Sekwencjonowanie RNA po kolei
|
|
|
- Ryszard Sosnowski
- 4 lat temu
- Przeglądów:
Transkrypt




1 ALEKSANDRA ŚWIERCZ

2 Sekwencjonowanie RNA po kolei RNA-seq Module, 2013, A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2
3 Różnice między eksperymentem mikromacierzowym a RNA-seq Przy użyciu mikromacierzy można badać poziom ekspresji znanych genów, natomiast wykorzystując RNA-seq można także wykryć nowe izoformy genów A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 3
4 Mikromacierze vs RNA seq Porównanie eksperymentów mikromacierzowych i RNA-seq pokazało, że: Jest duża zgodność w wynikach pomiędzy platformami, w szczególności pomiędzy wykrywaniem różnicowej ekspresji genów Platforma sekwencjonowania jest bardziej wrażliwa na wykrycie zmian, jest bardziej odporna na tło i różnice w powtórzeniach technicznych Zaletą RNA-seq jest porównanie poziomu ekspresji różnych genów między sobą (dla mikromacierzy można porównać ten sam gen między różnymi warunkami) Ograniczeniem RNA-seq jest natomiast wykrzywienie GC oraz niejednoznaczność w mapowaniu Większa jest moc statystyczna w wykrywaniu zmian, gdy odczyty występują w większej liczności A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 4
5 Dlaczego RNA-seq zamiast DNA-seq? Badanie funkcjonalności Genom jest taki sam, ale warunki eksperymentalne mogą mieć wpływ na różną ekspresję genów (np. traktowanie komórek lekarstwem, vs niczym nietraktowane, lub mysz dzika vs zmieniona genetycznie) Niektóre zmiany mogą być widoczne dopiero na poziome RNA Alternatywne izoformy Fuzja transkryptów (trans-splicing, transcription-induced chimerism) Edytowanie RNA - zmiana informacji w transkrypcie RNA przez reakcję chemiczną powodującą zmianę jednej zasady azotowej w inną (C->U, A->I, Inozyna interpretowana jako G). Przewidywanie sekwencji transkryptów z sekwencji genomu jest trudne: Alternatywny transkrypt Edytowanie RNA A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 5
6 Dlaczego RNA-seq zamiast DNA-seq? Interpretacja, czy poszczególne mutacje mają wpływ na sekwencje białkową Mutacje regulujące które wpływają na to czy izoformy mrna ulegają ekspresji i jak dużej Czy mutacje wpływają na promotory, eksonowe/intronowe motywy, miejsca splicingowe? Wpływ na białka kodujące mutacje somatyczne (często heterozygotyczne) Jeśli gen nie ulega ekspresji, mutacja w takim genie będzie mniej interesująca Jeśli gen ulega ekspresji tylko z alleli dzikiego typu, może to sugerować na utratę funkcjonalności (haploinsufficiency) Jeśli allel mutanta ulega ekspresji, może to oznaczać kandydata na target dla leku A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 6
7 RNA-seq razem z Ion Torent A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 7
8 Alamancos GP, Agirre E, Eyras E. (2014) Methods to study splicing from high-throughput RNA sequencing data. Methods Mol Biol 1126: A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 8
9 Trzy podejścia do mapowania RNA-seq A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 9
10 Trudności przy mapowaniu RNA Geny w genomach eukariotycznych zawierają introny, a sewkencje mrna są już ich pozbawione. Programy mapujące odczyty z eksperymentów RNA-seq muszą być w stanie dopasować sekwencje z przerwami Introny w genomach ssaków mają długość od 50 bp - 100,000 bp. Średnia długość transkryptu mrna u człowieka to 2227 bp Średnia długość eksonu to 235 bp Średnio w jednym genie jest 9 eksonów Około 20% odczytów które mapują się na łączeniach eksonów mapują się tylko na < 10 nukleotydach na drugim eksonie A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 10
11 Trudności przy mapowaniu RNA (2) Część sekwencji pochodzi z przetworzonych pseudogenów, z których niektóre lub wszystkie introny zostały usunięte (może to spowodować nieprawidłowe mapowanie odczytów) Genom ludzki posiada 14tys pseudogenów Pseudogeny mają sekwencję bardzo podobną do funkcjonalnych genów zawierających introny. W większości przypadków nie ulegają transkrypcji Problem w mapowaniu wynika stąd że odczyty, które mapują się na łączeniu eksonów, będą się mapowały w całości dokładnie lub z niewielkim błędem do pseudogenów, które nie zawierają intronów. Jeśli metoda mapująca mapuje najpierw odczyty w całości, a resztę próbuje dopasować z podziałem na eksony, to pominie odczyty które w całości zmapowane zostały do pseudogenów A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 11

12 D. Kim, G. Pertea, C. Trapnell, H. Pimentel, R. Kelley, S.L. Salzberg TopHat2: accurate alignment of transcriptomes in the presence of insertions, deletions and gene fusions Genome Biology 2013, 14:R36 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 12
13 Trudności przy mapowaniu RNA (3) Transkrypt badanego genomu może się różnić od genomu referencyjnego Różnice mogą być małe, typu SNP, insercje, delecje, niedopasowania Zmiany mogą być większe, rearanżacje chromosomowe przeniesienia dłuższych fragmentów, wiele kopii Małe zmiany nie wpływają znacznie na mapowanie trzeba dopuścić możliwość błędów w niedopasowaniu (może to niestety spowodować wiele miejsc mapowania) Większe zmiany: duże usunięcia, inwersje w obrębie tego samego chromosomu, oraz translokacje między-chromosomowe powodują że trudno znaleźć kolejne eksony genu fragment chrom. 2 fragment chrom. 5 W genomie badanym w stosunku do genomu referencyjnego część genu uległa translokacji oraz inwersji A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 13

14 TopHat2 pipeline Znane sygnały podziału eksonów GT-AG, GC-AG, AT-AC A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 14

15 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 15
16 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 16
17 Jak wyrażana jest ekspresja genu? RPKM Reads Per Kilobase of transcript per Million mapped reads FPKM Fragments Per Kilobase of transcript per Million mapped reads W RNA-Seq poziom ekspresji transkryptu jest proporcjonalny do liczby fragmentów cdna z którego pochodzi. Chociaż: Liczba fragmentów jest przechylona w kierunku większych genów Całkowita liczba fragmentów jest uzależniona od głębokości sekwencjonowania RPKM (FPKM) = (10 9 * C) / (N * L) C liczba zmapowanych odczytów (fragmentów) do genu/transkryptu/eksonu N całkowita liczba zmapowanych odczytów (fragmentów) w bibliotece L liczba nukleotydów w genie/transkrypcie/eksonie A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 17
18 Alternatywne do FPKM/RPKM Raw counts liczba odczytów/fragmentów przypadająca na gen/transkrypt Htseq-count zlicza liczbę odczytów przypadających na gen/ekson A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 18

19 Różne strategie przypisania odczytu do eksonu htseq-count A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 19
20 Alternatywny splicing W procesie splicingu łączone są ze sobą różne eksony z pre-mrna na różne sposoby, czasami z pominięciem niektórych eksonów, lub z zachowaniem niektórych intronów Jeśli warianty splicingowe dotyczą sekwencji kodującej, powstałe białka różnią się sekwencją aminokwasową, co może powodować np. zróżnicowanie funkcji. Jeśli warianty splicingowe dotyczą obszarów niekodujących może to wpływać np. na wzmocnienie translacji lub stabilność mrna. Rekordem w liczbie różnych wariantów splicingowych jest gen Dscam D. melanogaster, który ma ponad 38 tys. różnych wariantów (więcej niż liczba wszystkich genów) * * C. Ghigna, C. Valacca, G. Biamonti Alternative Splicing and Tumor Progression, Curr Genomics. Dec 2008; 9(8): A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 20
21 Różne warianty splicingowe A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 21
22 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 22
23 Różne warianty splicingowe Mutually exclusive exons A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 23

24 Jak Cufflinks radzi sobie z wykrywaniem alternatywnego splicingu? C. Trapnell, BA Williams, G Pertea, A Mortazavi, G Kwan, MJ van Baren, SL Salzberg, BJ Wold, L Pachter, Transcript assembly and quantification by RNA-Seq reveals unannotated transcripts and isoform switching during cell differentiation, Nature Biotechnology 28(5) 2010, p C Trapnell, DG Hendrickson, M Sauvageau, L Goff, JL Rinn, L Pachter, Differential analysis of gene regulation at transcript resolution with RNA-seq, Nature Biotechnology 31(1), 2013, p A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 24

25 Mapowanie odczytów sparowanych za pomocą TopHat-a. Każda para odczytów traktowana jest jako jedno dopasowanie. Odczyty mogą być zmapowane w całości, lub z podziałem pomiędzy eksonami A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 25
, są wierzchołkami w grafie. Wierzchołki są łączone pomiędzy parami kompatybilnych fragmentów.")
26 Cufflinks W pierwszym kroku wyszukiwane są pary niekompatybilnych fragmentów, które muszą pochodzić z innych izoform mrna (zaznaczone na żółto, niebiesko i czerwono). Fragmenty (sparowane odczyty), są wierzchołkami w grafie. Wierzchołki są łączone pomiędzy parami kompatybilnych fragmentów. Szarym kolorem zaznaczone są fragmenty, które mogą pochodzić z dowolnych transkryptów. Ścieżki w grafie odpowiadają wzajemnie wykluczającym się fragmentom, które mogą być połączone w izoformy. Graf może być pokryty minimalnie przez 3 ścieżki oznaczone 3 kolorami, co w efekcie daje 3 odrębne izoformy A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 26

27 Cufflinks Fragmenty są znakowane (tutaj kolorem) w zależności od tego z której izoformy pochodzą. Fioletowy fragment może pochodzić z niebieskiego lub czerwonego. Szare fragmenty mogą pochodzić z dowolnej izoformy. Cufflinks estymuje liczność transkryptu używając modelu statystycznego, w którym prawdopodobieństwo obserwowania każdego fragmentu jest liniową funkcją liczności transkryptów, z których mogą pochodzić. Ponieważ długość sekwencjonowanych fragmentów nie jest znana (sparowane odczyty są końcami fragmentów), a przypisanie fragmentu do różnych izoform powoduje że różna jest jego długość Cufflinks wyznacza rozkład długości odczytów. Rozkład ten jest następnie wykorzystywany do przypisania fragmentów do różnych izoform (fioletowy fragment byłby zbyt długi, gdyby został przypisany do czerwonego transkryptu). W ostatnim kroku program maksymalizuje prawdopodobieństwo liczności każdej z izoform i przydziela im odpowiednio numeryczne wartości (γ 1, γ 2, γ 3 ) A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 27

28 Cufflinks W powyższym przykładzie analizowany był tylko fragment jednego genu. Wszystkie fragmenty genu należy potem skleić całość. Podobnie analizowane są kolejne geny A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 28

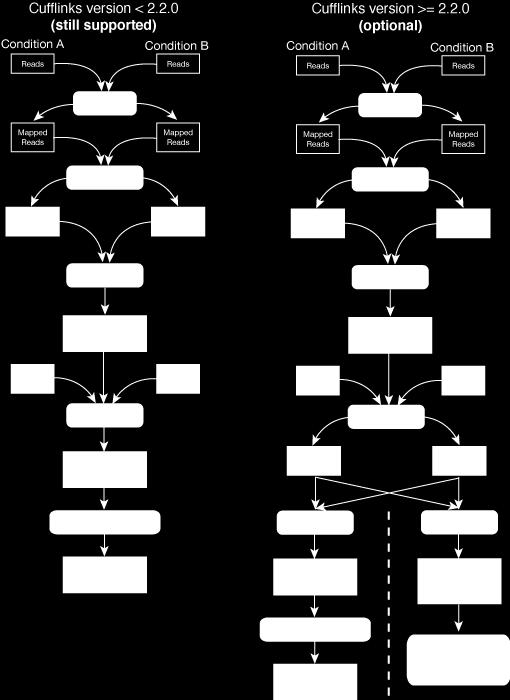
29 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 29
30 Do czego jest potrzebny cuffmerge? Pozwala na łączenie wyników z działania cufflinks a dla różnych próbek Jest to potrzebne ponieważ dla każdej próbki cufflinks może wykryć inną liczbę oraz inną strukturę transkryptów Odfiltrowywane są transkrypty, które są najprawdopodobniej artefaktami (transfrags) Opcjonalnie może także podać plik GTF w odniesieniu do genomu referencyjnego, w którym połączone będą dotychczas znane oraz nowe izoformy wraz z maksymalizacją jakości zasemblowanych transkryptów A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 30
 Methods to study splicing from high-throughput RNA sequencing data.")
31 Alamancos GP, Agirre E, Eyras E. (2014) Methods to study splicing from high-throughput RNA sequencing data. Methods Mol Biol 1126: A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 31
32 Normalizacja Celem normalizacji jest usunięcie systematycznych błędów (czyli wynikających z niedoskonałości technologii) przy zachowaniu informacji biologicznej i wygenerowanie wartości, które będą mogły być porównane pomiędzy eksperymentami, w szczególności jeśli były wygenerowane w innym czasie, miejscu, na innym sekwenatorze.

33 Różnicowa ekspresja genów
34 Szukamy odpowiedzi na pytania Przeprowadzony został eksperyment (2 lub kilka różnych warunków, kilka powtórzeń każdy) Zbadaliśmy, że eksperymenty są dobrej jakości Histogram, imageplot, Usunięte zostały błędy systematyczne Korekcja tła, normalizacja plotma, boxplot Które geny (na mikromacierzy/ wykryte przez RNA seq) uległy zróżnicowanej ekspresji? Czy wystarczy posortować po log ratio?
35 3 różne zbiory danych zbiór A Pobrano próbki od 20 pacjentów chorych na raka piersi przed i po 16- tygodniowym leczeniu chemioterapią. Zbadano je przy użyciu mikromacierzy. Chcemy zidentyfikować geny, które uległy podwyższonej i obniżonej ekspresji związanej z leczeniem Data are from the paper of Perou et al. (2000) and are available from the Stanford Microarray Database.
36 W każdym z zestawów szukamy genów o zróżnicowanej ekspresji W zestawie A mamy dane sparowane. Mamy 2 pomiary dla każdego pacjenta: przed i po chemii. Dane są ze sobą powiązane to co nas interesuje to różnica pomiędzy dwoma pomiarami (log ratio), aby wykryć geny z podwyższoną i obniżoną ekspresją (up- downregulated) Pomiary dla każdego pacjenta są odjęte. Sprawdzamy czy mediana lub średnia są różne od 0
37 3 różne zbiory danych zbiór B Pobrany został szpik kostny od 27 pacjentów cierpiących na białaczkę ALL (acute lymphoblastic leukemia) i od 11 pacjetów cierpiących na białaczkę typu AML (acute myleoid leukemia). Zanalizowano próbki używając mikromacierzy Affymetrixowych Chcemy zidentyfikować geny, które uległy podwyższonej i obniżonej ekspresji w ALL w porównaniu do AML Data are from the paper of Golub et al. (1999) and are available from the Stanford Microarray Database
38 W zestawie B mamy dane niesparowane. Mamy 2 grupy pacjentów i chcemy zaobserwować jaki jest związek pomiędzy pacjentami w jednej grupie a pacjentami w drugiej grupie. Mamy pomiary dla każdego pacjenta z obu grup. Sprawdzamy czy mediana lub średnia dla obu grup są różne.
39 3 różne zbiory danych zbiór C Badano 4 typy nowotworów złośliwych drobnookrągłoniebiesko-komórkowych (small round blue cell tumors): Neuroblastoma (nerwiak płodowy) NB, non-hodgkin lymphoma (chłonniak nieziarniczny) NHL, rhabdomyosarcoma (mięśniakomięsak prążkowanokomórkowy) RMS, Ewing tumors (mięsak Ewinga) EWS 63 próbki z tych nowotworów (12, 8, 20, 23 z każdej z grup) Chcemy zidentyfikować geny, które uległy zróżnicowanej ekspresji w jednej z tych 4 grup The data are from the paper of Khan et al. (2001) and are available from the Stanford Microarray Database.
40 Dane sparowane (zestaw A) i niesparowane (zestaw B) wymagają odmiennej analizy (sparowany i niesparowany test istotności t) Zestaw danych C składa się z 4 grup i wymaga bardziej skomplikowanej analizy, jak np. analizy wariancji (ANOVA)
 Wybieramy reprezentację kilku (dziesięciu) osobników Uogólniamy wyniki na całą populację")
41 Cała populacja vs wybrane osobniki Nie możemy zbadać całej populacji (np. chorych na raka) Wybieramy reprezentację kilku (dziesięciu) osobników Uogólniamy wyniki na całą populację (np. pacjentów chorych na raka)
42 Przeprowadzamy wnioskowanie statystyczne aby stwierdzić czy różnica w ekspresji genu pomiędzy jedną, a drugą grupą badanych osobników wynika z szumu w danych, z różnorodności pomiędzy osobnikami, czy rzeczywiście ze zróżnicowanej ekspresji Dlatego potrzebujemy POWTÓRZEŃ eksperymentów Grupa A Grupa B Im większa liczba powtórzeń, tym pewniejszy wynik
43 Hipoteza zerowa H 0 zakłada że gen nie uległ zróżnicowanej ekspresji H 1 różnica w ekspresji genu jest znacząca Zbiór A gen nie uległ zróżnicowanej ekspresji po chemii Zbiór B gen nie uległ zróżnicowanej ekspresji dla pacjentów z białaczką typu ALL i AML Jeśli hipoteza H 0 jest prawdziwa, to znaczy że nie została stwierdzona istotna statystycznie zmiana w ekspresji. Jeśli prawdopodobieństwo zaistnienia hipotezy H 0 jest poniżej pewnego progu, to możemy odrzucić hipotezę zerową, a przyjąć alternatywną.
44 Testy statystyczne Każdy test hipotezy zerowej tworzy model, który wyznacza prawdopodobieństwo obserwowanej statystyki, np. średnie zróżnicowanie ekspresji genów. To prawdopodobieństwo to p-value. Im mniejsze tym mniej prawdopodobne, że obserwowane dane pojawiły się przypadkowo i tym bardziej pewne wyniki. Zakładamy że zróżnicowana ekspresja obserwowana dla genów z niską wartością p- value z małym prawdopodobieństwem pojawiła się przypadkowo, a zatem jest skutkiem biologicznego efektu, który testujemy. p-value = 0.01 oznacza że jest 1% szansy na obserwowanie zróżnicowanej ekspresji przez przypadek
45 Testy parametryczne (dla danych z rozkładem normalnym) test t sparowany test t niesparowany Testy nieparametryczne Test Wilcoxona dla par obserwacji (Wilcoxon sign-rank test) Test Manna-Whitneya = test sumy rang Wilcoxona (Wilcoxon rank-sum test) Bootstrap pozwala ominąć założenie o rozkładzie normalnym danych (mulitifactor) Anova gdy mamy więcej niż 2 warunki (2 rodzaje próbek) do porównania ebayes gdy jest zbyt mało powtórzeń i nie można wyznaczyć wariancji model liniowy oraz złagodzona statystyka t
46 Jaki można popełnić błąd? Odrzucenie hipotezy zerowej Nie-odrzucenie hipotezy zerowej Hipoteza zerowa (H 0 ) jest prawdziwa False positive Błąd I typu True positive poprawne Hipoteza zerowa (H 0 ) jest fałszywa True negative poprawne False negative Błąd II typu Swoistość - specificity Moc testu - sensitivity
47 Błąd typu I (false positive) Odrzucona została hipoteza zerowa, która mówi że geny nie uległy zróżnicowanej ekspresji Uznajemy zatem że geny uległy zróżnicowanej ekspresji, chociaż faktycznie tak nie było Współczynnik błędów I typu jest nazywany rozmiarem testu i oznaczany przez α. Poziom istotności testu (significance) (1- α) swoistość (specificity)
48 Błąd II typu (false negative) Nie udało się odrzucić hipotezy zerowej, chociaż faktycznie nie była spełniona Nie udało nam się wykryć genów, które uległy zróżnicowanej ekspresji Oszacowanie prawdopodobieństwa popełnienia błędu II typu oznaczamy przez β. (1- β) nazywamy mocą testu lub czułością (sensitivity)
49 Wielokrotne testowanie - problem Z definicji p-value, każdy gen ma 1% szansy posiadania wartości p<0.01, czyli będzie znaczący przy poziomie istotności 1% Dla genów, oczekujemy że o 100 genów przejdzie próg p<0.01 o 10 genów przejdzie próg p<0.001 o 1 gen przejdzie próg p< Dla zestawu A mamy 9216 genów. Jeśli chemioterapia nie miałaby żadnego wpływu na zmianę ekspresji genów to i tak oczekiwalibyśmy, że dla 92 genów p<0.01 Czy gen naprawdę uległ zróżnicowanej ekspresji, czy jest to wynik błędu I typu (false positive)?
50 Kontrolowanie false positives Family-wise error rate (FWER) - Prawdopodobieństwo co najmniej jednego błędu I typu pomiędzy genami wybranymi jako znaczące FWER = Pr(FP > 0) Bonferroni False discovery rate (FDR) - Oczekiwana proporcja błędów I typu spośród odrzuconych FDR = E Q, gdzie Q = FP, jeśli R > 0 R 0, jeśli R = 0 Benjamini Hochberg R to suma False Positive i True Negative (czyli wszystkich z odrzuconą hipotezą)
51 Korekcja p-value Bonferroni Załóżmy że przeprowadziliśmy testowanie hipotezy dla każdego z n genów, wyznaczyliśmy: statystykę t i dla i-tego genu wartość p i dla i-tego genu Korekcja Bonferroni: p i = min(n pi, 1) Wybierając geny p i α kontrolujemy FWER na poziomie Pr(FP>0) α α- poziom istotności

52 Korekcja Bonferroni - wada Przy dużej liczbie genów korekcja może spowodować, że dla żadnego genu nie będziemy mogli odrzucić hipotezy zerowej
53 Korekcja Benjamini Hochberg Kontrolowanie FDR = E(FP/R) na poziomie α 1. Sortowanie wartości p: p r1 p r2 prn 2. Wyznaczenie: j' = max{j: p rj (j/n)* α} 3. Odrzucenie hipotezy H rj dla j=1,, j
54 Limma Liniowy model początkowo używany do analizy danych pochodzących z eksperymentów mikromacierzowych, następnie przystosowany do analizy danych RNA-seq Umożliwia na bardzo rozbudowany model porównania, poprzez zdefiniowanie design matrix oraz contrast matrix. > design <- model.matrix(~ 0+factor(c(1,1,1,2,2,3,3,3))) > colnames(design) <- c("group1", "group2", "group3") > contrast.matrix <- makecontrasts(group2-group1, group3- group2, group3-group1, levels=design) Umożliwia analizę trendów Control vs treated 1d 2d 4d 8d 12d Time points A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 55
55 DESeq Utworzony dla danych RNA-seq. Wymaga tabeli z wyznaczoną liczbą odczytów przypadających na dany gen. Normalizacja względem liczby wszystkich odczytów przypadających na próbkę > cds = estimatesizefactors( cds ) Estymacja wariancji wyznaczenie jak bardzo geny różnią się w ekspresji pomiędzy różnymi próbkami > cds = estimatedispersions( cds ) Wyznaczenie różnicowej ekspresji > res = nbinomtest( cds, "untreated", "treated" ) A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 56
56 Jak działa cuffdiff? Modelowanie zmienności w liczbie fragmentów dla każdego genu dla różnych powtórzeń estymacja wariacji Liczba fragmentów dla każdej izoformy jest estymowana dla każdego powtórzenia (jak poprzednio) razem z miarą niepewności pochodzącą od niejednoznacznie zmapowanych odczytów Transkrypty, z większą liczbą współdzielonych eksonów, a niewielką liczbą jednoznacznie przypisanych fragmentów będą miały mniejszą niepewność Algorytm łączy estymowaną niepewność razem ze zmiennością pomiędzy powtórzeniami poprzez model ujemnego rozkładu dwumianowego dla liczby fragmentów, w celu estymowania liczby niezgodności dla każdego transkryptu w każdej bibliotece Te estymowane niezgodności używane podczas testowania statystycznego pozwalają na znalezienie znaczących statystycznie genów i transkryptów, które uległy zróżnicowanej ekspresji A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 57

57 Różne programy porównanie wyników A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 58
58 Wizualizacja, np. cummerbund Automatycznie generuje zestaw wykresów do porównania ekspresji dla różnych (zadanych) próbek Wykresy z rozkładem wartości Wykresy z korelacją Wykresy MA Wykresy volcano Wykresy klastrowania, PCA, MDS w celu ogólnej oceny związku pomiędzy warunkami Heatmapy wykresy gęstości Wykresy z poziomu genów lub transkryptów pokazujące strukturę transkryptów i poziom ekspresji A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 59

59 A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 60

60 ` A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 61
61 Dwa sposoby patrzenia na dane Patrzymy na związek między genami wykorzystując ekspresję każdej próbki jako pomiar genu Patrzymy na związek między próbkami używając ekspresji każdego genu jako miarę dla każdej próbki z naukowego punktu widzenia jest to odrębna analiza z punktu widzenia metod to jest to samo
62 Klasyfikacja i klastrowanie Analiza dyskryminacyjna: KLASY ZNANE Klastrowanie: KLASY NIEZNANE
63 Metody eksploracji danych klastrowanie grupowanie ze sobą genów lub/i próbek w celu znalezienia podobieństw (np. hierachiczne, k-średnich, PAM partitioning around medoids, SOM self-organizing maps) projekcję wizualizacja próbek w przestrzeni dwuwymiarowej (principal component analysis analiza głównych składowych - PCA, skalowanie wielowymiarowe - MDS) Analiza dyskryminacyjna (klasyfikacja) dla każdej badanej klasy chcemy znaleźć wzorce z podzbioru genów, za pomocą których będziemy przydzielać nowe próbki do zadanych klas (k-nearest neigbors, centroid classification, liniowa analiza dyskryminacyjna LDA, SVM suport vector machines).

64 PCA - przykład
65 PCA - przykład

66 Hierarchiczne klastrowanie Heatmap i dendrogram
67 Analiza klastrowa/ Analiza skupień Cel analizy klastrowej Grupowanie kolekcji obiektów w grupy klastrów, takich że obiekty wewnątrz klastra będą do siebie bardziej podobne niż obiekty powiązane do innych klastrów. Dwa składniki potrzebne do tworzenia grup obiektów: Miara odległości W jaki sposób ocenić czy obiekty są do siebie podobne czy też nie? Algorytm do klastrowania Procedura do minimalizacji odległości pomiędzy obiektami w klastrze/grupie lub/i maksymalizacji odległości pomiędzy grupami

68 Analiza klastrowa Macierz ekspresji genów próbki Klastrowanie kolumn: grupowanie podobnych próbek geny Klastrowanie wierszy: grupowanie genów z podobną trajektorią Bi-klastrowanie: grupy genów mają podobną trajektorię dla podzbioru próbek
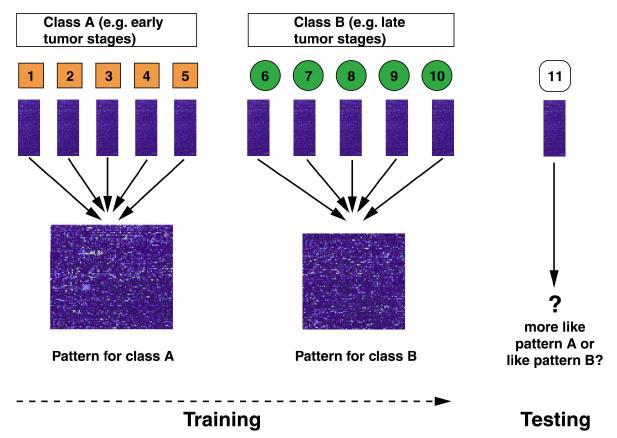
69 Analiza dyskryminacyjna
Co to jest transkryptom? A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2
 ALEKSANDRA ŚWIERCZ Co to jest transkryptom? A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2 Ekspresja genów http://genome.wellcome.ac.uk/doc_wtd020757.html A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH
ALEKSANDRA ŚWIERCZ Co to jest transkryptom? A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2 Ekspresja genów http://genome.wellcome.ac.uk/doc_wtd020757.html A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH
Ekspresja genów. A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2
 ALEKSANDRA ŚWIERCZ Ekspresja genów http://genome.wellcome.ac.uk/doc_wtd020757.html A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2 Różnice między eksperymentem mikromacierzowym a RNA-seq Przy użyciu mikromacierzy
ALEKSANDRA ŚWIERCZ Ekspresja genów http://genome.wellcome.ac.uk/doc_wtd020757.html A. Świercz ANALIZA DANYCH WYSOKOPRZEPUSTOWYCH 2 Różnice między eksperymentem mikromacierzowym a RNA-seq Przy użyciu mikromacierzy
RÓŻNICOWA EKSPRESJA GENÓW
 RÓŻNICOWA EKSPRESJA GENÓW Na poprzednim wykładzie skrót Wyniki eksperymentu nie są zgodne z oczekiwaniami Normalizacja Normalizacja Celem normalizacji jest usunięcie systematycznych błędów (czyli wynikających
RÓŻNICOWA EKSPRESJA GENÓW Na poprzednim wykładzie skrót Wyniki eksperymentu nie są zgodne z oczekiwaniami Normalizacja Normalizacja Celem normalizacji jest usunięcie systematycznych błędów (czyli wynikających
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
MIKROMACIERZE. dr inż. Aleksandra Świercz dr Agnieszka Żmieńko
 MIKROMACIERZE dr inż. Aleksandra Świercz dr Agnieszka Żmieńko Informacje ogólne Wykłady będą częściowo dostępne w formie elektronicznej http://cs.put.poznan.pl/aswiercz aswiercz@cs.put.poznan.pl Godziny
MIKROMACIERZE dr inż. Aleksandra Świercz dr Agnieszka Żmieńko Informacje ogólne Wykłady będą częściowo dostępne w formie elektronicznej http://cs.put.poznan.pl/aswiercz aswiercz@cs.put.poznan.pl Godziny
ANALIZA GRUPY GENÓW ANALIZA SKUPIEŃ
 ANALIZA GRUPY GENÓW ANALIZA SKUPIEŃ Na poprzednim wykładzie skrót Które geny znajdujące się na mikromacierzy uległy zróżnicowanej ekspresji? Cała populacja vs wybrane osobniki Nie możemy zbadać całej populacji
ANALIZA GRUPY GENÓW ANALIZA SKUPIEŃ Na poprzednim wykładzie skrót Które geny znajdujące się na mikromacierzy uległy zróżnicowanej ekspresji? Cała populacja vs wybrane osobniki Nie możemy zbadać całej populacji
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
Przykładowa analiza danych
 Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Przykładowa analiza danych W analizie wykorzystano dane pochodzące z publicznego repozytorium ArrayExpress udostępnionego na stronach Europejskiego Instytutu Bioinformatyki (http://www.ebi.ac.uk/). Zbiór
Statystyczna analiza danych
 Statystyczna analiza danych Testowanie wielu hipotez statystycznych na raz Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/31 Zdechła ryba i emocje http://www.wired.com/2009/09/fmrisalmon/
Statystyczna analiza danych Testowanie wielu hipotez statystycznych na raz Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/31 Zdechła ryba i emocje http://www.wired.com/2009/09/fmrisalmon/
Różnorodność osobników gatunku
 ALEKSANDRA ŚWIERCZ Różnorodność osobników gatunku Single Nucleotide Polymorphism (SNP) Różnica na jednej pozycji, małe delecje, insercje (INDELs) SNP pojawia się ~1/1000 pozycji Można je znaleźć porównując
ALEKSANDRA ŚWIERCZ Różnorodność osobników gatunku Single Nucleotide Polymorphism (SNP) Różnica na jednej pozycji, małe delecje, insercje (INDELs) SNP pojawia się ~1/1000 pozycji Można je znaleźć porównując
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Dane mikromacierzowe. Mateusz Markowicz Marta Stańska
 Dane mikromacierzowe Mateusz Markowicz Marta Stańska Mikromacierz Mikromacierz DNA (ang. DNA microarray) to szklana lub plastikowa płytka (o maksymalnych wymiarach 2,5 cm x 7,5 cm) z naniesionymi w regularnych
Dane mikromacierzowe Mateusz Markowicz Marta Stańska Mikromacierz Mikromacierz DNA (ang. DNA microarray) to szklana lub plastikowa płytka (o maksymalnych wymiarach 2,5 cm x 7,5 cm) z naniesionymi w regularnych
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Przybliżone algorytmy analizy ekspresji genów.
 Przybliżone algorytmy analizy ekspresji genów. Opracowanie i implementacja algorytmu analizy danych uzyskanych z eksperymentu biologicznego. 20.06.04 Seminarium - SKISR 1 Wstęp. Dane wejściowe dla programu
Przybliżone algorytmy analizy ekspresji genów. Opracowanie i implementacja algorytmu analizy danych uzyskanych z eksperymentu biologicznego. 20.06.04 Seminarium - SKISR 1 Wstęp. Dane wejściowe dla programu
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Statystyka Matematyczna Anna Janicka
 Statystyka Matematyczna Anna Janicka wykład IX, 25.04.2016 TESTOWANIE HIPOTEZ STATYSTYCZNYCH Plan na dzisiaj 1. Hipoteza statystyczna 2. Test statystyczny 3. Błędy I-go i II-go rodzaju 4. Poziom istotności,
Statystyka Matematyczna Anna Janicka wykład IX, 25.04.2016 TESTOWANIE HIPOTEZ STATYSTYCZNYCH Plan na dzisiaj 1. Hipoteza statystyczna 2. Test statystyczny 3. Błędy I-go i II-go rodzaju 4. Poziom istotności,
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
Naszym zadaniem jest rozpatrzenie związków między wierszami macierzy reprezentującej poziomy ekspresji poszczególnych genów.
 ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
ANALIZA SKUPIEŃ Metoda k-means I. Cel zadania Zadaniem jest analiza zbioru danych, gdzie zmiennymi są poziomy ekspresji genów. Podczas badań pobrano próbki DNA od 36 różnych pacjentów z chorobą nowotworową.
Prawdopodobieństwo i rozkład normalny cd.
 # # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
# # Prawdopodobieństwo i rozkład normalny cd. Michał Daszykowski, Ivana Stanimirova Instytut Chemii Uniwersytet Śląski w Katowicach Ul. Szkolna 9 40-006 Katowice E-mail: www: mdaszyk@us.edu.pl istanimi@us.edu.pl
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
Jak sprawdzić normalność rozkładu w teście dla prób zależnych?
 Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Przykład 1. (A. Łomnicki)
") Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH
 RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Wstęp Estymacja Testowanie. Efekty losowe. Bogumiła Koprowska, Elżbieta Kukla
 Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Bogumiła Koprowska Elżbieta Kukla 1 Wstęp Czym są efekty losowe? Przykłady Model mieszany 2 Estymacja Jednokierunkowa klasyfikacja (ANOVA) Metoda największej wiarogodności (ML) Metoda największej wiarogodności
Statystyczna analiza danych
 Statystyczna analiza danych ukryte modele Markowa, zastosowania Anna Gambin Instytut Informatyki Uniwersytet Warszawski plan na dziś Ukryte modele Markowa w praktyce modelowania rodzin białek multiuliniowienia
Statystyczna analiza danych ukryte modele Markowa, zastosowania Anna Gambin Instytut Informatyki Uniwersytet Warszawski plan na dziś Ukryte modele Markowa w praktyce modelowania rodzin białek multiuliniowienia
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
STATYSTYKA MATEMATYCZNA WYKŁAD 4. WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X.
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotn. istotności, p-wartość i moc testu
 Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
Wykład 2 Hipoteza statystyczna, test statystyczny, poziom istotności, p-wartość i moc testu Wrocław, 01.03.2017r Przykład 2.1 Właściciel firmy produkującej telefony komórkowe twierdzi, że wśród jego produktów
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
S t a t y s t y k a, część 3. Michał Żmihorski
 S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja) założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)
 założenie: znany rozkład populacji (wykorzystuje się dystrybuantę)") PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI 1. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Statystyczna analiza danych w programie STATISTICA (wykład 2) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Wyniki badań reprezentatywnych są zawsze stwierdzeniami hipotetycznymi, o określonych granicach niepewności
 Wyniki badań reprezentatywnych są zawsze stwierdzeniami hipotetycznymi, o określonych granicach niepewności Statystyka indukcyjna pozwala kontrolować i oszacować ryzyko popełnienia błędu statystycznego
Wyniki badań reprezentatywnych są zawsze stwierdzeniami hipotetycznymi, o określonych granicach niepewności Statystyka indukcyjna pozwala kontrolować i oszacować ryzyko popełnienia błędu statystycznego
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Elementy statystyki STA - Wykład 5
 STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
STA - Wykład 5 Wydział Matematyki i Informatyki Uniwersytet im. Adama Mickiewicza 1 ANOVA 2 Model jednoczynnikowej analizy wariancji Na model jednoczynnikowej analizy wariancji możemy traktować jako uogólnienie
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego
 Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
Korelacja oznacza współwystępowanie, nie oznacza związku przyczynowo-skutkowego Współczynnik korelacji opisuje siłę i kierunek związku. Jest miarą symetryczną. Im wyższa korelacja tym lepiej potrafimy
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
ZJAZD 4. gdzie E(x) jest wartością oczekiwaną x
 jest wartością oczekiwaną x") ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
ZJAZD 4 KORELACJA, BADANIE NIEZALEŻNOŚCI, ANALIZA REGRESJI Analiza korelacji i regresji jest działem statystyki zajmującym się badaniem zależności i związków pomiędzy rozkładami dwu lub więcej badanych
Ekonometria. Zajęcia
 Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
Ekonometria Zajęcia 16.05.2018 Wstęp hipoteza itp. Model gęstości zaludnienia ( model gradientu gęstości ) zakłada, że gęstość zaludnienia zależy od odległości od okręgu centralnego: y t = Ae βx t (1)
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
SIGMA KWADRAT. Weryfikacja hipotez statystycznych. Statystyka i demografia CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY
 SIGMA KWADRAT CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY Weryfikacja hipotez statystycznych Statystyka i demografia PROJEKT DOFINANSOWANY ZE ŚRODKÓW NARODOWEGO BANKU POLSKIEGO URZĄD STATYSTYCZNY
SIGMA KWADRAT CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY Weryfikacja hipotez statystycznych Statystyka i demografia PROJEKT DOFINANSOWANY ZE ŚRODKÓW NARODOWEGO BANKU POLSKIEGO URZĄD STATYSTYCZNY
TESTOWANIE HIPOTEZ Przez hipotezę statystyczną rozumiemy, najogólniej mówiąc, pewną wypowiedź na temat rozkładu interesującej nas cechy.
 TESTOWANIE HIPOTEZ Przez hipotezę statystyczną rozumiemy, najogólniej mówiąc, pewną wypowiedź na temat rozkładu interesującej nas cechy. Hipotezy dzielimy na parametryczne i nieparametryczne. Zajmiemy
TESTOWANIE HIPOTEZ Przez hipotezę statystyczną rozumiemy, najogólniej mówiąc, pewną wypowiedź na temat rozkładu interesującej nas cechy. Hipotezy dzielimy na parametryczne i nieparametryczne. Zajmiemy
Testy nieparametryczne
 Testy nieparametryczne 1 Wybrane testy nieparametryczne 1. Test chi-kwadrat zgodności z rozkładem oczekiwanym 2. Test chi-kwadrat niezależności dwóch zmiennych kategoryzujących 3. Test U Manna-Whitney
Testy nieparametryczne 1 Wybrane testy nieparametryczne 1. Test chi-kwadrat zgodności z rozkładem oczekiwanym 2. Test chi-kwadrat niezależności dwóch zmiennych kategoryzujących 3. Test U Manna-Whitney
Rozkład Gaussa i test χ2
 Rozkład Gaussa jest scharakteryzowany dwoma parametramiwartością oczekiwaną rozkładu μ oraz dyspersją σ: METODA 2 (dokładna) polega na zmianie zmiennych i na obliczeniu pk jako różnicy całek ze standaryzowanego
Rozkład Gaussa jest scharakteryzowany dwoma parametramiwartością oczekiwaną rozkładu μ oraz dyspersją σ: METODA 2 (dokładna) polega na zmianie zmiennych i na obliczeniu pk jako różnicy całek ze standaryzowanego
Przetarg nieograniczony na zakup specjalistycznej aparatury laboratoryjnej Znak sprawy: DZ-2501/6/17
 Część nr 2: SEKWENATOR NASTĘPNEJ GENERACJI Z ZESTAWEM DEDYKOWANYCH ODCZYNNIKÓW Określenie przedmiotu zamówienia zgodnie ze Wspólnym Słownikiem Zamówień (CPV): 38500000-0 aparatura kontrolna i badawcza
Część nr 2: SEKWENATOR NASTĘPNEJ GENERACJI Z ZESTAWEM DEDYKOWANYCH ODCZYNNIKÓW Określenie przedmiotu zamówienia zgodnie ze Wspólnym Słownikiem Zamówień (CPV): 38500000-0 aparatura kontrolna i badawcza
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
STATYSTYKA I DOŚWIADCZALNICTWO. Wykład 2
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu
 Ćwiczenie 4 Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu Wstęp CYP2D6 kodowany przez gen występujący w co najmniej w 78 allelicznych formach związanych ze zmniejszoną
Ćwiczenie 4 Oznaczenie polimorfizmu genetycznego cytochromu CYP2D6: wykrywanie liczby kopii genu Wstęp CYP2D6 kodowany przez gen występujący w co najmniej w 78 allelicznych formach związanych ze zmniejszoną
Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności. Dr Anna ADRIAN Paw B5, pok407
 Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Weryfikacja hipotez dotyczących postaci nieznanego rozkładu -Testy zgodności.
Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Weryfikacja hipotez dotyczących postaci nieznanego rozkładu -Testy zgodności.
( x) Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:
 Równanie regresji liniowej ma postać. By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : Gdzie:") ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
ma postać y = ax + b Równanie regresji liniowej By obliczyć współczynniki a i b należy posłużyć się następującymi wzorami 1 : xy b = a = b lub x Gdzie: xy = też a = x = ( b ) i to dane empiryczne, a ilość
Hipotezy statystyczne
 Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej próbki losowej. Hipotezy
Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej próbki losowej. Hipotezy
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4
, sprawozdanie z laboratorium 4") Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4 Konrad Miziński, nr albumu 233703 31 maja 2015 Zadanie 1 Wartości oczekiwane µ 1 i µ 2 oszacowano wg wzorów: { µ1 = 0.43925 µ = X
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4 Konrad Miziński, nr albumu 233703 31 maja 2015 Zadanie 1 Wartości oczekiwane µ 1 i µ 2 oszacowano wg wzorów: { µ1 = 0.43925 µ = X
Sekwencjonowanie Nowej Generacji ang. Next Generation Sequencing. Wykład 6 Część 1 NGS - wstęp Dr Wioleta Drobik-Czwarno
 Sekwencjonowanie Nowej Generacji ang. Next Generation Sequencing Wykład 6 Część 1 NGS - wstęp Dr Wioleta Drobik-Czwarno Macierze tkankowe TMA ang. Tissue microarray Technika opisana w 1987 roku (Wan i
Sekwencjonowanie Nowej Generacji ang. Next Generation Sequencing Wykład 6 Część 1 NGS - wstęp Dr Wioleta Drobik-Czwarno Macierze tkankowe TMA ang. Tissue microarray Technika opisana w 1987 roku (Wan i
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 Anna Skowrońska-Szmer lato 2016/2017 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją jako prawdziwą
Statystyka matematyczna i ekonometria Wykład 5 Anna Skowrońska-Szmer lato 2016/2017 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją jako prawdziwą
5. WNIOSKOWANIE PSYCHOMETRYCZNE
 5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
5. WNIOSKOWANIE PSYCHOMETRYCZNE Model klasyczny Gulliksena Wynik otrzymany i prawdziwy Błąd pomiaru Rzetelność pomiaru testem Standardowy błąd pomiaru Błąd estymacji wyniku prawdziwego Teoria Odpowiadania
Statystyka. #5 Testowanie hipotez statystycznych. Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik. rok akademicki 2016/ / 28
 Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
Analizy wielkoskalowe w badaniach chromatyny
 Analizy wielkoskalowe w badaniach chromatyny Analizy wielkoskalowe wykorzystujące mikromacierze DNA Genotypowanie: zróżnicowane wewnątrz genów RNA Komórka eukariotyczna Ekspresja genów: Które geny? Poziom
Analizy wielkoskalowe w badaniach chromatyny Analizy wielkoskalowe wykorzystujące mikromacierze DNA Genotypowanie: zróżnicowane wewnątrz genów RNA Komórka eukariotyczna Ekspresja genów: Które geny? Poziom
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice
 Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Księgarnia PWN: George A. Ferguson, Yoshio Takane - Analiza statystyczna w psychologii i pedagogice Przedmowa do wydania polskiego Przedmowa CZĘŚĆ I. PODSTAWY STATYSTYKI Rozdział 1 Podstawowe pojęcia statystyki
Hipotezy statystyczne
 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej
Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza zmienności czasowej danych mikromacierzowych
 Systemy Inteligencji Obliczeniowej Analiza zmienności czasowej danych mikromacierzowych Kornel Chromiński Instytut Informatyki Uniwersytet Śląski Plan prezentacji Dane mikromacierzowe Cel badań Prezentacja
Systemy Inteligencji Obliczeniowej Analiza zmienności czasowej danych mikromacierzowych Kornel Chromiński Instytut Informatyki Uniwersytet Śląski Plan prezentacji Dane mikromacierzowe Cel badań Prezentacja
Statystyczna analiza Danych
 Statystyczna analiza Danych Dla bioinformatyków Wykład pierwszy: O testowaniu hipotez Plan na dziś Quiz! Cele wykładu Plan na semestr Kryteria zaliczenia Sprawy organizacyjne Quiz (15 minut) Jakie znasz
Statystyczna analiza Danych Dla bioinformatyków Wykład pierwszy: O testowaniu hipotez Plan na dziś Quiz! Cele wykładu Plan na semestr Kryteria zaliczenia Sprawy organizacyjne Quiz (15 minut) Jakie znasz
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Zadania ze statystyki cz.8. Zadanie 1.
 Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Zadania ze statystyki cz.8. Zadanie 1. Wykonano pewien eksperyment skuteczności działania pewnej reklamy na zmianę postawy. Wylosowano 10 osobową próbę studentów, których poproszono o ocenę pewnego produktu,
Testowanie hipotez. Marcin Zajenkowski. Marcin Zajenkowski () Testowanie hipotez 1 / 25
 Testowanie hipotez 1 / 25") Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Testowanie hipotez Marcin Zajenkowski Marcin Zajenkowski () Testowanie hipotez 1 / 25 Testowanie hipotez Aby porównać ze sobą dwie statystyki z próby stosuje się testy istotności. Mówią one o tym czy uzyskane
Analiza wariancji - ANOVA
 Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
Analiza wariancji - ANOVA Analiza wariancji jest metodą pozwalającą na podział zmienności zaobserwowanej wśród wyników eksperymentalnych na oddzielne części. Każdą z tych części możemy przypisać oddzielnemu
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Systemy pomiarowo-diagnostyczne. Metody uczenia maszynowego wykład III 2016/2017
 Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe
Systemy pomiarowo-diagnostyczne Metody uczenia maszynowego wykład III bogumil.konopka@pwr.edu.pl 2016/2017 Wykład III - plan Regresja logistyczna Ocena skuteczności klasyfikacji Macierze pomyłek Krzywe