikacje czasu rzeczywistego Przetwarzanie większej liczby danych Przykład:
Programowanie współbieżne Wykład 2. Iwona Kochańska
 Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Programowanie współbieżne Wykład 2 Iwona Kochańska Miary skalowalności algorytmu równoległego Przyspieszenie Stały rozmiar danych N T(1) - czas obliczeń dla najlepszego algorytmu sekwencyjnego T(p) - czas
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona
 Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Wykład 2 Podstawowe pojęcia systemów równoległych, modele równoległości, wydajność obliczeniowa, prawo Amdahla/Gustafsona Spis treści: 1. Równoległe systemy komputerowe a rozproszone systemy komputerowe,
Programowanie współbieżne i rozproszone
 Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
Programowanie współbieżne i rozproszone WYKŁAD 1 dr inż. Literatura ogólna Ben-Ari, M.: Podstawy programowania współbieżnego i rozproszonego. Wydawnictwa Naukowo-Techniczne, Warszawa, 2009. Czech, Z.J:
PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI
 ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
ZESZYTY NAUKOWE 105-114 Dariusz CHAŁADYNIAK 1 PODSTAWY PRZETWARZANIA RÓWNOLEGŁEGO INFORMACJI Streszczenie W artykule poruszono wybrane podstawowe zagadnienia związane z przetwarzaniem równoległym. Przedstawiono
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
Tworzenie programów równoległych cd. Krzysztof Banaś Obliczenia równoległe 1 Metodologia programowania równoległego Przykłady podziałów zadania na podzadania: Podział ze względu na funkcje (functional
dr inż. Jarosław Forenc
 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 2018/2019 Wykład nr 10 (17.05.2019) Rok akademicki 2018/2019, Wykład
Procesory wielordzeniowe (multiprocessor on a chip) Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Krzysztof Banaś, Obliczenia wysokiej wydajności.") Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Procesory wielordzeniowe (multiprocessor on a chip) 1 Procesory wielordzeniowe 2 Procesory wielordzeniowe 3 Konsekwencje prawa Moore'a 4 Procesory wielordzeniowe 5 Intel Nehalem 6 Architektura Intel Nehalem
Architektury równoległe
 Architektury równoległe Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl Bartosz Borucki b.borucki@icm.edu.pl
Architektury równoległe Interdyscyplinarne Centrum Modelowania Matematycznego i Komputerowego Uniwersytet Warszawski http://www.icm.edu.pl Maciej Szpindler m.szpindler@icm.edu.pl Bartosz Borucki b.borucki@icm.edu.pl
Sprzęt komputerowy 2. Autor prezentacji: 1 prof. dr hab. Maria Hilczer
 Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
Sprzęt komputerowy 2 Autor prezentacji: 1 prof. dr hab. Maria Hilczer Budowa komputera Magistrala Procesor Pamięć Układy I/O 2 Procesor to CPU (Central Processing Unit) centralny układ elektroniczny realizujący
O superkomputerach. Marek Grabowski
 O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
O superkomputerach Marek Grabowski Superkomputery dziś Klastry obliczeniowe Szafy (od zawsze) Bo komputery są duże Półki i blade'y (od pewnego czasu) Większe upakowanie mocy obliczeniowej na m^2 Łatwiejsze
System mikroprocesorowy i peryferia. Dariusz Chaberski
 System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
System mikroprocesorowy i peryferia Dariusz Chaberski System mikroprocesorowy mikroprocesor pamięć kontroler przerwań układy wejścia wyjścia kontroler DMA 2 Pamięć rodzaje (podział ze względu na sposób
Analiza efektywności przetwarzania współbieżnego
 Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Analiza efektywności przetwarzania współbieżnego Wykład: Przetwarzanie Równoległe Politechnika Poznańska Rafał Walkowiak 1/4/2013 Analiza efektywności 1 Źródła kosztów przetwarzania współbieżnego interakcje
Systemy wbudowane. Uproszczone metody kosyntezy. Wykład 11: Metody kosyntezy systemów wbudowanych
 Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Systemy wbudowane Wykład 11: Metody kosyntezy systemów wbudowanych Uproszczone metody kosyntezy Założenia: Jeden procesor o znanych parametrach Znane parametry akceleratora sprzętowego Vulcan Początkowo
Numeryczna algebra liniowa
 Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Numeryczna algebra liniowa Numeryczna algebra liniowa obejmuje szereg algorytmów dotyczących wektorów i macierzy, takich jak podstawowe operacje na wektorach i macierzach, a także rozwiązywanie układów
Architektura komputerów
 Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Architektura komputerów Wykład 7 Jan Kazimirski 1 Pamięć podręczna 2 Pamięć komputera - charakterystyka Położenie Procesor rejestry, pamięć podręczna Pamięć wewnętrzna pamięć podręczna, główna Pamięć zewnętrzna
Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7
 Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7 dr Jacek Niemiec Instytut Fizyki Jądrowej PAN, Kraków Jacek.Niemiec@ifj.edu.pl www.oa.uj.edu.pl/j.niemiec/symulacjenumeryczne
Symulacje kinetyczne Par2cle In Cell w astrofizyce wysokich energii Wykład 7 dr Jacek Niemiec Instytut Fizyki Jądrowej PAN, Kraków Jacek.Niemiec@ifj.edu.pl www.oa.uj.edu.pl/j.niemiec/symulacjenumeryczne
Wprowadzenie do architektury komputerów. Taksonomie architektur Podstawowe typy architektur komputerowych
 Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
Wprowadzenie do architektury komputerów Taksonomie architektur Podstawowe typy architektur komputerowych Taksonomie Służą do klasyfikacji architektur komputerowych podział na kategorie określenie własności
OBLICZENIA RÓWNOLEGŁE I ROZPROSZONE
 OBLICZENIA RÓWNOLEGŁE I ROZPROSZONE emat 2: Projektowanie algorytmów równoległych - wprowadzenie Prowadzący: e-mail: http:// dr hab. inż. Zbigniew ARAPAA, prof. WA pok.225, tel.: 261-83-95-04 Zbigniew.arapata@wat.edu.pl
OBLICZENIA RÓWNOLEGŁE I ROZPROSZONE emat 2: Projektowanie algorytmów równoległych - wprowadzenie Prowadzący: e-mail: http:// dr hab. inż. Zbigniew ARAPAA, prof. WA pok.225, tel.: 261-83-95-04 Zbigniew.arapata@wat.edu.pl
Systemy operacyjne i sieci komputerowe Szymon Wilk Superkomputery 1
 i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
i sieci komputerowe Szymon Wilk Superkomputery 1 1. Superkomputery to komputery o bardzo dużej mocy obliczeniowej. Przeznaczone są do symulacji zjawisk fizycznych prowadzonych głównie w instytucjach badawczych:
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Programowanie Równoległe i Rozproszone
 Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
Programowanie Równoległe i Rozproszone Lucjan Stapp Wydział Matematyki i Nauk Informacyjnych Politechnika Warszawska (l.stapp@mini.pw.edu.pl) 1/69 PRiR Wykład 1 Ćwiczenia Zasady zaliczania Aktywność i
PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK
 1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
1 PROGRAMOWANIE WSPÓŁCZESNYCH ARCHITEKTUR KOMPUTEROWYCH DR INŻ. KRZYSZTOF ROJEK POLITECHNIKA CZĘSTOCHOWSKA 2 Trendy rozwoju współczesnych procesorów Budowa procesora CPU na przykładzie Intel Kaby Lake
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle. Krzysztof Banaś, Obliczenia wysokiej wydajności.
 Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Wydajność systemów a organizacja pamięci, czyli dlaczego jednak nie jest aż tak źle Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Organizacja pamięci Organizacja pamięci współczesnych systemów komputerowych
Klasyfikacja systemów komputerowych. Architektura harwardzka Zmodyfikowana architektura harwardzka. dr inż. Jarosław Forenc
 Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
Rok akademicki 2010/2011, Wykład nr 6 2/56 Plan wykładu nr 6 Informatyka 1 Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia niestacjonarne I stopnia Rok akademicki 2010/2011
Dr inż. hab. Siergiej Fialko, IF-PK,
 Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Dr inż. hab. Siergiej Fialko, IF-PK, http://torus.uck.pk.edu.pl/~fialko sfialko@riad.pk.edu.pl 1 Osobliwości przedmiotu W podanym kursie główna uwaga będzie przydzielona osobliwościom symulacji komputerowych
Architektura komputerów
 Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Architektura komputerów Wykład 12 Jan Kazimirski 1 Magistrale systemowe 2 Magistrale Magistrala medium łączące dwa lub więcej urządzeń Sygnał przesyłany magistralą może być odbierany przez wiele urządzeń
Budowa komputera Komputer computer computare
 11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
11. Budowa komputera Komputer (z ang. computer od łac. computare obliczać) urządzenie elektroniczne służące do przetwarzania wszelkich informacji, które da się zapisać w formie ciągu cyfr albo sygnału
10/14/2013 Przetwarzanie równoległe - wstęp 1. Zakres przedmiotu
 Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Literatura 1. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 2. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010. 3. Designing
Wydajność systemów a organizacja pamięci. Krzysztof Banaś, Obliczenia wysokiej wydajności. 1
 Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Wydajność systemów a organizacja pamięci Krzysztof Banaś, Obliczenia wysokiej wydajności. 1 Motywacja - memory wall Krzysztof Banaś, Obliczenia wysokiej wydajności. 2 Organizacja pamięci Organizacja pamięci:
Sprzęt czyli architektury systemów równoległych
 Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Sprzęt czyli architektury systemów równoległych 1 Architektura von Neumanna Program i dane w pamięci komputera Pojedynczy procesor: pobiera rozkaz z pamięci rozkodowuje rozkaz i znajduje adresy argumentów
Literatura. 11/16/2016 Przetwarzanie równoległe - wstęp 1
 Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Literatura 1. Wprowadzenie do obliczeń równoległych, Zbigniew Czech, Wydawnictwo Naukowe PWN, 2010, 2013 2. Introduction to Parallel Computing; Grama, Gupta, Karypis, Kumar; Addison Wesley 2003 3. Designing
Tworzenie programów równoległych. Krzysztof Banaś Obliczenia równoległe 1
 Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Tworzenie programów równoległych Krzysztof Banaś Obliczenia równoległe 1 Tworzenie programów równoległych W procesie tworzenia programów równoległych istnieją dwa kroki o zasadniczym znaczeniu: wykrycie
Operacje grupowego przesyłania komunikatów
 Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Operacje grupowego przesyłania komunikatów 1 Operacje grupowego przesyłania komunikatów Operacje, w ramach których ten sam komunikat lub zbiór komunikatów przesyłany jest pomiędzy więcej niż dwoma procesami
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM
 Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Algorytmy Równoległe i Rozproszone Część IV - Model PRAM Łukasz Kuszner pokój 209, WETI http://www.sphere.pl/ kuszner/ kuszner@sphere.pl Oficjalna strona wykładu http://www.sphere.pl/ kuszner/arir/ 2005/06
Systemy rozproszone. Państwowa Wyższa Szkoła Zawodowa w Chełmie. ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej w Lublinie
 Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone Rafał Ogrodowczyk *, Krzysztof Murawski **,*, Bartłomiej Bielecki * * Katedra Informatyki Państwowa Wyższa Szkoła Zawodowa w Chełmie ** Instytut Fizyki Uniwersytet Marii Curie-Skłodowskiej
Systemy rozproszone. na użytkownikach systemu rozproszonego wrażenie pojedynczego i zintegrowanego systemu.
 Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy rozproszone Wg Wikipedii: System rozproszony to zbiór niezależnych urządzeń (komputerów) połączonych w jedną, spójną logicznie całość. Połączenie najczęściej realizowane jest przez sieć komputerową..
Systemy operacyjne. Systemy operacyjne. Systemy operacyjne. Zadania systemu operacyjnego. Abstrakcyjne składniki systemu. System komputerowy
 Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
Systemy operacyjne Systemy operacyjne Dr inż. Ignacy Pardyka Literatura Siberschatz A. i inn. Podstawy systemów operacyjnych, WNT, Warszawa Skorupski A. Podstawy budowy i działania komputerów, WKiŁ, Warszawa
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,
 procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC,") RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
RDZEŃ x86 x86 rodzina architektur (modeli programowych) procesorów firmy Intel, należących do kategorii CISC, stosowana w komputerach PC, zapoczątkowana przez i wstecznie zgodna z 16-bitowym procesorem
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Definicja systemu operacyjnego (1) Miejsce,
Wprowadzenie. Dariusz Wawrzyniak. Miejsce, rola i zadania systemu operacyjnego w oprogramowaniu komputera
 Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego (2) Miejsce, rola i zadania systemu operacyjnego
Budowa Mikrokomputera
 Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Budowa Mikrokomputera Wykład z Podstaw Informatyki dla I roku BO Piotr Mika Podstawowe elementy komputera Procesor Pamięć Magistrala (2/16) Płyta główna (ang. mainboard, motherboard) płyta drukowana komputera,
Systemy operacyjne. Wprowadzenie. Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak
 Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Wprowadzenie Wykład prowadzą: Jerzy Brzeziński Dariusz Wawrzyniak Plan wykładu Definicja, miejsce, rola i zadania systemu operacyjnego Klasyfikacja systemów operacyjnych Zasada działania systemu operacyjnego
Programowanie Rozproszone i Równoległe
 Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Programowanie Rozproszone i Równoległe OpenMP (www.openmp.org) API do pisania wielowątkowych aplikacji Zestaw dyrektyw kompilatora oraz procedur bibliotecznych dla programistów Ułatwia pisanie programów
Wydajność obliczeń a architektura procesorów. Krzysztof Banaś Obliczenia Wysokiej Wydajności 1
 Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wydajność obliczeń a architektura procesorów Krzysztof Banaś Obliczenia Wysokiej Wydajności 1 Wydajność komputerów Modele wydajności-> szacowanie czasu wykonania zadania Wydajność szybkość realizacji wyznaczonych
Wykład 2. Temat: (Nie)zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:
zawodność sprzętu komputerowego. Politechnika Gdańska, Inżynieria Biomedyczna. Przedmiot:") Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
Wykład 2 Przedmiot: Zabezpieczenie systemów i usług sieciowych Temat: (Nie)zawodność sprzętu komputerowego 1 Niezawodność w świecie komputerów Przedmiot: Zabezpieczenie systemów i usług sieciowych W przypadku
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego
 Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
Składowanie, archiwizacja i obliczenia modelowe dla monitorowania środowiska Morza Bałtyckiego Rafał Tylman 1, Bogusław Śmiech 1, Marcin Wichorowski 2, Jacek Wyrwiński 2 1 CI TASK Politechnika Gdańska,
Informatyka 1. Wykład nr 5 ( ) Politechnika Białostocka. - Wydział Elektryczny. dr inŝ. Jarosław Forenc
 Politechnika Białostocka. - Wydział Elektryczny. dr inŝ. Jarosław Forenc") Informatyka Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 28/29 Wykład nr 5 (6.5.29) Rok akademicki 28/29, Wykład nr 5 2/43 Plan
Informatyka Politechnika Białostocka - Wydział Elektryczny Elektrotechnika, semestr II, studia stacjonarne I stopnia Rok akademicki 28/29 Wykład nr 5 (6.5.29) Rok akademicki 28/29, Wykład nr 5 2/43 Plan
Systemy wieloprocesorowe i wielokomputerowe
 Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Systemy wieloprocesorowe i wielokomputerowe Taksonomia Flynna Uwzględnia następujące czynniki: Liczbę strumieni instrukcji Liczbę strumieni danych Klasyfikacja bierze się pod uwagę: Jednostkę przetwarzającą
Cyfronet w CTA. Andrzej Oziębło DKDM
 Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
Cyfronet w CTA Andrzej Oziębło DKDM ACK CYFRONET AGH Akademickie Centrum Komputerowe CYFRONET Akademii Górniczo-Hutniczej im. Stanisława Staszica w Krakowie ul. Nawojki 11 30-950 Kraków 61 tel. centrali:
LEKCJA TEMAT: Zasada działania komputera.
 LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
LEKCJA TEMAT: Zasada działania komputera. 1. Ogólna budowa komputera Rys. Ogólna budowa komputera. 2. Komputer składa się z czterech głównych składników: procesor (jednostka centralna, CPU) steruje działaniem
PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016
 Rafał Walkowiak Wersja: jesień 2016") PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora
PR sprzęt (systemy z pamięcią współdzieloną) Rafał Walkowiak Wersja: jesień 2016 Wewnętrzna współbieżność przetwarzania procesora Uwarunkowania: 1. Dotychczas imponujący wzrost prędkości taktowania procesora